A Database-driven Decision Support System: Customized Mortality Prediction

Abstract
:1. Introduction
2. Experimental
2.1. MIMIC Database, Beth Israel Deaconess Medical Center (BIDMC), Boston, MA, USA
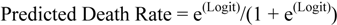
2.2. Registry of Cardiac Surgery Patients in Dunedin Hospital, University of Otago, New Zealand
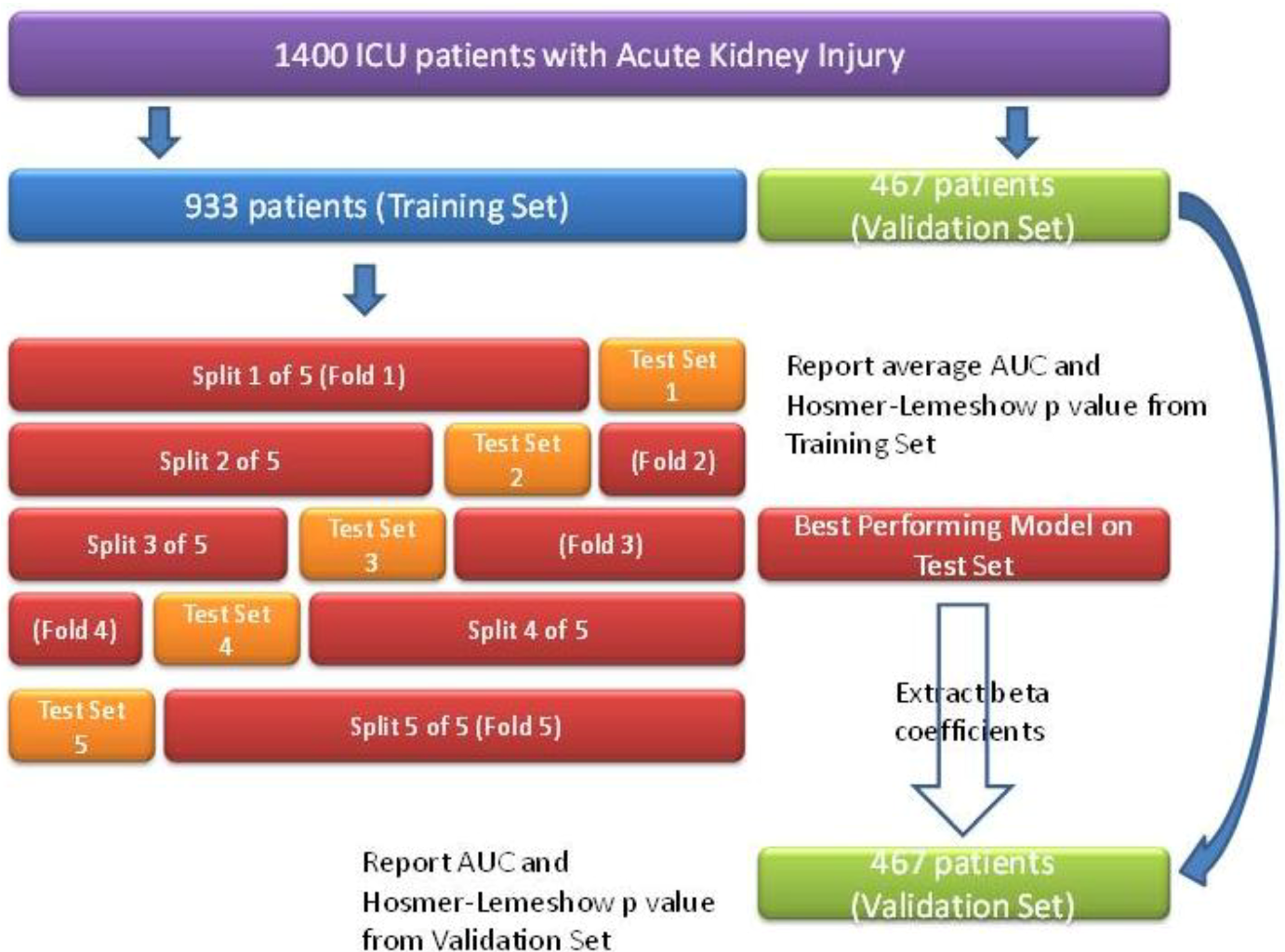
3. Results and Discussion
3.1. Results
3.1.1. ICU Patients with AKI

{kind=link}
| Accuracy | Mean Absolute Error | Area under the ROC Curve | |
|---|---|---|---|
| Logistic Regression | 72.9% | 0.367 | 0.738 |
| Bayesian Network | 73.2% | 0.306 | 0.761 |
| Artificial Neural Network | 81.9% | 0.227 | 0.875 |
| Estimate | Standard Error | z value | Pr (>|z|) | |
|---|---|---|---|---|
| Age | 5.54e−03 | 2.30e−03 | 2.41 | 0.02 |
| Maximum serum bilirubin (Day 2) | 4.58e−02 | 1.46e−01 | 0.31 | 0.75 |
| Maximum serum bilirubin (Day 3) | 1.66e−02 | 1.42e−01 | 0.12 | 0.91 |
| Minimum heart rate (Day 2) | 3.64e−03 | 5.44e−03 | 0.67 | 0.50 |
| Average systolic blood pressure (Day 1) | −8.61e−03 | 5.71e−03 | −1.51 | 0.13 |
| Minimum systolic blood pressure (Day 2) | −8.31e−04 | 6.25e−03 | −0.13 | 0.89 |
| Minimum systolic blood pressure (Day 3) | −2.18e−02 | 7.42e−03 | −2.94 | 0.003 |
| Average systolic blood pressure (Day 3) | 6.46e−03 | 7.71e−03 | 0.84 | 0.40 |
| Maximum respiratory rate (Day 3) | 1.58e−02 | 1.14e−02 | 1.38 | 0.17 |
| Standard deviation of the hematocrit (Day 2) | 1.05e−01 | 5.05e−02 | 2.08 | 0.04 |
| Minimum White Blood Cell count (Day 1) | −1.19e−03 | 1.98e−02 | −0.06 | 0.95 |
| Minimum White Blood Cell count (Day 2) | −7.07e−02 | 8.66e−02 | −0.82 | 0.41 |
| Average White Blood Cell count (Day 2) | 6.50e−02 | 8.59e−02 | 0.76 | 0.45 |
| Minimum White Blood Cell count (Day 3) | 3.36e−02 | 2.28e−02 | 1.47 | 0.14 |
| Maximum BUN (Day 2) | −1.66e−02 | 8.29e−03 | −2.00 | 0.05 |
| Maximum BUN (Day 3) | 2.98e−02 | 8.39e−03 | 3.56 | 0.0004 |
| Glasgow coma score (Day 1) | −4.42e−02 | 1.71e−02 | −2.59 | 0.01 |
| Maximum serum bicarbonate (Day 1) | 6.20e−03 | 1.83e−02 | 0.34 | 0.73 |
| Urine Output (Day 1) | −1.20e−04 | 8.44e−05 | −1.43 | 0.15 |
| Urine Output (Day 2) | −6.60e−05 | 6.75e−05 | −0.98 | 0.33 |
| Urine Output (Day 3) | −1.10e−04 | 7.44e−05 | −1.48 | 0.14 |
3.1.2. ICU Patients with SAH
| Accuracy | Mean Absolute Error | Area under the ROC Curve | |
|---|---|---|---|
| Logistic Regression | 89.0% | 0.158 | 0.945 |
| Bayesian Network | 87.7% | 0.127 | 0.958 |
| Artificial Neural Network | 83.6% | 0.168 | 0.868 |
| Estimate | Standard Error | z value | Pr (>|z|) | |
|---|---|---|---|---|
| Age | 0.05 | 0.02 | 2.64 | 0.008 |
| Average serum glucose | 0.02 | 0.01 | 2.50 | 0.01 |
| Maximum White Blood Cell count | 0.01 | 0.05 | 0.10 | 0.92 |
