
Accurate Annotation of Remote Sensing Images via Active Spectral Clustering with Little Expert Knowledge



Abstract
:
1. Introduction
- −
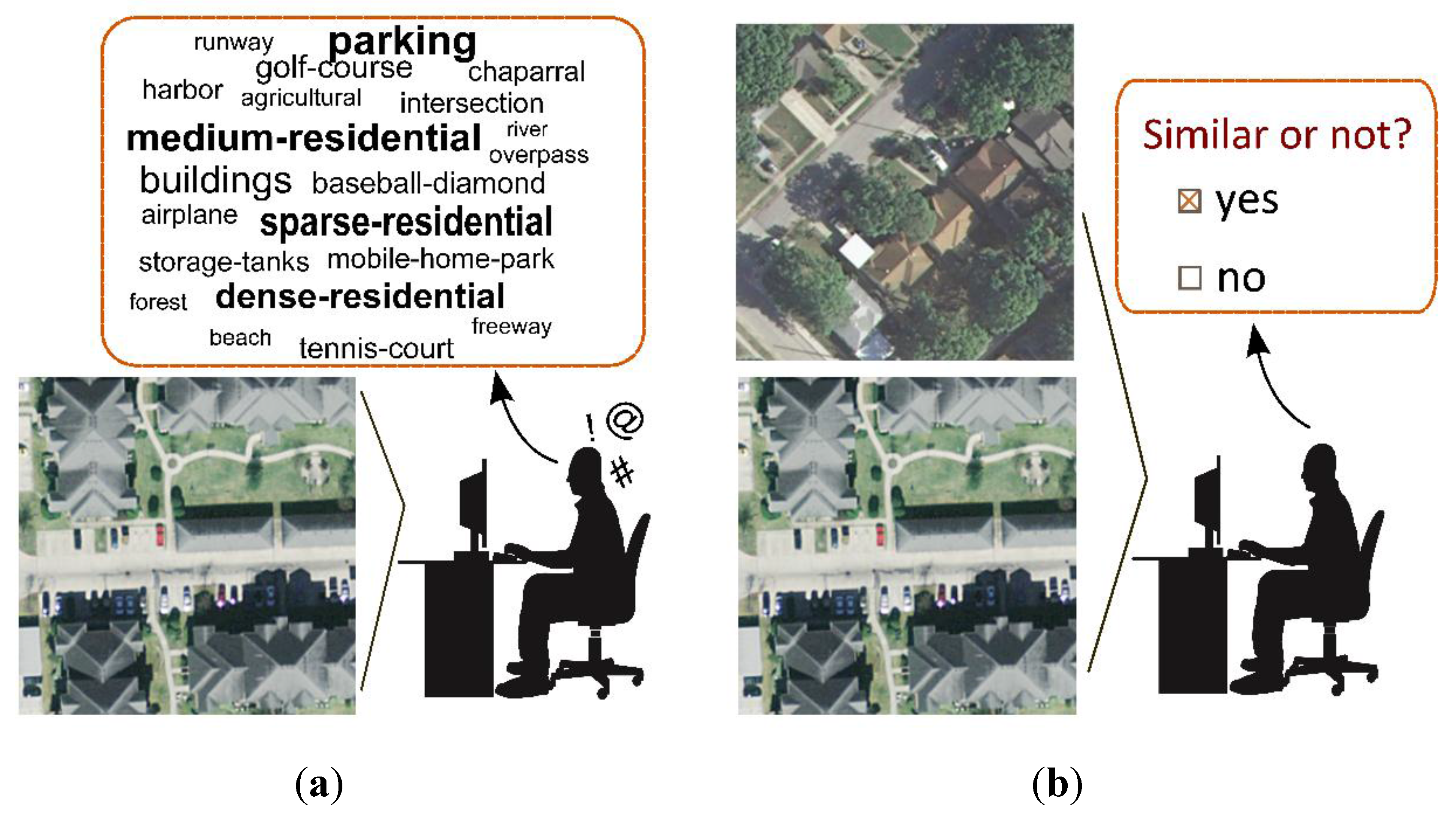
- We develop an active clustering method for the annotation of HRRS images with little expert knowledge. When pairwise constraints are used as prior information, the human annotator is required only to compare pairs of remote sensing images and determine whether they are similar. This approach can alleviate the human workload requirements in terms of both quality and quantity as well as the requirement for human expert knowledge.
- −
- We define a novel weighted node uncertainty measure for selecting the informative nodes from a graph, which offers stable performance and sufficiently low algorithm complexity for the implementation of real-time human–computer interactions.
- −
- We propose an adaptive strategy that can automatically update the number of clusters in the active spectral clustering algorithm. This makes it possible to annotate remote sensing images when the number of categories, or their specific labels, is still unknown.
