Optimal Selection of Clustering Algorithm via Multi-Criteria Decision Analysis (MCDA) for Load Profiling Applications



Abstract
:1. Introduction
1.1. Motivation
1.2. Solution Approach
- Criterion#1: Minimum number of parameters that need to be specified.
- Criterion#2: Minimum requirement for parameter updating.
- Criterion#3: Superior performance as measured by the most validity indicators.
- Criterion#4: High execution speed/minimum time requirement.
- Criterion#5: Generation of exploitable information about load data clusters.
- Criterion#6: Software availability.
1.3. Literature Survey and Contributions
- (1)
- A considerable number of different algorithms have been employed in different sets ranging from residential consumers to distribution feeders and aggregate system loads. This fact highlights the importance of efficient clustering. The comparison between algorithms is favoured over the sole application since it leads to more reliable results.
- (2)
- In the majority of cases, the conclusions drawn from the comparison are influenced by the type of the validity indicator. Each indicator measures either the compactness, the separation or both of the formulated clusters.
- (3)
- Apart from validity indicators, no study provides further criteria to strengthen the conclusions on algorithm selection.
- (1)
- In the present study, a comparison of the most common algorithms of the literature takes place. More specifically, 30 clustering algorithms are compared using 12 validity indicators. To the best of the authors’ knowledge, this is the first study that considers this number of algorithms and validity indicators. The scope is to gather the majority of the algorithms under a common analysis in order to discuss their advantages and disadvantages and provide the interested parties a guide on algorithm validation and selection.
