1. Introduction
Sinusoidal parameter estimation is a central task in engineering applications including sonar, power systems, measurement and instrumentation [
1], array signal processing and radar signal processing [
2], wireless communication, and speech analysis [
3]. Sinusoidal parameter estimation is also central to musical signal processing, specifically spectral audio signal processing [
4]. Tonal aspects of standard musical signals including the human singing voice and musical instrument sounds can be effectively modeled as the sum of multiple time-varying sinusoids [
5]. In the musical signal processing context, the number of sinusoids is generally not known a priori, making it difficult to apply techniques like MUSIC [
6] and ESPRIT [
7] which jointly estimate the parameters of a number of sinusoids; as well these techniques can be computationally expensive.
The problem of detecting multiple sinusoids in a musical signal is often framed as a successive search for a single sinusoid in the Short-Time Fourier Transform (STFT) domain [
8]. Framing the problem in this way essentially ignores the effect of interferers—nearby sinusoids whose sidelobes may tilt magnitude spectrum peaks slightly so that they no longer correspond exactly to sinusoidal components. Despite this, the approach of a successive search for sinusoids allows a complex problem to be broken down into many manageable simple problems without, e.g., any assumption of harmonic structure in the signal. Therefore, in this article, we formalize the problem as the search for a single sinusoid—in practical situations the search will be repeated in each frame until all sinusoids of interest are detected and their parameters estimated [
8].
Sinusoidal parameter estimation in the STFT domain is exploited heavily in multi-sinusoid analysis/synthesis methods [
5,
9,
10,
11,
12]. For these systems, as well as fundamental frequency detection [
13], audio coding, and music information retrieval (MIR), improving the estimation of sinusoidal parameters is very important.
Early work presents interpolation methods only for signals windowed by the rectangular window or Rife–Vincent Class I windows. For the case of arbitrary windows, only a few methods have been presented. The state of the art for arbitrary windows is represented by the estimators of Duda [
14] and Candan [
15].
In [
14], Duda builds on previous magnitude spectrum interpolators [
16,
17] derived for the Rife—incent Class I windows in order to build a first coarse estimator, whose error is compensated by an optimized polynomial remapping of the coarse estimated value to obtain a finer estimate, with the accuracy of the method controlled through the polynomial order of the remapping. In [
15], Candan proposes a method derived from his previous work on the rectangular window case [
18], itself building on a previous complex spectrum interpolator [
19], where a corrected interpolator is derived from the Taylor expansion of the signal’s Discrete-Time Fourier Transform (DTFT) around the sinusoid frequency location. This work also proposes an iterative mechanism to update the correction factor using the previous estimate, further improving its accuracy.
Another approach to this problem which is applicable to arbitrary windows involves parabolic interpolation over magnitude spectrum peaks [
4]. In [
12] it was shown that logarithmic scaling improves parabolic interpolation significantly. Inspired by this finding, we extend the basic parabolic interpolation approach by fitting a parabola to a
power-scaled magnitude spectrum—an approach we call the
XQIFFT. Intuitively, this approach nonlinearly scales the shape of a window transform’s main lobe so that it very closely resembles a parabola and parabolic fitting will be very accurate. This approach was introduced in [
20], where a coarse brute-force approach was used to optimize a power scaling coefficient and the XQIFFT was shown to greatly outperform parabolic fitting on a linear or logarithmic scale [
20] also contained a rudimentary noise analysis.
We extend the XQIFFT approach by replacing the brute force search with a cheaper and more accurate search algorithm that leverages Fibonacci search and Simpson quadrature to achieve optimal search speed and controlled numerical accuracy. Invariance properties of the XQIFFT are studied and it is shown that linear and logarithmic scalings can be considered special cases of the XQIFFT. We extend the noise analysis to a proper study relating estimator mean-squared error to signal-to-noise ratio. We compare the proposed estimator to two state-of-the-art estimators and the Cramér—Rao bound for unbiased estimators, and analyze the systematic bias due to noise. A case study on Hann-windowed signals shows that the optimal power-scaling coefficient is related to window length in a structured way.
In another study, we compare the XQIFFT to the state-of-the-art estimators of Duda [
14] and Candan [
15] as well as the linear- and logarithmically-scaled versions of the QIFFT for twelve common windowing functions. Although Duda [
14] and Candan [
15] do not directly compare their methods to the QIFFT family, our study shows that indeed their methods usually outperform the linear- and logarithmically-scaled versions of the QIFFT. Our main finding is that the XQIFFT outperforms the state-of-the-art estimators of Duda [
14] and Candan [
15] at high and low SNRs for ten out of twelve common windowing functions.
The structure of the remainder of this article is as follows.
Section 2 defines the problem of single sinusoidal parameter estimation.
Section 3 reviews previous work on extracting sinusoidal parameters from the three spectral bins surrounding a magnitude peak using parabolic interpolation.
Section 4 introduces our proposed method: the XQIFFT.
Section 5 contains an error definition, a study on the error properties, and a heuristic method for optimizing the power scaling of the XQIFFT. In
Section 6, we run experiments to study different aspects of the XQIFFT and compare it to two state-of-the-art estimators.
2. Problem Statement
A single complex discrete-time (sample index
n) sinusoid with a sampling period of
T is given by
In the most general case, the goal of sinusoid parameter estimation methods is to estimate the frequency
, amplitude
, and phase offset
ϕ of a sinusoid. In this work, we restrict ourselves to the case of estimating
and
only. It is common practice to reduce spectral leakage by applying a length-
N smoothing window
w to
to form a windowed signal
x with Discrete Fourier Transform (DFT)
X given by
where
k is the discrete frequency bin index and
W is the Discrete-Time Fourier Transform (DTFT) of the window
w defined by
The DTFT is defined for continuous rather than discrete frequencies, and in fact the DFT of a signal can be seen as a sampling of the DTFT at the frequencies indexed by k.
The window magnitude DTFT
for typical smoothing windows is characterized by a main lobe centered around dc. After shifting and scaling, the main lobe is centered at the fractional bin number
with a maximum amplitude
defined as:
In spectral analysis, it is natural to assume that the center of each main lobe in the magnitude spectrum is associated with a complex sinusoid. Other available techniques build an estimate using all the magnitude spectrum samples to increase peak-estimation accuracy [
21,
22,
23,
24,
25,
26], but these tend to be computationally costly.
Sinusoidal parameter estimation methods which operate on the DFT exploit the assumption that the peak in the magnitude spectrum is associated with a complex sinusoid—in this context finding the fractional bin index
and peak magnitude
of the window transform is considered equivalent to recovering the frequency
and amplitude
of the sinusoid. This allows the problem of parameter estimation to be abstracted into the problem of estimating underlying DTFT peaks. We consider only the parametrization
in the rest of the article to preserve the clarity and conciseness of the discussion independently of changes in the chosen window, sampling interval or DFT length, knowing that in the idealized case of a single sinusoid
are readily recovered from
using (
5).
3. Estimating Sinusoidal Parameters from 3 Bins of Spectrum
The methods in this article estimate
using some form of parabolic fit on the magnitude spectrum maximum at peak bin
and its lower and upper neighbors at bins
and
. For compactness, we introduce the magnitude spectrum value substitutions [
12]
A coarse way of estimating sinusoid parameters is to find peaks in the DFT magnitude spectrum
and use their frequency and amplitude as estimates. Here the sinusoid’s fractional bin index and magnitude
are estimated as
. The values associated with a peak bin
in the magnitude spectrum are
We call this method the nearest bin method, or “nearest” for short. Here the fractional bin estimate will always be an integer; hence the bin estimate of the nearest bin method can have up to bins of error. The nearest bin method is inherently limited by the finite frequency definition of the DFT. This lack of accuracy can be problematic, especially if typical DFT frequency definition falls below a satisfactory level (e.g., human perception in the lower frequency domain).
A typical engineering solution is to refine this coarse estimate by a fine search over
bins around this peak [
2,
14,
15,
18,
27,
28]. Approaches to refining the coarse estimate can be divided into
iterative approaches and
direct approaches [
27]. Iterative approaches (e.g., [
29]) involve multiple rounds of function evaluations or a series of DTFT evaluations that narrow in on the solution. Direct methods form the estimate
using a single function evaluation on
,
, and
. For many spectral audio applications, efficiency is important. This is especially true for real-time applications and applications based on processing huge data sets, e.g. MIR. For this reason, we focus on direct methods in particular. It is worth noting that as with most direct methods, the direct method presented in this article can be further refined into an interactive method using correction functions [
20,
30].
A popular class of techniques, sometimes referred to as the
Quadratically-Interpolated FFT (QIFFT) in the literature [
30,
31,
32,
33], is the subject of this article. Assuming that over a range of
bins around a peak bin
(i.e., between
and
), the underlying DTFT of a window transform is reasonably smooth, QIFFT methods fit a parabola to the magnitude spectrum and use the vertex of this parabola as a refined estimate of the true spectral peak. (Some other direct methods fit a predetermined parabola shape to the spectrum peak bin and its left and right neighbors, e.g., using least-squares regression [
34].) Parabolic fitting in the QIFFT is done by writing the Lagrange interpolating polynomial [
4,
35] that fits the three points
,
, and
, rearranging it into the vertex form of a parabola
with dummy bin index
κ, and then considering the vertex of the parabola
to be an estimate of the sinusoidal parameters. In terms of
,
α,
β, and
γ,
are:
Since it is performed directly on the magnitude spectrum, we denote this technique the “magnitude-spectrum QIFFT” or
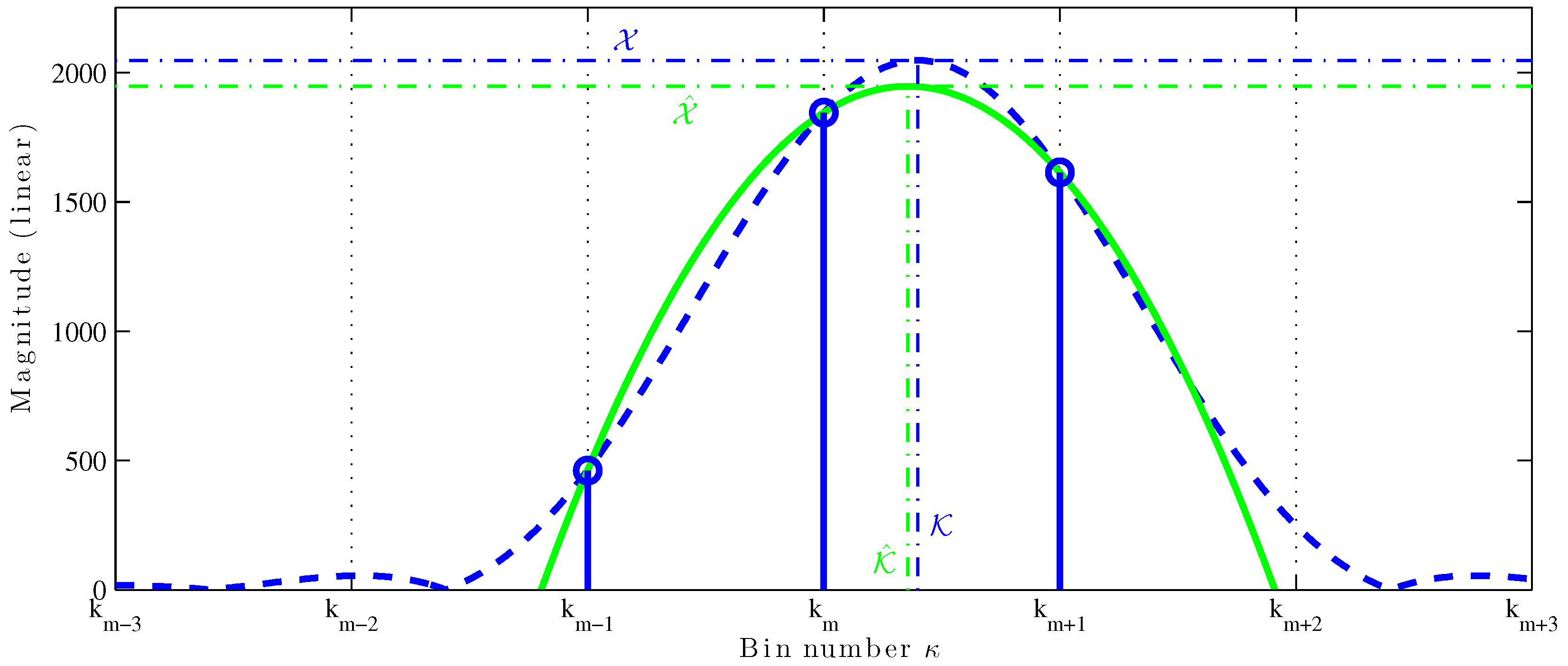
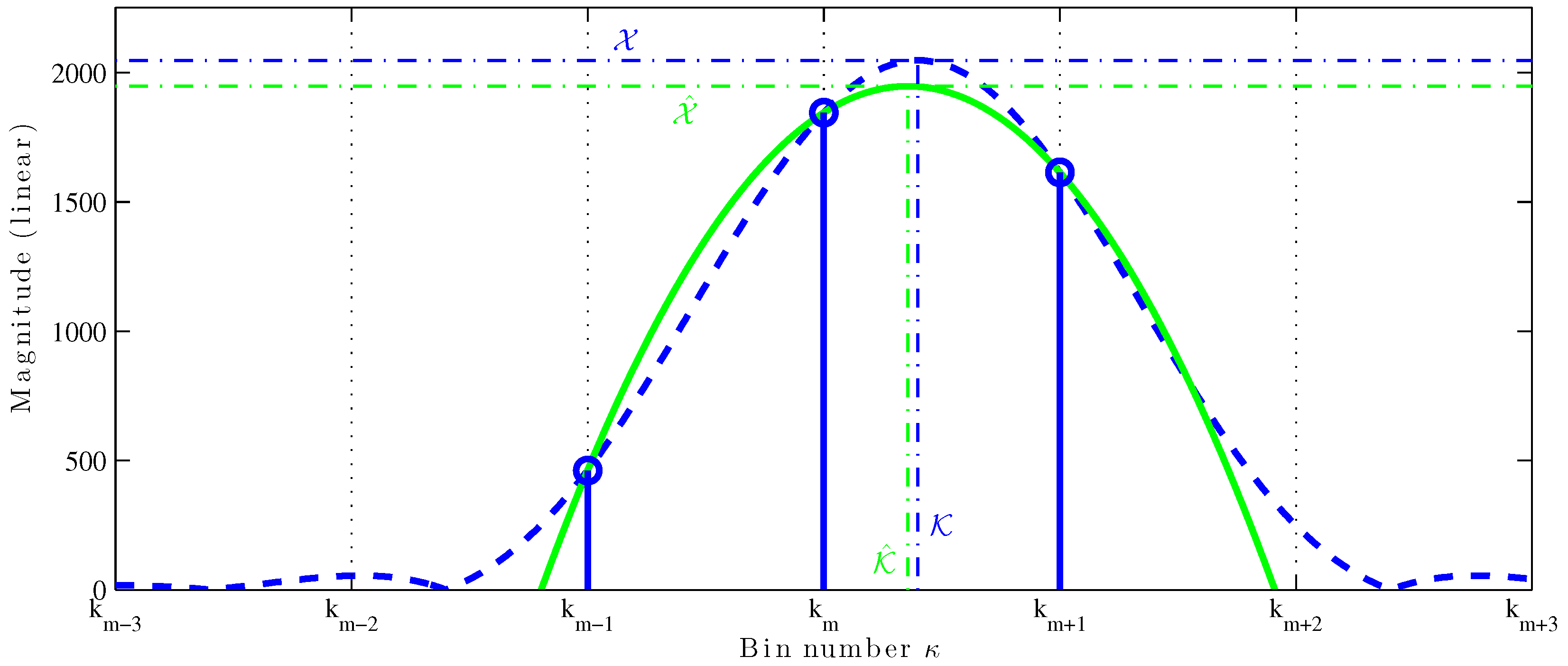
MQIFFT. The parabolic fitting is shown in
Figure 1. The thick dashed blue line is the DTFT of a length-4096 Hann-windowed sinusoid and the thick solid green line is a parabola fit to the top three bins (
,
, and
) of the magnitude DFT, shown as stemmed circle. The vertical dot-dashed lines mark the true fractional bin index
and the estimate
; the horizontal dot-dashed lines mark the true amplitude
and the estimate
. The QIFFT can be considered a perfect match to a truncated (order-2) Taylor series expansion of the window transform.
