1. Introduction
Automated extraction of man-made objects from aerial and satellite imagery has been explored for decades. Starting points for further research arose over time and have been influenced by many factors, such as the availability of very high resolution (VHR) optical satellite imagery. Increasing demands for updating geospatial databases call for the development of more advanced tools to minimize the human interaction in urban feature extraction and identification [
1,
2]. Road networks not only have vast usage in many applications, such as urban design, navigation, change detection, image registration [
3], transportation applications [
4,
5], personal navigation systems, or vehicle routing [
6], but also incorporate a vital component in most GIS systems.
Due to the variety of methods in the literature, a strict categorization of all approaches dealing with road extraction methods is a difficult task [
7]. For the sake of conciseness, we confine our literature review to the recent state-of-the-art approaches in road extraction from VHR images. For a detailed literature review on road extraction researches, which have been carried out before 2003, the reader is referred to Mena et al. [
7]. In 2006, Mayer et al. [
8] compiled a EuroSDR test and compared results of different approaches for automatic road extraction from VHR satellite and aerial images. Furthermore, comprehensive reviews of techniques for linear features extraction and road extraction are presented by Quackenbush [
9] and Das et al. [
10].
Das et al. [
10] introduced a hierarchical multi stage approach that integrates edge and region information of road segments. The edge map is generated using a “dominant singular measure” and multi-scale 1D Canny edge detector. In addition, road segments are classified utilizing a probabilistic support vector machine (PSVM). Edges and regions of road segments are merged using a “Constraint Satisfaction Neural Network with Complimentary Information Integration”. To improve the quality of extracted road network, false segments are reduced during a refinement step. The authors provided most parts of their dataset and results via [
11] which, afterwards, have been used in several studies [
12,
13,
14,
15,
16] and serve as a basis for evaluation and comparison of related approaches.
Grote et al. [
17] presented a region-based method for extraction of roads. In a normalized cut segmentation, they consider knowledge about the appearance of roads in the image via the weights of graph edges. In the next step, object grouping with color and edge criteria decreases oversegmentation of the image. Finally, road parts are extracted using shape and radiometric similarities. For the experiments, high-resolution color infrared images, as well as digital surface models (DSM), are used. The authors concluded that whereas the method can still produce reasonable results without a DSM, using the DSM improves the extraction considerably, as expected.
Nikfar et al. [
18] designed an object-based framework for road detection from IKONOS imagery based on multi-resolution segmentation and a Type-2 fuzzy logic system. They used a genetic algorithm to tune the implemented fuzzy system. The presented method produced impressive results with different datasets. However, it seems that incorporating more proper shape features can improve the detection result. Moreover, as concluded by the authors, employing a gap detection algorithm could decrease the missing parts of the road network.
Chaudhuri et al. [
14] proposed a semi-automated multistage framework which enhances the image based on a customized directional morphological filter. On this enhanced image they perform a directional segmentation which depends on the homogeneity of two road seed templates of different directions. A set of post-processing steps, including hole-filling, pruning, and segment linking, are then applied in order to improve the quality of results. The visual inspection of experimental results signifies the efficiency of the method, although a quantitative assessment of the results is missing and hinders further analysis.
Sun and Messinger [
19] developed an automatic knowledge-based system for road network extraction from multispectral images. Important edges are enhanced by exploiting a trilateral filter. A spectral flood-filling technique based on the spectral angle mapper and the Euclidean distance criteria is used to generate a binary asphalt image. This image inevitably contains objects like parking lots and building roofs that are similar to the road surface. Next, template-matching, followed by pruning, reduces these false alarms. The system output contains the extracted road centerlines, as well as width and orientation of road segments.
During the past few years, members of the Department of Land Surveying and Geo-informatics of the Hong Kong Polytechnic University reported many research output on the topic of road extraction from VHR images. Miao et al. [
13] integrated shape and spectral features to extract candidate road segments from a binary map obtained from edge filtering segmentation. For accurate centerline extraction from road segments multivariate adaptive regression splines (MARS) is utilized to avoid short spurs that keep the centerline smoothness. Shi et al. [
3] presented a two-stage framework to extract main roads by integrating spectral-spatial classification and shape features. Miao et al. [
20] presented a semi-automatic object-based method which improves the discrimination of linear features using object-based Frangi’s filter (OFF) and object-based shape filter (OSF) and detects road segments exploiting support vector machine (SVM) classification. In another study reported by Miao et al. [
21], tensor voting, principal curves, and the geodesic method are integrated to extract road centerlines. In this research, first-order tensor voting is utilized in order to generate feature points, which are then projected onto principal curves using a subspace constrained mean shift. Then the geodesic method is used to create the central line by linking the projected feature points. In a recent study [
22], an information fusion-based approach is proposed. This approach produces two binary road maps using an expectation maximization clustering and linearness filter. Next, centerlines of both road maps are extracted utilizing a modified RANdom SAmple Consensus (RANSAC) method. Then, a decision-level fusion (union of the results of both detection methods) and some regularization rules are exploited to generate the final road centerlines.
Yin et al. [
23] extended an ant colony optimization (ACO) algorithm which integrates some geometrical features of segmented objects and geometrical characteristics of extracted edges. Considering the fact that usually most of objects in road contexts share the direction of a road which they are related to, the proposed system injects the information, which exhibits the direction of extracted features, into the decision rule of the ant colony algorithm. To the best of our knowledge Zarrinpanjeh et al. [
24] is the first research work which exploited ACO for urban road map updating from high-resolution satellite imagery. The authors proposed a distributed framework which verifies the existing road map and extracts new roads through seed region growing segmentation and supervised classification and groups the results of these steps.
Wang et al. [
15] proposed a semi-automatic neural-dynamic tracking framework which consists of two processing steps: the training step and the tracking step and is based on deep convolutional neural networks to recognize the pattern of input data and a finite state machine to translate the recognized patterns to states and control the behavior of the tracker.
Ameri and Valadan [
25] motivated by research of Doucette et al. [
26], introduced a road vectorization method based on dynamic clustering. This approach utilizes a swarm-based optimization technique that relies on a modified cost function. Afterwards, results are enhanced using some morphological filters. Finally, a minimum spanning tree is used to construct a road network.
Wegner et al. [
6] presented a probabilistic representation of network structures to extract road networks from aerial images via a recover-and-select strategy. At the cost of many false positives, a large over-complete set of potential candidate paths is generated. Next, considering a feature vector, false positives are pruned from the detected paths by minimizing a global higher-order conditional random field energy.