- (2)
- All the studies of the literature that include a comparison use only strictly mathematical criteria. In this study, additional 5 criteria are introduced. This is justified by the increase of smart meter installations across the globe. This fact will lead to the collection of vast amount of Big Data; an efficient algorithm should not only lead to robust clusterings, as measured by the validity indicators but should correspond to low complexity in terms of input parameters requirements and execution speed.
- (3)
- The TOPSIS method is implemented in order to reach safe conclusions regarding the selection of an algorithm that satisfies a number of contradicting criteria.
2. Load Profiling Mathematical Background
2.1. Demand Representation
2.2. Clustering Algorithms
2.2.1. Partitional Clustering Algorithms
- Step#1.
- Initialization. A random selection of k patterns from set is held to serve as the initial centroids.
- Step#2.
- Clustering. For each iteration t = 1, …, T, where T is the number of total iterations of the algorithm and , the pattern is distributed to cluster , where k is selected so that
- Step#3.
- Centroids update. A re-calculation of centroids is made according to (2).
- Step#4.
- Termination. The algorithm terminates either when the maximum number of iterations T is met or when the improvement of between two subsequent iterations is lower than a pre-defined threshold , i.e.,
2.2.2. Hierarchical Clustering Algorithms
2.2.3. Fuzzy Clustering Algorithms
2.2.4. Neural Network-Based Clustering Algorithms
2.2.5. Other Clustering Algorithms
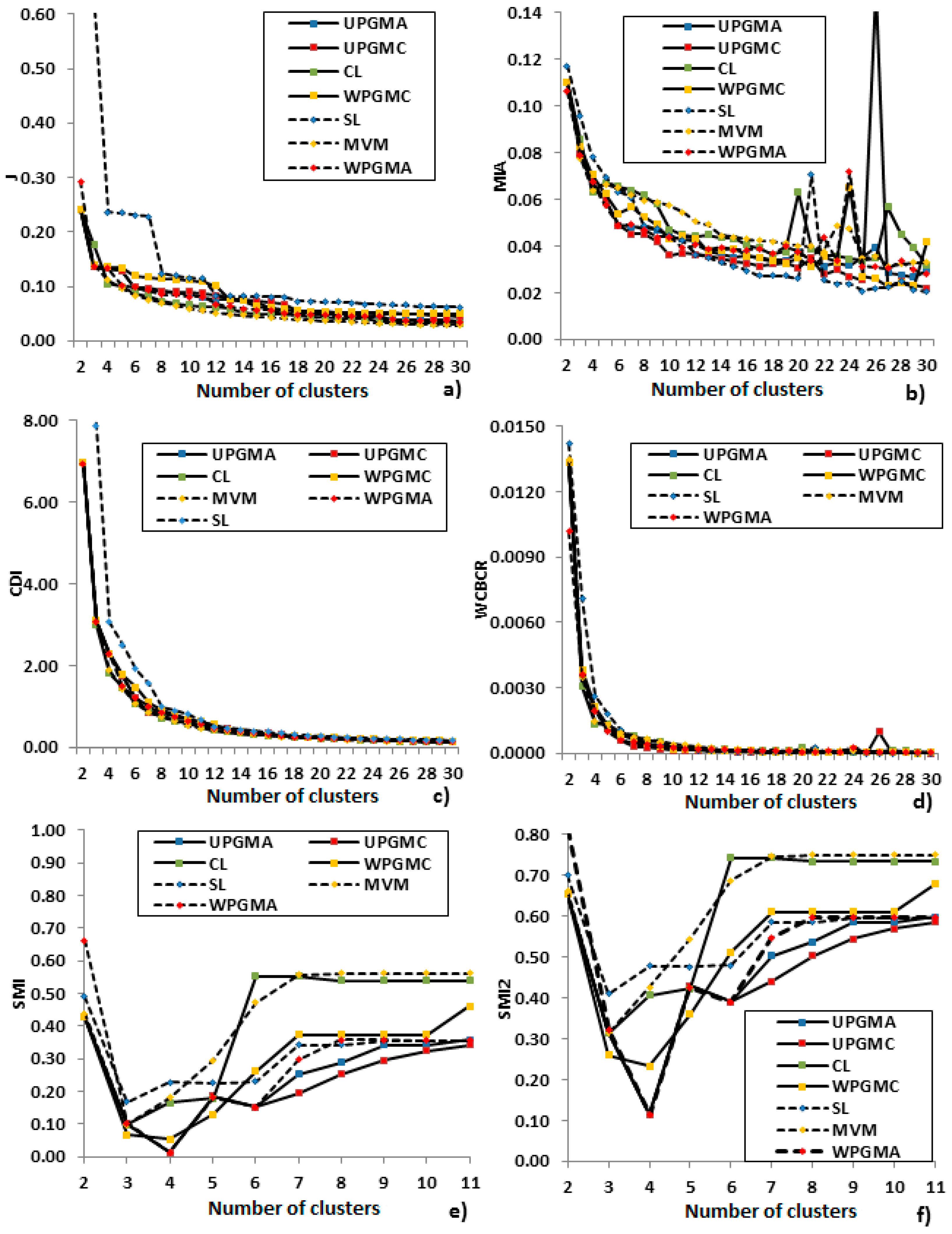
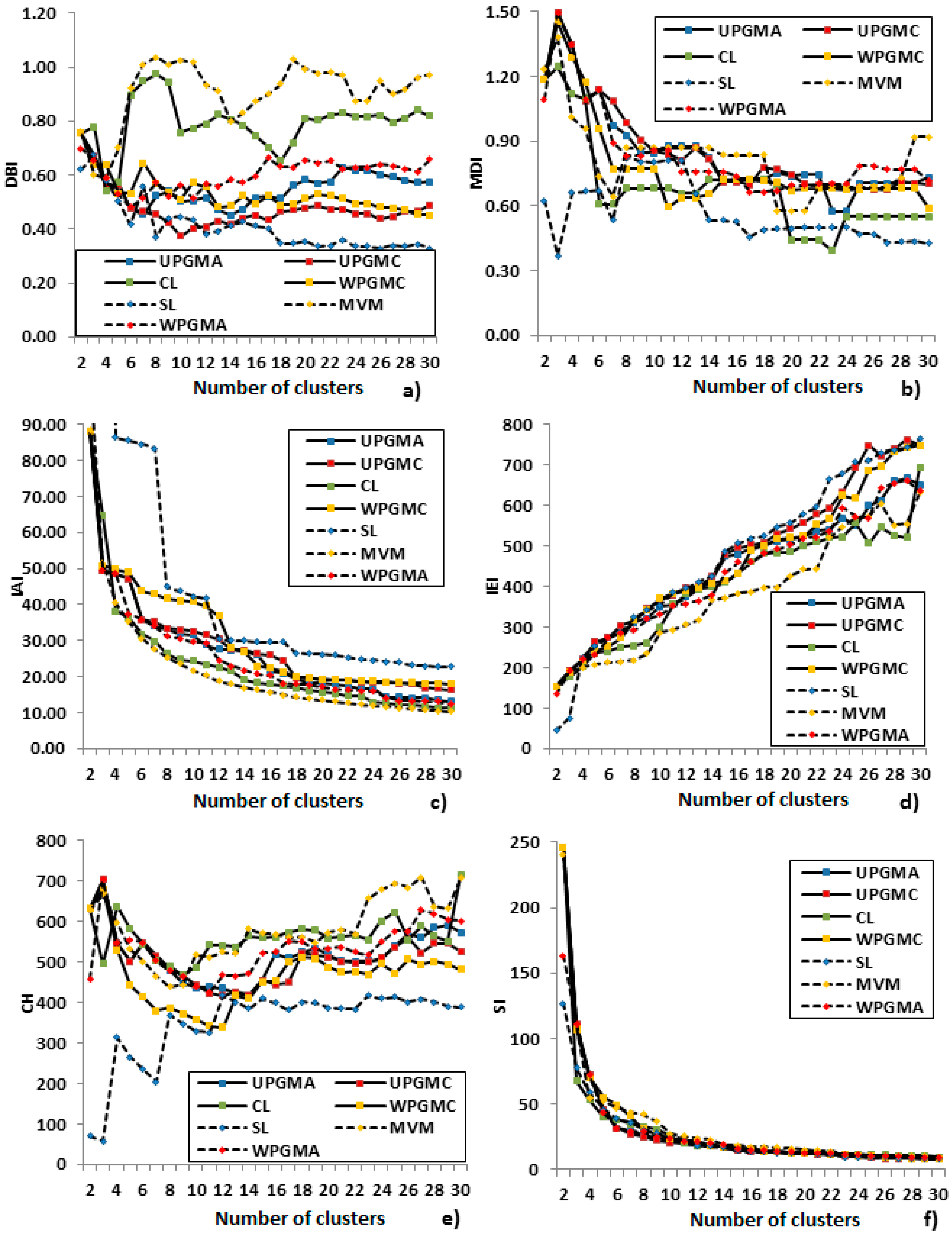
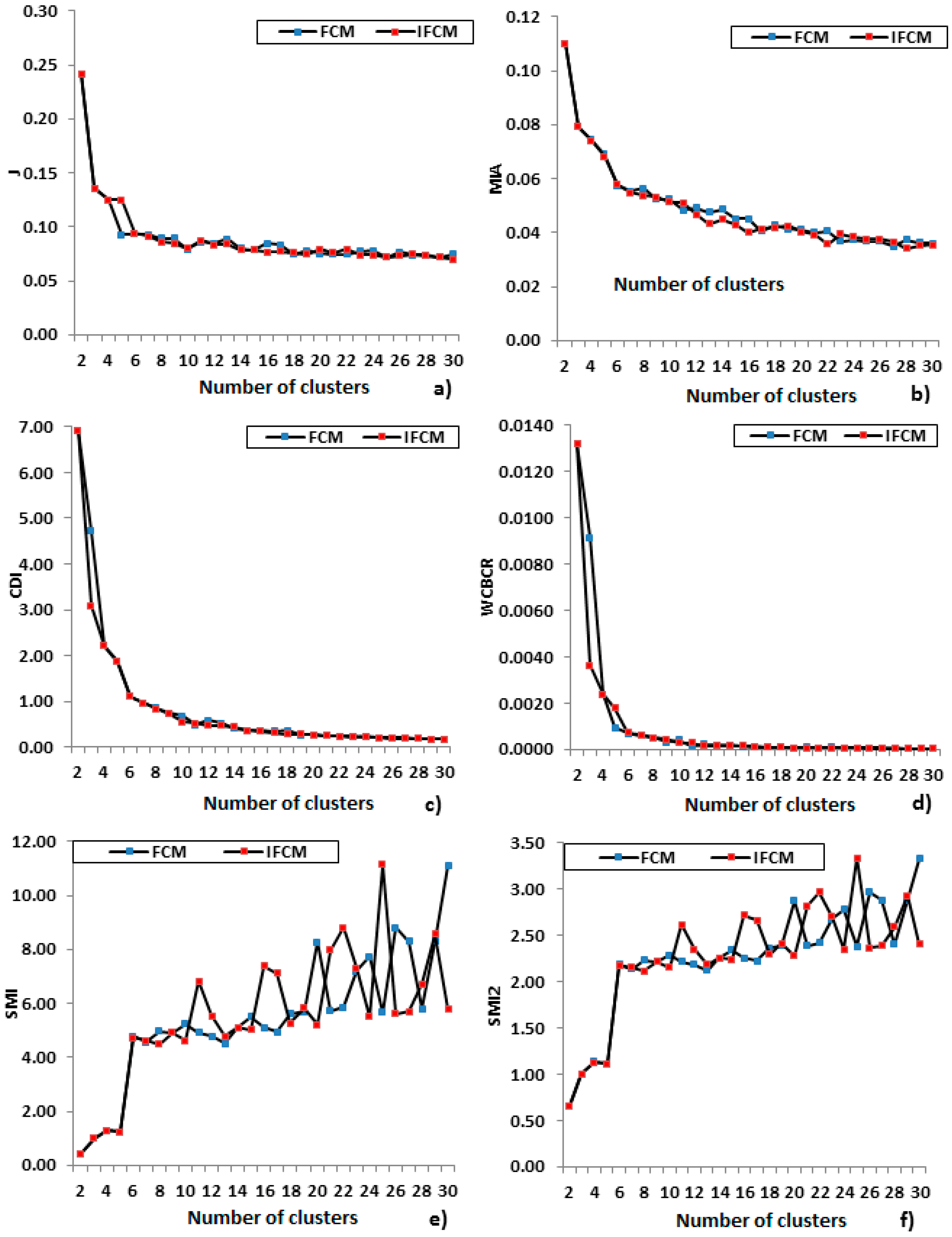
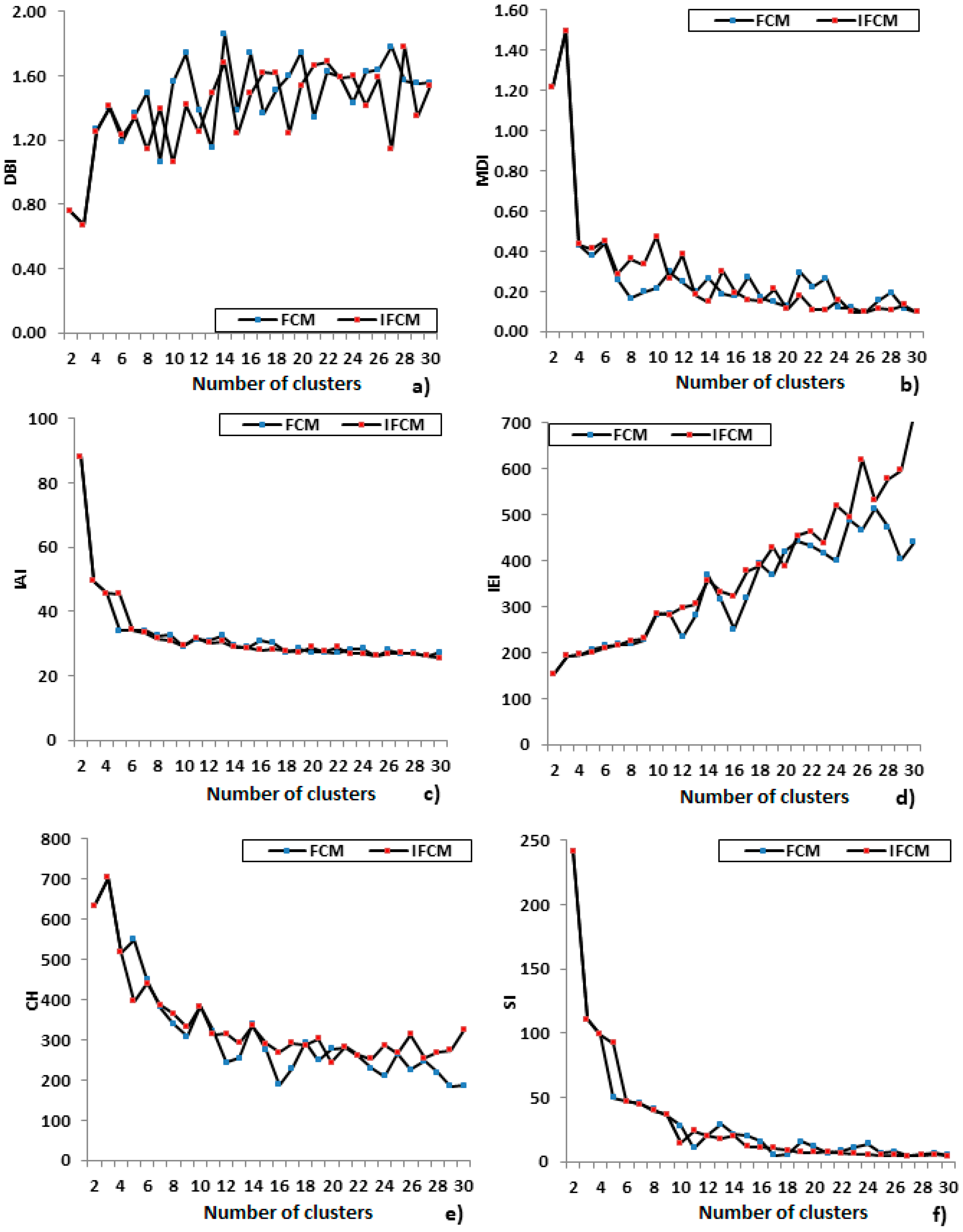
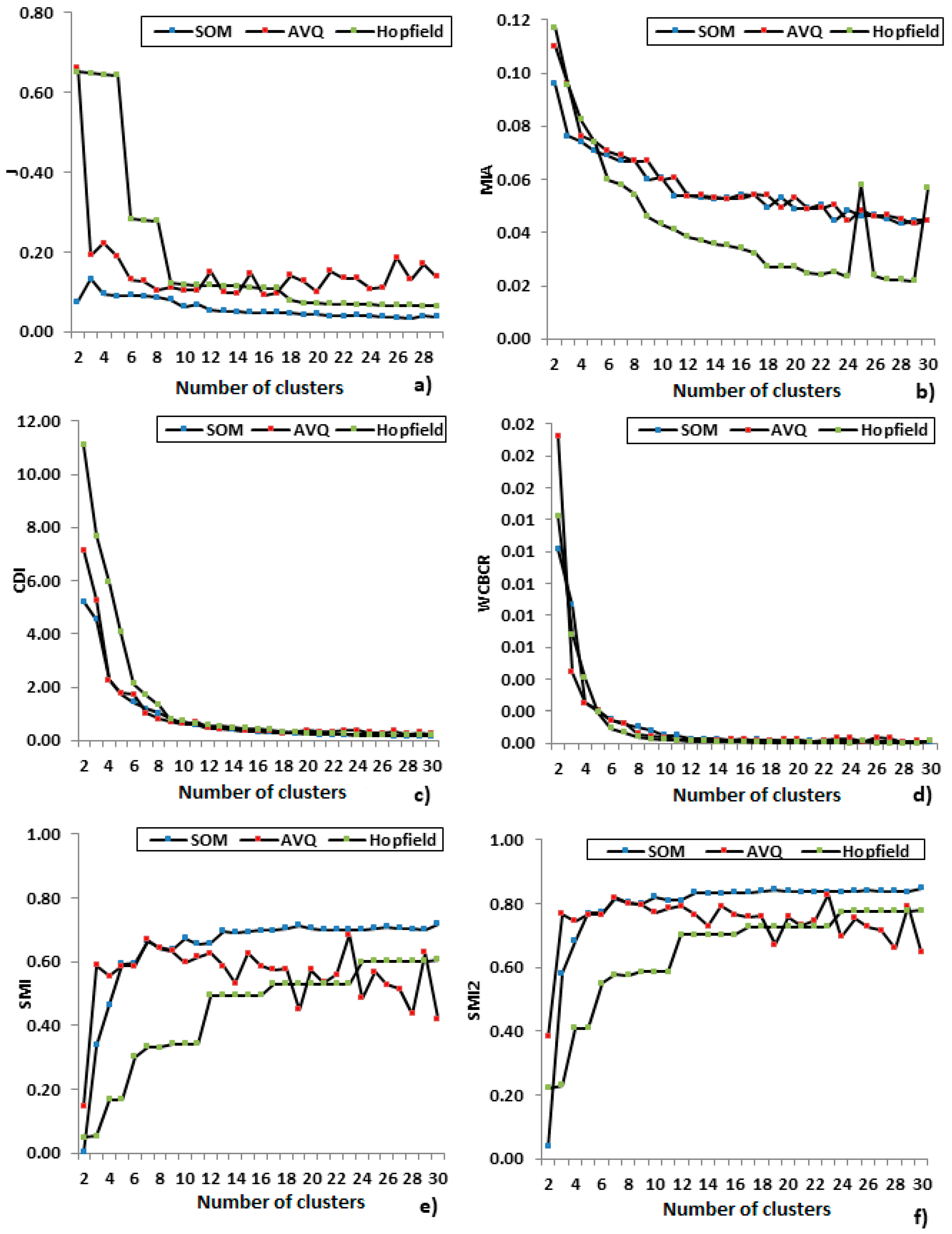
