A Spam Filtering Method Based on Multi-Modal Fusion


Abstract
:1. Introduction
2. MMA-MF Model Architectures
- Email preprocessing: separate the text and image data from an email to obtain the text dataset and the image dataset.
- Obtaining the optimal classifiers: the text dataset and the image dataset are used to train and optimize the LSTM model and the CNN model, respectively—finally getting the optimal LSTM model and the optimal CNN model.
- Obtaining the classification probability values: the image dataset is re-entered into the optimal CNN model to obtain the classification probability values of the image dataset as spam. Similarly, the text dataset is re-entered into the optimal LSTM model to obtain the classification probability values of the text dataset as spam. For an email that only has text data or image data, we use dropout ideology to set the corresponding model output probability value .
- Obtaining the optimal fusion model: the two classification probability values are fed into the fusion model to train and optimize it, ultimately getting the optimal fusion model.
2.1. Text Classification Model: LSTM Model
| Algorithm 1 Text Spam Classification Algorithm. |
| Input: Text Document T Output: Text spam classification probability value e
|
2.2. Image Classification Model: CNN Model
| Algorithm 2 Image Spam Classification Algorithm. |
| Input: Image m, size 128 × 128 RGB Output: Image spam classification probability value g
|
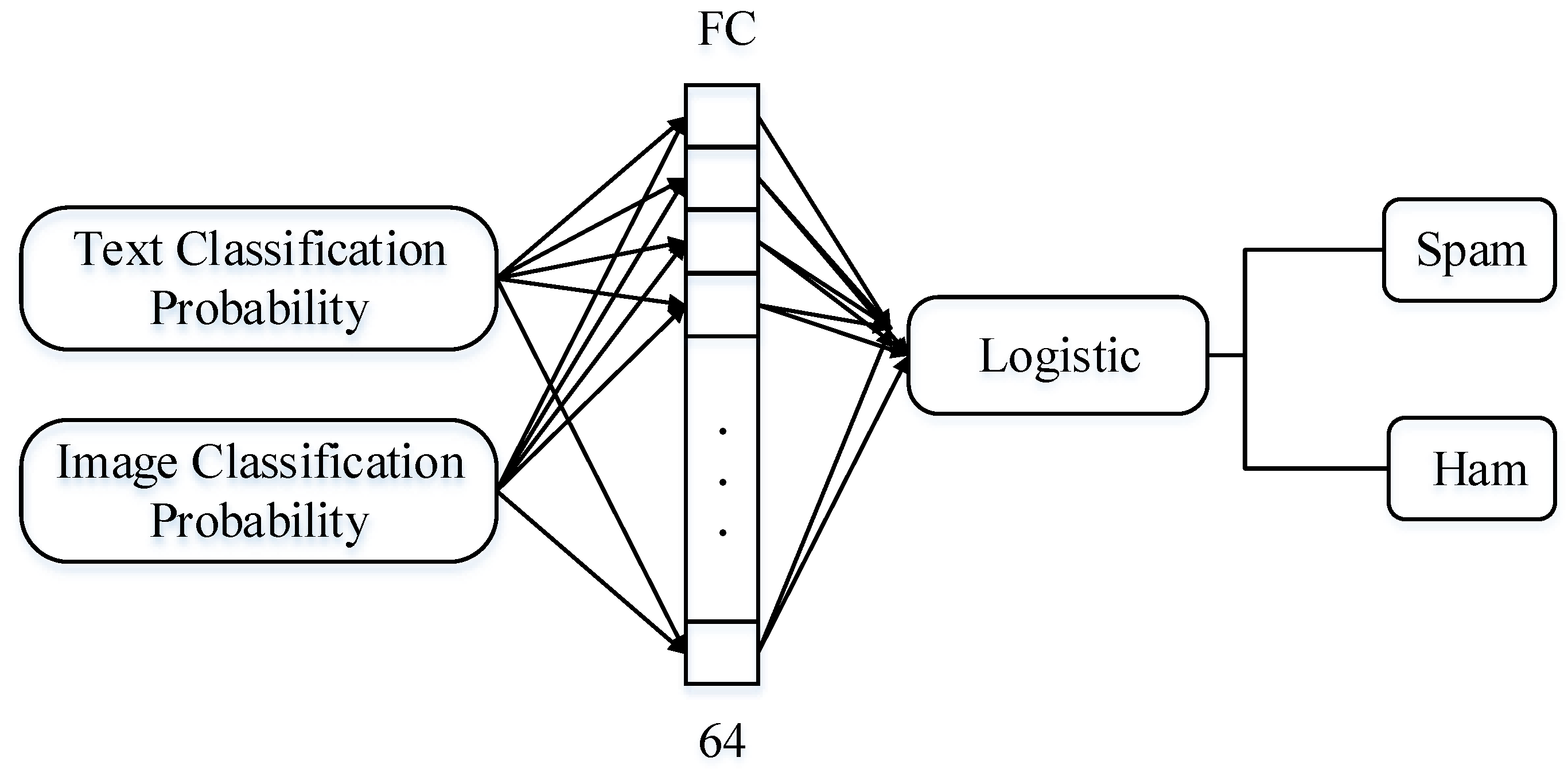
2.3. Fusion Model
3. Evaluation Metrics and Validation Scheme
3.1. Evaluation Metrics
- False Positive (FP): The number of legitimate emails (Ham) that are misclassified;
- False Negative (FN): The number of misclassified spam;
- True Positive (TP): The number of spam that are correctly classified;
- True Negative (TN): The number of legitimate emails (Ham) that are correctly classified.
