Integrated Understanding of Big Data, Big Data Analysis, and Business Intelligence: A Case Study of Logistics


Seoul Business School, aSSIST, 46 Ewhayeodae 2-gil, Seodaemun-gu, Seoul 03767, Korea
*
Author to whom correspondence should be addressed.
Sustainability 2018, 10(10), 3778; https://doi.org/10.3390/su10103778
Submission received: 5 October 2018
/
Revised: 16 October 2018
/
Accepted: 17 October 2018
/
Published: 19 October 2018
(This article belongs to the Special Issue Expert Systems: Applications of Business Intelligence in Big Data Environments)
Abstract
:Efficient decision making based on business intelligence (BI) is essential to ensure competitiveness for sustainable growth. The rapid development of information and communication technology has made collection and analysis of big data essential, resulting in a considerable increase in academic studies on big data and big data analysis (BDA). However, many of these studies are not linked to BI, as companies do not understand and utilize the concepts in an integrated way. Therefore, the purpose of this study is twofold. First, we review the literature on BI, big data, and BDA to show that they are not separate methods but an integrated decision support system. Second, we explore how businesses use big data and BDA practically in conjunction with BI through a case study of sorting and logistics processing of a typical courier enterprise. We focus on the company’s cost efficiency as regards to data collection, data analysis/simulation, and the results from actual application. Our findings may enable companies to achieve management efficiency by utilizing big data through efficient BI without investing in additional infrastructure. It could also give them indirect experience, thereby reducing trial and error in order to maintain or increase competitiveness.
1. Introduction
A growing number of corporations depend on various and continuously evolving methods of extracting valuable information through big data and big data analysis (BDA) for business intelligence (BI) to make better decisions. The term “big data” refers to large amounts of information or data at a certain point in time and within a particular scope. However, big data have a short lifecycle with rapidly decreasing effective value, which makes it difficult for academic research to keep up with their fast pace. In addition, big data have no limits regarding their type, form, or scale, and their scope is too vast to narrow them down to a specific area of study.
Big data can also simply refer to a huge amount of complex data, but their type, characteristics, scale, quality, and depth vary depending on the capabilities and purpose of each company. The same holds for the reliability and usability of the results gathered from analysis of the data. Previous studies generally agree on three main properties that define big data, namely, volume, velocity, and variety, or the “3Vs” [1,2,3,4], which have recently been expanded to “5Vs” with the addition of veracity/verification and value [5,6,7,8,9,10].
There are numerous multi-dimensional methods for choosing how much data to gather and how to analyze and utilize the data. In brief, the methodology for extracting valuable information and taking full advantage of it could be more important than the data’s quality and quantity. A substantial amount of research has been devoted to establishing and developing theories concerning big data, BDA, and BI to address this need, but it is still challenging for a company to find, understand, integrate, and use the findings of these studies, which are often conducted independently and cover only select aspects of the subject.
BDA refers to the overall process of applying advanced analytic skills, such as data mining, statistical analysis, and predictive analysis, to identify patterns, correlations, trends, and other useful techniques [11,12,13,14,15]. BDA contributes to increasing the operational efficiency and business profits, and is becoming essential to businesses as big data spreads and grows rapidly.
BI is a decision support system that includes the overall process of gathering extensive data, extracting useful data, and providing analytical applications. In general, BI has three common technological elements: a data warehouse integrating an online transaction processing system; a database addressing specific topics; online analytical processing that is used to analyze data in multi-dimensions in order to use those data; and data mining, which involves a series of technological methods for extracting useful knowledge from the gathered data [16,17,18,19,20].
Some areas of BI and BDA, such as data analysis and data mining, overlap. This is to be expected, as the raw data in BI have recently expanded to become big data in volume and scope. This has necessitated reorganization of the field and concepts of BI to provide business insights and enable better decision making based on BDA [21]. Although BI and BDA are generally studied independently, it is challenging and often unnecessary to distinguish between the two concepts when performing business tasks.
Given the cost of gathering and analyzing big data, it is important to identify what data to collect, the range of the data, and the most cost-effective purpose of the data using BI. For this purpose, it is effective to understand and apply the methodology based on experiences of companies shared through a case study. Therefore, the present study has the following aims. First, we explore the meaning of BI, big data, and BDA through a literature review and show that they are not separate methods, but rather an organically connected and integrated decision support system. Second, we use a case study to examine how big data and BDA are applied in practice through BI for greater understanding of the topic. The case study is conducted on a large and rapidly growing courier service in the logistics industry, which has a long history of research. In particular, we examine how the company efficiently allocates vehicles in hub terminals by collecting, analyzing, and applying big data to make informed decisions quickly, as well as uses BI to enhance productivity and cost-effectiveness.
The rest of the paper proceeds as follows. Section 2 reviews the research background and literature related to BI, big data, and BDA. Section 3 presents the case study for the company and industry and discusses the case in detail. Finally, Section 4 concludes by discussing the implications and directions for future research.
2. Literature Review
Big data have become a subject of growing importance, especially since Manyika et al. pointed out that they should be regarded as a key factor to increase corporate productivity and competitiveness [22]. Many researchers have shown interest in big data, as the rapid development of information and communication technology (ICT) generates a significant amount of data. This has led to lively discussions about the collection, storage, and application of such data. In 2012, Kang et al. argued that the value of big data lies in making forecasts by recognizing situations, creating new value, simulating different scenarios, and analyzing patterns through analysis of the data on a massive scale [23]. In 2011, only 38 studies related to big data and BDA were listed in the Science Citation Index Expanded (SCIE), Social Science Citation Index (SSCI), Arts & Humanities Citation Index (AHCI), and Emerging Sources Citation Index (ESCI), but in 2012, this number increased to 92, and then rapidly increased to 1009 in 2015 and 3890 in 2017 [24].
2.1. Toward an Integrated Understanding of Big Data, BDA, and BI
The research boom regarding big data has led to the development of BDA, through which valuable information is extracted from a company’s data. Companies are well aware of the increasing importance and investment need for BDA, as shown by Tankard [25], who claimed that a company can secure higher market share than its rivals and has the potential to increase its operating profit margin ratio by up to 60% by using big data effectively [25,26]. In the logistics industry, big data are used more widely than ever for supporting and optimizing operational processes, including supply chain management. Big data have been instrumental in developing new products and services, planning supply, managing inventory and risks, and providing customized services [26,27,28,29].
BI has a longer history of research than that of big data. In 1865, Richard Millar Devens mentioned the concept in the Cyclopaedia of Commercial and Business Anecdotes [30], after which Luhn began using it in its modern meaning in 1958 [31]. Thereafter, Vitt et al. defined BI as an information system and method for decision making that incorporates the four-step cycle of analysis, insight, action, and performance measurement [32]. Solomon suggested a framework of BI and argued that research in the area was necessary [20]. Then, Turban et al. [33] expanded the scope of research to embrace data mining, warehousing and acquisition, and business analysis, and a growing number of studies followed. Miškuf and Zolotová studied BI using Cognos—a BI solution system adopted by IBM—and the case of U.S. Steel to ascertain how to best apply enterprise/manufacturing intelligence to manage manufacturing data efficiently [30]. Van-Hau pointed out the lack of a general framework in BI that would allow businesses to integrate results and systematically use them, as well as discussed issues that needed to be researched further [34]. In summary, the concept of BI has been expanding with regard to application systems and technologies that support enterprises in making better choices by gathering, storing, analyzing, and accessing data more effectively [35].
