Abstract
Despite notable advancements in bot detection methods based on Graph Neural Networks (GNNs). The efficacy of Graph Neural Networks relies heavily on the homophily assumption, which posits that nodes with the same label are more likely to form connections between them. However, the latest social bots are capable of concealing themselves by extensively interacting with authentic user accounts, forging extensive connections on social graphs, and thus deviating from the homophily assumption. Consequently, conventional Graph Neural Network methods continue to face significant challenges in detecting these novel types of social bots. To address this issue, we proposed SqueezeGCN, an adaptive neighborhood aggregation with the Squeeze Module for Twitter bot detection based on a GCN. The Squeeze Module uses a parallel multi-layer perceptron (MLP) to squeeze feature vectors into a one-dimensional representation. Subsequently, we adopted the sigmoid activation function, which normalizes values between 0 and 1, serving as node aggregation weights. The aggregation weight vector is processed by a linear layer to obtain the aggregation embedding, and the classification result is generated using a MLP classifier. This design generates adaptive aggregation weights for each node, diverging from the traditional singular neighbor aggregation approach. Our experiments demonstrate that SqueezeGCN performs well on three widely acknowledged Twitter bot detection benchmarks. Comparisons with a GCN reveal improvements of 2.37%, 15.59%, and 1.33% for the respective datasets. Furthermore, our approach demonstrates improvements when compared to state-of-the-art algorithms on the three benchmark datasets. The experimental results further affirm the exceptional effectiveness of our proposed algorithm for Twitter bot detection.
1. Introduction
Twitter, a prominent social media platform, plays a crucial role in daily communication and enables the concise expression of thoughts [1]. However, the presence of numerous Twitter bots poses a significant challenge. While these accounts contribute to information dissemination, they also facilitate deliberate manipulation by malicious users. This manipulation fosters the dissemination of fake news and the orchestration of public opinion regarding crucial events [2,3,4]. These activities have detrimental effects on both the Twitter platform and society at large.
Initially, Twitter bot detection methods relied on feature analysis, which involved the extraction and design of features from user accounts [5,6,7,8]. Traditional classification methods were then employed to determine whether the accounts were machine-generated [9,10,11,12]. Nevertheless, these feature-based approaches possess limitations regarding their generalizability and reliability. To overcome these limitations, text-based methods have emerged as viable solutions that analyze text features and patterns. Leveraging natural language processing techniques, these approaches examine user descriptions and identify discrepancies between Twitter bots and genuine users [4,11,13,14,15,16]. However, traditional feature- and text-based methods face challenges and constraints due to the continuous evolution of Twitter bots and advancements in anti-detection technologies. Recognizing the complex interaction relationships within social networks, many researchers have turned to graph-based methods for detecting Twitter bots.
Significant advancements have recently been achieved in the field of Twitter bot detection through the utilization of Graph Neural Networks (GNNs) [17,18,19,20,21,22,23,24,25]. The methods in this category are predominantly founded on the homogeneity assumption. In such graphs, nodes of the same type manifest denser connections among themselves compared to nodes of different types. However, the camouflage techniques employed by social bots are not static and undergo continuous evolution in response to methods used for account detection [9].
To explore the characteristics of Twitter bots in recent years, our study followed the HOFA approach [1]. We conducted a histogram analysis of the homophily scores using three well-established detection datasets: Cresci-15 [26], Twibot-20 [27], and MGTAB [18]. These three datasets are among the few that contain user interaction relationships, making them very suitable for research using Graph Neural Networks. Many related studies have also been conducted based on these three datasets [1,19,28]. The homophily score denotes the proportion of connections within a node’s connectivity pattern that remain consistent with their corresponding class labels. The resulting findings are presented in Figure 1.
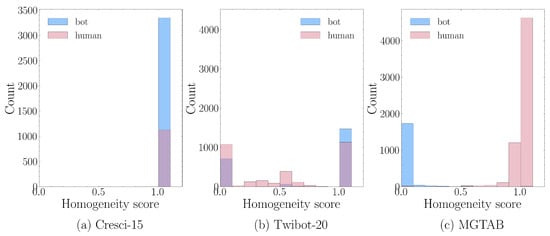
Figure 1.
Histogram of homogeneity scores for machine-generated accounts. The Cresci-15 dataset exhibits a unimodal distribution, while the Twibot-20 and MGTAB datasets exhibit bimodal distributions.
In the traditional Twitter bot dataset Cresci-15, Twitter bots exhibit comparatively higher homophily scores, indicating that, during this period, Twitter bots still conformed to the homophily assumption. In the latest Twitter bot detection datasets, Twibot-20 and MGTAB, Twitter bots exhibit a range of distinct behavioral patterns, primarily reflected in their heightened attention towards real users, as opposed to mutual reciprocation. This indicates that the latest Twitter bots have begun to camouflage themselves on relationship networks and no longer strictly adhere to the homophily assumption.
To address this issue, we propose SqueezeGCN, a novel Twitter bot detection algorithm based on neighborhood-adaptive aggregation. By integrating the Squeeze Model, the detection algorithm achieves adaptive aggregation of the relationship network. This algorithm allows for effective mitigation of the limitations imposed by the homophily assumption and effectively alleviates challenges posed by novel Twitter bots. Within the Squeeze Model, input features are dimensionally reduced to one-dimensional through a simple bypass MLP layer. The resulting values are then normalized with the sigmoid activation function and used as attention scores to aggregate neighboring relationships in the GCN [29] layer.