3.2. Validation Scheme
4. Experimental Results and Discussion
4.1. Corpus
4.2. Results and Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Seth, S.; Biswas, S. Multimodal Spam Classification Using Deep Learning Techniques. In Proceedings of the 2017 13th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), Jaipur, India, 4–7 December 2017; pp. 346–349. [Google Scholar]
- Bettencourt, J. Kaspersky Lab Spam and Phishing Report: FIFA 2018 and Bitcoin among 2017’s Most Luring Topics. Available online: https://usa.kaspersky.com/about/press-releases/2018_fifa-2018-and-bitcoin-among-2017-most-luring-topics (accessed on 15 February 2018).
- Carreras, X.; Marquez, L. Boosting trees for anti-spam email filtering. arXiv, 2001; arXiv:cs/0109015. [Google Scholar]
- Androutsopoulos, I.; Paliouras, G.; Michelakis, E. Learning to Filter Unsolicited Commercial E-Mail; DEMOKRITOS; National Center for Scientific Research: Paris, French, 2014. [Google Scholar]
- Sahami, M.; Dumais, S.; Heckerman, D.; Horvitz, E. A Bayesian approach to filtering junk e-mail. In Learning for Text Categorization: Papers from the 1998 Workshop; AAAI Technical Report WS-98-05; Monona Terrace Convention Center: Madison, WI, USA, 1998; Volume 62, pp. 98–105. [Google Scholar]
- Anayat, S.; Ali, A.; Ahmad, H.F. Using a probable weight based Bayesian approach for spam filtering. In Proceedings of the 8th International Multitopic Conference 2004, Lahore, Pakistan, 24–26 December 2004; pp. 340–345. [Google Scholar]
- Kim, H.J.; Shrestha, J.; Kim, H.N.; Jo, G.S. User action based adaptive learning with weighted bayesian classification for filtering spam mail. In Australasian Joint Conference on Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2006; pp. 790–798. [Google Scholar]
