1. Introduction
Synthetic Aperture Radar (SAR) can acquire the images of non-cooperative moving objects, such as aircrafts, ships, and celestial objects over a long distance under all weather and all day, which is now widely used in civil and military fields [
1]. SAR images contain rich target information, but because of different imaging mechanisms, SAR images are not as intuitive as optical images, and it is difficult for human eyes to recognize objects in SAR images accurately. Therefore, SAR automatic target recognition technology (SAR-ATR) has become an urgent need, which is also a hot topic in recent years.
SAR-ATR mainly contains two aspects: target feature extraction and target recognition. At present, target features that are reported in most studies include target size, peak intensity, center distance, and Hu moment. The methods of target recognition include template matching, model-based methods, and machine learning methods [
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15]. Machine learning methods have attracted increasing attention because appropriate models can be formed while using these methods. Machine learning methods commonly used for image recognition include support vector machines (SVM), AdaBoost, and Bayesian neural network [
16,
17,
18,
19,
20,
21,
22,
23,
24,
25]. In order to obtain better recognition results, traditional machine learning methods require preprocessing images, such as denoising and feature extraction. Fu et al. [
26] extracted Hu moments as the feature vectors of SAR images and used them to train SVM, and finally, achieved better recognition accuracy than directly training SVM with SAR images. Huan et al. [
21] used a non-negative matrix factorization (NFM) algorithm to extract feature vectors of SAR images, and combined SVM and Bayesian neural networks to classify feature vectors. However, in these cases, how to select and combine features is a difficult problem, and the preprocessing scheme is rather complex. Therefore, these methods are not practice-friendly, although they are somehow effective.
In recent years, deep learning has achieved great successes in the field of object recognition in images. Its advantage lies in the ability of using a large amount of data to train the networks and to learn the target features, which avoid complex preprocessing and can also achieve better results. Numerous studies have brought deep learning into the field of SAR-ATR [
27,
28,
29,
30,
31,
32,
33,
34,
35,
36,
37,
38,
39]. The most popular and effective model of deep learning is convolutional neural networks (CNNs), which is based on supervised learning, which requires a large number of labeled samples for training. However, in practical applications, people can only obtain unlabeled samples at first, and then label them manually. Semi-supervised learning enables the label prediction of a large number of unlabeled samples by training with a small number of labeled samples. Traditional semi-supervised methods in the field of machine learning include generative methods [
40,
41], semi-supervised SVM [
42], graph semi-supervised learning [
43,
44], and difference-based methods [
45]. With the introduction of deep learning, people begin to combine the classical statistical methods with deep neural networks to obtain better recognition results and to avoid complicated preprocessing. In this paper, we will combine traditional semi-supervised methods with deep neural networks, and propose a semi-supervised learning method for SAR automatic target recognition.
We intend to achieve two goals: one is to predict the labels of a large amount of unlabeled samples through training with a small amount of labeled samples and then extend the labeled set; and, the other one is to accurately classify multiple object types. To achieve the former target, we develop training methods of co-training [
46]. In each training round, we utilize the labeled samples to train two classifiers, then use each classifier to predict the labels of the unlabeled samples respectively, and select those positive samples with high confidence from the newly labeled ones and add them to the labeled set for the next round of training. We propose a stringent rule when selecting positive samples to increase the confidence of the predicted labels. In order to reduce the negative influence of those wrongly labeled samples, we introduce the standard noisy data learning theory [
47]. With advanced training processes, the recognition outcome of the classifier is getting better, and the number of the positive samples selected in each round of training is also increasing. Since the training process is supervised, we choose a CNN for the classifier due to the high performance on many other recognition tasks.
The core of our proposed method is to extend the labeled sample set with newly labeled samples, and to ensure that the extended labeled sample set enables the classifier to have better performance than the previous version. We have noticed the deep convolutional generative adversarial networks (DCGANs) [
48], which is very popular in recent years in the field of deep learning. The generator can generate fake images that are very similar to the real images by learning the features of the real images. We expect to expand the sample set with high-quality fake images for data enhancement to better achieve our goals. DCGANs contains a generator and a discriminator. We double the discriminator and use the two discriminators for joint training to complete the task of semi-supervised learning. Since the discriminator of DCGANs cannot be used to recognize multiple object types, some adjustments to the network structure are required. Salimans et al. [
49] proposed to replace the last layer of the discriminators with the softmax function to output a vector of the class probabilities. We draw on this idea and modify the classic loss function to achieve the adjustments. We also take the average value of the two classifier when computing the loss function of the generator, which have been proved to improve the training stability to some extent. We prove that our method performs better, especially when the number of the unlabeled samples is much greater than that of the labeled samples (which is a common scenario). By selecting high quality’s synthetically generated images for training, the recognition results are improved.
