Early Experience Analyzing Dietary Intake Data from the Canadian Community Health Survey—Nutrition Using the National Cancer Institute (NCI) Method


Abstract
:1. Introduction
| A. Choice of Model: | Which of the different NCI models should be implemented? |
| B. Covariates: | Which covariates should be included in the model? |
| C. Stratification versus Pooling: | Should age/sex groups be pooled to provide more precise estimates? |
| D. Outliers: | How should outliers be identified and when should they be removed? |
| E. Computational Time: | What is the computational time required by the NCI method? |
2. Materials and Methods
2.1. Data Set and Variables of Interest
- (i)
- A quick list (respondents reported all foods and beverages consumed in whatever order they wished);
- (ii)
- questions about specific food categories and frequently forgotten foods;
- (iii)
- questions about the time of consumption and type of meal (for example, lunch, dinner);
- (iv)
- questions seeking more detailed, precise descriptions of foods and beverages and quantities consumed;
- (v)
- a final review of food choices.
2.2. Statistical Methods
- If less than 5% of the 24-h recalls (unweighted) within each stratum had zero intake of the dietary component, the amount-only model is used;
- If greater than or equal to 5% of the 24-h recalls had zero intake, the two-part correlated model is fitted. The correlation between the probability of consumption and the amount consumed is assessed via its Fisher’s transformation using a smaller number of bootstrap replicates (e.g., 50). If it is found to be significant, the correlated model is selected. Otherwise, the uncorrelated model is chosen.
3. Results
3.1. Choice of Model
3.2. Covariates
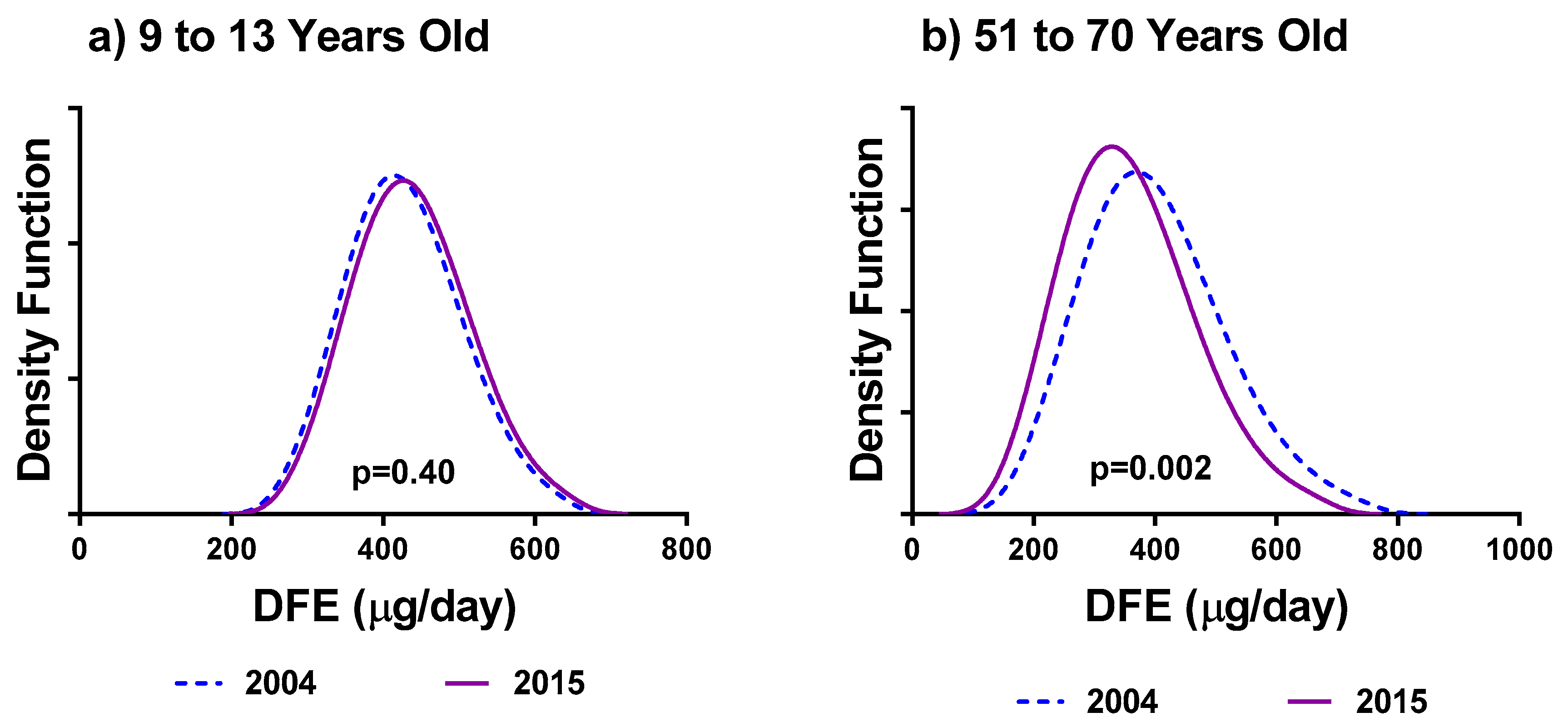
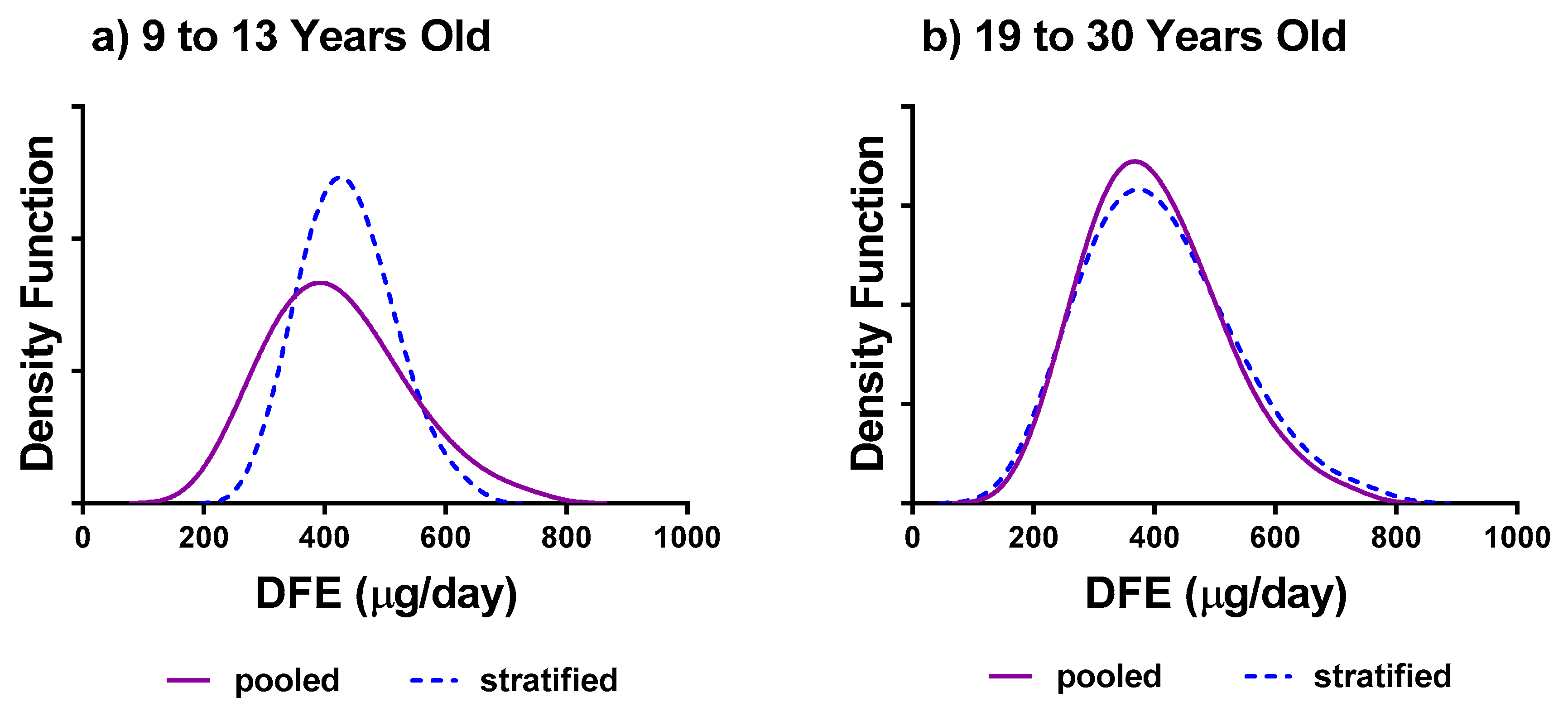
3.3. Stratification versus Pooling
3.4. Outliers
3.5. Computational Time
4. Discussion
- Consider the unweighted proportion of the 24-h recalls having zero intake of a nutrient or food in order to determine whether a one- or two-part model should be used.
