Abstract
Binary function similarity analysis evaluates the similarity of functions at the binary level to aid program analysis, which is popular in many fields, such as vulnerability detection, binary clone detection, and malware detection. Graph-based methods have relatively good performance in practice, but currently, they cannot capture similarity in the aspect of the graph position distribution and lose information in graph processing, which leads to low accuracy. This paper presents PDM, a graph-based method to increase the accuracy of binary function similarity detection, by considering position distribution information. First, an enhanced Attributed Control Flow Graph (ACFG+) of a function is constructed based on a control flow graph, assisted by the instruction embedding technique and data flow analysis. Then, ACFG+ is fed to a graph embedding model using the CapsGNN and DiffPool mechanisms, to enrich information in graph processing by considering the position distribution. The model outputs the corresponding embedding vector, and we can calculate the similarity between different function embeddings using the cosine distance. Similarity detection is completed in the Siamese network. Experiments show that compared with VulSeeker and PalmTree+VulSeeker, PDM can stably obtain three-times and two-times higher accuracy, respectively, in binary function similarity detection and can detect up to six-times more results in vulnerability detection. When comparing with some state-of-the-art tools, PDM has comparable Top-5, Top-10, and Top-20 ranking results with respect to BinDiff, Diaphora, and Kam1n0 and significant advantages in the Top-50, Top-100, and Top-200 detection results.
1. Introduction
Code reuse is widespread in software development to accelerate innovation and reduce development cost [1], while it introduces many problems such as program plagiarism and the reuse of vulnerable codes. To solve these problems with less manual work, Binary Code Similarity Detection (BCSD) is proposed and binary function similarity analysis has been widely used. By comparing candidate functions with the target function and calculating the similarity score, we can determine whether a function is as vulnerable as the target function and how similar they are, or we can use further cryptography-related algorithm recognition by locating encryption functions.
According to a large-scale measurement [2] in the state-of-the-art of BCSD, which was led by the Cisco Talos group last year, the graph-based embedding models and graph neural networks precede other studies in the accuracy of binary function similarity detection. Genius [3] and Gemini [4] are two representatives that introduce machine learning to binary code similarity detection, based on the graph structure of a function. Genius defines the Attributed Control Flow Graph (ACFG) first; Gemini further uses the graph embedding model structure2vec [5] based on deep learning to better represent the ACFG. VulSeeker [6] then adds dataflow information in ACFG to build a Labeled Semantic Flow Graph (LSFG) for graph embedding. However, the node attributes used are just statistical and structural features, lacking semantic information, and that is the limit of performance. Besides, they just use node embedding for a graph, which certainly loses information from unsampled nodes. Some recent methods leverage all the graph information to generate the final embedding vector. However, they do not take position distribution information into consideration. The position distribution determines whether two functions are similar more easily in some circumstances, which will be introduced in Section 3.
To summarize, current graph-based methods face three challenges:
- First, the current quality of node attributes’ representation prevents them from obtaining deep semantics.
- Second, some graph embedding models are based on node embedding methods such as random walk, which is a random sampling of adjacent nodes, and these models do not have a view of the whole function graph.
- The position distribution is also an often-overlooked feature, as in Figure 1, basic blocks can be grouped as different functional modules according to the attributes and their surroundings.
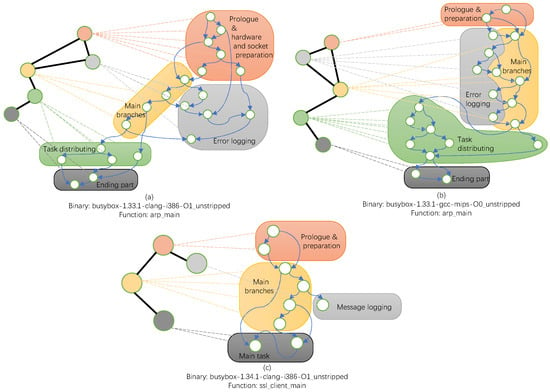 Figure 1. Functions with functional module division.
Figure 1. Functions with functional module division.
To solve these challenges, a graph-based method in three-step style for binary function similarity analysis is proposed in this paper. To increase the quality of node representation, we first constructed the ACFG+ of a function as the input to a graph embedding model. The ACFG+ is based on the ACFG, adding data dependencies and instruction embedding vectors. To enrich the information contained in the period of graph embedding, we propose a graph embedding model based on the Capsule Graph Neural Network (CapsGNN) [7]. Capsule transfers and calculates information with more dimensions, and dynamic routing leads the capsule input to the suitable output capsule. The ACFG+ is fed to the model, and it outputs the corresponding embedding vectors. Considering the position distribution for accuracy improvement, we added the DiffPool pooling mechanism [8] to the graph embedding model. The DiffPool layer is built on two GraphSAGE [9] layers to cluster nodes based on attributes and the position distribution of nodes, generating subgraphs to expand the scale of the graph and represent the position distribution feature.
We implemented a prototype Position Distribution Matters (PDM) and evaluated it as a binary function similarity detection task and vulnerability detection task. In the binary function similarity detection task, we compared with VulSeeker and PlamTree+VulSeeker and found that instruction embedding along with our designed model improves the accuracy by up to three-times and two-times, respectively. In the vulnerability detection task PDM also outperforms others in vulnerable functions’ (CVE-related) ranking and can compete with some popular state-of-the-art tools including BinDiff, Diaphora, and Kam1n0 in the Top-5, Top-10, and Top-20 ranking results and even outperform them in the Top-50, Top-100, and Top-200 ranking results.
In summary, our contributions include the following:
- We propose a graph-based method for binary function similarity analysis, which enriches information in graph embedding and takes position distribution information into consideration.
- We built a graph embedding model for the binary function using CapsGNN to provide the high-level information of the graph and used dynamic routing to transfer features to a suitable place of the embedding based on the distribution information.
