Embedded Deep Learning for Ship Detection and Recognition



Abstract
1. Introduction
- To decrease model parameters, we design a tiny network DNet for ship detection, and share the base convolutional layers with CNet.
- To address challenges of variations of ship license plate locations and text types, we propose a classification network CNet to recognize ships.
- We run the DCNet on embedded devices, which has good scalability and can handle a large number of video streams at the same time.
2. Related Work
2.1. Deep Learning
2.2. Vehicle Identification
2.3. Embedded Object Recognition
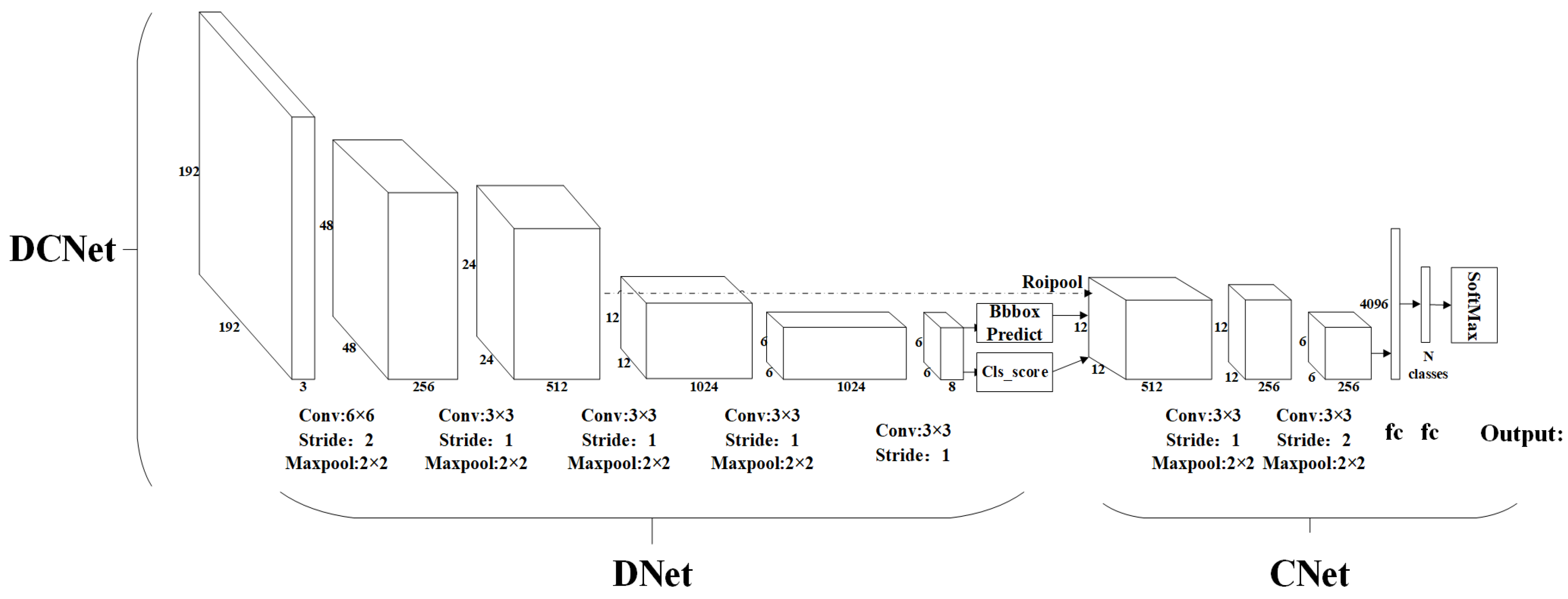
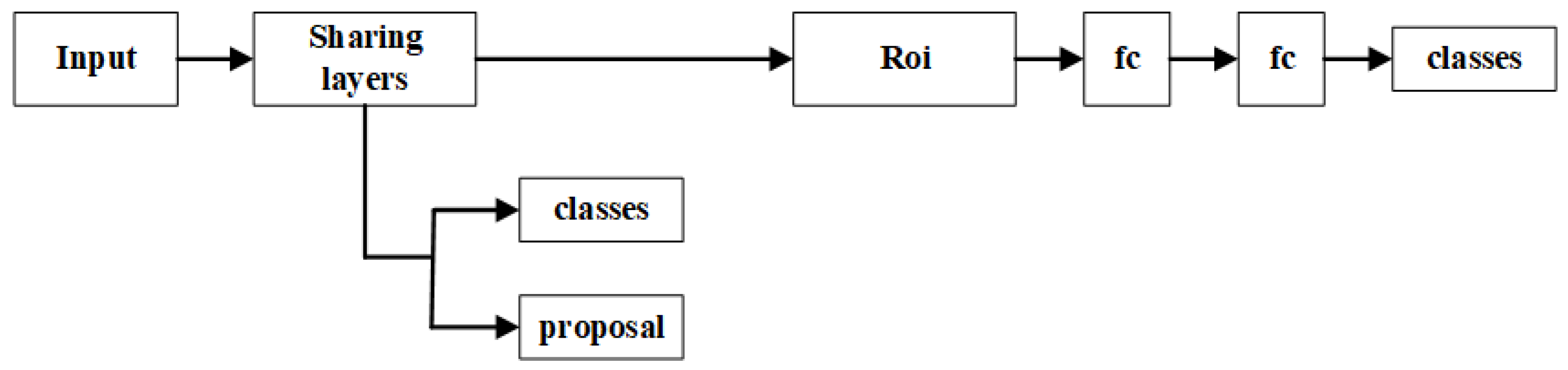
3. Designing a Recognition Neural Network-DCNet
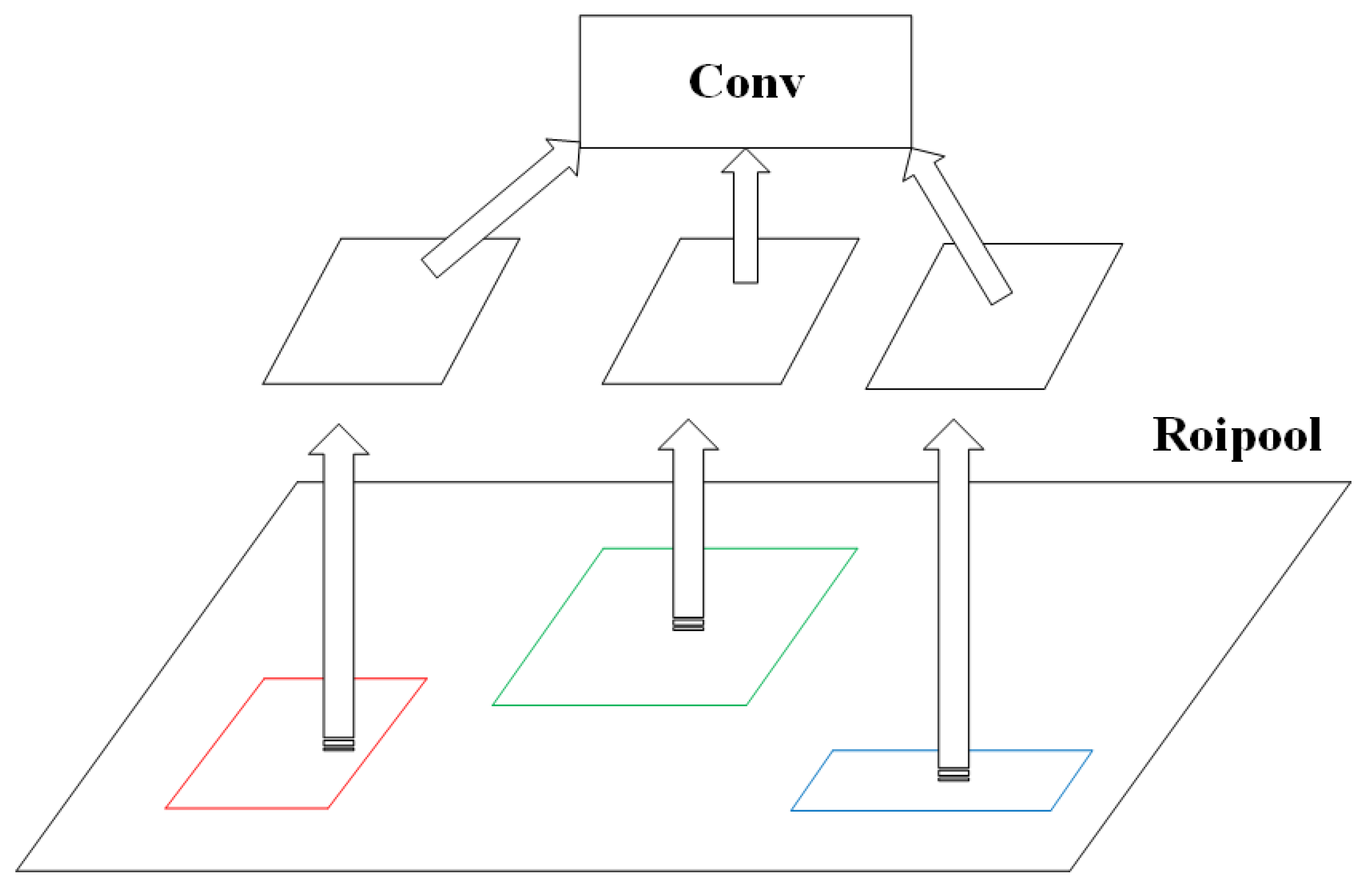
3.1. DNet
3.2. CNet
3.3. Training and Running
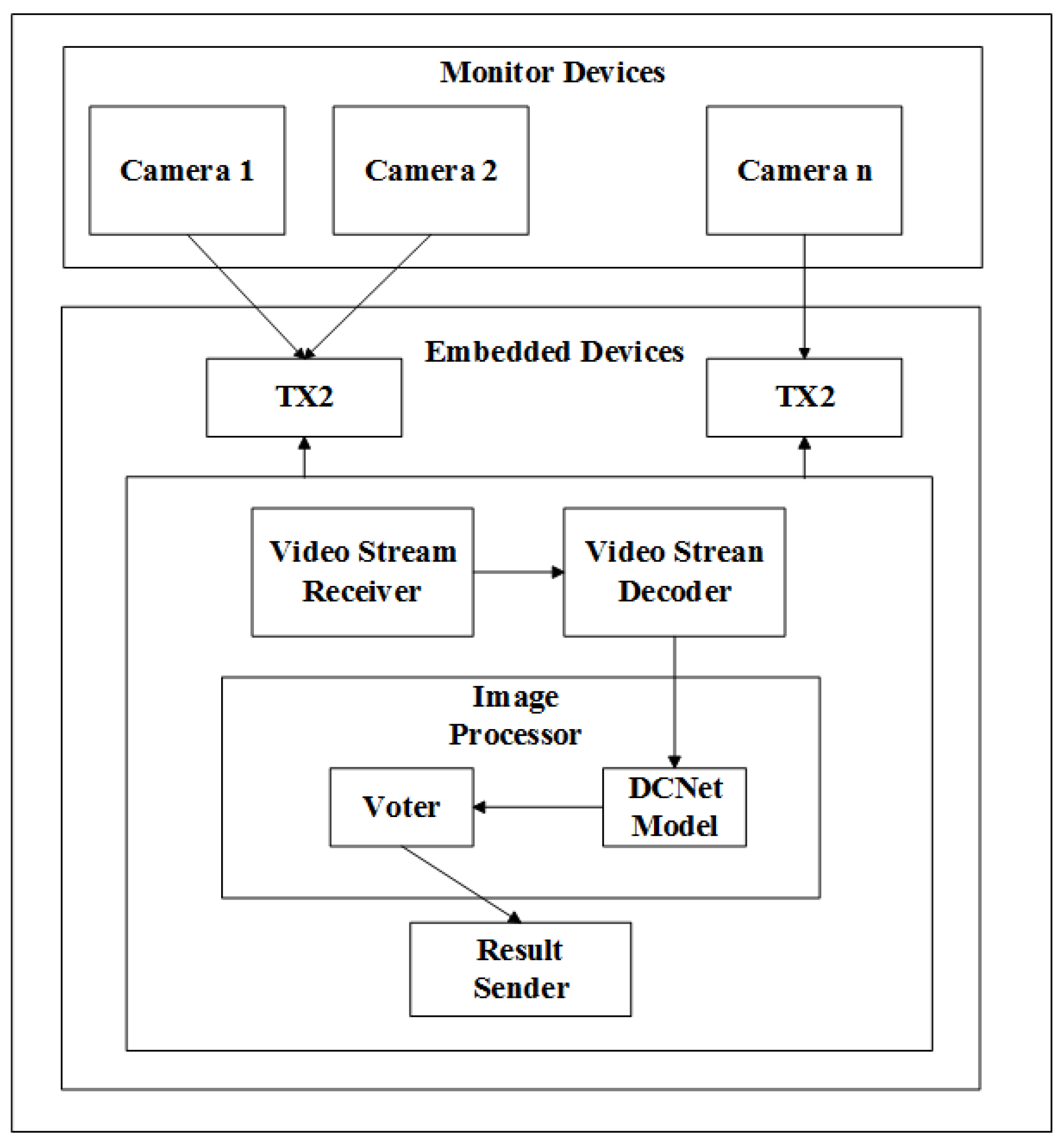
4. Architecture Design of ESDR-DL
5. Experiment Results
5.1. Algorithm Performance
5.2. System Performance
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Nomenclature
| ESDR-DL | Embedded Ship Detection and Recognition using Deep Learning |
| DCNet | Detection and Classification Network |
| DNet | Detection Network |
| CNet | Classification Network |
| DCNN | Deep Convolutional Neural Network |
| RPN | Region Proposal Network |
| RCNN | Region-based Convolutional Neural Network |
| ROI | Region Of Interest |
| DSP | Digital Signal Processing |
| PDA | Personal Digital Assistant |
| FPGA | Field-Programmable Gate Array |
| TDA3x SoC | Threat Discovery Appliance |
| SSD | Single Shot MultiBox Detector |
