
COVID-19 Image Classification: A Comparative Performance Analysis of Hand-Crafted vs. Deep Features

Abstract
1. Introduction
2. Related Work
2.1. Traditional ML-Based Techniques
2.2. DL-Based Techniques
2.3. Contribution
- Why COVID-19 Detection is Still Important?
- −
- Long-Term Effects: COVID-19 can cause lingering health problems even after recovery. Thus, early detection potentially helps in managing these effectively.
- −
- Variants and Future Outbreaks: New variants can emerge, and having robust detection systems is indispensable for future outbreaks.
- −
- Improved Healthcare Systems: Coherent detection tools can minimize unnecessary hospitalizations and allocate resources better.
- Why a Comparative Study for COVID-19 is important?
- −
- Benchmarking Progress: Contrasting different techniques allows us to identify the well-performing models and track advancements in the field.
- −
- Understanding Best-Performing Methods: Knowing best-performing methods guides future development to generalize and adapt for other classification tasks in biomedicine.
- −
- Focus on Improving Techniques: Even if the overall trend of COVID-19 is decreasing, a comparative analysis of various techniques could potentially identify and improve robust techniques for COVID-19 detection.
3. Methods
3.1. Handcrafted Descriptors for COVID-19 Image Classification
3.2. Deep Models for COVID-19 Images
- GoogLeNet (Inception) [73]: architecture relies on LeNet and AlexNet CNN models, but with the modification of depth and width of the layers. This model consists of 22 layers. It employs a parallel structure to significantly lessen the training time. As such, the model is designed to avoid patch-alignment problems by applying filter sizes of , , and .
- Inception-ResNet-v2 [74]: model consists of 164 layers. This model relies on the family of Inception, but instead comprises residual connections. As such, this model replaces the filter concatenation step of the Inception CNN model.
- Inception-v3 [71]: comprising 48 layers, tackles the challenge of positional variance in salient image features by employing a multi-branch architecture. This architecture allows the network to incorporate diverse kernel types at the same level (sizes of , , and pooling layers), effectively expanding the network’s receptive field. These Inception modules enable the concurrent execution of numerous kernels, fostering greater feature extraction diversity. This core concept was introduced in the initial Inception-v1 model. Building upon its predecessor, Inception-v3 addresses the representational bottleneck issue through enhanced strategies. Notably, it incorporates kernel factorization and batch normalization within its auxiliary classifiers, leading to improved performance.
- VGG-16 and VGG-19 [72]: developed by the Visual Geometry Group (VGG) at the University of Oxford, VGG models represent a family of CNNs known for their simplicity and performance. Notably, VGG-16 and VGG-19, with 16 and 19 convolutional layers respectively, gained recognition at the ILSVRC 2014 competition as runners-up. These architectures feature relatively large numbers of parameters, with VGG-16 reaching approximately 138 million parameters. Additionally, both models incorporate fully connected layers containing 4096 hidden units each.
- SqueezeNet v1.1 [65]: network commences with a convolutional layer (conv1), followed by a sequence of eight blocks, each containing 2–9 fire modules. Each fire module employs a squeeze convolution layer with a filter size of , followed by two expand layers. One of these expand layers utilizes a filter size of , while the other utilizes a filter size of . The resulting feature maps from both expand layers are subsequently concatenated to form the input for the subsequent squeeze layer, which then feeds into the next fire module within the block.
- DenseNet-201 [68]: architecture leverages the concept of residual learning, introduced in ResNet, for network optimization. While ResNet employs element-wise addition of previous feature maps to the output, DenseNet utilizes depth concatenation of both the current and preceding outputs. This architecture comprises 32 dense blocks, each containing two distinct convolutional layers with kernel sizes of and , respectively. Notably, these convolutional layers are preceded by batch normalization for improved convergence and training stability.
- ResNet-18 [67]: architecture leverages a series of eight basic building blocks, each containing a sequence of two convolutional layers. These convolutional layers utilize a fixed filter size of , ensuring consistent spatial feature extraction. Critically, each convolutional layer is followed by batch normalization, a technique that facilitates faster convergence and improved training stability. Notably, a key mechanism of ResNet-18 lies in the residual connection. This involves the element-wise addition of the current block’s output to the output of the preceding block, allowing the information flow to propagate efficiently through the network.
- ResNet-50 and ResNet-101 [67]: architectures comprise variations of the ResNet-18 model, differentiating themselves through their respective depths of 50 and 101 layers. Both architectures leverage the bottleneck residual module, which processes the input signal through two distinct branches: (1) Convolutional Processing Branch: This branch applies a series of convolutions with varying kernel sizes ( and ) interspersed with batch normalization and ReLU activation functions; (2) Skip Connection Branch: This branch directly transmits the input signal unaltered, preserving crucial low-level feature information.
- Xception [75]: model stands out for its exclusive reliance on depthwise separable convolution layers. This architectural decision fosters computational efficiency while maintaining representational power. The network encompasses 36 convolutional layers, organized into 14 individual blocks. Only the first and final blocks deviate from the standard structure by lacking residual connections. In contrast, all remaining blocks incorporate linear residual connections. This strategic use of residual connections facilitates gradient flow throughout the network, enhancing training and promoting optimal performance.
- MobileNet-v2 [66]: architecture incorporates two primary types of building blocks: (1) Linear Bottleneck Operations: These modules aim to achieve feature compression while maintaining representational power. (2) Skip Connections: These direct connections facilitate the flow of gradients and information across the network, mitigating the vanishing gradient problem that can occur in deep architectures. Both block types share fundamental operations, including convolution, batch normalization, and modified rectified linear unit (i.e., min (max (x, 0), 6)). The network comprises a total of 16 of these blocks, strategically arranged to achieve efficient feature extraction and classification performance.
CNN as Feature Extractor
4. Experiments and Results
4.1. Dataset
4.2. Nested Cross-Validation (CV)
- Accuracy , where , and indicate the number of true positives, true negatives, false positives, and false negatives, respectively.
- Sensitivity .
- Specificity .
- F-Measure
- The area under the curve () encapsulates the relationship between the true positive rate (sensitivity) and the false positive rate (1 − specificity)
- Positive Predictive Value () = TP/(TP + FP).
- Negative Predictive Value () = TN/(TN + FN).
- Geometric mean () is the square root of the product of sensitivity and specificity, or GM = .