| Standard deviation of the serum glucose | 0.13 | 0.32 | 0.41 | 0.68 |
| Average prothrombin time INR | 3.20 | 1.56 | 2.05 | 0.04 |
| Minimum Glasgow coma score | −0.01 | 0.17 | −0.06 | 0.95 |
| Maximum Glasgow coma score | 0.24 | 0.22 | 1.12 | 0.26 |
| Average Glasgow coma score | −0.60 | 0.33 | −1.80 | 0.07 |
| Minimum systolic blood pressure | −0.02 | 0.02 | −0.94 | 0.34 |
| Minimum serum sodium | 0.03 | 0.32 | 0.10 | 0.92 |
| Average serum sodium | −0.03 | 0.32 | −0.10 | 0.92 |
| Standard deviation of the serum sodium | 0.02 | 0.44 | 0.04 | 0.97 |
3.1.3. Elderly Patients Who Underwent Open Heart Surgery
| Accuracy | Mean Absolute Error | Area under the ROC Curve | |
|---|---|---|---|
| Logistic Regression | 80.0% | 0.201 | 0.854 |
| Bayesian Network | 96.4% | 0.129 | 0.931 |
| Artificial Neural Network | 96.4% | 0.045 | 0.941 |
| Estimate | Standard Error | z value | Pr (>|z|) | |
|---|---|---|---|---|
| Ejection fraction | 1.11 | 1.01 | 1.10 | 0.27 |
| Use of an intra-aortic balloon pump | 1.61 | 1.67 | 0.97 | 0.33 |
| Chest Reopening | 3.14 | 1.38 | 2.28 | 0.02 |
| Development of atrial fibrillation | 18.68 | 2.46 | −0.01 | 0.99 |
| Development of a post-operative infection | 0.77 | 1.19 | −0.65 | 0.52 |
3.2. Discussion
4. Conclusions
Acknowledgements
Conflict of Interest
References
- Celi, L.A.; Tang, R.J.; Villarroel, M.C.; Davidzon, G.; Lester, W.T.; Chueh, H.C. A clinical database-driven approach to decision support: Predicting mortality among patients with acute kidney injury. J. Healthcare Eng. 2011, 2, 97–109. [Google Scholar] [CrossRef]
- Saeed, M.; Villarroel, M.; Reisner, A.T.; Clifford, G.; Lehman, L.W.; Moody, G.; Heldt, T.; Kyaw, T.H.; Moody, B.; Mark, R.G. Multiparameter Intelligent Monitoring in Intensive Care II (MIMIC-II): A public-access intensive care unit database. Crit. Care Med. 2011, 39, 952–960. [Google Scholar] [CrossRef]
- Le Gall, J.; Lemeshow, S.; Saulnier, F. A new Simplified Acute Physiology Score (SAPS II) based on a European/North American multicenter study. JAMA 1993, 270, 2957–2963. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E.; Hall, M.A. Data Mining: Practical Machine Learning Tools and Techniques, 3rd ed.; Morgan Kaufmann Publishers: San Francisco, CA, USA, 2011; pp. 311–314. [Google Scholar]
- Celi, L.A.; Hinske, L.C.; Alterovitz, G.; Szolovits, P. Artificial intelligence to predict fluid requirement in the ICU: A proof-of-concept study. Crit. Care 2008, 12. [Google Scholar]
- Uchino, S.; Kellum, J.; Bellomo, R.; Doig, G.S.; Morimatsu, H.; Morgera, S.; Schetz, M.; Tan, I.; Bouman, C.; Macedo, E.; et al. Acute renal failure in critically ill patients: A multinational, multicenter study. JAMA 2005, 294, 813–818. [Google Scholar] [CrossRef]
