
A Low Cost Wireless Acoustic Sensor for Ambient Assisted Living Systems


 , and
, and 
Abstract
:1. Introduction
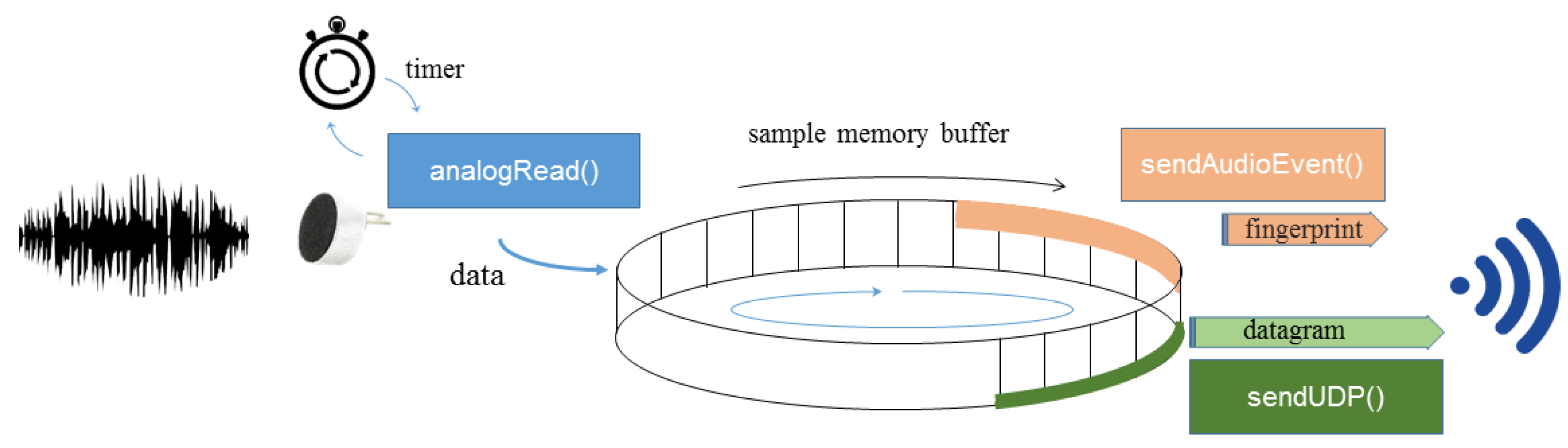
2. Wireless Acoustic Sensor
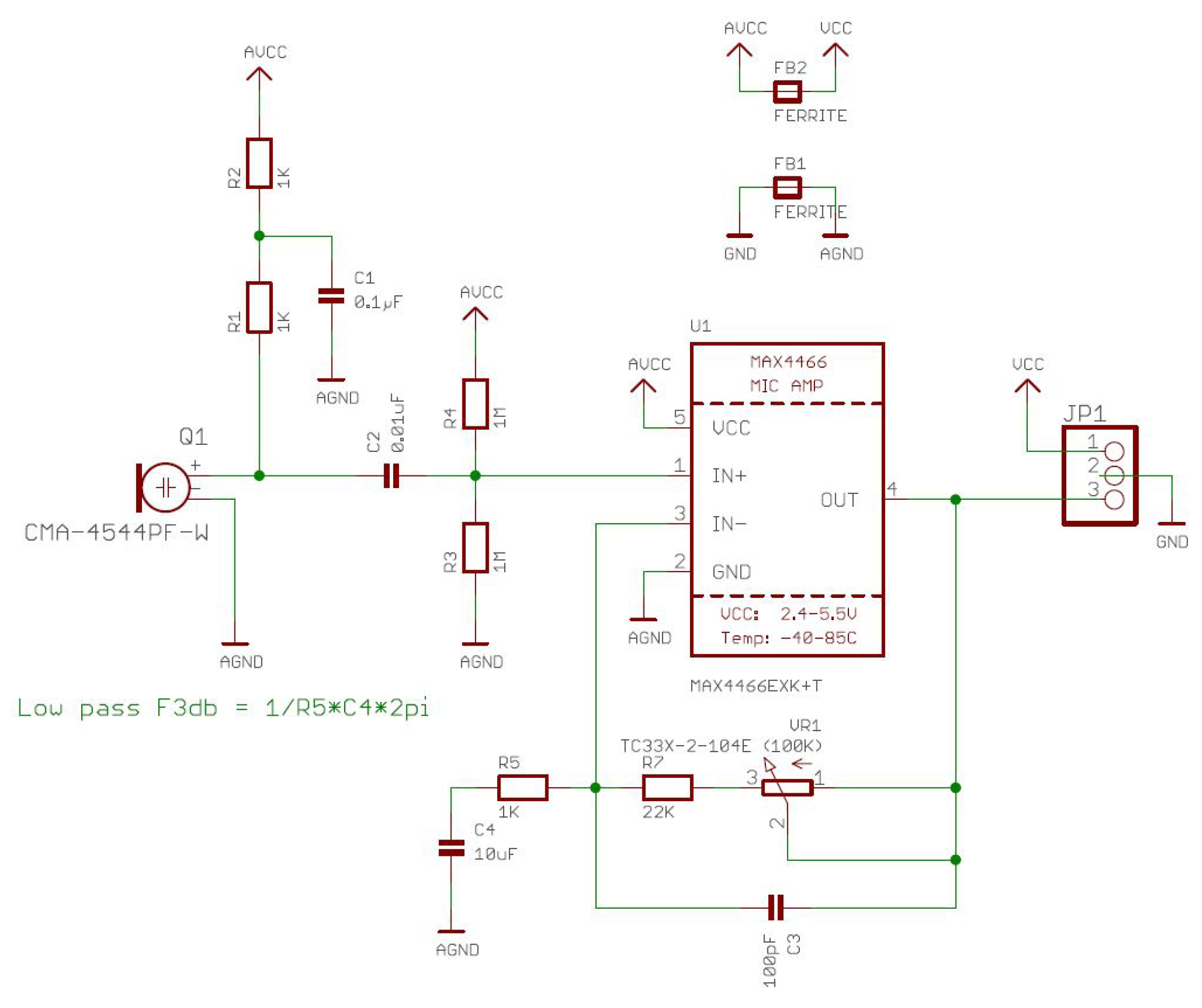
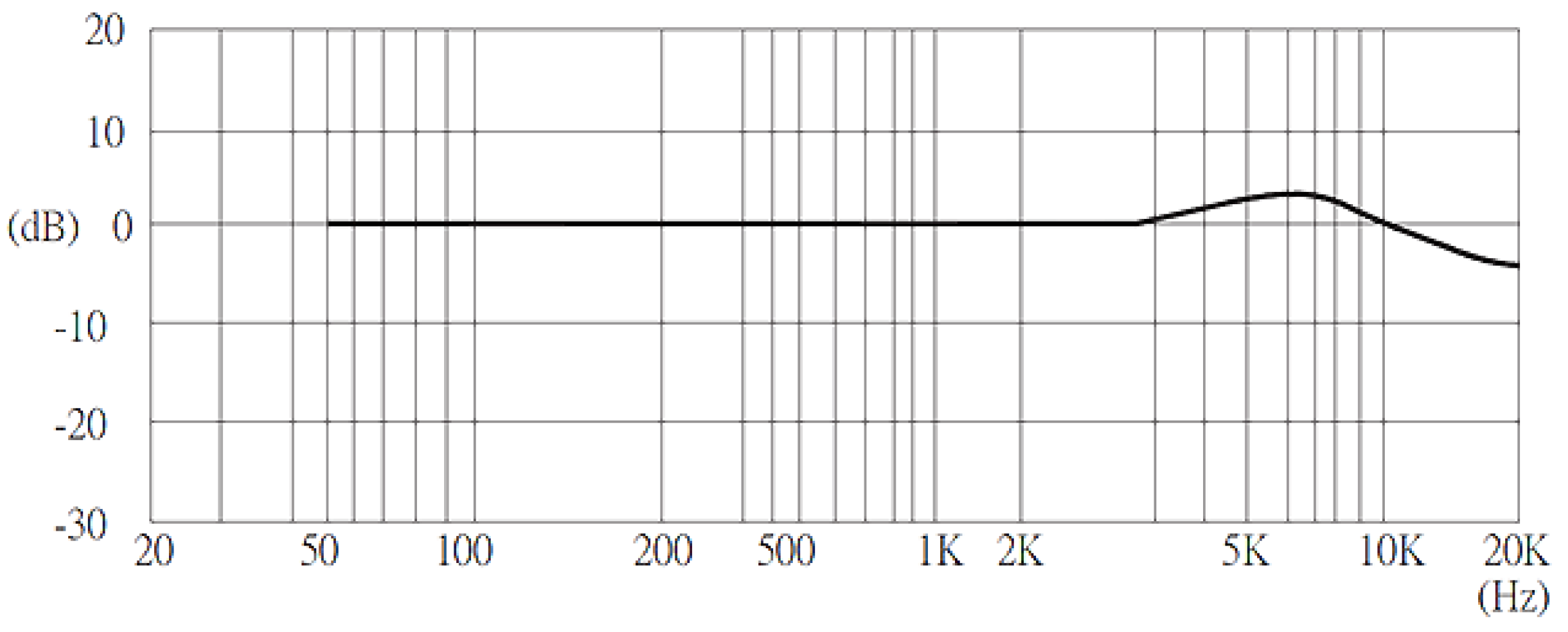
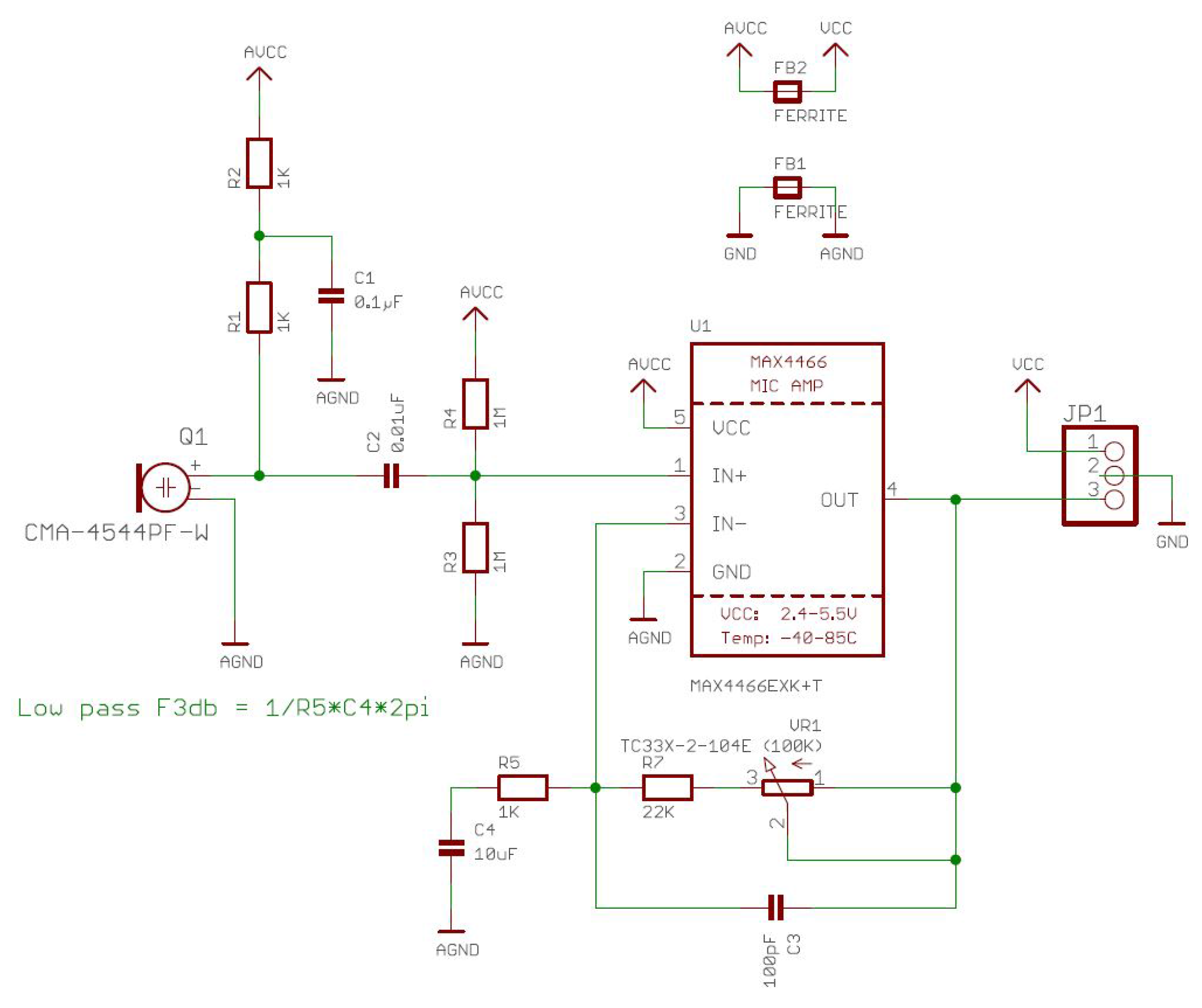
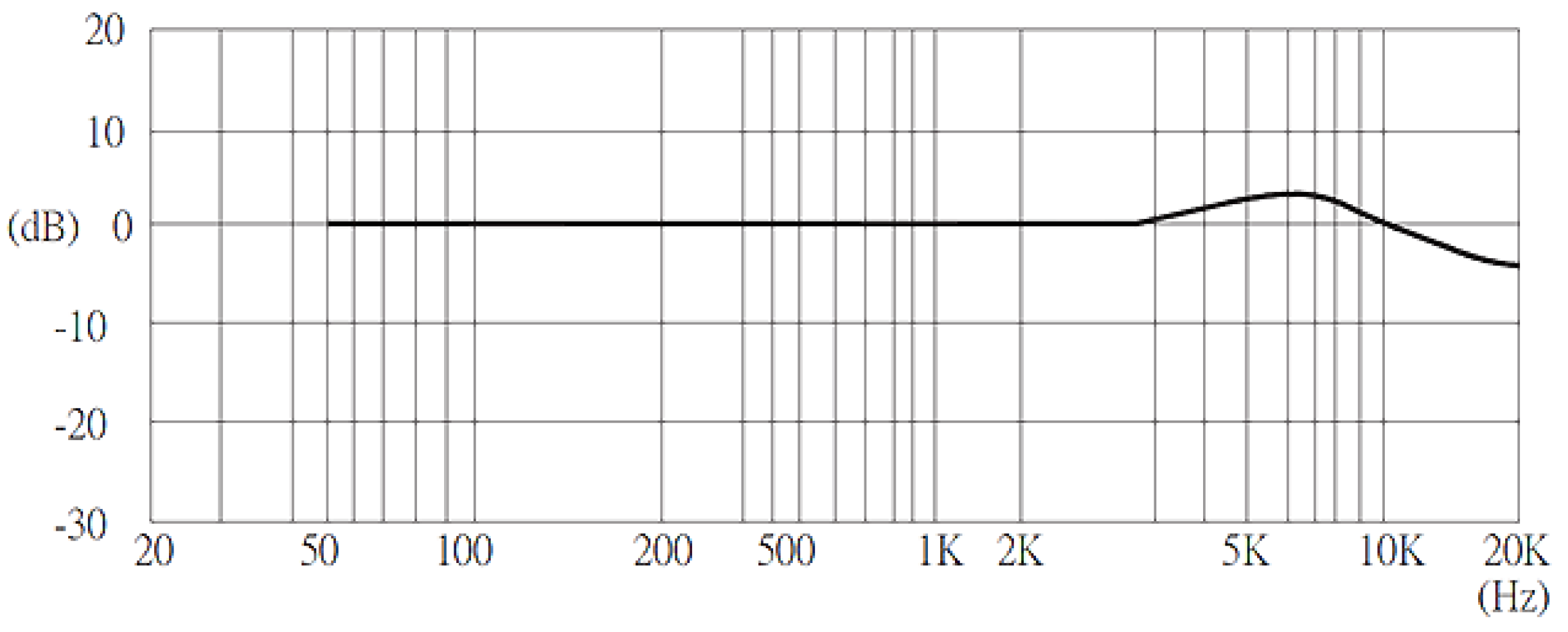
2.1. Audio Sensor
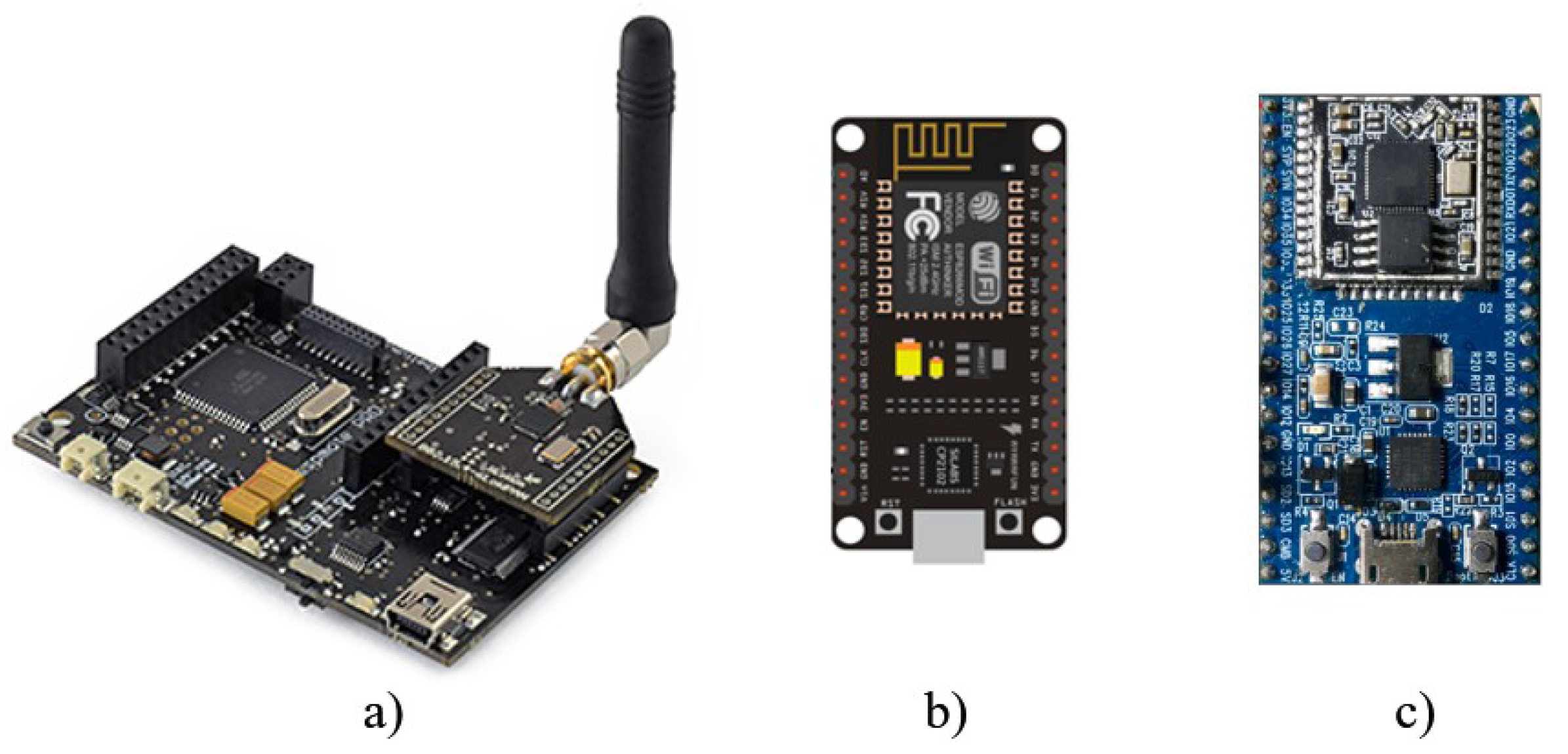
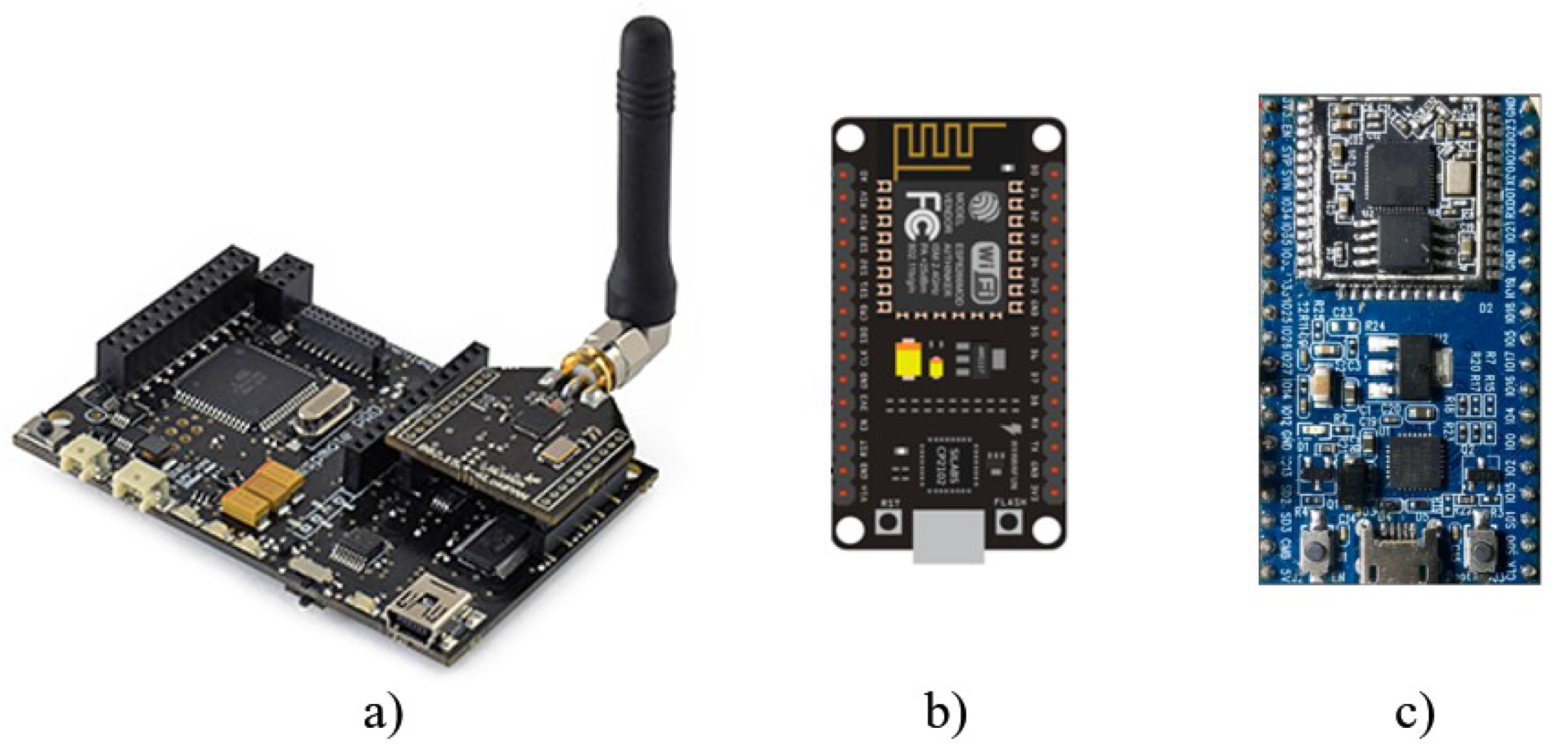
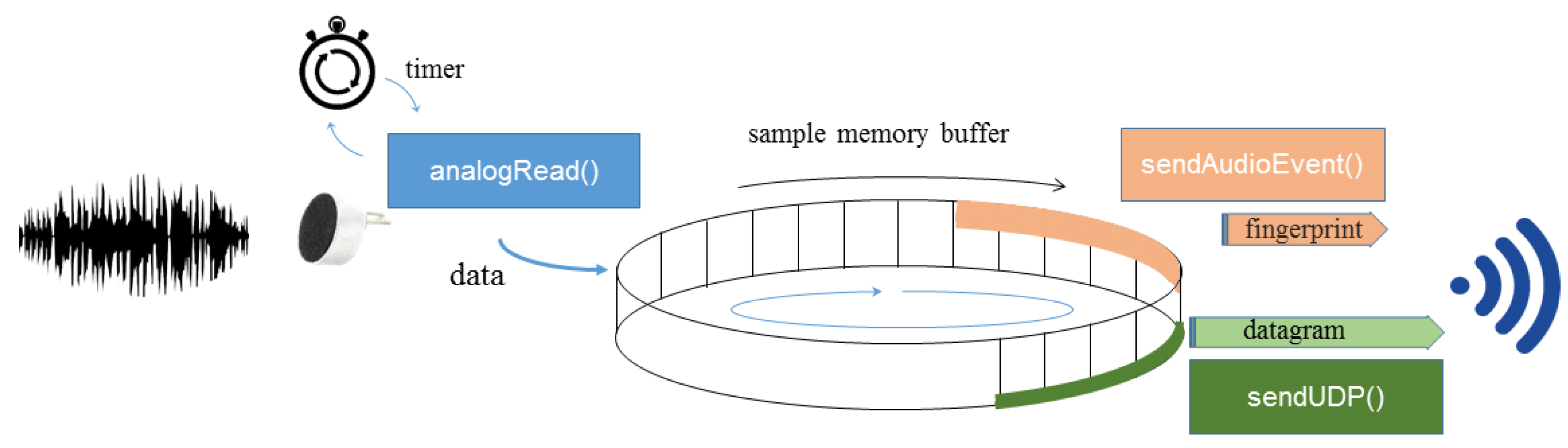
2.2. Microcontroller Based Board
3. System Validation Methods
3.1. Randomness Tests
3.1.1. Bartels Test
3.1.2. Cox Stuart Test
3.1.3. Mann-Kendall Test
3.1.4. Wald-Wolfowitz Test
3.2. Audio Fingerprint Matching
3.2.1. Chromaprint Process
3.2.2. Hamming Distance
3.2.3. Matching Algorithm
| Algorithm 1 Audio Fingerprint Matching |
| Require: Fingerprint of recorded audio, Require: Fingerprint of all original audios, for 1: all original fingerprints do for do end for ← end for return |
4. Results and Discussion
4.1. Acoustic Anechoic Chamber
4.2. Dataset
4.2.1. Randomness Tests
4.2.2. Audio Fingerprint Matching
4.3. Energy Consumption and Audio Proccesing Capabilities
5. Conclusions and Future Work
Author Contributions
Conflicts of Interest
References