QIFFT-derived methods are very attractive, as they all have the following desirable properties: (1) they can greatly reduce estimation error; (2) they are inexpensive (requiring only a few multiplies to find the refined peak frequency and amplitude estimates); (3) they can be used with
any window type with the notable exception of the non-zero-padded rectangular window as its main lobe width less that three bins [
30]; and (4) they can be combined seamlessly with zero padding to further increase their accuracy.
The property of being applicable to any window type is one of the main advantages of QIFFT-derived methods. Other popular direct parameter estimation techniques are derived from properties of the rectangular window (no windowing) [
2,
8,
18,
19,
36] or a particular window (e.g., [
1], Cosine window) or class of windows (e.g., [
16], Rife–Vincent class I windows). A few state-of-the-art methods are fully general and can be applied to any window, including methods by Duda [
14] and Candan [
15]. General methods have the distinct advantage of being portable to any window type, even those without analytic descriptions such as the Slepian (DPSS) window [
4]. For instance, Duda gives examples of applying his method to Dolph–Chebyshev and Kaiser–Bessel windowed signals [
14], which can only be approximated with Rife–Vincent class I windows and hence can’t take advantage of the approaches of, e.g., [
16].
4. Proposed Method: XQIFFT
The QIFFT fits a parabola to the magnitude spectrum directly, however, it is possible to implement variations of the QIFFT where we fit parabolas to a magnitude spectrum scaled by a nonlinear function
. To qualify as a scaling, the function f needs to be invertible (and thus monotonic) with its inverse denoted as
. This property is desirable for the fact that we may need to retrieve the amplitude value estimate on the original linear scale, and for the fact that this preserves the concavity property of the main lobe. These variations are based on nonlinear scalings of the magnitude spectrum estimate
by:
Rather than operating on α, β, and γ directly, these methods operate on nonlinear scalings , , and . Since is a linear scale estimate, we must also un-scale the vertex y-coordinate by .
4.1. Logarithmically-Scaled QIFFT
A variant of the QIFFT approach is available in the literature which is calculated through a parabolic fit on a logarithmically-scaled magnitude spectrum, which we denote the “logarithmically-scaled QIFFT” or LQIFFT.
The LQIFFT uses (
13) and (
14) with the following nonlinear scaling and unscaling functions:
The intuition leading to the use of logarithmic scaling in the QIFFT is that since the Fourier Transform (FT) of a continuous-time Gaussian window is also a Gaussian, the FT of a sinusoid will have a Gaussian-shaped main lobe. Since the logarithm of a Gaussian is exactly a parabola, using a parabolic fit on a logarithmically-scaled magnitude response of a Gaussian-windowed signal would give a perfect estimate of
. Considering that many popular smoothing window have a shape that can be seen as more closely approximating the shape of a Gaussian than a parabola, the logarithmic scaling was introduced in [
12,
31], and was shown to outperform the QIFFT on a linear scale for a variety of typical windows (Rectangular, Hann, Hamming, Blackman–Harris, Kaiser–Bessel). Note that changing the base of the logarithm has no impact on the resulting estimation—we arbitrarily choose the natural logarithm.
4.2. Power-Scaled QIFFT (XQIFFT)
While applying the QIFFT on a logarithmically-scaled magnitude spectrum was found to outperform the QIFFT on a linearly-scaled magnitude spectrum, some systematic error remains [
30]. To further reduce the estimation error of the QIFFT method, we review our proposed variation on the QIFFT method that performs a parabolic fit to a magnitude spectrum rescaled by a power function [
20].
The power-scaled QIFFT—the
XQIFFT—uses (
13) and (
14) and has a tuning parameter
p that controls the following nonlinear scaling and un-scaling functions:
The intuition leading to the XQIFFT is simply to try to scale the window transform shape to resemble a parabola. The performance of the XQIFFT depends heavily on choosing the tuning parameter
p properly to scale the shape of the main lobe to be maximally parabolic. The shape of the main lobe is highly dependent on window type, as well as zero-padding factor and window length. Hence the proper value of
p is also window-dependent. A simple procedure for choosing
p is presented later, in
Section 5.2.
4.3. Invariance Properties of QIFFT Methods
In this section, we show that for the XQIFFT along with the MQIFFT and LQIFFT, the estimate is insensitive to amplitude and that the amplitude estimate scales linearly as a function of the true amplitude . This property shows that the XQIFFT and its cousins are suitable for estimating sinusoids of any amplitude (other nonlinear scaling functions may not have these properties).
All the scalings discussed so far verify that the estimate in fractional bin index is insensitive to the true amplitude
, while the estimate
scales linearly as a function of the true amplitude
. Indeed, if we have another sinusoid of fractional bin number
and amplitude
, the QIFFT estimates (
11) and (
12) yield:
For the log-scaled QIFFT (
13)–(
16), we have the property that
, and
, so that:
For the power-scaled QIFFT (
13), (
14), (
17) and (
18), we have the property that
, and
, so that:
5. Estimation Error, Properties, and Reduction
In this section we provide error definitions (
Section 5.1) and study interpolation bias (
Section 5.2). Using these definitions, we propose a heuristic to find the optimal
p value for a given windowing situation (
Section 5.3). Finally, we mention correction functions which can unbias remaining systematic error (
Section 5.4) and noise sensitivity properties (
Section 5.5).
5.1. Error Definition
Following the error definition in [
31], we compute the error in a particular fractional bin index
and a particular magnitude estimate
as follows. For each true fractional bin
, the error in a particular fractional bin estimate is defined as
and the error in a magnitude estimate is defined proportionally by
Because of the invariance of to amplitude, and the linear dependency of to amplitude, these errors are thus independent of the true , so that we only need to index these by .
We also define the
worst-case bin estimates of the fractional bin as
and the magnitude as
, meaning the maximum errors obtained across all the possible fractional bin indices:
These errors have
means and
:
and
variances and
.
5.2. Interpolation Bias
We know that the MQIFFT and the LQIFFT present systematic fractional bin index and amplitude errors that are strongly dependent [
30] on the distance of the sinusoid’s true fractional bin index
from a bin center
.
indicates the
rounding function, which returns its argument rounded to the nearest integer. This distance, denoted by
, is defined as
By construction, bin estimates have odd symmetry around
and magnitude estimates have even symmetry around
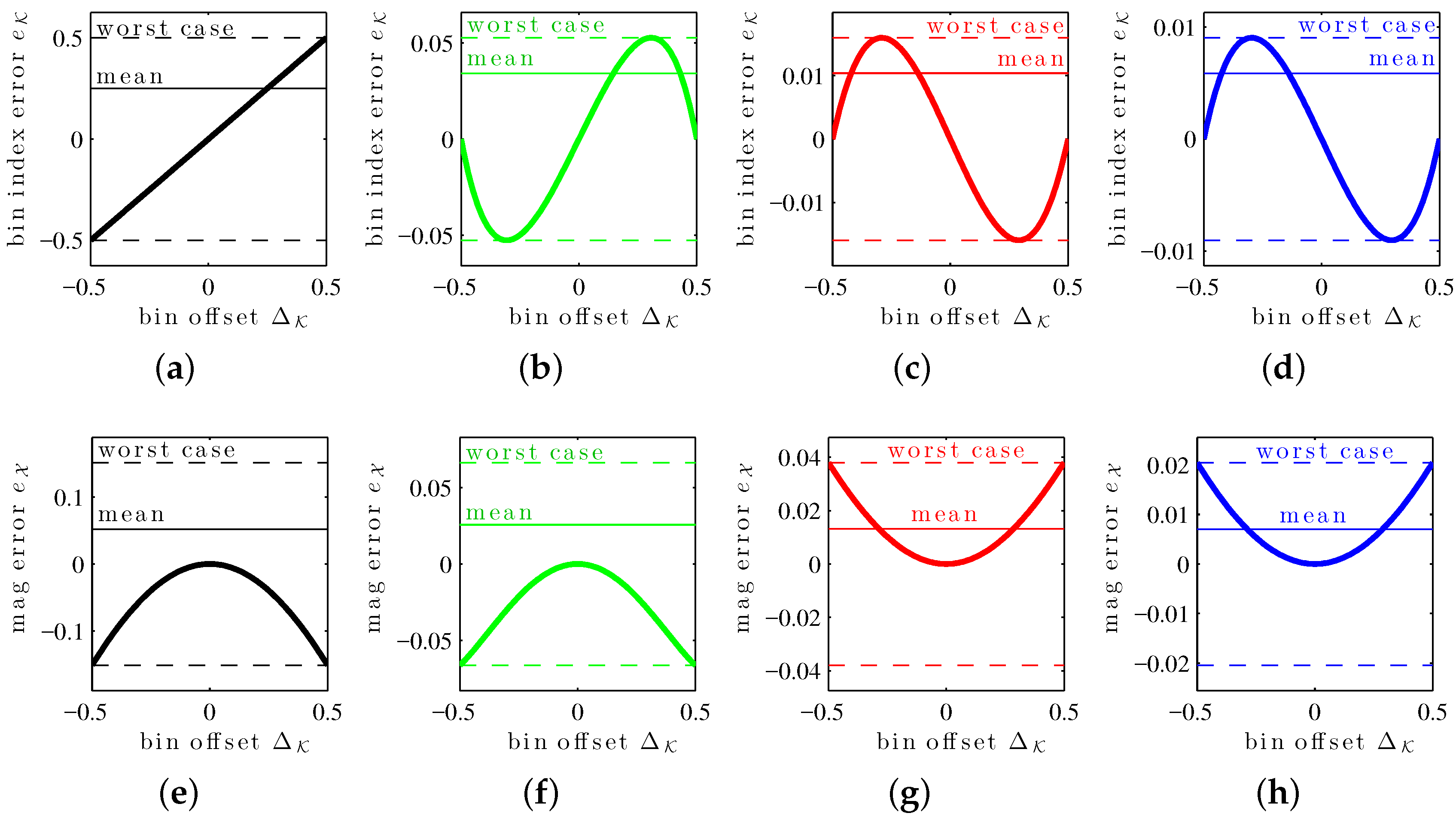
(symmetries exploited in the previous error mean and worst-case definitions). The errors in estimates associated with the XIQFFT have all these properties as well. These can be seen in the
bias curves in
Figure 2, which show
and
as a function of bin offset
for a length-4096 Hann window.
Note that while it may sometimes (for certain windows) be possible to obtain closed form solutions for those two statistics, these solutions are generally very complex, even for simple smoothing windows. In the context of this article, we propose instead the following heuristic to evaluate those statistics numerically with arbitrary precision.
Finding the worst-case errors
and
requires finding the global maximum on the appropriate bias curve in
Figure 2. Doing so numerically requires first to identify local maxima as the bias curves do not necessarily exhibit a single local maximum. We identify the regions containing a local maximum by computing the empirical error at a coarse sampling of the bin index space and finding the different local peaks that we associate with a single neighboring local maximum. We then run a Fibonacci search [
37,
38,
39] (pp. 275–278, [
40]) in the neighborhood of each found peak to find a local maximum. Using the Fibonacci search algorithm allows us to compute the location of that maximum up to a preset precision. We finally pick the global maximum as the largest local maximum.
Finding the mean errors
and
requires to evaluate the integral of the error function across the range of all possible bin indices (i.e., between
and
). To do so numerically, we run an adaptive integration algorithm, the Simpson’s quadrature algorithm [
41], on the empirical error function. This algorithm allows us to control the desired numerical precision of the final result.
