Custom Face Classification Model for Classroom Using Haar-Like and LBP Features with Their Performance Comparisons



Abstract
:1. Introduction
2. Cascade Object Detector
AdaBoost Algorithm for Selecting Features
- Given a training data with n pairs of images , where is a positive or negative image, and is the label allotted to each image. The value for positive images is 1, and that of negative images is 0.
- Initializing weights for positive and negative images, where m and l are the number of negative and positive images, respectively.
- For , where T is the number of stages of training and n pairs of images:
- The weights are normalized as
- Applying a single feature, for every feature, j, train a classifier , the weighted error is evaluated as
- Select the classifier that has the lowest error .
- Update the weight , where when is classified correctly, otherwise and .
- The final strong classifier, which is the combination of the weak classifiers, is expressed as follows:where .
- True-positives (TP): They are an actual object of interest that are correctly classified. The rate of the correctly classified object/faces can be determined as [20]:
- False-positives (FP): They are the non-object of interest that are wrongly classified as the true object.
- False-negatives (FN): They are an actual object of interest wrongly classified as negative. The False Negative Rate (FNR) can be obtained using Equation (3):
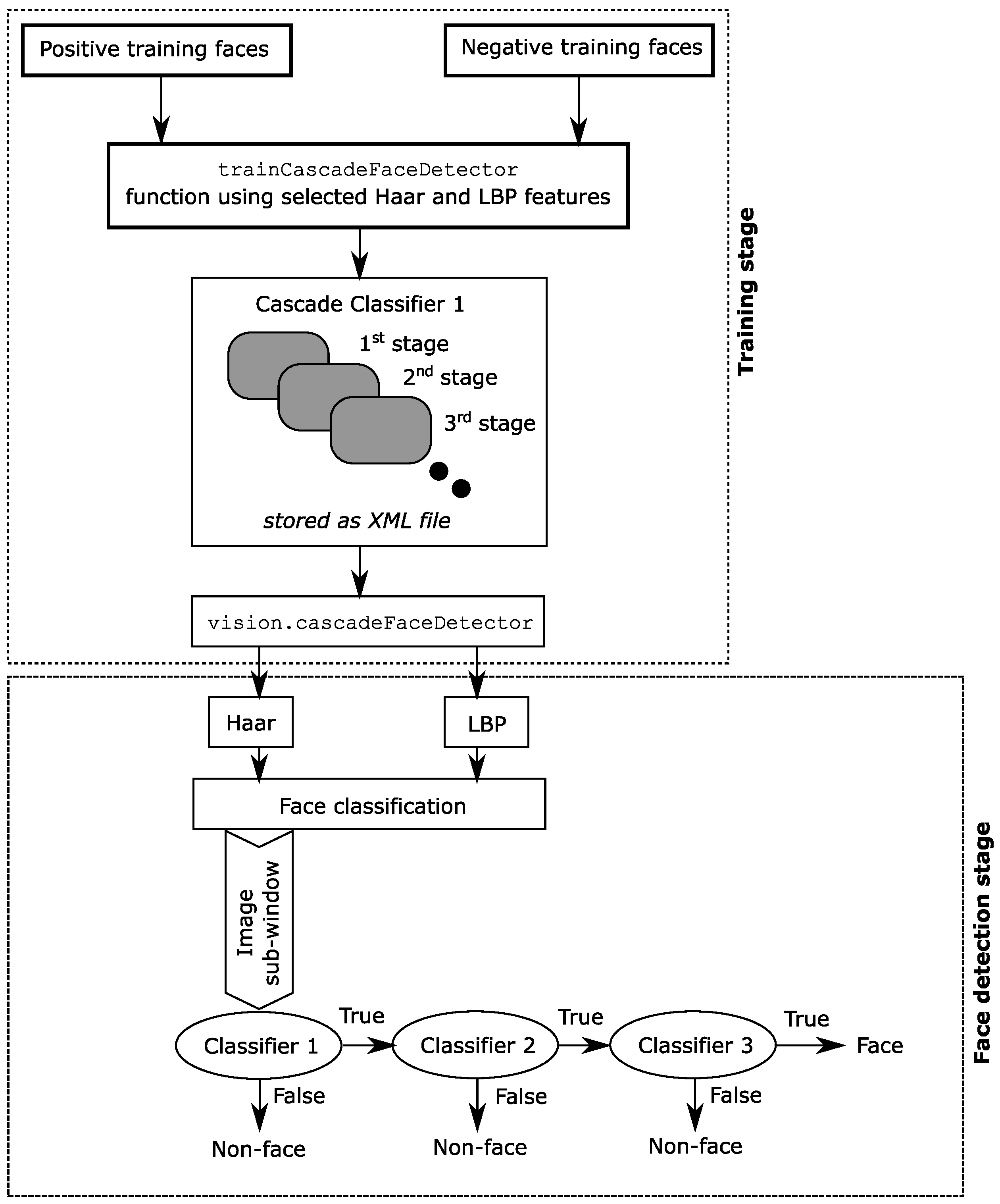
3. Our Proposed Method
3.1. Feature Evaluation
3.1.1. Haar-Like Features
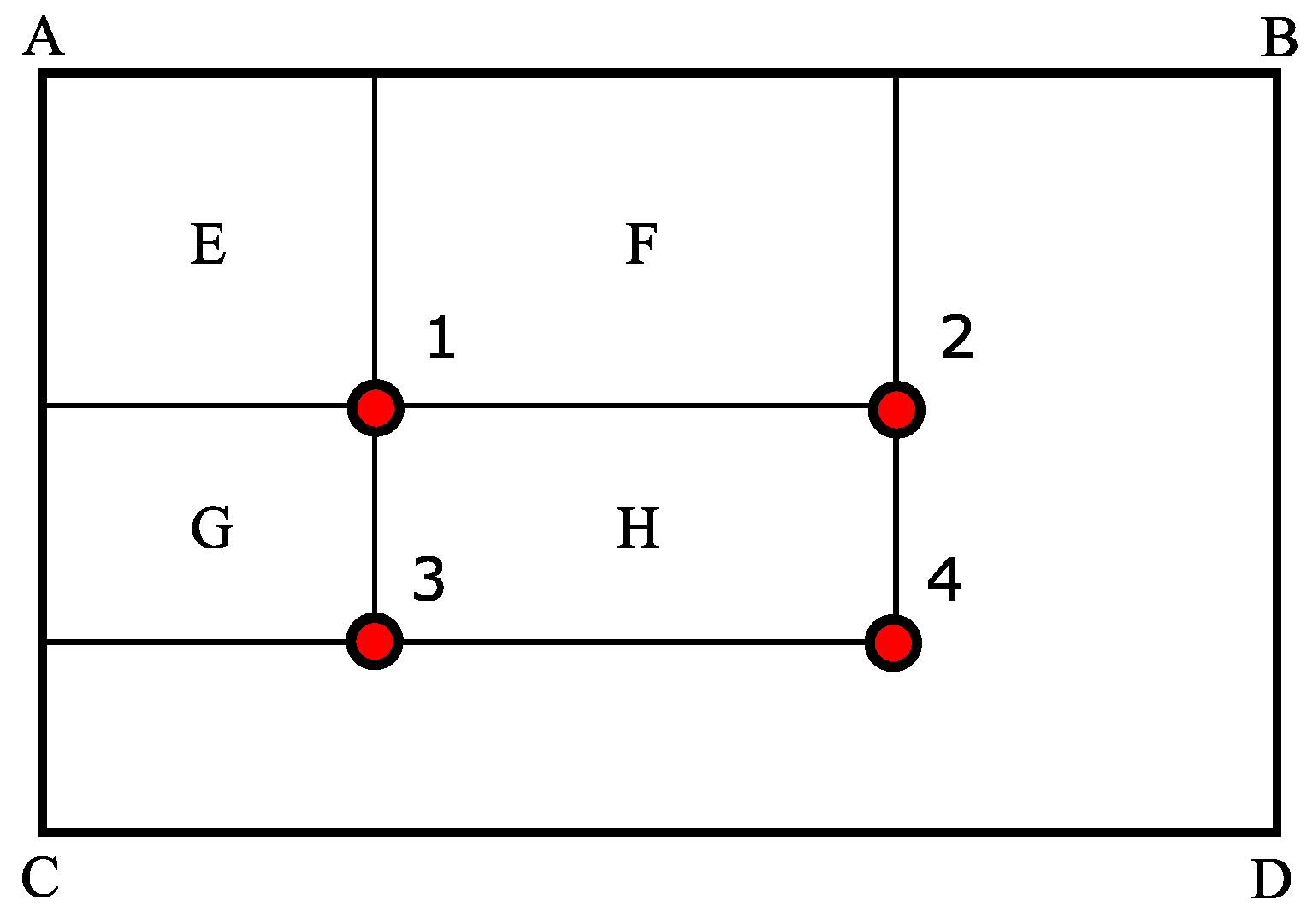
3.1.2. Integral Image
3.1.3. Attentional Cascade
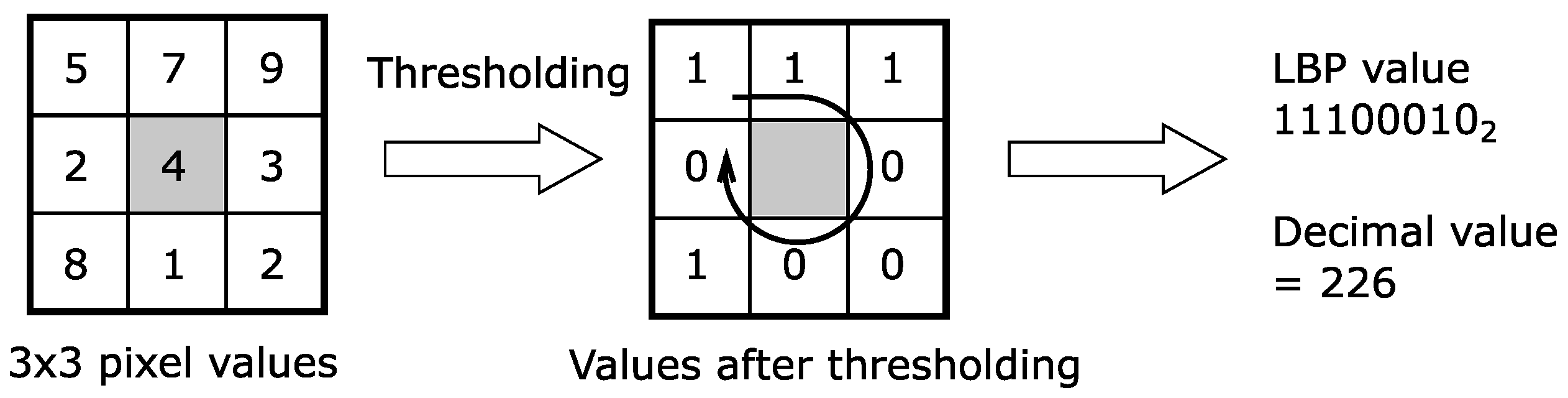
3.1.4. Local Binary Patterns (LBP) Features
4. Cascade Classifier Using the MATLAB’s trainCascadeObjectDetector Function
- Stage One training:
- -
- It calculates the number of positive samples it will use which should less than the number provided