The experimental results demonstrate that state-of-the-art performances are achieved by SqueezeGCN on MGTAB, Twibot-20, and the Cresci-15 benchmark. Our proposed method outperforms the existing detection algorithms, such as GCN [29], GCNII [30], GAT [31], and SGC [32]. Extensive experimental studies further confirm the effectiveness and robustness of our approach in the practical detection of emerging Twitter bots. In summary, our contributions can be summarized as follows:
- We proposed a novel Twitter bot detection method based on GNN neighborhood adaptive aggregation. This method incorporates a bypass attention mechanism to allocate adaptive weights to user nodes. The advantage of this approach lies in its ability to adjust node weights during the neighbor aggregation process of GCN based on individual node features, thereby enhancing the handling of low homogeneity.
- Our proposed Squeeze Module updates attention scores iteratively and integrates lower-order attention scores into the aggregation process of higher-order neighbors. With the Squeeze Module, GCN achieves more targeted aggregation of higher-order neighbor relationships, effectively alleviating the problem of over-smoothing.
- Extensive experiments were conducted on three publicly available Twitter bot detection datasets, demonstrating the significant superiority of our method over all existing Twitter bot detection baselines. Our approach achieves state-of-the-art performances in the Twitter bot detection domain compared to prior methods.
2. Related Work
2.1. Graph-Based Twitter Bot Detection
Graph-based methods have demonstrated superior performances in Twitter bot detection compared to feature-based and text-based methods [17]. These approaches represent user accounts as nodes and their interaction relationships as edges, constructing a graph to detect Twitter bots. Graph Convolutional Networks (GCNs) were initially employed by Alhosseini et al. [33]. for spam bot detection. Subsequent studies rapidly advanced the foundation of GCNs. Wu et al., for instance, pioneered the direct multi-class logistic regression on preprocessed features, significantly improving the efficiency without compromising the performance [34]. Additionally, Feng et al. proposed the use of Relational Graph Convolutional Networks (RGCN) [19] to identify Twitter bots, building upon the generalized GCN concept. In recent years, researchers have begun exploring the intrinsic heterogeneity present in social networks. Building upon this, Feng et al. introduced a method for Twitter bot detection utilizing a relational graph transformer [20], evaluating the model using various common machine learning techniques. Pham et al. introduced a graph-embedding-based representation learning approach to capture the relationships between bots and other entities in social networks [35]. Additionally, numerous studies have leveraged multimodal user information to combat deceptive bots. Guo et al. detected social bots by combining BERT and Graph Convolutional Networks [36]. Additionally, numerous studies have leveraged multimodal user information to combat deceptive bots. Guo et al. detected social bots by combining BERT and Graph Convolutional Networks [37].
In recent years, there have been significant advancements in the detection and identification of Twitter bots by leveraging network graph structures in social media platforms. Most existing social bot detection methods based on Graph Neural Networks are predominantly built upon the assumption of homogeneity [38]. However, they fail to fully leverage the network information formed by social accounts during interactions. To overcome this limitation, we introduce a novel approach called SqueezeGCN, which aims to adaptively construct neighbor aggregation strategies.
2.2. Neighborhood Aggregation in GNN
Neighbor aggregation is a crucial step of GNNs, which can significantly affect the model’s performance. The allocation of weights for neighbor aggregation is an essential factor in distinguishing different techniques. In the GCN proposed by Thomas Kipf et al. [29], neighbors are aggregated using reciprocal weights based on their geometric mean degrees. However, this fixed weight approach, which relies on prior knowledge of the graph structure, may limit the model’s performance when the dynamic adjustment of aggregation weights is needed for specific tasks. To overcome this limitation, GAT introduced the attention mechanism, which dynamically assigns different weights to neighboring nodes based on the task at hand to enable more accurate aggregation of node information. Although the concept of varying weights was initially proposed, constraints such as weight normalization and restrictions on weight existence have hindered further performance improvements. GCNII successfully mitigates the over-smoothing issue of higher-order GCNs through a weighted initial residual strategy, but its advantages are not significant in tasks where higher-order neighbors are not necessary. For capturing domain aggregation relationships, Sami Abu-El-Haija et al. developed an iterative mixing method that incorporates neighbor feature representations at various distances to effectively learn node relationships [39]. The innovative methods provide more aggregation options for neighborhood aggregation in GNNs. However, there is still scope for improving the models’ performances in novel Twitter bot detection. To address this issue, we propose the Squeeze Module for more effective neighborhood aggregation.
3. Preliminaries
3.1. Notations
In this section, we introduce the notation and symbols used throughout this paper. Let denote the heterogeneous graph network of the social platform, where represents the set of users, and denotes the total number of nodes. donates the set of edges in the network. represents the adjacency matrix of the graph with if there is an edge connecting vertices ,. Let denote the degree matrix of A, such that . Let donate the set of neighboring nodes of vertex . Let denote the feature matrix of the nodes, where each node can be represented as a feature vector of dimension F.
The homogeneity score of a node denotes the proportion of its neighbors sharing the same category, indicating the likelihood of intra-class connections. The calculation of this score is defined as follows:
3.2. Graph Neural Networks
Graph Neural Networks (GNNs) aim to learn node representations by incorporating graph connectivity information. This objective can be formulated as
where denotes the representation vector of the l-th layer of the GNN, where represents the original feature vector. refers to the combination function, while represents the aggregation function.
Graph Convolutional Network: Within the framework of a GCN, the aggregation form of the representation in the GNN can be expressed as follows:
where represents the learnable parameters in the GCN, and denotes the activation function. The above equation can also be written in matrix form:
where .
Graph Attention Network: The application of a GAT involves the utilization of a self-attention mechanism to assign weights to neighbor pairs, allowing for adaptation to nodes with varying degrees. The neighbor aggregation process of a GAT can be represented in vector form as
Here, . For simplicity, we omit the consideration of multi-head attention. The key distinction between a GAT and a GCN lies in the incorporation of the attention mechanism, which replaces the node degree as a measure of importance among neighbor pairs.