2. DCGANs-Based Semi-Supervised Learning
2.1. Framework
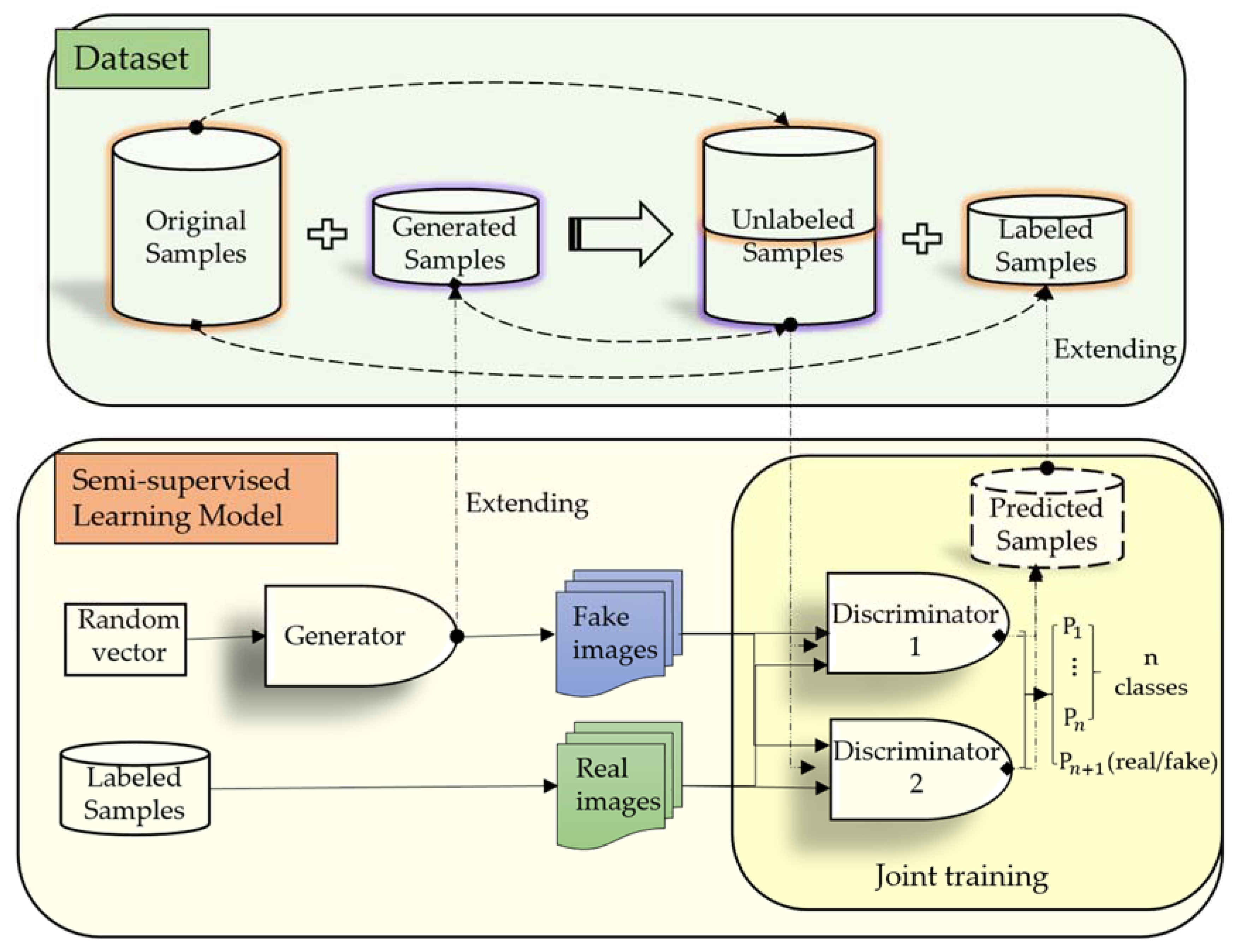
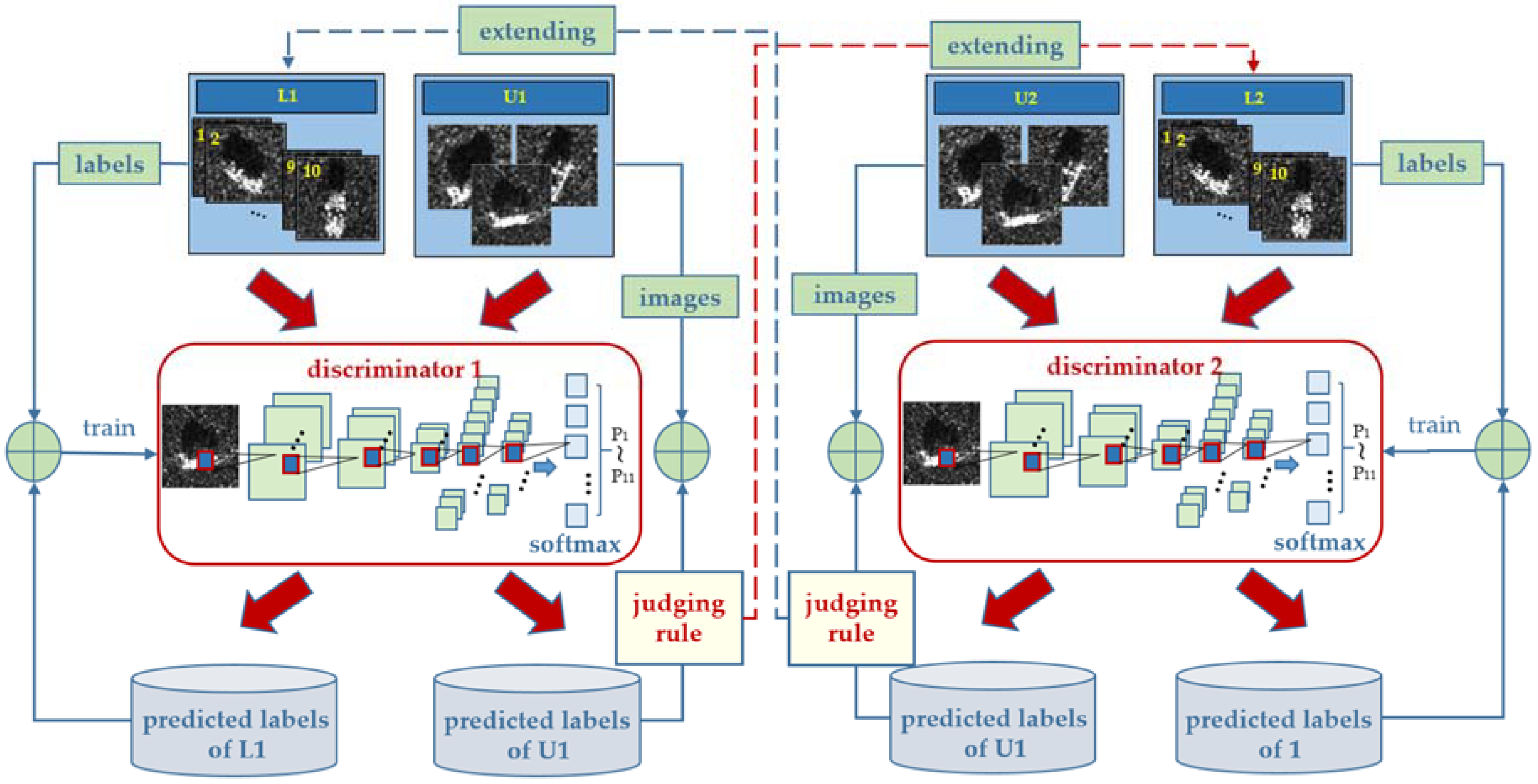
The framework of our method is shown in
Figure 1. There are two complete DCGANs in the framework, each contains one generator and two discriminators. To recognize multiple object types, we replace the last layer of the discriminators with a softmax function, and output a vector of that class probabilities. The last value in the vector represents the probability that the input sample is fake, while the others represent the probabilities that the input sample is real and that it belongs to a certain class. We modify the loss function of the discriminators to adapt to the adjustments, and take the average value of them when computing the loss function of the generator. The process of semi-supervised learning is accomplished through joint training of the two discriminators, and the specific steps in each training round are as follows: we firstly utilize the labeled samples to train the two discriminators, then use each discriminator to predict the labels of the unlabeled samples, respectively. We select those positive samples with high confidence from the newly labeled ones, and finally add them to each other’s labeled set for the next round of training when certain conditions are satisfied.
The datasets used for training are constructed according to the experiments, and there are two different cases: the first is to directly divide the original dataset into a labeled sample set and an unlabeled sample set to verify the effectiveness of the proposed semi-supervised method; the second is to select specific generated images of high quality as the unlabeled sample sets, select a portion from the original dataset, and form the labeled sample set to verify the effect of using the generated false images to train the networks.