- Yang, Z.; Nie, X.; Xu, W.; Guo, J. An approach to spam detection by naive Bayes ensemble based on decision induction. In Proceedings of the Sixth International Conference on Intelligent Systems Design and Applications (ISDA’06), Jinan, China, 16–18 October 2006; Volume 2, pp. 861–866. [Google Scholar]
- Androutsopoulos, I.; Paliouras, G.; Karkaletsis, V.; Sakkis, G.; Spyropoulos, C.D.; Stamatopoulos, P. Learning to filter spam e-mail: A comparison of a naive bayesian and a memory-based approach. arXiv, 2000; arXiv:cs/0009009. [Google Scholar]
- Jain, G.; Sharma, M.; Agarwal, B. Optimizing semantic LSTM for spam detection. Int. J. Inf. Technol. 2019, 11, 239–250. [Google Scholar] [CrossRef]
- Abi-Haidar, A.; Rocha, L.M. Adaptive spam detection inspired by a cross-regulation model of immune dynamics: A study of concept drift. In International Conference on Artificial Immune Systems; Springer: Berlin/Heidelberg, Germany, 2008; pp. 36–47. [Google Scholar]
- Shang, E.X.; Zhang, H.G. Image spam classification based on convolutional neural network. In Proceedings of the 2016 International Conference on Machine Learning and Cybernetics (ICMLC), Jeju, South Korea, 10–13 July 2016; Volume 1, pp. 398–403. [Google Scholar]
- Wang, Z.; Josephson, W.K.; Lv, Q.; Charikar, M.; Li, K. Filtering Image Spam with Near-Duplicate Detection; CEAS: Mountain View, CA, USA, 2007. [Google Scholar]
- Kumar, P.; Biswas, M. SVM with Gaussian kernel-based image spam detection on textual features. In Proceedings of the 2017 3rd International Conference on Computational Intelligence & Communication Technology (CICT), Ghaziabad, India, 9–10 February 2017; pp. 1–6. [Google Scholar]
- Xu, C.; Chiew, K.; Chen, Y.; Liu, J. Fusion of text and image features: A new approach to image spam filtering. In Practical Applications of Intelligent Systems; Springer: Berlin/Heidelberg, Germany, 2011; pp. 129–140. [Google Scholar]