- -
- It generates negative samples from the negative images provided by the user
- Stage Two training:
- -
- Adopt data from stage one
- -
- Classify all positive samples and then get rid of the misclassified negative samples
- -
- Use the same calculated number of positive samples
- -
- Create negative samples from the negative images provided using the sliding window and then adopt false-positive classified samples
- …
- Stage N training:
- -
- Use previous stages
- -
- Classify all positive sample and then get rid of the misclassified negatives
- -
- Use the same calculated numbers of positive samples
- -
- Create negative samples from the negative images provided using the sliding window and then adopt false-positive classified samples
5. Experimental Results
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Frean, A. Intel Sees Its Future in Face Recognition and Driverless Cars. The Times. Available online: https://www.thetimes.co.uk/article/intel-sees-its-future-in-face-recognition-and-driverless-cars-2jzsgmphj20 (accessed on 2 June 2005).
- Hoo, S.C.; Ibrahim, H. Biometric-based attendance tracking system for education sectors: A literature survey on hardware requireemnts. Sensors 2019, 7410478. [Google Scholar] [CrossRef]
- Adeshina, S.O.; Ibrahim, H.; Teoh, S.S. Literature survey on multi-camera system and its application. IEEE Access 2020, 8, 172892–172922. [Google Scholar]
- Shepley, A.J. Face Recognition in Unconstrained Conditions: A Systematic Review. 2019. Available online: http://arxiv.org/abs/1908.04404 (accessed on 30 March 2020).
- Li, Y.H.; Lo, I.C.; Chen, H.H. Deep face rectification for 360∘ dual-fisheye cameras. IEEE Trans. Image Process. 2021, 30, 264–276. [Google Scholar] [CrossRef] [PubMed]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; pp. 1193–1197. [Google Scholar]
