
Information and Meaning

Capgemini UK, Forge End, Woking, Surrey GU21 6DB, UK
Information 2016, 7(3), 41; https://doi.org/10.3390/info7030041
Submission received: 8 May 2016
/
Revised: 29 June 2016
/
Accepted: 5 July 2016
/
Published: 9 July 2016
Abstract
:This paper considers the relationship between information and meaning through an analysis of a set of measures of information. Since meaning is expressed using information the analysis of the measures illuminates the relationship. The conventions that govern the production and exchange of information are the outcome of selection processes, so the quality of information (as expressed in the measures) is subject to limitations caused by selection. These limitations are analysed using a technique called viewpoint analysis that enables the measures and their relationship with meaning to be examined. Viewpoint analysis is applied to several logical paradoxes and resolves them in a manner consistent with common sense. Finally, the approach is used to address Floridi’s questions about the philosophy of information associated with meaning.
1. Introduction
Meaning is expressed using information but the extent to which information is meaningful depends on the degree to which it can be trusted [1]. Because people have “innate biases” [2] with respect to the quality of information, this degree of trust is not always apparent to us. This paper discusses a structured approach, called viewpoint analysis, to analyse the degree of trustworthiness of information and its relationship with meaning.
Information is represented using a variety of modelling tools (e.g., different languages, mathematics, computer databases) with different ways of abstracting and representing information. Viewpoint analysis uses an approach (based on the Model for Information (MfI) in [1,3]) that addresses the drivers of trustworthiness and measures of information common to all tools. The model relates entities that process information (called Interacting Entities—IEs), selection processes and measures of information. Examples of IEs include people, animals, computer systems, firms, and political parties.
Section 2 provides an overview of MfI [1,3]. The interaction of IEs with their environment changes their properties. Through feedback loops, the existence or health of derived IEs (like children or updated versions of computer programs) is affected by these interactions, so any extended series of interactions acts as a selection process. In [4], the authors discuss selection in the context of the physical character of information and identify least-time free energy consumption as the selection criterion. However, to understand how selection affects pragmatic questions about information (as in [5], for example) we also need to consider emergent phenomena [6] not accessible at the level of physics. This paper, therefore, uses a complementary approach in which selection processes include natural selection, sexual selection, personal or group choices (including voting), and the market (and its impact on products like computer programs). These selection processes cause IEs (like Finance Managers, Mathematicians, healthcare systems) to evolve within information ecosystems each of which has its own conventions for interacting and using information.
Selection pressures drive IE interactions to improve the favourability of outcomes—firms try to make profits, people try to find partners, political parties try to get elected. The design and memory of IEs connects states of the environment (using descriptive information) with expected outcomes (using predictive information) and the actions needed to achieve those outcomes (using prescriptive information). It is this connection that gives meaning to information, not just in terms of recognition (what does “Joe Smith” mean?) but also in terms of wider connections (what is “Joe Smith” connected with and what is the strength of those connections?). Very favourable or very unfavourable outcomes (e.g., marriage, computer program failure, share price growth, death) are more meaningful than others. Section 3 discusses the relationship between outcomes and meaning.
Ecosystem conventions mean that information is relative (in agreement with [7,8], for example). Different ecosystems may measure different types of property in different ways and manipulate them with different levels of quality. Information can be reliable enough for those circumstances in which selection processes applied but outside this envelope the reliability can decrease. So, ecosystems and their modelling tools have limitations, examined in Section 4. A structured analysis technique, viewpoint analysis, is introduced to analyse the reliability of information.
2. The Model for Information
This section provides an overview of the Model for Information discussed in [1,3,5]. MfI enables an analysis of the relationship between ecosystems, interpretation, and information measures.
IEs interact with their environment. The interactions generate outcomes that determine the health (or even existence) of the IE and further IEs derived from it. The form of any IE is determined, to some extent, by a design pattern (using the term in the sense of [10]). Such patterns include DNA, system architecture or organisational design. Versions of IEs are derived from previous versions through some physical process using the pattern. Children are derived from their parents, new versions of computer systems are based on design changes to the original system and organisations develop by changing their structure, processes, roles, locations, and so forth. There may be no derived entity, one, several, or many entities for any original entity. In some cases, the derived entity may be a completely new entity (“reproduction” in biological terms); in some cases, it may be the existing entity (“growth” in biological terms).
In some cases, the interactions of an entity impact, or rely on, the health of a dependent entity or entities. Examples of this include a spouse, a parent, and an organisation using a computer system. In these cases, a favourable outcome for the entity impacts or relies on the health of the dependent entity or entities. As a result, there are two feedback mechanisms. In the first, interactions impact the properties of an entity and its ability to achieve favourable outcomes (for itself or dependent IEs). In the second, the interactions impact the pattern of the derived entity (and therefore its ability to deliver favourable outcomes). Any extended set of interactions therefore acts as a selection process and we can talk of the related selection pressures.
Selection processes have driven the creation of information ecosystems. In each case, a set of conventions develops that applies to relevant IEs and how they interact using Information Artefacts (IAs). The scope of these conventions includes the following:
- the symbols that are used;
- the structure of IAs and the rules that apply to them—different ecosystems use different modelling tools to communicate within the ecosystem;
- the ways in which concepts are connected;
- the ways in which IAs are created and analysed;
- the channels that are used to interact.
Information is not distinct from the physical world. It is the abstraction that IEs use for artefacts that conform to ecosystem conventions. Any set of symbol instances which meets the structuring requirements of an ecosystem we call ‘content’ (for that ecosystem).
Selection processes trade off information quality against friction—the amount of resource needed to achieve something [3]—to produce results that are good enough for the particular selection pressures under normal circumstances. However, this is no guarantee that the results will work well enough when circumstances change or in more extreme conditions. In some circumstances, particular levels of quality and friction may be required to improve the chances of a favourable outcome, but these requirements may not fit with ecosystem conventions.
In order to increase the chances of achieving favourable outcomes in response to the selection pressures, IEs detect relevant properties of the environment and act. To do this, they need to model and connect environment states, actions, and outcomes. As described in [5], they need to connect descriptive information (about the environment state) with predictive information (the potential impact on future outcomes) and prescriptive information (how to act). Kahneman [2] describes connections for people in the following terms:
“In the current view of how associative memory works, a great deal happens at once. An idea… activates many ideas, which in turn activate others. Furthermore, only a few of the activated ideas will register in consciousness; most of the work of associative thinking is silent, hidden from our conscious selves.”
