
Multi-Dimensional Fusion Deep Learning for Side Channel Analysis

Abstract
:1. Introduction
2. Background
2.1. Advanced Encryption Standard
2.2. Profiling SCA
- Capture profiling traces. Collect a set of N profiling traces, denoted as , by conducting AES-128 encryption operations on N random plaintexts and N corresponding random keys using the profiling device.
- Build leakage profile. The captured traces are first labeled according to the selected attack point. Afterwards, we train deep-learning models on these labeled traces to learn a leakage profile between traces and the key-dependent sensitive value.
- Measure traces from victim devices. Repeating the AES-128 encryption operation on the victim device(s) with an unknown key to obtain a set of M power traces denoted as .
- Extract the secret key. The pre-trained deep learning model is used to classify traces captured from the victim device(s) to acquire the score vector . Next, we can obtain the subkey candidate with the highest classification probability for trace according to the obtained score vector and the selected attack point. Afterwards, the attack is considered successful when the guessed subkey value with the highest classification probability matches the value of the real subkey .wherein is the first byte of the corresponding plaintext for trace and denotes the inverse of the SubByte procedure.
2.3. Points of Interest
- First, derive the intermediate value by using the known information of the profiling traces according to the selected attack point (SBox output in the first round of AES).
- Calculate the SNR between the power consumption trace data and the obtained intermediate value. Afterwards, select the trace segments with the highest SNR values as PoIs. Figure 2 represents the plot of a captured power trace and the SNR results of the corresponding traces.