GCNII: To overcome the limitations imposed by fixed aggregation coefficients in multi-layer GCN models, GCNII proposes two mechanisms: initial residual and identity connections. These mechanisms enable the deeper transformation of a GCN and enhance its expressive capacity. In GCNII, the l-th layer is defined as
The neighbor aggregation component can be expressed in vector form as
By focusing solely on the neighbor aggregation component, GCNII introduces initial vector residuals compared to the Vanilla GCN algorithm. When , GCNII degenerates into the Vanilla GCN algorithm.
4. Method
In this section, we first discuss the motivation proposed by SqueezeGCN. We then provide a detailed exposition of the fundamental principles of the Squeeze Module, which constitutes the basic block of SqueezeGCN’s network architecture. Additionally, we conduct a detailed comparative analysis of the underlying principles between our proposed model and previous social bot detection models such as GCN, thereby highlighting the novelty of our model. The overall architecture diagram of the proposed model is depicted in Figure 2.
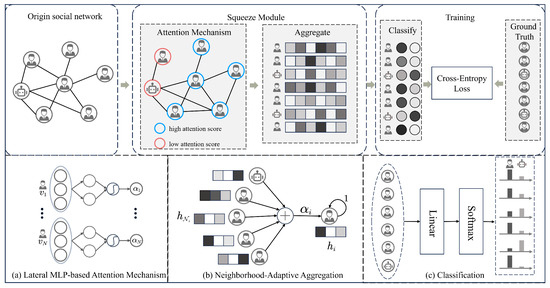
Figure 2.
The SqueezeGCN Network Architecture. Firstly, attention scores for each node are computed using a bypass MLP as an attention mechanism in the model. Then, the neighbor relationships of the nodes are aggregated using their respective attention scores. Finally, the aggregation vectors of the nodes are passed through linear and softmax layers to generate probabilities for different classes, and updates are conducted using cross-entropy.
4.1. Motivation
In this section, we first provide a detailed description of the characteristics of the datasets detected by two novel Twitter bots, namely Twibot-20 and MGTAB. We then identify why the current GNN series (GCN, GAT, GCNII) is ineffective on these two datasets. Finally, we propose our solution.
4.1.1. The Distribution Pattern of Homogeneity in Novel Bot Detection
As previously stated in the Introduction, the homogeneity distribution of users in Twibot-20 and MGTAB exhibits a distinctive bimodal pattern. In this section, we conduct a further analysis on nodes with homogeneity values ranging from 0 to 0.1. Specifically, we calculate the distribution of nodes with a homogeneity value of 0 among nodes with relatively low homogeneity values. The relationship selection for both datasets is based on “friends”. The analysis results are shown in Table 1.

Table 1.
Proportion of Heterogeneous Users.
In both datasets, the majority of nodes with low homogeneity values exhibit a value of 0, indicating complete dissimilarity between the neighbors and the node itself in terms of their categories. Consequently, we can deduce that homogeneity in the dataset of novel social machine accounts manifests as a bimodal distribution with peaks at high values and a value of 0. Subsequently, we demonstrate how this extreme distribution leads to consistent performances across most of the GCN series algorithms.
4.1.2. Limitations of GCNs in a Novel Bot Detection Task
In the GAT model, attention scores are introduced to enable the model to learn the importance of node pairs. A higher value of indicates greater importance of neighbor j with respect to node i. However, in the calculation of attention scores, normalization is required for the attention scores of all neighbors of a given node. When the homogeneity of a node is high, indicating consistency between the category of the node and its neighbor nodes, the attention scores in response to neighbor pairs tend to be higher. As a result, after normalization, the attention scores approach . When a node exhibits low homogeneity, it indicates that the categories of its neighboring nodes are inconsistent with those of the node itself. Correspondingly, the attention scores allocated to neighbor pairs tend to be lower, and following normalization, the attention scores also tend to converge towards . This observation reveals the model’s inability to differentiate between bimodal homogeneity distributions. As such, the attention mechanism becomes ineffective in these scenarios, and the representational capacity of the GAT does not surpass that of the GCN.
In contrast to the GCN, GCNII introduces substantial modifications in terms of neighbor aggregation. The most notable modification is the incorporation of initial residual connections, as shown in Equation (6). The degree of neighbor aggregation is controlled by the parameter , which is globally shared and remains consistent across distinct nodes. Consequently, GCNII also struggles to differentiate between bimodal homogeneity distributions. Therefore, in these scenarios, the representational capacity of GCNII does not surpass that of GCN.
Previous research [40] has demonstrated that the label propagation algorithm [41] exhibits a similar performance to the GCN in node classification tasks. To investigate the graph neural network’s ability to fit bimodal distributions while excluding the influence of inherent user characteristics and learnable parameters, the decision was made to employ the label propagation algorithm to explore the fit of GCN-based models to bimodal distributions.
In this study, we conducted experiments using the friends relationship in the MGTAB and Twibot-20 datasets as examples. To simulate real-world label propagation scenarios, we removed all isolated nodes and preserved the labels for all nodes. The label propagation algorithm was iteratively applied until convergence, and the resulting label distribution was compared with the original label distribution using a homogeneity histogram. Homogeneity histograms were generated for both the original and propagated labels, and the results are presented in Figure 3.
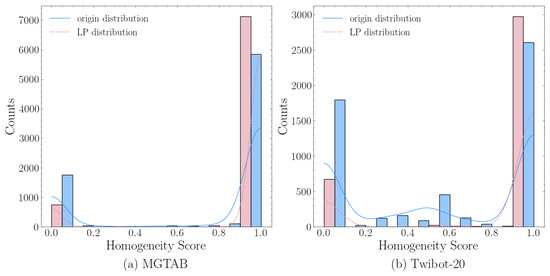
Figure 3.
Simulated propagation algorithm outputs’ homogeneity histograms and the homogeneity histograms of the original labels.
