A Novel Lightweight Approach for Video Retrieval on Mobile Augmented Reality Environment


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- To the best of our knowledge, this is the first attempt for video retrieval in Mobile Augmented Reality (MAR). Video retrieval is performed on mobile augmented reality environment by using both image and video queries.
- Firstly, we have extracted the top-k key frames from the videos using frame comparison scheme which significantly increases the efficiency.
- Furthermore, we proposed a novel, fast and robust frame based descriptor, namely Pyramid Ternary Histogram of Oriented Gradients (PTHOG), which extract the shape features from the texture-less virtual objects.
- Due to lacking’s of video dataset in the area of augmented reality, we also introduced an AVD8 [10] dataset with holograms and augmented reality environments that include both real world and virtual objects.
2. Related Work
2.1. Augmented Reality Based Research
2.2. Video Retrieval Based Research
3. Proposed Method
3.1. Pre-Processing
3.2. Top-K Key Frame Extraction
| Algorithm 1 Top-K Key Frame Extraction |
| Input: Video File Output: Top-K Key-Frames Key-Frame(video) for i ← to Number-of-Frames do A ← ReadFrame(video, i); B ← ReadFrame(video, i + 1); Threshold ← HistDifference(A, B); X[i] ← Threshold [sortedX, sortingIndices] ← sort(X, ’descend’); |
3.3. Pyramid Ternary Histogram of Oriented Gradients(PTHOG)
3.4. Double Bit Quantization (DBQ)
3.5. Similarity Measure
4. Experimental Results
4.1. Datasets
4.1.1. UCSB Dataset
4.1.2. AVD8 Dataset
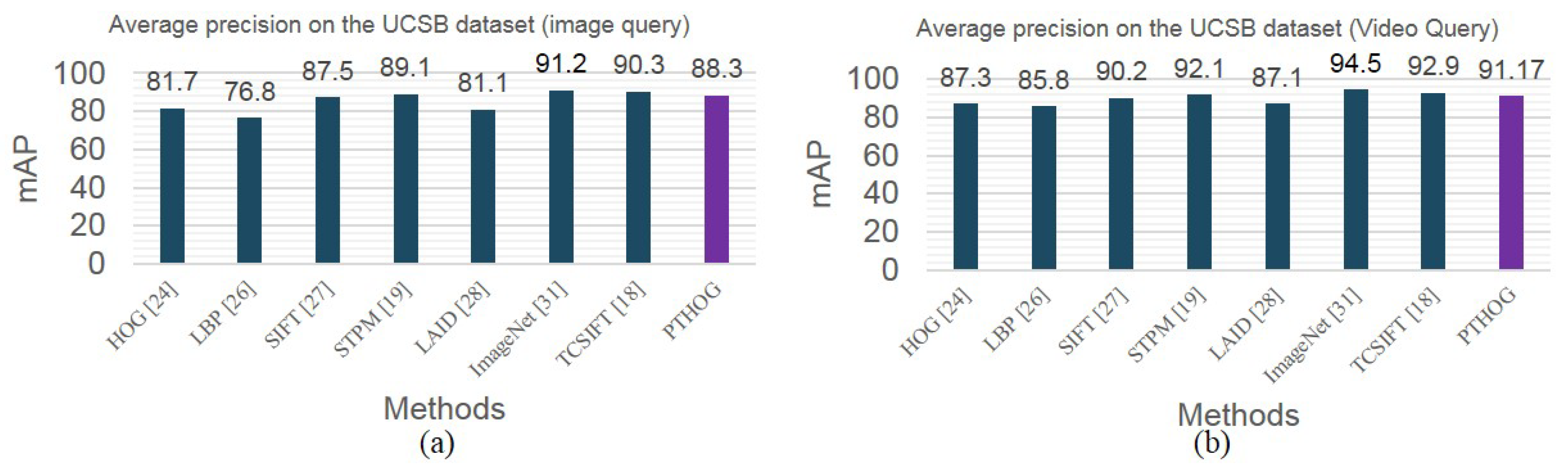
4.2. Experimental Results on UCSB Dataset
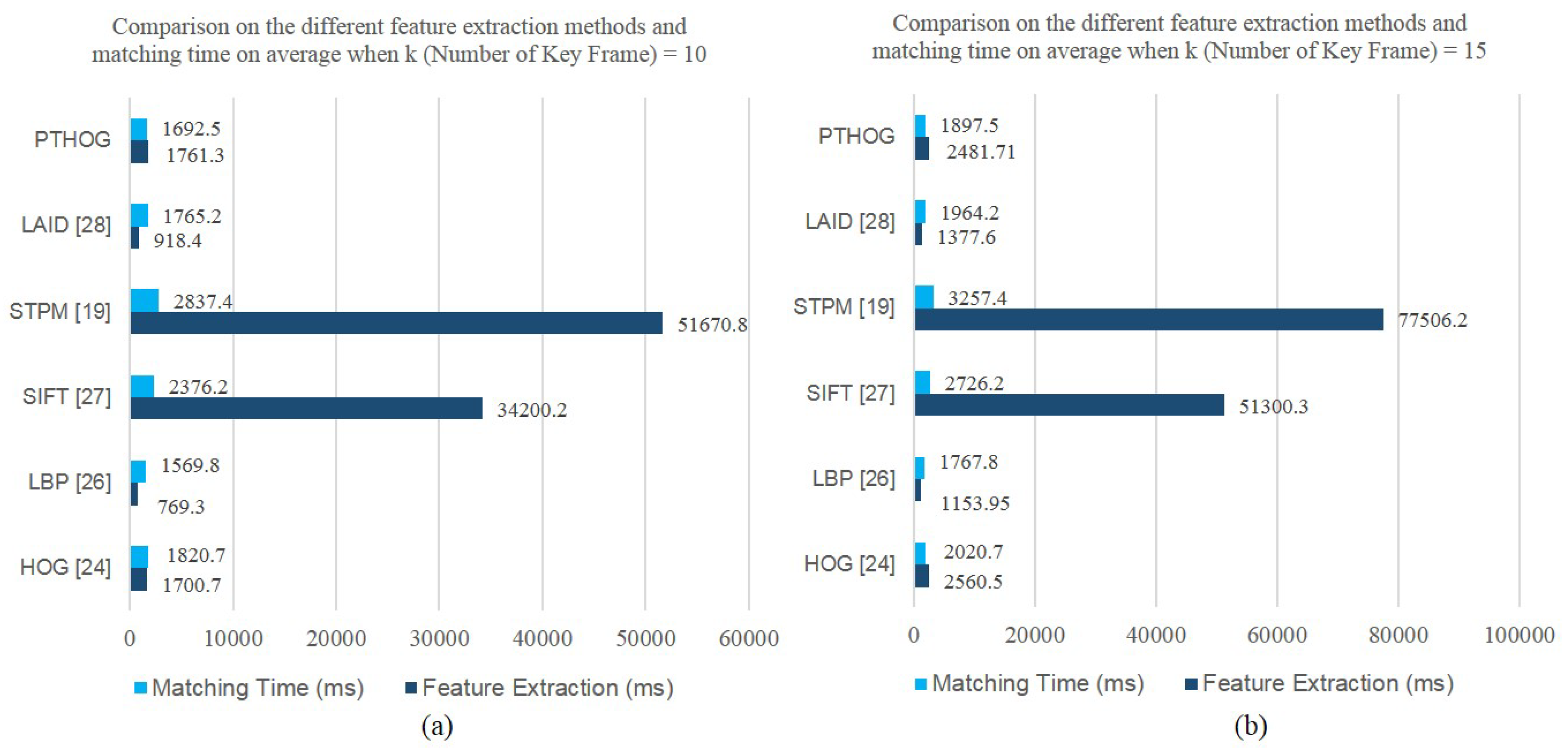
4.3. Experimental Results on AVD8 Dataset
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Guan, T.; He, Y.F.; Duan, L.Y.; Yu, J.Q. Efficient BOF generation and compression for on-device mobile visual location recognition. IEEE Multimed. 2014, 21, 32–41. [Google Scholar]
- Chen, P.; Peng, Z.; Li, D.; Yang, L. An improved augmented reality system based on AndAR. J. Vis. Commun. Image Represent. 2016, 37, 63–69. [Google Scholar] [CrossRef]
