A Lookahead Behavior Model for Multi-Agent Hybrid Simulation

Abstract
:1. Introduction
2. Related Works
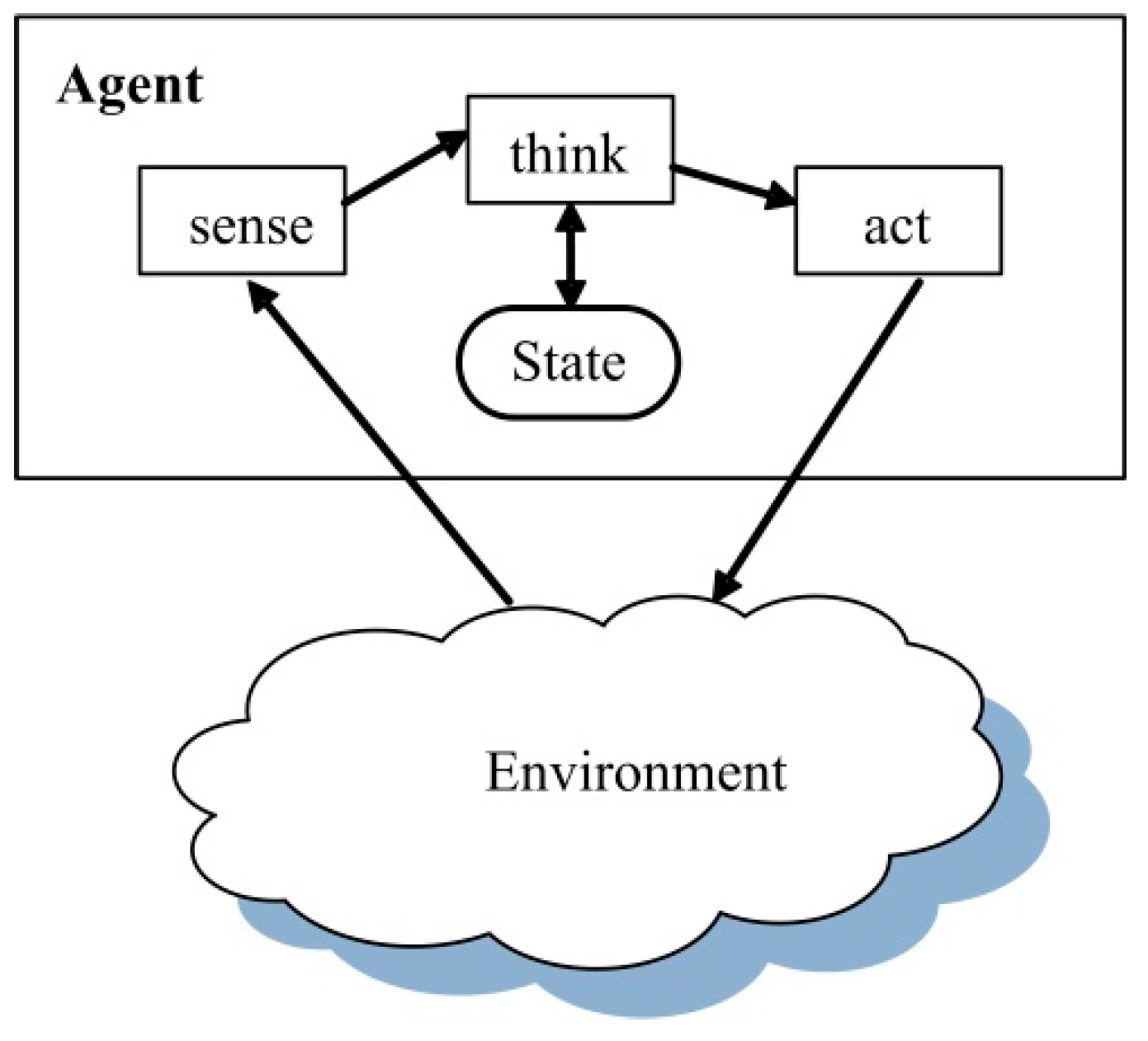
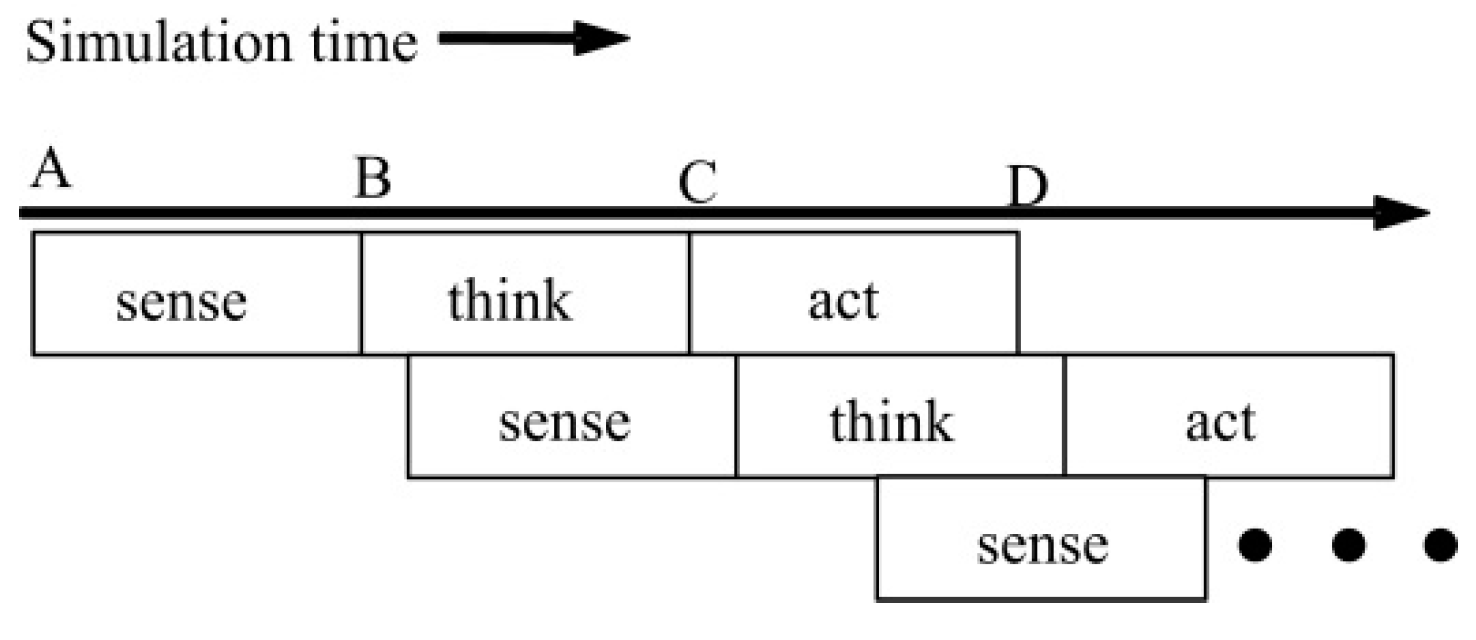
2.1. Traditional Agent Behavior Model
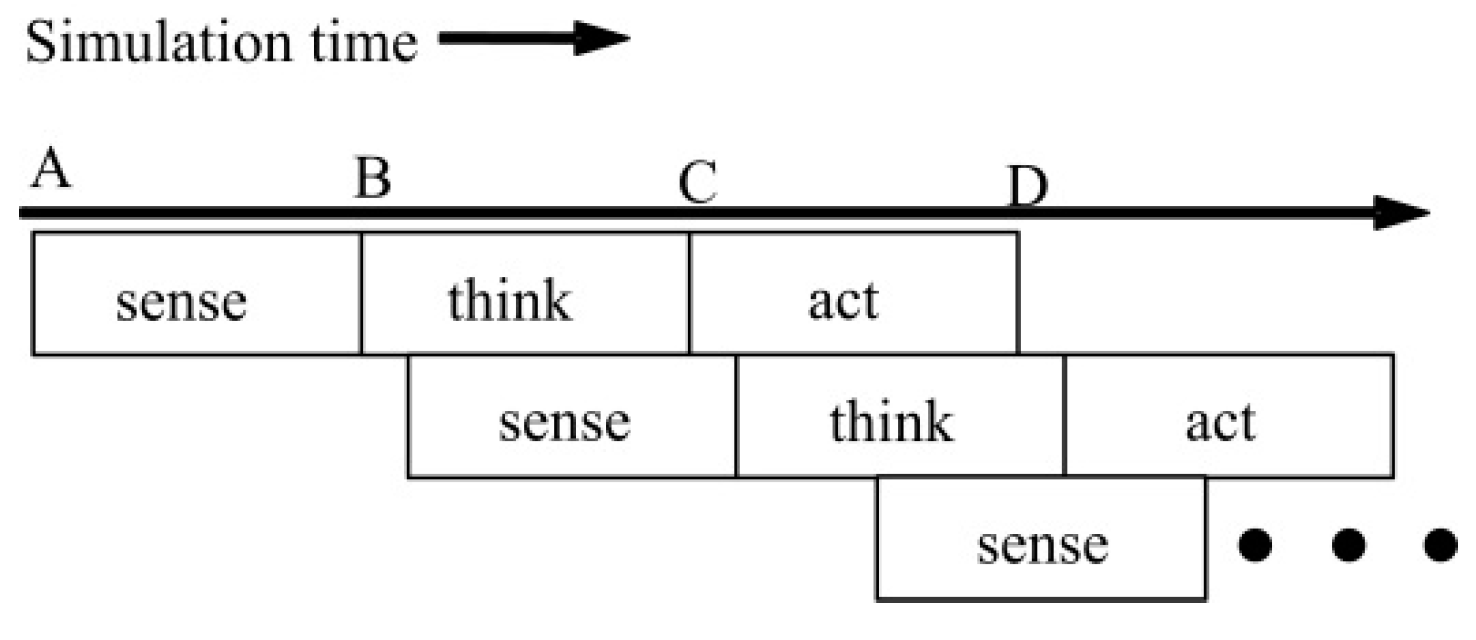
2.2. State Update Mechanism in Agent-Based Modeling
2.3. Approaches of Combining DES and Agent-Based Modeling
3. Problem Description