For both methods, the procedure described above is aimed at obtaining estimates with arbitrary numerical precision (allowed by the Fibonacci search and the adaptive integration algorithms), while minimizing the number of empirical error function evaluations required during the extremum search (allowed by the Fibonacci search algorithm) and not requiring the derivation of a closed form error function.
5.3. Choice of the Power-Scaling Factor p
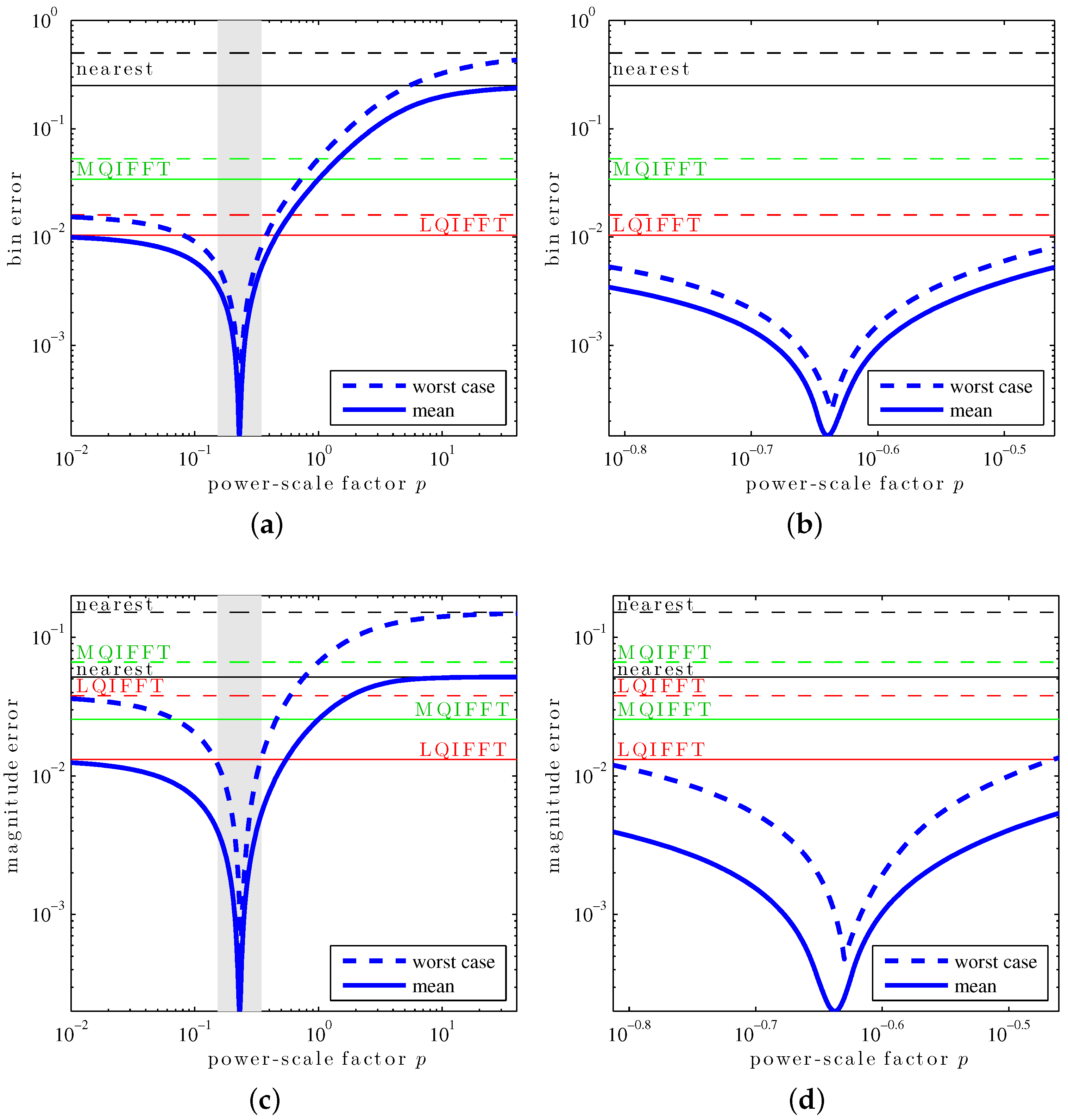
To demonstrate the XQIFFT and the process of choosing
p, we study one particular representative window in detail: a length-4096 (
) Hann window (p. 98, [
42]) [
43], defined as
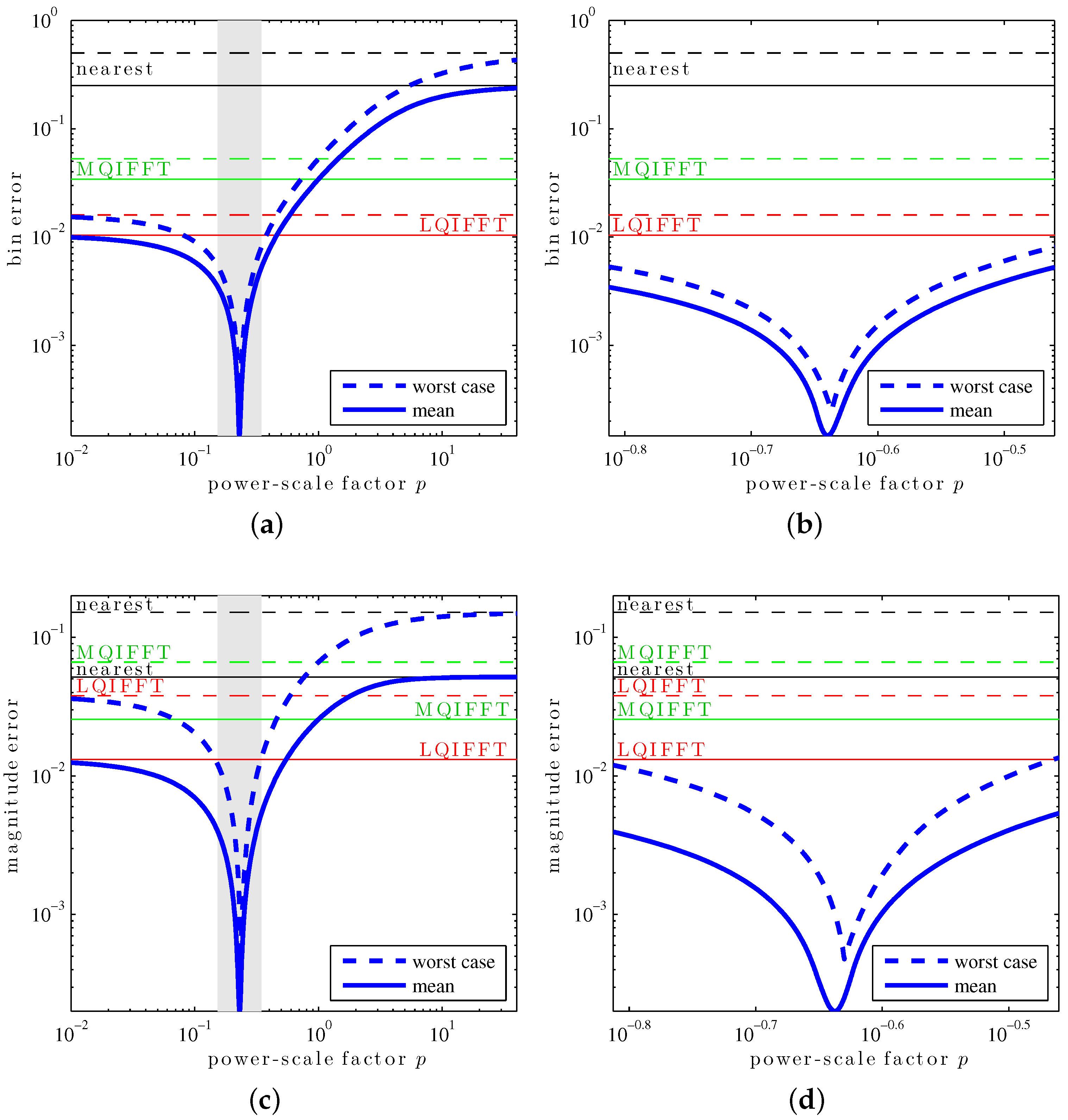
When computing the worst-case and mean errors for various values of power-scaling factor
p (
Figure 3), we can observe that the XQIFFT strongly outperforms the other QIFFT-derived methods if
p is picked appropriately. In particular, we see that there seems to exist a single value
p for which each statistic is minimized. This optimal value of
p is typically different for each statistic, as well as for the chosen smoothing window, DFT length, and zero-padding factor.
As the function exhibits a single minimum (i.e., it is unimodal), we propose here to find an optimal
p value numerically finding that minimum. Finding the minimum of a unimodal function can be done numerically by running a Fibonacci search on the desired error statistic. Such a heuristic yields a choice of
p minimizing the desired error statistic up to an arbitrary precision order, while minimizing the number of power-scaling factors
p for which we need to evaluate the statistic (using the proposed approach in
Section 5.2), and still without requiring the complex derivation of a closed form solution for the different statistics as a function of
p. Other estimators which allow for arbitrary windows also favor a computational rather than analytic approach [
14,
15].
Table 1 shows the different error statistics from
Figure 3 for the four different optimal cases. From the results, we can see that (1) for each error statistic, its associated optimal
p yields an error much smaller than the MQIFFT and LQIFFT; and (2) a
p value optimized for a given error statistic still yields small errors for the other ones, in particular,
p values that yield small fractional bin index estimation error also yield small amplitude estimation error.
Notice that in
Figure 3, the mean and worst-case bin and magnitude errors of the XQIFFT approach the performance of the nearest neighbor method for large values of
p. This can be explained by the asymptotic behavior of the XQIFFT estimator as
p approaches
∞. Because we have
and
,
and
and the XQIFFT estimate (
13), (
14), (
17) and (
18) reduces to the nearest neighor method:
Additionally, we can show that, as suggested by
Figure 3, the XQIFFT converges towards the LQIFFT as
p approaches 0. Indeed, from the Taylor expansion of the bin estimate (
13) using the XQIFFT scaling (
17) and (
18), we have that
,
and
. Hence, we get:
This matches (
13) for a logarithmic scaling, verifying that the XQIFFT’s bin estimate (
17) approaches the LQIFFT as
.
For the amplitude estimate (
14) using the XQIFFT scaling (
17) and (
18) we have
Similarly,
, such that:
Furthermore, since
, we have:
As
, we have
and we then get the following limit:
This matches (
14) for a logarithmic scaling, verifying that the XQIFFT’s amplitude estimate (
18) approaches the LQIFFT as
.
5.4. Correction Functions
Correction functions are known to unbias some of the systematic error of interpolation on linear and logarithmic scales.
