1. Introduction
The development of an autonomous vehicle system that enhances safety and traffic efficiency is in progress continuously; this system requires a road environment detection facility in order to control the host vehicle [
1,
2]. The detection of preceding vehicles plays a decisive role in realizing rational planning of the driving path, maintaining the correct distance, and ensuring driving safety for autonomous vehicles [
3,
4]. Recently, preceding vehicle detection has become a research hotspot due to its necessity for autonomous vehicles, and many detection algorithms have been proposed [
5,
6,
7,
8].
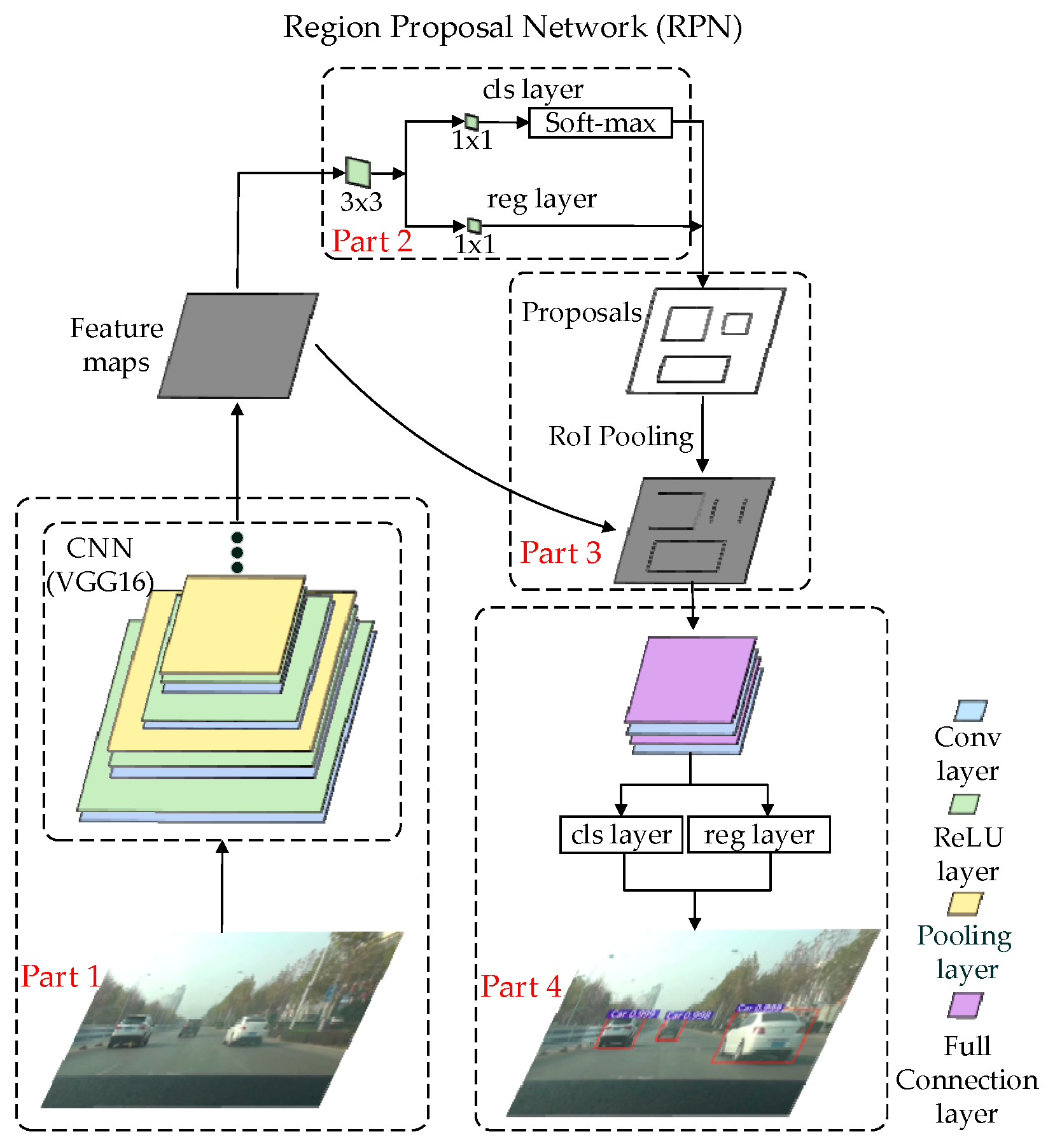
At present, methods of preceding vehicle detection are mainly divided into the traditional machine learning method and the deep learning method. The traditional machine learning method extracts vehicle features by feature extraction operators such as histogram of oriented gradient (HOG) [
9], Haar-like features [
10], etc., and inputs the features into a classifier such as support vector machine (SVM) [
11], AdaBoost [
12], etc. [
13,
14,
15,
16]. However, these methods design features manually, the design process is subjective, there is a lack of theoretical guidance, and the generalization ability is poor [
17,
18]. With the development of deep learning, convolutional neural networks (CNNs) are widely used because they can efficiently extract high-dimensional features of images and greatly improve detection accuracy [
19]. In 2014, Girshick [
20] proposed the region with a CNN (R-CNN) algorithm, using a selective search (SS) [
21] strategy to determine candidate regions and applying CNNs to object detection. Compared with the best results of a traditional manual detection algorithm on the PASCAL Visual Object Classes Challenge (VOC) 2012 [
22], the mean average precision (mAP) of the R-CNN algorithm was improved by more than 30%, reaching 53.3%. In 2015, Girshick [
23] proposed the Fast R-CNN algorithm to improve detection speed by optimizing R-CNN. However, using the SS strategy to determine candidate regions takes a lot of time; thus, in 2016, Ren [
24] proposed the Faster R-CNN algorithm, applying CNNs to the selection of candidate regions, and the region proposal network (RPN), which greatly improved the detection speed. Faster R-CNN has also become a mainstream method in the field of vehicle detection.