Poullis et al. [
27] presented a semi-automatic system to extract roads from VHR images or Light Detection and Ranging (LIDAR) data that benefits from capabilities of both perceptual organization and graph cut segmentation. During the encoding stage of a tensor voting process, a set of Gabor filter response images are tensorized. Next, in voting, the tensor field is organized. With a threshold-free classification, curves and junctions are extracted. By an orientation-based segmentation using graph-cuts parameters of a road model are used to discriminate road segments from other curves. Finally, road centerlines are extracted by using a set of Gaussian-based filters followed by a snake-based tracking procedure. Poullis ameliorated their system by introducing another framework called “Tensor Cuts” [
12]. In this new framework, labels are encoded as tensors to eliminate the need for a pre-classification of curve pixels.
Roads and objects in medical imaging, such as blood vessels or axons and dendrites in neurons, have similar structure and properties. This resulted in applicability of many proposed approaches in both fields. One of the recent approaches proposed by Sironi et al. [
28] considers the extraction of centerlines as a regression problem. The system computes the distance to the closest centerline exploiting a multistage regressors training process and then finds the centerlines and their scale by applying local maxima suppression on regressors. Impressive results are reported on gray-scale aerial images from sub-urban areas with just some false negatives at the end of roads and at small linear segments at the borders of the image.
In VHR images roads mainly appear as elongated homogeneous regions and linear characteristics of roads are not very salient [
29]. With the increasing availability of VHR satellite images the general trend in recent years has been towards conducting object (region)-based methods as shown by the reviewed literature. Another trend is exploiting both spectral and spatial information of objects. However, in urban areas, spectral and spatial characteristics of non-road structures can be similar to roads. Therefore, some studies utilize textural and contextual information to achieve a more accurate road network. Moreover, many approaches perform a post-processing step, such as a pruning to increase the correctness. In cases where adjacent objects, like trees, occlude the road surface or cast shadows on it, road detection often fails, which results in gaps between detected road parts. Therefore, some methods fill these discontinuities in road networks in order to increase the completeness and overall quality of the extracted roads.
In road extraction from VHR images significant progress has been achieved by the remote sensing and photogrammetry community, e.g., [
17,
18,
20,
25,
30], and by computer science researchers, e.g., [
1,
10,
12,
14,
31]. Nevertheless, the ultimate goal of designing and implementing a reliable automatic road extraction system is still far-off [
6,
12,
20,
21,
29].
This paper is organized as follows: after this literature review of recent state-of-the-art road extraction approaches,
Section 2 introduces our novel multi stage object-based approach for road extraction. Moreover, fundamental details of methods of our approach will be described. Experimental results obtained from our approach on three different datasets, as well as results of altogether seven other methods are reported and compared in
Section 3.
2. Proposed Approach and Methods
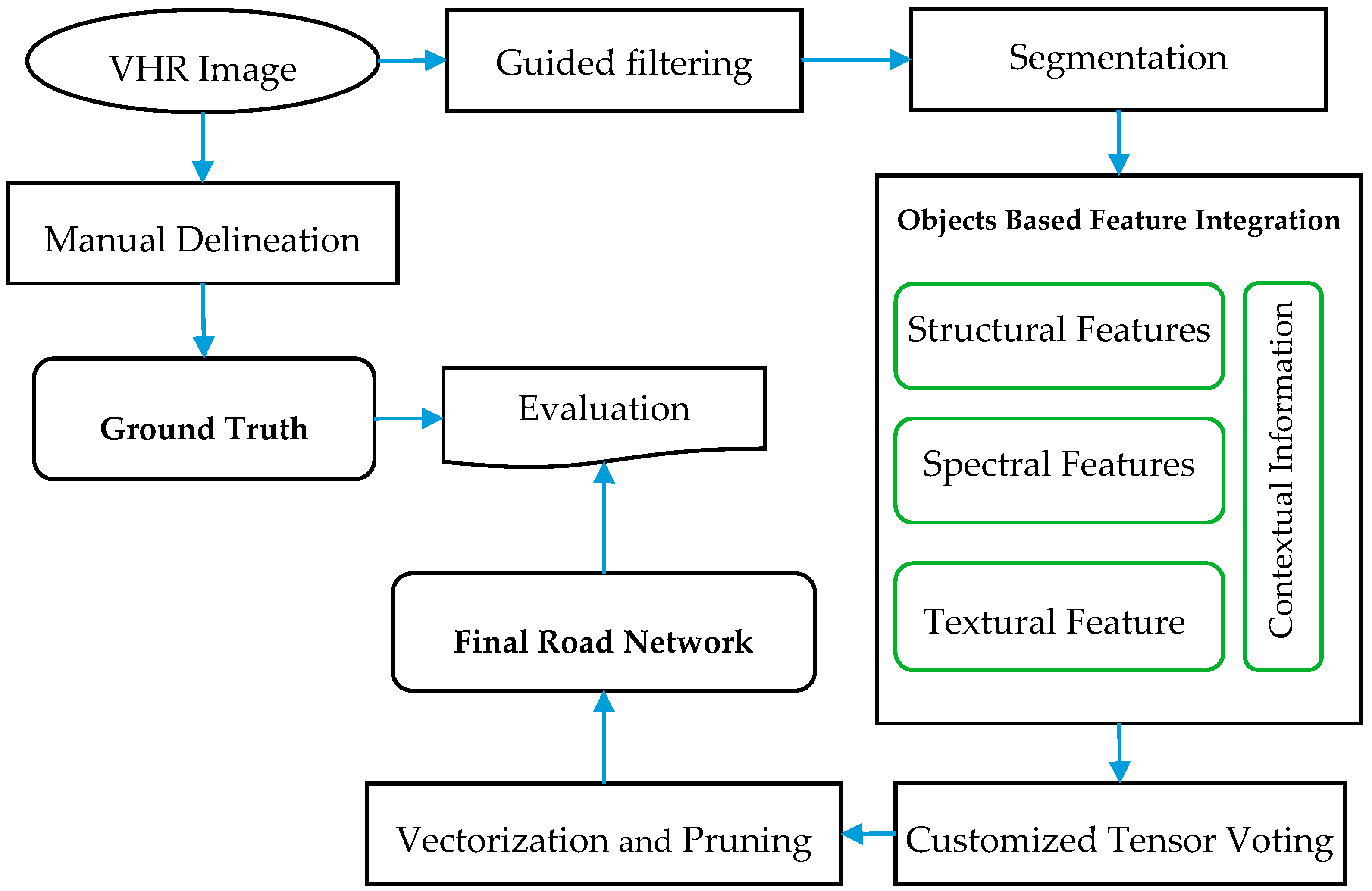
The proposed approach for road network extraction from VHR remotely sensed images based on context aware object based feature integration and customized tensor voting is depicted in
Figure 1.
