1. Introduction
3D reconstruction software, which takes in digital photos or videos and outputs 3D models, has been the goal of many researchers for past decades. When such software becomes available, 3D modeling might become a routine practice even for ordinary people using digital devices like digital cameras and smart phones, rather than a privilege enjoyed by those with professional equipment like laser-based scanners, structure light scanners, etc., not to mention the building of 3D models at city scale, where photo-based methods seem the most suitable choice. It’s possible to produce long list of existing research aimed at this ultimate goal.
Table 1 provides a short list of such work, identified by their technical features. For more work in this field, we refer readers to the review articles presented in [
1,
2,
3].
Multi-view 3D reconstruction can be traced back to binocular stereopsis based on window matching and triangulation. However, this window-based matching produces reliable results only for texture-rich regions. When it was extended to multi-view situations, it was adapted to feature-matching and triangulation, giving rise to Structure From Motion (SFM) [
4], which is widely used today for extraction of sparse seed points and camera calibration. To reconstruct the remaining regions and cope with difficulties like occlusion, non-Lambert illumination, photo noise, etc., many kinds of algorithm have been developed. They could be roughly classified into volume-based algorithms, depth-map fusion algorithms and feature-expansion algorithms.
Volume-based algorithms represent the space occupied by an object with voxels or a surrounding surface. Take the algorithm of Seitz et al. [
5] in
Table 1, for example, which discretizes a 3D scene into voxels and assigns colors to them, so as to achieve consistency with all the input images. To solve the occlusion problem, it decomposes the 3D scene into layers and sweeps them outward from the camera volume (the convex hull formed by the camera centers) in a single pass, with the constraint that no scene point is contained within the camera volume. This constraint on camera position was avoided by using a multi-sweep method, as suggested by Kutulakos et al. [
6]. The multi-sweep approach takes place in six principle directions. For each voxel, the activated cameras are located on one side of the sweep plane. Vogiatzis et al. [
8] explored another approach based on the idea that all potential causes of mismatches, like occlusion, image noise, lack of texture, or highlights, can be uniformly treated as outliers in the matching process. Matching is then seen as a process of robust model fitting to data that contains outliers. In [
8], the model was represented using a cost functional solved via global optimization using Graph-cuts. In [
7] the cost functional took into consideration the non-Lambertian appearance of the scene, and was minimized using the level set method. Volume-based algorithms reconstruct the entire object completely. However, many of them need a good initial estimation of the object to avoid converging into local minima. Their accuracy is usually limited by voxel size. As the size of the voxels becomes smaller, the number of voxels increases cubically, implying ahuge consumption of CPU time and memory. So volume-based algorithms have been demonstrated in the reconstruction of relatively small objects, as shown in
Table 1.
Depth-map fusion algorithms, in principle, are capable of dealing with both small objects and large scenes. Many of them make use of a two-stage approach that estimates a depth map for each image and then merges all the depth maps to extract a final surface [
17,
18]. Early multi-view depth-map fusion algorithms were simple extensions of window-based binocular stereo matchers, which often contained a large amount of noise. Many more advanced depth-map fusion algorithms were subsequently developed utilizing powerful optimization methods like graph cut [
9], expectation maximization [
19], sequential tree-reweighted message passing [
11], etc. These global optimization methods were either used in extraction of each depth map or in the final merging of all the depth maps. Goesele et al. [
10] and Tola et al. [
12] went back to find the depth locally. Goesele simply discarded the bad matches in texture-weak regions to avoid noise. Tola went much further by introducing a DAISY descriptor [
20]. The DAISY descriptor outperforms NCC, since it contains much more information than plain intensity distributions in small windows. For the selection of the best points instantiated from several different image pairs [
12], preference was given to the points obtained by larger focal length, larger baseline and closer camera. To the best of our knowledge, Tola attained the highest reconstruction accuracy [
1,
2]. More importantly, this accuracy was obtained on large-scale, high-resolution data sets with high efficiency, which is of great significance, since millions of high-resolution photos are produced everyday around the world. City-scale [
21] and civil-infrastructure [
22,
23,
24] reconstructions have been receiving a lot of attention recently.
Feature expansion algorithms provide another efficient way of producing dense 3D clouds. The basic idea of feature expansion or region growing was demonstrated as early as 1989 by Otto et al. [
13] for the processing of satellite photos. They started from a few seed points and performed area-based matching using Gruen’s adaptive least-squares correlation algorithm [
25]. Following successful matching, the distortion parameters were applied to nearby pixels as initial parameters, and the growing process was repeated for the remaining regions. Habbecke et al. [
15] provided a surface-growing approach in the form of disk expansion based on the discrepancy induced by the sum of squared differences (SSD). New disks were expanded by user-specified fractions of the parent disk’s minimal radius. Goesele et al. [
14] developed a feature expansion algorithm to find high-quality depth maps. They suppressed outliers through a combination of intelligent image selection at per-view and per-pixel levels, and a sequential expansion strategy based on a priority queue. Their algorithm was capable of addressing the extreme changes in lighting, scale, clutter, and other effects in large online-community photo collections. Furukawa et al. [
16] arrived at a patch-based feature expansion algorithm, Patch-based Multi-View Stereopsis (PMVS), which consisted of three key steps: match, expand, and filter. In the first step, sparse features were matched using Harris and difference-of-Gaussians operators. The last two steps iterate
n times to spread the initial matches to nearby pixels and obtain a dense set of patches. From Otto et al. to Furukawa et al., in addition to the improvements in performance, the three key steps in the feature expansion algorithm framework became increasingly clear. The last step—the filtering of outliers—was not fully implemented until Furukawa et al. As a result, [
14,
15] had to adopt greedy or best-first sequential strategies, as shown in
Table 1, to suppress outliers. With the filtering of outliers based on visibility and weak neighborhood regulation, [
16] was able to expand all the patches with the same priority. PMVS is now regarded as a state-of-the-art MVS algorithm. Nevertheless, there is still a lot of room for improvement in the framework and in the key steps of the feature expansion algorithm. For example, the assignment of the next expanding point still relies on a reference image, i.e., the assignment is conducted in a local coordinate system, rather than occurring directly in a fixed-world coordinate system.