In terms of the results, it is evident that the label propagation algorithm overfits to highly homogeneous parts and exhibits a poor fitting ability to low-homogeneity parts. This indirectly suggests that GCN-based algorithms may only fit one of the two peaks in bimodal distributions and cannot simultaneously fit both peaks.
4.1.3. Addressing GCN-Based Algorithm Limitations
To overcome the challenge of GCN-based algorithms’ inability to fit bimodal homogeneity distributions, we introduce SqueezeGCN. SqueezeGCN employs a bypass MLP to compress feature vectors into a one-dimensional representation and utilizes the sigmoid function as the node aggregation coefficient. This configuration allows for the allocation of different aggregation coefficients to distinct nodes, thereby effectively distinguishing between the two peaks in a bimodal homogeneity distribution. The SqueezeGCN model consists of four primary steps: (1) the extraction of node embeddings through feature extraction, (2) the derivation of an aggregation matrix using the Squeeze Module approach, (3) utilization of the aggregation matrix and linear layers to obtain aggregated embeddings, and (4) the employment of a multi-layer perceptron (MLP) classification for generating the classification results.
4.2. Squeeze Module
The high level of concealment and the absence of adherence to homogeneous assumptions are defining characteristics of novel Twitter bots. Consequently, traditional GCN methods may yield suboptimal performances. In order to tackle this limitation, the Squeeze Module is introduced to enable the adaptive aggregation of selected nodes.
More specifically, we redefine the iterative formula of the Vanilla GCN and establish an adaptive neighbor aggregation formula.
Above, represents the attention scores at the node level, where each element’s value falls within the range of [0,1]. Here, denote the learnable parameters. ⨂ denotes the element-wise Hadamard product. Similarly, we have , and , where is the i-th row vector of . By rewriting the matrix form in the equation above into a vector form, we obtain
Here, represents the attention weights of node in the l-th layer.
Comparing Equation (9) with the aggregation Equation (3) of GCN, it becomes evident that the attention-based Squeeze Module has been simplified to the aggregation coefficient . This coefficient governs the level of aggregation in the model and can be learned during training. In contrast, both GCNII and GCN employ a fixed value for this coefficient, rendering it unchangeable. Consequently, our model exhibits greater flexibility in learning suitable aggregation levels based on the topological connections of different nodes compared to these two models. In contrast, the aggregation Equation (5) of the GAT learns an aggregation coefficient for each edge. It is important to note that, for a given node, the sum of all its edge coefficients in the GAT must equal 1. This constraint restricts the expressive power of the model in scenarios with low homogeneity. In contrast, SqueezeGCN imposes restrictions on the aggregation coefficients within the range of 0 to 1, thereby ensuring enhanced expressive capacity in situations involving low homogeneity.
4.3. SqueezeGCN Classifier for Twitter Bot
To accomplish this task, we utilized a feature mapping layer to reduce the feature dimensionality to a predetermined size, a Squeeze Module for the adaptive aggregation of first-order relationships, and a result mapping layer to associate the aggregation outcomes with labels . This can be formally expressed as
Herein, denotes the feature mapping matrix and the result mapping matrix, while represents the Squeeze Module, which satisfies the following condition:
We aim to minimize the cross-entropy between the model’s output and the label Y as the training objective.
5. Experimental Settings
5.1. Datasets
Experiments were carried out on three datasets to evaluate the performance of our proposed method: the recently introduced Twitter bot detection dataset MGTAB, the Twibot-20 dataset, and the traditional social bot detection dataset Cresci-15. Detailed descriptions of these datasets are given as follows:
- The Cresci-15 dataset comprises a total of 5301 users that have been meticulously categorized as either genuine or automated accounts. This dataset offers valuable insights into the intricate network of follower and friend relationships among these users.
- The Twibot-20 dataset encompasses 229,580 users and 227,979 edges, with 11,826 accounts being judiciously classified as either genuine or automated. This dataset furnishes comprehensive details regarding the follower and friend relationships existing among these users.
- The MGTAB dataset represents a significant advancement in the realm of machine account detection, constructed upon an extensive corpus of raw data. Boasting a staggering volume of over 1.5 million users and 130 million tweets, this dataset offers a rich source of information pertaining to seven distinct types of relationships among these users. Furthermore, it meticulously classifies 10,199 accounts as either genuine or bots, facilitating a comprehensive analysis in this domain.
Prior to the experiments, we applied feature extraction techniques commonly utilized in related studies for data preprocessing. For the Cresci-15 dataset, six user attribute features and 768-dimensional tweet features extracted using BERT were employed [28]. Concerning the Twibot-20 dataset, 16 user attribute features and 768-dimensional tweet features extracted using BERT were utilized [28]. As for the MGTAB dataset, we selected the top 20 user attribute features with the highest information gain, in addition to 768-dimensional tweet features also extracted using BERT. In terms of user connection relationships, follower and friend relationships were considered across all three datasets. To better simulate real-world scenarios, a 1:1:8 split was adopted when allocating the test set. Table 2 provides an overview of the statistical details for the three datasets.
Table 2.
Statistical Summary of the Datasets.
5.2. Baseline Methods
To evaluate the performance of our model, a comparison was made with several classical Graph Neural Network (GNN) models, as described below:
[29]: Embedding vectors were obtained by aggregating first-order neighbors using graph convolutional methods. The aggregation results were then fed into an MLP for classification.
[31]: Attention mechanisms were employed to model the importance of node-to-node connections during aggregation.
[32]: This simplified version of the GCN reduced the model’s complexity by removing non-linear layers and representing all functions as a single linear transformation.
- [22]: By learning the distribution of neighbor node features conditioned on central node features through local enhancement, the GNN representation capability was enhanced.
[24]: The graph was decomposed into multiple subgraphs based on edge types. Convolution operations were applied to obtain node representations for each subgraph, and the representation vectors of nodes within each subgraph were aggregated.