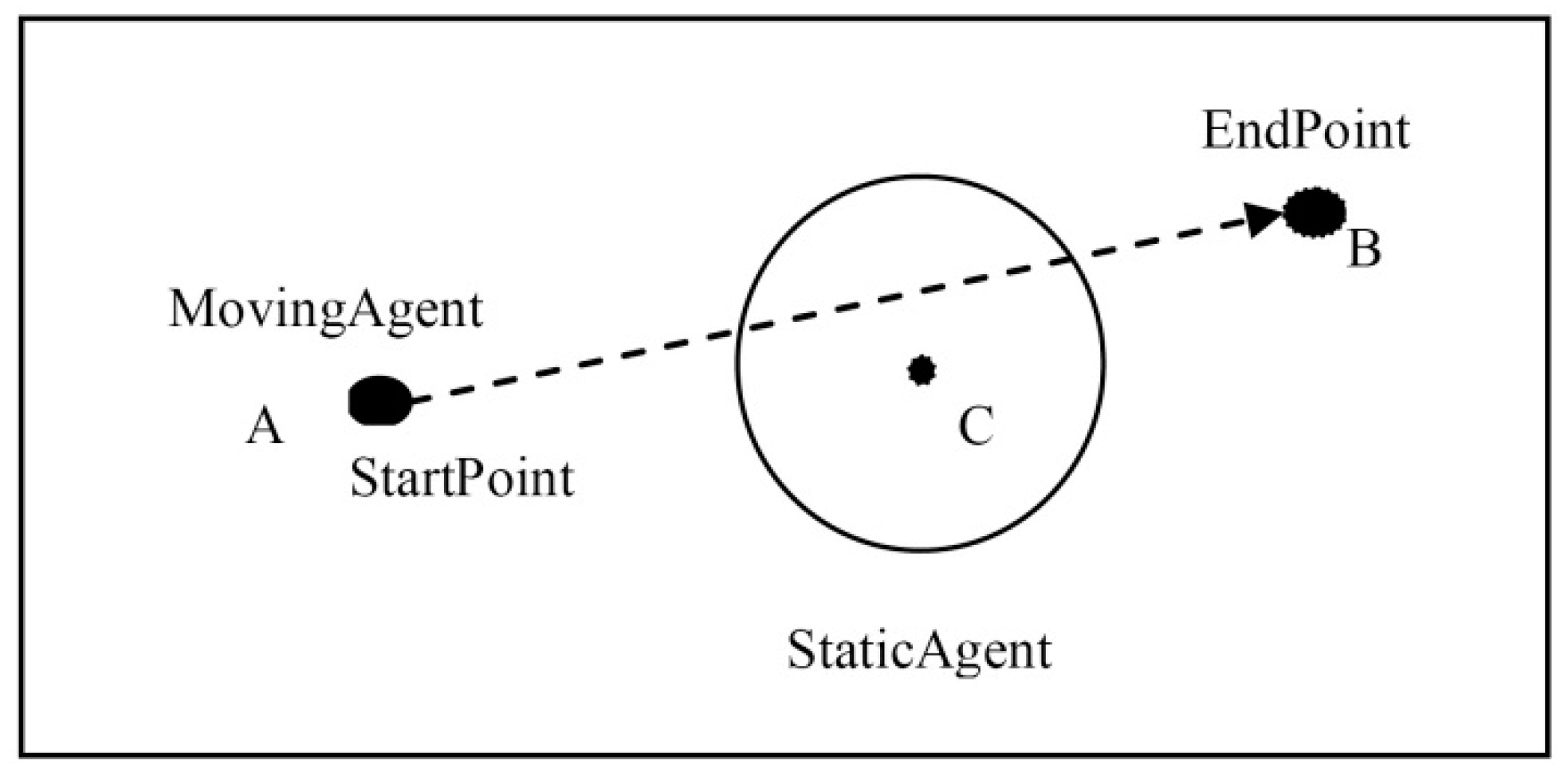
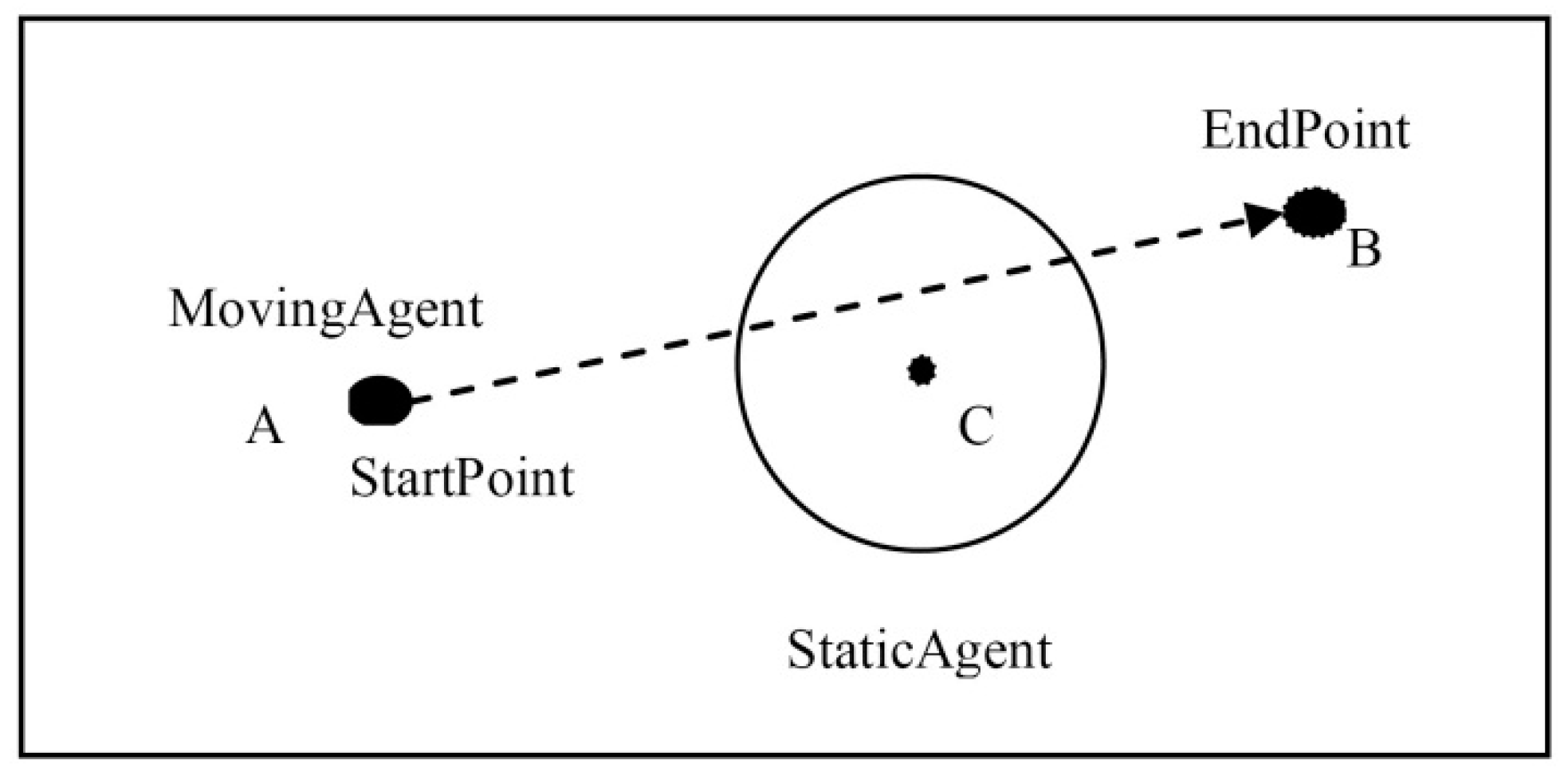
3.1. Context Overview
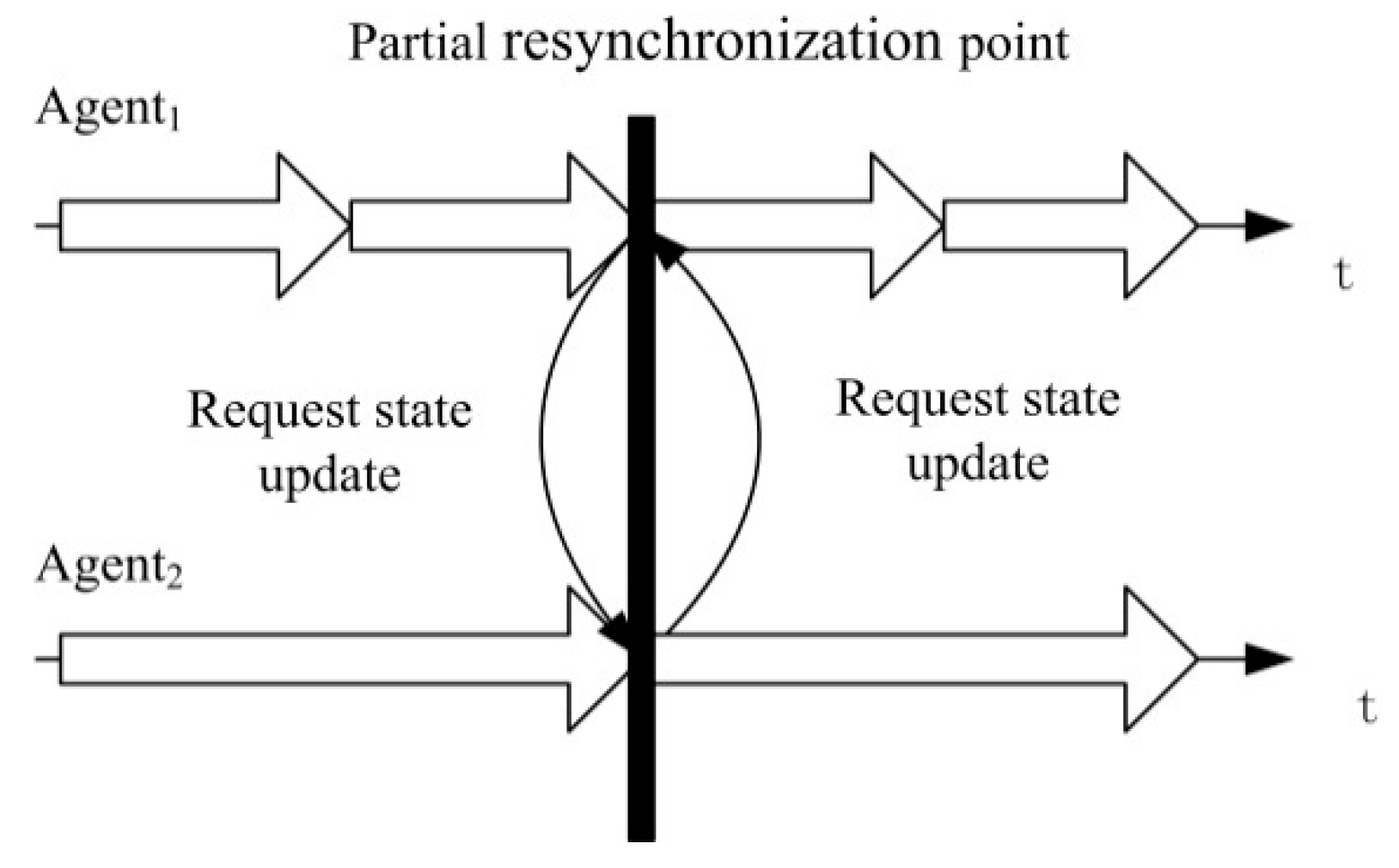
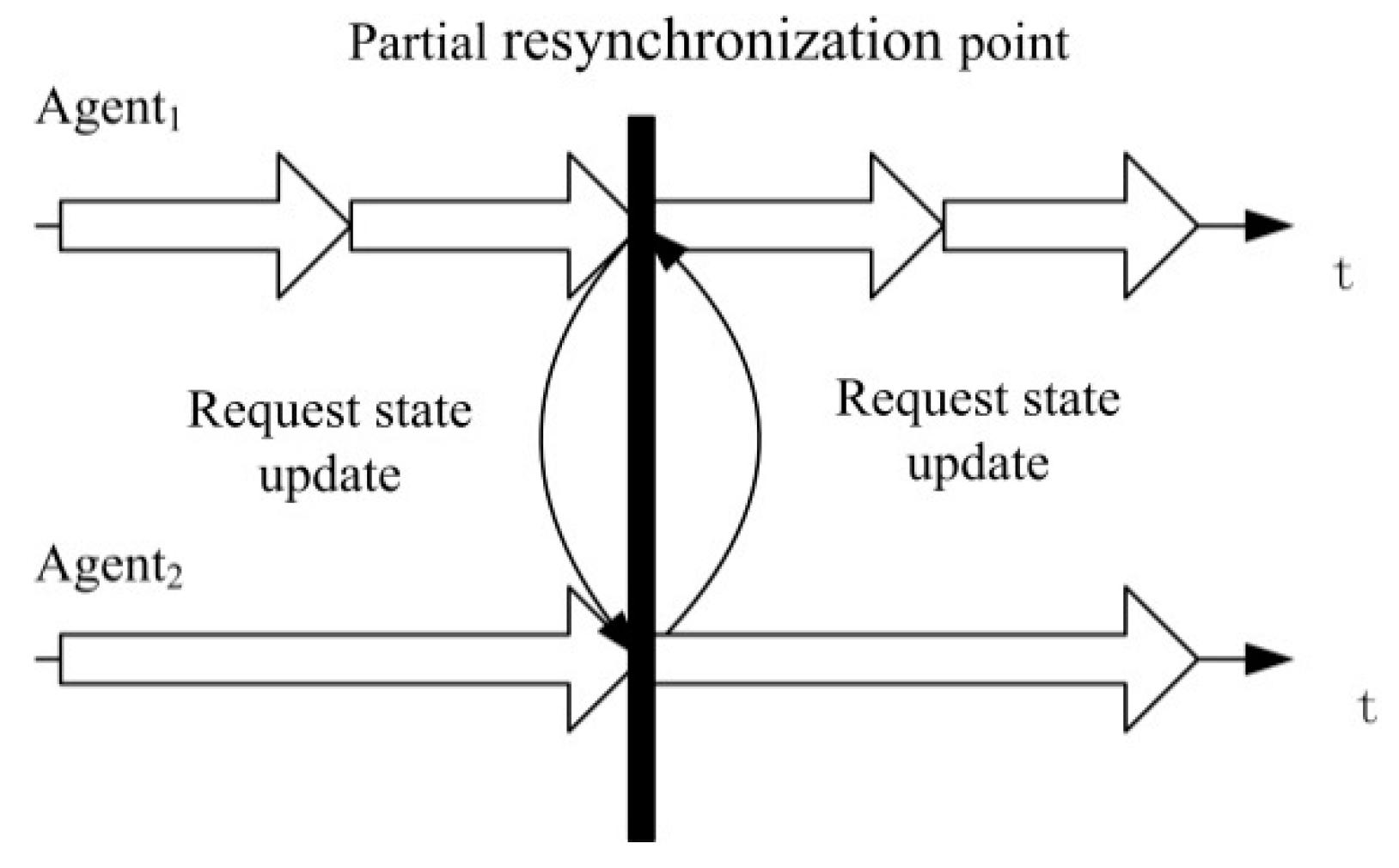
3.2. Main Problems of the PR
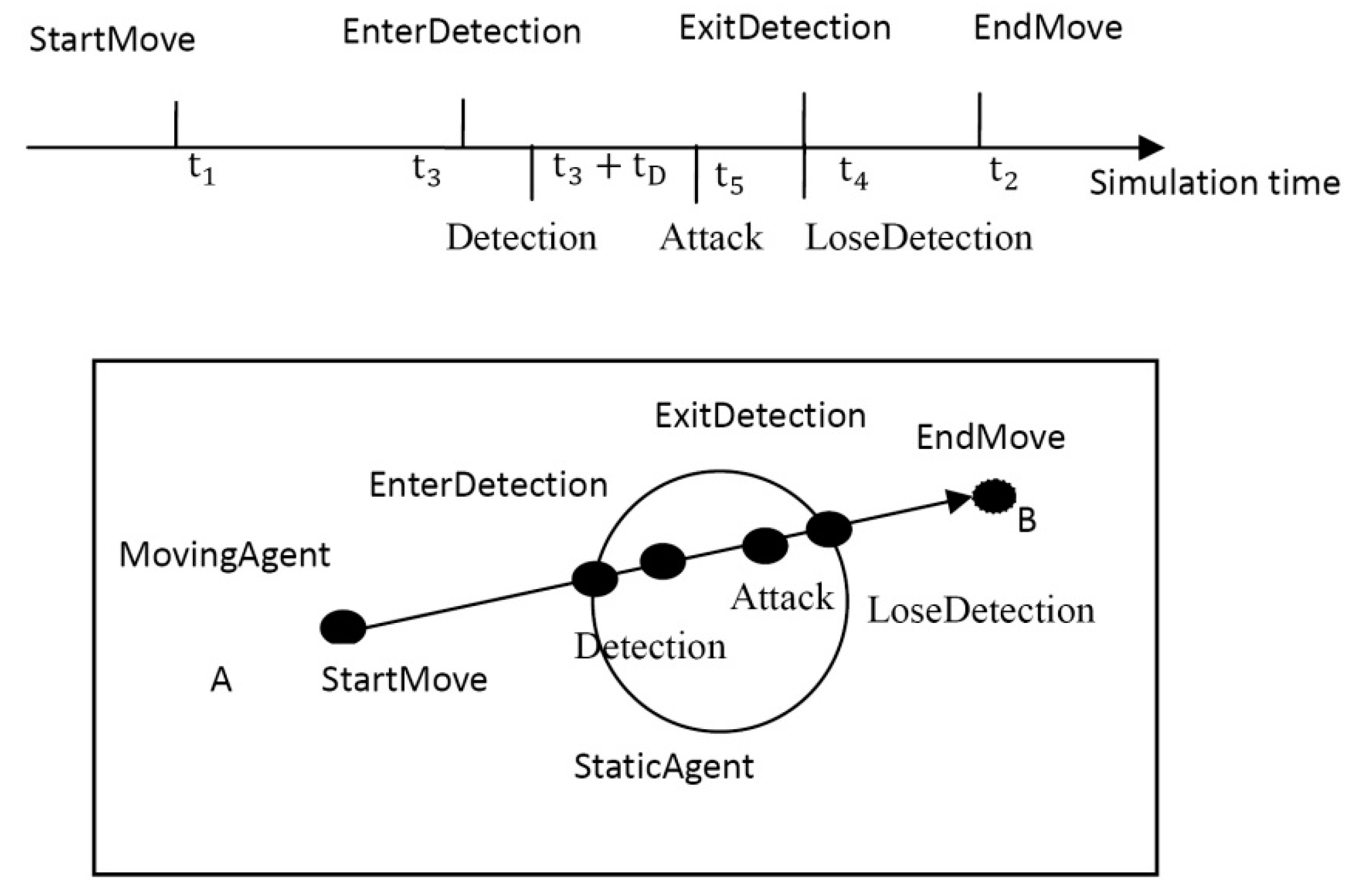
3.2.1. Resynchronization Interval Determination
3.2.2. Cyclic Dependency
- and , is the set of natural numbers,
- is the states of at time ,
- is the external state transition function of .
