
Tensor Block-Sparsity Based Representation for Spectral-Spatial Hyperspectral Image Classification




Abstract
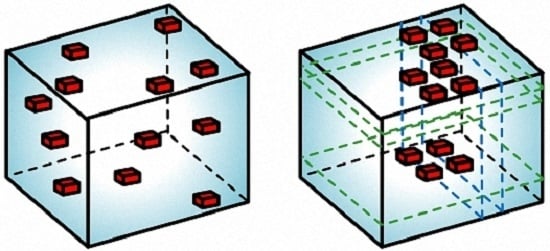
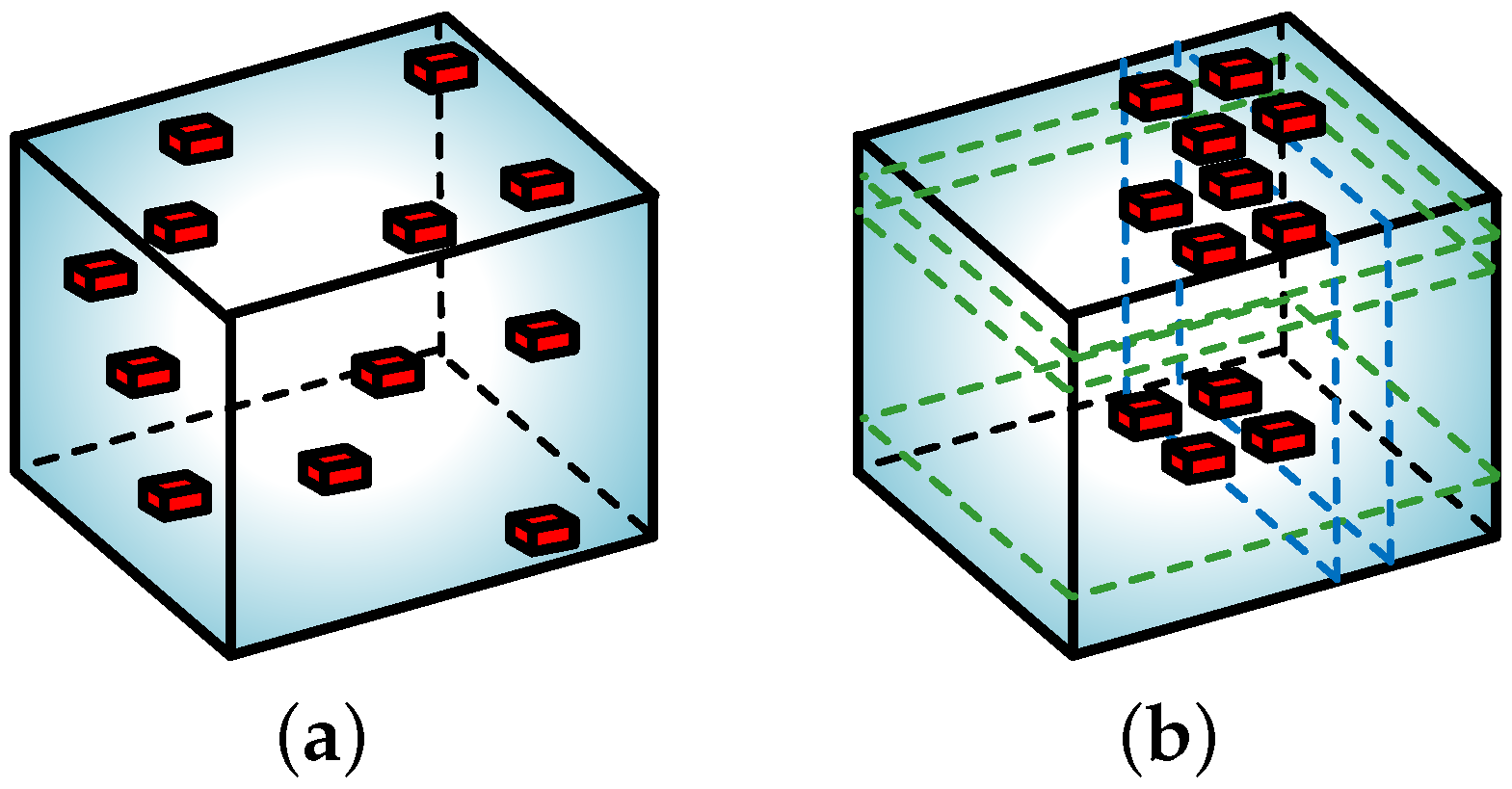
:
1. Introduction
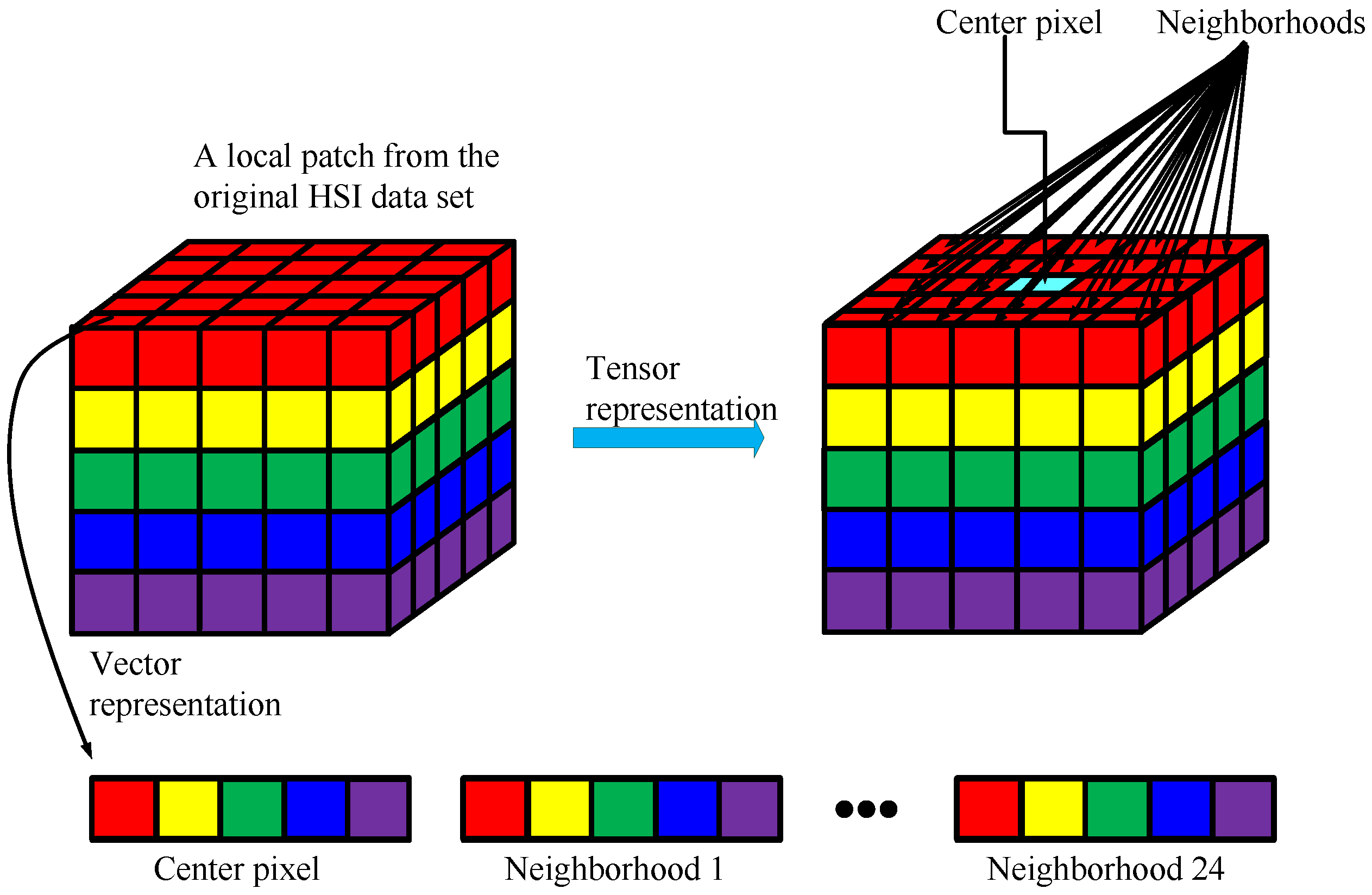
- Spectral-spatial information of pixels is preserved by treating the HSI cube as a third-order tensor. Compared to the vector-based methods, the proposed tensor-based method is capable of maintaining the structural information.
- Proper dictionaries are provided by tensor block-sparsity based learning. Instead of using all of the training samples to construct the dictionaries, the proposed method detects class-discriminative information for classification.
- Class label information is fully exploited by class-dependent block sparse representation. The proposed method learns the sparse coefficients by taking advantage of the class labels, while in general SRC methods, the label information is only used to calculate the residuals.
