
A Thin Plate Spline-Based Feature-Preserving Method for Reducing Elevation Points Derived from LiDAR


Abstract
:
1. Introduction
- the interpolation accuracy of TPS is comparative to that of MQ, yet the former is much faster than the latter by means of some advanced algorithms to solve the finite difference form of TPS. For example, the discrete cosine transform (DCT)-based TPS has the computational complexity of O (n log (n)) [33].
- hydrological features can be easily incorporated into DEMs by the available variant of TPS, i.e., ANUDEM. This leads to the hydrologically corrected DEMs.
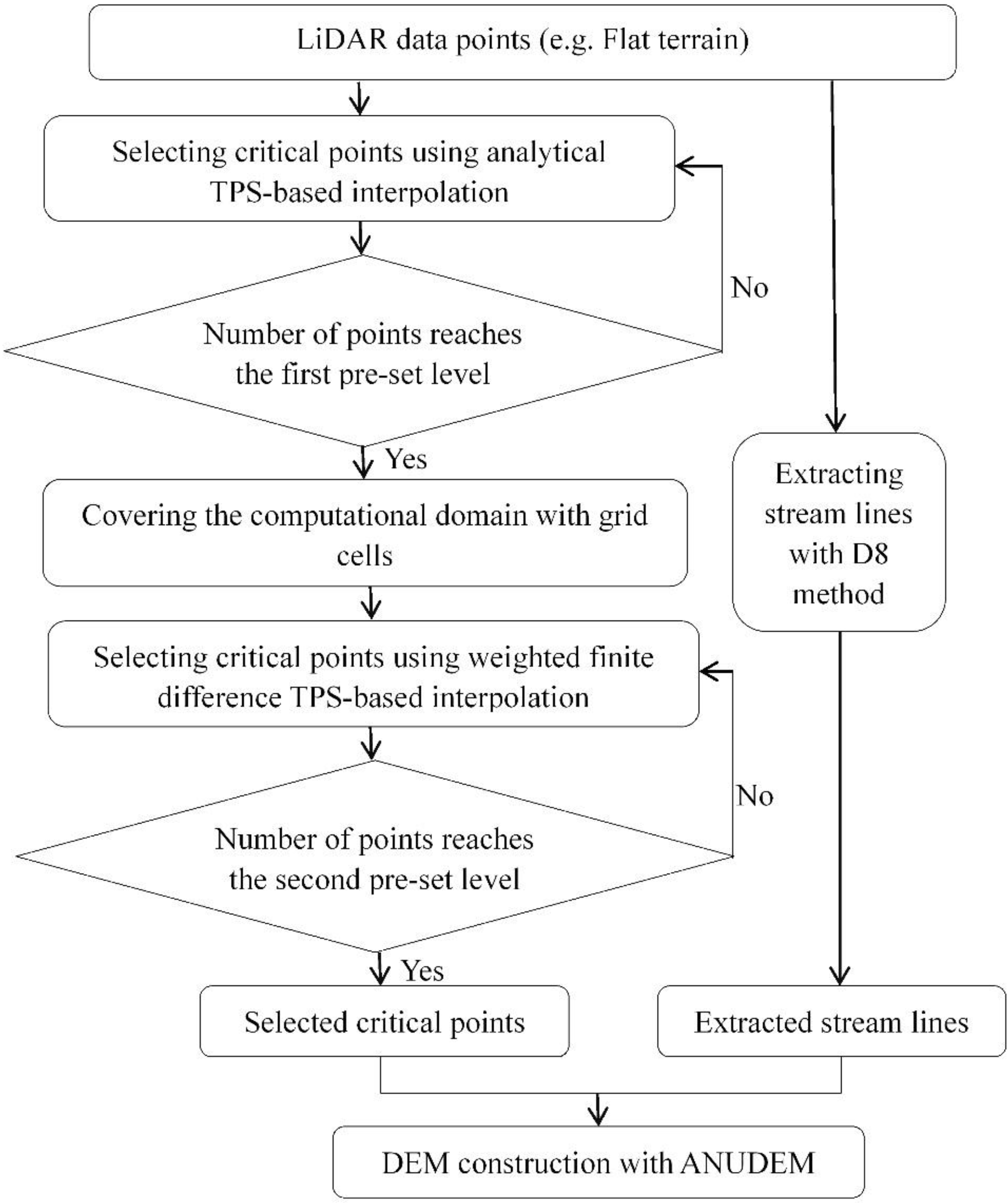
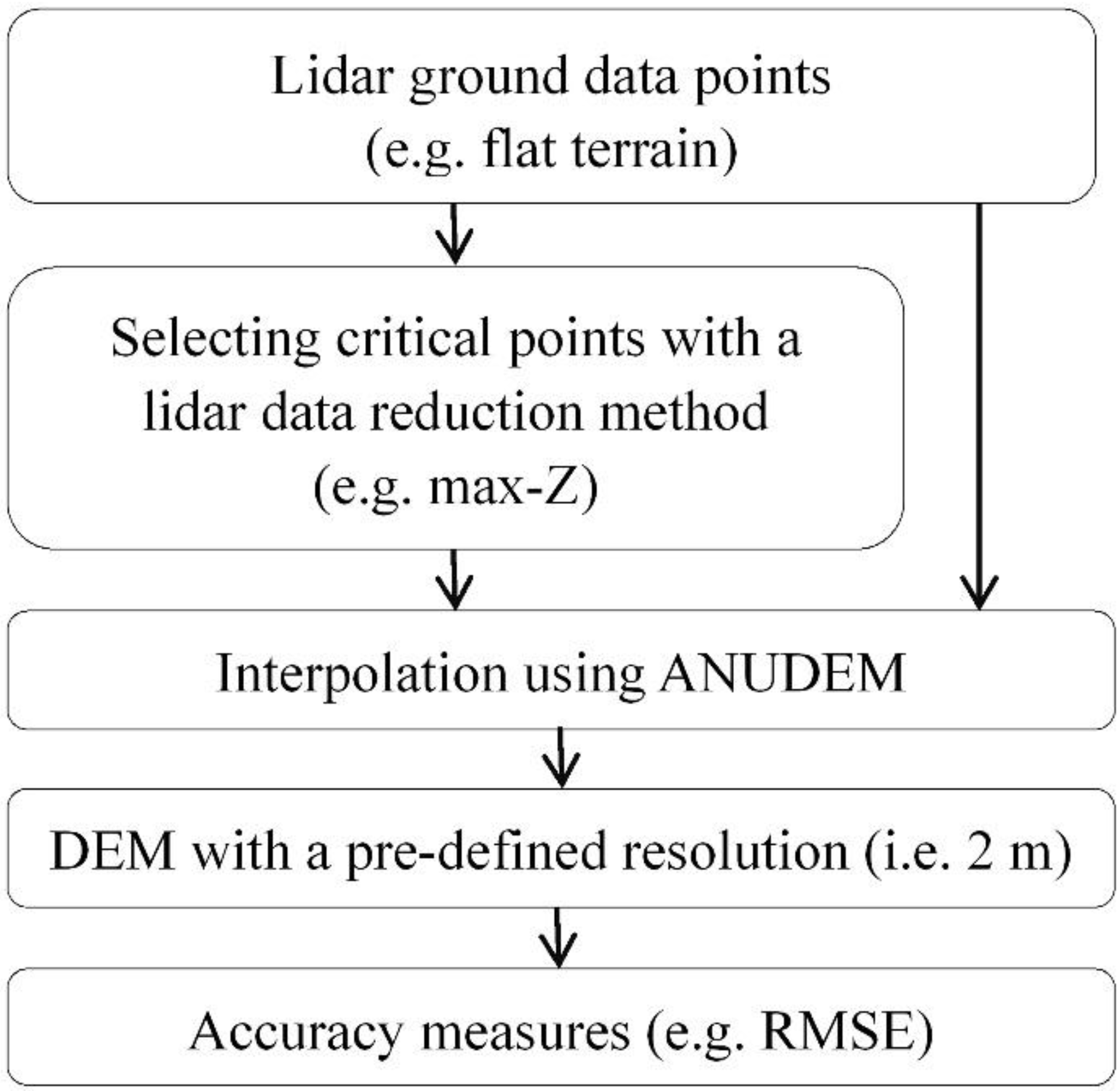
2. Proposed LiDAR Data Reduction Method
2.1. Thin Plate Spline (TPS)
2.2. Selecting Critical Points Based on TPS-Based Algorithms
- Initial critical point selection. In principle, all LiDAR points can be considered as candidates for the critical points. The two data points with the maximum and the minimum elevations are first selected, as they are the most probable to be terrain feature points. Thus, there are two groups of dataset, i.e., critical points and candidate points.