- Lima, J.P.; Roberto, R.; Simões, F.; Almeida, M.; Figueiredo, L.; Teixeira, J.M.; Teichrieb, V. Markerless tracking system for augmented reality in the automotive industry. Expert Syst. Appl. 2017, 82, 100–114. [Google Scholar] [CrossRef]
- Chatzopoulos, D.; Bermejo, C.; Huang, Z.; Hui, P. Mobile Augmented Reality Survey: From Where We Are to Where We Go. IEEE Access 2017, 5, 6917–6950. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant key-points. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Guan, W.; You, S.; Newmann, U. Efficient Matchings and Mobile Augmented Reality. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2012, 8. [Google Scholar] [CrossRef]
- Li, W.; Nee, A.Y.C.; Ong, S.K. A State-of-the-Art Review of Augmented Reality in Engineering Analysis and Simulation. Multimodal Technol. Interact. 2017, 1, 17. [Google Scholar] [CrossRef]
- Crivellaro, A.; Verdie, Y.; Yi, K.M.; Fua, P.; Lepetit, V. Tracking texture-less, shiny objects with descriptor fields. In Proceedings of the IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Munich, Germany, 10–12 September 2014. [Google Scholar]
- Kong, W.; Li, W.J. Double-Bit Quantization for Hashing. In Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012. [Google Scholar]
- AVD8 Dataset. Available online: https://sites.google.com/view/joolee/ (accessed on 18 August 2018).
- Shirahama, K.; Uehara, K.; Grzegorzek, M. Examining the Applicability of Virtual Reality Technique for Video Retrieval. In Proceedings of the 10th International Workshop on Content-Based Multimedia Indexing (CBMI), Annecy, France, 27–29 June 2012. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradsk, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the International Conference on Computer Vision (ICCV), Nara, Japan, 13–15 June 2011; pp. 2564–2571. [Google Scholar]
- Kaliciak, L.; Myrhaug, H.; Goker, A. Content-Based Image Retrieval in Augmented Reality. In Proceedings of the 8th International Symposium on Ambient Intelligence, Porto, Portugal, 21–23 June 2017. [Google Scholar]
- Hbali, Y.; Sadgal, M.; Fazziki, A.E.L. Markerless Augmented Reality based on Local Binary Pattern. In Proceedings of the International Conference on Signal Processing and Multimedia Applications (SIGMAP), Vienna, Austria, 28–30 August 2013. [Google Scholar]