However, for the Faster R-CNN algorithm, host vehicle speed changes and preceding vehicle occlusions have a certain influence on preceding vehicle detection. In the process of generating candidate proposals, RPN adopts the anchor design, but Zhang [
25] found that the mismatch of anchor size and small face reduced the detection accuracy of the small face, which is also suitable for small vehicles. Moreover, with changing host vehicle speed, the occurrence frequency of small, medium, and large vehicles may change, and the poor adaptation of anchor size to host vehicle speed also reduces the detection accuracy of small vehicles. Nonmaximum suppression (NMS) [
26] is applied in the Faster R-CNN algorithm to perform redundant removal in vehicle detection. Although the traditional NMS selects the detection results with high scores and deletes adjacent results that exceed the threshold, the strict screening of NMS will lead to failure of occluded vehicle detection.
Optimizing anchors can improve the detection accuracy of the Faster R-CNN algorithm for the preceding vehicle. Wang et al. [
27] matched the anchor size and receptive field to ensure that the network could obtain the appropriate number of vehicle features, improving the detection accuracy of Faster R-CNN on the KITTI dataset [
28]. Ma et al. [
29] chose anchor sizes that were object-adaptive and used self-adaptive anchors to enhance the structure of the Faster R-CNN algorithm, obtaining some success. Zhang et al. [
30] improved the detection accuracy of small vehicles by adding a new anchor size of 64 × 64 to the Faster R-CNN. Gao et al. [
31] added two smaller scales (32 × 32, 64 × 64) to the anchor box generation process to cover the high-frequency interval of the dataset between 30 and 60 pixels in width, and this method improved the Faster R-CNN performance on smaller vehicles. Generally, these methods are intended to make anchor size match vehicle size to achieve better detection of preceding vehicles, especially small vehicles, but they ignored a problem: With changing host vehicle speed, the occurrence of different sized vehicles will change, and anchors cannot adapt to this change.