Previous research has dealt mostly with management and decision support systems and applications in BI, as well as technological aspects such as algorithms and computing for big data and BDA. However, the research areas are broadening, and topics are becoming more diverse based on different macroeconomic environments, pace of technological progress, and division of the research field. Therefore, many studies on BI, big data, and BDA have been conducted separately. More importantly, big data research has a relatively short history, as it only started attracting significant attention since around 2012, when rapid development of ICTs led to discussions on how to gather and use the unprecedented amount of data generated. On the other hand, BI has long been a point of interest among researchers.
The boundaries between these concepts—big data, BDA, and BI—are often unclear and ambiguous for companies. Generally, BI consists of an information value chain for gathering raw data, turning these data into useful information, management decision making, driving business results, and raising corporate value [36]. However, considering that “raw data” have been expanded to “big data” owing to the development of ICT and data storage, it is safe to say that BI and big data/BDA are presently not independent methods but organically coexist as an integrated decision support system, incorporating all processes from data gathering to management decision making in business.
As research interest in big data began to grow since 2012, Chen et al. grouped previous works in the literature into BI and analytics and divided the evolution process of the subject into stages to examine the main characteristics and features of each stage [37]. Subsequently, Wixom et al. proposed the necessity of studying BI—including big data/BDA—and business analytics to address changes in the field, since there was increasing awareness about the use and need of big data after the BI Conference of the Communications of the Association for Information Systems in 2009 and 2010 [38]. Fan et al. studied BI in the marketing sector in a big data environment and concluded that big data and BDA are disruptive technologies that reorganize the processes of BI to gain business insights for better decision making [21]. In addition, Bala and Balachandran defined cloud computing and big data as the two of the most important technologies in recent years and explored the improvement of decision-making processes through BI by integrating these two key technologies for storing and distributing data using cloud computing [39]. These cases illustrate that an increasing number of researchers are approaching BI and big data/BDA as an integrated concept.
2.2. In-Depth Research through Case Studies
The growing interest in big data/BDA and rapid development in this area have strengthened BI as a decision support system, thereby promoting corporate management and enhancing business value by providing more valuable information to generate innovative ideas for new products and services. This has led to a rise in customer satisfaction, improved inventory and risk management, improved supply chain risk management, creation of competitive information, and provision of real-time business insights [26,27,28,29,40,41,42].
Considering the short lifecycle of big data and their use in companies, there are numerous, multi-dimensional methods for deciding how much data to gather and how to analyze and utilize the data speedily and effectively. As David et al. emphasized in The Parable of Google Flu: Traps in Big Data Analysis, the essential element is turning data into valuable information, not the quantity of data or new data itself [43]. It is thus important to establish a database of integrated convergent knowledge and continue to develop this by accumulating knowledge and experiences through case studies based on practical use that apply the principals of BI and big data/BDA effectively. Below, we list examples of successful studies on the use and application of big data/BDA in practice.
- Zhong et al. examined a big data approach that facilitates several innovations that can guide end-users to implement associated decisions through radio frequency identification (RFID) to support logistics management with RFID-Cuboids, map tables, and a spatiotemporal sequential logistics trajectory [44].
- Marcos et al. studied both the environment and approaches to conduct BDA, such as data management, model development, visualization, user interaction, and business models [45].
- Kim reported several successful cases of big data application. Examples include analysis of competing scenarios through 66,000 simulated elections conducted per day to understand the decisions of individual voters during the 2012 reelection campaign of former US president Barack Obama and delivery routes and time management based on vehicle and parcel locations adopted by UPS, a US courier service company [46].
- Wang et al. redefined big data business analytics of logistics and supply chain management as supply chain analytics and discussed its importance [47].
- Queiroz and Telles studied the level of awareness of BDA in Brazilian companies through surveys conducted via questionnaires and proposed a framework to analyze companies’ maturity in implementing BDA projects in logistics and supply chain management [48].
- Hopkins analyzed the impact of BDA and Internet of things (IoT), such as truck telematics and geo-information in supporting large logistics companies to improve drivers’ safety and operating cost-efficiency [49].
The above examples of big data/BDA used by governments or corporations, as well as entities dealing with methods in either specific or general areas, make it clear that there is an abundance of studies on the need for and efficiency of big data. However, big data and BDA have not been studied until recently, and few studies use real corporate examples—especially in the logistics industry—that provide valuable business insights through detailed methods and results.
Researchers should endeavor to provide second-hand experience through specific case studies using big data/BDA-based BI, and then accumulate and integrate such case studies to establish a database of integrated convergent knowledge. This could enable corporations to adjust to changing environments and improve the productivity and efficiency of the organization.
3. Practical Business Application
The present study aims to examine the overall status of the logistics industry (an industry with continuously growing demand and prominence) and the courier service industry (an industry used by more consumers than any other logistics market segment) as well as business applications related to big data/BDA and BI. The final aim is to assist corporations in reducing trial-and-error periods in management, establishing long-term strategies, and enhancing cost-effectiveness of the corporations.
3.1. Courier Service Overview
Given consumers’ increasing focus on personal service and convenience in consumer products, as well as global economic development, the manufacturing sector is converting from mass production of limited items to multi-item, small-scale production. This is rapidly increasing the volume and sales of courier services as more consumers buy online. Increased online purchases are also a result of ICT advances. According to the Korean Statistical Information Service, Korea’s e-retail sales amounted to KRW 79,954,478 million in 2017, an increase of 21.85% from KRW 65,617,046 million in 2016, and a massive 107.69% increase from 2013 [50]. The courier service industry has become the biggest beneficiary of this dramatic increase in the volume of goods transported and is a suitable yardstick to measure the growth of the logistics industry [51,52]. Traditionally, logistics was considered a support industry for manufacturing and consumption and was mainly perceived as a cost, but it has since emerged as the main industry connecting producers and consumers. Manufacturing corporations regard supply expansion based on ICT to meet consumers’ demands as a key growth strategy, and the courier service industry has shown remarkable growth owing to the sharp increase in the need for parcel transportation [53].
A courier service is generally defined as comprising the entire process of transportation, from receiving a parcel to packaging, transporting, and delivering the parcel to the final destination under the transporter’s responsibility and at the customer’s request [54,55]. The courier service industry usually faces oligopolistic market competition, as it is an enormous service system that requires huge initial investment. Courier service companies are normally large operational organizations that deal with large amounts of cargo, hub terminals, general information systems, and a wide range of transportation vehicles and consist of a complicated network of labor and equipment [51].