2.2. MO-DCGANs
The generator is a deconvolution neural network, whose input is a random vector and outputs a fake image that is very close to a real image by learning the features of the real images. While the discriminator of DCGANs is an improved convolutional neural network, and both fake and real images will be sent to the discriminator. The output of the discriminator is a number falling in the range of 0 and 1, if the input data is a real image then this output number is getting closer to 1, and if the input data is a fake image then this output number is getting closer to 0. Both the generator and the discriminator will be strengthened during the training process.
In order to recognize multiple object types, we conduct enhancement for the discriminators. Inspired by Salimans et al. [
49], we replace the output of the discriminator with a softmax function and make it a standard classifier for recognizing multiple object types. We name this model multi-output-DCGANs (MO-DCGANs). Assuming that the random vector
has a uniform noise distribution
, and
maps it to the data space of the real images; the input
of the discriminator, which is assumed to have a distribution
, is a real or fake image with label
. The discriminator outputs a
dimensional vector of logits
, which is finally turned into a
dimensional vector of class probabilities
by the softmax function:
A real image will be discriminated as one of the formerclasses, and a fake image will be discriminated as theclass.
We formulate the loss function of MO-DCGANs as a standard minimax game:
We do not take the logarithm of
directly in Equation (2), because the output neurons of the discriminator in our model have increased from 1 to
, and
no longer represents the probability that the input is a real image but a loss function, corresponding to a more complicated condition. We choose cross-entropy function as the loss function, and then
is computed as:
where
refers to the expected class,
represents the probability that the input sample belongs to
. It should be noted that
and
are one hot vectors. According to Equation (3),
can be further expressed as Equation (4) when the input is a real image:
When the input is a fake image,
can be simplified as:
Assume that there are
inputs both for the discriminator and the generator within each training iterations, and the discriminator is updated by ascending its stochastic gradient:
while the generator is updated by descending its stochastic gradient:
The discriminator and the generator are updated alternately, and their networks are optimized during this process. Therefore, the discriminator can recognize the input sample more accurately, and the generator can make its output images look closer to the real images.
2.3. Semi-Supervised Learning
The purpose of semi-supervised learning is to predict the labels of the unlabeled samples by learning the features of the labeled samples, and use these newly labeled samples for training to improve the robustness of the networks. The accuracy of the labels has a great influence on the subsequent training results. Correctly labeled samples can be used to optimize the networks, while the wrongly labeled samples will maliciously modify the networks and reduce the recognition accuracy. Therefore, improving the accuracy of the labels is the key to semi-supervised learning. We conduct semi-supervised learning by utilizing the two discriminators for joint training. During this process, the two discriminator learns the same features synchronously. But, their network parameters are always dynamically different because their input samples in each round of the training are randomly selected. We use the two classifiers with dynamic differences to randomly sample and classify the same batch of the samples, respectively, and to select a group of positive samples from the newly labeled sample set for training each other. The two discriminators promote each other, and they become better together. However, the samples that are labeled in this way have a certain probability of becoming noisy samples, which deteriorates the performance of the networks. In order to eliminate the adverse effects of this noisy sample on the network as much as possible, we here introduce a noisy data learning theory [
49]. There are two ways that are proposed to extend the labeled sample set in our model: one is to label the unlabeled samples from the original real images; the other is to label the generated fake images. The next two parts will describe the proposed semi-supervised learning method.
2.3.1. Joint Training
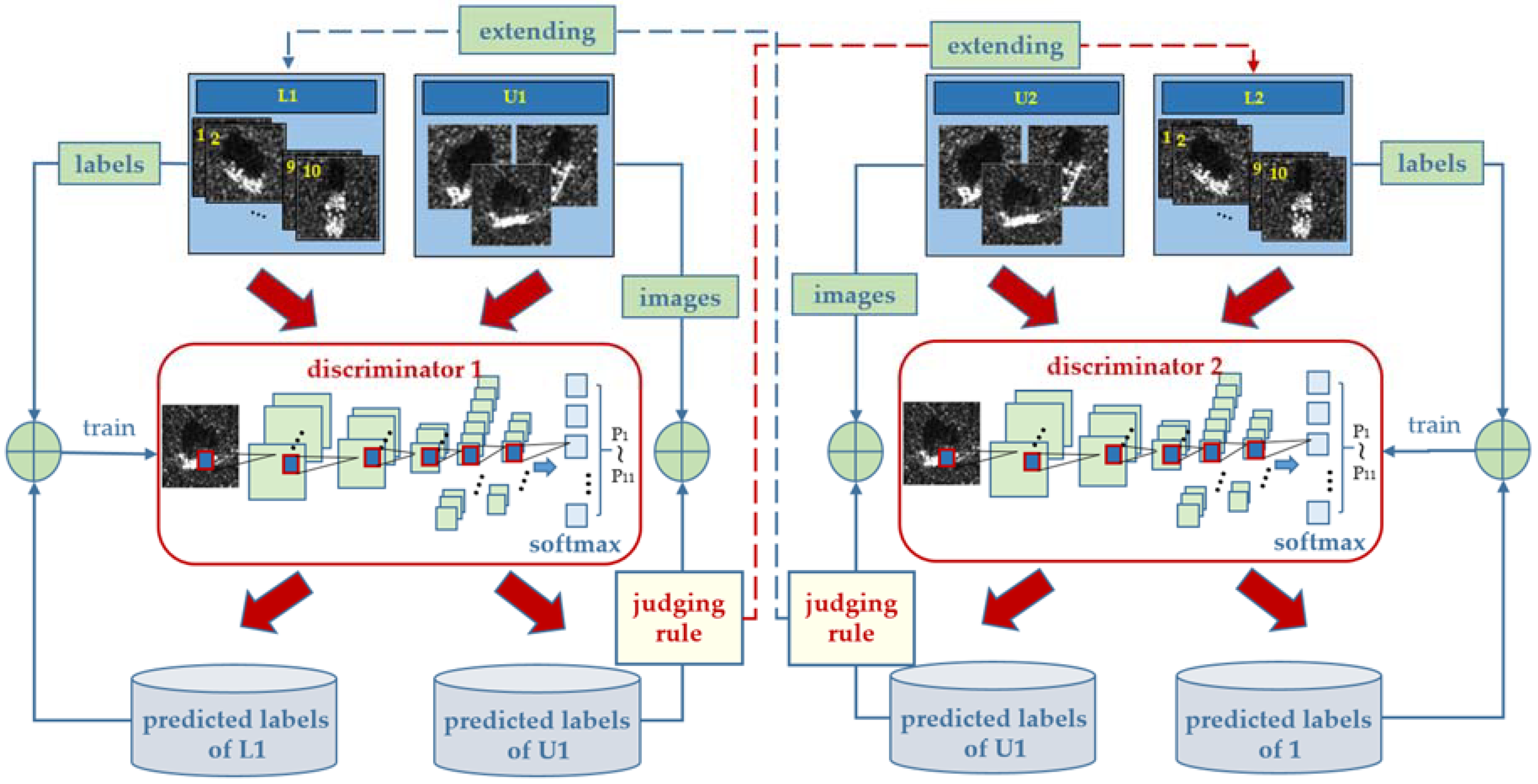
Numerous studies have shown that DCGANs training process is not stable, which fluctuates the recognition results. By doubling the discriminator in MO-DCGANs and by taking the average value of the two discriminators when computing the loss function, the fluctuations can be properly eliminated. This is because the loss function of a single classifier may be subject to large deviations in the training process, while taking the average value of the two discriminators can cancel the positive and negative deviations when ensuring that the performance of the two classifiers is similar. Meanwhile, we can use the two discriminators to complete semi-supervised learning tasks, which is inspired by the main idea of co-training. The two discriminators share the same generator, each forms a MO-DCGANs with the generator, and then we have two complete MO-DCGANs in our model. Every fake image from the generator will go into both the two discriminators. Let
and
represent the two discriminators, respectively, then Equation (7) becomes (8):
Let
and
represent the labeled sample sets of
and
, respectively, and
and
the unlabeled sample sets in the
training round. It should be emphasized that the samples in
and
are the same but in different orders, so do
and
. As shown in
Figure 2, the specific steps of the joint training are as follows:
- (1)
utilize () to train ();
- (2)
use () to predict the labels of the samples in; and,
- (3)
() selectspositive samples from the newly labeled samples according to certain criteria and adds them to () for the next round of training.
