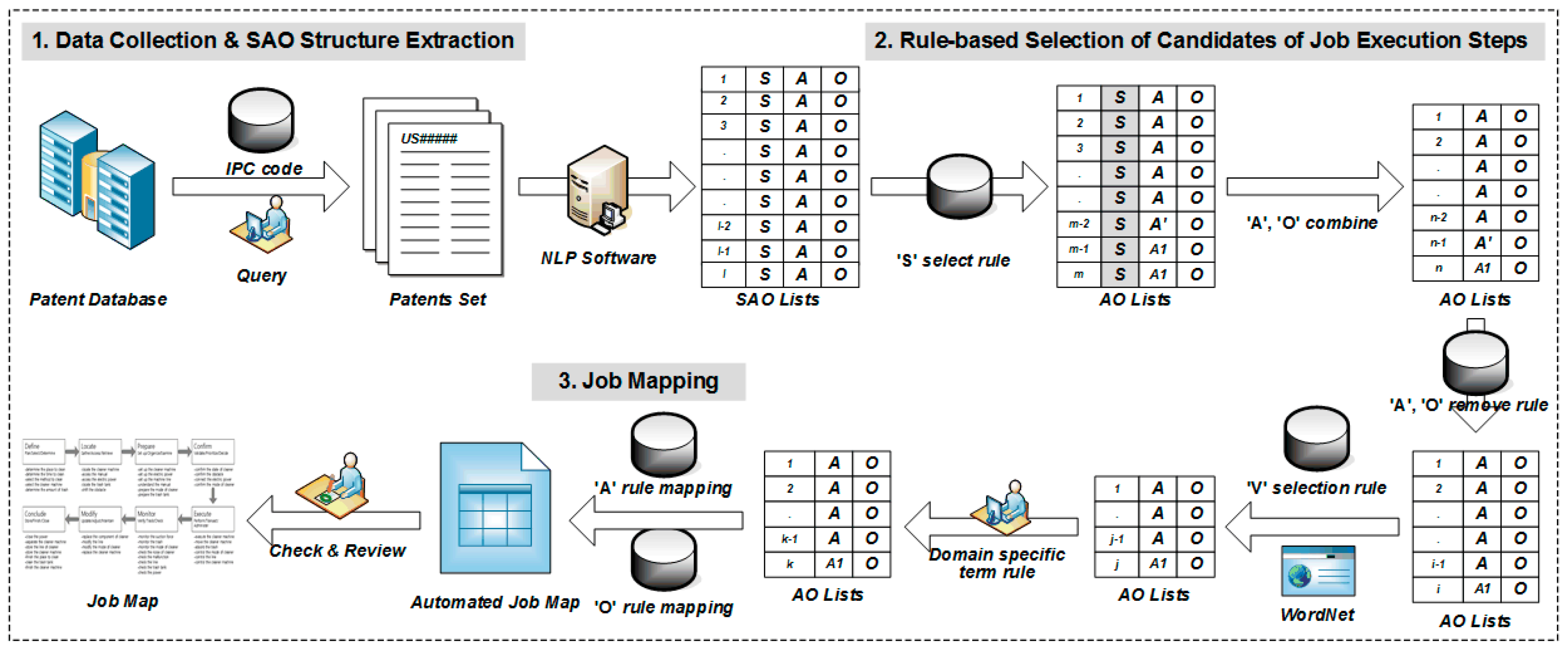
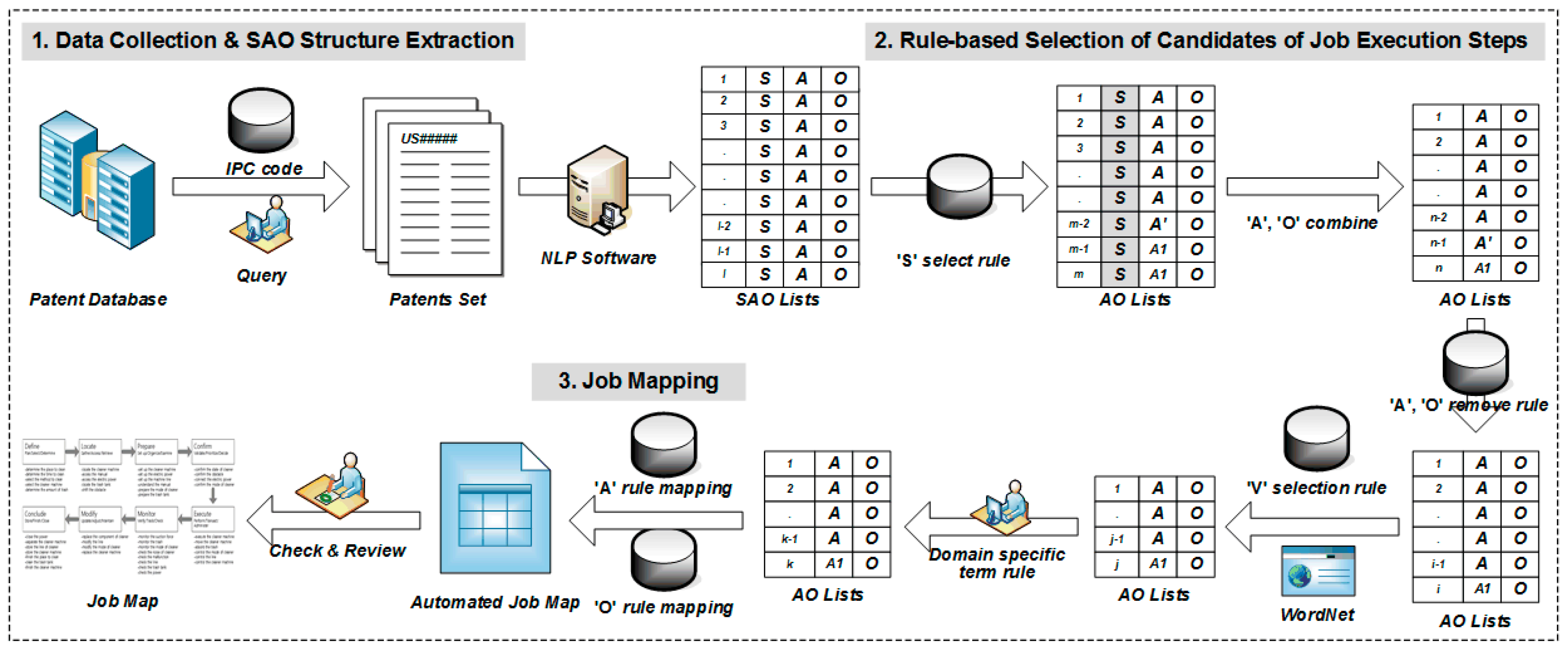
For Job Mapping, the overall process of the semi-automated method proposed in this study consists of three phases (
Figure 4). The first phase is to use International Patent Classification (IPC) codes to guide the collection of patent sets of the product group that is related to the Job, then to use NLP to extract the SAO structures from each patent document. The second phase is to apply rules to the candidate SAO structures to first select valid SAO structures for Job Mapping, then to apply action–selection rules, object–selection rules, and domain–knowledge rules to generate AO lists that can represent the detailed customer behaviors of the Job Map. The third phase is to apply verb-mapping rules and object-mapping rules to the selected AO lists to develop the Job Map. Finally, the user who performs the Job Mapping completes the Map by reviewing and checking it.
3.1. Data Collection and SAO Structure Extraction
