
A Comprehensive Step-by-Step Guide to Using Data Science Tools in the Gestion of Epidemiological and Climatological Data in Rice Production Systems
 ,
,
Abstract
:1. Introduction
2. Materials and Methods
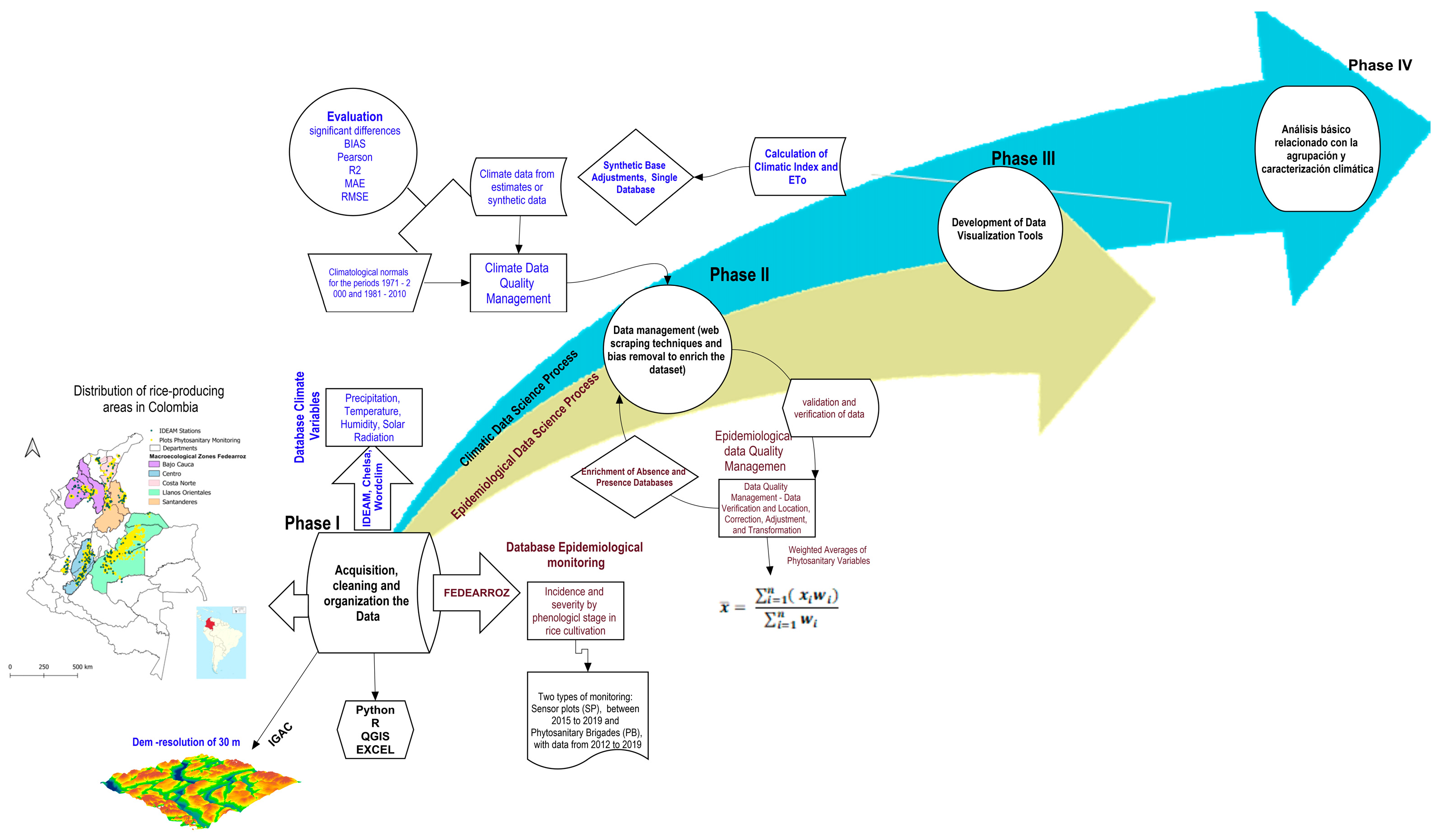
2.1. Description of Approach Used
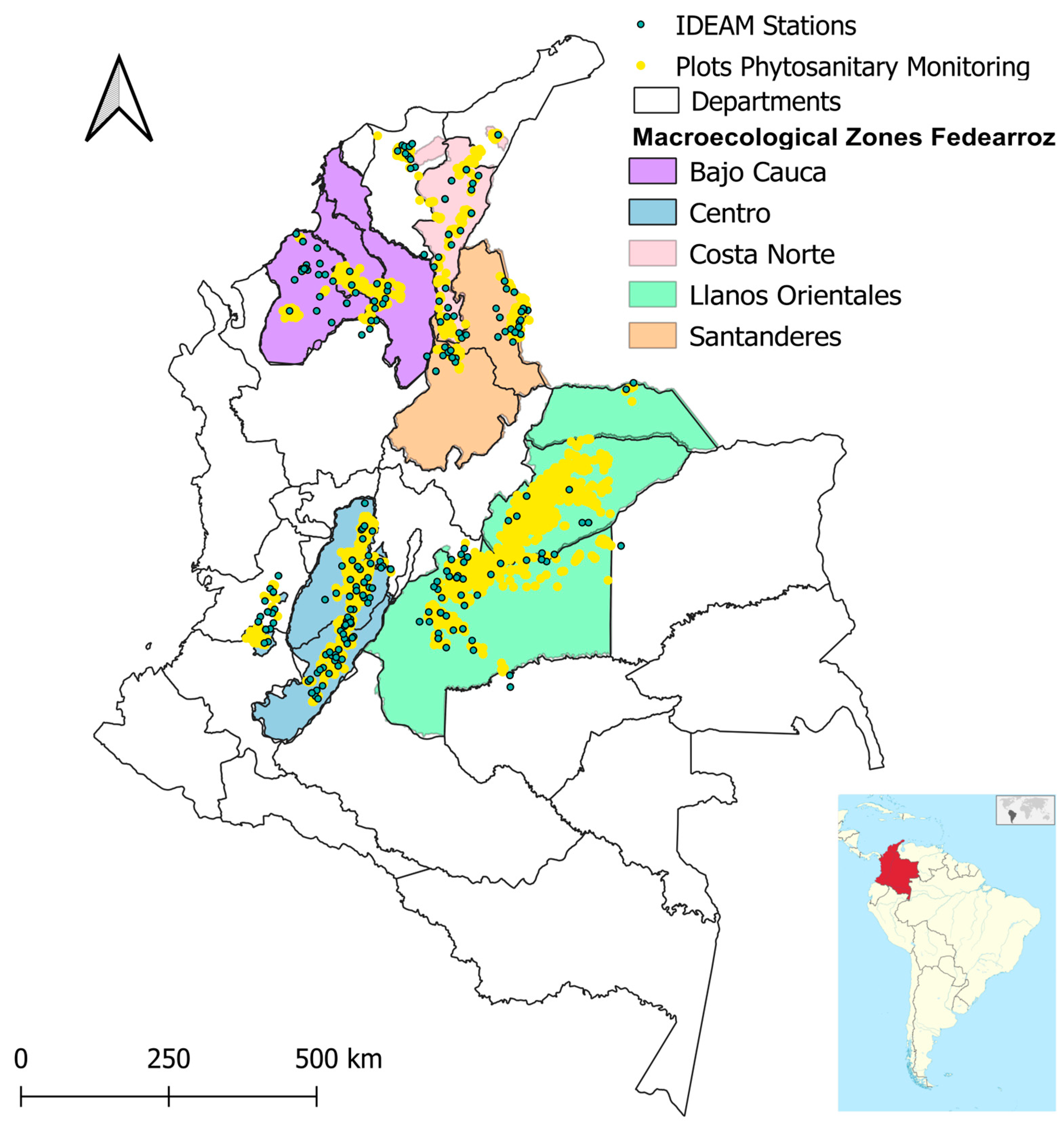
2.2. Basic Description of the Study Zone
2.3. Part A: Management of Epidemiological Data Associated with the Monitoring of Rice Diseases in Colombia
2.4. Data Quality Management and Visualization Tools for Rice Disease Intensity Estimators