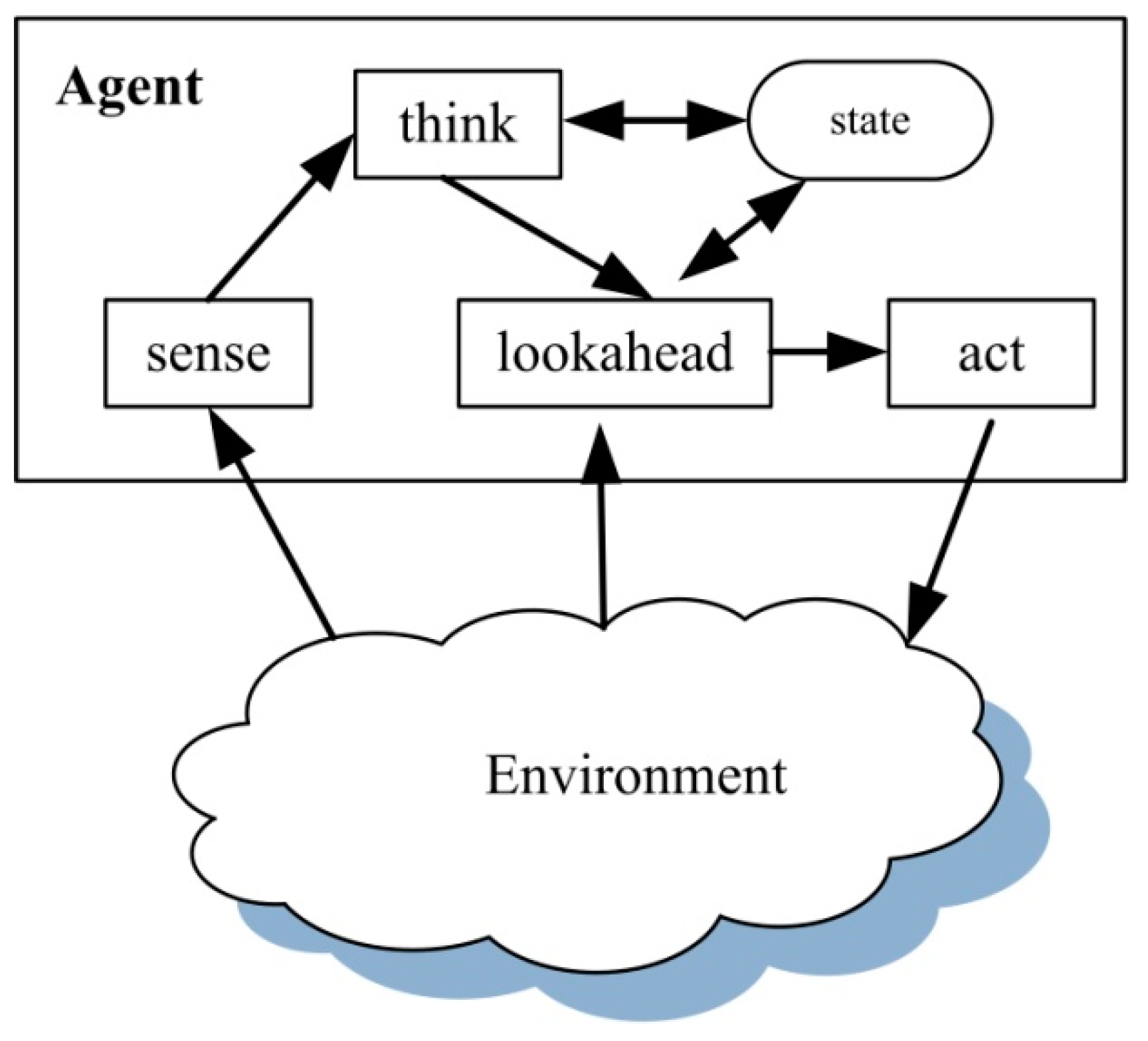
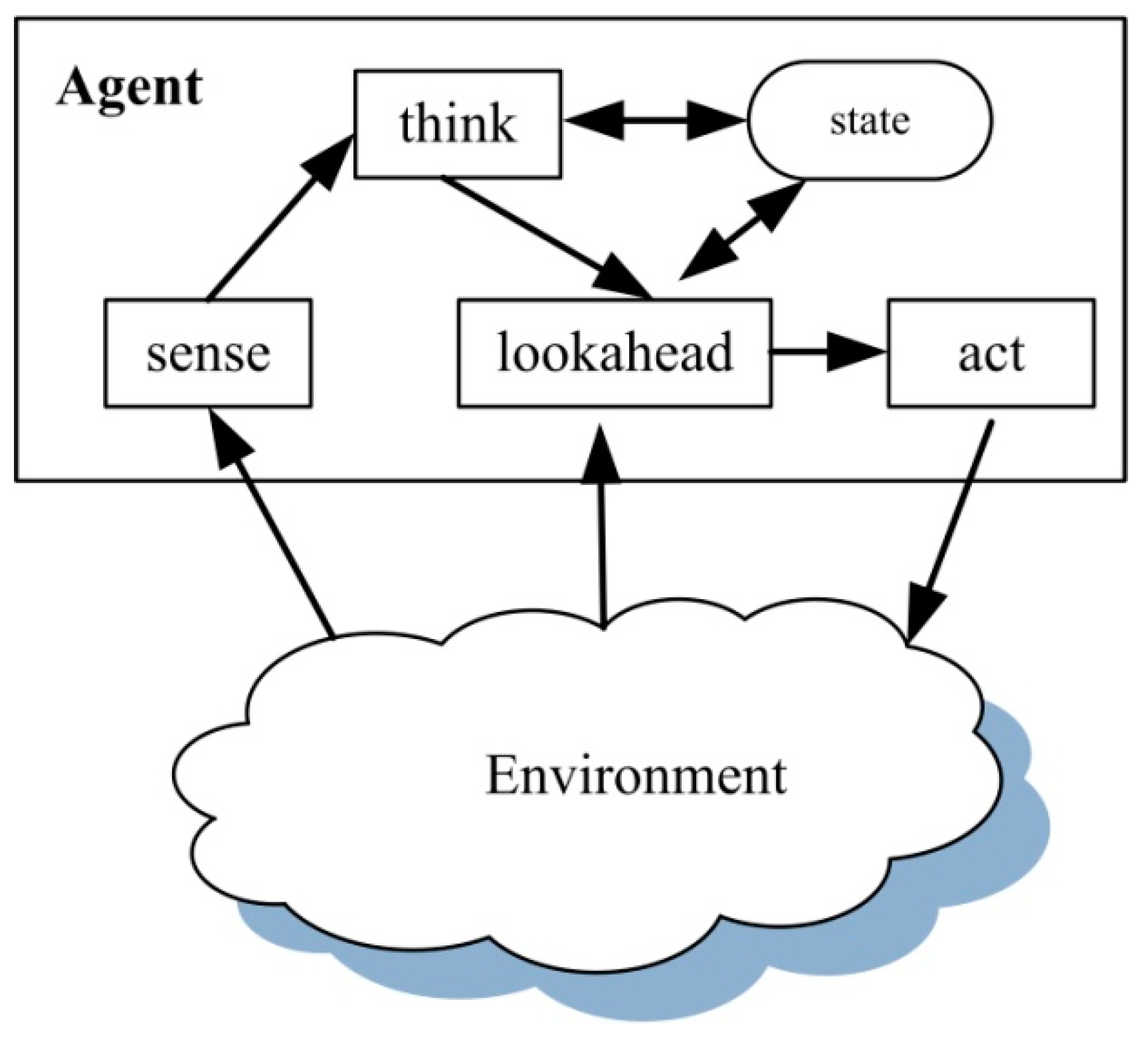
4. The Lookahead Behavior Model
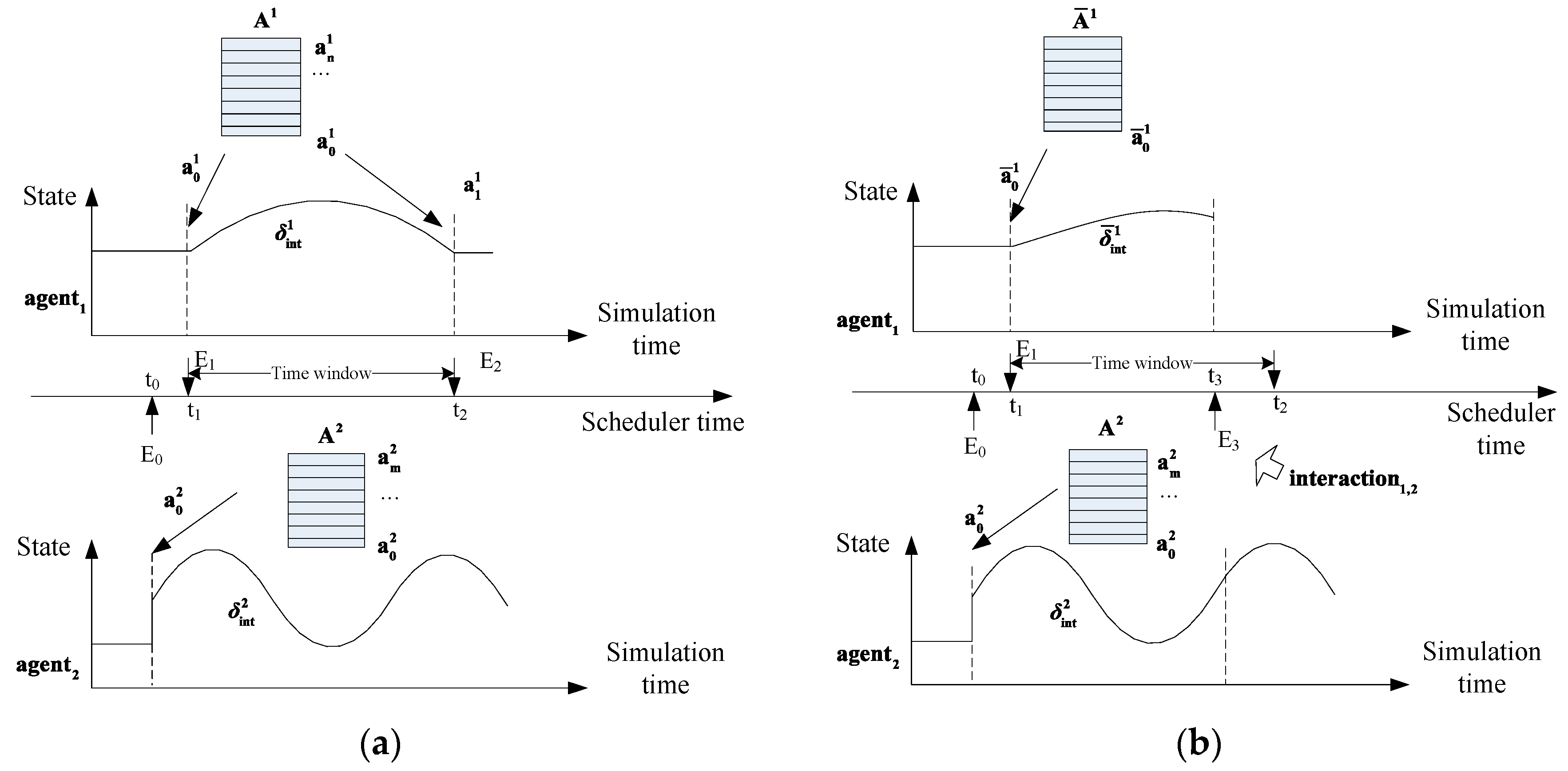
4.1. Time Window-Based Lookahead
- is the sender of interaction event, and can be or ;
- is the receiver of , and is an alternative choice;
- is the creating time of ;
- is the occurring time of ; and
- represents the corresponding interaction.
| Algorithm 1: Time window-based lookahead algorithm. |
| Input: next action to be performed at the moment by the primary Agent0: ; duration of action: Variables: // current simulation time Output: 1 2 = getAgentsMayInteractWithAction () 3 for each in the 4 = getCurrentPerformingAction() 5 = predictInteraction(,) 6 for each in the 7 = getPredictedTimeOfInteraction () 8 = getPredictedStateOfInteraction() 9 if() 10 = createEventFrominteraction(, , , ) 11 12 end if 13 end for 14 end for |
4.2. Estimate Value-Based Unlock
5. Case and Experiments
5.1. Case Scenario and Experiment Setup
- (1)
- Fixed time synchronization-based simulation (FS);
- (2)
- Variable time synchronization-based simulation (VS);
- (3)
- Complete resynchronization-based simulation (CR);
- (4)
- Partial resynchronization-based LBM simulation (LBM-PR).