| YOLO | You Only Look Once |
References
- Wang, Z.; Tang, W.; Zhao, L. Research on the modern port logistics development in the city-group, China. In Proceedings of the 2010 International Conference on IEEE Logistics Systems and Intelligent Management (ICLSIM), Harbin, China, 9–10 January 2010; pp. 1280–1283. [Google Scholar]
- Alderton, P.M. Port Management and Operations; Harbors: Suffolk, NY, USA, 2008. [Google Scholar]
- Xu, L.; Ren, J.S.J.; Liu, C.; Jia, J. Deep convolutional neural network for image deconvolution. In Proceedings of the International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 1790–1798. [Google Scholar]
- Zang, D.; Chai, Z.; Zhang, J.; Zhang, D.; Cheng, J. Vehicle license plate recognition using visual attention model and deep learning. J. Electron. Imaging 2015, 24, 033001. [Google Scholar] [CrossRef]
- Masood, S.Z.; Shu, G.; Dehghan, A.; Ortiz, E.G. License Plate Detection and Recognition Using Deeply Learned Convolutional Neural Networks. arXiv, 2017; arXiv:1703.07330. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast r-cnn. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv, 2015; arXiv:1506.02640v5. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. arXiv, 2016; arXiv:1612.08242. [Google Scholar]
- Wang, H.; Zhang, Z. A vehicle real-time detection algorithm based on YOLOv2 framework. In Proceedings of the Real-Time Image and Video Processing, Orlando, FL, USA, 15–19 April 2018; p. 22. [Google Scholar]