2.5. Part B: Climate Data Management and Analysis
2.5.1. Management of Data from Weather Stations
2.5.2. Management of Climate Data from Estimates or Synthetic Data
2.6. Evaluation of the Quality of Climatological Data from Estimates vs. In Situ Data
2.7. Practical Application of Climate Data Management: Agroclimatic Zoning for Rice-Producing Regions in Colombia
2.8. Basic Analysis of the Information, Libraries, and Software Used
3. Results
3.1. Data Gestion Tools Used
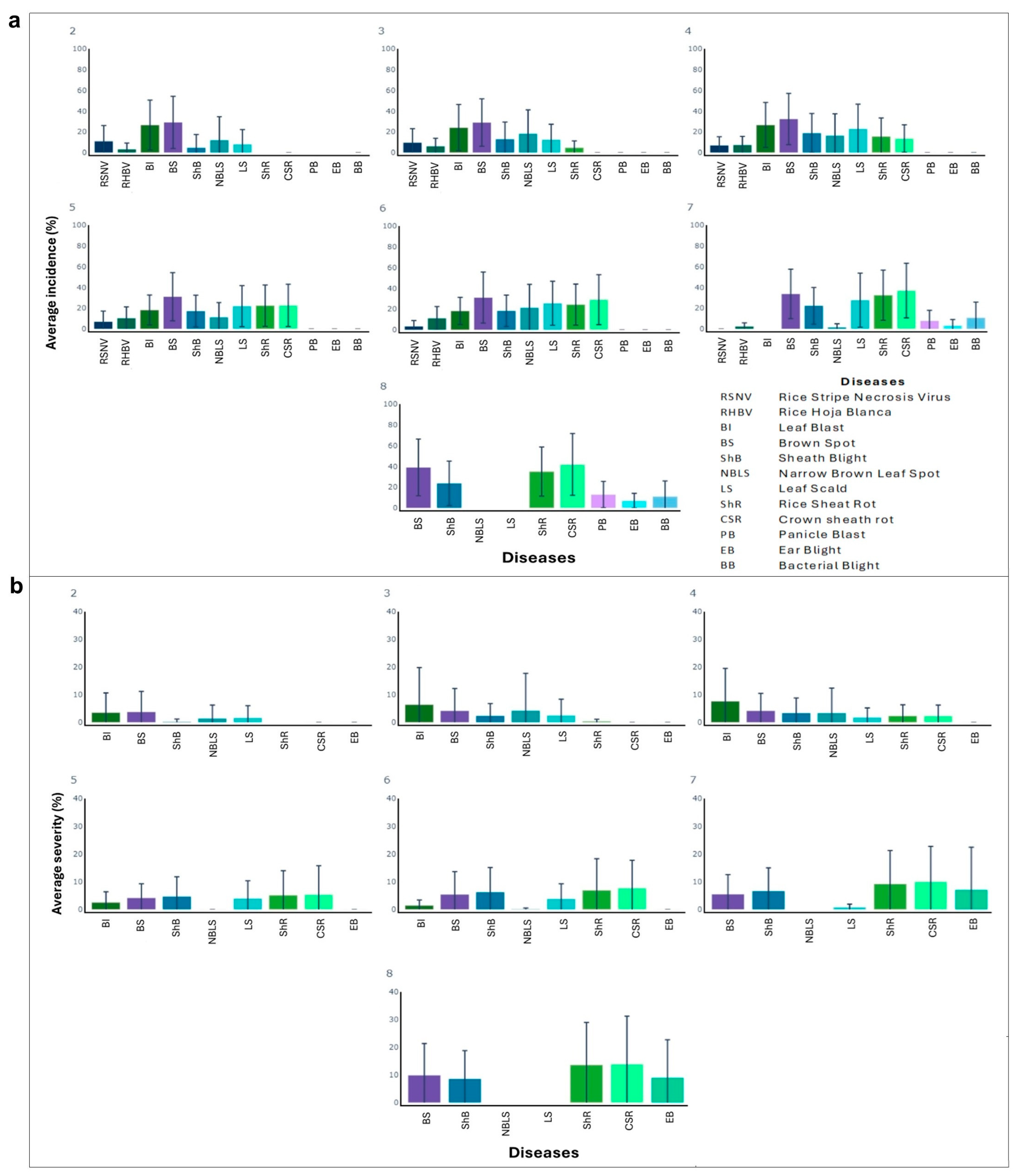
3.2. Part A: Data Quality Management and Visualization Tools for Rice Disease Intensity Estimators