5.2. Modeling of Lookahead
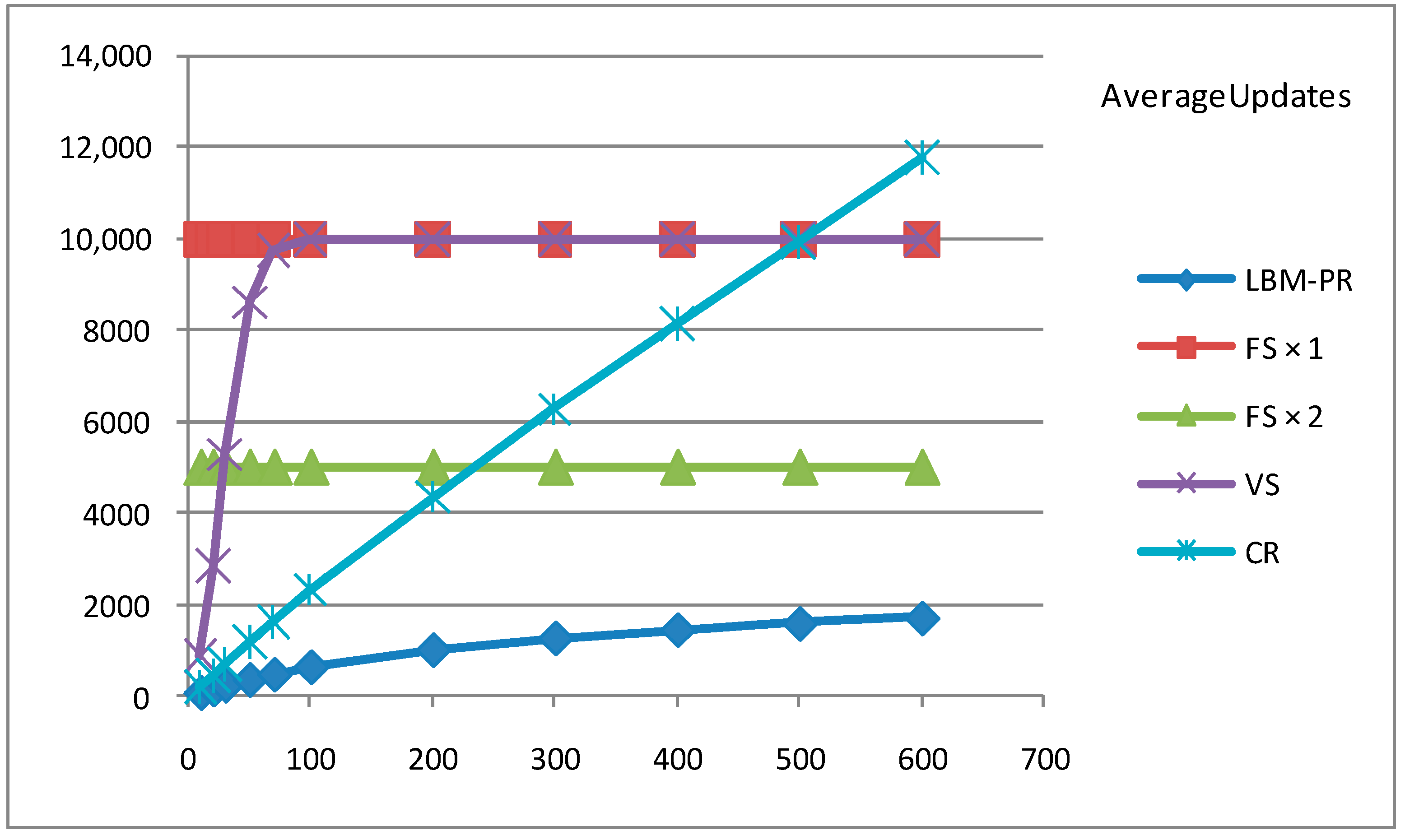
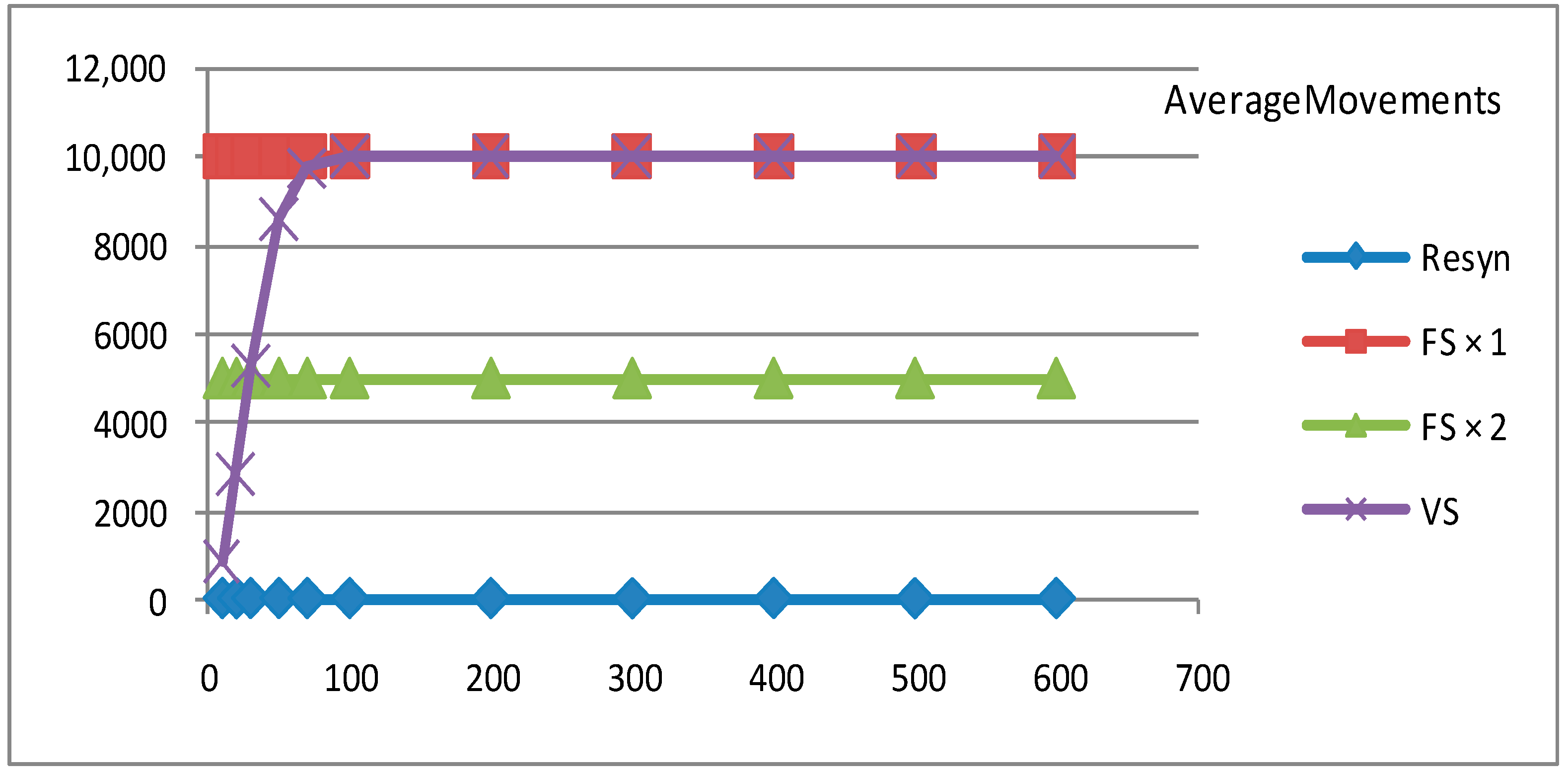
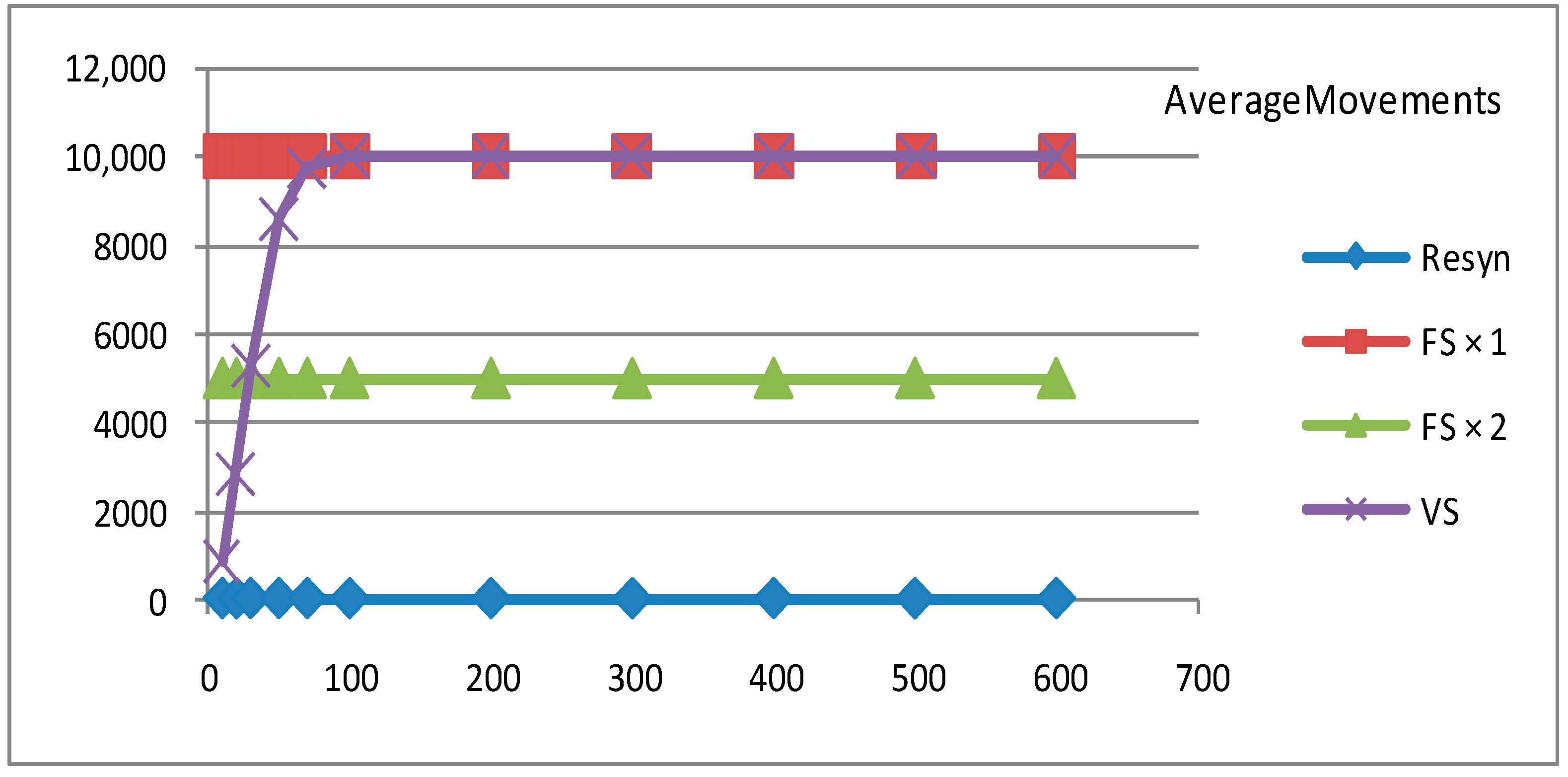
5.3. Experiment Results
6. Discussions
6.1. Characteristics
6.2. Applicable Scope
7. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Riley, P.F.; Riley, G.F. Next Generation Modeling III—Agents:Spades—A Distributed Agent Simulation Environment with Software-in-the-Loop Execution. In Proceedings of the 35th Conference on Winter Simulation: Driving Innovation, New Orleans, LA, USA, 7–10 December 2003; pp. 817–825. [Google Scholar]
- Uhrmacher, A.M.; Tyschler, P.; Tyschler, D. Modeling and simulation of mobile agents. Future Gener. Comput. Syst. 2000, 17, 107–118. [Google Scholar] [CrossRef]
- Theodoropoulos, G.; Logan, B. A framework for the Distributed Simulation of Agent-Based Systems. In Proceedings of the 13th European Simulation Multiconference (ESM’99), Warsaw, Poland, 1–4 June 1999; pp. 58–65. [Google Scholar]
- Hybinette, M.; Kraemer, E.; Xiong, Y.; Matthews, G.; Ahmed, J. Sassy: A design for a scalable agent-based simulation system using a distributed discrete event infrastructure. In Proceedings of the 2006 Winter Simulation Conference—(WSC 2006), Monterey, CA, USA, 3–6 December 2006; pp. 926–933. [Google Scholar]
- Sanchez, S.M.; Lucas, T.W. Exploring the world of agent-based simulations: Simple models, complex analyses. In Proceedings of the 2002 Winter Simulation Conference—(WSC 2002), San Diego, CA, USA, 8–11 December 2002; pp. 116–126. [Google Scholar]
- Kearns, M.; Singh, S.; Shelton, C.R.; Kormann, D.; Kormann, D. Cobot in lambdamoo: An adaptive social statistics agent. Auton. Agents Multi-Agent Syst. 2006, 13, 327–354. [Google Scholar]
- Scogings, C.; Hawick, K.A. Altruism amongst spatial predator-prey animats. In 11th International Conference on the Simulation and Synthesis of Living Systems (ALife XI); Bullock, S., Nobel, J., Watson, R., Bedau, M., Eds.; MIT Press: Winchester, UK, 2008; pp. 537–544. [Google Scholar]
- Cioffirevilla, C. Invariance and universality in social agent-based simulations. Proc. Natl. Acad. Sci. USA 2002, 99, 7314–7316. [Google Scholar] [CrossRef] [PubMed]
- Scogings, C.; Hawick, K.A. An agent-based model of the Battle of Isandlwana. In Proceedings of the 2012 Winter Simulation Conference—(WSC 2012), Raleigh, NC, USA, 9–12 December 2012; pp. 1–12. [Google Scholar]
- Ilachinski, A. Artificial War: Multiagent-Based Simulation of Combat; World Scientific: River Edge, NJ, USA, 2004. [Google Scholar]
- Beeker, E.R., III; Page, E.H. A case study of the development and use of a MANA-based federation for studying US border operations. In Proceedings of the 2006 Winter Simulation Conference, Monterey, CA, USA, 3–6 December 2006; pp. 841–847. [Google Scholar]
- Wu, S.; Shuman, L.; Bidanda, B.; Kelley, M.; Sochats, K.; Balaban, C. Agent-based discrete event simulation modeling for disaster responses. In Proceedings of the IIE Annual Conference and Expo 2008, Vancouver, BC, Canada, 17–22 May 2008; pp. 1908–1913. [Google Scholar]
- Zhang, B.; Chan, W.K.; Ukkusuri, S.V. Agent-based discrete-event hybrid space modeling approach for transportation evacuation simulation. In Proceedings of the Winter Simulation Conference 2011, Raleigh, NC, USA, 11–14 December 2011; Volume 16, pp. 199–209. [Google Scholar]
- Bouarfa, S.; Blom, H.A.; Curran, R.; Everdij, M.H. Agent-based modeling and simulation of emergent behavior in air transportation. Complex Adapt. Syst. Model. 2013, 1, 15. [Google Scholar] [CrossRef]
- Davis, P.K.; Kahan, J.P. Theory and Methods for Supporting High Level Military Decisionmaking; Rand Corporation: Santa Monica, CA, USA, 2007. [Google Scholar]
- Fishwick, P.A.; Kim, G.; Jin, J.L. Improved decision making through simulation based planning. Simul. Trans. Soc. Model. Simul. Int. 1996, 67, 315–327. [Google Scholar] [CrossRef]
- Schoemaker, P.J.H. Multiple scenario development—Its conceptual and behavioral foundation. Strat. Manag. J. 1993, 14, 193–213. [Google Scholar] [CrossRef]
- Lauren, M.; Stephen, R. Map-Aware Non-Uniform Automata (MANA)—A New Zealand Approach to Scenario Modelling. J. Battlef. Technol. 2002, 5, 27–31. [Google Scholar]
- Ross, J.L. A comparative study of simulation software for modeling stability operations. In Proceedings of the 2012 Symposium on Military Modeling and Simulation, Orlando, FL, USA, 26–30 March 2012. [Google Scholar]
- Lee, S.; Pritchett, A.R.; Goldsman, D. Hybrid agent-based simulation for analyzing the national airspace system. In Proceedings of the Winter Simulation Conference, Arlington, VA, USA, 9–12 December 2001; pp. 1029–1036. [Google Scholar]
- Chan, W.K.V.; Son, Y.J.; Macal, C.M. Agent-based simulation tutorial—Simulation of emergent behavior and differences between agent-based simulation and discrete-event simulation. In Proceedings of the Winter Simulation Conference, Baltimore, MD, USA, 5–8 December 2010; pp. 135–150. [Google Scholar]
- Brandolini, M.; Rocca, A.; Bruzzone, A.G.; Briano, C.; Petrova, P. Poly-functional intelligent agents for computer generated forces. In Proceedings of the Winter Simulation Conference, Washington, DC, USA, 5–8 December 2004; pp. 1045–1053. [Google Scholar]