4.3. Results and Analysis
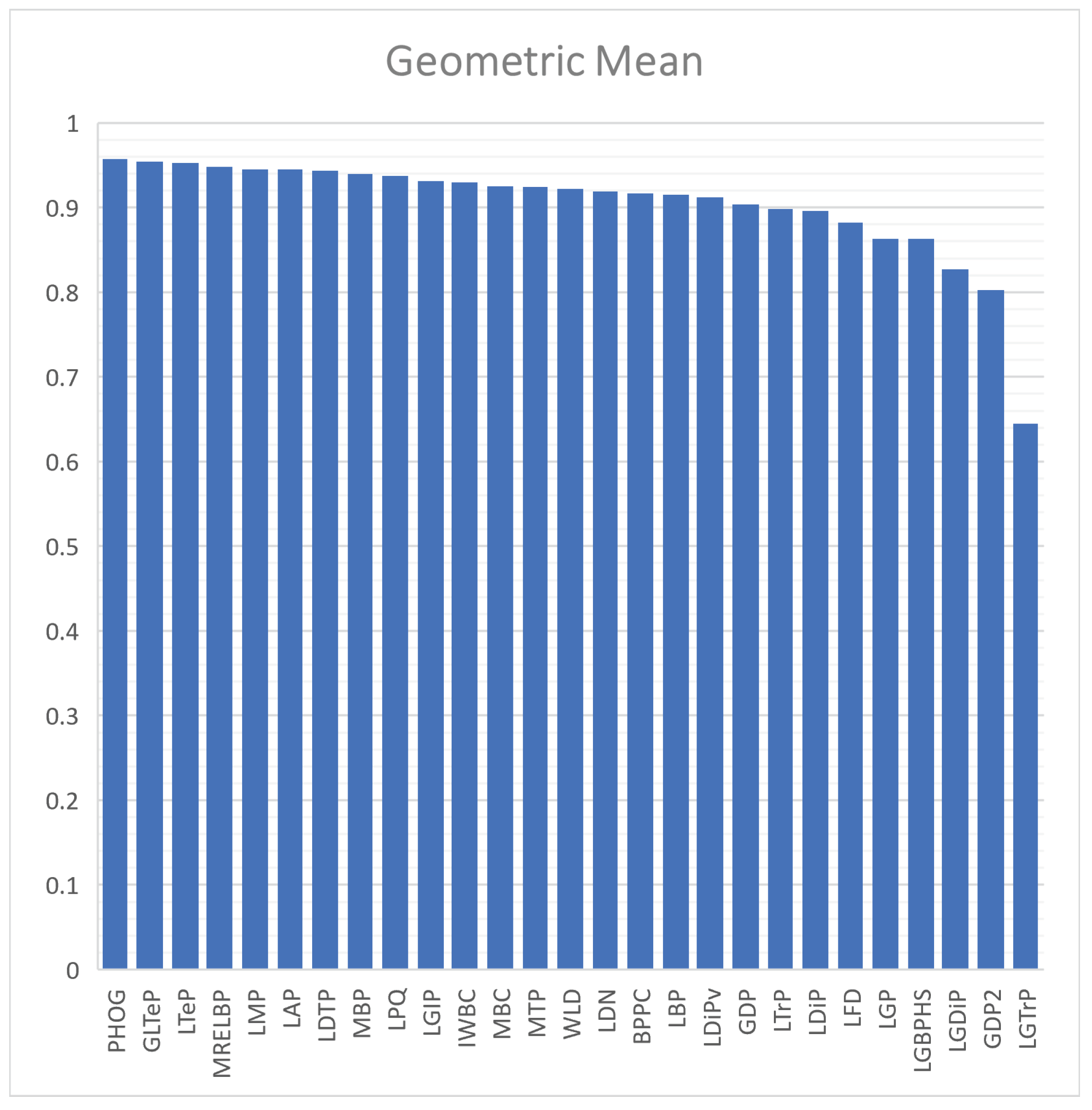
4.3.1. Classification Results Using Handcrafted Descriptors
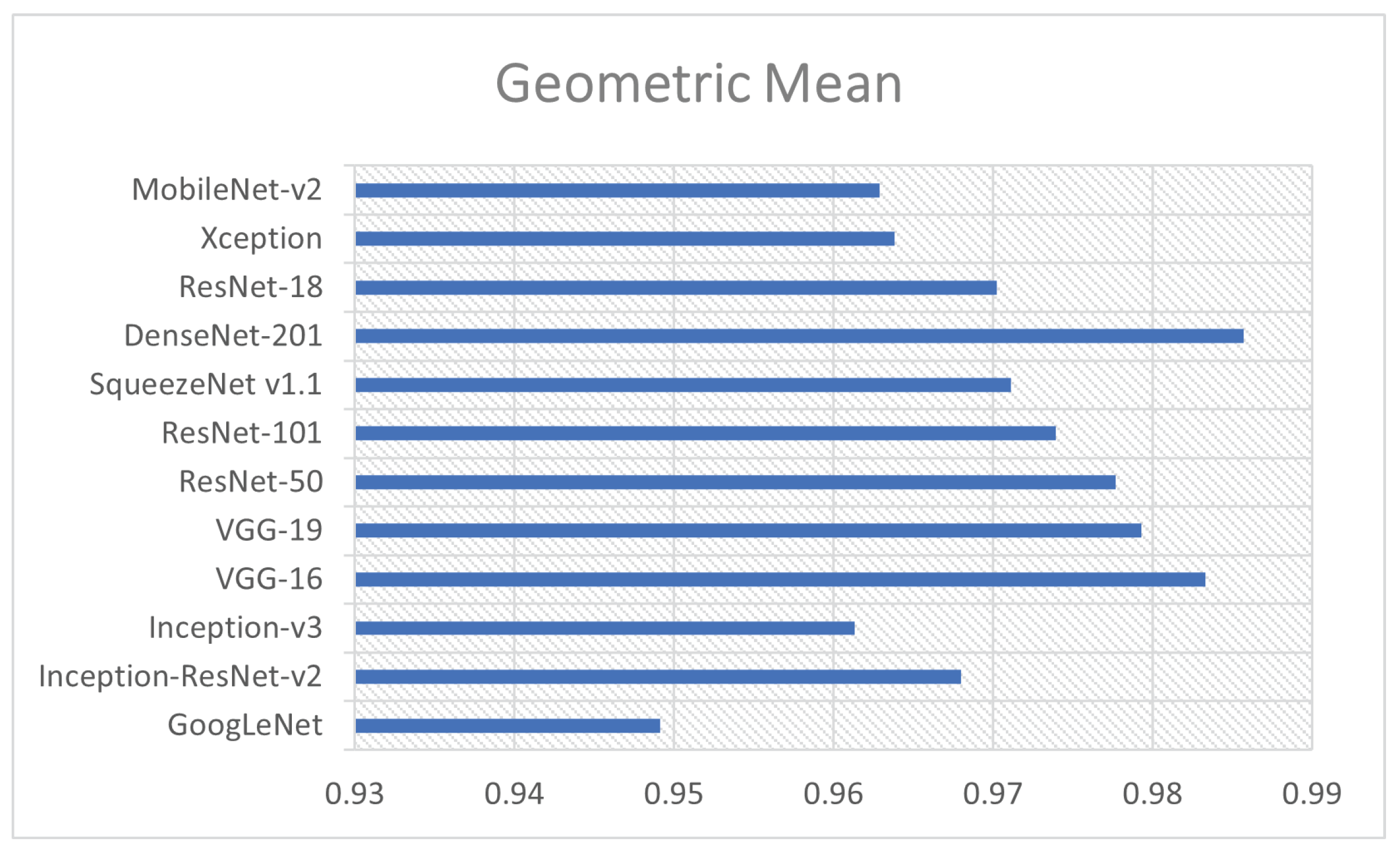
4.3.2. Classification Results Using Deep Features
4.4. Discussion
- Halder and Datta [99] investigated the efficacy of transfer learning employing pre-trained CNN models, namely DenseNet201, VGG16, ResNet50V2, and MobileNet. Each model was independently trained and tested with a ratio of 8:2 on both unmodified and augmented datasets. Notably, DenseNet201 exhibited exceptional performance, achieving an AUC of 1.00 and 0.99 for the unaugmented and augmented datasets, respectively. Moreover, training DenseNet201 with the augmented data yielded a test set accuracy of 97%, surpassing ResNet50V2 (96%), MobileNet (95%), and VGG16 (94%).