2.4. Metrics
3. Multi-Dimensional Fusion for DLSCAs
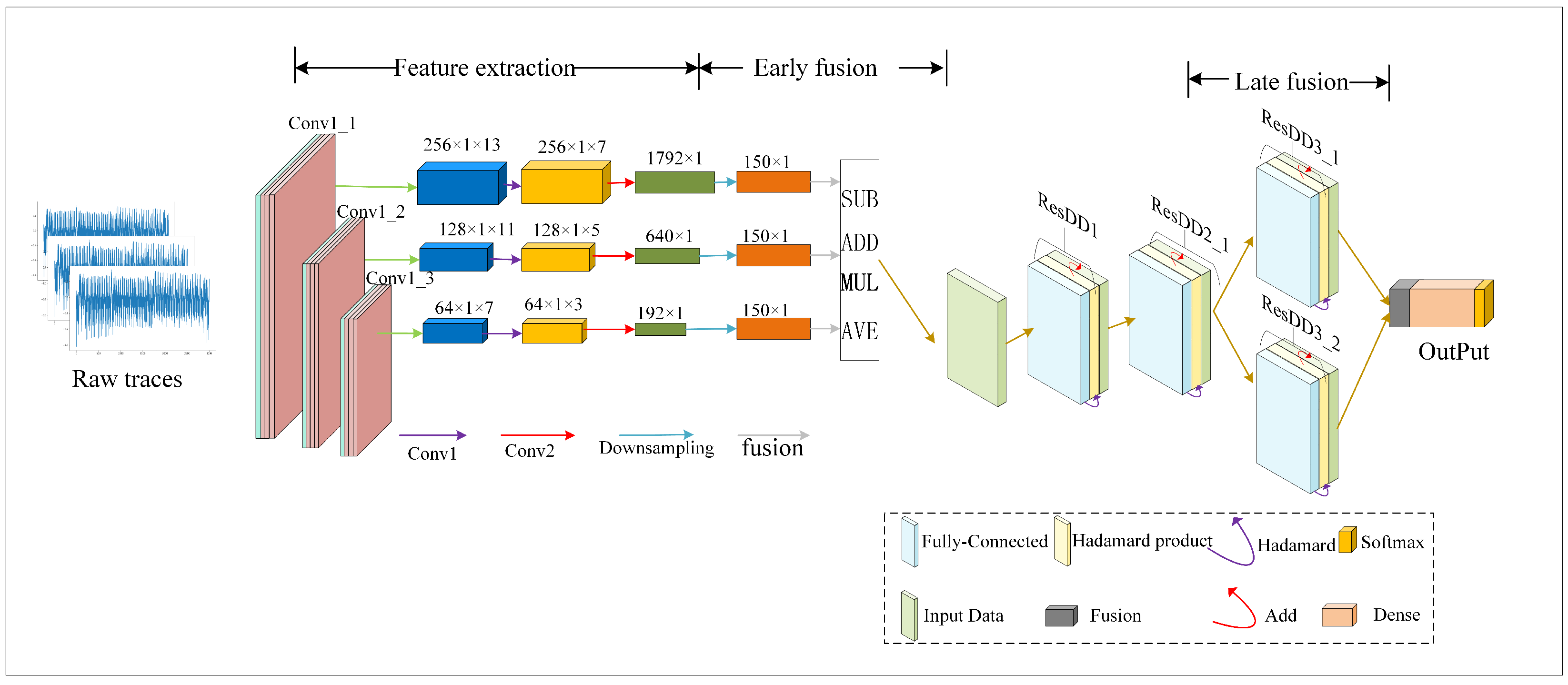
3.1. MD_CResDD Network
3.1.1. Multi-Scale Feature Fusion
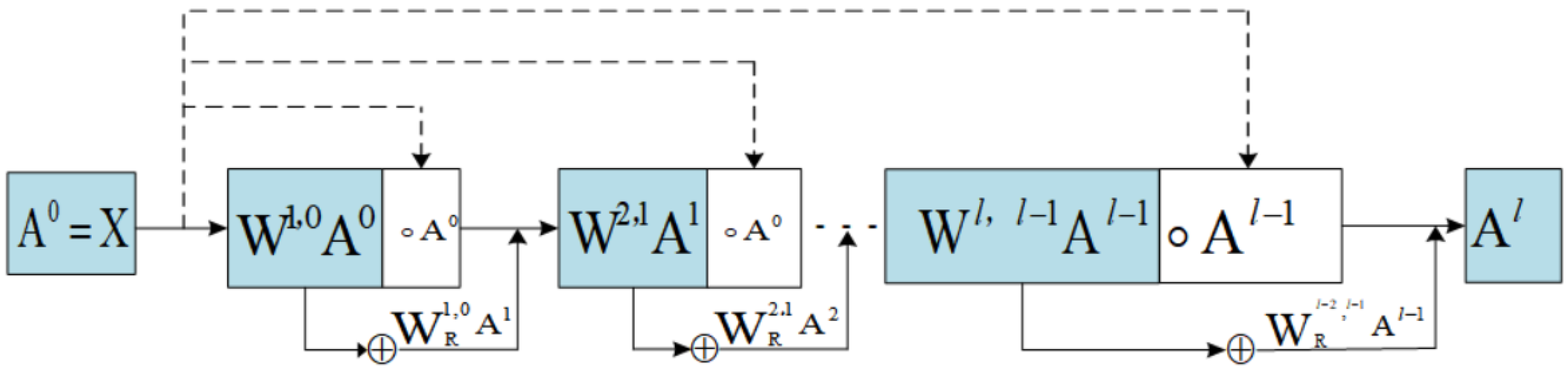
3.1.2. ResDD Network
4. DLSCAs Based on MD_CResDD Network
4.1. Experimental Setups
4.1.1. CW Dataset
4.1.2. Xmega Dataset
4.1.3. Software vs. Hardware Implementations of AES
- Flexibility: Software implementations are highly flexible and can be run on a wide range of devices, from computers to embedded systems. They are not tied to specific hardware, making them versatile for various applications.
- Ease of Updates and Maintenance: Software implementations can be easily updated and maintained. If there are improvements or security patches for the AES algorithm, they can be applied to the software without changing the hardware.
- Portability: AES software implementations are highly portable, allowing the same code to be used on different platforms, including different operating systems and architectures.
4.2. SCA Flow Based on MD_CResDD Network
- Data acquisition and pre-process. Data pre-processing including dataset split and PoIs selection.
- Build leakage profile. The established leakage model is continuously trained and optimised to learn a leakage profile between traces and the key-dependent sensitive value.
- Key recovery. In the AES-128 encryption algorithm, the key consists of 16 bytes. To recover each byte of the key, we follow a sequential approach. We derive the intermediate value state associated with the byte of the key that needs to be recovered using the trained model. Finally, we recover the target subkey from the derived intermediate value based on the known plaintext information. The complete process of the MD_CResDD based deep-learning side channel attack is illustrated in Figure 3.