- Huamin, F.; Xinghua, Y.; Biao, L.; Chao, J. A spam filtering method based on multi-modal features fusion. In Proceedings of the 2011 Seventh International Conference on Computational Intelligence and Security, Hainan, China, 3–4 December 2011; pp. 421–426. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Graves, A. Long short-term memory. In Supervised Sequence Labelling with Recurrent Neural Networks; Studies in Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2012; pp. 37–45. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: a simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Sanville, E.; Kenny, S.D.; Smith, R.; Henkelman, G. Improved grid-based algorithm for Bader charge allocation. J. Comput. Chem. 2007, 28, 899–908. [Google Scholar] [CrossRef] [PubMed]
- Wiens, T.S.; Dale, B.C.; Boyce, M.S.; Kershaw, G.P. Three way k-fold cross-validation of resource selection functions. Ecol. Model. 2008, 212, 244–255. [Google Scholar] [CrossRef]
- Pinheiro, J.C.; Bates, D.M. Approximations to the log-likelihood function in the nonlinear mixed-effects model. J. Comput. Graph. Stat. 1995, 4, 12–35. [Google Scholar]
- Bottou, L. Large-scale machine learning with stochastic gradient descent. In Proceedings of COMPSTAT’2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 177–186. [Google Scholar]
- Tieleman, T.; Hinton, G. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. Coursera Neural Netw. Mach. Learn. 2012, 4, 26–31. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv, 2014; arXiv:1412.6980. [Google Scholar]
- Zhou, C.; Sun, C.; Liu, Z.; Lau, F. A C-LSTM neural network for text classification. arXiv, 2015; arXiv:1511.08630. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv, 2015; arXiv:1502.03167. [Google Scholar]
- Bouvrie, J. Notes on Convolutional Neural Networks. 2006; Unpublished. [Google Scholar]
- Klimt, B.; Yang, Y. The enron corpus: A new dataset for email classification research. In European Conference on Machine Learning; Springer: Berlin/Heidelberg, Germany, 2004; pp. 217–226. [Google Scholar]