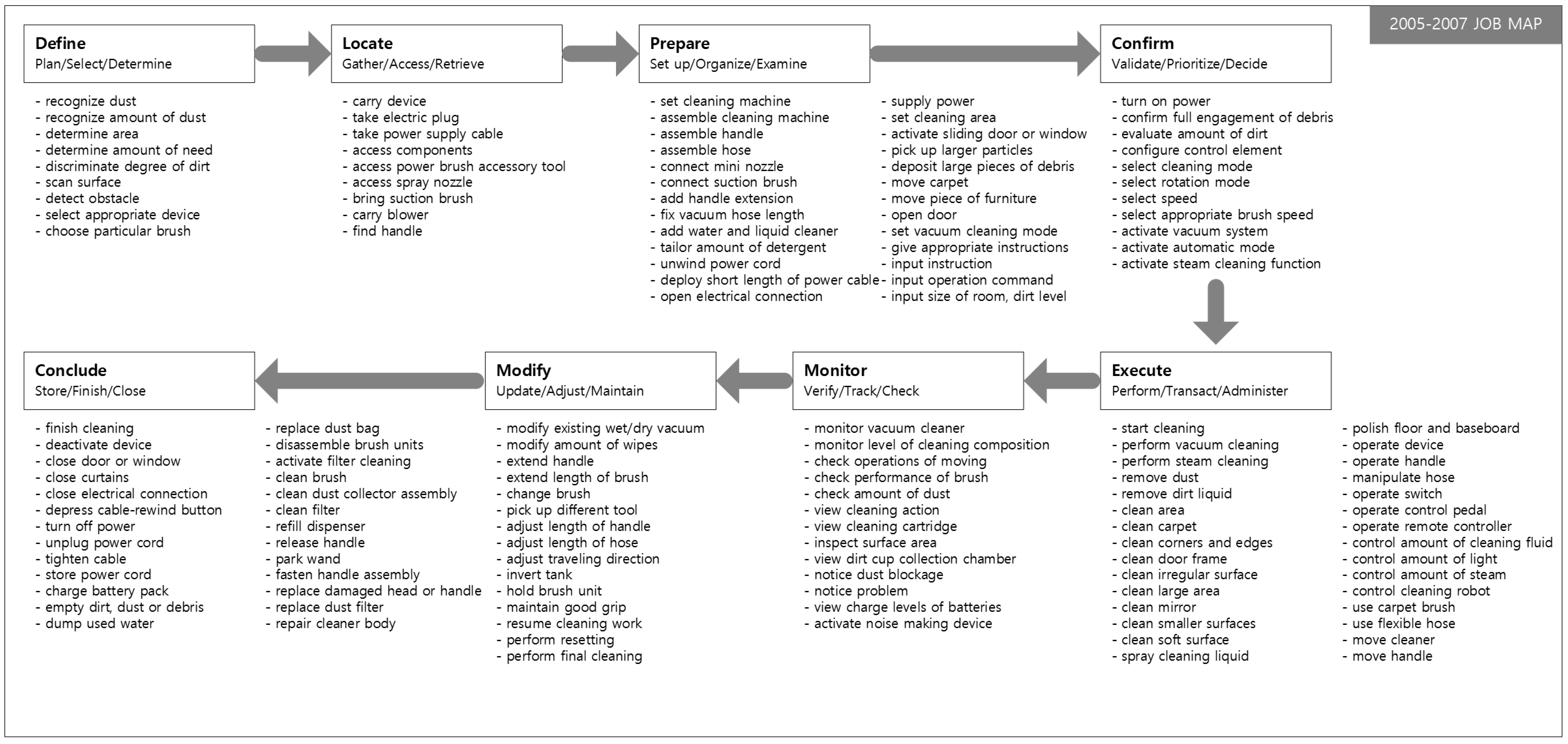
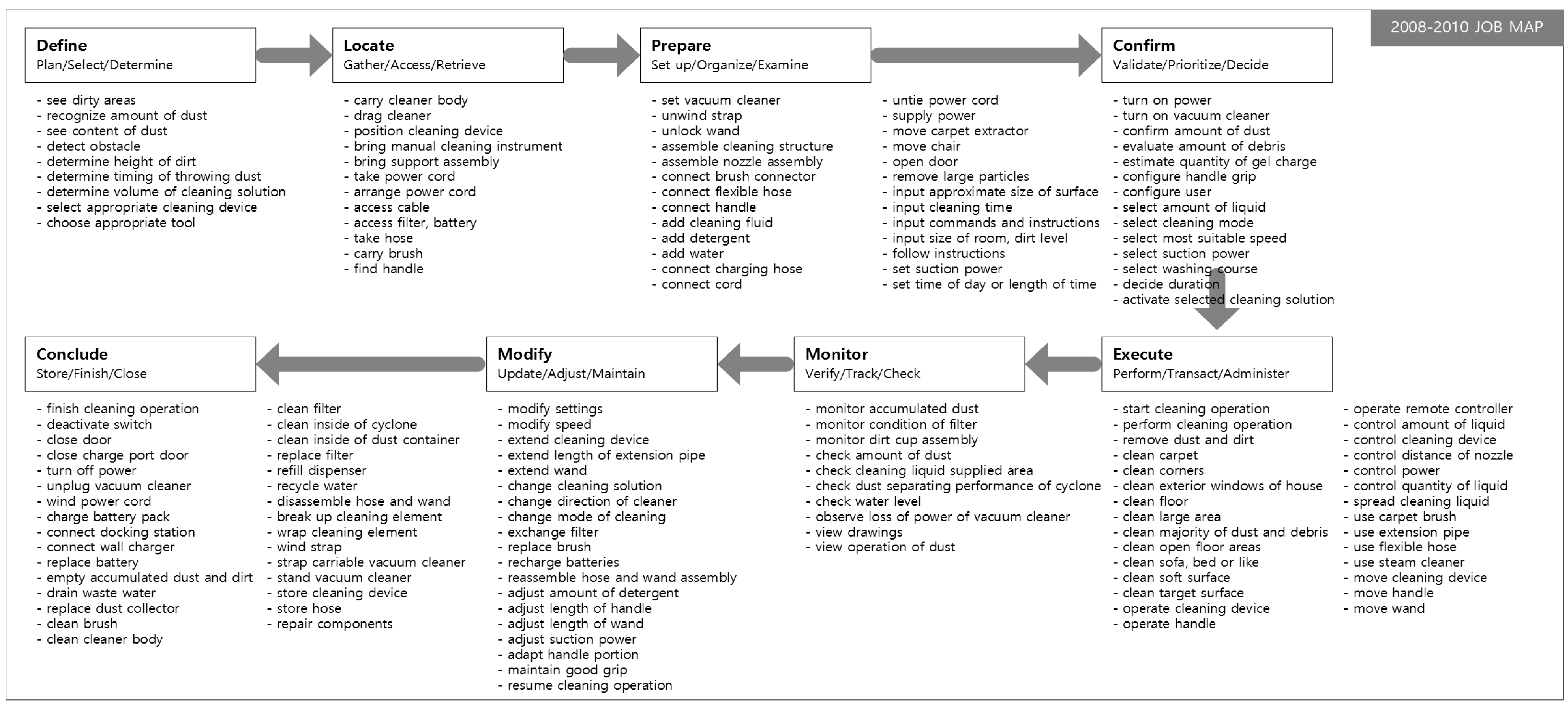
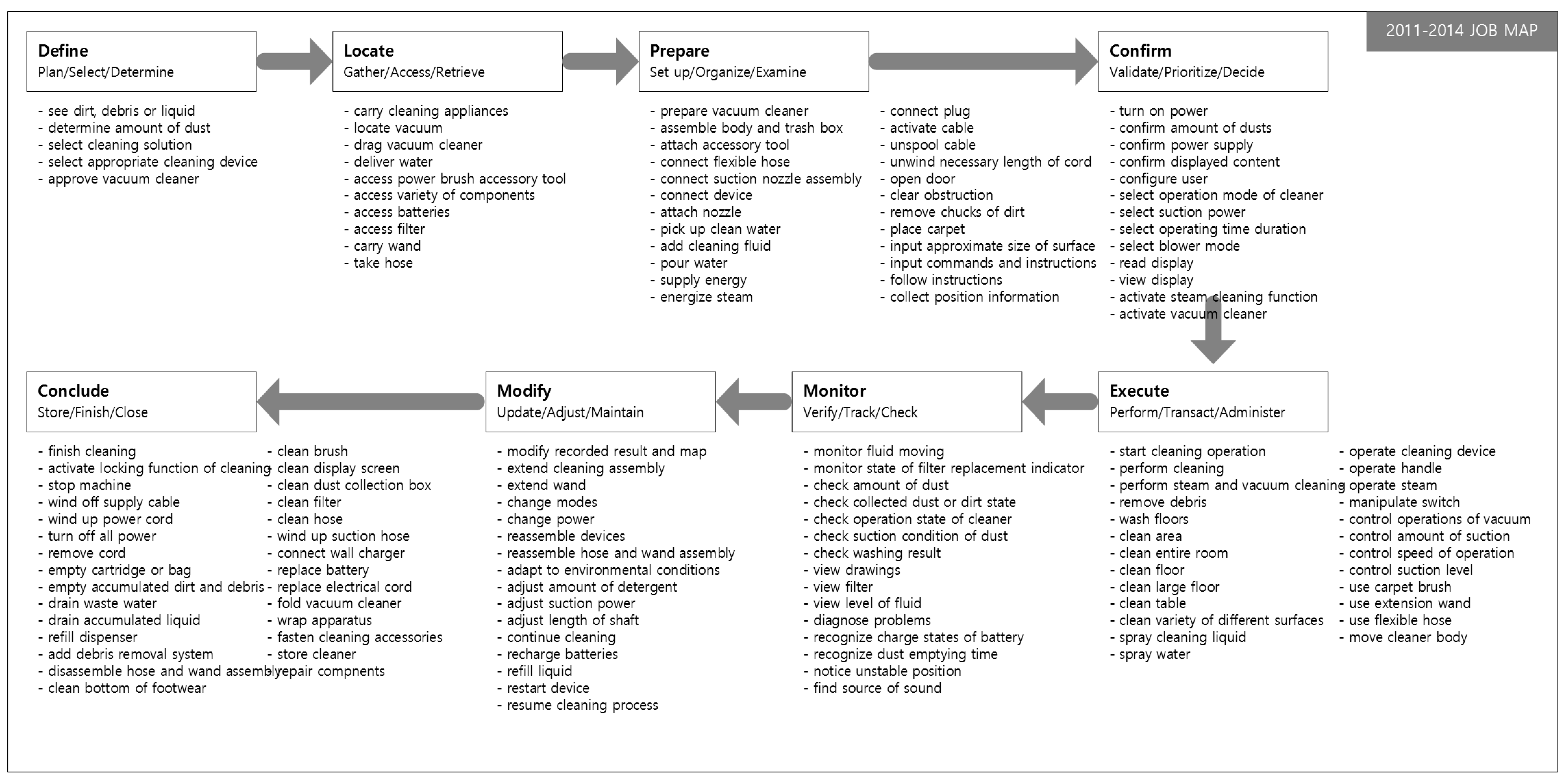
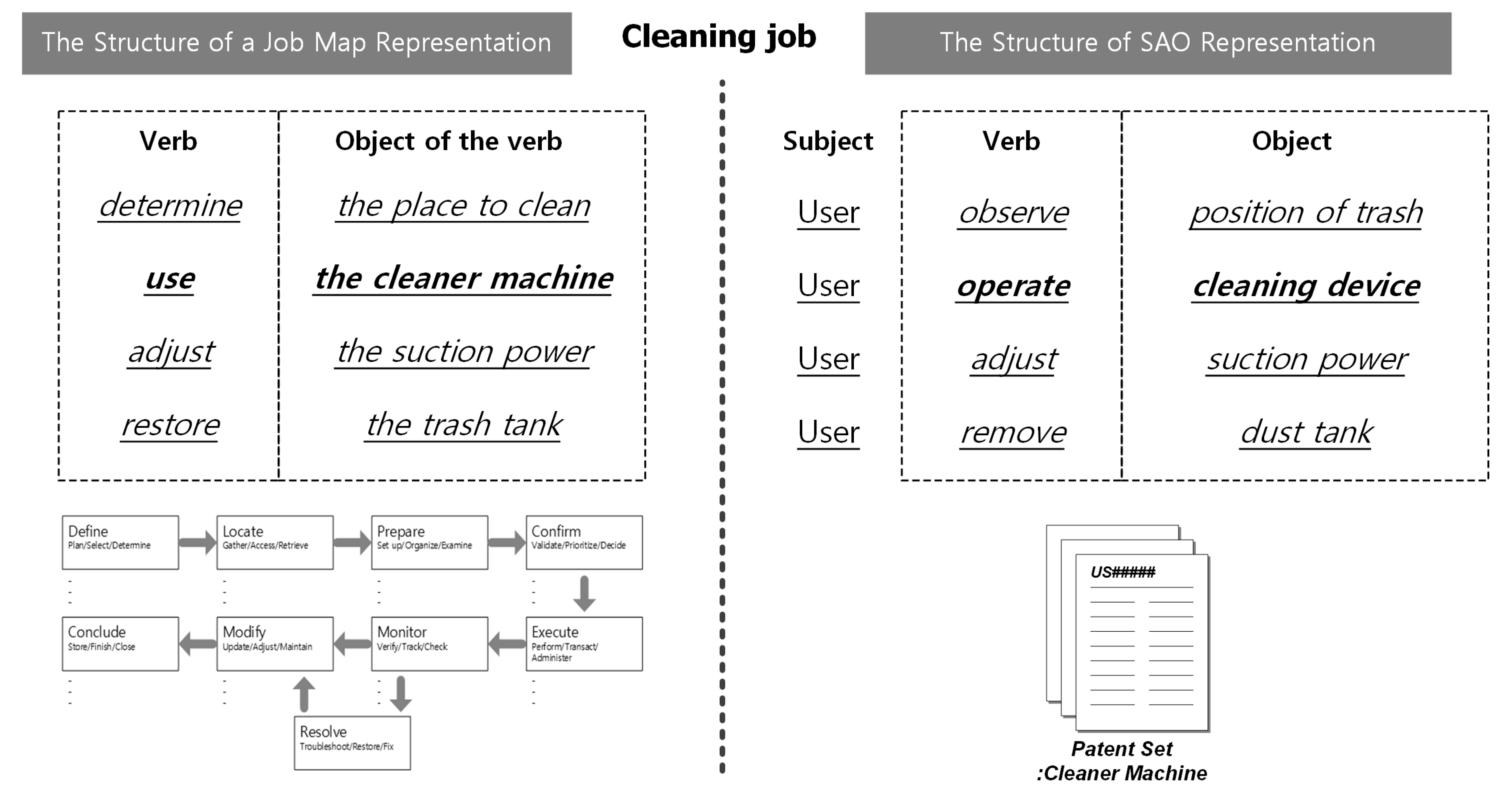
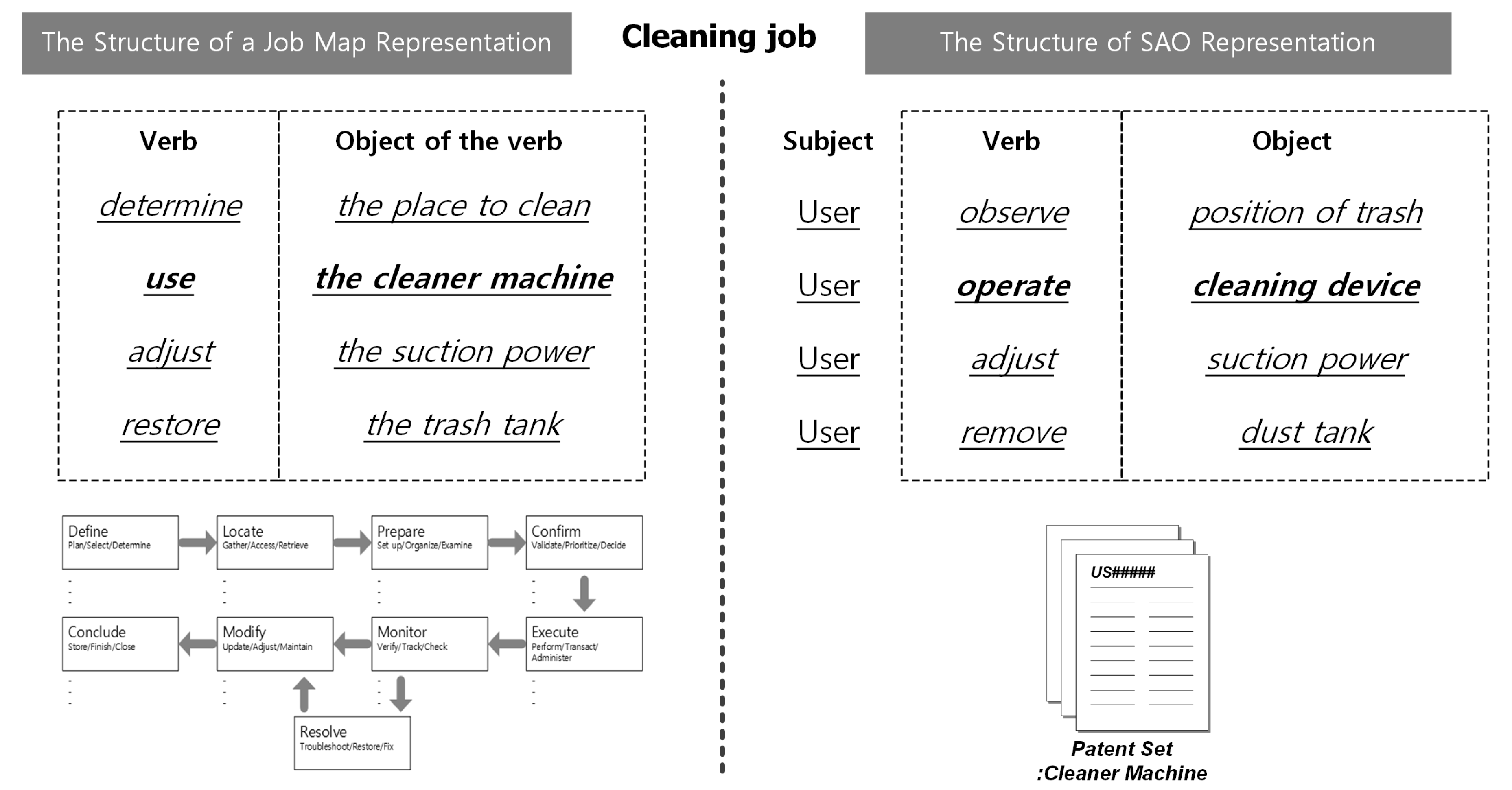
In this research, the Job Map presents the detailed actions of the customer, which are derived from patent data. Patent data are highly efficient to search and analyze because the patent specification format is standardized [
38,
39]. In addition, patent data include bibliographic information in addition to technical information, so various analyses are possible. The relevant fields in patent data for this study include “field of invention”, “description of related art”, “summary of the invention”, and “detailed description”. Information about customers who use the product can also be found in such data. To collect patent data, we use bulk patent dataset from Google Repository (Google, Menlo Park, CA, USA).
