In the last decade, the problem of privacy preserving of location data has been of particular concern to researchers. Hence, many research works have been conducted to reinforce the security level previous ones provide, such as the association of location data with pseudonyms.
More to the point,
k-anonymity method has been used to reinforce and quantify location data privacy. If
k-anonymity is achieved, a person cannot be distinguished from
other people [
4]. In the context of
k-anonymity, authors in [
4] proposed an enhanced Dummy-Location Selection (DLS) algorithm for users in LBS. From a different perspective, authors in [
14] aimed at the utility improvement of differentially private published datasets. More specifically, they showed that the amount of noise required to fulfill
-differential privacy can be reduced if noise is added to a
k-anonymous version of the dataset, where
k-anonymity is achieved through a specially designed micro-aggregation of all attributes. As a result of noise reduction, the general analytical utility of the anonymized output is increased. Moreover, authors in [
18] attempted to protect users’ private locations in location-based services adopting the spatial cloaking technique, which organizes users’ exact locations into cloaked regions. This method satisfies the
k-anonymity requirement within the cloaked region. They proposed a cloaking system model, which they called “anonymity of motion vectors” (AMV), that provides anonymity for spatial queries minimizing the cloaked region of a mobile user using motion vectors. The AVM creates a search area that includes the nearest neighbor objects to the querier who issued a cloaked region-based query. In addition, in [
19], the authors suggested a clustering based
k-anonymity algorithm and optimized it with parallelization. The experimental evaluation of the proposed approach shows that the algorithm performs better in information loss, due to anonymization, and its performance is compared with the existing algorithms such as KACA and Incognito.
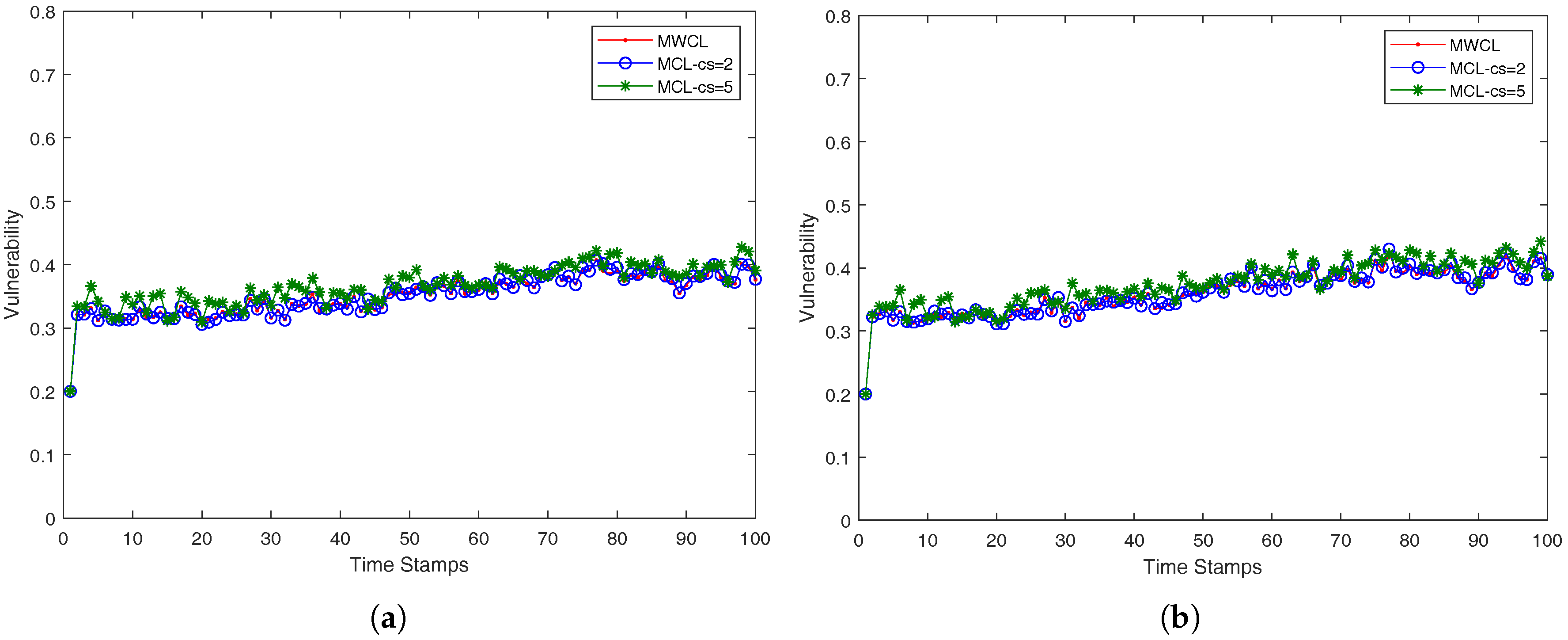
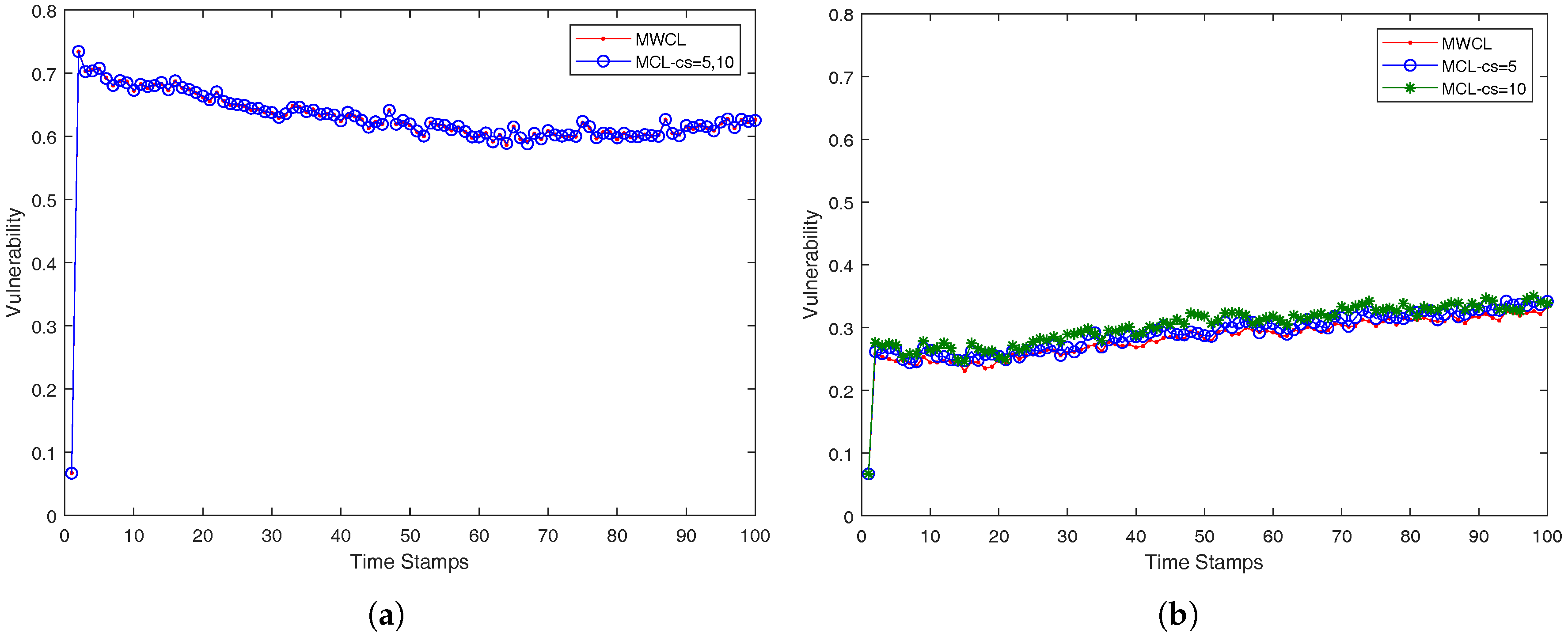
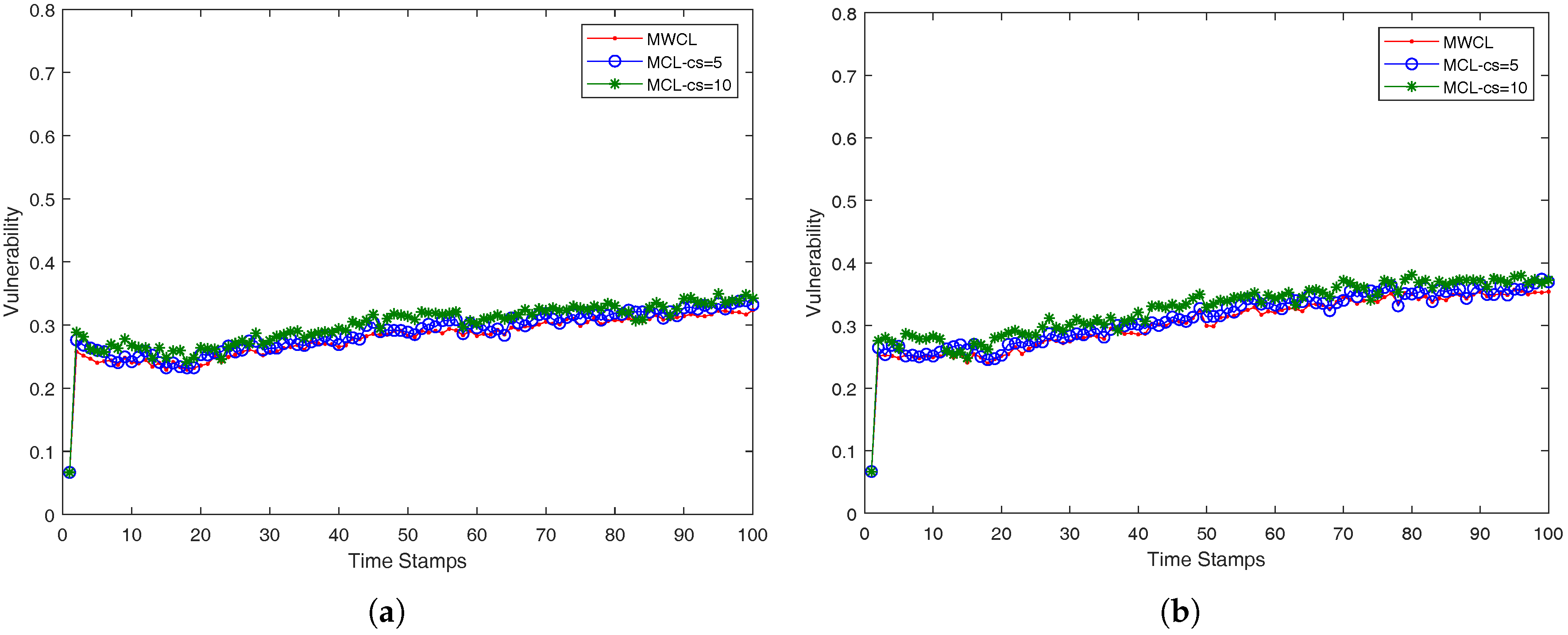
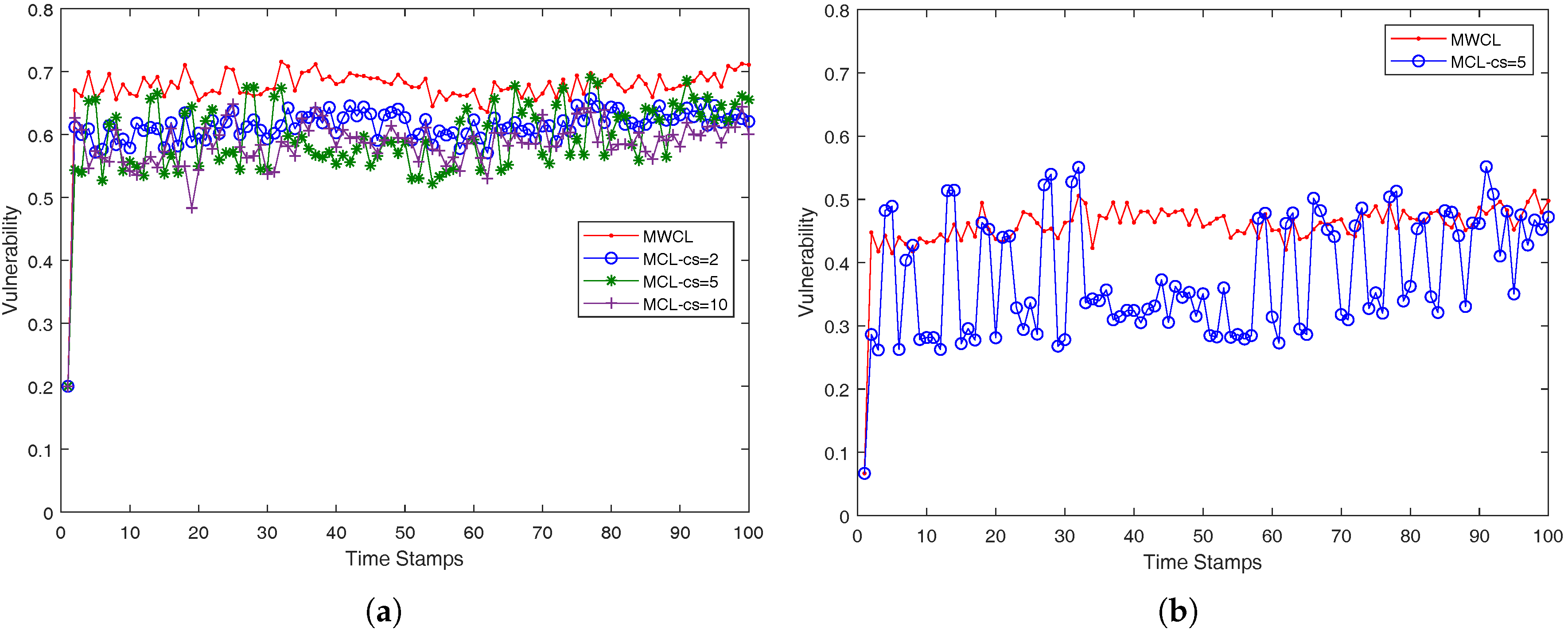
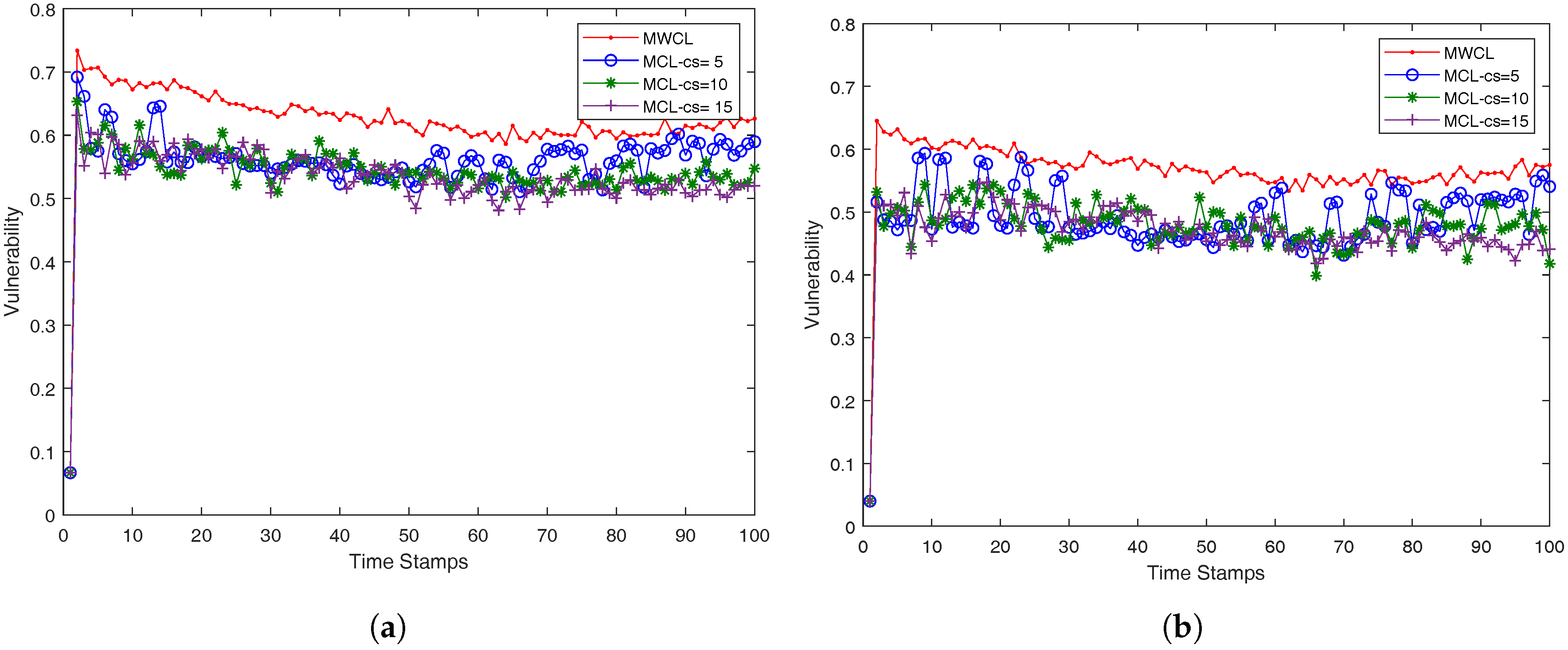
In our case, we approach the
k-anonymity preserving as follows. We investigated the impact of the used attributes (
x,
y,
g, and
v) in the robustness of the proposed methods, MWCL (Method-Without-CLustering) and MCL (Method-with-CLustering) which are presented in a compact form in Algorithms 3 and 4. Since, from time-stamp to time-stamp, the number of nearest neighbors may not remain the same and be less than