- If different categorical covariates are of interest (e.g., DRI age/sex groups; income levels), use the MIXTRAN macro to compute estimates of the parameters in two ways: (a) Pooling all levels by using a covariate and (b) separate analysis for every level of the covariate. In each case, compare the ratio of the within-between variance components, and consider a stratified analysis if this variance ratio is at least 30% higher or lower than for the other approach.
- When analyzing dietary components that are rarely consumed (i.e., very episodic), there might not be enough respondents with non-zero intake to obtain stable estimates of the variance components. In addition, estimated distributions may show large variability (i.e., large CVs), particularly in the tails of the distribution. For such cases, a recommendation would be to retain broader nutrient and/or covariate categories. For example, an analyst could model all meats instead of red meats; or pooling with other age/sex groups is a viable option, although not always recommended.
- Perform outlier detection by evaluating recalls which may affect equal variance assumptions. Remove outliers and re-fit using the MIXTRAN macro to evaluate the impact on parameter estimates.
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
Appendix A
List of Abbreviations:
| AMPM | Automated Multi-Pass Method |
| CCHS | Canadian Community Health Survey |
| CNF | Canadian Nutrient File |
| CV | Coefficient of Variation |
| DFE | Dietary folate equivalents |
| DRI | Dietary Reference Intake |
| EAR | Estimated Average Requirement |
| NCI method | National Cancer Institute method |
| NHANES | National Health and Nutrition Examination Survey |
| SE | Standard Error |
| SIDE | Software for Intake Distribution estimation |
References
- Statistics Canada. Canadian Community Health Survey 2015—Nutrition User Guide; Statistics Canada: Ottawa, ON, Canada, 2017. [Google Scholar]
- Krebs-Smith, S.M.; Guenther, P.M.; Subar, A.M.; Kirkpatrick, S.I.; Dodd, K.W. Americans do not meet federal dietary recommendations. J. Nutr. 2010, 140, 1832–1838. [Google Scholar] [CrossRef] [PubMed]
- Dodd, K.W.; Guenther, P.M.; Freedman, L.S.; Subar, A.F.; Kipnis, V.; Midthune, D.; Tooze, J.A.; Krebs-Smith, S.M. Statistical methods for estimating usual intake of nutrients and foods: A review of the theory. J. Am. Diet. Assoc. 2006, 106, 1640–1650. [Google Scholar] [CrossRef] [PubMed]
- National Cancer Institute. Usual Dietary Intakes: The NCI Method. 2018. Available online: https://epi.grants.cancer.gov/diet/usualintakes/method.html (accessed on 30 May 2019).
- Tooze, J.A.; Midthune, D.; Dodd, K.W.; Freedman, L.S.; Krebs-Smith, S.M.; Subar, A.F.; Guenther, P.M.; Carroll, R.J.; Kipnis, V. A new statistical method for estimating the usual intake of episodically consumed foods with application to their distribution. J. Am. Diet. Assoc. 2006, 10, 1575–1587. [Google Scholar] [CrossRef] [PubMed]
- Tooze, J.A.; Kipnis, V.; Buckman, D.W.; Carroll, R.J.; Freedman, L.S.; Guenther, P.M.; Krebs-Smith, S.M.; Subar, A.F.; Dodd, K.W. A mixed-effects model approach for estimating the distribution of usual intake of nutrients: The NCI method. Stat. Med. 2010, 29, 2857–2868. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nusser, S.M.; Carriquiry, A.L.; Dodd, K.W.; Fuller, W.A. A semi-parametric transformation approach to estimating usual nutrient intake distributions. J. Am. Stat. Assoc. 1996, 91, 1440–1449. [Google Scholar] [CrossRef]
- National Center for Health Statistics. National Health and Nutrition Examination Survey. Available online: https://www.cdc.gov/nchs/nhanes/index.htm (accessed on 5 July 2018).
- Health Canada. Reference Guide to Understanding and Using the Data—2015 Canadian Community Health Survey—Nutrition. 2017. Available online: https://www.canada.ca/en/health-canada/services/food-nutrition/food-nutrition-surveillance/health-nutrition-surveys/canadian-community-health-survey-cchs/reference-guide-understanding-using-data-2015.html (accessed on 30 May 2019).