2. Tensor Notations and Preliminaries
3. Sparse Representation Classifier
4. Tensor Block-Sparsity based Representation for HSI
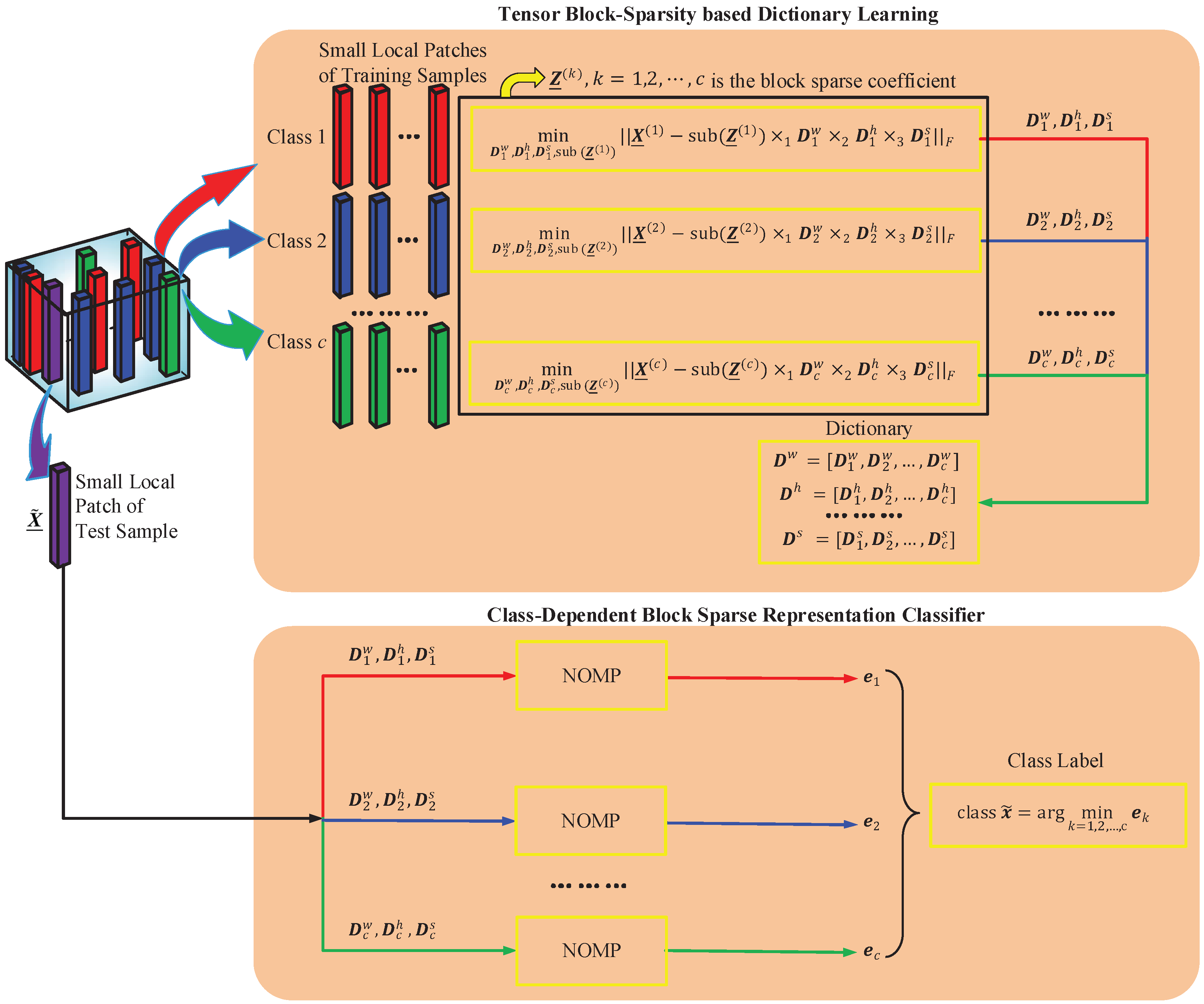
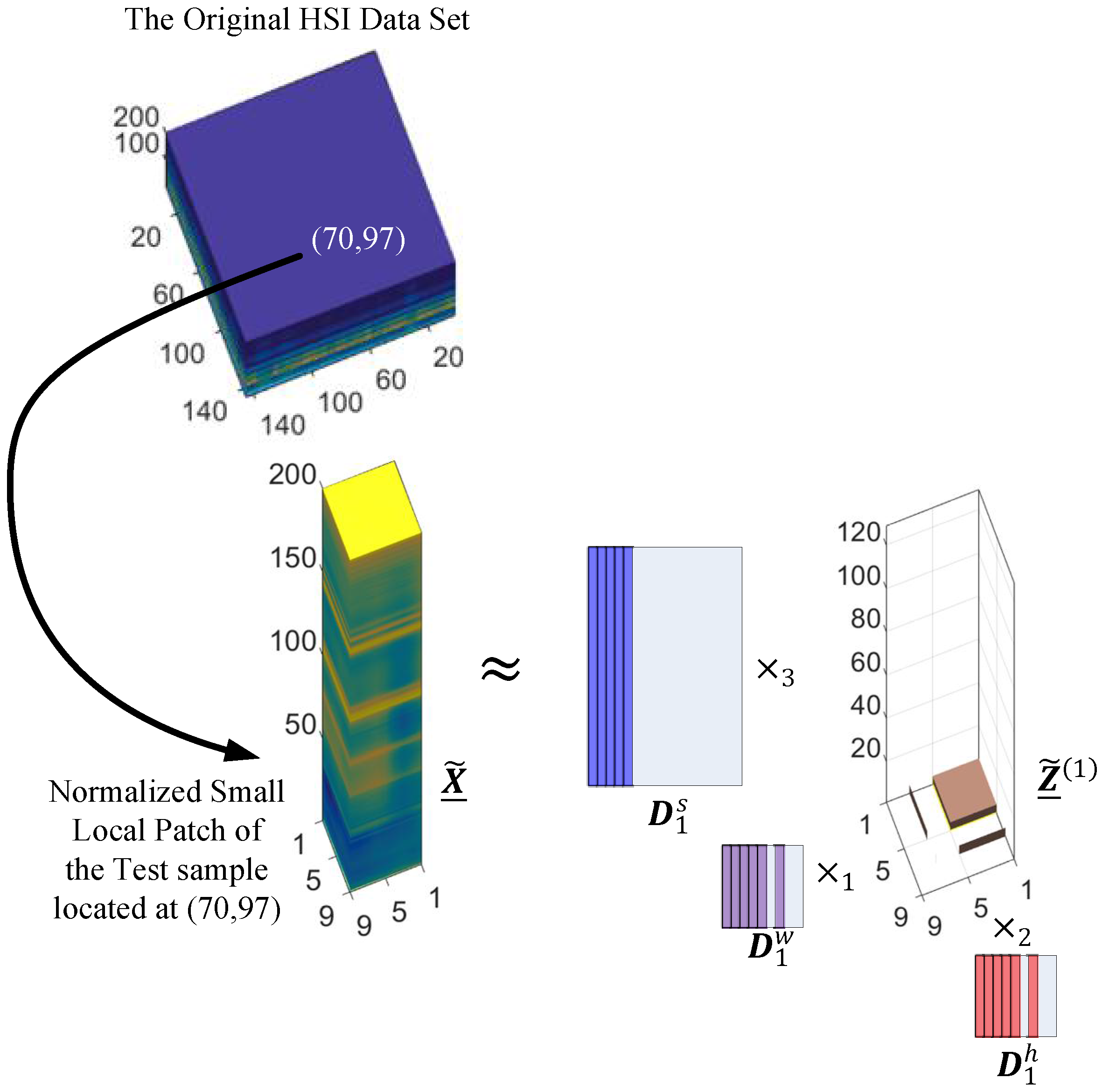
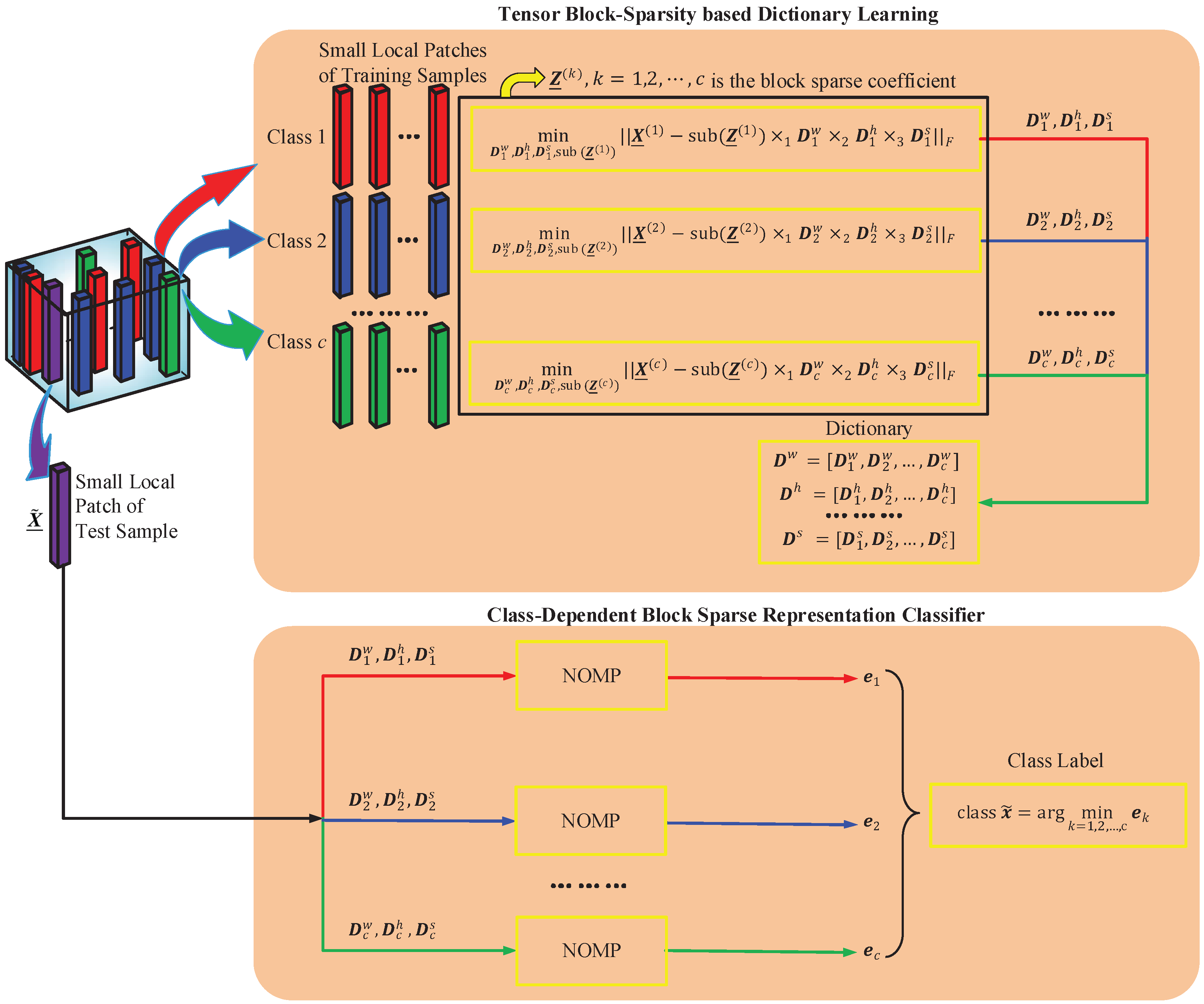
4.1. Tensor Block-Sparsity Based Dictionary Learning
4.2. Class-Dependent Block Sparse Representation Classifier
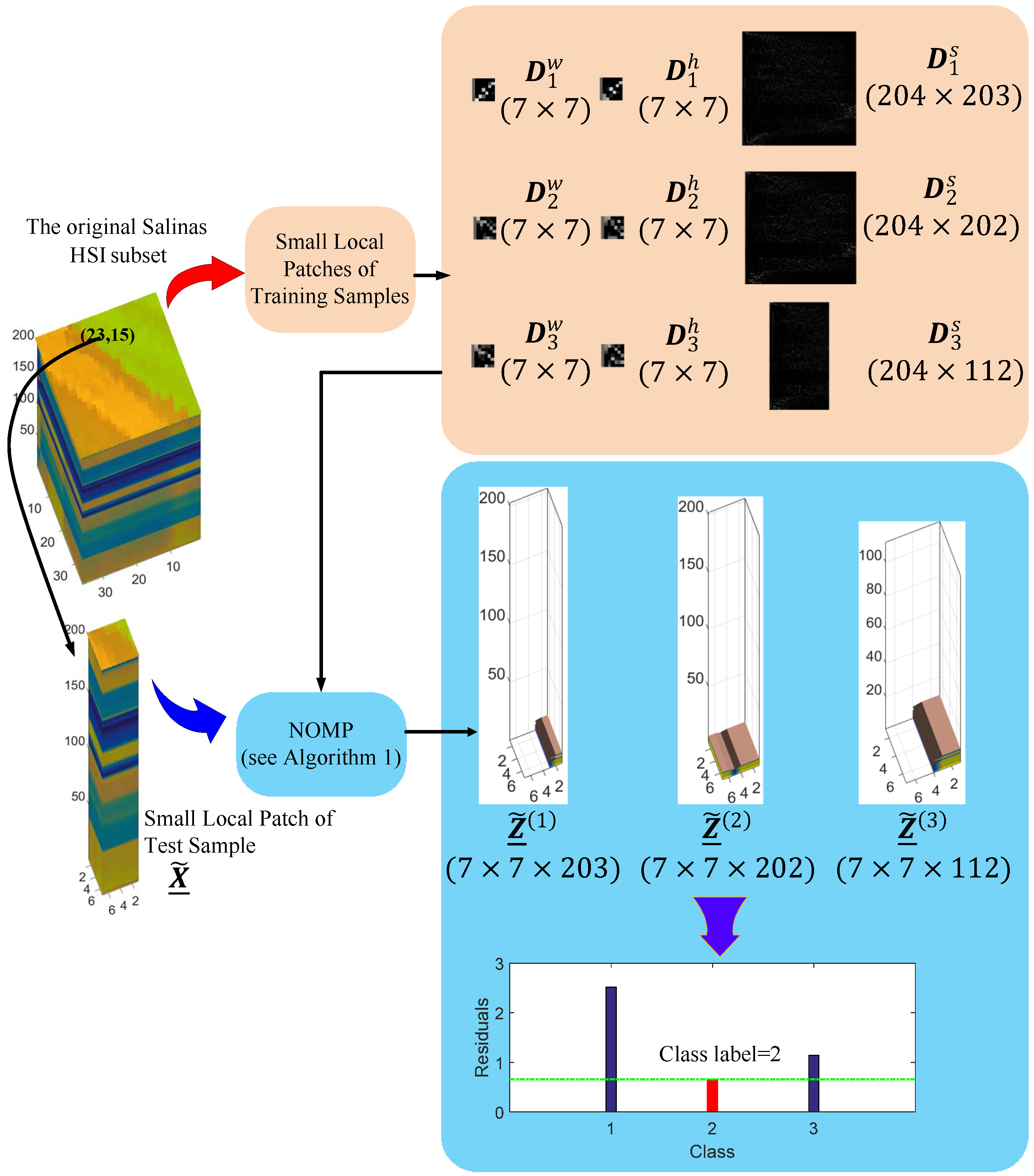
| Algorithm 1: Class-Dependent Block Sparse Representation Classifier | |
| Require: Dictionaries , , sparsity level S, test sample and its corresponding third-order tensor composed of the neighboring pixels | |
| Ensure: The class label of test sample | |
| 1: | for all do |
| 2: | Set , , and |
| 3: | while do |
| 4: | |
| 5: | Update the support set , , |
| 6: | Identify the vectorized version of by |
| 7: | Compute the residual |
| 8: | |
| 9: | end while |
| 10: | Calculate the norm of the kth residual , where is the vectorization of |
| 11: | end for |
| 12: | Determine the class label of by |
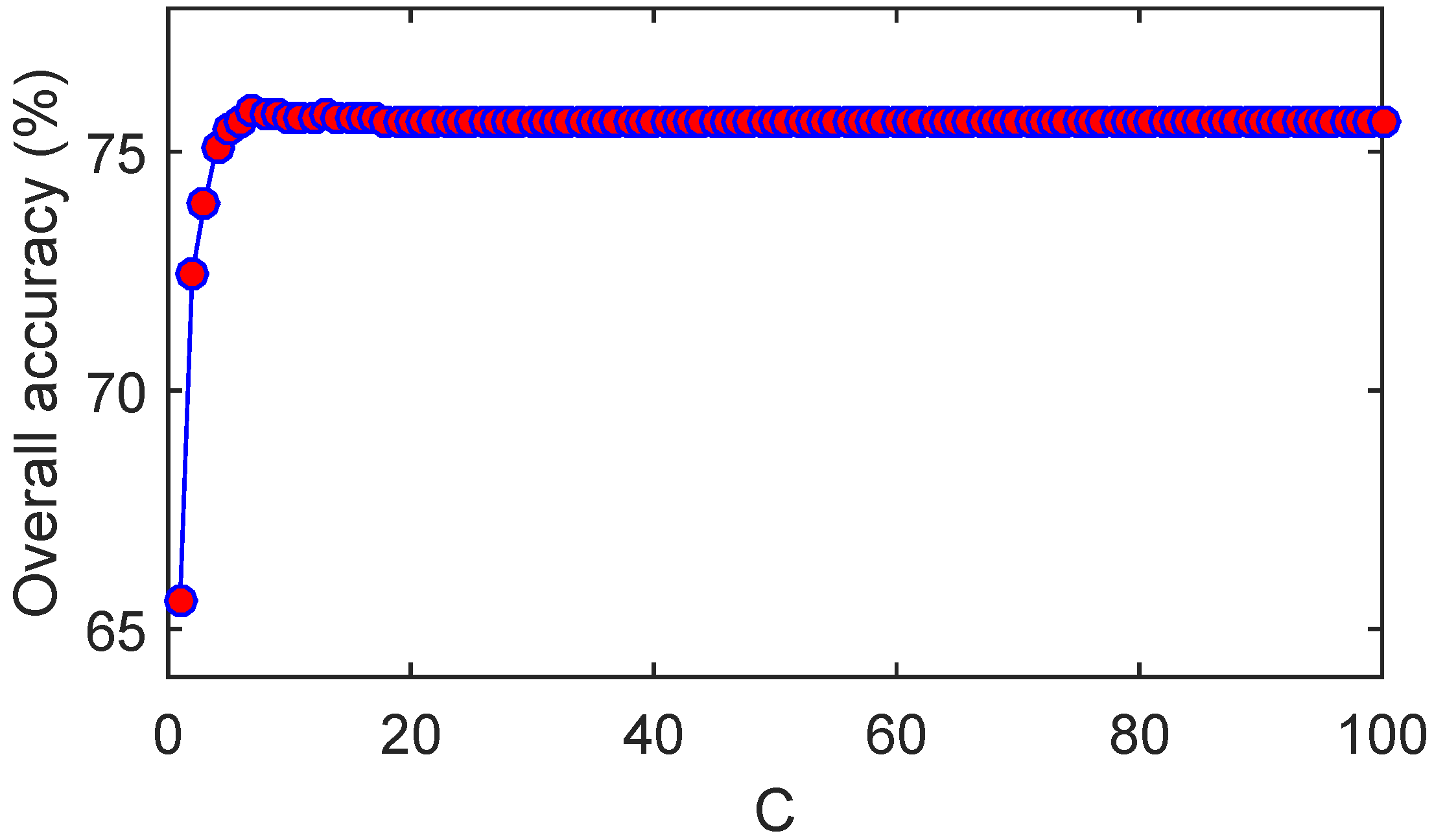
