1. Introduction
Technology has affected society. At the same time, society has been a huge influence on technological change [
1,
2]. We can understand society, therefore, by analyzing the results of developed technologies. In addition, we can predict the future of society using the results of future technology forecasting. Technology forecasting (TF) is forecasting the future state of a technology [
2,
3,
4,
5]. In the age of limitless competition of technology, it is important to know the future of technologies. Many studies related to TF have been conducted in diverse areas [
3,
5,
6,
7,
8,
9,
10,
11,
12]. Choi and Jun (2014) used statistical clustering based on Bayesian inference to find the vacant technology area of the future [
3]. They used patent documents for input data in their technology analysis. Jun et al. (2012) proposed a technological matrix map using patent data clustering [
4]. They performed the TF process using the results of technology clustering. In addition, Kim and Jun (2015) studied a graphical model based on causal inference and copula regression for the TF of the Apple Company [
5]. The research conducted a case study using the innovative technologies of the Apple Company, because Apple is a leading company in technological innovation [
9]. Conventional TF methods were based on qualitative and quantitative approaches such as Delphi and statistical patent analysis. However, the TF methods did not have a standard tool of forecasting like other forecasting processes, such as business or weather. Quantitative analysis models for business or weather forecasting have been studied for a long time [
13,
14]. Most of the textbook examples for forecasting are based on the statistical models related to business or weather [
15]. Recently, in this area, there are various models from statistical forecasting methods to machine learning based prediction models such as artificial neural networks [
16,
17,
18,
19]. On the other hand, studies on quantitative analysis models for TF have been started recently and active studies are still under way [
2]. Making a standard tool for TF is a challenge in the management of technology (MOT). In addition, TF is important in MOT for research and development (R&D) planning and new product development. Consequently, there have been many studies of TF for MOT using many techniques [
8,
20,
21]. They performed patent analysis for TF because a patent contains complete information regarding a developed technology. Many patent analyses for TF were based on quantitative approaches such as statistics and machine learning [
9,
22,
23,
24]. The most traditional methods of TF based on patent analysis had one problem in common [
22,
25]. There is a sparsity of patent keyword data structured from retrieved patent documents. After preprocessing with text mining techniques, most occurred frequencies of technological keywords in patent data have values of zero [
4,
25]. This problem creates a disadvantage for the performance of TF, and we had trouble analyzing keyword data. For example, most estimated probabilities of technological keywords have zeros. Consequently, it was difficult to plan any R&D strategy using the results.
To solve this problem, we propose an interval estimation method (IEM) in this paper. The proposed method is focused on a solution to the sparsity in patent analysis. We use an adjusted Wald confidence interval called the Agresti–Coull confidence interval to construct the IEM for efficient TF. We predict the future possibility of a keyword, not using point estimation, but interval estimation, because most point estimations are zero under the sparsity of structured patent data. In addition, we apply the proposed method to forecast the sustainable technology that improves the technological competition of a company. The sustainable technology is a technology to improve the technological competitions of a company or a technology field for sustainability [
26,
27]. Recently, Park and Jun (2017) studied on a sustainable technology analysis for three-dimensional printing technology using statistical methods [
28]. To show how our work can be applied to the real domain, we conduct a case study using Apple’s patents. The remainder of our paper is organized as follows.
Section 2 introduces the previous works related to technology analysis and interval estimation.
Section 3 proposes the IEM for sustainable technology forecasting.
Section 4 illustrates a case study with Apple’s patent data.
Section 5 concludes the paper.
3. Interval Estimation for Technology Forecasting
In this paper, we propose a method of interval estimation for the TF. Among the various methods for computing interval estimation, we use the Agresti–Coull confidence interval (which is called an adjusted Wald confidence interval) as follows [
43,
47,
48].
where
and
. The Agresti–Coull confidence interval is a similar form of Wald confidence interval. Additionally, if
z ≈ 2 in the Wilson confidence interval, the center of the Agresti–Coull confidence interval is identical to that of the Wilson confidence interval as follows:
The Agresti–Coull confidence interval is also interpreted as the center of the Wilson’s confidence interval, as a weighted average of
and
as follows:
Therefore, the point estimator converges to
as
. They compared actual coverage probabilities with 95% confidence level depending on sample size and the true proportion, and showed much better performance than the Wald and exact confidence intervals. They recommended it for all sample sizes and parameters. Using the adjusted Wald confidence interval, we can control many zero values of the structured data (document–term matrix) that is preprocessed from patent documents. To get patent documents related to target technology, we retrieve patents from patent databases of the world. The most popular databases, USPTO and WIPSON, are used. In the retrieved patent documents related to our target technology, we have to form the structured patent data for our IEM.
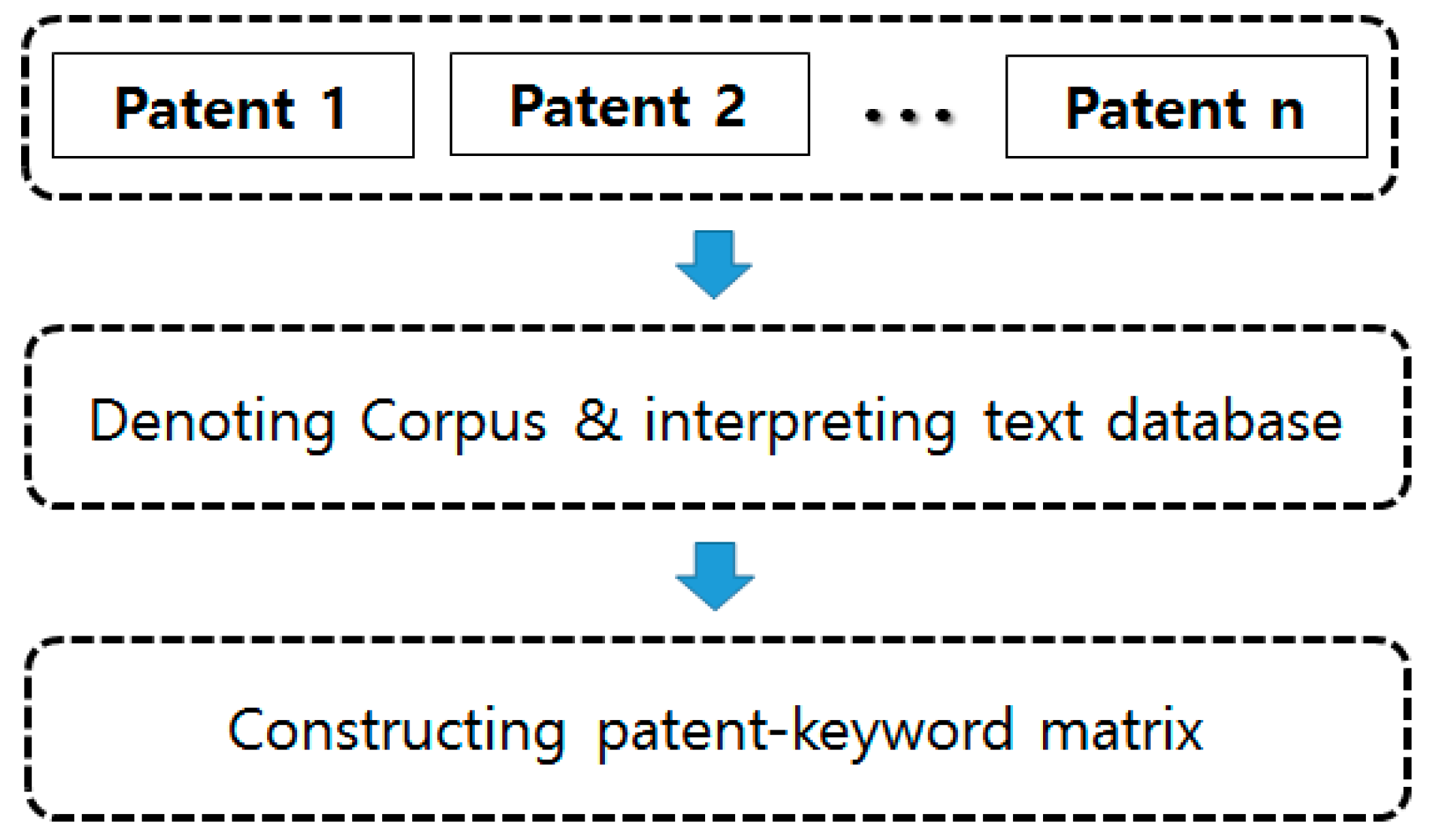
Figure 2 shows the process of our preprocessing to construct the structured patent data.
The text document collection based on the retrieved
n patent documents is denoted as a corpus, and it is interpreted as a text database. The
R data language and its “tm” package are used to construct a patent–keyword matrix from the interpreted text database [
37,
38,
49]. Using the text mining process, we get the structured patent data in top of
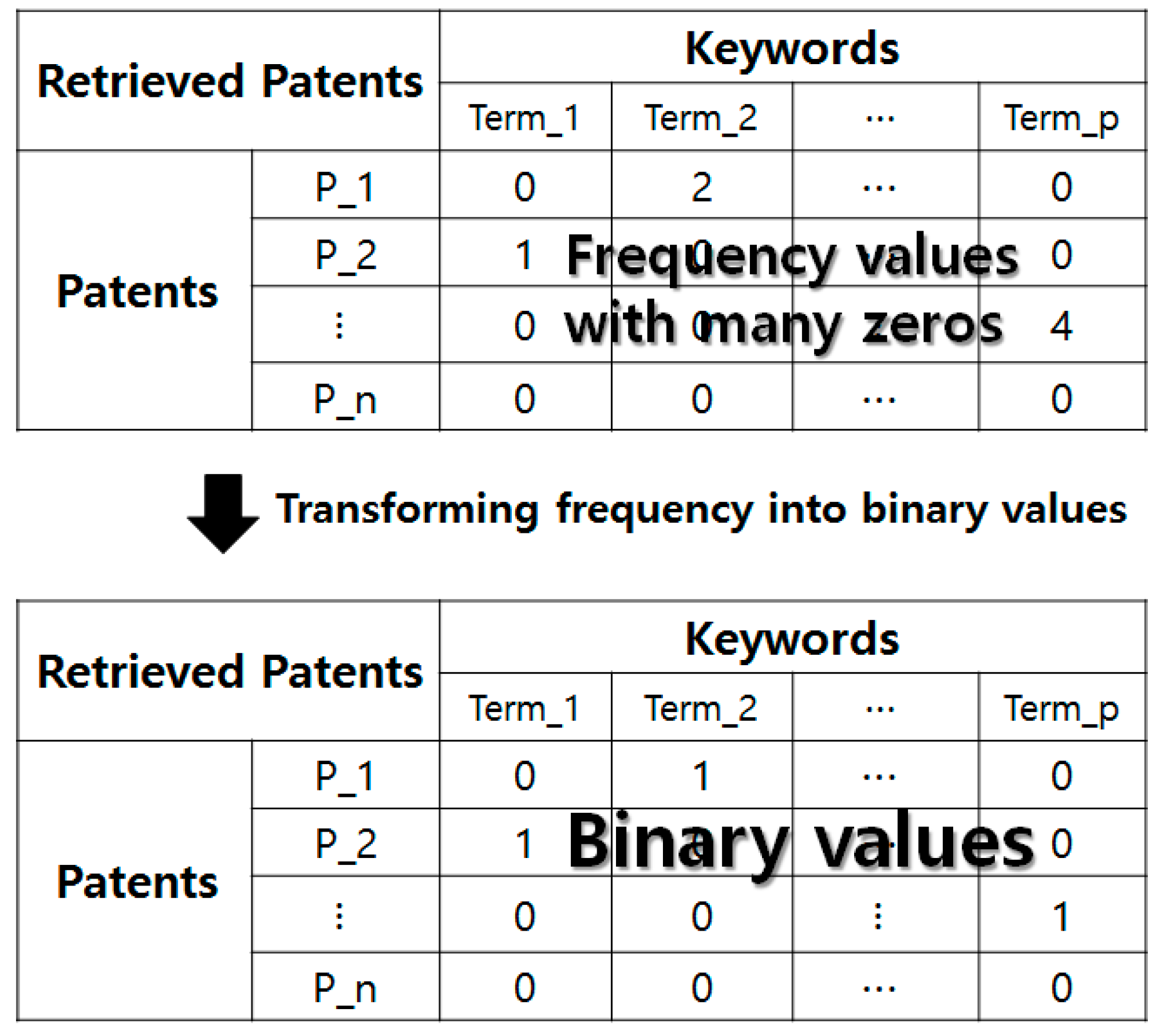
Figure 3.