2. Related Work
3. Background on the Annotation of Remote Sensing Images
3.1. Spectral Clustering
3.2. Characterization and Similarity of Remote Sensing Images
4. Methodology
4.1. Active Spectral Clustering of Remote Sensing Images
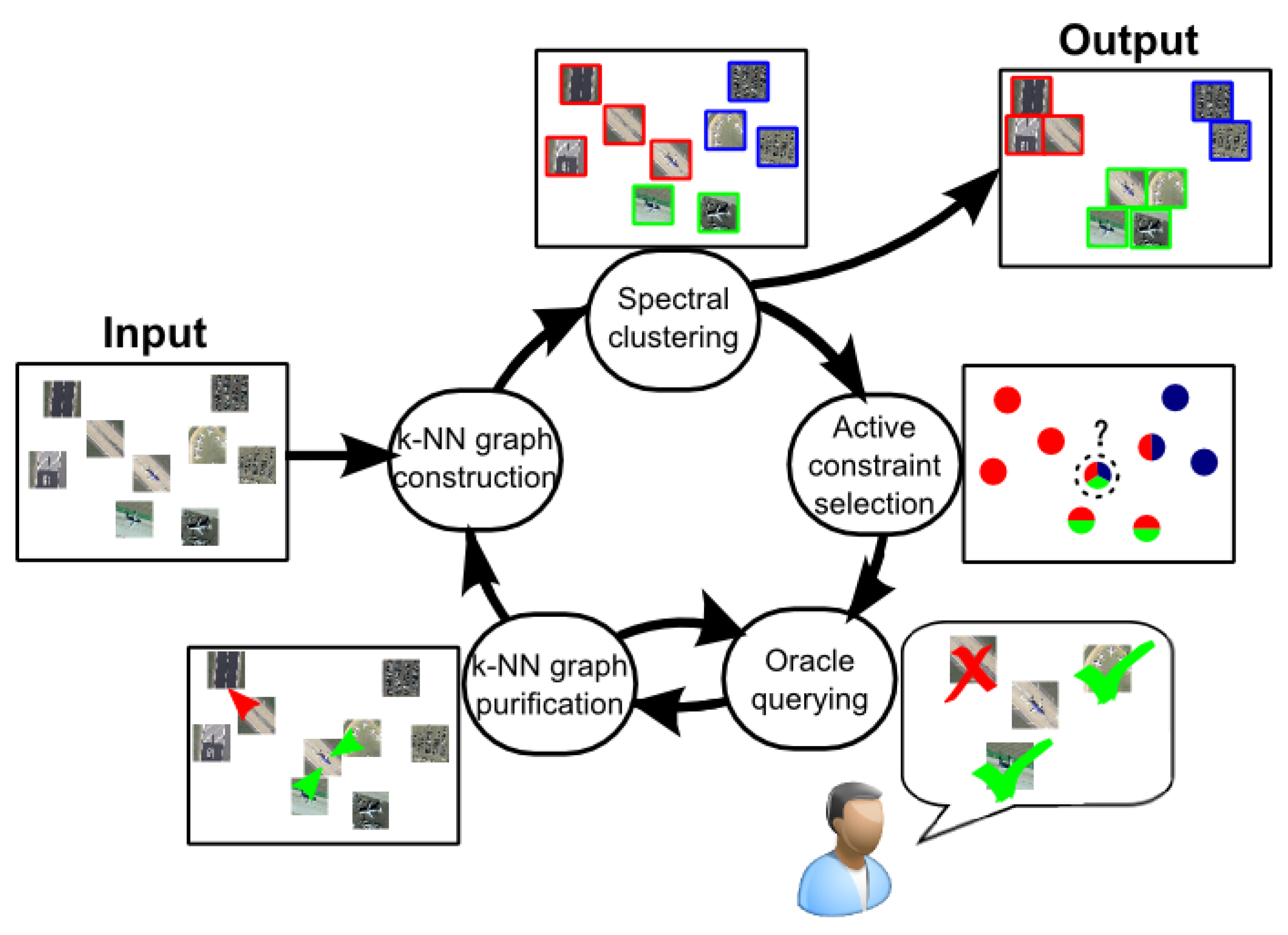
4.1.1. k-NN Graph Construction and Basic Spectral Clustering
4.1.2. Active Constraint Selection
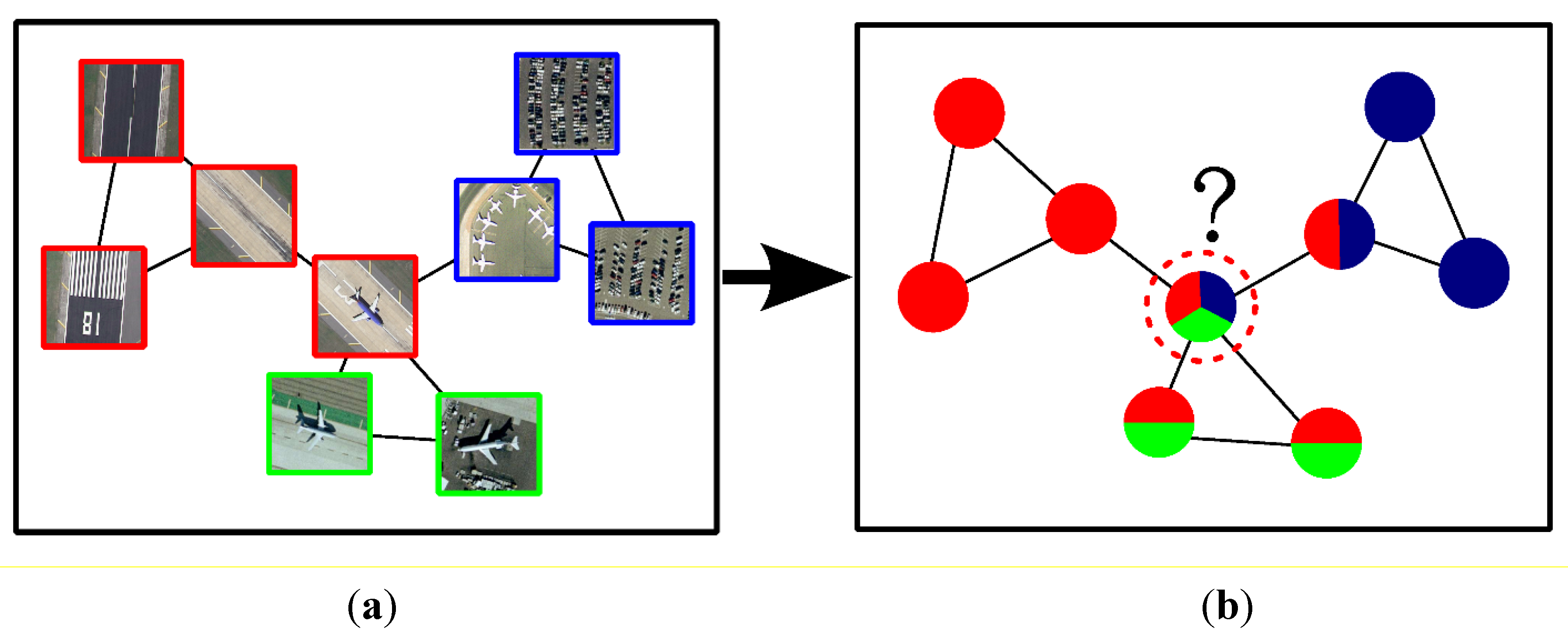
4.1.3. Oracle Querying
- ♦
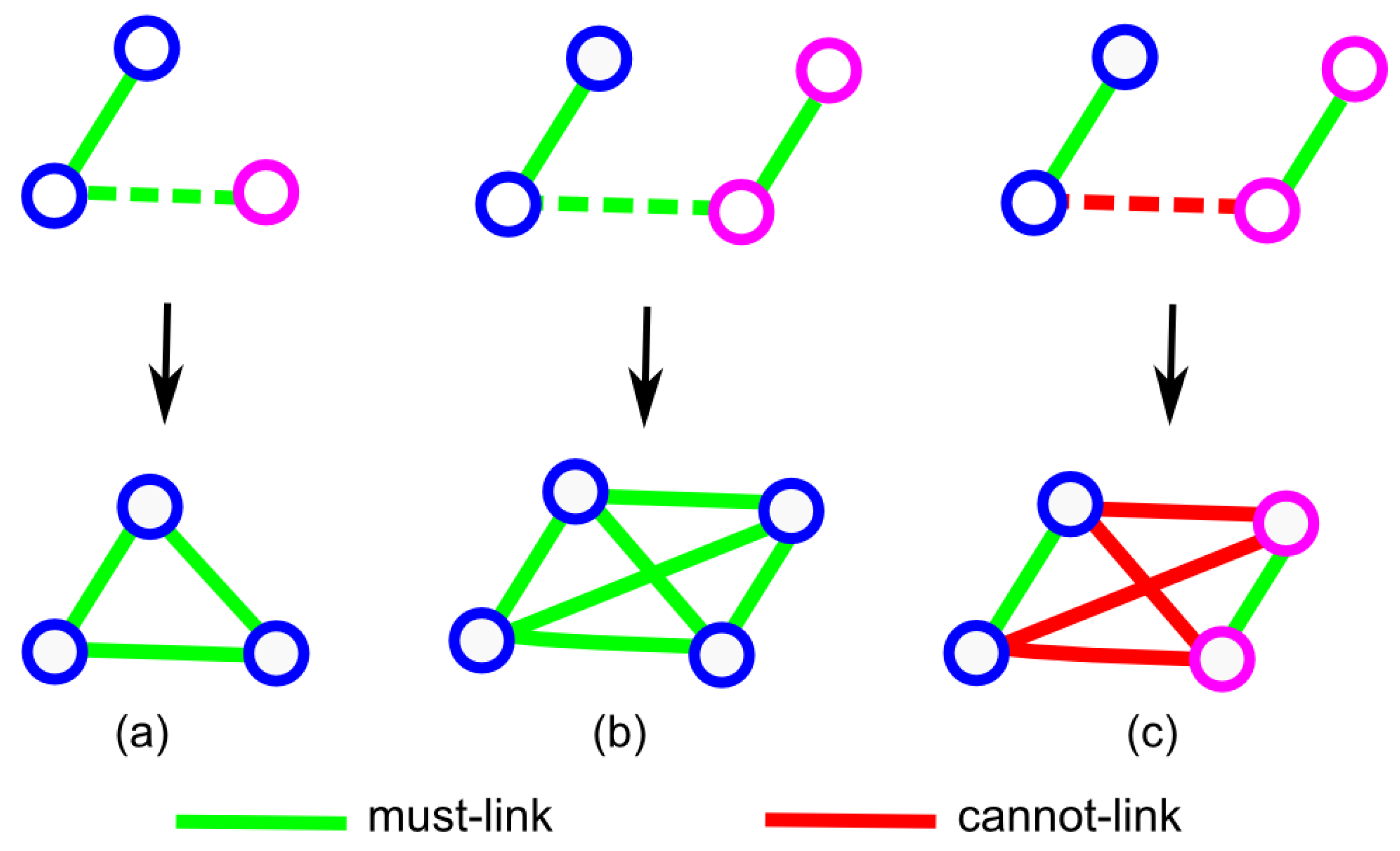
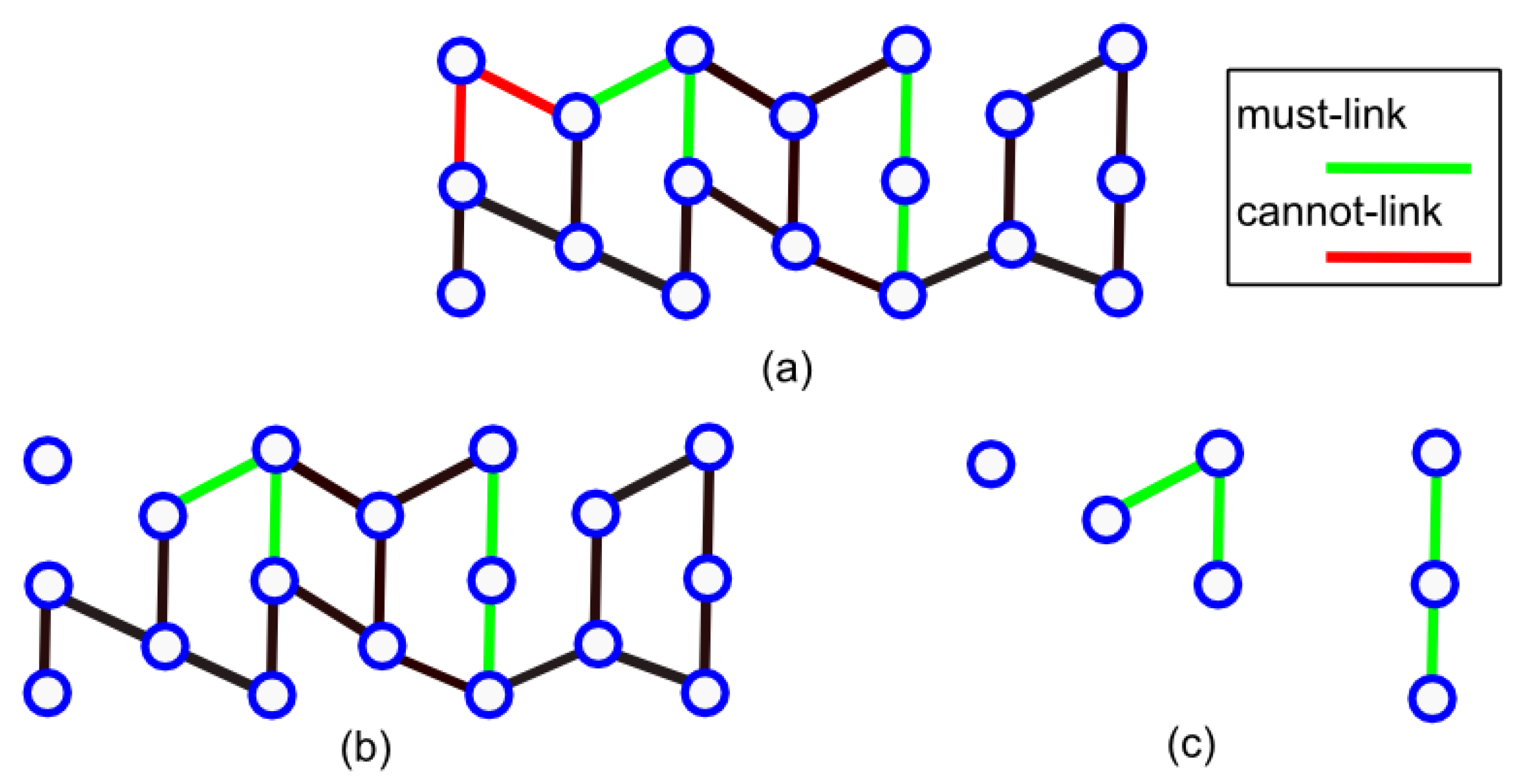
- All nodes in a single connected component formed by must-links should belong to the same class and be linked to each other by must-links. These fully connected components are called cliques in graph theory (see Figure 4a).
- ♦
- If a must-link exists between two cliques, then they should be merged and must-links should be added between their component nodes (see Figure 4b).
- ♦
- If a cannot-link exists between two cliques, then they should belong to different classes and cannot-links should be added between their component nodes (see Figure 4c).
