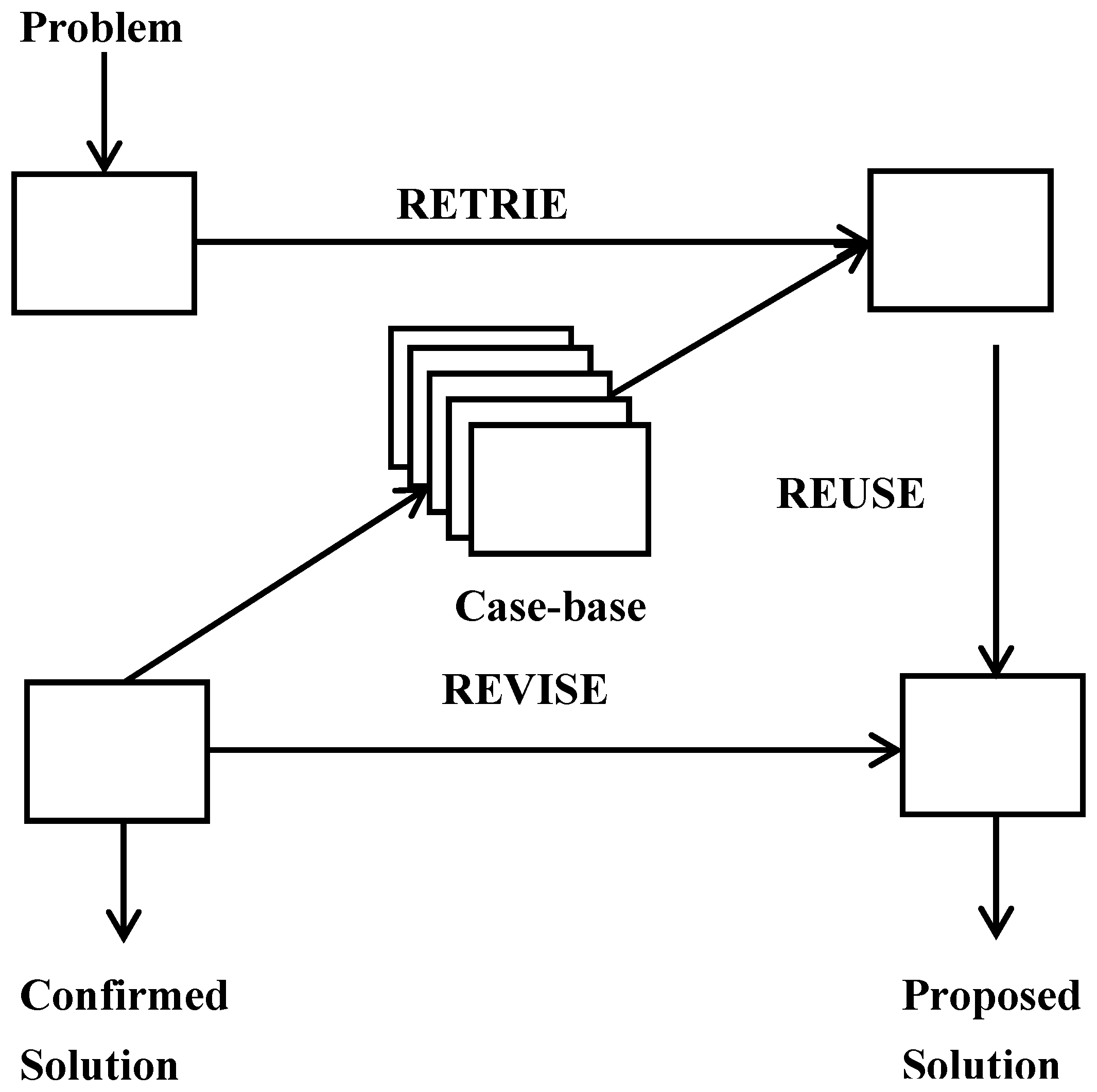
3.1. Introduction
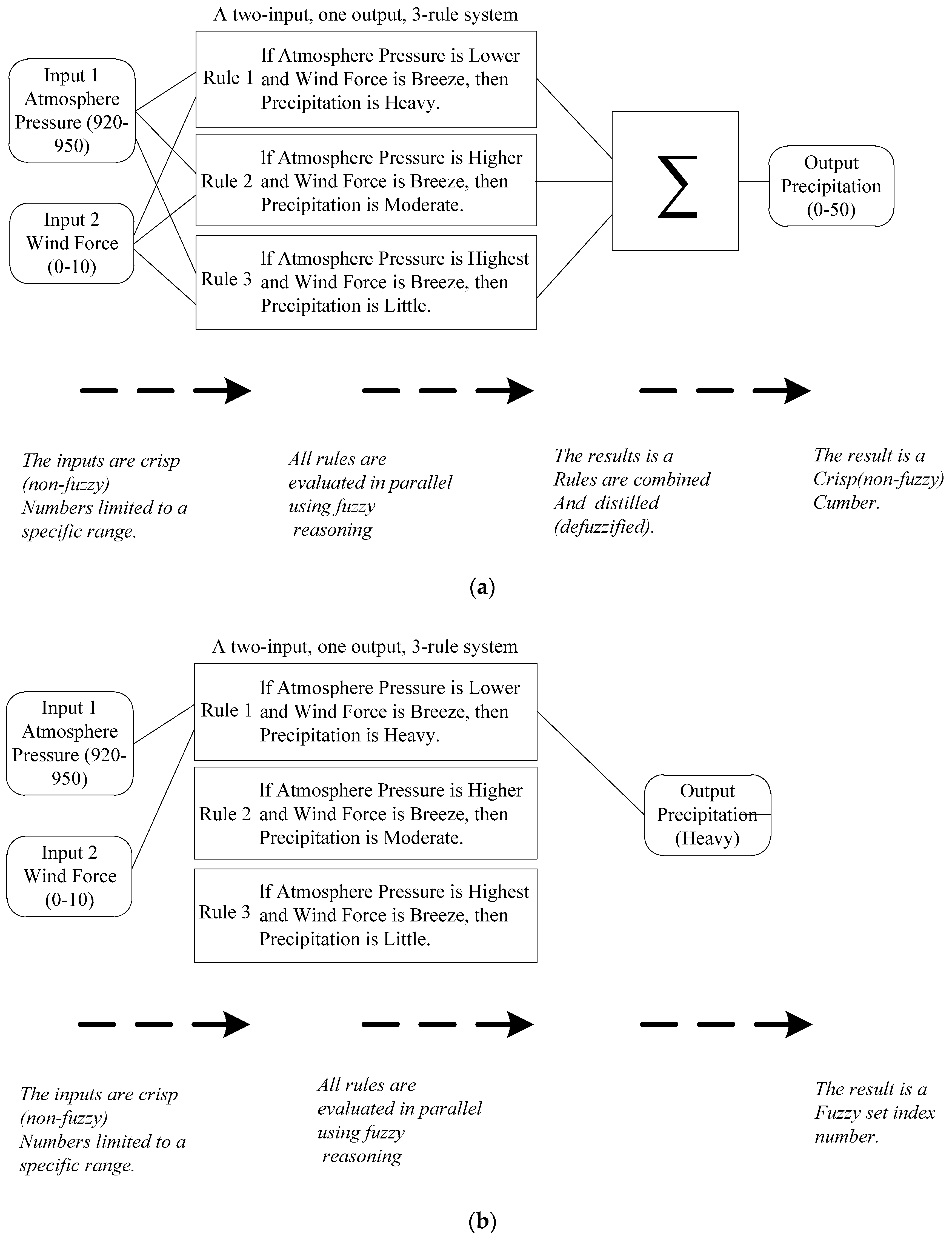
We may notice that fuzzy case-based reasoning system is a kind of fuzzy expert system, but differs from them significantly. Previous fuzzy expert systems make use of “fuzzy inference”, formulating the mapping from a given crisp input to a crisp output using fuzzy logic. The process of fuzzy inference involves all of the pieces that are described in Membership Functions, Logical Operations, and If-Then Rules. This section describes the steps of a fuzzy expert system and uses the example of the two-input, one-output, three-rule problem. The basic structure of this example is shown in the following diagram,