This paper presents a novel MVS algorithm based on homogeneous direct spatial expansion (MVS-HDSE). It extends the framework of the feature expansion algorithm by introducing an additional step for initial value modification utilizing already-expanded neighbor points. It also makes important improvements to existing steps in order to attain high accuracy and completeness while maintaining high efficiency. Briefly, the proposed algorithm adopts many unique measures, including:
Initial seed point extraction by the DAISY descriptor: in the seed point extraction step, the high-performance DAISY descriptor was introduced to increase the number and accuracy of seed points. Like Multi-View Reconstruction Environment (MVE) systems [
26] and Visual Structure From Motion (VSFM) systems [
27], the proposed algorithm can also get initial sparse seed points via SFM [
4], which first detects Scale-Invariant Feature Transform (SIFT) [
28] feature points in images and then matches the points between pairs of images. Seed points result from successfully-matched points following triangulation principles. However, the accuracy and number of seed points might reduce greatly due to mismatches or match failure. When the high-performance DAISY descriptor is used, the number of initial seed points might be increased multiple times, which is very helpful for reconstruction completeness and efficiency. This is because feature matching is now replaced by the DAISY descriptor’s similarity searching. The former is conducted between limited pairs of existing feature points, whereas the latter is performed along epipolar lines.
Homogeneous direct spatial expansion: in the expansion step, all 3D seed points are given with the same priority, i.e., every seed point is simultaneously expanded to nearby 3D points. This strategy is especially suitable for parallel computation, since it is neither necessary to keep a seed priority queue for sequential growth [
14], nor to grow a new seed point until it cannot grow anymore [
15]. Instead, every seed point is directly expanded in 3D space with a small step along its tangent plane, and the world coordinates of the expanded 3D points are recorded directly. In other words, it does not rely on images to find the initial positions of expanded points before optimization [
16]. Furthermore, it is not necessary to always update the record in all images which pixels have been optimized during optimization [
16], or to merge all the depth maps estimated from a number of images after optimization [
10,
11]. The expanding process ends automatically when a sufficient density of 3D points is achieved.
Conditional initial value modification: in the initial value modification step, modification is conducted when certain conditions are met. In theory, each point can be reconstructed independently via optimization, regardless of whether or not other points have been reconstructed. In reality, the initial position and normal of an expanding point are provided by adjacent seed points. If the initial values are far away from the true values, the optimization process might fail or result in a local minimum with low accuracy. So, it is important to modify the initial values to make them as close to the true values as possible. To do this, the proposed algorithm provides a so-called conditional-double-surface-fitting method. It is conditional because the fitted surface is only able to approximate the local variation of nearby real surfaces on the condition that the neighbor points of the expanding point are dense enough and centered around it. The surface fitting is conducted twice, since the second fitting becomes closer to the real surface after excluding those points with large residual errors in the first fitting. Then the point is projected back onto the fitted surface and the position and normal of the foot will be used as new initial values.
Adaptive consistency filtering: in the filtering step, adaptive consistency filtering is conducted. Points within a small area of an object’s surface are usually consistent. If one point is inconsistent with its neighbor points, it might be an outlier. We check the consistency of every point with regard to three aspects: smoothness, depth and normal. However, as will be explained latter, factors such as the real object’s surface curvature, neighbor point density, and occlusion might greatly influence the filtering process and even lead to wrong results. So, at first, a decision needs to be made for each point as to whether to carry out filtering and, if so, the thresholds for filtering are then adaptively adjusted.
Processing on multi-level image pyramid: in both the seed point extraction step and the expansion step, the algorithm is performed on a multi-level image pyramid. As a result, not only is the computation time reduced due to the small image size, also the number of both initial seed points and the successfully expanded points is increased considerably. Some points, which fail to expand on low-level images, may succeed on high-level images, resulting in much higher reconstruction completeness.
As can be seen in the later experiments, with the help of the above measures, our algorithm provides both high reconstruction accuracy and completeness.
The rest of the paper is organized as follows.
Section 2 presents the workflow of the proposed algorithm. Then it elaborates on the four key steps of the proposed algorithm.
Section 3 provides the experimental results and a comparison with other algorithms. Finally,
Section 4 gives a short conclusion.