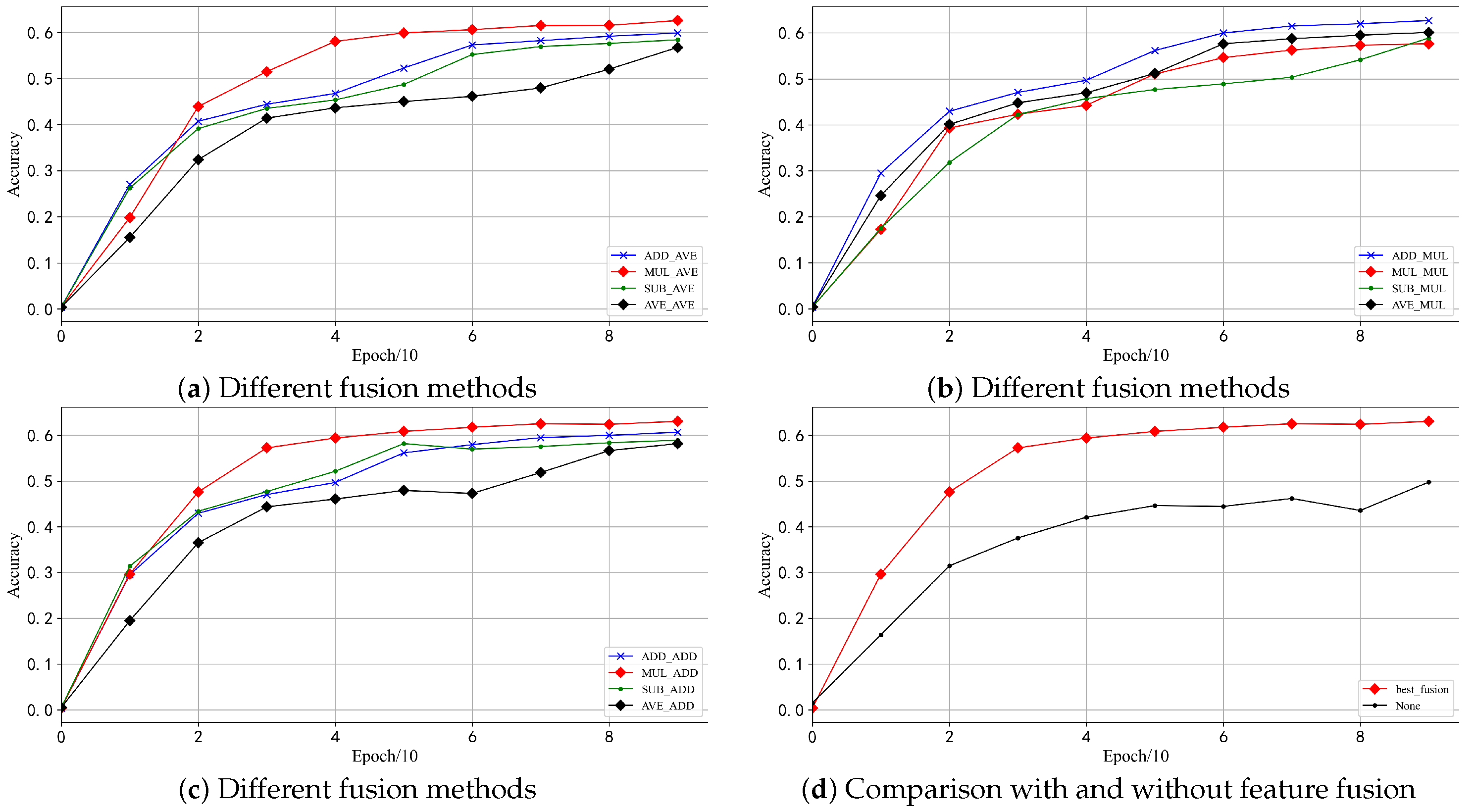
4.3. Impact of Different Fusion Methods on SCA
4.4. Impact of Different Residual Blocks on SCA
4.5. MD_CResDD Network Structure
5. Experimental Results
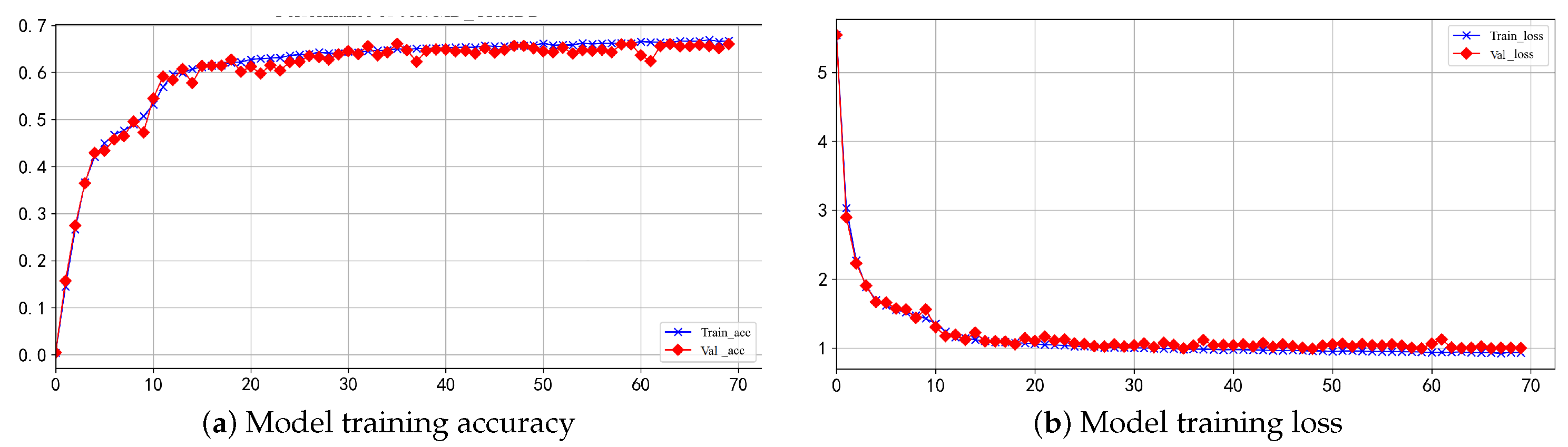
5.1. Experimental Results and Attacks for CW Datasets
5.2. Experimental Results on Xmega Dataset
5.3. Comparison of Several Deep Learning SCA
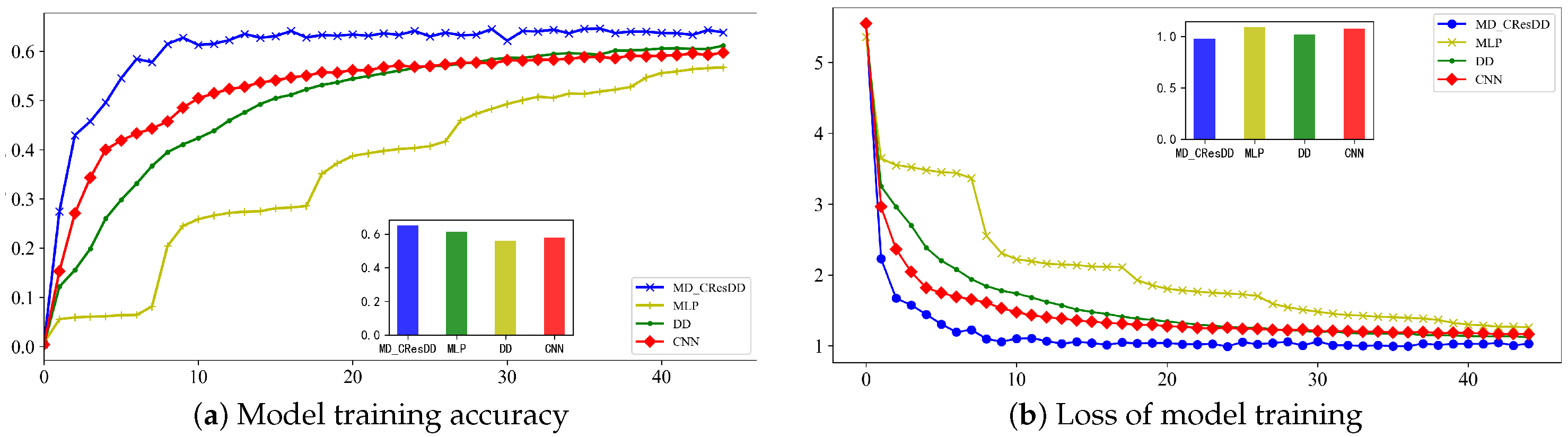