As it can be seen from
Figure 1, first, VHR remotely sensed imagery is smoothed utilizing “guided filter” to reduce road surface heterogeneity. Next, the filtered image is segmented using multi-resolution segmentation in order to generate image objects. A novel object linearity index is introduced as a structural descriptor of the objects. Structural, spectral, textural as well as contextual information of objects are integrated to extract the road binary map. Afterwards, Customized Tensor Voting (CTV) fills missing parts of the network. Finally, after road map vectorization, small spurs are eliminated in vector space. To assess the quality of the extracted road network, the final road network is compared with ground truth data utilizing three evaluation criteria. In our approach, no ancillary data, such as DSM or vector data provided by road databases is employed in order to avoid malfunction of the process if this kind of information is not available.
2.1. Guided Filter
It is well known that the appearance of objects in remote sensing images is closely related to the resolution of the images. The higher the resolution, the more details are visible. By looking at roads in VHR images, say at 1 m ground resolution, cars, trees that occlude parts of a road, and beyond that noise and many other small details are visible, for example, pavement color changes that originate from road surface repairs. Therefore, a smoothing step is necessary to reduce the destructive effect of these small obstacles on segmentation and thereupon on road extraction quality. The guided filter method [
32] offers the possibility to suppress details while, at the same time, preserving the edges by transferring the structures of the guidance image to the filtered output image.
According to [
32] a general linear translation-invariant filter that utilizes additional information from a given guidance image (
) can be formulated as:
where
and
are images before and after filtering,
and
are pixel indices, and the filter kernel
of the guided filter is defined as:
where
is a square window centered at the pixel
,
is the number of pixels in
,
and
are the mean and variance of
in
, and
τ is a regularization parameter which controls the degree of smoothness. It should also be mentioned that we use the VHR image itself as the guidance image. The main assumption of the guided filter is that the filter response is a local linear transformation of
I [
32]:
where
and
are two coefficients computed as:
where
is the average of
in
. Then, the filtering output at each pixel can be calculated as:
The quality of this process can strongly affect the effectiveness of the segmentation and the whole road extraction process.
2.2. Segmentation
Image segmentation is defined as a procedure which completely partitions a scene into disjoint homogenous regions of pixels such that each region is homogenous according to some coherent features (color, shape, and texture), whereas the union of two adjacent regions is not homogenous [
29,
33,
34,
35]. Major categories of current state-of-the-art segmentation methods are: (1) pixel-based; (2) edge-based; (3) region-based; and (4) hybrid image segmentation [
34,
36,
37,
38].
In this paper, the multi-resolution segmentation approach introduced by Baatz and Schäpe [
39] is utilized for image segmentation which considers objects as the smallest meaningful processing entities. This reduces the salt-and-pepper effects which are typical for pixel based classification methods [
20,
40] and exploits the full information, both of the physics of the sensor measurements and the context within the scene [
41].
Multi-resolution segmentation is a bottom up region-merging technique starting with one-pixel objects. In each merging step, the algorithm tries to minimize the fusion factor of resulting objects, which is defined as:
where
and
are the weight of spectral (color) heterogeneity and weight of shape heterogeneity, respectively, and
and
are the difference in spectral heterogeneity and difference in shape heterogeneity, respectively. It should be noted that, there are some researches on optimizing the multi resolution segmentation parameters [
42,
43]. However, optimum segmentation is still an open research area. The interested reader can find the details of the algorithm in [
39,
41,
42,
43]. A successful implementation of this concept is the Trimble eCognition Developer software package, which catalyzed a boost of its exploitation in considerable research works [
18,
35,
40,
44,
45].
2.3. Object-Based Feature Integration
After segmentation, each pixel is assigned to an object. In order to distinguish road segments from other segments their properties should be taken into account. The most dominant characteristics of roads in VHR images include: (1) roads are mostly elongated structures with bounded width [
1,
46,
47]; (2) roads do not appear as a small segment or patch [
10,
13]; (3) usually the road surface is at least locally homogeneous [
1,
18,
35]; and (4) roads have a limited and smoothly changing local curvature [
48,
49].
Integration of these characteristic of roads can seldom be found at other objects in VHR images. Therefore, these four characteristics define our basic model of a road object.
To address the first characteristic, we propose a novel linearity index called the skeleton-based object linearity index (SOLI) to discriminate elongated road-like objects from other objects.
The skeleton-based object linearity index is defined for each object as:
where
is an object, and
is the length of the main line of the object’s skeleton. The main line of the object is the main skeleton of the object whose “legs” are refined at the end parts of skeleton (
Figure 2c),
is the area of the object,
is the width range of all roads in the network that integrate external road-specific knowledge into the index.
is the maximum object-based distance map value defined as:
where
is the pixel index and
is the distance map value of each pixel of
.
Employing in Equation (7) guarantees that very narrow and long segments like some shadow casts and sidewalks are not further considered because of SOLI values of 0.
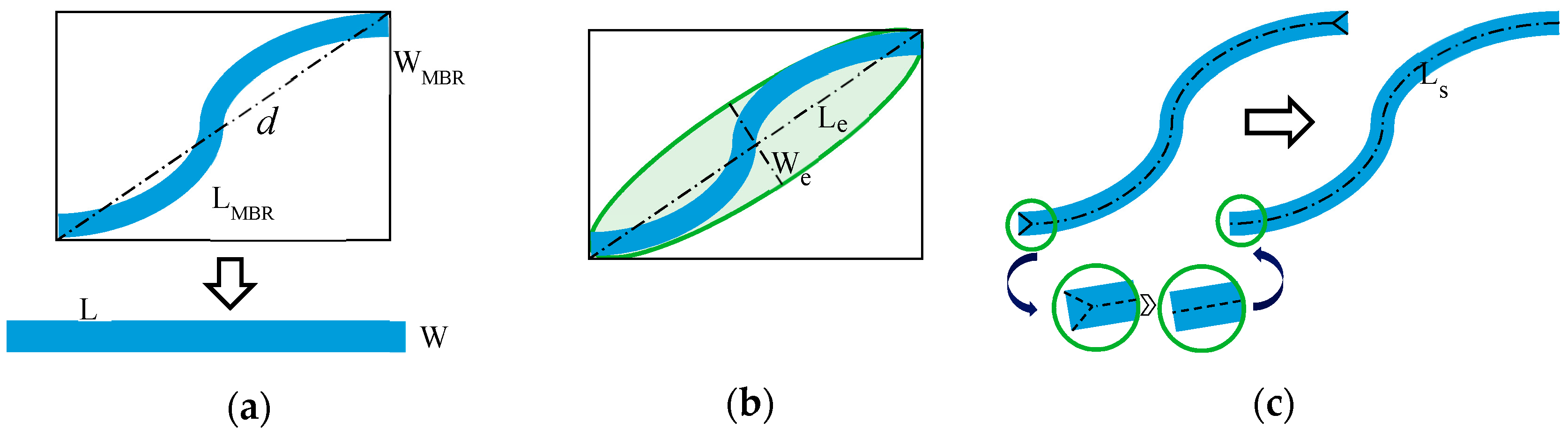
There are similar indices, like Linearity Feature Index (LFI) [
13], which uses the diagonal
(
Figure 2a) instead of
and LFIe [
50] which uses the length to width ratio
(illustrated in
Figure 2b of an approximating ellipse) for the linearity. The measurement of the length of the object via the skeleton improves the approximation of the real length of the object. Furthermore, SOLI takes advantage of explicit a priori knowledge like that of
.