3.3. Part B: Management of Climatological Data from In Situ and Estimated or Synthetic Stations
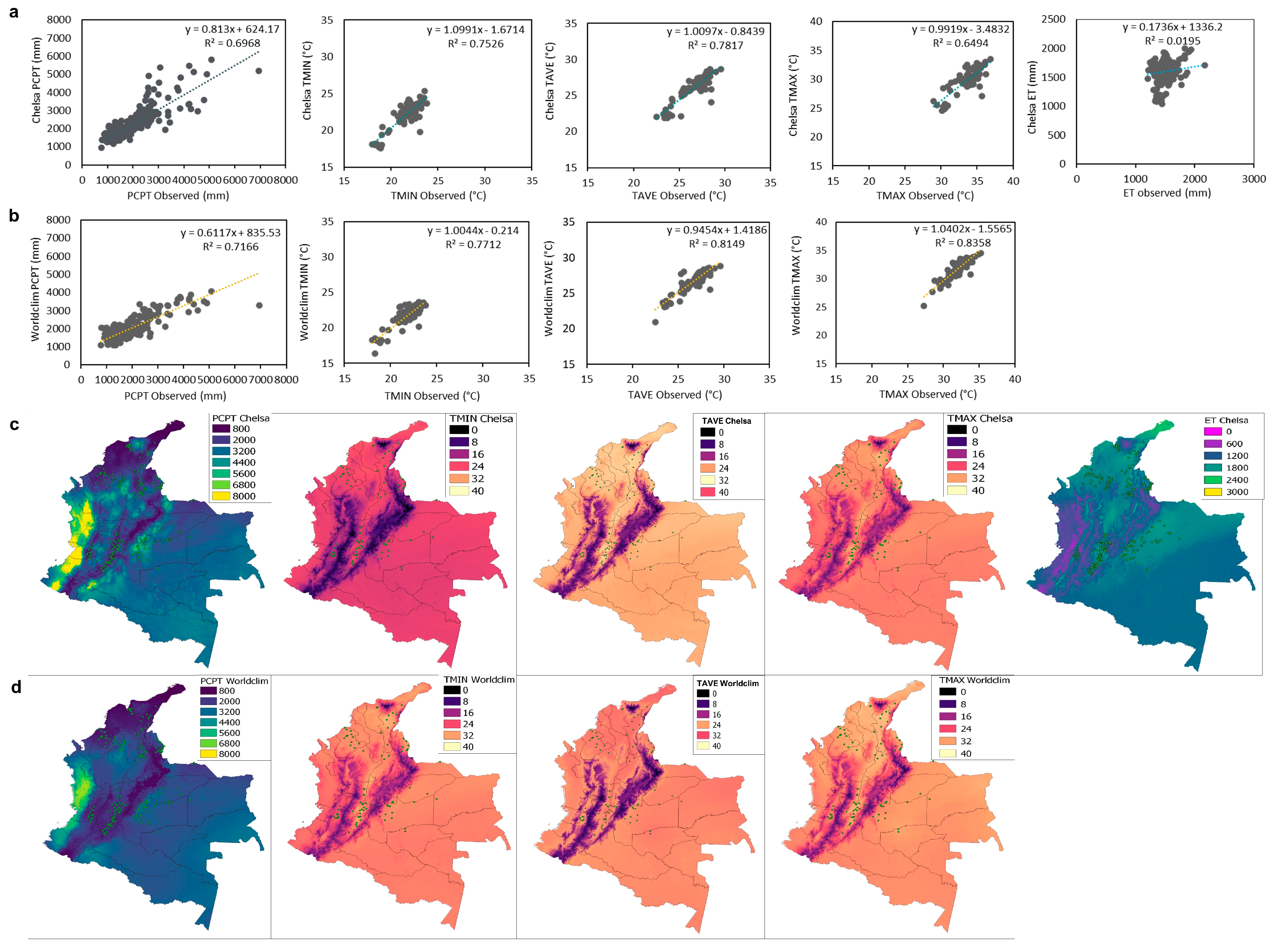
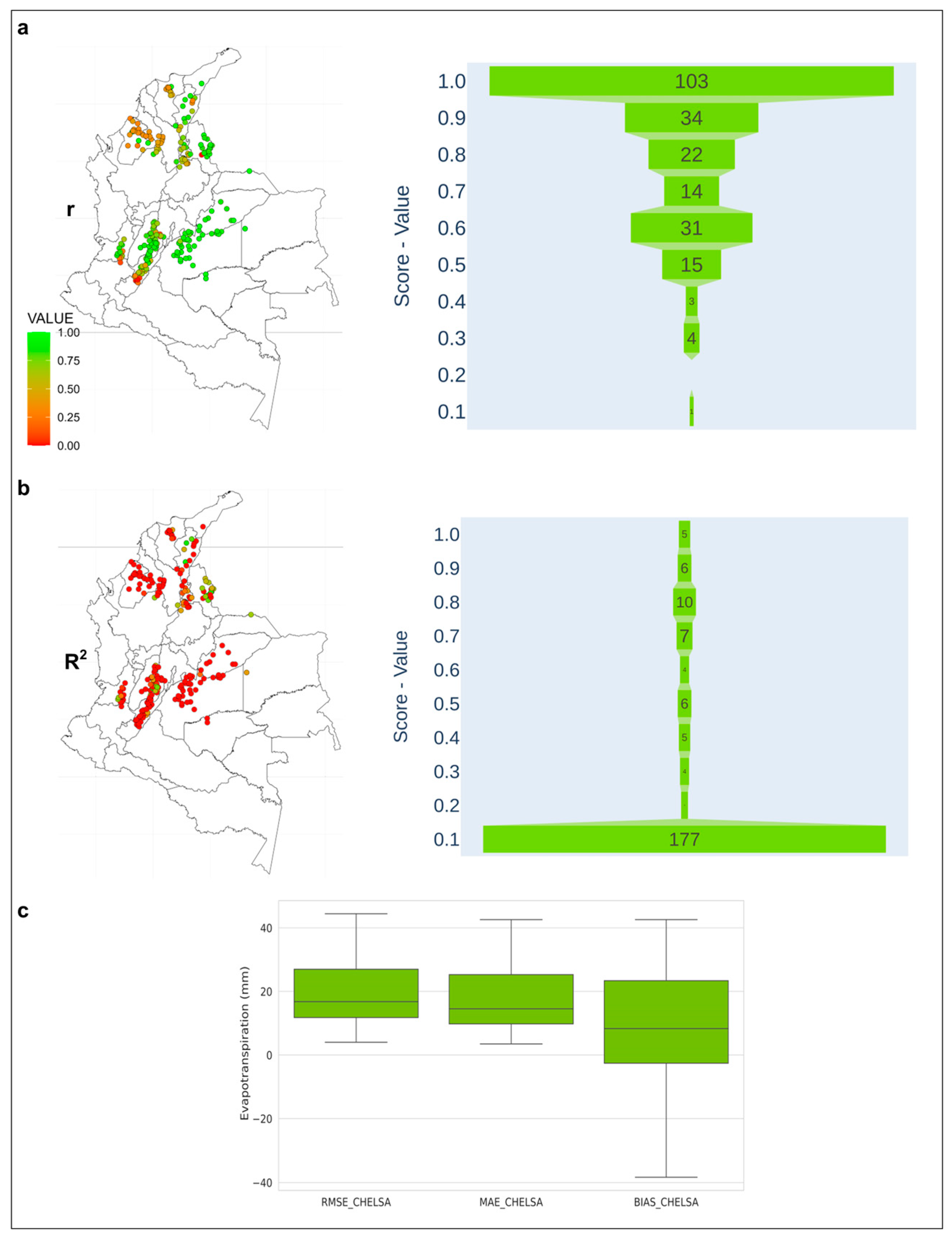
3.4. Evaluation of the Quality of Climatological Data from Estimates vs. Data from In Situ Stations
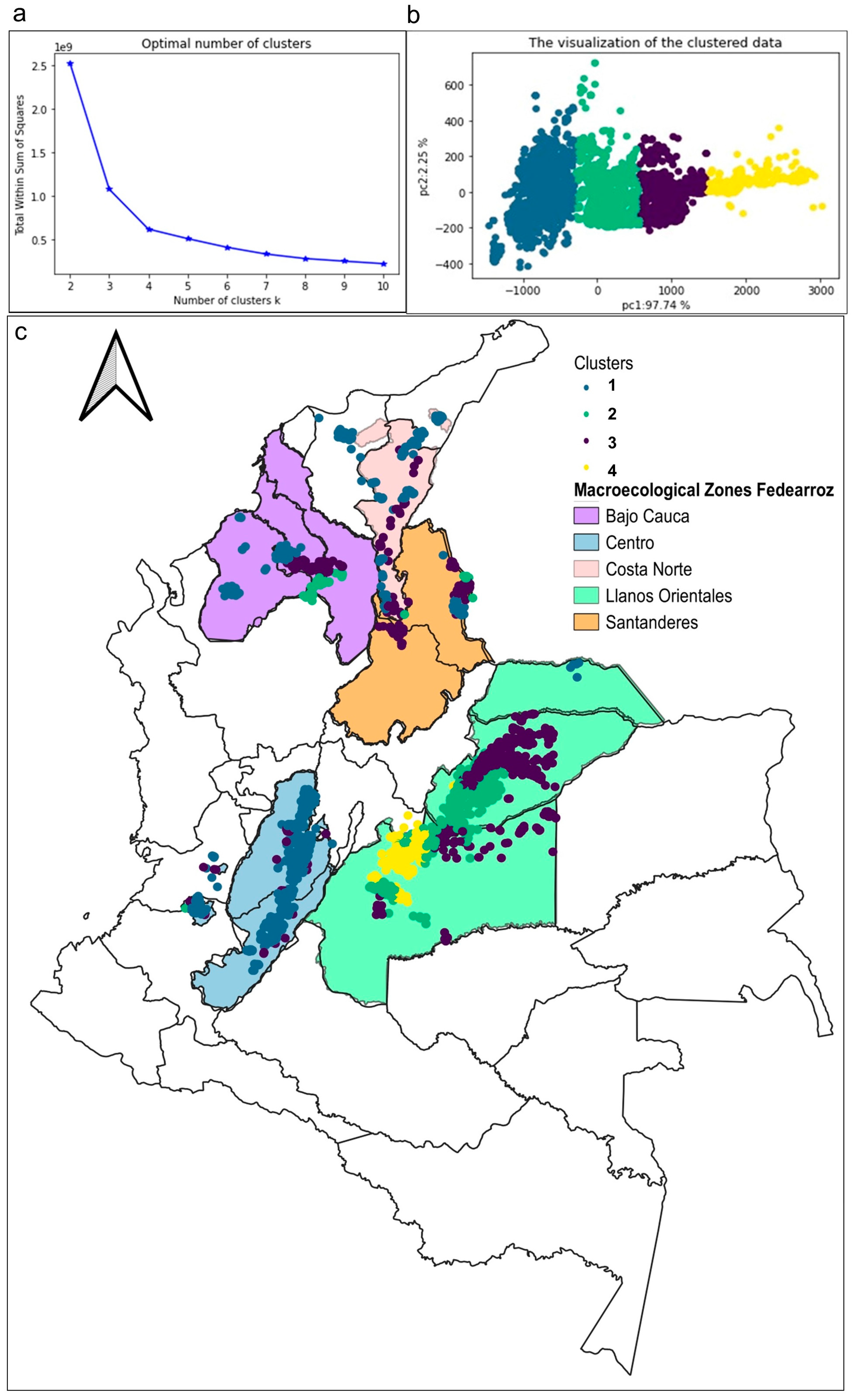
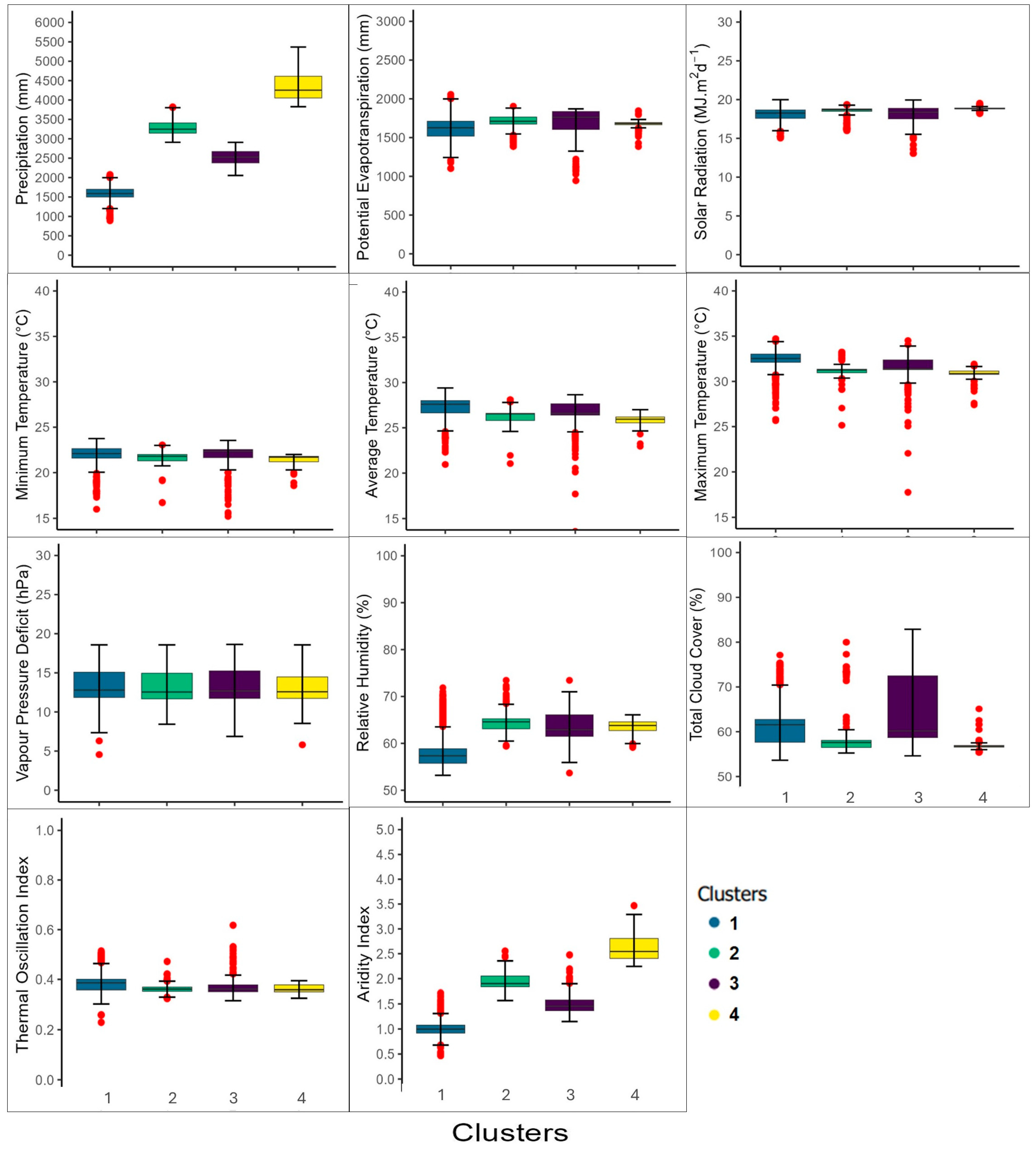
3.5. Agroclimatic Zoning for Rice-Producing Regions in Colombia
4. Discussion
4.1. Management of Epidemiological and Climatic Data in Rice Production Systems
4.2. Agroclimatic Zoning for Rice-Producing Regions in Colombia