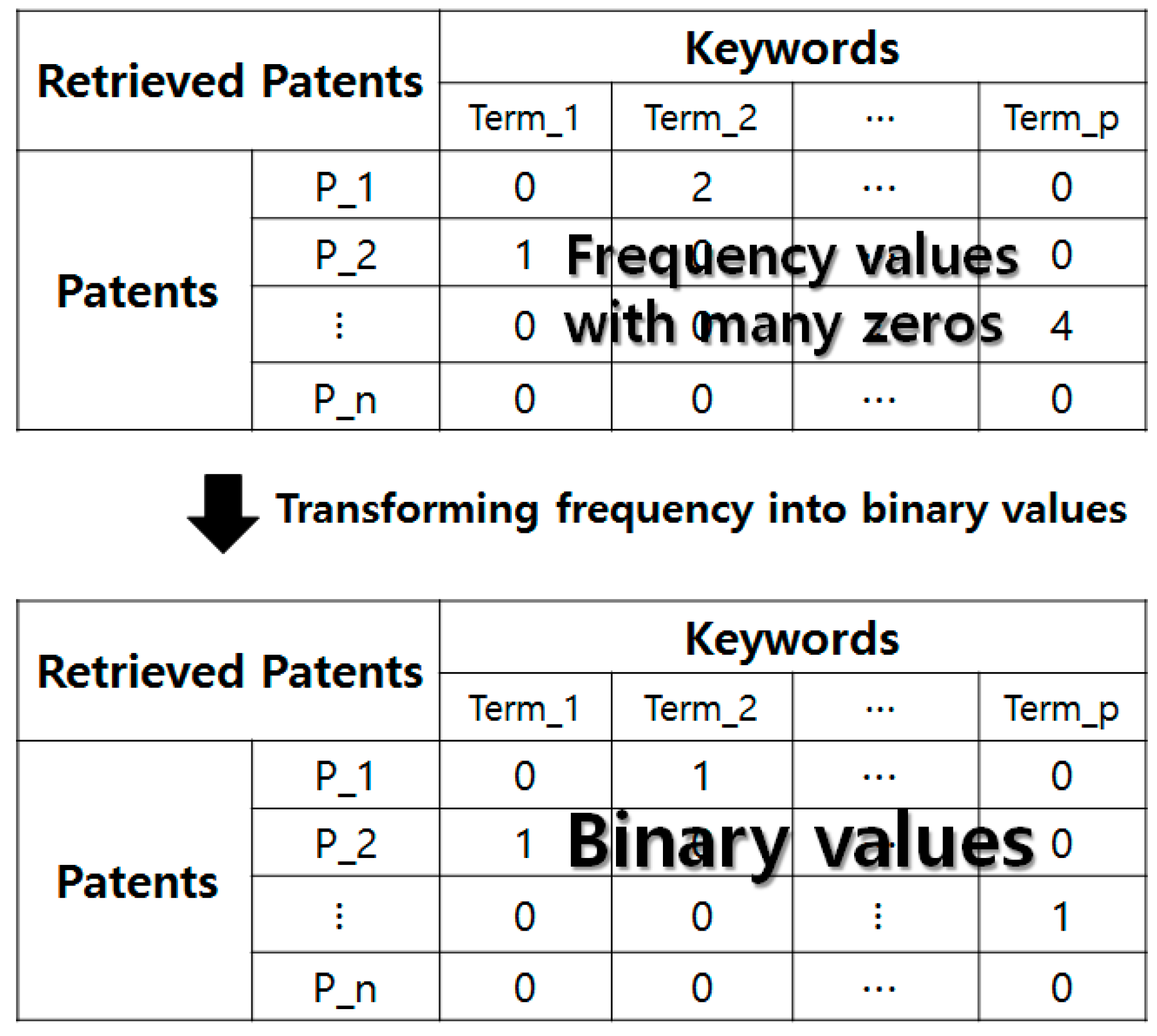
The patent–keyword matrix consists of patents and keywords as its rows and columns, respectively. Each element of the matrix is the occurred frequency value of a keyword in a patent. Next, we transform the patent data of frequency values into structured data with binary values for the interval estimation in bottom of
Figure 3. In this paper, we use this matrix for our IEM in Apple’s TF. We encounter the sparsity problem in this data structure of
Figure 3, because many elements of the matrix are zero values. We have to select a methodology to overcome this problem. In our research, we propose an IEM based on the adjusted Wald confidence interval. Therefore, we perform the IEM from the patent documents related to the target technology according to the following process.
- (Step 1)
Collecting patent document data
- (1-1)
Selection of target technology
- (1-2)
Retrieval of patents related to target technology from patent databases
- (Step 2)
Constructing structured patent data
- (2-1)
Collected patent documents imported to R data system
- (2-2)
Denoting corpus and interpreting text database using patent documents
- (2-3)
Building patent–keyword matrix with occurred frequency of keyword
- (2-4)
Changing occurred frequency to binary value
- (Step 3)
Computing interval estimation of patent keyword
- (3-1)
Using Agresti–Coull confidence interval for IEM
- (3-2)
Computing interval estimation of technology keyword for TF
- (Step 4)
Forecasting future technology
- (4-1)
Using IEM results of all patent keywords
- (4-2)
Assigning representative technology to each keyword
- (4-3)
Predicting future state of target technology
In this paper, we forecast future technologies using the results of our IEM. We compute the estimated intervals of all patent keywords using the IEM. In addition, we can set data related technology to the “data” keyword. The mean (), upper, and lower values of interval estimation provide valuable information to forecast future technology. The larger the values are, the more important the technological keyword is. In statistics, half of the width is called as a margin of error, and the square root part in Equation (5) is called the standard error. Both of them are measures of errors for the interval estimation. The errors are depended on the estimate for p and a sample size, n. With bigger p and less n, the errors are increasing, and the widths are getting wider. It could be interpreted that more errors and wider widths when a bigger p is estimated with smaller sample size. It is quite reasonable. The estimation is not stable with small sample. We should suggest wider interval estimation for better confidence. In the next section, we perform a case study of Apple’s technology.
4. Case Study of Apple Technology
To show how the proposed method can be used to address a real problem, we carried out a case study using Apple’s patent data. Apple has been leading the technological innovation of the global information and communication (ICT) industry [
9,
10,
50,
51,
52]. Jun and Park (2013) examined the technological innovation of Apple using patent analysis [
9]. They analyzed the patent documents of Apple with time series regression, K-means clustering, and social network analysis to understand the technologies of Apple. Additionally, Kim and Jun (2015) studied graphical causal inference and copula regression to analyze the technological keywords of Apple patents [
5]. The authors used the technological relationships among Apple’s patent keywords to understand the technological structure of Apple. Previous studies related to Apple’s technologies did not consider technological changes over time and the scope of change in the patent keywords of Apple. We proposed an IEM for building the variable interval of Apple’s keywords over time. We used Apple’s patents issued between 1977 and 2010. We also searched patent data in the patent database of WIPS Corporation [