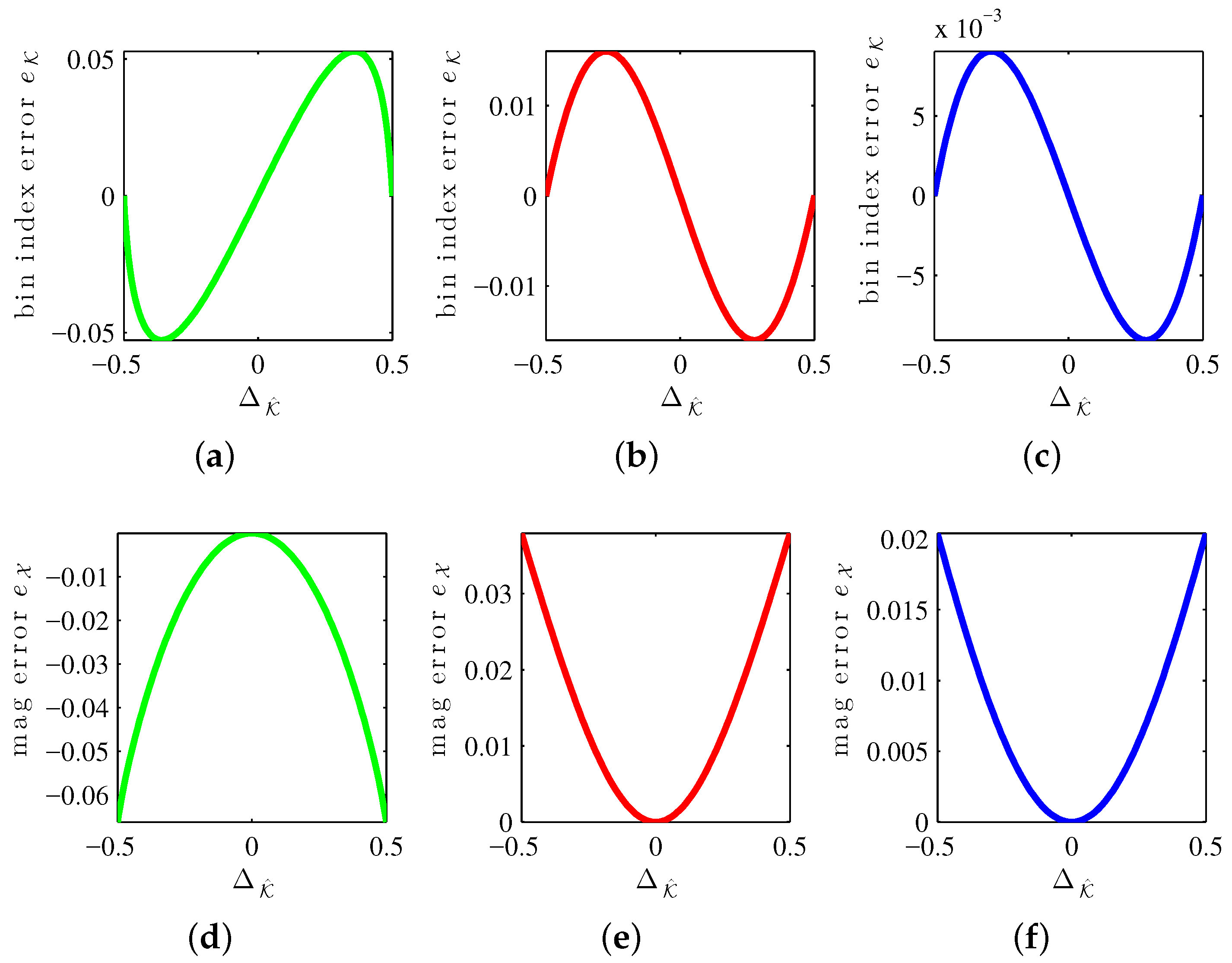
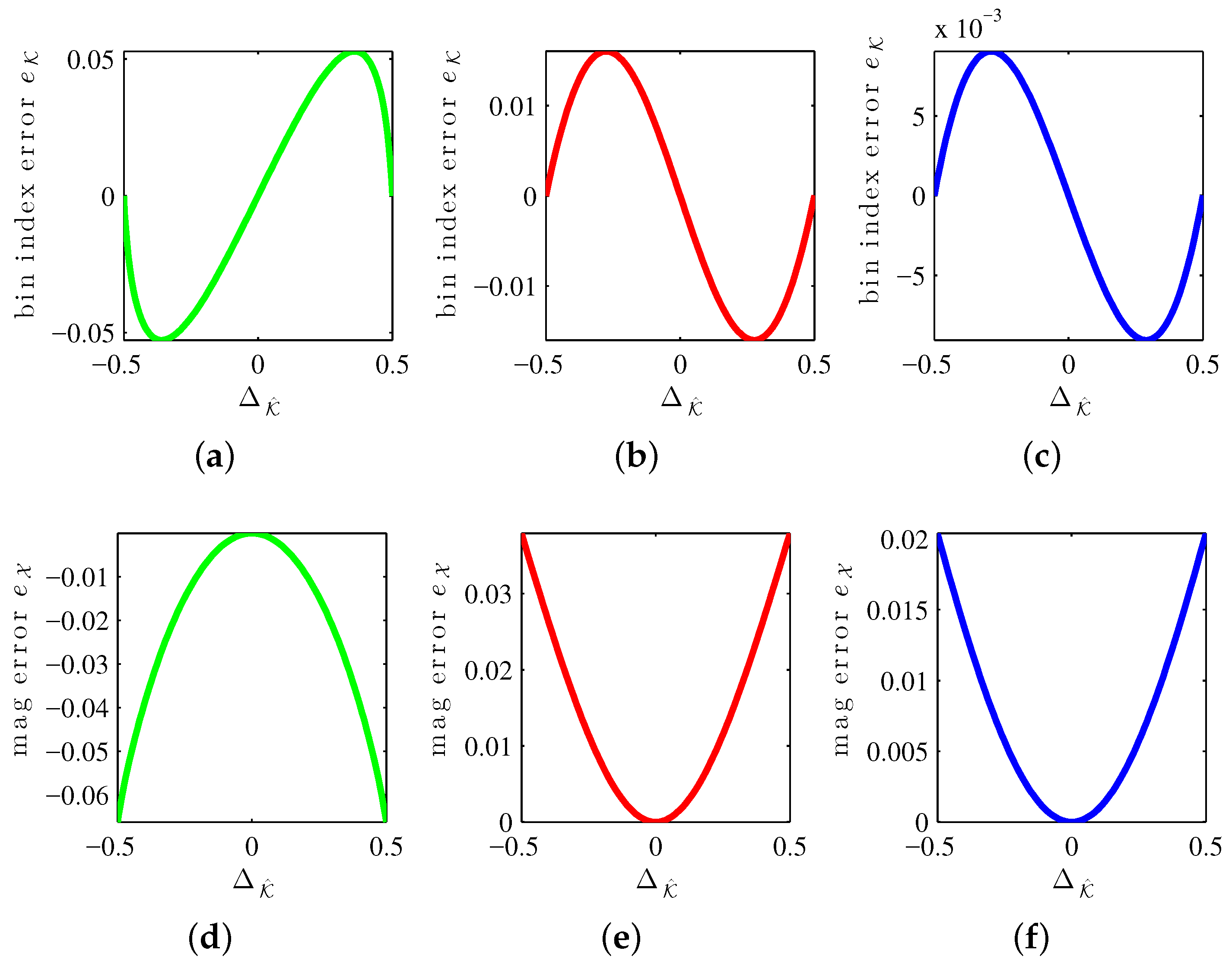
Figure 4 shows systematic error curves for the MQIFFT, LQIFFT, and XQIFFT as a function of the bin estimate offset
. Similar to the bin offset (
31), the bin estimate offset is defined by
The reason to index the correction curves by
instead of
is that when implementing correction functions, the true value
(and hence
which depends on it according to (
31)) is not known. Only the estimate
(and hence
) is known.
Notice that all of the error curves shown in
Figure 4 are highly structured. This means that it is possible to design parametric correction functions to match these curves and unbias the estimates somewhat, leading to further refinements. It should also be possible to create a tabulation of these curves when it is not convenient to develop a parametric equation. The limit of the efficacy of correction functions is controlled by the level of fitness of the fit curve or the density of a tabulation. Abe and Smith report correction functions for the LQIFFT [
30] and Werner proposes magnitude and bin correction functions for the XQIFFT [
20]. As we are focused solely on direct methods, a discussion of the particular form or performance of XQIFFT correction functions is outside the scope of this article since correction functions are considered to be iterative methods [
27].
5.5. Sensitivity to Noise
We analyze how the parameter estimation is affected by the presence of noise in the signal. To do so we corrupt the signal
with different realizations of an additive white Gaussian noise random process (with zero-mean and standard deviation
σ) at different levels of signal-to-noise ratio (SNR). The SNR is computed as the ratio of the amplitude of the sinusoid by the standard deviation of the noise:
In this analysis, we quantify the effect of added noise by looking at the distribution of the noisy estimates around the noiseless estimates . As such, we decorrelate the influence of the systematic bias associated with the estimator from the influence of the noise by reporting the bias and variance of for various bin index offsets.
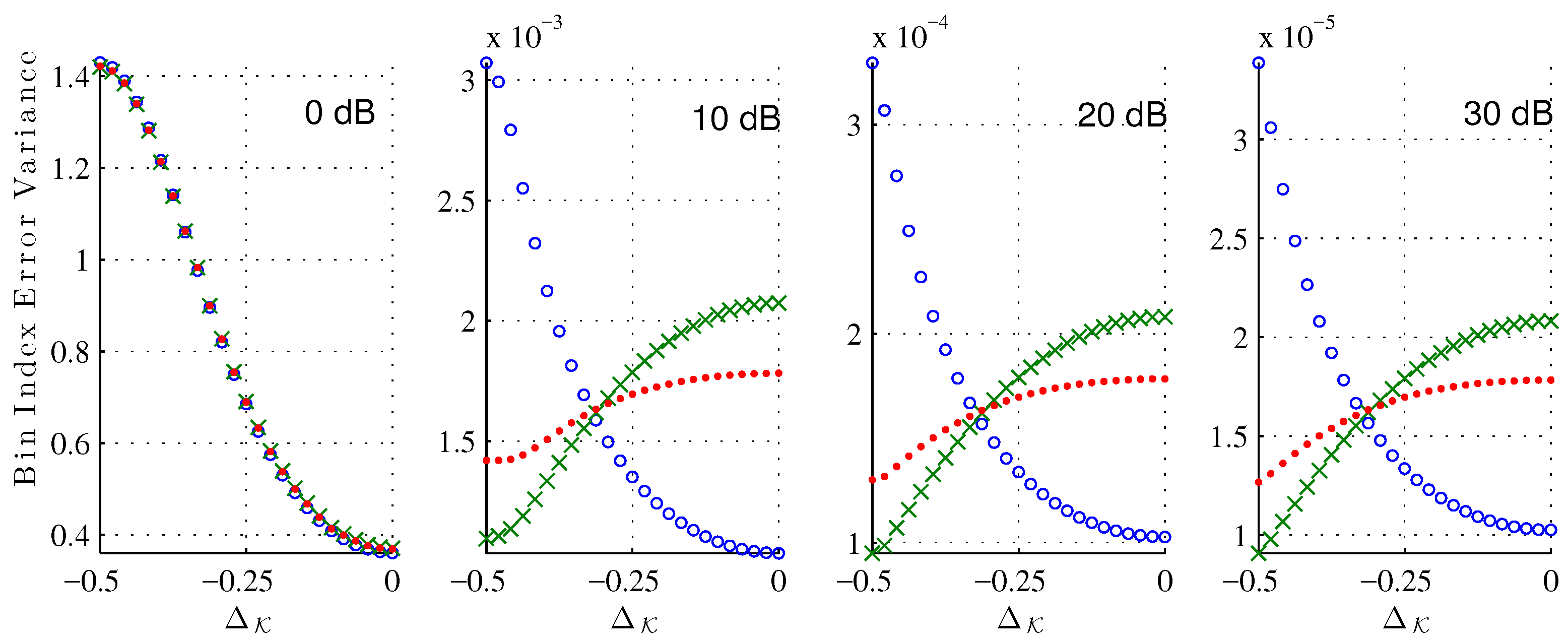
In the following experiments, we consider a length-64 Hann window. We sample uniformly the bin index in . For each bin index, we generated noise trials to get reliable estimates of the bin index error bias and variance.
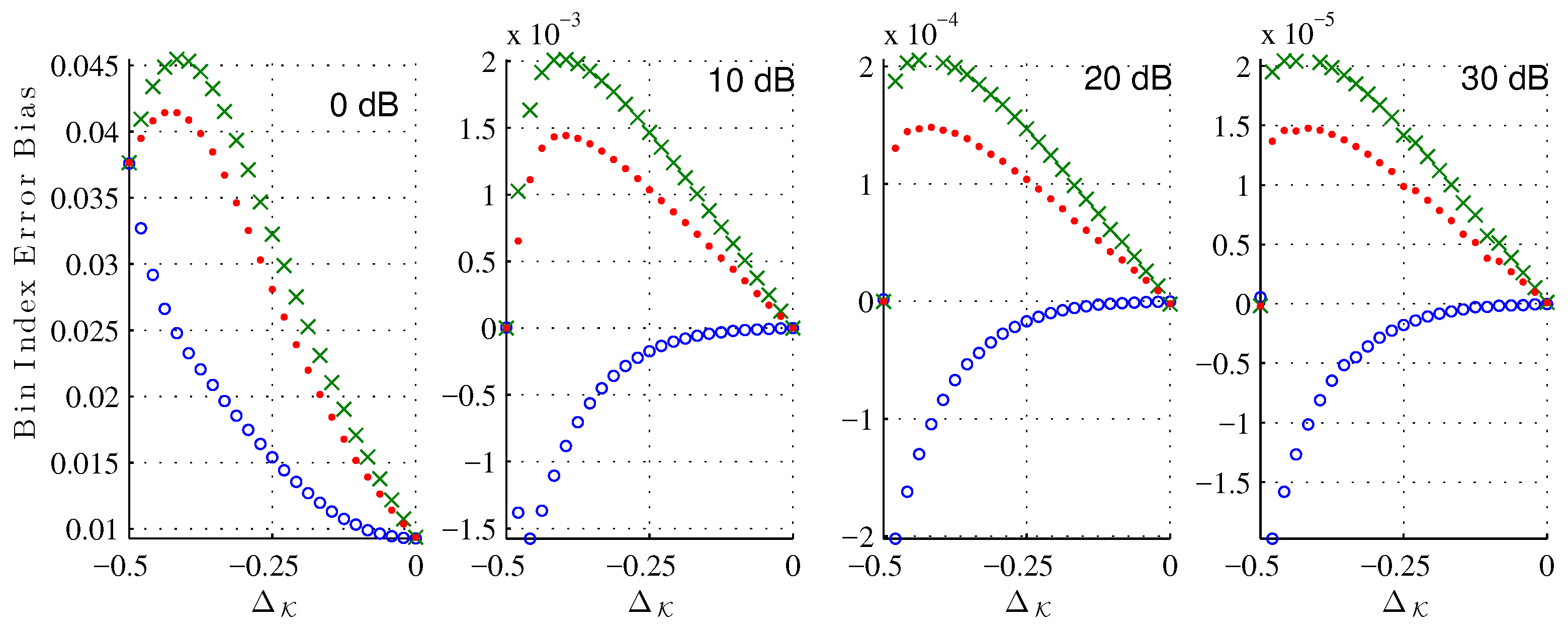
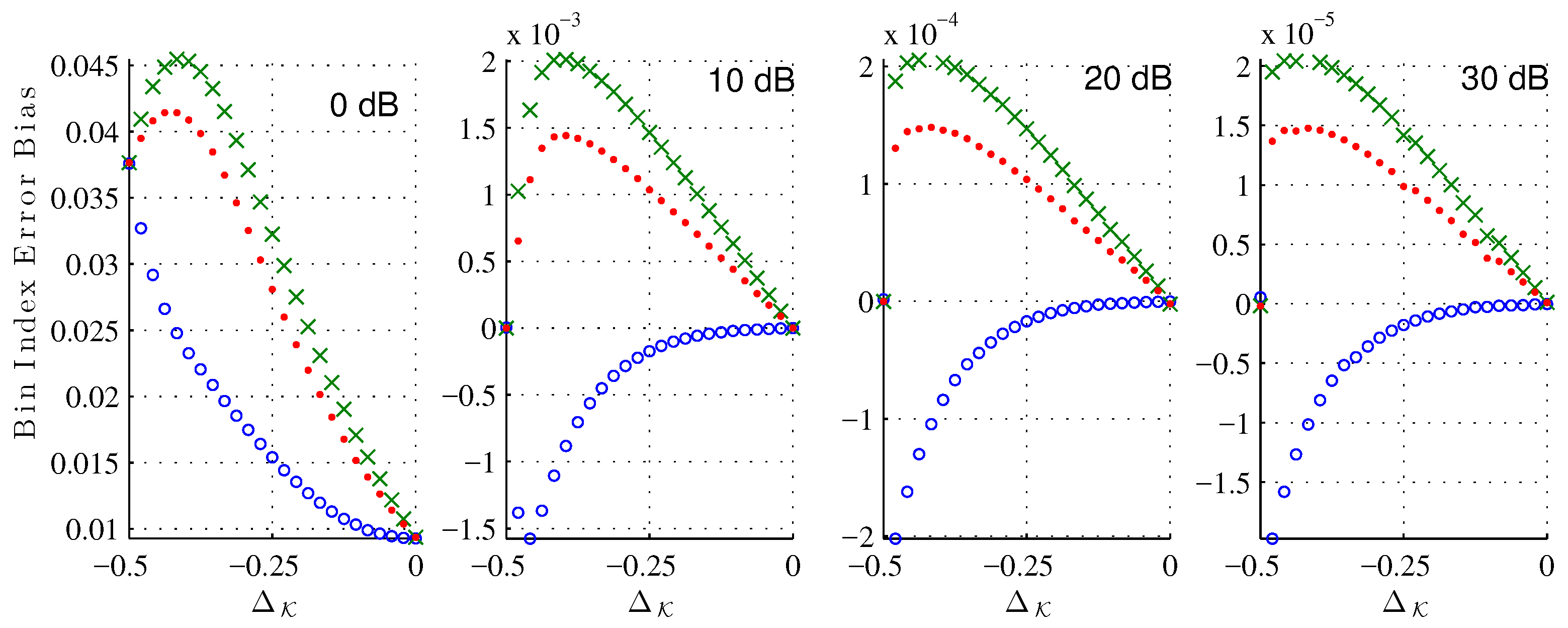
Figure 5 shows the bias of the bin index estimate (
25) due to the noise corruption alone at various signal-to-noise ratios (SNR). As expected, for each estimator the bias decreases as the SNR increases. Across all
and tested SNRs, the XQIFFT (
) has a noise bias between that of the MQIFFT and the LQIFFT. Considering that the XQIFFT tends towards the LQIFFT as
p approaches zero (as shown in
Section 5.3) and is identical to the MQIFFT when
, the XQIFFT with a value of
can be considered an intermediate between the MQIFFT and LQIFFT. So, it is unsurprising that its noise bias also falls between the two. Interestingly, the bias is nonzero for most offsets
. This means that the presence of noise actually shifts the mean error of our estimator away from the systematic bias already present in the noiseless estimation.