5.3.1. Comparison Experiments on the CW Datasets
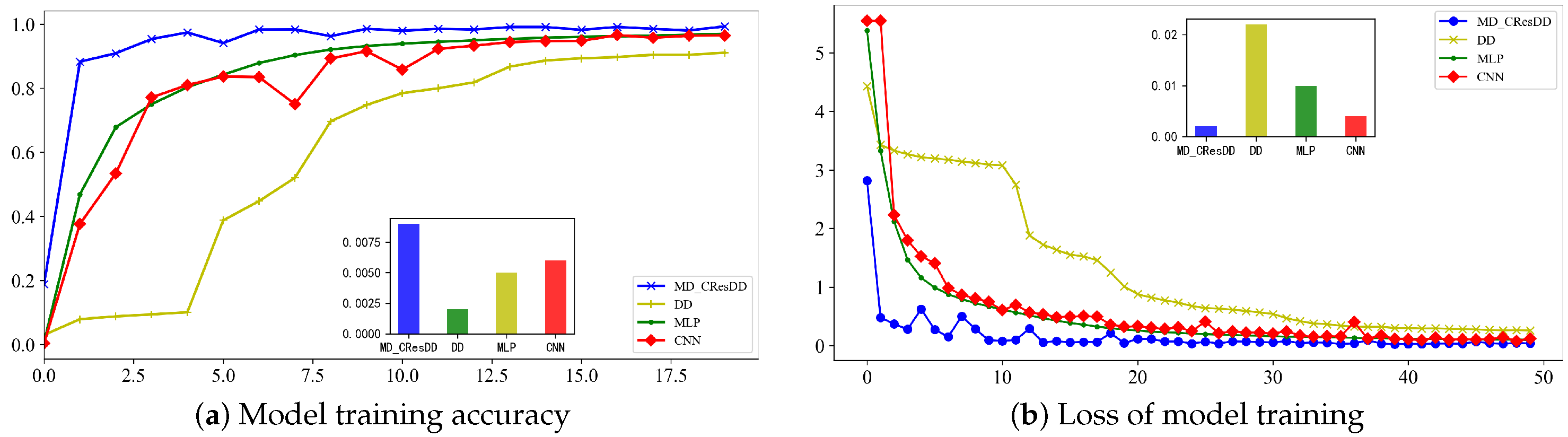
5.3.2. Comparison Experiments on Xmega Datasets
5.3.3. Discussion
6. Conclusions and Future Works
6.1. Conclusions
6.2. Future Works
- Investigate and assess the performance and effectiveness of the MD_CResDD network in various cryptographic implementations. Our ongoing exploration of MD_CResDD on new datasets, such as the wireless side channel, includes assessing its performance under different software or hardware configurations implementing encryption algorithms. By conducting these studies, we can gain valuable insights into the potential and effectiveness of the MD_CResDD network in different cryptographic scenarios. Ultimately, this research will provide crucial insights to deepen our understanding of the applicability and effectiveness of the MD_CResDD network.