- Dredze, M.; Gevaryahu, R.; Elias-Bachrach, A. Learning Fast Classifiers for Image Spam; CEAS: Mountain View, CA, USA, 2007; p. 2007-487. [Google Scholar]
- Gao, J.; Lanchantin, J.; Soffa, M.L.; Qi, Y. Black-box Generation of Adversarial Text Sequences to Evade Deep Learning Classifiers. arXiv, 2018; arXiv:1801.04354. [Google Scholar]
- Nguyen, B.P.; Tay, W.L.; Chui, C.K. Robust biometric recognition from palm depth images for gloved hands. IEEE Trans. Hum. Mach. Syst. 2015, 45, 799–804. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Range | Optimal Value |
|---|---|---|
| learning rate | [0.001, 0.01, 0.1, 0.2] | 0.001 |
| batch size | [8, 16, 32] | 32 |
| epochs | [10, 20, 30] | 30 |
| dropout rate | [0.2, 0.3, 0.4] | 0.3 |
| optimization algorithm | [SGD [23], RMSprop [24], Adam [25] | Adam |
| Hyperparameter | Range | Optimal Value |
|---|---|---|
| learning rate | [0.001, 0.01, 0.1, 0.2] | 0.01 |
| batch size | [5, 10, 20] | 20 |
| epochs | [8, 16, 32] | 32 |
| optimization algorithm | [SGD, RMSprop, Adam] | SGD |
| Layer (Type) | Output Shape | Param |
|---|---|---|
| conv2d_1 (Conv2D) | (None, 128, 128, 32) | 2432 |
| batch_normalization_1 | (Batch (None, 128, 128, 32) | 128 |
| activation_1 (Activation) | (None, 128, 128, 32) | 0 |
| max_pooling2d_1 | (MaxPooling2 (None, 64, 64, 32) | 0 |
| conv2d_2 (Conv2D) | (None, 64, 64, 64) | 51264 |
| batch_normalization_2 | (Batch (None, 64, 64, 64) | 256 |
| activation_2 (Activation) | (None, 64, 64, 64) | 0 |
| max_pooling2d_2 | (MaxPooling2 (None, 32, 32, 64) | 0 |
| conv2d_3 (Conv2D) | (None, 32, 32, 64) | 102464 |
| batch_normalization_3 | (Batch (None, 32, 32, 64) | 256 |
| activation_3 (Activation) | (None, 32, 32, 64) | 0 |
| max_pooling2d_3 | (MaxPooling2 (None, 16, 16, 64) | 0 |
| flatten_1 (Flatten) | (None, 16384) | 0 |
| dense_1 (Dense) | (None, 64) | 1048640 |