Computer systems make these connections through the design of programs, the structure and modelling of their data and, increasingly, through analytics techniques like machine learning [5]. Firms use analytics technology to connect inputs (e.g., web page access) and memory (e.g., transaction history and statistical correlations) with potential outcomes (e.g., the propensity to buy particular products) and the response to the user (e.g., recommended products)—there is a more extensive discussion in [5]. Connections, in these senses, are ecosystem processes that link information in one form with information in another form and provide output in the form of ecosystem content that describes the relationship. These connections can be modelled and analysed using graphs [11] or, a generalisation of graphs, linnets [3].
Call a slice a contiguous subset of space-time. A slice can correspond to an entity at a point in time (or more properly within a very short interval of time), a fixed piece of space over a fixed period of time or, much more generally, an event that moves through space and time. This definition allows great flexibility in discussing information. For example, slices are sufficiently general to support a common discussion of both nouns and verbs, the past and the future.
Different ecosystems capture different properties of slices in different formats. For example, different sciences model the world in different ways. For a computer system a person may just be modelled using some database fields (like address, transaction history and so forth) whereas people have much richer memories.
Even though they may agree, for example, on some facts and acknowledged science, different ecosystems may interpret some content very differently. For example, in the world of IT, as more and more data becomes available (linked to the Big Data trend [5]) computer systems can no longer impose a single data model based on a particular ecosystem convention. Instead, systems reconcile different, potentially incompatible, ecosystem models and rely on probabilities rather than certainty [5]. The relationship between ecosystems and truth is discussed in [1]—the conventions of different ecosystems mean that their approach to truth and the quality standards required to demonstrate it may be very different.
IEs have two generic types of memory: content memory and event memory. Content memory contains symbolic content—for example, database tables of textual customer names and addresses in computers. Event memory captures the properties of slices directly—for example, sound recordings, images or video. Event memory also contains metadata that describes the slice that the properties refer to—for example, its location, date/time or duration.
As discussed in [1,3], information in IAs is structured in terms of chunks and assertions. Chunks (for example, nouns, adjectives, phrases, one or other side of Mathematical equations, database field values) specify constraints. Assertions (for example, sentences, equations, values in database tables) make hypotheses about the relationship between different constraints. An interpretation of a chunk corresponds to a set of slices that match the constraint. An interpretation of an assertion hypothesises a relationship between interpretations of chunks. Some difficulties with information are associated with implausibility (as defined in [1]—see Table 1) for which the actual relationship between the interpretations of chunks differs from that of the interpretation of the assertion as a whole (e.g., “blue things are orange”).
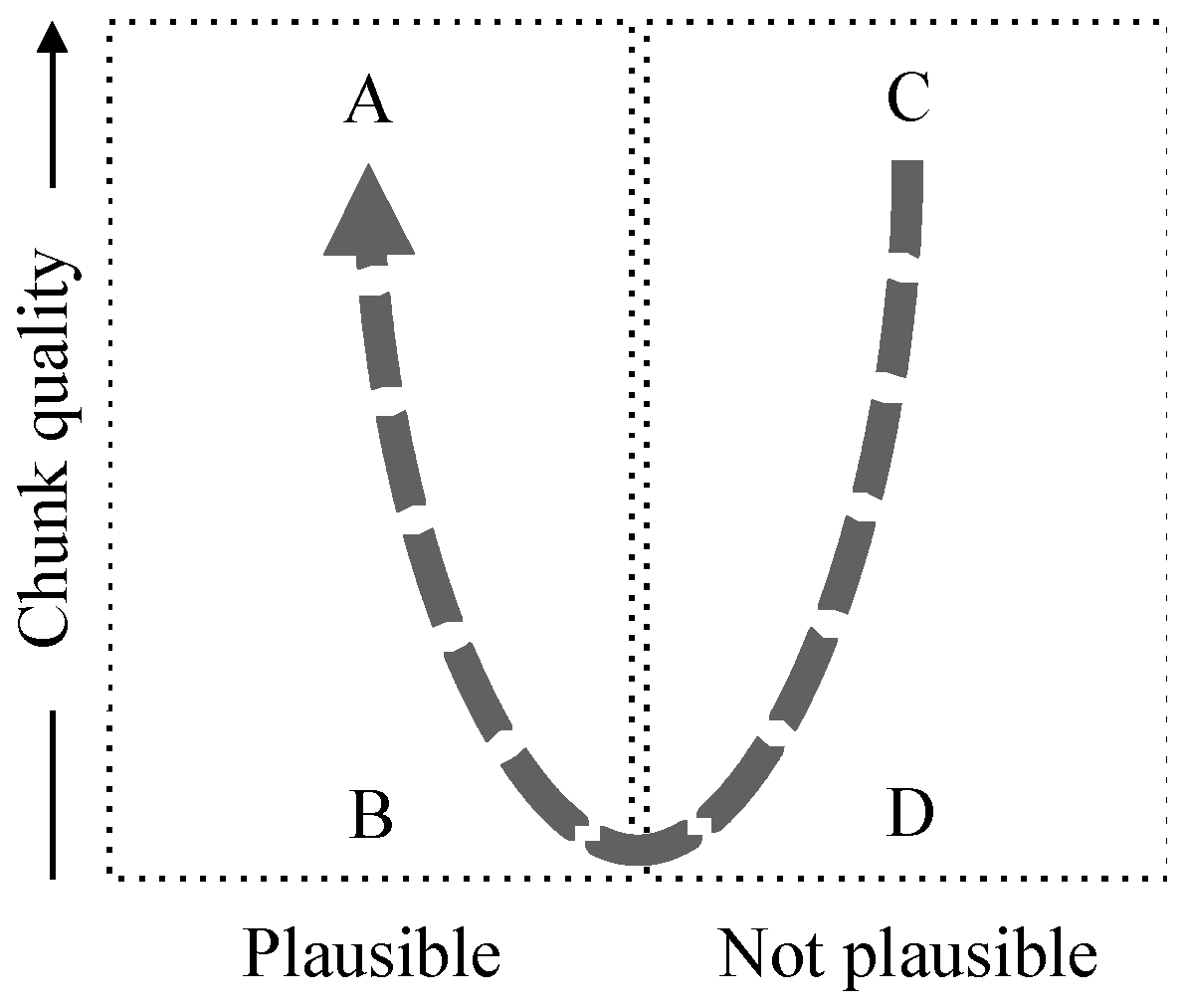
Another key measure is trustworthiness (see Table 1). Trustworthiness can be described using Figure 1 (copied from [1]). As the name implies, it assesses the degree to which an IA can be trusted by combining the quality of the chunks with the plausibility of the assertion. In Figure 1, the vertical axis relates to the chunk quality and assumes that the two chunks are of comparable quality but, with that caveat, it shows some interesting zones marked A, B, C and D. (The vertical axis is only indicative since chunk quality is a partial order not a total order.)