Note that the newly labeled samples will be regarded as unlabeled samples and will be added toin the next round. Therefore, in each round, all the original unlabeled samples will be labeled, and the selected positive samples are different. As the number of training increases, unlabeled samples will be fully utilized, and the pool of positive samples is increased and diversified. andare independent from each other in the first two steps. Each time, they select different samples, and they always maintain dynamic differences throughout the process. The difference will gradually decrease after lots of rounds of training and all of the unlabeled samples have been labeled and used to trainand, and the unlabeled samples include the complete features of the unlabeled samples.
A standard is adopted when we select the positive samples. When considering that if the probabilities outputs by the softmax function are very close, then it is not sensible to assign the label with the largest probability to the unlabeled input sample. But, if the maximum probability is much larger than the average of all the remaining probabilities, then it is reasonable to do so. Based on this, we propose a stringent judging rule: if the largest class probability
and the average of all the remaining probabilities satisfy Equation (9), then we can determined that the sample belongs to the class corresponding to
.
where
is the total number of the classes,
is a coefficient that measures the difference between
and all of the remaining probabilities. The value
is related to the performance of the networks. The better the network performance is, the larger the value of
is, and the specific value can be adjusted during the network training.
2.3.2. Noisy Data Learning
In the process of labeling the unlabeled samples, we often meet wrongly labeled samples, which are regarded as noise and will degrade the performance of the network. We look at the application shown in [
45], which was based on the noisy data learning theory presented in [
47] to reduce the negative effect of the noisy samples. According to the theory, if the labeled sample set
has the probably approximate correct (PAC) property, then the sample size
satisfies:
where
is the size of the newly labeled sample set,
is the confidence,
is the recognition error rate of the worst hypothetic case,
is an upper bound of the recognition noise rate, and
is a hypothetical error that helps the equation be established.
Let
and
denote the samples labeled by the discriminator in the
th and the
th training rounds. The size of sample sets
and
are
and
, respectively. Let
denote the noise rate of the original labeled sample set, and
denotes the prediction error rate. Then, the total recognition noise rate of
in the
th training round is:
If the discriminator is refined through using
to train the networks in the
th training round, then
. In Equation (10), all of the parameters are constant except for
and
. So, only when
the equation can still be established. When considering that
is very small in Equation (11), then
is bound to be satisfied if
. Assuming that
, when
is far bigger than
, we randomly subsample
whilst guaranteeing
. It has been proved that if Equation (12) holds, where
denotes the size of sample set
after subsampling, then
is satisfied.
To ensure that
is still bigger than
after subsampling,
should satisfy:
Since it is hard to estimate
on the unlabeled samples, we utilize the labeled samples to compute
. Assuming that the number of the correctly labeled samples among the total labeled sample set is
, then
can be computed as:
The proposed semi-supervised learning algorithm is presented in Algorithm 1. It should be emphasized that the process of the semi-supervised training is only related to the two discriminators, so the training part of the generator is omitted here.
| Algorithm 1. Semi-supervised learning based on multi-output DCGANs. |
Inputs: Original labeled training sets and, original unlabeled training sets and, the prediction sample sets and , the discriminators D1 and D2, the error rates and , the update flags of the classifiers and .
Outputs: Two vectors of class probabilities and. |
- 1.
Initialization: for , , - 2.
Joint training: Repeat until 400 epoch for - (1)
If, then. - (2)
Use to train and get. - (3)
Allow to label positive samples in U and add them to. - (4)
Allow to measure with. - (5)
If, then . - (6)
If and, then. - (7)
If , then ) and. - (8)
If, then.
- 3.
Output:
|
3. Experiments and Discussions
3.1. MSTAR Dataset
We perform our experiments on the Moving and Stationary Target Acquisition and Recognition (MSTAR) database, which is co-funded by National Defense Research Planning Bureau (ADRPA) and the U.S. Air Force Research Laboratory (AFRL). Ten classes of vehicle objects in the MSTAR database are chosen in our experiments, i.e., 2S1, ZSU234, BMP2, BRDM2, BTR60, BTR70, D7, ZIL131, T62, and T72. The SAR and the corresponding optical images of each class are shown in
Figure 3.