- Kolhe, N.; Stevens, P.; Crowe, A.; Lipkin, G.W.; Harrison, D.A. Case mix, outcome and activity for patients with severe acute kidney injury during the first 24 h after admission to an adult general critical care unit: Application of predictive models from a secondary analysis of the ICNARC Case Mix Programme Database. Crit. Care 2008, 12. [Google Scholar] [CrossRef]
- Hop, J.; Rinkel, G.; Algra, A.; van Gijn, J. Case-fatality rates and functional outcome after subarachnoid hemorrhage: A systematic review. Stroke 1997, 28, 660–664. [Google Scholar] [CrossRef]
- Rosen, D.S.; Macdonald, R.L. Subarachnoid hemorrhage grading scales: A systematic review. Neurocrit. Care 2005, 2, 110–118. [Google Scholar] [CrossRef]
- Roques, F.; Nashef, S.A.M.; Michel, P.; Gauducheau, E.; de Vincentiis, C.; Baudet, E.; Cortina, J.; David, M.; Faichney, A.; Gabrielle, F.; et al. Risk factors and outcome in European cardiac surgery: Analysis of the EuroSCORE multinational database of 19030 patients. Eur. J. Cardiothorac. Surg. 1999, 15, 816–823. [Google Scholar] [CrossRef]
- Collart, F.; Feier, H.; Kerbaul, F.; Mouly-Bandini, A.; Riberi, A.; Mesana, T.G.; Metras, D. Valvular surgery in octogenarians: Operative risk factors, evaluation of Euroscore and long term results. Eur. J. Cardiothorac. Surg. 2005, 27, 276–280. [Google Scholar] [CrossRef]
- Shanmugam, G.; West, M.; Berg, G. Additive and logistic EuroSCORE performance in high risk patients. Interact. Cardiovasc. Thorac. Surg. 2005, 4, 299–303. [Google Scholar] [CrossRef]
- Patel, P.; Grant, B. Application of mortality prediction systems to individual intensive care units. Intensive Care Med. 1999, 25, 977–982. [Google Scholar] [CrossRef]
- Strand, K.; Flaaten, H. Severity scoring in the ICU: A review. Acta Anaesthesiol. Scand. 2008, 52, 467–478. [Google Scholar] [CrossRef]
© 2012 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Celi, L.A.; Galvin, S.; Davidzon, G.; Lee, J.; Scott, D.; Mark, R. A Database-driven Decision Support System: Customized Mortality Prediction. J. Pers. Med. 2012, 2, 138-148. https://doi.org/10.3390/jpm2040138
Celi LA, Galvin S, Davidzon G, Lee J, Scott D, Mark R. A Database-driven Decision Support System: Customized Mortality Prediction. Journal of Personalized Medicine. 2012; 2(4):138-148. https://doi.org/10.3390/jpm2040138
Chicago/Turabian StyleCeli, Leo Anthony, Sean Galvin, Guido Davidzon, Joon Lee, Daniel Scott, and Roger Mark. 2012. "A Database-driven Decision Support System: Customized Mortality Prediction" Journal of Personalized Medicine 2, no. 4: 138-148. https://doi.org/10.3390/jpm2040138
APA StyleCeli, L. A., Galvin, S., Davidzon, G., Lee, J., Scott, D., & Mark, R. (2012). A Database-driven Decision Support System: Customized Mortality Prediction. Journal of Personalized Medicine, 2(4), 138-148. https://doi.org/10.3390/jpm2040138