36]. Using text mining techniques including natural language processing [
37,
38], we made a corpus from searched patent documents and constructed document–term matrix which consists of patent documents (rows) and occurred terms (columns). To select the keywords representing Apple’s technologies, we had help from the domain experts of Apple in the Korea Intellectual Property Strategy Agency (KISTA) [
53]. We extracted sixteen major keywords from the collected patent documents related to Apple, as follows: audio, computer, content, data, device, digital, display, image, information, interface, media, memory, network, system, user, and video. To analyze the patent documents of Apple, we formed structured data called patent keyword matrix using text mining techniques. The columns and rows represent patent keywords and years in this matrix, and the elements of the matrix contain the occurred frequency values of keywords by year. Using this data matrix, we computed interval estimations for each keyword. We grouped the sixteen keywords into four technological groups. Like the approach to keyword selection of Apple technology, we got help from the domain experts of Apple in the Korea Intellectual Property Strategy Agency (KISTA) for technological classification of Apple.
Table 1 shows the four technological groups of Apple keywords and their representative technologies.
In
Table 1, Group 1 consists of four keywords (i.e., “content”, “data”, “information”, and “memory”) and we defined the representative technology of this group as “Data”. In the same way, the representative technologies of Groups 2–4 are “Application”, “System”, and “User Interface”, respectively. The four major technologies are considered to assess Apple’s technological sustainability. We computed the interval estimations of the keywords and keyword groups.
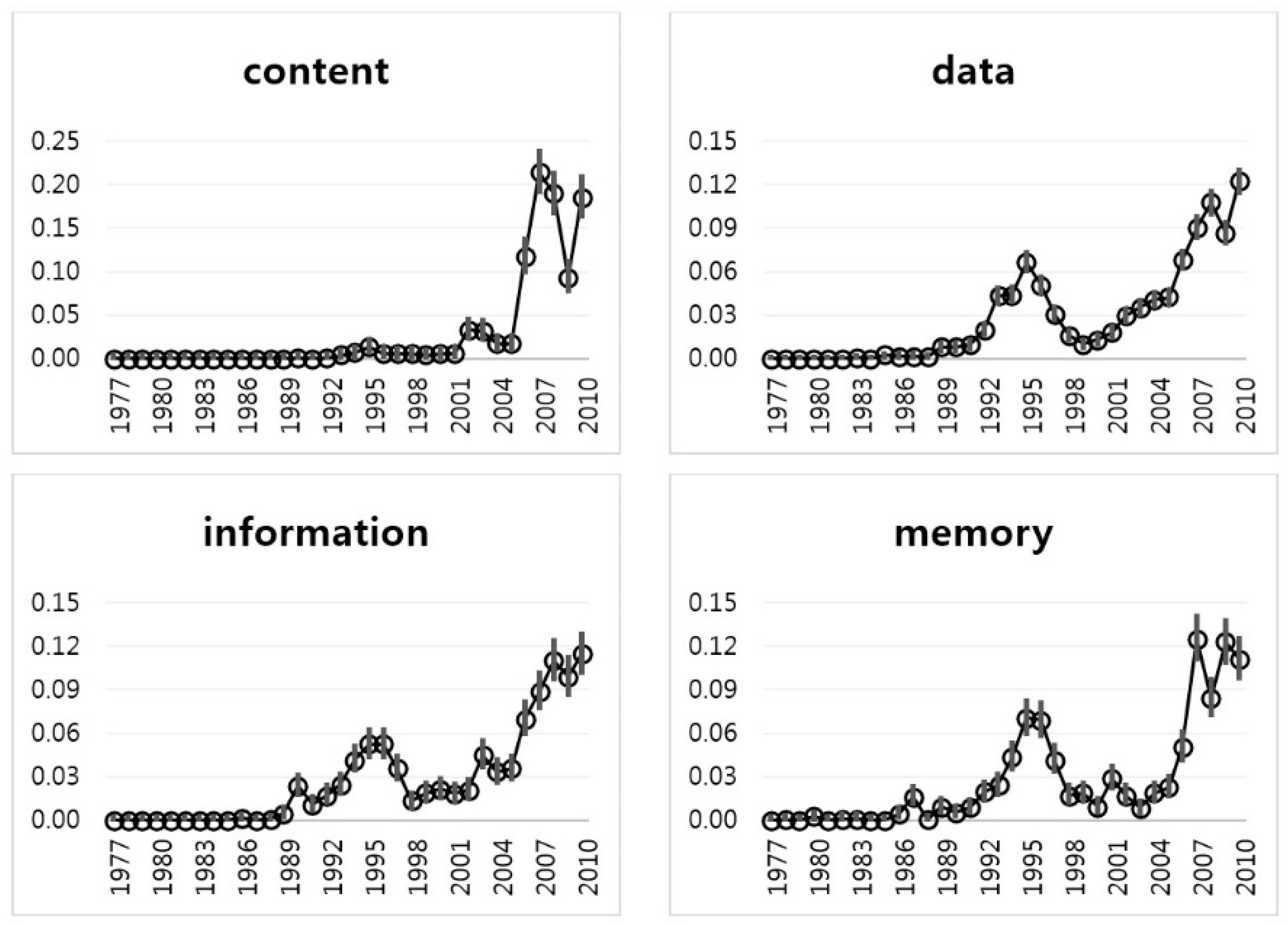
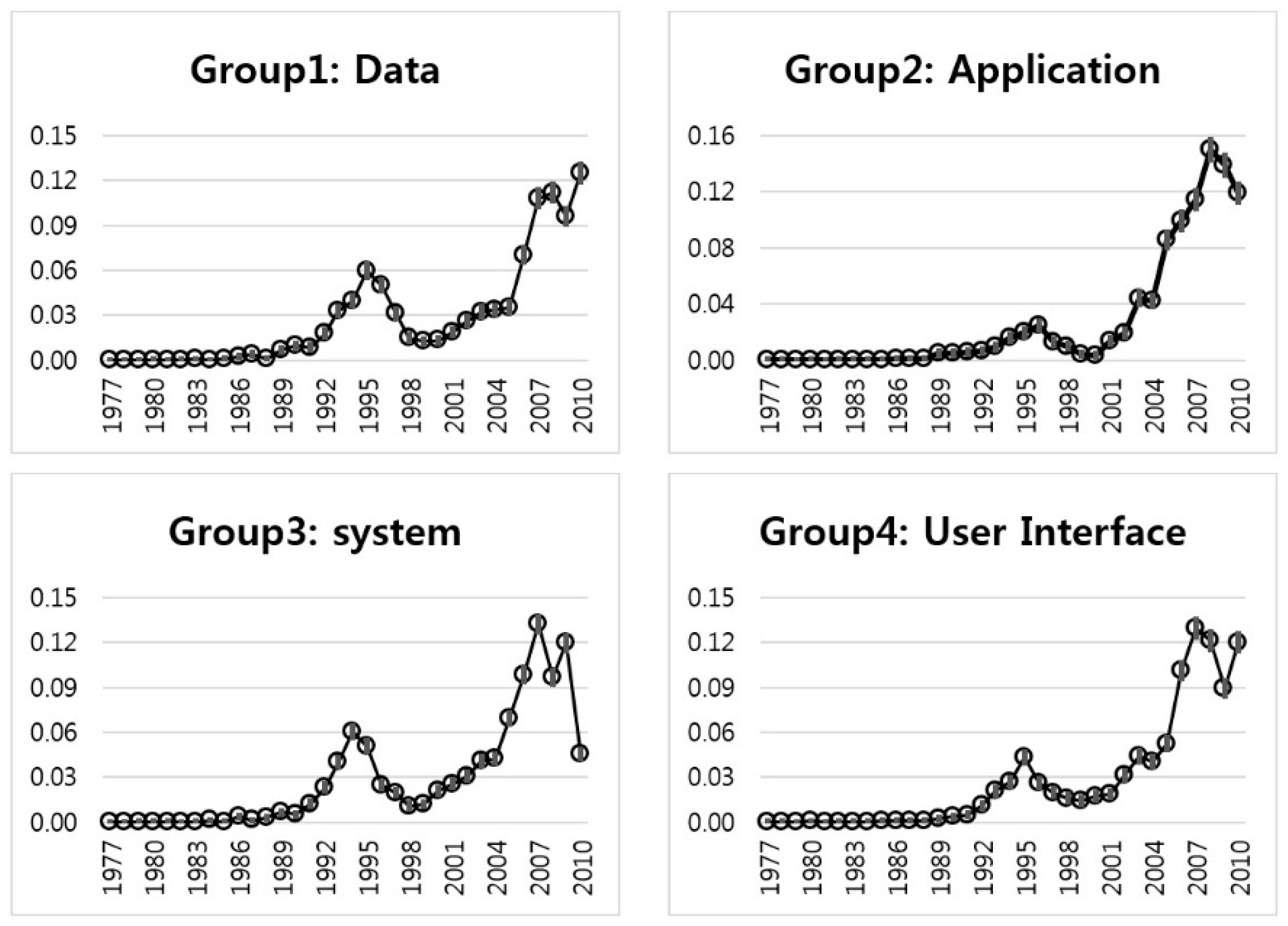
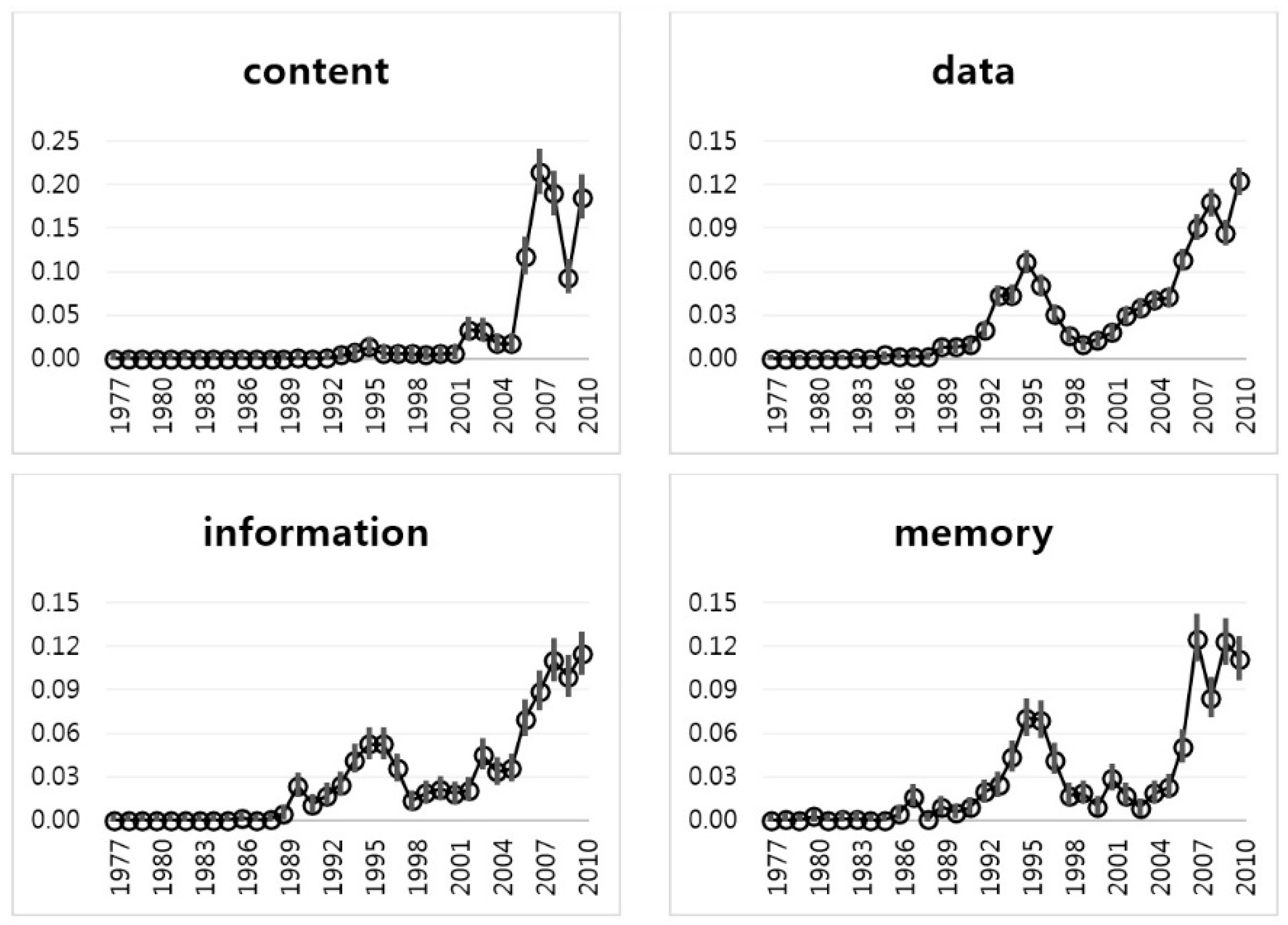
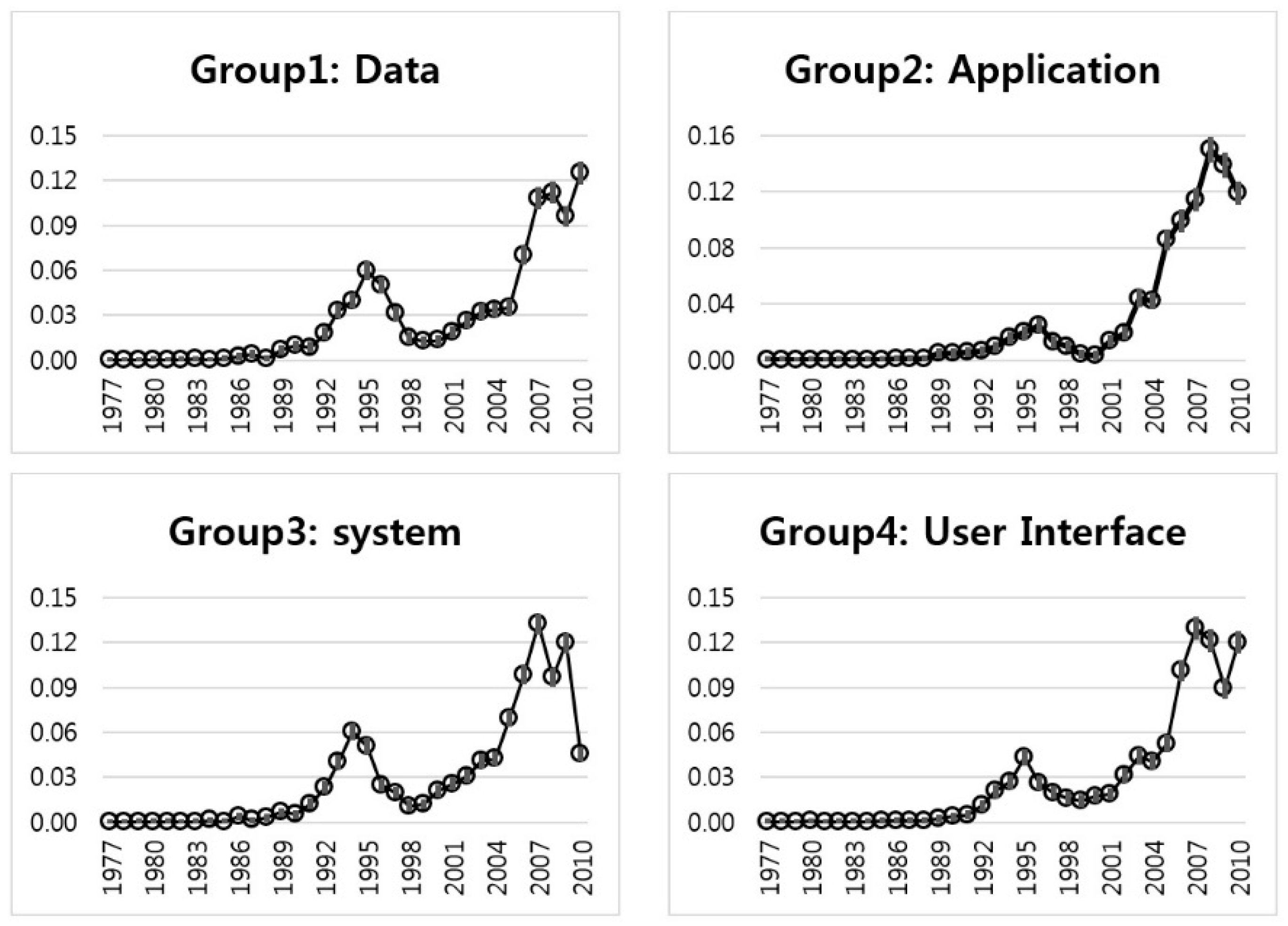
Figure 4 shows the interval estimation plots of four keywords in Group 1. The “content” keyword rose in the late 2000s, dropped in 2009, and then increased again in 2010. The keywords of “data”, “information”, and “memory” were at their peak in 1995. Later, they continued to decrease, but, recently, they have increased rapidly. In the late 1990s, Apple launched a new computer called the iMac. At that time, Apple first turned a profit. We determined that the technology of Group 1 is the sustainable technology of Apple. To discover more detail about the Group 1 technology, we show IEM values, such as the estimate, lower limit, and upper limit of the proportion (
) IE of each keyword by year in
Table 2. Because there was very little frequency before the 1990s, most of the mean values of the keywords were close to zero.
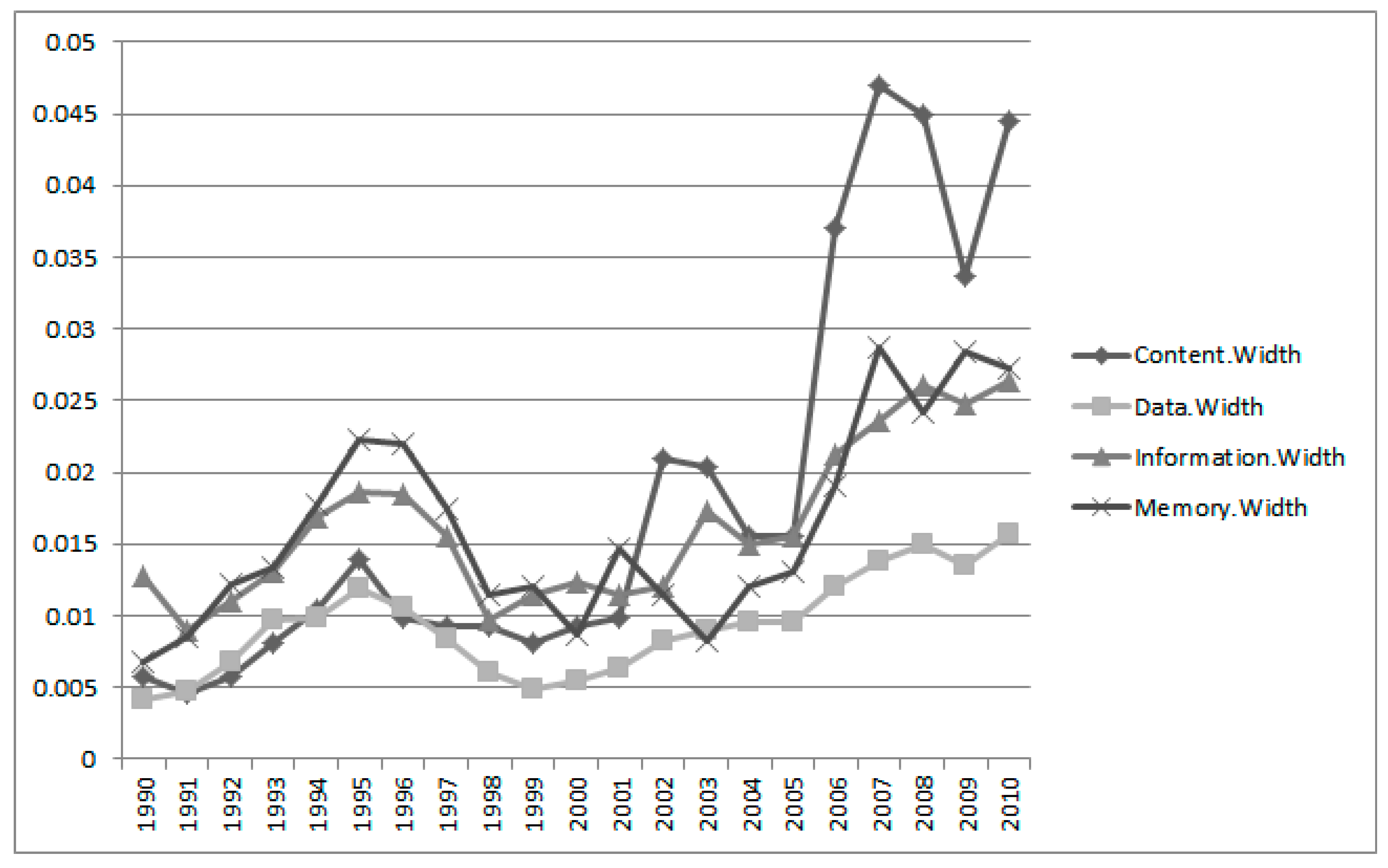
In
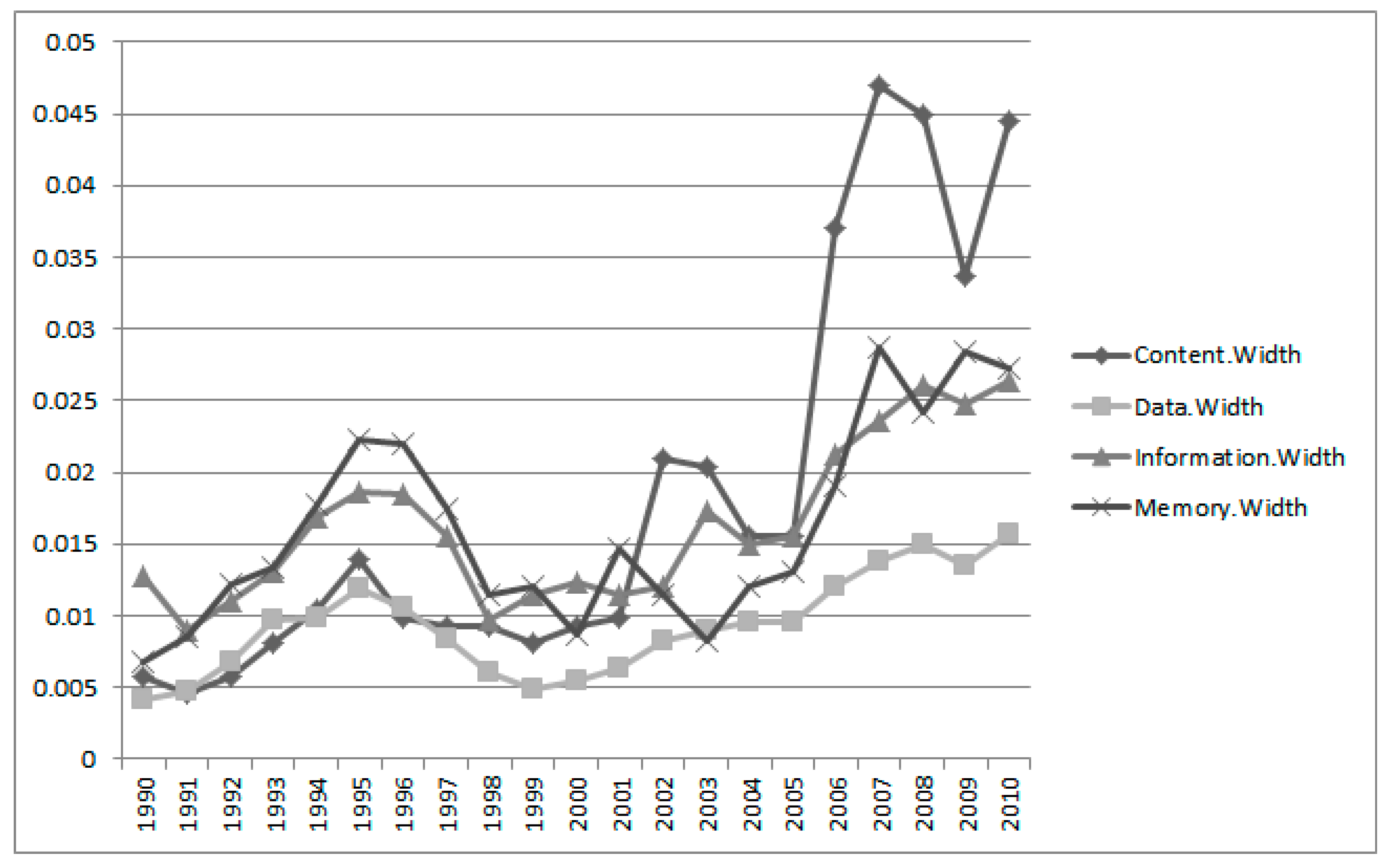
Figure 5 we extracted meaningful interval estimations results since 1990 from
Table 2 to determine the variability of the keywords over time. The interval estimation widths of the keywords of Group 1 were computed from the absolute difference between the upper and lower limits. The width value of the keyword “data” is the smallest one in Group 1. This means that the technology based on data does not fluctuate over time within the Apple technology. In a relative sense, the width value of the keyword “content” fluctuates more than other keywords in Group 1.