- Levi, K.; Weiss, Y. Learning object detection from a small number of examples: The importance of good features. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004; p. 2. [Google Scholar]
- Li, Q.; Niaz, U.; Merialdo, B. An improved algorithm on Viola-Jones object detector. In Proceedings of the 10th International Workshop on Content-Based Multimedia Indexing (CBMI), Annecy, France, 27–29 June 2012; pp. 55–60. [Google Scholar]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Gray scale and rotation invariant texture classification with local binary patterns. Lect. Notes Comput. Sci. 2000, 1842, 404–420. [Google Scholar]
- Ahonen, A.; Hadid, A.; Pietikainen, M. Face description with local binary patterns: Application to face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 2037–2041. [Google Scholar] [CrossRef] [PubMed]
- Kortli, Y.; Jridi, M.; Al Falou, A.; Atri, M. A novel face detection approach using Local Binary Pattern histogram and support vector machine. In Proceedings of the 2018 International Conference on Advanced Systems and Electric Technologies (IC_ASET), Hammamet, Tunisia, 22–25 March 2018; pp. 28–33. [Google Scholar]
- Kadir, K.; Kamaruddin, M.K.; Nasir, H.; Safie, S.I.; Bakti, Z.A.K. A comparative study between LBP and Haar-like features for face detection using OpenCV. In Proceedings of the 4th International Conference on Engineering Technology and Technopreneuship (ICE2T), Kuala Lumpur, Malaysia, 27–29 August 2014; pp. 335–339. [Google Scholar]
- Jonathon, P.; Moon, H.; Rizvi, S.A.; Rauss, P.J. The FERET evaluation methodology for face-recognition algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1090–1104. [Google Scholar]
- Tarr, M.J. Stimulus Images Courtesy (Center for the NeuralBasis of Cognition and Department of Psychology, Carnegie MellonUniversity (Brown University)). 2004. Available online: http://cbcl.mit.edu/softwaredatasets/heisele/facerecognitiondatabase.html (accessed on 4 October 2020).