- In the graph embedding model, we added the DiffPool layer to generate the subgraph, by node clustering based on attributes and position information, to supplement the graph information and represent the position distribution feature.
- We implemented a prototype, PDM, and conducted an evaluation on two tasks to prove its effectiveness. Experiments showed that PDM outperforms other research on binary function similarity detection by up to three-times in accuracy. In the vulnerable function ranking task, PDM can compete with state-of-the-art tools and is even better in some circumstances.
The rest of our paper is organized as follows. Section 2 presents some related work. Section 3 introduces our motivation and insights in detail. Section 4 introduces our method and the designed graph embedding model. The evaluation is implemented in Section 5, and the discussion follows in Section 6.
2. Related Work
We summarize recent BCSD methods into several categories and introduce some graph-based methods with relatively good performance.
2.1. Binary Code Similarity Detection
First, we introduce some state-of-the-art solutions using different techniques with different innovations.
Fuzzy hashing methods based on hashing techniques, such as Local Sensitive Hashing (LSH) and its variants, are often used in IDA Pro plugins such as Catalog1 [10], BinDiff [11], and Diaphora [12]. On the same platform, they achieve high detection accuracy, while cross-architecture problems are hard for them. FunctionSimSearch [13] uses the SimHash algorithm to compute a fuzzy hash based on the function CFG and assembly codes and is potentially capable of cross-platform challenges.
To add syntactic, structural, and semantic information, the Attributed Control Flow Graph (ACFG) is proposed to represent a function. The ACFG was first presented by Genius [3], composed of statistical features of basic blocks and a Control Flow Graph (CFG) of the function; Gemini [4] and some other research continued to use the ACFG and in VulSeeker [6]; it adds Data Flow Graph (DFG) edges in it to include data dependency information.
Despite the graph structure, the quality of node representation matters in the ACFG’s construction. word2vec is adopted in many research works [14,15] to embed binary instructions into vectors, and it is Asm2Vec [16], which derives from PV-DM [17], that boost instruction embedding quality to a high level. The pre-training model Bert [18] is also applied to instruction embedding by PalmTree [19], and it benefits many downstream program analysis works. To overcome the obstacles caused by the cross-architecture, researchers explore translating instructions [20] or embedding similar instructions on different platforms close to each other in a vector space [21].
As opposed to static analysis, dynamic analysis has been used to increase accuracy by providing dynamic features. VulSeeker-Pro [22] and BinSeeker [23] are an emulation-enhanced type of VulSeeker; they use emulation execution to filter results (Top-K list) generated by VulSeeker and will definitely improve accuracy. Patchecko [24] has a similar routine, combining static and dynamic analysis. Trex [25] is a recent work considering the execution semantics of instructions in micro-traces, using hierarchical transformer and pre-training techniques. The dynamic analysis is surely a benefit to improving detection performance, while the overheads sometimes hinder their being widely used.
In a recent large-scale measurement of works in BCSD, graph-based methods such as the GMN [26] perform better than other works, which means related research is promising.
2.2. Graph-Based Methods in BCSD
Two representatives are Genius and Gemini, which introduce machine learning to graph-based binary code similarity detection. Genius utilizes spectral clustering to generate a codebook and calculates the similarity between a specific ACFG and each representative ACFG in the codebook based on the bipartite graph matching algorithm. Gemini further uses the graph embedding model structure2vec [5] based on deep learning to better represent the ACFG, in which structure2vec focuses on the similarity of the spatial structure. Based on Gemini, VulSeeker then adds dataflow analysis and adds DFG edges into the ACFG to build a Labeled Semantic Flow Graph (LSFG), then modifies a semantics-aware deep neural network based on structure2vec to achieve higher accuracy. DeepBinDiff [15] is proposed to improve the accuracy of binary diffing relying on both semantic information and program-wide control flow information to generate basic block embeddings, in which graph matching and the Text-Associated DeepWalk algorithm (TADW) [27] are leveraged to represent graphs. However, the above-mentioned research works all use node embedding methods such as random walk, which only concern adjacent nodes instead of looking at the whole graph, and this will definitely lose information during processing of the input graph.
Asteria [28] is a deep-learning-based binary function encoding method for the Abstract Syntax Tree (AST) of a function, and it is implemented using Tree-LSTM [29] inside to learn the semantic representation of a function from its AST. OrderMatters [30] uses the Message-Passing Neural Network (MPNN) [31] to process graph attributes and CNN(ResNet) [32] to extract node order. CodeCMR [33] is an end-to-end cross-modal retrieval network for binary source code matching, and in binary feature extraction, it proposes a GNN model with the Hierarchy-like structure of BiLSTM layers with Max Pooling (HBMP) [34] node embeddings, using Gated Graph Sequence Neural Networks (GGNNs) [35] with message passing and the Set2Set graph pooling method to perform graph embedding. The GMN has been proven by a large scale of measurement to be an effective method for BCSD, and it provides two ideas for similarity matching: one is a traditional graph embedding network to enable similarity reasoning in vector spaces; another is the Graph Matching Network (GMN) leveraging the cross-graph attention-based mechanism. The methods mentioned above use neural networks to learn graph features and achieve good results, while, despite the insufficient information of the input function graph, the position distribution feature is not considered as well.
3. Motivation
Since basic blocks contain only a few instructions and there are just a few frequently used instructions in a binary, many basic blocks look similar to each other. Actually, it is the distribution that gives meaning to a group of basic blocks (nodes in graph) at a functional level, because different position distributions of nodes lead to different partitions of functional modules, and this can be used in similarity detection.