- Alshazly et al. [100] investigated the application of transfer learning to various pre-trained CNN architectures, including SqueezeNet, Inception, ResNet, ResNeXt, Xception, ShuffleNet, and DenseNet. Five-fold cross-validation was utilized to evaluate the efficacy of their approach. Their ResNet101 model demonstrated remarkable performance, achieving average accuracy, precision, sensitivity, specificity, and F1-score values of 99.4%, 99.6%, 99.1%, 99.6%, and 99.4%, respectively.
- Ragab et al. [101] proposed a multi-modal fusion architecture for COVID-19 image classification. Their system leverages the pre-trained CNNs, namely AlexNet, GoogleNet, ShuffleNet, and ResNet-18, alongside hand-crafted features derived from statistical analysis, discrete wavelet transform, and grey-level co-occurrence matrix. They employed five-fold cross-validation to evaluate the efficacy of their approach. This hybrid methodology achieved performance, attaining an average accuracy, sensitivity, specificity, and precision of approximately 99% across all evaluation metrics.
- Shaik and Cherukuri [102] presented an ensemble learning approach for COVID-19 image classification that leverages the combined prediction of diverse pre-trained CNN architectures. They employ a collection of eight models, including VGG16, VGG19, InceptionV3, ResNet50, ResNet50V2, InceptionResNetV2, Xception, and MobileNet. Each model is fine-tuned using an 80/20 data split for training and validation, respectively. This ensemble approach achieved an accuracy of 98.99%, precision of 98.98%, recall of 99.00%, and F-measure of 98.99%.
- Gaur et al. [103] presented a method that leverages the spectral information within each image channel (red, green, and blue) by applying a 2D-empirical wavelet transform. This decomposition generates five frequency sub-bands, which are subsequently augmented to enhance data variability. These augmented sub-bands then serve as the input for training a DenseNet121 classification model. To ensure a statistically robust evaluation, the dataset was randomly split into 1000 training, 100 validation, and 152 testing images prior to data augmentation. This strategy yielded a performance of accuracy of 85.50%, F-measure of 85.28%, and AUC of 96.6%.
- Canayaz et al. [104] explores the efficacy of Bayesian optimization in enhancing the performance of various machine learning algorithms for COVID-19 image classification. The authors propose and evaluate the application of this optimization technique to MobilNetv2, ResNet-50, SVM, and k-nearest neighbor (kNN) models. The proposed method consists of three steps: (1) train and optimize the deep learning models, (2) utilize trained models as feature extractors, and (3) train a machine learning algorithm. Notably, the ResNet-50 architecture, when optimized via Bayesian optimization and employed as a feature extractor for kNN (trained on 1968 COVID-19 images and tested on 492), yielded an accuracy of 99.37%, accompanied by a precision of 99.38%, recall of 99.36%, and F-score of 99.37%.
- Attallah and Samir [105] presented a two-stage framework for COVID-19 image classification that leverages spectral-temporal and spatial information. In the first stage, their method employs discrete wavelet decomposition (DWT) to extract frequency-domain features from the images, represented as heatmaps. These features are subsequently used to train a ResNet CNN model. Simultaneously, the original images are utilized to train a separate ResNet CNN model, capturing spatial information. Subsequently, both pipelines converge in a feature fusion stage, where spectral-temporal features are integrated with spatial features extracted from the second ResNet. To address dimensionality, the combined feature set is subjected to dimensionality reduction before being fed into support vector machine (SVM) classifiers. This strategy achieved a classification accuracy of 99.7% under a 5-fold cross-validation scheme.
- Kundu et al. [106] explored an ensemble learning approach by leveraging transfer learning. Their method, employing bootstrap aggregating (bagging) of three pre-trained architectures Inception v3, ResNet34, and DenseNet201 were examined under a 5-fold cross-validation scheme. The ensemble model achieved an accuracy of 97.81%, precision of 97.77%, sensitivity (recall) of 97.81%, and specificity of 97.77%.
- Islam and Nahiduzzaman [107] proposed employing a custom CNN architecture for extracting deep features. These features are subsequently fed into traditional machine learning algorithms, encompassing Gaussian Naive Bayes, Support Vector Machine, Decision Tree, Logistic Regression, and Random Forest. The output of these five learning algorithms is ensembled to find the final prediction. The proposed model undergoes training on 2109 COVID-19 images and evaluation on a separate set of 373 images. The model achieved an accuracy of 99.73%, an F1-score of 99.73%, a recall of 100%, and a precision of 99.46%.
- Choudhary et al. [108] introduced an approach for COVID-19 detection on resource-constrained devices, focusing on “important weights-only” transfer learning. This method optimizes pre-trained deep learning models for deployment on point-of-care devices by selectively pruning less essential weight parameters. Their experiments were conducted on VGG16 and ResNet34 architectures. The proposed method was evaluated while using 1,687 samples for training, 420 samples for validation, and 375 samples for testing. The pruned ResNet34 model achieved an accuracy of 95.47%, a sensitivity of 0.9216, an F1-score of 0.9567, and a specificity of 0.9942 while exhibiting reductions in computational requirements: 41.96% fewer floating-point operations and 20.64% fewer weight parameters compared to the unpruned model.