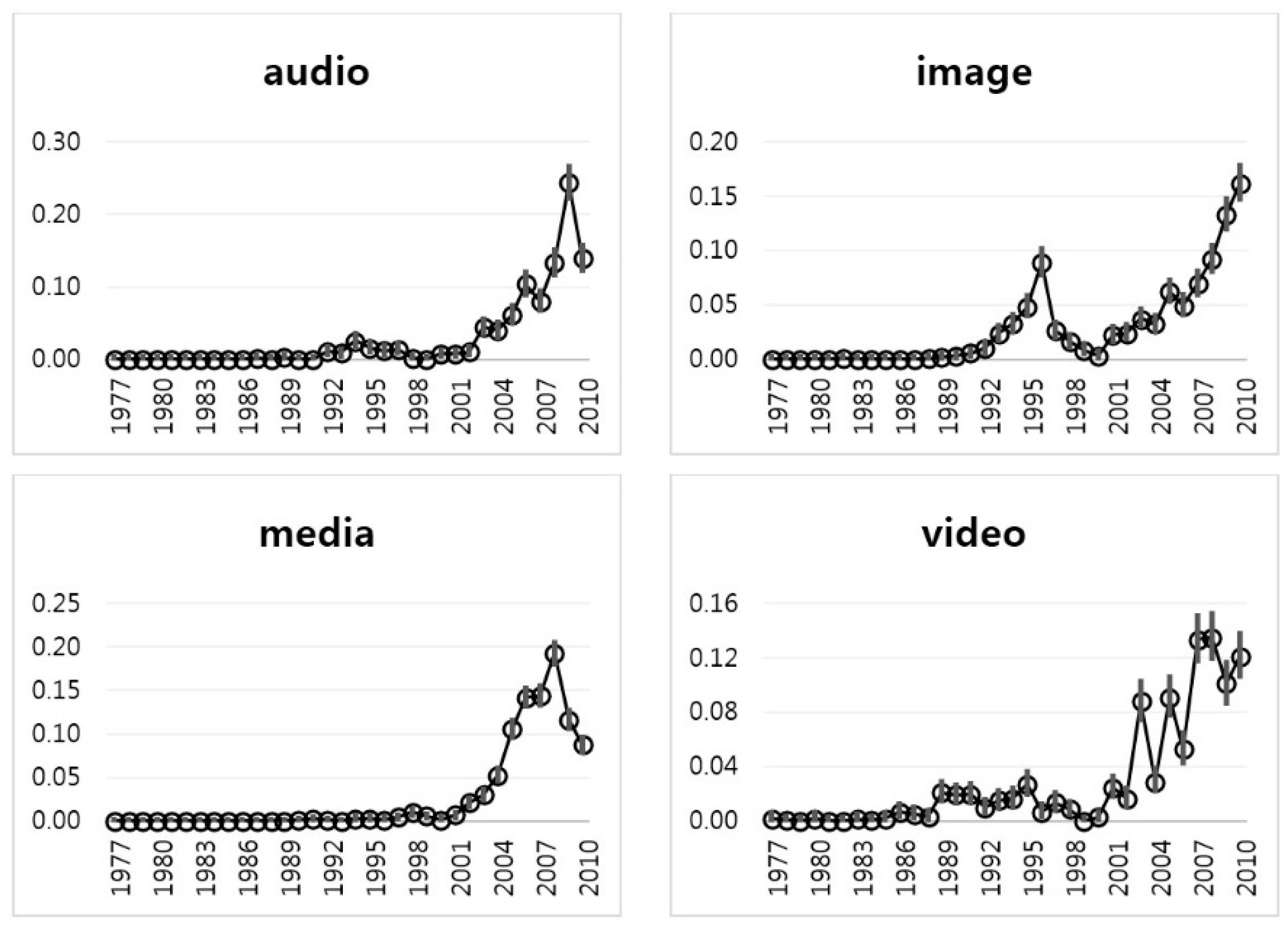
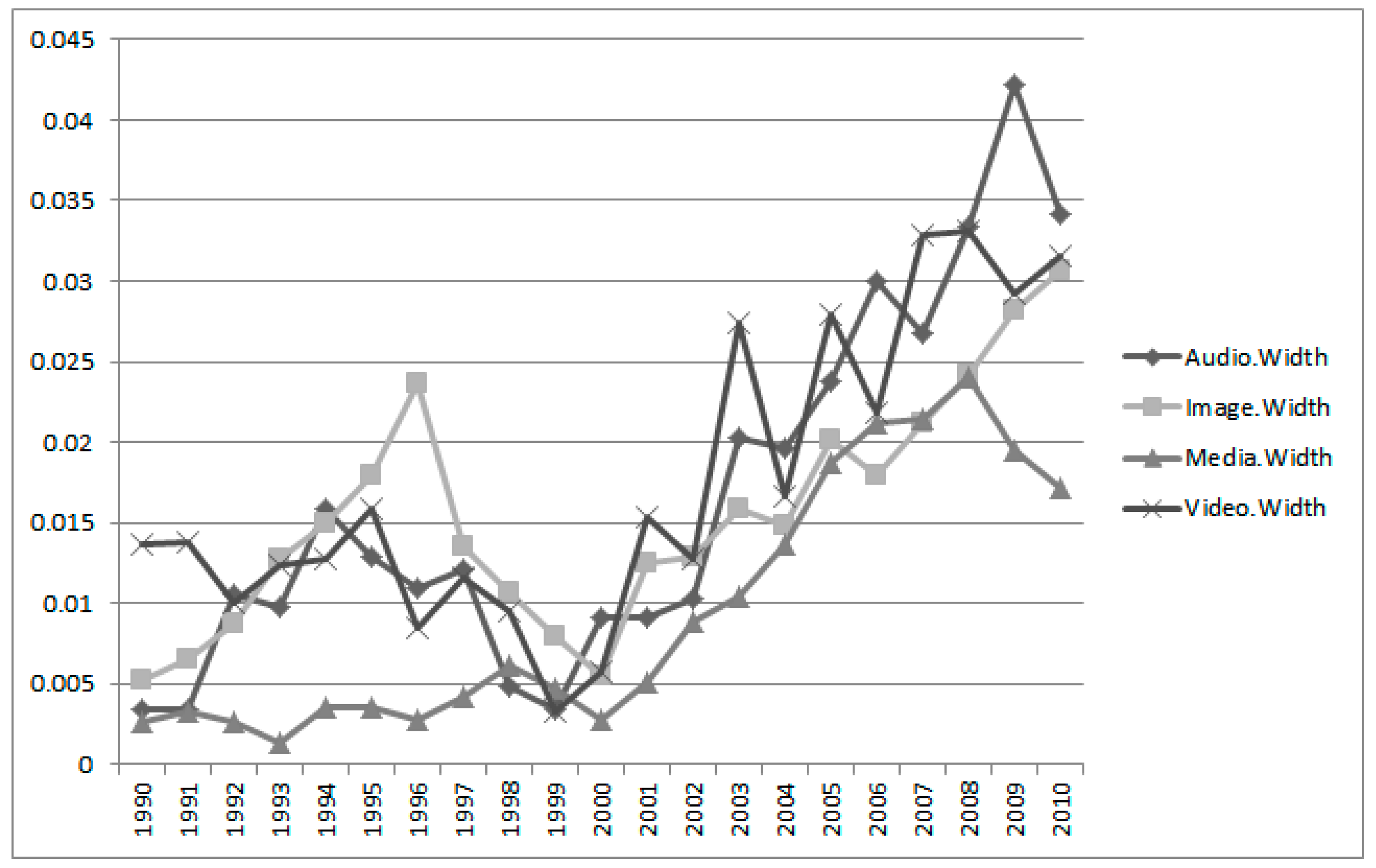
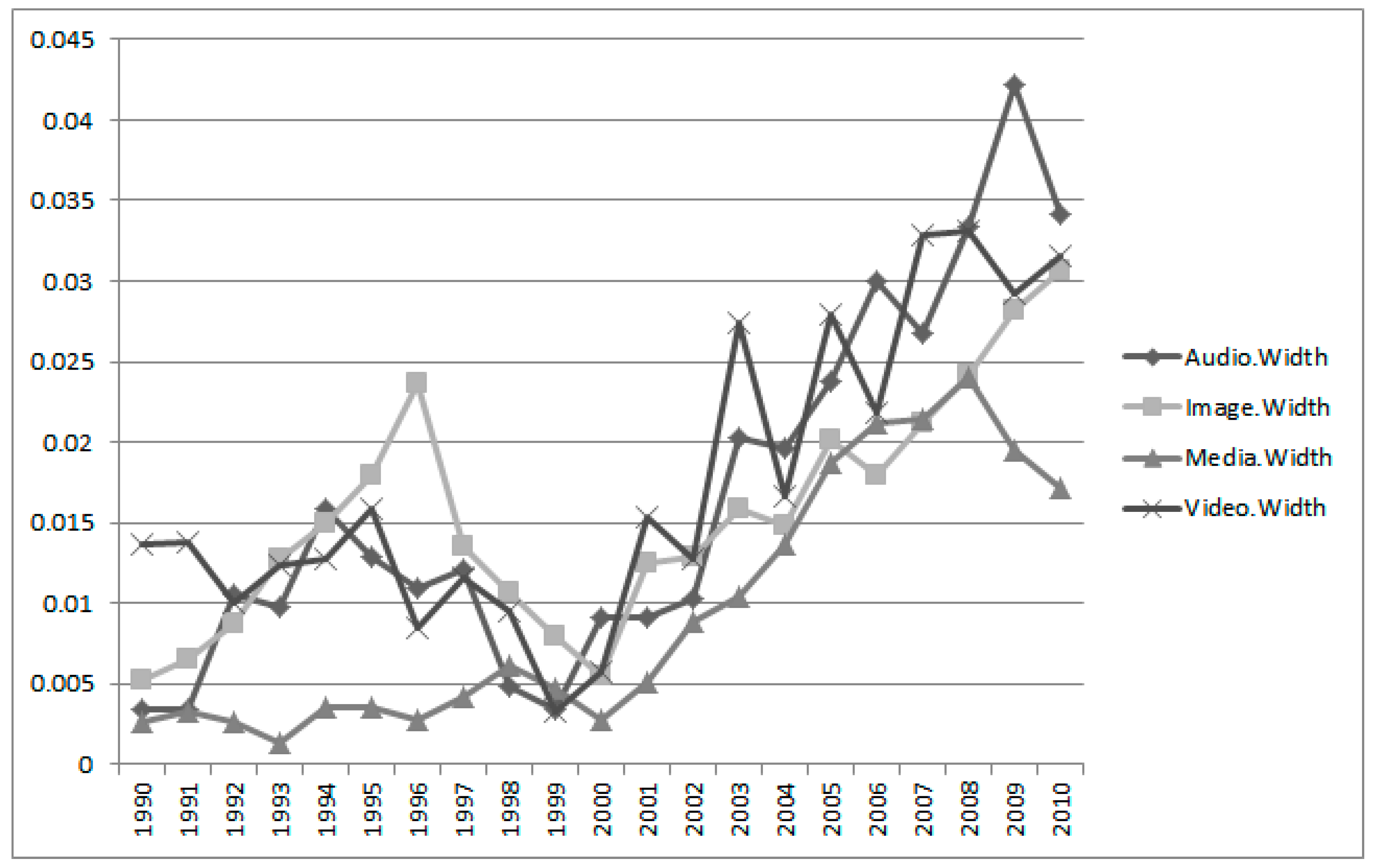
Next,
Figure 6 shows the IE plots for Group 2 (i.e., “Application”) with keywords “audio”, “image”, “media”, and “video”. The time trends of most Group 2 keywords differ from the keywords of Group 1. They have no peaks in the late 1990s, except for the keyword of “image”. The keyword “audio” has a peak in 2009. This means that the “audio” technology of Apple was researched and developed relatively recently. The “media” technology is similar to the technology based on “audio”. However, the technology of “video” has fluctuated since the 2000s.