| batch_normalization_4 | (Batch (None, 64) | 256 |
| activation_4 (Activation) | (None, 64) | 0 |
| dense_2 (Dense) | (None, 32) | 2080 |
| dense_3 (Dense) | (None, 2) | 66 |
| Prediction | Actual | |
|---|---|---|
| Spam | Ham | |
| Spam | TP | FN |
| Ham | FP | TN |
| Type | Original Dataset | Before Remove Duplicates | After Remove Duplicates |
|---|---|---|---|
| Text | Enron Ham Enron Spam | 17,108 16,537 | 1500 4500 |
| Image | Personal Image Ham Personal Image Spam Spam Archive Image Spam | 2021 3298 16,031 | 1393 130 1263 |
| Mixed Dataset 1 | Ham:Enron&Personal Image Spam:Enron&Personal Image&Archive Image | 19,129 35,866 | (Text:Image) 600:600 (Text:Image) 600:600 |
| Mixed Dataset 2 | Ham:Enron&Personal Image Spam:Enron&Personal Image&Archive Image | 19,129 35,866 | (Text:Image) 600:300 (Text:Image) 600:300 |
| Type | Training Dataset Size | Testing Dataset Size |
|---|---|---|
| Text | 5000 | 1000 |
| Image | 2322 | 464 |
| Mixed Dataset 1 Mixed Dataset 2 | 960 | 240 |
| Fold | Accuracy | Recall | F1-Score | Precision |
|---|---|---|---|---|
| MMA-MF Model for Text Dataset | ||||
| 1 | 0.9842 | 0.9784 | 0.9724 | 0.9850 |
| 2 | 0.9867 | 0.9815 | 0.9747 | 0.9850 |
| 3 | 0.9867 | 0.9819 | 0.9765 | 0.9900 |
| 4 | 0.9825 | 0.9771 | 0.9727 | 0.9800 |
| 5 | 0.9842 | 0.9789 | 0.9753 | 0.9850 |
| 0.9848 | 0.9796 | 0.9743 | 0.9850 | |
| MMA-MF Model for Image Dataset | ||||
| 1 | 0.9335 | 0.9264 | 0.9289 | 0.9050 |
| 2 | 0.9256 | 0.9263 | 0.9275 | 0.9001 |
| 3 | 0.9150 | 0.9233 | 0.9183 | 0.9350 |
| 4 | 0.9235 | 0.9283 | 0.9297 | 0.9200 |
| 5 | 0.9344 | 0.9272 | 0.9271 | 0.9250 |
| 0.9264 | 0.9263 | 0.9263 | 0.9170 | |
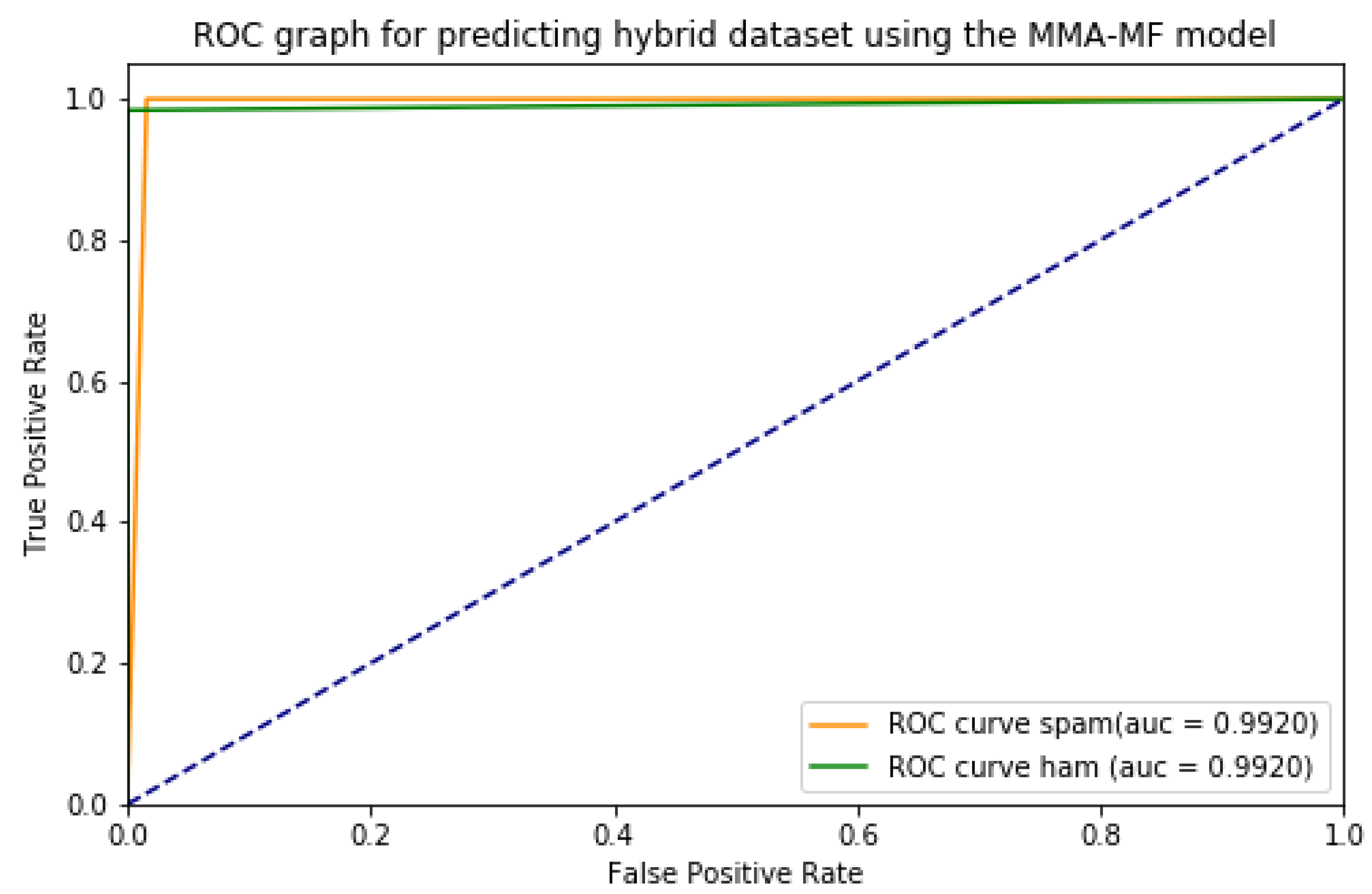
| MMA-MF Model for Hybrid Dataset 1 | ||||
| 1 | 0.9792 | 0.9792 | 0.9792 | 0.9750 |
| 2 | 0.9917 | 0.9920 | 0.9917 | 0.9900 |
| 3 | 0.9750 | 0.9758 | 0.9750 | 0.9750 |
| 4 | 0.9917 | 0.9911 | 0.9916 | 0.9900 |