- Statistics Canada. Canadian Community Health Survey (CCHS) Cycle 2.2 (2004) Nutrition—General Health (including Vitamin & Mineral Supplements) & 24-Hour Dietary Recall Components User Guide. 2008. Available online: http://www23.statcan.gc.ca/imdb-bmdi/document/5049_D24_T9_V1-eng.pdf (accessed on 30 May 2019).
- Moshfegh, A.J.; Rhodes, D.G.; Baer, D.J.; Murayi, T.; Clemens, J.C.; Rumpler, W.V.; Paul, D.R.; Sebastian, R.S.; Kuczynski, K.J.; Ingwersen, L.A.; et al. The US Department of Agriculture Automated Multiple-Pass Method reduces bias in the collection of energy intakes. Am. J. Clin. Nutr. 2008, 88, 324–332. [Google Scholar] [CrossRef] [PubMed]
- Health Canada. Compendium of Data Tables for Usual Intakes of Energy, Nutrients & Other Dietary Components from Food (2004 and 2015 CCHS-Nutrition) derived from Statistics Canada’s 2004 and 2015 Canadian Community Health Survey, Nutrition, Share file, Ottawa. 2019; in progress. [Google Scholar]
- Otten, J.; Hellwig, J.; Meyers, L. Dietary DRI Reference Intakes; National Academies Press: Washington, DC, USA, 2006. [Google Scholar]
- Huybrechts, I.; de Bacquer, D.; Cox, B.; Temme, E.H.M.; van Oyen, H.; de Backer, G.; de Henauw, S. Variation in energy and nutrient intakes among pre-school children: Implications for study design. Eur. J. Public Health 2008, 18, 509–516. [Google Scholar] [CrossRef] [PubMed]
- Black, J.L.; Billette, J.-M. Do Canadians meet Canada Food Guide’s recommendations for fruits and vegetables? Appl. Physiol. Nutr. Metab. 2013, 38, 234–242. [Google Scholar] [CrossRef] [PubMed]
- Black, J.L.; Billette, J.-M. Fast food intake in Canada: Differences among Canadians with diverse demographic, socio-economic and lifestyle characteristics. Can. J. Public Health 2015, 106, e52–e58. [Google Scholar] [CrossRef] [PubMed]
- Garriguet, D. Beverage consumption of Canadian adults. Health Rep. 2008, 19, 23–29. [Google Scholar] [PubMed]
- Kirkpatrick, S.I.; Dodd, K.W.; Parsons, R.; Ng, C.; Garriguet, D.; Tarasuk, V. Household Food Insecurity is a Stronger Marker of Adequacy of Nutrient Intakes among Canadian Compared to American Youth and Adults. J. Nutr. 2015, 145, 1596–1603. [Google Scholar] [CrossRef] [PubMed]
- McLaren, L.; Heidinger, S.; Dutton, D.J.; Tarasuk, V.; Campbell, N.R. A repeated cross-sectional study of socio-economic inequities in dietary sodium consumption among Canadian adults: Implications for national sodium reduction strategies. Int. J. Equity Health 2014, 13, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Freedman, L.S.; Guenther, P.M.; Dodd, K.W.; Krebs-Smith, S.M.; Midthune, D. The population distribution of ratios of usual intakes of dietary components that are consumed every day can be estimated from repeated 24-hour recalls. J. Nutr. 2010, 140, 111–116. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Krebs-Smith, S.M.; Midthune, D.; Perez, A.; Buckman, D.; Kipnis, V.; Freedman, L.S.; Dodd, K.W.; Carroll, R.J. Fitting a bivariate measurement error model for episodically consumed dietary components. Int. J. Biostat. 2011, 7, 1. [Google Scholar] [CrossRef]
