A Modified Bayesian Network Model to Predict Reorder Level of Printed Circuit Board


Abstract
:Featured Application
Abstract
1. Introduction
2. Variables Specification and Data Preprocessing
2.1. Variables Specification
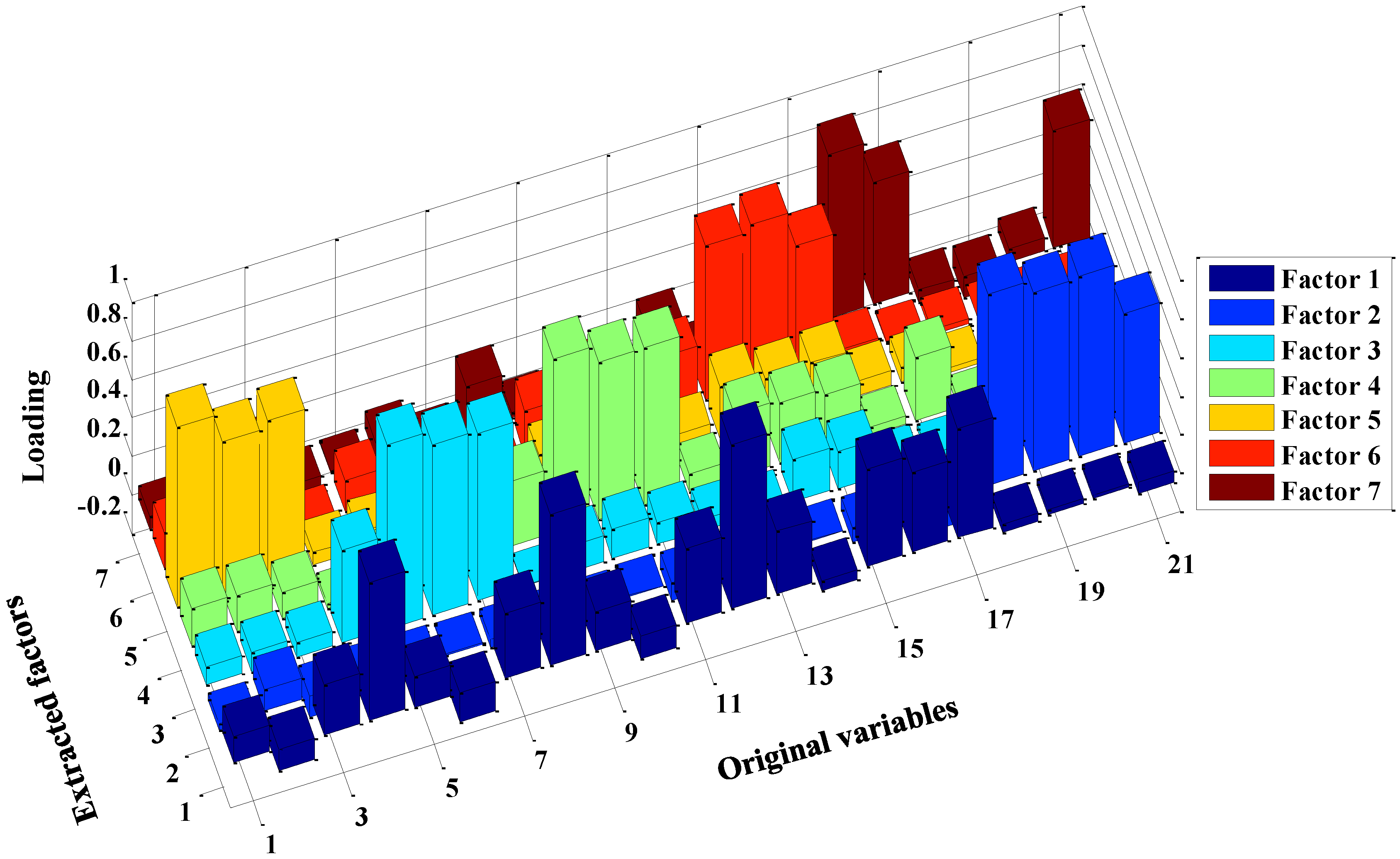
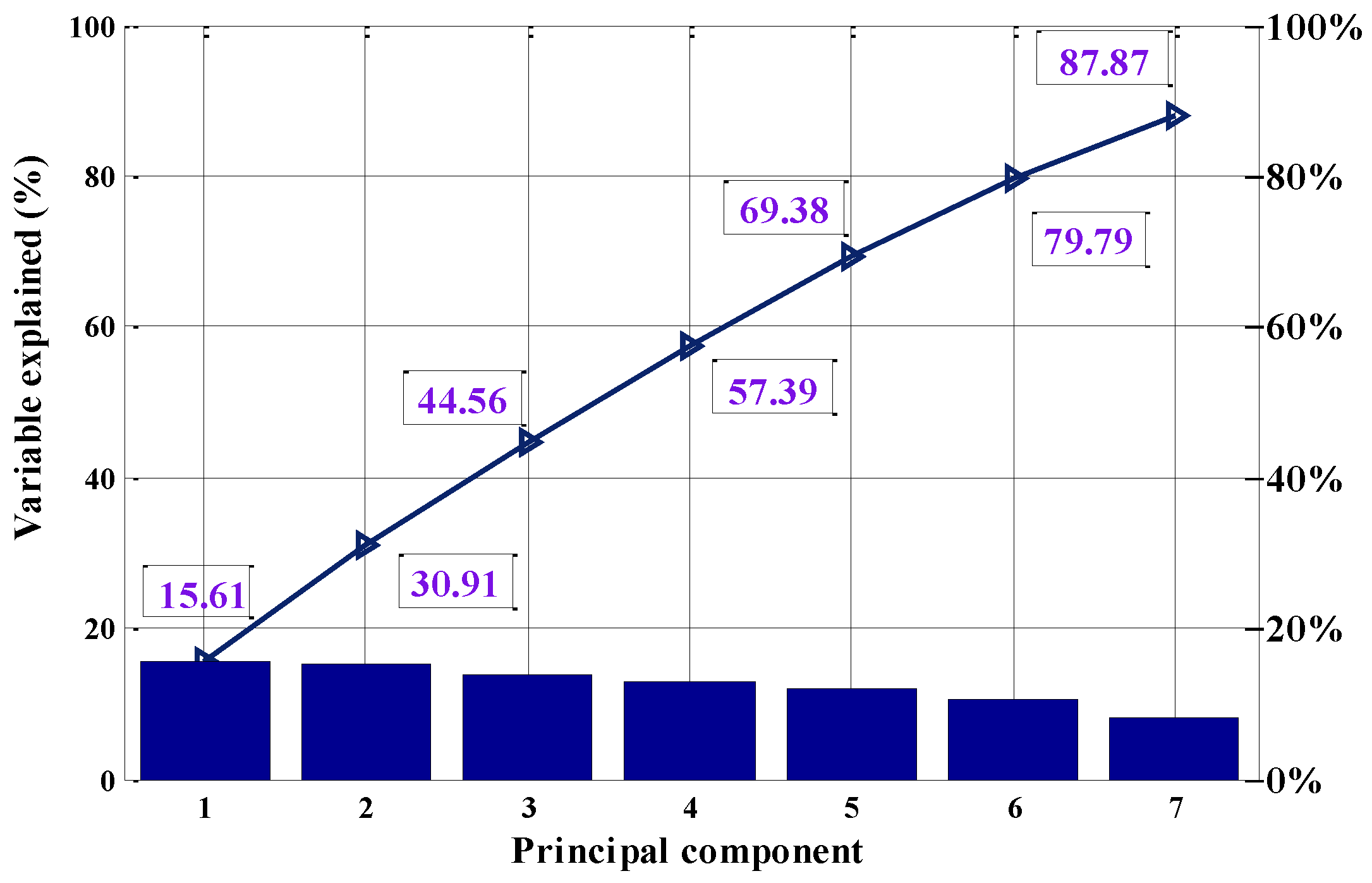
2.2. Principal Component Analysis
| Algorithm 1. Factors extraction based on PCA. |
|
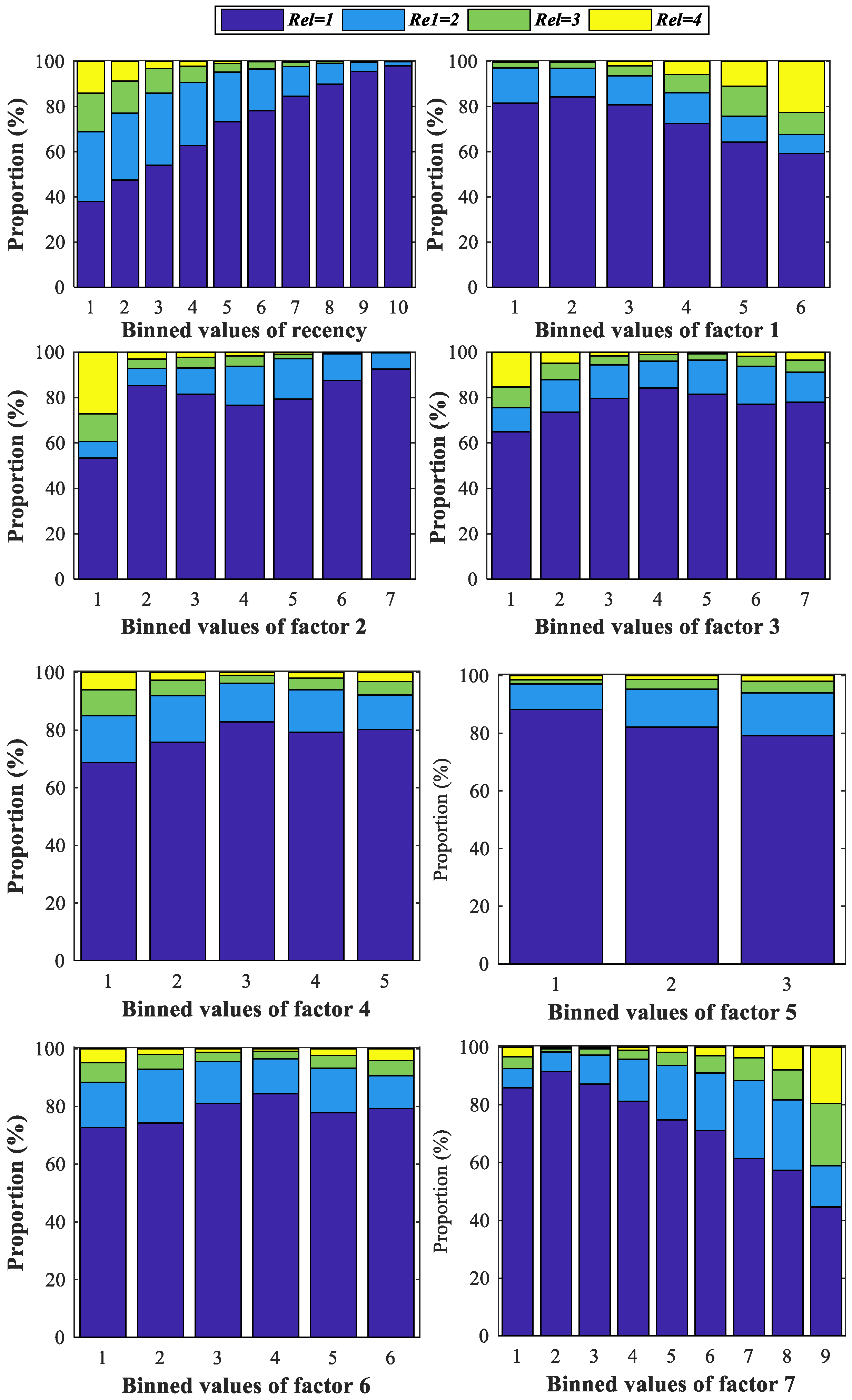
2.3. Data Discretization