- The development of effective countermeasures against DLSCAs is of utmost importance in safeguarding our devices. To address this concern, future efforts should focus on devising strategies to protect devices from DLSCAs. Promising design directions include reducing physical leakage during the implementation of cryptographic algorithms and enhancing the interference between leakage and physical leakage. By minimizing the extent of physical leakage and increasing the complexity of the side-channel information, these countermeasures aim to fortify the security of devices against DLSCAs.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| SCAs | Side-Channel Attacks |
| DLSCAs | Deep-Learning Side-Channel Attacks |
| MD_CResDD | Multi-Dimensional Fusion Convolutional Residual Dendrite |
| MLP | Multilayer Perceptrons |
| CNN | Convolutional Neural Networks |
| DD | Dendrite Network |
| ResDD | Residual Dendrite Network |
| AES | Advanced Encryption Standard |
| DES | Data Encryption Standard |
| POIS | Points of Interests |
| PA | Power Analysis |
| SNR | Signal-to-Noise Ratio |
| CPU | Central Processing Unit |
| GPU | Graphics Processing Unit |
| FD | Failure Detector |
References
- Hu, W.J.; Fan, J.; Du, Y.X.; Li, B.S.; Xiong, N.; Bekkering, E. MDFC–ResNet: An agricultural IoT system to accurately recognize crop diseases. IEEE Access 2020, 8, 115287–115298. [Google Scholar] [CrossRef]
- Kocher, P.C. Timing attacks on implementations of Diffie-Hellman, RSA, DSS, and other systems. In Proceedings of the Advances in Cryptology—CRYPTO’96: 16th Annual International Cryptology Conference, Santa Barbara, CA, USA, 18–22 August 1996; Springer: Berlin/Heidelberg, Germany, 1996; pp. 104–113. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 8 November 2022).
- Cagli, E.; Dumas, C.; Prouff, E. Convolutional neural networks with data augmentation against jitter-based countermeasures: Profiling attacks without pre-processing. In Proceedings of the Cryptographic Hardware and Embedded Systems–CHES 2017: 19th International Conference, Taipei, Taiwan, 25–28 September 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 45–68. [Google Scholar]
- Wang, R.; Wang, H.; Dubrova, E.; Brisfors, M. Advanced far field EM side-channel attack on AES. In Proceedings of the 7th ACM on Cyber-Physical System Security Workshop, Virtual, 7 June 2021; pp. 29–39. [Google Scholar]
- Wong, S.C.; Gatt, A.; Stamatescu, V.; McDonnell, M.D. Understanding data augmentation for classification: When to warp? In Proceedings of the 2016 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Gold Coast, Australia, 30 November–2 December 2016; pp. 1–6. [Google Scholar]
- Benadjila, R.; Prouff, E.; Strullu, R.; Cagli, E.; Dumas, C. Deep learning for side-channel analysis and introduction to ASCAD database. J. Cryptogr. Eng. 2020, 10, 163–188. [Google Scholar] [CrossRef]
- Das, D.; Golder, A.; Danial, J.; Ghosh, S.; Raychowdhury, A.; Sen, S. X-DeepSCA: Cross-device deep learning side channel attack. In Proceedings of the 56th Annual Design Automation Conference 2019, Las Vegas, NV, USA, 2–6 June 2019; pp. 1–6. [Google Scholar]
- Wang, H.; Forsmark, S.; Brisfors, M.; Dubrova, E. Multi-source training deep-learning side-channel attacks. In Proceedings of the 2020 IEEE 50th International Symposium on Multiple-Valued Logic (ISMVL), Miyazaki, Japan, 9–11 November 2020; pp. 58–63. [Google Scholar]
- Wu, L.; Perin, G.; Picek, S. The best of two worlds: Deep learning-assisted template attack. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2021, 2021, 413–437. [Google Scholar] [CrossRef]
- Chari, S.; Rao, J.R.; Rohatgi, P. Template attacks. In Proceedings of the International Workshop on Cryptographic Hardware and Embedded Systems, Redwood Shores, CA, USA, 13–15 August 2002; Springer: Berlin/Heidelberg, Germany, 2002; pp. 13–28. [Google Scholar]