Zone A represents assertions that are most likely to be true (relative to the ecosystem)—plausible and supported by high chunk quality. Zone C represents assertions that can be considered contradictions—those that have a relation that does not correspond to a reliable (high quality) relation between the chunks. Zones B and D correspond to low chunk quality and are correspondingly unreliable. The dotted line shows increasing trustworthiness.
Interpretation is discussed in [1]. When interpreting an IA, the IE maps chunks to sets of slices by searching its memory to identify content and event matches and connections. Kahneman [2] describes the process for people in terms of “associative memory”. Computer systems match their input to their database. If the interpretation produces content only (as in mathematics or in cases of self-reference, for example) then the interpretation relates to the set of slices representing that content ([3] describes how symbols, content, and slices are related). In other cases, the interpretation will also involve event slices. This distinction is important in the discussion of ecosystem limitations in Section 4.
Any interpretation therefore depends on the relevant ecosystem, the capabilities of the particular IE and the circumstances of the IE at the time (e.g., Kahneman [2] describes the importance of simple effects like hunger and tiredness on the decision-making of people). We call this the viewpoint of the IE at a particular time.
Modelling tools use a variety of rules for their content ranging from very little (e.g., animal alarm calls, text sequences in database fields) to more complicated (e.g., first or second order logics). The analysis in this paper is independent of the structure and rules of specific modelling tools. Instead, it focusses on a set of information measures (see Table 1) that apply in all cases and to the connections between descriptive, predictive, and prescriptive content made by an IE.
3. Outcomes, Meaning, and Information Measures
This section contains a discussion of the relationship between outcomes for IEs, information measures, meaning and a simple measure of meaningfulness, event connectivity, based on the discussion in [5].
Interpretation and reference are closely related—any chunk refers to something determined by the connections made. This topic has been much studied, particularly in relation to language (see, for example, [9,12]). We can model different types of reference by different types of connection and in different ecosystems the nature of the connections will be correspondingly different. The Logician Ecosystem requires connections that meet the rules of logic, and similarly in the Mathematical Ecosystem. On the other hand, what we could call the Conversational English Ecosystem (i.e., people talking informally in English) may draw on any connection that people make, regardless of logic or evidence. In a computer program, the connections (e.g., the relationship between inputs and the database) are determined by the design of the program.
When interpreting an IA, the IE searches its memory to identify matches. These matches are connected, to some degree, with different possible actions and potential outcomes and each of these may be associated with examples of slices in event memory. For people, event memory (containing memories of events, images, sounds, and smells) is important in connecting content with the real world. In older specialised computer systems (e.g., systems directly connected to sensors like radar or sonar) event memory was also important. More recently, the amount of event memory stored in images, music, and video has exploded and digital systems increasingly incorporate them. The relationship between content and event memory is becoming richer as increasingly sophisticated tools can extract metadata from events (e.g., facial recognition, geo-referencing, and augmented reality).
The nature of the search is discussed in [1]. There are the following three general options for the interpretation of a chunk in an IA. An IE may not be able to interpret a chunk (perhaps it corresponds to a different ecosystem). A chunk may refer only to content slices (e.g., in mathematics or in cases of self-reference). Or a chunk may refer to slices that are not content. Since interpretation is ecosystem and context-dependent, the same chunk in the same position in an IA may be interpreted in each of these ways by different IEs or even by the same IE in different circumstances.
For the discussion below, an important measure is event connectivity: does the interpretation of information relate it to events or just content? Since outcomes are determined by events and meaning is driven by outcomes, low event connectivity implies low meaningfulness.
An understanding of the connections between an IA and potential outcomes depends on memory and stored connections (or what we call experience in people) and this wider connectivity is one of the conventional differences between data, information, knowledge, and wisdom [13].
4. Ecosystem Convention Limitations
Selection pressures select for a range of circumstances and we should not always expect good results for anything lying outside this range. There may be a mismatch between the level of information measures delivered by ecosystem conventions and the measures needed to achieve the outcome required. The following types of limitations are explored in this section:
- Ecosystem inertia: the lag in changes to ecosystem conventions when the environment changes;
- Connection strategy mismatch: limitations in how an IE searches and makes connections;
- Interpretation tangling: inadvertent mixing of interpretations from different ecosystems when chunks are used in more than one modelling tool (e.g., the use of language in mathematics);
- Tool limitations: limitations with respect to the characteristics of particular modelling tools;
- Physical mismatch: the ability to define references in modelling tools which cannot be interpreted with high quality because they violate the physical constraints that apply to the interpretation process or the slices which they refer to.
4.1. Ecosystem Inertia
Selection processes take time to work even if the environment is stable. In [5], this topic is examined in the case of digital change, but the issue applies equally in many cases. Kuhn’s discussion of paradigm shifts in science [14] is an example. As Max Planck [15] (quoted in [14]) describes it:
“A new scientific truth does not triumph by convincing its opponents…but rather because its opponents eventually die, and a new generation grows up that is familiar with it.”
In organisations, “change resistance” is a well-known concept. For example [16]:
“One of the most baffling and recalcitrant of the problems which business executives face is employee resistance to change.”