| Algorithm 2. Entropy-based data discretization. |
| Input: Samples S, samples size N, variable , classes of reorder level , and maximum number of binned interval MaxIntv. Output: Split points for the variable , the number of final split point , and binned values for variable Iteration Initialize empty set and ; Rank sample S according to in ascending order and the position are taken as its possible split points; for k = 1 to MaxIntv; Compute E(S) according to Equation (1); tempN = N; tempj = 0; for j = 2 to ; sp = 1; tempj = j Get the value of at the position for (updated) sample S and suppose it is Tj; , ←the number of samples in the two intervals and separated by ; , , , ←the number of samples with in , , respectively; , ; Compute , , , and according to Equations (1)–(3) respectively; if satisfies MDLP; Append to and sp to ; sp ++; update , ; break; end; end; if ; break; end; end; return and . |
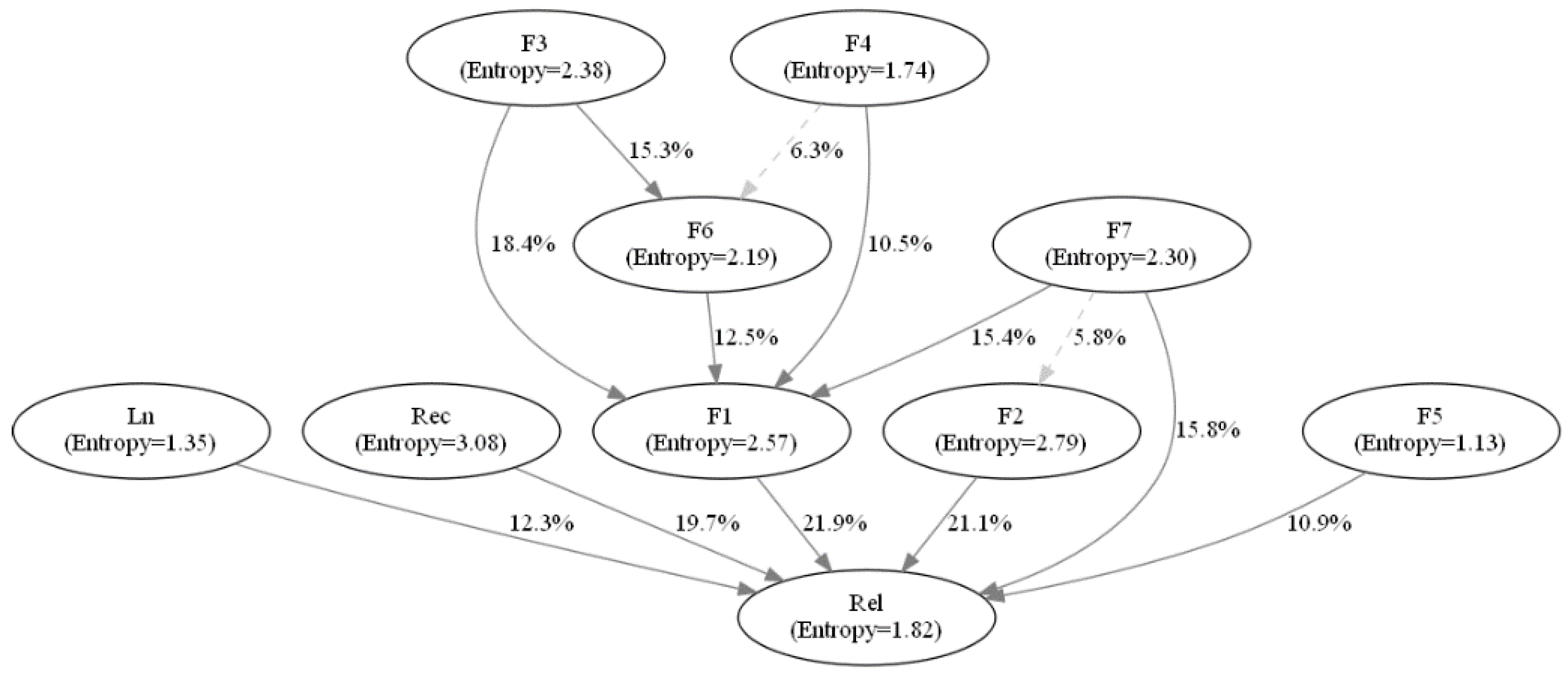