- Performing interpolation to all candidate points by the analytical TPS with the pre-selected critical points. The interpolation errors of all candidate points are computed.
- Selecting the critical point. Based on above explanation, the point with the largest interpolation error is more important than others. Thus, it is selected as the critical point.
- Repeating 2 and 3 until the number of selected points reaches a pre-determined threshold (e.g., 100).
- Covering the computational domain of the study site using the grid cells whose resolution is same to the DEM to be constructed.
- Assigning the values of the pre-selected critical points to the grid cells where they are located.
- Performing interpolation by the weighted finite difference TPS. Thus, the values of the unknown grids are estimated.
- Computing interpolation error of each candidate point. We first find the grid cell where the candidate point locates, and then compute the elevation difference between the point elevation and the corresponding grid cell value. By means of this scheme, the location difference between the sample points and the corresponding central points of DEM grids can be avoided [40].
- Selecting the critical point whose interpolation error is the largest.
- Assigning the value of the newly selected critical point to the grid cell where it is located.
- Repeating (7) and (10) until the total number of selected points reaches a pre-specified level or the largest interpolation error is smaller than a pre-defined tolerance.
2.3. Hydrologically Corrected DEM Construction
3. Materials and Results
3.1. Study Sites and LiDAR Data Collection






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Terrain Statistics | Flat | Undulating | Hilly | Mountainous |
|---|---|---|---|---|
| Minimum elevation (m) | 1405.8 | 3129.4 | 1003.2 | 3891.6 |
| Maximum elevation (m) | 1411.9 | 3384.2 | 1321.5 | 4214.4 |
| Mean elevation (m) | 1409.1 | 3241.8 | 1154.0 | 4048.8 |
| Standard deviation (m) | 1.23 | 55.2 | 67.57 | 74.34 |
| Mean slope (°) | 2.993 | 30.31 | 38.87 | 54.04 |
| Terrain roughness | 1.002 | 1.205 | 1.309 | 2.9469 |
| Number of ground points | 647,516 | 235,765 | 100,204 | 250,736 |
| Point post-spacing (m) | 1.3 | 1.6 | 1.9 | 1.2 |
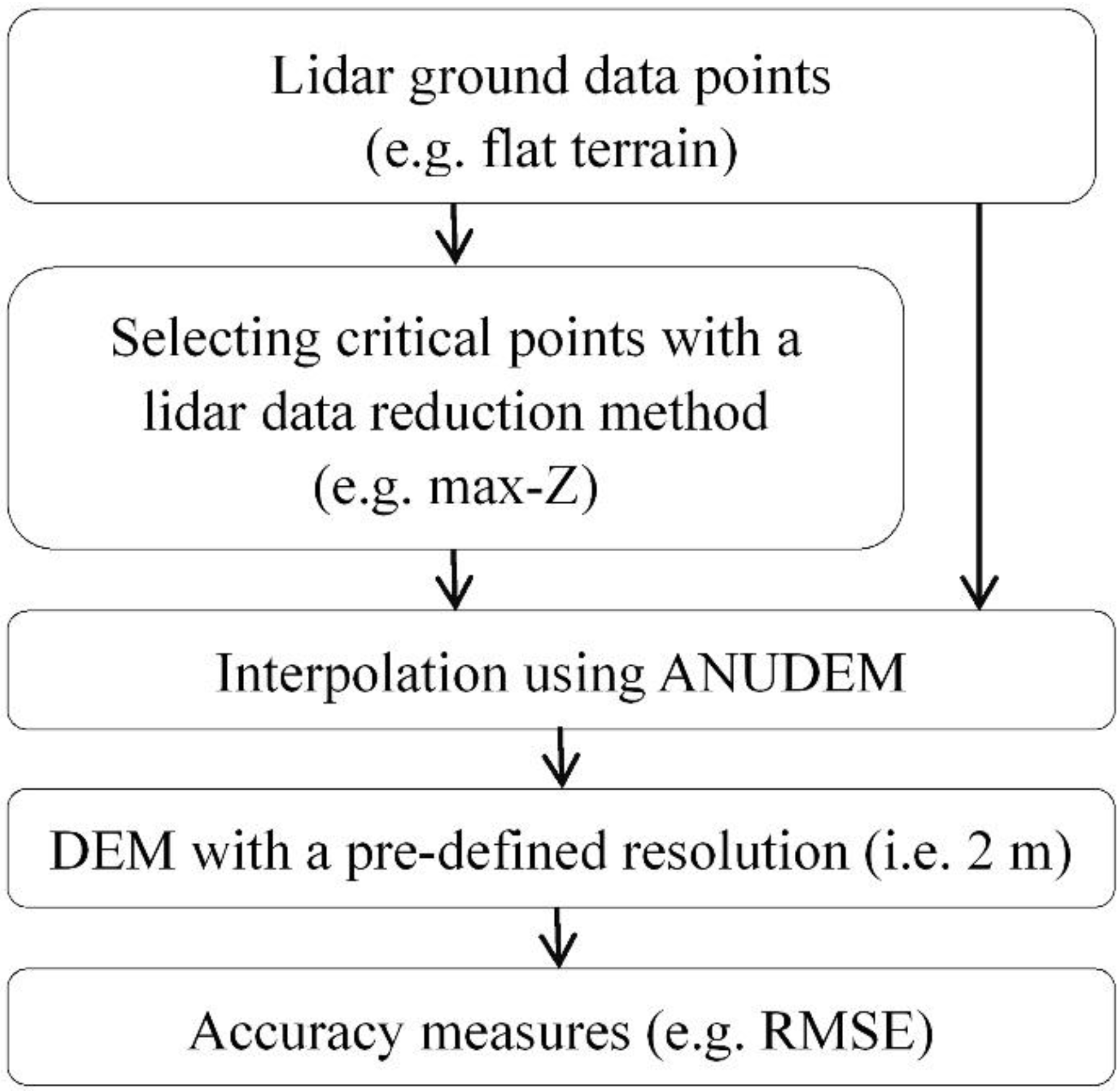
3.2. Accuracy Measures
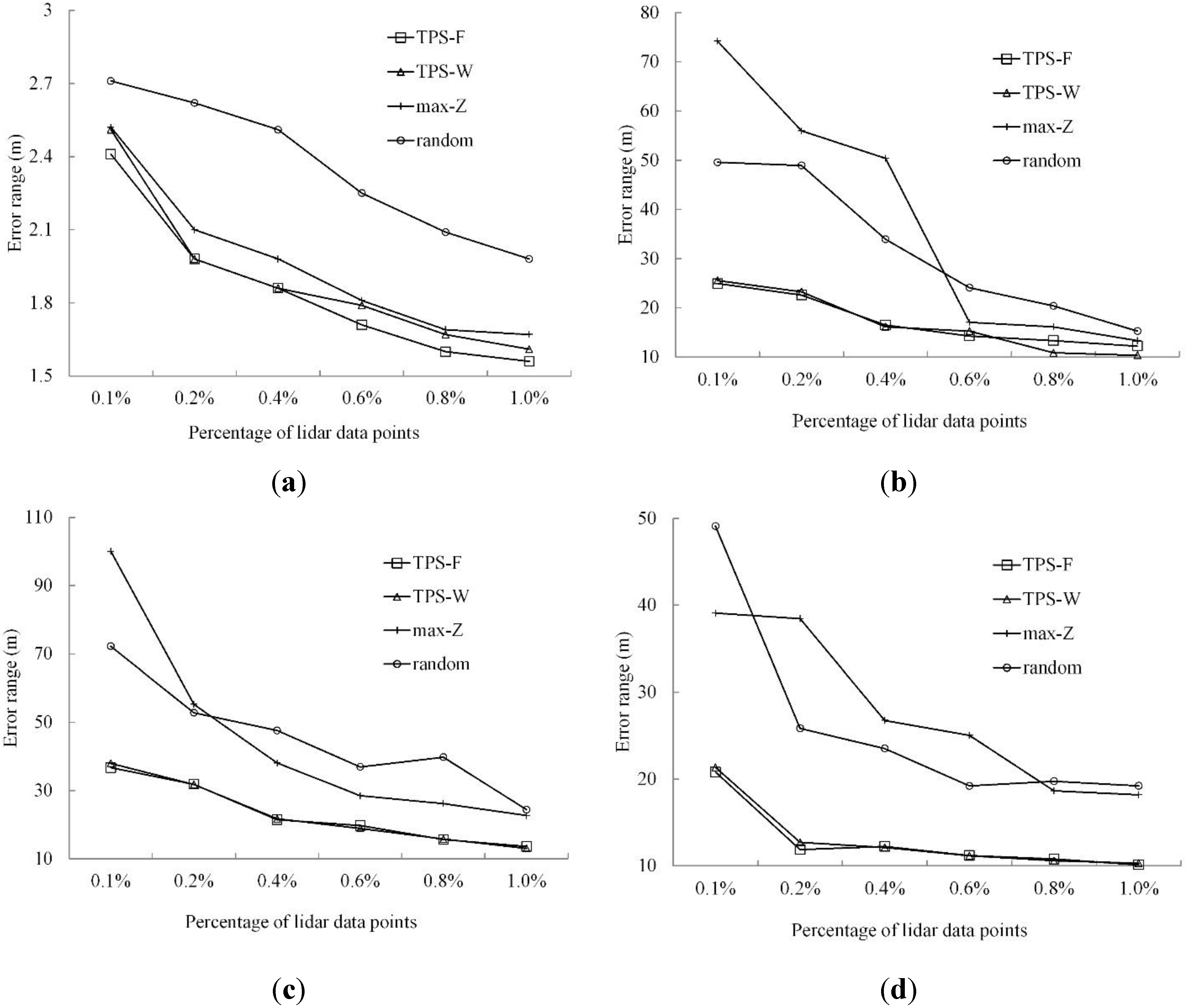
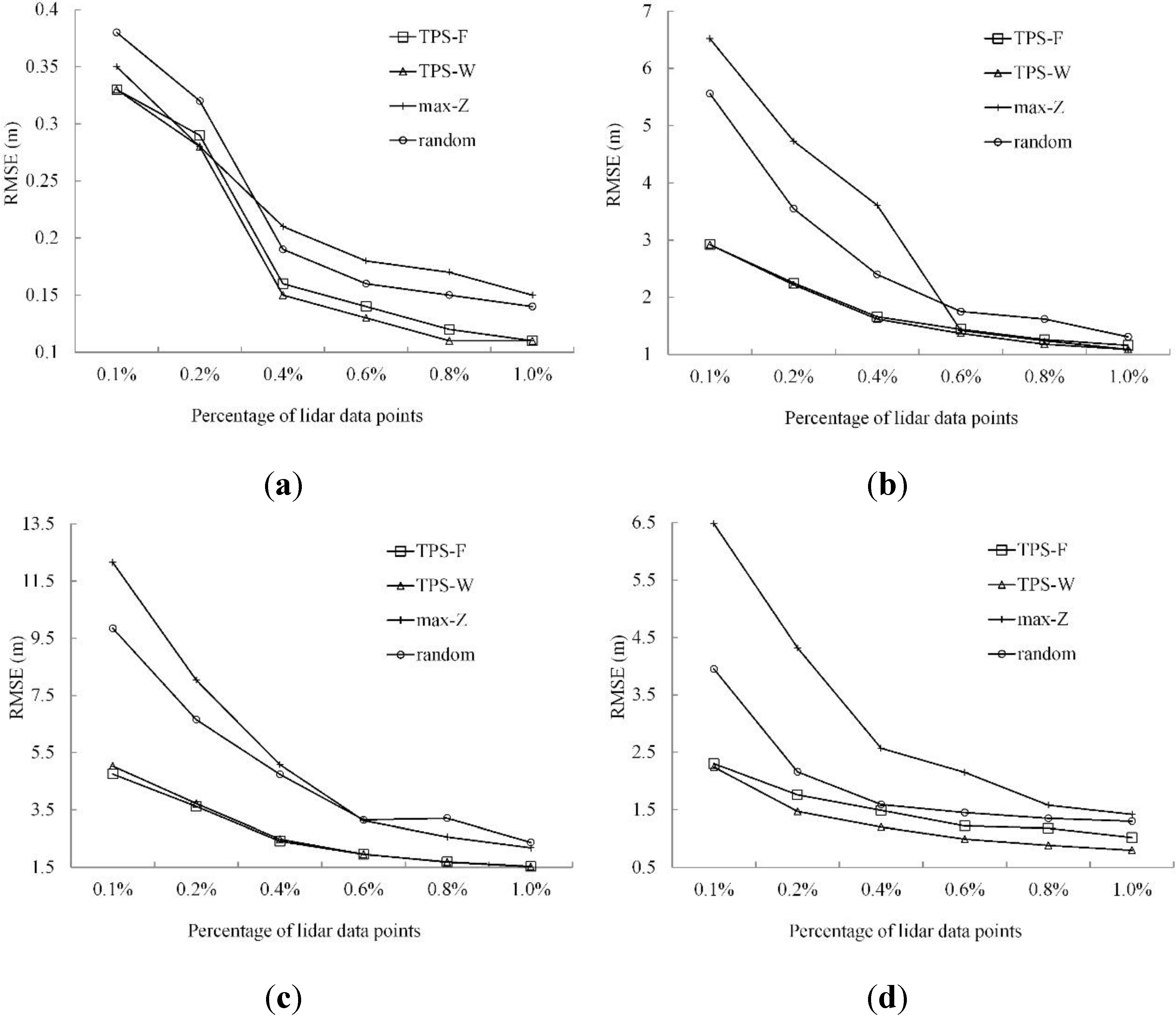
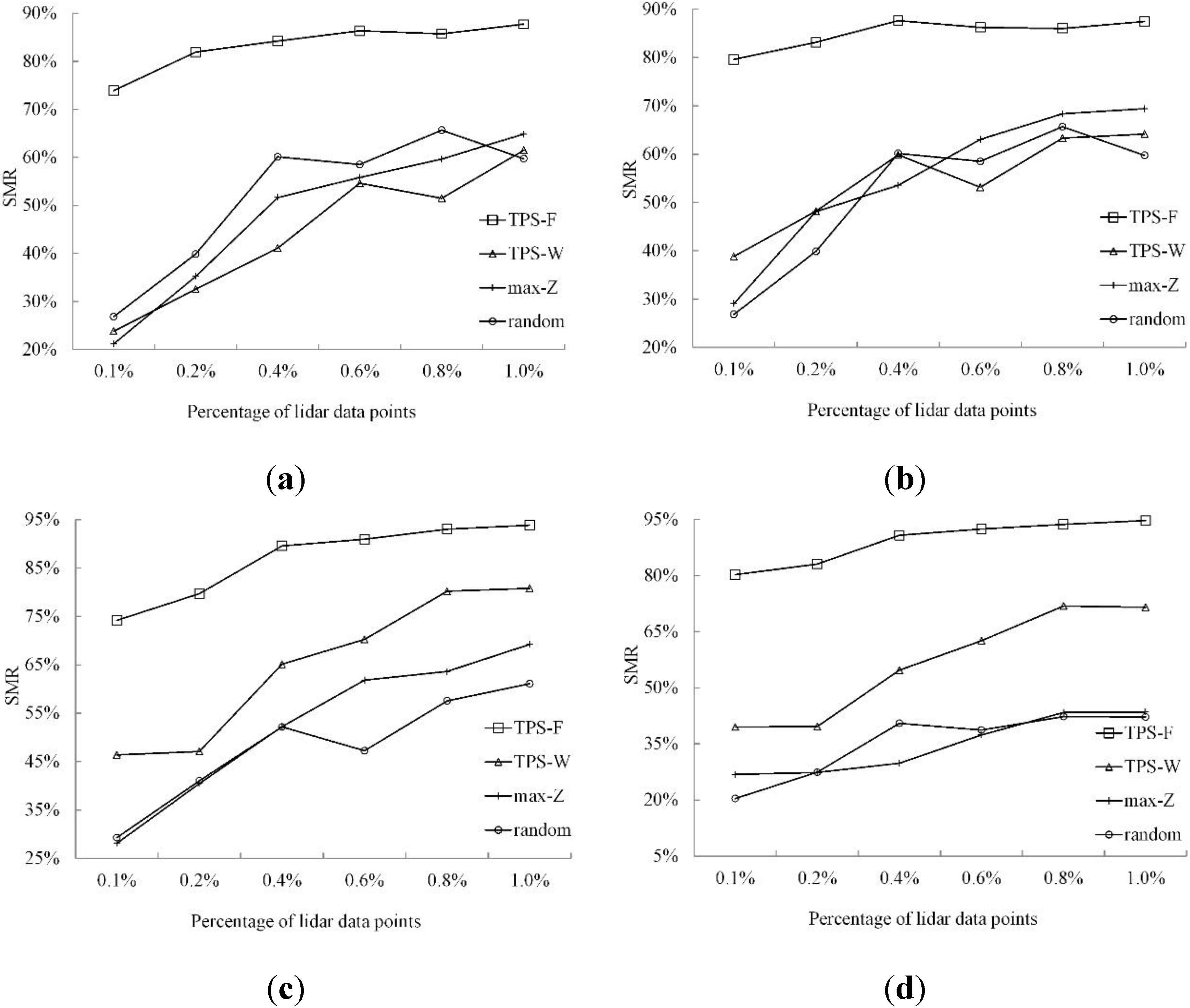
3.3. Results
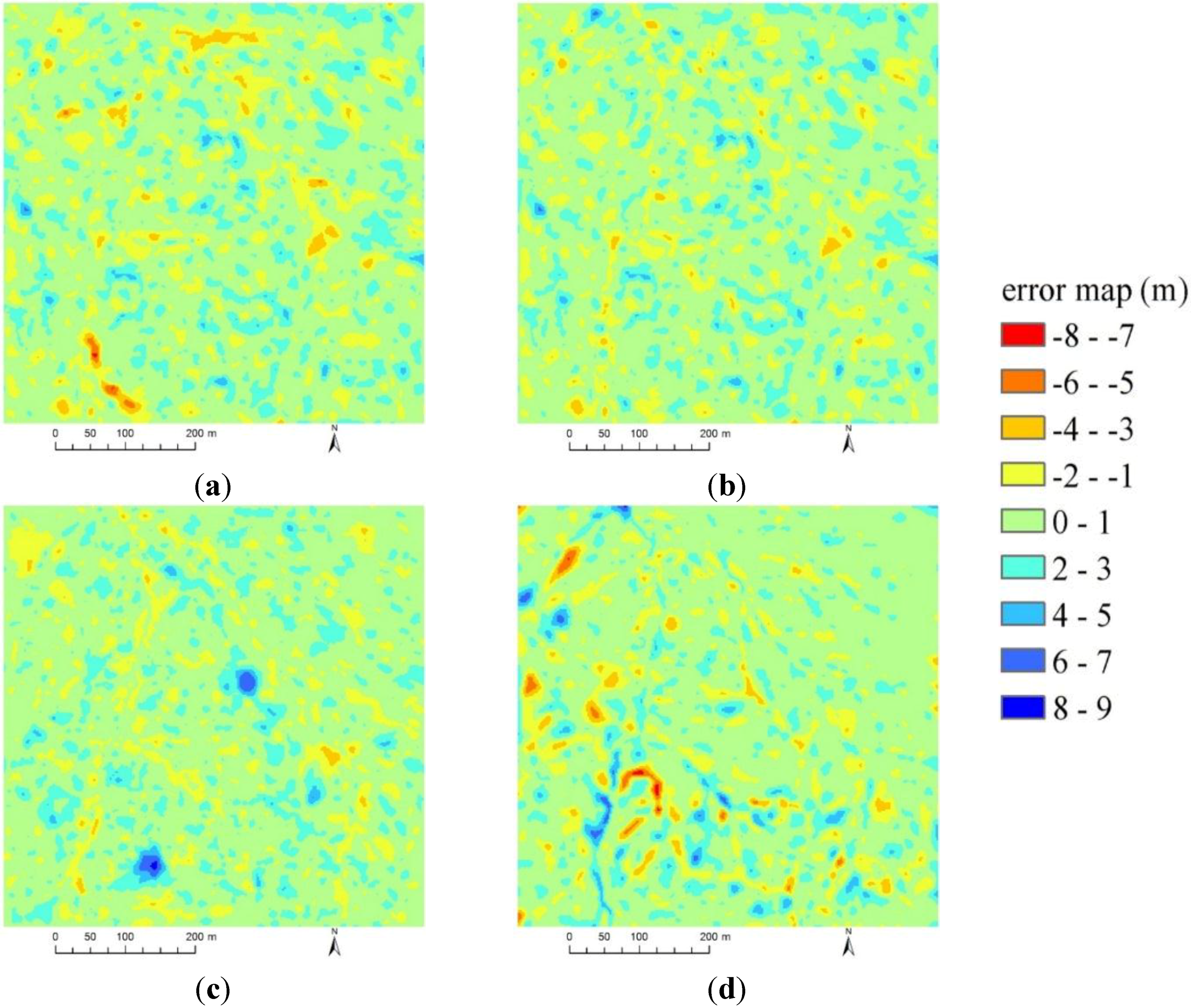