Table 3 shows the detailed IEM results of Group 2.
Using the estimate, lower, and upper values, we constructed the interval estimation widths of the keywords of Group 2 in
Figure 7. Unlike the visualization result of Group 1, they show large fluctuations. In particular, by the year 2000 the range of fluctuations was larger than before. We concluded, therefore, that the technology of “Data” (Group 1) is more stable than the “Application” technology (Group 2).
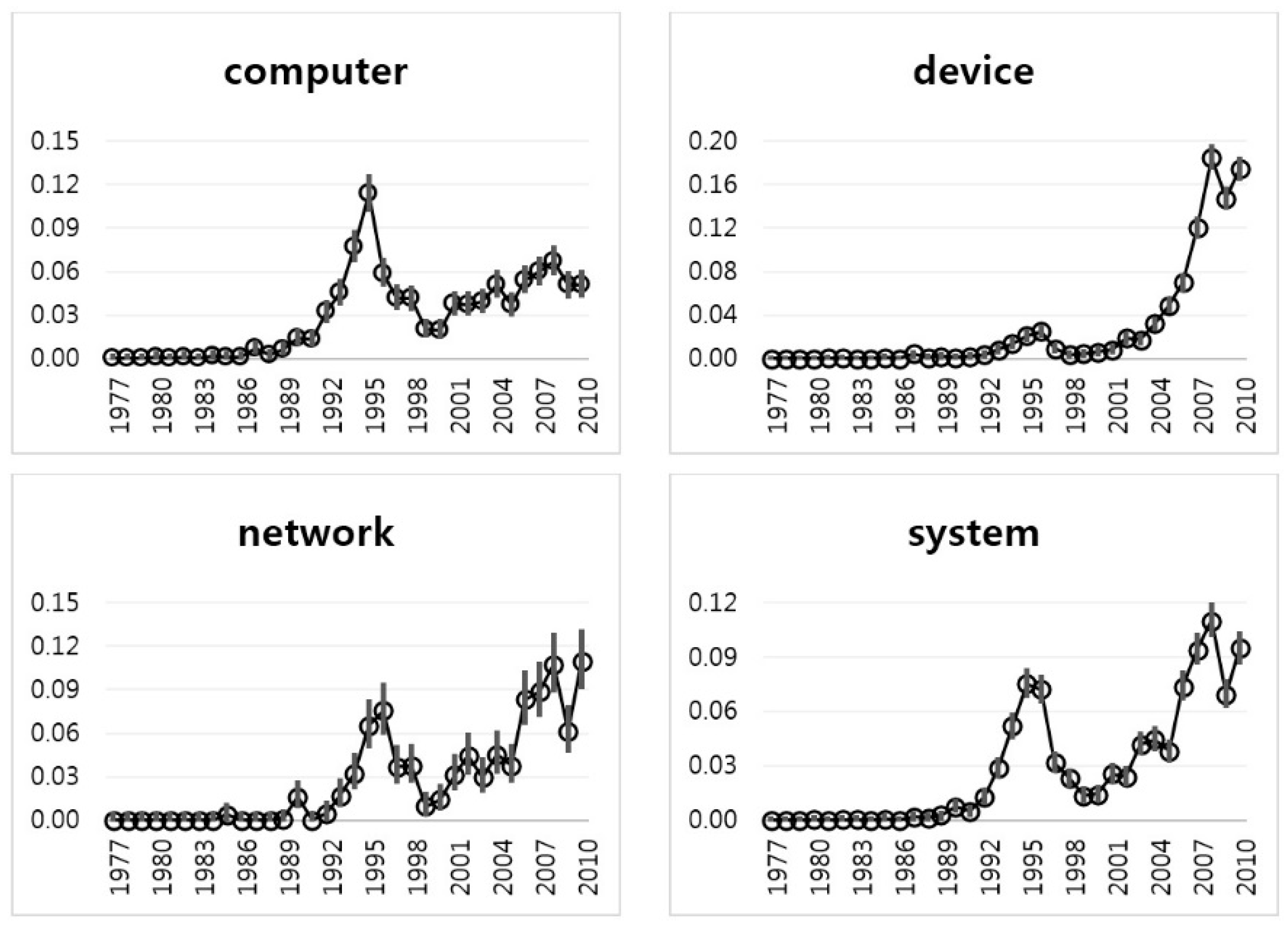
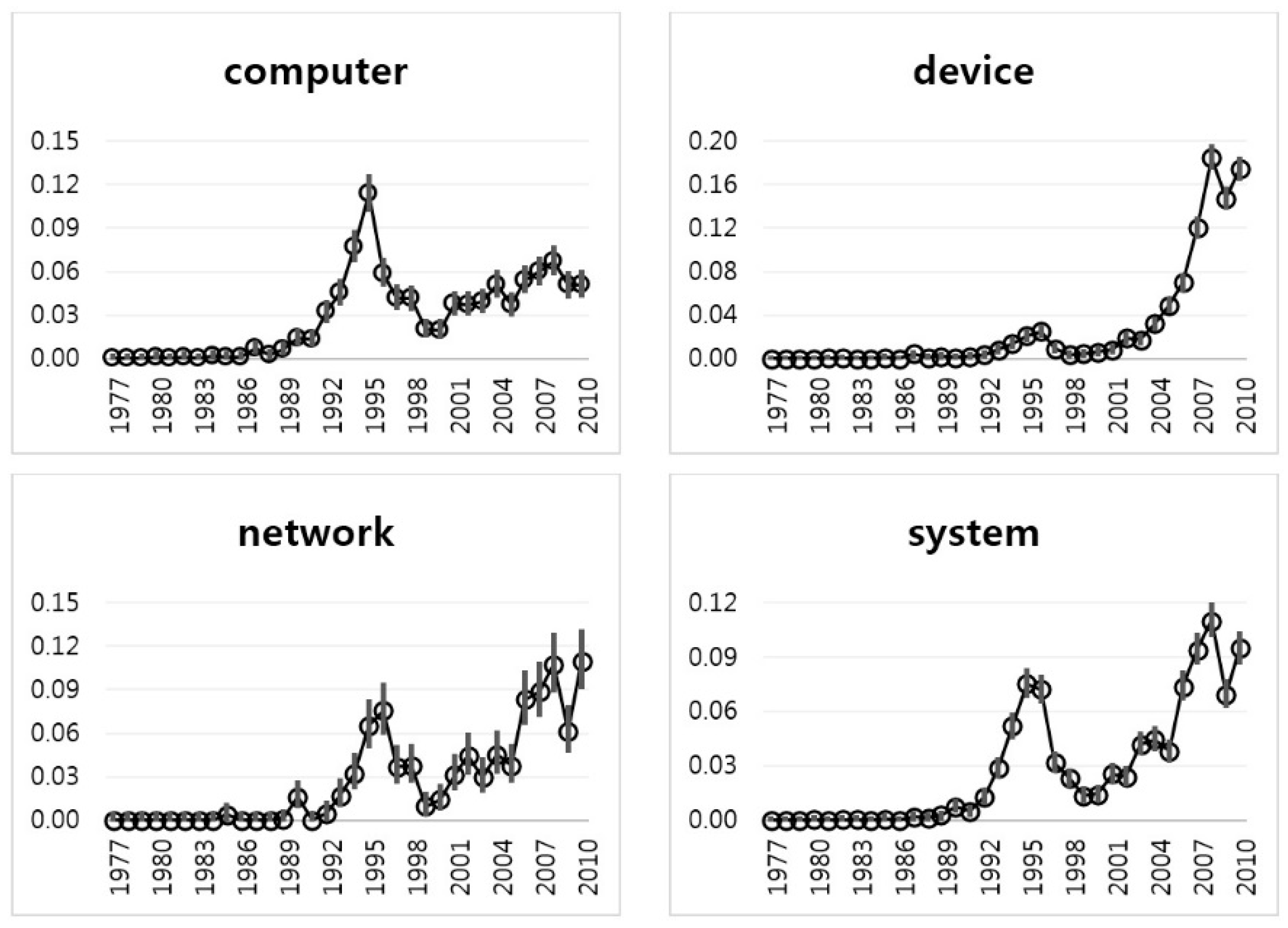
Figure 8 shows the IE plots of Group 3 with the keywords of “computer”, “device”, “network”, and “system”. The trends of “computer”, “network”, and “system” are similar to those of the keywords of Group 1. They have peaks in 1995. The keyword of “device”, however, has a peak in 2007. This is more recent than other keywords in Group 3. We show more detailed IEM results of Group 3 keywords in
Table 4. We found that the sparsity of Group 3 is less than that of Group 1 or Group 2, because most mean values of Group 3 keywords are not zero. This means that the technology of Group 3 (System technology) is very active in the Apple Company.