- Wu, X.E.; Mel, B.W. Capacity-enhancing synaptic learning rules in a medial temporal lobe online learning model. Neuron 2009, 62, 31–41. [Google Scholar] [CrossRef] [PubMed]
- Liu, G.; Wang, J. Dendrite net: A white-box module for classification, regression, and system identification. IEEE Trans. Cybern. 2021, 52, 13774–13787. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Wang, W.; Wenxin, Y. Side channel attacks based on dendritic networks. J. Xiangtan Univ. (Natural Sci. Ed.) 2021, 2, 16–30. [Google Scholar]
- Liu, G. It may be time to improve the neuron of artificial neural network. TechRxiv 2023. [Google Scholar] [CrossRef]
- Daemen, J.; Rijmen, V. The Design of Rijndael; Springer: Berlin/Heidelberg, Germany, 2002; Volume 2. [Google Scholar]
- Crocetti, L.; Baldanzi, L.; Bertolucci, M.; Sarti, L.; Carnevale, B.; Fanucci, L. A simulated approach to evaluate side-channel attack countermeasures for the Advanced Encryption Standard. Integration 2019, 68, 80–86. [Google Scholar] [CrossRef]
- Bookstein, A.; Kulyukin, V.A.; Raita, T. Generalized hamming distance. Inf. Retr. 2002, 5, 353–375. [Google Scholar] [CrossRef]
- Ngai, C.K.; Yeung, R.W.; Zhang, Z. Network generalized hamming weight. IEEE Trans. Inf. Theory 2011, 57, 1136–1143. [Google Scholar] [CrossRef]
- Picek, S.; Heuser, A.; Jovic, A.; Bhasin, S.; Regazzoni, F. The Curse of Class Imbalance and Conflicting Metrics with Machine Learning for Side-channel Evaluations. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2019, 1, 209–237. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Gidon, A.; Zolnik, T.A.; Fidzinski, P.; Bolduan, F.; Papoutsi, A.; Poirazi, P.; Holtkamp, M.; Vida, I.; Larkum, M.E. Dendritic action potentials and computation in human layer 2/3 cortical neurons. Science 2020, 367, 83–87. [Google Scholar] [CrossRef] [PubMed]
- Mel, B.W. Information processing in dendritic trees. Neural Comput. 1994, 6, 1031–1085. [Google Scholar] [CrossRef]
- London, M.; Häusser, M. Dendritic computation. Annu. Rev. Neurosci. 2005, 28, 503–532. [Google Scholar] [CrossRef] [PubMed]
- Kizhvatov, I. Side channel analysis of AVR XMEGA crypto engine. In Proceedings of the 4th Workshop on Embedded Systems Security, Grenoble, France, 15 October 2009; pp. 1–7. [Google Scholar]
- Wang, H.; Brisfors, M.; Forsmark, S.; Dubrova, E. How diversity affects deep-learning side-channel attacks. In Proceedings of the 2019 IEEE Nordic Circuits and Systems Conference (NORCAS): NORCHIP and International Symposium of System-on-Chip (SoC), Helsinki, Finland, 29–30 October 2019; pp. 1–7. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Add | Subtract | Multiply | Average | |
|---|---|---|---|---|
| Add | 0.621 | 0.643 | 0.641 | 0.613 |
| Subtract | 0.004 | 0.004 | 0.004 | 0.004 |
| Multiply | 0.651 | 0.629 | 0.005 | 0.606 |
| Average | 0.636 | 0.637 | 0.635 | 0.623 |
| Optimizer | Adam |
|---|---|
| Learning rate | 0.0001 |
| Loss function | Cross-Entropy |
| Mini_batch | 128 |
| Epoch | 400 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, T.; Wang, H.; He, D.; Xiong, N.; Liang, W.; Wang, J. Multi-Dimensional Fusion Deep Learning for Side Channel Analysis. Electronics 2023, 12, 4728. https://doi.org/10.3390/electronics12234728
Deng T, Wang H, He D, Xiong N, Liang W, Wang J. Multi-Dimensional Fusion Deep Learning for Side Channel Analysis. Electronics. 2023; 12(23):4728. https://doi.org/10.3390/electronics12234728
Chicago/Turabian StyleDeng, Tuo, Huanyu Wang, Dalin He, Naixue Xiong, Wei Liang, and Junnian Wang. 2023. "Multi-Dimensional Fusion Deep Learning for Side Channel Analysis" Electronics 12, no. 23: 4728. https://doi.org/10.3390/electronics12234728
APA StyleDeng, T., Wang, H., He, D., Xiong, N., Liang, W., & Wang, J. (2023). Multi-Dimensional Fusion Deep Learning for Side Channel Analysis. Electronics, 12(23), 4728. https://doi.org/10.3390/electronics12234728