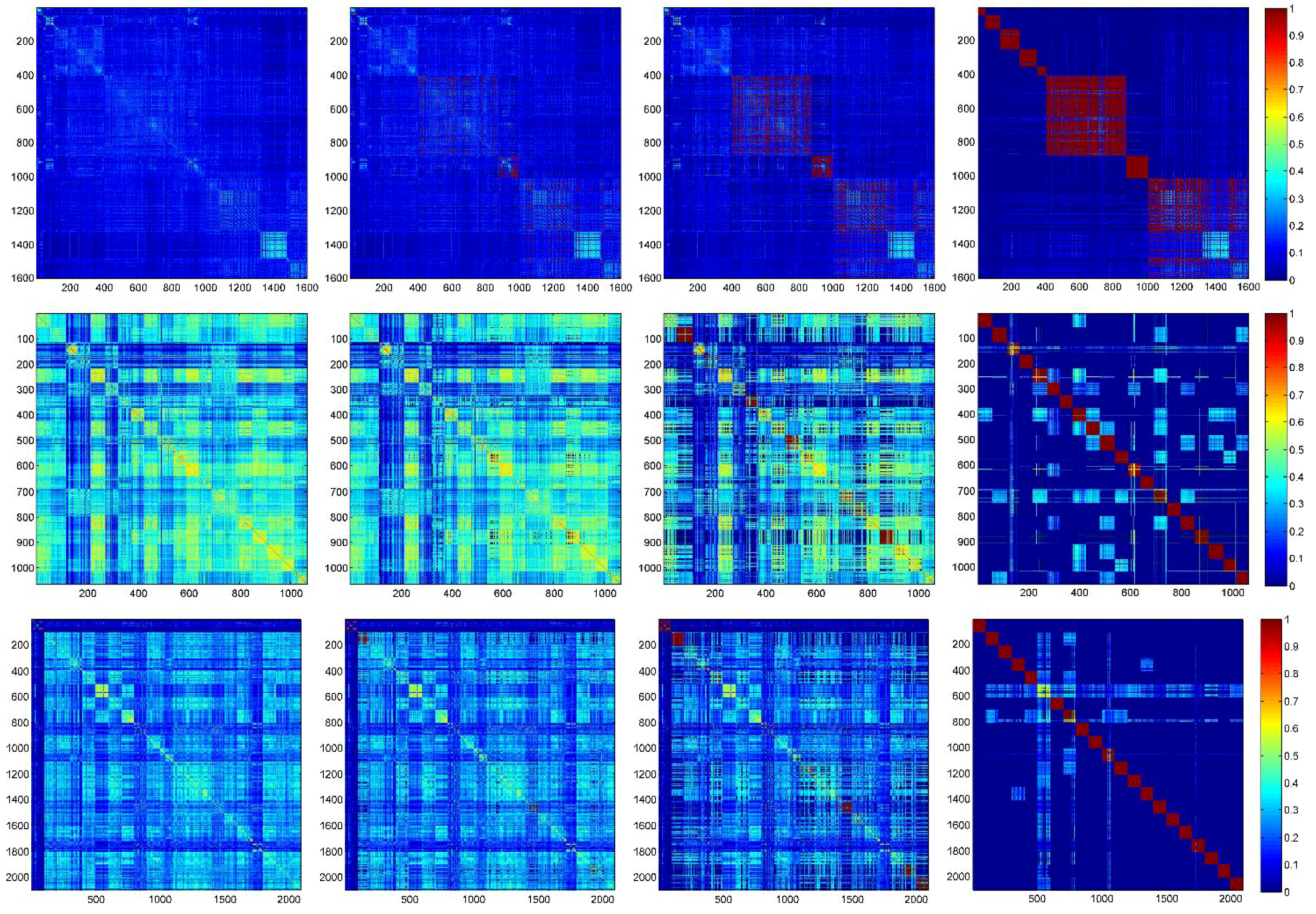
4.1.4. Two-Step k-NN Graph Purification Process
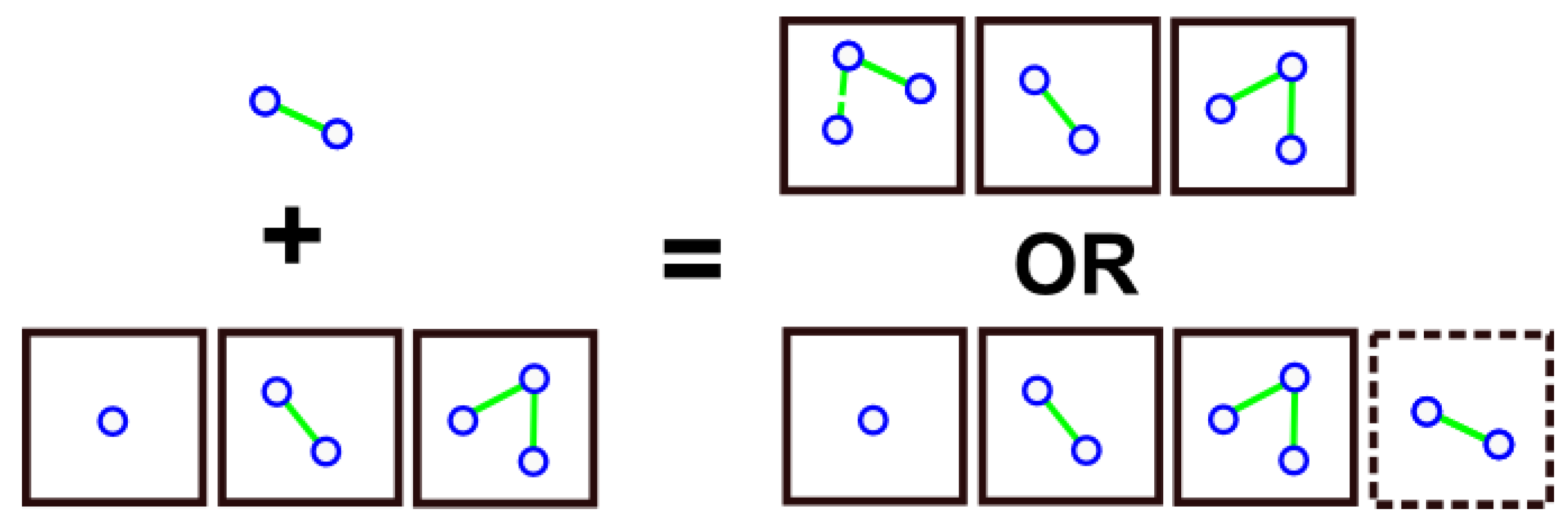
4.1.5. Stopping Criterion
4.1.6. Pseudocode
|
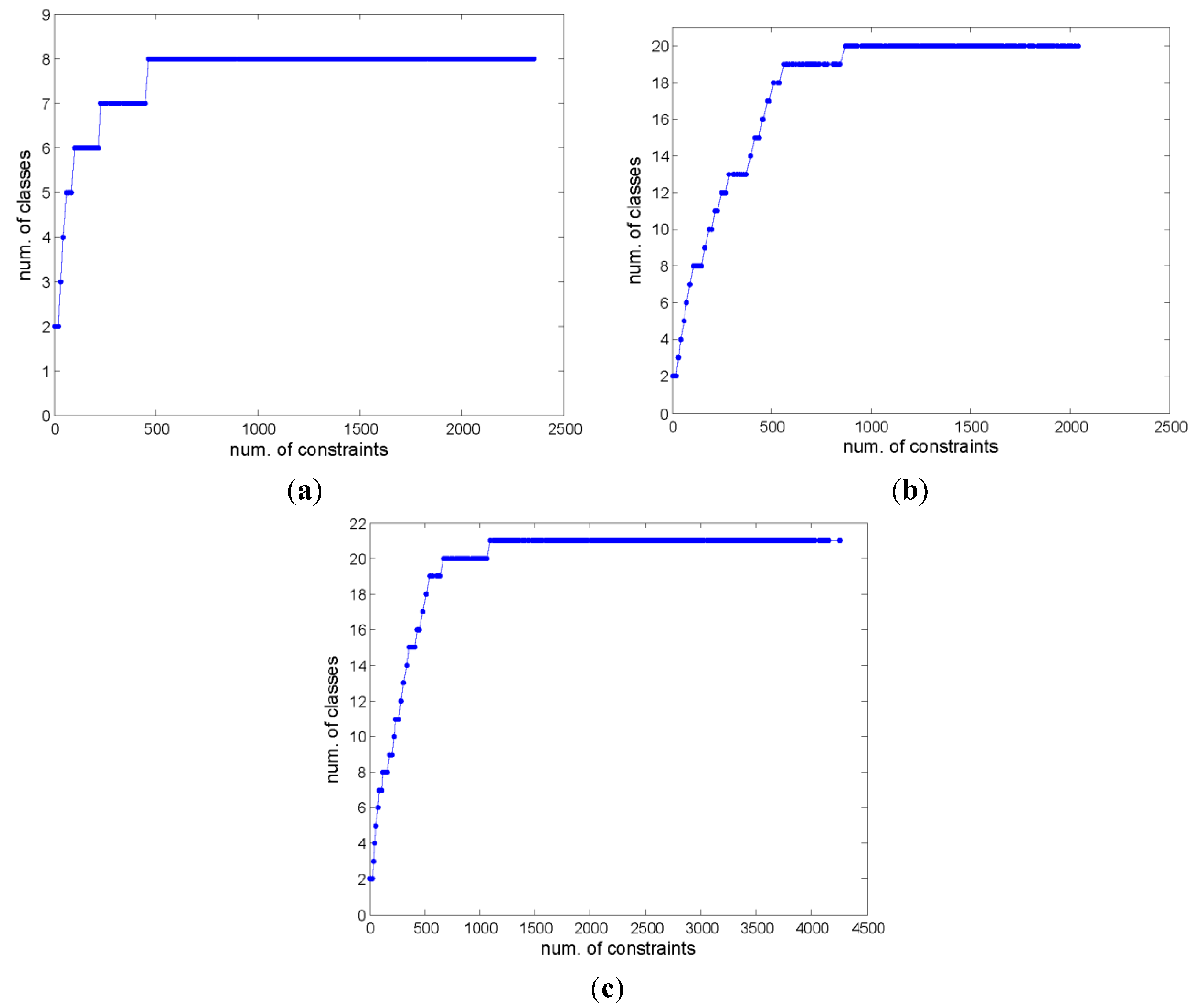
4.2. Adaptive Active Spectral Clustering of Remote Sensing Images
|
5. Experiments
5.1. Description of the Datasets
- −
- UC Merced (UCM) Dataset [47]: This dataset consists of 21 scene categories (including land-cover classes, e.g., forest and agricultural, and object classes, e.g., airplanes and tennis courts) with a pixel resolution of one foot. Each class contains 100 images with dimensions of 256 × 256 pixels. Examples from each class in the dataset are shown in Figure 7.
- −
- −
- Beijing Dataset [17]: This dataset consists of a large high-resolution satellite image captured by GeoEye-1 of Majuqiao Town, located in the southwest Tongzhou District in Beijing. The original image, with dimensions of 4000 × 4000 pixels, is cut by a uniform grid into regions with dimensions of 100 × 100 pixels. These 1600 image regions are annotated with 8 classes (such as bare land, factories, and rivers). The original image and a sample from each class are shown in Figure 9.



5.2. Experimental Setting
5.2.1. Evaluation Measures
5.2.2. Comparison Baseline and State-of-the-Art Methods
- ♦
- Random: A baseline algorithm that is similar to the proposed ASC algorithm but randomly samples pairwise constraints rather than using active learning.
- ♦
- RandomA: A baseline algorithm that is similar to the proposed AASC algorithm but randomly samples pairwise constraints rather than using active learning.
- ♦
- CCSKL [58]: A constrained spectral clustering algorithm that uses spectral learning and randomly sampled pairwise constraints.
- ♦
- PKNN [35]: An active spectral clustering algorithm that also iteratively refines a k-NN graph.
- ♦
- HACC [37]: An active and hierarchical clustering method that selects the pairwise constraints that lead to the maximal expected change in the clustering results.
- ♦
- ASC: Our proposed active spectral clustering algorithm for remote sensing images, described in Section 4.1.
- ♦
- AASC: Our proposed adaptive active spectral clustering algorithm for remote sensing images, described in Section 4.2.