3. Modified Bayesian Network Model Development
3.1. Bayesian Network
| Algorithm 3. Modified BN structure establishment. |
|
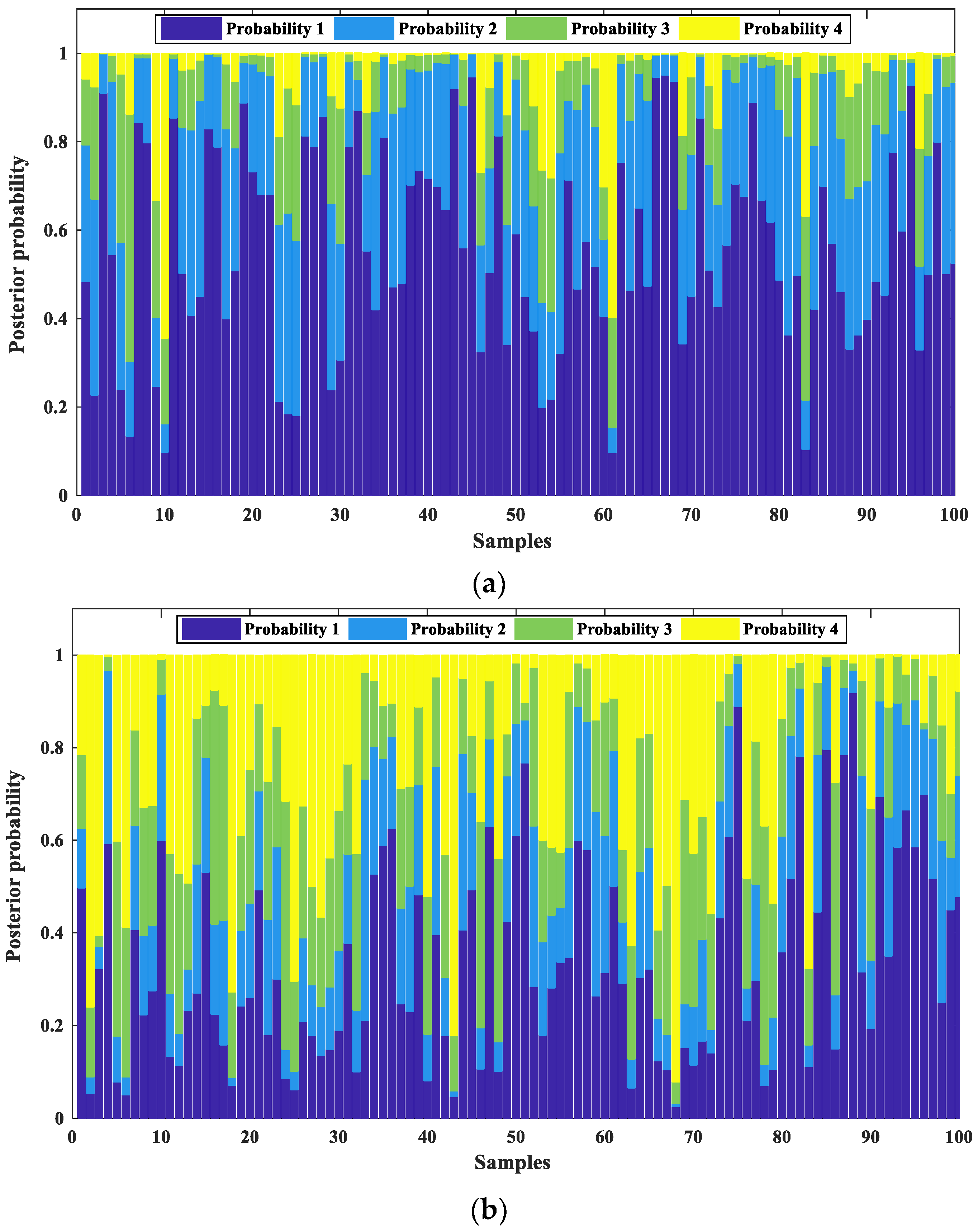
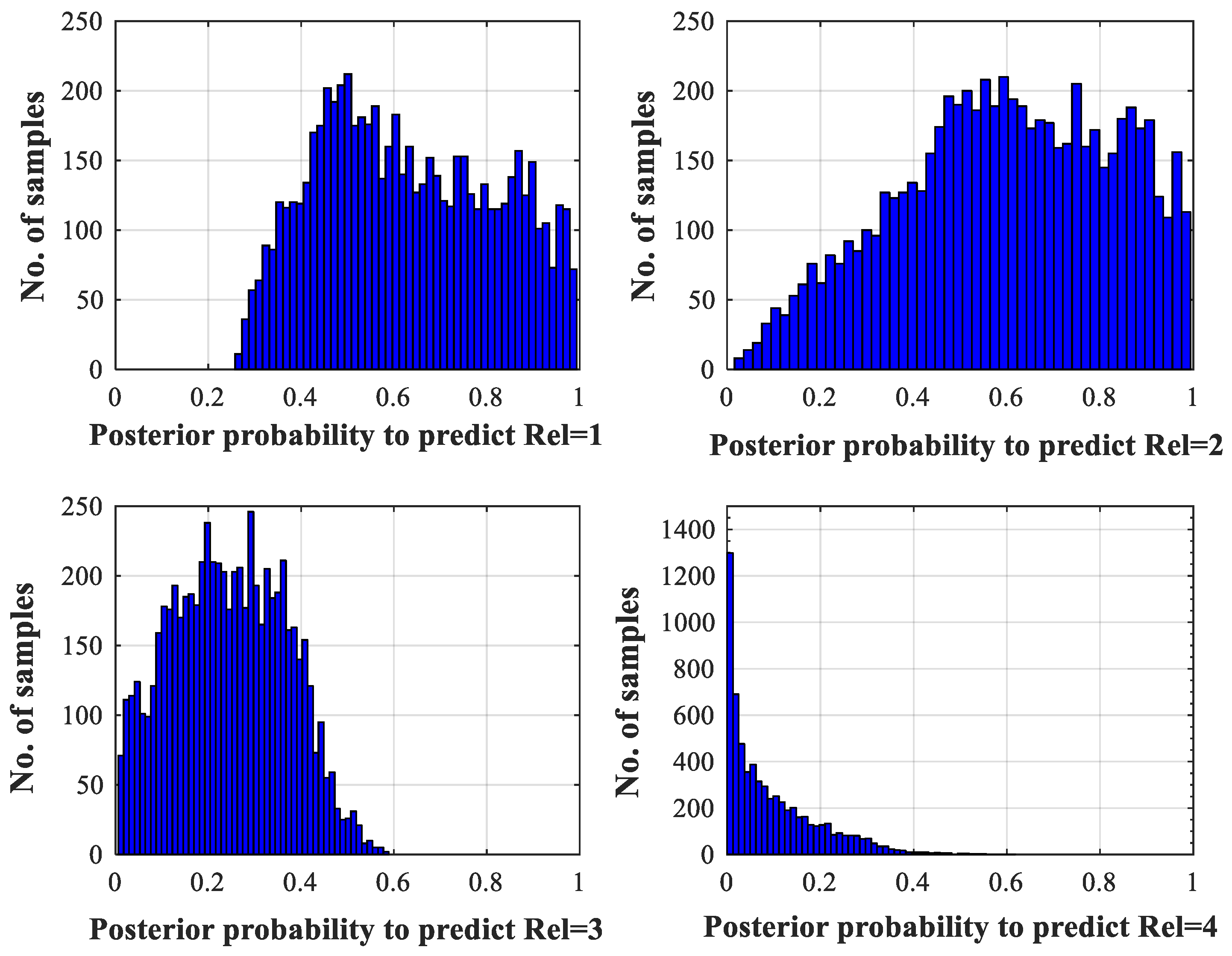
3.2. Conditional Expected Loss-Based Classification
| Algorithm 4. Conditional expected loss-based classification. |
|
4. Model Evaluation
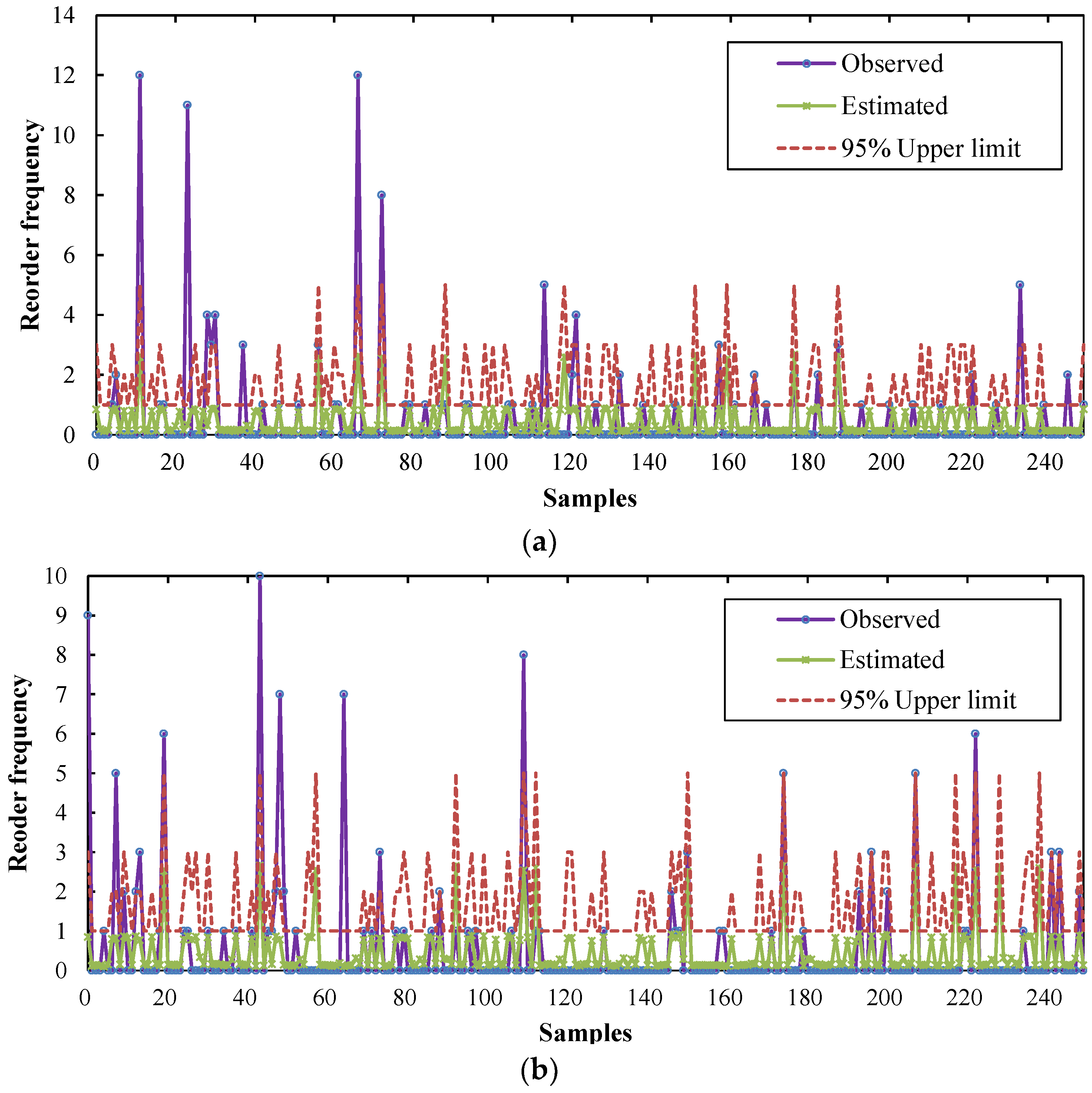
4.1. Estimation of Reorder Frequency
4.2. Evaluation Indicators
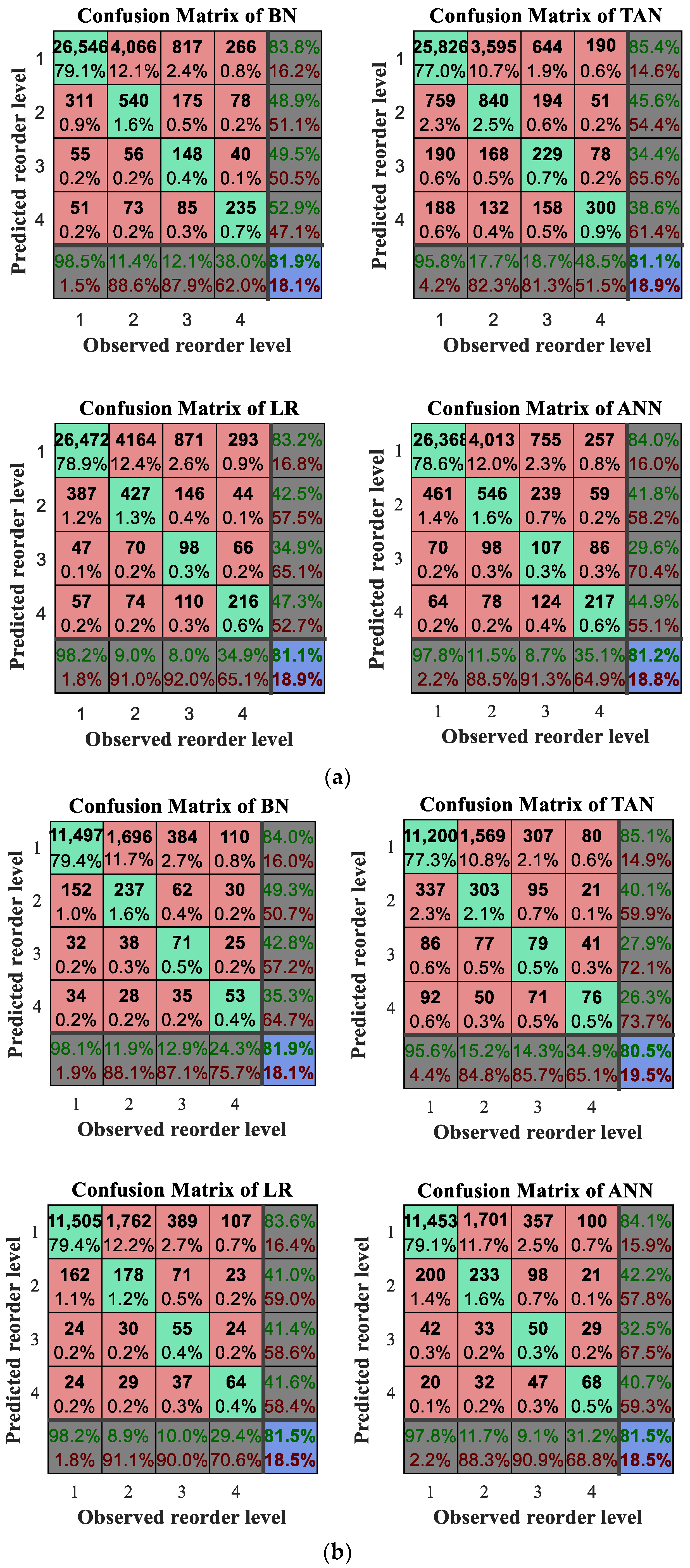
4.3. Experimental Results
| Algorithm 5. Monte Carlo simulation of reorder times. |
|
5. Conclusions
- The tricky problem of identifying repeated orders for batch production was transformed into a reorder level prediction problem and then a reorder level prediction model based on modified causal Bayesian network was proposed. From the historically accumulated data in a PCB manufacturer, different characteristic variables were extracted and specified for the model.