2. The Algorithm
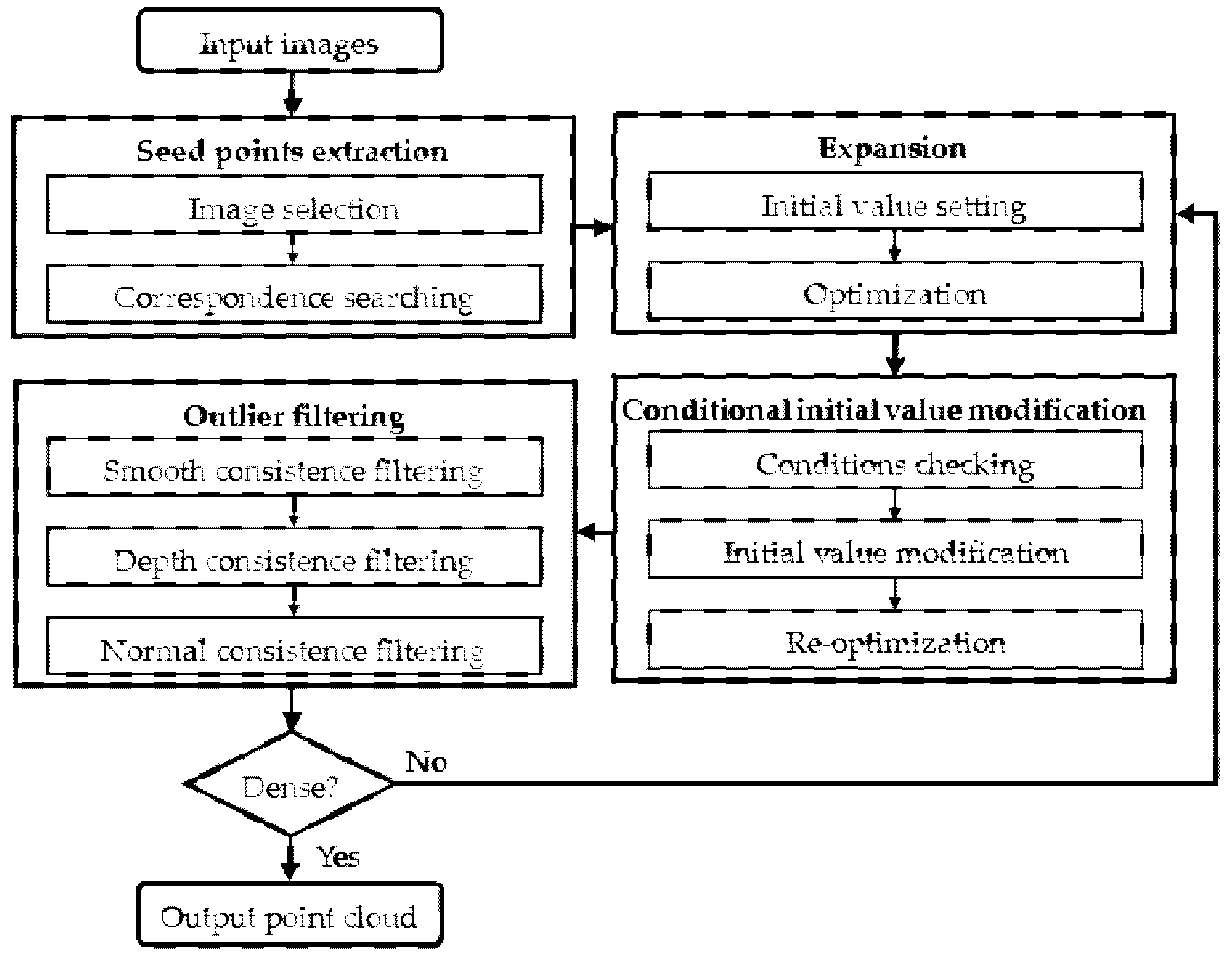
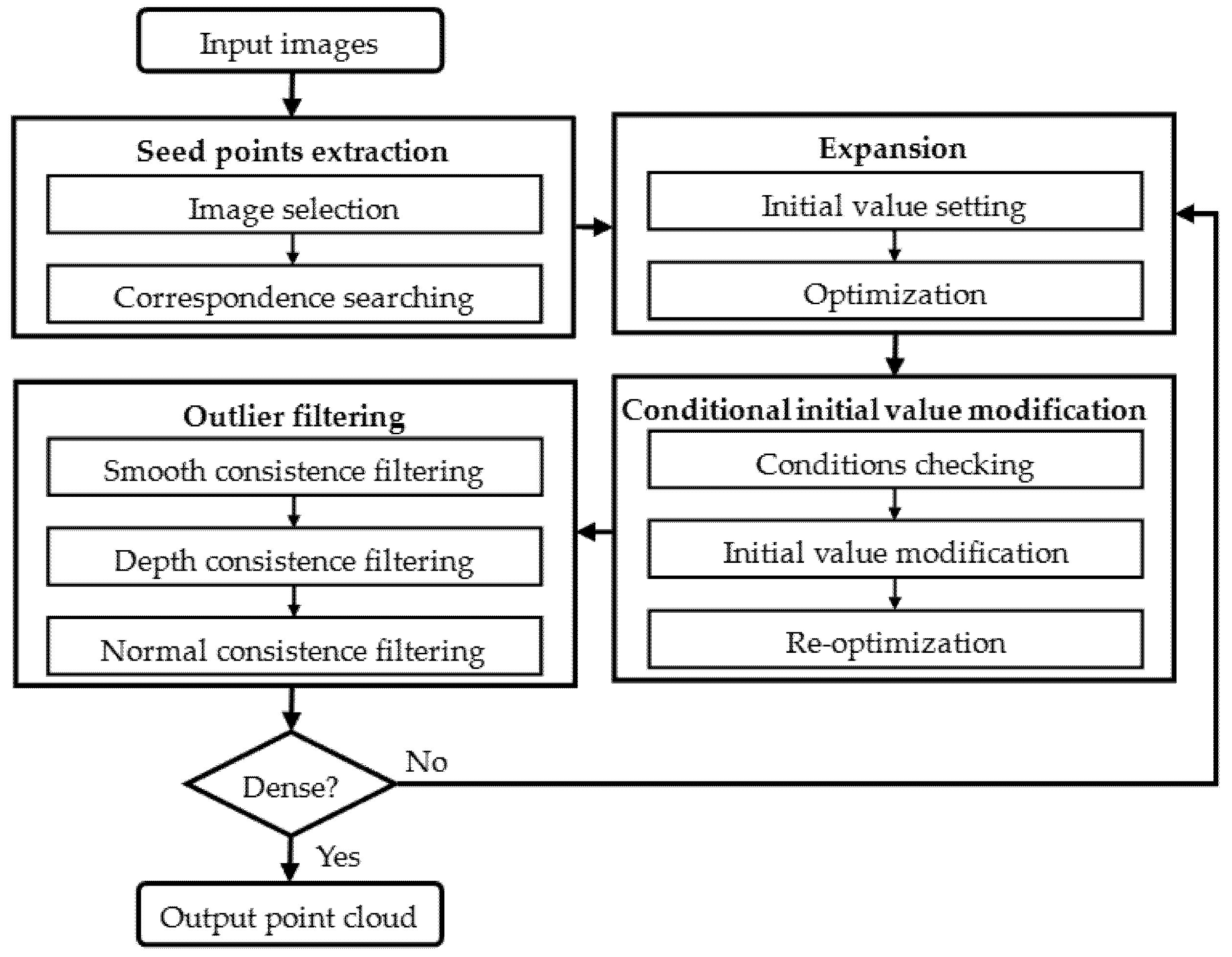
As shown in
Figure 1, the proposed algorithm contains four key steps, namely seed point extraction, expansion, conditional initial value modification and outlier filtering. Firstly, sparse initial seed points are extracted from input images through a process of image selection, followed by a correspondence-search along epipolar lines; Secondly, new points are expanded on the basis of the initial positions and normals set from the seed points, and optimized for a potential increase in accuracy; Thirdly, the expanded points are modified and re-optimized on the condition that their neighbor points are sufficiently dense and centered on them. Note that once a point has been successfully modified and re-optimized, it will not be modified again; Fourthly, the outliers are deleted via consistency filtering with regard to smoothness, depth and normal. The successfully-expanded points are then used as new seeds and the last three key steps loop again and again until the final 3D point cloud becomes dense enough. More detailed descriptions are as follows.