- Chang, C.Y.; Kuo, C.H.; Chen, J.C.; Wang, T.C. Design and implementation of an IoT access point for smart home. Appl. Sci. 2015, 5, 1882–1903. [Google Scholar] [CrossRef]
- Peruzzini, M.; Germani, M.; Papetti, A.; Capitanelli, A. Smart Home Information Management System for Energy-Efficient Networks. In Collaborative Systems for Reindustrialization, Proceedings of the 14th IFIP WG 5.5 Working Conference on Virtual Enterprises, PRO-VE 2013 Dresden, Germany, 30 September–2 October 2013; Springer: Heidelberg, Germany, 2013; pp. 393–401. [Google Scholar]
- Amendola, S.; Lodato, R.; Manzari, S.; Occhiuzzi, C.; Marrocco, G. RFID technology for IoT-based personal healthcare in smart spaces. IEEE Internet Things J. 2014, 1, 144–152. [Google Scholar] [CrossRef]
- Sánchez-Rosario, F.; Sanchez-Rodriguez, D.; Alonso-Hernández, J.B.; Travieso-González, C.M.; Alonso-González, I.; Ley-Bosch, C.; Ramírez-Casañas, C.; Quintana-Suárez, M.A. A low consumption real time environmental monitoring system for smart cities based on ZigBee wireless sensor network. In Proceedings of the 2015 International Wireless Communications and Mobile Computing Conference (IWCMC), Dubrovnik, Croatia, 24–25 August 2015; IEEE: Washington, DC, USA, 2015; pp. 702–707. [Google Scholar]