- Weyrauch, B.; Heisele, B.; Blanz, V. Component-based face recognition with 3D morphable models 2: Generation of 3D face model. IEEE Work. Face Process. Video 2004. Available online: http://www.bheisele.com/fpiv04.pdf (accessed on 4 October 2020).
- Guennouni, S.; Ahaitouf, A.; Mansouri, A. A comparative study of multiple object detection using Haar-like feature selection and local binary patterns in several platforms. Model. Simul. Eng. 2015. [Google Scholar] [CrossRef] [Green Version]
- Adouani, A.; Henia, W.M.B.; Lachiri, Z. Comparison of Haar-like, HOG and LBP approaches for face detection in video sequences. In Proceedings of the 16th International Multi-Conference on Systems, Signals & Devices (SSD), Istanbul, Turkey, 21–24 March 2019; pp. 266–271. [Google Scholar]
- Alionte, E.; Lazar, C. A practical implementation of face detection by using Matlab cascade object detector. In Proceedings of the 19th International Conference on System Theory, Control and Computing (ICSTCC), Cheile Gradistei, Romania, 14–16 October 2015; pp. 785–790. [Google Scholar]
- MathWorks 2020 Train a Cascade Object Detector. Available online: https://www.mathworks.com/help/vision/ug/train-a-cascade-object-detector.html (accessed on 13 August 2020).
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Rojas, R. AdaBoost and the Super Bowl of Classifiers: A Tutorial Introduction to Adaptive Boosting. 2009. Available online: http://www.inf.fu-berlin.de/inst/ag-ki/rojas_home/documents/tutorials/adaboost4.pdf (accessed on 16 August 2020).
- Mena, A.P.; Bachiller Mayoral, M.; Díaz-Lópe, E. Comparative study of the features used by algorithms based on Viola and Jones face detection algorithm. In International Work-Conference on the Interplay Between Natural and Artificial Computation, Proceedings of the IWINAC 2015: Bioinspired Computation in Artificial Systems, Elche, Spain, 1–5 June 2015; Springer: Cham, Switzerland, 2015; Volume 9108, pp. 175–183. [Google Scholar]
- Papageorgiou, C.P.; Oren, M.; Poggio, T. General framework for object detection. In Proceedings of the Sixth International Conference on Computer Vision (IEEE Cat. No.98CH36271), Bombay, India, 7 January 1998; pp. 555–562. [Google Scholar]
- Ojala, T.; Pietikainen, M.; Harwood, D. A comparative study of texture measures with classification based on feature distributions. Pattern Recognit. 1996, 29, 51–59. [Google Scholar] [CrossRef]
- Heikkila, M.; Pietikainen, M. A texture-based method for detecting moving objects. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 657–662. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kellokumpu, V.; Zhao, G.; Pietikainen, M. Human activity recognition using a dynamic texture based method. In Proceedings of the British Machine Vision Conference (BMVC 2008), Leeds, UK, 1–4 September 2008. [Google Scholar]
- Oliver, A.; Llado, X.; Freixenet, J.; Marti, J. False positive reduction in mammographic mass detection using local binary patterns. In International Conference on Medical Image Computing and Computer-Assisted Intervention, Proceedings of the MICCAI 2007, Brisbane, Australia, 29 October–2 November 2007: Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4791, pp. 659–666. [Google Scholar]
- Lucieer, A.; Stein, A.; Fisher, P. Multivariate texture-based segmentation of remotely sensed imagery for extraction of objects and their uncertainty. Int. J. Remote Sens. 2005, 26, 2917–2936. [Google Scholar] [CrossRef]
- Kluckner, S.; Pacher, G.; Grabner, H.; Bischof, H.; Bauer, J. A 3D teacher for car detection in aerial images. In Proceedings of the IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007. [Google Scholar]
- Huijsmans, D.P.; Sebe, N. Content-based indexing performance: A class size normalized precision, recall, generality evaluation. IEEE Int. Conf. Image Process. 2003, 3, 733–736. [Google Scholar]
- Grangier, D.; Bengio, S. A discriminative kernel-based model to rank images from text queries. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1371–1384. [Google Scholar] [CrossRef] [PubMed]
- Attia, A.; Dayan, S. Detecting and Counting Tiny Faces. 2018. Available online: http://arxiv.org/abs/1801.06504 (accessed on 20 December 2020).