- Zhang, S.; Midthune, D.; Guenther, P.M.; Krebs-Smith, S.M.; Kipnis, V.; Dodd, K.W.; Buckman, D.W.; Tooze, J.A.; Freedman, L.; Carroll, R.J. A new multivariate measurement error model with zero-inflated dietary data, and its application to dietary assessment. Ann. Appl. Stat. 2011, 5, 1456–1487. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
| DRI Age/Sex Group | Method | Ratio of Within/Between | 2015 Usual Intake Distribution | |||||
|---|---|---|---|---|---|---|---|---|
| Mean | Percentiles | % < EAR | ||||||
| 5th | 50th | 90th | 95th | |||||
| Children 1–3 years | Pooled | 3.6 | 281.7 | 174.1 | 275.8 | 377.2 | 408.5 | <3 |
| Stratified | 1.6 | 281 | 144 | 273.4 | 403.8 | 445.4 | F | |
| % Diff1 | 0.2 | 17.3 | 0.9 | 7.1 | 9 | |||
| Children 4–8 years | Pooled | 3.6 | 401.1 | 265.2 | 394.6 | 520.2 | 560.4 | <3 |
| Stratified | 5.5 | 398.8 | 284.3 | 392.9 | 500.1 | 533.9 | 0 | |
| % Diff | 0.6 | 7.2 | 0.4 | 3.9 | 4.7 | |||
| Females 9–13 years | Pooled | 2.5 | 421.9 | 249.9 | 410.1 | 578.7 | 634.2 | 5.01 E |
| Stratified | 6.5 | 438.2 | 318.5 | 433.5 | 540.4 | 574.3 | <3 | |
| % Diff | 3.9 | 27.5 | 5.7 | 6.6 | 9.4 | |||
| Females 14–18 years | Pooled | 2.5 | 412.7 | 244.9 | 400.8 | 564.8 | 620.1 | 24.87 |
| Stratified | 1.9 | 412.2 | 219.1 | 398.9 | 588.5 | 649.6 | 28.41 | |
| % Diff | 0.1 | 10.5 | 0.5 | 4.2 | 4.8 | |||
| Females 19–30 years | Pooled | 2.5 | 399.6 | 233.4 | 387.4 | 550.4 | 607.3 | 25.95 |
| Stratified | 2.1 | 407.3 | 226.7 | 394.4 | 572.5 | 632.3 | 25.87 | |
| % Diff | 1.9 | 2.9 | 1.8 | 4 | 4.1 | |||
| Females 31–50 years | Pooled | 2.5 | 401 | 234.9 | 389.5 | 551.2 | 604.1 | 25.11 |
| Stratified | 3.5 | 407.5 | 255.8 | 397.8 | 545.2 | 593.6 | 20.37 E | |
| % Diff | 1.6 | 8.9 | 2.1 | 1.1 | 1.7 | |||
| Females 51–70 years | Pooled | 2.5 | 369.8 | 214 | 358.2 | 512.6 | 563.5 | 35.05 |
| Stratified | 1.9 | 358.9 | 201.9 | 347.7 | 502.3 | 555.5 | 39.55 | |
| % Diff | 2.9 | 5.7 | 2.9 | 2 | 1.4 | |||
| Female 71+ years | Pooled | 2.5 | 339.7 | 193.1 | 329.3 | 473.1 | 522.7 | 46.29 |
| Stratified | 1.8 | 332.2 | 193.7 | 323.3 | 458 | 501.2 | 48.52 | |
| % Diff | 2.2 | 0.3 | 1.8 | 3.2 | 4.1 | |||
| DRI Age/Sex Group | Method | Ratio of Within/Between | Mean | Percentiles | |||
|---|---|---|---|---|---|---|---|
| 5th | 50th | 90th | 95th | ||||
| Children 2–3 years | Pooled 1 | 8.1 | 17.5 | 5.6 E | 15.7 | 30.3 | 35.4 |
| Stratified 2 | 7.4 | 16.3 | 4.2 E | 14.6 | 29.1 | 34.4 | |
| % Diff4 | 6.7 | 24.2 | 7.1 | 3.7 | 2.9 | ||
| Children 4–8 years | Pooled | 8.1 | 24.5 | 8.2 E | 22.2 | 41.3 | 48 |
| Stratified 2 | 7.4 | 22.7 | 6.36 E | 20.7 | 39.5 | 46.1 | |
| % Diff | 7.4 | 23.9 | 7.2 | 4.5 | 4 | ||
| Females 9–13 years | Pooled | 8.1 | 27.7 | 9.5E | 25.5 | 46.3 | 53.3 |
| Stratified | 6.1 | 29.9 | F | 27.1 | 51.6 | 60.3 E | |
| % Diff | 7.6 | F | 6 | 11.4 | 13.1 | ||
| Females 14–18 years | Pooled | 8.1 | 28.7 | 9.3 E | 26 | 49.1 | 57.2 |