k, the robustness is decreased, namely the probability one mobile user is identified from its anonymity set may be higher than the optimum value
. The proposed MCL (Method-with-CLustering) method in Algorithm 4 adopts a simple K-means clustering micro-aggregation technique that maintains
k-anonymity, which was the aim of this study. However, the proposed approach in Algorithm 4 has some limitations and drawbacks. Firstly, it works for numeric or continuous location data, but does not work for categorical data. Secondly, although there may exist natural relations among attributes such as angle and velocity with Cartesian coordinates, the proposed algorithm cannot incorporate such information to find more desirable solutions. Moreover, the focus is too heavily placed on preserving
k nearest neighbors to guarantee mobile users anonymity. As a result, the algorithm lacks the ability to address other issues (e.g.,
l-diversity and
t-closeness) that previous works address to find more desirable solutions. Additionally, the method MCL (Method-With-CLustering), i.e., Algorithm 4, tries to minimize the within-cluster sum of squares and maximize intra-cluster sum of squares, so that the number of records in each partition is greater than
k. Using K-means, there is no guarantee that the optimum is found, thus the quality of the resulting anonymized data cannot be guaranteed. Similar to all greedy algorithms, the K-means algorithm will reach a local, but not necessarily a global, minimum. Hence, the information loss is not minimized even though clusters are formed such that they contain at least
k similar objects. In addition to, the Algorithm 4, designed for MCL (Method-with-CLustering), assigns mobile users to the nearest cluster by squared Euclidean distance. Using a different distance function may stop the algorithm from converging. Hence, as a first approach, we focused on this version of K-means. Moreover, the proposed technique cannot handle effectively hidden latent patterns, outliers, missing values, corrupted signals, noise, artifacts, and other disturbances. To this end, deep learning techniques and neural networks (e.g., convolution, recurrent or feed-forward neural networks) [
20,
21,
22,
23,
24], due to their wide range of applications, are being studied to investigate how and to what extent they can improve the performance of our approach for spatiotemporal databases [
25]. The main idea of using deep learning, known as feature learning, is to extract more effective representations of spatiotemporal database records to compute similarity between moving objects and perform clustering of mobile objects with similar motion patterns with higher performance and accuracy, such that the privacy preserving techniques achieve much lower vulnerability close to
. In a future work, the simultaneous use of deep learning methods with K-means, various modifications of K-means or other clustering algorithms will be used to investigate the impact on
k-anonymity. Finally, our aim was to extend this work for large-scale trajectory data and transfer the whole processing in a distributed computing environment based on Hadoop. Apache Spark is the most promising environment with high performance in parallel computing, designed to efficiently deal with supervised machine learning algorithms, e.g.,
k-NN [
26]. Deep Learning, which is part of a broader family of machine learning methods, gains more and more attention due to the rising volume of data. Thus, deep learning platforms have been designed for mining values in big data [
27]. A future direction is to design above methods and experiments in big data environments [
28,
29,
30,
31] and investigate their scalability and running time performance under different datasets and parameters
k, K combinations.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}