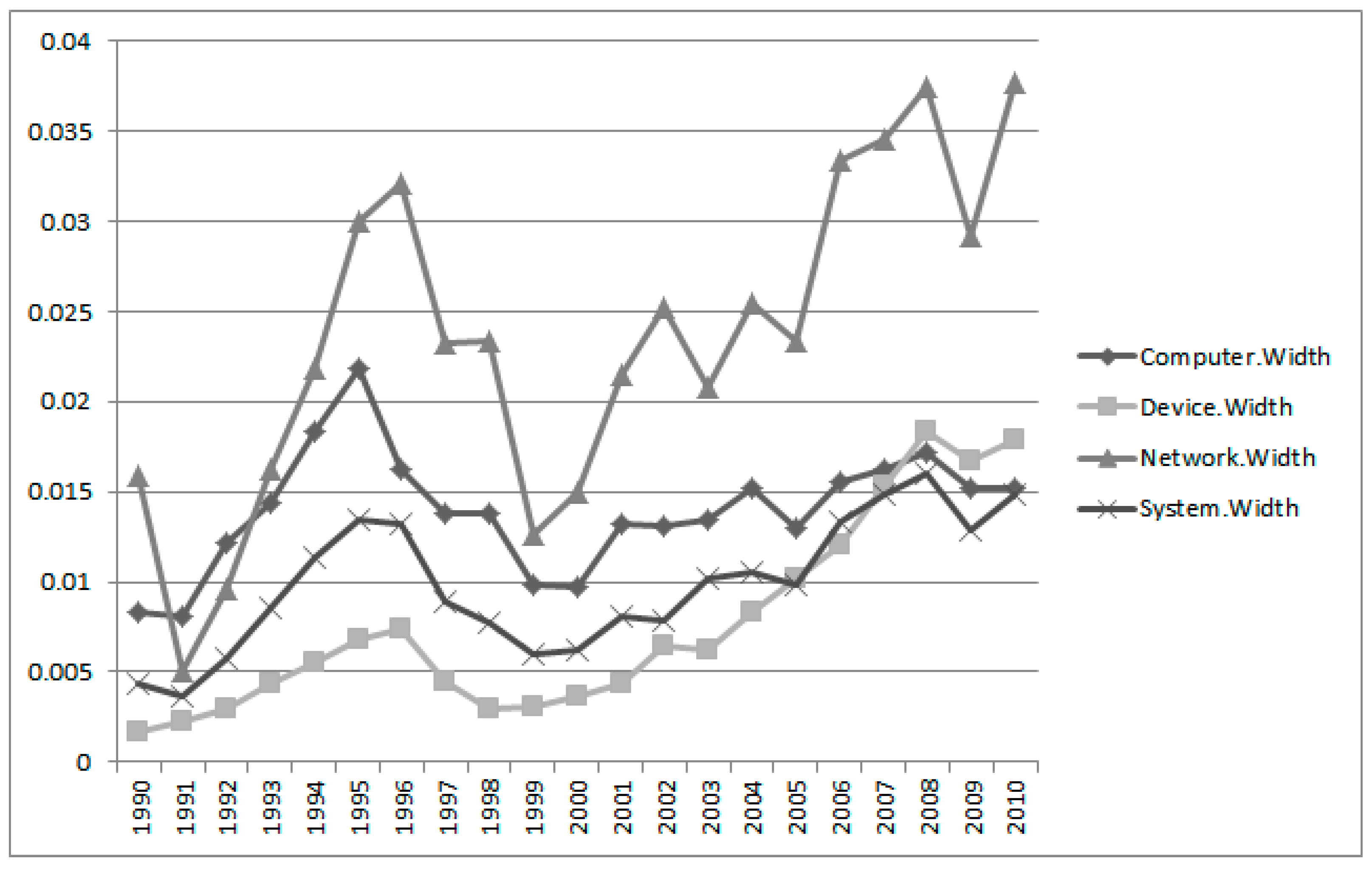
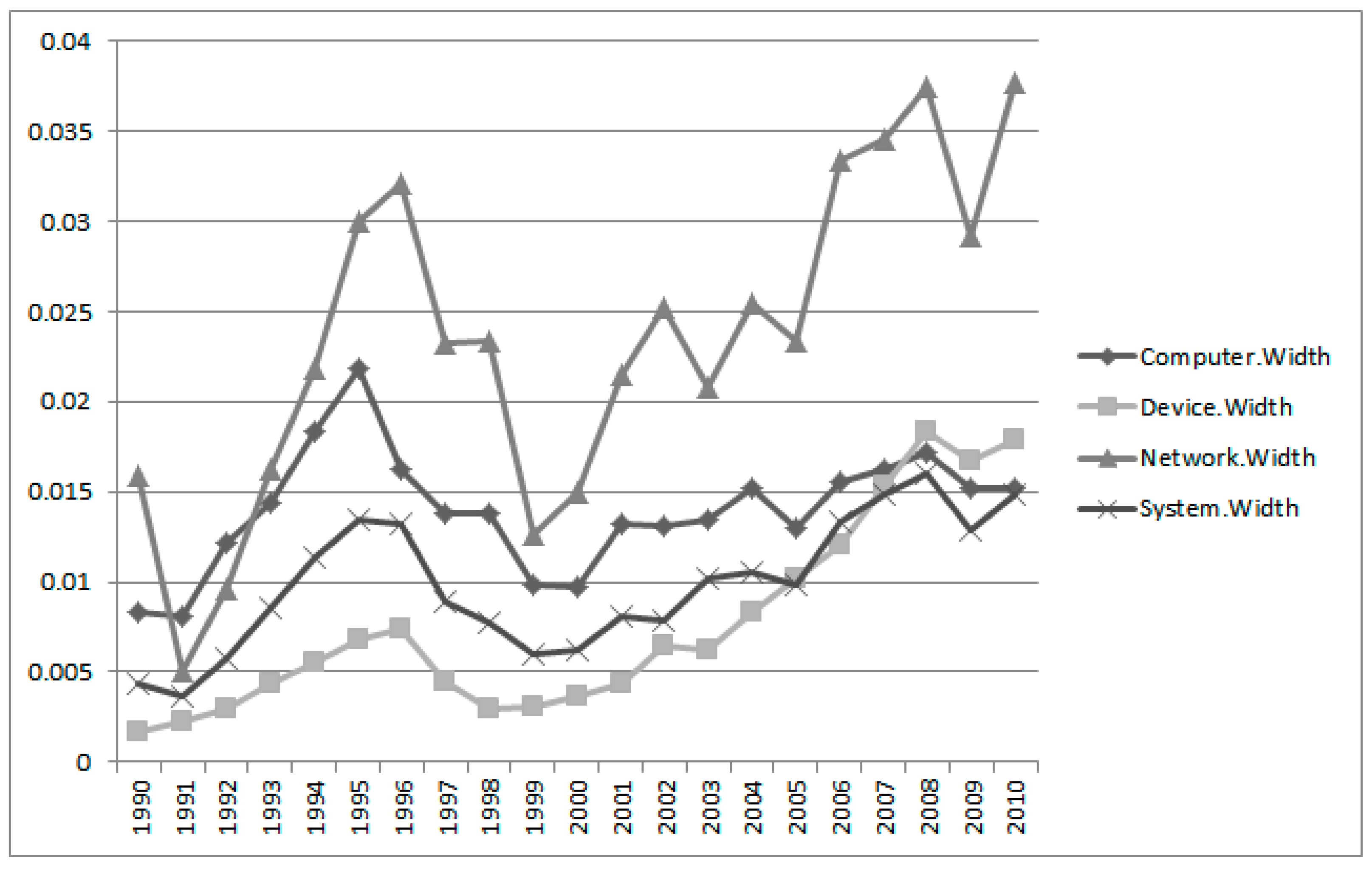
In
Figure 9, we calculated the visualization of interval estimation widths of Group 3 using the results of
Table 4. The results show that the variations of Group 3 keywords are stable except for “network”. We conclude, therefore, that the technology based on Group 3 is sustainable in the Apple Company.
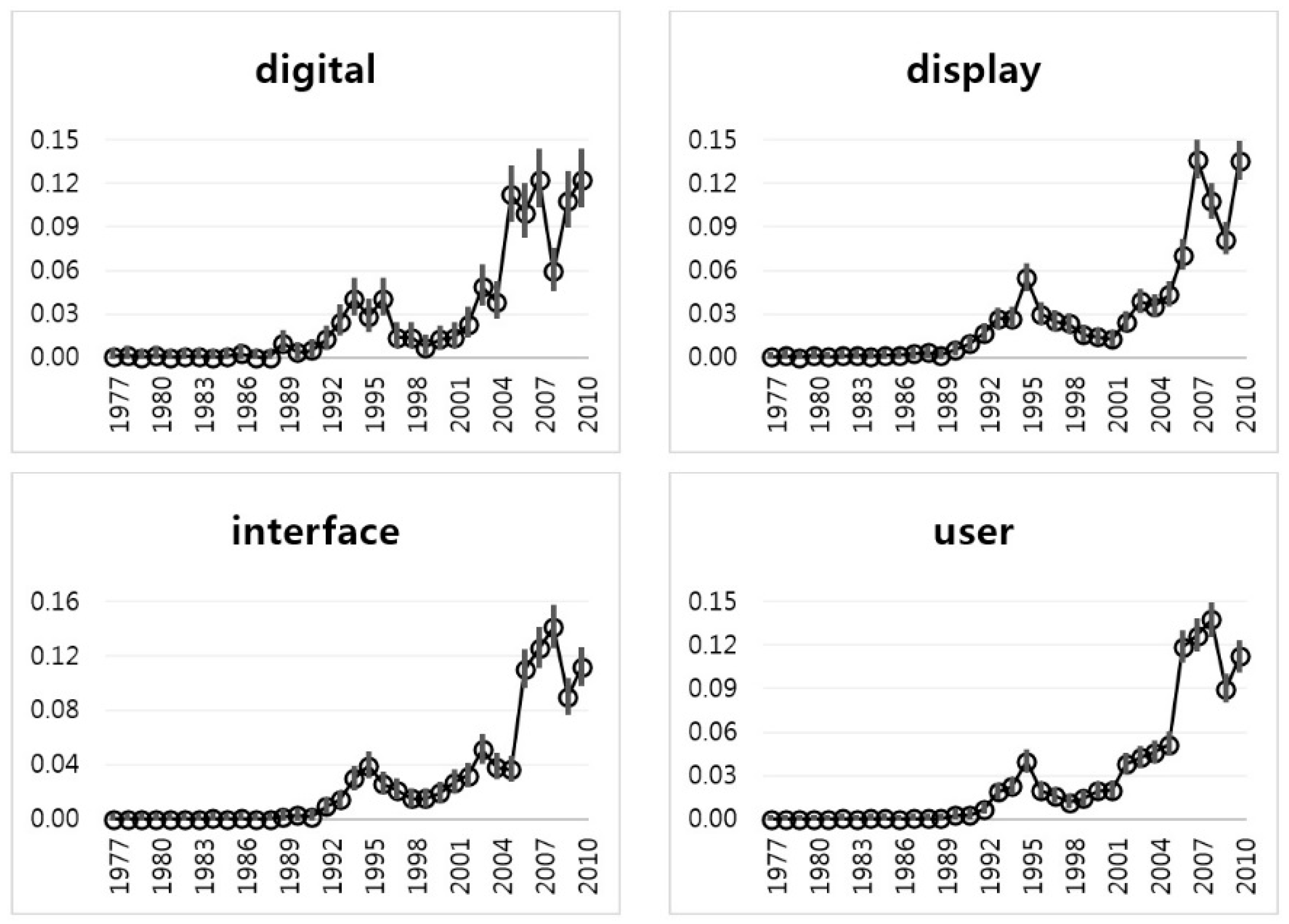
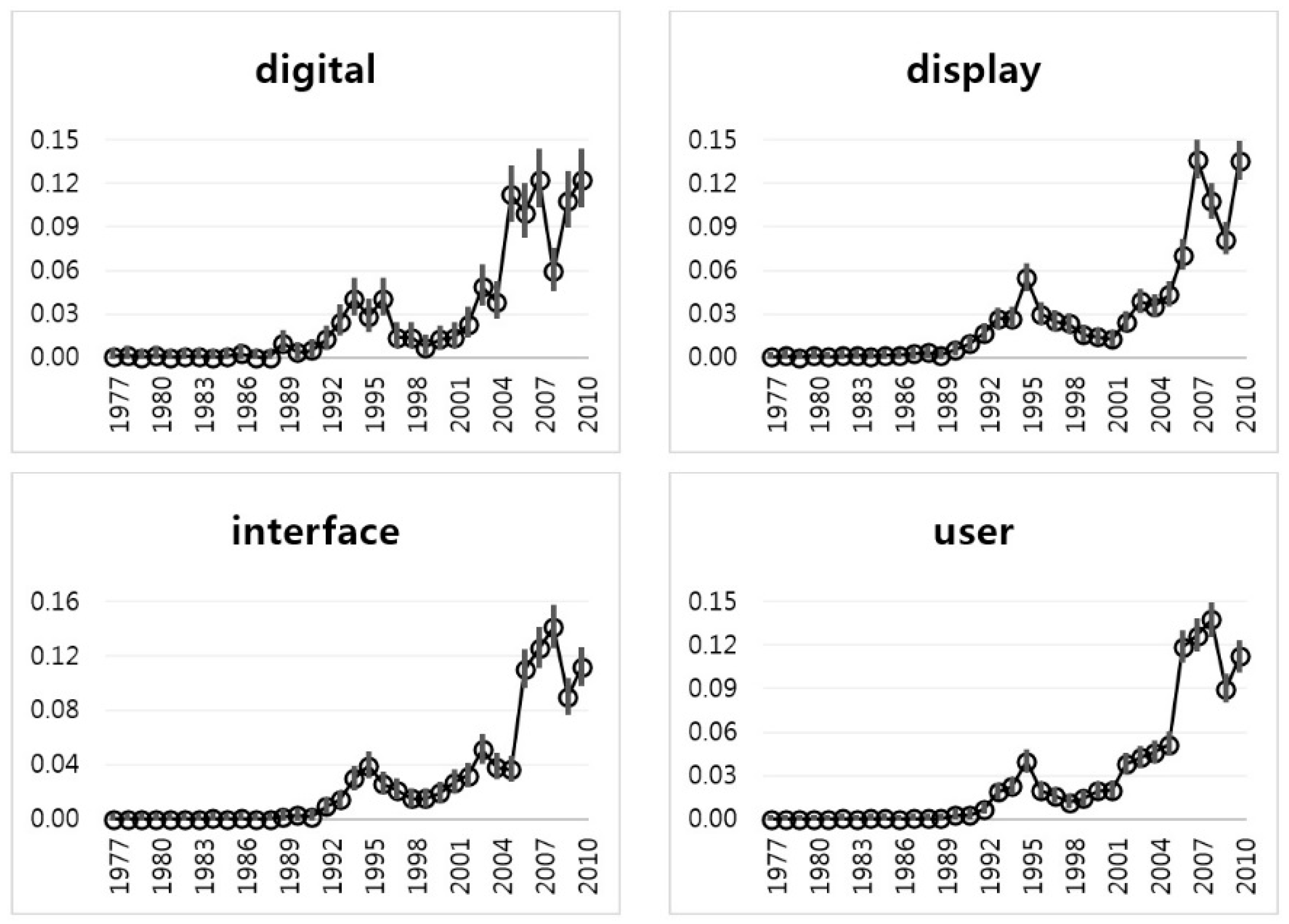
Next,
Figure 10 represents the interval estimation plots of Group 4. The technological trends of Group 4 keywords are similar to the trend of Group 1. The relative height of Group 4, however, is lower than that of Group 1. We see that the technology of Group 4 (User Interface technology) is collaborative with the technology of Group 1 (Data technology). This means that Apple has developed the technologies of user interface and data together.
Table 5 expresses the interval estimation results of the keywords in Group 4. Like the results of Group 3, the sparseness of Group 4 has relaxed somewhat. We see that the mean values of the keywords in Group 4 increase steadily.