5.3. Experimental Results and Analysis
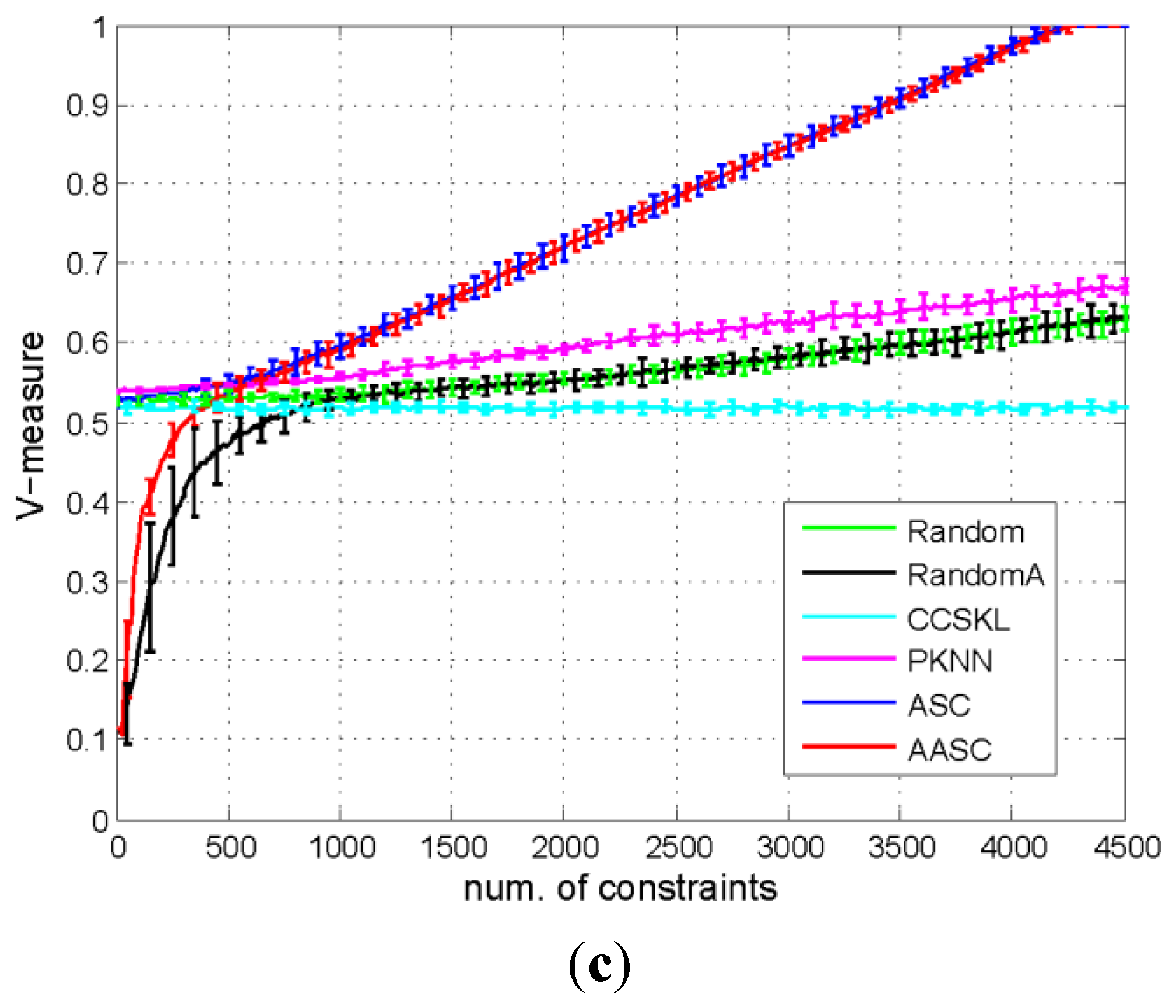
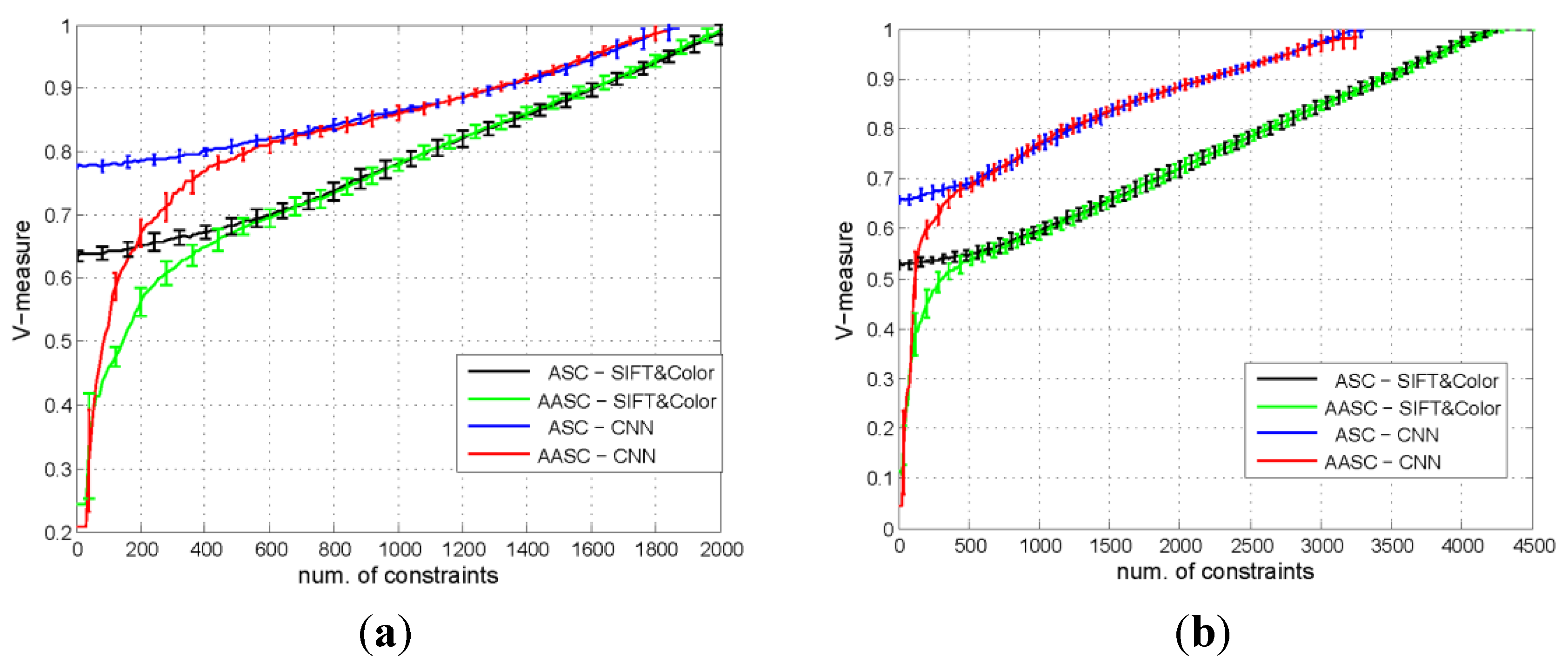
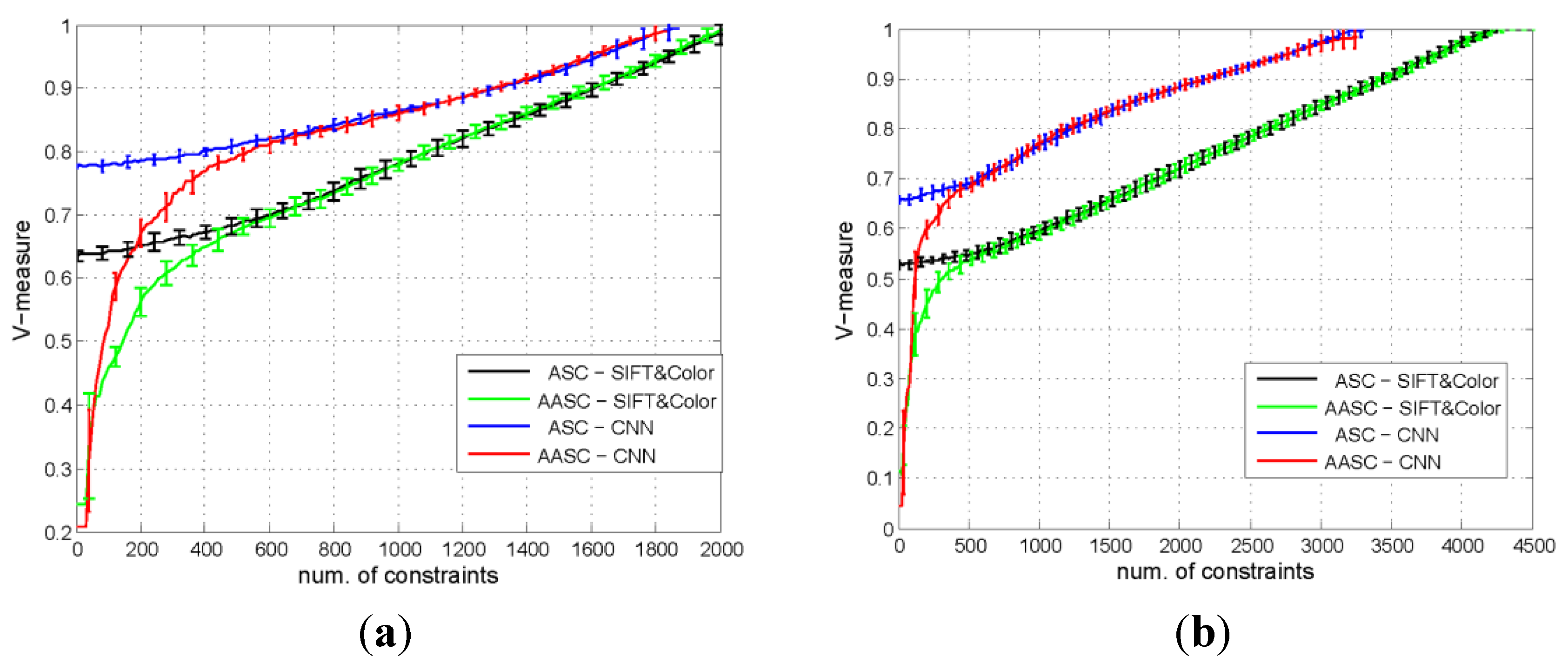
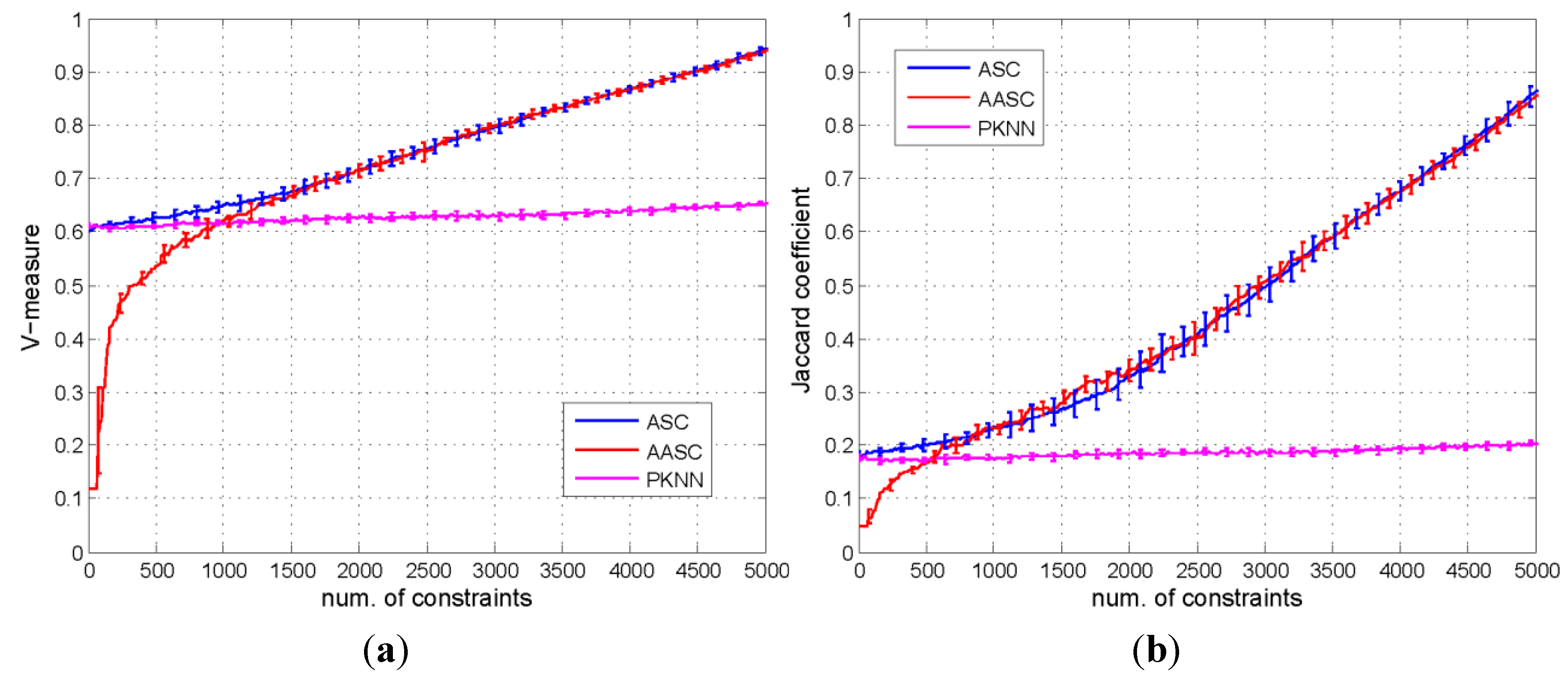
5.3.1. Comparison of the Performances of the Different Algorithms
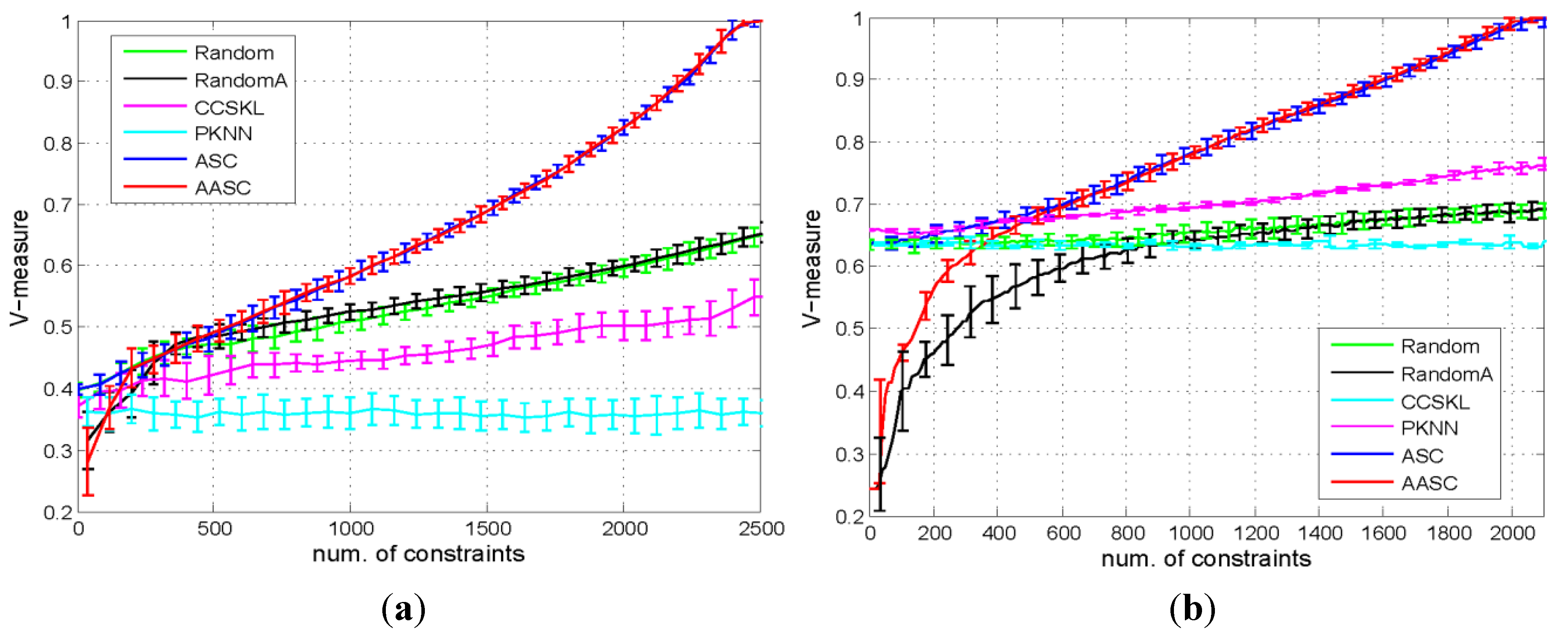
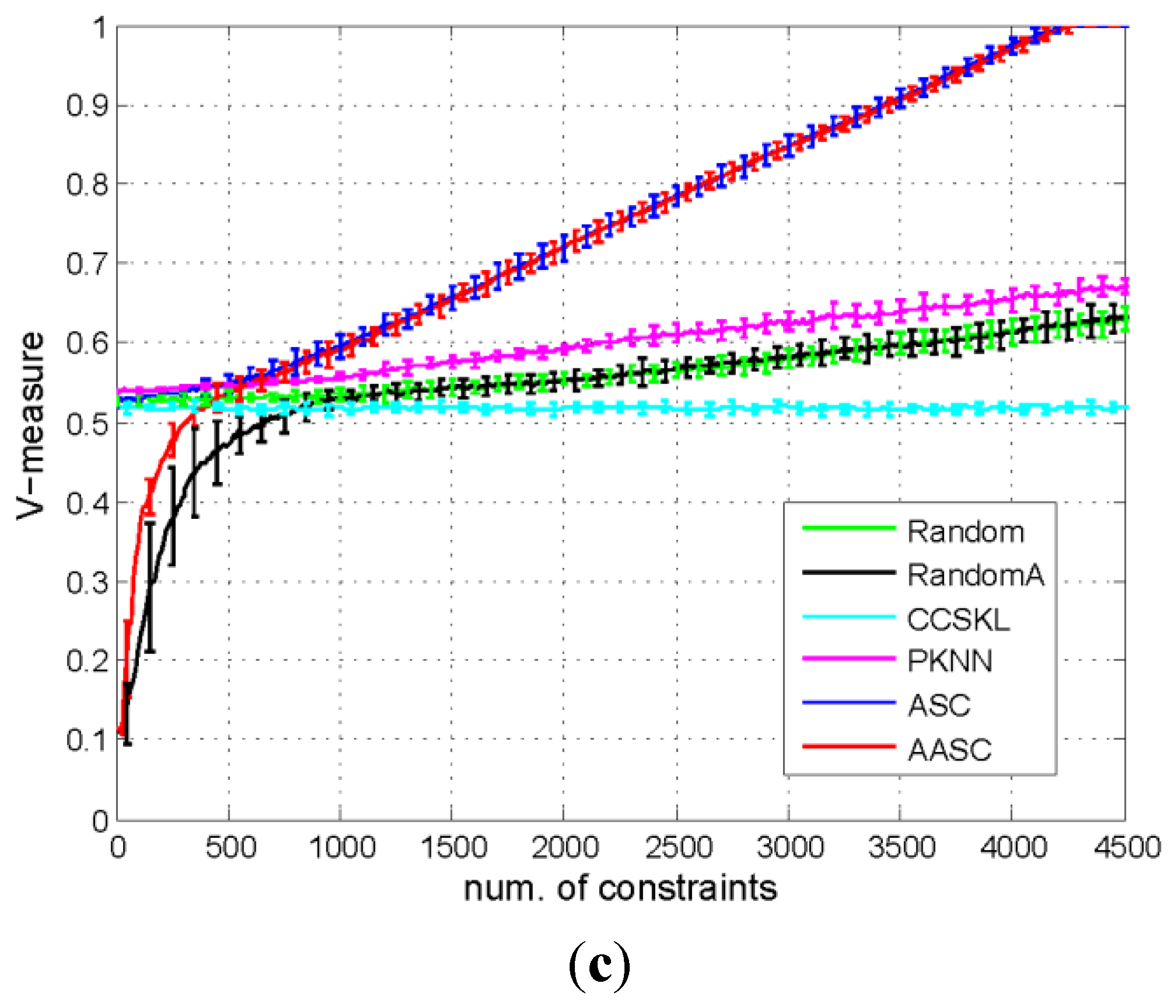
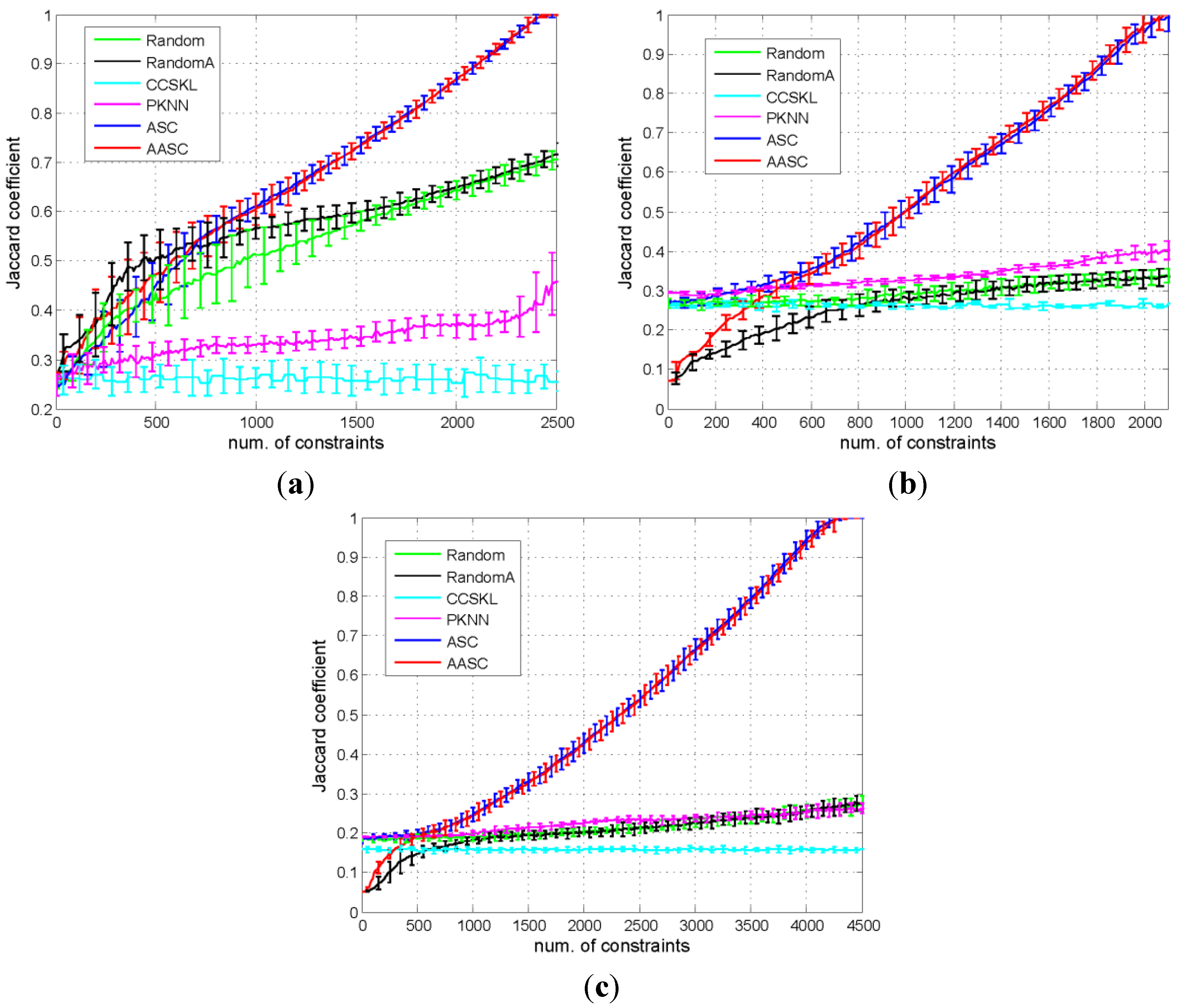
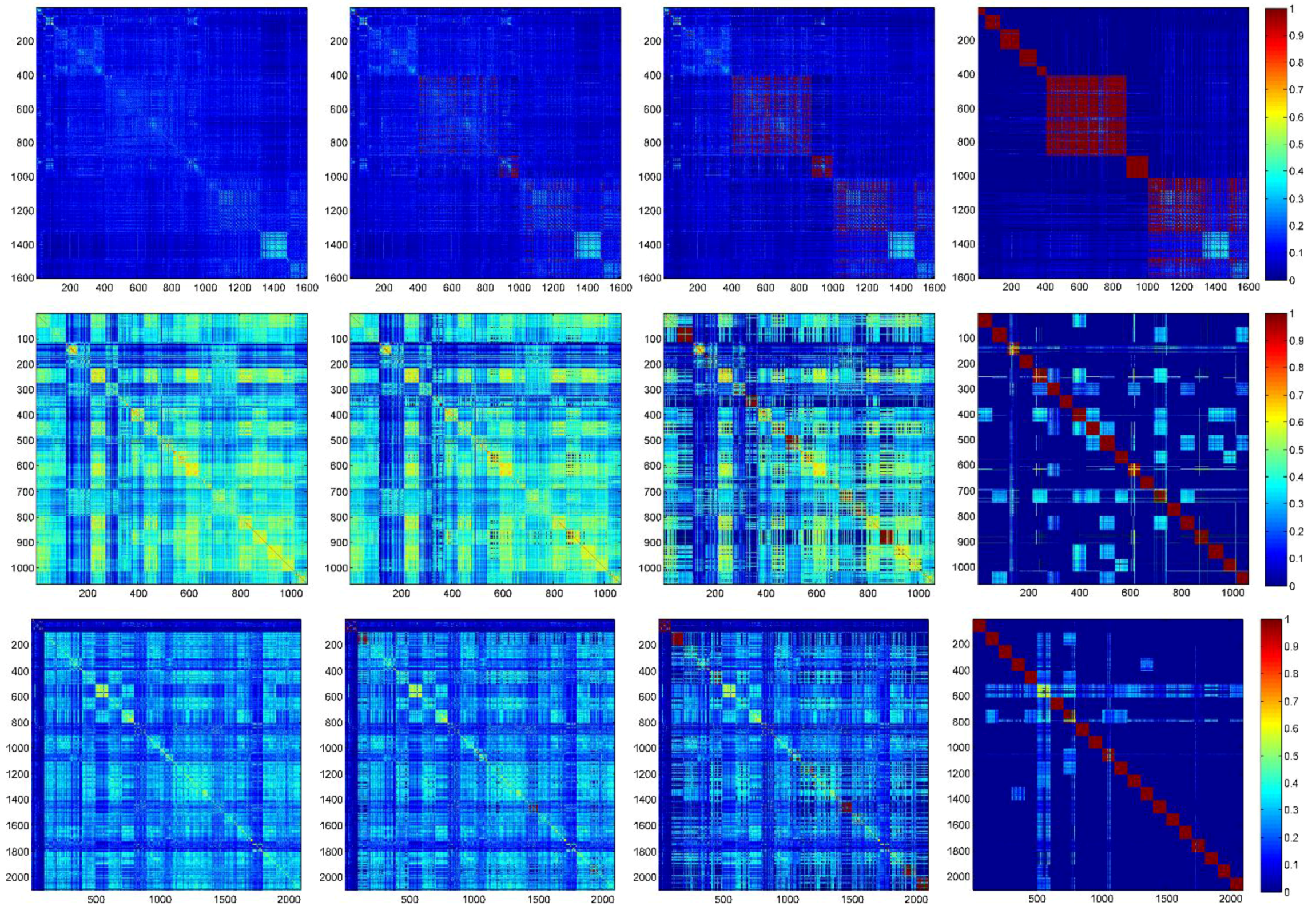

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | #Samples/#Pairs | ASC | AASC | ||
|---|---|---|---|---|---|
| #Constraints | Ratio | #Constraints | Ratio | ||
| Beijing | 1600/1279200 | 2380 | 0.19% | 2352 | 0.18% |
| WHU-RS | 1063/564453 | 1966 | 0.35% | 2042 | 0.36% |
| UCM | 2100/2203950 | 4239 | 0.19% | 4260 | 0.19% |
| Dataset | #Constraints | Time (Total/Each ) | ||
|---|---|---|---|---|
| HACC | ASC | HACC | ASC | |
| UCM-5-10 | 62 | 57 | 108 s/1.7 s | 0.6 s/0.01 s |
| UCM-5-20 | 168 | 157 | 26 min/9.2 s | 0.9 s/5 ms |
| UCM-10-10 | 305 | 277 | 50 min/9.84 s | 1.2 s/4.9 ms |
| UCM-10-20 | 553 | 441 | 44 h/286 s | 2.44 s/5.5 ms |
| UCM-21-10 | 1034 | 1019 | 142 h/494 s | 4.68 s/4.6 ms |