2.1. Sparse Seed Point Extraction
Tola [
12] successfully used the high-performance DAISY descriptor in a depth-map fusion algorithm. Here we try to use the DAISY descriptor in our feature expansion algorithm to extract initially sparse seed points. When feature points in a reference image are described by the DAISY descriptors, their correspondences in another image can be searched along epipolar lines. However, several peaks might be encountered in the search, and the maximum peak does not always produce the right correspondence [
11]. To solve this ambiguity, the proposed algorithm searches the correspondences of one feature point in several images. Only if all correspondences are successfully found—in other words, the feature point and all its correspondences are related to a single 3D point—is the 3D point regarded as a potential seed point. The detailed process is as follows.
Firstly, each image is selected in turn as a reference image. For each reference image, at least three auxiliary images around it are selected. The parallax between any two selected images (including reference image) should be in the proper range; otherwise, matching accuracy might be reduced due to too small a parallax, and matching might even fail due to too few common regions caused by a large parallax. To ensure proper selection, scores for all candidate images can be calculated by Equation (1), and the image with highest score selected.
In Equation (1),
si is the score of
ith image,
A is the set of all selected images (including the reference image). In our experiment,
u = 15.
θi,j is the angle between the optical axis of the
ith camera and the
jth camera. Usually,
Ci =
Ci,j = 1. If the
ith and the
jth cameras are on the same side of the camera for the reference image,
Ci,j = 0.5. If the
ith camera is far away from the camera for the reference image,
Ci = 0.5.
σ1 is defined as follows:
Secondly, correspondences for one feature point are searched in the selected images. For every feature point
d in the reference image, the epiploar line
l in an auxiliary image can be calculated by
l =
F ×
d, where the fundamental matrix
F can be determined by at least 7 or more known matched feature points, since it contains a degree of freedom (DOF) of 7 DOF. Once enough matched feature points have been found,
F can be computed using a random sample consensus (RANSAC) algorithm [
29]. Then the correspondence of point
d is searched at one pixel intervals along
l based on the angles between DAISY descriptors. The angles are sorted in ascending order, with smaller angles indicating higher similarity. If the similarity at one point is obviously larger than that at other points as required by Expression (3) in all auxiliary images, a candidate 3D seed point can be calculated using triangulation principles and the Single Value Decomposition (SVD) method. To ensure that the found correspondences and the feature point
d are related to a single 3D point, the mean reprojection error of a candidate 3D seed point in the reference and auxiliary images is calculated. A candidate 3D point becomes a true 3D seed point if its mean reprojection error is less than a threshold
therr.
In Expression (3), r should be smaller than one. θi is the angle between DAISY descriptors of the feature point d and its candidate correspondences.
Since seed point extraction is performed on a multi-level image pyramid, different levels should have different thresholds therr. In our experiments for the first three levels in the image pyramid, therr = 1, 0.5 and 0.25 pixels, and r = 0.9, 0.8 and 0.7, respectively. This is because higher-level images have lower resolutions, so the threshold values become gradually stricter. Once a feature point is successfully matched, it is marked in the reference and auxiliary images to avoid repeated matching.
Finally, the normal of sparse seed points is estimated by a so-called conditional-double-surface-fitting method. This relies on the fact that the local object surface around a 3D seed point can be represented by a quadratic surface fitted over its neighboring seed points. Therefore, the normal of a 3D seed point can be estimated from the normal of the fitted surface. This works well on the condition that the surrounding seed points are sufficiently dense, and the 3D seed point is not far from the center of the surrounding points. Details of the conditional-double-surface-fitting method will be discussed a little later in
Section 2.3. If the above conditions are not satisfied for a 3D seed point, its normal will simply be set as the line from itself through the optical center of the reference image.