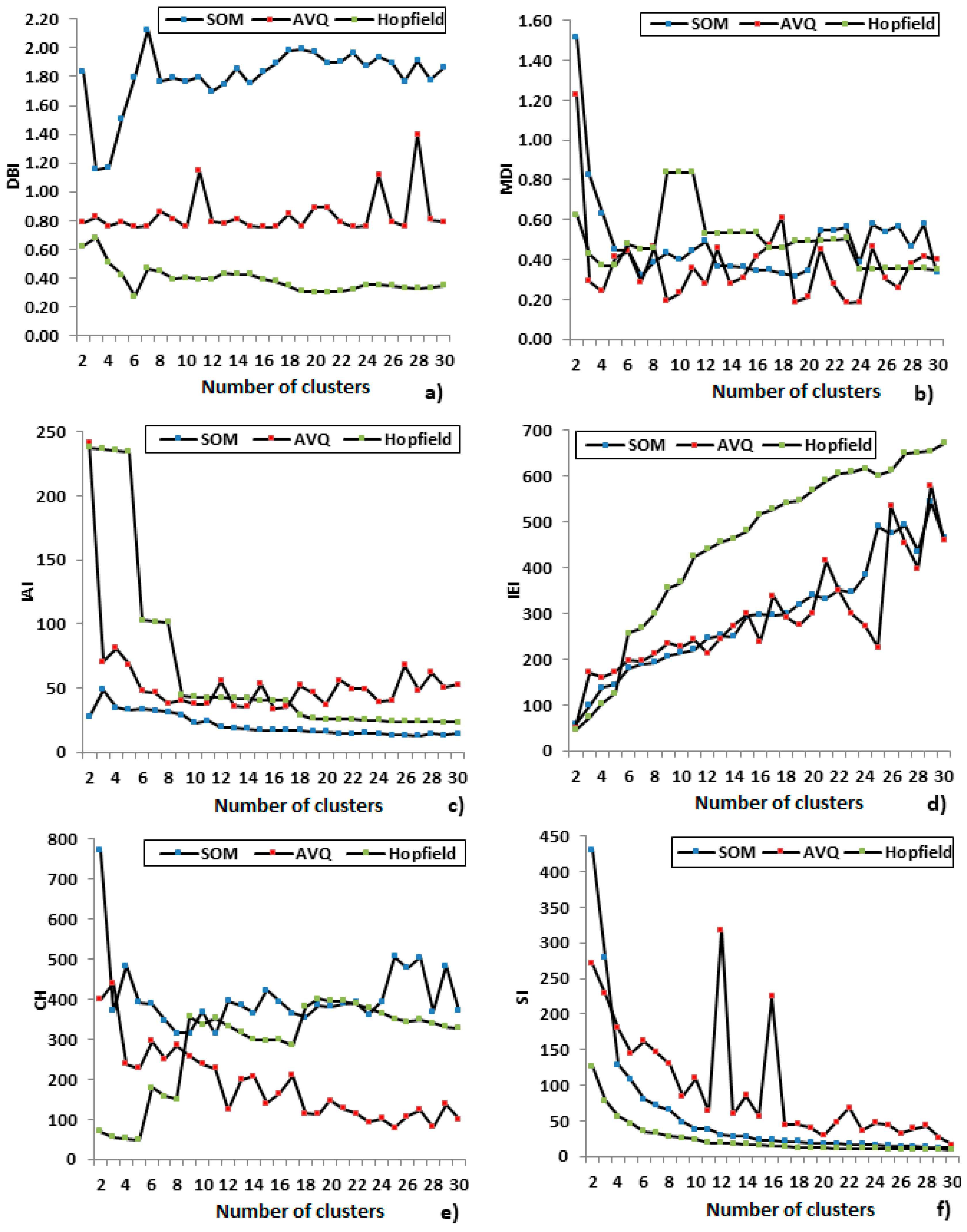
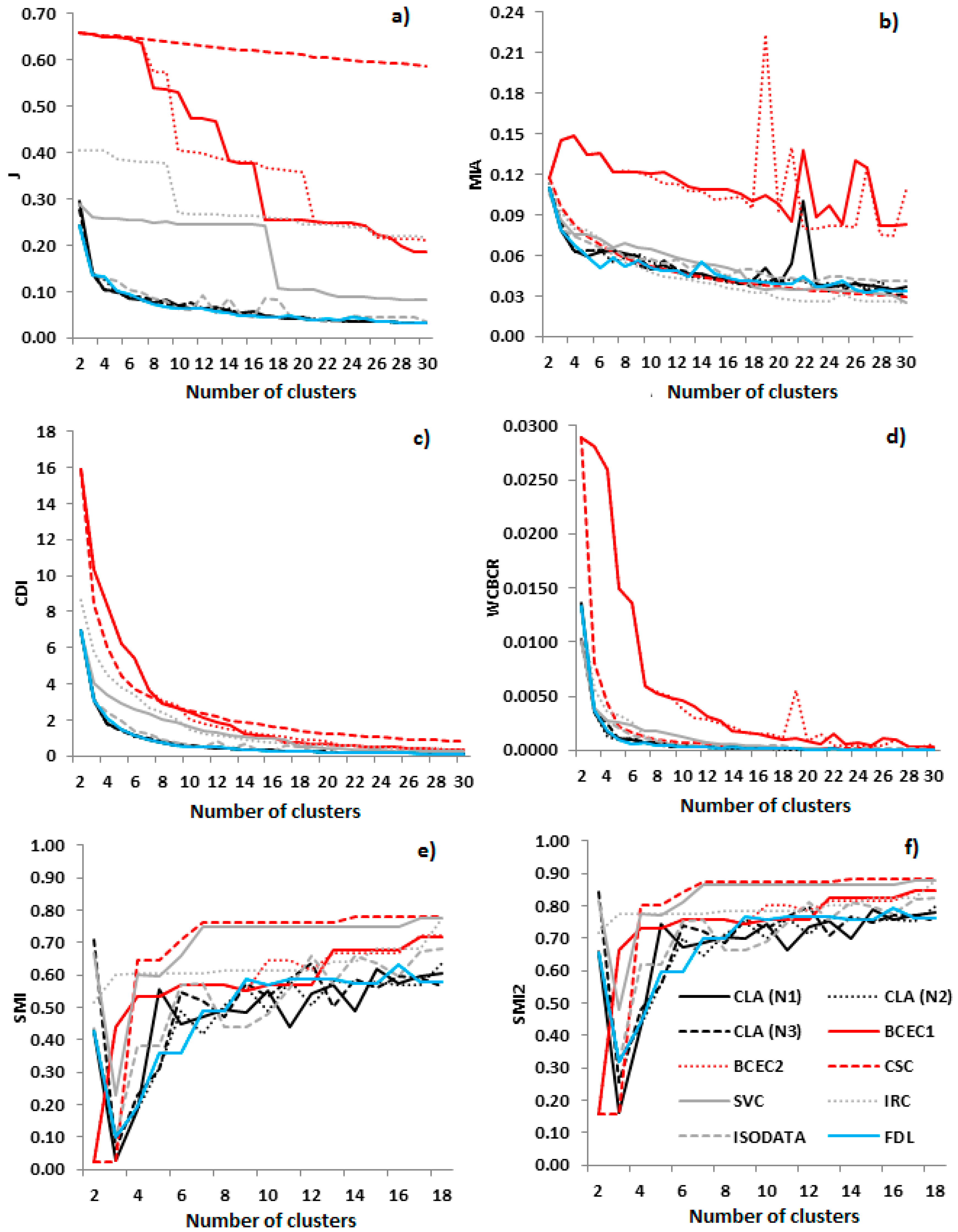
2.3. Clustering Evaluation
- The Euclidean distance between and
- The subset of that belongs to the cluster Ck is denoted as Sk. The Euclidean distance between the centroid ck of the kth cluster and the subset Sk is the mean of the Euclidean distances deucl(ck, Sk) between ck and each member of Sk:
- The mean of the inner-distances between the patterns and members of the subset Sk is:
- The Mean Square Error J, which refers to the sum of distances between the patterns and the clusters that belong to:
- The Mean Index Adequacy (MIA), which refers to the average of the distances of the clusters:
- The Clustering Dispersion Indicator (CDI), which refers to the ratio of the mean intra-set distance between the patterns in the same cluster and the inter-set distance between the clusters centroids:
- The ratio of Within Cluster Sum of Squares to Between Cluster Variation (WCBCR), which corresponds to the ratio of the distance of each pattern from its cluster centroid and the sum of distances of the set Ck:
- The Similarity Matrix Indicator (SMI), which takes into account the maximum of the centroid distances:
- The Similarity Matrix Indicator 2 (SMI2), which takes into account the root of maximum of the centroid distances:
- The Davies-Bouldin Index (DBI), which relates the mean distance of each cluster with the distance to the closest cluster:
- The Modified Dunn Index (MDI), which takes into the minimum of the centroid distances:
- The Intra Cluster Index (IAI), which corresponds to the overall sum of the distances between patterns and centroids:
- The Inter Cluster Index (IEI), which corresponds to the sum of distances between the cluster centroids and the arithmetic mean:where p is the arithmetic mean of set X.