- PCA was employed for data compression and factors extraction. Yet, an entropy minimization based method was presented to discretize variable and extracted factors. They could facilitate data compression, input type reduction, and better classification performance.
- In order to avoid the defect of TAN BN that easily misses strong links between nodes and generates redundant weak links, CMI and LSP were combined for the establishment of the BN structure.
- By using Monte Carlo simulations, the confidence upper limits of reorder frequency within six months were determined and the influence of the random nature of reorder was reduced.
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Marques, A.C.; Cabrera, C.J.; Malfatti, C.F. Printed circuit boards: A review on the perspective of sustainability. J. Environ. Manag. 2013, 131, 298–306. [Google Scholar] [CrossRef] [PubMed]
- Ngai, E.W.T.; Xiu, L.; Chau, D.C.K. Application of data mining techniques in customer relationship management: A literature review and classification. Exp. Syst. Appl. 2009, 36, 2592–2602. [Google Scholar] [CrossRef]
- Dursun, A.; Caber, M. Using data mining techniques for profiling profitable hotel customers: An application of RFM analysis. Tour. Manag. Perspect. 2016, 18, 153–160. [Google Scholar] [CrossRef]
- Chen, Y.L.; Kuo, M.H.; Wu, S.Y.; Tang, K. Discovering recency, frequency, and monetary (RFM) sequential patterns from customers’ purchasing data. Electron. Commer. Res. Appl. 2009, 8, 241–251. [Google Scholar] [CrossRef]
- Hu, Y.; Yeh, T. Discovering valuable frequent patterns based on RFM analysis without customer identification information. Knowl. Syst. 2014, 61, 76–88. [Google Scholar] [CrossRef]
- Coussement, K.; Filip, A.M.V.B.; Bock, K.W. Dataac accuracy’s impt on segmentation performance: Benchmarking RFM analysis, logistic regression, and decision trees. J. Bus. Res. 2014, 67, 2751–2758. [Google Scholar] [CrossRef]
- Mohammadzadeh, M.; Hoseini, Z.Z.; Derafshi, H. A data mining approach for modeling churn behavior via RFM model in specialized clinics case study: A public sector hospital in Tehran. Procedia Comput. Sci. 2017, 120, 23–30. [Google Scholar] [CrossRef]
- Song, M.N.; Zhao, X.J.; Haihong, E.; Qu, Z.H. Statistics-based CRM approach via time series segmenting RFM on large scale data. Knowl. Syst. 2017, 132, 21–29. [Google Scholar] [CrossRef]
- Liu, J. Using big data database to construct new GFuzzy text mining and decision algorithm for targeting and classifying customers. Comput. Ind. Eng. 2018. [Google Scholar] [CrossRef]
- Sarti, S.; Darnall, N.; Testa, F. Market segmentation of consumers based on their actual sustainability and health-related purchases. J. Clean. Prod. 2018, 192, 270–280. [Google Scholar] [CrossRef]
- Murray, P.W.; Agard, B.; Barajas, M.A. Forecast of individual customer’s demand from a large and noisy dataset. Comput. Ind. Eng. 2018, 118, 33–43. [Google Scholar] [CrossRef]
- De Caigny, A.; Coussement, K.; Bock, K.W.D. A new hybrid classification algorithm for customer churn prediction based on logistic regression and decision trees. Eur. J. Oper. Res. 2018, 269, 760–772. [Google Scholar] [CrossRef]
- Zerbino, P.; Aloini, D.; Dulmin, R.; Mininno, V. Big Data-enabled customer relationship management: A holistic approach. Inform. Proc. Manag. 2018. [Google Scholar] [CrossRef]
- Wang, G.; Xu, T.H.; Tang, T.; Yuan, T.M.; Wang, H.F. A Bayesian network model for prediction of weather-related failures in railway turnout systems. Expert Syst. Appl. 2017, 69, 247–256. [Google Scholar] [CrossRef]
- Arias, J.; Gamez, J.A.; Puerta, J.M. Learning distributed discrete Bayesian network classifiers under MapReduce with Apache Spark. Knowl. Based Syst. 2017, 11, 16–26. [Google Scholar] [CrossRef]
- Thorson, J.T.; Johnson, K.F.; Methot, R.D.; Taylor, I.G. Model-based estimates of effective sample size in stock assessment models using the Dirichlet-multinomial distribution. Fish. Res. 2017, 192, 84–93. [Google Scholar] [CrossRef]
- Mack, D.L.C.; Biswas, G.; Koutsoukos, X.D.; Mylaraswamy, D. Learning Bayesian network structures to augment aircraft diagnostic reference models. IEEE Trans. Autom. Sci. Eng. 2017, 14, 358–369. [Google Scholar] [CrossRef]
- Alonso-Montesinos, J.; Martínez-Durbán, M.; Sagrado, J.; Águila, I.M.D.; Batlles, F.J. The application of Bayesian network classifiers to cloud classification in satellite images. Renew. Energy 2016, 97, 155–161. [Google Scholar] [CrossRef]
- Hosseini, S.; Barker, K. Modeling infrastructure resilience using Bayesian networks: A case study of inland waterway ports. Comput. Ind. Eng. 2016, 93, 252–266. [Google Scholar] [CrossRef]