Figure 2a. From
Figure 2a, we see that the inputs of a fuzzy expert system are crisp and the outputs are also crisp; in intermediate layers, fuzzy logic is used for predicting the outcomes given an input set based on the background knowledge—fuzzy rules and the membership functions. Our fuzzy case-based reasoning system is shown in
Figure 2b. From
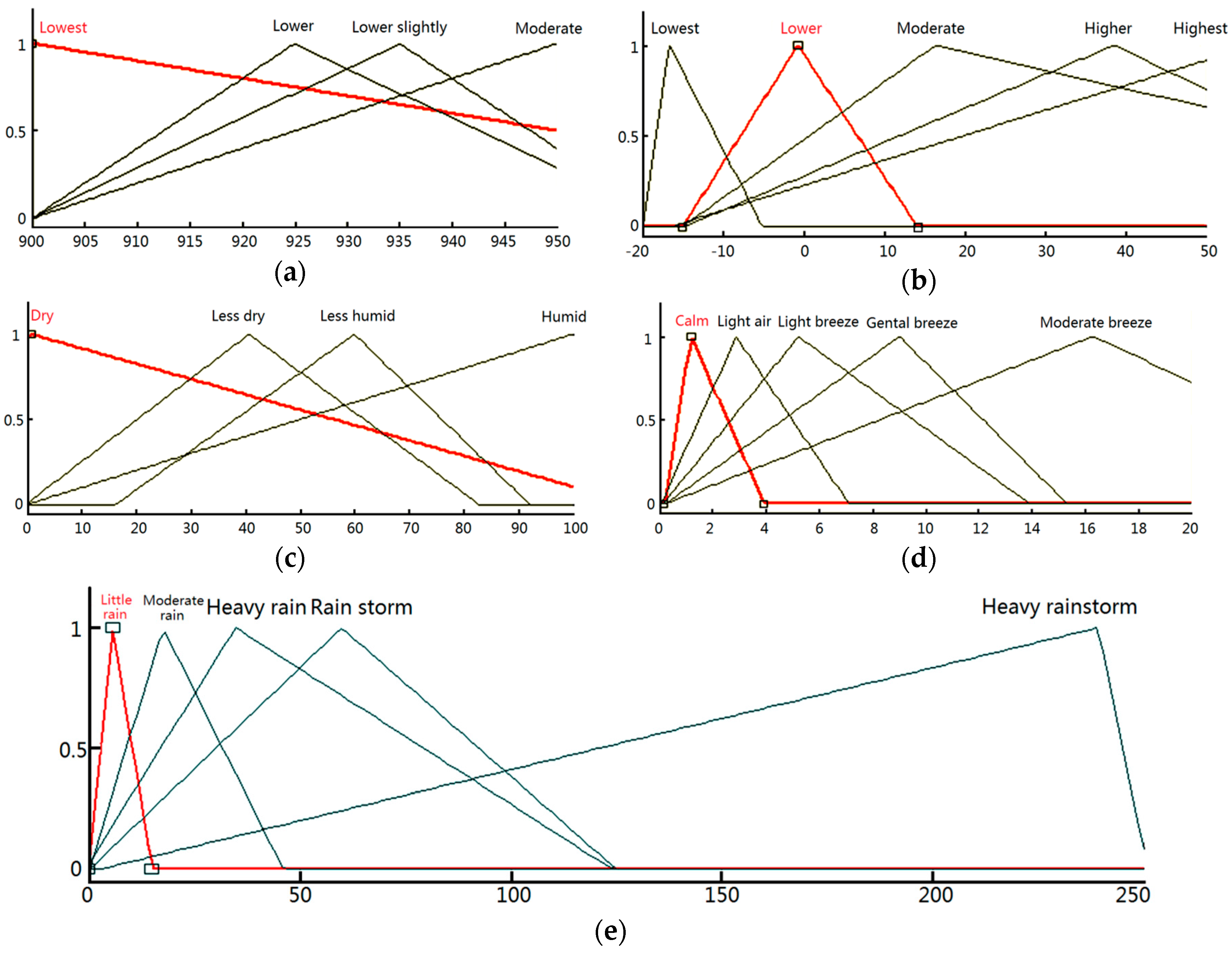
Figure 2b, we first transfer the crisp inputs into fuzzy ones. Assume input 1 (Atmosphere Pressure) is “Lower” and input 2 (Wind Force) is “Breeze”, according to the case base created in advance, then the output (Precipitation) is “Heavy”, which is a fuzzy output.