Optimizing NMS can improve the performance of occluded vehicle detection. Bodla et al. [
32] proposed a Soft-NMS algorithm with a penalty coefficient, which does not need to retrain the original model and can be easily integrated into any object detection algorithm using NMS, reducing the missed object detection rate. Zhao et al. [
33] applied Soft-NMS to object detection, including vehicles, and proved that compared to NMS, the detection accuracy of the optimized Faster R-CNN could be improved by 1%–2% on the PASCAL VOC 2007. However, the above methods have a shortcoming: Soft-NMS is an optimized NMS algorithm by introducing the penalty coefficient of linear and Gaussian weighting, but it does not consider the impact of optimizing the penalty coefficients.
Thus, in this paper, we propose the speed classification random anchor (SCRA) and Q-square penalty coefficient (Q-SPC) methods to improve the detection accuracy of preceding vehicles when host vehicle speed changes and occlusion happens. The main contributions of this paper can be summarized as follows:
The factor of speed is introduced: Through a real vehicle experiment, the vehicle speed is divided into three stages: 0–20, 20–60, and 60–120 km/h. The sizes of preceding vehicles at different speed stages are collected, and the k-means clustering algorithm [
34] is used to analyze the rule of preceding vehicle sizes at different speed stages.
The relationship between the rule of preceding vehicle size and anchor size is established; at different speed stages, anchors are redesigned according to clustering results and random selection mode.
The detection results of preceding occluded vehicles are analyzed, the optimization requirements are put forward, and according to the requirements, the Q-SPC method is applied to optimize Soft-NMS.
This paper is organized as follows: First, the overall structure of the Faster R-CNN, RPN, NMS, and Soft-NMS algorithms are introduced. Second, according to the real vehicle experiment, the relationship between vehicle speed, preceding vehicle size, and anchor size is established; anchors are redesigned; and the SCRA method is put forward. Then, the Q-SPC method is proposed according to the detection results of occluded vehicles. Finally, in order to verify the effectiveness of the optimized algorithm, experimental verification is carried out.
4. Design of Optimized Faster R-CNN Algorithm
The working principles of the SCRA and Q-SPC methods are shown in
Figure 4. The SCRA method was used to optimize anchors, and the Q-SPC method was used to optimize Soft-NMS.
As shown in
Figure 4a, taking speed into account, we proposed the SCRA method to make anchor sizes fit vehicle sizes. The design steps of the SCRA method are as follows:
Step 1. The speed of the host vehicle is introduced, and according to the experiment, speed is divided into three stages: 0–20, 20–60, and 60–120 km/h. In order to make anchor sizes fit vehicle sizes, the rule of vehicle sizes should be analyzed at different speed stages. Thus, by collecting images and labels, the width (W) and height (H) of each vehicle are acquired.
Step 2. To analyze the rule of vehicle sizes at different speed stages, we employed the k-means clustering algorithm to deal with the width and height.
Step 3. Based on the results of clustering and postprocessing cluster centroids, maximum and minimum vehicle size, weighted mean value of cluster centroids, and extracted vehicle aspect ratios, anchors will be redesigned.
Step 4: Based on data such as cluster centroids and aspect ratios, too many anchors are generated; select anchors randomly to make the quantity reasonable.
Step 5: After finishing the above steps, the original anchors are updated with the redesigned anchors.
For our Q-SPC method, the design steps are as follows:
Step 1. The Faster R-CNN algorithm is used with NMS to deal with bounding boxes, because we want to optimize the Soft-NMS; thus, the NMS is replaced by Soft-NMS. Then the Faster R-CNN is used on the vehicle occlusion dataset, and the detection results are generated.
Step 2. Analyzing these results, some requirements are proposed. To satisfy requirements, the Q-times multiplication of penalty coefficients is adopted.
Step 3. Use optimized Soft-NMS to update Soft-NMS.
In the following sections, we introduce our SCRA and Q-SPC methods in detail.
4.1. Relationship between Anchors and Preceding Vehicle Size
4.1.1. The Rule of Preceding Vehicle Size at Different Speed Stages
In this section, in order to fit anchor sizes to vehicle sizes at different speed stages, we needed to divide the speed into stages and to explore the rule of vehicles size at different speed stages. Thus, a real vehicle experiment was carried out to search reasonable speed stages and collect the images. The parameters of the actual vehicle experiment are shown in
Table 1.
Here, the frame rate of camera is 104 fps, the resolution is 640 × 480, and the camera is mounted behind the front windshield.