2.2. Expansion
2.2.1. Homogeneous Direct Spatial Expansion
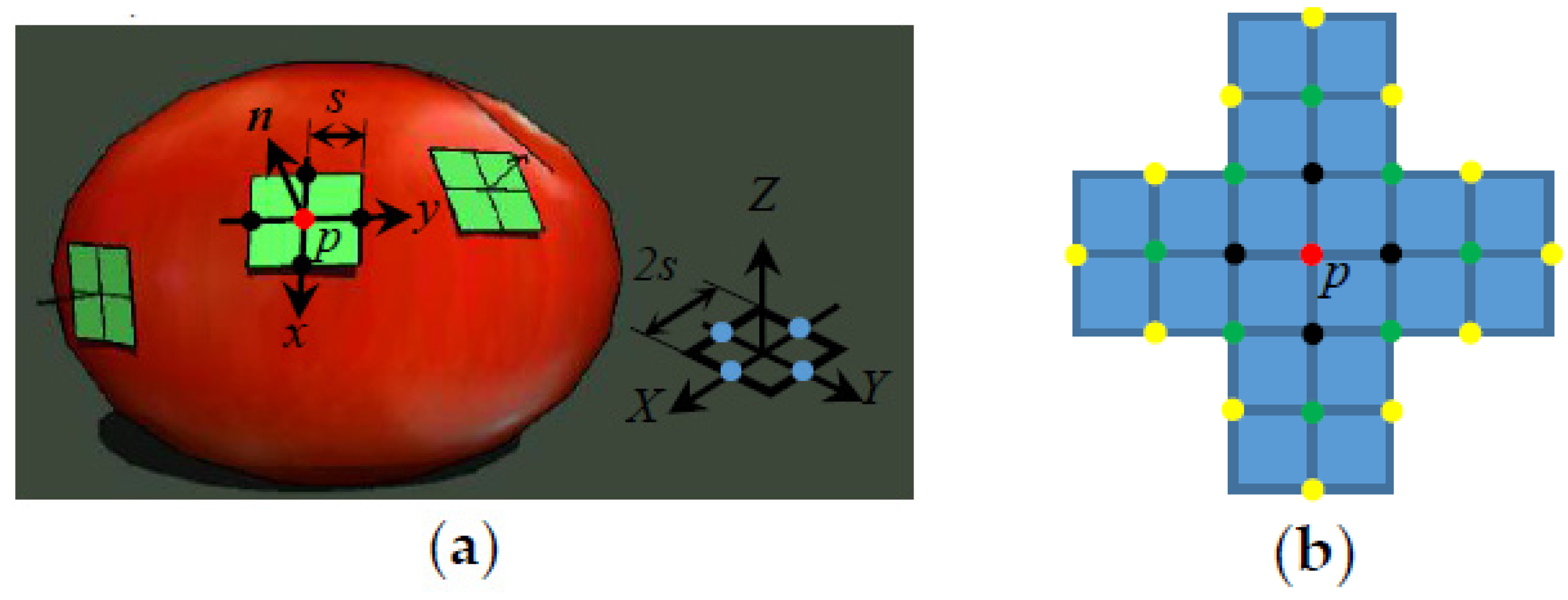
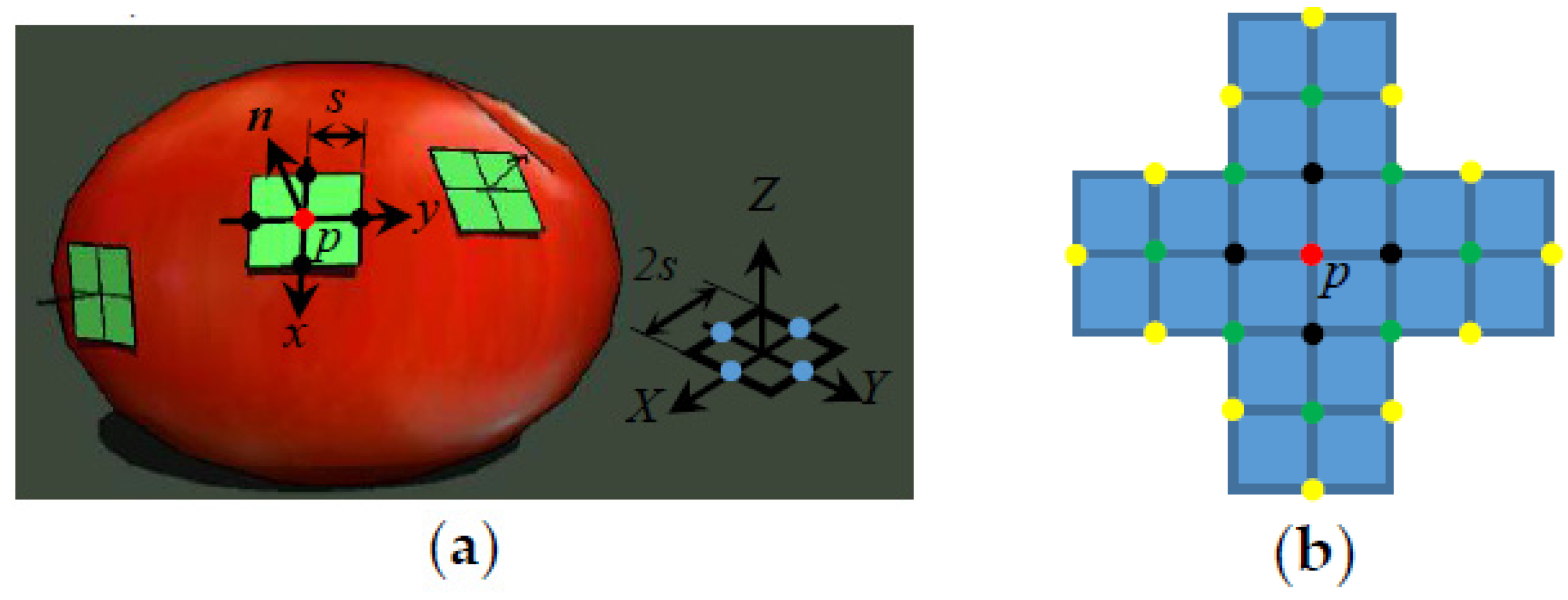
When the initial sparse seed points are extracted, they will be expanded simultaneously with a predefined small step
s to nearby 3D points along two perpendicular directions, as illustrated in
Figure 2. Each seed, taking the red point
p in
Figure 2a as an example, is expanded directly in 3D space along its tangent plane to four (black) points for later optimization. After the first iteration of expansion, the newly expanded (black) points are used as new seed points and expanded in a similar way to nearby (green) points in
Figure 2b. This process repeats until the density of the 3D points is sufficient. To avoid overlap, any point that appears close to an existing point will be deleted either before or after optimization, which ensures that the final points are distributed evenly and with proper density.