- Lin, K.; Chen, M.; Deng, J.; Hassan, M.M.; Fortino, G. Enhanced fingerprinting and trajectory prediction for IoT localization in smart buildings. IEEE Trans. Autom. Sci. Eng. 2016, 13, 1294–1307. [Google Scholar] [CrossRef]
- Memon, M.; Wagner, S.R.; Pedersen, C.F.; Beevi, F.H.A.; Hansen, F.O. Ambient assisted living healthcare frameworks, platforms, standards, and quality attributes. Sensors 2014, 14, 4312–4341. [Google Scholar] [CrossRef] [PubMed]
- Rashidi, P.; Mihailidis, A. A survey on ambient-assisted living tools for older adults. IEEE J. Biomed. Health Inform. 2013, 17, 579–590. [Google Scholar] [CrossRef] [PubMed]
- European Comission. Active and Assisted Living Programme. ICT for Ageing Well. Available online: http://www.aal-europe.eu/ (accessed on 1 June 2017).
- Erden, F.; Velipasalar, S.; Alkar, A.Z.; Cetin, A.E. Sensors in Assisted Living: A survey of signal and image processing methods. IEEE Signal Proc. Mag. 2016, 33, 36–44. [Google Scholar] [CrossRef]
- Vacher, M.; Portet, F.; Fleury, A.; Noury, N. Development of audio sensing technology for ambient assisted living: Applications and challenges. Int. J. E-Health and Medical Commun. 2011, 2, 35–54. [Google Scholar] [CrossRef]