- Chen, J.H.; Tang, I.L.; Chang, C.H. Enhancing the detection rate of inclined faces. In Proceedings of the IEEE Trustcom/BigDataSE/ISPA, Helsinki, Finland, 20–22 August 2015; Volume 2, pp. 143–146. [Google Scholar]
- Milborrow, S.; Morkel, J.; Nicolls, F. The MUCT landmarked face database. In Proceedings of the Pattern Recognition Association of South Africa, Stellenbosch, South Africa, 22–23 November 2010; pp. 32–34. [Google Scholar]
- Jain, V.; Learned-Miller, E. FDDB: A Benchmark for Face Detection in Unconstrained Settings. 2010. Available online: http://works.bepress.com/eric_learned_miller/55/ (accessed on 5 December 2020).
- Dhar, S.; Guo, J.; Liu, J.; Tripathi, S.; Kurup, U.; Shah, M. On-Device Machine Learning: An Algorithms and Learning Theory Perspective. 2019. Available online: https://arxiv.org/abs/1911.00623 (accessed on 24 December 2020).
- Adjabi, I.; Ouahabi, A.; Benzaoui, A.; Taleb-Ahmed, A. Past, present, and future of face recognition: A review. Electronics 2020, 9, 1188. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
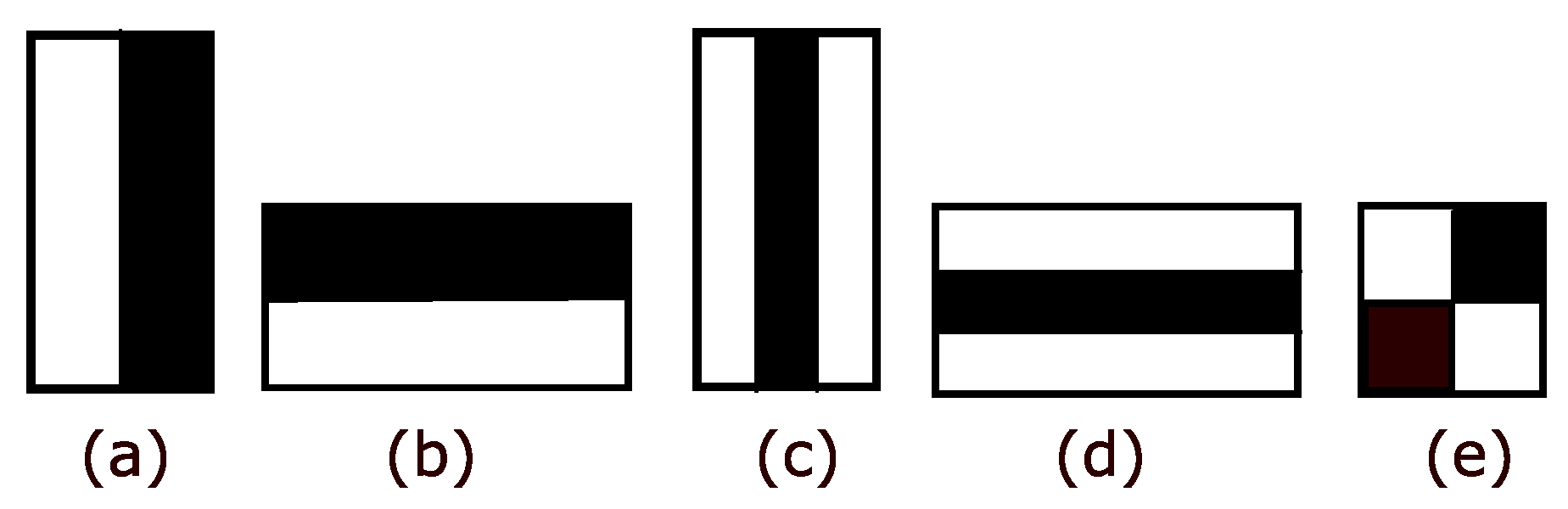{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
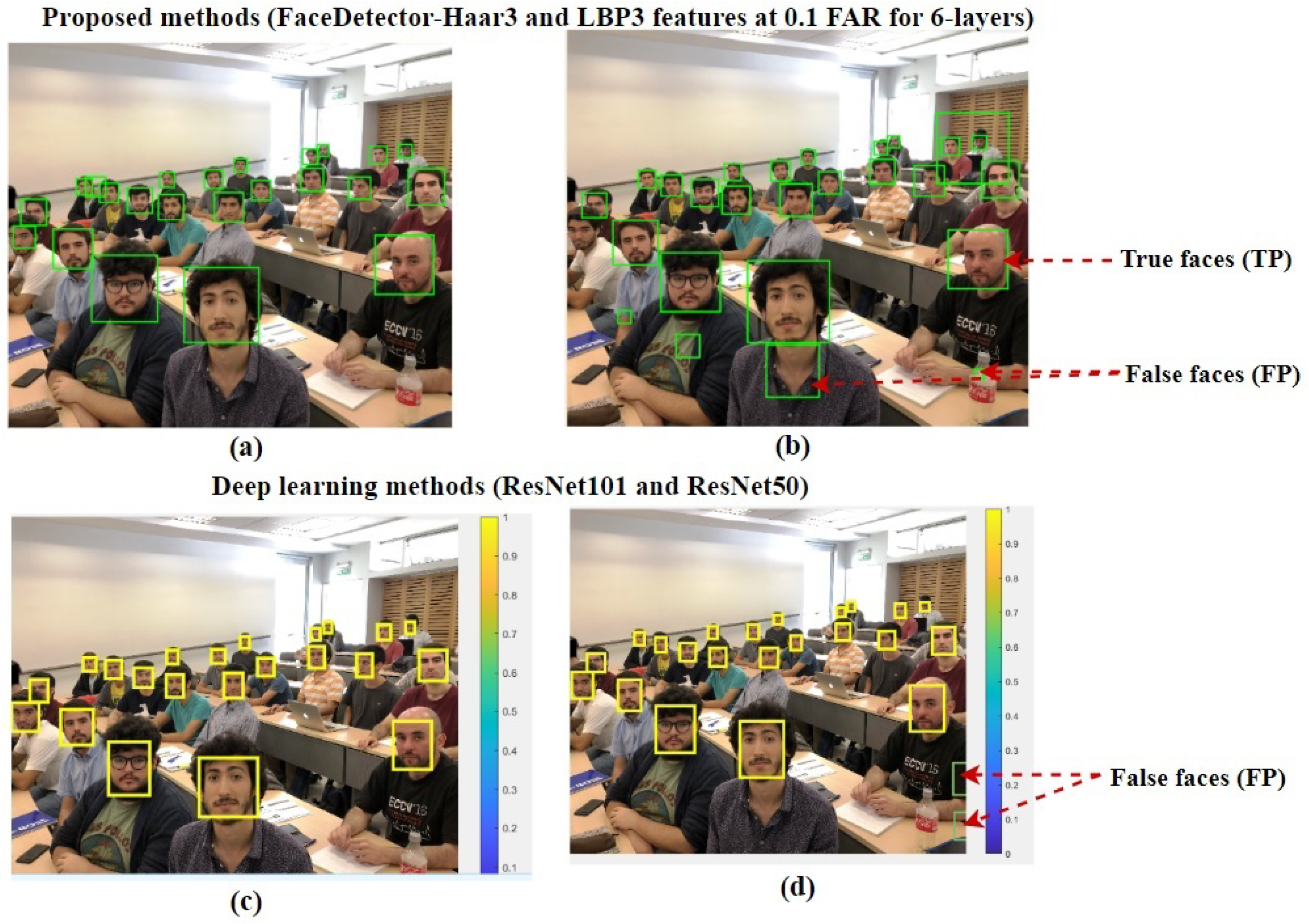{kind=link}
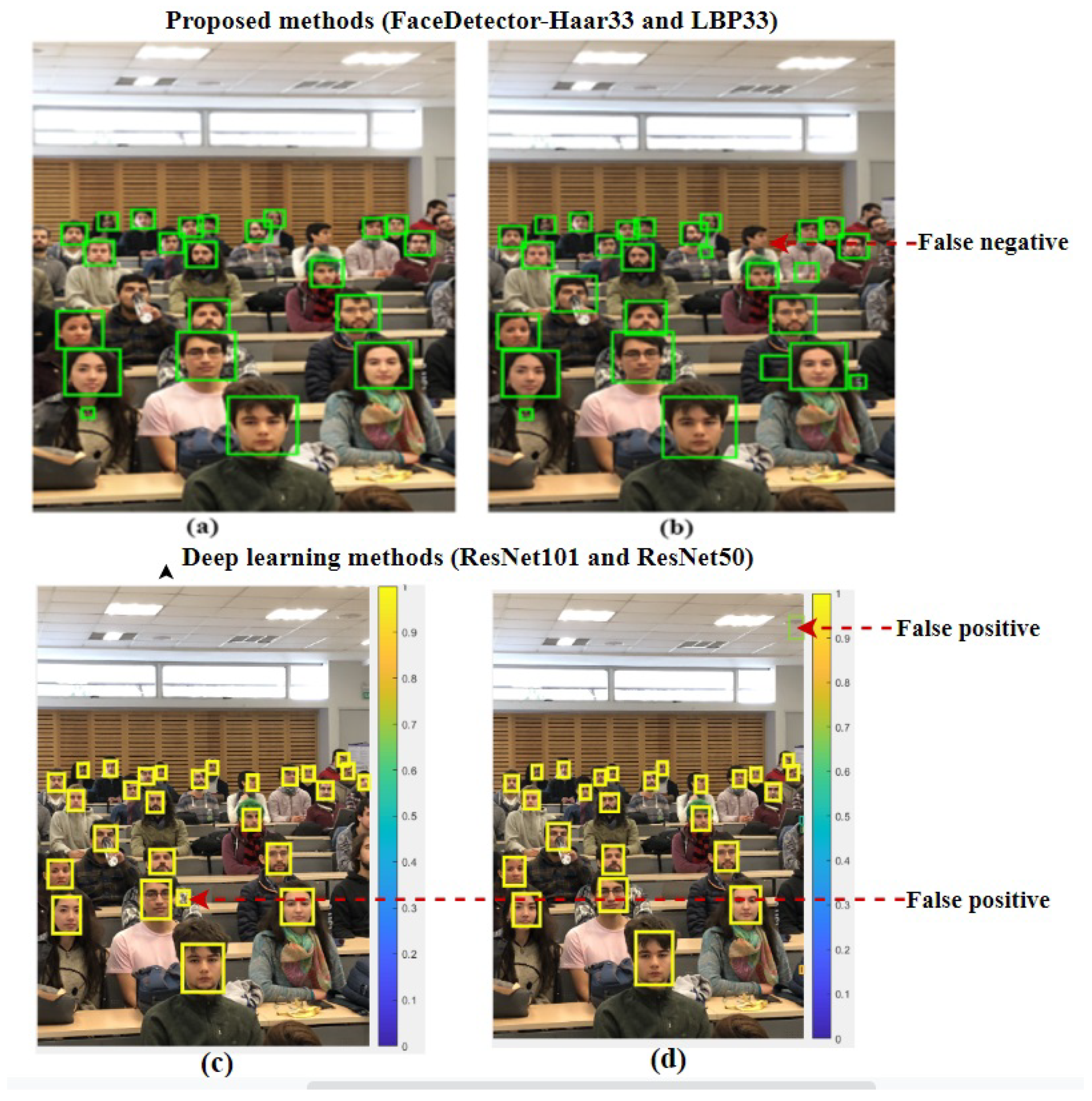{kind=link}
{kind=link}
| Detector | DT | FAR | TP | FN | FP | TPR in % | FNR in % |