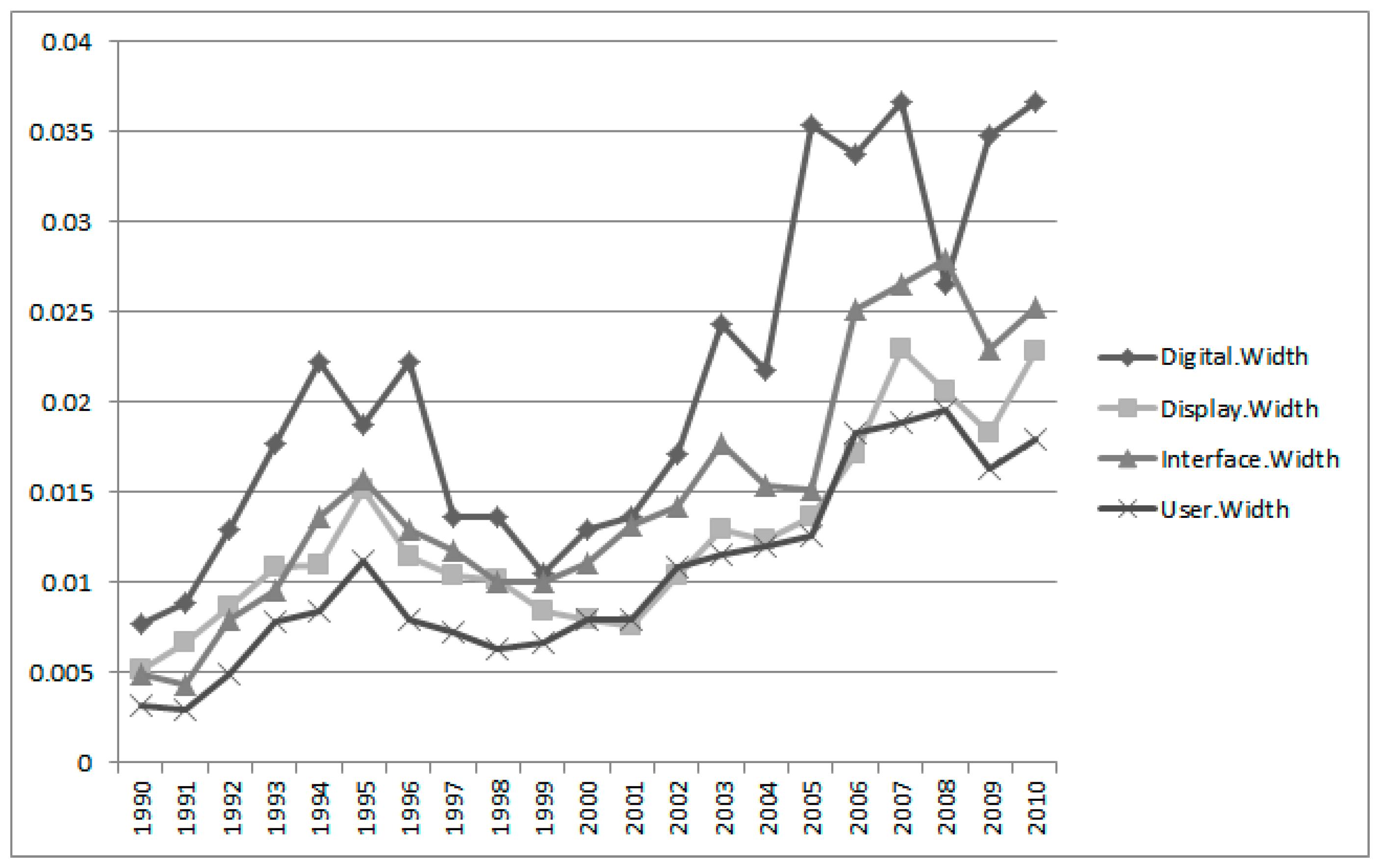
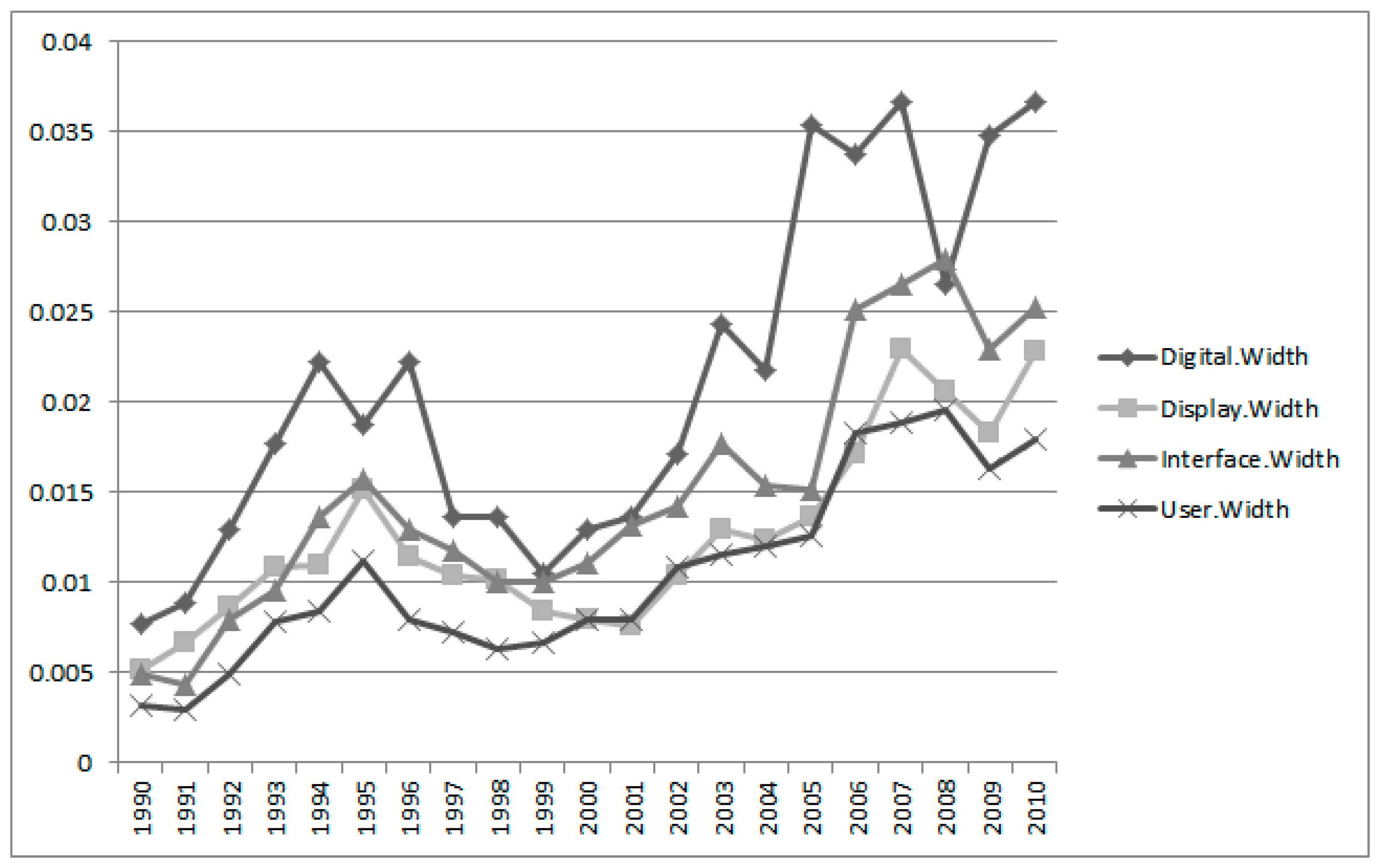
Figure 11 shows interval estimation widths of Group 4 keywords. The fluctuation of the “digital” keyword is larger than other keywords of Group 4.
Until now, we explained the IEM results according to technological groups. Finally, we carried out the IEM for all integrated groups.
Figure 12 shows the interval estimation plots of all groups. The technologies of Groups 1, 3, and 4 have their peaks in 1995. However, the Group 2 technology has its peak in 2007. We see that the Apple Company has recently been focusing on technology based on application.
Table 6 shows the interval estimation results of all groups.
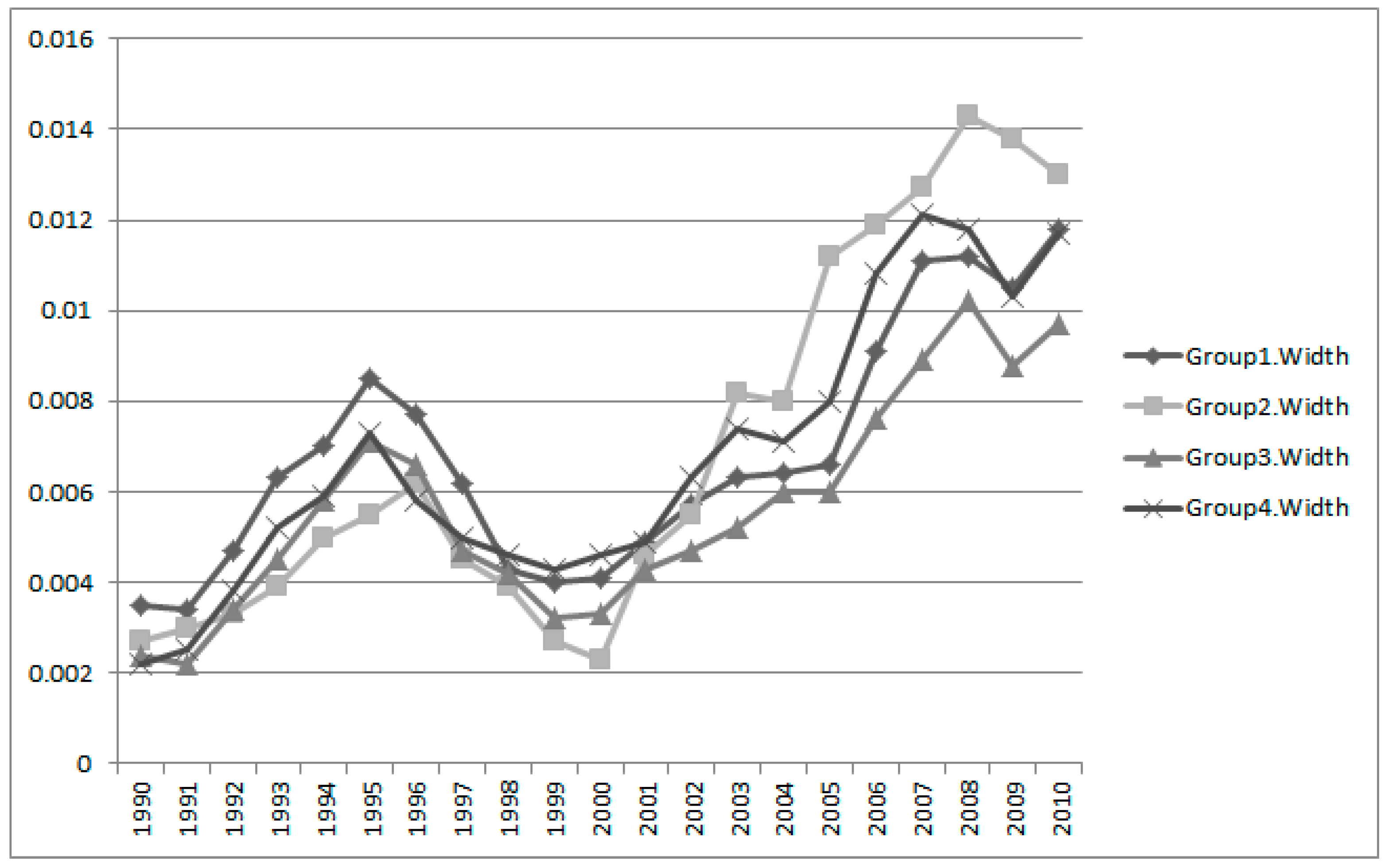
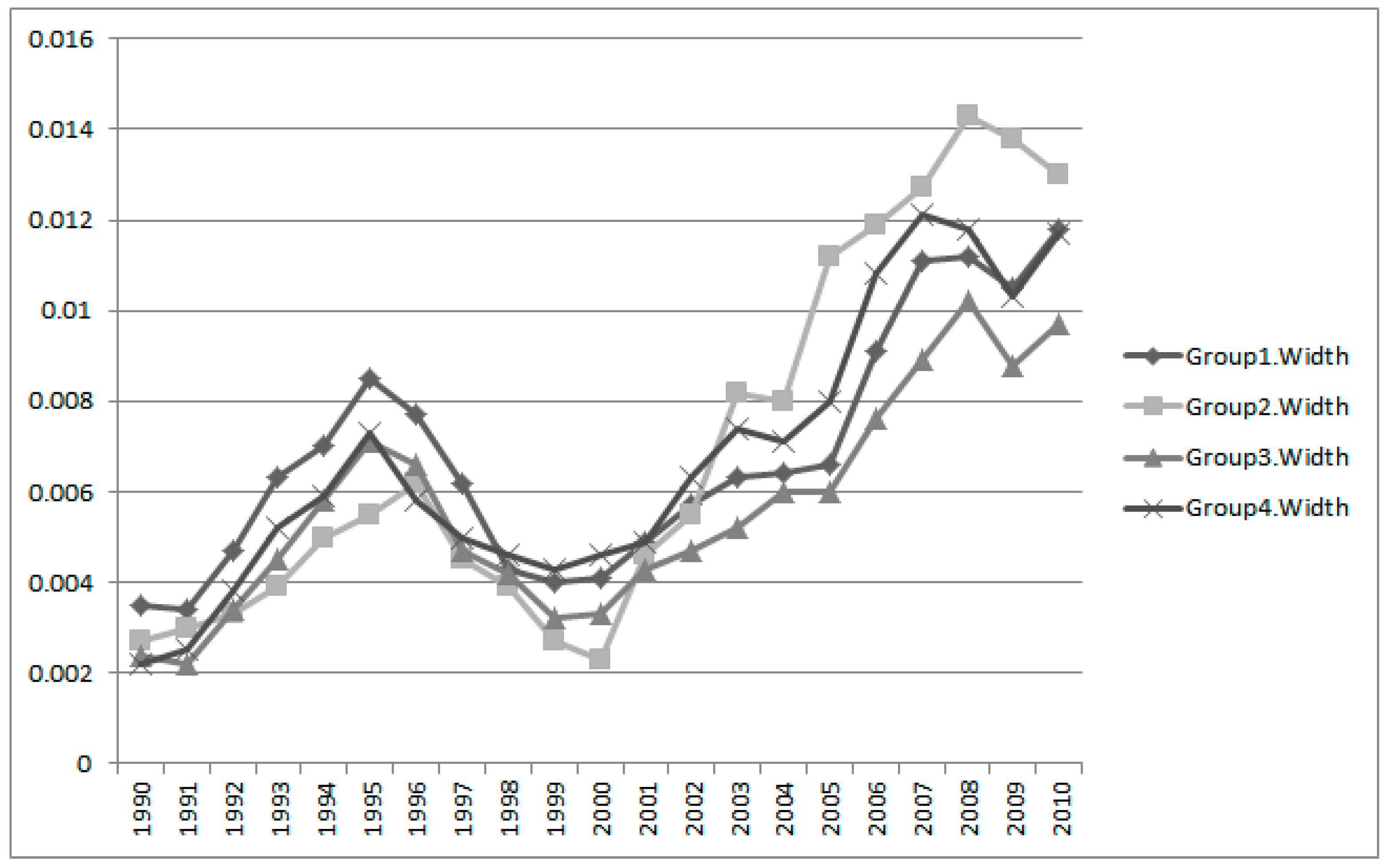
Using the results of
Table 6, we computed the interval estimation widths of all groups in
Figure 13.