- Kivelä, I.; Gao, C.; Luomala, J.; Hakala, I. Design of Noise Measurement Sensor Network: Networking and Communication Part. In Proceedings of the Fifth International Conference on Sensor Technologies and Applications, Sensorcomm, French Riviera, France, 21–27 August 2011; pp. 280–287. [Google Scholar]
- Paulo, J.; Fazenda, P.; Oliveira, T.; Carvalho, C.; Felix, M. Framework to Monitor Sound Events in the City Supported by the FIWARE platform. In Proceedings of the 46th Congreso Español de Acústica, Valencia, Spain, 21–23 October 2015; pp. 21–23. [Google Scholar]
- Alías, F.; Socoró, J.C. Description of anomalous noise events for reliable dynamic traffic noise mapping in real-life urban and suburban soundscapes. Appl. Sci. 2017, 7, 146. [Google Scholar] [CrossRef]
- Sevillano, X.; Socoró, J.C.; Alías, F.; Bellucci, P.; Peruzzi, L.; Radaelli, S.; Coppi, P.; Nencini, L.; Cerniglia, A.; Bisceglie, A.; et al. DYNAMAP—Development of low cost sensors networks for real time noise mapping. Noise Mapp. 2016, 3, 172–189. [Google Scholar] [CrossRef]
- Segura Garcia, J.; Pérez Solano, J.J.; Cobos Serrano, M.; Navarro Camba, E.A.; Felici Castell, S.; Soriano Asensi, A.; Montes Suay, F. Spatial Statistical Analysis of Urban Noise Data from a WASN Gathered by an IoT System: Application to a Small City. Appl. Sci. 2016, 6, 380. [Google Scholar] [CrossRef]