- The Calinski index (CH) or Minimum Variance Criterion (VRC), which refers to the ratio of the separation among the different clusters and the separation within the same cluster:
- The Scatter Index (SI), which corresponds to the ratio of distances between the patterns and the arithmetic mean to the distances between the centroids and the arithmetic mean:
3. TOPSIS
- Step#1.
- Build the decision matrix with i alternatives and j solutions:
- Step#2.
- Construct the normalized denoted as R with elements according to the following equation:
- Step#3.
- Construct the weighted matrix R denoted as V according to:where and is the weight that solution is connected with criterion It should be noted that the weights are fixed by the decision maker. The weights are user-centric and their values influence the results of the decision making. This fact is an inherent characteristic of TOPSIS method. Thus, TOPSIS offers a framework for the decision maker to include its expertise on a decision problem by setting the weights and reach into a solution that is in accordance to his/hers needs.
- Step#4.
- Calculate the ideal and the anti-ideal solution according to:where and are the positive and negative impact, respectively. More specifically, the ideal solution refers to is the maximum value for the positive impact and the minimum value for the negative impact in each column. Similarly, the anti-ideal solution, is the minimum and the maximum values for the positive and the negative impacts in each column, respectively.
- Step#5.
- Calculate the distances between each solution and the ideal and anti-ideal solutions:
- Step#6.
- Calculate the mean distance between each solution and anti-ideal solution as:
- Step#7.
- Sort the solutions according to the value.
4. Results
4.1. Algorithms Comparison
4.2. Algorithms Selection
5. Conclusions
- Partitional algorithms are ranked 1st if only validity indicators are used. In 10 indicators, a partitional algorithm ranks 1st. The most robust partitional algorithm is Modified K-means#1. It ranks 1st in 3 indicators and 2nd in 5. The minCEntropy follows as it ranks 1st in 3 indicators also. No fuzzy and neural-network based algorithms are present in the lists of Table 8. From the algorithms of the rest category, IRC, CLA, SVC and BCEC2 are present. The CLA is the most robust algorithm from this category.
- Computational time is an important factor. In this comparison, hierarchical clustering outclasses the other categories. SOM, AVQ, FDL and ISODATA are not recommended due to high time requirements.
- ISODATA and SOM are not recommended in problems where low complexity in terms of input parameter requirements is crucial. In this case, hierarchical algorithms are preferred.
- Software implementation availability is significant in cases of lack of programing skills, need for tested and verified codes or other factors. According to this criterion, hierarchical clustering, K-means, K-medoids and FCM are available in commercial and freely distributed packages.
Author Contributions
Conflicts of Interest
References
- Park, C.K.; Kim, H.J.; Kim, Y.S. A study of factors enhancing smart grid consumer engagement. Energy Pol. 2014, 72, 211–218. [Google Scholar] [CrossRef]
- Gangale, F.; Mengolini, A.; Onyeji, I. Consumer engagement: An insight from smart grid projects in Europe. Energy Pol. 2013, 60, 621–628. [Google Scholar] [CrossRef]
- Boisvert, R.N.; Cappers, P.A.; Neenan, B. The benefits of customer participation in wholesale electricity markets. Elect. J. 2002, 15, 41–51. [Google Scholar] [CrossRef]
- Grigoras, G.; Scarlatache, F. Knowlegde extraction from Smart Meters for consumer classification. In Proceedings of the 2014 International Conference and Exposition on Electrical and Power Engineering, Iasi, Romania, 16–18 October 2014; pp. 978–982. [Google Scholar]
- Uhrig, M.; Mueller, R.; Leibfried, T. Statistical consumer modelling based on smart meter measurement data. In Proceedings of the 2014 International Conference on Probabilistic Methods Applied to Power Systems, Durham, UK, 7–10 July 2014; pp. 1–6. [Google Scholar]
- Garpetun, L.; Nylén, P.O. Benefits from smart meter investments. In Proceedings of the 22nd International Conference and Exhibition on Electricity Distribution, Stockholm, Sweden, 10–13 June 2013; pp. 1–4. [Google Scholar]
- Depuru, S.S.S.R.; Wang, L.; Devabhaktuni, V. Smart meters for power grid: Challenges, issues, advantages and status. Renew. Sust. Energy Rev. 2011, 15, 2376–2742. [Google Scholar] [CrossRef]
- Al-Wakeel, A.; Wu, J.; Jenkins, N. k-means based load estimation of domestic smart meter measurements. Appl. Energy 2017, 194, 333–342. [Google Scholar] [CrossRef]
- Jardini, J.A.; Tahan, C.M.V.; Gouvea, M.R.; Ahn, S.U.; Figueiredo, F.M. Daily load profiles for residential, commercial and industrial low voltage consumers. IEEE Trans. Power Del. 2000, 15, 375–380. [Google Scholar] [CrossRef]
- Chang, R.F.; Lu, C.N. Load profiling and its applications in power market. In Proceedings of the 2003 IEEE Power Engineering Society General Meeting, Toronto, ON, Canada, 13–17 July 2003; pp. 974–978. [Google Scholar]
- Tsekouras, G.J.; Kotoulas, P.B.; Tsirekis, C.D.; Dialynas, E.N.; Hatziargyriou, N.D. A pattern recognition methodology for evaluation of load profiles and typical days of large electricity customers. Elect. Power Syst. Res. 2008, 78, 1494–1510. [Google Scholar] [CrossRef]
- Harris, C. Electricity Markets, Pricing, Structures and Economics; John Wiley&Sons Inc.: West Sussex, UK, 2006. [Google Scholar]
- Rathod, R.R.; Garg, R.D. Regional electricity consumption analysis for consumers using data mining techniques and consumer meter reading data. Int. J. Elect. Power Energy Syst. 2016, 78, 368–374. [Google Scholar] [CrossRef]
- Aghabozorgi, S.; Shirkhorshidi, A.S.; Wah, T.Y. Time-series clustering-A decade review. Inf. Sciences 2015, 53, 16–38. [Google Scholar] [CrossRef]
- Cornuéjols, A.; Wemmert, C.; Gançarski, P.; Bennani, Y. Collaborative clustering: Why, when, what and how. Inf. Sci. 2018, 39, 81–95. [Google Scholar] [CrossRef]
- Saxena, A.; Prasad, M.; Gupta, A.; Bharill, N.; Patel, O.P.; Tiwari, A.; Er, M.J.; Ding, W.; Lin, C.T. A review of clustering techniques and developments. Neurocomputing 2017, 167, 664–681. [Google Scholar] [CrossRef]
- Chicco, G. Overview and performance assessment of the clustering methods for electrical load pattern. Energy 2012, 42, 68–80. [Google Scholar] [CrossRef]
- Gerbec, D.; Gasperic, S.; Smon, I.; Gubina, F. Consumers’ load profile determination based on different classification methods. In Proceedings of the 2003 IEEE Power Engineering Society General Meeting, Toronto, ON, Canada, 3–17 July 2003; pp. 990–995. [Google Scholar]
- Hwang, C.L.; Yoon, K. Multiple Attribute Decision Making: Methods and Applications; Springer: New York, NY, USA, 1981. [Google Scholar]
- Union of the Electricity Industry (EUROELECTRIC). Metering, Load Profiles and Settlement in Deregulated Markets; Union of the Electricity Industry: Brussels, Belgium, 2000. [Google Scholar]
- The Pacific Gas and Electric Company (PG&E). Available online: Https://www.pge.com/ (accessed on 26 December 2017).
- Southern California Edison (SCE). Available online: Https://www.sce.com/ (accessed on 26 December 2017).