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mitra, D.; De Los Santos-Villalobos, S.; Parra-Cota, F.I.; Montelongo, A.M.G.; Blanco, E.L.; Lira, V.L.; Olatunbosun, A.N.; Khoshru, B.; Mondal, R.; Chidambaranathan, P.; et al. Rice (Oryza sativa L.) plant protection using dual biological control and plant growth-promoting agents: Current scenarios and future prospects. Pedosphere 2023, 33, 268–286. [Google Scholar] [CrossRef]
- The Food and Agriculture Organization Corporate Statistical Database (FAOSTAT), 2023 Crops and livestock products (Rice) 2023.
- DANE, FNA. Boletin Tecnico. Encuesta Nacional de Arroz Mecanizado (ENAM) I y II Semestre 2020; Departamento Administrativo Nacional de Estadistica (DANE) y Fondo Nacional del Arroz de Fedearroz (FNA): Colombia, South America, 2020; p. 55. Available online: https://www.dane.gov.co/index.php/estadisticas-por-tema/agropecuario/encuesta-de-arroz-mecanizado/encuesta-nacional-de-arroz-mecanizado-enam-historicos (accessed on 8 October 2021).
- Federación Nacional de Arroceros, FEDEARROZ. Fondo Nacional del Arroz (FNA) Contexto mundial y nacional del cultivo del arroz 2000–2020, 2021.