[25]: High-frequency information within the GCN was explored, resulting in a GCN that adaptively combines high and low-frequency information.
- [34]: Designed for heterogeneous graphs, this model utilizes a self-gated frequency-selective filter, enabling the adaptive selection of different frequencies of information without assuming homogeneity.
[21]: This model incorporates an adaptive frequency response filter that controls the flow of information in different feature channels.
[30]: Overcomes the over-smoothing issue present in the Vanilla GCN by introducing initial residual and identity mapping techniques.
[39]: By iteratively mixing neighbor feature representations at different distances, this model learns complex relationships between nodes, enabling the better capture of intricate node associations.
All the models mentioned above were implemented based on the source code provided by the authors of the paper.
5.3. Evaluation Metrics
The performance of our classification models was assessed using two metrics, namely Marco-F1 and Accuracy.
For evaluating the performance in binary classification tasks, we adopted the standard notation. In this notation, stand for the count of true positive instances, represent true negative instances, denote false positive instances, and correspond to false negative instances.
5.4. Implementation and Configuration
The models were trained using the AdamW optimizer for a total of 200 epochs. A learning rate of 0.01 was set for all models, and an L2 regularization term of 5 × 10−4 was applied. Dropout rates ranging from 0.3 to 0.5 were utilized. The input and output dimensions of the GNN layers were fixed at either 128 or 256. For GAT, four attention heads were employed. In the RF-GNN, the number of base classifiers was set to 10. The hyperparameters denoted as were used in the GCNII.
The PyTorch and PyTorch Geometric frameworks were utilized for implementing SqueezeGCN. All experiments were conducted on a single NVIDIA RTX3090 GPU with 24 GB of memory, 8CPU cores and 16 GB CPU memory.
6. Experiment Results
In order to assess the performance of SqueezeGCN, a series of experiments was conducted with the objective of addressing the following research questions:
Q1: How is the algorithm’s performance across different datasets? Additionally, what can be said about its effectiveness and robustness? (Section 6.1)
Q2: To what extent does the algorithm adaptively aggregate neighboring information, and what level of interpretability does it offer? (Section 6.2)
Q3: How does our algorithm alleviate the over-smoothing issue encountered in GNNs? (Section 6.3)
6.1. Evaluation
The average performance of our algorithm and all baselines on the test set are compared and presented in Table 3.
Table 3.
Average performance of different algorithms for social media account detection, with bold representing the best performance and underlining indicating the second-best performance.
Improvements of 2.37%, 15.59%, and 1.33% were observed in our algorithm compared to the GCN on three datasets, respectively. When compared to other variants of GCN, improvements were also noted. In addition, our approach achieved improvement rates of 0.69%, 2.54%, and 0.12% when compared to state-of-the-art algorithms on the three datasets. Notably, our algorithm outperformed methods such as RFA-GCN, AdaGCN, and FAGCN, which utilize high-frequency information. This suggests that specialized processing strategies for high-frequency information in Twitter bot detection may not be necessary. Treating nodes with higher contents of high-frequency information as unimportant nodes and reducing the aggregation weight can lead to better performances.
Furthermore, to investigate the robustness of our algorithm, we conducted additional experiments using seven different topological relationships from the MGTAB dataset. By comparing the performance discrepancies between GCN and our proposed SqueezeGCN under various topological structures, we obtained valuable insights. The corresponding results are presented in Table 4.
Table 4.
Performance of the algorithm with different topological structures. With bold representing the best performance of various models for different Relationships, and underlining indicating the second-best performance.
Performance discrepancies of up to 9.87% were observed in the GCN when utilizing various edge types. This can be attributed to the equal treatment of each node’s status during aggregation, resulting in poor robustness and an inability to adapt to complex relationships within social networks. While the GAT, which incorporates attention mechanisms to assign different weights to neighbors, partially addresses this issue, its normalized weight calculation method for every node is not suitable for diverse and generally low-homogeneity novel Twitter bot detection. Experimental results demonstrate an 8.63% disparity in GAT performance when considering different types of social relationships. In contrast, our algorithm dynamically selects appropriate aggregation weights based on the respective topological structures. When examining different types of edge connections, our model exhibits a maximum performance disparity of merely 1.14%, effectively reducing the reliance on the graph topology and enhancing the algorithm’s robustness.
6.2. Explorations on the Interpretability of the Squeeze Module
The effectiveness of the proposed Squeeze Module is demonstrated in this subsection, considering both graph-level and node-level perspectives.
Graph-level: The average attention score of all nodes in the first GNN layer, denoted as , is defined to reflect the level of aggregation among nodes. A value of s = 1 aligns with the Vanilla GCN algorithm, indicating that no node is considered to be negligible during aggregation. Conversely, when s = 0, the model degenerates to MLP, suggesting poor topological properties of the graph structure for the given task. Sun et al. [42] demonstrated that the performance of GCN is closely tied to the topological structure of the graph. Therefore, the performance of the Vanilla GCN can reflect the topological properties of the graph. The average attention score of SqueezeGCN can reflect the average aggregation level of the nodes. An ideal attention score would exhibit a low average aggregation level on graphs with poor topological properties and a high average aggregation level on graphs with good topological properties. If we consider the performance of the Vanilla GCN as the evaluation criterion for the graph topology, we can hypothesize that there is a positive correlation between the performance of the Vanilla GCN and the average attention scores of the SqueezeGCN. To validate this hypothesis, we conducted experiments using seven different graph structures from the MGTAB dataset. We calculated the average accuracy of the Vanilla GCN under five randomly selected seeds as well as the average attention scores of the SqueezeGCN and performed a visual analysis. The results are shown in Figure 4.