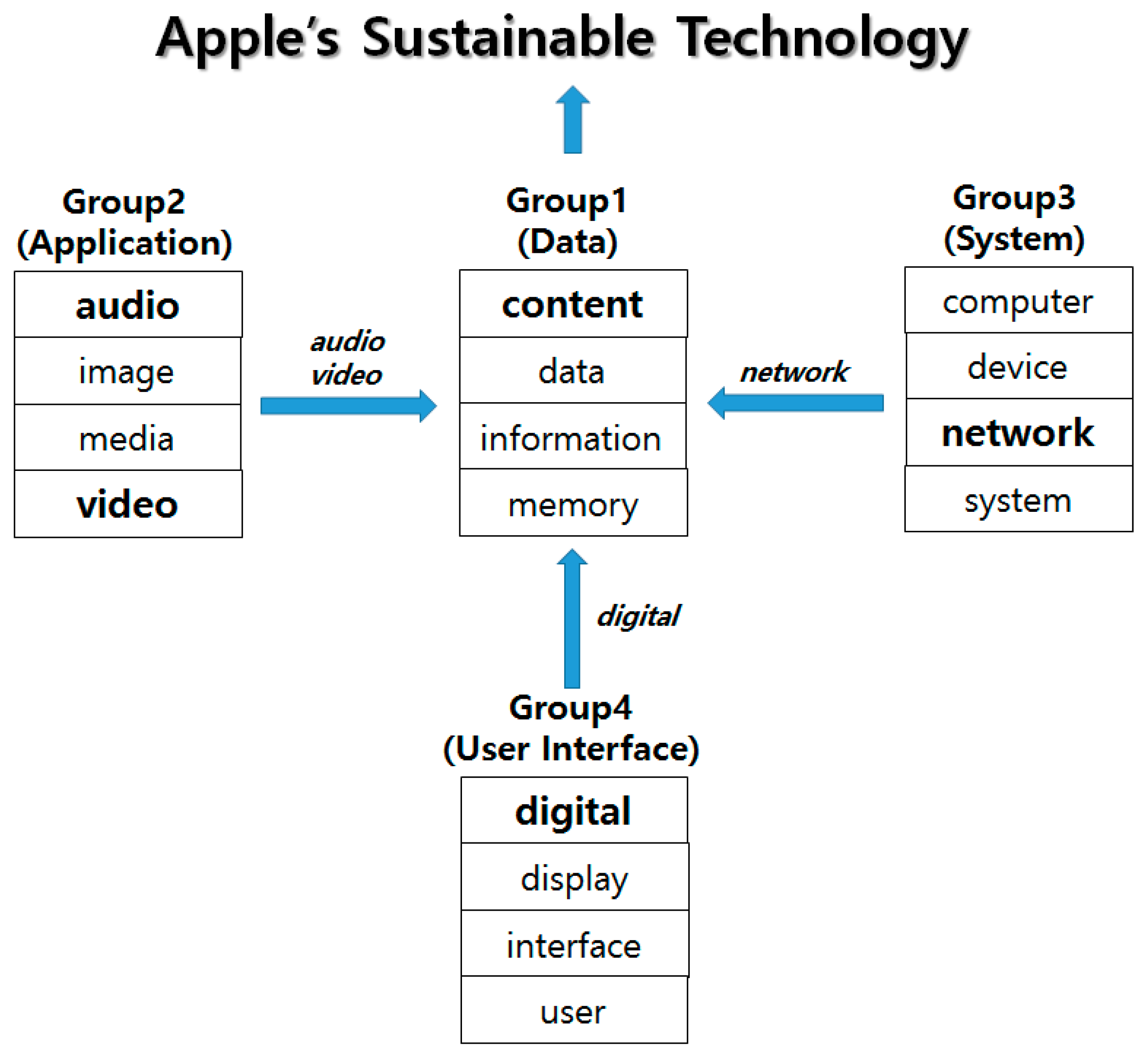
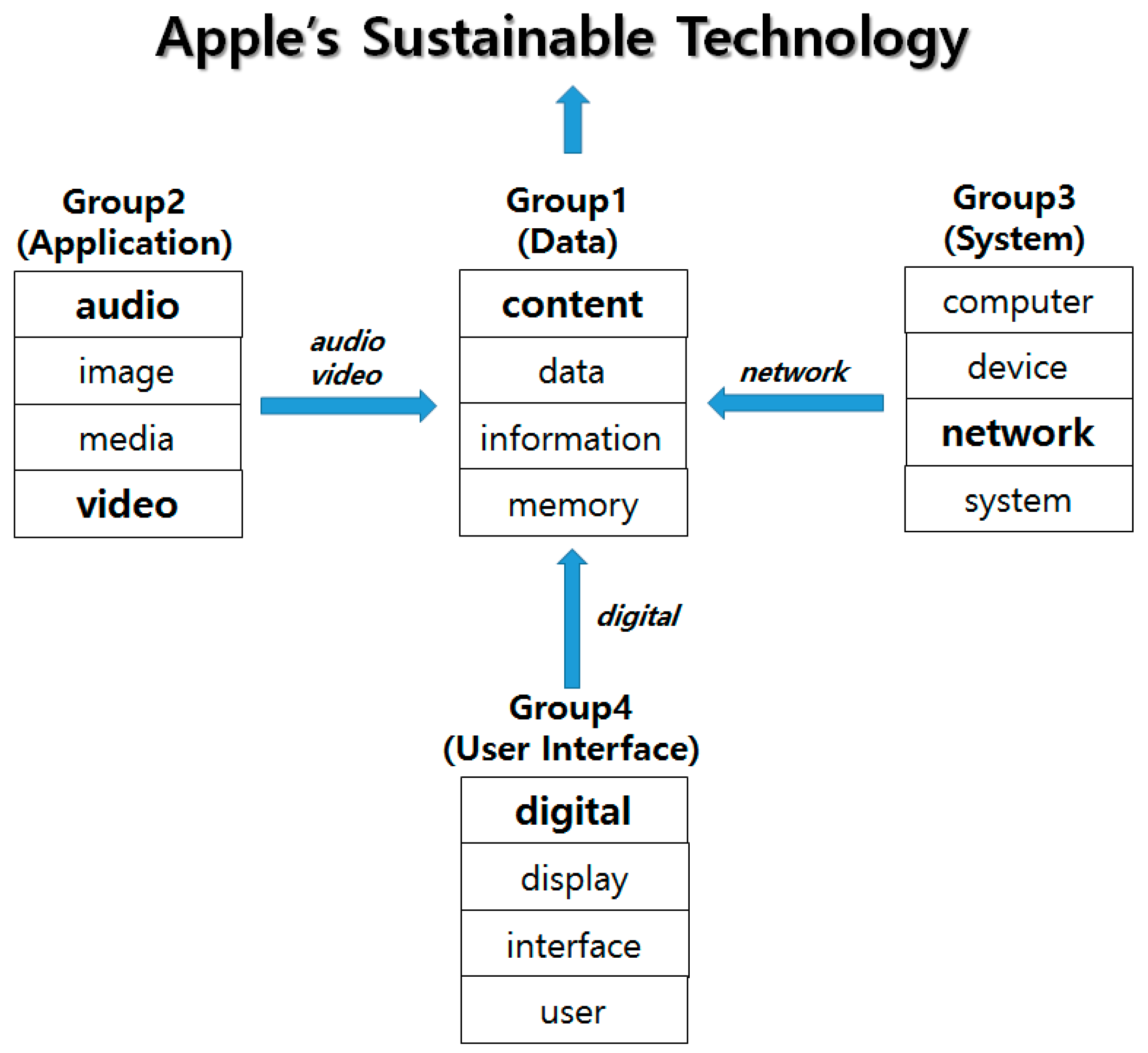
We see that the fluctuation patterns of all groups are similar. In 1995, the peaks of all fluctuations were visible, and recently fluctuations have increased. From the IEM results of all keywords and groups, we obtained the technological structure for Apple’s sustainability in
Figure 14.
Group 1 consists of four keywords (i.e., “content”, “data”, “information”, and “memory”). Using the four keywords, we defined the representative technology of Group 1 as data-based technology. Among these keywords, the “content” keyword has the most influence on the Group 1 technology. In
Figure 14, we expressed the keyword in bold. The same interpretations used for Group 1 apply to the other groups in
Figure 14. The technology of Group 2 is influenced by the technologies based on “audio”, “image”, “media”, and “video”. The technologies of “audio” and “video” dominate the Group 2 technology. Among the four keywords included in Group 3, the “network” keyword has the most influence on the system-based technology of Group 3. Therefore, the technologies of Groups 2–4 affect the technology of Group 1. Apple possesses technologies related to application, system, and user interface, and they have become the basis for developing the data technology. Consequently, this technology structure drives the sustainable technology of Apple. In general analysis without sparsity problem, the frequency values are better data than the binary data. The sparsity problem causes analytical difficulties in patent data analysis. Thus, diverse studies were performed to overcome the problem. In this paper, we also tried to solve the problem by proposed interval estimation method using binary values, and we showed the validity of our method.
5. Discussion
Recently, technology analysis has relied on patent analysis by objective and quantitative statistical models rather than Delphi survey that is based on expert subjective knowledge. Thus, many studies related to patent data analysis have been performed in diverse fields. In order to use statistical models for patent data, we first have to convert the retrieved patent documents into a formal data structure. The structured patent data is a matrix consisting of patent keywords and their frequency values. Each row and column of the matrix represent a patent and a technological keyword, respectively. An element of the matrix is the frequency value of each keyword occurred in a patent document. In general, this matrix is very sparse, that is, most elements have a value of zero. Therefore, most of studies on patent analysis tried to solve the sparsity problem, and carried out statistical modeling or machine learning algorithm for technology analysis. TF is also an attractive field in technology analysis. Because companies want to know the future state of technology in order to increase their market competitiveness. The traditional TF studies mainly consisted of regression analysis that confirms the relation between technologies, time series analysis that analyzes the trend of technology over time, or cluster analysis that groups similar technologies. In the studies, each TF model was independently developed and used. However, our IEM-based TF method is a technology analysis that considered the technological trends of patent keywords over time and technological relations between patent keywords simultaneously. In particular, the TF results are expressed in the form of interval instead of single predictive value, reflecting both the diversity of prediction and uncertainty. In addition, we divided Apple’s technologies into four sub technology groups, and estimated the confidence intervals of occurred frequencies of technological keywords included in four groups. From the results of our proposed method, we can find the future trends of technological keywords of Apple’s technology, and predict Apple's future product development through a combination of the keywords with similar trends. We can apply the proposed method not only to Apple but also to other companies' technology analysis, so that we can predict product development as well as understand the technology possessed by the company. Our research does not provide a specific R&D plan for TF. If we want to a build detailed plan for technology development, we need help from the experts in the relevant field of technology. Future research needs to consider a methodology that can provide more specific R&D plan.
6. Conclusions
We proposed a statistical method of patent keyword analysis for TF. We used an interval estimation to make the proposed IEM. In addition, we applied text mining techniques to construct structured patent data suitable for statistical analysis using the R data language and its “tm” package. The structured data consisted of a patent–keyword matrix with occurred frequencies of all selected keywords, and we converted the frequency values to binary data for the IEM. From the results of IEM, we obtained the mean and confidence interval for each keyword. We assigned a representative technology to each keyword, and forecasted the future of the given technology. In this paper, we applied our IEM to Apple’s technology. We found that Apple’s product technology is based on four technological groups. They are data, application, system, and user interface technologies. In addition, the data technology is core and is a sustainable technology necessary for future development. The other technologies (i.e., application, system, and user interface) affect the development of the data technology. We used patents in 34 years between 1977 and 2010. However, in early years, there were few patents with 0 frequency. Only from 1990 some patents could be selected. Using only patents in the most current 20 years, we tried to forecast technology, and they are also only Apple’s patents. However, when we want to apply in general, they are not enough to forecast technology. To generalize the outputs, we should use interval estimation. We could use 95% interval estimation to forecast technology with 95% confidence in general.
This research contributes to an understanding of technological relationships, R&D planning, and new product development in a company. Our research has a limitation because we only used one interval estimation, though the estimation is superior to other interval estimations. In addition, we provided the technological structure for Apple’s sustainable technology by the results of our interval estimation. This does not show directly the future technology of Apple, but the domain experts of Apple technology can perform technology forecasting using the results of our case study of Apple. Thus, the final implication of this paper is depended upon the roles of domain experts. In our future work, we will study the integrated method of diverse interval estimations for TF. This connects the result of interval estimation to TF directly without the efforts of domain experts.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}