1. Introduction
To achieve the transformation and upgrade of China’s manufacturing, the “Made in China 2025” plan [
1] proposed a basic guideline with innovation-driven, quality first, green development, structure optimization, and talent-oriented objectives. Therefore, quality, as the lifeline in manufacturing, has attracted the attention of manufacturers and researchers. To control and improve manufacturing quality, many techniques are implemented into the manufacturing process. Among them, manufacturing quality prediction, as one of the effective ways to control and improve manufacturing quality, has been developed using various data mining techniques.
Statistical quality control [
2] based on cause–effect relationships, e.g., linear regression [
3], non-linear regression [
4], inference learning [
5], and expert systems [
6], has been widely used to assess the quality performance of manufacturing processes. The successful application of these approaches is attributed to certain stable or constant production processes, which thus makes them unsuitable for the fast-increasing complexity and high-dimensionality of modern manufacturing. To address this issue, artificial intelligence (AI) is stepping into the academic field of these researchers due to its self-learning ability without taking into account manufacturing processes [
7,
8,
9,
10]. Artificial neural networks (ANNs) and machine learning (ML) are two typical representatives of AI techniques, and have achieved successful application in manufacturing quality prediction, e.g., self-organizing neural networks [
11], back propagation neural networks (BPNNs) [
12], radial basis function neural networks [
13], probability neural networks [
14], support vector machines (SVMs) [
15], and extreme learning machines [
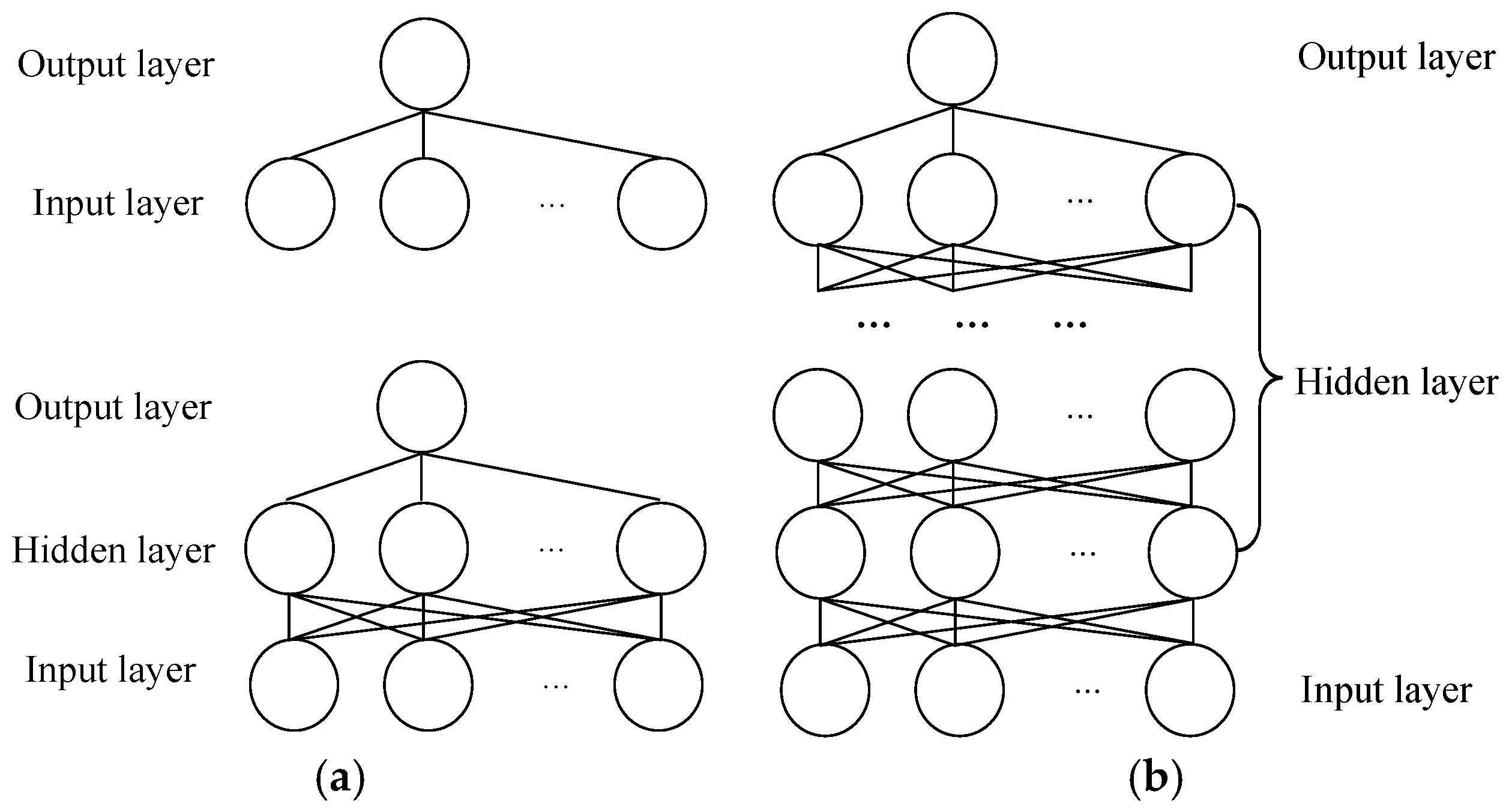
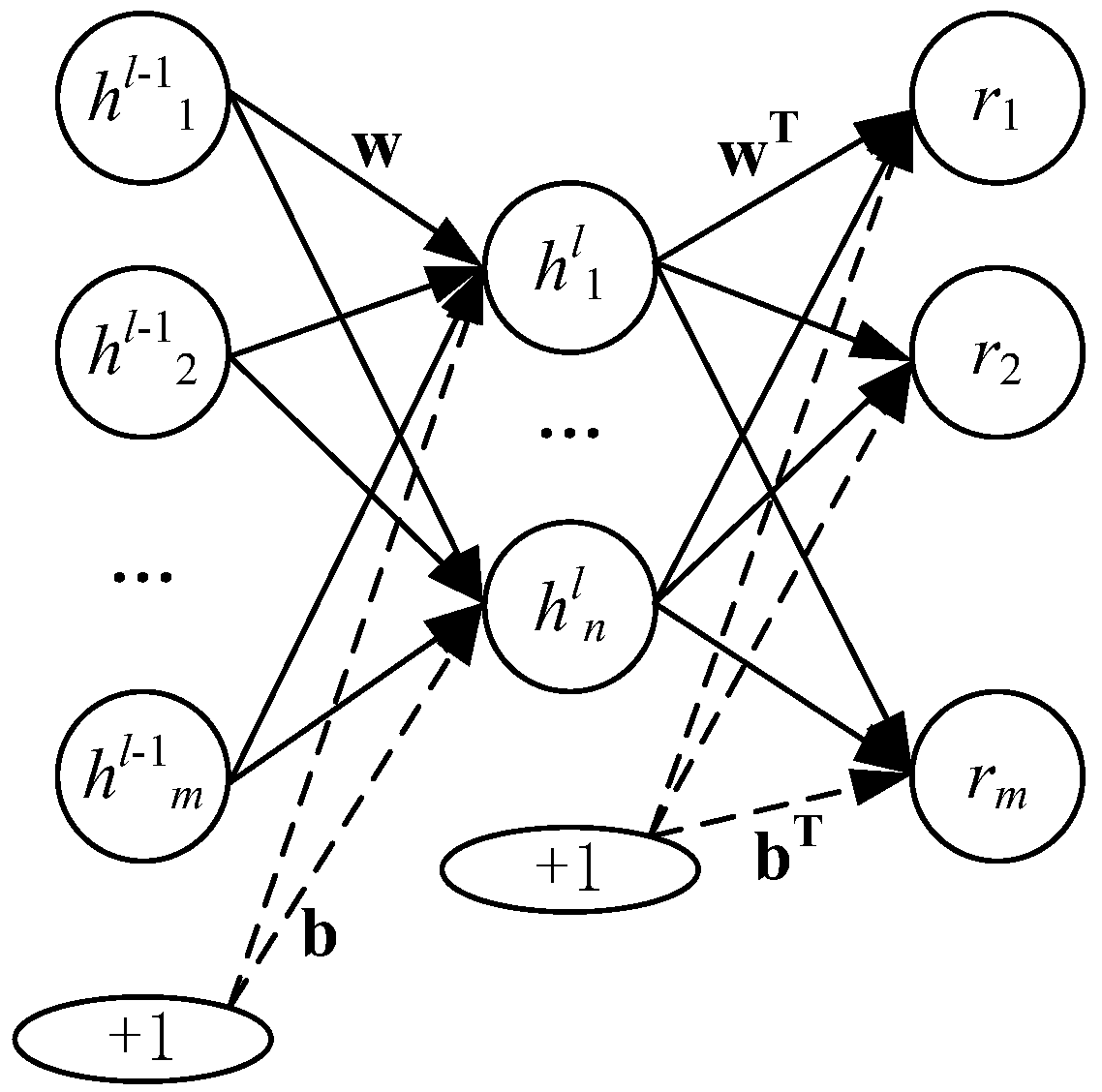
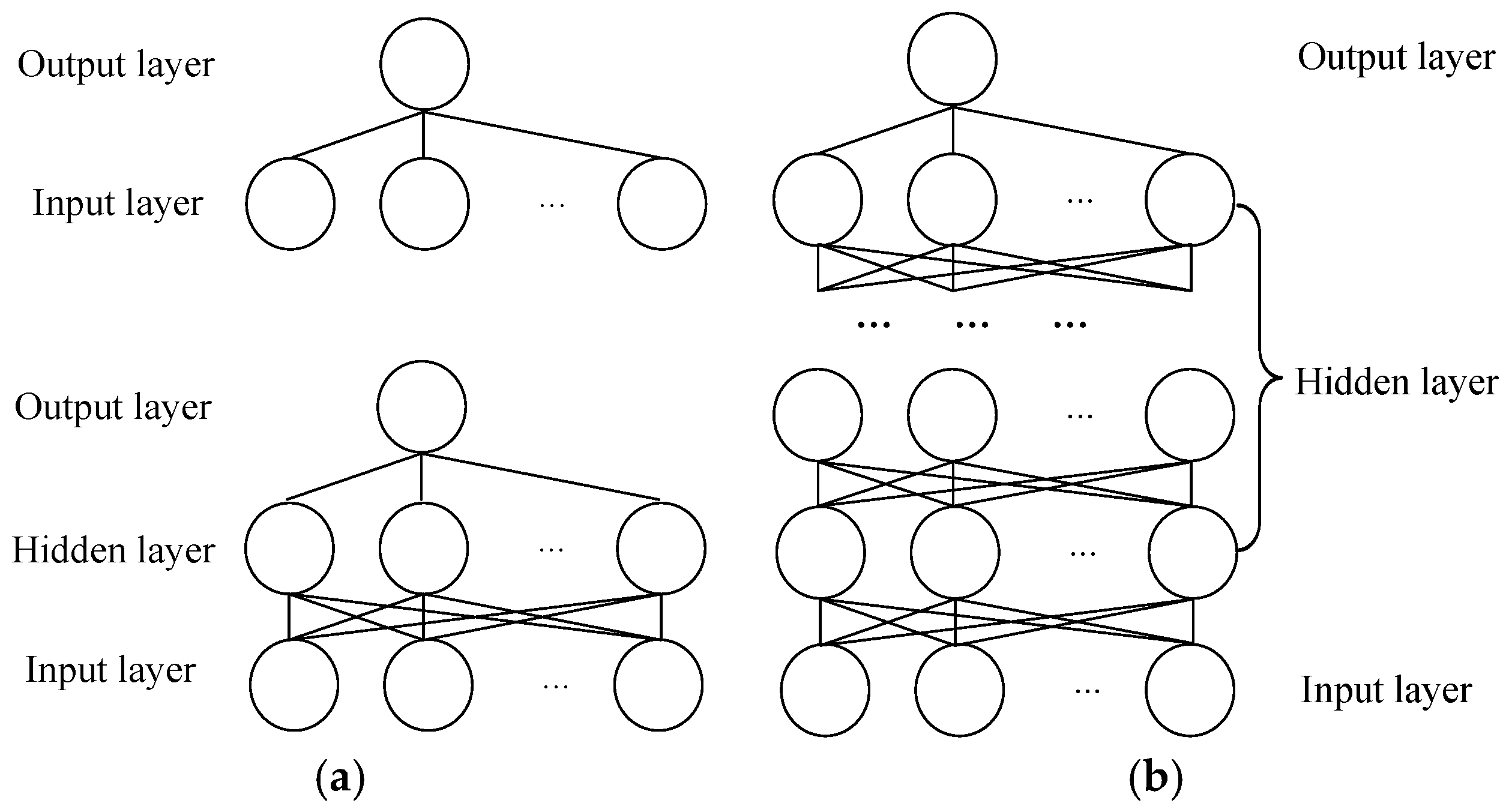
16]. Affected by multiple parameters from multi-stage manufacturing processes, ANN and ML modeling exhibit feature learning difficulties and network calculation complexities due to their “shallow” architecture, i.e., the model has one hidden layer or none at all (a traditional ANN has one hidden layer and classical ML is based on a kernel function without a hidden layer). To improve prediction accuracy, it is thus imperative to enhance the feature learning capability using a “deep” representation technique.
In 2006, the deep learning (DL) technique was proposed [
17] and it has become a hot research topic in AI. It has been proven to be effective for many fields, e.g., fault diagnosis [
18], pattern recognition [
