3.1. Dynamic Multi-Thresholds (DMT)
As mentioned earlier, different types of applications may share one physical resources, fixed thresholds are not suitable for environments with dynamic workloads. Thus, the system should adaptively adjust its behavior by considering different system workloads. Based on that, we propose a novel adjustment mechanism for threshold-based VM consolidation by comparing the current threshold of each defined parameter with their future value, which is predicted by forecasting each VM’s future utilization on CPU, RAM and Network bandwidth. To further efficiently minimize the consumption of energy during each consolidation, two other parameters of SLA and VM migration costs are taken into consideration. Thus, our proposed dynamic multi-thresholds can be represented as follows:
The multi-thresholds
is defined by a combination threshold of lower utilization
, upper utilization
, SLA violation ratio
and the number of VM migration
. Below
represents the lower thresholds of CPU utilization ratio, RAM utilization ratio and Network bandwidth consumption, respectively, while
represents the upper ones.
The adjustment of dynamic multi-thresholds to timely fit the whole cloud resources can be simplified into two main parameters, including
and
. These two thresholds can be efficiently calculated by forecasting each future utilization ratio based on Linear Regression (
Section 3.1.1). While the parameter of
can be viewed as a limitation factor of dynamic threshold by deciding whether to change current threshold or not (
Section 3.1.2).
will be discussed to further improve the selection of VM in
Section 3.2.
3.1.1. Predict Future Utilization on Linear Regression
Since the nonlinear regression has larger time and computational overhead than linear regression, which affects the overall system load to a certain extent, the value obtained by the prediction algorithm is only used as a reference for the threshold adjustment. If too much computational overhead is spent on the prediction while the subsequent adjustment mechanism is ignored, this is not conducive to the dynamic adjustment of the threshold. Based on the above concern and the experiment results, we select linear regression as our prediction algorithm and the next section will give the details of mechanism for the dynamic adjustment of the specific threshold.
As Linear Regression [
12] is a popular approach to statistically estimate the relationship between different inputs and outputs, it can approximate a regression function by modeling the relationship between input and output variables in a straight line, where
and
are regression coefficients.
To measure the goodness of a regression function is to compare the predicted output variable (
) with the real one (
) in data point
i, as their difference
can be considered as the magnitude of the residual at each of the
data points.
The proposed LR algorithm approximates a prediction function based on the linear regression method. The function shows the linear relationship between the future and current CPU utilization in all hosts as follows: where
and
are regression coefficient parameters, while
and
are the expected and current total CPU utilization values of all hosts, respectively.
Here and are calculated by estimating the last CPU utilization in all hosts. In our experiment, the value of is set to 15 in our simulation, because the interval of utilization measurements is eight minutes. The history value of each resource utilization over two hours ago is significant to forecast its short-time future utilization.
Moreover, the value obtained by the prediction algorithm is only used as a reference for the threshold adjustment, and the predicted value is not completely used as a future threshold value. Therefore, the following adjustment mechanism can be seen as a secondary selection and adjustment of the predicted value. That is to say, the dynamic adjustment mechanism of the thresholds shown in
Section 3.1.2 not only considers the value predicted by linear regression obtained in this section, but also compares the current overall workload of the system.
3.1.2. DMT Adjustment Mechanism
To efficiently balance the consumption of energy cost and SLA violation, the rules of dynamically adjusting parameter and within and are restricted to SLA violation threshold . We divided the problem into the following two situations, where the can be calculated by statistic Interquartile range of SLA violation on all hosts.
Since the
is below the threshold of SLA violation (
Table 2), our purpose of this situation can mainly focus on energy saving. When the predicted utilization
of all hosts is greater than the current threshold
in the case of the parameter of CPU, this means that there will be many CPU requests by VMs in the future. In such a case, we choose to replace
by
, since the higher the upper threshold, the less VM migration will take place and the more the energy will be saved. At the same time, when
is below
, keep the previous value of
instead of replacing. If
is below the current lower threshold
in CPU parameter
, this means that there will be fewer requests of CPU resources in the future. In such a case, we choose to replace
by
, since the lower the
, the more the hosts will be switched to sleep mode to eliminate the idle power consumption, and all VMs that are on low resource utilization host will be migrated to other suitable hosts. Otherwise, keep
as its previous value.