- Hakala, I.; Kivela, I.; Ihalainen, J.; Luomala, J.; Gao, C. Design of Low-Cost Noise Measurement Sensor Network: Sensor Function Design. In Proceedings of the 2010 First International Conference on Sensor Device Technologies and Applications (SENSORDEVICES), Venice, Italy, 18–25 July 2010; IEEE: Washington, DC, USA, 2010; pp. 172–179. [Google Scholar]
- Ahmed, A.; Ahmed, E. A Survey on Mobile Edge Computing. In Proceedings of the 2016 10th International Conference on Intelligent Systems and Control (ISCO), Coimbatore, India, 7–8 January 2016; IEEE: Washington, DC, USA, 2016; pp. 1–8. [Google Scholar]
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge computing: Vision and challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Alsina-Pagès, R.M.; Navarro, J.; Alías, F.; Hervás, M. homeSound: Real-Time Audio Event Detection Based on High Performance Computing for Behaviour and Surveillance Remote Monitoring. Sensors 2017, 17, 854. [Google Scholar] [CrossRef] [PubMed]
- Mach, P.; Becvar, Z. Mobile edge computing: A survey on architecture and computation offloading. IEEE Commun. Surv. Tutor. 2017, 19, 1628–1656. [Google Scholar] [CrossRef]
- Adafruit. Electret Microphone Amplifier. Available online: https://www.adafruit.com/product/1063 (accessed on 15 July 2017).