3.3.1. Qualitative Analysis




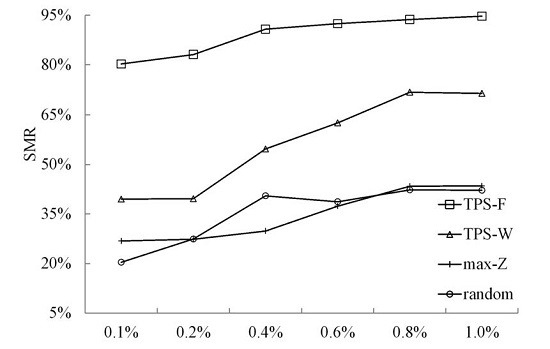
3.3.2. Quantitative Analysis
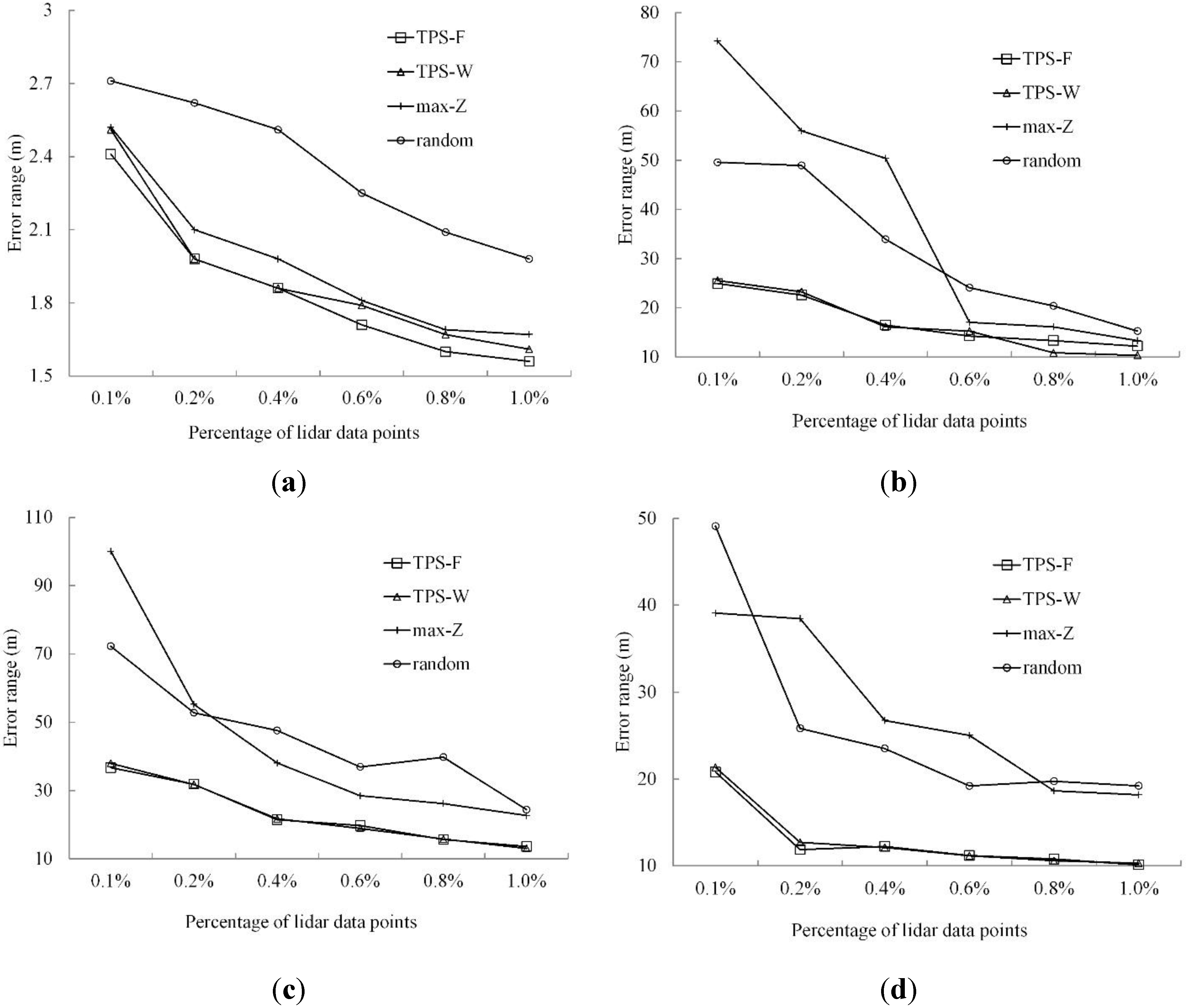
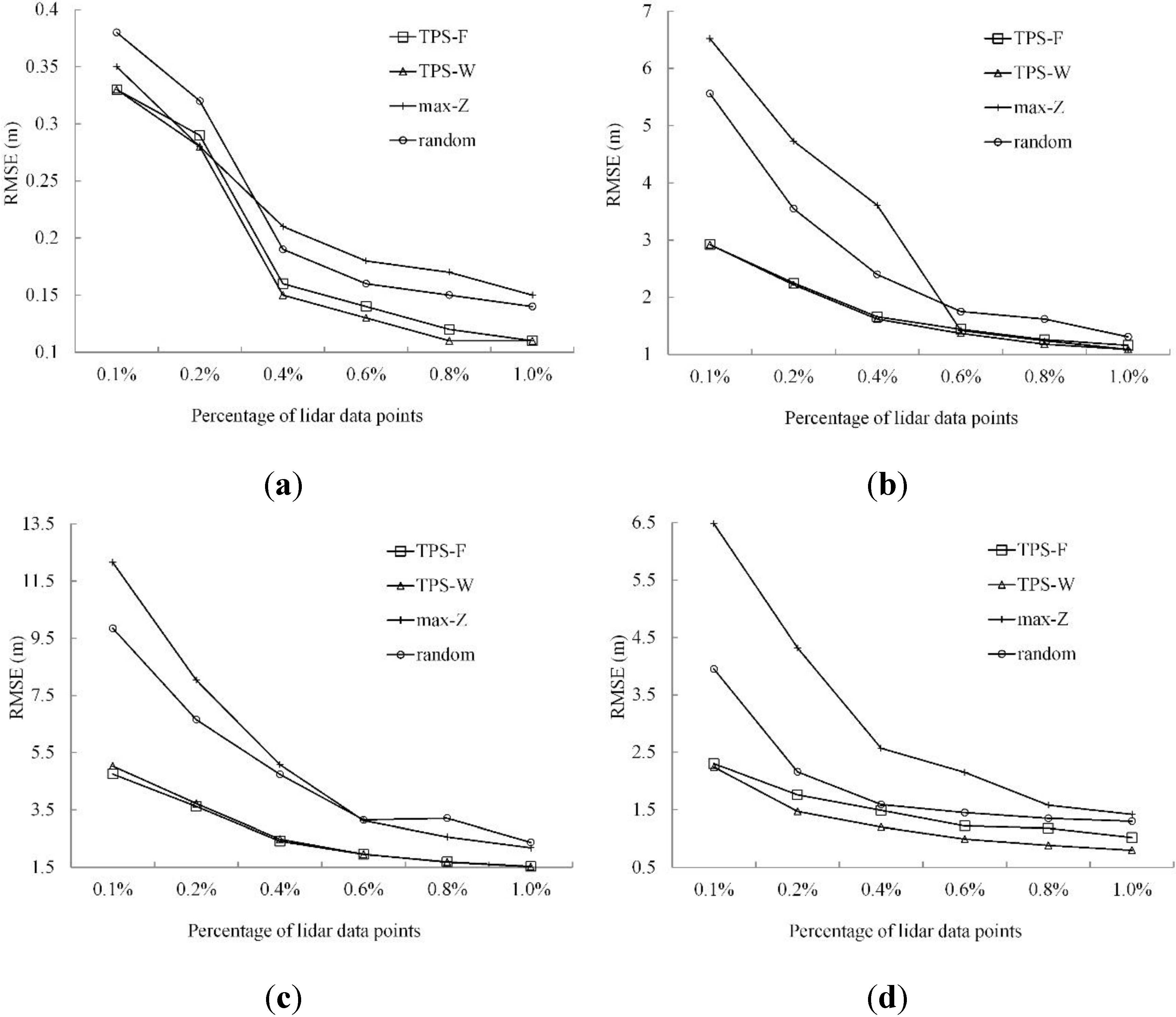
| Terrain Morphology | Percentage of LiDAR Data Points | Method | |||
|---|---|---|---|---|---|
| TPS-F | TPS-W | Max-Z | Random | ||
| Flat | 0.1% | 2.21 | 2.13 | 1.88 | 1.08 |
| 0.2% | 2.45 | 2.42 | 2.11 | 1.27 | |
| 0.4% | 2.66 | 2.71 | 2.43 | 1.44 | |
| 0.6% | 2.76 | 2.84 | 2.54 | 1.53 | |
| 0.8% | 2.84 | 2.85 | 2.61 | 1.62 | |
| 1.0% | 2.86 | 2.89 | 2.62 | 1.64 | |
| On average | 2.63 | 2.64 | 2.36 | 1.43 | |
| sUndulating | 0.1% | 29.74 | 29.18 | 26.70 | 26.38 |
| 0.2% | 29.93 | 29.37 | 27.63 | 27.25 | |
| 0.4% | 30.14 | 29.74 | 28.39 | 28.04 | |
| 0.6% | 30.36 | 30.05 | 29.97 | 28.36 | |
| 0.8% | 30.42 | 30.27 | 30.06 | 28.53 | |
| 1.0% | 30.51 | 30.39 | 30.16 | 28.72 | |
| On average | 30.18 | 29.84 | 28.82 | 27.88 | |
| Hilly | 0.1% | 36.52 | 35.54 | 33.09 | 31.33 |
| 0.2% | 37.93 | 37.19 | 35.45 | 33.02 | |
| 0.4% | 38.31 | 37.66 | 36.64 | 34.64 | |
| 0.6% | 38.61 | 38.17 | 37.11 | 35.59 | |
| 0.8% | 38.75 | 38.37 | 37.41 | 35.86 | |
| 1.0% | 38.78 | 38.44 | 37.77 | 36.50 | |
| On average | 38.15 | 37.56 | 36.24 | 34.49 | |