5. Conclusions and Future Studies
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, J.; Liao, X.; Qian, S.; Yuan, J.; Wang, F.; Liu, Y.; Wang, Z.; Wang, F.S.; Liu, L.; Zhang, Z. Community transmission of severe acute respiratory syndrome coronavirus 2, Shenzhen, China, 2020. Emerg. Infect. Dis. 2020, 26, 1320. [Google Scholar] [CrossRef] [PubMed]
- Ghinai, I.; McPherson, T.D.; Hunter, J.C.; Kirking, H.L.; Christiansen, D.; Joshi, K.; Rubin, R.; Morales-Estrada, S.; Black, S.R.; Pacilli, M.; et al. First known person-to-person transmission of severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) in the USA. Lancet 2020, 395, 1137–1144. [Google Scholar] [CrossRef] [PubMed]
- Morens, D.M.; Fauci, A.S. Emerging pandemic diseases: How we got to COVID-19. Cell 2020, 182, 1077–1092. [Google Scholar] [CrossRef] [PubMed]
- Poudel, A.N.; Zhu, S.; Cooper, N.; Roderick, P.; Alwan, N.; Tarrant, C.; Ziauddeen, N.; Yao, G.L. Impact of COVID-19 on health-related quality of life of patients: A structured review. PLoS ONE 2021, 16, e0259164. [Google Scholar] [CrossRef]
- Arevalo-Rodriguez, I.; Buitrago-Garcia, D.; Simancas-Racines, D.; Zambrano-Achig, P.; Del Campo, R.; Ciapponi, A.; Sued, O.; Martinez-Garcia, L.; Rutjes, A.W.; Low, N.; et al. False-negative results of initial RT-PCR assays for COVID-19: A systematic review. PLoS ONE 2020, 15, e0242958. [Google Scholar] [CrossRef] [PubMed]
- Axiaq, A.; Almohtadi, A.; Massias, S.A.; Ngemoh, D.; Harky, A. The role of computed tomography scan in the diagnosis of COVID-19 pneumonia. Curr. Opin. Pulm. Med. 2021, 27, 163–168. [Google Scholar] [CrossRef] [PubMed]
- Fang, Y.; Zhang, H.; Xie, J.; Lin, M.; Ying, L.; Pang, P.; Ji, W. Sensitivity of chest CT for COVID-19: Comparison to RT-PCR. Radiology 2020, 296, E115–E117. [Google Scholar] [CrossRef] [PubMed]
- Ai, T.; Yang, Z.; Hou, H.; Zhan, C.; Chen, C.; Lv, W.; Tao, Q.; Sun, Z.; Xia, L. Correlation of chest CT and RT-PCR testing for coronavirus disease 2019 (COVID-19) in China: A report of 1014 cases. Radiology 2020, 296, E32–E40. [Google Scholar] [CrossRef] [PubMed]
- Hassan, H.; Ren, Z.; Zhao, H.; Huang, S.; Li, D.; Xiang, S.; Kang, Y.; Chen, S.; Huang, B. Review and classification of AI-enabled COVID-19 CT imaging models based on computer vision tasks. Comput. Biol. Med. 2022, 141, 105123. [Google Scholar] [CrossRef]
- Saygılı, A. A new approach for computer-aided detection of coronavirus (COVID-19) from CT and X-ray images using machine learning methods. Appl. Soft Comput. 2021, 105, 107323. [Google Scholar] [CrossRef] [PubMed]
- Shi, F.; Wang, J.; Shi, J.; Wu, Z.; Wang, Q.; Tang, Z.; He, K.; Shi, Y.; Shen, D. Review of artificial intelligence techniques in imaging data acquisition, segmentation, and diagnosis for COVID-19. IEEE Rev. Biomed. Eng. 2020, 14, 4–15. [Google Scholar] [CrossRef] [PubMed]
- Elaziz, M.A.; Hosny, K.M.; Salah, A.; Darwish, M.M.; Lu, S.; Sahlol, A.T. New machine learning method for image-based diagnosis of COVID-19. PLoS ONE 2020, 15, e0235187. [Google Scholar] [CrossRef] [PubMed]
- Ismael, A.M.; Şengür, A. The investigation of multiresolution approaches for chest X-ray image based COVID-19 detection. Health Inf. Sci. Syst. 2020, 8, 29. [Google Scholar] [CrossRef]
- Alam, M.; Akram, M.U.; Fareed, W. Deep Learning-based Analysis and Classification of COVID Patients Through CT Images. In Proceedings of the IEEE 2023 3rd International Conference on Artificial Intelligence (ICAI), Wuhan, China, 17–19 November 2023; pp. 136–141. [Google Scholar]
- Reis, H.C.; Turk, V. COVID-DSNet: A novel deep convolutional neural network for detection of coronavirus (SARS-CoV-2) cases from CT and Chest X-Ray images. Artif. Intell. Med. 2022, 134, 102427. [Google Scholar] [CrossRef] [PubMed]
- Alinsaif, S. Unraveling Arrhythmias with Graph-Based Analysis: A Survey of the MIT-BIH Database. Computation 2024, 12, 21. [Google Scholar] [CrossRef]
- Özkaya, U.; Öztürk, Ş.; Barstugan, M. Coronavirus (COVID-19) classification using deep features fusion and ranking technique. In Big Data Analytics and Artificial Intelligence Against COVID-19: Innovation Vision and Approach; Springer: Cham, Switzerland, 2020; pp. 281–295. [Google Scholar]
- Rahmani, A.M.; Azhir, E.; Naserbakht, M.; Mohammadi, M.; Aldalwie, A.H.M.; Majeed, M.K.; Taher Karim, S.H.; Hosseinzadeh, M. Automatic COVID-19 detection mechanisms and approaches from medical images: A systematic review. Multimed. Tools Appl. 2022, 81, 28779–28798. [Google Scholar] [CrossRef] [PubMed]
- Benameur, N.; Mahmoudi, R.; Zaid, S.; Arous, Y.; Hmida, B.; Bedoui, M.H. SARS-CoV-2 diagnosis using medical imaging techniques and artificial intelligence: A review. Clin. Imaging 2021, 76, 6–14. [Google Scholar] [CrossRef] [PubMed]
- Serena Low, W.C.; Chuah, J.H.; Tee, C.A.T.; Anis, S.; Shoaib, M.A.; Faisal, A.; Khalil, A.; Lai, K.W. An overview of deep learning techniques on chest X-ray and CT scan identification of COVID-19. Comput. Math. Methods Med. 2021, 2021, 5528144. [Google Scholar] [CrossRef] [PubMed]