- Libelium. Waspmote Platform. Available online: http://www.libelium.com/products/waspmote/ (accessed on 3 May 2017).
- Espressif. ESP8266 Specification. Available online: https://espressif.com/en/products/hardware/esp8266ex/overview (accessed on 15 July 2017).
- Espressif. ESP32 Specification. Available online: https://espressif.com/en/products/hardware/esp32/overview (accessed on 15 July 2017).
- Bartels, R. The rank version of von Neumann’s ratio test for randomness. J. Am. Stat. Assoc. 1982, 77, 40–46. [Google Scholar] [CrossRef]
- Cox, D.R.; Stuart, A. Some quick sign tests for trend in location and dispersion. Biometrika 1955, 42, 80–95. [Google Scholar] [CrossRef]
- Kendall, M. Rank Correlation Methods; Oxford University Press: New York, NY, USA, 1990. [Google Scholar]
- Wald, A.; Wolfowitz, J. On a test whether two samples are from the same population. Ann. Math. Stat. 1940, 11, 147–162. [Google Scholar] [CrossRef]
- Von Neumann, J. Distribution of the ratio of the mean square successive difference to the variance. Ann. Math. Stat. 1941, 12, 367–395. [Google Scholar] [CrossRef]
- Cano, P.; Batlle, E.; Kalker, T.; Haitsma, J. A review of audio fingerprinting. J. VLSI Signal Proc. Syst. Signal Image Video Technol. 2005, 41, 271–284. [Google Scholar] [CrossRef]
- Lukáš, L. Chromaprint. Available online: https://acoustid.org/chromaprint (accessed on 3 May 2017).
- Freesound. Dataset of Audio Clips. Available online: http://freesound.org/ (accessed on 1 July 2017).
- Condes, E. ArduinoFFT. Available online: https://github.com/kosme/arduinoFFT (accessed on 28 July 2017).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Environmental Sound | Duration (s) | Number of Records |
|---|---|---|
| S1—Traffic jam in a city | 49 | 3 |
| S2—People on a street without traffic | 34 | 3 |
| S3—Very strong traffic | 70 | 5 |
| S4—City park with children | 33 | 3 |
| S5—Pedestrian zone of a city with traffic | 32 | 3 |
| S6—Inside of a noisy room by traffic | 60 | 4 |
| S7—Ambulance passing with the siren | 29 | 4 |
| S8—Drilling machine in a city | 18 | 3 |
| S9—Police car passing with the siren | 28 | 3 |
| S10—Ambulance siren. Doppler effect | 24 | 3 |
| S11—Dense traffic in a city | 72 | 5 |
| S12—Indoor door slam | 23 | 3 |
| S13—Indoor gun shots | 98 | 3 |
| S14—Slicing vegetables in a kitchen | 40 | 3 |
| Record | Bartels | Cox Stuart | Mann-Kendall | Wald-Wolfowitz |
|---|---|---|---|---|
| S1-R1 | 0 | 0.06 | ≈0 | 0 |
| S1-R2 | 0 | 0.01 | ≈0 | 0 |
| S1-R3 | 0 | 0.09 | ≈0 | 0 |
| S2-R1 | 0 | ≈0 | ≈0 | 0 |
| S2-R2 | 0 | ≈0 | ≈0 | 0 |
| S2-R3 | 0 | ≈0 | ≈0 | 0 |
| S3-R1 | 0 | ≈0 | ≈0 | 0 |
| S3-R2 | 0 | 0.02 | ≈0 | 0 |
| S3-R3 | 0 | 0.12 | ≈0 | 0 |
| S3-R4 | 0 | 0.13 | ≈0 | 0 |
| S3-R5 | 0 | 0.09 | ≈0 | 0 |
| S4-R1 | 0 | ≈0 | 0 | 0 |
| S4-R2 | 0 | ≈0 | 0 | 0 |
| S4-R3 | 0 | ≈0 | ≈0 | 0 |
| S5-R1 | 0 | ≈0 | ≈0 | 0 |
| S5-R2 | 0 | ≈0 | 0 | 0 |
| S5-R3 | 0 | ≈0 | 0 | 0 |
| S6-R1 | 0 | ≈0 | 0 | 0 |
| S6-R2 | 0 | ≈0 | 0 | 0 |
| S6-R3 | 0 | ≈0 | 0 | 0 |
| S6-R4 | 0 | ≈0 | 0 | 0 |
| S7-R1 | 0 | 0.07 | 0 | 0 |
| S7-R2 | 0 | 0.08 | ≈0 | 0 |
| S7-R3 | 0 | 0.02 | ≈0 | 0 |
| S7-R4 | 0 | ≈0 | ≈0 | 0 |
| S8-R1 | 0 | ≈0 | ≈0 | 0 |
| S8-R2 | 0 | 0.01 | ≈0 | 0 |
| S8-R3 | 0 | ≈0 | ≈0 | 0 |
| S9-R1 | 0 | ≈0 | 0 | 0 |
| S9-R2 | 0 | ≈0 | 0 | 0 |
| S9-R3 | 0 | 0.01 | 0 | 0 |
| S10-R1 | 0 | 0.03 | ≈0 | 0 |
| S10-R2 | 0 | 0.03 | ≈0 | 0 |
| S10-R3 | 0 | 0.06 | ≈0 | 0 |
| S11-R1 | 0 | ≈0 | ≈0 | 0 |
| S11-R2 | 0 | 0.01 | ≈0 | 0 |
| S11-R3 | 0 | ≈0 | ≈0 | 0 |