- Zhaoxia, W.; Minrui, F.; Dajun, D.; Min, Z. Decentralized Event-Triggered Average Consensus for Multi-Agent Systems in CPSs with Communication Constraints. J. Battlef. Technol. 2015, 2, 248–257. [Google Scholar]
- Zeigler, B.P.; Kim, T.G.; Praehofer, H. Theory of Modeling and Simulation, 2nd ed.; Academic Press: San Diego, CA, USA, 2000; p. 474. [Google Scholar]
- Zhenhua, W.; Juanjuan, X.; Huanshui, Z. Consensus seeking for discrete-time multi-agent systems with communication delay. IEEE/CAA J. Autom. Sin. 2015, 2, 151–157. [Google Scholar]
- Wu, Y.; He, X. Secure Consensus Control for Multi-Agent Systems with Attacks and Communication Delays. IEEE/CAA J. Autom. Sin. 2017, 4, 136–142. [Google Scholar] [CrossRef]
- Hou, M.; Zhu, H.; Zhou, M.C.; Arrabito, G.R. Optimizing Operator-Agent Interaction in Intelligent Adaptive Interface Design: A Conceptual Framework. IEEE Trans. Syst. Man Cybern. Part C 2011, 41, 161–178. [Google Scholar] [CrossRef]
- Banks, J.; Carson, J.S., II; Nelson, B.L.; Nicol, D.M. Discrete-Event System Simulation, 4th ed.; Person Education: New York, NY, USA, 2005. [Google Scholar]
- Qian, X.; Yu, J.; Dai, R. A new discipline of science-the study of open complex giant system and its methodology. Nature 1990, 13, 3–10. [Google Scholar]
- Oguara, T.; Chen, D.; Theodoropoulos, G.; Logan, B.; Lees, M. An adaptive load management mechanism for distributed simulation of multi-agent systems. In Proceedings of the IEEE International Symposium on Distributed Simulation and Real-Time Applications, Montreal, QC, Canada, 10–12 October 2005; pp. 179–186. [Google Scholar]
- Reifelhoess, P. SPADES: A System for Parallel-Agent, Discrete-Event Simulation; American Association for Artificial Intelligence: Menlo Park, CA, USA, 2003; pp. 41–42. [Google Scholar]
- Scogings, C.J.; Hawick, K.A.; James, H.A. Tools and techniques for optimisation of microscopic artificial life simulation models. In Proceedings of the IASTED International Conference on Modelling, Simulation and Optimization, Gaborone, Botswana, 11–13 September 2006; pp. 90–95. [Google Scholar]
- Hu, X.; Muzy, A.; Ntaimo, L. A hybrid agent-cellular space modeling approach for fire spread and suppression simulation. In Proceedings of the 37th Conference on Winter Simulation, Orlando, FL, USA, 4–7 December 2005; pp. 248–255. [Google Scholar]
- Klingener, J.F. Programming combined discrete-continuous simulation models for performance. In Proceedings of the 28th conference on Winter simulation, Coronado, CA, USA, 8–11 December 1996; pp. 833–839. [Google Scholar]
- Dubiel, B.; Tsimhoni, O. Integrating agent based modeling into a discrete event simulation. In Proceedings of the 2005 Winter Simulation Conference—(WSC 2005), Lake Buena Vista, FL, USA, 4–7 December 2005; pp. 1029–1037. [Google Scholar]
- Wu, S. Agent-Based Discrete Event Simulation Modeling and Evolutionary Real-Time Decision Making for Large-Scale Systems. Ph.D. Thesis, University of Pittsburgh, Pittsburgh, PA, USA, 2008. [Google Scholar]
- Hiniker, P.J. A model of command and control processes for JWARS: Test results from controlled experiments and simulation runs. In Proceedings of the 7th International Command & Control Research & Technology Symposium, Quebec City, QC, Canada, 16–20 September 2002; pp. 1–16. [Google Scholar]
- Mason, C.R.; Moffat, J. An agent architecture for implementing command and control in military simulations. In Proceedings of the Winter Simulation Conference, Arlington, VA, USA, 9–12 December 2001; pp. 721–729. [Google Scholar]
- Lim, K.L.; Mann, I.; Santos, R.; Tobin, B.; Berryman, M.J.; Abbott, D.; Ryan, A. Adaptive battle agents: Complex adaptive combat models. In Microelectronics, MEMS, and Nanotechnology; SPIE: New York, NY, USA, 2005; pp. 48–60. [Google Scholar]
- Hiniker, P. The loaded loop: A complex adaptive systems model of C2 processes in combat. In Proceedings of the RAND Modeling of C2 Decision Processes Workshop, Mclean, VA, USA, 31 July–2 August 2001. [Google Scholar]
- Skinner, A.; Mcintyre, G.A. The Joint Warfare System (JWARS): A modeling and analysis tool for the defense department. In Proceedings of the Winter Simulation Conference 2011, Raleigh, NC, USA, 11–14 December 2011; pp. 691–696. [Google Scholar]
- Huang, K.D.; Zhao, X.Y.; Yang, S.L.; Yang, M.; Hu, F.H.; Cai, Y. System design description infrastructure overview for military simulation and analysis system. J. Syst. Simul. 2012, 24, 2439–2447. [Google Scholar]
- Yang, M.; Zhao, X.-Y.; Cai, Y.; Huang, K.-D. Key technologies of high performance simulation for analytical simulation evaluation. J. Syst. Simul. 2012, 24, 49–53, 81. [Google Scholar]
- Liu, B.H.; Huang, K.D. Multi-resolution modeling: Present status and trends. Acta Simul. Syst. Sin. 2004, 16, 1150–1154. [Google Scholar]
- Hawick, K.A.; James, H.A.; Scogings, C. High-performance Spatial Simulations and optimisations on 64-bit architectures. In Proceedings of the International Conference on Modeling, Scotland, UK, 24–29 July 2005; pp. 129–135. [Google Scholar]