- Hussain, L.; Nguyen, T.; Li, H.; Abbasi, A.A.; Lone, K.J.; Zhao, Z.; Zaib, M.; Chen, A.; Duong, T.Q. Machine-learning classification of texture features of portable chest X-ray accurately classifies COVID-19 lung infection. BioMed. Eng. Online 2020, 19, 88. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y. COVID-19 classification based on gray-level co-occurrence matrix and support vector machine. In COVID-19: Prediction, Decision-Making, and Its Impacts; Springer: Singapore, 2021; pp. 47–55. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Ismael, A.M.; Şengür, A. Deep learning approaches for COVID-19 detection based on chest X-ray images. Expert Syst. Appl. 2021, 164, 114054. [Google Scholar] [CrossRef]
- Haque, K.F.; Abdelgawad, A. A deep learning approach to detect COVID-19 patients from chest X-ray images. AI 2020, 1, 27. [Google Scholar] [CrossRef]
- Jain, G.; Mittal, D.; Thakur, D.; Mittal, M.K. A deep learning approach to detect COVID-19 coronavirus with X-Ray images. Biocybern. Biomed. Eng. 2020, 40, 1391–1405. [Google Scholar] [CrossRef] [PubMed]
- Saiz, F.; Barandiaran, I. COVID-19 detection in chest X-ray images using a deep learning approach. Int. J. Interact. Multimed. Artif. Intell. 2020. [Google Scholar] [CrossRef]
- Sahin, M.E.; Ulutas, H.; Yuce, E.; Erkoc, M.F. Detection and classification of COVID-19 by using faster R-CNN and mask R-CNN on CT images. Neural Comput. Appl. 2023, 35, 13597–13611. [Google Scholar] [CrossRef] [PubMed]
- Avola, D.; Bacciu, A.; Cinque, L.; Fagioli, A.; Marini, M.R.; Taiello, R. Study on transfer learning capabilities for pneumonia classification in chest-x-rays images. Comput. Methods Programs Biomed. 2022, 221, 106833. [Google Scholar] [CrossRef] [PubMed]
- Kathamuthu, N.D.; Subramaniam, S.; Le, Q.H.; Muthusamy, S.; Panchal, H.; Sundararajan, S.C.M.; Alrubaie, A.J.; Zahra, M.M.A. A deep transfer learning-based convolution neural network model for COVID-19 detection using computed tomography scan images for medical applications. Adv. Eng. Softw. 2023, 175, 103317. [Google Scholar] [CrossRef] [PubMed]
- Nanni, L.; Ghidoni, S.; Brahnam, S. Deep features for training support vector machines. J. Imaging 2021, 7, 177. [Google Scholar] [CrossRef] [PubMed]
- Angelov, P.; Almeida Soares, E. SARS-CoV-2 CT-scan dataset: A large dataset of real patients CT scans for SARS-CoV-2 identification. MedRxiv 2020. [Google Scholar] [CrossRef]
- Britain, R.S.G. Machine Learning: The Power and Promise of Computers That Learn by Example: An Introduction; Royal Society: London, UK, 2017. [Google Scholar]
- Shawe-Taylor, J.; Sun, S. A review of optimization methodologies in support vector machines. Neurocomputing 2011, 74, 3609–3618. [Google Scholar] [CrossRef]
- Kutyniok, G.; Labate, D. Introduction to shearlets. In Shearlets: Multiscale Analysis for Multivariate Data; Springer: New York, NY, USA, 2012; pp. 1–38. [Google Scholar]
- Do, M.N.; Vetterli, M. The contourlet transform: An efficient directional multiresolution image representation. IEEE Trans. Image Process. 2005, 14, 2091–2106. [Google Scholar] [CrossRef] [PubMed]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Turan, C.; Lam, K.M. Histogram-based local descriptors for facial expression recognition (FER): A comprehensive study. J. Vis. Commun. Image Represent. 2018, 55, 331–341. [Google Scholar] [CrossRef]
- Sebe, N.; Tian, Q.; Loupias, E.; Lew, M.S.; Huang, T.S. Evaluation of salient point techniques. Image Vis. Comput. 2003, 21, 1087–1095. [Google Scholar] [CrossRef]
- Shojaeilangari, S.; Yau, W.Y.; Li, J.; Teoh, E.K. Feature extraction through binary pattern of phase congruency for facial expression recognition. In Proceedings of the 2012 12th International Conference on Control Automation Robotics & Vision (ICARCV), Guangzhou, China, 5–7 December 2012; pp. 166–170. [Google Scholar]
- Ahmed, F. Gradient directional pattern: A robust feature descriptor for facial expression recognition. Electron. Lett. 2012, 48, 1203–1204. [Google Scholar] [CrossRef]
- Islam, M.S. Gender classification using gradient direction pattern. Sci. Int. 2013, 25, 797–799. [Google Scholar]
- Valstar, M.; Pantic, M. Fully automatic facial action unit detection and temporal analysis. In Proceedings of the IEEE 2006 Conference on Computer Vision and Pattern Recognition Workshop (CVPRW’06), New York, NY, USA, 17–22 June 2006; p. 149. [Google Scholar]
- Yang, B.Q.; Zhang, T.; Gu, C.C.; Wu, K.J.; Guan, X.P. A novel face recognition method based on IWLD and IWBC. Multimed. Tools Appl. 2016, 75, 6979–7002. [Google Scholar] [CrossRef]
- Islam, M.S.; Auwatanamo, S. Facial expression recognition using local arc pattern. Trends Appl. Sci. Res. 2014, 9, 113. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Jabid, T.; Kabir, M.H.; Chae, O. Local directional pattern (LDP)–A robust image descriptor for object recognition. In Proceedings of the 2010 7th IEEE International Conference on Advanced Video and Signal Based Surveillance, Boston, MA, USA, 29 August–1 September 2010; pp. 482–487. [Google Scholar]
- Kabir, M.H.; Jabid, T.; Chae, O. A local directional pattern variance (LDPv) based face descriptor for human facial expression recognition. In Proceedings of the 2010 7th IEEE International Conference on Advanced Video and Signal Based Surveillance, Boston, MA, USA, 29 August–1 September 2010; pp. 526–532. [Google Scholar]
- Rivera, A.R.; Castillo, J.R.; Chae, O.O. Local directional number pattern for face analysis: Face and expression recognition. IEEE Trans. Image Process. 2012, 22, 1740–1752. [Google Scholar] [CrossRef] [PubMed]