4.2. Connection Strategy Mismatch
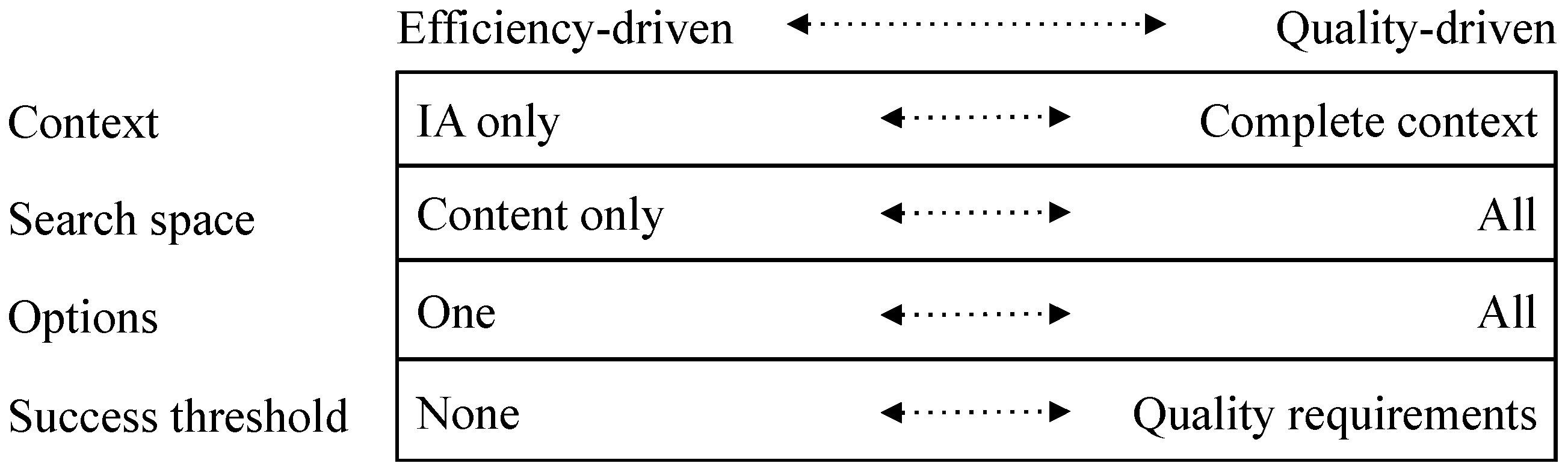
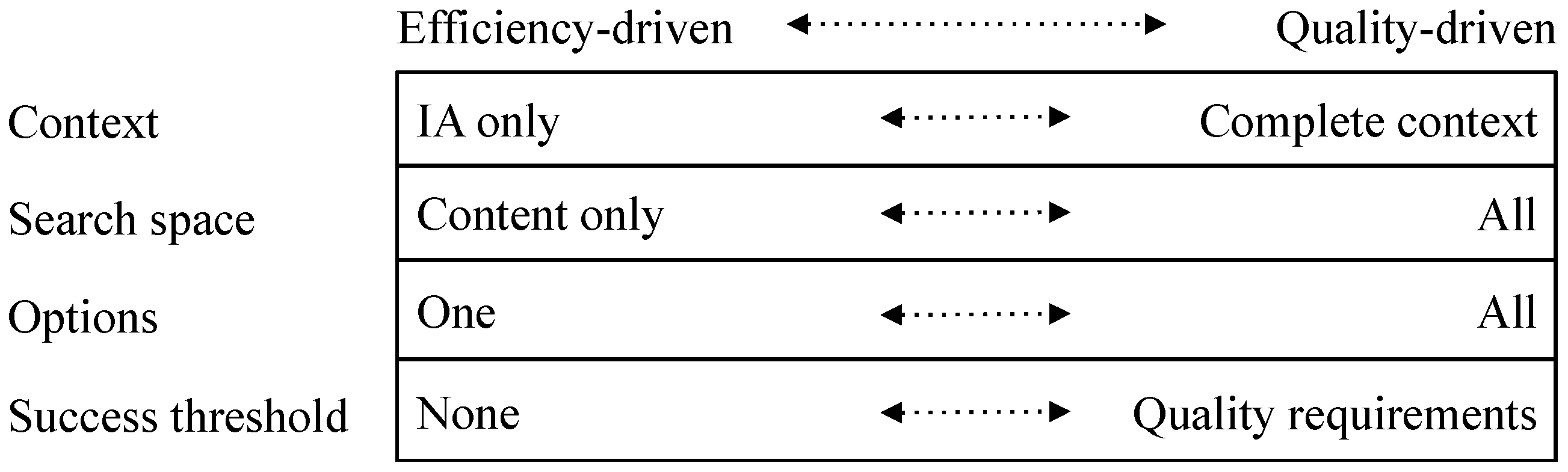
Interpretation is a complicated process and is subject to ecosystem and context-dependent constraints. In [1], the concept of connection strategy is introduced—it defines the factors that determine the extent to which an interpretation is thorough (see Figure 2). For each factor there may be a mismatch between the requirements to achieve the outcome required and the nature of the connection strategy.
The context defines what the IE takes into account as part of interpretation—is it just the IA or is it the IA in its context? For example, if A is talking to B, does B consider just what A is saying or also take into account A’s current emotional state; the Logician Ecosystem will focus on the content only. More generally, context has a major role in the assessment of quality. In practice, it is too difficult for IEs to assess quality so they often use proxies—the provenance of an IA (linked to authority, brand, reputation, or other characteristics) provides a shortcut [3]. In [19], the authors express this idea elegantly (with respect to documents):
“For information has trouble, as we all do, testifying on its own behalf... Piling up information from the same source doesn’t increase reliability. In general, people look beyond information to triangulate reliability.”
In these cases, the interpreting IE trusts that the IE providing the IA is reliable and that the reliability will transfer to the IA. This trust is an attribute of ecosystems.
The last two factors in Figure 2 are options and success threshold. The option factor is straightforward—does the IE just accept the first match, require several, or all? The success threshold defines what constitutes a match—is there a quality standard to be met? Because of the potentially resource heavy overhead, it is natural that ecosystem conventions have included shortcuts that are good enough in many circumstances. Some examples of assessments that are included in ecosystem conventions are included in [3].
Search space is the final factor; there is a wide range of possibilities here. How much memory should be searched? Should the search include just IE memory or other memory (e.g., ecosystem memory)? What types of connection should be included in the search? How many degrees of separation are to be included in connections?