In our experiment, based on the status of the experiment vehicle and the speed limit conditions on urban roads and motorways, we chose four speed stages: 0–20, 20–60, 60–90, and 90–120 km/h (
Table 2). When the vehicle exceeded 60 km/h, due to the high speed and large distance, the preceding vehicle size was small; moreover, when the vehicle exceeded 90 km/h, fewer vehicles were in front of the host vehicle, and the vehicle size was too small; in the process of labeling, vehicles had a similar size, and the width and height of each vehicle were almost the same (as shown in
Figure 5). The rule of vehicles size may be unconvincing; thus, 90–120 km/h is not a suitable speed to analyze the rule of vehicle size. We grouped 60–90 and 90–120 km/h together, and divided the speed into 0–20, 20–60, and 60–120 km/h.
Here, the definition of More, Fewer, and Much Fewer can be expressed by the mean of the number of preceding vehicles in per image; in this paper, we used 2.5, 1.5, and 0.5 to represent the approximate average values which correspond to More, Fewer, and Much Fewer, respectively.
In our experiment, we collected and screened images with a resolution of
at different speed stages, then each image was labeled manually to obtain the width and height of preceding vehicles in the image; the types of selected vehicles are car and SUV. The parameters of the screened images are shown in
Table 3.
In this paper, we classify the preceding vehicle sizes as small, medium, large, and very large. Small, medium, and large are preceding vehicle sizes in the vehicle running experiment, and we added very large as a new size to fit some vehicles when the speed of the experimental vehicle is 0. As the k-means algorithm is a classical clustering algorithm which can set the number of clusters, and in order to corresponding to four vehicle sizes, k-means algorithm was adopted to deal with the width and height of preceding vehicles (K = 4). The clustering results at different speed stages are shown in
Figure 6.
However, it can be seen from the clustering results that there are too few vehicle sizes in cluster 4. Clusters 3 and 4 are recombined, and the centroids of clusters 3 and 4 are recombined by weighting. According to Equation (7), the centroid of new cluster A
is obtained. The cluster centroids and number of vehicle sizes per cluster at each speed stage are shown in
Table 4.
Among them, represent the horizontal and vertical coordinates of cluster centroid, and represents the number of vehicle sizes in each cluster.
Here, the horizontal and vertical coordinates of cluster centroids represent the width and height of preceding vehicles, respectively.
After recombination, the new cluster is obtained, and the vehicle sizes are redefined as small, medium, and large, corresponding to clusters 1, 2, and A, respectively. Each cluster is described by the mean of all values of this cluster (cluster centroid); thus, the cluster centroid is selected to describe the vehicle sizes that belong to this cluster. Fitting anchor sizes to vehicle sizes, as shown in Equation (1), vehicle size should include not only width and height, but also the aspect ratio (width/height); thus, the proportion of vehicle aspect ratios in clusters 1, 2, and A at different speed stages is collected to provide the basis for the design of anchors, and the results are shown in
Figure 7.
4.1.2. Anchor Design Based on Vehicle Pixel Dimensions
In this section, without considering the aspect ratios, we defined the anchors as initial anchors, and after processing initial anchors by aspect ratio, we defined them as final anchors. At different speed stages, the occurrence frequency ratio of different vehicle sizes determines the number of initial anchors (
NIA) belonging to the cluster, and the proportion of vehicle aspect ratios in each cluster determines the number of aspect ratios (
NAR) belonging to the cluster. The number of final anchors corresponding to this cluster is
, and the number of final anchors corresponding to the vehicle speed stage is
; K = 1, 2, A. At each speed stage, the design principles of
NIA of each cluster are as follows: (1) The
NIA should meet the occurrence frequency ratio of vehicle sizes shown in
Table 5 as much as possible. (2) The
NIA of each cluster should sum to 9 to meet the design of the original Faster R-CNN:
k = 9. (3) The
NIA should be larger than 1, so that the size of the anchor is variable to cover more vehicle sizes. The design principles of
NAR of each cluster are as follows: (1) Compared with
NIA, the ratio of
should be closer to the occurrence frequency ratios of vehicle sizes shown in
Table 5. (2) Corresponding to the aspect ratios shown in
Figure 7, the
NAR should be as large as possible. The values of
NIA and
NAR are shown in
Table 6.