| UCM | - | 4239 | - | 231 s/0.05 s |
| Beijing | - | 2380 | - | 175 s/0.07 s |
| WHU-RS | - | 1966 | - | 39 s/0.02 s |
| Dataset | #Classes | #Samples for each class | #Total |
|---|---|---|---|
| UCM-5-10 | 5 | 10 | 50 |
| UCM-5-20 | 5 | 20 | 100 |
| UCM-10-10 | 10 | 10 | 100 |
| UCM-10-20 | 10 | 20 | 200 |
| UCM-21-10 | 21 | 10 | 210 |
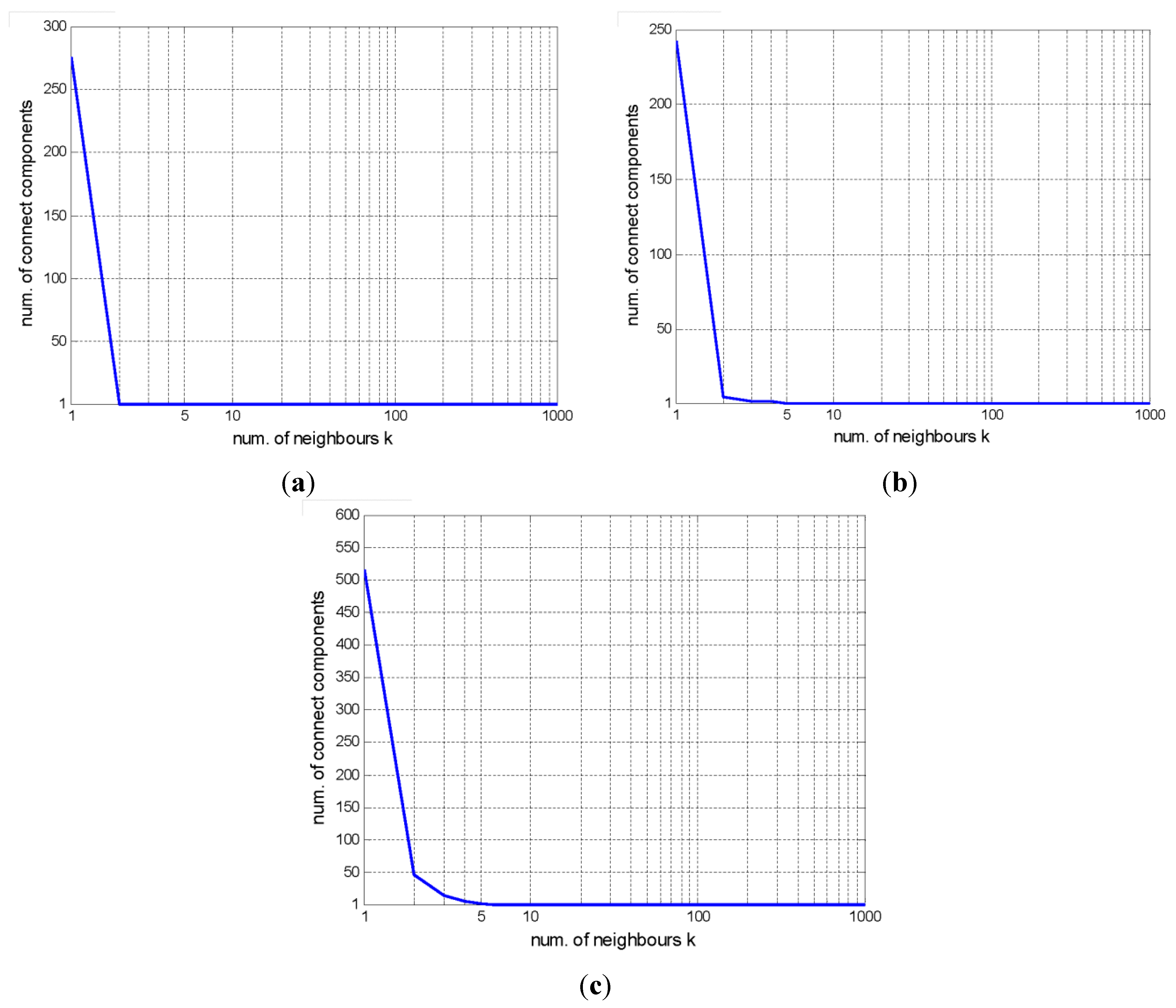
5.3.2. Effect of the Number of Neighbors k
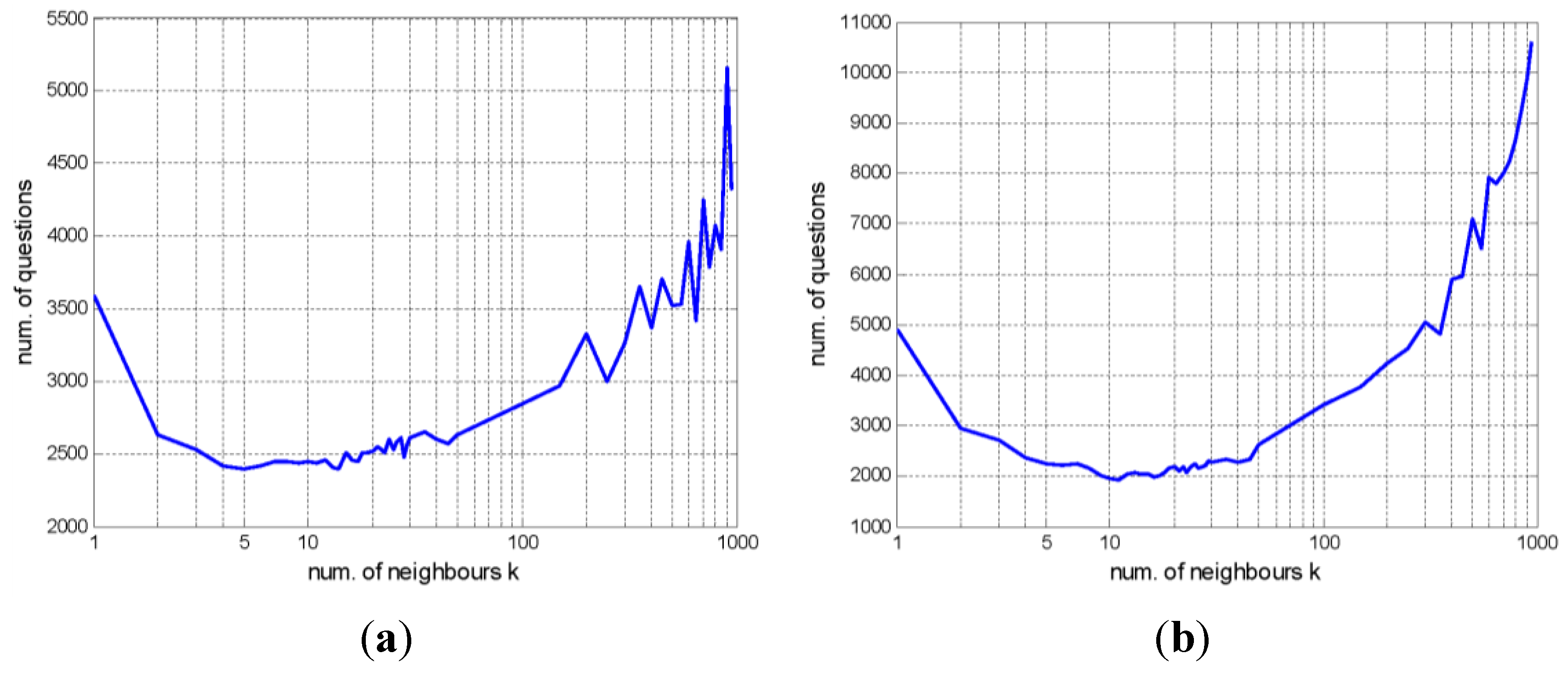
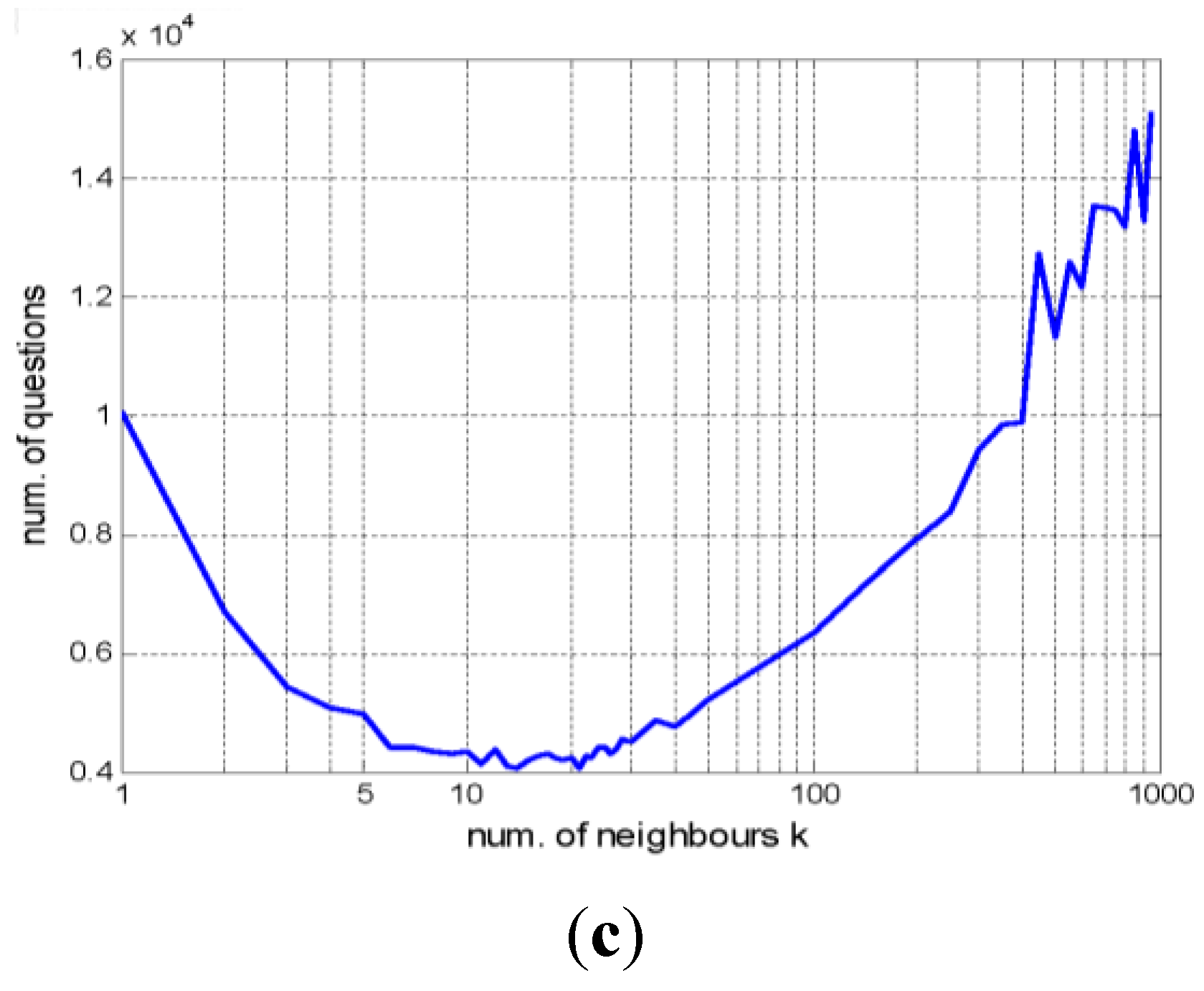
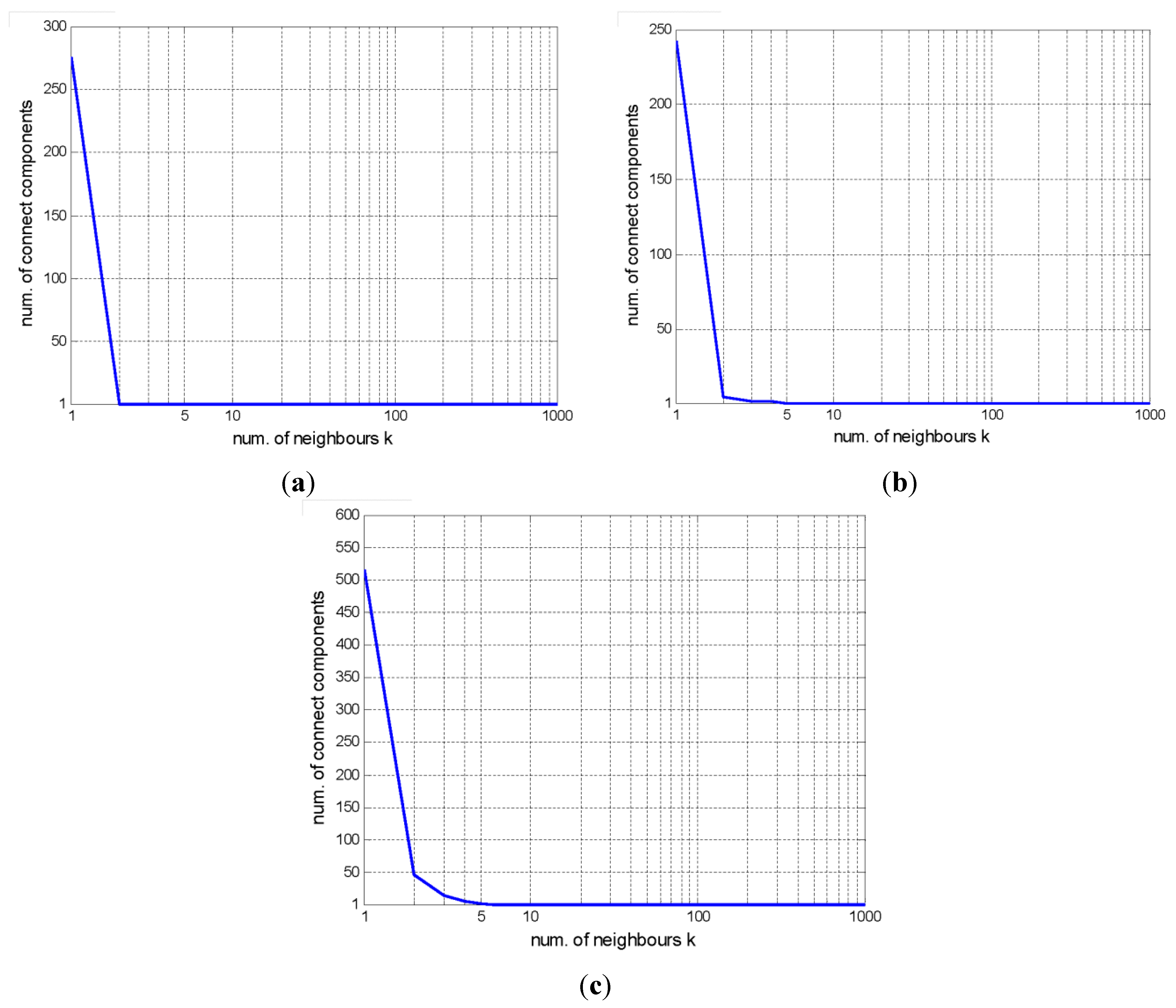
5.3.3. Scene Annotation Results for Remote Sensing Images
6. Discussion
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Tuia, D.; Camps-Valls, G. Recent advances in remote sensing image processing. In Proceedings of International Conference on Image Processing, Cairo, Egypt, 7–10 November 2009; pp. 3705–3708.
- Richards, J.A. Remote Sensing Digital Image Analysis; Springer: Berlin, Germany, 1999; Volume 3. [Google Scholar]
- Li, D.; Zhang, L.; Xia, G.-S. Automatic analysis and mining of remote sensing big data. Acta Geod. Cartogr. Sin. 2014, 43, 1211–1216. [Google Scholar]