|---|---|---|---|---|---|---|---|
| FaceDetector-Haar1 | 1.0939 s | 0.01 | 18 | 4 | 0 | 81.82 | 18.18 |
| FaceDetector-LBP1 | 0.9724 s | 0.01 | 18 | 4 | 0 | 81.82 | 18.18 |
| FaceDetector-Haar2 | 1.1301 s | 0.05 | 20 | 2 | 0 | 90.91 | 9.09 |
| FaceDetector-LBP2 | 1.4496 s | 0.05 | 21 | 1 | 17 | 95.45 | 4.55 |
| FaceDetector-Haar3 | 1.0555 s | 0.10 | 22 | 0 | 1 | 100.00 | 0.00 |
| FaceDetector-LBP3 | 1.2290 s | 0.10 | 21 | 1 | 4 | 95.45 | 4.55 |
| HR-ResNet101 | 139.5256 s | - | 22 | 0 | 1 | 100.00 | 0.00 |
| HR-ResNet50 | 110.1023 s | - | 22 | 0 | 2 | 91.67 | 0.00 |
| Detector | DT | FAR | TP | FN | FP | TPR in % | FNR in % |
|---|---|---|---|---|---|---|---|
| FaceDetector-Haar11 | 1.1454 s | 0.01 | 20 | 6 | 1 | 76.92 | 23.08 |
| FaceDetector-LBP11 | 1.0124 s | 0.01 | 21 | 5 | 0 | 80.77 | 19.23 |
| FaceDetector-Haar22 | 1.0637 s | 0.05 | 20 | 6 | 1 | 76.92 | 23.08 |
| FaceDetector-LBP22 | 1.1136 s | 0.05 | 21 | 5 | 0 | 80.77 | 19.23 |
| FaceDetector-Haar33 | 1.0451 s | 0.10 | 21 | 5 | 1 | 80.77 | 19.23 |
| FaceDetector-LBP33 | 1.0738 s | 0.10 | 22 | 4 | 5 | 81.48 | 18.52 |
| HR-ResNet101 | 56.0617 s | - | 24 | 2 | 1 | 95.60 | 0.08 |
| HR-ResNet50 | 29.8578 s | - | 26 | 0 | 1 | 92.86 | 0.00 |
| Detector | DT | FAR | TP | FN | FP | TPR | FNR | |
|---|---|---|---|---|---|---|---|---|