- Liu, Y.; Wei, D.; Zhang, N.; Zhao, M. Vehicle-license-plate recognition based on neural networks. In Proceedings of the 2011 IEEE International Conference on Information and Automation, Shenzhen, China, 6–8 June 2011; pp. 363–366. [Google Scholar]
- Lin, D.; Lin, F.; Lv, Y.; Cai, F.; Cao, D. Chinese Character CAPTCHA Recognition and Performance Estimation via Deep Neural Network. Neurocomputing 2018, 28, 11–19. [Google Scholar] [CrossRef]
- Arth, C.; Limberger, F.; Bischof, H. Real-Time License Plate Recognition on an Embedded DSP-Platform. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition 2007, Minneapolis, MN, USA, 17–22 June 2007. [Google Scholar] [CrossRef]
- Kamat, V.; Ganesan, S. An efficient implementation of the Hough transform for detecting vehicle license plates using DSP’S. In Proceedings of the Real-Time Technology and Applications Symposium, Chicago, IL, USA, 15–17 May 1995; pp. 58–59. [Google Scholar]
- Kang, J.S.; Kang, M.H.; Park, C.H.; Kim, J.H.; Choi, Y.S. Implementation of embedded system for vehicle tracking and license plates recognition using spatial relative distance. In Proceedings of the International Conference on Information Technology Interfaces, Cavtat, Croatia, 7–10 June 2003; Volume 1, pp. 167–172. [Google Scholar]
- Bellas, N.; Chai, S.M.; Dwyer, M.; Linzmeier, D. FPGA implementation of a license plate recognition SoC using automatically generated streaming accelerators. In Proceedings of the 20th IEEE International Parallel & Distributed Processing Symposium, Rhodes Island, Greece, 25–29 April 2006. [Google Scholar]