- Savary, S.; Nelson, A.; Willocquet, L.; Pangga, I.; Aunario, J. Modeling and mapping potential epidemics of rice diseases globally. Crop Prot. 2012, 34, 6–17. [Google Scholar] [CrossRef]
- Savary, S.; Willocquet, L.; Pethybridge, S.J.; Esker, P.; McRoberts, N.; Nelson, A. The global burden of pathogens and pests on major food crops. Nat. Ecol. Evol. 2019, 3, 430–439. [Google Scholar] [CrossRef] [PubMed]
- Lal, M. Diversity analysis of Rhizoctonia solani causing sheath blight of rice in India. Afr. J. Biotechnol. 2014, 13, 4595–4605. [Google Scholar]
- Bregaglio, S.; Titone, P.; Hossard, L.; Mongiano, G.; Savoini, G.; Piatti, F.M.; Paleari, L.; Masseroli, A.; Tamborini, L. Effects of agro-pedo-meteorological conditions on dynamics of temperate rice blast epidemics and associated yield and milling losses. Field Crops Res. 2017, 212, 11–22. [Google Scholar] [CrossRef]
- Sun, S.; Bao, Y.; Lu, M.; Liu, W.; Xie, X.; Wang, C.; Liu, W. A comparison of models for the short-term prediction of rice stripe virus disease and its association with biological and meteorological factors. Acta Ecol. Sin. 2016, 36, 166–171. [Google Scholar] [CrossRef]
- Faybishenko, B.; Versteeg, R.; Pastorello, G.; Dwivedi, D.; Varadharajan, C.; Agarwal, D. Challenging problems of quality assurance and quality control (QA/QC) of meteorological time series data. Stoch. Env. Res. Risk Assess. 2022, 36, 1049–1062. [Google Scholar] [CrossRef]
- Fathi, M.; Haghi Kashani, M.; Jameii, S.M.; Mahdipour, E. Big Data Analytics in Weather Forecasting: A Systematic Review. Arch. Comput. Methods Eng. 2022, 29, 1247–1275. [Google Scholar] [CrossRef]
- Wang, T.; Li, Z.; Ma, Z.; Gao, Z.; Tang, G. Diverging identifications of extreme precipitation events from satellite observations and reanalysis products: A global perspective based on an object-tracking method. Remote Sens. Environ. 2023, 288, 113490. [Google Scholar] [CrossRef]
- Dee, D.P.; Uppala, S.M.; Simmons, A.J.; Berrisford, P.; Poli, P.; Kobayashi, S.; Andrae, U.; Balmaseda, M.A.; Balsamo, G.; Bauer, P.; et al. The ERA-Interim reanalysis: Configuration and performance of the data assimilation system. Q. J. R. Meteorol. Soc. 2011, 137, 553–597. [Google Scholar] [CrossRef]
- Karger, D.N.; Conrad, O.; Böhner, J.; Kawohl, T.; Kreft, H.; Soria-Auza, R.W.; Zimmermann, N.E.; Linder, H.P.; Kessler, M. Climatologies at high resolution for the earth’s land surface areas. Sci. Data 2017, 4, 170122. [Google Scholar] [CrossRef] [PubMed]
- Fick, S.E.; Hijmans, R.J. WorldClim 2: New 1-km spatial resolution climate surfaces for global land areas. Int. J. Climatol. 2017, 37, 4302–4315. [Google Scholar] [CrossRef]
- Bastidas Osejo, B.; Betancur Vargas, T.; Alejandro Martinez, J. Spatial distribution of precipitation and evapotranspiration estimates from Worldclim and Chelsa datasets: Improving long-term water balance at the watershed-scale in the Urabá region of Colombia. Int. J. Sustain. Dev. Plan. 2019, 14, 105–117. [Google Scholar] [CrossRef]
- Jiménez-Valverde, A.; Rodríguez-Rey, M.; Peña-Aguilera, P. Climate data source matters in species distribution modelling: The case of the Iberian Peninsula. Biodivers. Conserv. 2021, 30, 67–84. [Google Scholar] [CrossRef]
- Alsafadi, K.; Mohammed, S.; Mokhtar, A.; Sharaf, M.; He, H. Fine-resolution precipitation mapping over Syria using local regression and spatial interpolation. Atmos. Res. 2021, 256, 105524. [Google Scholar] [CrossRef]
- Ramirez-Gil, J.G.; Morales-Osorio, J.G. Diseases and disorders associated with different stages of crop development and factors that determine the incidence in Hass avocado crops. Rev. Ceres Viçosa 2021, 68, 71–82. [Google Scholar] [CrossRef]
- Davy, R.; Kusch, E. Reconciling high resolution climate datasets using KrigR. Environ. Res. Lett. 2021, 16, 124040. [Google Scholar] [CrossRef]
- Kansakar, P.; Hossain, F. A review of applications of satellite earth observation data for global societal benefit and stewardship of planet earth. Space Policy. 2016, 36, 46–54. [Google Scholar] [CrossRef]
- Balsamo, G.; Agusti-Panareda, A.; Albergel, C.; Arduini, G.; Beljaars, A.; Bidlot, J.; Blyth, E.; Bousserez, N.; Boussetta, S.; Brown, A.; et al. Satellite and In Situ Observations for Advancing Global Earth Surface Modelling: A Review. Remote Sens. 2018, 10, 2038. [Google Scholar] [CrossRef]
- Pfeiffer, D.U.; Stevens, K.B. Spatial and temporal epidemiological analysis in the Big Data era. Prev. Vet. Med. 2015, 122, 213–220. [Google Scholar] [CrossRef]
- Simonsen, L.; Gog, J.R.; Olson, D.; Viboud, C. Infectious Disease Surveillance in the Big Data Era: Towards Faster and Locally Relevant Systems. J. Infect. Dis. 2016, 214, S380–S385. [Google Scholar] [CrossRef]
- Kambatla, K.; Kollias, G.; Kumar, V.; Grama, A. Trends in big data analytics. J. Parallel. Distrib. Comput. 2014, 74, 2561–2573. [Google Scholar] [CrossRef]
- Biswas, S.; Wardat, M.; Rajan, H. The Art and Practice of Data Science Pipelines: A Comprehensive Study of Data Science Pipelines in Theory, in-the-Small, and in-the-Large. In Proceedings of the 44th International Conference on Software Engineering, Association for Computing Machinery, New York, NY, USA, 5 July 2022; pp. 2091–2103. [Google Scholar]
- Becerra, I.; Castro, L.; Cortes, C.; Del Valle, C.; Díaz, A.; Flórez, A.; Fonseca, M.; Viveros, J.; Unidad de Planificación Rural Agropecuaria UPRA. 2020 Plan de ordenamiento productivo del arroz en Colombia para el desarrollo, estabilidad y especialización de la cadena arrocera colombiana 2020–2038.
- Cuevas, A.; Higuera, M.O.L.; Federación Nacional de Arroceros (FEDEARROZ). Fondo Nacional del Arroz (FNA). Adopción Masiva De Tecnología. Guía Para El Monitoreo Y Manejo De Enfermedades. 2017. Available online: https://fedearroz.s3.amazonaws.com/media/documents/cartilla_enfermedades_DqWlBTF.pdf (accessed on 8 October 2021).
- Federación Nacional de Arroceros (FEDEARROZ). 2015 Protocolo para el Monitoreo lotes sensores de enfermedades e insectos fitófagos en el cultivo de arroz en Colombia. Documento interno 2015.
- Federación Nacional de Arroceros (FEDEARROZ). 2015 Protocolo Brigada Fitosanitaria Nacional en el cultivo de arroz en Colombia. Documento interno 2015.