4.3. A Synthetic Example
5. Experimental Section
5.1. Data Sets
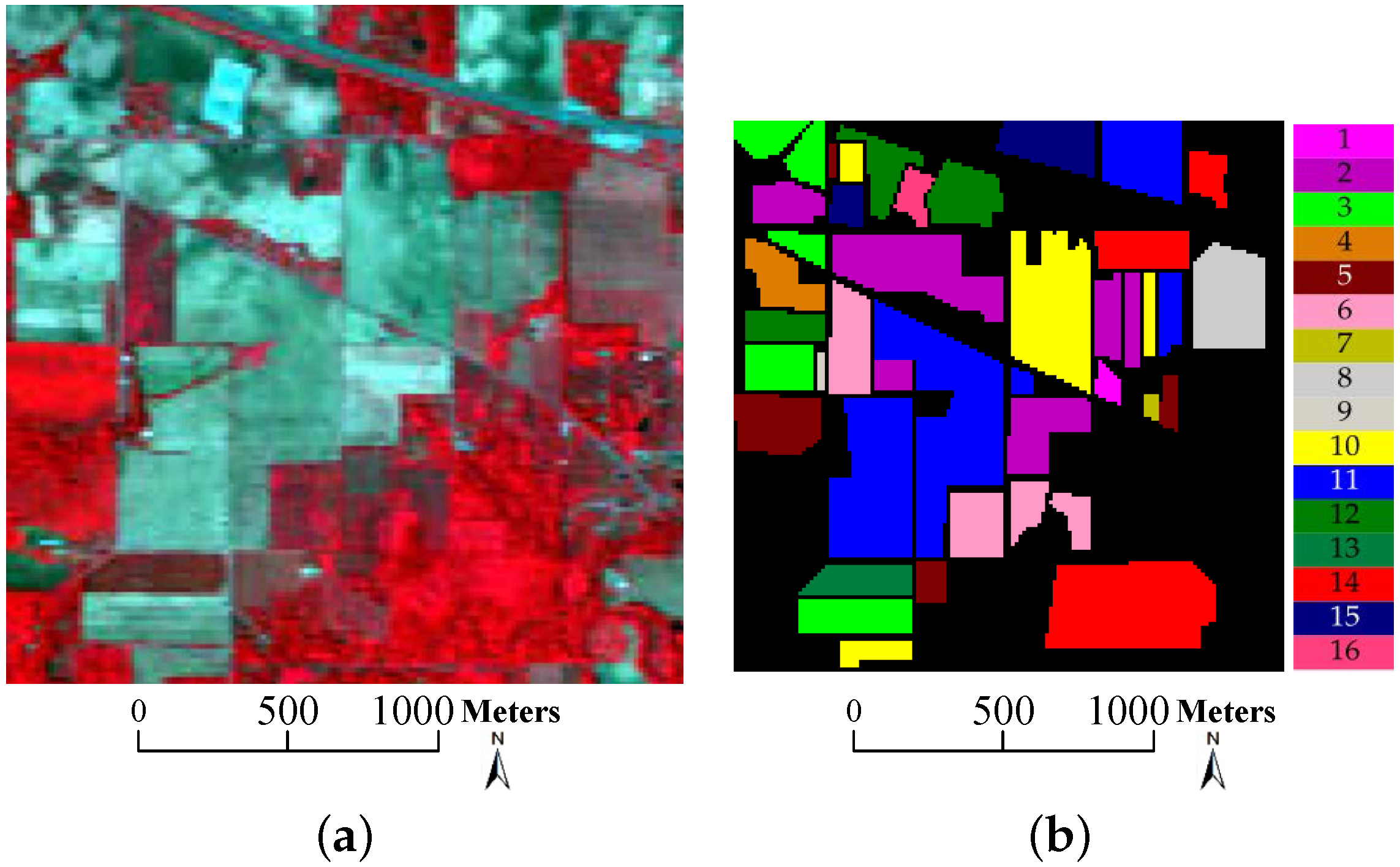
- Indian Pines data: this data set was acquired by the Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) over a mixed forest/agricultural region from Northwestern Indiana in June 1992. The image size is 145 × 145 × 220 (, , ) with 145 × 145 pixels and 220 spectral bands. The spatial resolution is 20 m per pixel and the 220 spectral bands cover 0.4–2.5 m range, of which 20 noisy and water-vapor absorption bands (bands 104–108, 150–163, and 220) are removed so that 200 bands are reserved for experiments. Figure 5 displays the three-band false color composite image along with the corresponding ground truth. This data set contains 16 classes of interest and 10366 labeled pixels ranging unbalanced from 20 to 2468, which poses a big challenge for the classification problem. The number of samples for each class is listed in Table 1, whose background color corresponds to different classes of land covers.