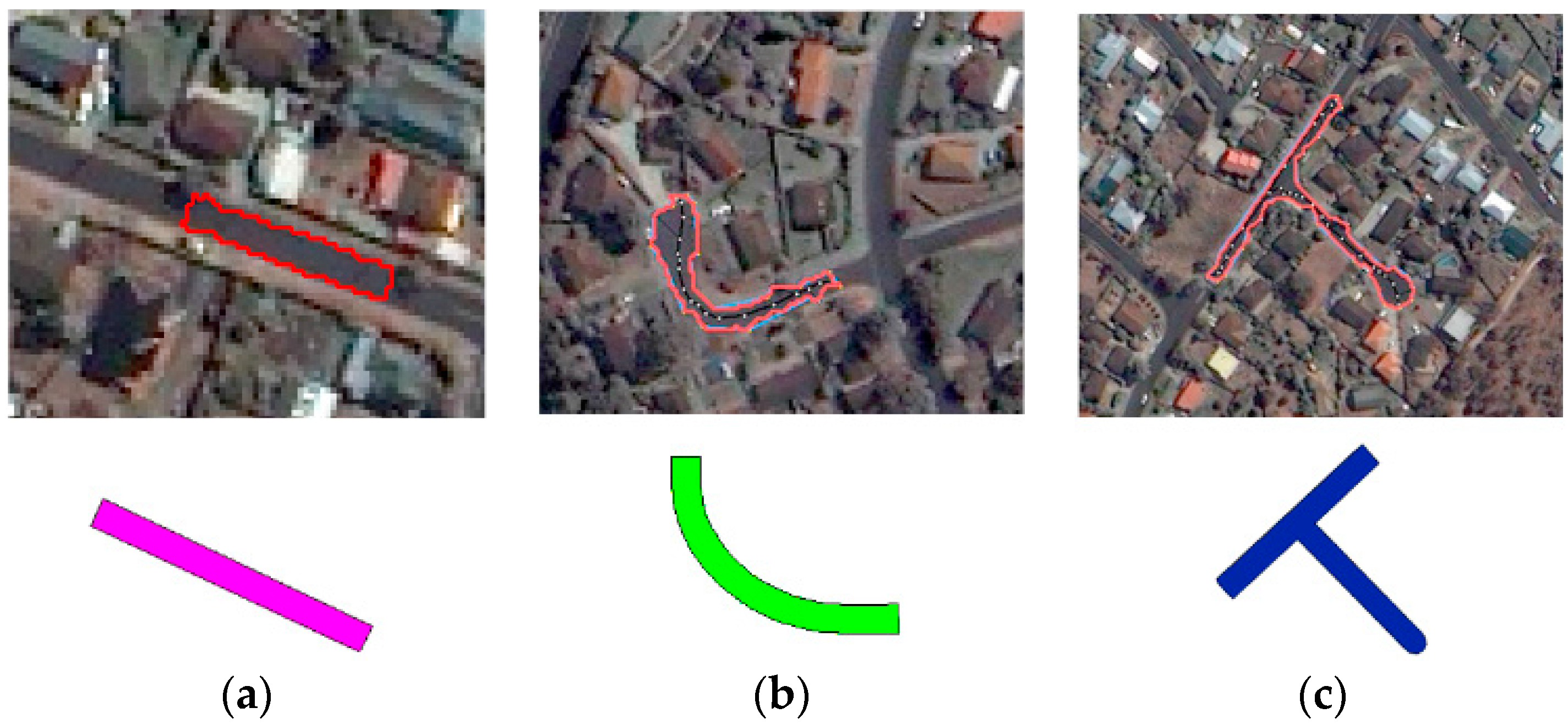
Our experimental results confirm that the proposed index outperforms the LFI and LFIe especially for curved or branched regions. In
Figure 3 some examples are depicted which illustrates that, for different objects, the length to width approximation by the SOLI is close to reality.
Considering the definition of different linearity indices (
Figure 2), it is obvious that all indices can measure the linearity of the rectangular object in
Figure 3a. However, LFI underestimates the linearity of the objects in
Figure 3b,c. That is because the diagonal of the minimum bounding box is not a good approximation for the lengths of these objects. Moreover, this underestimation leads to overestimating the width of the object (to keep the area constant) which magnifies the overall inaccuracy in calculating the object’s linearity. LFIe, which uses the axes of the ellipse, is also not a suitable index for curved and branched objects. In most cases, the major axis of the ellipse is smaller than the real length of the curved and branched objects and the minor axis is larger than the real width of these objects. SOLI, which estimates the length of the object by the length of its main skeleton, can efficiently quantify the linearity of these curved and branched objects.
To consider the second characteristic, i.e., a small region, is not likely to be a road segment, area-based filtering [
14,
25] is employed. Moreover, we add contextual information to avoid the elimination of small road segments which are connected to at least two road segments (detected by SOLI). Those small segments are remaining as potential road objects.
The standard deviation of all pixel values of an object can be used as a measure of homogeneity to take into account the third property in the road model [
1,
10,
51]. We use an adaptive threshold for this measure to take the size of the objects into account. Due to our application i.e., road detection, elongated objects are of more interest, a length-based adaptive threshold is used as:
where
stands for standard deviation of pixel values of the object, T is a constant threshold and
is same as in Equation (7). Moving the length of the object to the left side of the equation yields standard deviation value weighted by length of each object:
where
is the weighted standard deviation of object
in each band and can be used as an efficient measure of homogeneity for objects with different size.