- Wang, F. Fuzzy supervised classification of remote sensing images. IEEE Trans. Geos. Remote Sens. 1990, 28, 194–201. [Google Scholar] [CrossRef]
- Bandyopadhyay, S.; Maulik, U.; Mukhopadhyay, A. Multiobjective genetic clustering for pixel classification in remote sensing imagery. IEEE Trans. Geos. Remote Sens. 2007, 45, 1506–1511. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Aksoy, S.; Koperski, K.; Tusk, C.; Marchisio, G.; Tilton, J.C. Learning Bayesian classifiers for scene classification with a visual grammar. IEEE Trans. Geos. Remote Sens. 2005, 43, 581–589. [Google Scholar] [CrossRef]
- Friedl, M.; Brodley, C. Decision tree classification of land cover from remotely sensed data. Remote Sens. Environ. 1997, 61, 399–409. [Google Scholar] [CrossRef]
- Han, M.; Zhu, X.; Yao, W. Remote sensing image classification based on neural network ensemble algorithm. Neurocomputing 2012, 78, 133–138. [Google Scholar] [CrossRef]
- Xu, Y.; Huang, B. Spatial and temporal classification of synthetic satellite imagery: Land cover mapping and accuracy validation. Geosp. Inf. Sci. 2014, 17, 1–7. [Google Scholar] [CrossRef]