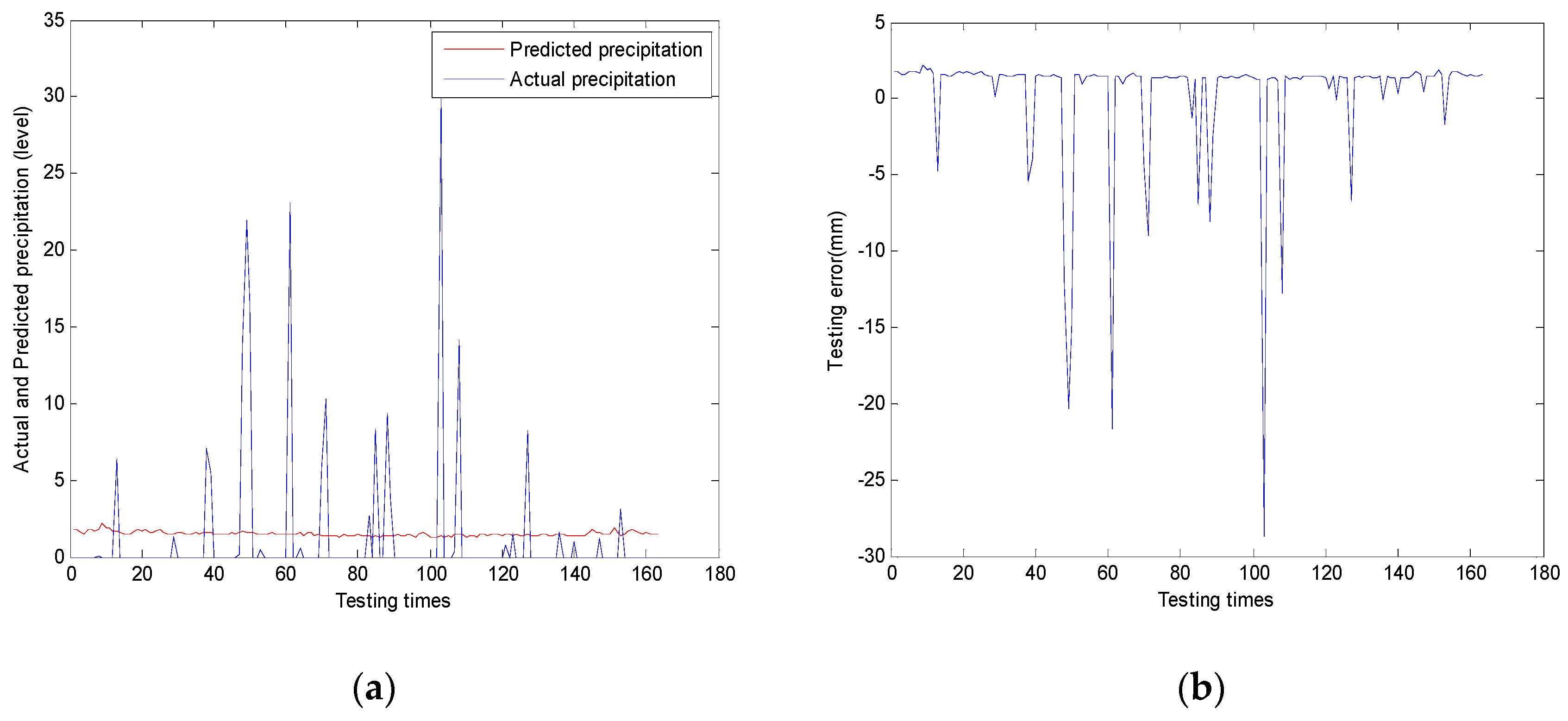
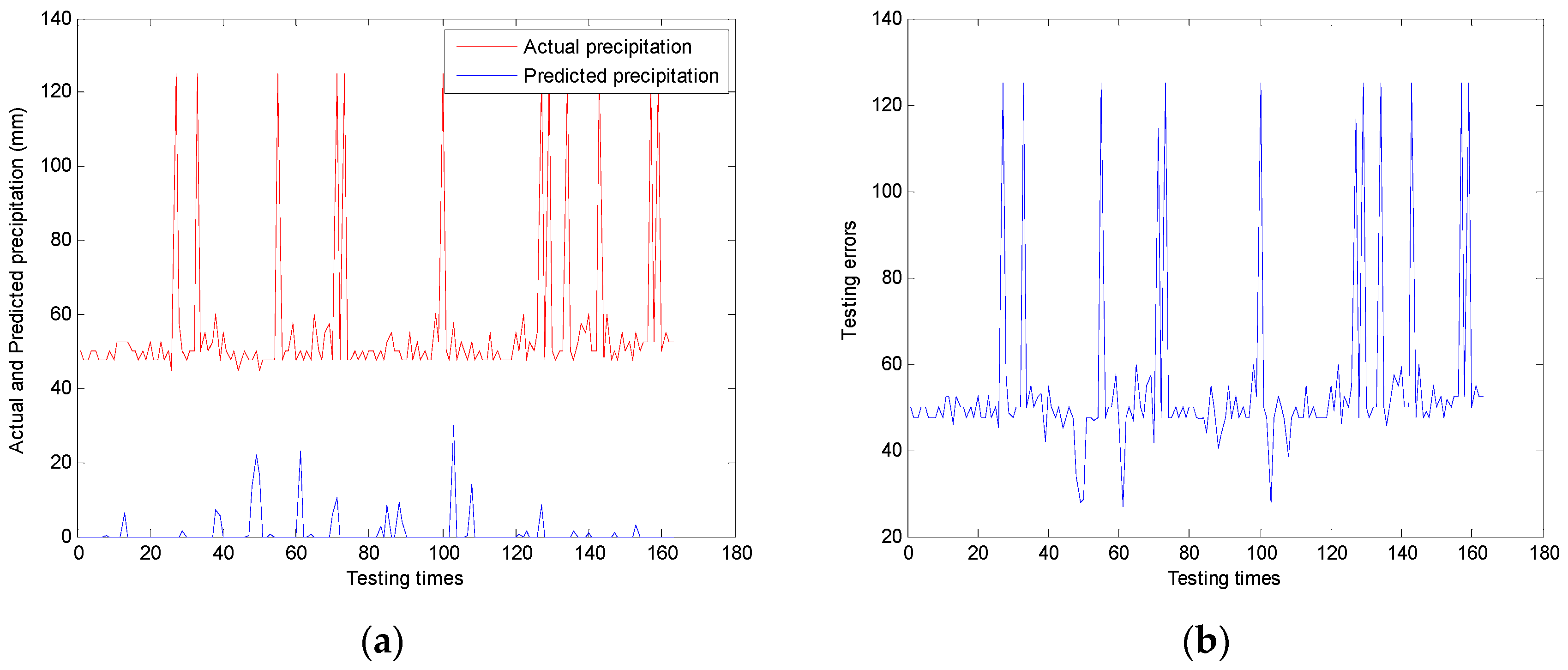
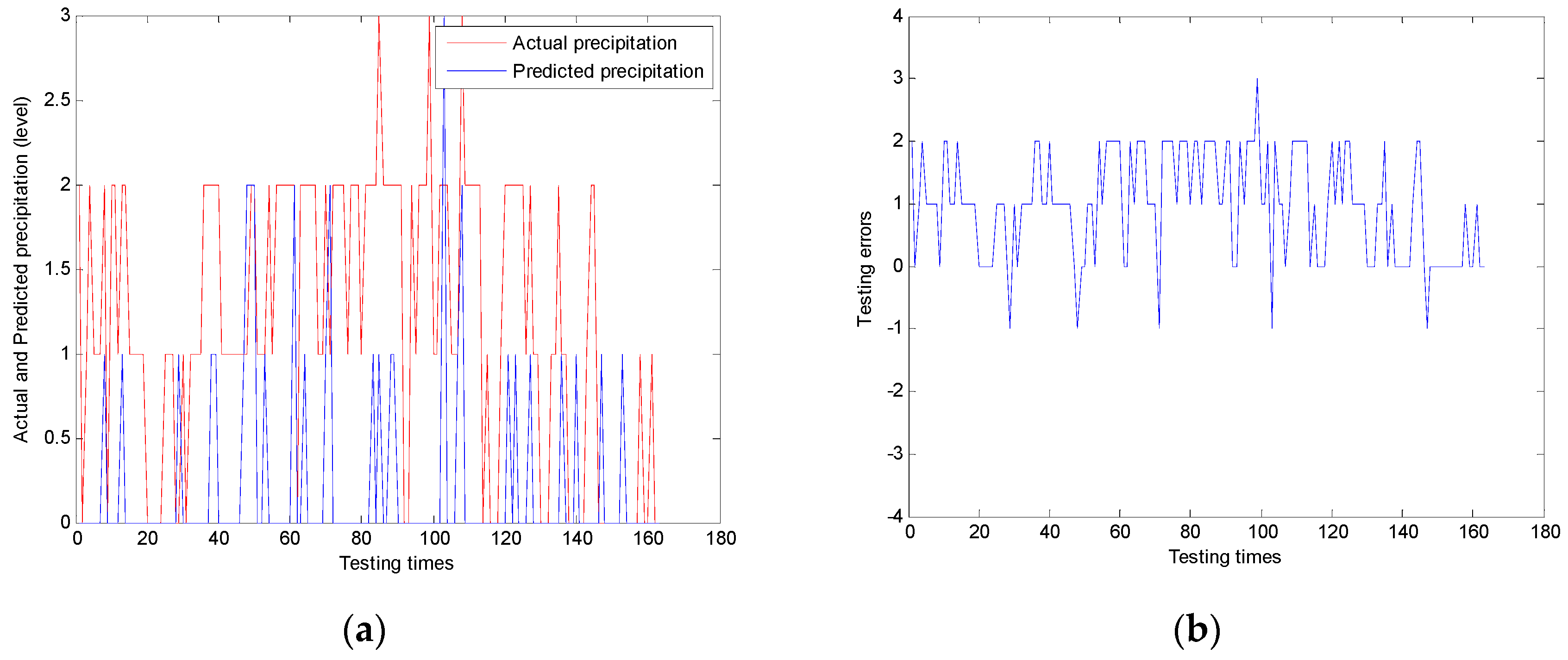
The most important reason for changing crisp cases into fuzzy ones is that the prediction results may get better with the fuzzication process. It is well known that the need for accurate prediction is apparent when considering the benefits that it has. However, experiments show that the accurate crisp patterns make some accurate prediction results useless and meaningless. We also add the “vague” concept into the pattern reduction problem. It is somewhat vague inputs that make the outcomes of prediction more meaningful and accurate.
Some would say that this better prediction accuracy might be achieved by sacrificing the output precision, and sometimes that is the case. The disadvantage of this system is that it can increase the prediction accuracy, but must sacrifice the precision.
Sometimes, however, this is not the case. Experiments and the proof show that with the output precision unchanged (only change the inputs fuzzification), the prediction accuracy can still be increased. These phenomena can be intuitively understood because fuzzy