| 5 | 0.9792 | 0.9787 | 0.9791 | 0.9800 |
| 0.9833 | 0.9834 | 0.9833 | 0.9820 | |
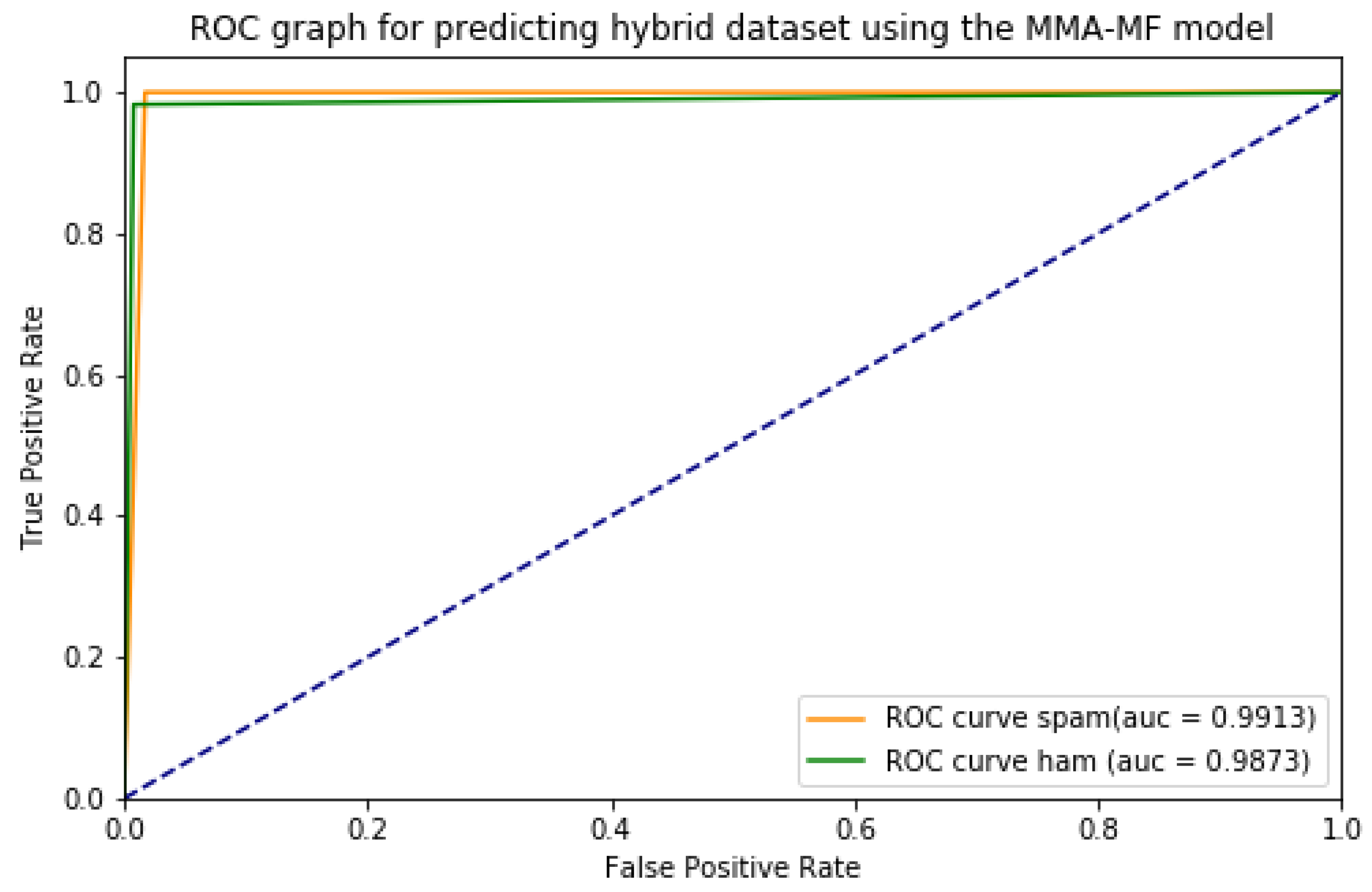
| MMA-MF Model for Hybrid Dataset 2 | ||||
| 1 | 0.9875 | 0.9877 | 0.9875 | 0.9850 |
| 2 | 0.9875 | 0.9867 | 0.9874 | 0.9900 |
| 3 | 0.9833 | 0.9846 | 0.9833 | 0.9800 |
| 4 | 0.9896 | 0.9913 | 0.9895 | 0.9850 |
| 5 | 0.9750 | 0.9759 | 0.9750 | 0.9750 |
| 0.9846 | 0.9852 | 0.9845 | 0.9830 | |
| Dataset Type | Model | Accuracy | Recall | F1-Score | Precision |
|---|---|---|---|---|---|
| Text | Char-CNN | 0.9563 | - | - | - |
| BiLSTM | 0.9640 | - | - | - | |
| Naive Bayes | 0.9600 | - | 0.9600 | - | |
| ICRM | 0.9400 | - | 0.9500 | - | |
| Image | Naive Bayes | 0.8504 | - | 0.9103 | - |
| ID3 Decision Tree | 0.8900 | - | 0.9000 | - | |
| Hybrid Dataset 1 | SVM | 0.9825 | 0.9825 | 0.9825 | 0.9810 |
| Classical k-NN | 0.9783 | 0.9781 | 0.9783 | 0.9770 | |
| Enhanced k-NN | 0.9825 | 0.9830 | 0.9825 | 0.9820 | |
| Random Forest | 0.9833 | ||||
| Hybrid Dataset 2 | SVM | 0.9842 | 0.9844 | 0.9841 | |
| Classical k-NN | 0.9808 | 0.9813 | 0.9808 | 0.9790 | |
| Enhanced k-NN | 0.9842 | 0.9844 | 0.9842 | 0.9820 | |
| Random Forest | 0.9833 | 0.9834 | 0.9833 | 0.9810 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, H.; Liu, Q.; Zhou, S.; Luo, Y. A Spam Filtering Method Based on Multi-Modal Fusion. Appl. Sci. 2019, 9, 1152. https://doi.org/10.3390/app9061152
Yang H, Liu Q, Zhou S, Luo Y. A Spam Filtering Method Based on Multi-Modal Fusion. Applied Sciences. 2019; 9(6):1152. https://doi.org/10.3390/app9061152
Chicago/Turabian StyleYang, Hong, Qihe Liu, Shijie Zhou, and Yang Luo. 2019. "A Spam Filtering Method Based on Multi-Modal Fusion" Applied Sciences 9, no. 6: 1152. https://doi.org/10.3390/app9061152
APA StyleYang, H., Liu, Q., Zhou, S., & Luo, Y. (2019). A Spam Filtering Method Based on Multi-Modal Fusion. Applied Sciences, 9(6), 1152. https://doi.org/10.3390/app9061152