Unlike situation 1, when
is higher than
, this means that situation 2 has already caused much SLA violation in the current stage (
Table 3). Since too much SLA violation will lead to a lower QoS, the key to dealing with this problem is to reduce the workload of high load hosts. Based on the goal of dropping SLA violation, we choose to keep the previous upper value
when
is higher than
and replace the
of
when
is lower than
because the higher upper threshold may easily lead to high SLA violation. On the other hand, when
is lower than
, keeping the precious lower threshold will help prevent low load hosts from migrating all VMs to other hosts which will help reduce SLA violation. Similarly, when
is higher than
, replacing
of
could drop the SLA violation and thus help improve the QoS.
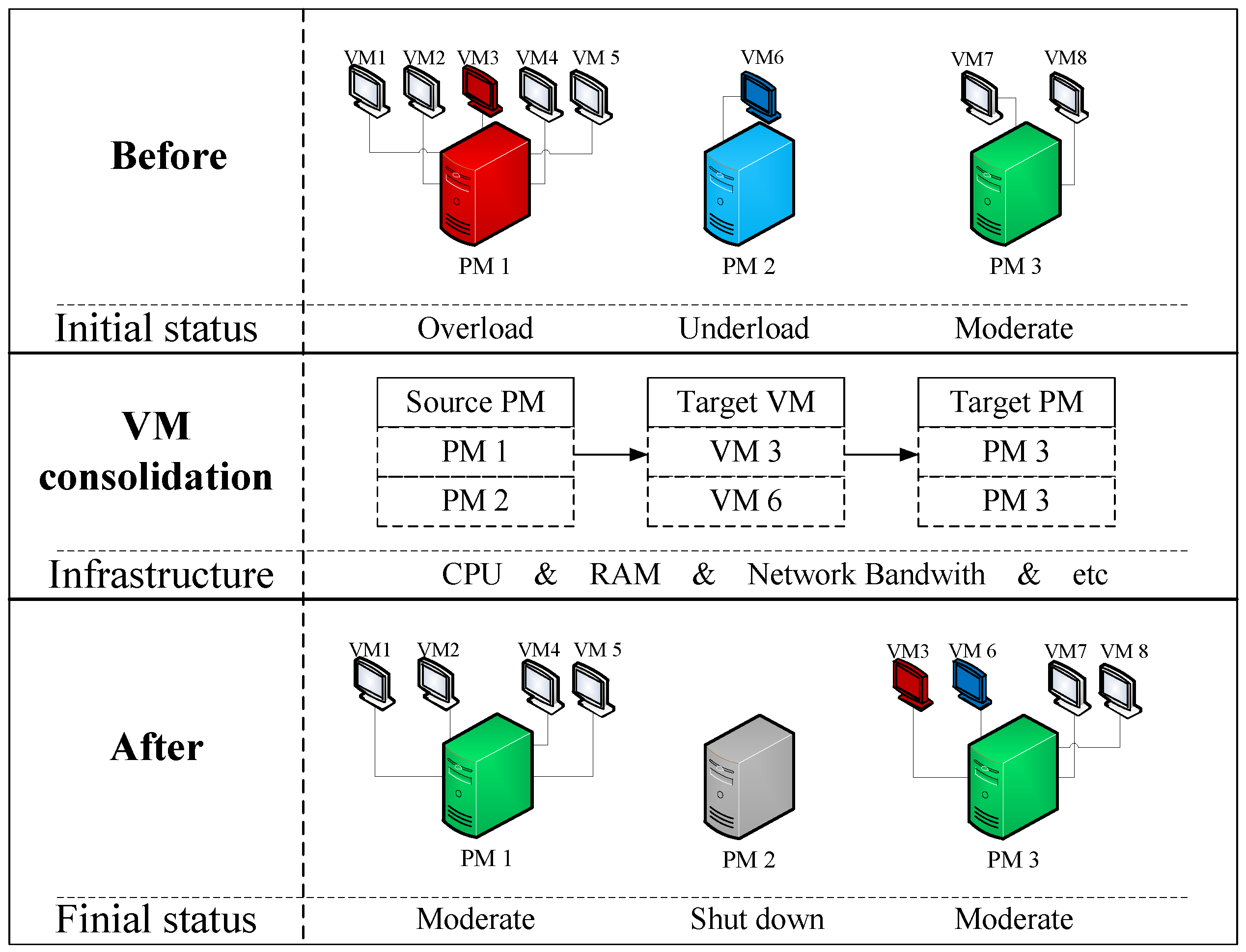
For a brief description, we only take the threshold of CPU utilization () of all hosts as an example, showing how it dynamically adjusts its current thresholds by comparing its current value with the predicted one. Similarly, the procedure of adjusting the other two parameters of RAM () and Bandwidth () can also following these steps. Many details for selecting source PM based on this DMT are shown below.