ones may solve a problem better than a more accurate one. Sometimes, several elements together take effect, and if we divide them then we will not be able to get desired results.
3.2. Transfer Crisp Cases to Fuzzy Ones
Susan Haack once claimed that a many-valued logic requires neither intermediate terms between true and false, nor a rejection of bivalence. Her suggestion was that the intermediate terms (i.e., the gradations of truth) can always be restated as conditional if-then statements, and by implication, that fuzzy logic is fully reducible to binary true-or-false logic. This interpretation of a long sequence of if-then statements is often enormously less efficient than membership functions, although they have the same meaning to represent a fuzzy set [
27,
28,
29,
30,
31]. However, this point is obviously of great importance for computer programmers.
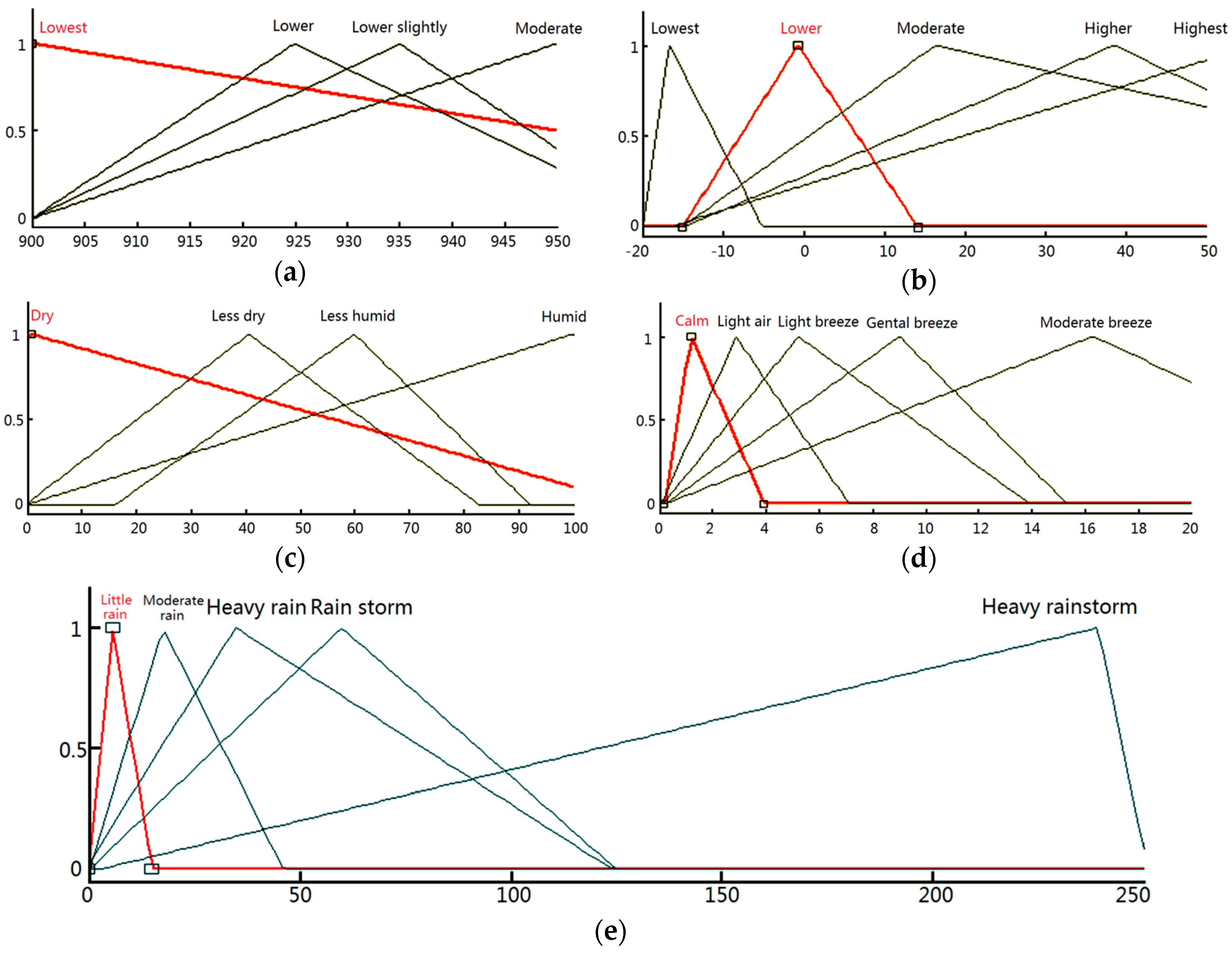
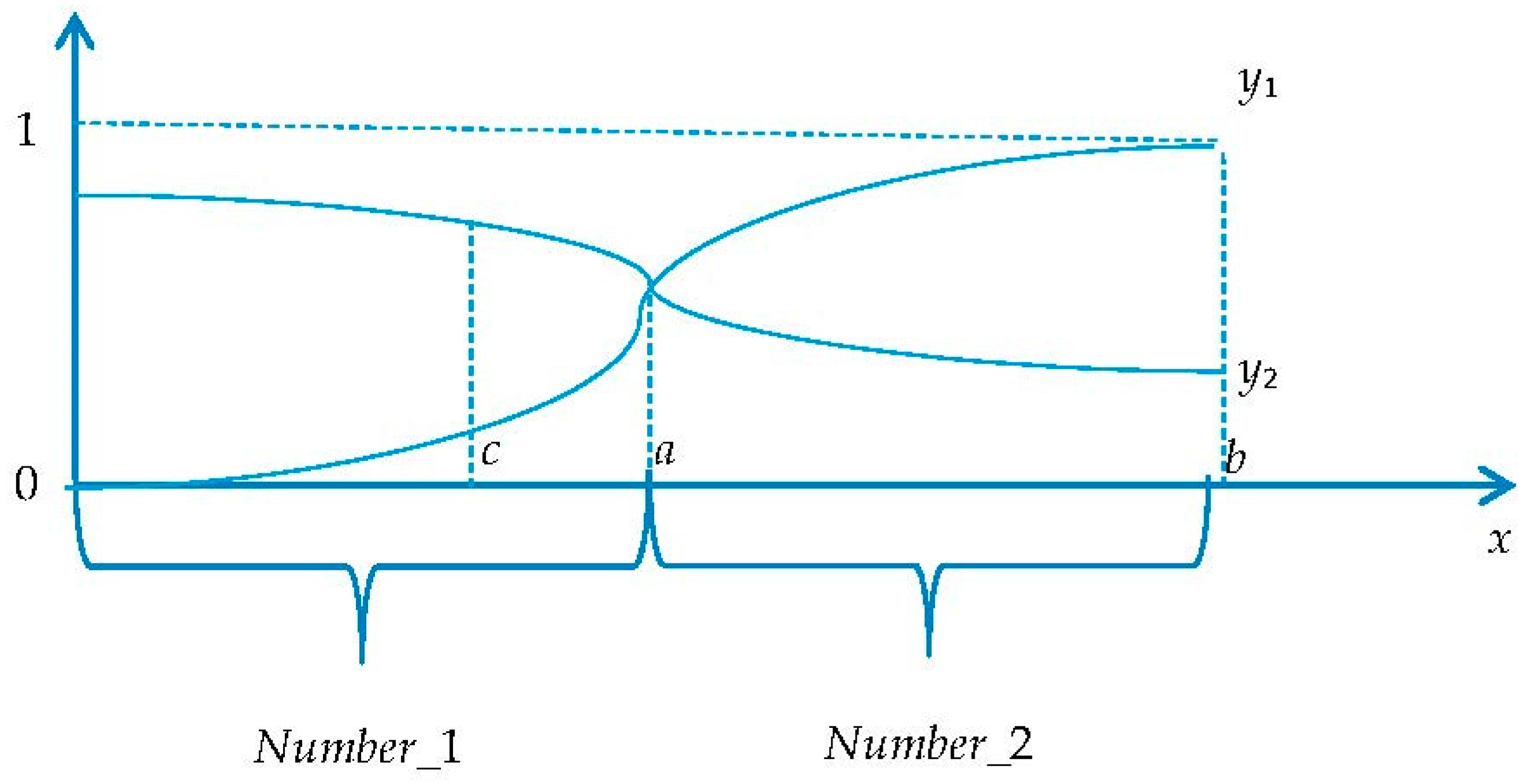
In our paper, we change Susan Haack’s idea to represent a fuzzy set by a long sequence of if-then statements. Specifically, an interval is the “if” part of a “if-then” statement, and the positive integer is the “then part” of it. An example is given in
Figure 3. Usually, different fuzzy sets are represented by different membership functions shown in
Figure 3, for example shown as
y1 and
y2, correspondingly match with “Small” and “Large”. In real ideal circumstance, there is no overlapping between the original domain(
x), but sometimes in real world,
y1 and
y2 share the same domain (shown in
Figure 3), and given a crisp number
c that partially belongs to Small and partially belongs to Large, which fuzzy set should
c belong to? According to the maximum degree principle,
c belongs to the fuzzy set Small since
y2(
c) >
y1(
c). Thus, we fuzzify one premise of a case by interpreting an interval as a number. If one premise of a case falls within an interval, we set it to a numerical value. From the
Figure 3, if a premise is between 0 and
a,
y2(
c) >
y1(
c), we set the interval value to Number_1; if the premise is between
a and
b,
y2(
c) >
y1(
c), we set the interval value to Number_2. Now we fuzzify a case by fuzzifying each compositive element (premise) using the interval transfer method mentioned above. Thus, each element is transferred to a fuzzy set denoted by a crisp positive integer.