- Wang, Q.; Zhang, W.C.; Tang, Y.; Zhao, B.; Qiu, L.P.; Gao, X.; Shao, G.H.; Xiong, W.H.; Shi, K.Q. A new load survey method and its application in component based load modeling. In Proceedings of the 2010 International Conference on Power System Technology, Hangzhou, China, 24–28 October 2010; pp. 1–5. [Google Scholar]
- Zhang, J.; Yan, A.; Chen, Z.; Gao, K. Dynamic synthesis load modeling approach based on load survey and load curves analysis. In Proceedings of the 2008 Third International Conference on Electric Utility Deregulation and Restructuring and Power Technologies, Nanjing, China, 6–9 April 2008; pp. 1067–1071. [Google Scholar]
- Chen, C.S.; Hwang, J.C.; Huang, C.W. Application of load survey systems to proper tariff design. IEEE Trans. Power Syst. 1997, 12, 1746–1751. [Google Scholar] [CrossRef]
- Chen, C.S.; Hwang, J.C.; Tzeng, Y.M.; Huang, C.W.; Cho, M.Y. Determination of customer load characteristics by load survey system at Taipower. IEEE Trans. Power Del. 1996, 11, 1430–1436. [Google Scholar] [CrossRef]
- Tsekouras, G.J.; Hatziargyriou, N.D.; Dialynas, E.N. Two-stage pattern recognition of load curves for classification of electricity customers. IEEE Trans. Power Syst. 2007, 22, 1120–1128. [Google Scholar] [CrossRef]
- Panapakidis, I.P.; Christoforidis, G.C. Implementation of modified versions of the K-means algorithm in power load curves profiling. Sustain. Cities Soc. 2017, 35, 83–93. [Google Scholar] [CrossRef]
- Chicco, G.; Napoli, R.; Piglione, F. Comparisons among clustering techniques for electricity customer classification. IEEE Trans. Power Syst. 2006, 21, 933–940. [Google Scholar] [CrossRef]
- Rhodes, J.D.; Cole, W.J.; Upshaw, C.R.; Edgar, T.F.; Webber, M.E. Clustering analysis of residential electricity demand profiles. Appl. Energy 2014, 135, 461–471. [Google Scholar] [CrossRef]
- Benítez, I.; Quijano, A.; Díez, J.L.; Delgado, I. Dynamic clustering segmentation applied to load profiles of energy consumption from Spanish customers. Int. J. Elect. Power Energy Syst. 2014, 55, 437–448. [Google Scholar] [CrossRef]
- Kim, Y.I.; Shin, J.H.; Song, J.J.; Yang, I.K. Customer clustering and TDLP (Typical Daily Load Profile) generation using the clustering algorithm. In Proceedings of the IEEE T&D Asia Conference and Exposition, Seoul, Korea, 26–30 October 2009; pp. 1–4. [Google Scholar]
- Koolen, D.; Sadat-Razavi, N.; Ketter, W. Machine learning for identifying demand patterns of home energy management systems with dynamic electricity pricing. Appl. Sci. 2017, 7, 1160. [Google Scholar] [CrossRef]
- Jota, P.R.S.; Silva, V.R.B.; Jota, F.G. Building load management using cluster and statistical analyses. Int. J. Elect. Power Energy Syst. 2011, 33, 1498–1505. [Google Scholar] [CrossRef]
- Notaristefano, A.; Chicco, G.; Piglione, F. Data size reduction with symbolic aggregate approximation for electrical load pattern grouping. IET Gener. Trans. Distrib. 2013, 7, 108–117. [Google Scholar] [CrossRef]
- Zakaria, Z.; Lo, K.L.; Sohod, M.H. Application of fuzzy clustering to determine electricity consumers’ load profiles. In Proceedings of the First International Power and Energy Conference, Putra Jaya, Malaysia, 28–29 November 2006; pp. 99–103. [Google Scholar]
- Lo, K.L.; Zakaria, Z.; Sohod, M.H. Determination of consumers’ load profiles based on two-stage fuzzy C-means. In Proceedings of the 5th WSEAS International Conference on Power Systems and Electromagnetic Compatibility, Corfu, Greece, 23–25 August 2005; pp. 212–217. [Google Scholar]
- Binh, P.T.T.; Ha, N.H.; Tuan, T.C.; Khoa, L.D. Determination of representative load curve based on fuzzy K-means. In Proceedings of the 4th International Power Engineering and Optimization Conference, Shah Alam, Malaysia, 23–24 June 2010; pp. 281–286. [Google Scholar]
- Anuar, N.; Zakaria, Z. Determination of fuzziness parameter in load profiling via Fuzzy C-Means. In Proceedings of the 2011 IEEE Control and System Graduate Research Colloquium, Shah Alam, Malaysia, 27–28 June 2011; pp. 139–142. [Google Scholar]
- Prahastono, I.; King, D.J.; Ozveren, C.S.; Bradley, D. Electricity load profile classification using fuzzy C-means method. In Proceedings of the 43rd International Universities Power Engineering Conference, Padova, Italy, 1–4 September 2008; pp. 1–5. [Google Scholar]
- Iglesias, F.; Kastner, W. Analysis of similarity measures in times series clustering for the discovery of building energy patterns. Energies 2013, 6, 579–597. [Google Scholar] [CrossRef]
- Anuar, N.; Zakaria, Z. Electricity load profile determination by using Fuzzy C-Means and Probability Neural Network. Energy Proc. 2012, 14, 1861–1869. [Google Scholar] [CrossRef]
- Gerbec, D.; Gasperic, S.; Smon, I.; Gubina, F. Allocation of the load profiles to consumers using probabilistic neural networks. IEEE Trans. Power Syst. 2005, 20, 548–555. [Google Scholar] [CrossRef]
- Chang, R.F.; Lu, C.N. Load profile assignment of low voltage customers for power retail market applications. IEE Proc. Gener. Trans. Distrib. 2003, 150, 263–267. [Google Scholar] [CrossRef]
- Verdú, S.V.; García, M.O.; Franco, F.J.G.; Encinas, N.; Marín, A.G.; Molina, A.; Lázaro, E.G. Characterization and identification of electrical customers through the use of self-organizing maps and daily load parameters. In Proceedings of the 2004 IEEE PES Power Systems Conference and Exposition, New York, NY, USA, 10–13 October 2004; pp. 809–966. [Google Scholar]
- Verdu, S.V.; Garcia, M.O.; Senabre, C.; Marin, A.G.; Franco, F.J.G. Classification, filtering and identification of electrical customer load patterns through the use of self-organizing maps. IEEE Trans. Power Syst. 2006, 21, 1672–1682. [Google Scholar] [CrossRef]
- McLoughlin, F.; Duffy, A.; Conlon, M. Analysing domestic electricity smart metering data using self organising maps. In Proceedings of the 2012 CIRED Workshop on the Integration of Renewables into the Distribution Grid, Lisbon, Portugal, 29–30 May 2012; pp. 1–4. [Google Scholar]
- Chicco, G.; Scutariu, M.; Napoli, R.; Piglione, F.; Postolache, P.; Toader, C. A review of concepts and techniques for emergent customer categorization. In Proceedings of the Telmark Discussion Forum, London, UK, 2–4 September 2002; pp. 51–58. [Google Scholar]
- Valero, S.; Ortiz, M.; Senabre, C.; Alvarez, C.; Franco, F.J.G.; Gabaldon, A. Methods for customer and demand response policies selection in new electricity markets. IET Proc. Gener. Trans. Distrib. 2007, 1, 104–110. [Google Scholar] [CrossRef]
- Wang, Z.; Bian, S.; Liu, Y.; Liu, Z. The load characteristics classification and synthesis of substations in large area power grid. Int. J. Elect. Power Energy Syst. 2013, 48, 71–82. [Google Scholar] [CrossRef]
- Rodrigues, F.; Duarte, J.; Figueiredo, V.; Vale, Z.; Cordeiro, M. A comparative analysis of clustering algorithms applied to load profiling. Mach. Learn. Data Min. Pat. Recogn. Lect. Notes Comp. Sci. 2003, 2734, 73–85. [Google Scholar]
- Figueiredo, V.; Rodriguez, F.; Vale, Z.; Gouveia, J.B. An electricity energy consumer characterization framework based on data mining techniques. IEEE Trans. Power Syst. 2005, 20, 596–602. [Google Scholar] [CrossRef]
- Benabbas, F.; Khadir, M.T.; Fay, D.; Boughrira, A. Kohonen map combined to the K-means algorithm for the identification of day types of Algerian electricity load. In Proceedings of the 7th Computer Information Systems and Industrial Management Applications, Ostrava, Czech Republic, 26–28 June 2008; pp. 78–83. [Google Scholar]
- Räsänen, T.; Voukantsis, D.; Niska, H.; Karatzas, K.; Kolehmainen, M. Data-based method for creating electricity use load profiles using large amount of customer-specific hourly measured electricity use data. Appl. Energy 2010, 87, 3538–3545. [Google Scholar] [CrossRef]
- Park, S.; Ryu, S.; Choi, Y.; Kim, J.; Kim, H. Data-driven baseline estimation of residential buildings for demand response. Energies 2015, 8, 10239–10259. [Google Scholar] [CrossRef]
- Hernández, L.; Baladrón, C.; Aguiar, J.M.; Carro, B.; Sánchez-Esguevillas, A. Classification and clustering of electricity demand patterns in industrial parks. Energies 2012, 5, 5215–5228. [Google Scholar] [CrossRef]
- López, J.J.; Aguado, J.A.; Martín, F.; Munoz, F.; Rodríguez, A.; Ruiz, J.E. Electric customer classification using Hopfield recurrent ANN. In Proceedings of the 5th International Conference on European Electricity Market, Lisboa, Portugal, 28–30 May 2008; pp. 1–6. [Google Scholar]
- Chicco, G.; Napoli, R.; Postolache, P.; Scutariu, M.; Toader, C. Customer characterization options for improving the tariff offer. IEEE Trans. Power Syst. 2003, 18, 381–387. [Google Scholar] [CrossRef]
- Carpaneto, E.; Chicco, G.; Napoli, R.; Scutariu, M. Customer classification by means of harmonic representation of distinguishing features. In Proceedings of the 2003 IEEE Bologna Power Tech Conference, Bologna, Italy, 23–26 June 2003; pp. 1–7. [Google Scholar]