Another feature that is used to measure the homogeneity of the object surface is entropy based on gray level co-occurrence matrix (GLCM). The power of the gray level co-occurrence approach is that it characterizes the spatial interrelationships of the gray levels in an image. The lack of consideration of the shape aspects of the objects is the most important shortcoming of GLCM based processing [
52]. However, in our approach road shape properties are modeled with structural features like SOLI. The entropy value for each object (
) can be defined as [
52]:
where
and
are the row and column indices, and
is the normalized value in the cell
,
.
The fourth property of the road model demands for small values of both curvature and standard deviation of curvature of the main line of road segments. The curvature of each segment can be evaluated by the directional change of neighboring mainlines of segment [
49]. For a non-rectangular shape, the “main line” is actually a polyline. Therefore, the standard deviation of the curvature is evaluated by the standard deviation of the absolute values of the directional changes of the main line parts and it can be expressed as:
where
represents the absolute value of the
th deflection angle of the object’s main line. Considering
as number of line segments of the main line, then
.
2.4. Tensor Voting
Medioni et al. [
53,
54] proposed tensor voting (TV) which generally relies on data communication between image features called tokens and provides an efficient framework for the inference of perceptually salient information. Raw local features which are directly extracted from data (e.g., satellite images) are often noisy and incomplete due to several reasons, such as a change in environmental condition like lighting in imaging, sensor imperfectness, as well as scene complexities, like an abundance of shadows cast and other types of occlusions in real world remotely-sensed images. TV is a non-iterative algorithm for the robust inference of features from noisy and sparse data. According to TV framework, each token can be encoded as a symmetric tensor in a quadratic form and is defined as:
where
are the eigenvalues of tensor in descending order and
are their corresponding eigenvectors. Such a tensor can be graphically depicted as an ellipse in 2-D, and an ellipsoid in 3-D.
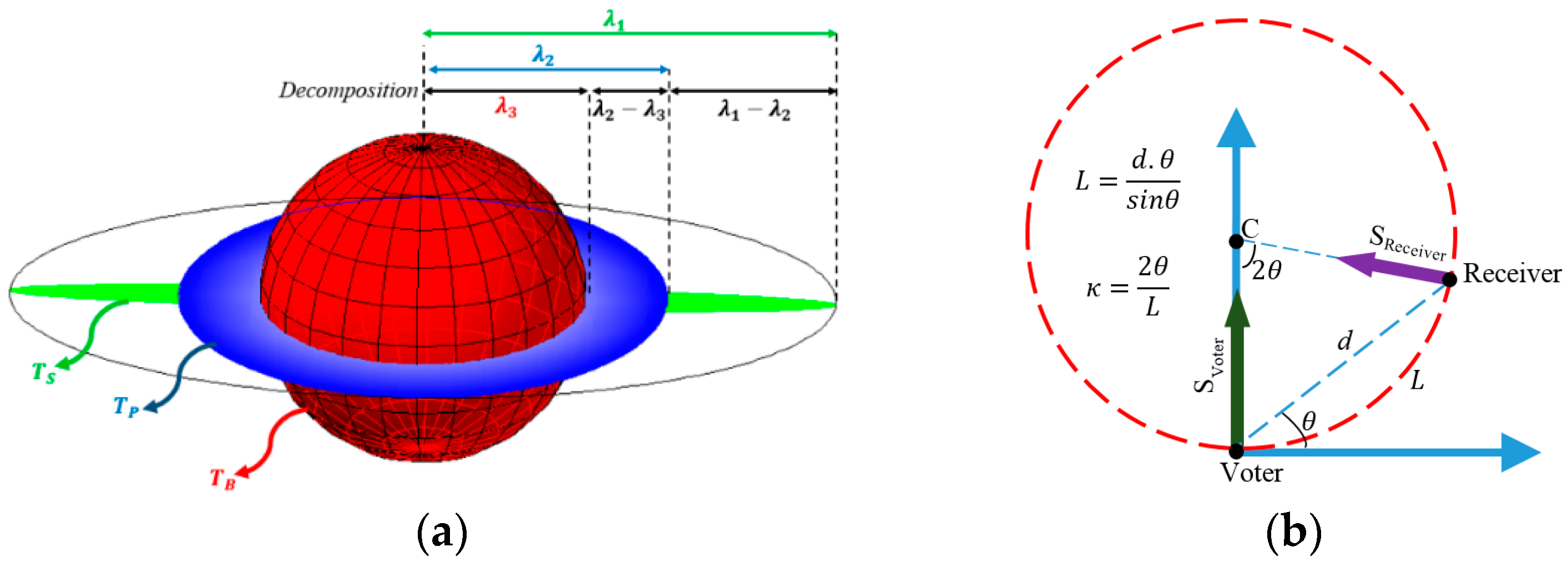
Figure 4a illustrates representation of tensors of second order in 3-D and provides additional interpretations of the eigen-decomposition. Here, the shape of the tensor defines the type of the captured information and the associated size represents the saliency [
53].
By applying spectrum theorem which states that any tensor can be expressed as a linear combination of ball, plate and stick tensors,
T can be decomposed [
53]:
Medioni et al. [
53] expressed the 2-D stick tensor as the fundamental voting field and represented that all other voting fields can be derived from the 2-D stick tensor. Tokens represented in tensor space obtained from encoding process (voters) will propagate their information and communicate with other tokens during a voting process which is illustrated in
Figure 4b. The strength of the vote at receiver site is expressed by a so-called decay function:
where
is the path length,
is the curvature of the path, σ is the scale of voting which is the only free and data-dependent parameter of the algorithm and determines the range within which tokens can influence each other and
is a parameter which is a function of σ and controls the relative weight of path length and curvature [
57], and is defined as:
After the pixels have been encoded with tensors, the information they contain is subsequently propagated to their neighbors. Dense tensor maps, which are generated after voting stage, would be used as the input to an extremal feature extraction algorithm in order to extract the connected road map.
Tensor voting as a very efficient and multi-purpose framework, formulates a number of computer vision problems as a perceptual organization approach in a unified way, with minor problem-specific adaptations [
57]. Nevertheless, some issues, such as its high execution time due to considerable stages of numerical integration, limited its applicability in many fields [
55]. Different modifications have been proposed to tackle the time complexity of TV. Generally, most of these propositions try to find a closed solution for the problem [
58], which was proven incorrect in [
59], or optimizing the calculations of the plate and ball voting fields as the most time consuming parts of TV [
56]. Therefore, applying TV to road gap filling requires further purpose-dependent customization.