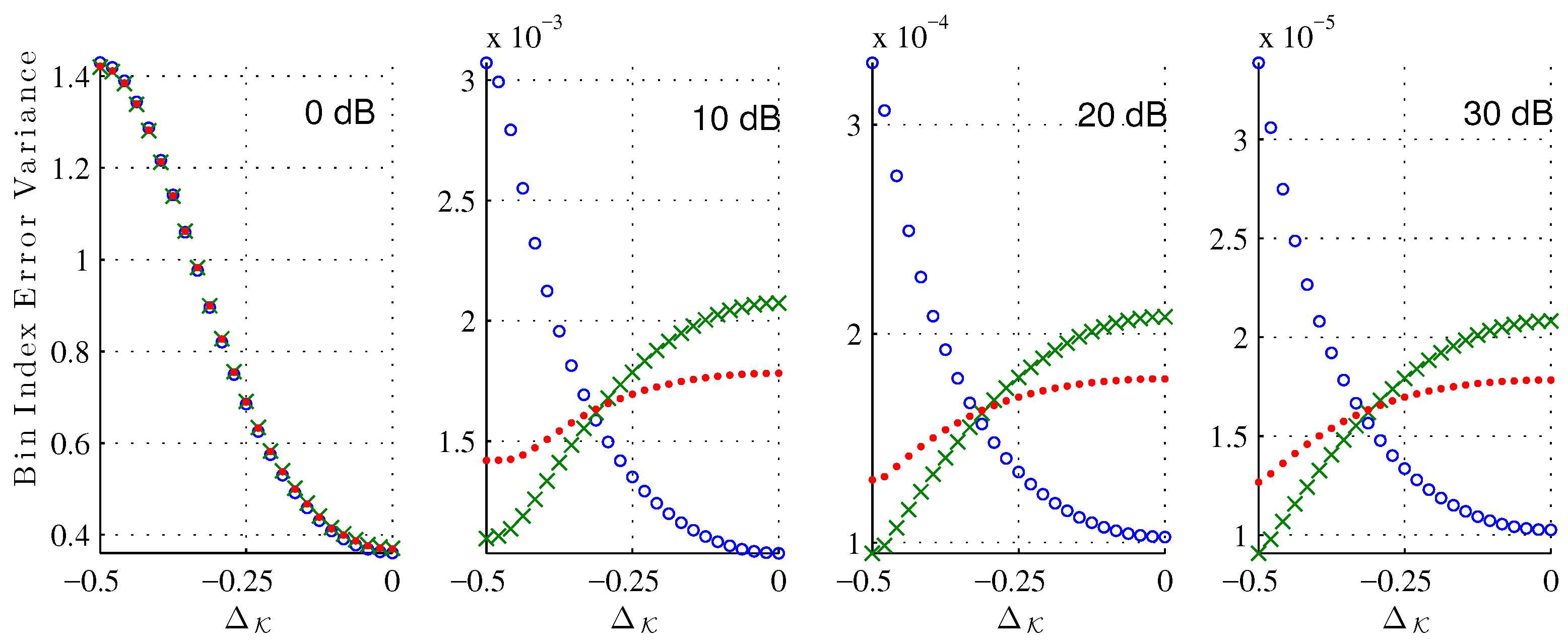
Figure 6 shows the bin index error variance around the error mean. Again, the variance of the XQIFFT (
) is between the MQIFFT and the LQIFFT, and we can notice that its variance has less variation across the different bin index offsets
.
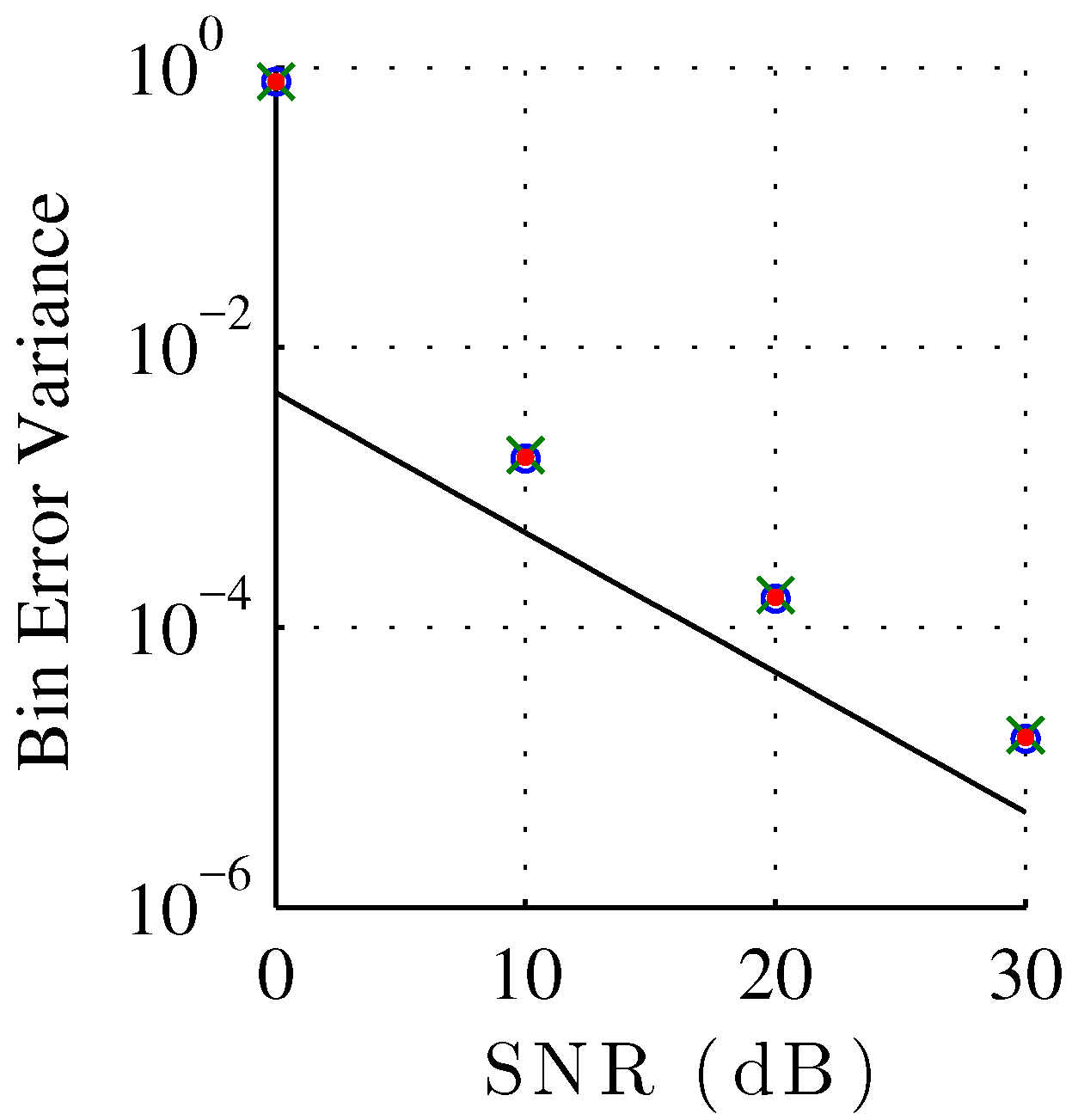
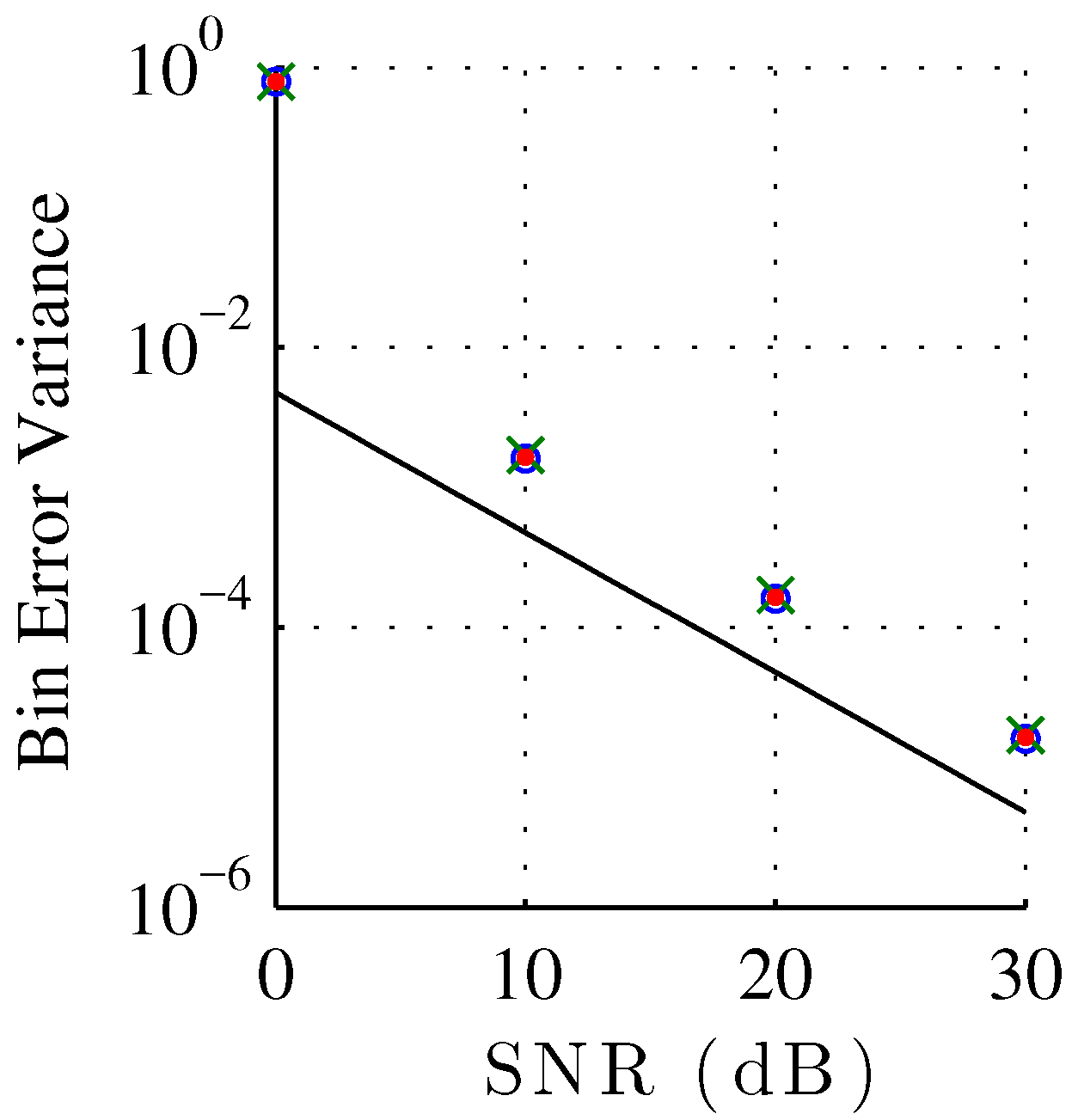
Figure 7 shows the bin index error variance of each estimator plotted against SNR, compared against the Cramér–Rao bound for unbiased estimators. Normalizing to bin width, the Cramér–Rao bound for a discrete-time signal corrupted by additive white Gaussian noise, with unknown phase and unknown amplitude is [
44]
where
is the signal length,
σ is the noise standard deviation, and
the sinusoid amplitude. To compare against the Cramér–Rao bound for unbiased estimation, we recompute the variance of the bin index estimation error under the assumption of a zero bias. Though we showed in
Figure 5 that the estimation is not actually unbiased, the bias is commonly neglected for the noise robustness analysis of sinusoidal parameter analysis. Notice that all the QIFFT-based methods have a similar robustness against noise independently of the chosen magnitude spectrum scaling function. This result highly contrasts against the systematic estimation bias, which is highly sensitive to the choice of scaling function. We can also observe the expected thresholding effect at 0 dB [
44], as the peak finding initial step becomes unreliable. The thresholding effect can also be observed in
Figure 5 and
Figure 6 where the behavior of the error bias and variance are very different for the 0 dB case.