The initial normal of a newly-expanded point is set the same as that of the seed point, whereas its initial world coordinate is calculated as follows. As shown in
Figure 2a, first a square with a side length of 2
s is drawn on the
XY plane of the world coordinate system, with the centers of the four sides (blue points) placed symmetrically on the
X- and
Y-axis, respectively. The world coordinates of the four blue points are denoted as
B. Next, the square is moved until its center coincides with point
p and its normal (
Z-axis positive direction) coincides with the normal of point
p. The corresponding rotation matrix
R can then be computed using the method in [
30]. Then the new positions of the centers of the four sides (now marked black) of the square represent the initial positions of the four expanding points. Their world coordinates
E can be computed by
where
px,
py,
pz are the world coordinates of point
p.
2.2.2. Optimization
As the initial position and normal are not accurate, iterative optimization based on photo-consistency is conducted to get the final accurate position and normal. Yet before the iterative optimization, a reference image and some auxiliary images need to be selected for each expanding point. For image selection, we mainly follow the methods in [
14]. What we emphasize here is that only the best reference image is selected, which poses a view direction (i.e., one leading from the point to the optical center) as close as possible to the normal of the point and at a relatively shorter view distance as well. This is because only such an image can provide a relatively high resolution and relatively complete information of the region around the expanding point. After the selection of a reference image
R, several auxiliary images around it are selected, which provide view direction changes usually from 15 to 40 degrees. The former is selected to guarantee the highest possible reconstruction accuracy of the position of the expanding point on its tangent plane, whereas the later mainly serve to determine its position along its normal. After each iteration of optimization, auxiliary images with low similarity will be replaced and never be selected again if the reference image remains the same. After every four iterations, the position and normal of the point may increase in accuracy, and a new reference image with a view angle
θr2 (the angle between the normal of the point and the vector from the point to the center of the camera) smaller than the previous view angle
θr1 by an amount larger than
thp, as indicated by Expression (5), will be considered to replace the previous one. The threshold
thp is set to prevent the frequent replacement of reference images. As the experiment shows, if the view angle is not large (
θr2 < 30), a small change of view angle (
θr1 −
θr2 < 10) will produce little difference, even if the reference image is changed. However, a very small change of view angle (
θr1 −
θr2 > 5) may result in significant improvement if the view angle is relatively large (
θr2 > 30). Once the reference image has been replaced, auxiliary images are reselected with all previously-replaced images reactivated.
In Expression (5), θr1 and θr2 are the view angles in degree.
After the selection of reference and auxiliary images, the iterative optimization based on photo-consistency can be conducted following [
14]. When the final position and normal of an expanding point become accurate, the two
m ×
m windows centered at its projections, one in the reference image and one in the auxiliary image, would have a similar intensity distribution to Equation (6)
where
IR and
IK are the intensities in the reference image
R and auxiliary image
K, respectively. (
s,
t) is the pixel coordinate of the expanding point in the reference image. (
s + i,
t + j) and (
s + i,
t + j)
K are the (
i,
j)th pixel coordinates in the reference image and auxiliary image
K.
i,
j = (
m − 1)/2, …, (
m + 1)/2.
cK is a constant.
K = 1, …,
n, with
n being the number of auxiliary images.
The relation between pixel coordinates (
s + i,
t + j) and (
s + i,
t + j)
K can be found based on the fact that they correspond to the same 3D point
X(
s + i,
t + j). Along the line from the optical center
OR of the reference image through the (
s + i,
t + j) pixel in the reference image, one can find the world coordinate of a 3D point
X(
s + i,
t + j) using Equation (7)
where
rR(
s + i,
t + j) is the normalized vector from the optical center
OR of reference image to (
s + i,
t + j) pixel in the reference image. The term (
h + ihs + jht) represents the depth at the (
s + i,
t + j) pixel in the reference image, where
h is the depth of the (
s,
t) pixel in the reference image,
hs and
ht are the rates of depth-change per pixel along row and column directions in the reference image.
Projecting 3D point
X(
s + i,
t + j) back on an auxiliary image
K, we get
where
PK is the camera matrix of image
K.
Substituting Equations (7) and (8) into Equation (6) and expand it in Taylor’s series with only linear terms, we get
where
dh,
dhs and
dht are increments of
h,
hs and
ht. As the initial values of
h,
hs and
ht are not accurate, the values of
h,
hs and
ht are updated with
dh,
dhs and
dht and solved iteratively. When
dh,
dhs and
dht approach zero, Equation (9) approximates Equation (6) well and
h,
hs and
ht attain their final accurate values. Substituting the final
h,
hs and
ht in Equation (7), the final 3D position and normal (encoded by
hs and
ht) can be determined.
In the above optimization, some parameters are adjusted automatically to cope with various situations. For example, in the case of texture weak areas, the window size should be increased following expression (10) to include enough textures to improve accuracy.
In Expression (10), σ22 is the intensity variance of the m × m window in the reference image (m should not be large than 21) and thσ2 is a threshold value.
In case of a smaller number of images and/or big view angles, the required number of auxiliary images and the similarity for convergence are decreased to make the reconstruction as successful as possible. In any case the view angle of the reference image should be within 80 degrees after reconstruction, or else the reconstructed point might be inaccurate and should be deleted.
It was discovered in experiments that some points, which had failed to optimize based on the original high-resolution image, might succeed based on the same image at a reduced resolution. So, a multi-level image pyramid is established, and the optimization of a point commences at a lower-level image, until it ends successfully or images of all levels have been tested.