- Makar, M.; Chandrasekhar, V.; Tsai, S.S.; Chen, D.; Girod, B. Interframe Coding of Feature Descriptors for Mobile Augmented Reality. IEEE Trans. Image Process. 2014, 23, 3352–3367. [Google Scholar] [CrossRef] [PubMed]
- Pombo, L.; Marques, M.M. Marker-based augmented reality application for mobile learning in an urban park. In Proceedings of the International Symposium on Computers in Education (SIIE), Lisbon, Portugal, 9–11 Novembe 2017. [Google Scholar]
- Wang, C.S.; Hung, S.H.; Chiang, D.J. A markerless augmented reality mobile navigation system with multiple targets display function. In Proceedings of the IEEE International Conference on Applied System Innovation (ICASI), Sapporo, Japan, 13–17 May 2017. [Google Scholar]
- Zhang, B. Design of mobile augmented reality game based on image recognition. EURASIP J. Image Video Process. 2017, 90. [Google Scholar] [CrossRef]
- Rao, J.; Qiao, Y.; Ren, F.; Wang, J.; Du, Q. A Mobile Outdoor Augmented Reality Method Combining Deep Learning Object Detection and Spatial Relationships for Geovisualization. Sensors 2017, 17, 1951. [Google Scholar] [CrossRef] [PubMed]
- Joolee, J.B.; Lee, Y.K. Video Retrieval Based on Image Queries Using THOG For Augmented Reality Environments. In Proceedings of the IEEE International Conference on Big Data and Smart Computing (BigComp), Shanghai, China, 15–17 January 2018. [Google Scholar]
- Zhu, Y.; Huang, X.; Huang, Q.; Tian, Q. Large-scale video copy retrieval with temporal-concentration SIFT. Neurocomputing 2015, 187, 83–91. [Google Scholar] [CrossRef]
- Choi, J.; Wang, Z.; Lee, S.C.; Jeon, W.J. A spatiotemporal pyramid matching for video retrieval. Comput. Vis. Image Understand. 2013, 117, 660–669. [Google Scholar] [CrossRef]
- Liu, W.; Ma, H.; Qi, H.; Zhao, D.; Chen, Z. Deep learning hashing for mobile visual search. EURASIP J. Image Video Process. 2017, 17. [Google Scholar] [CrossRef]
- Priya, G.G.L.; Domnic, S. Shot based keyframe extraction for ecological video indexing and retrieval. Ecol. Inform. 2013, 23, 107–117. [Google Scholar] [CrossRef]