| in % | in % | |||||||
| Six stages | FaceDetector-Haar1 | 1.094 s | 0.01 | 18 | 4 | 0 | 81.82 | 18.18 |
| FaceDetector-Haar2 | 1.130 s | 0.05 | 20 | 2 | 0 | 90.91 | 9.09 | |
| FaceDetector-Haar3 | 1.056 s | 0.10 | 22 | 0 | 1 | 100.00 | 0.00 | |
| FaceDetector-LBP1 | 0.972 s | 0.01 | 18 | 4 | 0 | 81.82 | 18.18 | |
| FaceDetector-LBP1 | 1.460 s | 0.05 | 21 | 1 | 17 | 95.45 | 4.55 | |
| FaceDetector-LBP3 | 1.229 s | 0.10 | 21 | 1 | 4 | 95.45 | 4.55 | |
| Eight stages | FaceDetector-Haar11 | 1.145 s | 0.01 | 20 | 6 | 1 | 76.92 | 23.08 |
| FaceDetector-Haar22 | 1.064 s | 0.05 | 20 | 6 | 1 | 76.92 | 23.08 | |
| FaceDetector-Haar33 | 1.045 s | 0.10 | 21 | 5 | 1 | 80.77 | 19.23 | |
| FaceDetector-LBP11 | 1.012 s | 0.01 | 21 | 5 | 0 | 80.77 | 19.23 | |
| FaceDetector-LBP22 | 1.114 s | 0.05 | 21 | 5 | 0 | 80.77 | 19.23 | |
| FaceDetector-LBP33 | 1.074 s | 0.10 | 22 | 4 | 5 | 81.48 | 18.52 | |
| Tiny Face | HR-ResNet101 (1) | 139.526 s | - | 22 | 0 | 1 | 100.00 | 0.00 |
| (ResNet101 and ResNet50) | HR-ResNet50 (1) | 110.102 s | - | 22 | 0 | 2 | 91.67 | 0.00 |
| for | HR-ResNet101 (2) | 56.062 s | - | 24 | 2 | 1 | 95.60 | 0.08 |
| Image (1) and (2) | HR-ResNet50 (2) | 29.858 s | - | 26 | 0 | 1 | 92.86 | 0.00 |
| Approach | MUCT Dataset | LFW Dataset | ||
|---|---|---|---|---|