- Hosseini, S.; Barker, K. A Bayesian network model for resilience-based supplier selection. Int. J. Prod. Econ. 2016, 180, 68–87. [Google Scholar] [CrossRef]
- Li, B.C.; Yang, Y.L. Complexity of concept classes induced by discrete Markov networks and Bayesian networks. Pattern Recognit. 2018. [Google Scholar] [CrossRef]
- Liu, B.; Hu, J.; Yan, F.; Turkson, R.F.; Lin, F. A novel optimal support vector machine ensemble model for NOx emissions prediction of a diesel engine. Measurement 2016, 92, 183–192. [Google Scholar] [CrossRef]
- Ramrez-Gallego, S.; Krawczyk, B.; Woniak, M.; Woniak, M.; Herrera, F. A survey on data preprocessing for data stream mining: Current status and future directions. Neurocomputing 2017, 239, 39–57. [Google Scholar] [CrossRef]
- Fayyad, U.; Irani, K. Multi-interval discretization of continuous-valued attributes for classification learning. Int. J. Conf. Artif. Intel. 1993, 1022–1029. [Google Scholar]
- Boonchuay, K.; Sinapiromsaran, K.; Lursinsap, C. Decision tree induction based on minority entropy for the class imbalance problem. Pattern Anal. Appl. 2017, 20, 769–782. [Google Scholar] [CrossRef]
- Tahan, M.H.; Asadi, S. MEMOD: A novel multivariate evolutionary multi-objective discretization. Soft Comput. 2017, 22, 1–23. [Google Scholar] [CrossRef]
- Zhao, Y.; Xiao, F.; Wang, S. An intelligent chiller fault detection and diagnosis methodology using bayesian belief network. Energy Build. 2013, 57, 278–288. [Google Scholar] [CrossRef]
- Jun, H.B.; Kim, D. A Bayesian network-based approach for fault analysis. Expert Syst. Appl. 2017, 81, 332–348. [Google Scholar] [CrossRef]
- Wang, S.C.; Gao, R.; Wang, L.M. Bayesian network classifiers based on Gaussian kernel density. Expert Syst. Appl. 2016, 51, 207–217. [Google Scholar] [CrossRef]
- Gan, H.X.; Zhang, Y.; Song, Q. Bayesian belief network for positive unlabeled learning with uncertainty. Pattern Recogn. Lett. 2017, 90, 28–35. [Google Scholar] [CrossRef]
- Friedman, N.; Geiger, D.; Goldszmidt, M. Bayesian network classifiers. Mach. Learn. 1997, 29, 131–163. [Google Scholar] [CrossRef]
- Imme, E.U. Georgia Tech Research Report: Tutorial on How to Measure Link Strengths in Discrete Bayesian Networks; Woodruff School of Mechanical Engineering, Georgia Institute of Technology: Atlanta, GA, USA, 2009. [Google Scholar]
- Confusion Matrix. Available online: https://en.wikipedia.org/wiki/Confusion_matrix (accessed on 11 October 2017).
- Liu, H.; Tian, H.Q.; Li, Y.F.; Zhang, L. Comparison of four Adaboost algorithm based artificial neural networks in wind speed predictions. Energy Convers. Manag. 2015, 92, 67–81. [Google Scholar] [CrossRef]
- Cortes, C.; Gonzalvo, X.; Kuznetsov, V.; Mohri, M.; Yang, S. AdaNet: Adaptive structural learning of artificial neural networks. arXiv, 2016; arXiv:1607.01097. [Google Scholar]
- Sharma, A.; Sahoo, P.K.; Tripathi, R.K.; Meher, L.C. Artificial neural network-based prediction of performance and emission characteristics of CI engine using polanga as a biodiese. Int. J. Ambient Energy 2016, 37, 559–570. [Google Scholar] [CrossRef]
- Saravanan, K.; Sasithra, S. Review on classification based on artificial neural networks. Int J. Ambient Syst. Appl. 2014, 2, 11–18. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | Symbols | Description |
|---|---|---|
| Layer number | Ln | PCB is made of resin, substrate, and copper foil and the Ln is the number of copper foil layers. |
| Continued days | Condays | Interval days between the first order date and a set date. |
| Recency | Rec | A period between the last order date and a set date. |
| Maximum/minimum/mean of delivery interval days | Delind_Max/Min/Mean | Days between order date and required delivery date in the past 30 months. |
| Maximum/minimum/mean of interval days | Interval_Max/Min/Mean | Days between two adjacent order dates in the past 30 months. |
| Frequency in 30 months | Fre3 | Reorder frequency within 30 months before a set date. |
| Frequency | Fre | Reorder frequency before a set date. |
| Maximum/minimum/mean/sum of delivery area (m2) | Area_Max/Min/Mean/Sum | Delivery area of the past 30 months before a set date. |
| Maximum/minimum/mean/sum of money (CNY) | Mon_Max/Min/Mean/Sum | Transaction money of the past 30 months before a set date. |
| Maximum/minimum/mean/sum of delivery quantity | Qaun_Max/Min/Mean/Sum | Delivery quantity of the past 30 months before a set date. |
| Reorder level | Rel | 1, 2, 3, and 4 levels corresponding to the reorder frequency 0, 1–2, 3–5, and >5 within six months, respectively. |
| Samples | Number (Proportion of Different Reorder Levels %) | Total Number | |||