- James, S. Weighted Averaging. An Introduction to Data Analysis Using Aggregation Functions in R; Springer International Publishing: Cham, Switzerland, 2016; pp. 75–95. ISBN 978-3-319-46761-0. [Google Scholar]
- Instituto Geografico Agustín Codazzi (IGAC). Modelo digital de elevación de Colombia (DEM), resolución de 30 m. 2011.
- Hubbard, K.G. Spatial variability of daily weather variables in the high plains of the USA. Agric. For. Meteorol. 1994, 68, 29–41. [Google Scholar] [CrossRef]
- Camargo, M.B.P.; Hubbard, K.G. Spatial and temporal variability of daily weather variables in sub-humid and semi-arid areas of the united states high plains. Agric. For. Meteorol. 1999, 93, 141–148. [Google Scholar] [CrossRef]
- Singrodia, V.; Mitra, A.; Paul, S. A Review on Web Scrapping and its Applications. In Proceedings of the 2019 International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, 23–25 January 2019; pp. 1–6. [Google Scholar]
- Dumont, M.; Saadi, M.; Oudin, L.; Lachassagne, P.; Nugraha, B.; Fadillah, A.; Bonjour, J.L.; Muhammad, A.; Dörfliger, N.; Plagnes, V. Assessing rainfall global products reliability for water resource management in a tropical volcanic mountainous catchment. J. Hydrol. Reg. Stud. 2022, 40, 101037. [Google Scholar] [CrossRef]
- Hijmans, R.J.; Cameron, S.E.; Parra, J.L.; Jones, P.G.; Jarvis, A. Very high resolution interpolated climate surfaces for global land areas. Int. J. Climatol. 2005, 25, 1965–1978. [Google Scholar] [CrossRef]
- Schober, P.; Boer, C.; Schwarte, L.A. Correlation Coefficients: Appropriate Use and Interpretation. Anesth. Analg. 2018, 126, 1763–1768. [Google Scholar] [CrossRef]
- Tjur, T. Coefficients of Determination in Logistic Regression Models—A New Proposal: The Coefficient of Discrimination. Am. Stat. 2009, 63, 366–372. [Google Scholar] [CrossRef]
- Lash, T.L.; Fox, M.P.; MacLehose, R.F.; Maldonado, G.; McCandless, L.C.; Greenland, S. Good practices for quantitative bias analysis. Int. J. Epidemiol. 2014, 43, 1969–1985. [Google Scholar] [CrossRef] [PubMed]
- Karunasingha, D.S.K. Root mean square error or mean absolute error? Use their ratio as well. Inf. Sci. 2022, 585, 609–629. [Google Scholar] [CrossRef]
- Oliver, J.E. (Ed.) Aridity Indexes. In Encyclopedia of World Climatology; Springer Netherlands: Dordrecht, The Netherlands, 2005; pp. 89–94. ISBN 978-1-4020-3266-0. [Google Scholar]
- The United Nations Educational, Scientific and Cultural Organization (UNESCO). Map of the World Distribution of Arid Regions: Explanatory Note; UNESCO: London, UK, 1979; ISBN 92-3-101484-6. [Google Scholar]
- Cleves-Leguizamo, J.A.; Ramírez-Castañeda, L.N.; Díaz, E.D. Proposal of an empirical model to estimate the productivity of ‘Valencia’ orange (Citrus sinensis L. Osbeck) in the Colombian low tropics. Rev. Colomb. Cienc. Hortic 2021, 15, e10860. [Google Scholar] [CrossRef]
- Benavides, H.; Simbaqueva, O.; IDEAM, UPME. Atlas de Radiación Solar, Ultravioleta y Ozono de Colombia; Fundación Unversitaria Los Libertadores: Bogotá, Colombia, 2017; ISBN 978 958 8067 94 0. [Google Scholar]
- Carvalho, M.J.; Melo-Gonçalves, P.; Teixeira, J.C.; Rocha, A. Regionalization of Europe based on a K-Means Cluster Analysis of the climate change of temperatures and precipitation. Phys. Chem. Earth Parts A/B/C 2016, 94, 22–28. [Google Scholar] [CrossRef]
- Sa’adi, Z.; Shahid, S.; Shiru, M.S. Defining climate zone of Borneo based on cluster analysis. Theor. Appl. Clim. 2021, 145, 1467–1484. [Google Scholar] [CrossRef]
- Ramirez-Gil, J.G.; Lopera, A.A.; Garcia, C. Calcium phosphate nanoparticles improve growth parameters and mitigate stress associated with climatic variability in avocado fruit. Heliyon 2023, 9, e18658. [Google Scholar] [CrossRef]
- Kurita, T. Principal Component Analysis (PCA). In Computer Vision: A Reference Guide; Springer International Publishing: Cham, Switzerland, 2019; pp. 1–4. ISBN 978-3-030-03243-2. [Google Scholar]
- Wu, S.; Wai, H.-T.; Li, L.; Scaglione, A. A Review of Distributed Algorithms for Principal Component Analysis. Proc. IEEE 2018, 106, 1321–1340. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Abirami, K.; Mayilvahanan, P. Performance analysis of K-means and bisecting K-means algorithms in Weblog data. Int. J. Emerg. Technol. Eng. Res. 2016, 4, 6. [Google Scholar]
- Jung, S.; Moon, J.; Hwang, E. Cluster-Based Analysis of Infectious Disease Occurrences Using Tensor Decomposition: A Case Study of South Korea. Int. J. Env. Res. Public. Health 2020, 17, 4872. [Google Scholar] [CrossRef] [PubMed]
- Bholowalia, P.; Kumar, A. EBK-Means: A Clustering Technique based on Elbow Method and K-Means in WSN. Int. J. Comput. Appl. 2014, 105, 17–24. [Google Scholar]
- QGIS Development Team. Quantum GIS Geographic Information System (Open Source) Geospatial Foundation Project; 2020.