| Stratified | 3 | 23.8 | F | 20.1 | 44.9 | 54.7 | |
| % Diff | 17.2 | F | 22.9 | 8.6 | 4.3 | ||
| Females 19–30 years | Pooled | 7.3 | 31.6 | 9.5 E | 28.8 | 54.7 | 63.5 |
| Stratified 3 | 7.8 | 32.4 | 8.0 E | 29 | 58.6 | 68.5 | |
| % Diff | 2.5 | 15.4 | 0.7 | 7.1 | 7.8 | ||
| Females 31–50 years | Pooled | 7.3 | 35.3 | 11.1 E | 32.4 | 59.9 | 69.1 |
| Stratified 3 | 7.8 | 35.9 | 9.3 E | 32.8 | 63.3 | 73.2 | |
| % Diff | 1.6 | 16.6 | 1.2 | 5.5 | 5.9 | ||
| Females 51–70 years | Pooled | 7.3 | 38.5 | 12.5 E | 35.6 | 64.6 | 74.6 |
| Stratified | 5.5 | 36.8 | 16.4 E | 34.5 | 57.1 | 65.1 | |
| % Diff | 4.5 | 30.8 | 3.2 | 11.6 | 12.7 | ||
| Females 71+ years | Pooled | 7.3 | 34.4 | 10.9 E | 31.8 | 58.1 | 67 |
| Stratified | 3 | 31.3 | F | 27.2 | 58.3 | 69.9 | |
| % Diff | 9.2 | F | 14.4 | 0.3 | 4.3 | ||
| DRI Age/Sex Group | No. of Bootstrap Replicates | Pooled | Stratified | ||||
|---|---|---|---|---|---|---|---|
| SE of Mean | SE of 5th Percentile | SE of 95th Percentile | SE of Mean | SE of 5th Percentile | SE of 95th Percentile | ||
| Children 1–3 years | 250 | 6.9 | 14.2 | 17.5 | 8.5 | 12.5 | 16.3 |
| 500 | 6.5 | 14.6 | 18.5 | 8.1 | 12.3 | 17 | |
| Children 4–8 years | 250 | 7.8 | 15.9 | 24.1 | 8.7 | 24.2 | 35.5 |
| 500 | 7.9 | 16.7 | 25.3 | 8.9 | 24.6 | 35 | |
| Females 9–13 years | 250 | 6.6 | 8.1 | 14.4 | 10.3 | 21.6 | 27.7 |
| 500 | 6.8 | 8.3 | 14.6 | 10.2 | 22.2 | 28.2 | |
| Females 14–18 years | 250 | 7.4 | 8.4 | 15.3 | 11.9 | 15 | 28.7 |
| 500 | 7.7 | 8.5 | 15.7 | 11.7 | 14.5 | 29.4 | |
| Females 19–30 years | 250 | 9.3 | 8.8 | 18.3 | 13.8 | 16.1 | 36.1 |
| 500 | 8.8 | 8.4 | 17.8 | 13.6 | 15.9 | 34.9 | |
| Females 31–50 years | 250 | 6.9 | 8.1 | 14.1 | 10.2 | 20.9 | 35 |
| 500 | 6.7 | 8.1 | 14 | 9.9 | 20.8 | 34.7 | |
| Females 51–70 years | 250 | 4.7 | 7.3 | 11.1 | 6.3 | 11.4 | 18.2 |
| 500 | 4.9 | 7.5 | 11.2 | 6.3 | 11.5 | 17.9 | |
| Females 71+ years | 250 | 4.3 | 6.7 | 10.7 | 5.7 | 8.4 | 15.3 |
| 500 | 4.6 | 6.7 | 11.1 | 6 | 8.5 | 14.7 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Davis, K.A.; Gonzalez, A.; Loukine, L.; Qiao, C.; Sadeghpour, A.; Vigneault, M.; Wang, K.C.; Ibañez, D. Early Experience Analyzing Dietary Intake Data from the Canadian Community Health Survey—Nutrition Using the National Cancer Institute (NCI) Method. Nutrients 2019, 11, 1908. https://doi.org/10.3390/nu11081908
Davis KA, Gonzalez A, Loukine L, Qiao C, Sadeghpour A, Vigneault M, Wang KC, Ibañez D. Early Experience Analyzing Dietary Intake Data from the Canadian Community Health Survey—Nutrition Using the National Cancer Institute (NCI) Method. Nutrients. 2019; 11(8):1908. https://doi.org/10.3390/nu11081908
Chicago/Turabian StyleDavis, Karelyn A., Alejandro Gonzalez, Lidia Loukine, Cunye Qiao, Alireza Sadeghpour, Michel Vigneault, Kuan Chiao Wang, and Dominique Ibañez. 2019. "Early Experience Analyzing Dietary Intake Data from the Canadian Community Health Survey—Nutrition Using the National Cancer Institute (NCI) Method" Nutrients 11, no. 8: 1908. https://doi.org/10.3390/nu11081908