| Mountainous | 0.1% | 34.03 | 33.13 | 33.89 | 33.27 |
| 0.2% | 34.44 | 34.40 | 34.07 | 33.35 | |
| 0.4% | 34.91 | 34.61 | 34.35 | 33.99 | |
| 0.6% | 35.02 | 34.74 | 34.43 | 33.94 | |
| 0.8% | 35.07 | 34.78 | 34.49 | 34.09 | |
| 1.0% | 35.32 | 34.81 | 34.53 | 34.20 | |
| On average | 34.80 | 34.41 | 34.29 | 33.81 | |
| Terrain Morphology | Percentage of LiDAR Data Points | Method | |||
|---|---|---|---|---|---|
| TPS-F | TPS-W | Max-Z | Random | ||
| Flat | 0.1% | 1.0012 | 1.0011 | 1.0009 | 1.0003 |
| 0.2% | 1.0015 | 1.0014 | 1.0011 | 1.0003 | |
| 0.4% | 1.0018 | 1.0018 | 1.0015 | 1.0005 | |
| 0.6% | 1.0019 | 1.0020 | 1.0016 | 1.0005 | |
| 0.8% | 1.0020 | 1.0020 | 1.0017 | 1.0006 | |
| 1.0% | 1.0020 | 1.0020 | 1.0017 | 1.0006 | |
| On average | 1.0017 | 1.0017 | 1.0014 | 1.0005 | |
| Undulating | 0.1% | 1.1950 | 1.1889 | 1.1434 | 1.1416 |
| 0.2% | 1.2002 | 1.1949 | 1.1584 | 1.1528 | |
| 0.4% | 1.2042 | 1.2013 | 1.1688 | 1.1640 | |
| 0.6% | 1.2067 | 1.2042 | 1.2030 | 1.1710 | |
| 0.8% | 1.2073 | 1.2061 | 1.2049 | 1.1726 | |
| 1.0% | 1.2079 | 1.2076 | 1.2057 | 1.1767 | |
| On average | 1.2036 | 1.2005 | 1.1807 | 1.1631 | |
| Hilly | 0.1% | 1.2722 | 1.2588 | 1.2227 | 1.1931 |
| 0.2% | 1.2973 | 1.2857 | 1.2587 | 1.2172 | |
| 0.4% | 1.3029 | 1.2932 | 1.2734 | 1.2381 | |