|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | ||
| All | 38,678 (80.54) | 6734 (14.02) | 1777 (3.70) | 837 (1.74) | 48,026 |
| Training | 26,963 (80.39) | 4735 (14.11) | 1225 (3.65) | 619 (1.85) | 33,542 |
| Test | 11,715 (80.88) | 1999 (13.80) | 552 (3.80) | 218 (1.52) | 14,484 |
| No. | Variables Name | Factors | Interpretation |
|---|---|---|---|
| 1–3 | Delind_Mean/Min/Max | 1 (F1) | Qaun_Sum/Mon_Sum/Area_Sum |
| 4–7 | Qaun_Sum/Mean/Min/Max | 2 (F2) | Interval_Mean/Min/Max, Condays |
| 8–11 | Mon_Sum/Mean/Min/Max | 3 (F3) | Qaun_Mean/Min/Max |
| 12–15 | Area_Sum/Mean/Min/Max | 4 (F4) | Mon_Mean/Min/Max |
| 16–17 | Fre/Fre3 | 5 (F5) | Delind_Mean/Min/Max |
| 18–20 | Interval_Mean/Min/Max | 6 (F6) | Area_Mean/Min/Max |
| 21 | Condays | 7 (F7) | Fre/Fre3/Condays |
| Variables (Factors) | Spilt Points |
|---|---|
| Ln | 4, 10 |
| Rec | 11, 36, 67, 114, 172, 195, 325, 440, 714 |
| F1 | −0.09, 0.002, 0.211, 1.221, 2.436 |
| F2 | −0.767, −0.634, −0.496, 0.026, 0.787, 1718 |
| F3 | −0.532, −0.311, −0.251, −0.173, −0.024, 0.534 |
| F4 | −0.802, −0.481, −0.09, 0.872 |
| F5 | −0.1097, 0.443 |
| F6 | −0.879, −0.586, −0.329, 0.009, 1.432 |
| F7 | −1.009, 0.628, 0.386, 0.023, 0.401,1.335, 1.865, 3.501 |
| Variables and Factors | Ln | Rec | F1 | F2 | F3 | F4 | F5 | F6 | F7 |
|---|---|---|---|---|---|---|---|---|---|
| Ln | 1 | 0.0018 | 0.002 | 0.0023 | 0.0703 | 0.0729 | 0.0307 | 0.0934 | 0.0023 |
| Rec | 1 | 0.01 | 0.019 | 0.005 | 0.041 | 0.0047 | 0.0108 | 0.0277 | |
| F1 | 1 | 0.0681 | 0.1004 | 0.141 | 0.0411 | 0.1098 | 0.1108 | ||
| F2 | 1 | 0.0357 | 0.0125 | 0.0121 | 0.0226 | 0.1445 | |||
| F3 | 1 | 0.099 | 0.041 | 0.2215 | 0.087 | ||||
| F4 | 1 | 0.0461 | 0.1121 | 0.0192 | |||||
| F5 | 1 | 0.0891 | 0.0144 | ||||||
| F6 | 1 | 0.027 | |||||||
| F7 | 1 |
| Predicted Value | Overserved Value | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Recency = 2–3 | Recency = 4–5 | Recency = 6–10 | ||||||||||
| 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | |
| 1 | 0 | 1.2 | 1.25 | 1.3 | 0 | 1.15 | 1.2 | 1.25 | 0 | 1.1 | 1.15 | 1.2 |
| 2 | 1.3 | 0 | 0.8 | 0.9 | 1.35 | 0 | 0.75 | 0.85 | 1.4 | 0 | 0.7 | 0.8 |
| 3 | 1.35 | 0.75 | 0 | 0.9 | 1.4 | 0.8 | 0 | 0.85 | 1.45 | 0.85 | 0 | 0.8 |
| 4 | 1.45 | 0.85 | 0.75 | 0 | 1.5 | 0.9 | 0.8 | 0 | 1.55 | 0.95 | 0.85 | 0 |
| Reorder Level | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| Mean value for training samples | 0 | 1.28 | 3.67 | 10.03 |
| Mean value for test samples | 0 | 1.27 | 3.67 | 10.28 |
| Mean value for all samples | 0 | 1.28 | 3.67 | 10.09 |
| Reorder Level | Different Clusters | ||||||
|---|---|---|---|---|---|---|---|
| C1 | C2 | C3 | C4 | C5 | C6 | C7 | |
| 1 | 89.67 | 91.88 | 65.87 | 58.87 | 89.60 | 42.60 | 92.49 |
| 2 | 9.42 | 7.32 | 24.84 | 31.50 | 7.03 | 23.25 | 6.67 |
| 3 | 0.78 | 0.64 | 7.06 | 7.99 | 2.18 | 17.79 | 0.65 |
| 4 | 0.13 | 0.16 | 2.23 | 1.64 | 1.18 | 16.36 | 0.19 |
| Terminology | Description |
|---|---|
| True positive (TP) | Number of correctly predicted instances for each column |
| False negative (FN) | Number of incorrectly predicted instances for each column |
| False positive (FP) | Number of incorrectly predicted instances for each row |
| True negative (TN) | Number of correctly predicted instances for each row |
| Sensitivity or true positive rate (TPR) | TP/(TP+FN) |
| False negative rate (FNR) | 1-TPR |
| Specificity or true negative rate (TNR) | TN/(TN+FP) |
| False positive rate (FPR) | 1-TNR |
| Positive predictive value (PPV) | TP/(TP+FP) |
| False discovery rate (FDR) | 1-PPV |
| Accuracy (ACC) | (TP+TN)/Total instances |
| Classifiers | Training Samples | Test Samples | ||||
|---|---|---|---|---|---|---|
| MSE | MAE | MAPE | MSE | MAE | MAPE | |
| Modified BN | 689.98 | 0.2306 | 10.6965 | 291.74 | 0.2239 | 11.0818 |
| TAN | 666.8964 | 0.2421 | 11.5641 | 302.2279 | 0.2509 | 11.9724 |
| AdaBoost | 738.0686 | 0.2407 | 11.2314 | 308.0735 | 0.2358 | 11.0472 |
| ANN | 692.7819 | 0.2349 | 11.3129 | 293.1946 | 0.2346 | 11.1991 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lv, S.; Kim, H.; Jin, H.; Zheng, B. A Modified Bayesian Network Model to Predict Reorder Level of Printed Circuit Board. Appl. Sci. 2018, 8, 915. https://doi.org/10.3390/app8060915
Lv S, Kim H, Jin H, Zheng B. A Modified Bayesian Network Model to Predict Reorder Level of Printed Circuit Board. Applied Sciences. 2018; 8(6):915. https://doi.org/10.3390/app8060915
Chicago/Turabian StyleLv, Shengping, Hoyeol Kim, Hong Jin, and Binbin Zheng. 2018. "A Modified Bayesian Network Model to Predict Reorder Level of Printed Circuit Board" Applied Sciences 8, no. 6: 915. https://doi.org/10.3390/app8060915