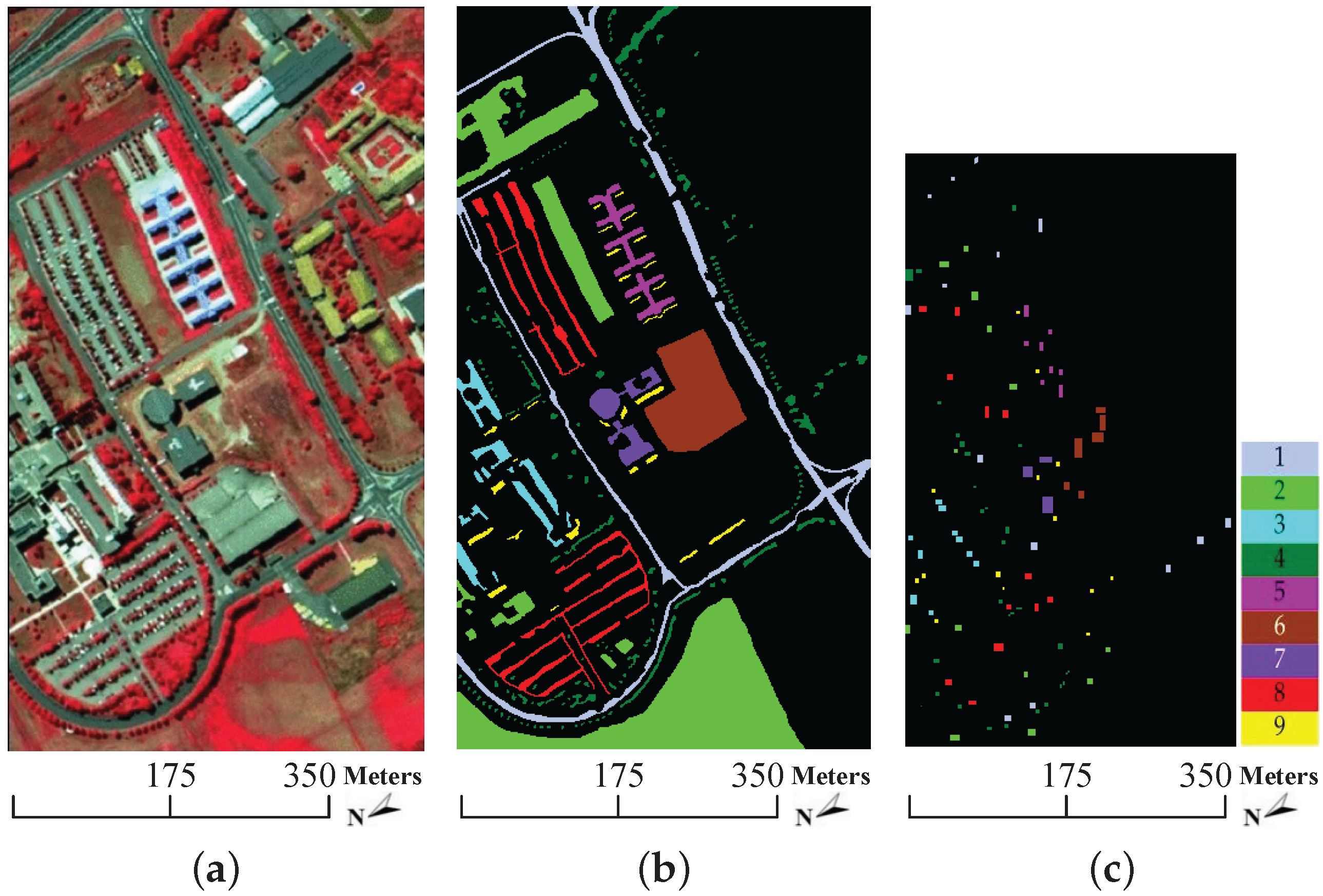
- University of Pavia data: this data set was acquired by the Reflective Optics System Imaging Spectrometer (ROSIS) over the urban site of the University of Pavia, northern Italy, in July 2002. The original size is 610 × 340 × 115 (, , ) with 610 × 340 pixels and 115 spectral bands. The spatial resolution is 1.3 m per pixel and the 115 spectral bands cover 0.43–0.86 m, of which the 12 noisiest channels are removed and 103 spectral bands remain for experiments. Figure 6 shows the false color composite image, the ground truth data and the available training samples. Table 1 lists the number of samples for each class together with the available training samples. Analogous to the Indian Pines data, the background color also corresponds to different classes of land covers. As shown in Table 1, this image consists of 9 classes of land covers and each class contains more than 900 pixels. However, the available training samples of each class are less than 600.
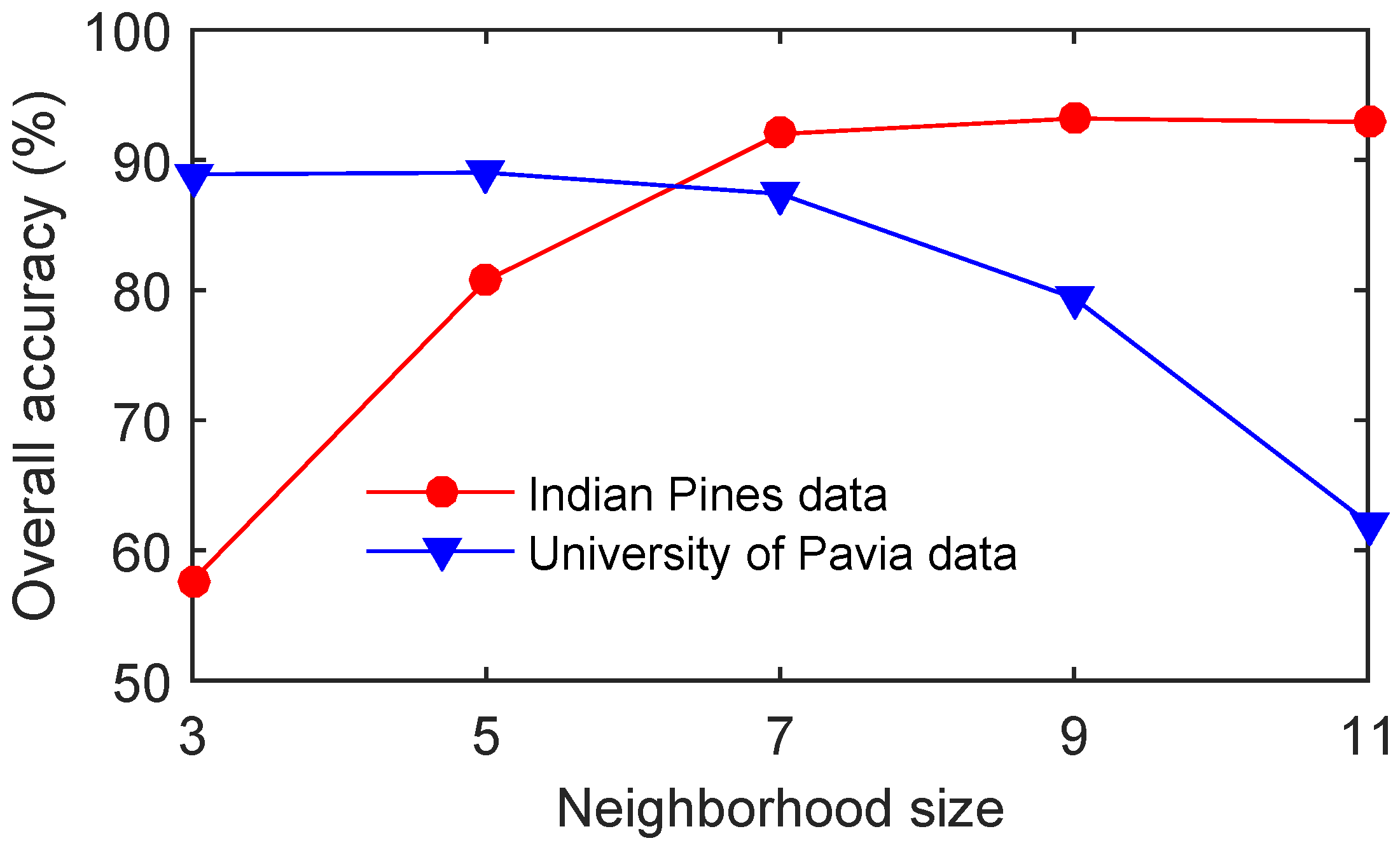
5.2. Experimental Design
- SVM: the classical SVM [10] with a single radial basis function (RBF) kernel;
- CRC: the test sample is approximated by the linear combination of the training samples in a least squares sense [33].
- SOMP: the spectral-spatial SRC incorporating spatial information by JSM and solved by SOMP [13];
- SADL: the spatial-aware classification technique [29] whose dictionary is obtained by structured dictionary learning and sparse coefficients are classified by linear SVM (Different from the SVM, SVMCK, 3D-DWT and LTDA, SADL applies the linear SVM for two reasons: (1) the SADL of this paper is consistent with [29], which employs linear SVM; (2) the sparse codes of SADL are discriminative enough to be well classified by the linear SVM.);
- 3D-DWT: the texture features are obtained by 3D-DWT and the classification results are given by RBF-based SVM [36];
- cdSRC: the SRC for each class is solved by OMP and the class label is jointly determined by the residual and Euclidean distance [35];
- pLSRC-S: the spectral-spatial SRC [32] with spatial smooth and the dictionary is learned by a modified patch-based learning SRC.