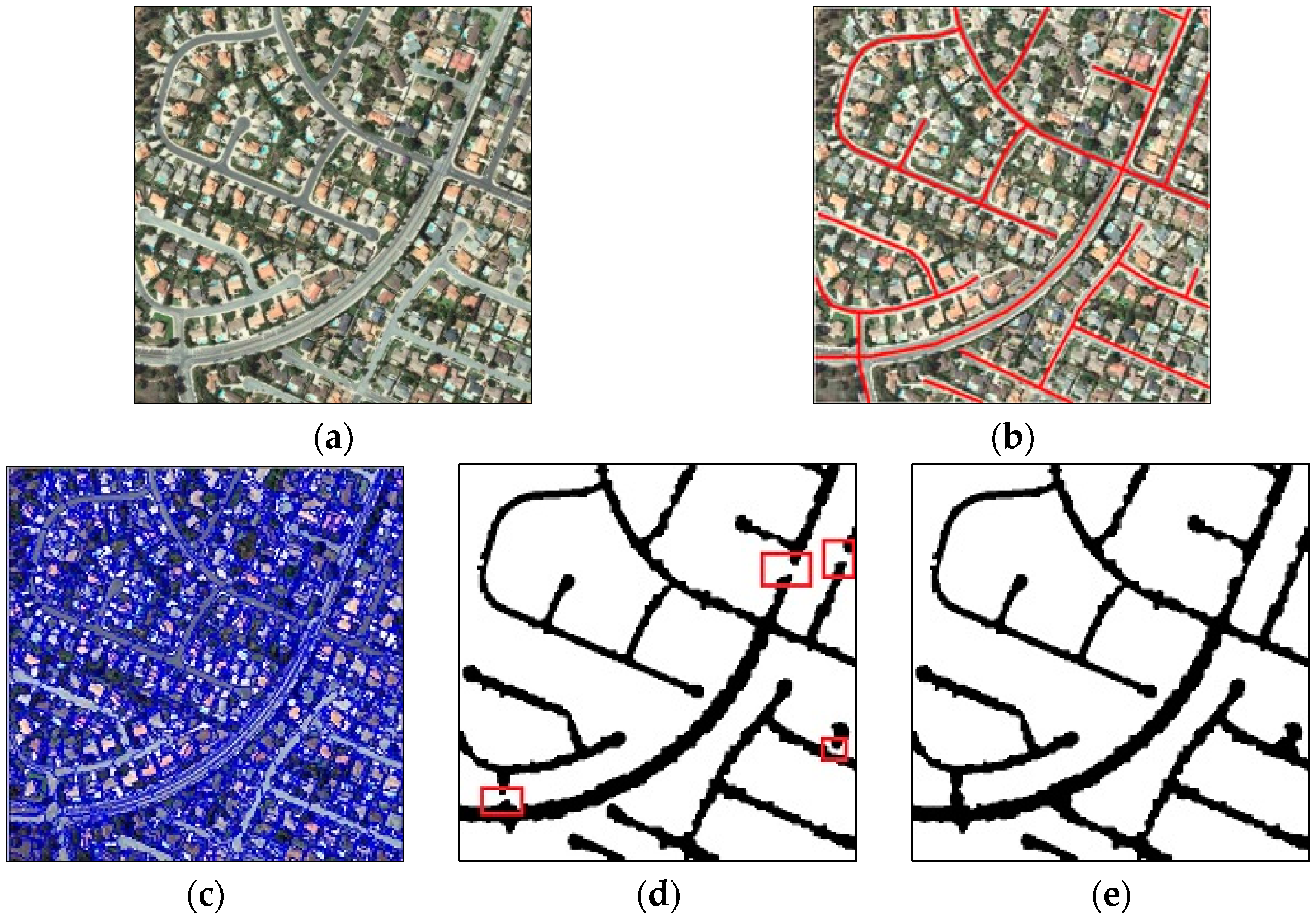
In this paper, we customized TV in order to suit our goal i.e., connected components-based road gap filling. This customization consists of: (1) eliminating voters which are inside the road region and using just those voters which are located on the boundary of the binary road map in the voting process; (2) changing the propagation angular limit from π/4 to π/8. The former step in our customization not only reduces the computation time dramatically, but also has no destructive effect on results. The later customization will avoid undesired shape artifacts in filled areas. It is worth mentioning that restricting the angular vote propagation has no effect on the ball voting field and just makes the stick voting cone narrower, which has no considerable disturbing effect on road gap filling due to local linearity and curvature limitation of the roads.
2.5. Vectorization and Pruning
For centerline extraction from enhanced road binary map, a skeletonization approach can be employed which is based on a thinning algorithm. For most applications, a road map skeleton has far more points than necessary to represent roads network [
35]. Furthermore, thinning may result in some spurs. Shi [
60] conducted a survey of the literature on line simplification algorithms and their evaluation. After comparing shape and displacement measures for the most popular simplification methods, it was concluded that the Douglas-Peucker algorithm is the most accurate one. The Douglas-Peucker algorithm not only decreases the number of nodes but also retains the similarity of the simplified road shape as close as possible to the original one and it ensures that the simplified road curve is no worse than a specified tolerance. After vectorization, further processing, such as efficient pruning in vector space is possible [
35].
To remove spurs of the centerlines caused, for example, by segmentation leakage or existence of attached spectrally-similar objects to the road network like driveways, we employed a pruning step on vector road data. Boundary fluctuations may result in some extraneous skeleton branches. We consider as an extraneous branch a skeleton segment for which only one of its endpoints is connected to another segment and has a length smaller than the average width of the roads. A contextual constraint is also employed to avoid removing short lines which are part of the main line of the network. Those small branches whose direction slightly differs from the direction of the last part of the connected road centerline segments are not removed.
2.6. Evaluation Metrics
In this research, three popular evaluation metrics defined by Wiedemann et al. [
61,
62] will be adopted. These metrics include completeness, correctness, and quality. In order to calculate the completeness, a buffer with a specified width is built around each segment of the extracted road centerline. All reference lines inside the buffer zone are called “matched reference”. The completeness is the percentage of the reference network that lies within the buffer zone around the extracted data and is defined as follows:
In order to calculate the correctness, a buffer is constructed around each segment of the reference data. All extracted road centerlines that are inside the buffer zone are called “matched extraction”. The correctness is the percentage of the extracted data which lie within the buffer around the reference network, and is defined as follows:
The Quality can be calculated as:
In our study, no geographical database for the road network was available. Thus, reference road networks are delineated manually from the images.