3.1.3. Source PM Selection Based on DMT
To select a proper source PM, the first step is to detect their workload based on the comparation of each parameter in DMT (Algorithm 1).
| Algorithm 1 Load Detection (LD) |
- 1
Input: - 2
Output: load_status - 3
foreach in - 4
if (some parameter * in fit ) - 5
load_status = 1 - 6
else if (all parameter * in fit ) - 7
load_status = 2 - 8
else - 9
load_status = 0 - 10
return load_status
|
Here we take three parameters (CPU, RAM, Bandwidth) of the whole system to reflect its total resource utilization by each PM with different numbers of virtual machines in it (Algorithm 2). For each host, if one of its parameters is over the upper threshold or all of them are below the lower threshold, it will be selected as one of the target physical machines in
which contains the migration list of all target hosts (
Table 1). At the same time, PMs with higher SLA violation than the threshold
will first be selected to
, and will be set to higher priority.
| Algorithm 2 Source PM Selection |
- 1
Input: - 2
Output: - 3
foreach in - 4
if () then - 5
← - 6
else - 7
if (LD () == 1) then - 8
← - 9
← select VMs on VM selection policy - 10
if (LD () == 2) then - 11
← - 12
← all VMs in - 13
set to sleep mode or switch off - 14
return selected source PMs
|
To avoid too much energy consumption caused by the frequent migration of VMs and the low QoS caused by the short shut down during each migration, we decided to prioritize the implementation order of VM consolidation. That is, first migrate some VMs from overload hosts to lower load hosts, and then set all VMs on hosts with low load to migrated out and switch these hosts to sleep mode or shut down.
Thus, DMT has been set to adaptively fit the cloud environment of source PM selection until now, while the parameter of
in multi-thresholds will later be taken into consideration in
Section 3.2 for helping the selection of target VM during VM consolidation. Once a PM is detected to be overloaded or low load by our defined dynamic multi-thresholds, the next step is to select proper VMs to migrate from this host and we will further discuss the adaptive VM consolidation strategies on the improvement of VM selection and placement based on the dynamic multi-thresholds in
Section 3.2 and
Section 3.3.
3.2. The Improved MW-MVM Algorithm for VM Selection
To efficiently choose proper target VMs on each selected
with fewer VM migrations, [
11] first proposed MVM (Minimization of VM Migration) algorithm. The main idea of this method is to sort the CPU utilization of each VM in descending order, and then select the targeted VM to migrated out in two criterions. One of the criterion is that the VM’s CPU utilization should be higher than the difference between the upper threshold and each PM’s present overall CPU utilization. Another criterion is that, compared to values on all VMs, the difference between the new utilization and the upper threshold on each selected VM is the minimum. If there is no suitable VM that satisfied these two criteria, the VM in
that has the highest resource utilization will be selected. Unless the new utilization of this source PM is under the upper threshold, all of the above processes will not be repeated any more.
The inadequacy of this method is that it only takes one parameter (CPU utilization) into consideration, while different overload PMs usually have different requests on other resources. Based on that, we try to improve this method within our multi-thresholds by using different weights to efficiently allocate VMs. Below is an example showing the detail of our improved method.
Assume that the current multi-thresholds are
, and the load thresholds are
. The utilization ratio of resource * on
can be calculated as
where * represents CPU in
, RAM in
, Bandwidth in
, respectively. Thus, resource utilization ratio on
can be expressed as
.