Here, ratios are obtained through the result of clustering shown in
Table 4; at each speed stage, the ratio of each type (corresponding to cluster K) is
.
After obtaining the
NIA and
NAR, the vehicle sizes and aspect ratios should be selected. According to the acquired data at different speed stages, we established a method to select vehicle sizes. The method of selection and data chosen at different speed stages are shown in
Figure 8. The selected vehicle sizes should satisfy the
NIA condition and have a span to make anchor sizes more reasonable.
When the vehicle speed is 0–20 km/h, the cluster centroid of clusters 1, 2, and A is
,
, and
, respectively, the minimum vehicle size of cluster 1 is
, the maximum vehicle size of cluster A is
, corresponding to
Figure 8, and the vehicle sizes corresponding to each cluster are selected:
The selected aspect ratios should satisfy the
NAR condition and cover the aspect ratios shown in
Figure 7 as much as possible. According to the proportion of different vehicle aspect ratios and
NAR in each cluster, aspect ratios
R corresponding to each cluster are selected:
When vehicle speed is 20–60 km/h, the cluster centroid of clusters 1, 2, and A is
,
, and
, respectively, the weighted mean value of the centroid of clusters 1 and 2 is
, the minimum vehicle size of cluster 1 is
, the maximum vehicle size of cluster A is
, corresponding to
Figure 8, and the vehicle sizes and aspect ratios
R corresponding to each cluster are selected:
When the speed exceeds 60 km/h, the cluster centroid of clusters 1, 2, and A is
,
, and
, respectively, the minimum vehicle size of cluster 1 is
, the maximum vehicle size of cluster A is
, the weighted mean value of centroid of clusters 1 and 2 is
, the average of cluster centroid 1 and minimum vehicle size is
, corresponding to
Figure 8, and the vehicle sizes and aspect ratios
R corresponding to each cluster are selected:
Due to different clusters corresponding to different vehicle sizes, the anchor sizes are fit to vehicle sizes, so initial anchors correspond to different clusters as well. After selecting the width and height of vehicle sizes, the width (
) and height (
) of initial anchors are obtained by Equation (8):
After obtaining the width and height of initial anchors, aspect ratio
R should be considered. The corresponding final anchor sizes are acquired; thus, Equation (1) is optimized as Equation (9), and the final anchor sizes at different speed stages are obtained by Equation (9):
where
S represents the speed stage;
K represents the
Kth cluster at
S, and
K = 1, 2, A;
i, j represent the
ith selected initial anchor size and the
jth selected aspect ratio
R, and
i = 1
S,K, 2
S,K, …,
NIAS,K,
j = 1
S,K, 2
S,K, …,
NARS,K; and
,
represent the width and height of the final anchor. In Faster R-CNN, the size of images is
; in our experiment, the size of collected images is
, so we multiplied by the expansion factor of 1.25.
4.2. Random Selection of Anchors
In order to adjust the number of anchors and improve the generalization ability of the training model, a random anchor structure is proposed in this paper. The purpose is as follows:
There are many repetitions in the final anchor sizes, so the random selection of anchor sizes is adopted to reduce repeatability.
Anchors are constantly changing to enhance the generalization ability of the training model.
Compared with k = 9, increasing the number of anchors will increase the proposals, cover more possible object areas, and improve the generalization ability of the training model.
Compared with the Faster R-CNN algorithm, we designed 27, 31, and 37 final anchors at the three speed stages, and the repeatability is strong. Therefore, in order to adjust the number of final anchor sizes and improve the generalization ability of the training model, a random selection model is proposed by Equation (10):
where
represents randomly extracted
m data from
j data. In this paper,
, so at each speed stage, the number of final anchor sizes is 18, and the anchor sizes in the Faster R-CNN algorithm [
41] are updated by final anchor sizes.