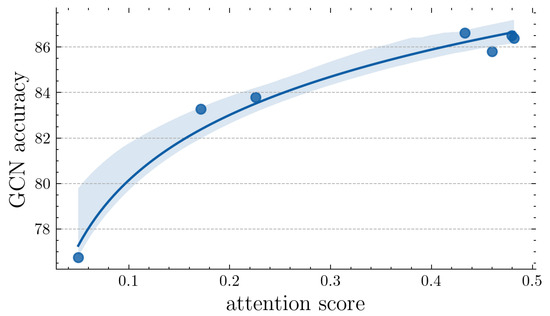
Figure 4.
Relationship between attention scores under different topological structures and the accuracy of the GCN.
Upon observing the average attention scores corresponding to SqueezeGCN, a clear positive relationship between the average attention scores and the performance of the GCN is evident. This indicates that, in the presence of well-structured topologies, SqueezeGCN tends to assign greater weights to node aggregations. Conversely, SqueezeGCN tends to assign lower weights to node aggregations when there is a poor topology to avoid unnecessary aggregations and pay more attention to the original features.
Node-level: At the node level, a key advantage of our algorithm over that of the Vanilla GCN is its adaptive assignment of lower aggregation weights to nodes with lower homogeneity. The algorithm can effectively fit not only highly homogeneous nodes but also low-homogeneity ones. This enables the fitting of bimodal distributions in the dataset and fundamentally enhances the representation ability of the GCN. We conducted experiments on SqueezeGCN and Vanilla GCN using the friends relation and a 1:1:8 dataset partitioning method in MGTAB and Twibot-20 and compared the homogeneity of the misclassified nodes. The final results are shown in Figure 5.
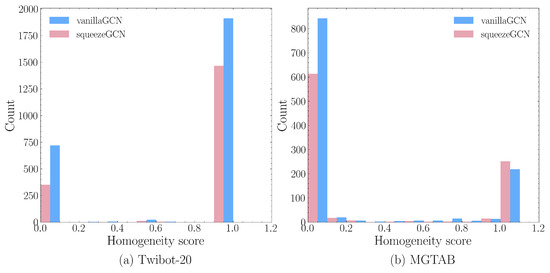
Figure 5.
Histograms of homogeneity scores for misclassified nodes in the Twibot-20 and MGTAB datasets.
Our experiments revealed the following phenomena: for nodes with homogeneity scores ranging from 0 to 0.1, SqueezeGCN exhibited performance improvements of 51.18% and 27.04% on the Twibot-20 and MGTAB datasets, respectively. This indicates that the Squeeze Module enhances the algorithm’s performance on Twitter bots with lower homogeneity. Additionally, we observed that our algorithm not only significantly improves the fitting of low-homogeneity nodes, but also performs comparably to the Vanilla GCN in terms of fitting high-homogeneity nodes. Therefore, we believe that our algorithm is effective for fitting bimodal distributions of novel datasets compared to the GCN series of algorithms.
6.3. Analysis of Model Depth
In this subsection, the effectiveness of the proposed SqueezeGCN in mitigating the common over-smoothing issue in GNNs is demonstrated.
Within the GCN framework, the k-th GCN layer aggregates k-hop neighborhood relations. Previous studies have indicated that excessive layering in the GCN results in the over-smoothing problem, leading to a performance degradation. However, in SqueezeGCN, the aggregation level of nodes is adaptively selected by each layer. This approach avoids the unnecessary aggregation of less important high-order relations that can cause over-smoothing [43,44].
To compare the performance of SqueezeGCN, GCN, GAT, and GCNII at various network depths, we conducted an experiment with the number of GCN layers set as {1, 2, 3, 4, 5}. The results are depicted in Figure 6.
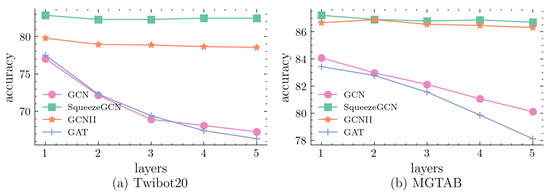
Figure 6.
Relationship between the accuracy and different datasets.
Both the GCN and GAT achieved their best performances when using only one layer. As the number of layers increased, these models exhibited significant declines in performance. This indicates the presence of the over-smoothing issue in the GCN models. While the GCNII partially mitigated the over-smoothing phenomenon, its overall performance was inferior to that of our proposed SqueezeGCN. Notably, our algorithm’s performance did not show a significant impact with an increase in the number of layers, demonstrating its ability to alleviate the effects of over-smoothing while ensuring a high detection accuracy.
7. Conclusions
The detection of Twitter bot poses a significant and challenging task, especially considering the increasing sophistication and stealthiness of bot accounts in recent years. To tackle this emerging challenge, an effective algorithm for detecting Twitter bot accounts based on neighborhood-adaptive aggregation is proposed in this study. Our approach incorporates self-attention to assign weights adaptively to nodes, thus capturing the significance of neighboring nodes. An extensive evaluation of our model was conducted on multiple benchmark datasets, including MGTAB, Cresci-15, and Twibot-20, for bot detection. The results demonstrate the superior performance and robustness of our model compared to previous approaches. Moreover, our experimental findings indicate that our model can mitigate the inherent over-smoothing issue in GCN to some extent.
In summary, SqueezeGCN has emerged as an innovative solution in the realm of identifying and detecting malicious social bots on the prominent social media platform Twitter. With its remarkable efficacy in aiding decision-making processes, this tool offers a significant improvement in efficiently uncovering such accounts. The implications of this advancement extend to combating the pervasive challenge of online armies, averting the escalation of extreme online public opinion outbreaks and ultimately safeguarding social stability. As such, the practical value and overarching significance of SqueezeGCN in this domain are undeniable.