The first phase of Job Mapping is to define the Job and the group of products that are needed to perform it and to select IPC codes related to the product group. Because the Job Map considers the entire process to complete resolving a job, data are collected over a wide range of product groups rather than for a specific product. For example, beyond the patents associated with vacuum cleaners, patents related to the required tools used should also be examined. The IPC code can be found in any IPC code browser or IPC code dictionary. In addition, missing patents should be added to the category defined in IPC codes. A user can check other IPC codes referenced by the retrieved patents, or can add use query searching to add a patent set.
When the IPC code associated with the product group is selected, a set of patents that belong to the IPC code is collected. Because the goal of the proposed methods to use as much data as possible in the content of patents, the scope of patents related to the term and rights is set to include all published patents. This large amount of data increases the reliability of the results of Job Mapping and enables further analyses. When the entire patent set is selected, the contents of the patent document such as “abstract”, “field”, “introduction”, “summary”, “description of invention”, and the basic bibliographic information are stored. The patent data can be collected using patent search sites provided by the United States Patent and Trademark Office (USPTO) or other similar organizations, or by using a commercial patent search site.
Next, NLP is used to extract the contents of the collected patent automatically in SAO form from patent documents. This step can use any NLP analysis software such as Stanford parser, Alchemy API, Antelope, or Knowledgist. To determine the exact meaning of the SAO structure, each structure must be associated with existing patent documents.
3.2. Rule-Based Selection of Candidates of Job Execution Steps