| 0.6% | 1.3086 | 1.3022 | 1.2810 | 1.2540 | |
| 0.8% | 1.3106 | 1.3051 | 1.2848 | 1.2567 | |
| 1.0% | 1.3108 | 1.3061 | 1.2910 | 1.2662 | |
| On average | 1.3004 | 1.2919 | 1.2686 | 1.2376 | |
| Mountainous | 0.1% | 1.2282 | 1.2128 | 1.2262 | 1.2106 |
| 0.2% | 1.2338 | 1.2332 | 1.2295 | 1.2133 | |
| 0.4% | 1.2452 | 1.2388 | 1.2304 | 1.2220 | |
| 0.6% | 1.2481 | 1.2410 | 1.2307 | 1.2213 | |
| 0.8% | 1.2495 | 1.2416 | 1.2309 | 1.2238 | |
| 1.0% | 1.2552 | 1.2417 | 1.2311 | 1.2255 | |
| On average | 1.2433 | 1.2349 | 1.2298 | 1.2194 | |
| Terrain Morphology | ANUDEM | TIN | IDW | Kriging | MC |
|---|---|---|---|---|---|
| Flat | 0.11 | 0.14 | 0.15 | 0.24 | 0.23 |
| Undulating | 1.09 | 1.13 | 3.16 | 1.26 | 4.11 |
| Hilly | 1.52 | 1.55 | 5.62 | 3.62 | 6.67 |
| Mountainous | 0.80 | 0.87 | 2.52 | 1.22 | 10.36 |
| On average | 0.88 | 0.92 | 2.86 | 1.59 | 5.34 |
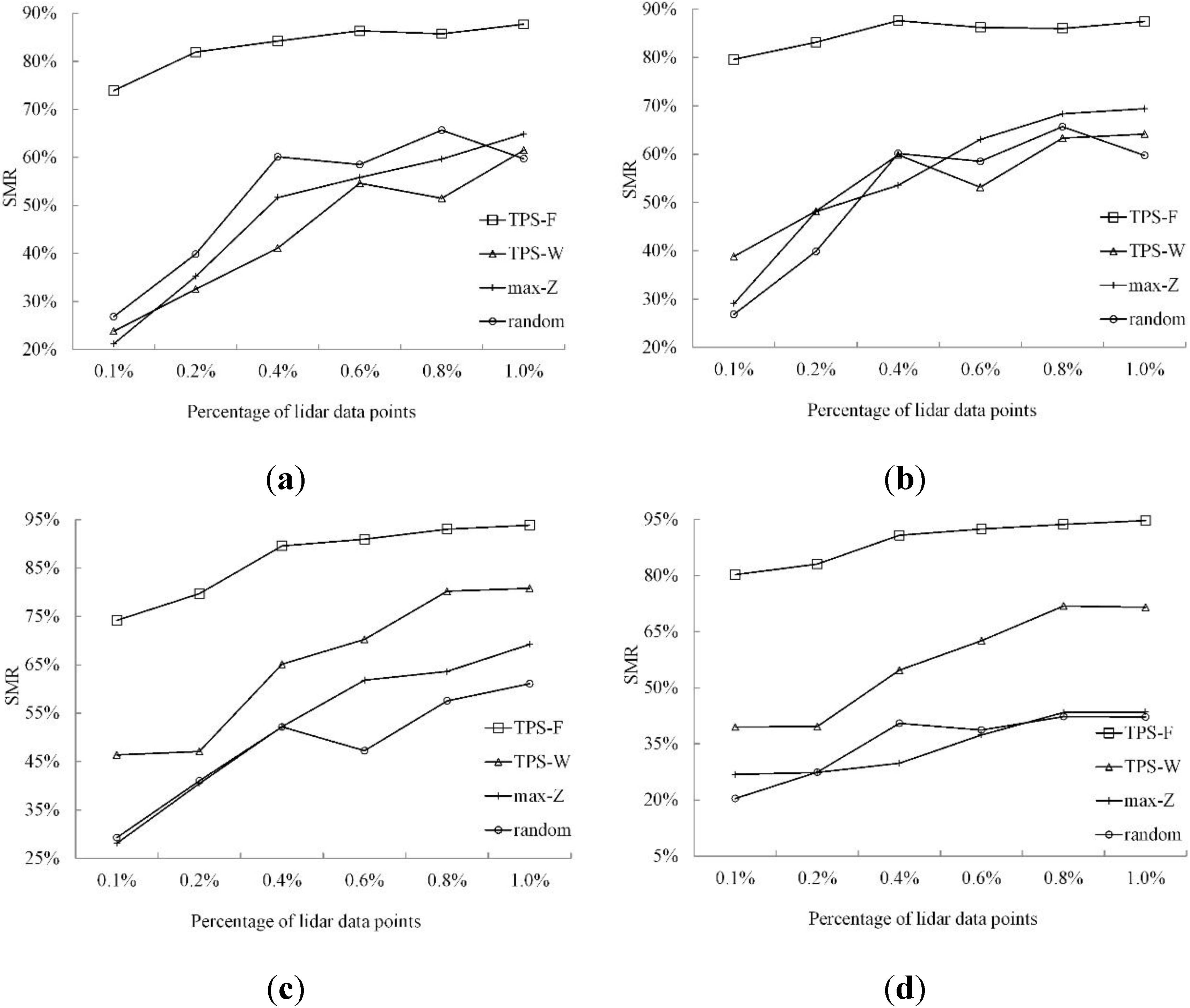
4. Discussion
- Purpose and available LiDAR data. The purpose of PF is to filter the raw LiDAR data including ground and non-ground points and to obtain a DEM. Our purpose is to reduce the huge amount of LiDAR-derived ground points to solve the serious time and memory consumption problems in the context of DEM construction.