5.3. Classification Results and Discussions of Experiment 1
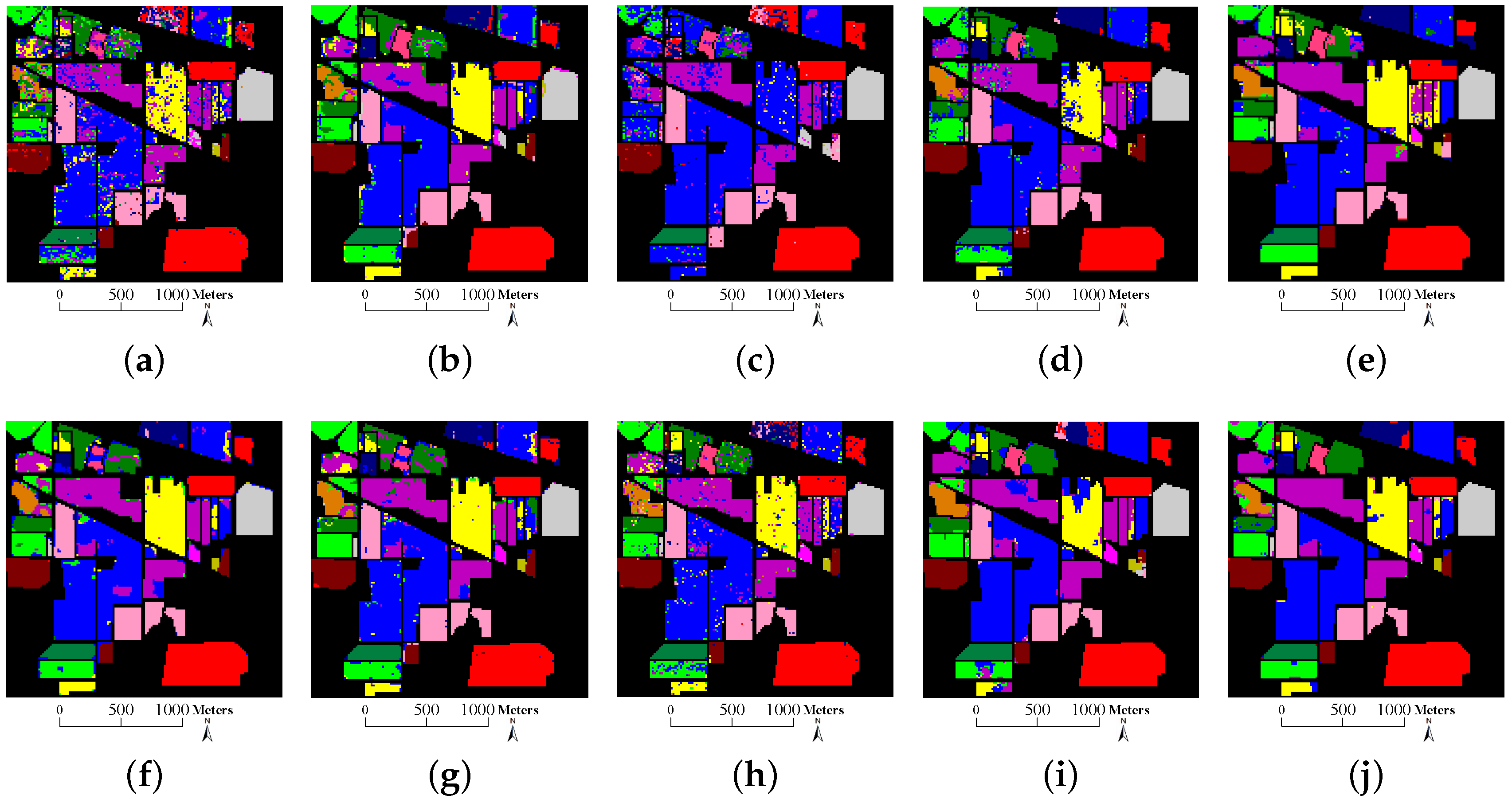
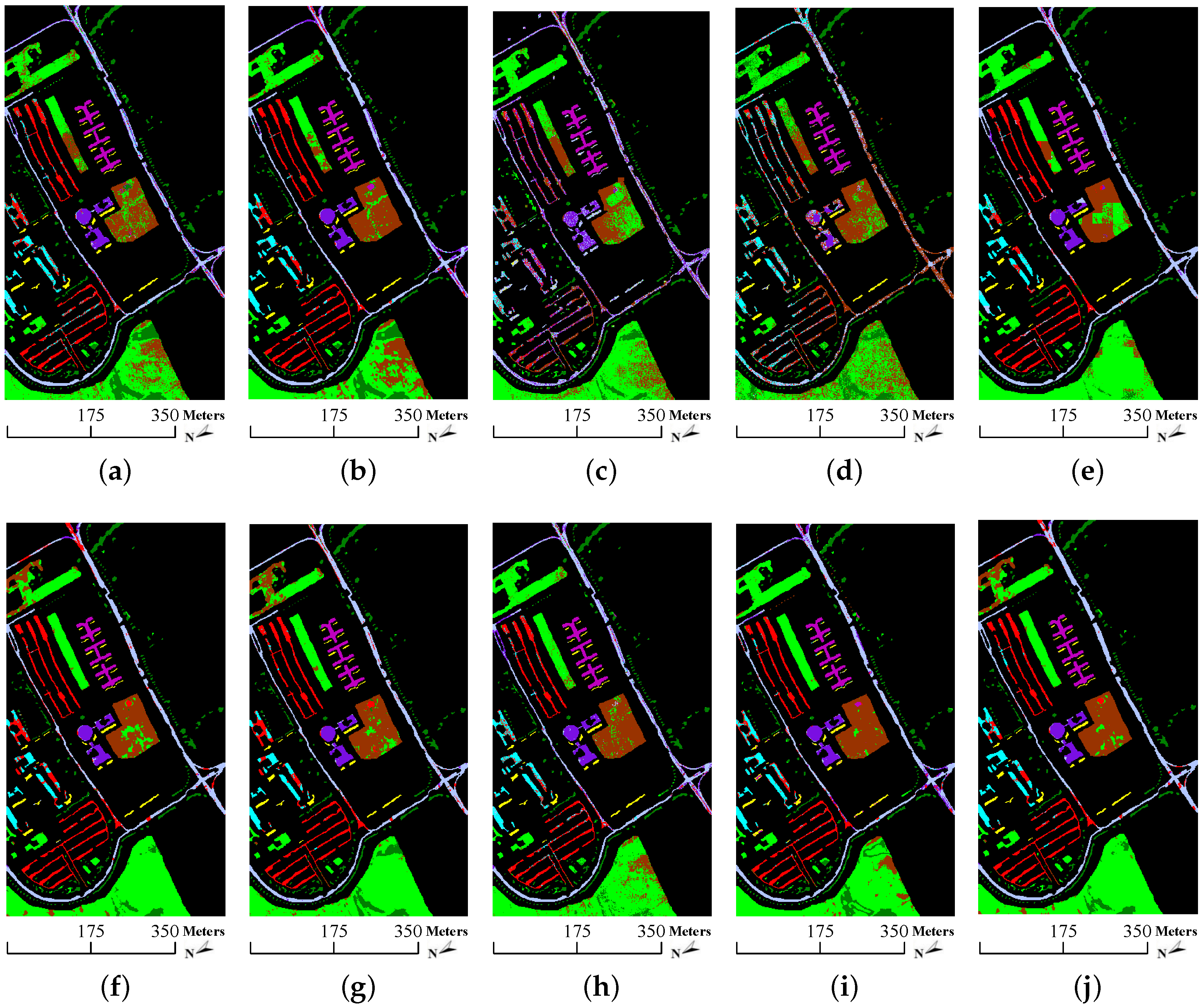
- SVM, CRC and cdSRC provide a more salt-and-pepper-like appearance than other methods. As shown in Figure 10 and Figure 11, there are many scattered salt-and-pepper-like errors in SVM, CRC and cdSRC, while the classification errors of SVMCK, SOMP, SADL, 3D-DWT, LTDA, pLSRC-S and tbSRC are spatially concentrated. This is because SVM, CRC and cdSRC only use the spectral information of the HSI, while the others integrate additional relevant information (i.e., spatial information) and develop it into spectral-spatial methods. As displayed in Table 2 and Table 3, the OAs of SVM are almost 10% to 20% lower than those of the other ones. More specifically, SVMCK provides much better results than SVM. This validates the advantage of spatial information for HSI classification;
- Although cdSRC is based only on spectral characteristics, it still yields impressive classification results. As shown in Table 2, the OA, AA and κ of cdSRC achieve 90.35%, 89.35%, and 88.98%, respectively, which are comparable to those of the SADL and 3D-DWT. Similar properties can also be found in Table 3. Such phenomena imply that incorporating the class label information in the process of calculating the sparse coefficients helps to improve the classification performance;
- For the Indian Pines data, SOMP achieves comparable classification accuracies to those of SVMCK, which indicates that the training samples inside a window surrounding a central pixel are taken as part of the best atoms. As shown in Table 2, the OA and κ of SOMP are respectively 1.02% and 1.11% higher than those of SVMCK, but the AA of SOMP is 3.08% lower than that of SVMCK. Because the 9th class (i.e., oats) of the Indian Pines data covers a narrow area (see Figure 5b), SOMP offers poor results for this class. For the University of Pavia data, SOMP falls far behind the other methods. As displayed in Table 3, the OA, AA and κ of SOMP are as low as 56.92%, 59.47% and 46.23%, respectively. The reason why SOMP cannot perform well may be because the available training samples (see Figure 6c) are composed of small patches and thus the window around a pixel may contain no training samples. More particularly, the 1st, 7th and 8th classes (i.e., asphalt, bitumen and bricks) of the University of Pavia data cover very narrow regions (see Figure 6b). As a consequence, the classification results of those classes are specifically poor (see Table 3);
- Among the collaborative/sparse representation-based methods (i.e., CRC, SOMP, cdSRC, pLSRC-S and tbSRC), pLSRC-S and tbSRC yield better classification performance than CRC, SOMP and cdSRC. This is partly because the dictionary learned by pLSRC-S and tbSRC can effectively represent the test samples, while the dictionary in CRC, SOMP and cdSRC is conventionally formed by all of the training samples and thus is not proper for capturing crucial class-discriminative information. As shown in Table 3, the OA of tbSRC is 25.27%, 32.11% and 3.25% higher than that of CRC, SOMP and cdSRC, respectively. Moreover, we can also observe that the SADL attains significant classification accuracies because a structured dictionary is effectively learned. For instance, the OA of SADL achieves 91.66% in Table 2. Those phenomena highlight the importance of dictionary learning;
- The tensor or 3-D based methods (i.e., 3D-DWT, LTDA and tbSRC) generally lead to better or comparable performance to that of SADL. As shown in Table 3, the OA of 3D-DWT and tbSRC are 0.79% and 2.75% higher than that of SADL, respectively, whereas the OA of LTDA is 0.33% lower than that of SADL. Similar results can also be found in Table 2. Therefore, the classification results demonstrated in Table 2 and Table 3 validate the excellent ability of 3D-DWT, LTDA and tbSRC in identifying spectral-spatial structures of HSI cubes. Moreover, tbSRC provides the best performance among all the above-mentioned methods. As depicted in Figure 10 and Figure 11, the classification maps of tbSRC are closer to the ground truth (see Figure 5b and Figure 6b) than those of other methods. Without 3-D tensors for spatial treatment, the proposed tbSRC will roughly reduce to a special case of the cdSRC. Based on the experimental results (see Table 2 and Table 3) on the two real-world HSIs, the OA of the spatial treatment will improve about 3% beyond the spectral information;
- As displayed in Table 2 and Table 3, the standard deviation of OA in the tbSRC is slightly lower than those of the other methods, which indicates that the tbSRC is stable. Regarding the computational efforts, the tensor block-sparsity based dictionary learning can be effectively implemented by Tucker decomposition, and tbSRC takes most of its computational cost in class-dependent block sparse representation, which requires no more than operations with n denoting the number of test samples, and , respectively. In the experiments, the computation time of tbSRC is comparable with that of other methods. As shown in Table 2, although the tbSRC takes a little more time than other methods, it can complete the classification task in no longer than 5 min.