The next phase is to derive specific task related to customer behavior, which is a component of the Job Map. In this study, we defined rules to derive candidates that are likely to be detailed Jobs. The first classification step is to identify the set of SAO structure that is related to the customer’s behavior, purpose, and other requirements. SAO structures are selected first if the subject (noun) is a word related to the customer. Because the patent document is clearly and concisely described, it is an easy task to confirm that the subject part is related to the customer.
The first step in this process is to extract nouns that can be related to the customers and their behaviors (
Table 1). These nouns or noun phrases are related to ‘using’, ‘people’, and ‘body parts’. In addition to this, the user who performs the Job mapping task can add nouns that he or she thinks are valid and can provide domain-specific terms according to the product group.
The next step is to identify AO structures that are likely to describe tasks that are components of the Job Map. The SAO set that is selected first has a subject associated with the customer. In the second classification step, the rules are defined and classified by verb and object elements (
Table 2).
To define AO structures, we select verbs from three categories. First, AO structures that include a verb associated with “technology view” are highly related to technical solutions or technical outcomes; therefore, these structures should be retained. Second, verbs related ‘components’ are greatly related to the product itself, and, third, verbs related to “emotion” are likely to refer to responses of the customer. We refer to the study of Choi, et al. [
40], which is one of the existing SAO analysis studies, to define verbs of technology and product components. In addition, we add an emotion category because of the necessity for the Job Map analysis of the experience of the user. Lastly, verbs that are not likely to refer to the jobs should be eliminated.