4. Conclusions
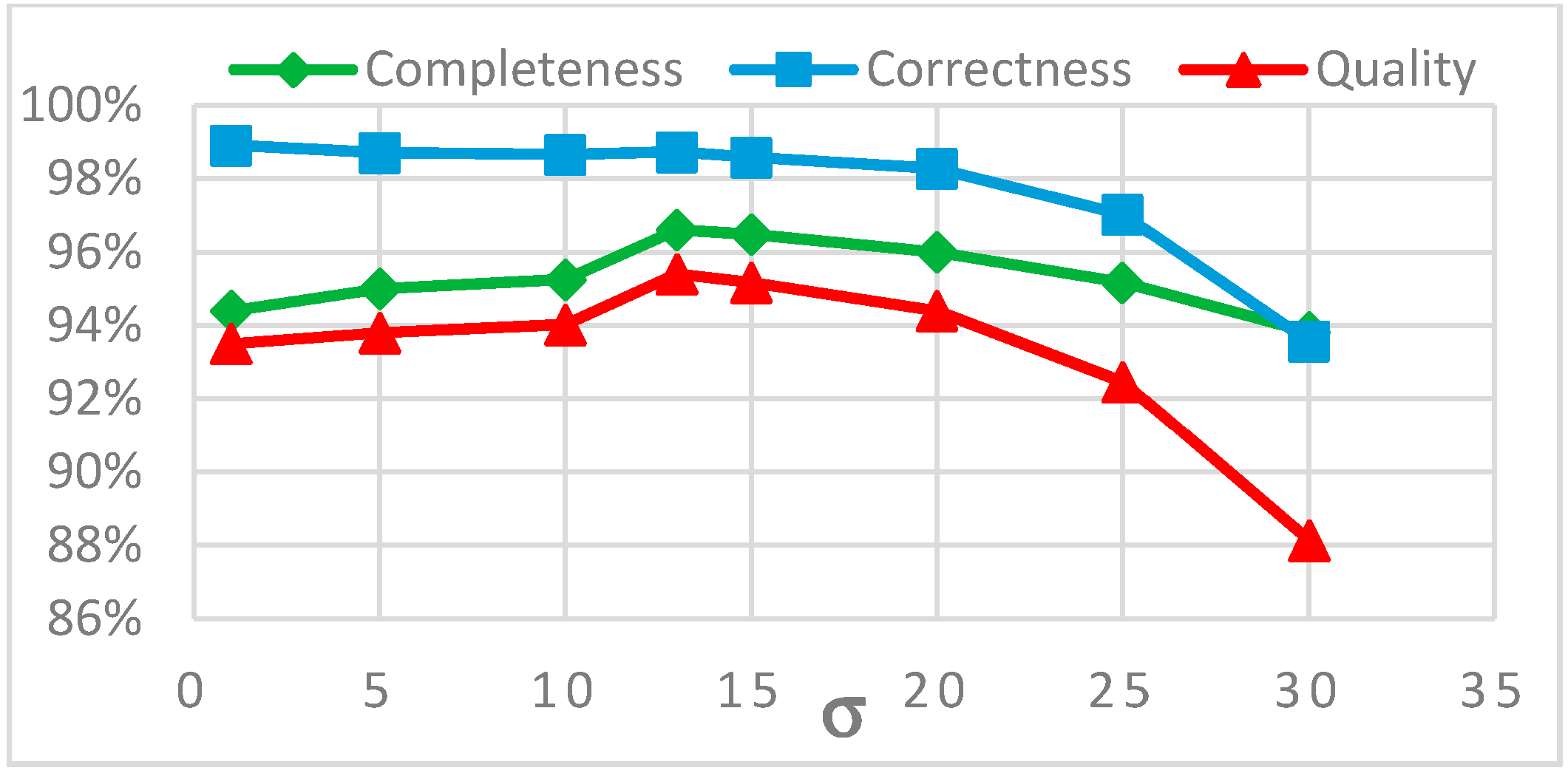
In this paper, a novel multi-stage object-based approach for road extraction from VHR satellite images is proposed. Edge-preserving guided filtering improves the segmentation quality significantly. A novel skeleton based linearity index called SOLI is proposed which approximates linearity of objects very well even if they are curved or include branches. Context aware feature integration based on SOLI, as well as spectral and textural features, leads to an efficient detection of road segments. For road-filling network gaps, the TV algorithm is customized to improve its computational efficiency. By limiting the voters to pixels that lie on the boundary of the extracted road segments, a considerable improvement of the computational efficiency of TV is achieved. The analysis of the impact of the scale parameter of TV on the quality of the result indicates that a σ range of [w, 2w] leads to the highest quality values.