4.3. Q-square Penalty Coefficient
Compared with NMS, the Soft-NMS algorithm establishes a smoothing relationship between IoU and confidence score
and proposes the penalty coefficients
of linear and Gaussian weighting; thus, the detection accuracy of occluded objects is improved by reducing the confidence score instead of strictly deleting the candidate boxes. The Soft-NMS algorithm was applied to the Faster R-CNN to replace NMS for detection of occluded preceding vehicles. From the detection results, there are several situations (as shown in
Figure 9), and we optimized Soft-NMS from three aspects:
When vehicle occlusion is slight, occluded vehicles can be detected using the Soft-NMS algorithm; thus, we expect that the penalty intensity of our optimized Soft-NMS algorithm can be as consistent as possible with the original Soft-NMS algorithm, so the effect of detection remains as constant as possible.
When vehicle occlusion is serious, occluded vehicles cannot be detected using the Soft-NMS algorithm; thus, we expect that the penalty intensity of our optimized Soft-NMS algorithm can be stronger, the confidence score drops more sharply, and score ranking is lower, to reduce the influence of heavily occluded detection boxes.
When vehicle occlusion is between the above two conditions, some occluded vehicles can be detected using Soft-NMS, while some cannot be detected; thus, we explored the influence of adjusting penalty intensity on detection of occluded preceding vehicles.
Therefore, to meet the above requirements, according to Equations (11) and (12), the Q-SPC method is proposed, and the
of linear and Gaussian weighting are obtained by Equations (11) and (12), respectively:
where Q represents the times of multiplication; in this paper, Q = 1, 2, …, 7,
Threshold = 0.3, and
.
Figure 10 shows the relationships between the penalty coefficient of linear weighting, Gaussian weighting, and the value of IoU, as well as the relationship between penalty coefficients and the power of Q. As shown in
Figure 10a, when IoU < threshold,
can make the penalty intensity stay in the same condition as Soft-NMS when occlusion is slight, while with increased IoU, the penalty intensity is stronger and the confidence score drops more sharply; and with increased Q, the intensity of punishment also changes. As shown in
Figure 10b, when occlusion is slight, punishment is maintained as far as possible, but compared with linear weighting, the effect of preservation is not enough, and other effects are basically the same as linear weighting. Therefore, the method of multiplying the penalty coefficient by Q times can satisfy the requirements of optimized Soft-NMS.
The optimized confidence score
is obtained by Equation (13):
According to the confidence score, the code of Soft-NMS [
42] is optimized, the possible object detection boxes are rescreened to improve the occluded vehicle detection accuracy of Faster R-CNN.
6. Results and Discussion
In
Table 11, for the test sets belonging to different speed stages (TestData1, TestData2, and TestData3), the models with the highest AP values are Models 1, 2, and 3. With increased speed, the AP of both the optimized Faster R-CNN and Faster R-CNN algorithms declines, but compared to the Faster R-CNN algorithm, based on the SCRA method, the improvement in detection accuracy is 7.65%, 9.27%, and 15.14%, respectively.
Here, in order to make a comparison with our proposed algorithm, we selected the best detection result of nonoptimized Faster R-CNN for each test set, and we defined the acquired detection model as Model 0. Under separate training modes, we used Faster R-CNN to process the training and test sets belonging to same speed stage; under the overall training mode, Faster R-CNN was used to train all data, and the corresponding model 0 was used to test TestData all, TestData 1, TestData 2, and TestData 3.
The test results under overall training mode are shown in
Table 12. For TestData1, TestData2, and TestData3, the models with the highest test results are Models 1, 2, and 3, and all AP values for overall training mode are higher than those for separate training modes. This means that the increased training set data samples have a positive impact on the detection accuracy, and compared to the Faster R-CNN algorithm, based on the SCRA method, the improvement in detection accuracy is 8.22%, 10.66%, and 16.11%, respectively.
The experimental results show the following:
For the test sets collected at different speed stages, no matter which data training mode we chose, the highest test results of TestData1, TestData2, and TestData3 are with Models 1, 2, and 3. That means that using the vehicle speed to adjust the anchor size adaptively can achieve the best detection effect.