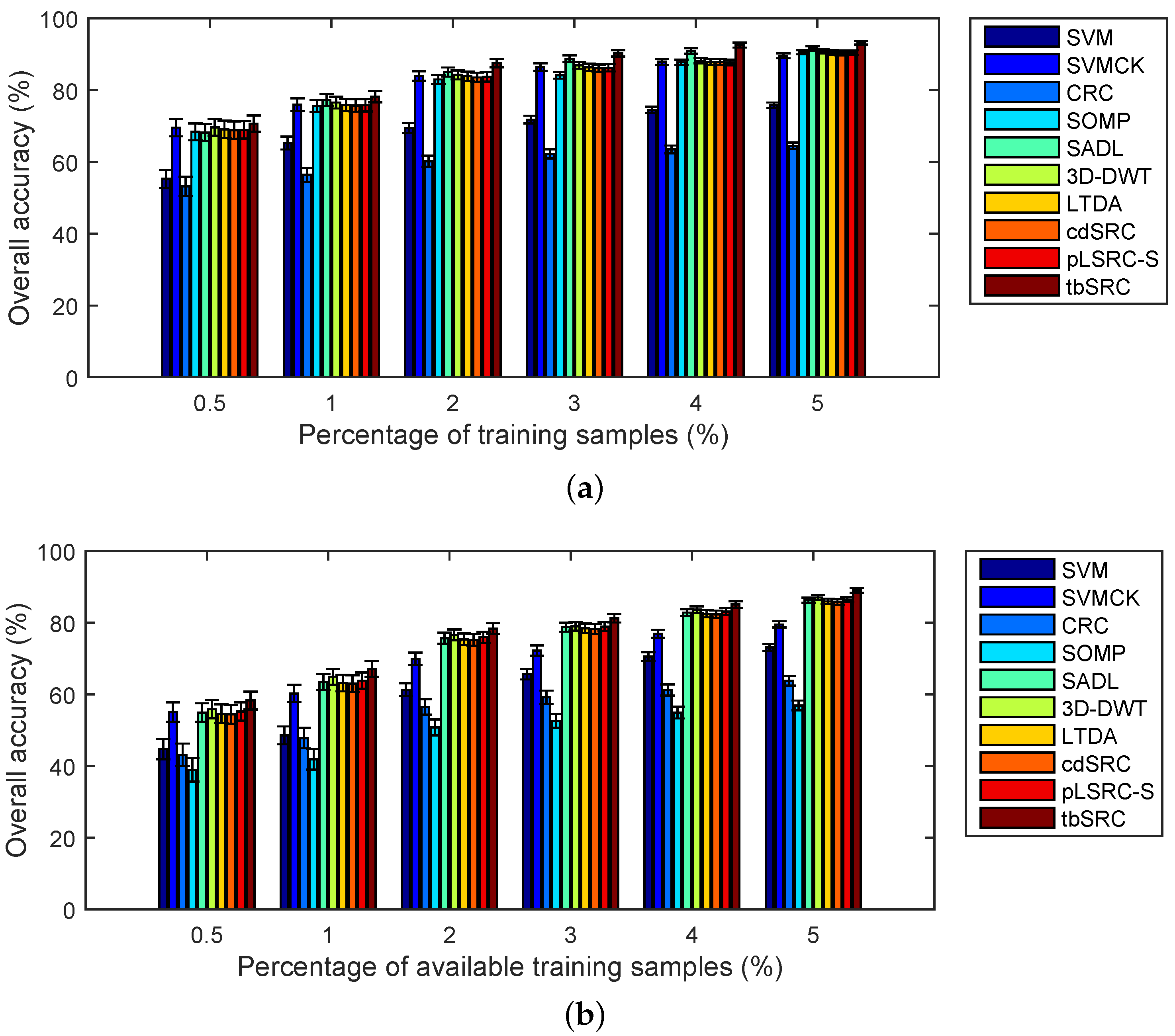
5.4. Classification Results and Discussions of Experiment 2
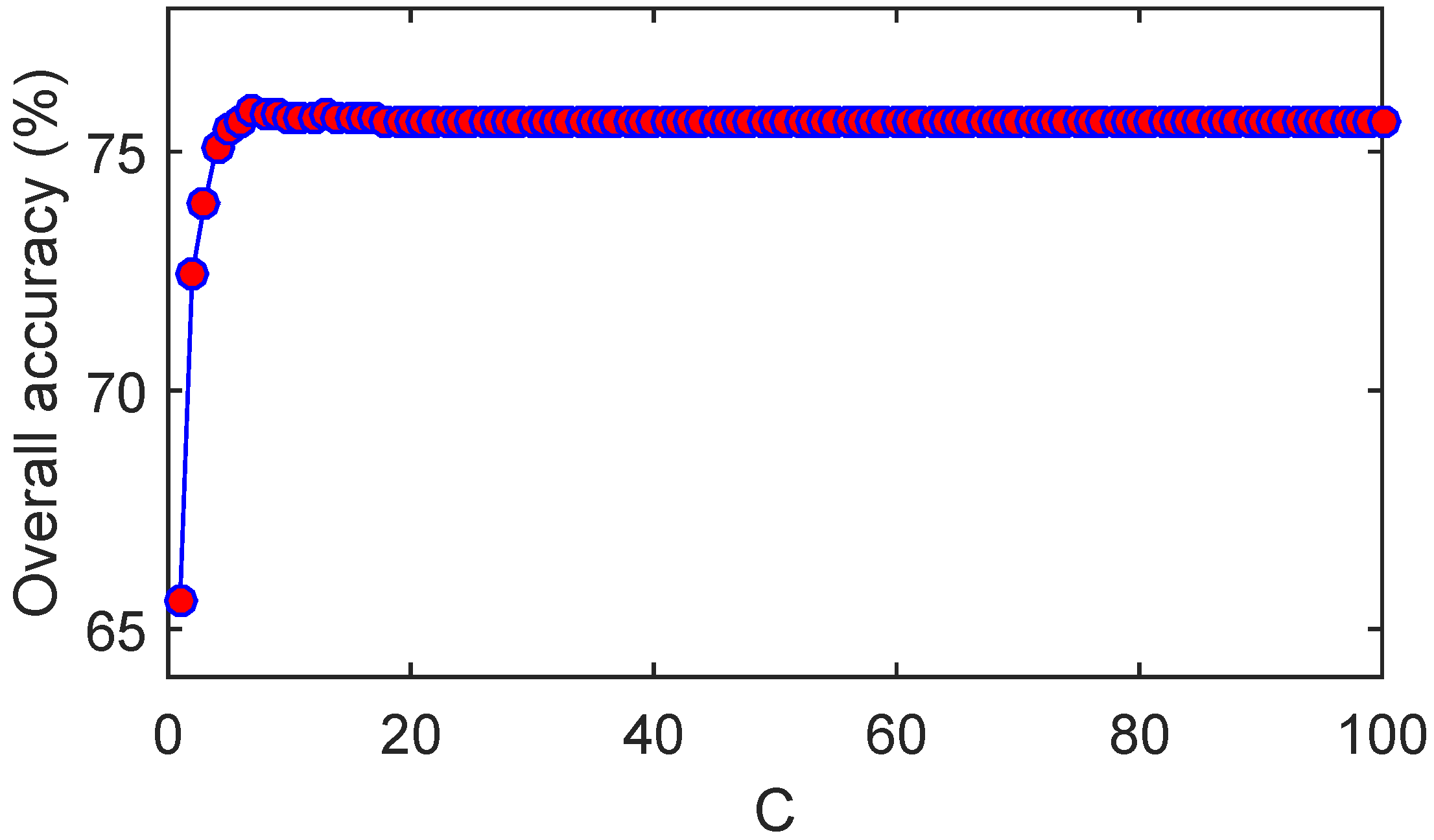
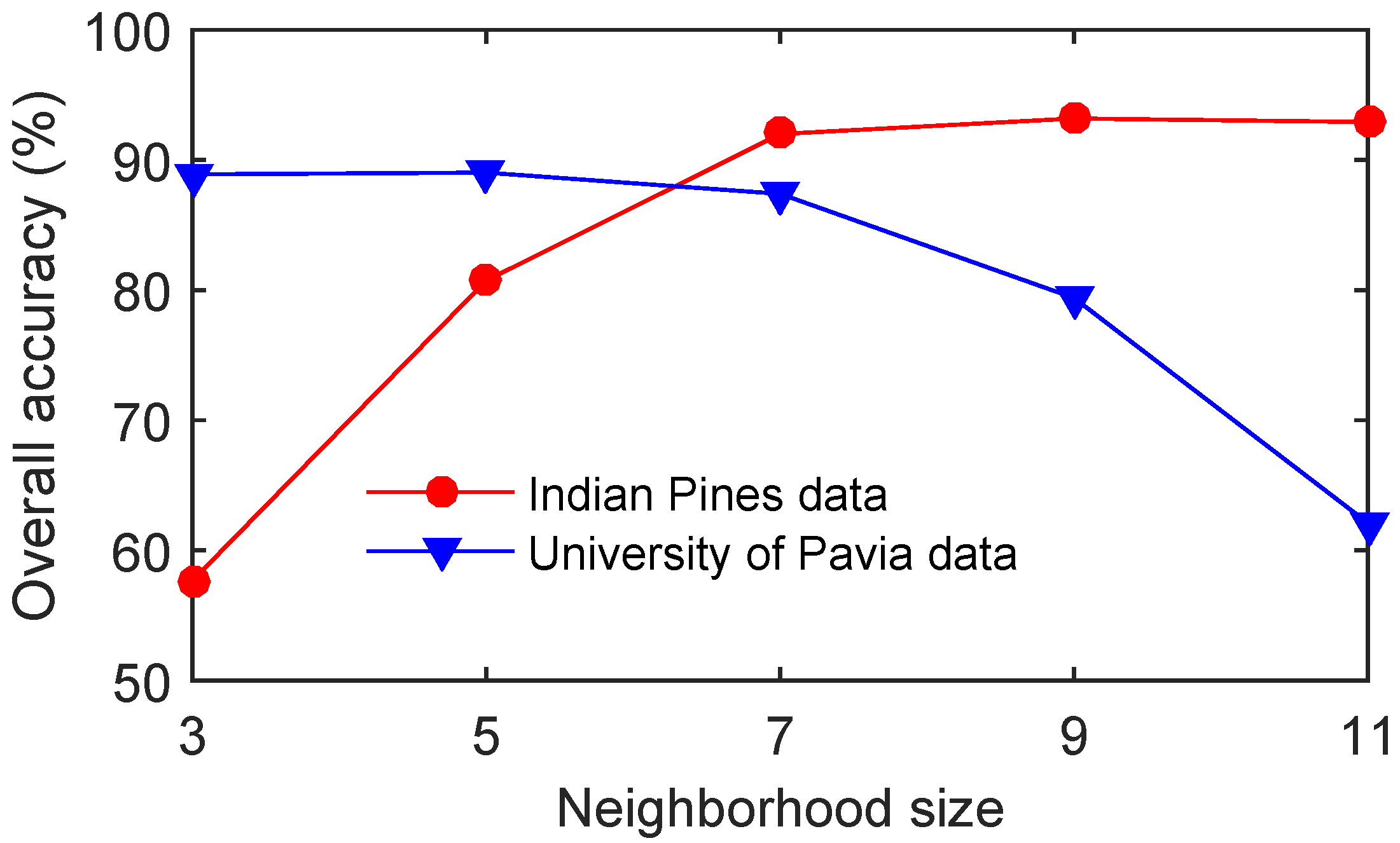
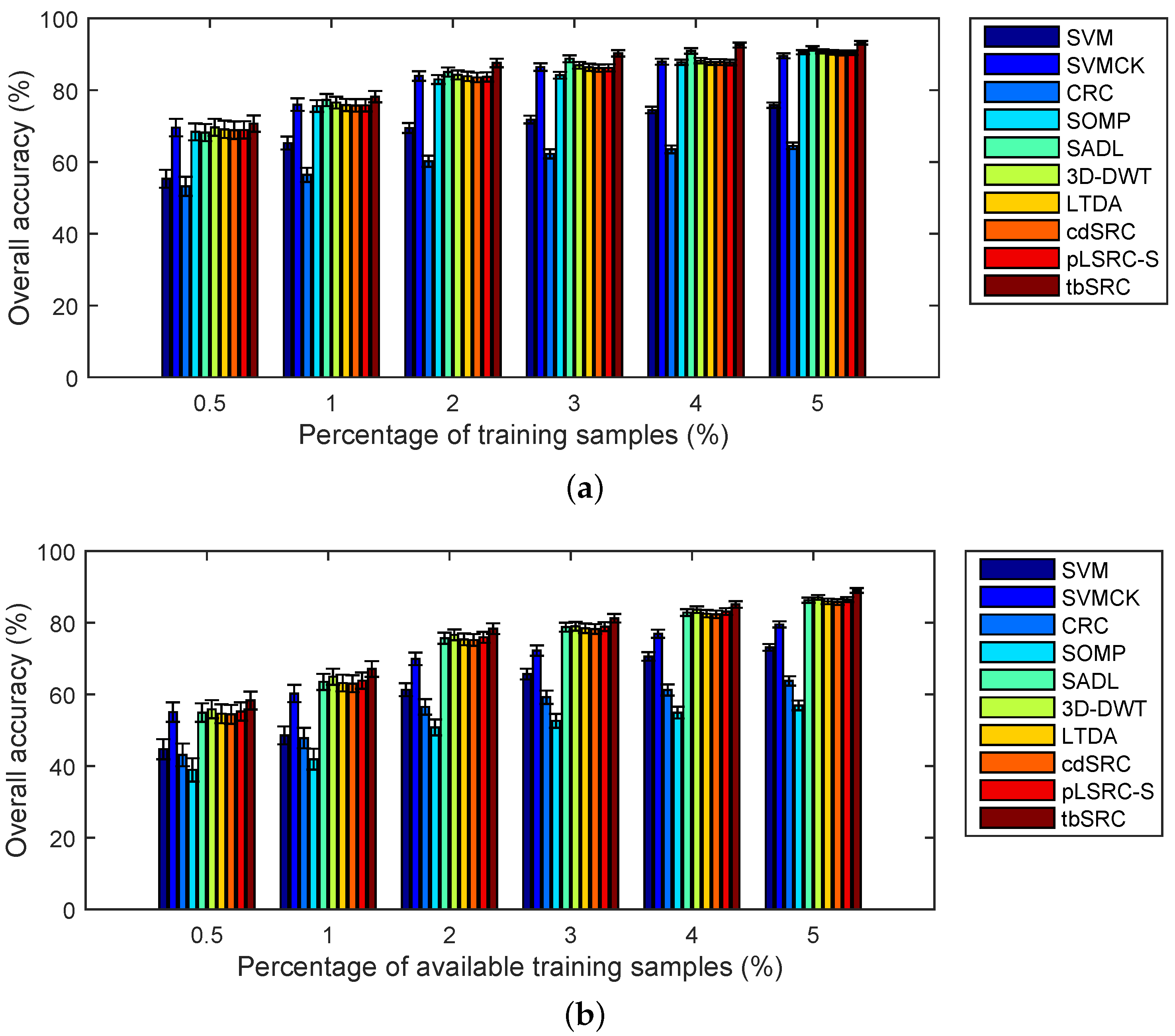
- As expected, the classification accuracy increases when the number of training samples increases. As depicted in Figure 12a, the OA of tbSRC is much lower than 90% when only 0.5% of labeled samples of the Indian Pines data are selected as training samples, while the OA is more than 90% with 5% of labeled samples as training samples;
- tbSRC is demonstrated to be superior to other methods with a small number of labeled samples, while SADL, 3D-DWT, LTDA, cdSRC and pLSRC-S trail marginally behind tbSRC. As observed from Figure 12a, although only 1% of labeled samples of the Indian Pines data are chosen selected as training samples, the OA of tbSRC almost reaches 80%, while the OAs of SADL, 3D-DWT, LTDA, cdSRC and pLSRC-S are slightly lower than that of tbSRC. Moreover, it is interesting to note that SADL, 3D-DWT, LTDA, cdSRC and pLSRC-S can achieve comparable performance. As shown in Figure 12a, the variations among OAs of those five methods are quite small. Similar results can also be discerned from Figure 12b;
- For the Indian Pines data, SOMP exhibits comparable classification accuracies to those of SVMCK. As illustrated in Figure 12a, the gap between SOMP and SVMCK is narrow, regardless what ratios of samples are chosen as training samples. However, SOMP delivers the worst results compared with the other seven methods for the other two data sets. Figure 12b reveals that the OA of SOMP is lower than 60% even when 5% of the available training samples is selected, whereas the OAs of the other methods (except CRC) are higher than 60% when using as low as 2% of the available training samples.