2.3. Conditional Initial Value Modification
As mentioned above, the optimization of a 3D point p is sensitive to its initial position and normal. When 3D points become dense enough after some iterations of expansion, it is possible to predicate the local variation of a surface by quadratic fitting over a number of neighboring 3D points. The fitted surface is used to modify the initial value. This is done following a so-called conditional-double-surface-fitting method, as described below.
Before each fitting, an average distance from N1 neighbor points to point p is calculated to check whether the neighbor points are dense enough. Only on the condition that < thd is a quadratic fitting performed, since at this time the fitted surface might approximate the local surface well.
Then the center
and average normal
of its neighbor points are computed. The fitting will be carried out in a new coordinate system which take
as the origin and
as the
Z-axis. The new coordinates of point
p and its neighbor points can be computed by
where
is the transposition of the rotation matrix, which rotates the
Z-axis of the world coordinate system to
.
Pn and
P are the coordinates of point
p and its neighbor points in the new and old coordinate systems, respectively.
Next, edge points are removed from neighbor points to find a more accurate center. To do this, the
x and
y components of
Pn are sorted and the new center
is computed by averaging over 80% of the central points, using Equation (12)
where
,
are the
x and
y components of
.
Ns ≈ 0.1 × (
N1 + 1).
Ne ≈ 0.9 × (
N1 + 1).
Psnx and
Psny are the sorted
x and
y components of
Pn. Since the fitted surface usually matches well with the true surface only near the center, if point
p is far away from the new center, the fitting and the modification procedure will be stopped. The point
p is regarded as near the new center if it satisfies
where
pnx and
pny are the
x and
y components of points
p in new coordinate system.
thc is a fixed threshold.
If the above two conditions are satisfied, quadratic surface fitting will be conducted twice following Equation (14)
where
c1 to
c6 are coefficients.
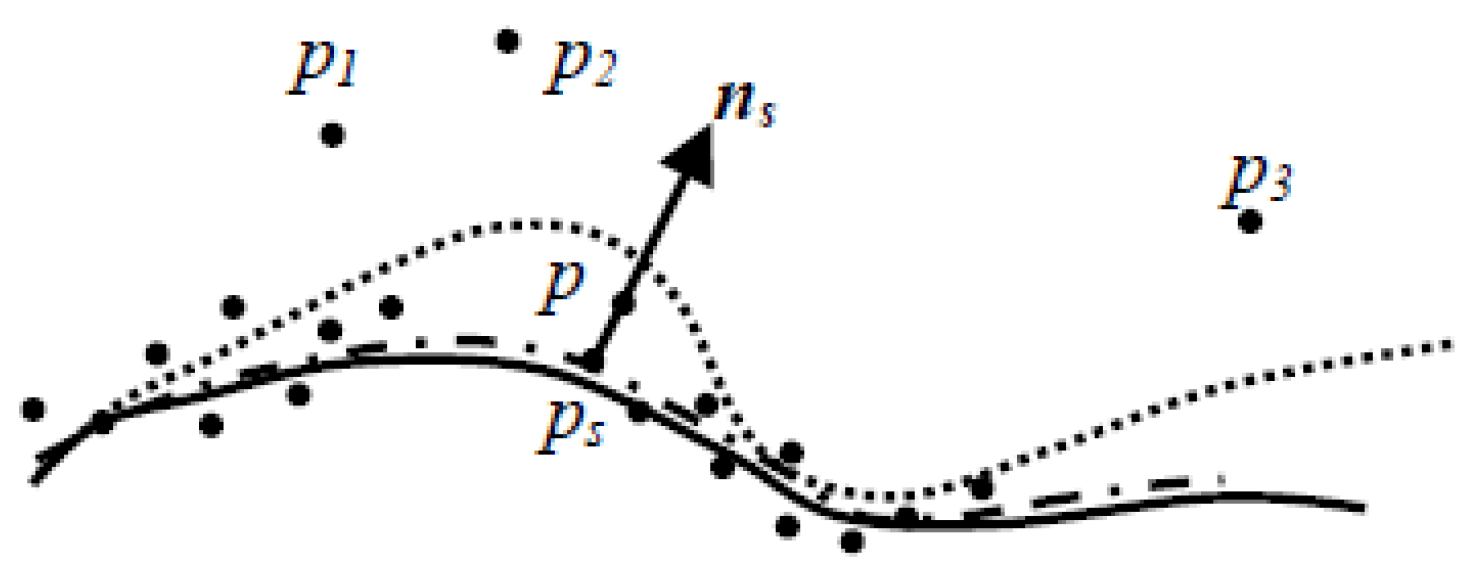
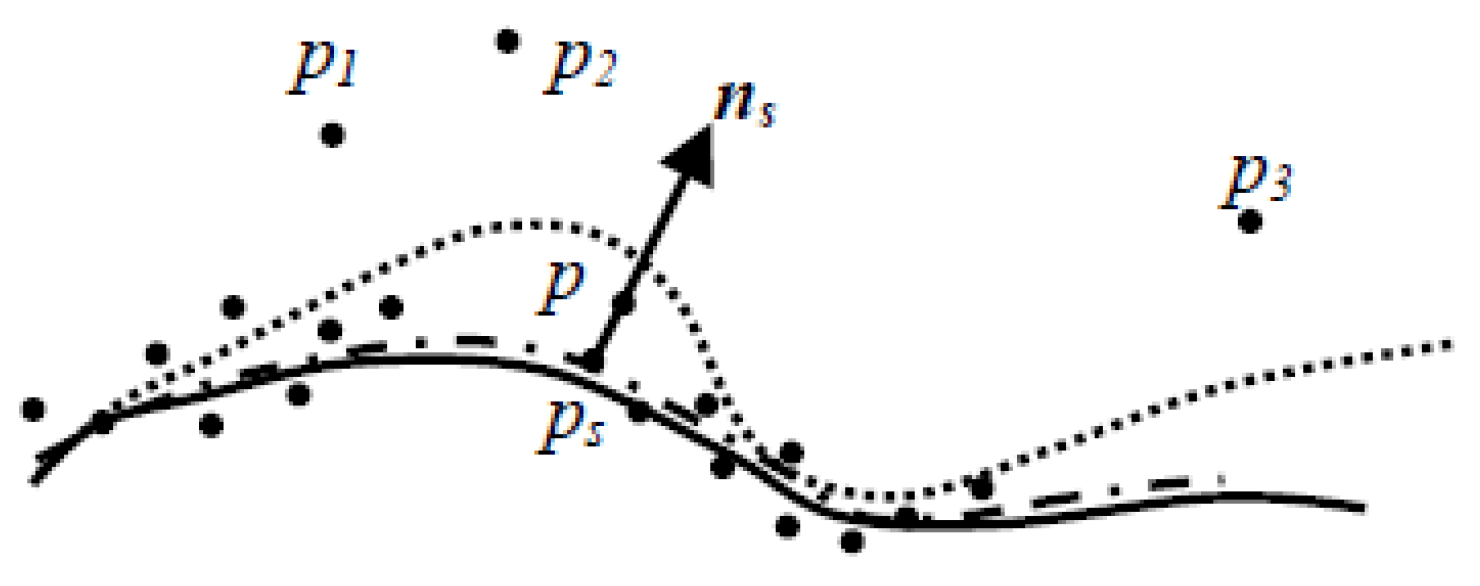
As illustrated in
Figure 3, the surface after the first fitting (dotted line) might lay a little away from the true surface (solid line) due to the existence of some irregular points
p1~3. In our experiments, we sort the distances of point
p and its neighbors to the fitted surface in descending order. Instead of identifying each irregular point using a threshold, we simply discarded the first 15% of points and used the rest of the points for the second fitting.
The fitted surface after the second fitting (dashed line) might lay much closer to the true surface, in which case point
p is projected onto the fitted surface and the position and normal of the foot
ps are used to modify the initial value. The position of the foot
ps can be estimated by Equation (15)
where
psx,
psy,
psz are the coordinates of
ps in the new coordinate system. The normal
ns of the fitted surface at
ps can be computed by Equation (16)
where
stands for the cross-product.
Right after the modification of the initial values of point p, an optimization process is conducted and the result is recorded only when NCC is higher than before and both its distance to the fitted surface and the angle between its normal and ns is not large.
2.4. Adaptive Consistency Filtering
After optimization, the outliers are filtered away based on consistency. The neighbor points within a small area are usually consistent. Filters for checking the consistency of the smoothness, depth and normal of neighbor points are introduced below.
2.4.1. Smoothness Consistency Filter