Davis previously examined the usefulness of courier services by using information technology in the logistics industry [56]. DeLone and McLean showed that a successful information system environment is a significant factor influencing user satisfaction as it models its influences on individuals and organizations [57]. Kim et al. focused on the use of transportation routes, freight distribution centers, and brokerage points for efficient parcel transportation via main roads [58]. Visser and Lanzendorf [59] analyzed the effects of business-to-consumer (B2C) e-commerce for cargo transportation, revealing that an increase in the demand for courier services leads to changes in freight per ton, distance, size, and fill rate of trucks. The authors illustrated the relationship between consolidation and transportation routes in courier companies [59]. Jeong et al. discussed the allocation of service centers to terminals with a given number of cargo terminals and locations [60], while Goh and Min examined the time of delivery by the capacity of cargo terminals [61]. Meanwhile, Sherif et al. presented an integrated model of the number and location of warehouses, allocation of customers to warehouses, and number and routes of vehicles to minimize transportation cost, fixed cost, operational cost, and route cost [62]. Lim et al. focused on the improvement of service quality while considering price reduction due to the increase of online demand, volume of delivery, and short-term responses, as well as the lack of mid- and long-term responses due to increase in online transactions [63]. Park et al. investigated methods of increasing productivity while considering both logistics and employees by utilizing a wireless Internet system [64], while Kim and Choi explored the effects of a corporation’s logistics technology on courier services based on online shopping malls as courier service users [65].
In summary, most previous research concerning the courier service industry focused on the analysis of courier service networks and delivery efficiency in terms of optimal logistics structures, methods for improving service quality, and minimization of costs in terms of operational requirements. Only a few case studies gathered and analyzed big data or BI applications in the field, considering the increase in e-commerce delivery demand.
3.2. Case Study: CJ Logistics
This study uses the case of CJ Logistics, Korea’s largest logistics company. It examines the sorting process, especially regarding decisions about loading/unloading docks and hub terminals, which are at the core of courier services, to examine the effective use of big data/BDA through BI.
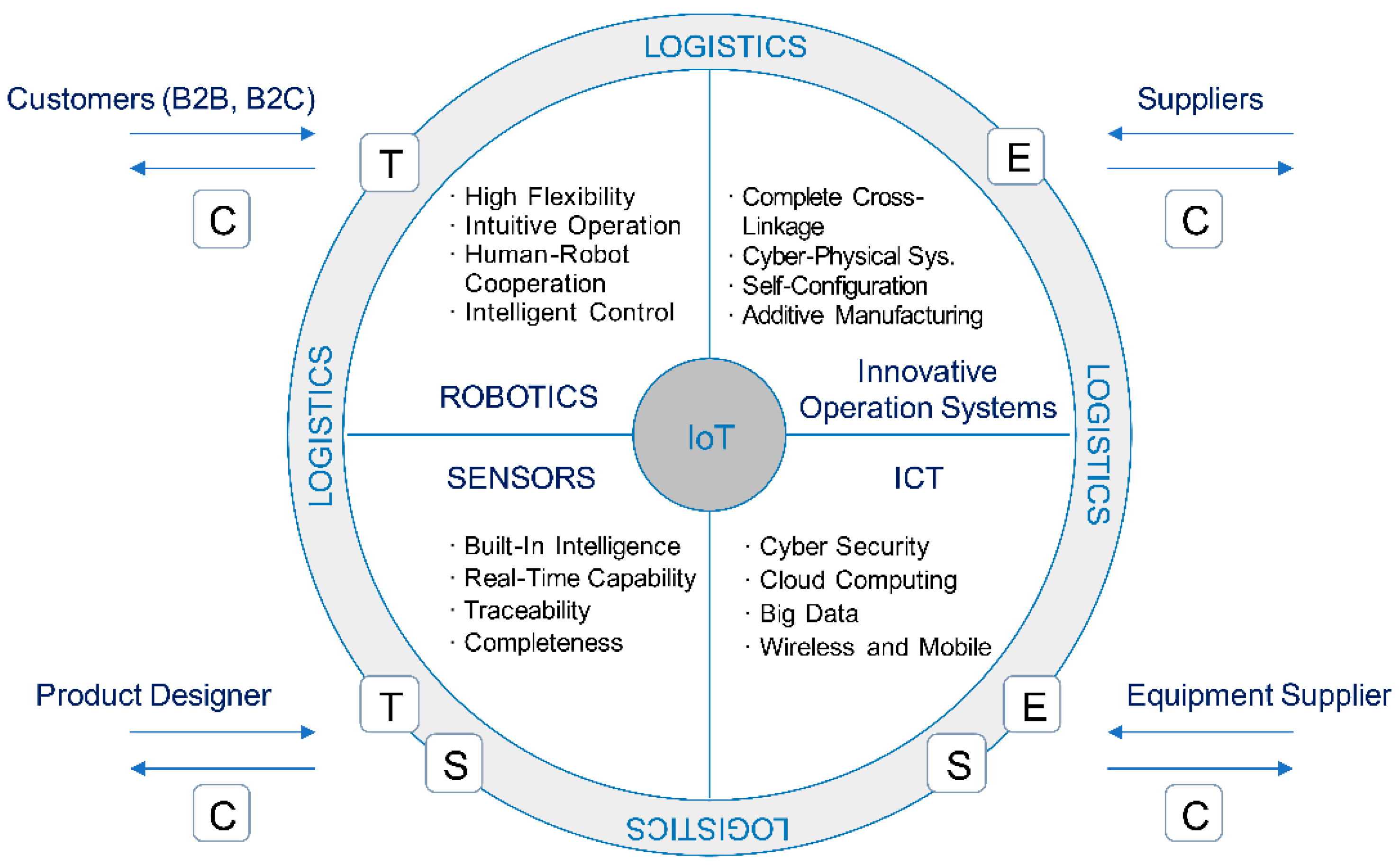
CJ Logistics was selected as the research subject as it is the largest logistics service provider in Korea with the highest market share and sales revenue of KRW 7110.3 billion in 2017 [66]. In addition, as shown in Figure 1 (big data case of CJ Logistics, March 2018), the company is an innovation leader in the industry. It is traditionally considered a 3D business that uses BI based on high-tech automation-oriented technology, engineering, and system and solution plus consulting (TES + C), while actively and rapidly adopting big data/BDA at the same time.
CJ Logistics is a market leader equipped with cutting-edge logistics technologies, including real-time tracking of freight, an integrated courier and freight tracking system that enables users to view customer information and requirements, satellite vehicle tracking, and temperature control systems [67]. In 2017, CJ Logistics invested more than KRW 120 billion to automate its sorting process through sub-terminals to aid sustainable growth. CJ Logistics’ infrastructure is more than three times bigger than that of its closest competitor in the courier service industry. With five hub terminals, more than 270 sub-terminals, and more than 16,000 vehicles, CJ Logistics processes more than 5.3 million packages per day. Its mega hub terminal in Gwangju, Gyeonggi-do Province—which was due for completion in August 2018 with an investment of more than KRW 400 billion—will utilize convergence technologies such as big data, robots, and IoT to expand its services for the convenience of its customers across Korea. This will include same-day delivery, same-day return, and scheduled delivery services. The company is simultaneously moving forward with its planned international growth. At the end of 2017, CJ Logistics had a global network of 238 centers in 137 cities and 32 countries. It opened the Shenyang Flagship Center, a mammoth logistics center in Shenyang, China, on 15 June 2018. The purpose of this investment was to accelerate the company’s business in northern Asia, including three provinces of northeastern China—Liaoning, Jilin, and Heilongjiang. The company has implemented huge capital expenditure to broaden its business efficiently, laying the groundwork for sustainable growth and expansion by raising the entrance barrier for rivals (big data case of CJ Logistics, March 2018).