| S11-R4 | 0 | 0.06 | ≈0 | 0 |
| S11-R5 | 0 | ≈0 | ≈0 | 0 |
| S12-R1 | 0 | 0.01 | ≈0 | 0 |
| S12-R2 | 0 | 0.01 | 0 | 0 |
| S12-R3 | 0 | ≈0 | 0 | 0 |
| S13-R1 | 0 | ≈0 | 0 | 0 |
| S13-R2 | 0 | ≈0 | 0 | 0 |
| S13-R3 | 0 | 0.01 | 0 | 0 |
| S14-R1 | 0 | 0.05 | 0 | 0 |
| S14-R2 | 0 | ≈0 | 0 | 0 |
| S14-R3 | 0 | 0.06 | 0 | 0 |
| Record | S1 | S2 | S3 | S4 | S5 | S6 | S7 | S8 | S9 | S10 | S11 | S12 | S13 | S14 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S1-R1 | 773 | 1088 | 1075 | 1086 | 1132 | 1107 | 1249 | 1232 | 1096 | 1257 | 1111 | 1232 | 1060 | 1146 |
| S1-R2 | 1025 | 1086 | 1047 | 1050 | 1111 | 1182 | 1323 | 1121 | 1146 | 1164 | 1053 | 1234 | 1040 | 1239 |
| S1-R3 | 883 | 1012 | 1022 | 996 | 1151 | 1108 | 1227 | 1152 | 1111 | 1180 | 1101 | 1252 | 923 | 1114 |
| S2-R1 | 1058 | 351 | 995 | 1017 | 1087 | 1100 | 1237 | 1118 | 1138 | 1208 | 997 | 1170 | 855 | 1156 |
| S2-R2 | 1047 | 336 | 961 | 962 | 1083 | 1120 | 1231 | 1150 | 1161 | 1245 | 1022 | 1091 | 838 | 1127 |
| S2-R3 | 1093 | 1088 | 1083 | 1070 | 1124 | 1224 | 1265 | 1162 | 1230 | 1288 | 1105 | 1204 | 1098 | 1194 |
| S3-R1 | 1115 | 992 | 549 | 1002 | 1111 | 1037 | 1288 | 1212 | 1099 | 1298 | 1072 | 1150 | 890 | 1034 |
| S3-R2 | 1144 | 995 | 486 | 1053 | 1121 | 1110 | 1253 | 1277 | 1127 | 1289 | 1102 | 1138 | 924 | 1116 |
| S3-R3 | 1138 | 1037 | 459 | 1053 | 1223 | 1126 | 1225 | 1247 | 1178 | 1290 | 1097 | 1203 | 927 | 1144 |
| S3-R4 | 1122 | 1036 | 427 | 1035 | 1117 | 1091 | 1303 | 1116 | 1179 | 1276 | 1081 | 1081 | 962 | 1060 |
| S3-R5 | 1112 | 1066 | 485 | 1126 | 1180 | 1177 | 1247 | 1198 | 1168 | 1276 | 1061 | 1177 | 1023 | 1183 |
| S4-R1 | 1032 | 939 | 1003 | 370 | 1133 | 1051 | 1250 | 1157 | 1160 | 1249 | 1064 | 1195 | 833 | 1159 |
| S4-R2 | 1035 | 978 | 996 | 396 | 1107 | 1133 | 1187 | 1159 | 1135 | 1270 | 1061 | 1150 | 867 | 1142 |
| S4-R3 | 1102 | 1051 | 1089 | 313 | 1122 | 1128 | 1280 | 1182 | 1218 | 1172 | 1116 | 1211 | 951 | 1164 |
| S5-R1 | 1112 | 1112 | 1060 | 1134 | 377 | 1102 | 1215 | 1157 | 1178 | 1262 | 1088 | 1162 | 1081 | 1163 |
| S5-R2 | 1095 | 1024 | 1033 | 1132 | 1053 | 1064 | 1246 | 1170 | 1119 | 1376 | 1058 | 1143 | 973 | 1121 |
| S5-R3 | 1140 | 1080 | 1108 | 1182 | 403 | 1108 | 1236 | 1174 | 1204 | 1270 | 1135 | 1193 | 1102 | 1150 |
| S6-R1 | 1209 | 1171 | 1153 | 1161 | 1131 | 591 | 1240 | 1198 | 1318 | 1306 | 1155 | 1188 | 1172 | 1010 |
| S6-R2 | 1141 | 1019 | 1080 | 1141 | 1059 | 598 | 1248 | 1149 | 1191 | 1277 | 1099 | 1166 | 1022 | 1066 |
| S6-R3 | 1043 | 1035 | 972 | 1051 | 1107 | 1040 | 1365 | 1106 | 1088 | 1152 | 1073 | 1153 | 1055 | 1059 |
| S6-R4 | 1134 | 1051 | 1026 | 1164 | 1093 | 485 | 1289 | 1151 | 1172 | 1275 | 1152 | 1185 | 1007 | 1039 |
| S7-R1 | 1167 | 1121 | 1089 | 1153 | 1150 | 1178 | 1026 | 1220 | 1196 | 1170 | 1145 | 1095 | 1059 | 1129 |
| S7-R2 | 1208 | 1217 | 1091 | 1215 | 1247 | 1205 | 991 | 1226 | 1209 | 1234 | 1183 | 1179 | 1183 | 1169 |
| S7-R3 | 1236 | 1192 | 1133 | 1256 | 1273 | 1225 | 340 | 1371 | 1283 | 1311 | 1166 | 1159 | 1335 | 1212 |
| S7-R4 | 1201 | 1174 | 1136 | 1165 | 1216 | 1174 | 351 | 1246 | 1247 | 1240 | 1151 | 1196 | 1242 | 1227 |
| S8-R1 | 981 | 1096 | 1155 | 1069 | 1096 | 1196 | 1265 | 949 | 1091 | 1079 | 977 | 1186 | 982 | 1218 |
| S8-R2 | 1015 | 1111 | 1123 | 1047 | 1036 | 1161 | 1274 | 340 | 1095 | 1077 | 986 | 1181 | 986 | 1236 |
| S8-R3 | 1007 | 1093 | 1136 | 1071 | 1081 | 1189 | 1289 | 847 | 1079 | 1027 | 975 | 1217 | 988 | 1238 |
| S9-R1 | 1113 | 1138 | 1111 | 1133 | 1151 | 1036 | 1380 | 1056 | 1040 | 1103 | 1099 | 1167 | 1098 | 1018 |