- Dykes, J.; Abdul-Rahman, A.; Archambault, D.; Bach, B.; Borgo, R.; Chen, M.; Enright, J.; Fang, H.; Firat, E.E.; Freeman, E.; et al. Visualization for epidemiological modelling: Challenges, solutions, reflections and recommendations. Phil. Trans. R. Soc. A. 2022, 380, 20210299. [Google Scholar] [CrossRef] [PubMed]
- Mehta, S.; Singh, B.; Dhakate, P.; Rahman, M.; Islam, M.A. Rice, Marker-Assisted Breeding, and Disease Resistance. In Disease Resistance in Crop Plants; Wani, S.H., Ed.; Springer International Publishing: Cham, Switzerland, 2019; pp. 83–111. ISBN 978-3-030-20727-4. [Google Scholar]
- Asibi, A.E.; Chai, Q.; Coulter, J.A. Rice Blast: A Disease with Implications for Global Food Security. Agronomy 2019, 9, 451. [Google Scholar] [CrossRef]
- Bobrowski, M.; Weidinger, J.; Schickhoff, U. Is New Always Better? Frontiers in Global Climate Datasets for Modeling Treeline Species in the Himalayas. Atmosphere 2021, 12, 543. [Google Scholar] [CrossRef]
- Pabón, J.D.; Eslava, J.A.; Gómez, R. Generalidades de la distribución espacial y temporal de la temperatura del aire y de la precipitación en Colombia. Meteorol. Colomb. 2001, 4, 47–59. [Google Scholar]
- Legates, D.R.; McCabe, G.J., Jr. Evaluating the use of “goodness-of-fit” Measures in hydrologic and hydroclimatic model validation. Water Resour. Res. 1999, 35, 233–241. [Google Scholar] [CrossRef]
- Karger, D.N.; Wilson, A.M.; Mahony, C.; Zimmermann, N.E.; Jetz, W. Global daily 1 km land surface precipitation based on cloud cover-informed downscaling. Sci. Data 2021, 8, 307. [Google Scholar] [CrossRef]
- De Oliveira-Júnior, J.F.; Correia Filho, W.L.F.; De Barros Santiago, D.; De Gois, G.; Da Silva Costa, M.; Da Silva Junior, C.A.; Teodoro, P.E.; Freire, F.M. Rainfall in Brazilian Northeast via in situ data and CHELSA product: Mapping, trends, and socio-environmental implications. Environ. Monit. Assess. 2021, 193, 263. [Google Scholar] [CrossRef] [PubMed]
- Velikou, K.; Lazoglou, G.; Tolika, K.; Anagnostopoulou, C. Reliability of the ERA5 in Replicating Mean and Extreme Temperatures across Europe. Water 2022, 14, 543. [Google Scholar] [CrossRef]
- Ullah, H.; Akbar, M.; Khan, F. Construction of homogeneous climatic regions by combining cluster analysis and L-moment approach on the basis of Reconnaissance Drought Index for Pakistan. Int. J. Climatol. 2020, 40, 324–341. [Google Scholar] [CrossRef]
- Jaramillo-Robledo, A.; Chaves-Córdoba, B. Distribución De La Precipitación En Colombia Analizada Mediante Conglomeración Estadística. Cenicafé 2000, 51, 102–113. [Google Scholar]
- Yoshida, S. Physiological Aspects of Grain Yield. Annu. Rev. Plant. Physiol. 1972, 23, 437–464. [Google Scholar] [CrossRef]
- Yoshida, S. Rice. In Ecophysiology of Tropical Crops; Elsevier: Amsterdam, The Netherlands, 1977; pp. 57–87. ISBN 978-0-12-055650-2. [Google Scholar]
- Rokonuzzaman, M.; Rahman, M.; Yeasmin, M.; Islam, M. Relationship between precipitation and rice production in Rangpur district. Progress. Agric. 2018, 29, 10–21. [Google Scholar] [CrossRef]
- Delerce, S.; Dorado, H.; Grillon, A.; Rebolledo, M.C.; Prager, S.D.; Patiño, V.H.; Garcés Varón, G.; Jiménez, D. Assessing Weather-Yield Relationships in Rice at Local Scale Using Data Mining Approaches. PLoS ONE 2016, 11, e0161620. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Abbreviation | Physical Unit | Period | Periodicity | Source |
|---|---|---|---|---|---|
| Precipitation | PCPT | mm | 1981–2010 | Monthly multiannual | CHELSA |
| Minimum temperature | TMIN | °C | 1971–2000 (WC) y 1981–2010 (CH) | Monthly multiannual | CHELSA and Worldclim |
| Average temperature | TAVE | °C | 1971–2000 (WC) y 1981–2010 (CH) | Monthly multiannual | CHELSA and Worldclim |
| Maximum temperature | TMAX | °C | 1971–2000 (WC) y 1981–2010 (CH) | Monthly multiannual | CHELSA and Worldclim |
| Solar radiation | RSDS | MJ m−2 d−1 | 1981–2010 | Monthly multiannual | CHELSA |
| Evapotranspiration potential (Penman–Monteith) | ET | mm | 1981–2010 | Monthly multiannual | CHELSA |
| Relative humidity | RH | % | 1981–2010 | Monthly multiannual | CHELSA |
| Vapor pressure deficit | VPD | hPa | 1981–2010 | Monthly multiannual | CHELSA |
| Total cloud cover | TCC | % | 1981–2010 | Monthly multiannual | CHELSA |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodríguez-Almonacid, D.V.; Ramírez-Gil, J.G.; Higuera, O.L.; Hernández, F.; Díaz-Almanza, E. A Comprehensive Step-by-Step Guide to Using Data Science Tools in the Gestion of Epidemiological and Climatological Data in Rice Production Systems. Agronomy 2023, 13, 2844. https://doi.org/10.3390/agronomy13112844
Rodríguez-Almonacid DV, Ramírez-Gil JG, Higuera OL, Hernández F, Díaz-Almanza E. A Comprehensive Step-by-Step Guide to Using Data Science Tools in the Gestion of Epidemiological and Climatological Data in Rice Production Systems. Agronomy. 2023; 13(11):2844. https://doi.org/10.3390/agronomy13112844
Chicago/Turabian StyleRodríguez-Almonacid, Deidy Viviana, Joaquín Guillermo Ramírez-Gil, Olga Lucia Higuera, Francisco Hernández, and Eliecer Díaz-Almanza. 2023. "A Comprehensive Step-by-Step Guide to Using Data Science Tools in the Gestion of Epidemiological and Climatological Data in Rice Production Systems" Agronomy 13, no. 11: 2844. https://doi.org/10.3390/agronomy13112844