- Rivera, A.R.; Castillo, J.R.; Chae, O. Local directional texture pattern image descriptor. Pattern Recognit. Lett. 2015, 51, 94–100. [Google Scholar] [CrossRef]
- Lei, Z.; Ahonen, T.; Pietikäinen, M.; Li, S.Z. Local frequency descriptor for low-resolution face recognition. In Proceedings of the 2011 IEEE International Conference on Automatic Face & Gesture Recognition (FG), Santa Barbara, CA, USA, 21–23 March 2011; pp. 161–166. [Google Scholar]
- Zhang, W.; Shan, S.; Gao, W.; Chen, X.; Zhang, H. Local gabor binary pattern histogram sequence (lgbphs): A novel non-statistical model for face representation and recognition. In Proceedings of the 10th IEEE International Conference on Computer Vision (ICCV’05), Washington, DC, USA, 17–20 October 2005; Volume 1, pp. 786–791. [Google Scholar]
- Ishraque, S.Z.; Banna, A.H.; Chae, O. Local Gabor directional pattern for facial expression recognition. In Proceedings of the 2012 IEEE 15th International Conference on Computer and Information Technology (ICCIT), Chittagong, Bangladesh, 22–24 December 2012; pp. 164–167. [Google Scholar]
- Zhou, L.; Wang, H. Local gradient increasing pattern for facial expression recognition. In Proceedings of the 2012 19th IEEE International Conference on Image Processing, Orlando, FL, USA, 30 September–3 October 2012; pp. 2601–2604. [Google Scholar]
- Islam, M.S. Local gradient pattern—A novel feature representation for facial expression recognition. J. AI Data Min. 2014, 2, 33–38. [Google Scholar]
- Ahsan, T.; Jabid, T.; Chong, U.P. Facial expression recognition using local transitional pattern on Gabor filtered facial images. IETE Tech. Rev. 2013, 30, 47–52. [Google Scholar] [CrossRef]
- Mohammad, T.; Ali, M.L. Robust facial expression recognition based on local monotonic pattern (LMP). In Proceedings of the 14th International Conference on Computer and Information Technology (ICCIT 2011), Dhaka, Bangladesh, 22–24 December 2011; pp. 572–576. [Google Scholar]
- Ojansivu, V.; Heikkilä, J. Blur insensitive texture classification using local phase quantization. In Proceedings of the Image and Signal Processing: 3rd International Conference (ICISP 2008), Cherbourg-Octeville, France, 1–3 July 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 236–243. [Google Scholar]
- Bashar, F.; Khan, A.; Ahmed, F.; Kabir, M.H. Robust facial expression recognition based on median ternary pattern (MTP). In Proceedings of the IEEE 2013 International Conference on Electrical Information and Communication Technology (EICT), Khulna, Bangladesh, 13–15 February 2014; pp. 1–5. [Google Scholar]
- Jabid, T.; Chae, O. Local transitional pattern: A robust facial image descriptor for automatic facial expression recognition. In Proceedings of the International Conference on Computer Convergence Technology, Seoul, Republic of Korea, 28–30 September 2011; pp. 333–344. [Google Scholar]
- Lu, J.; Liong, V.E.; Zhou, J. Cost-sensitive local binary feature learning for facial age estimation. IEEE Trans. Image Process. 2015, 24, 5356–5368. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Lao, S.; Fieguth, P.W.; Guo, Y.; Wang, X.; Pietikäinen, M. Median robust extended local binary pattern for texture classification. IEEE Trans. Image Process. 2016, 25, 1368–1381. [Google Scholar] [CrossRef] [PubMed]
- Bosch, A.; Zisserman, A.; Munoz, X. Representing shape with a spatial pyramid kernel. In Proceedings of the 6th ACM International Conference on Image and Video Retrieval, Amsterdam, The Netherlands, 9–11 July 2007; pp. 401–408. [Google Scholar]
- Li, S.; Gong, D.; Yuan, Y. Face recognition using Weber local descriptors. Neurocomputing 2013, 122, 272–283. [Google Scholar] [CrossRef]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8697–8710. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Maguolo, G.; Nanni, L. A critic evaluation of methods for covid-19 automatic detection from x-ray images. Inf. Fusion 2021, 76, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Aswathy, A.; Hareendran, A.; SS, V.C. COVID-19 diagnosis and severity detection from CT-images using transfer learning and back propagation neural network. J. Infect. Public Health 2021, 14, 1435–1445. [Google Scholar]
- Li, C.; Yang, Y.; Liang, H.; Wu, B. Transfer learning for establishment of recognition of COVID-19 on CT imaging using small-sized training datasets. Knowl.-Based Syst. 2021, 218, 106849. [Google Scholar] [CrossRef] [PubMed]
- Lahsaini, I.; Daho, M.E.H.; Chikh, M.A. Deep transfer learning based classification model for COVID-19 using chest CT-scans. Pattern Recognit. Lett. 2021, 152, 122–128. [Google Scholar] [CrossRef]
- Pinki, F.T.; Masud, M.A.; Ferdousi, J.; Eva, F.Y.; Rana, M.M.R. SVM Based COVID-19 Detection from CT Scan Image using Local Feature. In Proceedings of the IEEE 2021 International Conference on Electronics, Communications and Information Technology (ICECIT), Online, 14–16 September 2021; pp. 1–4. [Google Scholar]
- Kaur, T.; Gandhi, T.K. Classifier fusion for detection of COVID-19 from CT scans. Circuits Syst. Signal Process. 2022, 41, 3397–3414. [Google Scholar] [CrossRef]
- Islam, M.K.; Habiba, S.U.; Khan, T.A.; Tasnim, F. COV-RadNet: A Deep Convolutional Neural Network for Automatic Detection of COVID-19 from Chest X-rays and CT Scans. Comput. Methods Programs Biomed. Update 2022, 2, 100064. [Google Scholar] [CrossRef] [PubMed]