When selecting AO structures, removing meaningless words (called stopwords) is a very important task. Unfortunately, in NLP research, there is still no perfect way to remove stopwords automatically. Generally, through a trial-and-error process, the analyst chooses stopwords to improve the performance of the target NLP application. In this paper, we recommend the use of data from the Google dictionary [
41], which is the most general stopword dictionary. One way is to exclude AOs that have objects containing pronouns or rhetoric and that are in the dictionary. The aforementioned SAO parsers in NLP analysis software can extract a considerable amount of AO structures from patent documents. Thus, the filtering out of some AO structures with stopwords should not be a problem, given the variety and volume of big patent data. After removing the AO structures, the analyst can eliminate more additional meaningless AOs as needed.
In the second classification process, the user merges semantically similar AO structures into a single AO structure. For example, a plural verb is the same as its singular form. Furthermore, if nouns or noun phrases in the object part are synonymous, they can be integrated into one AO. The NLP technology is applied to handle the integration of synonyms. For example, WordNet, a dictionary that already defines the relationships of words and phrases [
42,
43,
44], can be used to obtain semantic similarity information of words. In addition, the recently developed Word2Vec technology [
45,
46], which expresses the relationships among words in a vector space, can be used to measure the distance between similar words by using the measure of cosine distance. Finally, the user applies rules to define verbs and objects that are not relevant to the detailed jobs and removes AO structures that use these subjects or objects.
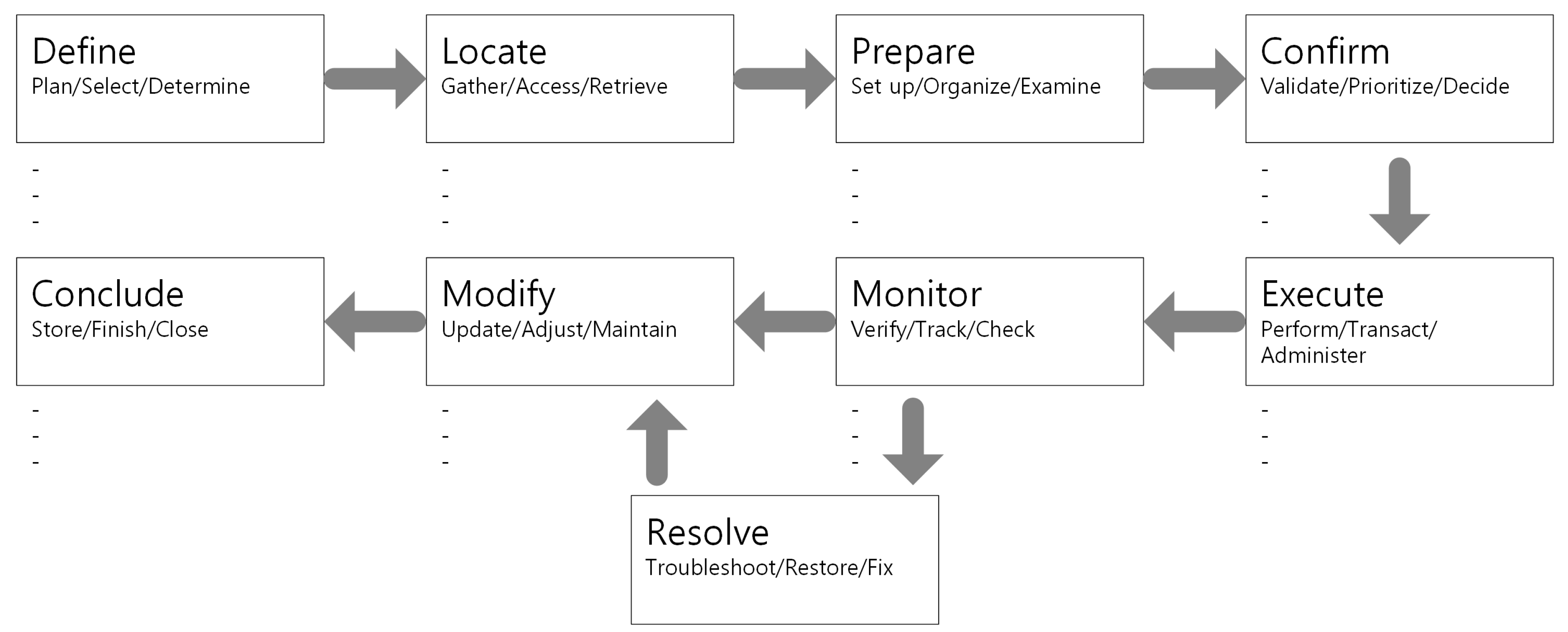
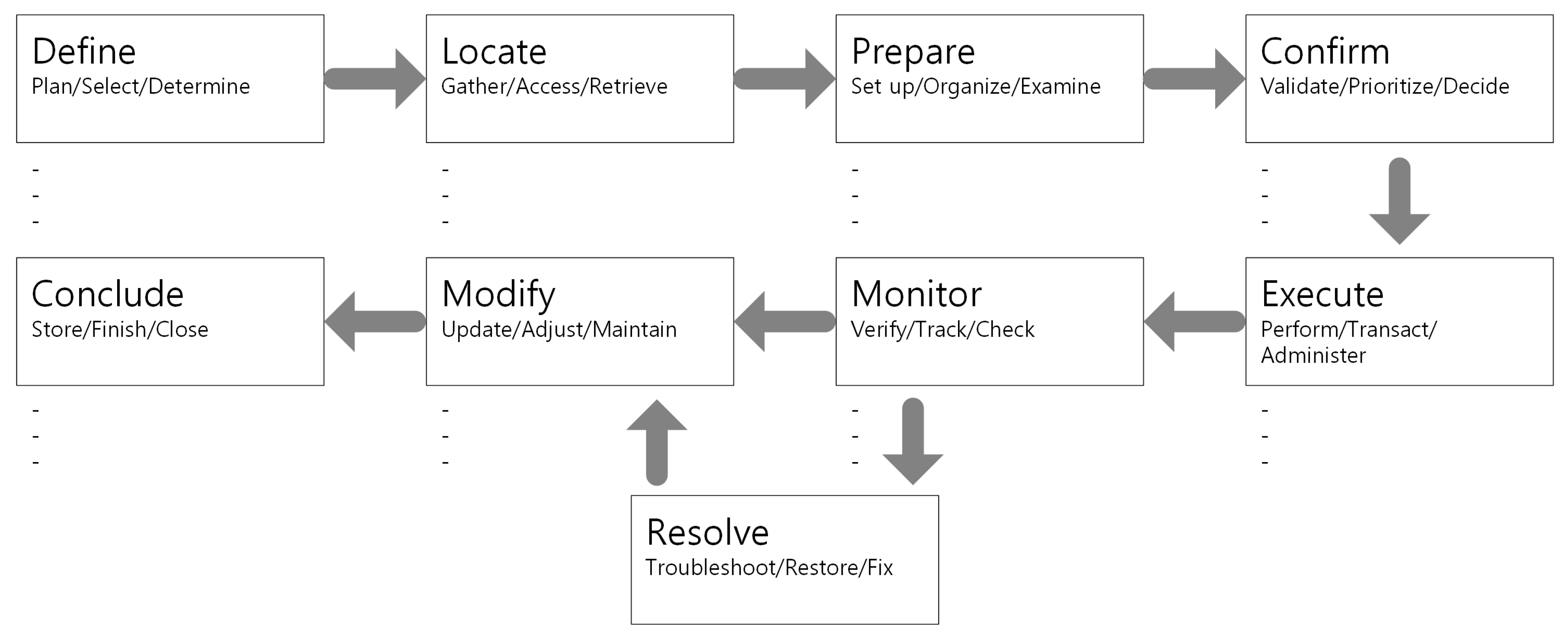
The third step is to closely examine the remaining AO structures to select candidates that are likely to describe detailed Jobs. This selection process uses the verb in the general guidelines to define Jobs that belong to each step in the Job Map. In this step, candidate AOs are identified based on verbs that are related to each step of the Job Map (
Table 3). This study uses the eight-step process (
Figure 1); the ninth ‘resolve’ step can be added as necessary. The user can add or remove steps as appropriate. As previously described, verbs such as synonyms and antonyms of the verbs in the guidelines are defined as rules for this step. A lexical database such as WordNet (