We define the formula for the relative difference
between upper threshold and actual utilization of resource * on
as
Thus, the relative different of
is
, which can then be used as the weights for choosing minimum number VMs since the weights showing the maximize corresponding overload of each resource on
. The weights of all VMs on
can then be calculated as
Here represents the allocated resource in each VM, which indicates the number of various resources that the virtual machine has occupied and calculated by (7) shows the difference of each threshold, as the higher value of each resource means the more corresponding of migration requests. Thus, by multiplying and , the weight of all VMs in can be calculated. For in , its weight is represented as , which is used to decide the selection of target VM, as well as the number of VMs that need to be migrated out.
To minimize VM migration times, all weights are sorted in descending order. As the higher the weight is, the higher the corresponding request is, the lower the migration times will be. The host () first select the VM with the highest weights and add it to the waiting list, then it will be checked again for being overload (Algorithm 3). If it is still considered as being overloaded, the VM selection policy is applied again to select another VM to migrate from the host. This will be repeated until the host is considered as being not overloaded. The last step is to check the migration number of these selected VMs in the waiting list. If the migration number of some selected VMs has gone over the set threshold , it will not be added, otherwise, VMs in the waiting list will be added to which contains all VMs that need to be migrated.
| Algorithm 3 Improved Multi-weights MVM policy (MW-MVM) |
- 1
Input: , - 2
Output: - 3
foreach in - 4
- 5
calculate using formula (8) - 6
order = . sortDescendingOrder() - 7
foreach in - 8
waitingList ← with highest value in order - 9
← - 10
update of - 11
if (LD () then - 12
Break - 13
foreach in waitingList - 14
if (migration_num( < )) then - 15
← - 16
if () - 17
return
|
Without loss of generality, all overload hosts can follow these steps to select the minimum number of VMs. While for low load hosts, all VMs within it will be migrated out and there is no need to execute this VM selection policy before VM allocation and the placement of these selected VMs in the waiting list to which PM is discussed in the next section.
3.3. VM Placement Using Modified MW-BF Algorithm
The VM placement is similar to a bin packing problem on variable bin sizes and prices, where bins represent the physical nodes; items are the VMs that had to be allocated; bin sizes are the available resource capacities (CPU, RAM, Bandwidth, etc.) of the nodes; and prices correspond to the power consumption by the nodes. As the bin packing problem is NP-hard, to solve it we apply a modification of the Best Fit (BF) algorithm by considering the multi-weight of the VM that needs to be allocated. In our modification (MW-BF), we sort all the PMs in the ascending of its resource utilization ratio, multiplied by the weights of the allocating VM. This allocates each VM to a host that provides the least increase of the power consumption and chooses the most power-efficient one by leveraging the heterogeneity of each node.
Use matrix
to represent each resource utilization ratio of all PMs, defined as:
The product of multi-weights and resource utilization of each PM for allocating VM selected from
can be calculated as:
The pseudo-code for the algorithm is presented in Algorithm 4. The complexity of the algorithm is n·m, where n is the number of nodes and m is the number of VMs that have to be allocated. After these steps, the waiting list then contains PMs that need to be migrated in.
| Algorithm 4 Modified Multi-weights Best fit (MW-BF) |
- 1
Input: , - 2
Output: placement of VMs - 3
. sortDescendingUtilization() - 4
foreach VM in do - 5
calculate each using Formula (10) - 6
. sortAscendingUtilization() - 7
if PM has enough resource for VM then - 8
← PM - 9
minEnergy ← MAX - 10
allocatedPM ← NULL - 11
foreach PM in do - 12
energy ← estimateEnergy (PM, VM) in (13) - 13
if energy < minEnergy then - 14
allocatedPM ← PM - 15
minEnergyr ← energy - 16
if allocatedPM NULL then - 17
allocate VM to allocatedPM - 18
return placement of VMs
|
The VM first selects the PM with least and adds it to the waiting list (), then it will be checked for being overload. To maximize the utilization of the remaining resource on these destination PMs, all product are sorted in descending order. In general, the least the product of resource utilization and weights is, the more the corresponding resource it will leave, which means that the VM would have enough remaining resources to use and thus it could efficiently decrease the cost of the frequent migration of VMs.






{kind=link}
{kind=link}
{kind=link}
{kind=link}