- Peng, L.; Wang, C.; Tian, G.; Liu, G.; Li, G.; Lu, Y.; Yang, J.; Chen, M.; Li, Z. Analysis of CT scan images for COVID-19 pneumonia based on a deep ensemble framework with DenseNet, Swin transformer, and RegNet. Front. Microbiol. 2022, 13, 995323. [Google Scholar] [CrossRef] [PubMed]
- Singh, V.K.; Kolekar, M.H. Deep learning empowered COVID-19 diagnosis using chest CT scan images for collaborative edge-cloud computing platform. Multimed. Tools Appl. 2022, 81, 3–30. [Google Scholar] [CrossRef] [PubMed]
- DOLMA, Ö. COVID-19 and Non-COVID-19 Classification from Lung CT-Scan Images Using Deep Convolutional Neural Networks. Int. J. Multidiscip. Stud. Innov. Technol. 2023, 7, 53–60. [Google Scholar] [CrossRef]
- Tiwari, S.; Jain, A.; Chawla, S.K. Diagnosing COVID-19 From Chest CT Scan Images Using Deep Learning Models. Int. J. Reliab. Qual. e-Healthc. (IJRQEH) 2022, 11, 1–15. [Google Scholar] [CrossRef]
- Premamayudu, B.; Bhuvaneswari, C. COVID-19 Automatic Detection from CT Images through Transfer Learning. Int. J. Image Graph. Signal Process. 2022, 14, 48–95. [Google Scholar] [CrossRef]
- Zahir, M.J.B.; Azim, M.A.; Chy, A.N.; Islam, M.K. A Fast and Reliable Approach for COVID-19 Detection from CT-Scan Images. J. Inf. Syst. Eng. Bus. Intell. 2023, 9, 288–304. [Google Scholar] [CrossRef]
- Ibrahim, W.R.; Mahmood, M.R. Classified COVID-19 by densenet121-based deep transfer learning from CT-scan images. Sci. J. Univ. Zakho 2023, 11, 571–580. [Google Scholar] [CrossRef]
- Ibrahim, M.R.; Youssef, S.M.; Fathalla, K.M. Abnormality detection and intelligent severity assessment of human chest computed tomography scans using deep learning: A case study on SARS-COV-2 assessment. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 5665–5688. [Google Scholar] [CrossRef] [PubMed]
- Gupta, K.; Bajaj, V. Deep learning models-based CT-scan image classification for automated screening of COVID-19. Biomed. Signal Process. Control 2023, 80, 104268. [Google Scholar] [CrossRef] [PubMed]
- Duong, L.T.; Nguyen, P.T.; Iovino, L.; Flammini, M. Automatic detection of COVID-19 from chest X-ray and lung computed tomography images using deep neural networks and transfer learning. Appl. Soft Comput. 2023, 132, 109851. [Google Scholar] [CrossRef] [PubMed]
- Ali, N.G.; El Sheref, F.K. A Hybrid Model for COVID-19 Detection using CT-Scans. Int. J. Adv. Comput. Sci. Appl. 2023, 14, 627–633. [Google Scholar] [CrossRef]
- Farjana, A.; Liza, F.T.; Al Mamun, M.; Das, M.C.; Hasan, M.M. SARS CovidAID: Automatic detection of SARS CoV-19 cases from CT scan images with pretrained transfer learning model (VGG19, RESNet50 and DenseNet169) architecture. In Proceedings of the IEEE 2023 International Conference on Smart Applications, Communications and Networking (SmartNets), Istanbul, Turkey, 25–27 July 2023; pp. 1–6. [Google Scholar]
- Lim, Y.J.; Lim, K.M.; Lee, C.P.; Chang, R.K.Y.; Lim, J.Y. COVID-19 identification and analysis with CT scan images using densenet and support vector machine. In Proceedings of the IEEE 2023 11th International Conference on Information and Communication Technology (ICoICT), Melaka, Malaysia, 23–24 August 2023; pp. 254–259. [Google Scholar]
- Motwani, A.; Shukla, P.K.; Pawar, M.; Kumar, M.; Ghosh, U.; Alnumay, W.; Nayak, S.R. Enhanced framework for COVID-19 prediction with computed tomography scan images using dense convolutional neural network and novel loss function. Comput. Electr. Eng. 2023, 105, 108479. [Google Scholar] [CrossRef] [PubMed]
- Perumal, M.; Srinivas, M. DenSplitnet: Classifier-invariant neural network method to detect COVID-19 in chest CT data. J. Vis. Commun. Image Represent. 2023, 97, 103949. [Google Scholar] [CrossRef]
- Krishnan, A.; Rajesh, S.; Gollapinni, K.; Mohan, M.; Srinivasa, G. A Comparative Analysis of Chest X-rays and CT Scans Towards COVID-19 Detection. In Proceedings of the IEEE 2023 4th International Conference for Emerging Technology (INCET), Belgaum, India, 26–28 May 2023; pp. 1–7. [Google Scholar]
- Halder, A.; Datta, B. COVID-19 detection from lung CT-scan images using transfer learning approach. Mach. Learn. Sci. Technol. 2021, 2, 045013. [Google Scholar] [CrossRef]
- Alshazly, H.; Linse, C.; Barth, E.; Martinetz, T. Explainable COVID-19 detection using chest CT scans and deep learning. Sensors 2021, 21, 455. [Google Scholar] [CrossRef]
- Ragab, D.A.; Attallah, O. FUSI-CAD: Coronavirus (COVID-19) diagnosis based on the fusion of CNNs and handcrafted features. PeerJ Comput. Sci. 2020, 6, e306. [Google Scholar] [CrossRef]
- Shaik, N.S.; Cherukuri, T.K. Transfer learning based novel ensemble classifier for COVID-19 detection from chest CT-scans. Comput. Biol. Med. 2022, 141, 105127. [Google Scholar] [CrossRef] [PubMed]
- Gaur, P.; Malaviya, V.; Gupta, A.; Bhatia, G.; Pachori, R.B.; Sharma, D. COVID-19 disease identification from chest CT images using empirical wavelet transformation and transfer learning. Biomed. Signal Process. Control 2022, 71, 103076. [Google Scholar] [CrossRef]
- Canayaz, M.; Şehribanoğlu, S.; Özdağ, R.; Demir, M. COVID-19 diagnosis on CT images with Bayes optimization-based deep neural networks and machine learning algorithms. Neural Comput. Appl. 2022, 34, 5349–5365. [Google Scholar] [CrossRef] [PubMed]