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Bioucas-Dias, J.M.; Plaza, A.; Camps-Valls, G.; Scheunders, P.; Nasrabadi, N.M.; Chanussot, J. Hyperspectral remote sensing data analysis and future challenges. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–36. [Google Scholar] [CrossRef]
- Song, H.; Wang, Y. A spectral-spatial classification of hyperspectral images based on the algebraic multigrid method and hierarchical segmentation algorithm. Remote Sens. 2016, 8. [Google Scholar] [CrossRef]
- Sun, X.; Yang, L.; Zhang, B.; Gao, L.; Gao, J. An endmember extraction method based on artificial bee colony algorithms for hyperspectral remote sensing images. Remote Sens. 2015, 7, 16363–16383. [Google Scholar] [CrossRef]
- Sun, W.; Jiang, M.; Li, W.; Liu, Y. A symmetric sparse representation based band selection method for hyperspectral imagery classification. Remote Sens. 2016, 8. [Google Scholar] [CrossRef]
- Sun, W.; Zhang, L.; Zhang, L.; Lai, Y.M. A dissimilarity-weighted sparse self-representation method for band selection in hyperspectral imagery classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016. [Google Scholar] [CrossRef]
- Jia, X.; Kuo, B.C.; Crawford, M.M. Feature mining for hyperspectral image classification. Proc. IEEE 2013, 101, 676–697. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, X.; Jia, X. Spectral-spatial classification of hyperspectral data based on deep belief network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2381–2392. [Google Scholar] [CrossRef]
- Wu, Z.; Wang, Q.; Plaza, A.; Li, J.; Liu, J.; Wei, Z. Parallel implementation of sparse representation classifiers for hyperspectral imagery on GPUs. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2912–2925. [Google Scholar] [CrossRef]
- Liang, H.; Li, Q. Hyperspectral imagery classification using sparse representations of convolutional neural network features. Remote Sens. 2016, 8, 99. [Google Scholar] [CrossRef]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer-Verlag: New York, NY, USA, 1995. [Google Scholar]
- Ramzi, P.; Samadzadegan, F.; Reinartz, P. Classification of hyperspectral data using an AdaBoostSVM technique applied on band clusters. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2066–2079. [Google Scholar] [CrossRef]
- Baldeck, C.; Asner, G.P. Single-species detection with airborne imaging spectroscopy data: A comparison of support vector techniques. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2501–2512. [Google Scholar] [CrossRef]
- Chen, Y.; Nasrabadi, N.M.; Tran, T.D. Hyperspectral image classification via kernel sparse representation. IEEE Trans. Geosci. Remote Sens. 2013, 51, 217–231. [Google Scholar] [CrossRef]
- Fang, L.; Li, S.; Kang, X.; Benediktsson, J.A. Spectral-spatial hyperspectral image classification via multiscale adaptive sparse representation. IEEE Trans. Geosci. Remote Sens. 2014, 52, 7738–7749. [Google Scholar] [CrossRef]
- Sun, X.; Nasrabadi, N.M.; Tran, T.D. Task-driven dictionary learning for hyperspectral image classification with structured sparsity constraints. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4457–4471. [Google Scholar] [CrossRef]
- Ly, N.H.; Du, Q.; Fowler, J.E. Collaborative graph-based discriminant analysis for hyperspectral imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2688–2696. [Google Scholar] [CrossRef]
- Ly, N.H.; Du, Q.; Fowler, J.E. Sparse graph-based discriminant analysis for hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2014, 52, 3872–3884. [Google Scholar]
- Li, J.; Huang, X.; Gamba, P.; Bioucas, J.; Zhang, L.; Benediksson, J.; Plaza, A. Multiple feature learning for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1592–1606. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Gomez-Chova, L.; Muñoz-Marí, J.; Vila-Francés, J.; Calpe-Maravilla, J. Composite kernels for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2006, 3, 93–97. [Google Scholar] [CrossRef]
- Tuia, D.; Camps-Valls, G.; Matasci, G.; Kanevski, M. Learning relevant image features with multiple-kernel classification. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3780–3791. [Google Scholar] [CrossRef]
- He, Z.; Wang, Q.; Shen, Y.; Sun, M. Kernel sparse multitask learning for hyperspectral image classification with empirical mode decomposition and morphological wavelet-based features. IEEE Trans. Geosci. Remote Sens. 2014, 52, 5150–5163. [Google Scholar]
- Li, J.; Marpu, P.R.; Plaza, A.; Bioucas-Dias, J.M.; Benediktsson, J.A. Generalized composite kernel framework for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2013, 51, 4816–4829. [Google Scholar] [CrossRef]
- He, Z.; Li, J. Multiple data-dependent kernel for classification of hyperspectral images. Expert Syst. Appl. 2015, 42, 1118–1135. [Google Scholar] [CrossRef]
- Tarabalka, Y.; Fauvel, M.; Chanussot, J.; Benediktsson, J.A. SVM-and MRF-based method for accurate classification of hyperspectral images. IEEE Geosci. Remote Sens. Lett. 2010, 7, 736–740. [Google Scholar] [CrossRef]
- Li, J.; Bioucas-Dias, J.; Plaza, A. Spectral-spatial hyperspectral image segmentation using subspace multinomial logistic regression and Markov random fields. IEEE Trans. Geosci. Remote Sens. 2012, 50, 809–823. [Google Scholar] [CrossRef]
- Srinivas, U.; Chen, Y.; Monga, V.; Nasrabadi, N.M.; Tran, T.D. Exploiting sparsity in hyperspectral image classification via graphical models. IEEE Geosci. Remote Sens. Lett. 2013, 10, 505–509. [Google Scholar] [CrossRef]
- Zhang, H.; Li, J.; Huang, Y.; Zhang, L. A nonlocal weighted joint sparse representation classification method for hyperspectral imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2056–2065. [Google Scholar] [CrossRef]
- Chen, Y.; Nasrabadi, N.M.; Tran, T.D. Hyperspectral image classification using dictionary-based sparse representation. IEEE Trans. Geosci. Remote Sens. 2010, 49, 3973–3985. [Google Scholar] [CrossRef]
- Soltani-Farani, A.; Rabiee, H.R.; Hosseini, S.A. Spatial-aware dictionary learning for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 527–541. [Google Scholar] [CrossRef]
- Sun, X.; Qu, Q.; Nasrabadi, N.M.; Tran, T.D. Structured priors for sparse-representation-based hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1235–1239. [Google Scholar]
- Du, P.; Xue, Z.; Li, J.; Plaza, A. Learning discriminative sparse representations for hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 9, 1089–1104. [Google Scholar] [CrossRef]
- Wang, Z.; Nasrabadi, N.M.; Huang, T.S. Spatial-spectral classification of hyperspectral images using discriminative dictionary designed by learning vector quantization. IEEE Trans. Geosci. Remote Sens. 2014, 52, 4808–4822. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, M.; Feng, X. Sparse representation or collaborative representation: Which helps face recognition? In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 471–478.
- Rubinstein, R.; Bruckstein, A.M.; Elad, M. Dictionaries for sparse representation modeling. Proc. IEEE. 2010, 98, 1045–1057. [Google Scholar] [CrossRef]
- Cui, M.; Prasad, S. Class-dependent sparse representation classifier for robust hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2683–2695. [Google Scholar] [CrossRef]
- Qian, Y.; Ye, M.; Zhou, J. Hyperspectral image classification based on structured sparse logistic regression and three-dimensional wavelet texture features. IEEE Trans. Geosci. Remote Sens. 2012, 51, 2276–2291. [Google Scholar] [CrossRef]
- Lin, T.; Bourennane, S. Hyperspectral image processing by jointly filtering wavelet component tensor. IEEE Trans. Geosci. Remote Sens. 2013, 51, 3529–3541. [Google Scholar] [CrossRef]
- Jia, S.; Zhu, Z.; Shen, L.; Li, Q. A two-stage feature selection framework for hyperspectral image classification using few labeled samples. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 1023–1035. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Tao, D.; Huang, X. Tensor discriminative locality alignment for hyperspectral image spectral–spatial feature extraction. IEEE Trans. Geosci. Remote Sens. 2013, 51, 242–256. [Google Scholar] [CrossRef]
- Tsai, F.; Lai, J.S. Feature extraction of hyperspectral image cubes using three-dimensional gray-level cooccurrence. IEEE Trans. Geosci. Remote Sens. 2013, 51, 3504–3513. [Google Scholar] [CrossRef]
- Yang, S.; Wang, M.; Li, P.; Jin, L.; Wu, B.; Jiao, L. Compressive hyperspectral imaging via sparse tensor and nonlinear compressed sensing. IEEE Trans. Geosci. Remote Sens. 2015, 53, 5943–5957. [Google Scholar] [CrossRef]
- Zhong, Z.; Fan, B.; Duan, J.; Wang, L.; Ding, K.; Xiang, S.; Pan, C. Discriminant tensor spectral-spatial feature extraction for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1028–1032. [Google Scholar] [CrossRef]
- Peng, Y.; Meng, D.; Xu, Z.; Gao, C.; Yang, Y.; Zhang, B. Decomposable nonlocal tensor dictionary learning for multispectral image denoising. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 2949–2956.