| S9-R2 | 1164 | 1195 | 1143 | 1245 | 1192 | 1061 | 1322 | 1156 | 402 | 1228 | 1128 | 1199 | 1106 | 1052 |
| S9-R3 | 1140 | 1129 | 1142 | 1191 | 1199 | 1160 | 1314 | 1139 | 445 | 1195 | 1110 | 1231 | 1052 | 1193 |
| S10-R1 | 1151 | 1118 | 1065 | 1160 | 1275 | 1201 | 1227 | 1355 | 1186 | 1380 | 1160 | 1197 | 1194 | 1097 |
| S10-R2 | 1149 | 1061 | 1060 | 1124 | 1173 | 1105 | 1322 | 1250 | 1073 | 1305 | 1157 | 1219 | 1192 | 1128 |
| S10-R3 | 1191 | 1140 | 1092 | 1095 | 1205 | 1200 | 1206 | 1218 | 1152 | 1299 | 1112 | 1237 | 1175 | 1148 |
| S11-R1 | 1072 | 1031 | 1105 | 1071 | 1106 | 1147 | 1259 | 1121 | 1136 | 1334 | 483 | 1141 | 903 | 1125 |
| S11-R2 | 1070 | 1084 | 1085 | 1059 | 1125 | 1112 | 1207 | 1090 | 1129 | 1287 | 538 | 1238 | 981 | 1162 |
| S11-R3 | 997 | 1066 | 1121 | 1051 | 1080 | 1138 | 1280 | 1030 | 1111 | 1190 | 483 | 1175 | 922 | 1249 |
| S11-R4 | 1144 | 1174 | 1161 | 1208 | 1132 | 1095 | 1187 | 1192 | 1179 | 1311 | 358 | 1167 | 1136 | 1156 |
| S11-R5 | 1066 | 1022 | 1082 | 1038 | 1125 | 1086 | 1261 | 1163 | 1178 | 1340 | 488 | 1170 | 931 | 1068 |
| S12-R1 | 1227 | 1222 | 1195 | 1219 | 1166 | 1140 | 1181 | 1263 | 1265 | 1297 | 1194 | 495 | 1288 | 1192 |
| S12-R2 | 1094 | 1055 | 1051 | 1033 | 1125 | 1115 | 1252 | 1029 | 1102 | 1193 | 1080 | 1024 | 953 | 1183 |
| S12-R3 | 1121 | 1095 | 1122 | 1094 | 1140 | 1156 | 1262 | 1122 | 1233 | 1228 | 1054 | 1009 | 1074 | 1149 |
| S13-R1 | 1039 | 1031 | 991 | 1019 | 1110 | 1076 | 1400 | 972 | 1108 | 1031 | 985 | 1169 | 758 | 1060 |
| S13-R2 | 1029 | 966 | 956 | 942 | 1140 | 1036 | 1323 | 1036 | 1015 | 1128 | 986 | 1165 | 618 | 1058 |
| S13-R3 | 953 | 954 | 994 | 860 | 1099 | 1072 | 1246 | 1045 | 1055 | 1142 | 937 | 1217 | 372 | 1180 |
| S14-R1 | 1082 | 1052 | 1077 | 1111 | 1113 | 1148 | 1293 | 1071 | 1102 | 1140 | 1120 | 1158 | 985 | 758 |
| S14-R2 | 1078 | 979 | 1022 | 1085 | 1106 | 1095 | 1295 | 1093 | 1122 | 1172 | 1117 | 1159 | 1001 | 768 |
| S14-R3 | 1244 | 1158 | 1129 | 1228 | 1170 | 931 | 1381 | 1233 | 1110 | 1360 | 1219 | 1092 | 1156 | 249 |
| Experiment | Average Current (mA) | Energy Consumption (W) |
|---|---|---|
| A—Audio recording | 139 | 0.695 |
| B—Audio recording and FFT | 141 | 0.705 |
| C—Audio recording and UDP sending | 165 | 0.825 |
| Number of Samples | Simultaneous Sampling | Average Execution Time (ms) |
|---|---|---|
| 128 | No | 3.32 |
| 128 | Yes | 4.45 |
| 256 | No | 7.04 |
| 256 | Yes | 9.43 |
| 512 | No | 14.92 |
| 512 | Yes | 19.97 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Quintana-Suárez, M.A.; Sánchez-Rodríguez, D.; Alonso-González, I.; Alonso-Hernández, J.B. A Low Cost Wireless Acoustic Sensor for Ambient Assisted Living Systems. Appl. Sci. 2017, 7, 877. https://doi.org/10.3390/app7090877
Quintana-Suárez MA, Sánchez-Rodríguez D, Alonso-González I, Alonso-Hernández JB. A Low Cost Wireless Acoustic Sensor for Ambient Assisted Living Systems. Applied Sciences. 2017; 7(9):877. https://doi.org/10.3390/app7090877
Chicago/Turabian StyleQuintana-Suárez, Miguel A., David Sánchez-Rodríguez, Itziar Alonso-González, and Jesús B. Alonso-Hernández. 2017. "A Low Cost Wireless Acoustic Sensor for Ambient Assisted Living Systems" Applied Sciences 7, no. 9: 877. https://doi.org/10.3390/app7090877
APA StyleQuintana-Suárez, M. A., Sánchez-Rodríguez, D., Alonso-González, I., & Alonso-Hernández, J. B. (2017). A Low Cost Wireless Acoustic Sensor for Ambient Assisted Living Systems. Applied Sciences, 7(9), 877. https://doi.org/10.3390/app7090877