Author Contributions
Conceptualization, C.F. and S.S.; methodology, C.F.; software, Y.Z. (Yongmao Zhang); validation, Y.Z. (Yuxin Zhang) and S.S.; formal analysis, C.F.; investigation, S.S.; resources, B.Y. and J.C.; data curation, K.Q. and S.S.; writing—original draft preparation, C.F.; writing—review and editing, S.S. and Y.Z. (Yuxin Zhang); visualization, Y.Z. (Yongmao Zhang); supervision, K.Q.; project administration, K.Q. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
MGTAB: https://drive.google.com/uc?export=download&id=1gbWNOoU1JB8RrTu2a5j9KMNVa9wX72Fe, accessed on 3 March 2023.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Ye, S.; Tan, Z.; Lei, Z.; He, R.; Wang, H.; Zheng, Q.; Luo, M. HOFA: Twitter Bot Detection with Homophily-Oriented Augmentation and Frequency Adaptive Attention. arXiv 2023, arXiv:2306.12870. [Google Scholar]
- Cresci, S.; Di Pietro, R.; Spognardi, A.; Tesconi, M.; Petrocchi, M. Demystifying Misconceptions in Social Bots Research. arXiv 2023, arXiv:2303.17251. [Google Scholar]
- Rossi, S.; Rossi, M.; Upreti, B.R.; Liu, Y. Detecting political bots on Twitter during the 2019 Finnish parliamentary election. In Proceedings of the 53rd Hawaii International Conference on System Sciences, Maui, HI, USA, 7–10 January 2020. [Google Scholar]
- Cresci, S.; Di Pietro, R.; Petrocchi, M.; Spognardi, A.; Tesconi, M. The paradigm-shift of social spambots: Evidence, theories, and tools for the arms race. In Proceedings of the 26th International Conference on World Wide Web Companion, Perth, Australia, 3–7 April 2017. [Google Scholar]
- Hayawi, K.; Mathew, S.; Venugopal, N.; Masud, M.M.; Ho, P.H. DeeProBot: A hybrid deep neural network model for social bot detection based on user profile data. Soc. Netw. Anal. Min. 2022, 12, 43. [Google Scholar] [CrossRef] [PubMed]
- Mazza, M.; Cresci, S.; Avvenuti, M.; Quattrociocchi, W.; Tesconi, M. Rtbust: Exploiting temporal patterns for botnet detection on twitter. In Proceedings of the 10th ACM Conference on Web Science, Amsterdam, The Netherlands, 27–30 May 2018. [Google Scholar]
- Miller, Z.; Dickinson, B.; Deitrick, W.; Hu, W.; Wang, A.H. Twitter spammer detection using data stream clustering. Inf. Sci. 2014, 260, 64–73. [Google Scholar] [CrossRef]
- Lee, K.; Eoff, B.; Caverlee, J. Seven months with the devils: A long-term study of content polluters on twitter. In Proceedings of the 5th International AAAI Conference on Weblogs and Social Media, Catalonia, Spain, 17–21 July 2011. [Google Scholar]
- Elmas, T.; Overdorf, R.; Aberer, K. Characterizing retweet bots: The case of black market accounts. In Proceedings of the 16th International AAAI Conference on Web and Social Media, Atlanta, GA, USA, 6–9 June 2022. [Google Scholar]
- Kudugunta, S.; Ferrara, E. Deep neural networks for bot detection. Inf. Sci. 2018, 467, 312–322. [Google Scholar] [CrossRef]
- Feng, S.; Wan, H.; Wang, N.; Li, J.; Luo, M. Satar: A self-supervised approach to twitter account representation learning and its application in bot detection. In Proceedings of the 30th ACM International Conference on Information and Knowledge Management, Gold Coast, QLD, Australia, 1–5 November 2021. [Google Scholar]
- Ferrara, E.; Varol, O.; Davis, C.; Menczer, F.; Flammini, A. The rise of social bots. Commun. ACM 2016, 59, 96–104. [Google Scholar] [CrossRef]
- Knauth, J. Language-agnostic twitter-bot detection. In Proceedings of the 12th International Conference on Recent Advances in Natural Language Processing, Varna, Bulgaria, 2–4 September 2019. [Google Scholar]
- Wei, F.; Nguyen, U.T. Twitter bot detection using bidirectional long short-term memory neural networks and word embeddings. In Proceedings of the 1st IEEE International Conference on Trust, Privacy and Security in Intelligent Systems, and Applications, Los Angeles, CA, USA, 12–14 December 2019. [Google Scholar]
- Cai, C.; Li, L.; Zeng, D. Detecting social bots by jointly modeling deep behavior and content information. In Proceedings of the 26th ACM International Conference on Information and Knowledge Management, Singapore, 6–10 November 2017. [Google Scholar]
- Dukić, D.; Keča, D.; Stipić, D. Are you human? Detecting bots on Twitter Using BERT. In Proceedings of the 7th IEEE International Conference on Data Science and Advanced Analytics, Sydney, NSW, Australia, 6–9 October 2020. [Google Scholar]
- Feng, S.; Tan, Z.; Wan, H.; Wang, N.; Chen, Z.; Zhang, B.; Zheng, Q.; Zhang, W.; Lei, Z.; Yang, S.; et al. TwiBot-22: Towards graph-based Twitter bot detection. Adv. Neural Inf. Process. Syst. 2022, 35, 35254–35269. [Google Scholar]
- Shi, S.; Qiao, K.; Chen, J.; Yang, S.; Yang, J.; Song, B.; Wang, L.; Yan, B. Mgtab: A multi-relational graph-based twitter account detection benchmark. arXiv 2023, arXiv:2301.01123. [Google Scholar]
- Feng, S.; Wan, H.; Wang, N.; Luo, M. BotRGCN: Twitter bot detection with relational graph convolutional networks. In Proceedings of the 13th IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Hague, Zuid-Holland, Netherlands, 8–11 November 2021. [Google Scholar]