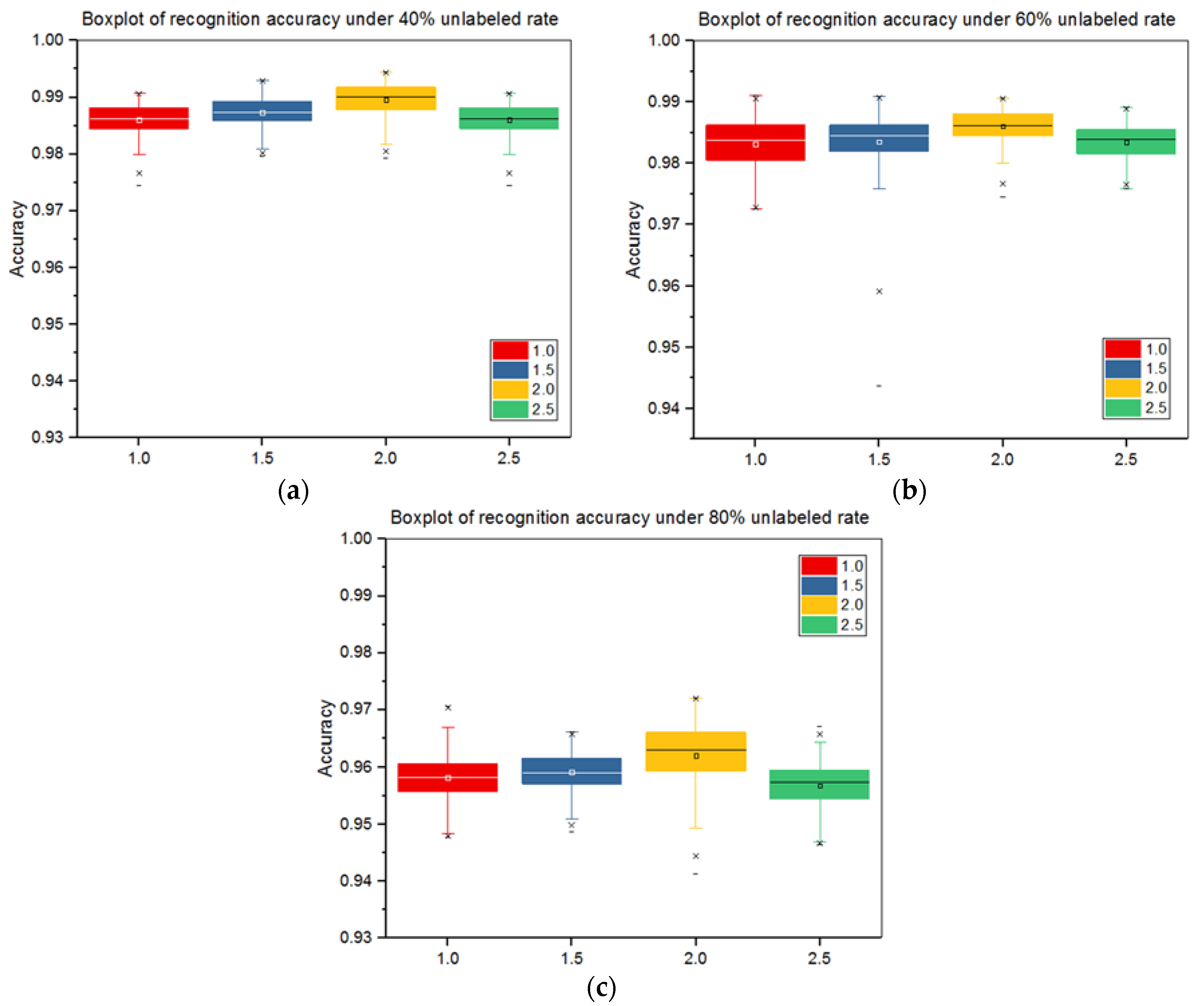
3.2. Experiments with Original Training Set under Different Unlabeled Rates
In the first experiment, we partition the original training set that contains 2747 SAR target chips in 17° depression into labeled and unlabeled sample sets under different unlabeled rates, including 20%, 40%, 60%, and 80%. Then, we use the total 2425 SAR target chips in 15° depression for testing. The reason why the training set and the test set take different depressions is that the object features are different in different depressions, which can ensure the generalization ability of our model.
Table 1 lists the detailed information of the target chips that are involved in this experiment, and
Table 2 lists the specific numbers of the labeled and unlabeled samples under different unlabeled rates. We use L to denote the labeled sample set, U to unlabeled sample set, and NDLT to noisy data learning theory. L+U represents the results obtained by using joint training alone, while L+U+NDLT represents the results that were obtained by using joint training and the noisy data learning theory together. We firstly utilize the labeled samples for supervised training and obtain supervised recognition accuracy (SRA). Then, we simultaneously use the labeled and unlabeled samples for semi-supervised training and obtain semi-supervised recognition accuracy (SSRA). Finally, we calculate the improvement of SSRA over SRA. Both SRA and SSRA are calculated by averaging the 150th to 250th training rounds accuracy of D1 and D2 to reduce accuracy fluctuations. In this experiment, we take
= 2.0 in Equation (9). The experimental results are shown in
Table 3.
When comparing the results of L+U and L+U+NDLT, we can conclude that the recognition accuracy is improved after we have introduced the noisy data learning theory. This is because the noisy data will degrade the network performance, and the noisy data learning theory will reduce this negative effect and therefore bring about better recognition results. While comparing the results of L and L+U+NDLT, it can be concluded that the networks will learn more feature information after using the unlabeled samples for training, thus the results of L+U+NDLT is higher than L. We also observe that as the unlabeled rate increases, the average SSRA decreases, while it will obtain higher improvement. It should be noted that the recognition results of the ten classes largely differ. Some classes can achieve high recognition accuracy with only a small number of labeled samples, therefore, the recognition accuracy will not be significantly improved after the unlabeled samples participate in training the networks, such as 2S1, T62, and ZSU234. Their accuracy improvements under different unlabeled rates fall within 3%, but their SRAs and SSRAs are still over 98%. While some classes can obtain large accuracy improvement by utilizing a large number of unlabeled samples for semi-supervised learning, and the more unlabeled samples, the more improvement. Taking BTR70 as an example, its accuracy improvement is 13.94% under an 80% unlabeled rate, but its SRA and SSRA are only 84.94% and 96.78%, respectively.
To directly compare the experimental results, we plot the recognition accuracy curves of L, L+U, and L+U+NDLT corresponding to individual unlabeled ratios, as shown in
Figure 4. It is observed that the three curves in
Figure 4a look very close, L+U and L+U+NDLT are gradually higher than L in (b,c), and L+U, L+U+NDLT is over L in (d). This indicates that the larger the unlabeled rate is, the more the accuracy improvement can be obtained. Since semi-supervised learning may result in incorrectly labeled samples, which makes it impossible for newly labeled samples to perform, as well as the original labeled samples, the recognition effect will be better with a lower unlabeled rate (simultaneously a higher labeled rate). The experimental result shows that the semi-supervised method that is proposed in this paper is more suitable for those cases when the number of the labeled samples is very small, which is in line with the expectation.