CJ Logistics mainly uses a hub-and-spoke system, which connects points via hubs or logistics centers dealing with massive cargo volumes in its courier service; it also uses a point-to-point operational system directly connecting origins and destinations. The point-to-point system delivers to and from terminals, saving time on package arrivals while alleviating capacity issues during the peak season. However, growing volumes may increase costs, as they require more investment in terminals; a volume imbalance among terminals can cause unnecessary additional costs. On the other hand, in the hub-and-spoke system, packages are gathered and sorted in a large terminal before being delivered to a destination terminal. The advantage of this system is that it reduces arrival time to the terminals, easing the imbalance in volume. However, the disadvantages are that it may delay deliveries to distant or rural areas during the peak season and requires a large-scale hub terminal [67].
Since CJ Logistics mostly uses the hub-and-spoke system, whose core is the logistics process at the hub terminal, this study focuses on decisions concerning the loading/unloading docks in the process. This focus point was selected for the following reasons. First, few previous studies have focused on this segment, even though it has greater room for improvement regarding productivity and efficiency than other segments. Second, the importance of this segment may have been overlooked, since standardizing the process is challenging owing to differences in the environment, such as the distance between buildings or shape of the space. Third, there are many other difficulties to address, including outsourcing, warehouse management, freight payment, inventory management, packing, customs clearance, and customer claims [51]. Many courier service providers allocate hub terminal docks for loading/unloading simply according to terminal conditions, such as the distance between docks and number of packages, mostly based on past experience. By contrast, CJ Logistics has dramatically improved productivity and efficiency by “seeing the unseen” through the use of big data/BDA and promoting faster and better decision making through BI.
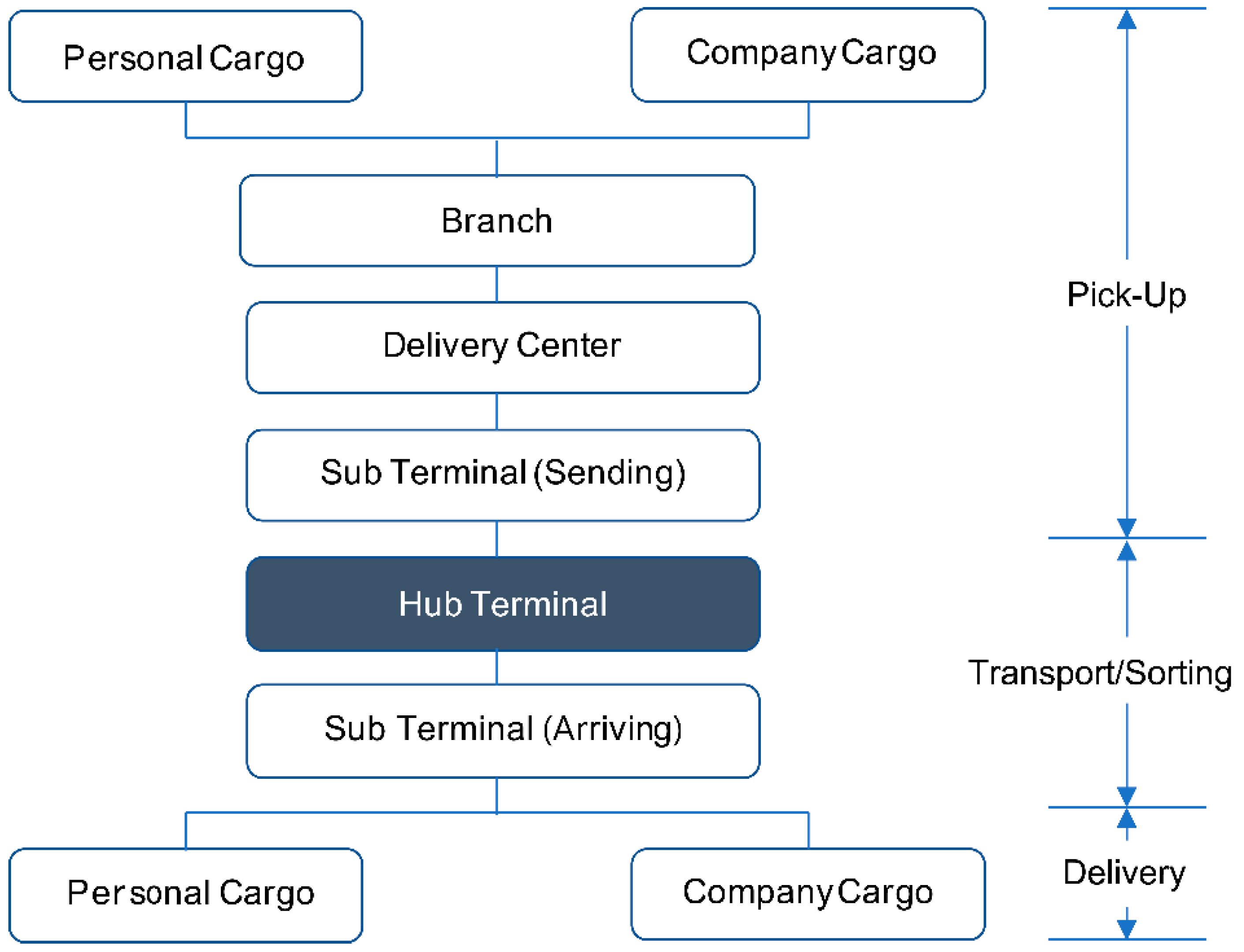
The hub terminal process was selected from the three general stages of courier services, namely, pick-up, transport/sorting, and delivery (Figure 2). This process was selected because it is the central process connecting pick-ups from different locations with delivery to different destinations [68,69].
An incident that occurs at the hub terminal can have a serious impact on the entire cycle—from pick-up to delivery—and could cause a bottleneck effect at hub terminals. This is a significant issue that needs to be addressed to secure growth in the industry, as it can paralyze transportation and delivery within a company on a large scale. Resolving this issue alongside difficulties in other areas by using big data/BDA could improve company productivity and efficiency as a whole.
3.2.1. Data and Methodology
CJ Logistics witnessed a drastic rise in online and offline B2C transactions, experiencing a compound annual growth rate of 9.9% from 2011 to 2016. In addition, the courier company’s market share rose from 42% in 2015 to 46% in 2017. To accommodate this growth, the company increased the number and size of its vehicles, established a demand forecasting system, and improved its peer-to-peer (P2P) network. These measures increased the daily delivery per person from 262 boxes to 344 boxes between 2015 and 2017, while the sorting capacity of hub terminals was improved from around 4.4 million cases to 5.3 million cases during the same period. However, since the company’s hub terminal capacity had reached its limit, bottlenecks in the logistics process were becoming serious. As a result, the rate of remaining cargo increased by 3.1%, and the overnight delivery rate dropped by 2.3% between 2015 and 2017. This situation makes it clear that it is imperative for the company to find a solution through methods that could enhance hub terminal capacity.