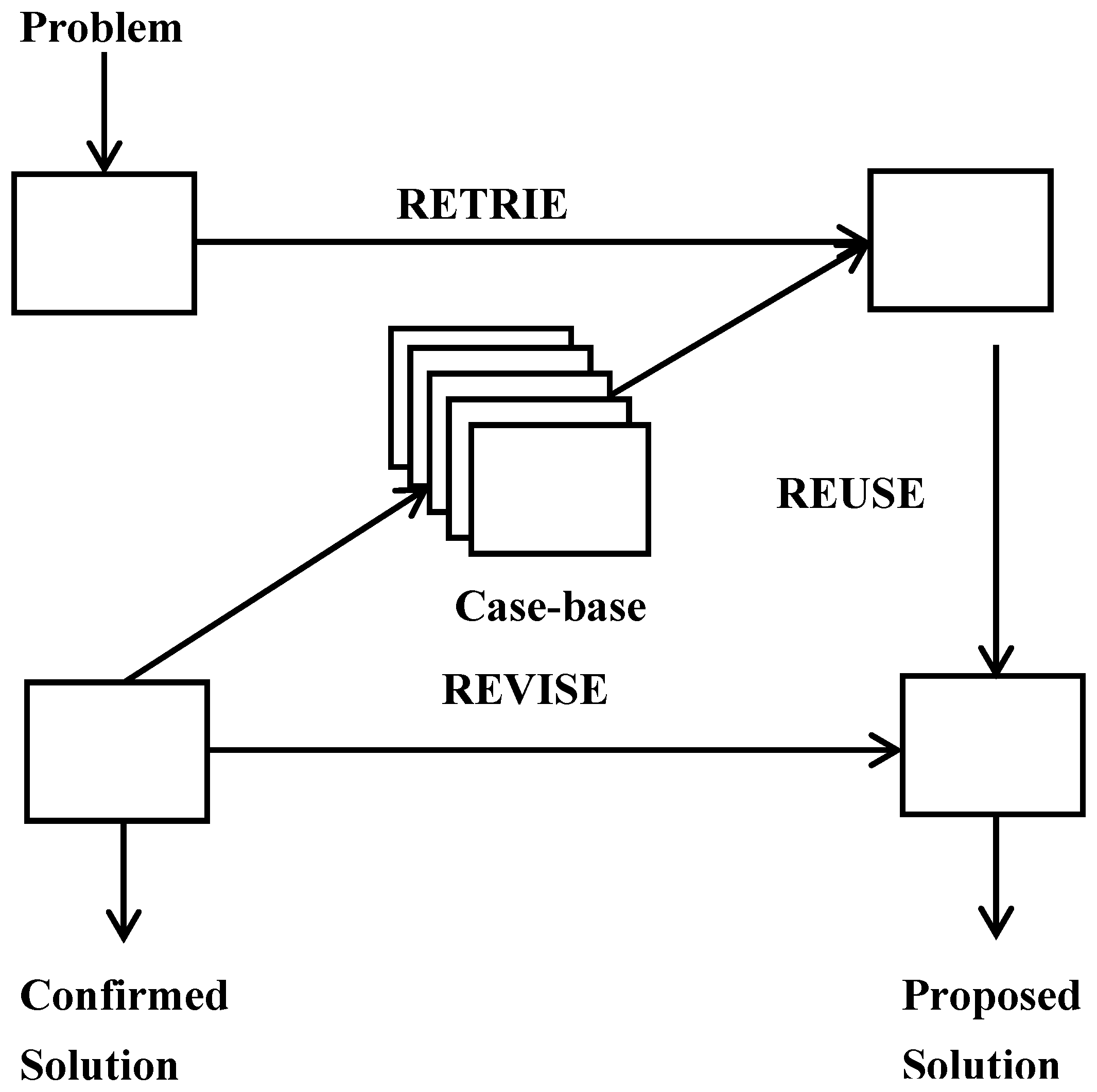
In real circumstance, a case in case-based reasoning is complicated and can be represented in various forms. Traditional approaches can be classified into three main categories: feature vector representations, structured representations, and textual representations. More sophisticated approaches make use of hierarchical representations. For particular tasks such as designing and planning, highly specific representations have been developed. Developments have been made in the process of refining in case-based reasoning as shown above. However, in this paper, we take the opposite direction and reduce the complexity of cases and their total number (different case elements may be transferred to the same number and correspondingly previous different cases are changed to the same). Most important of all, the prediction results may get better with the fuzzification process.
3.3. Fuzzy Case-Based Algorithm
The fuzzy case-based algorithm is the algorithm executed in the fuzzy case-based reasoning system and symbols used are shown in
Table 2.
/* we assume that there are r fuzzy cases (rules) in the base with the same structure and each case is composed of n fuzzy premises (features) in each case and one fuzzy output.*/
Stage 1: In this stage, crisp numbers are mapped to corresponding fuzzy sets. We divided these fuzzy sets according to different intervals.
Stage 2:
for j = 1 to r
PreCount[] = 0; // set PreCount[] to zero
for i = 1 to n
if (cnew.p ==cji)
PreCount[j] ++ ;
end
end
if (PreCount[j] == n) // PreCount[j] == n when the j th fuzzy rule’s premises are the same to the new coming rule