19], and time series forecast [
20,
21]. Compared with the “shallow” models, DL has many hierarchical levels in a hidden layer, that is, the information representation is delivered from lower levels to higher levels, which makes the information representation more abstract and nonlinear for the higher levels. Through representations by the hierarchical levels, the “deeper” feature of multi-parameter manufacturing quality can be fitted by regression models sufficiently [
22]. To our best knowledge, there has been little literature that has reported on applications for manufacturing quality prediction using the deep framework. Therefore, the DL technique can provide a possibility for manufacturing quality prediction.
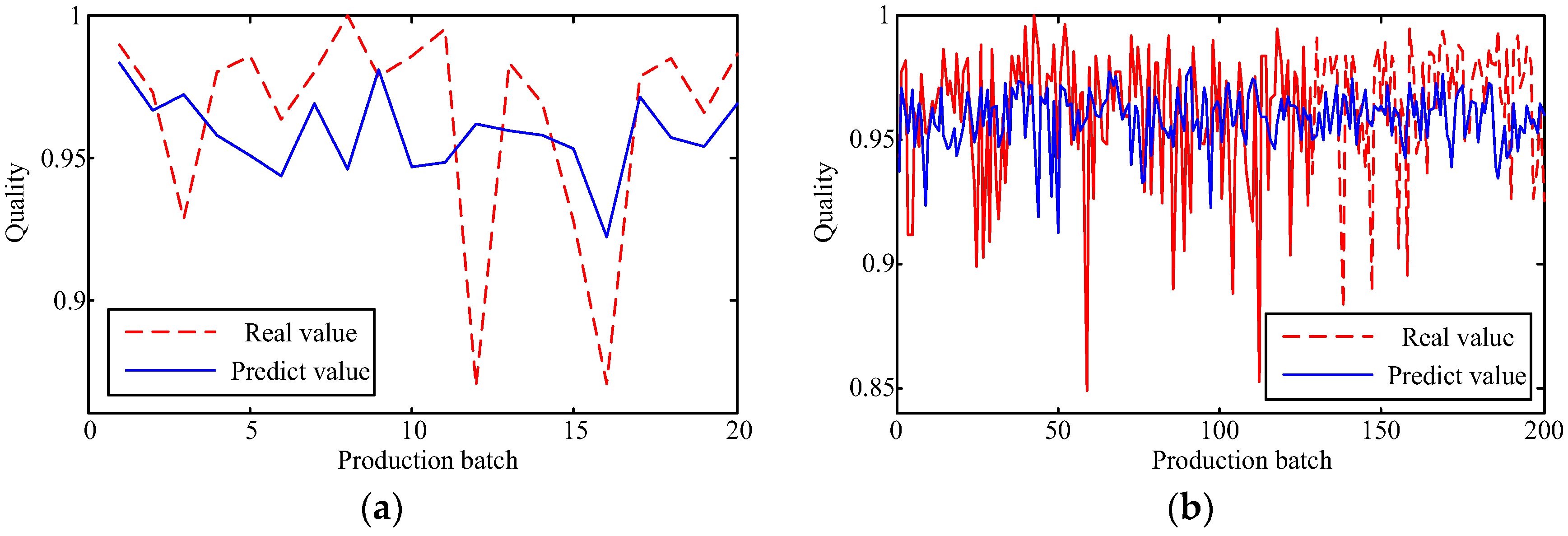
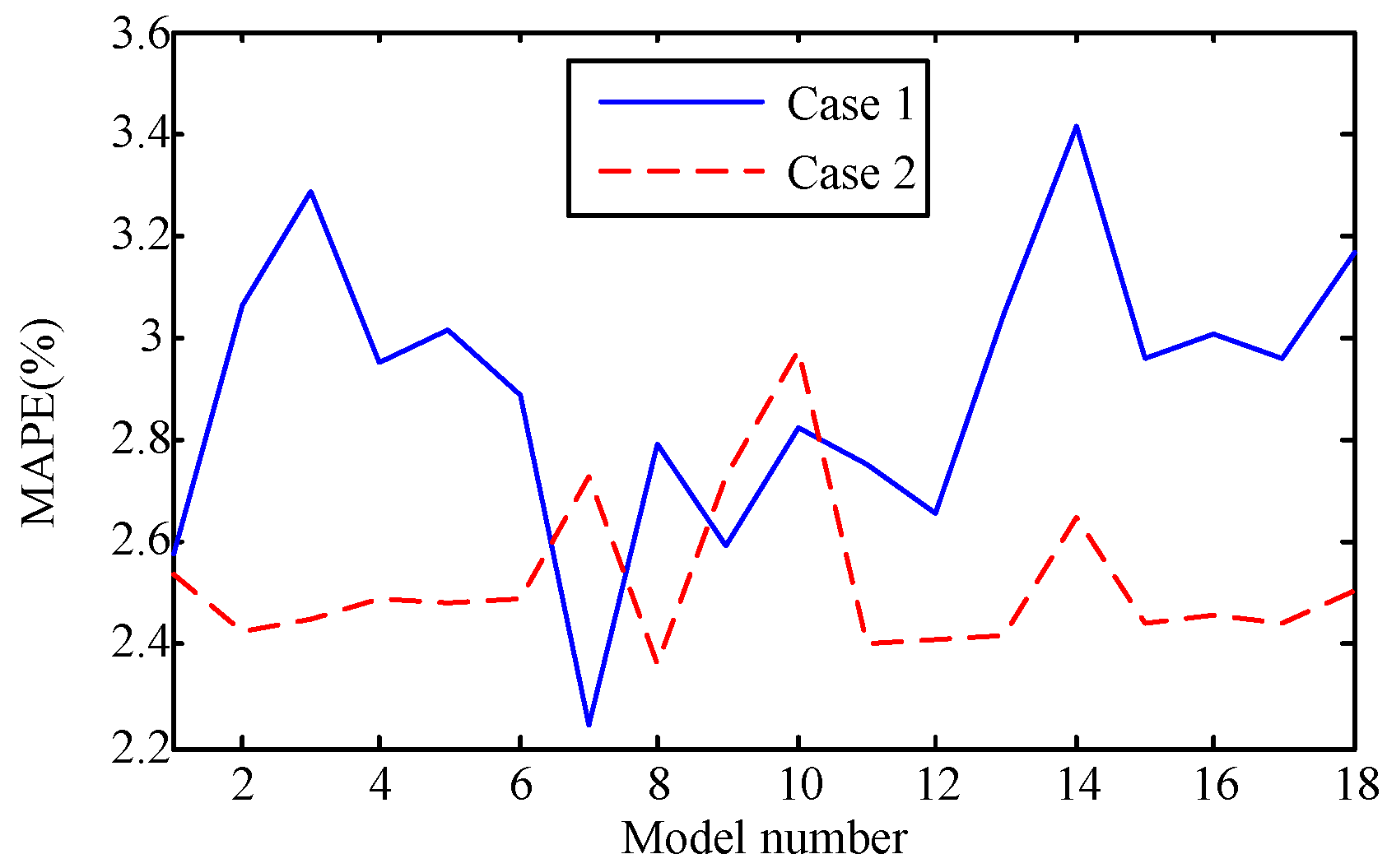
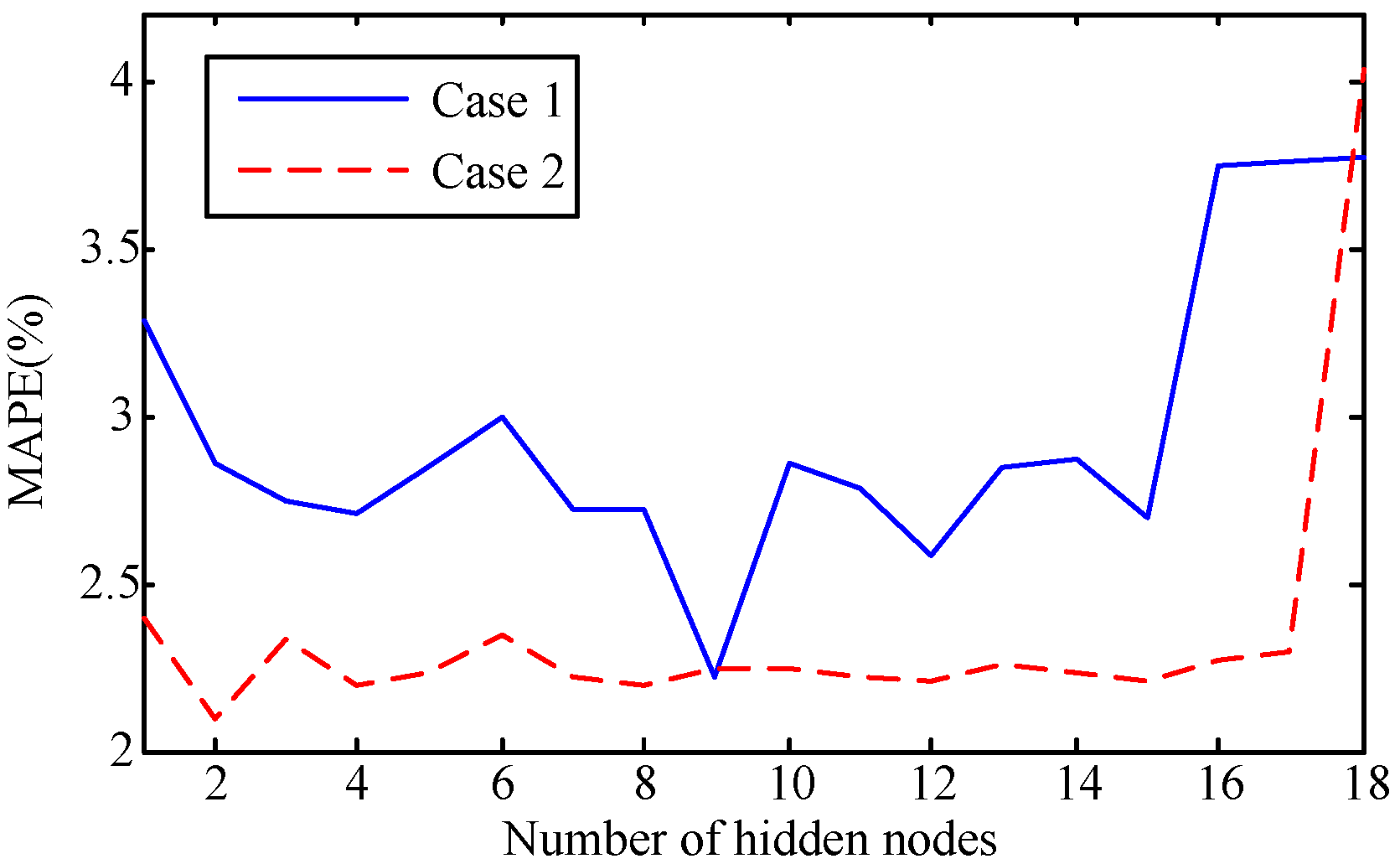
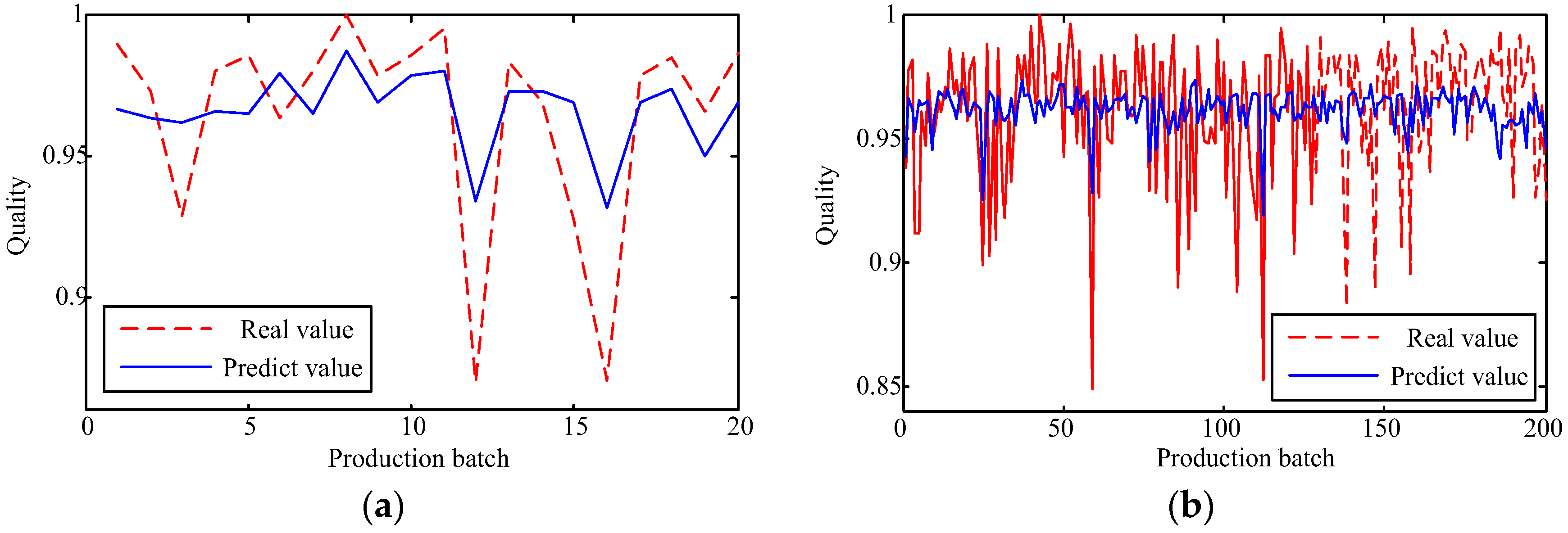
This paper attempts to make a comparison of two feature learning patterns to investigate their performances for predicting manufacturing quality, including the feed forward neural network (FFNN), the least squares support vector machine (LSSVM), the deep restricted Boltzmann machine (DRBM), and the stack autoencoder (SAE). To reveal the feature learning capacity of the four models, two kinds of manufacturing data with multiple parameters are involved.