To address this issue, CJ Logistics decided to integrate BDA into its existing decision-making processes to understand the current situation better, enabling the company to make better-informed choices and identify future directions. Daejeon hub was chosen for the pilot test. First, information was gathered on roughly 75 million inbound invoices and 240 million packages at Daejeon hub terminal out of a total of 260 million inbound invoices and 720 million packages at hub terminals. The information was gathered over a three-month period between November 2016 and January 2017. This information was used to generate extensive data on the unloading docks at the hub terminal as well as on routes, transition points, moving time, loading docks, remaining cargo, and sorting personnel for BDA. Based on the results, the shortest distance between loading and unloading docks, time metrics, and vehicle loading information were integrated with application methods (as shown later in this subsection). The simulation produced results that would have been impossible to obtain by conventional dock allocation methods that are based on classification codes and number of packages. By reflecting the results at different sites, CJ Logistics was able to increase its hub terminal capacity, as shown in the following paragraphs.
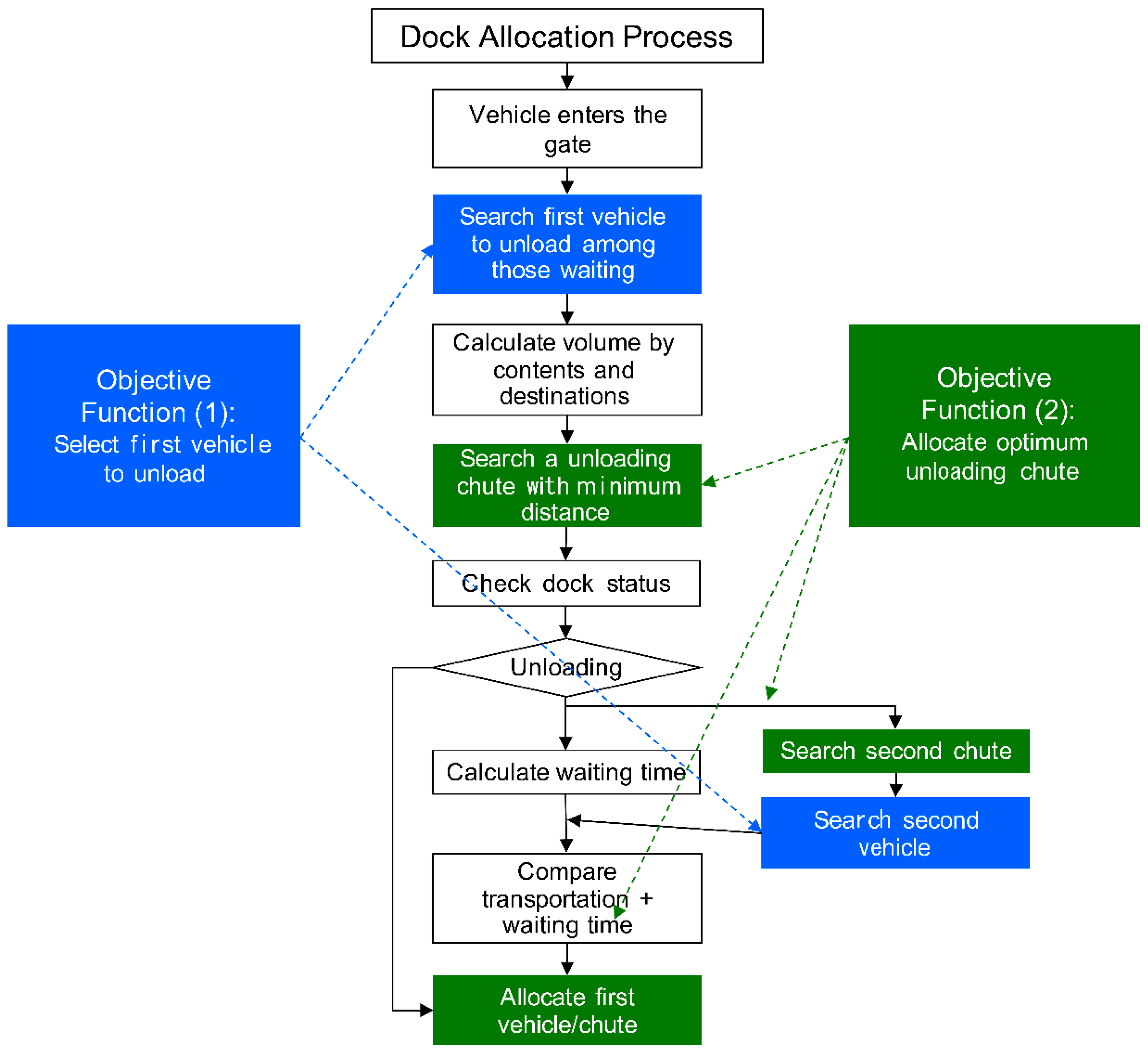
Packages delivered by customers are collected at sub-terminals in each region and transported to hub terminals by truck. Vehicles entering the hub terminal wait for dock allocation and are then unloaded or loaded after being allocated, as per the process shown in Figure 3. In the entire dock allocation process, CJ Logistics reflected at least two types of objective functions to identify the first-in-line vehicle to unload among those waiting, the closest unloading chute, and the second-in-line chute and vehicle in terms of waiting time while unloading vehicles to optimize dock allocation in the hub terminal.
Objective function (1) sets the weighting factor for unloading priority and reflects the number of packages using the volume information in the vehicles for application based on four types of “reference information”, namely, (1) loading priority of waiting vehicles by route; (2) customer classification according to special sale customers, premium customers, and general customers; (3) vehicle classification according to unloading only, unloading/loading, and loading only; and (4) content classification according to console, produce, and general. These unloading priorities were set within the “constraints” of the remaining vehicles that had not been unloaded, and vehicles waiting for more than three hours that should have been unloaded first. Table 1 presents vehicle unloading priorities based on weighting factor and time.
Objective function (1): Selection of vehicles to unload first
W: weighting factor for unloading priority, N: number of packages.
Objective function (2) pertains to optimum unloading chute allocation. This was calculated using volume by loading chute for each vehicle, travel time between unloading/loading chutes, content information, and reflected travel time under the constraints. The function includes minimization of congestion through equal allocation of vehicles, minimization of travel between buildings, and allocation of vehicles with more than 30% console content to a special console unloading zone, based on two types of reference information. The reference information includes (1) travel time between loading/unloading chutes and (2) unloading service time for maximum, minimum, and average volume.
Objective function (2): Optimum unloading chute allocation
L: Volume in the vehicles by loading chutes, T: Travel time between loading/unloading chutes.
Although vehicles are assigned to docks through optimum chutes, by considering operational status at the docks and the fact that unloading procedures can change at any time, the function repeats the optimization of the dock allocation process to decide whether a vehicle should be placed on hold or assigned to a second dock, or whether a second-in-line vehicle should be sent first to increase efficiency. Information from the BDA was used in connection with balancing the volume among loading docks through tracking analysis of individual products, fast delivery by development of new P2P routes, expansion of hub terminal capacity, and volume analysis of products for higher productivity and efficiency.