Figure 1 is an example of three Control Flow Graphs (CFGs) and their functional module divisions, showing how position distribution matters in function representation. The graphs and modules in Figure 1a,b are both from function arp_main() in busybox, but with different architectures, compilers, and optimization options. They may not look so similar, while after clustering nodes to generate a subgraph based on functional partitioning, we can obtain identical subgraphs from Figure 1a,b, which reveals their similarity in binary code.
The different basic blocks constitute different functional partitions. Blocks consisting of a function prologue and hardware-checking API calls can be grouped as the starting and preparation part of the function. The error-logging module is the cluster of blocks containing output operations. Blocks with many conditional statements and connecting nodes in the error-logging module are classified as the main branches of the function. The task-distributing module is the group of blocks connected by main branches and having major API calls inside. Blocks with only register-clearing and stack-recovering operations, if clustered, can be regarded as the end part of the function.
As shown in Figure 1a,c, arp_main() and ssl_client_main() are functions in busybox with the same compiling method. They are functions sharing similar API calls; however, similar calls do not make them similar in function, because the different distribution of nodes makes different function module divisions. In ssl_client_main(), the blocks having register-clearing and stack-recovering instructions are clustered with blocks having API calls to become one new module: main task, instead of two modules in arp_main(): task distributing and ending part, which leads to different subgraphs extracted from the module division result. Therefore, we can use methods such as node clustering to perform function module division for similarity detection. It should be noted that the rules of division are not fully based on functionality; perhaps, some high-dimensional feature is also involved, according to the result after attribute-based clustering.
4. Methodology
To deal with the insufficient characterization of graphs and the neglect of position distribution information in current methods, we propose a graph-based binary function similarity analysis method in 3-step style, which is shown in Figure 2. Firstly, the enhanced Attributed Control Flow Graph (ACFG+) of a function containing more information is constructed, by adding instruction embedding vectors and data dependencies to the ACFG. Secondly, we design a graph embedding model using the Capsule Graph Neural Network (CapsGNN) [7] and DiffPool pooling mechanism [8], and the ACFG+ is fed into the model to obtain the corresponding embedding vectors. Thirdly, embedding vectors of different binary functions are input into a Siamese network using the cosine distance to calculate the similarity scores between different function ACFG+s.
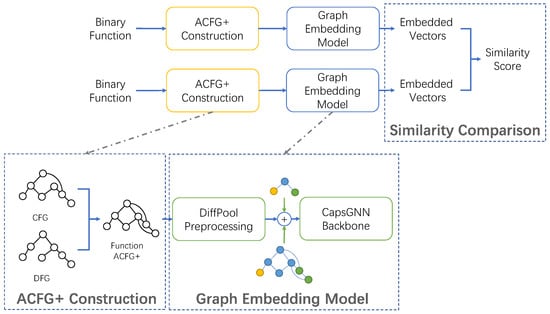
Figure 2.
Overview.
4.1. ACFG+ Construction
The Control Flow Graph (CFG) is commonly used in program analysis, and the Attributed CFG (ACFG) represents nodes in the CFG as statistical features and structural features. We employed the instruction embedding technique to add semantic information to the nodes and added edges offered by the DFG, which contains the data dependency information. With these methods, the ACFG+ can be constructed.
The instruction embedding technique represents every instruction in the same vector space, and the model we used is based on the pre-training model Bert [18], which regards the instruction as the sentence and regards the opcodes and operands as the tokens. Pre-training tasks include Next Instruction Prediction (NIP), Instruction Order Prediction (IOP,) and Mask Language Model (MLM). NIP and IOP are modified versions of Next Sentence Prediction (NSP) in Bert, and MLM is similar to that in Natural Language Processing (NLP). NIP cares about the probability that two instructions are connected in sequence; IOP lets the model learn about the sequence of data writing and reading; hence, the control flow information and dataflow dependencies are considered, respectively.
As shown in Figure 3, pairwise instructions are used in the pre-training period. When applying to instruction embedding, only single instructions are input to the model. We mention that the ACFG+ construction module is not the main contribution of our method; therefore, it is only mentioned to show the complete workflow of our framework.
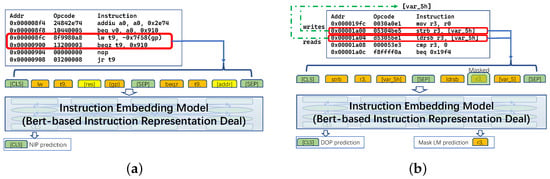
Figure 3.
Instruction embedding model. (a) Next Instruction Prediction (NIP); (b) Instruction Order Prediction (IOP).
4.2. Graph Embedding Model Based on Position Distribution
The graph embedding model is the main contribution of this paper. The backbone network we selected is the Capsule Graph Neural Network (CapsGNN), with capsule layers and a dynamic routing mechanism inside. To enrich the graph information and take the position distribution information into account, we added the DiffPool pooling layer to generate the subgraph. Figure 4 shows the structure of our model.
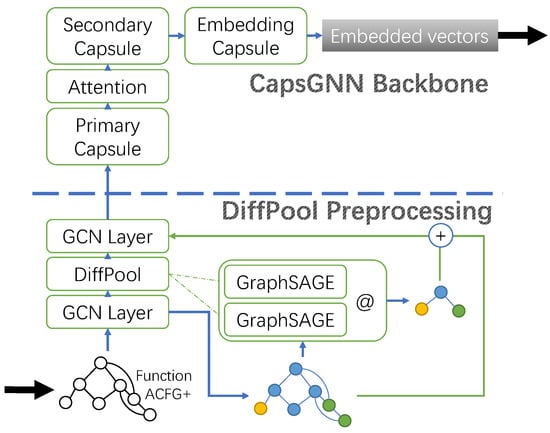
Figure 4.
Network structure of the graph embedding model.