- Zhao, S.; Yao, H.; Sun, X. Video classification and recommendation based on affective analysis of viewers. Neurocomputing 2013, 119, 101–110. [Google Scholar] [CrossRef]
- Bosch, A.; Zisserman, A.; Munoz, X. Representing shape with a spatial pyramid kernel. In Proceedings of the 6th ACM International Conference on Image and Video Retrieval, Amsterdam, The Netherlands, 9–11 July 2007; pp. 401–408. [Google Scholar]
- Jun, B.; Choi, I.; Kim, D. Local Transform Features and Hybridization for Accurate Face and Human Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1423–1436. [Google Scholar] [CrossRef] [PubMed]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Gauglitz, S.; Höllerer, T.; Turk, M. Evaluation of Interest Point Detectors and Feature Descriptors for Visual Tracking. Int. J. Comput. Vis. 2011, 94, 335–360. [Google Scholar] [CrossRef]
- Ishraque, S.Z.; Shoyaib, M.; Abdullah-Al-Wadud, M.; Hoque, M.M.; Chae, O. A local adaptive image descriptor. New Rev. Hypermed. Multimed. 2013, 19, 286–298. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikäinen, M.; Mäenpää, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, Nevada, 3–6 December 2012. [Google Scholar]














© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Joolee, J.B.; Uddin, M.A.; Khan, J.; Kim, T.; Lee, Y.-K. A Novel Lightweight Approach for Video Retrieval on Mobile Augmented Reality Environment. Appl. Sci. 2018, 8, 1860. https://doi.org/10.3390/app8101860
Joolee JB, Uddin MA, Khan J, Kim T, Lee Y-K. A Novel Lightweight Approach for Video Retrieval on Mobile Augmented Reality Environment. Applied Sciences. 2018; 8(10):1860. https://doi.org/10.3390/app8101860
Chicago/Turabian StyleJoolee, Joolekha Bibi, Md Azher Uddin, Jawad Khan, Taeyeon Kim, and Young-Koo Lee. 2018. "A Novel Lightweight Approach for Video Retrieval on Mobile Augmented Reality Environment" Applied Sciences 8, no. 10: 1860. https://doi.org/10.3390/app8101860
APA StyleJoolee, J. B., Uddin, M. A., Khan, J., Kim, T., & Lee, Y.-K. (2018). A Novel Lightweight Approach for Video Retrieval on Mobile Augmented Reality Environment. Applied Sciences, 8(10), 1860. https://doi.org/10.3390/app8101860