- Mao, H.; Yao, S.; Tang, T.; Li, B.; Yao, J.; Wang, Y. Towards real-time object detection on embedded systems. IEEE Trans. Emerg. Top. Comput. 2016, 6, 417–431. [Google Scholar] [CrossRef]
- Jagannathan, S.; Desappan, K.; Swami, P.; Mathew, M.; Nagori, S.; Chitnis, K.; Marathe, Y.; Poddar, D.; Narayanan, S. Efficient object detection and classification on low power embedded systems. In Proceedings of the 2017 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 8–10 January 2017; pp. 233–234. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Zhang, W.; Zhang, Y.; Zhai, J.; Zhao, D.; Xu, L.; Zhou, J.; Li, Z.; Yang, S. Multi-source data fusion using deep learning for smart refrigerators. Comput. Ind. 2018, 95, 15–21. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, Z.; Liu, X.; Gong, W.; Sun, H.; Zhou, J.; Liu, Y. Deep Learning based Real-Time Fine-grained Pedestrian Recognition using Stream Processing. IET Intell. Transp. Syst. 2018, 12. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Datasets | mAP | FPS | Proposed Year |
|---|---|---|---|---|
| SSD300 | VOC 2007 + 2012 | 74.3 | 46 | 2016 |
| SSD500 | VOC 2007 + 2012 | 76.8 | 19 | 2016 |
| Faster-RCNN | VOC 2007 + 2012 | 73.2 | 31 | 2015 |
| YOLO | VOC 2007 + 2012 | 63.4 | 45 | 2015 |
| YOLOv2 | VOC 2007 + 2012 | 76.8 | 67 | 2016 |
| Tiny YOLO | VOC 2007 + 2012 | 57.1 | 207 | 2016 |
| Versions | Jeston TX2 |
|---|---|
| GPU | NVIDIA Pascal 256 CUDA core |
| CPU | 64-bit Denver 2 and A57 CPUs |
| Memory | 8 GB 128-bit LPDDR4 |
| Storage | 32 GB eMMC |
| Video Encode | 4 K × 2 K 60 Hz |
| Video Decode | 4 K × 2 K 60 Hz |
| Camera | 1.4 Gpix/s 2.5 Gbps per lane |