This model is divided into two parts: the DiffPool preprocessing module and the CapsGNN backbone. The DiffPool preprocessing module consists of the GCN layer and one DiffPool layer, to propagate node attributes and expand the graph scale based on node attribute clustering. The CapsGNN backbone includes the primary capsule layer, attention layer, secondary capsule layer, and embedding capsule layer, to map the neuron data into the capsule data, perform capsule calculation, and output embedding vectors. We introduce the DiffPool preprocessing module and the CapsGNN backbone following the order of input.
4.2.1. DiffPool Preprocessing
In order to consider the position distribution information and enrich graph information, we employed the DiffPool pooling mechanism. With the CapsGNN as the basis of our model, there are several GCN layers in the front, and we applied the DiffPool pooling mechanism to them to supplement information and take the position distribution into account. It is a differentiable pooling method that is used in many graph classification models to extract hierarchical information by clustering nodes and generating small-scale subgraphs for several levels, such as pooling in Convolution Neural Networks (CNNs). However, in this paper, we regard it as a learning-based subgraph generating method, and after every DiffPool layer, the new graph will be composed of the original input graph and newly generated subgraph, as in Figure 4.
DiffPool layers use two GraphSAGE models to generate an assignment matrix and an embedding matrix, respectively. GraphSAGE is an inductive algorithm for computing node embeddings and generates embeddings by sampling and aggregating features from a node’s local neighborhood. The attribute passing within the local neighborhood enables a node to represent its neighbors as a degree, and the scale of attribute passing can be global after several iterations. According to the position distribution of the nodes in the graph, the result of node attributes after passing and aggregation obtains related information, and since we set the model to output fewer dimensions, we finally obtain a learning-based clustering model, using the position distribution of the graph.
The assignment matrix and embedding matrix are computed by the input nodes and adjacency matrix , at layer l:
With these two matrices, we can generate a subgraph with cluster nodes and adjacency matrix , applying the following two equations:
By this means, the nodes are clustered first in every DiffPool layer, then mapped to a new node matrix with a fixed size, which is where the position distribution of the graph nodes works. Different positions of nodes lead to different partitions of the graph function modules, as shown in Figure 1. The fixed size of the graph requires a corresponding adjacency matrix , and the two matrices form a new subgraph.
The DiffPool layers combined with the GCN layers are used as the preprocessing of the function ACFG+. The GCN in our model is used to perform the general representation of a graph, and with the message passing mechanism, the attribute features can be added to the graph embedding.
4.2.2. Capsule Graph Neural Network as the Backbone
To enrich the information included in the graph processing period, we chose CapsGNN as the backbone network. Inside the capsule, it transfers vectors instead of scalars, and the direction of the vectors was preserved during the calculation, which means a kind of high-level feature of the graph. There is a dynamic routing mechanism in the capsule calculation that helps the capsule propagate the properties captured from the previous layer to suitable graph capsules in the next layer; by this means, the position distribution plays a role in calculation and representation.
The graph computed by the neuron via the GCN in the past will first be mapped through the primary capsule layer in Figure 4 to the format that the capsule can handle. What the primary capsule layer does is it uses N layers of convolution, the same number as the capsule dimension, which is defined by the hyperparameter, to map each attribute of nodes into vectors with N dimensions. Then, a layer with the attention mechanism is added to scale each node capsule for comparison between vastly differently sized graphs, and the model will focus more on the relevant part of the graph. After that, a secondary capsule layer is added for capsule calculation.
Figure 5 shows the different structures of the neuron and capsule. In a neuron, the data processed inside are all scalars, corresponding to all attributes of a node. However, in a capsule, the data are all in vector format with direction information, that is higher-level features for graphs and nodes.
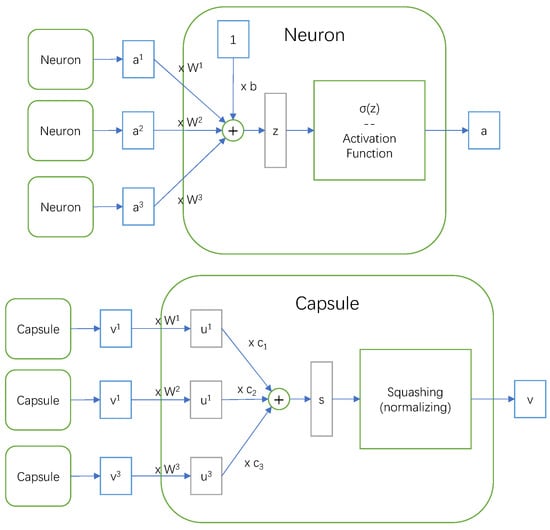
Figure 5.
Structure of a neuron and a capsule.
The calculations in a neuron include a weighted sum of outputs from all previous-layer neurons and an activation function operation. Inside the capsule, the calculations contain dynamic routing and squashing, as shown in Figure 5. The dynamic routing mechanism aims at transmitting suitable properties to a suitable place, and different from matrices , , and , which are learned during backward propagation, the coupling coefficients , , and are learned during forward propagation.
Figure 6 shows the detailed dynamic routing process. First of all, we set the max number of iteration as T and the current iteration number as r and initialized and to 0. Then, and are calculated from the softmax result of and , using weighted averaging. and are the weighted result of previous capsules, so the of the first iteration can be calculated as:
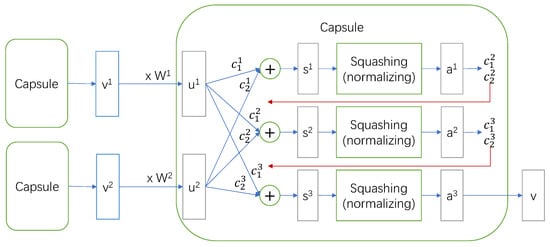
Figure 6.
Dynamic routing mechanism.