The rest of the paper is organized as follows.
Section 2 introduces the FFNN, the LSSVM, the DRBM, and the SAE, respectively.
Section 3 presents the application data.
Section 4 gives the results with relevant discussion.
Section 5 concludes this study.
5. Conclusions
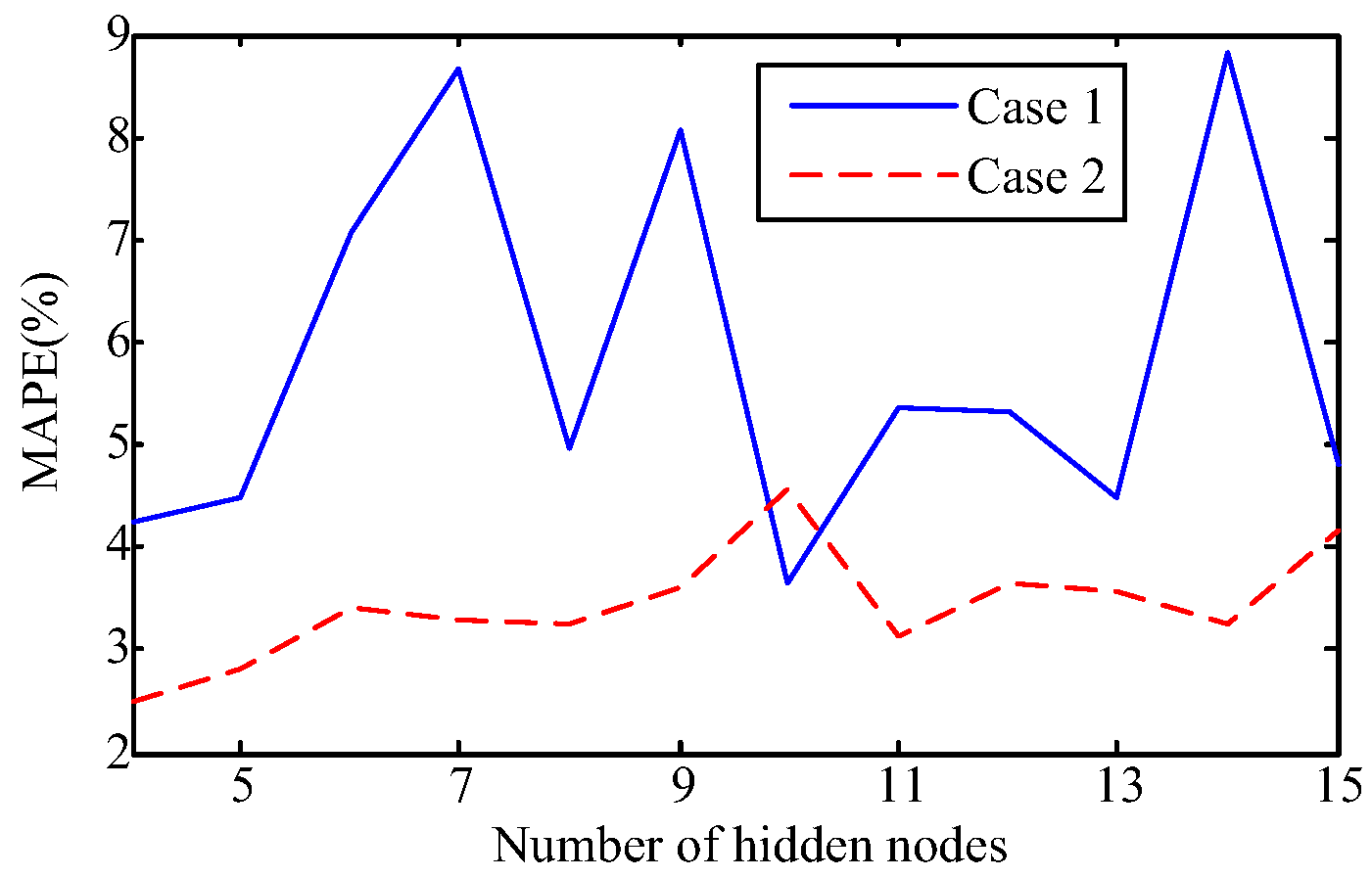
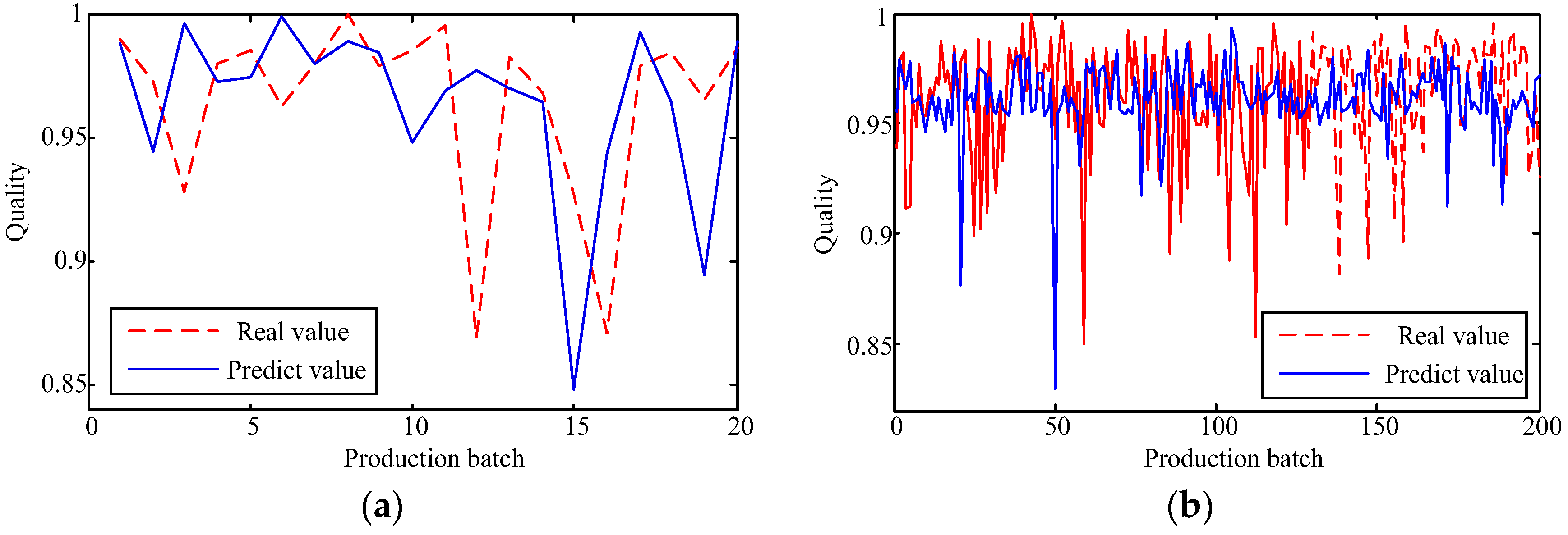
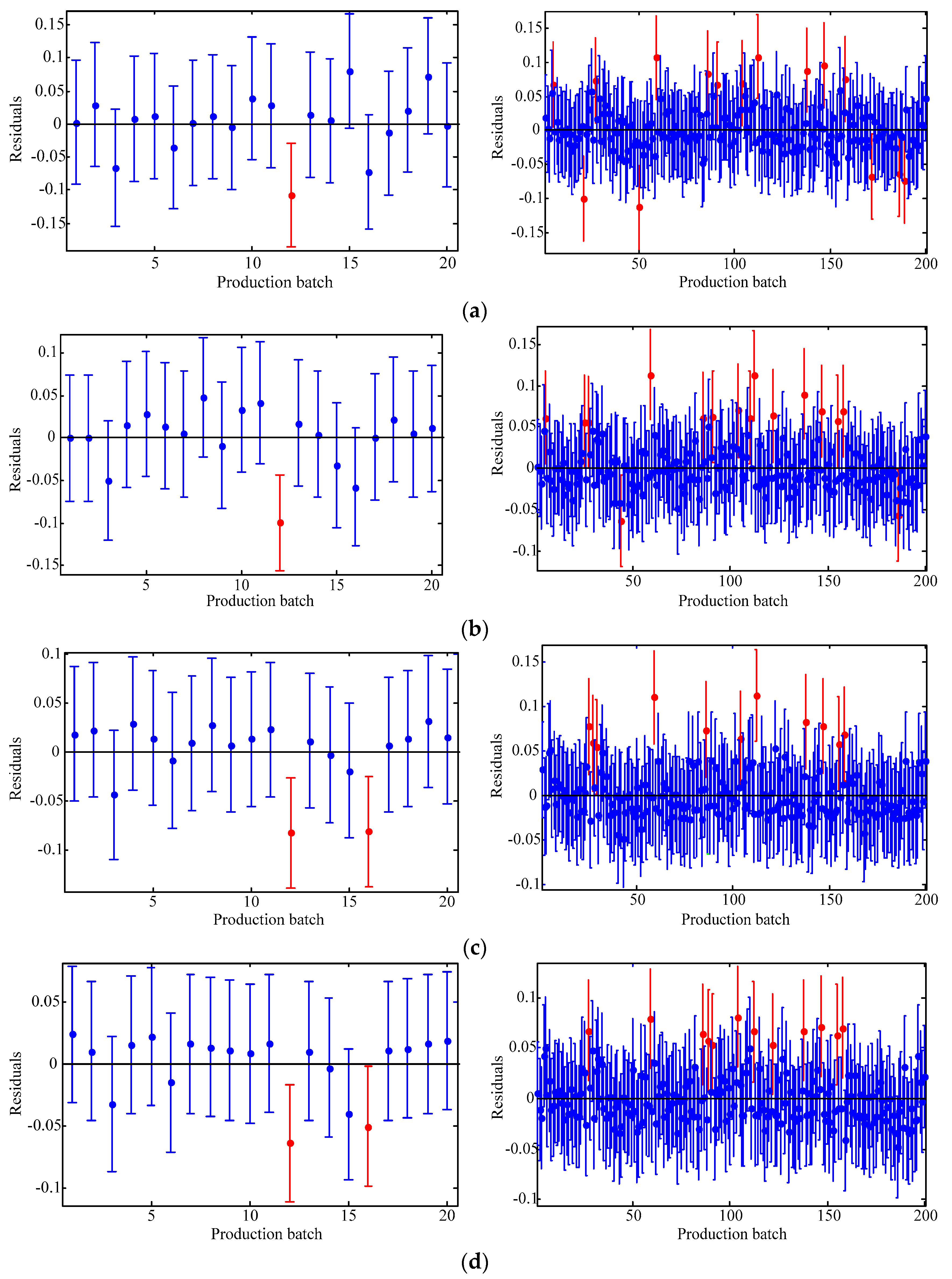
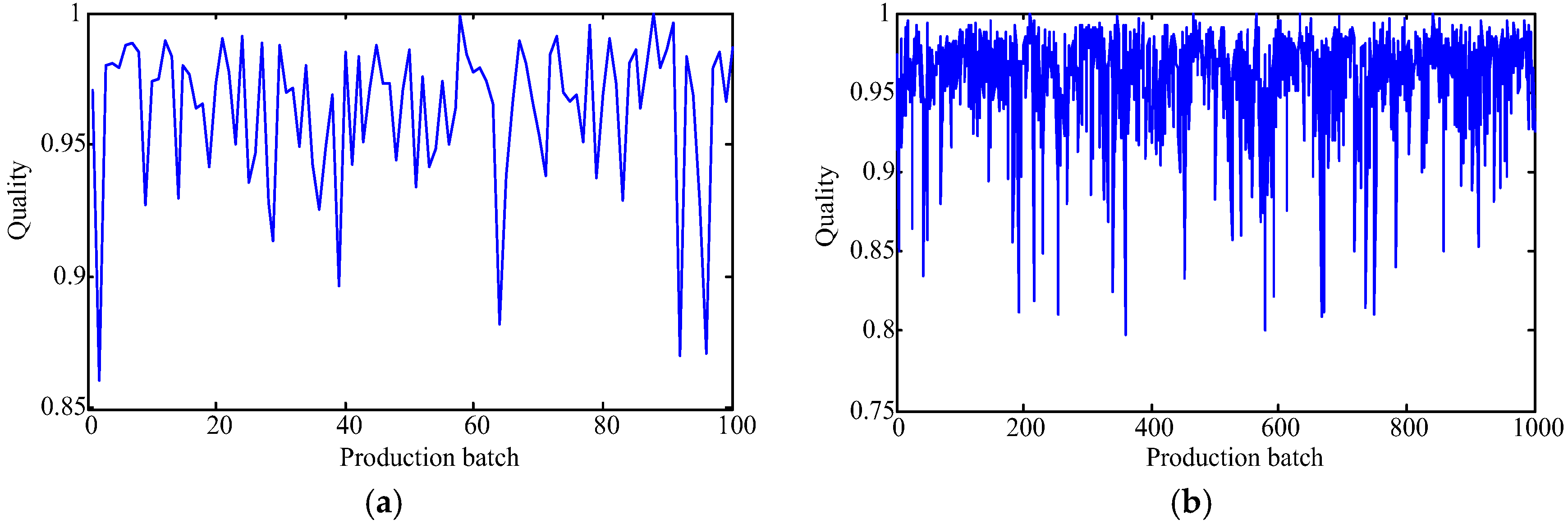