- Feng, S.; Tan, Z.; Li, R.; Luo, M. Heterogeneity-aware twitter bot detection with relational graph transformers. In Proceedings of the 36th AAAI Conference on Artificial Intelligence, Palo Alto, CA, USA, 22 February–1 March 2022. [Google Scholar]
- Shi, S.; Qiao, K.; Yang, S.; Wang, L.; Chen, J.; Yan, B. AdaGCN: Adaptive Boosting Algorithm for Graph Convolutional Networks on Imbalanced Node Classification. arXiv 2021, arXiv:2105.11625. [Google Scholar]
- Wu, S.; Fei, H.; Ren, Y.; Ji, D.; Li, J. Learn from syntax: Improving pair-wise aspect and opinion terms extractionwith rich syntactic knowledge. arXiv 2021, arXiv:2105.02520. [Google Scholar]
- Magelinski, T.; Beskow, D.; Carley, K.M. Graph-hist: Graph classification from latent feature histograms with application to bot detection. In Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Chen, J.; Huang, F.; Peng, J. Msgcn: Multi-subgraph based heterogeneous graph convolution network embedding. Appl. Sci. 2021, 11, 9832. [Google Scholar] [CrossRef]
- Bo, D.; Wang, X.; Shi, C.; Shen, H. Beyond low-frequency information in graph convolutional networks. In Proceedings of the 35th AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021. [Google Scholar]
- Cresci, S.; Di Pietro, R.; Petrocchi, M.; Spognardi, A.; Tesconi, M. Fame for sale: Efficient detection of fake Twitter followers. Decis. Support Syst. 2015, 80, 56–71. [Google Scholar] [CrossRef]
- Feng, S.; Wan, H.; Wang, N.; Li, J.; Luo, M. Twibot-20: A comprehensive twitter bot detection benchmark. In Proceedings of the 30th ACM International Conference on Information and Knowledge Management, Gold Coast, QLD, Australia, 1–5 November 2021. [Google Scholar]
- Shi, S.; Qiao, K.; Yang, J.; Song, B.; Chen, J.; Yan, B. Over-Sampling Strategy in Feature Space for Graphs based Class-imbalanced Bot Detection. arXiv 2023, arXiv:2302.06900. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the 4th International Conference on Learning Representations, San Juan, PR, USA, 2–4 May 2016. [Google Scholar]
- Chen, M.; Wei, Z.; Huang, Z.; Ding, B.; Li, Y. Simple and deep graph convolutional networks. In Proceedings of the 37th International Conference on Machine Learning, Vienna, Austria, 7–12 July 2020. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Wu, F.; Souza, A.; Zhang, T.; Fifty, C.; Yu, T.; Weinberger, K. Simplifying graph convolutional networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019. [Google Scholar]
- Ali Alhosseini, S.; Bin Tareaf, R.; Najafi, P.; Meinel, C. Detect me if you can: Spam bot detection using inductive representation learning. In Proceedings of the Companion Proceedings of the 2019 World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019. [Google Scholar]
- Wu, L.; Lin, H.; Hu, B.; Tan, C.; Gao, Z.; Liu, Z.; Li, S.Z. Beyond homophily and homogeneity assumption: Relation-based frequency adaptive graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2023. [Google Scholar] [CrossRef] [PubMed]
- Pham, P.; Nguyen, L.T.; Vo, B.; Yun, U. Bot2Vec: A general approach of intra-community oriented representation learning for bot detection in different types of social networks. Inf. Syst. 2022, 103, 101771. [Google Scholar] [CrossRef]
- Guo, Q.; Xie, H.; Li, Y.; Ma, W.; Zhang, C. Social bots detection via fusing bert and graph convolutional networks. Symmetry 2021, 14, 30. [Google Scholar] [CrossRef]
- Lei, Z.; Wan, H.; Zhang, W.; Feng, S.; Chen, Z.; Li, J.; Zheng, Q.; Luo, M. Bic: Twitter bot detection with text-graph interaction and semantic consistency. arXiv 2022, arXiv:2208.08320. [Google Scholar]
- Liu, Y.; Tan, Z.; Wang, H.; Feng, S.; Zheng, Q.; Luo, M. BotMoE: Twitter Bot Detection with Community-Aware Mixtures of Modal-Specific Experts. arXiv 2023, arXiv:2304.06280. [Google Scholar]
- Abu-El-Haija, S.; Perozzi, B.; Kapoor, A.; Alipourfard, N.; Lerman, K.; Harutyunyan, H.; Ver Steeg, G.; Galstyan, A. Mixhop: Higher-order graph convolutional architectures via sparsified neighborhood mixing. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019. [Google Scholar]
- Chen, D.; Lin, Y.; Zhao, G.; Ren, X.; Li, P.; Zhou, J.; Sun, X. Topology-imbalance learning for semi-supervised node classification. Adv. Neural Inf. Process. Syst. 2021, 34, 29885–29897. [Google Scholar]
- Raghavan, U.N.; Albert, R.; Kumara, S. Near linear time algorithm to detect community structures in large-scale networks. Phys. Rev. E 2007, 76, 036106. [Google Scholar] [CrossRef] [PubMed]
- Sun, Q.; Li, J.; Yuan, H.; Fu, X.; Peng, H.; Ji, C.; Li, Q.; Yu, P.S. Position-aware structure learning for graph topology-imbalance by relieving under-reaching and over-squashing. In Proceedings of the 31st ACM International Conference on Information and Knowledge Management, Atlanta, GA, USA, 17–21 October 2022. [Google Scholar]
- Li, Q.; Han, Z.; Wu, X.M. Deeper insights into graph convolutional networks for semi-supervised learning. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Oono, K.; Suzuki, T. Graph neural networks exponentially lose expressive power for node classification. arXiv 2019, arXiv:1905.10947. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).