After that, needs to be processed by the squashing function to obtain the output of this capsule, and this operation is more like a vector normalization. However, before the final iteration, we can only obtain a temporary result:
The intermediate result is used to calculate and in the next iteration, and that is the online learning process of dynamic routing:
After the last iteration, the result is the v that the capsule finally output.
This mechanism is similar to the attention mechanism in structure, but more like clustering in operation, because finally, the capsule will output a vector that is close to the capsule input with more prominent features. In this way, the capsule propagates attribute information to a more suitable place of embedding or a capsule in the next layer.
After the calculation in the secondary capsule layer, another embedding capsule layer is added to generate embedding vectors of the original input graph, and these two layers work the same internally.
4.2.3. Similarity Comparison
After graph embedding, we can obtain a vector containing semantic, structural, and position distribution features. A Siamese network composed of two weight-sharing graph embedding models mentioned above is constructed to calculate function similarity scores, using the cosine distance.
For some special scenarios, such as patch identification and version detection, they need two anchor functions of different patching statuses or different versions for comparison. After we obtain the function ACFG+ embeddings, we still calculate the cosine distance to see whether the target function is closer to a vulnerable or patched function or which version it belongs to. In these circumstances, a triplet network is useful.
5. Evaluation
5.1. Implementation Details
In the ACFG+ construction stage, the CFG and DFG are extracted by Radare2 [36] scripts. The attributes of the nodes are generated by a Bert-based Instruction Representation Deal (BIRD), which we proposed and implemented based on the PalmTree model, and there are only subtle differences between them in the pre-training tasks. We implemented the graph embedding model on top of the CapsGNN and modified the DiffPool layers to adapt them to our purpose. All of them were written in Python using the Pytorch framework.
As for the hyperparameters, in PalmTree: Layers = 12, Attention_head = 8, and Embedding_dimension = 128; we set: Layers = 12, Attention_head = 8, and Embedding_dimension = 64. In this way, we shrank the embedding size of instructions, but obtained a comparable quality of embedding result. In CapsGNN, we set the hyperparameters: Iteration(dynamic routing) = 3, Attention_dimension = 32, Capsule_dimension = 32, Capsule_number = 8. To apply the DiffPool mechanism, we also added GCN layers and set some related hyperparameters: GCN_filter = 32, GCN_layer = 3, DiffPool_dimension = 8.
To train the instruction embedding model, we prepared massive instructions with control flow and data flow relationships and trained the model through three pre-training tasks. As it is not a classification model, we directly made up paired function samples and used the output embeddings to calculate contrastive loss (for the Siamese network) and triplet loss (for the triplet network) for training, using the cosine distance.
When preparing the dataset, we actually selected three functions as a set: one function was used as an function; another function as pos will be selected in different binaries, but with the same version and the same function name; the remaining one as neg can be a totally different function. With this function set, we can easily compute the contrastive loss and triplet loss, and both models were evaluated in experiments.
5.2. Experimental Setup
5.2.1. Hardware Configuration
All the experiments were conducted on a dedicated server with an Intel Xeon Gold 6230R CPU@104 × 4 GHz (Intel, Santa Clara, CA, USA), one RTX 3090 GPU, and 256 GB memory.
5.2.2. Tasks
We evaluated PDM on two tasks.
The first task was binary function similarity detection on a dataset composed of openssl and busybox. When the same source code was compiled to different binaries, we checked whether the same source binaries had higher similarity scores.
The second task was applying the model to a specific application scenario, vulnerability detection, on a dataset consisting of collected CVE-related functions. We took real CVE vulnerability as the target to see the performance of PDM on vulnerability discovery.
5.2.3. Datasets
The training dataset included openssl (libcrypto.so and libssl.so) v1.0.1u and busybox v1.21.1, and the programs were compiled to ×86, ARM and MIPS architectures with both 32 and 64 bitness and compiled on clang-5.0, clang-7.0, gcc-5.5.0, and gcc-7.3.0, with the O0, O1, O2, and O3 optimization options.
Dataset 1 is for Task 1, which includes openssl (libcrypto.so and libssl.so) v1.1.1f and busybox v1.33.1, and the programs were compiled to ×86, ARM and MIPS architectures with both 32 and 64 bitness and compiled on clang-10.0.0 and gcc-9.4.0, with the O0, O1, O2, O3, and Os optimization options.
Dataset 2 is for Task 2, which includes busybox v1.33.1 and busybox v1.34.1, compiled to ×86, ARM and MIPS architectures with both 32 and 64 bitness and compiled on clang-10.0.0 and gcc-9.4.0, with the O0, O1, O2, O3, and Os optimization options.
5.2.4. Baselines
To prove our idea is effective, we chose to compare it with VulSeeker, which uses structure2vec to perform graph embedding, and PalmTree + VulSeeker, which further replace the manually selected features with learning-based instruction embedding to perform basic block representation and have been proven to perform better.
To demonstrate the effectiveness of position distribution information and some other factors, we modified our embedding model into four versions. The model with only the CapsGNN structure and trained by the contrastive loss function (normally used in the Siamese network) is shown as PDMs-diffpool, and the model trained by triplet loss (used in the triplet network) is shown as PDMt-diffpool. The model with the CapsGNN structure adding the DiffPool mechanism and trained by contrastive loss is shown as PDMs, and the model trained by triplet loss is shown as PDMt.
We also selected BinDiff, Diaphora, and Kam1n0 [37] (including two algorithms: asm-clone and Asm2Vec), three IDA Pro plugins representative of the industrial field, to compare with PDM and see the difference in accuracy.
5.3. Task 1: Binary Function Similarity Detection
In the first task, we trained PDM using the training dataset to generate graph embedding vectors of functions. A Siamese network composed of two graph embedding models was built to calculate the similarity scores of functions, using the cosine distance.