From this noise sensitivity study, we can see that as long as the systematic error dominates, the best estimator will be the estimator with the lowest systematic bias—the XQIFFT with a properly-chosen value of p. At low SNR, the noise variance dominates and the methods all have a very similar compounded bias. A study on the compounded mean-squared error (MSE) comparing the XQIFFT to state-of-the-art estimators is given in the following Section.
6. Results
In this results section, the XQIFFT is compared to other QIFFT variants and two state-of-the-art estimators which, like the XQIFFT, are direct methods which can be used on any window. These two estimators are Duda’s [
14] and the first step of Candan’s [
15]. Candan also has a second refinement step that we do not compare to, since it corresponds to an iterative method and we are limiting our comparison to the class of direct methods.
First, we study the optimal p as a function of window length for the Hann window; Second, we study the MSE of each bin estimator for the case of a length-4096 Han window; Third, we expand that study to twelve common windows, showing that the XQIFFT minimizes MSE across all SNRs for two of the twelve tested windows.
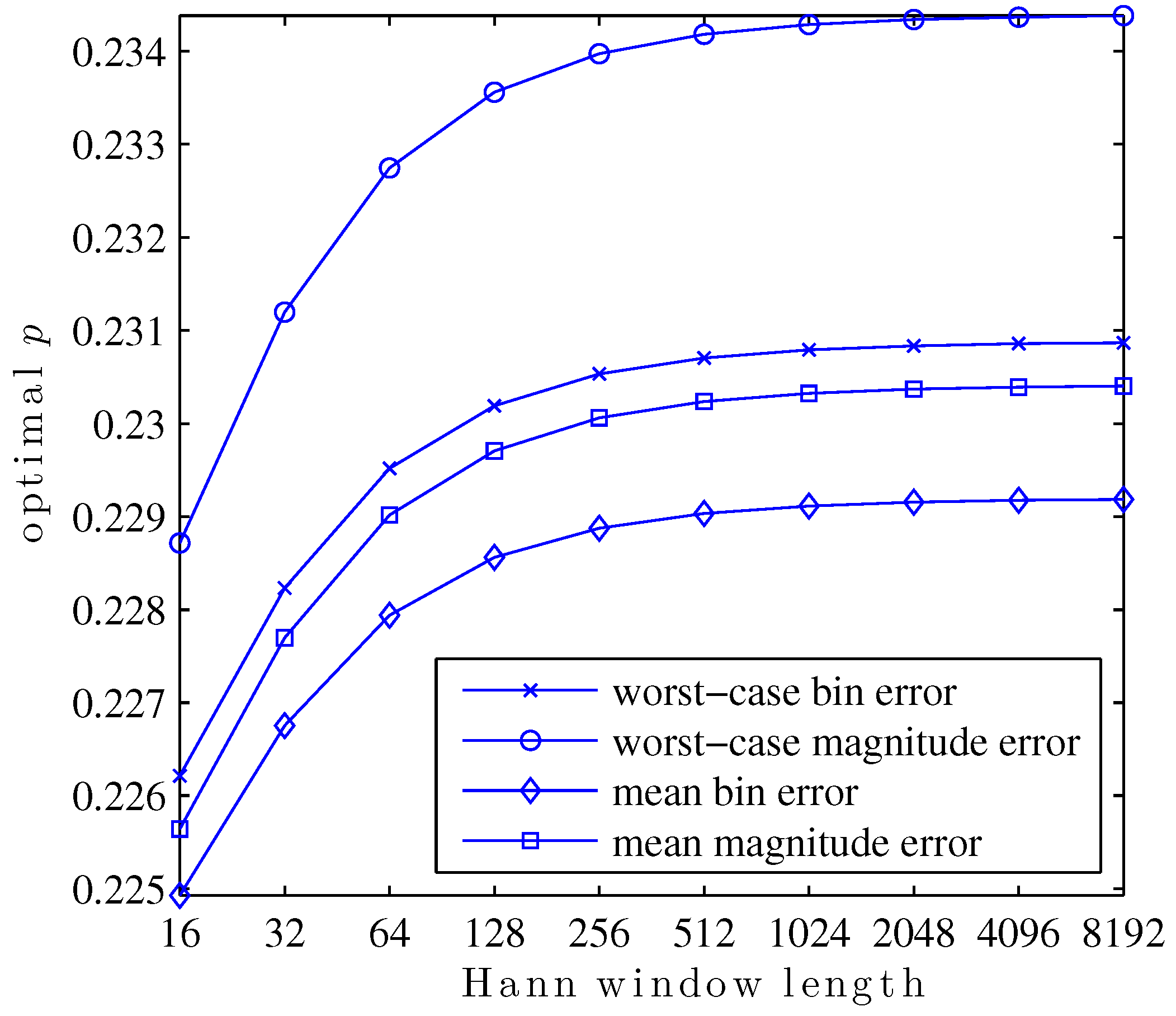
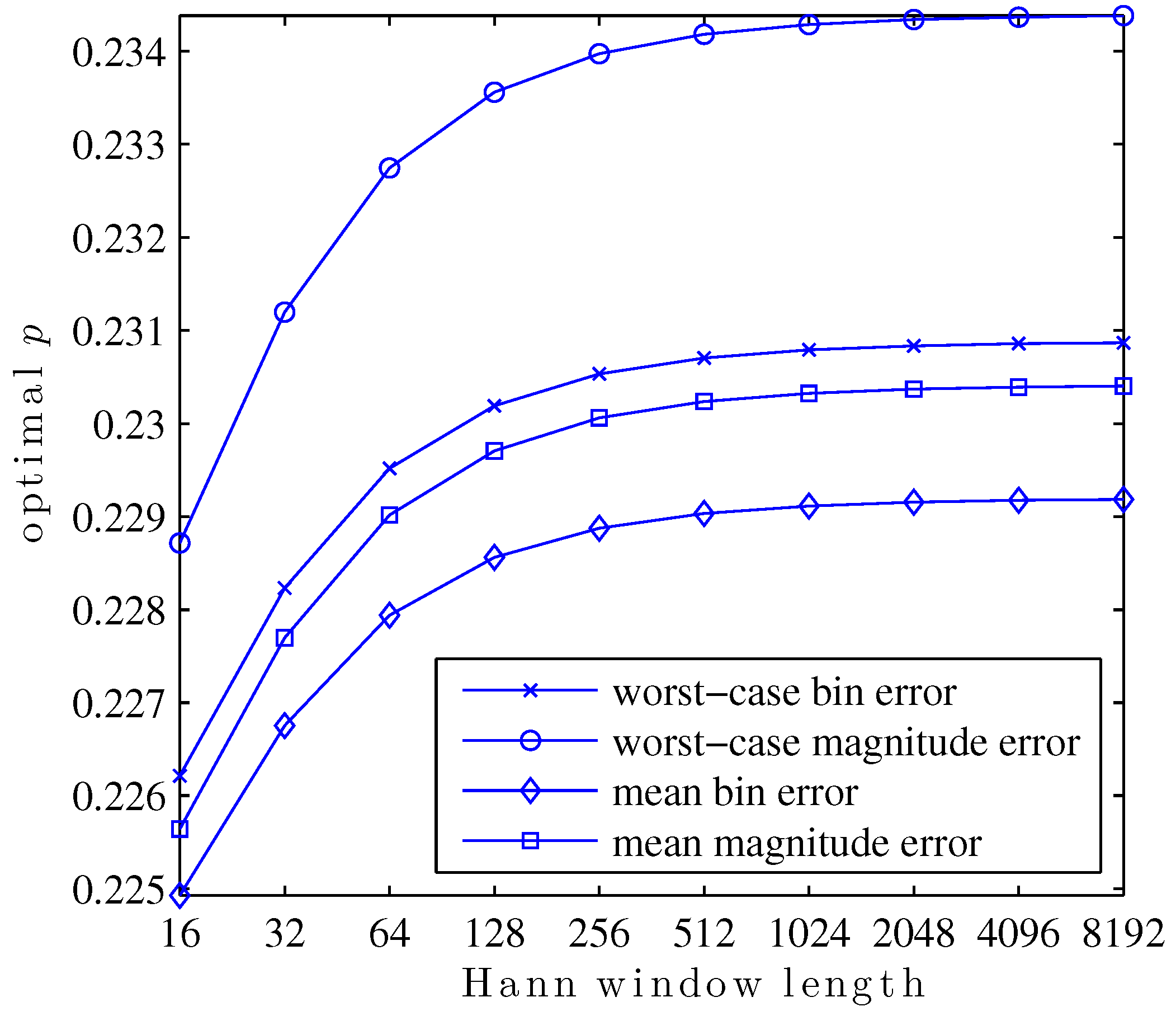
6.1. Optimal p as a Funtion of Window Length
In this first study, the search for values of
p which optimize
,
,
, or
is repeated for Hann windows of various lengths, powers of two from 16 to 8192. The result is a family of curves, given in
Figure 8, showing the optimal value of
p for each window length and optimized metric.
This plot exemplifies a few interesting aspects of the search for optimal p. For any particular metric, the optimal p is a function of the shape of the main lobe within the region bins of its center. The reason for this is that the true DTFT peak may not be further than bins from a DFT bin. Since only the three closest bins are used to calculate any QIFFT-derived estimate, parts of the main lobe shape further than DFT bins of the DTFT peak will never be used directly in a QIFFT-derived method.
Main lobe shape is, of course, defined by the window type. A subtler but important point is that main lobe shape changes appreciably as a function of window length. This is due to the aliasing of sidelobe components of the window transform. For the Hann window, aliased sidelobe components have a decreasing effect on the main lobe shape as the window gets long due to the sidelobe rolloff of 18 dB/octave—in
Figure 8 this is visible as a “flattening out” of the curves as window length increases.
Another interesting facet of this family of curves is its structure. The optimal
p depends in a structured way on the window length. The same way that, e.g., Candan fits a polynomial to tabulated bias correction factors to avoid tabulating and storing every single possibility [
15], it would be possible to fit a function to this family of curves to predict the optimal
p for a particular metric and window shape without performing the optimization each time.