- Bouwens, C.L.; Barnes, S.B.; Pratt, D.; Melim, P. Adapting forces modeling and simulation applications for use on high performance computational systems. In Proceedings of the Spring Simulation Multiconference, Orlando, FL, USA, 11–15 April 2010; p. 148. [Google Scholar]
- Prochnow, D.L.; Furness, C.Z.; Roberts, J. The use of the Joint Theater Level Simulation (JTLS) with the High Level Architecture (HLA) to produce distributed training environments. In Proceedings of the Simulation Interoperability Workshop, Orlando, FL, USA, 26–31 March 2000. [Google Scholar]
- James, K.K. Methodology for Alerting-System Performance Evaluation. J. Guid. Control Dyn. 1996, 19, 438–444. [Google Scholar]
- Jonsson, B.; Perathoner, S.; Thiele, L.; Yi, W. Cyclic dependencies in modular performance analysis. In Proceedings of the ACM International Conference on Embedded Software, Atlanta, GA, USA, 19–24 October 2008; pp. 179–188. [Google Scholar]
- Kim, T.G.; Zeigler, B.P. The DEVS Formalism: Hierarchical, Modular Systems Specification in an Object Oriented Framework. Proceedings of 1987 Winter Simulation Conference, Atlanta, GA, USA, 14 December 1987; pp. 559–566. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mechanism | All States Need to Be Updated? | All Agents Need to Be Updated? | Update Synchronizationly or Not? |
|---|---|---|---|
| FS | Yes | Yes | Synchronizationly |
| VS | Yes | Yes | Synchronizationly |
| OS | Yes | Yes | Synchronizationly + Asynchronously rollback |
| CR | No | Yes | Asynchronously |
| PR | No | No | Asynchronously |
| Approaches | Degree of Utilizing Efficiency Improvement of DES | Degree of Implementation | Can Dynamics Be Fully Modeled? | Available State Update Mechanism |
|---|---|---|---|---|
| SD | Completely | Hard | Not | CR/PR |
| CTD | Low | Simple | Yes | FS/VS/OS |
| PTD | Relatively low | Relatively simple | Yes | FS/VS/OS + CR/PR |
| IMD | Completely | Relatively hard | Yes | CR/PR |
| Symbol | Nomenclature |
|---|---|
| The number of agents in the system | |
| The th agent, | |
| The act performed by the th agent at time and this action is the th action it performs, | |
| The time set | |
| The current simulation time, | |
| The start time of the th action for the th agent , | |
| The duration of the th action for the th agent , | |
| The state of the th agent at time where | |
| The estimated state of the th agent at time predicted at time where | |
| The set of all the states of the th agent | |
| The set of all the lookahead states of the th agent | |
| The sequence of all actions performed by the th agent before time | |
| The set of the beginning time of acts performed by the th agent before time | |
| The set of all the actions of the th agent | |
| The set of the system’s actions | |
| The set of the system’s states | |
| The internal state transition function of the th agent | |
| The external state transition function of the th agent; it indicates that the state transition of the th agent occurred at one specific moment is related to the system’s existing acts and states | |
| The lookahead function of the state of the th agent; this implies that the state of the th agent predicted at one specific moment is related to the system’s existing acts and states | |
| A compound function of and for the second agent |
| Parameter | Value |
|---|---|
| Size of virtual space | 10,000 × 10,000 |
| Number of agents in total | 10, 20, 30, 50, 70, 100, 200, 300, 400, 500, 600 |
| Speed of MovingAgent | Random number, 1–100 |
| Detection radius of StaticAgent | Random number, 0–50 |
| Aspects | Original TBM | Delayed TBM | LBM |
|---|---|---|---|
| Steps contained in a cycle | Sense, think, and act | Sense, think, and act | Sense, think, lookahead, and act |
| The relationship of steps | Serial in a cycle, indispensible for each step | Serial in a cycle with arbitrary delays between two steps, indispensible for think step | Think/sense can be skipped, indispensible for lookahead before each action |
| The relationship of cycles | Fixed time interval | Arbitrary delay | Arbitrary |
| Ability to conduct simultaneously | No | Yes (except for think step) | Yes |
| Number of updates | More | More | Less |
| Number of resynchronizations | More | More | Less |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, M.; Peng, Y.; Ju, R.-S.; Xu, X.; Yin, Q.-J.; Huang, K.-D. A Lookahead Behavior Model for Multi-Agent Hybrid Simulation. Appl. Sci. 2017, 7, 1095. https://doi.org/10.3390/app7101095
Yang M, Peng Y, Ju R-S, Xu X, Yin Q-J, Huang K-D. A Lookahead Behavior Model for Multi-Agent Hybrid Simulation. Applied Sciences. 2017; 7(10):1095. https://doi.org/10.3390/app7101095
Chicago/Turabian StyleYang, Mei, Yong Peng, Ru-Sheng Ju, Xiao Xu, Quan-Jun Yin, and Ke-Di Huang. 2017. "A Lookahead Behavior Model for Multi-Agent Hybrid Simulation" Applied Sciences 7, no. 10: 1095. https://doi.org/10.3390/app7101095
APA StyleYang, M., Peng, Y., Ju, R.-S., Xu, X., Yin, Q.-J., & Huang, K.-D. (2017). A Lookahead Behavior Model for Multi-Agent Hybrid Simulation. Applied Sciences, 7(10), 1095. https://doi.org/10.3390/app7101095