| Connectivity | 1 Gigabit Ethernet, 802.11ac WLAN |
| Method | Device | Accuracy | Efficiency (FPS) | Power (w) | Energy Efficiency (fps/w) |
|---|---|---|---|---|---|
| Tiny YOLO | TX2 | 0.9316 | 18.91 | 7.84 | 2.41 |
| DNet | TX2 | 0.9233 | 34.87 | 7.73 | 4.51 |
| Tiny YOLO | GTX TITAN X | 0.9492 | 155.24 | 180 | 0.86 |
| DNet | GTX TITAN X | 0.9297 | 298.43 | 177 | 1.68 |
| Grid Cells Number | Detection Accuracy | Efficiency |
|---|---|---|
| 4 × 4 | 0.7642 | 59 |
| 5 × 5 | 0.8310 | 51 |
| 6 × 6 | 0.9233 | 43 |
| 7 × 7 | 0.9251 | 38 |
| 8 × 8 | 0.9282 | 32 |
| 9 × 9 | 0.9263 | 21 |
| Detection Accuracy | |
|---|---|
| 0.1 | 0.5216 |
| 0.2 | 0.7442 |
| 0.3 | 0.7513 |
| 0.4 | 0.8121 |
| 0.5 | 0.9021 |
| 0.6 | 0.9113 |
| 0.7 | 0.9233 |
| 0.8 | 0.9035 |
| 0.9 | 0.8945 |
| Accuracy | |||
|---|---|---|---|
| 1 | 0 | 0 | 0.83 |
| 0 | 1 | 0 | 0.85 |
| 0 | 0 | 1 | 0.80 |
| 0.33 | 0.34 | 0.33 | 0.84 |
| 0.25 | 0.5 | 0.25 | 0.85 |
| 0.3 | 0.5 | 0.2 | 0.86 |
| 0.2 | 0.5 | 0.3 | 0.85 |
| TX2-1 | entrance camera-1 |
| TX2-2 | entrance camera-2 |
| TX2-3 | entrance camera-3 |
| TX2-3 | entrance camera-4 |
| TX2-4 | inside port camera-1 |
| TX2-5 | inside port camera-2 |
| TX2-6 | inside port camera-3 |
| TX2-6 | inside port camera-4 |
| TX2-7 | inside port camera-5 |
| TX2-7 | inside port camera-6 |
| Camera | S | D-P | D-R | R-P | R-R | T |
|---|---|---|---|---|---|---|
| entrance camera-1 | 903 | 0.86 | 0.80 | 0.82 | 0.74 | 27 fps |
| entrance camera-2 | 903 | 0.86 | 0.79 | 0.82 | 0.74 | 27 fps |
| entrance camera-3 | 887 | 0.85 | 0.79 | 0.81 | 0.74 | 27 fps |