5.3.1. ROC and AUC Performance
The ROC curves and AUC values in the training phase of all versions of PDM and other compared methods are shown in Figure 7. ROC means Receiver Operating Characteristic, with the false positive rate as the abscissa of the curve and the true positive rate as the ordinate, and AUC means the Area Under this Curve. A higher value of the AUC demonstrates better performance.
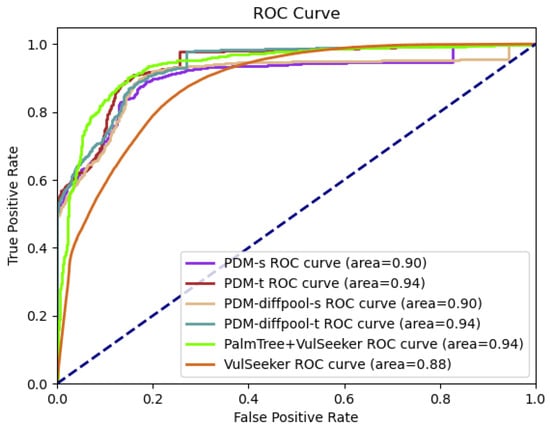
Figure 7.
ROC curves and AUC values for VulSeeker, PalmTree + VulSeeker, and four versions of PDM.
All four versions of PDM beat VulSeeker, and the models using triplet loss had the best performance, which means instruction embedding and the designed graph embedding model both benefit. PalmTree + VulSeeker can compete with PDMt-diffpool and PDMt, and these three work better in the training phase than PDMs-diffpool and PDMs, showing the triplet loss is better for our embedding model in training.
5.3.2. Detection Accuracy Performance
The evaluation was conducted on Dataset 1. We chose to start traversing from each function in each binary and compared every traversed function with 100 randomly selected functions (including the function from the same source code) from another different binary, but with same source code. Using the Siamese graph embedding network to calculate the similarity scores in each comparison, we can sort 100 results into a list for each traversed function. In each list, we can obtain the ranking results of binary function similarity detection.
According to the ranking of matched functions in the list, we can test PDM and other compared methods using some standard measures: Mean Reciprocal Rank (MRR), Precision@10, Precision@50, Recall@1, and F1-scores. The MRR is a measure to evaluate ranking systems, which calculates the mean value of the sum of the reciprocal of each ranking. Precision@10 denotes the ratio of correctly matched function ranking in Top-10, and Precision@50 denotes the ratio of correctly matched function ranking in Top-50. Recall@1 is the recall of ranking and captures the ratio of matching the correct function (from same source code) at rank 1. The F1-scores reflects the harmonic mean of precision and recall, and it is calculated by the precision and recall:
As shown in Table 1, on Dataset 1, VulSeeker can only achieve fairly low accuracy, and combining PalmTree to add instruction embedding information makes it better. All versions of PDM obtained higher MRR values, precision, recall, and F-scores than VulSeeker and PalmTree + VulSeeker, reflecting the effectiveness of our method. PDMt significantly outperformed the other methods, and PDMs outperformed PDMs-diffpool, which means the DiffPool mechanism helps and position distribution information really matters. PDMt-diffpool was only second to PDMt and had better results than PDMs and other methods, denoting that the triplet loss function seems better when training the graph embedding model than the contrastive loss function.

Table 1.
Accuracy on the general dataset.
We also inspected the detailed accuracy in a specific condition and identified three kinds of conditions: comparing binaries with different optimization options (O0, O1, O2, O3, Os), which is identified as XO (Cross-Optimization option), comparing binaries with different compilers (clang, gcc), which is identified as XC (Cross-Compiler), comparing binaries with different architectures (×86, ARM, MIPS, etc.), which is identified as XA (Cross-Architecture). As shown in Table 2, PDMs and PDMt have higher MRR scores and recall scores than the others in condition XO. In condition XC, PDMt-diffpool and PDMt are better, and PDMs-diffpool and PDMs work better in condition XA.
Table 2.
Accuracy in conditions XO, XC, and XA.
5.4. Task 2: Vulnerability Detection
In Task 2, we applied PDM to vulnerability detection, that is setting the vulnerable function as the target to perform similarity detection. There were four CVEs selected for this task: CVE-2021-42377 (function hush_main), CVE-2021-42380 (function clrvar), CVE-2021-42381 (function hash_init), and CVE-2021-42385 (function evaluate). As for the dataset, we trimmed Dataset 2 and kept eight programs to search and one program as the target, which are shown in Table 3, and they retained the diversity, including different architectures, different versions, different compilers, and different optimization options.
Table 3.
Information list of Busybox.
For every CVE function, we ranked the similarity score calculated according to the functions in the other eight programs and counted the number of real CVE functions ranked in the Top-5, Top-10, Top-20, Top-50, Top-100, and Top-200. The statistical results in Figure 8 show that all types of PDM had better performance than VulSeeker and PalmTree + VulSeeker in the Top-5, Top-10, and Top-20 results, showing that enriching graph information and using the position distribution feature are practical. PDM also outperformed other compared methods in the Top-50, Top-100, and Top-200 results, which means having better completeness.
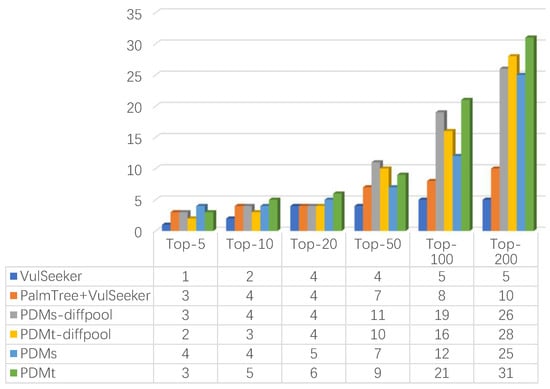
Figure 8.