- Carpaneto, E.; Chicco, G.; Napoli, R.; Scutariu, M. Electricity customer classification using frequency–domain load pattern data. Int. J. Elect. Power Energy Syst. 2006, 28, 13–20. [Google Scholar] [CrossRef]
- Panapakidis, I.P.; Alexiadis, M.C.; Papagiannis, G.K. Application of competitive learning clustering in the load time series segmentation. In Proceedings of the 48th International Universities’ Power Engineering Conference, Dublin, Ireland, 2–5 September 2013; pp. 1–6. [Google Scholar]
- Mutanen, A.; Ruska, M.; Repo, S.; Järventausta, P. Customer classification and load profiling method for distribution systems. IEEE Trans. Power Del. 2011, 26, 1755–1763. [Google Scholar] [CrossRef]
- Chicco, G.; Napoli, R.; Piglione, F. Application of clustering algorithms and self organising maps to classify electricity customers. In Proceedings of the IEEE 2003 Power Tech Conference, Bologna, Italy, 23–26 June 2003; pp. 1–7. [Google Scholar]
- Gerbec, D.; Gasperic, S.; Smon, I.; Gubina, F. Determination and allocation of typical load profiles to the eligible consumers. In Proceedings of the 2003 IEEE Power Tech Conference, Bologna, Italy, 23–26 June 2003; pp. 1–5. [Google Scholar]
- Chicco, G.; Scutariu, M.; Napoli, R.; Piglione, F.; Postolache, P.; Toader, C. Application of clustering techniques to load pattern-based electricity customer classification. In Proceedings of the 18th International Conference on Electricity Distribution, Turin, Italy, 6–9 June 2005; pp. 1–5. [Google Scholar]
- Chicco, G.; Napoli, R.; Piglione, F.; Postolache, P.; Scutariu, M.; Toader, C. Emergent electricity customer classification. IEE Proc. Gener. Trans. Distrib. 2005, 152, 164–172. [Google Scholar] [CrossRef]
- Tsekouras, G.J.; Kanellos, F.D.; Kontargyri, V.T.; Karanasiou, I.S.; Salis, A.D.; Mastorakis, N.E. A new classification pattern recognition methodology for power system typical load profiles. WSEAS Trans. Circ. Syst. 2008, 7, 1090–1104. [Google Scholar]
- Kohan, N.M.; Moghaddam, M.P.; Bidaki, S.M.; Yousefi, G.R. Comparison of modified K-means and hierarchical algorithms in customers load curves clustering for designing suitable tariffs in electricity market. In Proceedings of the 43rd International Universities Power Engineering Conference, Padova, Italy, 1–4 September 2008; pp. 1–5. [Google Scholar]
- Kohan, N.M.; Moghaddam, M.P.; Bidaki, S.M. Evaluating performance of WFA k-means and Modified Follow the Leader methods for clustering load curves. In Proceedings of the IEEE 2009 Power Systems Conference and Exposition, Seattle, WA, USA, 15–18 March 2009; pp. 1–5. [Google Scholar]
- Kohan, N.M.; Moghaddam, M.P.; Sheikh-El-Eslami, M.K.; Bidaki, S.M. Improving WFA k-means technique for demand response programs applications. In Proceedings of the IEEE 2009 Power & Energy Society General Meeting, Calgary, AB, Canada, 26–30 July 2009; pp. 1–5. [Google Scholar]
- Bidoki, S.M.; Kohan, N.M.; Sadreddini, M.H.; Zolghadri Jahromi, M.; Moghaddam, M.P. Evaluating different clustering techniques for electricity customer classification. In Proceedings of the 2010 IEEE PES Transmission and Distribution Conference and Exposition, New Orleans, LA, USA, 19–22 April 2010; pp. 1–5. [Google Scholar]
- Bidoki, S.M.; Kohan, N.M.; Gerami, S. Comparison of several clustering methods in the case of electrical load curves classification. In Proceedings of the 16th Conference on Electrical Power Distribution Networks, Bandar Abbas, Iran, 19–20 April 2011; pp. 1–7. [Google Scholar]
- López, J.J.; Aguado, J.A.; Martín, F.; Munoz, F.; Rodríguez, A.; Ruiz, J.E. Hopfield–K-means clustering algorithm: A proposal for the segmentation of electricity customers. Electr. Power Syst. Res. 2011, 81, 716–722. [Google Scholar] [CrossRef]
- Chicco, G.; Akilimali, J.S. Renyi entropy-based classification of daily electrical load patterns. IET Gener. Trans. Distrib. 2010, 4, 736–745. [Google Scholar] [CrossRef]
- Chicco, G.; Ilie, I.S. Support vector clustering of electrical load pattern data. IEEE Trans. Power Syst. 2009, 24, 1619–1628. [Google Scholar] [CrossRef]
- Marques, D.Z.; de Almeida, K.A.; de Deus, A.M.; da Silva Paulo, A.R.G.; da Silva Lima, W. A comparative analysis of neural and fuzzy cluster techniques applied to the characterization of electric load in substations. In Proceedings of the 2004 IEEE/PES Transmission and Distribution Conference and Exposition Latin America, Sao Paulo, Brazil, 8–11 November 2004; pp. 908–913. [Google Scholar]
- Panapakidis, I.P.; Alexiadis, M.C.; Papagiannis, G.K. Load profiling in the deregulated electricity markets: A review of the applications. In Proceedings of the 9th International Conference on the European Energy Market, Florence, Italy, 10–12 May 2012; pp. 1–6. [Google Scholar]
- Panapakidis, I.; Asimopoulos, N.; Dagoumas, A.; Christoforidis, G.C. An improved Fuzzy C-Means algorithm for the implementation of demand side management measures. Energies 2017, 10, 1407. [Google Scholar] [CrossRef]
- Panapakidis, I.P.; Alexiadis, M.C.; Papagiannis, G. Evaluation of the performance of clustering algorithms for a high voltage industrial consumer. Eng. Appl. Art. Intell. 2015, 38, 1–13. [Google Scholar] [CrossRef]
- Batrinu, F.; Chicco, G.; Napoli, R.; Piglione, F.; Postolache, P.; Scutariu, M.; Toader, C. Efficient iterative refinement clustering for electricity customer classification. In Proceedings of the 2005 IEEE Russia Power Tech Conference, St. Petersburg, Russia, 27–30 June 2005; pp. 1–7. [Google Scholar]
- McLoughlin, F.; Duffy, A.; Conlon, M. A clustering approach to domestic electricity load profile characterisation using smart metering data. Appl. Energy 2015, 141, 190–199. [Google Scholar] [CrossRef]
- Kang, J.; Lee, J.H. Electricity customer clustering following experts’ principle for demand response applications. Energies 2015, 8, 12242–12265. [Google Scholar] [CrossRef]
- Apetrei, D.; Silvas, I.; Albu, M.; Postolache, P. Consideration on relationship between load dispatching and load profile clustering. In Proceedings of the 10th International Conference on Environment and Electrical Engineering, Rome, Italy, 8–11 May 2011; pp. 1–4. [Google Scholar]
- Mori, H.; Yuihara, A. Deterministic annealing clustering for ANN-based short-term load forecasting. IEEE Trans. Power Syst. 2011, 16, 545–551. [Google Scholar] [CrossRef]
- Mahmoudi-Kohan, N.; Parsa Moghaddam, M.; Sheikh-El-Eslami, M.K.; Shayesteh, E. A three-stage strategy for optimal price offering by a retailer based on clustering techniques. Int. J. Electr. Power Energy Syst. 2010, 32, 1135–1142. [Google Scholar] [CrossRef]
- Li, Y.; Guo, P.; Li, X. Short-term load forecasting based on the analysis of user electricity behaviour. Algorithms 2016, 9, 80. [Google Scholar] [CrossRef]
- Gao, Y.; Sun, Y.; Wang, X.; Chen, F.; Ehsan, A.; Li, H.; Li, H. Multi-objective optimized aggregation of demand side resources based on a self-organizing map clustering algorithm considering a multi-scenario technique. Energies 2017, 10, 144. [Google Scholar] [CrossRef]
- Li, Y.H.; Wang, J.X. Flexible transmission network expansion planning considering uncertain renewable generation and load demand based on hybrid clustering analysis. Appl. Sci. 2016, 6, 3. [Google Scholar] [CrossRef]
- Qiu, X.; Zhang, L.; Ren, Y.; Suganthan, P.N.; Amaratunga, G. Ensemble deep learning for regression and time series forecasting. In Proceedings of the 2014 IEEE Symposium on Computational Intelligence in Ensemble Learning (CIEL), Orlando, FL, USA, 9–12 December 2014; pp. 1–6. [Google Scholar]
- Qiu, X.; Zhang, L.; Suganthan, P.N.; Amaratunga, G.A.J. Oblique random forest ensemble via Least Square Estimation for time series forecasting. Inf. Sci. 2017, 420, 249–262. [Google Scholar] [CrossRef]
- Steinley, D. K-means clustering: A half-century synthesis. Br. J. Math. Stat. Psychol. 2006, 59, 1–34. [Google Scholar] [CrossRef] [PubMed]
- Xu, R.; Wunsch, D. Clustering, 1st ed.; John Wiley & Sons Inc.: Hoboken, NJ, USA, 2006. [Google Scholar]
- De Oliveria, J.V.; Pedrycz, W. Advances in Fuzzy Clustering and Its Applications, 1st ed.; John Wiley & Sons: Chichester, UK, 2007; pp. 373–424. [Google Scholar]
- Grossberg, S. Adaptive pattern classification and universal recoding: I. Parallel development and coding of neural feature detectors. Biolog. Cyber. 1976, 23, 121–134. [Google Scholar] [CrossRef]
- Kohonen, T. Self-Organisation and Associative Memory, 3rd ed.; Springer: Berlin, Germany, 1989. [Google Scholar]
- Zyoud, S.H.; Fuchs-Hanusch, D. A bibliometric-based survey on AHP and TOPSIS techniques. Exp. Syst. Appl. 2017, 78, 158–181. [Google Scholar] [CrossRef]
- Aalami, H.A.; Parsa Moghaddam, M.; Yousefi, G.R. Modeling and prioritizing demand response programs in power markets. Elec. Power Syst. Res. 2010, 80, 426–435. [Google Scholar] [CrossRef]
- MathWorks®. Available online: https://www.mathworks.com (accessed on 26 December 2017).