The object surface within a small area is usually smooth. Using the above conditional-double-surface-fitting method, it is possible to approximate a local surface by quadratic fitting and identify an outlier based on its distance from the fitted surface. If a point
p sits at a distance larger than a threshold
thr from the fitted surface, then it is filtered out. The threshold
thr is set adaptively, in consideration of the density of neighbor points and the curvature of the true surface. It adopts a larger value in cases of sparse neighbor points or high curvature, as described by Equation (17)
where
a1,
a2 and
a3 are fixed constants. The surface curvature is represented by
δn, which is the variance of the normal of
N1 neighbor points computed by Equation (18). As indicated by Equation (17), the threshold
thr becomes bigger as
and/or
δn increase to deal with sparse neighbor points and high local curvature of the surface.
In Equation (18), ni is the normal of the ith neighbor point when i = 0, n0 being the normal of point p.
2.4.2. Depth Consistency Filter
A small area of an object surface can usually be approximated by a plane. This assumes that the depth difference between point p and its neighbor points is small.
The average depth difference between point
p and all its neighbor points whose projections on the same selected image are inside a 5 × 5 pixel window centered at the projection of
p can be computed by Equation (19)
where
h and
hj are the depths of point
p and its neighbor points.
N2 is the number of its neighbor points in the 5 × 5 pixel-window.
On the other hand, the depth difference between point
p and a neighbor point
pt can be estimated as
s ×
tan θ,
θ being the view angle defined above. When the object surface is in parallel with the image plane, i.e.,
θ = 0, the distance between
p and
pt is roughly
s (the expansion step
s is approximately preset as the space resolution on the object surface related to a one pixel interval), and the depth difference between
p and
pt is nearly zero. When the object surface inclines by an angle
θ, the depth difference between
p and
pt increases to approximately
s × tan
θ. So we can roughly set a threshold value
thdh for
by
where
thdh is simply fixed as 1.8
s or 10
s to avoid an extremely small or extremely large threshold when
θ < 30 or > 70. Since
thdh increases with
θ, so the allowable depth difference between neighbor points adapts automatically to larger values at larger view angles. The depth of point
p is regarded as discontinuous if the average depth difference
is bigger than
thdh.
Besides outliers, occlusion can also lead to depth discontinuity. As illustrated in
Figure 4a, when observed from a camera with an optical center
O1, the depth around point
p is discontinuous due to occlusion. When observed from another camera with an optical center
O2, the discontinuity disappears. By contrast, in the case of an outlier, the depth discontinuity will always exist, regardless of viewpoints, as illustrated in
Figure 4b. To distinguish these two situations, we checked the depth discontinuity of point
p in every selected image. If the depth is discontinuous in the majority of the selected images (i.e., in more than sixty percent of total selected images), the point is identified as an outlier and filtered out.
2.4.3. Normal Consistency Filter
3D points within a very small region usually point in a direction with small deviation. If the normal n0 of point p is far away from the average of its neighbor points’ normal ni, as judged by dot production in Expression (21), then it should be filtered out.
In expression (21), N3 is the number of neighbor points within 3 s from point p. thdp is a threshold value.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}