- Bruzzone, L.; Persello, C. A novel context-sensitive semisupervised SVM classifier robust to mislabeled training samples. IEEE Trans. Geos. Remote Sens. 2009, 47, 2142–2154. [Google Scholar] [CrossRef]
- Ruiz, P.; Mateos, J.; Camps-Valls, G.; Molina, R.; Katsaggelos, A.K. Bayesian active remote sensing image classification. IEEE Trans. Geos. Remote Sens. 2014, 52, 2186–2196. [Google Scholar] [CrossRef]
- Munoz-Mari, J.; Tuia, D.; Camps-Valls, G. Semisupervised classification of remote sensing images with active queries. IEEE Trans. Geos. Remote Sens. 2012, 50, 3751–3763. [Google Scholar] [CrossRef]
- Davidson, I.; Wagstaff, K.; Basu, S. Measuring Constraint-Set Utility for Partitional Clustering Algorithms; Springer Berlin Heidelberg: Berlin, Germany, 2006; pp. 115–126. [Google Scholar]
- Settles, B. Active Learning. Synthesis Lectures on Artificial Intelligence and Machine Learning; Morgan and Clay Pool: Long Island, NY, USA, 2012; Volume 6, pp. 1–114. [Google Scholar]
- Wang, Z.; Xia, G.-S.; Xiong, C.; Zhang, L. Spectral active clustering of remote sensing images. In Proceedings of IEEE Geoscience and Remote Sensing Symposium, Quebec, QC, Canada, 13–18 July 2014; pp. 1737–1740.