One question is particularly relevant: does the search include content only (using the rules of a particular modelling tool) or also events (for events stored in event memory)? Call the former “content interpretation” and the latter “event interpretation”. In both cases, the interpretation connects the IA with sets of slices, but in the first case, the slices will be content slices only. For example:
- a Logician or Mathematician may treat the content of an IA as a set of symbols with rules (content interpretation);
- a computer query may just search for the string “John Smith” (content interpretation);
- a person may also consider memories of John Smith as a person (event interpretation);
- more generally, people may relate content to events that they remember (for example, relating people to holidays, parties, or other social events)—this is a major focus of modern social media (event interpretation).
Formal systems (like mathematics and logic) use content interpretation. Where mathematics is used, science uses event interpretation to form the links between mathematics and the physical world.
Popper [20] discussed this point when he suggested that a statement can be logically true but also falsifiable as a statement about the world. His example was “2 apples + 2 apples = 4 apples”. The first interpretation (“logically true”) relies on content interpretation using mathematics. By contrast, the second interpretation relies on event interpretation. The first uses mathematics as the modelling tool and the second uses both language and mathematics and subjects the IA to a more rigorous event search. For his example, it is easy to see that the interpretations coincide fairly readily. However if we consider the example “2 piles + 2 piles = 4 piles” (included in [1]) then it is more difficult. The second form of interpretation depends on what “+” means since it is also possible that “2 piles + 2 piles = 1 pile” (or other numbers). In this case the quality of the assertion is reduced.
4.3. Interpretation Tangling
The discussion above assumes that the rules of modelling tools are followed but this may not always be the case. Where chunks are used in common between modelling tools there are choices about how to interpret the chunks. Popper’s example (discussed in Section 4.2) shows how alternative interpretations are possible. Wittgenstein also referred to the idea in (see [21,22]):
“[I]t is essential to mathematics that its signs are also employed in mufti”
“[i]t is the use outside mathematics, and so the meaning [‘Bedeutung’] of the signs, that makes the sign-game into mathematics”
If we consider mathematics as an example, much of its terminology is based on language. For each such chunk, people have a choice about whether they use a formal, Mathematical, interpretation or whether the interpretation is based on informal language use. However, as Kahneman [2] has pointed out, people have innate biases when interpreting information and this choice may not be explicit and reasoned. This provides the possibility for interpretation tangling—people inadvertently using language-based interpretation when considering a formal system.
Computer programs can suffer from the same problem. Different programs may use different and incompatible data models for the same entity (for example, a customer) and may inadvertently use the wrong model if data is exchanged between them.
4.4. Tool Limitations
People have different expectations about different modelling tools. We are used to limitations with programming languages and their impact on system failures. Fundamental limitations with mathematics were a big surprise (see, for example, [23]) but the limitations of language are better understood [24].
Languages are flexible and (for people in the particular ecosystem) economical but this flexibility comes with a price—language has built-in limitations that have an impact on quality. In [24], Pinker discusses this topic and states:
“The constituents of common sense […] like causation, force, time and substance […] worked well enough in the world in which our minds evolved, but they can leave our common sense ill-equipped to deal with some of the conceptual challenges of the modern world.”
In terms of the measures in Table 1, this implies that language has a problem with resolution.
Individual words do not have an exact interpretation and so, in different circumstances, the same chunk may be interpreted in different ways—this is a problem with precision (see Table 1). Wittgenstein expressed this idea in the following way [25]:
“For a large class of cases of the employment of the word ‘meaning’—though not for all—this way can be explained in this way: the meaning of a word is its use in the language”
At the other extreme is mathematics. Where languages are flexible and economical but have the problems of resolution and precision, mathematics can resolve to an arbitrary degree and is precise. However, this comes at the cost of very high friction. Mathematics is hard to learn and its application is limited (e.g., there is still no solution to the three-body problem). Relating mathematics to the real world, which is the domain of science, can also be dauntingly hard and incur very high friction (think of the cost of the Large Hadron Collider).
A rich modelling tool will enable chunks to be created that over-constrain—that do not match any set of slices (under a reasonable interpretation). In [26], Chomsky used the example “colorless green ideas sleep furiously”. Mathematics can also over-constrain (for example, four-colourings of K5 in graph theory [11]). Indeed, one of the objectives of mathematics is to identify such examples and find how different constraints relate to each other.
4.5. Physical Mismatch
In some modelling tools, it is possible to make references that violate physical constraints or offer unspecified alternatives based on different physical possibilities. Content interpretation provides examples because it disconnects interpretation from the physical environment. There are two main causes of this mismatch: references to the interpretation process itself and references that imply infinite processing.
Some information quality measures are an outcome of interpretation (see the detailed discussion in [1]). So, in an assertion that relates to one of these measures (like “false” in the Liar Paradox) the assertion refers to its own interpretation. This may be a physical impossibility since interpretation is viewpoint-dependent and has not taken place when the assertion is defined. We can try to get round this discrepancy in different ways. For example, we can assume that the interpretation to apply is the ecosystem interpretation not an individual IE interpretation; but how can the ecosystem interpretation be established in the first place—don’t the logical paradoxes establish that this is not sufficient, at least in some cases? Or, we can assume that the interpretation is recursive; but this takes us into the territory of infinity discussed below. It may be possible to resolve these difficulties in specific cases, but assertions referring to their own interpretation may violate physical limitations.
Infinity poses different questions based on the fundamental physical limitations which apply: content is finite and all IEs have access to limited resources. The argument here is not about infinity as a concept—“∞” is a symbol that can be manipulated like any other. Instead, the issue is whether an interpretation will complete with the required level of quality and friction in the relevant ecosystem. In an environment driven by selection pressures, inaction (corresponding to an interpretation that does not complete) is unlikely to provide a satisfactory outcome—instead there will be a reduction in quality.
4.6. Computer Simulation
What can be done about these limitations? The fundamental issue is a mismatch between the assumptions about information measures that are implied in ecosystem conventions and the measures required to achieve the outcome required. So the limitations can be overcome if they can be matched—[5] discusses a resolution in the case of digital technology.
Languages and mathematics evolved in very different times. But, recently, under the influence of Moore’s Law [27], the friction associated with technology-enabled information has reduced dramatically—in many cases, by orders of magnitude [5]. This has enabled an explosion in the use of computer simulations for everything from climate change to financial markets. Unlike languages and (non-computerised) mathematics, computer simulations allow the connection strategy and information measures to be analysed and defined. As a result, computer simulations provide a mechanism for overcoming the limitations discussed in this section.