3.3. Quality Evaluation of Generated Samples
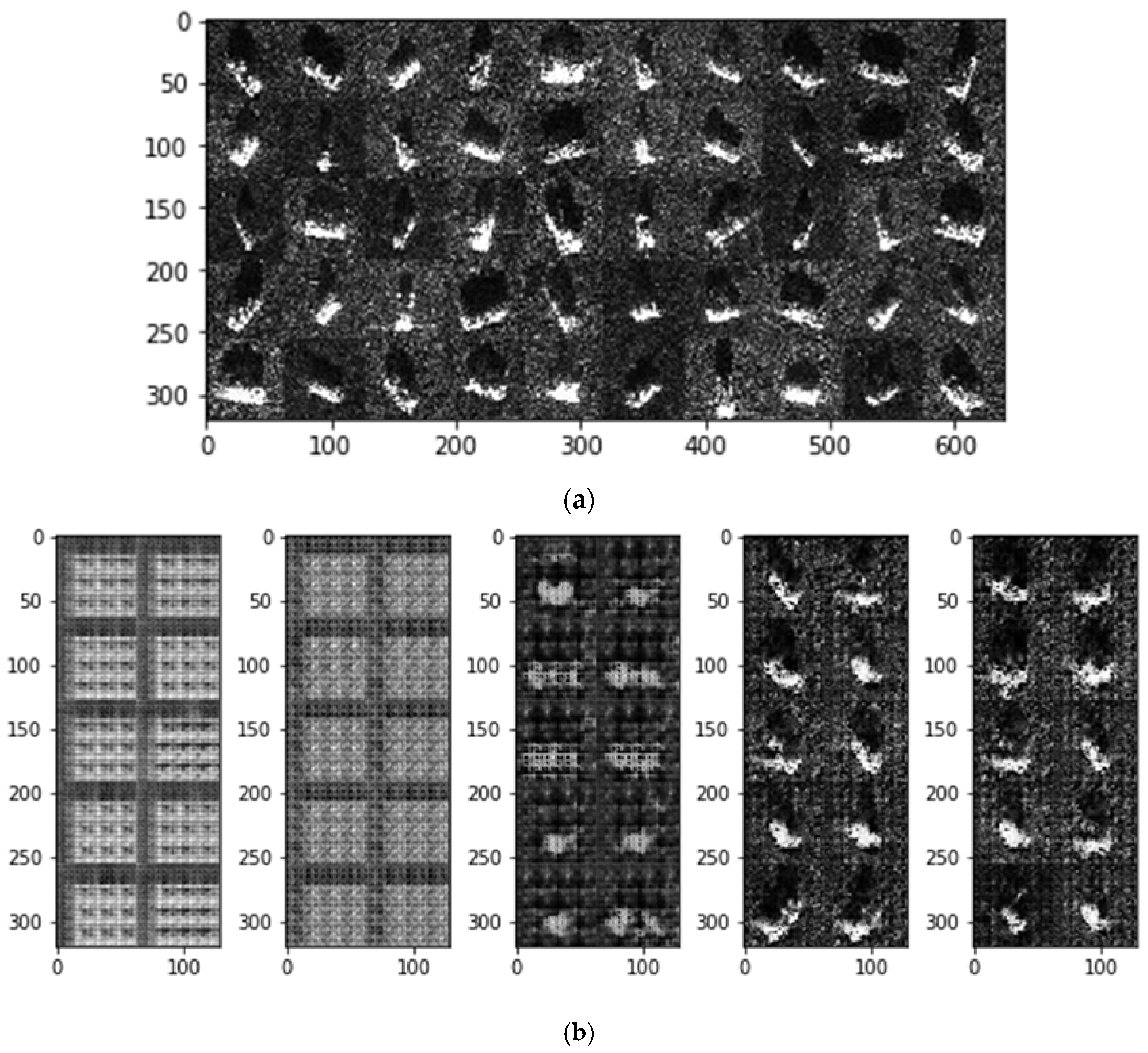
One important reason why we adopt DCGANs is that we hope to use the generated unlabeled images for network training in order to improve the performance of our model, when there are only a small number of labeled samples. In this way, we can not only make full use of the existing labeled samples, but also obtain better results than just using the labeled samples for training. We analyze the quality of the generated samples before using them. We randomly select 20%, 30%, and 40% labeled samples (respectively, including 550, 824, and 1099 images) from the original training set for supervised training, then extract images generated in the 50th, 150th, 250th, 350th, and 450th epoch. It should be noted that in this experiment, we want to extract as many high-quality generated images as possible during the training process to improve the network performance. Therefore, we do not limit the number of these high-quality images, then the unlabeled rates cannot be guaranteed to be 40%, 60%, and 80%, respectively.
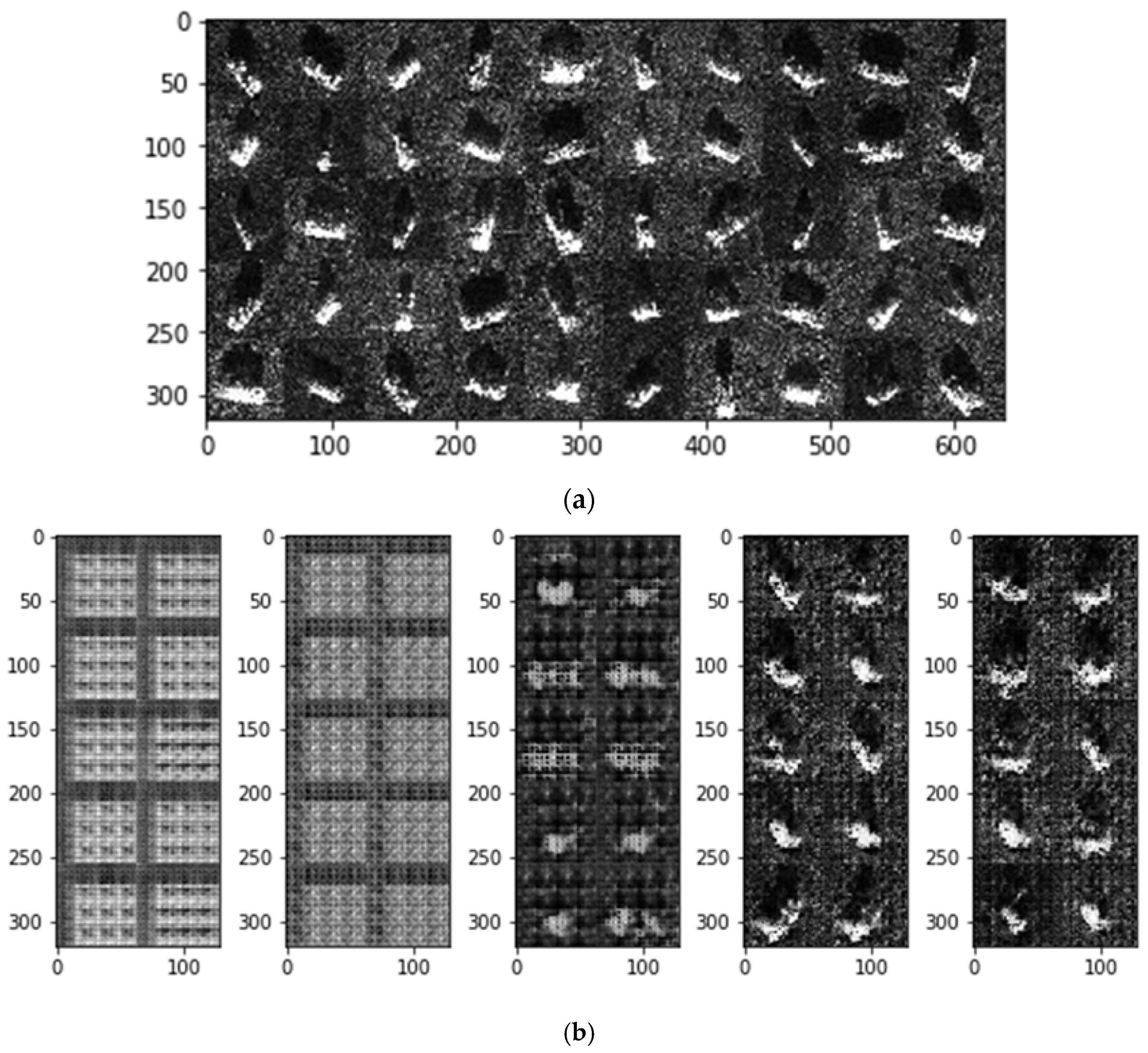
Figure 5a shows the original SAR images, and (b–d) show the images generated with 1099, 824, and 550 labeled samples, respectively. In (b,c), each group of images from left to right is generated in the 50th, 150th, 250th, 350th, and 450th epoch.