3.2.2. Simulation and Adoption Result
On 6 November 2016, vehicle number “98 Ba 3490” loaded with cargo from Jungrang sub-terminal arrived at Daejeon hub terminal, unloaded, and then should have reloaded 249 items (52.8% of the total load) on the B1 and 1st floors of Building A, 177 items (37.5% of the total load) on the 1st and 2nd floors of Building B, and 46 items (9.7% of the total load) on the 1st floor of Building C as can be seen in Figure 4a, and the number of items in the red box indicate the quantity that should be loaded in the individual dock. Therefore, the vehicle was allocated to Dock D7 of Building A, since there were more packages to load at Building A than at the other docks (see the purple dot in Figure 4a). It took 57 min and 34 s to complete the unloading/loading process.
However, a simulation based on big data/BDA revealed that dock allocation according to the number of items to load, as shown earlier in this subsection, was very inefficient. The choice of Dock D7, Building A was ranked 41st, as evident from the ranking table in Figure 4b, in terms of efficiency, and unloading at Dock F8, Building B proved most efficient (see the blue dot in Figure 4b). This information could not be determined before the BDA. The simulation results showed that unloading at Dock F8, Building B could decrease the vehicle’s travel time to around one-fifth of the actual time it took when using Dock D7, Building A. The actual travel time was three times greater than the simulated travel time. When a simulation was conducted using the entire fleet of vehicles, the overall efficiency of the hub terminal rose, reducing travel time by more than 20 min, even when unloading at Dock D7, Building A.
CJ Logistics shared the simulation results through the internal reporting system using BI, thus enabling management to make decisions optimizing dock allocations and considering the flow of cargo traffic in hub terminals. As a result, the flow of products improved dramatically, raising the processing rate per hour as well as the rate of overnight deliveries, while lowering the rate of remaining freight. In Daejeon hub terminal, the average distribution time per vehicle was 52 min and 42 s during the thanksgiving season in 2016. This time decreased to 44 min and 7 s during the same period in 2017, a remarkable improvement of 16.3%. Building on such positive results, CJ Logistics subdivided the distribution model by days of the week, seasons, and events, and fine-tuned the metrics of optimum paths. This system was applied to mega hubs in metropolitan areas. By late 2017, the system had been applied throughout the country. The remaining cargo was reduced by 14% from the previous year, and the overnight delivery rate increased by 2.8% in 2017. In summary, CJ Logistics achieved a phenomenal rise in productivity and cost-effectiveness through the use of big data/BDA. It still used the existing infrastructure but expanded the application of BI based on BDA to make decisions across business segments, for long-term strategies, and for additional investment by management.
4. Discussion and Conclusions
Business activities that are believed to be sufficiently empirical and productive to ensure efficiency can benefit from different perspectives and breakthroughs upon acquiring and analyzing big data, and can be realized through BI. The value of big data depends on the types of data extracted and how they are utilized. The crucial factor, however, is the method of turning raw data into valuable information, and not the quality or quantity of the data. Therefore, it is vital to identify the type and scope of data to be collected according to their purpose and focus area. The efficient use of big data may provide an opportunity to a small or medium enterprise to become a large corporation or market leader by taking advantage of meaningful information, and for a large corporation to maintain its market share and ensure sustainable growth and competitiveness. Many studies have been conducted on BI, big data, and BDA so far, but for enterprises to implement changes, it is necessary for them to understand intuitively that BI, big data, and BDA cannot be separated, but should be integrated and utilized in the management decision support system as a whole. As the case study of CJ Logistics shows, the process of collecting and analyzing big data and applying it through BI is separated neither individually nor progressively.
The limitations of this case study include the facts that the big data have been derived from a limited date range, there are differences in the infrastructure and situation of each company, and the case study represents only a portion of a company within a specific industry. Nonetheless, we believe that this case study can be directly applied to other logistics companies within the same sector and, therefore, can help these companies achieve time and cost efficiency without much trial and error. Our study can also have a positive long-run impact by informing companies in the logistics industry, as well as in other industries, of the possibility of increasing the efficiency and productivity of their existing infrastructure without additional investment. CJ Logistics’ process of expanding and applying the experience gained through the combined use of BI, big data, and BDA to all of its business divisions can be a valuable example for other companies and may provide insights concerning future business directions and reduced trial and error. Future studies can expand on this research to provide practical knowledge and experience by collecting and sharing similar case studies, including those about volumetric analysis through ITS (Intelligence Scanner) of goods, volume management through production of boxes for each customer, classification of customers based on volume density, and etc. which are based on practical business applications to build integrated knowledge.
Author Contributions
Conceptualization, D.-H.J. and H.-J.K.; methodology, D.-H.J.; software, D.-H.J.; validation, D.-H.J. and H.-J.K.; formal analysis, D.-H.J.; investigation, D.-H.J.; resources, D.-H.J.; data curation, D.-H.J.; writing—original draft preparation, D.-H.J.; writing—review and editing, D.-H.J. and H.-J.K.; visualization, D.-H.J.; supervision, D.-H.J. and H.-J.K.; project administration, D.-H.J. and H.-J.K.
Funding
This research received no external funding.
Conflicts of Interest
CJ Logistics provided some part of the data for the case study to Dong Hui Jin and validated all the data used in this study.
References
- Laney, D. 3D Data Management: Controlling Data Volume, Velocity and Variety; Application Delivery Strategy; META Group: Stamford, CT, USA, 2001; Volume 949. [Google Scholar]
- McAfee, A.; Brynjolfsson, E. Big data: The management revolution. Harv. Bus. Rev. 2012, 90, 60–68. [Google Scholar] [PubMed]
- Fosso Wamba, S.; Akter, S.; Edwards, A.; Chopin, G.; Gnanzou, D. How ‘big data’ can make big impact: Findings from a systematic review and a longitudinal case study. Int. J. Prod. Econ. 2015, 165, 234–246. [Google Scholar] [CrossRef]
- Wang, Y.; Kung, L.; Wang, W.Y.C.; Cegielski, C.G. An integrated big data analytics-enabled transformation model: Application to health care. Inf. Manag. 2018, 55, 64–79. [Google Scholar] [CrossRef]
- White, M. Digital workplaces: Vision and reality. Bus. Inf. Rev. 2012, 209, 205–214. [Google Scholar] [CrossRef]
- Kambatla, K.; Kollias, G.; Kumar, V.; Grama, A. Trends in big data analytics. J. Parallel Distrib. Comput. 2014, 74, 2561–2573. [Google Scholar] [CrossRef]
- Addo-Tenkorang, R.; Helo, P.T. Big data applications in operations/supply-chain management: A literature review. Comput. Ind. Eng. 2016, 101, 528–543. [Google Scholar] [CrossRef]
- Richey, R.G.; Morgan, T.R.; Lindsey-Hall, K.; Adams, F.G. A global exploration of big data in the supply chain. Int. J. Phys. Distrib. Logist. Manag. 2016, 46, 710–739. [Google Scholar] [CrossRef]
- Yu, W.; Chavez, R.; Jacobs, M.A.; Feng, M. Data-driven supply chain capabilities and performance: A resource-based view. Transp. Res. E Logist. 2018, 114, 371–385. [Google Scholar] [CrossRef]
- Roßmann, B.; Canzaniello, A.; Von der Gracht, H.; Hartmann, E. The future and social impact of Big Data Analytics in Supply Chain Management: Results from a Delphi study. Technol. Forecast. Soc. Chang. 2018, 130, 135–149. [Google Scholar] [CrossRef]
- Russom, P. Big Data Analytics. TDWI Best Practices Report, Fourth Quarter. 2011. Available online: tdwi.org (accessed on 12 July 2018).