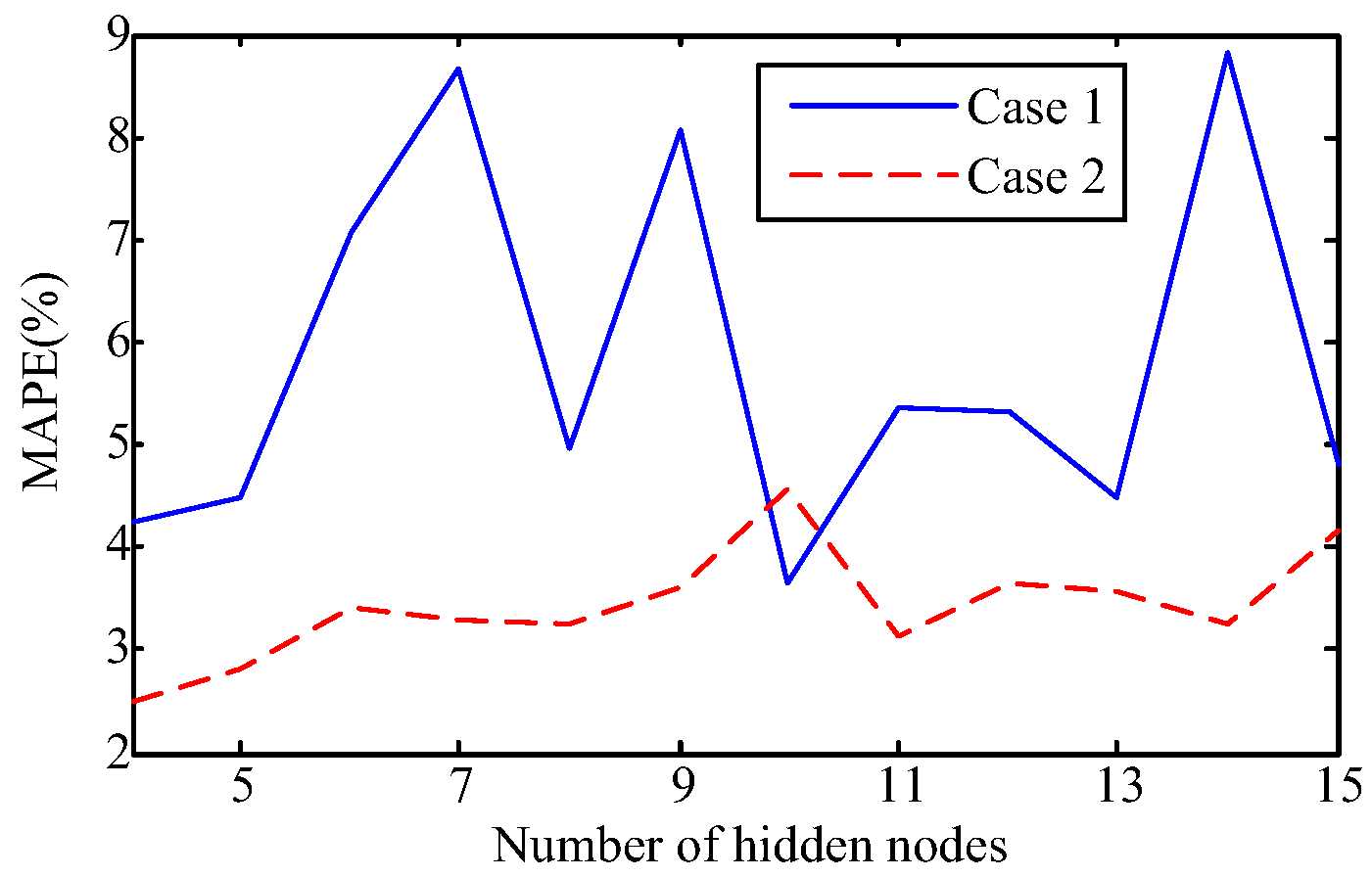
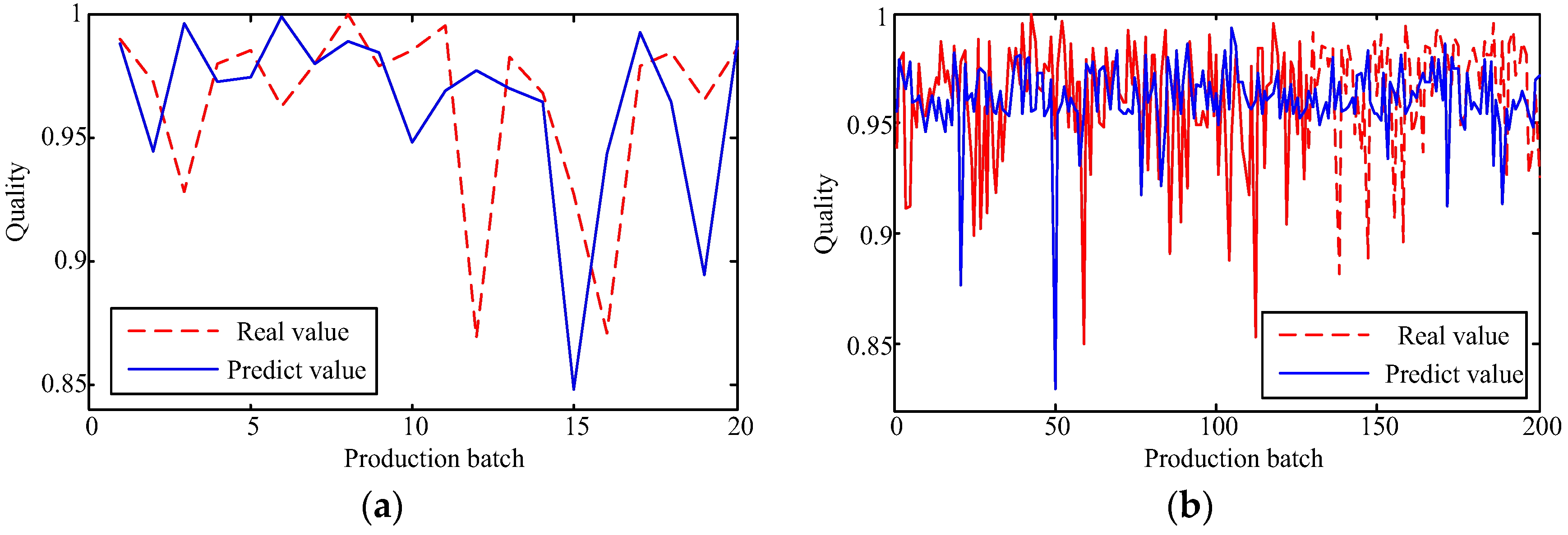
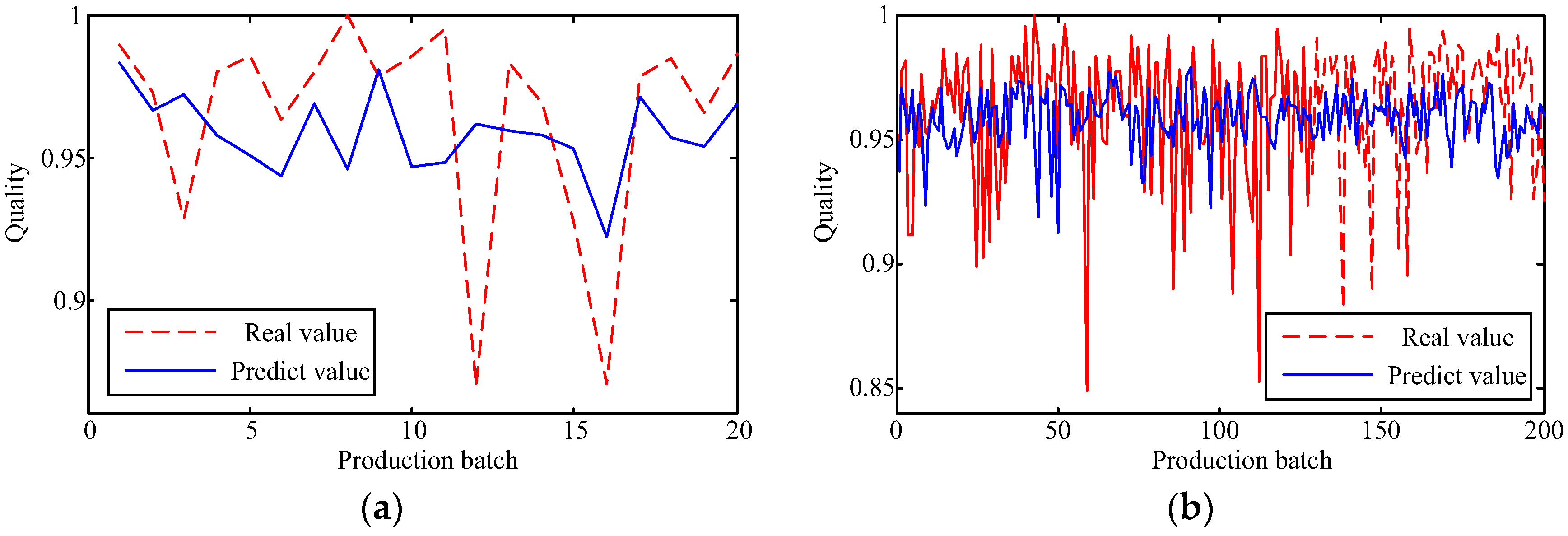
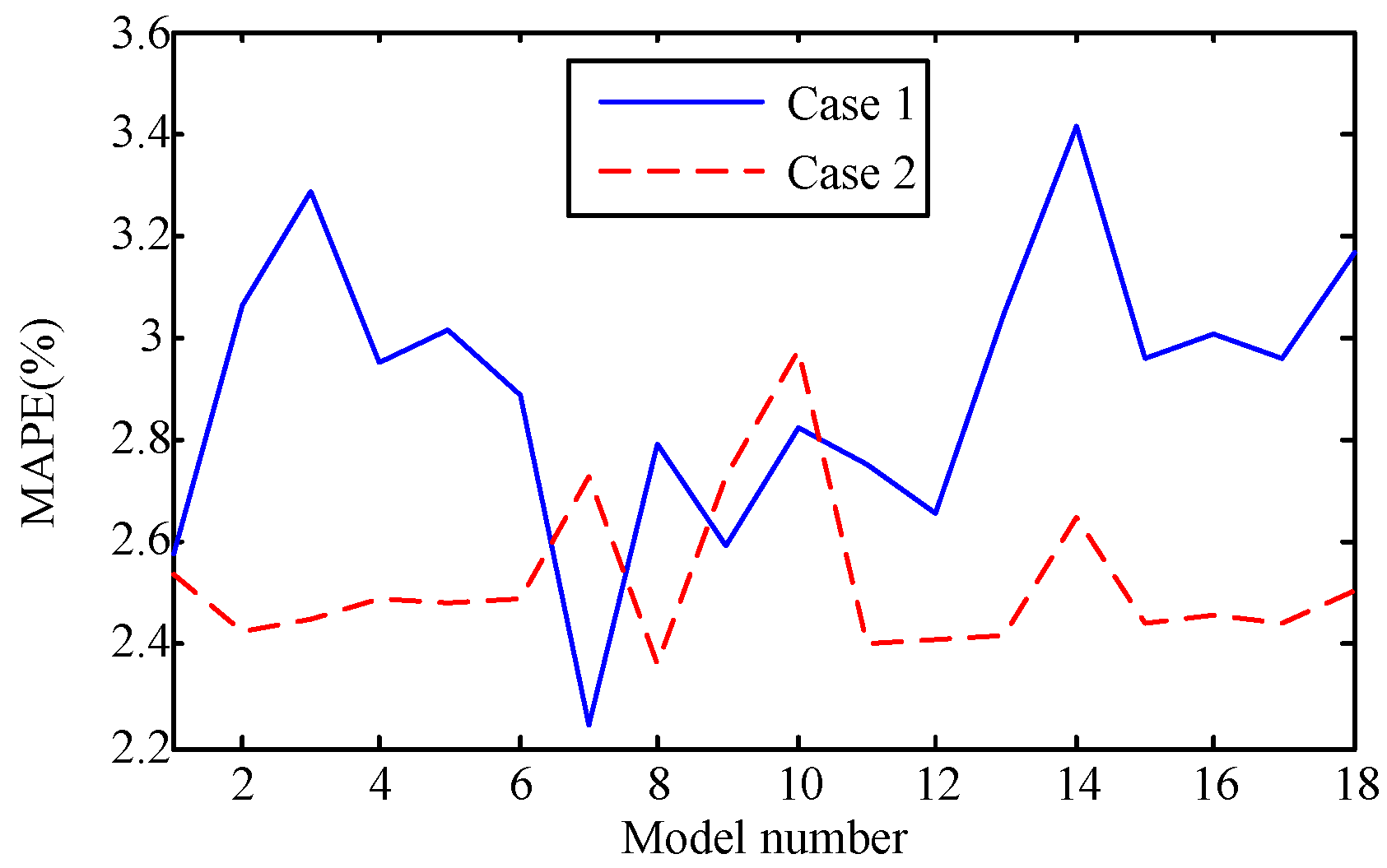
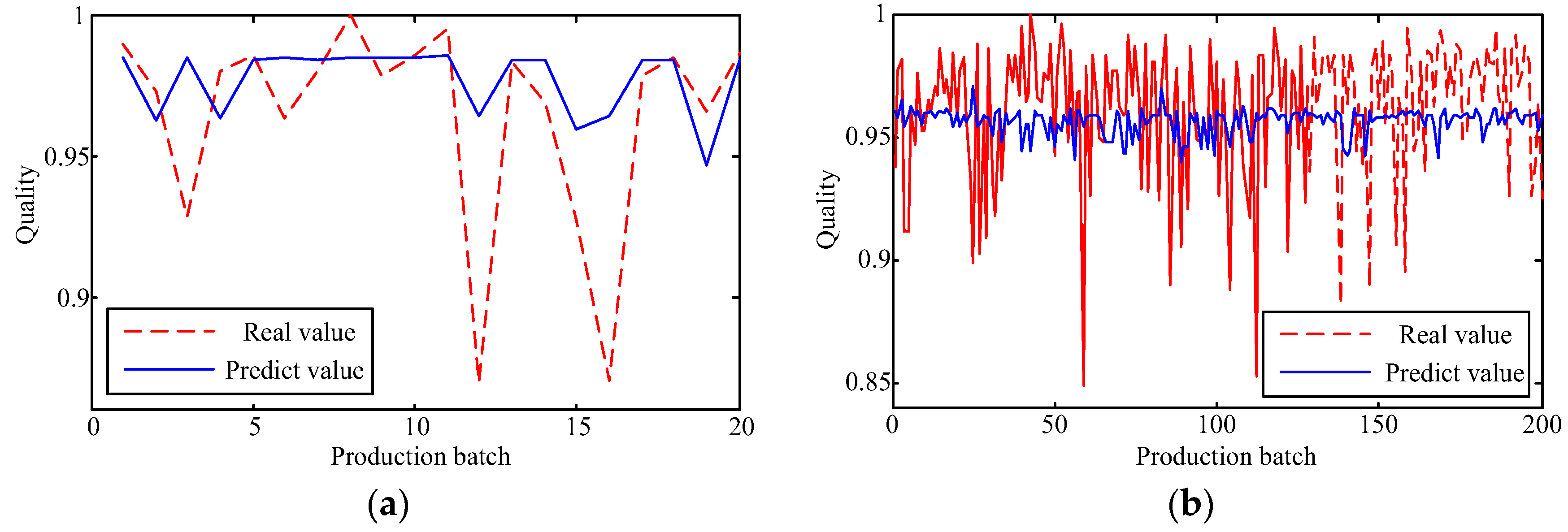
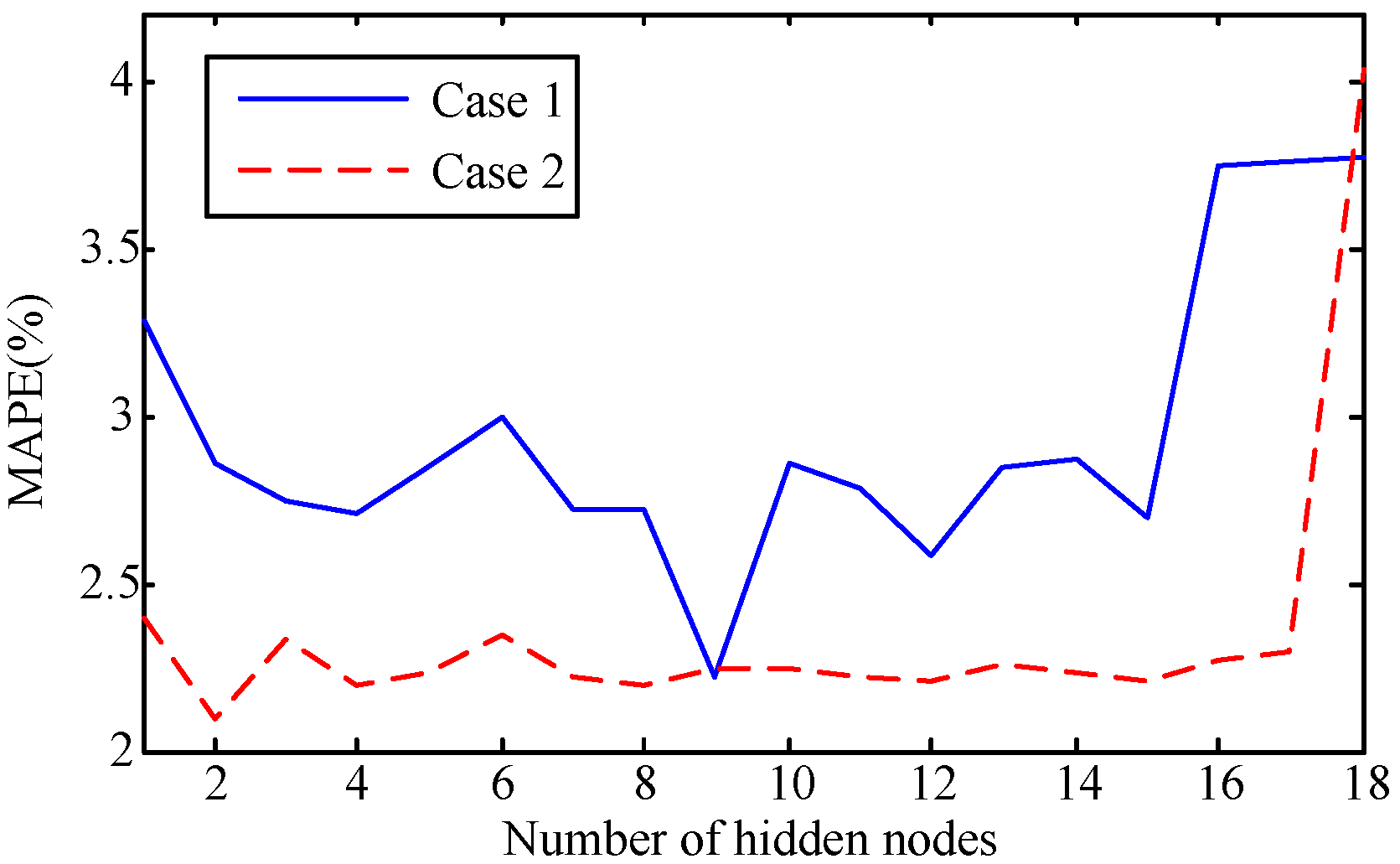
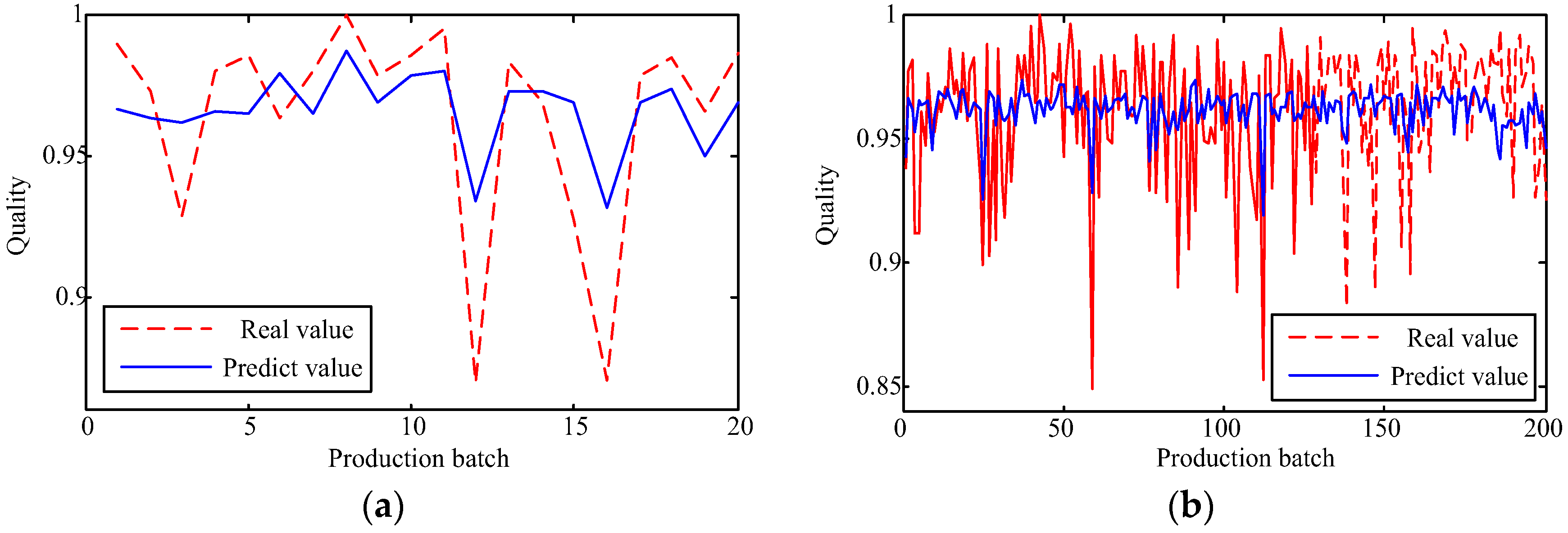
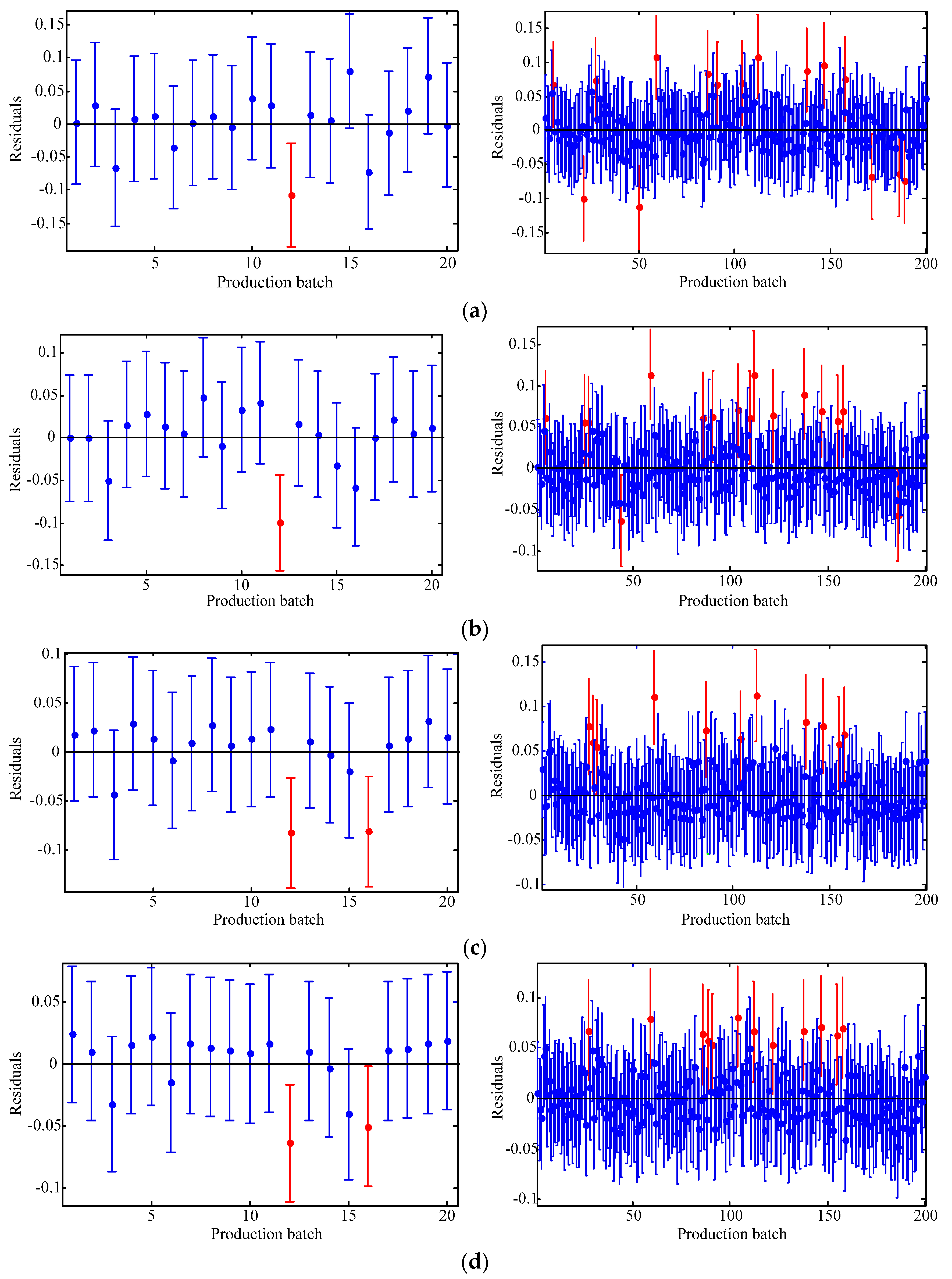
The capability of shallow and deep learning to predict manufacturing quality is tested and compared in this paper. The candidates include the FFNN with one hidden layer, the LSSVM with no hidden layers, the DRBM, and the SAE. For this purpose, the trial and error method is adopted to select the optimal model with the simplest structures (except for the LSSVM), which are specified by the paired t-test results. Two cases, i.e., small samples (100 batches) and big samples (1000 batches), are investigated. The comparison of the model results has shown that: (1) the performances of the deep framework consisting of two or three hidden layers are better than those of the shallow architectures in terms of the MAPE, the RMSE, the TS, and the PCC criteria; (2) the performances of the deep framework depend on the sample size in terms of the number of the prediction outliers, i.e., the bigger the sample size is, the better the performance is; and (3) the deep framework and the shallow architecture are significantly different statistically. Based on the findings of this study, it can be stated that the deep learning techniques considered can be successfully applied to establish accurate manufacturing prediction models, especially for big data. In a future study, the authors will focus on the popularization and application of the deep learning techniques in other manufacturing enterprises.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}