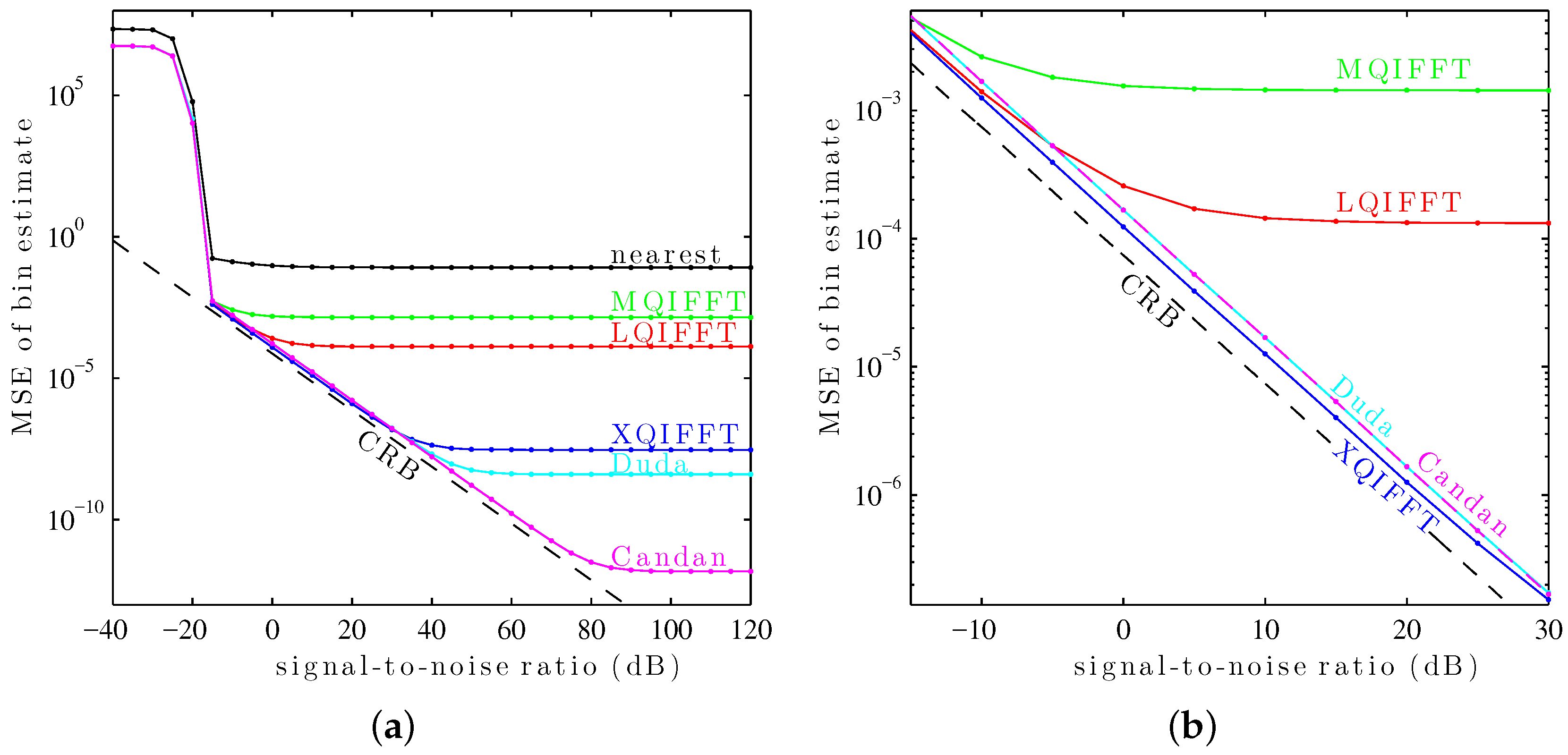
6.2. Bin Estimate MSE as a Function of SNR (Hann)
In this second study, the performance of the XQIFFT and other QIFFT-derived methods is compared to the state-of-the-art direct methods of Duda [
14] and Candan [
15] using again a length-4096 Hann window. Here, we choose
to minimize
as we found earlier. As before, the complex sinusoids are corrupted by additive white Gaussian noise. For each SNR from
to 120, in intervals of 5 dB,
sinusoids are tested with bin offsets of
to
. The MSE of bin estimate is plotted against SNR for each method and the Cramér–Rao bound (CRB) in
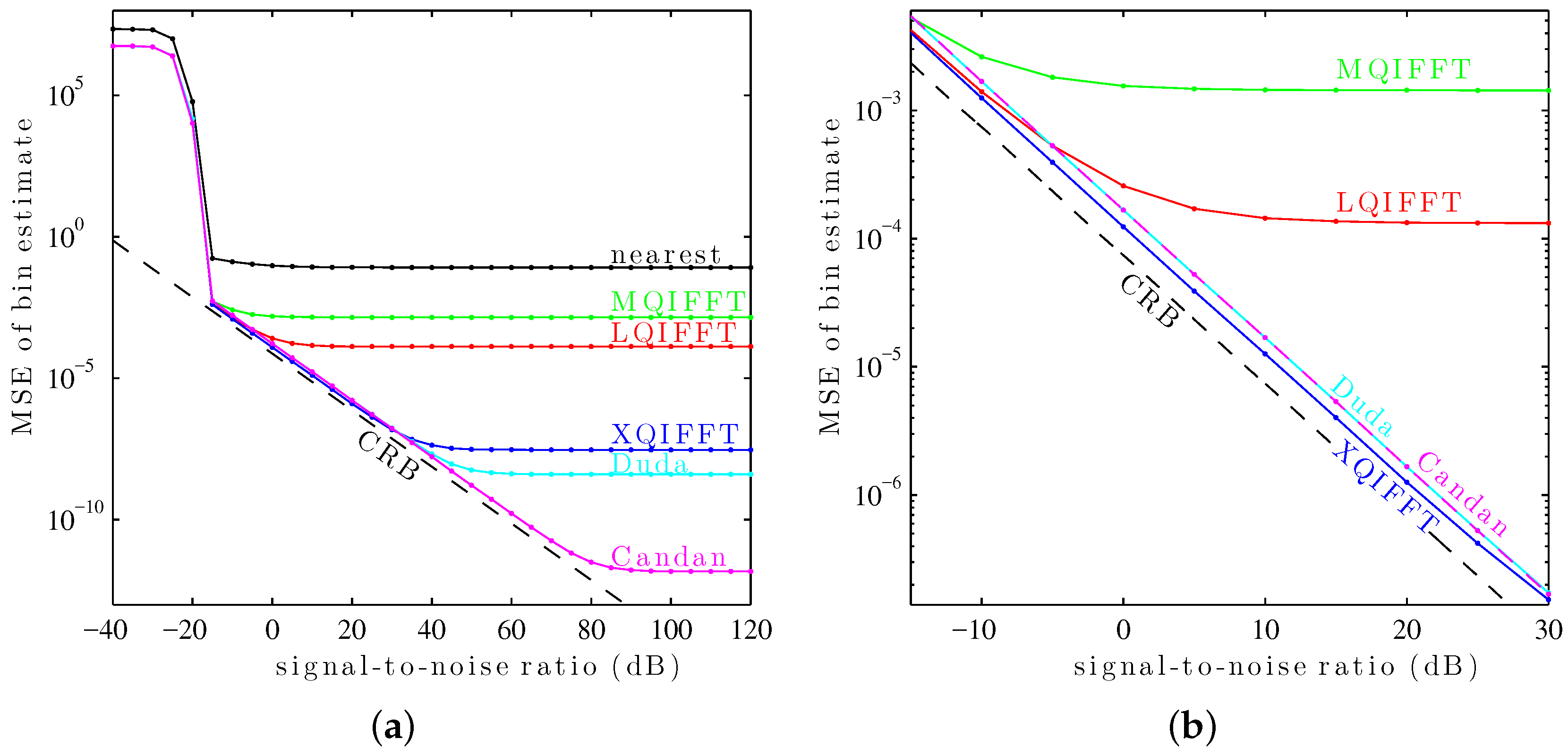
Figure 9a.
This plot shows a “thresholding” effect at low SNR (below db). All of the tested methods use as their coarse estimate the maximum of the magnitude spectrum. The thresholding effect arises when the DFT samples are so noisy that the coarse estimate no longer reliably picks the DFT bin closest to the true fractional bin index . At low SNRs, the MSE of each method is dominated by noise—as SNR increases, the variance decreases. At high SNRs, the variance of each method is dominated by its systematic bias—noise no longer contributes much to the MSE so the traces “flatten out.”
For this particular window, the length-4096 Hann window,
Figure 9a shows that Candan has the best performance at high SNRs (above 30 dB), followed by Duda, followed by the XQIFFT. However, at low SNRs (between
and 30 dB), the XQIFFT has better performance than both Duda and Candan and gets closer to the Cramér–Rao bound—a zoomed detail on this region is shown in
Figure 9b.
6.3. Bin Estimate MSE as a Function of SNR (Twelve Windows)
In this third study, the performance of the XQIFFT and other QIFFT-derived methods is compared to the state-of-the-art direct methods of Duda [
14] and Candan [
15] for
twelve common length-4096 windows. These windows include the Hann window, the Bartlett–Hann window [
45], the Bartlett window [
4], the Hamming window [
4], the Blackman window [
4], the Blackman–Harris window [
43], the Gaussian window [
43], the Digital Prolate Spheroidal Sequence (DPSS/Slepian) window (with time–halfbandwidth product
) [
4], the Kaiser–Bessel window (
) [
46], the Nuttall window [
47], the Dolph–Chebyshev window (sidelobes at
dB) [
43], and the Tukey window (with a 50% taper) [
48]. For each of the twelve windows,
p is chosen to minimize
using the procedure explained earlier. The values of
p used for each window are given in
Table 2.
Again, the complex sinusoids are corrupted by additive white Gaussian noise. For each SNR from
to 120, in intervals of 5 dB,
sinusoids are tested with bin offsets of
to
. The MSE of the bin estimate is plotted against SNR for each method and the Cramér–Rao bound (CRB) in
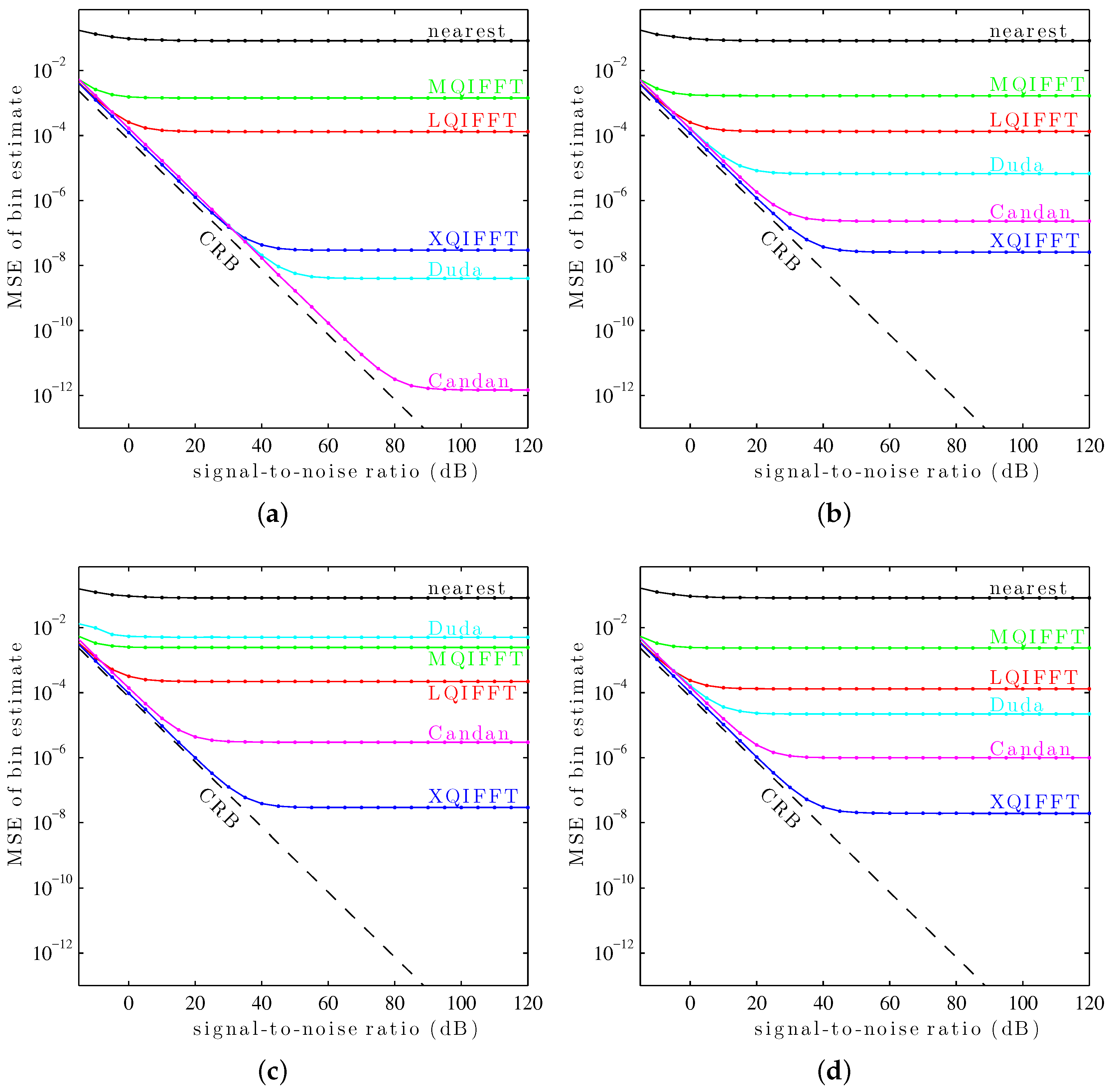
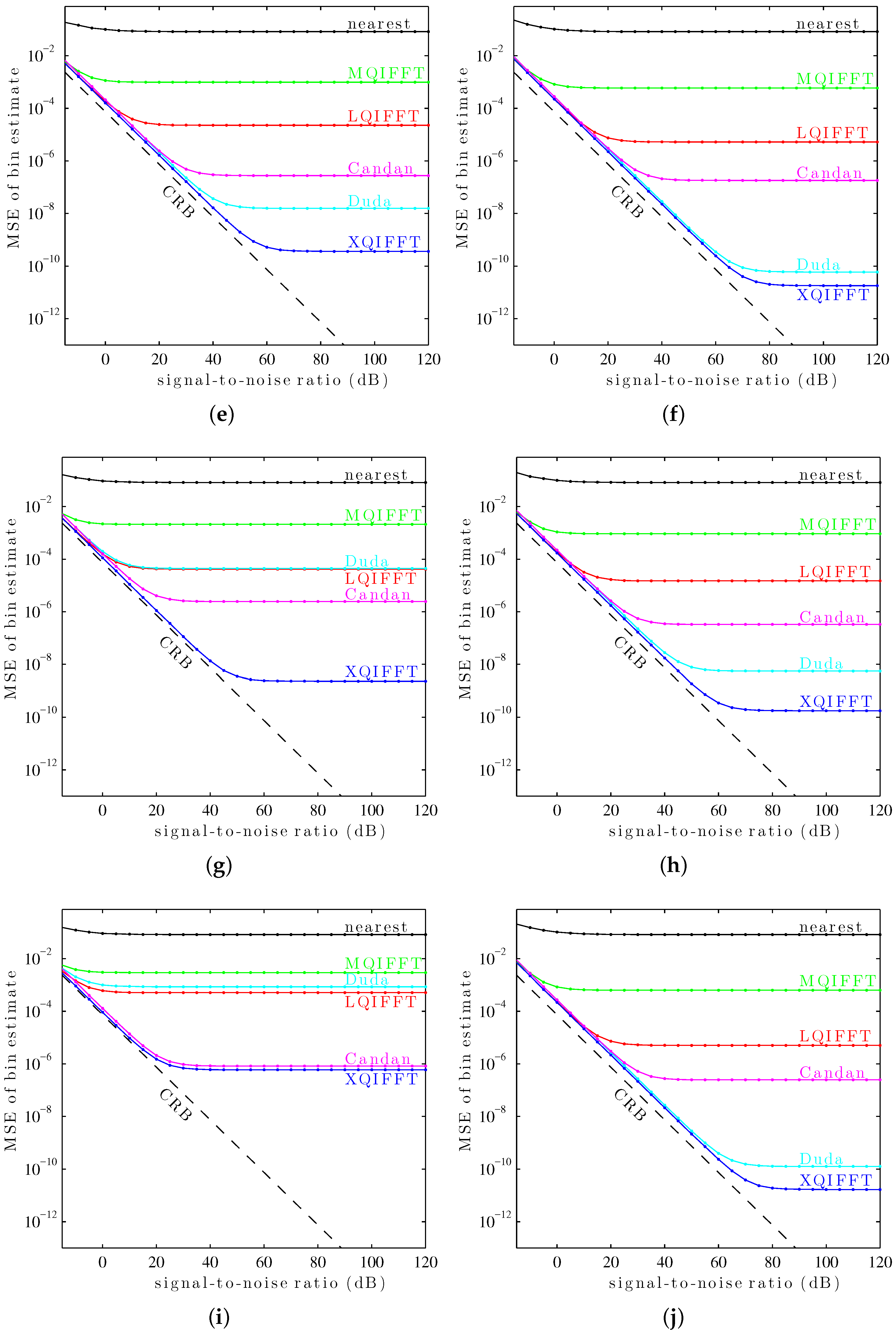
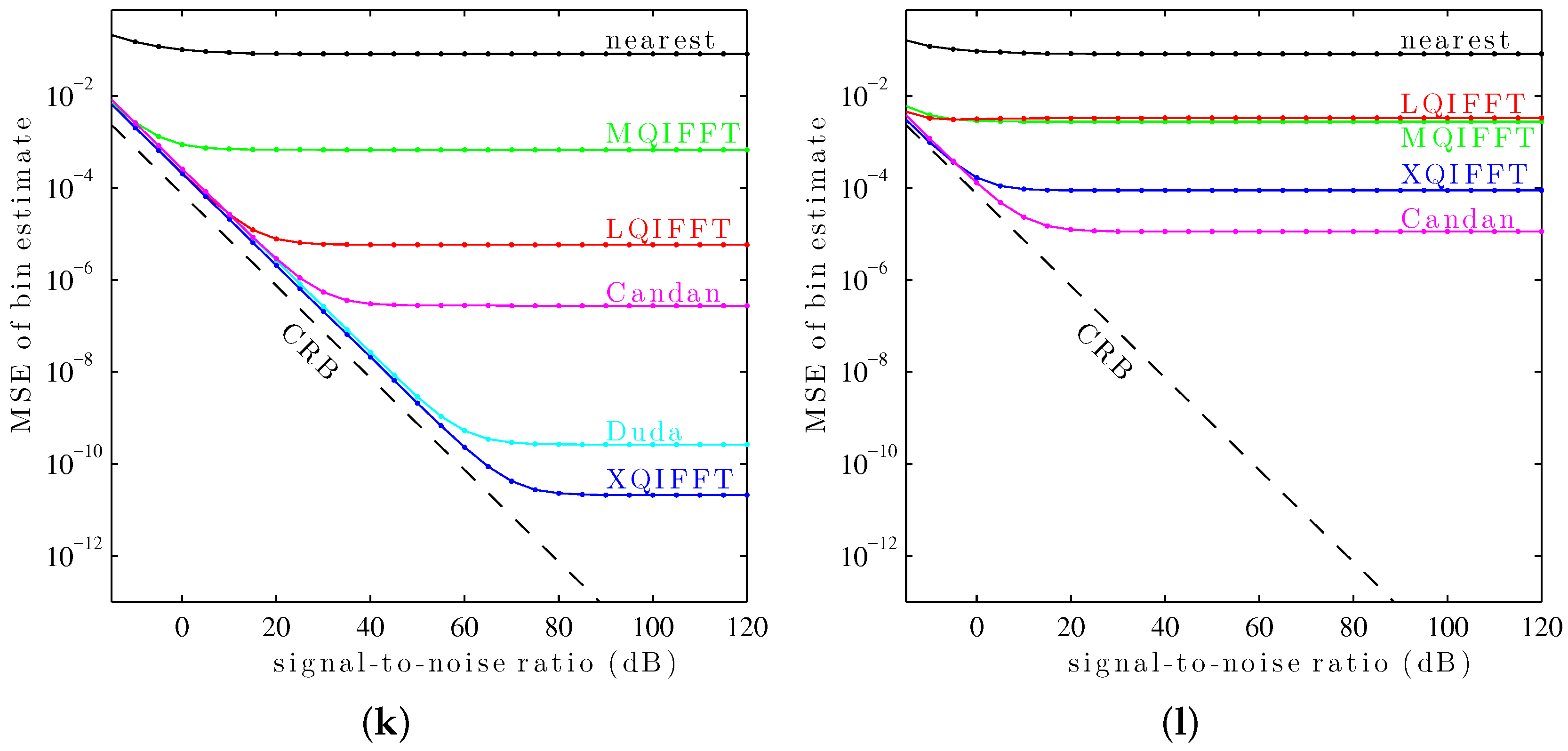
Figure 10.