- Rouse, M. Big Data Analytics. 2012. Available online: http://searchbusinessanalytics.techtarget.com/definition/big-data-analytics (accessed on 12 July 2018).
- LaValle, S.; Lesser, E.; Shockley, R.; Hopkins, M.S.; Kruschwitz, N. Big data, analytics and the path from insights to value. MIT Sloan Manag. Rev. 2013, 52, 21–31. [Google Scholar]
- Loshin, D. Big Data Analytics: From Strategic Planning to Enterprise Integration with Tools, Techniques, NoSQL, and Graph; Elsevier: Waltham, MA, USA, 2013. [Google Scholar]
- Tiwari, S.; Wee, H.M.; Daryanto, Y. Big data analytics in supply chain management between 2010 and 2016: Insights to industries. Comput. Ind. Eng. 2018, 115, 319–330. [Google Scholar] [CrossRef]
- Gilad, B.; Herring, J.P. The Art and Science of Business Intelligence Analysis; JAI Press Ltd.: Greenwich, UK, 1996. [Google Scholar]
- Davenport, T.; Prusak, L. Working Knowledge; HBS Press: Boston, MA, USA, 1998. [Google Scholar]
- Berson, A.; Smith, S.; Thearling, K. Building Data Mining Application for CRM; McGraw-Hill: New York, NY, USA, 2000. [Google Scholar]
- Simon, A.; Shaffer, S. Data Warehousing and Business Intelligence for E-Commerce; Morgan Kaufmann Publishers: San Francisco, CA, USA, 2001. [Google Scholar]
- Solomon, N. Business intelligence. Commun. Assoc. Inf. Syst. 2004, 13, 177–195. [Google Scholar]
- Fan, S.; Raymond, Y.K.; Lau, J.; Zhaob, L. Demystifying big data analytics for business intelligence through the lens of marketing mix. Big Data Res. 2015, 2, 28–32. [Google Scholar] [CrossRef]
- Manyika, J.; Chui, M.; Brown, B.; Bughin, J.; Dobbs, R.; Roxburgh, C.; Byers, A.H. Big Data: The Next Frontier for Innovation, Competition, and Productivity; McKinsey Global Institute: Washington, DC, USA, 2011. [Google Scholar]
- Kang, M.; Kim, S.; Park, S. Analysis and utilization of big data. J. Inf. Sci. Soc. 2012, 30, 25–32. [Google Scholar]
- Liang, T.; Liu, Y. Research landscape of business intelligence and big data analytics: A bibliometrics study. Expert Syst. Appl. 2018, 111, 2–10. [Google Scholar] [CrossRef]
- Tankard, C. Big data security. Netw. Secur. 2012, 7, 5–8. [Google Scholar] [CrossRef]
- Ram, J.; Zhang, C.; Koronios, A. The implications of big data analytics on business intelligence: A qualitative study in China. Procedia Comput. Sci. 2016, 87, 221–226. [Google Scholar] [CrossRef]
- Wang, L.; Alexander, C.A. Big data driven supply chain management and business administration. Am. J. Econ. Bus. Adm. 2015, 7, 60–67. [Google Scholar] [CrossRef]
- Vera-Baquero, A.; Palacios, R.C.; Stantchev, V.; Molloy, O. Leveraging big-data for business process analytics. Learn. Organ. 2015, 22, 215–228. [Google Scholar] [CrossRef]
- Tan, K.H.; Zhan, Y.Z.; Ji, G.; Ye, F.; Chang, C. Harvesting big data to enhance supply chain innovation capabilities: An analytic infrastructure based on deduction graph. Int. J. Prod. Econ. 2015, 165, 223–233. [Google Scholar] [CrossRef] [Green Version]
- Miškuf, M.; Zolotová, I. Application of Business Intelligence Solutions on Manufacturing Data. In Proceedings of the 13th International Symposium on Applied Machine Intelligence and Informatics, Herl’any, Slovakia, 22–24 January 2015. [Google Scholar]
- Luhn, H.P. A business intelligence system. IBM J. Res. Dev. 1958, 2, 314–319. [Google Scholar] [CrossRef]
- Vitt, E.; Luckevich, M.; Misner, S. Business Intelligence; Microsoft Press: Redmond, WA, USA, 2002. [Google Scholar]
- Turban, E.; Aronson, J.E.; Liang, T.P. Decision Support and Intelligence Systems; Prentice-Hall: Upper Saddle River, NJ, USA, 2005. [Google Scholar]
- Van-Hau, T. Getting value from business intelligence systems: A review and research agenda. Decis. Support Syst. 2017, 93, 111–124. [Google Scholar]
- Turban, E.; Volonino, L. Information Technology for Management, 7th ed.; John Wiley & Sons, Inc.: New York, NY, USA, 2010. [Google Scholar]
- Larsona, D.; Chang, V. A review and future direction of agile, business intelligence, analytics and data science. Int. J. Inf. Manag. 2016, 36, 700–710. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.; Chiang, R.H.; Storey, V.C. Business intelligence and analytics: From big data to big impact. MIS Q. 2012, 36, 1165–1188. [Google Scholar] [CrossRef]
- Wixom, B.; Ariyachandra, T.; Douglas, D.; Goul, M.; Gupta, B.; Iyer, L.; Kulkarni, U.; Mooney, J.G.; Phillips-Wren, G.; Turetken, O. The current state of business intelligence in academia: The arrival of big data. Commun. Assoc. Inf. Syst. 2014, 34, 1–13. [Google Scholar]
- Bala, M.; Balachandran, S.P. Challenges and benefits of deploying big data analytics in the cloud for business intelligence. Procedia Comput. Sci. 2017, 112, 1112–1122. [Google Scholar]
- Davenport, T.H. How strategists use ‘big data’ to support internal business decisions, discovery and production. Strat. Leadersh. 2014, 42, 45–50. [Google Scholar] [CrossRef]
- Narayanan, V. Using big-data analytics to manage data deluge and unlock real-time business insights. J. Equip. Lease Financ. 2014, 32, 1–7. [Google Scholar]
- Erevelles, S.; Fukawa, N.; Swayne, L. Big data consumer analytics and the transformation of marketing. J. Bus. Res. 2016, 69, 897–904. [Google Scholar] [CrossRef]
- Lazer, D.; Kennedy, R.; King, G.; Vespignani, A. The parable of Google flu: Traps in big data analysis. Science 2014, 343, 1203–1205. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhong, R.Y.; Huang, G.Q.; Lan, S.; Dai, Q.Y.; Chen, X.; Zhang, T. A big data approach for logistics trajectory discovery from RFID-enabled production data. Int. J. Prod. Econ. 2015, 165, 260–272. [Google Scholar] [CrossRef]
- Marcos, D.; Assunção, R.N.; Calheiros, S.B.; Marco, A.S.; Netto, R.B. Big data computing and clouds: Trends and future directions. J. Parallel Distrib. Comput. 2015, 79, 3–15. [Google Scholar]
- Kim, Y. Enterprise innovation through the introduction of big data-based advanced analysis system: Case and methodology. IE Mag. 2013, 20, 43–49. [Google Scholar]
- Wang, G.; Gunasekaran, A.; Ngai, E.W.T.; Papadopoulos, T. Big data analytics in logistics and supply chain management: Certain investigations for research and applications. Int. J. Prod. Econ. 2016, 176, 98–110. [Google Scholar] [CrossRef] [Green Version]
- Queiroz, M.M.; Telles, R. Big data analytics in supply chain and logistics: An empirical approach. Int. J. Logist. Manag. 2018, 29, 767–783. [Google Scholar] [CrossRef]
- Hopkins, J.; Hawking, P. Big data analytics and IoT in logistics: A case study. Int. J. Logist. Manag. 2018, 29, 575–591. [Google Scholar] [CrossRef]
- Korean Statistical Information Service. 2018. Available online: http://kostat.go.kr/portal/korea/index.action (accessed on 18 October 2018).