We can see that as the training epoch increases, the quality of the generated images gradually becomes higher. In
Figure 5b, objects in the generated images are already roughly outlined in the 250th epoch, and the generated images are very similar to the original images in the 350th epoch. In
Figure 5c, objects in the generated images are clear until the 450th epoch is taken. In
Figure 5c, the quality of the generated images is still poor in the 450th epoch.
In order to confirm the observations that are described above, we select 1000 images from each group of the generated images shown in
Figure 5b–d and, respectively, input them into a well-trained discriminator, then count the total number of the samples that satisfy the rule shown in Equation (9), as presented in
Section 2.3.1. We still use
α = 2.0 in this formula. We believe that those samples which satisfy the rule are of high quality and can be used to train the model. The results listed in
Table 4 are consistent with what we expect.
3.4. Experiments with Unlabeled Generated Samples under Different Unlabeled Rates
This experiment will verify the impact of the high-quality generated images on the performance of our model. We have confirmed in
Section 3.2 that the semi-supervised recognition method that is proposed in this paper leads to satisfactory results in the case of a small number of labeled samples. Therefore, this experiment will be related to this case. The labeled samples in this experiment are selected from the original training set, and the generated images are used as the unlabeled samples. The testing set is unchanged. According to the conclusions made in
Section 3.3, we select 1099, 824, 550 labeled samples from the original training set for supervised training, then, respectively, extract those high-quality generated samples in the 350th, 450th, and 550th epoch, and utilize them for semi-supervised training. It should be emphasized that since the number of the selected high-quality images is uncertain, the total amount of the labeled and unlabeled samples no longer remains at 2747. The experimental results are shown in
Table 5.
It can be found that the average SSRA will obtain better improvement with less labeled samples. Different objects vary greatly in accuracy improvement. The generated samples of some types can provide more feature information, so our model will perform better after using these samples for training, and the recognition accuracy will also be improved significantly, such as BRDM2 and D7. Their accuracy improvements will significantly increase as the number of the labeled samples decreases. Note that BRDM2 performs worse with 1099 labeled samples, but much better with 550 labeled samples. This is because the quality of the generated images is much worse than that of the real image, therefore, the generated images will make the recognition worse when there is a large number of labeled samples. When the number of the labeled samples is too small, using a large number of generated samples can effectively improve the SSRA, but the SSRA cannot exceed the SRA of a little more labeled samples, such as the SRA of 824 and 1099 labeled samples. However, the generated samples of some types become worse as the number of the labeled samples decrease, and thus the improvement tends to be smaller, such as BTR70. Meanwhile, some generated samples are not suitable for network training, such as ZIL131. Its accuracy is reduced after the generated samples participate in the training, and we believe that the overall accuracy will be improved by removing these generated images.