By using the overall training mode, all the experimental results of Models 1, 2, and 3 were higher than with the Faster R-CNN algorithm. This proves that the rule of preceding vehicle size is effective and reasonable.
With increased vehicle speed, the occurrence frequency of small vehicles increased and the accuracy of the Faster R-CNN was gradually reduced, but the detection accuracy of the optimized algorithm was improved more obviously. This proves that the optimized anchors can match vehicle sizes, especially for small vehicles.
When preceding vehicle size was small and the color close to the background, sometimes there were some false positives of preceding vehicles detection.
Comparing separate and overall training, separate training modes had a poor detection effect on the test sets that do not belong to the corresponding speed stage, but under the overall training mode, the detection effect was better, and the generalization ability of overall training mode was better.
For occlusion of preceding vehicles, the Faster R-CNN algorithm was trained, and NMS, Soft-NMS based on linear weighting penalty coefficient and on Gaussian weighting penalty coefficient taking the influence of parameter
into account, and optimized Soft-NMS based on Q-SPC algorithm were applied to test separately, and the detection effect of occluded preceding vehicles is shown in
Figure 12.
The following can be seen from the experimental results:
When Q = 1, compared with NMS, applying nonoptimized Soft-NMS (linear weighting, Gaussian weighting with , Gaussian weighting with ) for occluded preceding vehicles, detection accuracy improved by nearly 2%, and the effect of Soft-NMS based on linear weighting penalty coefficient was slightly better than that of Gaussian weighting penalty coefficient.
With increased Q, detection accuracy increased continuously. For the optimized Soft-NMS with linear weighting, AP reached the maximum when Q = 4; for the optimized Soft-NMS with Gaussian weighting, AP reached the maximum when Q = 6, and δ had little effect on the detection accuracy. On the whole, the effect of the linear weighting penalty coefficient was better than that of the Gaussian weighting penalty coefficient.
With the introduction of the Q-SPC method, for occluded vehicles, compared with the detection result when Q = 1, detection accuracy by Faster R-CNN improved 1%–2%, and the best Q values of linear and Gaussian weighting were 4 and 6, so this method has a certain effect.
According to our requirements, to optimize Soft-NMS, the ability of Gaussian weighting to maintain the penalty intensity was not enough, and this is one reason why the effect of Gaussian weighting was worse compared with linear weighting.
Figure 13 shows the test results based on the optimized Faster R-CNN algorithm using the SCRA method and the nonoptimized Faster R-CNN algorithm.
Figure 13d shows the test results of occluded preceding vehicles based on the optimized Soft-NMS using the Q-SPC method and nonoptimized Soft-NMS.
7. Conclusions
In this paper, to improve the detection accuracy of preceding vehicles, an optimized Faster R-CNN algorithm based on SCRA and Q-SPC methods was proposed. Firstly, the reasons for degraded detection accuracy when the host vehicle speed increases were analyzed, and the factor of vehicle speed was introduced to redesign the anchors. Redesigned anchors can adapt to changes of preceding vehicle size when the host vehicle speed increases, and the SCRA method was proposed. Secondly, to achieve better performance on occluded vehicles, the Q-SPC method was proposed to optimize the Faster R-CNN algorithm. Finally, the experimental results showed that introducing the factor of host vehicle speed to make anchors adapt to vehicle size can bring 7%–17% accuracy improvement, and the method of Q-times multiplication of penalty coefficients can bring 1%–2% accuracy improvement for occluded vehicles. It was proved that the SCRA and Q-SPC methods have certain significance for improved accuracy of preceding vehicle detection.
In this paper, we improved the detection accuracy of preceding vehicles, and our method had no influence on detection speed, but Faster R-CNN is a two-stage algorithm, which causes this algorithm not to work in real time. In the next step, we will try to optimize the structure of Faster R-CNN to improve the detection speed and try to extend our design to one-stage detection algorithms such as you look only once (YOLO) [
45] or single shot multibox detector (SSD) [
46]. Moreover, other types of vehicles such as buses and trucks and the influence of moving targets such as pedestrians and bikes were not considered. In the future, we will focus on diverse vehicle types and the impact of other road factors.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}