| TPR for Haar (%) | TPR for LBP (%) | TPR for Haar (%) | TPR for LBP (%) | |
| Chen et al. [33] | 16.41 | 77.33 | - | - |
| Kortli et al. [11] | 98.04 | 91.21 | - | - |
| Adouani et al. [17] | - | - | 92.68 | 60.37 |
| Proposed | 98.55 | 91.87 | 92.71 | 91.26 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Adeshina, S.O.; Ibrahim, H.; Teoh, S.S.; Hoo, S.C. Custom Face Classification Model for Classroom Using Haar-Like and LBP Features with Their Performance Comparisons. Electronics 2021, 10, 102. https://doi.org/10.3390/electronics10020102
Adeshina SO, Ibrahim H, Teoh SS, Hoo SC. Custom Face Classification Model for Classroom Using Haar-Like and LBP Features with Their Performance Comparisons. Electronics. 2021; 10(2):102. https://doi.org/10.3390/electronics10020102
Chicago/Turabian StyleAdeshina, Sirajdin Olagoke, Haidi Ibrahim, Soo Siang Teoh, and Seng Chun Hoo. 2021. "Custom Face Classification Model for Classroom Using Haar-Like and LBP Features with Their Performance Comparisons" Electronics 10, no. 2: 102. https://doi.org/10.3390/electronics10020102
APA StyleAdeshina, S. O., Ibrahim, H., Teoh, S. S., & Hoo, S. C. (2021). Custom Face Classification Model for Classroom Using Haar-Like and LBP Features with Their Performance Comparisons. Electronics, 10(2), 102. https://doi.org/10.3390/electronics10020102