4.7. Viewpoint Analysis
Previous sections have demonstrated the relationship between information and meaning and the limitations that lurk behind any interpretation. Information is relative and interpretation is driven by the viewpoint of an IE. The viewpoint includes the relevant ecosystem (incorporating the ecosystem conventions), the capabilities of the IE itself and the specific circumstances of the interpretation.
If we are to understand interpretation, we need to understand the impact of the viewpoint. Since ecosystems are different, it is helpful to understand the differences and how they manifest themselves—we call this approach viewpoint analysis. The previous sections have discussed the following components of viewpoint analysis:
- analysis of the viewpoint (ecosystem, IE, and the purpose of the interpretation);
- the structure of the IA, its interpretation, and associated information measures;
- the applicability of the limitations applied above.
By applying these ideas to particular questions about meaning, the limitations and their impact can be understood.
5. Logical Paradoxes
Some of the severest tests of meaning are provided by logical paradoxes. The discussion in [9] includes the following description of the general case:
“When solving paradoxes we might […] refer to them as paradoxes of non-wellfoundedness.”
It is this aspect of “non-wellfoundedness” which this section discusses. Using the viewpoint analysis approach described above, the logical paradoxes are not paradoxical. Instead, they are examples of the limitations described in Section 4.
The paradoxes become paradoxical in the Logician Ecosystem. This uses content interpretation and abstracts away details of the physical world to focus on the rules of logic. So, some general points apply. The first is low event connectivity—by their nature the paradoxes relate only to content and not more widely. The second is interpretation tangling—to varying degrees they mix mathematical or logical ideas with informal language but provide no guidance about how to combine them. Finally, the assertions in the paradoxes are not trustworthy, in the sense defined in this paper. They are designed so that an assertion and its interpretation contradict each other—the definition of implausibility. These general points are enough in themselves to illuminate the nature of the paradoxes—they are not meaningful because they are not trustworthy and have low event connectivity—but we can also use viewpoint analysis in more detail. Consider the Liar Paradox and Berry’s Paradox [9].
The Liar Paradox concerns the assertion “This sentence is false.” which is true if and only if it is false in the Logician Ecosystem. The assertion is equivalent to:
(the set of slices corresponding to “this sentence”) ⊆ (the set of slices which are interpreted as “false” in the ecosystem).
But the interpretation, itself, is equivalent to:
(the set of slices corresponding to “This sentence is false.”) ⊆ (the set of slices which are interpreted as “true” in the ecosystem).
Because “this sentence” refers to “This sentence is false.” these are contradictory within the Logician Ecosystem.
Using the definition of implausibility above, on the face of it this is just an implausible assertion in which the hypothesis in the assertion differs from the actual relationship between the interpreted chunks. But, in this case, we have a set of deeper problems. The assertion refers to its own interpretation and so encounters the physical mismatch limitations described in Section 4.5. To view this another way, consider T and F, the sets of slices interpreted as “true” and “false” and L, the interpretation of “this sentence”. There are the following three possibilities:
- because of the physical limitation, problem L does not lie in T or F and so the assertion is not meaningful;
- T intersects F and (as implied by the paradox) L lies in the intersection—in this case, the interpretation cannot discriminate “true” and “false”, so the chunk quality of “true” and “false” is low;
- T does not intersect F and L lies in one or the other—in this case, the assertion is implausible.
So we are forced to conclude that the assertion is either not meaningful (1) or not trustworthy (2, 3) as well as the general points made above.
Interpretation tangling exacerbates these difficulties. Within the Logician Ecosystem “true” is a symbol that has a particular place in the rules of logic. This is not necessarily the same as “true” in the sense of an interpretation that is trustworthy. So the same word suffers from multiple interpretations, one of which applies to individual chunks and the other to the overall assertion.
Berry’s paradox is based on the phrase π = “the least number that cannot be referred to by a description containing less than 100 symbols” which contains 93 symbols. Consider, then, the assertion α = “The number referred to by π exists.” and apply the viewpoint analysis technique.
“Referred_to” is vague. It does not form part of the mathematics ecosystem and is subject to the imprecision of language. However, the paradox relies on a rigorous interpretation which “referred_to” is not capable of providing, so this is an example of interpretation tangling. In the absence of a rigorous definition, we can conclude that π is low quality. This implies that the assertion α is implausible and therefore not trustworthy (in addition to the generic content interpretation difficulties outlined above).
6. Floridi’s Questions about Information and Meaning
In [6], Floridi asked a series of questions about the philosophy of information. In this section, we address the following questions that relate to meaning and the topics addressed in this paper:
- P4: The data grounding problem: how can data acquire their meaning?
- P5: The problem of alethisation: how can meaningful data acquire their truth value?
- P7: Informational semantics: can information explain meaning?
- P16: The problem of localisation: can information be naturalised?
6.1. P4: The Data Grounding Problem
Floridi expresses this question in the following way:
“The data grounding problem: how can data acquire their meaning?”
He also references the question as posed by Harnad [28]:
“How can the meanings of the meaningless symbol tokens, manipulated solely on the basis of their (arbitrary) shapes, be grounded in anything but meaningless symbols?”
As posed by Harnad, the problem presupposes content interpretation—that content is interpreted only in terms of content. Various sections above discuss the difficulties with content interpretation but, of course, event interpretation is also possible. Event interpretation establishes the relationship between information and the real world, the associated meaning and the degree of meaningfulness.
6.2. P5: The Problem of Alethisation
Floridi expresses this question in the following way:
“How can meaningful data acquire their truth value?”
The question as posed assumes a simple geometry for information measures—that there is a single relevant measure. The approach taken in this paper and also, with respect to truth, in [1] is that there is a richer position which can be uncovered by examining different measures of information. In [1], there is a discussion of a range of measures associated with truth, and their underlying geometry, culminating in a discussion of trustworthiness (called “reliability of plausibility” in [1]).