| entrance camera-4 | 891 | 0.86 | 0.80 | 0.80 | 0.73 | 27 fps |
| inside port camera-1 | 1532 | 0.89 | 0.84 | 0.84 | 0.79 | 13 fps |
| inside port camera-2 | 1129 | 0.87 | 0.82 | 0.80 | 0.75 | 13 fps |
| inside port camera-3 | 1413 | 0.90 | 0.85 | 0.85 | 0.78 | 13 fps |
| inside port camera-4 | 1410 | 0.89 | 0.84 | 0.84 | 0.79 | 13 fps |
| inside port camera-5 | 1611 | 0.89 | 0.85 | 0.82 | 0.79 | 13 fps |
| inside port camera-6 | 1611 | 0.88 | 0.85 | 0.82 | 0.80 | 13 fps |
| Camera | Rain-S | Rain-P | Ran-R | Smog-S | Smog-P | Smog-R | Dusk-S | Dusk-P | Dusk-R |
|---|---|---|---|---|---|---|---|---|---|
| entrance camera-1 | 46 | 0.72 | 0.65 | 114 | 0.61 | 0.52 | 203 | 0.83 | 078 |
| entrance camera-2 | 46 | 0.74 | 0.65 | 114 | 0.59 | 0.51 | 203 | 0.87 | 0.80 |
| entrance camera-3 | 39 | 0.69 | 0.56 | 99 | 0.49 | 0.39 | 211 | 0.85 | 0.79 |
| entrance camera-4 | 40 | 0.70 | 0.55 | 103 | 0.48 | 0.40 | 225 | 0.83 | 0.80 |
| inside port camera-1 | 70 | 0.75 | 0.70 | 91 | 0.64 | 0.51 | 293 | 0.82 | 0.76 |
| inside port camera-2 | 58 | 0.71 | 0.64 | 69 | 0.60 | 0.55 | 233 | 0.80 | 0.71 |
| inside port camera-3 | 132 | 0.79 | 0.71 | 155 | 0.70 | 0.53 | 254 | 0.83 | 0.79 |
| inside port camera-4 | 140 | 0.74 | 0.70 | 169 | 0.67 | 0.59 | 254 | 0.85 | 0.80 |
| inside port camera-5 | 129 | 0.78 | 0.73 | 143 | 0.72 | 0.56 | 223 | 0.85 | 0.76 |
| inside port camera-6 | 129 | 0.75 | 0.71 | 143 | 0.70 | 0.51 | 223 | 0.80 | 0.77 |
| Camera | Rain-S | Rain-P | Ran-R | Smog-S | Smog-P | Smog-R | Dusk-S | Dusk-P | Dusk-R |
|---|---|---|---|---|---|---|---|---|---|