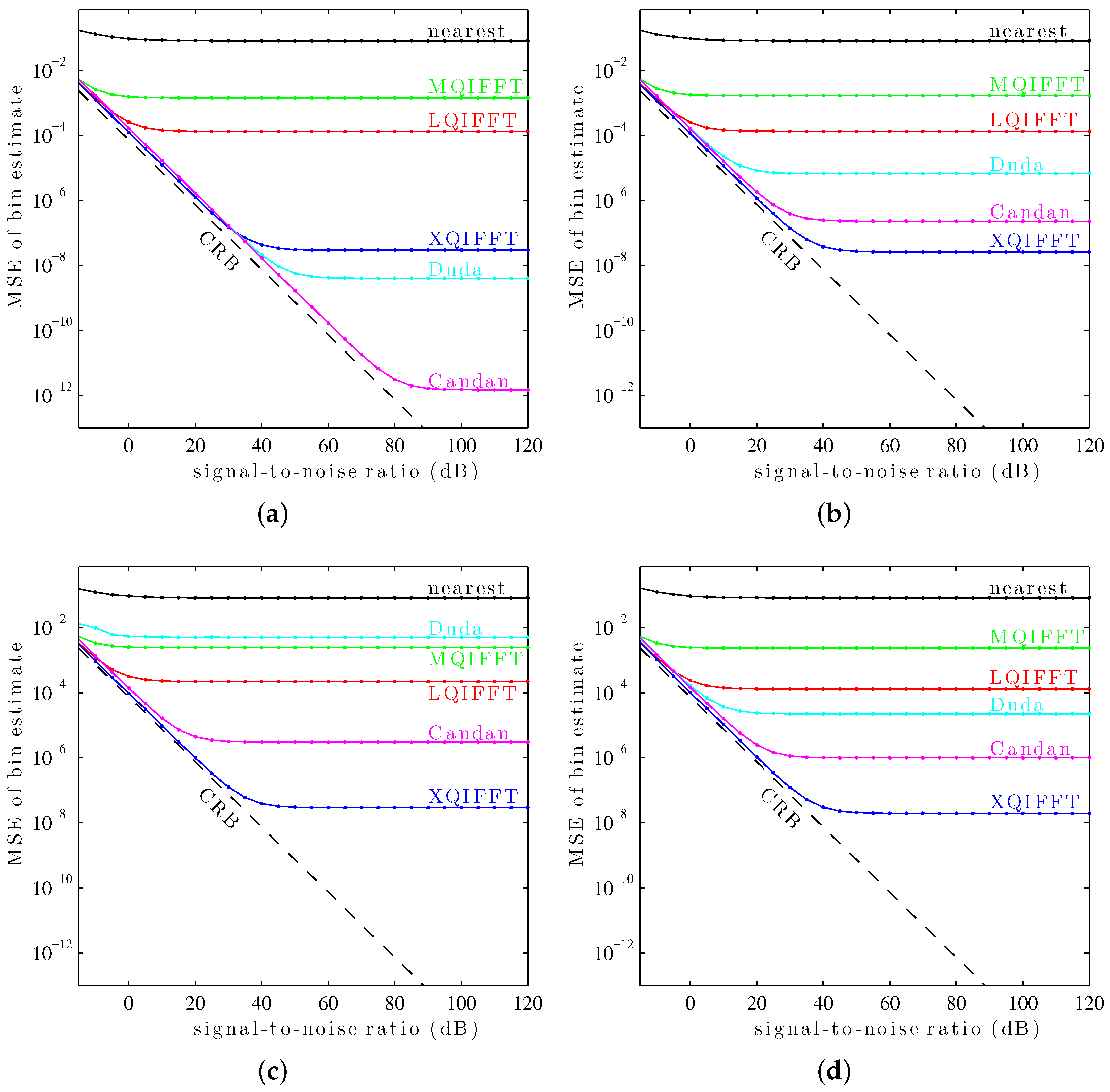
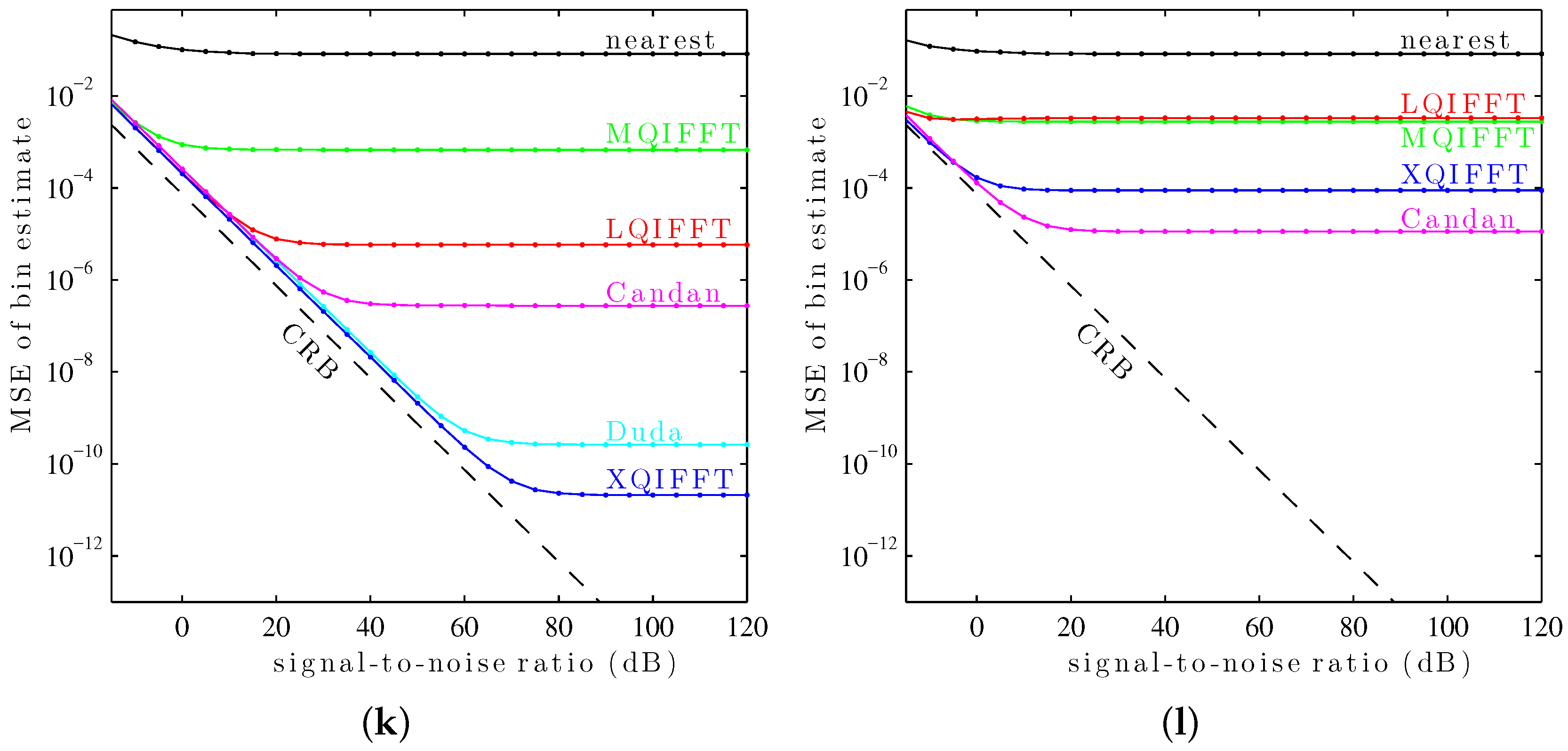
It can be seen in
Figure 10 that the XQIFFT (with a properly-chosen
p according to
Table 2) has the lowest MSE error across the entire range of SNRs for every tested window except the Hann window and the Tukey window (50% taper). In some cases the XQIFFT outperforms its closest competitor by several orders of magnitude.
Figure 10 demonstrates that the XQIFFT is applicable to a wide range of common windows and that it even outperforms the state of the art for most tested windows. In a broader sense, this demonstrates that the best choice of method is highly dependent on the window type which is used—the performance ordering of different methods is highly variable, although for most windows tested the XQIFFT has the best performance. It is also interesting to note that of all the windows tested, the Nuttall window using the XQIFFT has the lowest MSE of bin estimate at high SNR. This implies that Nuttall using XQIFFT achieves the lowest systematic bias of the windows and estimators tested.
7. Conclusions
In this article, we detailed the concept of sinusoidal parameter estimation using quadratic interpolation over three bins of a power-scaled DFT surrounding a magnitude spectrum peak. This method, the XQIFFT, improves on existing quadratic interpolation methods based on linear and logarithmic scaling. We presented a heuristic for optimizing the XQIFFT power-scaling exponent p for a particular window type/window length/zero-padding factor. We presented an analysis of noise sensitivity of the proposed estimator, the dependency of the optimal exponent on window length, and a comparison with competing methods in noisy conditions under twelve common window types. We observed that across the entire tested SNR range, the proposed XQIFFT had a lower bin estimate MSE than the state-of-the-art direct estimates of Duda and Candan for ten of the twelve tested windows. From examining the high SNR regions we can also say that for ten of the twelve tested windows the XQIFFT has a lower systematic bias than the state-of-the-art methods as well. For the remaining two windows tested (Hann and Tukey), the XQIFFT has a lower MSE only at low SNR.
When implementing the XQIFFT, the reader may choose the correct value of
p in one of two ways depending on their application. For common windows whose lengths are between 512 and 4096 samples, linear interpolation between the values of
p reported in
Table 2 may be used to approximate the optimal value of
p to five decimal places. For even more precision or for window types or lengths not reported in
Table 2, the reader may use the generalized procedure reported in
Section 5.3 to produce an optimal value of
p.
Future work should consider applying the XQIFFT-style magnitude spectrum scaling to types of estimators that rely on techniques other than parabolic interpolation. We expect that for other approaches that rely in some way on main lobe shape, the main-lobe-shaping philosophy of the XQIFFT may yield improvements.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}