- Jo, Y.; Yoon, M. Analysis of courier service market of South Korea. Korea Technol. Innov. Soc. 2001, 245–270. [Google Scholar]
- Ho, J.S.Y.; Teik, D.O.L.; Tiffany, F.; Kok, L.F.; The, T.Y. Logistic Service Quality among Courier Services in Malaysia. In International Conference on Economics, Business Innovation, IPEDR; IACSIT Press: Singapore, 2012; Volume 38, pp. 113–117. [Google Scholar]
- Lee, C. A study on the strengthening competitiveness of railway logistics business with the growth of the courier business. J. Vocat. Rehabil. 2002, 25, 75–95. [Google Scholar]
- Park, Y. A study on the domestic express courier service’s present situation and further theme in the era of e-commerce. Korean J. Bus. Adm. 2003, 39, 1425–1444. [Google Scholar]
- Jung, J.; Kim, C. A Study on Quality Improvement of Courier Service Using Quality Function Deployment. In Proceedings of the Conference of the Korean Society of Business Administration, Seoul, Korea, 24–25 November 2015; pp. 451–468. [Google Scholar]
- Davis, F.D. Perceived usefulness, perceived ease of use, and user acceptance of information technology. MIS Q. 1989, 13, 361–391. [Google Scholar] [CrossRef]
- DeLone, W.H.; McLean, E.R. Information system success: The quest for the dependent variable. Inf. Syst. Res. 1992, 3, 60–92. [Google Scholar] [CrossRef]
- Kim, W.; Lim, S.; Park, S. Transportation plan of trunk transport problem with small quantity. Ind. Eng. 2000, 13, 471–478. [Google Scholar]
- Visser, E.J.; Lanzendorf, M. Mobility and accessibility effects of b2c E-commerce: A literature survey. J. Soc. Econ. Geogr. 2004, 95, 189–205. [Google Scholar]
- Jeong, K.; Goh, C.; Shin, J. Model for the assignment and scheduling of container transport vehicles. Logist. Res. 2005, 13, 141–154. [Google Scholar]
- Goh, C.; Min, H. Cargo terminal capacity and order deadline time decision in courier service. Logist. Res. 2006, 14, 43–58. [Google Scholar]
- Sherif, H.L.; Fattouh, M.; Issa, A. Location/allocation and routing decisions in supply chain network design. J. Model. Manag. 2006, 1, 173–183. [Google Scholar]
- Lim, H.; Lim, J.; Lee, H. An exploratory study on the effective operation of the logistics network for courier service by the growth of online shopping. Korea Mark. J. 2007, 9, 97–129. [Google Scholar]
- Park, S.; Kang, Y.; Suh, Y. A study on the success factors of using wireless Internet system in logistics/courier service companies. Inf. Syst. Res. 2009, 18, 127–150. [Google Scholar]
- Kim, S.; Choi, Y. Impact of logistics information technology on the satisfaction of courier service. J. Korea Port Econ. Assoc. 2011, 27, 91–112. [Google Scholar]
- Data Analysis, Retrieval, and Transfer System (DART) of Financial Supervisory Service; Understanding of CJ and Logistics Industry; CJ Group: Seoul, Korea, 2018.
- Lee, S.; Jeong, I. A case study on comparative analysis of courier service information system. Bus. Intell. Res. 2009, 28, 1–24. [Google Scholar]
- Korea Consumer Agency. Use of Courier Service and Survey; Korea Consumer Agency: Seoul, Korea, 2000. [Google Scholar]
- Choi, K. System thinking for increasing the operational efficiency of courier service network. Korean Syst. Dyn. Res. 2011, 12, 89–114. [Google Scholar]
Figure 1.
Technology, engineering, system and solution plus consulting (TES + C) of CJ Logistics.

Figure 2.
General courier service structure.

Figure 3.
Optimization of dock allocation process.

Figure 4.
(a) Before optimization of dock allocation; DaeJeon Hub Terminal of CJ Logistics; (b) After optimization of dock allocation using BDA; DaeJeon Hub Terminal of CJ Logistics.
Figure 4.
(a) Before optimization of dock allocation; DaeJeon Hub Terminal of CJ Logistics; (b) After optimization of dock allocation using BDA; DaeJeon Hub Terminal of CJ Logistics.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Selection of vehicle unloading priorities according to weighting factor and time.
| Order | Category | W (Before 0:00) | W (After 0:00) |
|---|---|---|---|
| 1 | Special sale customer | 50 | 3 |
| 2 | Route for loading first | 30 | 50 |
| 3 | Console volume | 8 | 15 |
| 4 | Produce | 7 | 10 |
| 5 | Premium customer | 3 | 20 |
| 6 | First-in, first-out (FIFO) | 2 | 2 |
Note: W: weighting factor for unloading priority.
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Jin, D.-H.; Kim, H.-J. Integrated Understanding of Big Data, Big Data Analysis, and Business Intelligence: A Case Study of Logistics. Sustainability 2018, 10, 3778. https://doi.org/10.3390/su10103778
AMA Style
Jin D-H, Kim H-J. Integrated Understanding of Big Data, Big Data Analysis, and Business Intelligence: A Case Study of Logistics. Sustainability. 2018; 10(10):3778. https://doi.org/10.3390/su10103778
Chicago/Turabian StyleJin, Dong-Hui, and Hyun-Jung Kim. 2018. "Integrated Understanding of Big Data, Big Data Analysis, and Business Intelligence: A Case Study of Logistics" Sustainability 10, no. 10: 3778. https://doi.org/10.3390/su10103778
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.