cnew.o = cj(n+1);
cnew.push();
end
end
Countj = 0
if k = 1 to r
if (PreCount[j] ! = 0)
Countj = 1;
break;
end
if (Countj == 0) // Countj == 0 means the new coming case(rule) is a new one.
CasebasedReasoning();
/* “CasebasedReasoning()” is a function that could doing the case-based reasoning. */
else cnew.o = cb(n+1)
cnew.push();
end
|
Stage 3: We use CasebasedReasoning() function to simulate the inference process.
Stage 4: We return to Stage 1 but keep the original fuzzy classification on fuzzy outputs unchanged. Thus, we maintain the precision and show a change in prediction accuracy with the change in fuzzy classification of fuzzy inputs.
/* “restricted domain” means the reasonable range of the output. If we hope to restrict the range of the output to {1, 2, 3, 4, 5}, the restricted domain is {1, 2, 3, 4, 5}. β is a threshold to control the similarity degree of the output and the element of the restricted domain.*/
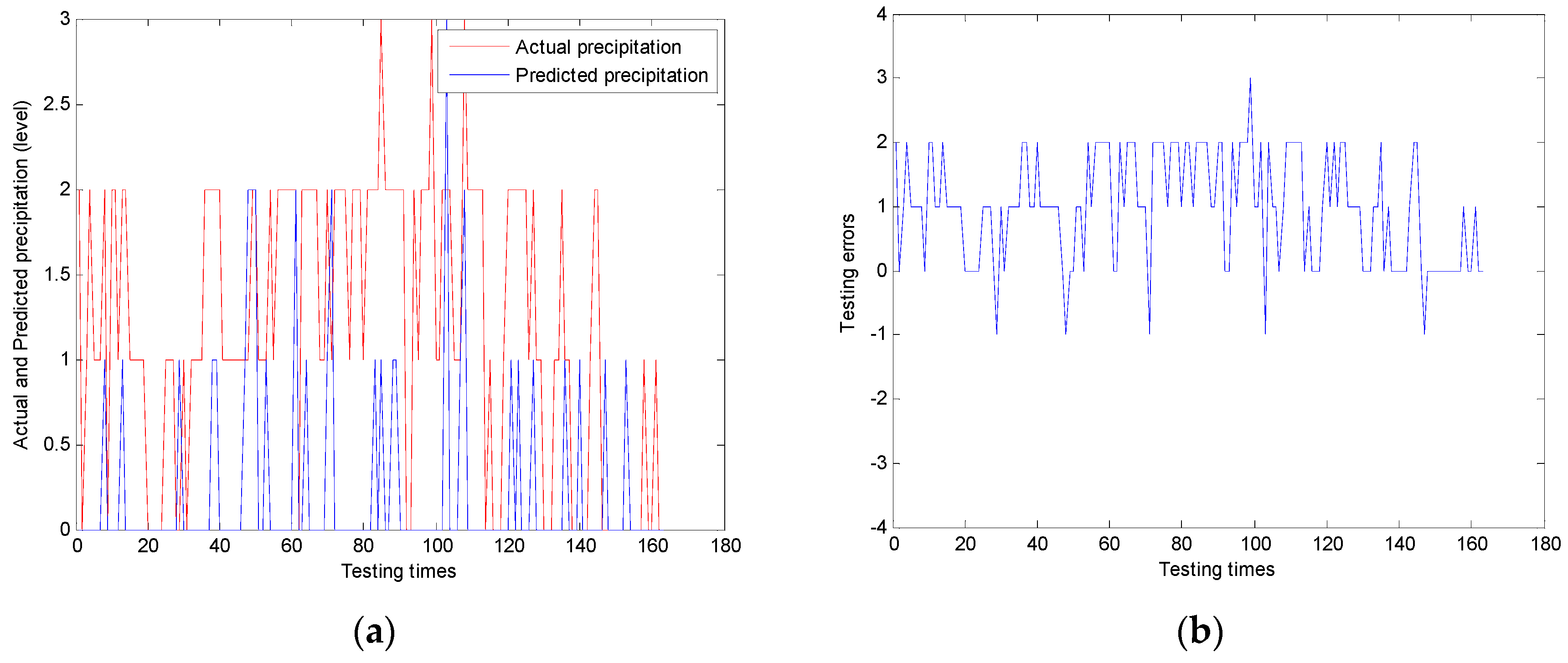
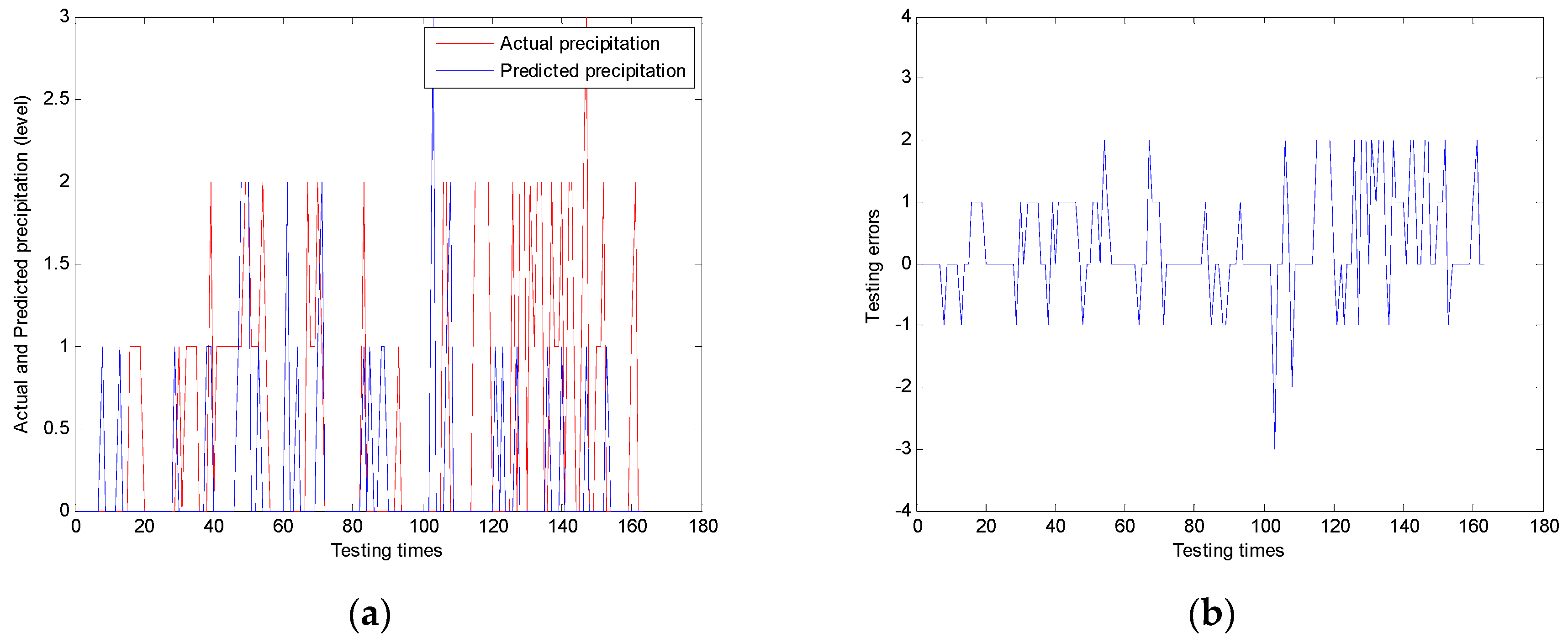
Definition 3.2: let
Correctp be number of correct predictions and let overall number of predictions be
Totalp. The hitting rate
Hitrate is defined as:
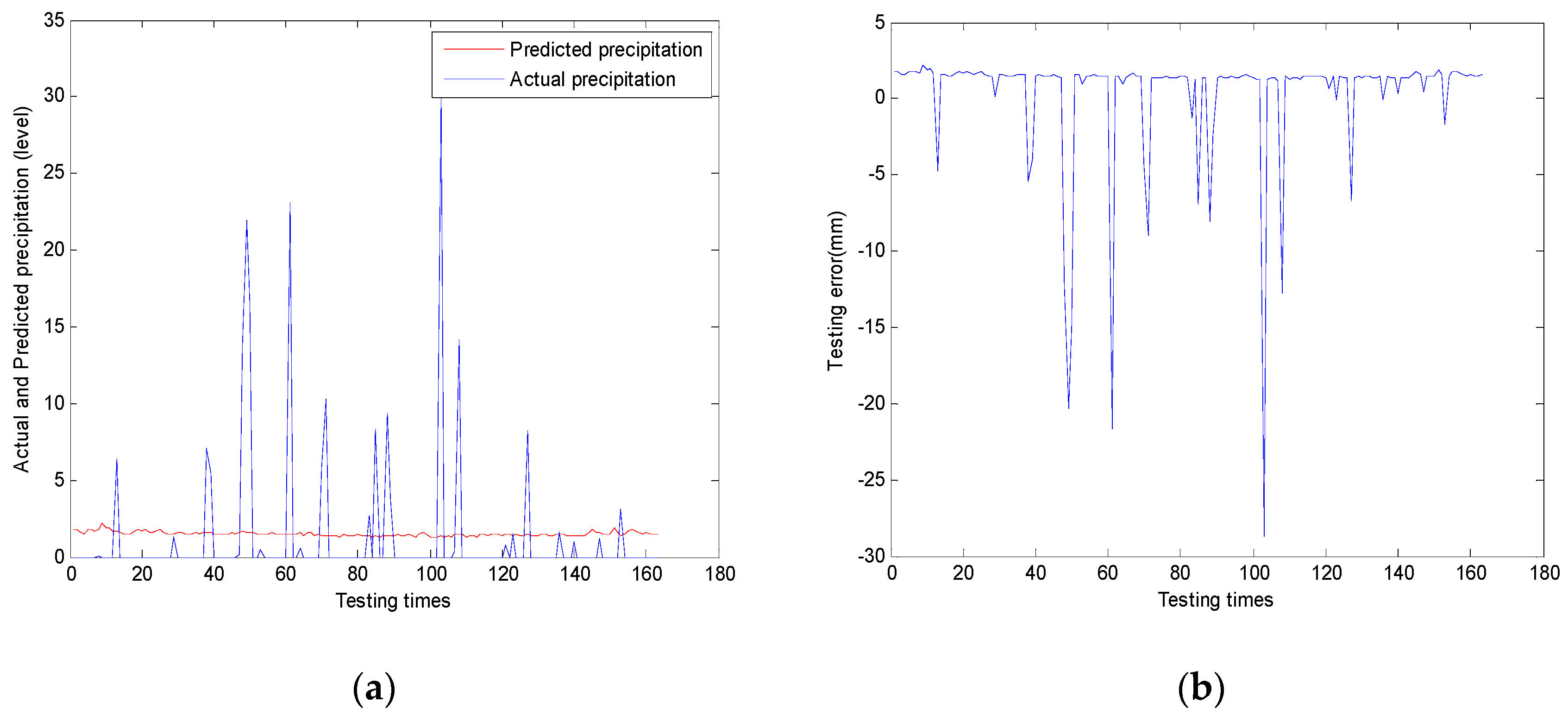
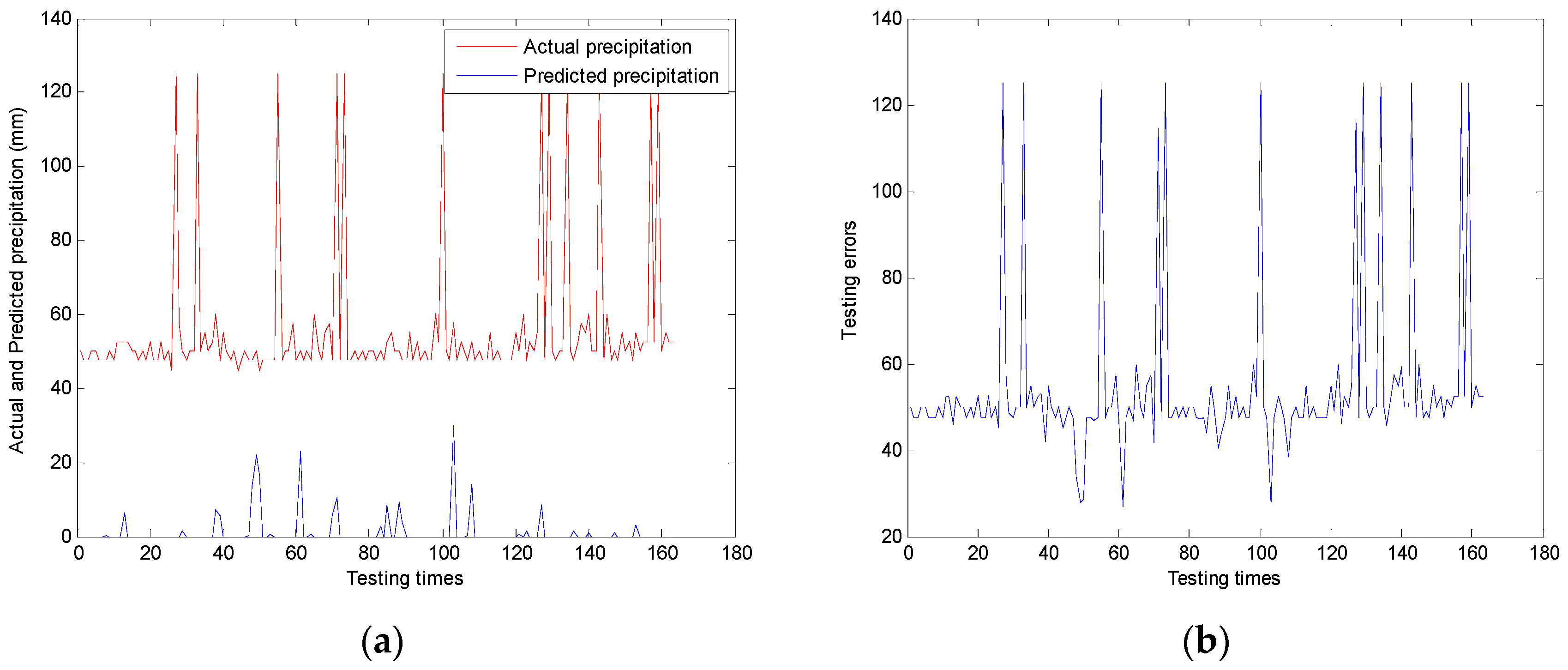
3.4. Analysis and Proof
The fuzzification process of case elements can be understood as the process of merging on adjacent intervals.
Assume that there are two fuzzy cases with only one input and one output: c1 and c2 are crisp numbers of two adjacent intervals, or in other words, the index numbers of two adjacent fuzzy sets; high_pro{e1, e2, …, en} means that the events to occur with a high possibility given a specific input, for example “1” or “2”; te1, te2, …, ten is the occurring times of events e1 to en in the case base given the same input.