- WOLFRAM. Available online: https://www.wolfram.com (accessed on 26 December 2017).
- The R Project for Statistical Computing. Available online: https://www.r-project.org (accessed on 26 December 2017).
- WEKA The University of Waikato. Available online: https://www.cs.waikato.ac.nz/ml/weka (accessed on 26 December 2017).
- Microsoft. Available online: https://www.visualstudio.com (accessed on 26 December 2017).
- Python™. Available online: https://www.python.org (accessed on 26 December 2017).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | ||||
|---|---|---|---|---|
| Single Linkage (SL) | 0.50 | 0.50 | 0 | 0.50 |
| Complete Linkage (CL) | 0.50 | 0.50 | 0 | 0.50 |
| Unweighted Pair Group Method Average (UPGMA) | 0.50 | 0 | 0 | |
| Weighted Pair Group Method Average (WPGMA) | 0.50 | 0.50 | 0 | 0 |
| Weighted Pair Group Method Centroid (WPGMC) | 0.50 | 0.50 | −0.25 | 0 |
| Unweighted Pair Group Method Centroid (UPGMC) | 0 | |||
| Minimum Variance Method (MVM) or the Ward’s method | 0 |
| Algorithm | Parameters for Determination |
|---|---|
| K-means | 1. Maximum number of iterations 2. Initial centroids (optional) 3. Minimum objective function improvement threshold |
| Modified K-means#1 | 1. Maximum number of iterations 2. Optimal coefficients 3. Minimum objective function improvement threshold |
| Modified K-means#2 | 1. Maximum number of iterations 2. Coefficients 3. Minimum objective function improvement threshold |
| WFA K-means | 1. Maximum number of iterations 2. Initial centroids (optional) 3. Minimum objective function improvement threshold |
| IWFA K-means | 1. Maximum number of iterations 2. Optimal coefficients 3. Minimum objective function improvement threshold |
| Hopfield K-means | 1. Maximum number of iterations for Hopfield ANN 2. Maximum number of iterations K-means 3. Minimum objective function improvement threshold |
| minCEntropy | 1. Maximum number of iterations 2. Parameter 3. Minimum objective function improvement threshold |
| K-means_A | 1. Maximum number of iterations 2.Minimum objective function improvement threshold |
| K-means_B | 1. Maximum number of iterations 2.Minimum objective function improvement threshold |
| K-medoids | 1. Maximum number of iterations 2. Initial centroids (optional) 3.Minimum objective function improvement threshold |
| Algorithm | Parameters for Determination |
|---|---|
| SL | Merging stopping criterion |
| CL | Merging stopping criterion |
| UPGMA | Merging stopping criterion |
| WPGMA | Merging stopping criterion |
| WPGMC | Merging stopping criterion |
| UPGMC | Merging stopping criterion |
| MVM | Merging stopping criterion |
| Algorithm | Parameters for Determination |
|---|---|
| FCM | 1. Maximum number of iterations 2. Initial centroids (optional) 3. Minimum objective function improvement 4. Fuzzy parameter 5. Initial values of matrix U |
| ΙFCM | 1. Maximum number of iterations for the K-means 2. Maximum number of iterations for the FCM 3. Initial centroids for the K-means (optional) 4.Minimum objective function improvement threshold for the K-means 5.Minimum objective function improvement threshold for the FCM 6. Fuzzy parameter |
| Algorithm | Parameters for Determination |
|---|---|
| AVQ | 1. Maximum number of iterations 2. Constant parameter of the learning rate |
| SOM | 1. Dimension (1D or 2D) 2. Map shape 3. Map size 4. Weights initialization 5. Learning method 6.Learning function (type, initial learning rate, training epochs) 7.Neighborhood function (type, initial neighbourhood radius) |
| Hopfield | Maximum number of iterations |
| Algorithm | Parameters for Determination |
|---|---|
| FDL | 1. Maximum number of iterations 2. Initial centroids (optional) 3. Parameter |
| ISODATA | 1. Maximum number of clusters 2. Maximum number of clusters for merging 3. Maximum number of iterations 4. Threshold of number of patterns in a cluster 5. Threshold of distance for cluster merging 6. Threshold of standard deviation for cluster split 7. Minimum distance between patterns and centroid |
| BCEC1 | Merging stopping criterion |
| BCEC2 | Merging stopping criterion |
| CSC | Merging stopping criterion |
| SVC | 1.Parameter that controls the number of outliers 2. Scale parameter of the Gaussian kernel 3. Minimum distance 4. Cluster formation threshold |
| IRC | 1. Maximum number of iterations 2. Parameter |
| CLA | 1. Maximum number of iterations 2. Initial centroids (optional) 3. Constant term of learning rate (winner neuron) 4. Constant term of learning rate (rest neurons) |
| Algorithm | Parameter |
|---|---|
| K-means | - |
| Modified K-means#1 | - |
| Modified K-means#2 | - |
| WFA K-means | - |
| IWFA K-means | - |
| Hopfield K-means | - |
| minCEntropy | - |
| Κ-means_A | - |
| Κ-means_B | - |
| K-medoids | - |
| SL | - |
| CL | - |
| UPGMA | - |
| WPGMA | - |
| WPGMC | - |
| UPGMC | - |
| MVM | - |
| FCM | - |
| IFCM | - |
| SOM | - |
| AVQ | - |
| Hopfield | - |
| FDL | Parameter |
| CLA | - |
| IRC | Parameter |
| BCEC1 | - |
| BCEC2 | - |
| CSC | - |
| SVC | 1. Minimum distance 2. Cluster formation threshold |
| ISODATA | 1. Maximum number of clusters 2. Maximum number of clusters for merging 3. Maximum number of iterations 4. Threshold of number of patterns in a cluster 5. Threshold of distance for cluster merging 6. Threshold of standard deviation for cluster split 7.Minimum distance between patterns and centroid |
| Validity Indicator | Algorithms’ Ranking | Validity Indicator | Algorithms’ Ranking |
|---|---|---|---|
| J | 1. minCEntropy 2. Modified K-means#1 3. MVM 4. K-means_A | MDI | 1. IRC 2. IWFA K-means 3. Modified K-means#1 4. BCEC2 |
| MIA | 1. SL 2. IWFA K-means 3. UPGMC 4. UPGMA | IAI | 1. minCEntropy 2. Modified K-means#1 3. MVM 4. K-means_A |
| CDI | 1. minCEntropy 2. Modified K-means#1 3. MVM 4. K-medoids | IEI | 1. IWFA K-means 2. Modified K-means#1 3. SVC 4. IRC |
| WCBCR | 1. SL 2. UPGMC 3. Modified K-means#1 4. UPGMA | CH | 1. Modified K-means#1 2. IWFA K-means 3. minCEntropy 4. MVM |
| SMI | 1. Modified K-means#1 2. CLA (N3) 3. MVM 4. CLA (N2) | SI | 1. IWFA K-means 2. Modified K-means#1 3. SL 4. UPGMC |
| SMI2 | 1. Modified K-means#1 2. CLA (N3) 3. MVM 4. CLA (N2) | DBI | 1. K-medoids 2. SL 3. UPGMC 4. UPGMA |
| Algorithm | Execution Time (s) | Ratio |
|---|---|---|
| K-means | 8.31 | 1 |
| Modified K-means# 1 | 978.81 | 117.78 |
| Modified K-means#2 2 | 15.93 | 1.91 |
| WFA K-means | 8.44 | 1.01 |
| IWFA K-means 1 | 713.80 | 85.89 |
| Hopfield K-means | 49.53 | 5.96 |
| minCEntropy | 691.73 | 83.24 |