- Hu, F.; Yang, W.; Chen, J.; Sun, H. Tile-level annotation of satellite images using multi-level max-margin discriminative random field. Remote Sens. 2013, 5, 2275–2291. [Google Scholar] [CrossRef]
- Yang, W.; Yin, X.; Xia, G.-S. Learning high-level features for satellite image classification with limited labeled samples. IEEE Trans. Geos. Remote Sens. 2015, 53, 4472–4482. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.-S.; Wang, Z.; Huang, X.; Zhang, L.; Sun, H. Unsupervised feature learning via spectral clustering of multidimensional patches for remotely sensed scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2015–2030. [Google Scholar] [CrossRef]
- Liénou, M.; Maître, H.; Datcu, M. Semantic annotation of satellite images using latent Dirichlet allocation. IEEE Geos. Remote Sens. Lett. 2010, 7, 28–32. [Google Scholar] [CrossRef]
- Zhong, Y.; Zhang, L.; Gong, W. Unsupervised remote sensing image classification using an artificial immune network. Int. J. Remote Sens. 2011, 32, 5461–5483. [Google Scholar] [CrossRef]
- Hu, F.; Wang, Z.; Xia, G.-S.; Zhang, L. Fast binary coding for satellite image scene classification. In Proceedings of IEEE Geoscience and Remote Sensing Symposium, Milan, Italy, 26–31 July 2015.
- Foody, G.M.; Mathur, A.; Sanchez-Hernandez, C.; Boyd, D.S. Training set size requirements for the classification of a specific class. Remote Sens. Environ. 2006, 104, 1–14. [Google Scholar] [CrossRef]
- Tuia, D.; Volpi, M.; Copa, L.; Kanevski, M.; Munoz-Mari, J. A survey of active learning algorithms for supervised remote sensing image classification. IEEE J. Sel. Top. Signal Proces. 2011, 5, 606–617. [Google Scholar] [CrossRef]
- Shi, Q.; Du, B.; Zhang, L. Spatial coherence-based batch-mode active learning for remote sensing image classification. IEEE Trans. Image Proces. 2015, 24, 2037–2050. [Google Scholar] [CrossRef] [PubMed]
- Xu, J.; Hang, R.; Liu, Q. Patch-based active learning (PtAl) for spectral-spatial classification on hyperspectral data. Int. J. Remote Sens. 2014, 35, 1846–1875. [Google Scholar] [CrossRef]
- Tuia, D.; Kanevski, M.; Marí, J.M.; Camps-Valls, G. Cluster-based active learning for compact image classification. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Honolulu, HI, USA, 25–30 July 2010; pp. 2824–2827.
- Demir, B.; Bovolo, F.; Bruzzone, L. Detection of land-cover transitions in multitemporal remote sensing images with active-learning-based compound classification. IEEE Trans. Geos. Remote Sens. 2012, 50, 1930–1941. [Google Scholar] [CrossRef]
- Tuia, D.; Munoz-Mari, J.; Camps-Valls, G. Remote sensing image segmentation by active queries. Pattern Recogn. 2012, 45, 2180–2192. [Google Scholar] [CrossRef]
- Demir, B.; Bruzzone, L. A novel active learning method in relevance feedback for content-based remote sensing image retrieval. IEEE Trans. Geos. Remote Sens. 2015, 53, 2323–2334. [Google Scholar] [CrossRef]
- Taheri, S.H.; Bagheri, S.S.; Fell, F.; Schaale, M.; Fischer, J.; Tavakoli, A.; Preusker, R.; Tajrishy, M.; Vatandoust, M.; Khodaparast, H. Application of the active learning method to the retrieval of pigment from spectral remote sensing reflectance data. Int. J. Remote Sens. 2009, 30, 1045–1065. [Google Scholar] [CrossRef]
- Demir, B.; Persello, C.; Bruzzone, L. Batch-mode active-learning methods for the interactive classification of remote sensing images. IEEE Trans. Geos. Remote Sens. 2011, 49, 1014–1031. [Google Scholar] [CrossRef]
- Sun, S.J.; Zhong, P.; Xiao, H.T.; Wang, R.S. Active learning with Gaussian process classifier for hyperspectral image classification. IEEE Trans. Geos. Remote Sens. 2015, 53, 1746–1760. [Google Scholar] [CrossRef]
- Tuia, D.; Ratle, F.; Pacifici, F.; Kanevski, M.F.; Emery, W.J. Active learning methods for remote sensing image classification. IEEE Trans. Geos. Remote Sens. 2009, 47, 2218–2232. [Google Scholar] [CrossRef]
- Xiong, C.; Johnson, D.; Corso, J.J. Spectral active clustering via purification of the k-nearest neighbor graph. In Proceedings of European Conference on Data Mining, Lisbon, Portugal, 21–23 July 2012.
- Mallapragada, P.K.; Jin, R.; Jain, A.K. Active query selection for semi-supervised clustering. In Proceedings of the 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–4.
- Biswas, A.; Jacobs, D. Active image clustering with pairwise constraints from humans. Int. J. Comput. Vis. 2014, 108, 133–147. [Google Scholar] [CrossRef]
- Xu, Q.; Desjardins, M.; Wagstaff, K.L. Active constrained clustering by examining spectral eigenvectors. In Proceedings of the 8th International Conference on Discovery Science, Singapore, 8–11 October 2005; pp. 294–307.
- Wang, X.; Davidson, I. Active spectral clustering. In Proceedings of IEEE 10th International Conference on Data Mining, Sydney, Australia, 14–17 December 2010; pp. 561–568.
- Wagstaff, K.; Cardie, C. Clustering with Instance-Level Constraints. In Proceedings of AAAI-00, Austin, TX, USA, 30 July–3 August 2000; pp. 1097–1097.
- Klein, D.; Kamvar, S.D.; Manning, C.D. From instance-level constraints to space-level constraints: Making the most of prior knowledge in data clustering. In Proceedings of the 19th International Conference on Machine Learning, Sydney, Australia, 8–12 July 2002.
- Basu, S.; Banerjee, A.; Mooney, R.J. Active semi-supervision for pairwise constrained clustering. In Proceedings of the 4th SIAM International Conference on Data Mining, Lake Buena Vista, FL, USA, 22–24 April 2004; pp. 333–334.
- Eriksson, B.; Dasarathy, G.; Singh, A.; Nowak, R.D. Active clustering: Robust and efficient hierarchical clustering using adaptively selected similarities. In Proceedings of International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 260–268.
- Von Luxburg, U. A tutorial on spectral clustering. Stat. Comput. 2007, 17, 395–416. [Google Scholar] [CrossRef]
- Ng, A.Y.; Jordan, M.I.; Weiss, Y. On spectral clustering: Analysis and an algorithm. In Proceedings of NIPS, Vancouver, BC, Canada, 3–8 December 2001; pp. 849–856.
- Lowe, D. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of 18th SIGSPATIAL International Conference on Advances in GIS, San Jose, CA, USA, 2–5 November 2010; pp. 270–279.
- Csurka, G.; Dance, C.; Fan, L.; Willamowski, J.; Bray, C. Visual categorization with bags of keypoints. workshop Stat. Learn. Comput. Vis. 2004, 1, 1–2. [Google Scholar]
- Xia, G.-S.; Delon, J.; Gousseau, Y. Accurate junction detection and characterization in natural images. Int. J. Comput. Vis. 2014, 106, 31–56. [Google Scholar] [CrossRef]
- Liu, G.; Xia, G.-S.; Huang, X.; Yang, W.; Zhang, L. A perception-inspired building index for automatic built-up area detection in high-resolution satellite images. In Proceedings of Geoscience and Remote Sensing Symposium, Melbourne, Australia, 21–26 July 2013; pp. 3132–3135.
- Xia, G.-S.; Delon, J.; Gousseau, Y. Shape-based invariant texture indexing. Int. J. Comput. Vis. 2010, 88, 382–403. [Google Scholar] [CrossRef]
- Liu, G.; Xia, G.-S.; Yang, W.; Zhang, L. Texture analysis with shape co-occurrence patterns. In Proceedings of International Conference on Pattern Recognition (ICPR), Stockholm, Sweden, 24–28 August 2014; pp. 1627–1632.
- Swain, M.J.; Ballard, D.H. Color indexing. Int. J. Comput. Vis. 1991, 7, 11–32. [Google Scholar] [CrossRef]
- Ting, D.; Huang, L.; Jordan, M. An analysis of the convergence of graph Laplacians. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010.
- Xia, G.-S.; Yang, W.; Delon, J.; Gousseau, Y. Structural high-resolution satellite image indexing. In Proceedings of ISPRS TC VII Symposium–100 Years, Vienna, Austria, 5–7 July 2010; pp. 298–303.
- Tan, P.-N.; Steinbach, M.; Kumar, V. Introduction to Data Mining; Addison Wesley: Boston, MA, USA, 2006. [Google Scholar]
- Rosenberg, A.; Hirschberg, J. V-measure: A conditional entropy-based external cluster evaluation measure. EMNLP-CoNLL ACL 2007, 7, 410–420. [Google Scholar]
- Li, Z.; Liu, J. Constrained clustering by spectral kernel learning. In Proceedings of International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 421–427.
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678.
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xia, G.-S.; Wang, Z.; Xiong, C.; Zhang, L. Accurate Annotation of Remote Sensing Images via Active Spectral Clustering with Little Expert Knowledge. Remote Sens. 2015, 7, 15014-15045. https://doi.org/10.3390/rs71115014
Xia G-S, Wang Z, Xiong C, Zhang L. Accurate Annotation of Remote Sensing Images via Active Spectral Clustering with Little Expert Knowledge. Remote Sensing. 2015; 7(11):15014-15045. https://doi.org/10.3390/rs71115014
Chicago/Turabian StyleXia, Gui-Song, Zifeng Wang, Caiming Xiong, and Liangpei Zhang. 2015. "Accurate Annotation of Remote Sensing Images via Active Spectral Clustering with Little Expert Knowledge" Remote Sensing 7, no. 11: 15014-15045. https://doi.org/10.3390/rs71115014