case(1) and case(2) can be expressed as follows:
case(1): if x1 = c1, y1 = high_pro{e1, e2, …, en}1
case(2): if x1 = c2, y2 = high_pro{e1, e2, …, en}2.
If
max{te1, te2, …, ten}1 = tei and max{te1, te2, …, ten}2 = tej,
then high_pro{e1, e2,…, en}1 = ei and high_pro{e1, e2, …, en}1 = ej.
Before merge,
case(1): if x1 = c1, y1 = high_pro{e1, e2, …, en}1 = ei
case(2): if x1 = c2, y2 = high_pro{e1, e2, …, en}2 = ej.
- (1)
if case(1) and case(2) are fit for the new coming case(the case-based reasoning system can predict the correct value for the new coming case), the predicted value and the expected value should be:
c1 → ei;
c2 → ej
After merging,
c12 → ei or ej
prediction accuracy would decrease, except ei = ej since the prediction accuracy won’t change in this case.
- (2)
if case(1) and case(2) are not fit for the new coming rule(the case-based reasoning system cannot predict the correct value for the new coming case), assume the expected value is shown as below:
c1 → ew
c2 → ep
After merging,
c12 → high_pro{e1, e2, …, en}12
max{te1, te2, …, ten}12 = max{(te11 + te12), …, (ten1 + ten2)}
if max{(te11 + te12), …, (ten1 + ten2)} = (tew1 + tew2), then high_pro{e1, e2, …, en}12 = ew,
the prediction accuracy would increase after merge;
if max{(te11 + te12), …, (ten1 + ten2)} = (tep1 + tep2), then high_pro{e1, e2, …, en}12 = ep,
the prediction accuracy would increase after merge;
if ew = ep, the prediction accuracy would also increase after merge.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}