We have found that when the number of the labeled samples is less than 500, there is almost no high-quality generated samples. Therefore, we will not consider using the generated samples for training in this case.
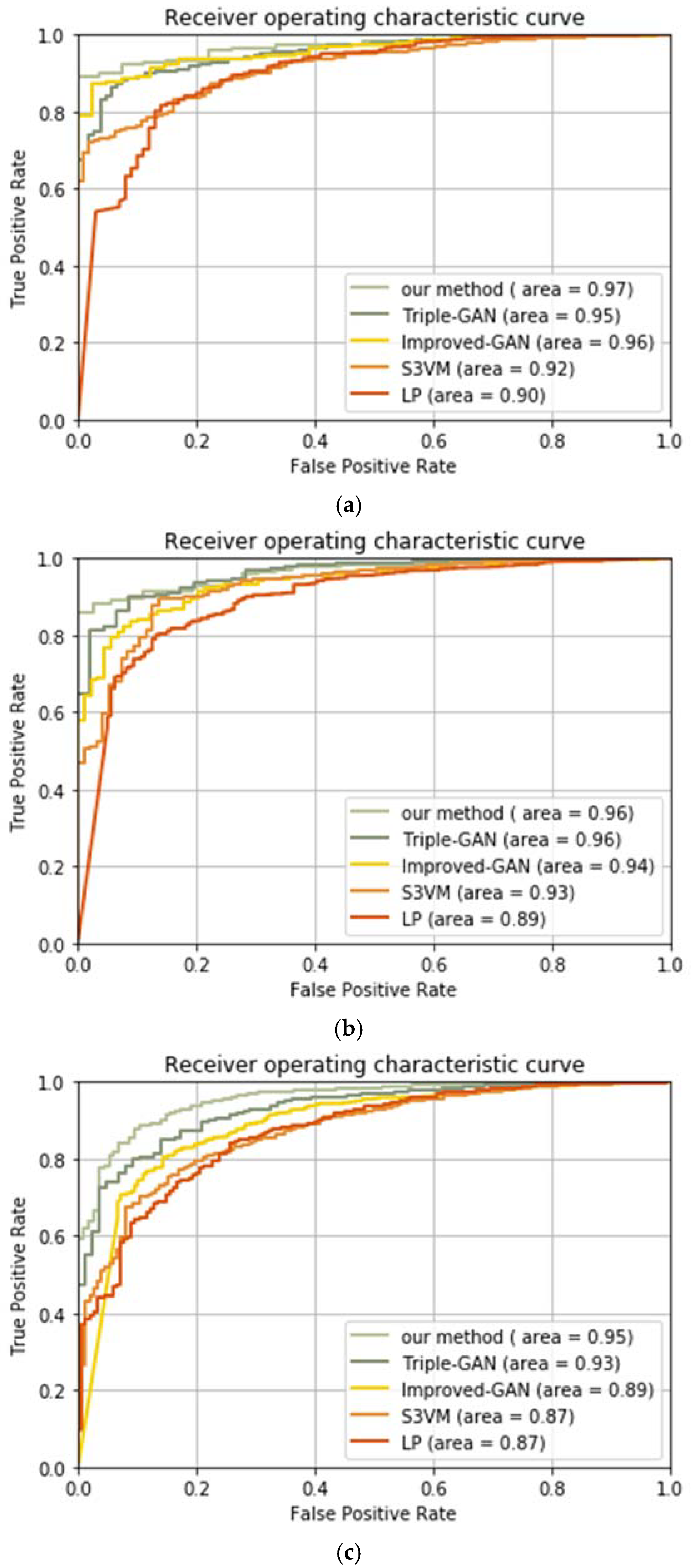
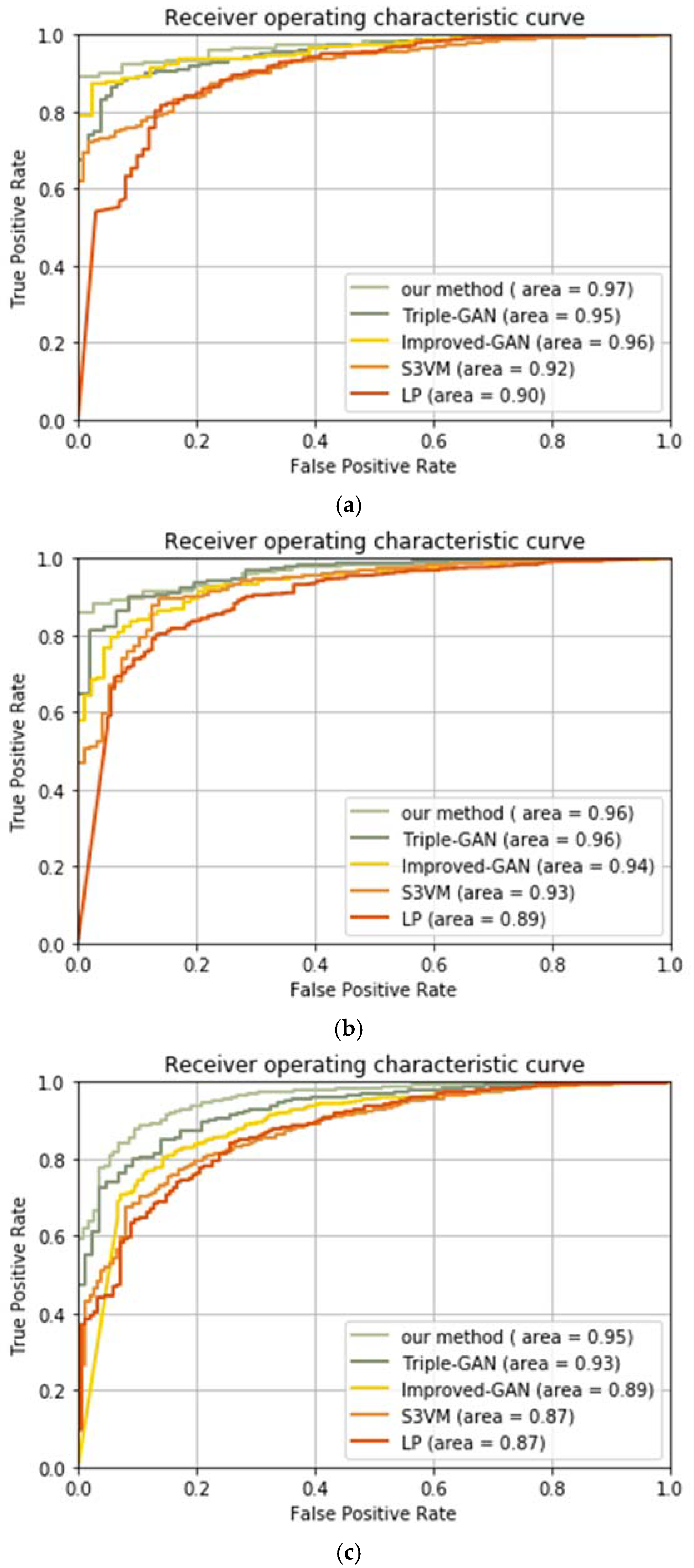
3.5. Comparison Experiment with Other Methods
In this part, we compare the performance of our method with several other semi-supervised learning methods, including label propagation (LP) [
50], progressive semi-supervised SVM with diversity P
VM-D [
42], Triple-GAN [
51], and improved-GAN [
49]. LP establishes a similar matrix and propagates the labels of the labeled samples to the unlabeled samples, according to the degree of similarity. P
VM-D selects the reliable unlabeled samples to extend the original labeled training set. Triple-GAN consists of a generator, a discriminator, and a classifier, whilst the generator and the classifier characterize the conditional distributions between images and labels, and the discriminator solely focuses on identifying fake images-label pairs. Improved-GAN adjusts the network structure of GANs, which enables the discriminator to recognize multiple object types.
Table 6 lists the accuracies of each method under different unlabeled rates.
We can conclude from
Table 6 that our method performs better than the other methods. There are mainly two reasons for this: one is that CNNs is used as the classifier in our model, which can extract more abundant features than the traditional machine learning methods, such as LP and P
VM-D, also other GANs that consist of no CNNs, such as Triple-GAN and improved-GAN; the other is that we have introduced the noisy data learning theory, and it has been proved that the negative effect of noisy data can be reduced with this theory, and therefore bring better recognition results. It can be found that as the unlabeled rate increases, the system performance becomes worse. Especially when the unlabeled rate increases to 80%, the recognition accuracy of LP and Improved-GAN decreases to 73.17% and 87.52%, respectively, meaning that these two methods cannot cope with the situations where there are few labeled samples. While P
VM-D, Triple-GAN, and our method can achieve high recognition accuracy with a small number of labeled samples, and our method has the best performance with individual unlabeled rates. In practical applications, label samples are often difficult to obtain, so a good semi-supervised method should be able to use a small number of labeled samples to obtain high recognition accuracy. In this sense, our method is promising.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}