Figure A1 in
Appendix A) can be used effectively for this purpose [
42,
43,
44].
Some AO structures may be domain-specific. In this case, the creator of the Job Map and the domain experts would add rules for the verb and object parts. These semi-automatic procedures identify the AO candidates that are likely to become detailed Jobs of the Job Map.
3.3. Job Mapping
The next phase is to map the candidate AO sets to each step of the Job Map. At the beginning of this process, the candidates AO set need not be mapped perfectly, because, at the end of the procedure, the Job Map is reviewed and revised. However, if the set of AO candidates to be mapped in the Job Map is provided at this process, the workload can be reduced in the final procedure and the reliability of the result can be increased.
Candidate AOs can be mapped automatically to the Job Map by two sets of rules: verb phrases and object phrases. The first method utilizes the verbs related to ‘steps’ (
Table 3) and semantic verbs. During construction of the Job Map, candidate AOs that are related to more than one step are not assigned to one of them; this assignment is finalized during the review process. Additional verbs that are defined according to the product group are mapped by the same method. The second method is to define object phrases that are relevant to each step, then to map candidate AOs to the Job Map accordingly. For example, the dust tank is generally used after the cleaning job is finished, so this timing defines a rule to map to the eighth ‘Conclude’ step. By this process, a set of candidate Jobs is derived, and then the candidate jobs are mapped step-by-step to create an initial Job Map.
The final phase of the overall method is to finalize the Job Map. In this process, researchers who use a Job Map check the results obtained to this point, and then select AOs that become the detailed Jobs and map them at each step of the Job Map. Domain experts can also participate in the review and obtain reliable results. During the automatic mapping process, a researcher must map detailed jobs that are related to more than one step or that have no step; to do this, a researcher loads the original patent document linked to the AO structures, and then checks the part at which the AO structure is presented. Finally, the Job Map is completed by reviewing according to guidelines (
Table 4).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}