Vulnerability ranking compared with VulSeeker and PalmTree + VulSeeker.
Besides VulSeeker and PalmTree + VulSeeker, some state-of-the-art tools were also used to compare. As shown in Figure 9, BinDiff and Asm2Vec can outperform in the Top-5, Top-10, and Top-20 results relying on their strong hashing techniques, while in Top-50, Top-100, and Top-200, they were still incapable of catching up with our method, because they cannot solve cross-architecture problems just using hashing.
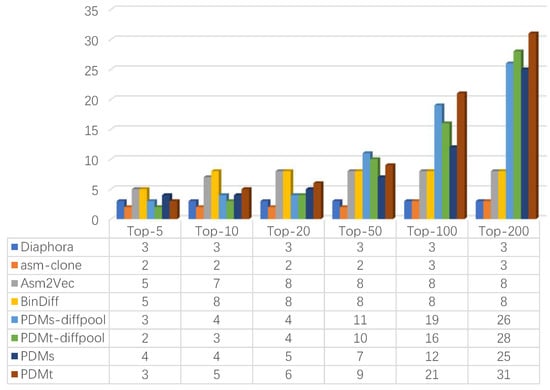
Figure 9.
Vulnerability ranking compared with state-of-the-art tools.
6. Discussion
In this paper, we proposed a graph-based binary function similarity detection method in three-step style to perform detection and designed a graph embedding model based on CapsGNN and DiffPool to consider position distribution information and some high-level information of a graph, which helps to increase accuracy. This method takes two binary functions as the input, constructing the ACFG+ and applying the graph embedding model to represent the feature vector of each function. Both the widely used Siamese network and triplet network were applied to calculate the similarity scores of functions, using the vector distance calculation algorithm. We implemented a prototype PDM, and the evaluation showed that it outperformed other tools in the binary function similarity detection task and vulnerability detection task.
However, there are limitations that need to be solved in future work. When current learning-based methods become more and more accurate, they can deal better with the invariant problems, which is classifying different forms of functions with the same source into one category. However, learning-based methods cannot handle the equivariant problems well for now, which is to distinguish two similar functions with subtle differences in source. Tasks such as patch identification and version detection involve both invariant and equivariant problems, hence requiring dynamic analysis and some other heuristic methods. Besides, the cross-architecture ability heavily relies on the extracted graph structure similarity and the quality of instruction embedding; both aspects can be improved using ready-made tools.
Author Contributions
Conceptualization and methodology, T.W. and Z.P.; validation, T.W., L.Y., and Y.Y.; formal analysis, T.W. and L.Y.; investigation, T.W., Z.P., and L.Y.; resources, data curation, and visualization, T.W. and L.Y.; supervision, project administration, and funding acquisition, Z.P. The authors read and approved the final manuscript, as well as the author order. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Key R & D Program of China, Grant Number 2021YFB3100500.
Data Availability Statement
The data presented in this study are available on https://github.com/TyeYeah/PositionDistributionMatters (accessed on 22 June 2022).
Acknowledgments
This work was supported by National Key R & D Program of China. The authors thank the support from the College of Electronic Engineering, National University of Defense Technology.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| ACFG | Attributed Control Flow Graph |
| ACFG+ | Enhanced Attributed Control Flow Graph |
| AST | Abstract Syntax Tree |
| BCSD | Binary Code Similarity Detection |
| CapsGNN | Capsule Graph Neural Network |
| CFG | Control Flow Graph |
| CVE | Common Vulnerabilities and Exposures |
| DFG | Data Flow Graph |
| GCN | Graph Convolution Network |
| GGNN | Gated Graph Sequence Neural Networks |
| GMN | Graph Matching Network |
| GraphSAGE | Graph SAmple and aggreGatE |
| HBMP | Hierarchy-like structure of BiLSTM layers with Max Pooling |
| LSFG | Labeled Semantic Flow Graph |
| MPNN | Message-Passing Neural Network |
| TADW | Text-Associated DeepWalk algorithm |
References
- Luo, Z.; Wang, B.; Tang, Y.; Xie, W. Semantic-based representation binary clone detection for cross-architectures in the internet of things. Appl. Sci. 2019, 9, 3283. [Google Scholar] [CrossRef] [Green Version]
- Marcelli, A.; Graziano, M.; Ugarte-Pedrero, X.; Fratantonio, Y.; Mansouri, M.; Balzarotti, D. How Machine Learning Is Solving the Binary Function Similarity Problem; Usenix Association: Berkeley, CA, USA, 2018. [Google Scholar]
- Feng, Q.; Zhou, R.; Xu, C.; Cheng, Y.; Testa, B.; Yin, H. Scalable graph-based bug search for firmware images. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 480–491. [Google Scholar]
- Xu, X.; Liu, C.; Feng, Q.; Yin, H.; Song, L.; Song, D. Neural network-based graph embedding for cross-platform binary code similarity detection. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 363–376. [Google Scholar]
- Dai, H.; Dai, B.; Song, L. Discriminative embeddings of latent variable models for structured data. In Proceedings of the International Conference on Machine Learning (PMLR), Paris, France, 29 April–1 May 2016; pp. 2702–2711. [Google Scholar]
- Gao, J.; Yang, X.; Fu, Y.; Jiang, Y.; Sun, J. Vulseeker: A semantic learning based vulnerability seeker for cross-platform binary. In Proceedings of the 2018 33rd IEEE/ACM International Conference on Automated Software Engineering (ASE), Montpellier, France, 3–7 September 2018; pp. 896–899. [Google Scholar]
- Xinyi, Z.; Chen, L. Capsule graph neural network. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Ying, Z.; You, J.; Morris, C.; Ren, X.; Hamilton, W.; Leskovec, J. Hierarchical graph representation learning with differentiable pooling. Adv. Neural Inf. Process. Syst. 2018, 31, 2332. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. Adv. Neural Inf. Process. Syst. 2017, 30, 2216. [Google Scholar]
- FCatalog. xorpd. Available online: https://www.xorpd.net/pages/fcatalog.html (accessed on 22 June 2022).