Section 3 above discusses meaning. The trustworthiness of content and other measures are determined both by the content itself and by its interpretation (from a particular viewpoint). With respect to any ecosystem, IE and context, there are measures of content that enable an understanding of the degree of meaningfulness of an IA and its trustworthiness. Viewpoint analysis will determine these, but within the ecosystem itself, the measures may be assessed to different degrees.
6.3. P7: Informational Semantics and P16: The Problem of Localisation
Floridi asks the questions:
“Can information explain meaning?” and
“Can information be naturalised?…The problem here is whether there is information in the world independently of forms of life capable to extract it and, if so, what kind of information is in question”.
He links these two questions together in the following manner:
“Since P7 asks whether meaning can be at least partly be grounded in an objective, mind- and language-independent notion of information (naturalization of intensionality), it is strictly connected with P16…”
This paper argues that information can explain meaning in the context of selection processes and the need for IEs to achieve favourable outcomes. The approach is also mind and language-independent. Meaning is grounded in a notion of information linked with physical processes and a set of measures of information.
However, information is not independent of IEs. Information corresponds to a set of physical properties created, analysed, and manipulated by IEs conforming to a set of ecosystem conventions that have evolved as a result of selection processes. The set of IEs includes entities (like computer systems) that are not alive.
7. Conclusions
What we call information has evolved from a range of different selection processes in different information ecosystems. In each case, ecosystem conventions have evolved that determine the quality of information. These conventions were suitable for the circumstances under which they developed but contain fundamental limitations outside these circumstances. Many difficulties with meaning (like the logical paradoxes, for example) encounter these limitations.
The impact of the limitations can be analysed using the viewpoint analysis technique described in this paper. The interpretation of information is relative to the ecosystem, IE, and the circumstances of interaction—the viewpoint. By analysing the viewpoint and its impact on measures of information, the relationship between meaning and information can be clarified. This analysis confirms a common sense description of the ways in which logical paradoxes are not well-founded.
The link with information ecosystems and the physical world provides an answer to some of Floridi’s questions about the relationship between information and meaning.
Acknowledgments
Many thanks are due to the referees for their constructive comments.
Conflicts of Interest
The author declares no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| IA | Information Artefact |
| IE | Interacting Entity |
| MfI | Model for Information |
References
- Walton, P. Measures of information. Information 2015, 6, 23–48. [Google Scholar] [CrossRef]
- Kahneman, D. Thinking, Fast and Slow; Macmillan: London, UK, 2011. [Google Scholar]
- Walton, P. A Model for Information. Information 2014, 5, 479–507. [Google Scholar] [CrossRef]
- Karnani, M.; Pääkkönen, K.; Annila, A. The physical character of information. Proc. R. Soc. A 2009, 465, 2155–2175. [Google Scholar] [CrossRef]
- Walton, P. Digital information and value. Information 2015, 6, 733–749. [Google Scholar] [CrossRef]
- Floridi, L. The Philosophy of Information; Oxford University Press: Oxford, UK, 2011. [Google Scholar]
- Burgin, M. Theory of Information: Fundamentality, Diversity and Unification; World Scientific Publishing: Singapore, 2010. [Google Scholar]
- Logan, R.K. What Is Information? Why Is It Relativistic and What Is Its Relationship to Materiality, Meaning and Organization. Information 2012, 3, 68–91. [Google Scholar] [CrossRef] [Green Version]
- Bolander, T. Self-Reference, the Stanford Encyclopedia of Philosophy. Spring 2015 Edition. Edward, N.Z., Ed.; Available online: http://plato.stanford.edu/archives/spr2015/entries/self-reference/ (accessed on 29 June 2016).
- Avgeriou, P.; Uwe, Z. Architectural patterns revisited: A pattern language. In Proceedings of the 10th European Conference on Pattern Languages of Programs (EuroPlop 2005), Bavaria, Germany, 6–10 July 2005.
- Harary, F. Graph Theory; Addison-Wesley: Reading, MA, USA, 1969. [Google Scholar]
- Reimer, M.; Michaelson, E. Reference, the Stanford Encyclopedia of Philosophy. Winter 2014 Edition. Edward, N.Z., Ed.; Available online: http://plato.stanford.edu/archives/win2014/entries/reference/ (accessed on 29 June 2016).
- Zins, C. Conceptual approaches for defining data, information, and knowledge. J. Am. Soc. Inf. Sci. Technol. 2007, 58, 479–493. [Google Scholar] [CrossRef]
- Kuhn, T.S. The Structure of Scientific Revolutions, Enlarged 2nd ed.; University of Chicago Press: Chicago, IL, USA, 1970. [Google Scholar]
- Planck, M. Scientific Autobiography and Other Papers; Frank, Gaynor, Translator; Williams & Northgate: London, UK, 1950. [Google Scholar]
- Lawrence, P.R. How to Deal with Resistance to Change. Harvard Business Rev. 1954, 32, 49–57. [Google Scholar] [CrossRef]
- Norris, P. Digital Divide: Civic Engagement, Information Poverty and the Internet Worldwide; Cambridge University Press: New York, NY, USA, 2001. [Google Scholar]
- Government Digital Inclusion Strategy. 2014. Available online: https://www.gov.uk/government/publications/government-digital-inclusion-strategy/government-digital-inclusion-strategy (accessed on 29 June 2016).
- Brown, J.S.; Duguid, P. The Social Life of Information; Harvard Business Press: Boston, MA, USA, 2000. [Google Scholar]
- Ryle, G.; Lewy, C.; Popper, K.R. Symposium: Why are the calculuses of logic and arithmetic applicable to reality? In Proceedings of the Logic and Reality, Symposia Read at the Joint Session of the Aristotelian Society and the Mind Association, Manchester, UK, 5–7 July 1946; pp. 20–60.
- Wittgenstein, L. Remarks on the Foundations of Mathematics, Revised Edition; Anscombe, G.E.M., Translator; von Wright, G.H., Rhees, R., Anscombe, G.E.M., Eds.; Basil Blackwell: Oxford, UK, 1978. [Google Scholar]
- Wittgenstein’s Lectures on the Foundations of Mathematics; Diamond, C. (Ed.) Cornell University Press: Ithaca, NY, USA, 1976.
- From Frege to Gödel: A Source Book in Mathematical Logic, 3rd ed.; Van Heijenoort, J. (Ed.) Harvard University Press: Cambridge, MA, USA, 1967; pp. 1879–1931.