- Attallah, O.; Samir, A. A wavelet-based deep learning pipeline for efficient COVID-19 diagnosis via CT slices. Appl. Soft Comput. 2022, 128, 109401. [Google Scholar] [CrossRef]
- Kundu, R.; Singh, P.K.; Ferrara, M.; Ahmadian, A.; Sarkar, R. ET-NET: An ensemble of transfer learning models for prediction of COVID-19 infection through chest CT-scan images. Multimed. Tools Appl. 2022, 81, 31–50. [Google Scholar] [CrossRef] [PubMed]
- Islam, M.R.; Nahiduzzaman, M. Complex features extraction with deep learning model for the detection of COVID19 from CT scan images using ensemble based machine learning approach. Expert Syst. Appl. 2022, 195, 116554. [Google Scholar] [CrossRef] [PubMed]
- Choudhary, T.; Gujar, S.; Goswami, A.; Mishra, V.; Badal, T. Deep learning-based important weights-only transfer learning approach for COVID-19 CT-scan classification. Appl. Intell. 2023, 53, 7201–7215. [Google Scholar] [CrossRef]
- Gunraj, H.; Wang, L.; Wong, A. Covidnet-ct: A tailored deep convolutional neural network design for detection of covid-19 cases from chest ct images. Front. Med. 2020, 7, 608525. [Google Scholar] [CrossRef] [PubMed]
- Alinsaif, S.; Lang, J. 3D shearlet-based descriptors combined with deep features for the classification of Alzheimer’s disease based on MRI data. Comput. Biol. Med. 2021, 138, 104879. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
| ID | Method | Abbreviation | Dimension |
|---|---|---|---|
| 1 | Binary Pattern of Phase Congruency [40] | BPPC | 1062 |
| 2 | Gradient Directional Pattern [41] | GDP | 256 |
| 3 | Gradient Direction Pattern [42] | GDP2 | 8 |
| 4 | Gradient Local Ternary Pattern [43] | GLTeP | 512 |
| 5 | Improved Weber Binary Coding [44] | IWBC | 2048 |
| 6 | Local Arc Pattern [45] | LAP | 272 |
| 7 | Local Binary Pattern [46] | LBP | 59 |
| 8 | Local Directional Pattern [47] | LDiP | 56 |
| 9 | Local Directional Pattern Variance [48] | LDiPv | 56 |
| 10 | Local Directional Number Pattern [49] | LDN | 56 |
| 11 | Local Directional Texture Pattern [50] | LDTP | 72 |
| 12 | Local Frequency Descriptor [51] | LFD | 512 |
| 13 | Local Gabor Binary Pattern Histogram Sequence [52] | LGBPHS | 256 |
| 14 | Local Gabor Directional Pattern [53] | LGDiP | 280 |
| 15 | Local Gradient Increasing Pattern [54] | LGIP | 37 |
| 16 | Local Gradient Pattern [55] | LGP | 7 |
| 17 | Local Gabor Transitional Pattern [56] | LGTrP | 256 |
| 18 | Local Monotonic Pattern [57] | LMP | 256 |
| 19 | Local Phase Quantization [58] | LPQ | 256 |
| 20 | Local Ternary Pattern [59] | LTeP | 512 |
| 21 | Local Transitional Pattern [60] | LTrP | 256 |
| 22 | Monogenic Binary Coding [61] | MBC | 3072 |
| 23 | Median Binary Pattern [59] | MBP | 256 |
| 24 | Median Robust Extended Local Binary Pattern [62] | MRELBP | 800 |
| 25 | Median Ternary Pattern [59] | MTP | 512 |
| 26 | Pyramid of Histogram of Oriented Gradients [63] | PHOG | 168 |
| 27 | Weber Local Descriptor [64] | WLD | 32 |
| Model’s Name | Layer | Length |
|---|---|---|
| GoogLeNet | pool5-7x7_s1 | 1024 |
| Inception-ResNet-v2 | avg_pool | 1536 |
| Inception-v3 | avg_pool | 2048 |
| VGG-16 | fc6 | 4096 |
| VGG-19 | fc6 | 4096 |
| ResNet-50 | avg_pool | 2048 |
| ResNet-101 | pool5 | 2048 |
| SqueezeNet v1.1 | pool10 | 1000 |
| DenseNet-201 | avg_pool | 1920 |
| ResNet-18 | pool5 | 512 |
| Xception | avg_pool | 2048 |
| MobileNet-v2 | global_average_pooling2d_1 | 1280 |
| ID | Method | ACC | SN | SP | FM | AUC | PPV | NPV | GM |
|---|---|---|---|---|---|---|---|---|---|
| 1 | BPPC | ||||||||
| 2 | GDP | ||||||||
| 3 | GDP2 | ||||||||
| 4 | GLTeP | 0 | |||||||
| 5 | IWBC | ||||||||
| 6 | LAP | ||||||||
| 7 | LBP | ||||||||
| 8 | LDiP | ||||||||
| 9 | LDiPv | ||||||||
| 10 | LDN | ||||||||
| 11 | LDTP | ||||||||
| 12 | LFD | ||||||||
| 13 | LGBPHS | ||||||||
| 14 | LGDiP | ||||||||
| 15 | LGIP | ||||||||
| 16 | LGP | ||||||||
| 17 | LGTrP | ||||||||
| 18 | LMP | ||||||||
| 19 | LPQ | ||||||||
| 20 | LTeP | ||||||||
| 21 | LTrP | ||||||||
| 22 | MBC | ||||||||
| 23 | MBP | ||||||||
| 24 | MRELBP | ||||||||
| 25 | MTP | ||||||||
| 26 | PHOG | ||||||||
| 27 | WLD |
| Model’s Name | ACC | SN | SP | FM | AUC | PPV | NPV | GM |
|---|---|---|---|---|---|---|---|---|
| GoogLeNet | ||||||||
| Inception-ResNet-v2 | ||||||||
| Inception-v3 | ||||||||
| VGG-16 | ||||||||
| VGG-19 | ||||||||
| ResNet-50 | ||||||||
| ResNet-101 | ||||||||
| SqueezeNet v1.1 | ||||||||
| DenseNet-201 | ||||||||
| ResNet-18 | ||||||||
| Xception | ||||||||
| MobileNet-v2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alinsaif, S. COVID-19 Image Classification: A Comparative Performance Analysis of Hand-Crafted vs. Deep Features. Computation 2024, 12, 66. https://doi.org/10.3390/computation12040066
Alinsaif S. COVID-19 Image Classification: A Comparative Performance Analysis of Hand-Crafted vs. Deep Features. Computation. 2024; 12(4):66. https://doi.org/10.3390/computation12040066
Chicago/Turabian StyleAlinsaif, Sadiq. 2024. "COVID-19 Image Classification: A Comparative Performance Analysis of Hand-Crafted vs. Deep Features" Computation 12, no. 4: 66. https://doi.org/10.3390/computation12040066
APA StyleAlinsaif, S. (2024). COVID-19 Image Classification: A Comparative Performance Analysis of Hand-Crafted vs. Deep Features. Computation, 12(4), 66. https://doi.org/10.3390/computation12040066