- BinDiff. Zynamics. Available online: https://www.zynamics.com/bindiff.html (accessed on 22 June 2022).
- Koret, J. Diaphora. Available online: https://github.com/joxeankoret/diaphora (accessed on 22 June 2022).
- Dullien, T. FunctionSimSearch. Available online: https://github.com/googleprojectzero/functionsimsearch (accessed on 22 June 2022).
- Zuo, F.; Li, X.; Young, P.; Luo, L.; Zeng, Q.; Zhang, Z. Neural machine translation inspired binary code similarity comparison beyond function pairs. arXiv 2018, arXiv:1808.04706. [Google Scholar]
- Duan, Y.; Li, X.; Wang, J.; Yin, H. Deepbindiff: Learning program-wide code representations for binary diffing. In Proceedings of the Network and Distributed System Security Symposium, San Diego, CA, USA, 27 February–3 March 2020. [Google Scholar]
- Ding, S.H.; Fung, B.C.; Charland, P. Asm2vec: Boosting static representation robustness for binary clone search against code obfuscation and compiler optimization. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 472–489. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the International Conference on Machine Learning (PMLR), Beijing, China, 21–26 June 2014; pp. 1188–1196. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Li, X.; Qu, Y.; Yin, H. Palmtree: Learning an assembly language model for instruction embedding. In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, Online, Korea, 15–19 November 2021; pp. 3236–3251. [Google Scholar]
- Zhang, X.; Sun, W.; Pang, J.; Liu, F.; Ma, Z. Similarity metric method for binary basic blocks of cross-instruction set architecture. In Proceedings of the 2020 Workshop on Binary Analysis Research Internet Society, San Diego, CA, USA, 23–26 February 2020. [Google Scholar]
- Redmond, K.; Luo, L.; Zeng, Q. A cross-architecture instruction embedding model for natural language processing-inspired binary code analysis. arXiv 2018, arXiv:1812.09652. [Google Scholar]
- Gao, J.; Yang, X.; Fu, Y.; Jiang, Y.; Shi, H.; Sun, J. Vulseeker-pro: Enhanced semantic learning based binary vulnerability seeker with emulation. In Proceedings of the 2018 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Athens, Greece, 23–28 August 2018; pp. 803–808. [Google Scholar]
- Gao, J.; Jiang, Y.; Liu, Z.; Yang, X.; Wang, C.; Jiao, X.; Yang, Z.; Sun, J. Semantic learning and emulation based cross-platform binary vulnerability seeker. IEEE Trans. Softw. Eng. 2019, 47, 2575–2589. [Google Scholar] [CrossRef]
- Sun, P.; Garcia, L.; Salles-Loustau, G.; Zonouz, S. Hybrid firmware analysis for known mobile and iot security vulnerabilities. In Proceedings of the 2020 50th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Valencia, Spain, 29 June 2020; pp. 373–384. [Google Scholar]
- Pei, K.; Xuan, Z.; Yang, J.; Jana, S.; Ray, B. Trex: Learning execution semantics from micro-traces for binary similarity. arXiv 2020, arXiv:2012.08680. [Google Scholar]
- Li, Y.; Gu, C.; Dullien, T.; Vinyals, O.; Kohli, P. Graph matching networks for learning the similarity of graph structured objects. In Proceedings of the International Conference on Machine Learning (PMLR), Long Beach, CA, USA, 9–15 June 2019; pp. 3835–3845. [Google Scholar]
- Yang, C.; Liu, Z.; Zhao, D.; Sun, M.; Chang, E. Network representation learning with rich text information. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Yang, S.; Cheng, L.; Zeng, Y.; Lang, Z.; Zhu, H.; Shi, Z. Asteria: Deep learning-based AST-encoding for cross-platform binary code similarity detection. In Proceedings of the 2021 51st Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Taipei, Taiwan, 21–24 June 2021; pp. 224–236. [Google Scholar]
- Tai, K.S.; Socher, R.; Manning, C.D. Improved semantic representations from tree-structured long short-term memory networks. arXiv 2015, arXiv:1503.00075. [Google Scholar]
- Yu, Z.; Cao, R.; Tang, Q.; Nie, S.; Huang, J.; Wu, S. Order matters: Semantic-aware neural networks for binary code similarity detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 1145–1152. [Google Scholar]
- Gilmer, J.; Schoenholz, S.S.; Riley, P.F.; Vinyals, O.; Dahl, G.E. Neural message passing for quantum chemistry. In Proceedings of the International Conference on Machine Learning (PMLR), Sydney, Australia, 6–11 August 2017; pp. 1263–1272. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Yu, Z.; Zheng, W.; Wang, J.; Tang, Q.; Nie, S.; Wu, S. Codecmr: Cross-modal retrieval for function-level binary source code matching. Adv. Neural Inf. Process. Syst. 2020, 33, 3872–3883. [Google Scholar]
- Talman, A.; Yli-Jyrä, A.; Tiedemann, J. Natural language inference with hierarchical bilstm max pooling architecture. arXiv 2018, arXiv:1808.08762. [Google Scholar]
- Li, Y.; Tarlow, D.; Brockschmidt, M.; Zemel, R. Gated graph sequence neural networks. arXiv 2015, arXiv:1511.05493. [Google Scholar]
- radare2. Radare. Available online: https://rada.re/n/radare2.html (accessed on 22 June 2022).
- McGill-DMaS. Kam1n0-Community. Available online: https://github.com/McGill-DMaS/Kam1n0-Community (accessed on 22 June 2022).
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).