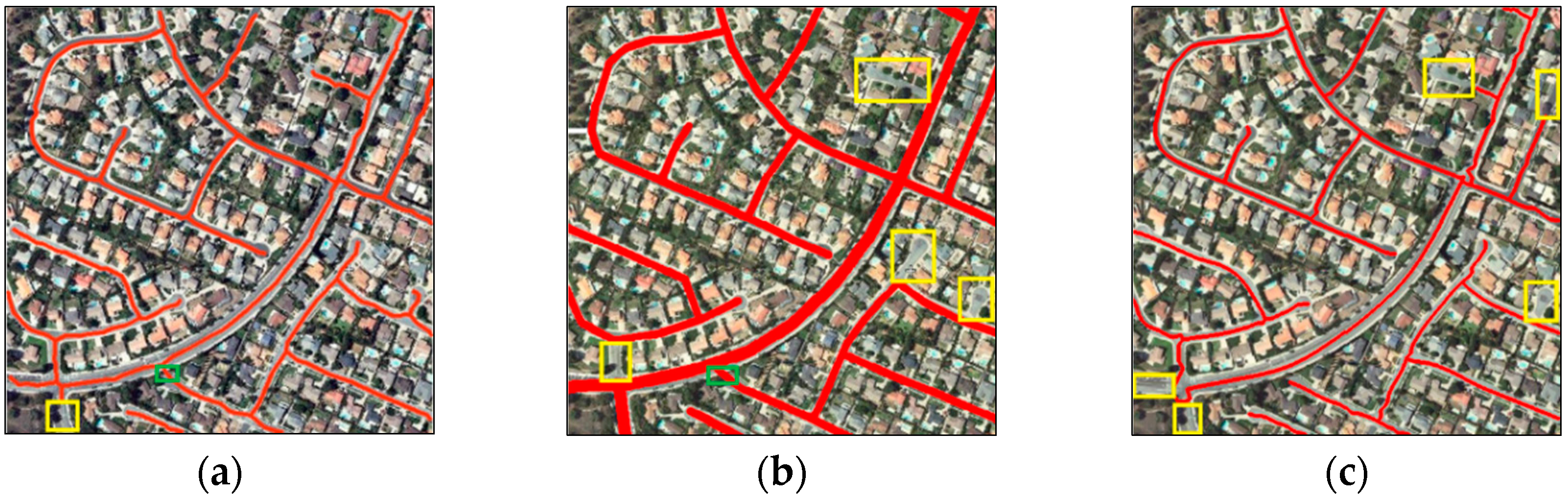
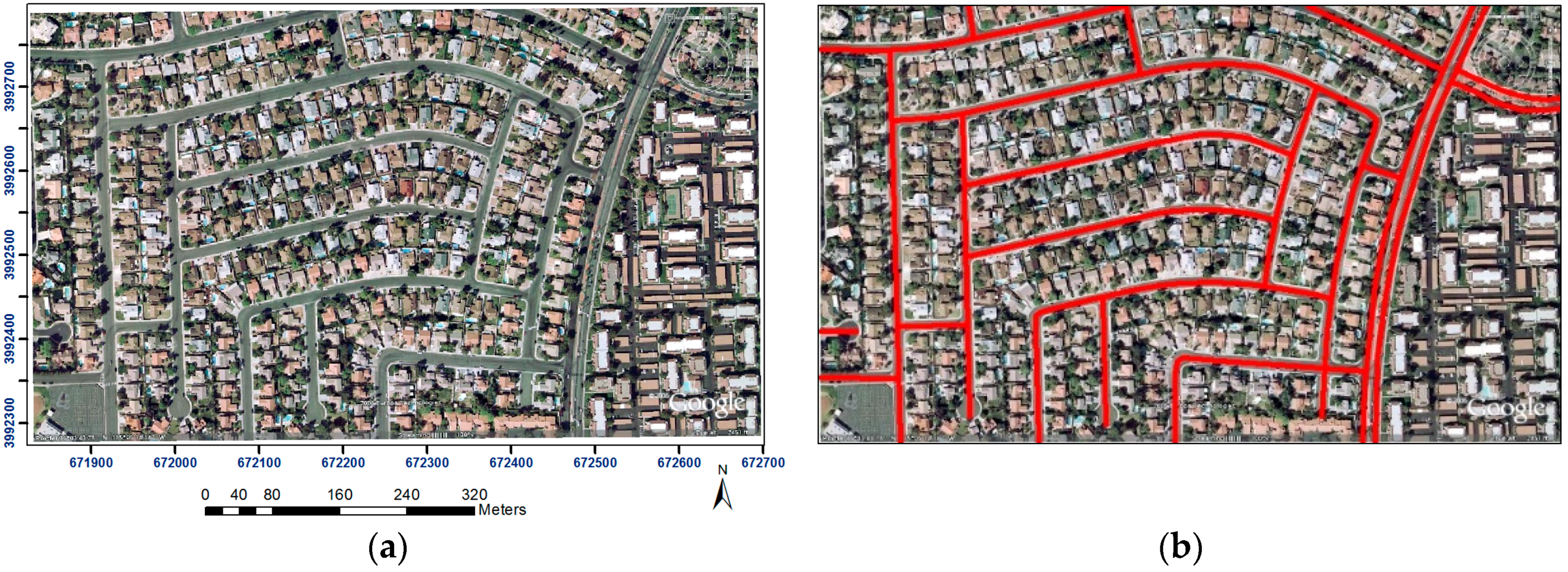
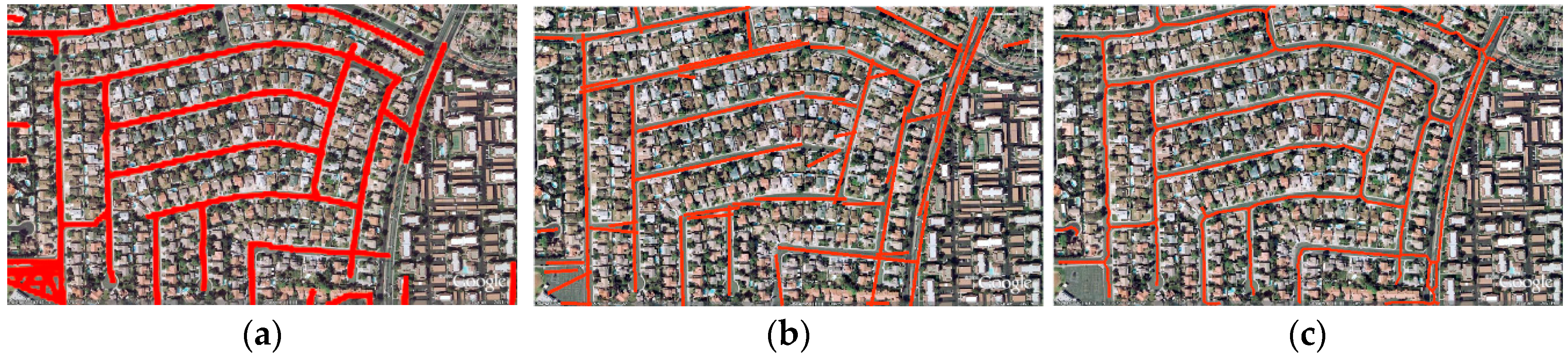
The experimental investigations are carried out with three publically available datasets which have been used by other researchers. In the investigations of the evaluation criteria, we have achieved quality measures of more than 84% for all datasets which demonstrates that the proposed approach fulfills the applicability criteria recommended in the EuroSDR test report [
8].
By comparing our results with published results of altogether seven state-of-the-art methods, we found that, with respect to all three evaluation criteria (completeness, correctness, and quality), our results are always among the two best in all different datasets. The rationale for this lies mainly in the combination of guided filtering with segmentation, the context-aware integration of SOLI with other object related features, and the gap filling with CTV. Nevertheless, there are ample opportunities to improve the road extraction approach. Our future research will focus on three complementary issues: (1) incorporating edge information of the images to achieve more accurate roadsides; (2) reinforcing the proposed approach by a graph data structure to improve the quality of the extracted road network, especially in the case of highly occluded roads and more complex scenes; and (3) analyzing the topology of the road network to suit the extracted road network for applications which topological consistency is essential for them.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}