- Pinker, S. The Stuff of Thought; Viking: New York, NY, USA, 2007. [Google Scholar]
- Wittgenstein, L. Philosophical Investigations, 3rd ed.; Blackwell Publishing: Oxford, UK, 1953; Anscombe, G.E.M., Translator. [Google Scholar]
- Chomsky, N. Syntactic Structures; Mouton: Paris, France; The Hague, The Netherlands, 1957; p. 15. [Google Scholar]
- Moore, G.E. Cramming more components onto integrated circuits. Electronics 1965, 38, 114–117. [Google Scholar] [CrossRef]
- Harnad, S. The Symbol Grounding Problem. Phys. D 1990, 42, 335–346. [Google Scholar] [CrossRef]
Figure 1.
Trustworthiness, Plausibility and Chunk Quality.
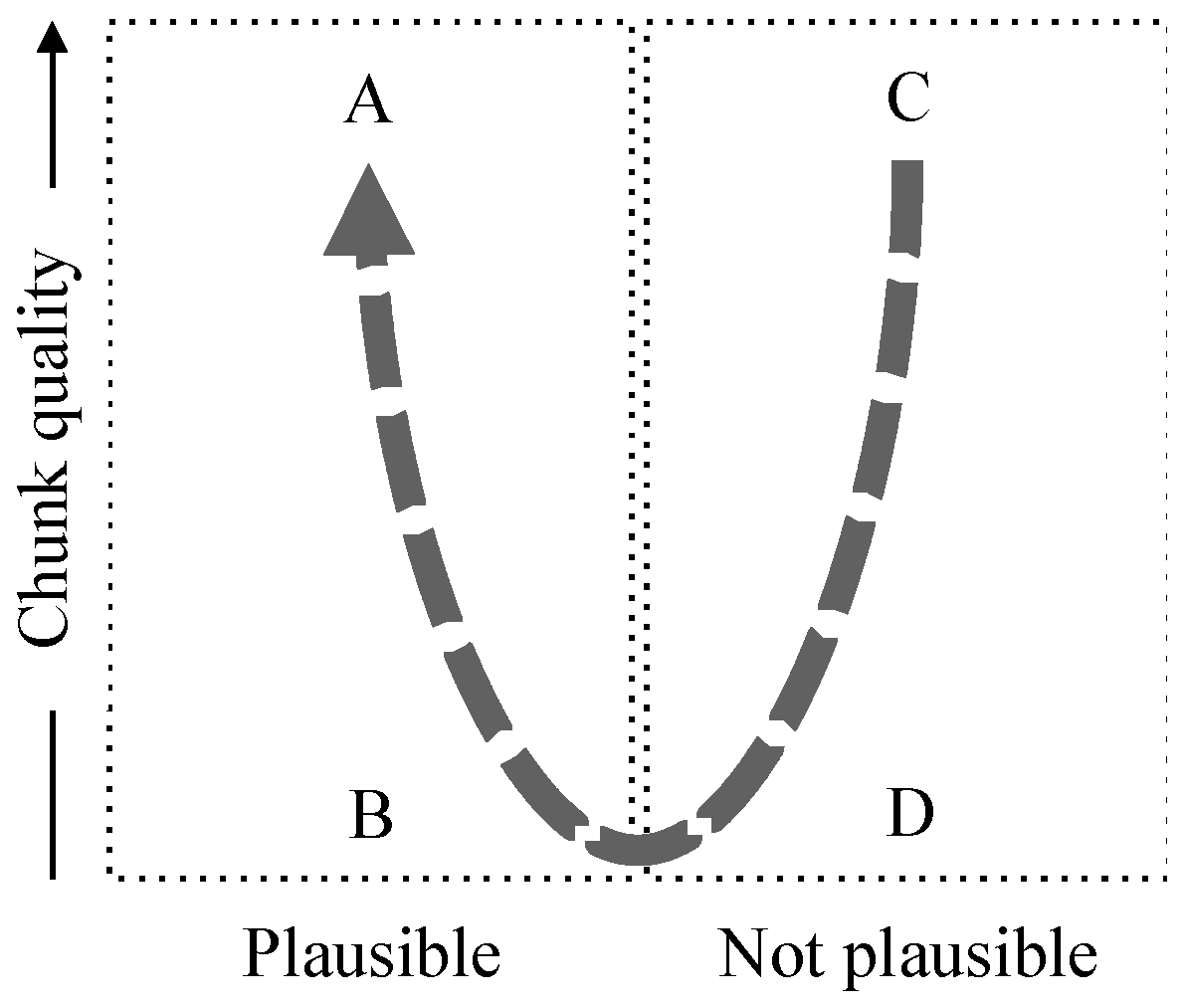
Figure 2.
Connection Strategy.

{kind=link}
{kind=link}
| Measure | Description |
|---|---|
| Chunk: coverage | Coverage captures the number of properties of slices that are incorporated in a chunk and how tightly the value constrains the property. |
| Chunk: resolution | Resolution measures the extent to which the interpretation can discriminate different slices. |
| Chunk: precision | Precision measures the degree to which different interpretations of the same content are the same. |
| Chunk: accuracy | Accuracy measures the proximity of an interpretation to the ecosystem interpretation. |
| Assertion: plausibility | Plausibility measures whether the actual relationship between the interpretation of chunks differs from that of the interpretation of the assertion as a whole. |
| Assertion: trustworthiness | Trustworthiness (called reliability of plausibility in [MoI]) is a combined measure of chunk quality and plausibility, where plausibility measures whether or not the interpretation of the corresponding chunks matches the set theoretic relationship implied by the assertion. See Figure 1. |
| Passage: trustworthiness | The trustworthiness of passages is derived from the trustworthiness of the assertions it contains and their consistency. |
| Friction | Friction measures the resources required for some process related to information (e.g., transmission, interpretation). |
© 2016 by the author; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Walton, P. Information and Meaning. Information 2016, 7, 41. https://doi.org/10.3390/info7030041
AMA Style
Walton P. Information and Meaning. Information. 2016; 7(3):41. https://doi.org/10.3390/info7030041
Chicago/Turabian StyleWalton, Paul. 2016. "Information and Meaning" Information 7, no. 3: 41. https://doi.org/10.3390/info7030041
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.