| Κ-means_A | 8.27 | 0.99 |
| K-means_B | 8.16 | 0.98 |
| K-medoids | 9.22 | 1.10 |
| SL | 3.59 | 0.43 |
| CL | 3.69 | 0.44 |
| UPGMA | 3.67 | 0.44 |
| WPGMA | 3.68 | 0.44 |
| WPGMC | 3.71 | 0.44 |
| UPGMC | 3.73 | 0.44 |
| MVM | 3.70 | 0.44 |
| FCM | 10.91 | 1.31 |
| IFCM | 13.32 | 1.60 |
| SOM (1D) | 1148 | 138.14 |
| AVQ 3 | 1244.70 | 149.78 |
| Hopfield | 44.69 | 5.37 |
| FDL | >>0 | >>1 |
| CLA 4 | 848.97 | 102.16 |
| IRC | 6.41 | 0.77 |
| BCEC1 5 | 6.83 | 0.82 |
| BCEC2 5 | 6.61 | 0.79 |
| CSC 5 | 6.53 | 0.78 |
| SVC | 27.54 | 3.31 |
| ISODATA | >>0 | >>1 |
| Algorithm | Empty Clusters | Outliers Tracking |
|---|---|---|
| K-means | No | No |
| Modified K-means#1 | No | No |
| Modified K-means#2 | No | No |
| WFA K-means | No | No |
| IWFA K-means | No | No |
| Hopfield K-means | No | No |
| minCEntropy | No | No |
| Κ-means_A | No | No |
| K-means_B | No | No |
| K-medoids | No | No |
| SL | No | Yes |
| CL | No | Yes |
| UPGMA | No | Yes |
| WPGMA | No | Yes |
| WPGMC | No | Yes |
| UPGMC | No | Yes |
| MVM | No | Yes |
| FCM | Yes | No |
| IFCM | Yes | No |
| SOM | No | No |
| AVQ | Yes | No |
| Hopfield | No | No |
| FDL | No | Yes |
| CLA | Yes | No |
| IRC | No | Yes |
| BCEC1 | No | Yes |
| BCEC2 | No | Yes |
| CSC | No | Yes |
| SVC | No | Yes |
| ISODATA | Yes | No |
| Algorithm | Availability |
|---|---|
| K-means | 1. Matlab 2. Mathematica 3. SPSS 4. SAS 5. R 6. Weka 7. C++/C# 8. Python 9. Matlab 3rd party code |
| Modified K-means#1 | In-house software |
| Modified K-means#2 | In-house software |
| WFA K-means | In-house software |
| IWFA K-means | In-house software |
| Hopfield K-means | In-house software |
| minCEntropy | Matlab 3rd party code |
| Κ-means_A | In-house software |
| K-means_B | In-house software |
| K-medoids | 1. Matlab 2. Mathematica 3. SPSS 4. SAS 5. R 6. Weka 7. C++/C# 8. Python 9. Matlab 3rd party code |
| Hierarchical algorithms | 1. Matlab 2. Mathematica 3. SPSS 4. SAS 5. R 6. Weka 7. C++/C# 8. Python 9. Matlab 3rd party code |
| FCM | 1. Matlab 2. Mathematica 3. R 4. C++/C# 5. Python 6. Matlab 3rd party code |
| IFCM | In-house software |
| SOM | 1. Matlab 2. R 3. Weka 4. C++/C# 5. Python 6. Matlab 3rd party code |
| AVQ | 1. Matlab 2. Weka 3. Python |
| Hopfield | 1. Matlab 2. R 3. C++/C# 4. Python 5. Matlab 3rd party code |
| FDL | In-house software |
| CLA | Matlab 3rd party code |
| IRC | In-house software |
| BCEC1 | In-house software |
| BCEC2 | In-house software |
| CSC | In-house software |
| SVC | 1. R 2. Python 2. Matlab 3rd party code 3. In-house software |
| ISODATA | 1. R 2. Python 2. Matlab 3rd party code 3. In-house software |
| Scale | Linguistic Term in Positive Impact | Linguistic Term in Negative Impact |
|---|---|---|
| 1 | Poor | Extremely strong |
| 2 | Intermediate value | Intermediate value |
| 3 | Moderate | Very strong |
| 4 | Intermediate value | Intermediate value |
| 5 | Strong | Strong |
| 6 | Intermediate value | Intermediate value |
| 7 | Very strong | Moderate |
| 8 | Intermediate value | Intermediate value |
| 9 | Extremely strong | Poor |
| Algorithm | C#1 | C#2 | C#3 | C#4 | C#5 | C#6 |
|---|---|---|---|---|---|---|
| K-means | 3 | 1 | 1 | 8.31 | 3 | 9 |
| Modified K-means#1 | 3 | 1 | 9 | 978.81 | 3 | 1 |
| Modified K-means#2 | 3 | 1 | 1 | 15.93 | 3 | 1 |
| WFA K-means | 3 | 1 | 1 | 8.44 | 3 | 1 |
| IWFA K-means | 3 | 1 | 9 | 713.80 | 3 | 1 |
| Hopfield K-means | 3 | 1 | 1 | 49.53 | 3 | 1 |
| minCEntropy | 3 | 1 | 9 | 691.73 | 3 | 2 |
| Κ-means A | 3 | 1 | 5 | 8.27 | 3 | 1 |
| K-means B | 3 | 1 | 1 | 8.16 | 3 | 1 |
| K-medoids | 3 | 1 | 7 | 9.22 | 3 | 9 |
| SL | 1 | 1 | 7 | 3.59 | 4 | 9 |
| CL | 1 | 1 | 1 | 3.69 | 4 | 9 |
| UPGMA | 1 | 1 | 5 | 3.67 | 4 | 9 |
| WPGMA | 1 | 1 | 1 | 3.68 | 4 | 9 |
| WPGMC | 1 | 1 | 1 | 3.71 | 4 | 9 |
| UPGMC | 1 | 1 | 5 | 3.73 | 4 | 9 |
| MVM | 1 | 1 | 5 | 3.70 | 4 | 9 |
| FCM | 5 | 1 | 1 | 10.91 | 1 | 6 |
| IFCM | 6 | 1 | 1 | 13.32 | 1 | 1 |
| SOM (1D) | 7 | 1 | 1 | 1148 | 3 | 6 |
| AVQ | 2 | 1 | 1 | 1244.70 | 1 | 3 |
| Hopfield | 1 | 1 | 1 | 44.69 | 3 | 5 |
| FDL | 3 | 2 | 1 | 2489.40 | 4 | 1 |
| CLA | 4 | 1 | 5 | 848.97 | 1 | 2 |
| IRC | 2 | 2 | 3 | 6.41 | 4 | 1 |
| BCEC1 | 1 | 1 | 1 | 6.83 | 4 | 1 |
| BCEC2 | 1 | 1 | 1 | 6.61 | 4 | 1 |
| CSC | 1 | 1 | 1 | 6.53 | 4 | 1 |
| SVC | 4 | 3 | 3 | 27.54 | 4 | 3 |
| ISODATA | 7 | 7 | 1 | 2489.40 | 1 | 3 |
| Algorithm | Rank | |||
|---|---|---|---|---|
| K-means | 0.24 | 0.16 | 0.60 | 14 |
| Modified K-means#1 | 0.31 | 0.09 | 0.78 | 8 |
| Modified K-means#2 | 0.21 | 0.19 | 0.53 | 23 |
| WFA K-means | 0.21 | 0.19 | 0.53 | 22 |
| IWFA K-means | 0.32 | 0.08 | 0.81 | 7 |
| Hopfield K-means | 0.21 | 0.19 | 0.53 | 24 |
| minCEntropy | 0.33 | 0.07 | 0.82 | 6 |
| Κ-means_A | 0.29 | 0.12 | 0.71 | 9 |
| K-means_B | 0.21 | 0.19 | 0.53 | 21 |
| K-medoids | 0.34 | 0.06 | 0.86 | 2 |
| SL | 0.36 | 0.04 | 0.91 | 1 |
| CL | 0.26 | 0.14 | 0.64 | 11 |
| UPGMA | 0.33 | 0.07 | 0.82 | 3 |
| WPGMA | 0.26 | 0.14 | 0.64 | 10 |
| WPGMC | 0.26 | 0.14 | 0.64 | 12 |
| UPGMC | 0.33 | 0.07 | 0.82 | 5 |
| MVM | 0.33 | 0.07 | 0.82 | 4 |
| FCM | 0.21 | 0.19 | 0.52 | 25 |
| IFCM | 0.19 | 0.22 | 0.46 | 26 |
| SOM | 0.15 | 0.25 | 0.38 | 28 |
| AVQ | 0.16 | 0.24 | 0.39 | 27 |
| Hopfield | 0.24 | 0.16 | 0.59 | 15 |
| FDL | 0.09 | 0.31 | 0.23 | 29 |
| CLA | 0.23 | 0.17 | 0.58 | 24 |
| IRC | 0.25 | 0.15 | 0.62 | 13 |
| BCEC1 | 0.23 | 0.17 | 0.58 | 20 |
| BCEC2 | 0.23 | 0.17 | 0.58 | 19 |
| CSC | 0.23 | 0.17 | 0.58 | 18 |
| SVC | 0.23 | 0.17 | 0.58 | 16 |
| ISODATA | 0.01 | 0.39 | 0.02 | 30 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Panapakidis, I.P.; Christoforidis, G.C. Optimal Selection of Clustering Algorithm via Multi-Criteria Decision Analysis (MCDA) for Load Profiling Applications. Appl. Sci. 2018, 8, 237. https://doi.org/10.3390/app8020237
Panapakidis IP, Christoforidis GC. Optimal Selection of Clustering Algorithm via Multi-Criteria Decision Analysis (MCDA) for Load Profiling Applications. Applied Sciences. 2018; 8(2):237. https://doi.org/10.3390/app8020237
Chicago/Turabian StylePanapakidis, Ioannis P., and Georgios C. Christoforidis. 2018. "Optimal Selection of Clustering Algorithm via Multi-Criteria Decision Analysis (MCDA) for Load Profiling Applications" Applied Sciences 8, no. 2: 237. https://doi.org/10.3390/app8020237
APA StylePanapakidis, I. P., & Christoforidis, G. C. (2018). Optimal Selection of Clustering Algorithm via Multi-Criteria Decision Analysis (MCDA) for Load Profiling Applications. Applied Sciences, 8(2), 237. https://doi.org/10.3390/app8020237