- Sivalingam, R.; Boley, D.; Morellas, V.; Papanikolopoulos, N. Tensor dictionary learning for positive definite matrices. IEEE Trans. Image Process. 2015, 24, 4592–4601. [Google Scholar] [CrossRef] [PubMed]
- Tan, S.; Zhang, Y.; Wang, G.; Mou, X.; Cao, G.; Wu, Z.; Yu, H. Tensor-based dictionary learning for dynamic tomographic reconstruction. Phys. Med. Biol. 2015, 60, 2803–2818. [Google Scholar] [CrossRef] [PubMed]
- Duarte, M.F.; Baraniuk, R.G. Kronecker compressive sensing. IEEE Trans. Image Process. 2012, 21, 494–504. [Google Scholar] [CrossRef] [PubMed]
- Caiafa, C.F.; Cichocki, A. Computing sparse representations of multidimensional signals using kronecker bases. Neural Comput. 2013, 25, 186–220. [Google Scholar] [CrossRef] [PubMed]
- Caiafa, C.F.; Cichocki, A. Multidimensional compressed sensing and their applications. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2013, 3, 355–380. [Google Scholar] [CrossRef]
- Kolda, T.G.; Bader, B.W. Tensor decompositions and applications. SIAM Rev. 2009, 51, 455–500. [Google Scholar] [CrossRef]
- Guo, X.; Huang, X.; Zhang, L.; Zhang, L. Hyperspectral image noise reduction based on rank-1 tensor decomposition. ISPRS J. Photogramm. Remote Sens. 2013, 83, 50–63. [Google Scholar] [CrossRef]
- Velasco-Forero, S.; Angulo, J. Classification of hyperspectral images by tensor modeling and additive morphological decomposition. Pattern Recognit. 2013, 46, 566–577. [Google Scholar] [CrossRef] [Green Version]
- Tropp, J.A.; Gilbert, A.C. Signal recovery from random measurements via orthogonal matching pursuit. IEEE Trans. Inf. Theory 2007, 53, 4655–4666. [Google Scholar] [CrossRef]
- Chen, S.S.; Donoho, D.L.; Saunders, M.A. Atomic decomposition by basis pursuit. SIAM J. Sci. Comput. 1998, 20, 33–61. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Tucker, L.R. Some mathematical notes on three-mode factor analysis. Psychometrika 1966, 31, 279–311. [Google Scholar] [CrossRef] [PubMed]
- Fauvel, M.; Tarabalka, Y.; Benediktsson, J.A.; Chanussot, J.; Tilton, J.C. Advances in spectral-spatial classification of hyperspectral images. Proc. IEEE 2013, 101, 652–675. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indian Pines Data | University of Pavia Data | ||||||
|---|---|---|---|---|---|---|---|
| Class | Name | No.S | Class | Name | No.S | No. ATS | |
| 1 | alfalfa | 54 | 1 | asphalt | 6631 | 548 | |
| 2 | corn-no till | 1434 | 2 | meadows | 18,649 | 540 | |
| 3 | corn-min till | 834 | 3 | gravel | 2099 | 392 | |
| 4 | corn | 234 | 4 | trees | 3064 | 524 | |
| 5 | grass/pasture | 497 | 5 | metal sheets | 1345 | 265 | |
| 6 | grass/trees | 747 | 6 | bare soil | 5029 | 532 | |
| 7 | grass/pasture-mowed | 26 | 7 | bitumen | 1330 | 375 | |
| 8 | hay-windrowed | 489 | 8 | bricks | 3682 | 514 | |
| 9 | oats | 20 | 9 | shadows | 947 | 231 | |
| 10 | soybean-no till | 968 | |||||
| 11 | soybean-min till | 2468 | |||||
| 12 | soybean-clean till | 614 | |||||
| 13 | wheat | 212 | |||||
| 14 | woods | 1294 | |||||
| 15 | bldg-grass-tree-drives | 380 | |||||
| 16 | stone-steel towers | 95 | |||||
| Total | 10,366 | Total | 42,776 | 3921 | |||
| Class | SVM | SVMCK | CRC | SOMP | SADL | 3D-DWT | LTDA | cdSRC | pLSRC | tbSRC |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 41.18 | 64.71 | 0 | 77.12 | 76.47 | 80.39 | 81.05 | 88.24 | 89.41 | 98.04 |
| 2 | 72.98 | 83.70 | 67.11 | 91.09 | 90.49 | 88.03 | 84.90 | 86.12 | 91.42 | 88.91 |
| 3 | 55.43 | 85.98 | 9.57 | 80.72 | 92.05 | 89.90 | 91.58 | 81.31 | 80.12 | 88.13 |
| 4 | 40.99 | 59.46 | 0 | 81.68 | 73.20 | 62.16 | 82.88 | 77.03 | 85.77 | 77.03 |
| 5 | 87.29 | 90.25 | 61.12 | 86.86 | 98.62 | 91.10 | 91.17 | 97.46 | 85.25 | 90.89 |
| 6 | 89.28 | 99.15 | 96.64 | 98.68 | 96.76 | 97.18 | 97.09 | 98.45 | 98.11 | 95.63 |
| 7 | 79.17 | 95.83 | 0 | 52.78 | 100 | 91.67 | 97.22 | 91.67 | 79.17 | 83.33 |
| 8 | 98.49 | 98.92 | 99.93 | 100 | 100 | 97.84 | 98.92 | 98.92 | 100 | 97.84 |
| 9 | 27.78 | 44.44 | 0 | 5.56 | 97.22 | 77.78 | 98.15 | 83.33 | 12.22 | 88.89 |
| 10 | 69.31 | 86.07 | 2.50 | 74.79 | 88.90 | 89.99 | 89.52 | 90.53 | 78.17 | 87.38 |
| 11 | 80.03 | 92.36 | 94.47 | 94.45 | 90.03 | 92.11 | 90.63 | 91.72 | 94.64 | 97.31 |
| 12 | 60.03 | 77.36 | 17.93 | 85.65 | 86.62 | 84.39 | 79.41 | 83.02 | 85.01 | 89.88 |
| 13 | 94.53 | 99.50 | 99.25 | 98.34 | 98.51 | 95.52 | 98.18 | 99.50 | 99.30 | 93.53 |
| 14 | 95.69 | 98.13 | 99.43 | 99.08 | 97.60 | 98.54 | 98.35 | 97.56 | 99.54 | 98.94 |
| 15 | 32.41 | 88.64 | 20.36 | 93.91 | 80.61 | 86.43 | 86.70 | 70.36 | 73.46 | 96.40 |
| 16 | 50.00 | 84.44 | 90.19 | 78.89 | 87.78 | 54.44 | 65.19 | 94.44 | 90.89 | 93.33 |
| OA | 75.83 | 89.56 | 64.48 | 90.58 | 91.66 | 90.85 | 90.57 | 90.35 | 90.45 | 93.19 |
| (0.74) | (0.68) | (0.91) | (0.59) | (0.62) | (0.58) | (0.64) | (0.67) | (0.65) | (0.52) | |
| AA | 67.16 | 84.31 | 47.41 | 81.23 | 90.93 | 86.09 | 89.43 | 89.35 | 83.91 | 91.59 |
| (2.20) | (2.12) | (2.31) | (1.89) | (1.85) | (1.88) | (1.91) | (2.10) | (2.31) | (1.63) | |
| κ | 72.28 | 88.09 | 57.57 | 89.20 | 90.50 | 89.52 | 89.25 | 88.98 | 89.06 | 92.22 |
| (0.86) | (0.75) | (1.05) | (0.61) | (0.64) | (0.60) | (0.69) | (0.73) | (0.72) | (0.54) | |
| Time(s) | 5.07 | 13.56 | 6.58 | 188.04 | 30.76 | 32.54 | 15.51 | 231.93 | 32.56 | 261.25 |
| Class | SVM | SVMCK | CRC | SOMP | SADL | 3D-DWT | LTDA | cdSRC | pLSRC | tbSRC |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 70.49 | 76.36 | 53.89 | 37.66 | 87.18 | 83.93 | 87.80 | 75.22 | 80.35 | 89.12 |
| 2 | 66.26 | 73.87 | 75.26 | 57.10 | 88.00 | 88.31 | 82.82 | 85.59 | 86.56 | 86.99 |
| 3 | 58.07 | 71.67 | 27.00 | 48.32 | 68.26 | 52.67 | 58.40 | 73.00 | 71.79 | 77.08 |
| 4 | 95.02 | 93.82 | 88.02 | 95.98 | 97.99 | 95.67 | 99.45 | 94.27 | 86.23 | 94.16 |
| 5 | 97.66 | 99.19 | 99.91 | 99.55 | 99.77 | 99.01 | 98.83 | 99.28 | 99.82 | 99.10 |
| 6 | 74.50 | 81.22 | 60.65 | 78.17 | 70.30 | 82.20 | 84.32 | 91.27 | 96.22 | 89.85 |
| 7 | 87.77 | 85.12 | 71.46 | 19.37 | 86.44 | 88.99 | 91.85 | 93.37 | 90.93 | 91.85 |
| 8 | 83.53 | 92.90 | 21.94 | 27.29 | 88.91 | 96.94 | 95.51 | 88.76 | 94.03 | 94.08 |
| 9 | 99.87 | 99.03 | 9.69 | 71.82 | 99.94 | 97.99 | 99.62 | 99.62 | 55.60 | 99.62 |
| OA | 73.11 | 79.53 | 63.76 | 56.92 | 86.28 | 87.07 | 85.95 | 85.78 | 86.48 | 89.03 |
| (0.95) | (0.88) | (1.32) | (1.38) | (0.71) | (0.68) | (0.78) | (0.80) | (0.70) | (0.65) | |
| AA | 81.46 | 85.91 | 56.42 | 59.47 | 87.42 | 87.30 | 88.73 | 88.93 | 84.61 | 91.32 |
| (0.82) | (0.79) | (1.21) | (1.24) | (0.65) | (0.59) | (0.75) | (0.72) | (0.68) | (0.55) | |
| κ | 65.92 | 73.71 | 52.43 | 46.23 | 81.69 | 82.82 | 81.61 | 81.34 | 82.22 | 85.51 |
| (1.12) | (0.92) | (1.42) | (1.47) | (0.80) | (0.72) | (0.88) | (0.91) | (0.76) | (0.68) | |
| Time(s) | 6.42 | 25.61 | 46.58 | 303.42 | 77.66 | 51.61 | 25.14 | 501.73 | 80.54 | 541.23 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, Z.; Li, J.; Liu, L. Tensor Block-Sparsity Based Representation for Spectral-Spatial Hyperspectral Image Classification. Remote Sens. 2016, 8, 636. https://doi.org/10.3390/rs8080636
He Z, Li J, Liu L. Tensor Block-Sparsity Based Representation for Spectral-Spatial Hyperspectral Image Classification. Remote Sensing. 2016; 8(8):636. https://doi.org/10.3390/rs8080636
Chicago/Turabian StyleHe, Zhi, Jun Li, and Lin Liu. 2016. "Tensor Block-Sparsity Based Representation for Spectral-Spatial Hyperspectral Image Classification" Remote Sensing 8, no. 8: 636. https://doi.org/10.3390/rs8080636