| entrance camera-1 | 46 | 0.53 | 0.45 | 114 | 0.36 | 0.20 | 203 | 0.79 | 0.72 |
| entrance camera-2 | 46 | 0.45 | 0.38 | 114 | 0.31 | 0.18 | 203 | 0.81 | 0.75 |
| entrance camera-3 | 39 | 0.46 | 0.36 | 99 | 0.29 | 0.21 | 211 | 0.82 | 0.74 |
| entrance camera-4 | 40 | 0.45 | 0.32 | 103 | 0.26 | 0.15 | 225 | 0.83 | 0.73 |
| inside port camera-1 | 70 | 0.55 | 0.41 | 91 | 0.34 | 0.21 | 293 | 0.80 | 0.72 |
| inside port camera-2 | 58 | 0.52 | 0.45 | 69 | 0.29 | 0.17 | 233 | 0.75 | 0.70 |
| inside port camera-3 | 132 | 0.49 | 0.39 | 155 | 0.39 | 0.23 | 254 | 0.80 | 0.74 |
| inside port camera-4 | 140 | 0.54 | 0.45 | 169 | 0.35 | 0.19 | 254 | 0.82 | 0.76 |
| inside port camera-5 | 129 | 0.48 | 0.43 | 143 | 0.32 | 0.24 | 223 | 0.80 | 0.75 |
| inside port camera-6 | 129 | 0.51 | 0.41 | 143 | 0.25 | 0.12 | 223 | 0.84 | 0.75 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, H.; Zhang, W.; Sun, H.; Xue, B. Embedded Deep Learning for Ship Detection and Recognition. Future Internet 2019, 11, 53. https://doi.org/10.3390/fi11020053
Zhao H, Zhang W, Sun H, Xue B. Embedded Deep Learning for Ship Detection and Recognition. Future Internet. 2019; 11(2):53. https://doi.org/10.3390/fi11020053
Chicago/Turabian StyleZhao, Hongwei, Weishan Zhang, Haoyun Sun, and Bing Xue. 2019. "Embedded Deep Learning for Ship Detection and Recognition" Future Internet 11, no. 2: 53. https://doi.org/10.3390/fi11020053
APA StyleZhao, H., Zhang, W., Sun, H., & Xue, B. (2019). Embedded Deep Learning for Ship Detection and Recognition. Future Internet, 11(2), 53. https://doi.org/10.3390/fi11020053