- Ground seed selection. The PF method selects ground seeds by a local minimum method. Thus, there are many initial seeds including ground and non-ground points. Yet, there are only two ground seeds in our method. Namely, the points with the maximum and minimum elevations.
- DEM resolution. The PF method uses three levels of DEMs with the resolutions from fine to coarse. Yet, in the first step, our method performs interpolations to each candidate with the pre-selected ground points without using grid cells. In the second step, our method only use one level of grid cells with the resolution same to the resultant DEM.
- TPS computation. The PF method only uses a local analytical TPS to perform interpolations. Yet, our method respectively employs the analytical and finite difference TPSs to perform interpolations in the process of critical point selection and uses the ANUDEM to incorporate feature lines into DEMs. Moreover, all the three versions of TPS are used in a global form.
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Hladik, C.; Alber, M. Accuracy assessment and correction of a lidar-derived salt marsh digital elevation model. Remote Sens. Environ. 2012, 121, 224–235. [Google Scholar] [CrossRef]
- Ackermann, F. Airborne laser scanning—present status and future expectations. ISPRS J. Photogramm. Remote Sens. 1999, 54, 64–67. [Google Scholar] [CrossRef]
- Wehr, A.; Lohr, U. Airborne laser scanning—An introduction and overview. ISPRS J. Photogramm. Remote Sens. 1999, 54, 68–82. [Google Scholar] [CrossRef]
- Milan, D.J.; Heritage, G.L.; Large, A.R.G.; Fuller, I.C. Filtering spatial error from DEMs: Implications for morphological change estimation. Geomorphology 2011, 125, 160–171. [Google Scholar] [CrossRef]
- Vo, A.-V.; Truong-Hong, L.; Laefer, D.F.; Bertolotto, M. Octree-based region growing for point cloud segmentation. ISPRS J. Photogramm. Remote Sens. 2015, 104, 88–100. [Google Scholar] [CrossRef]
- Anderson, E.S.; Thompson, J.A.; Crouse, D.A.; Austin, R.E. Horizontal resolution and data density effects on remotely sensed LiDAR-based DEM. Geoderma 2006, 132, 406–415. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, Z. Effects of LiDAR data reduction and breaklines on the accuracy of digital elevation model. Surv. Rev. 2011, 43, 614–628. [Google Scholar] [CrossRef]
- Meng, Q.; Borders, B.; Madden, M. High-resolution satellite image fusion using regression kriging. Int. J. Remote Sens. 2010, 31, 1857–1876. [Google Scholar] [CrossRef]
- Makarovic, B. From progressive to composite sampling for digital terrain models. Geo-Processing 1979, 1, 145–166. [Google Scholar]
- Makarovic, B. Progressive sampling for digital terrain models. ITC J. 1973, 3, 397–416. [Google Scholar]
- Lee, J. Comparison of existing methods for building triangular irregular network, models of terrain from grid digital elevation models. Int. J. Geogr. Inf. Sci. 1991, 5, 267–285. [Google Scholar] [CrossRef]
- Heller, M. Triangulation algorithms for adaptive terrain modelling. In Proceedings of the 4th International Symposium on Spatial Data Handling, Zürich, Switzerland, 23–27 July 1990; pp. 163–174.
- Weibel, R. Models and experiments for adaptive computer-assisted terrain generalization. Cartogr. Geogr. Inf. Sci. 1992, 19, 133–153. [Google Scholar] [CrossRef]
- Heritage, G.L.; Milan, D.J.; Large, A.R.G.; Fuller, I.C. Influence of survey strategy and interpolation model on dem quality. Geomorphology 2009, 112, 334–344. [Google Scholar] [CrossRef]
- Ai, T. The drainage network extraction from contour lines for contour line generalization. ISPRS J. Photogramm. Remote Sens. 2007, 62, 93–103. [Google Scholar] [CrossRef]
- Garland, M.; Heckbert, P.S. Surface Simplification Using Quadric Error Metrics; Technical Report for School of Computer Science; Carnegie Mellon University: Pittsburgh, PA, USA, 1997. [Google Scholar]
- Heckbert, P.S.; Garland, M. Survey of Polygonal Surface Simplification Algorithms; Technical Report for School of Computer Science; Carnegie Mellon University: Pittsburgh, PA, USA, 1997. [Google Scholar]
- Cignoni, P.; Montani, C.; Scopigno, R. A comparison of mesh simplification algorithms. Comput. Graph. 1998, 22, 37–54. [Google Scholar] [CrossRef]
- Chang, K.-T. Introduction to Geographic Information Systems; McGraw-Hill Science: New York, NY, USA, 2010. [Google Scholar]
- De Floriani, L.; Falcidieno, B.; Nagy, G.; Pienovi, C. A hierarchical structure for surface approximation. Comput. Graph. 1984, 8, 183–193. [Google Scholar] [CrossRef]
- Zhou, Q.M.; Chen, Y.M. Generalization of dem for terrain analysis using a compound method. ISPRS J. Photogramm. Remote Sens. 2011, 66, 38–45. [Google Scholar] [CrossRef]
- Schroeder, W.J.; Zarge, J.A.; Lorensen, W.E. Decimation of triangle meshes. Comput. Graph. 1992, 26, 65–70. [Google Scholar] [CrossRef]
- Schroder, F.; Roßbach, P. Managing the complexity of digital terrain models. Comput. Graph. 1994, 18, 775–783. [Google Scholar] [CrossRef]
- Ciampalini, A.; Cignoni, P.; Montani, C.; Scopigno, R. Multiresolution decimation based on global error. Vis. Comput. 1997, 13, 228–246. [Google Scholar] [CrossRef]
- Chen, C.F.; Yan, C.Q.; Cao, X.W.; Guo, J.Y.; Dai, H.L. A greedy-based multiquadric method for LiDAR-derived ground data reduction. ISPRS J. Photogramm. Remote Sens. 2015, 102, 110–121. [Google Scholar] [CrossRef]
- Lichtenstein, A.; Doytsher, Y. Geospatial aspects of merging DTM with breaklines. In Proceedings of the FIG Working Week, Athens, Greece, 22–27 May 2004; pp. 1–15.
- Zakšek, K.; Podobnikar, T. An effective DEM generalization with basic GIS operations. In Proceedings of the 8th ICA Workshop on Generalization and Multiple Representation, A Coruńa, Spain, 7–8 July 2005.
- Hutchinson, M.F. A new procedure for gridding elevation and stream line data with automatic removal of spurious pits. J. Hydrol. 1989, 106, 211–232. [Google Scholar] [CrossRef]
- Callow, J.N.; Van Niel, K.P.; Boggs, G.S. How does modifying a dem to reflect known hydrology affect subsequent terrain analysis? J. Hydrol. 2007, 332, 30–39. [Google Scholar] [CrossRef]
- Wheaton, J.M.; Brasington, J.; Darby, S.E.; Sear, D.A. Accounting for uncertainty in dems from repeat topographic surveys: Improved sediment budgets. Earth Surf. Proc. Land 2010, 35, 136–156. [Google Scholar] [CrossRef]
- Li, X.; Chen, Y.; Liu, X.; Li, D.; He, J. Concepts, methodologies, and tools of an integrated geographical simulation and optimization system. Int. J. Geogr. Inf. Sci. 2010, 25, 633–655. [Google Scholar] [CrossRef]
- Chen, Y.M.; Zhou, Q.M. A scale-adaptive dem for multi-scale terrain analysis. Int. J. Geogr. Inf. Sci. 2013, 27, 1329–1348. [Google Scholar] [CrossRef]
- Garcia, D. Robust smoothing of gridded data in one and higher dimensions with missing values. Comput. Stat.Data Anal. 2010, 54, 1167–1178. [Google Scholar] [CrossRef] [PubMed]
- Wise, S. Assessing the quality for hydrological applications of digital elevation models derived from contours. Hydrol. Process. 2000, 14, 1909–1929. [Google Scholar] [CrossRef]
- Murphy, P.N.C.; Ogilvie, J.; Meng, F.-R.; Arp, P. Stream network modelling using LiDAR and photogrammetric digital elevation models: A comparison and field verification. Hydrol. Process. 2008, 22, 1747–1754. [Google Scholar] [CrossRef]
- Eilers, P.H.C. A perfect smoother. Anal. Chem. 2003, 75, 3631–3636. [Google Scholar] [CrossRef] [PubMed]
- Billings, S.D.; Newsam, G.N.; Beatson, R.K. Smooth fitting of geophysical data using continuous global surfaces. Geophysics 2002, 67, 1823–1834. [Google Scholar] [CrossRef]
- Wahba, G. Spline Models for Observational Data; SIAM: Philadelphia, PA, USA, 1990. [Google Scholar]
- Hofierka, J.; Cebecauer, T.; Šúri, M. Optimisation of interpolation parameters using cross-validation. In Digital Terrain Modelling; Peckham, R.J., Jordan, G., Eds.; Springer: New York, NY, USA, 2007; pp. 67–82. [Google Scholar]
- Yue, T.X.; Du, Z.P.; Song, D.J. A new method of surface modelling and its application to DEM construction. Geomorphology 2007, 91, 161–172. [Google Scholar] [CrossRef]
- Hutchinson, M.F.; Xu, T.; Stein, J.A. Recent progress in the ANUDEM elevation gridding procedure. In Procceedings of the Geomorphometry 2011, Redlands, CA, USA; Available online: http://geomorphometry.org/HutchinsonXu2011 (accessed on 12 July 2015).
- Mark, D.M. Automated detection of drainage networks from digital elevation models. Cartographica 1984, 21, 168–178. [Google Scholar] [CrossRef]
- Li, X.; Cheng, G.; Liu, S.; Xiao, Q.; Ma, M.; Jin, R.; Che, T.; Liu, Q.; Wang, W.; Qi, Y.; et al. Heihe watershed allied telemetry experimental research (hiwater): Scientific objectives and experimental design. Bull. Am. Meteorol. Soc. 2013, 94, 1145–1160. [Google Scholar] [CrossRef]
- Li, Z.L. Mathematical models of the accuracy of digital terrain model surfaces linearly constructed from square gridded data. Photogramm. Rec. 1993, 14, 661–674. [Google Scholar] [CrossRef]
- Gao, J. Resolution and accuracy of terrain representation by grid DEMs at a micro-scale. Int. J. Geogr. Inf. Sci. 1997, 11, 199–212. [Google Scholar] [CrossRef]
- Aguilar, F.J.; Aguera, F.; Aguilar, M.A.; Carvajal, F. Effects of terrain morphology, sampling density, and interpolation methods on grid DEM accuracy. Photogramm. Eng. Remote Sens. 2005, 71, 805–816. [Google Scholar] [CrossRef]
- Chu, H.-J.; Wang, C.-K.; Huang, M.-L.; Lee, C.-C.; Liu, C.-Y.; Lin, C.-C. Effect of point density and interpolation of LiDAR-derived high-resolution DEMs on landscape scarp identification. GISci. Remote Sens. 2014, 51, 731–747. [Google Scholar] [CrossRef]
- Kraus, K.; Karel, W.; Briese, C.; Mandlburger, G. Local accuracy measures for digital terrain models. Photogramm. Rec. 2006, 21, 342–354. [Google Scholar] [CrossRef]
- Kraus, K.; Pfeifer, N. Determination of terrain models in wooded areas with airborne laser scanner data. ISPRS J. Photogramm. Remote Sens. 1998, 53, 193–203. [Google Scholar] [CrossRef]
- Axelsson, P. DEM generation from laser scanner data using adaptive tin models. Int. Arch. Photogramm. Remote Sens. 2000, 33, 111–118. [Google Scholar]
- Haugerud, R.; Harding, D. Some algorithms for virtual deforestation (VDF) of LiDAR topographic survey data. Int. Arch. Photogramm. Remote Sens. 2001, 34, 211–218. [Google Scholar]
- Evans, J.S.; Hudak, A.T. A multiscale curvature algorithm for classifying discrete return LiDAR in forested environments. IEEE Trans. Geosci. Remote Sens. 2007, 45, 1029–1038. [Google Scholar] [CrossRef]
- Mongus, D.; Žalik, B. Parameter-free ground filtering of LiDAR data for automatic DTM generation. ISPRS J. Photogramm. Remote Sens. 2012, 67, 1–12. [Google Scholar] [CrossRef]
- Roberts, S.; Hegland, M.; Altas, I. Approximation of a thin plate spline smoother using continuous piecewise polynomial functions. SIAM J. Numer. Anal. 2003, 41, 208–234. [Google Scholar] [CrossRef]
- Chaplot, V.; Darboux, F.; Bourennane, H.; Leguédois, S.; Silvera, N.; Phachomphon, K. Accuracy of interpolation techniques for the derivation of digital elevation models in relation to landform types and data density. Geomorphology 2006, 77, 126–141. [Google Scholar] [CrossRef]
- Fuller, I.C.; Large, A.R.; Milan, D.J. Quantifying channel development and sediment transfer following chute cutoff in a wandering gravel-bed river. Geomorphology 2003, 54, 307–323. [Google Scholar] [CrossRef]
- Fuller, I.C.; Hutchinson, E.L. Sediment flux in a small gravel-bed stream: Response to channel remediation works. New Zealand Geogr. 2007, 63, 169–180. [Google Scholar] [CrossRef]
- Schwendel, A.C.; Fuller, I.C.; Death, R.G. Assessing DEM interpolation methods for effective representation of upland stream morphology for rapid appraisal of bed stability. River Res. Appl. 2012, 28, 567–584. [Google Scholar] [CrossRef]
- Guo, Q.; Li, W.; Yu, H.; Alvarez, O. Effects of topographic variability and lidar sampling density on several DEM interpolation methods. Photogramm. Eng. Remote Sens. 2010, 76, 701–712. [Google Scholar] [CrossRef]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, C.; Li, Y.; Yan, C.; Dai, H.; Liu, G. A Thin Plate Spline-Based Feature-Preserving Method for Reducing Elevation Points Derived from LiDAR. Remote Sens. 2015, 7, 11344-11371. https://doi.org/10.3390/rs70911344
Chen C, Li Y, Yan C, Dai H, Liu G. A Thin Plate Spline-Based Feature-Preserving Method for Reducing Elevation Points Derived from LiDAR. Remote Sensing. 2015; 7(9):11344-11371. https://doi.org/10.3390/rs70911344
Chicago/Turabian StyleChen, Chuanfa, Yanyan Li, Changqing Yan, Honglei Dai, and Guolin Liu. 2015. "A Thin Plate Spline-Based Feature-Preserving Method for Reducing Elevation Points Derived from LiDAR" Remote Sensing 7, no. 9: 11344-11371. https://doi.org/10.3390/rs70911344