MapReduce Algorithm for Location Recommendation by Using Area Skyline Query


Abstract
1. Introduction
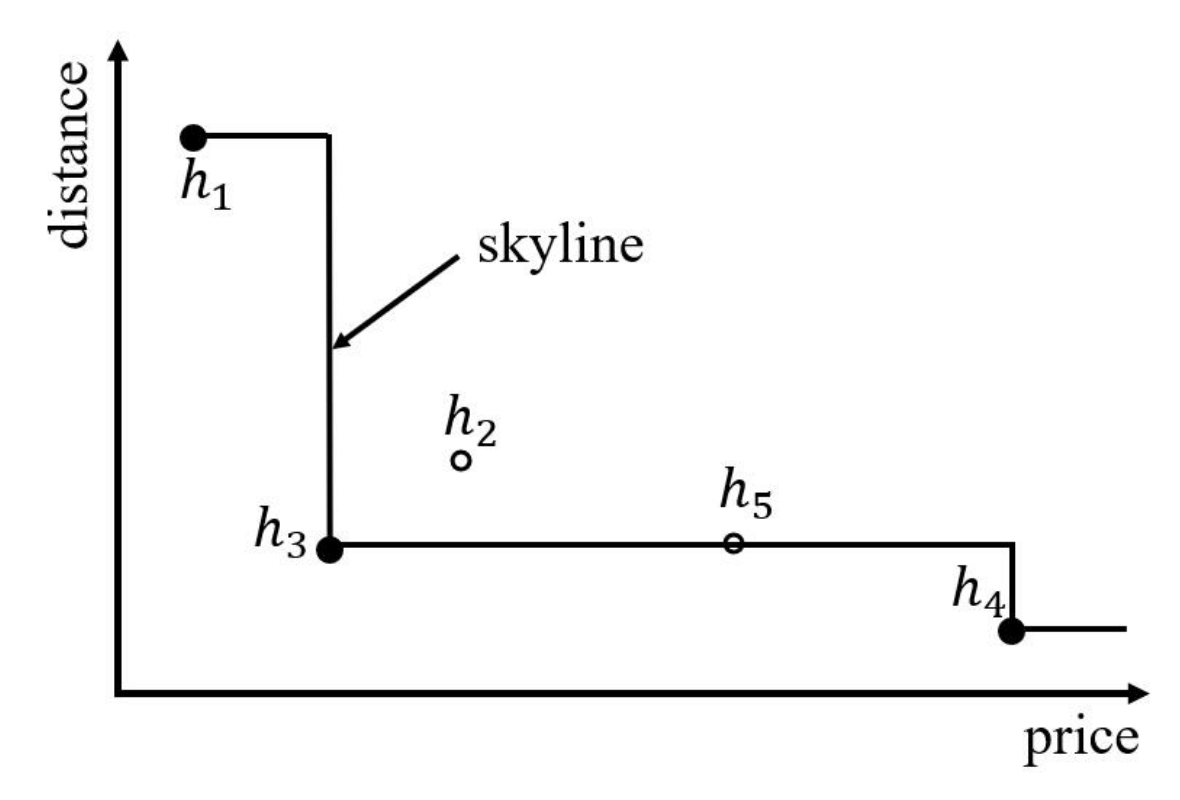
1.1. Skyline Query
1.2. Spatial Skyline Query
1.3. Area Skyline Query
- We develop MapReduce-based area skyline query computation, which is a distributed algorithm to address the poor performance problem for the grid-based area skyline queries.
- We propose an efficient algorithm of the MapReduce-based computation.
- We conduct an extensive performance evaluation, which shows the high efficiency and scalability of our proposed algorithm.
2. Related Works
2.1. Skyline Query
2.2. Spatial Skyline Query
2.3. MapReduce Based Skyline Computation
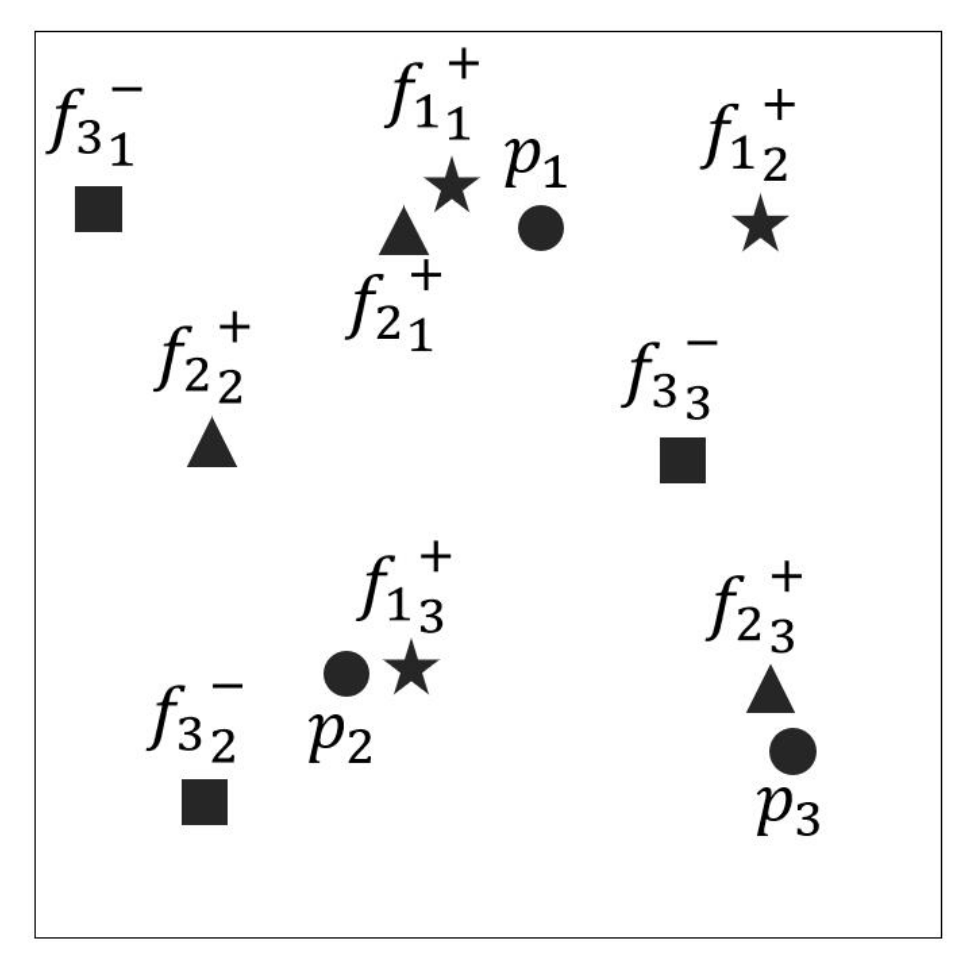
3. MapReduce-Based Area Skyline
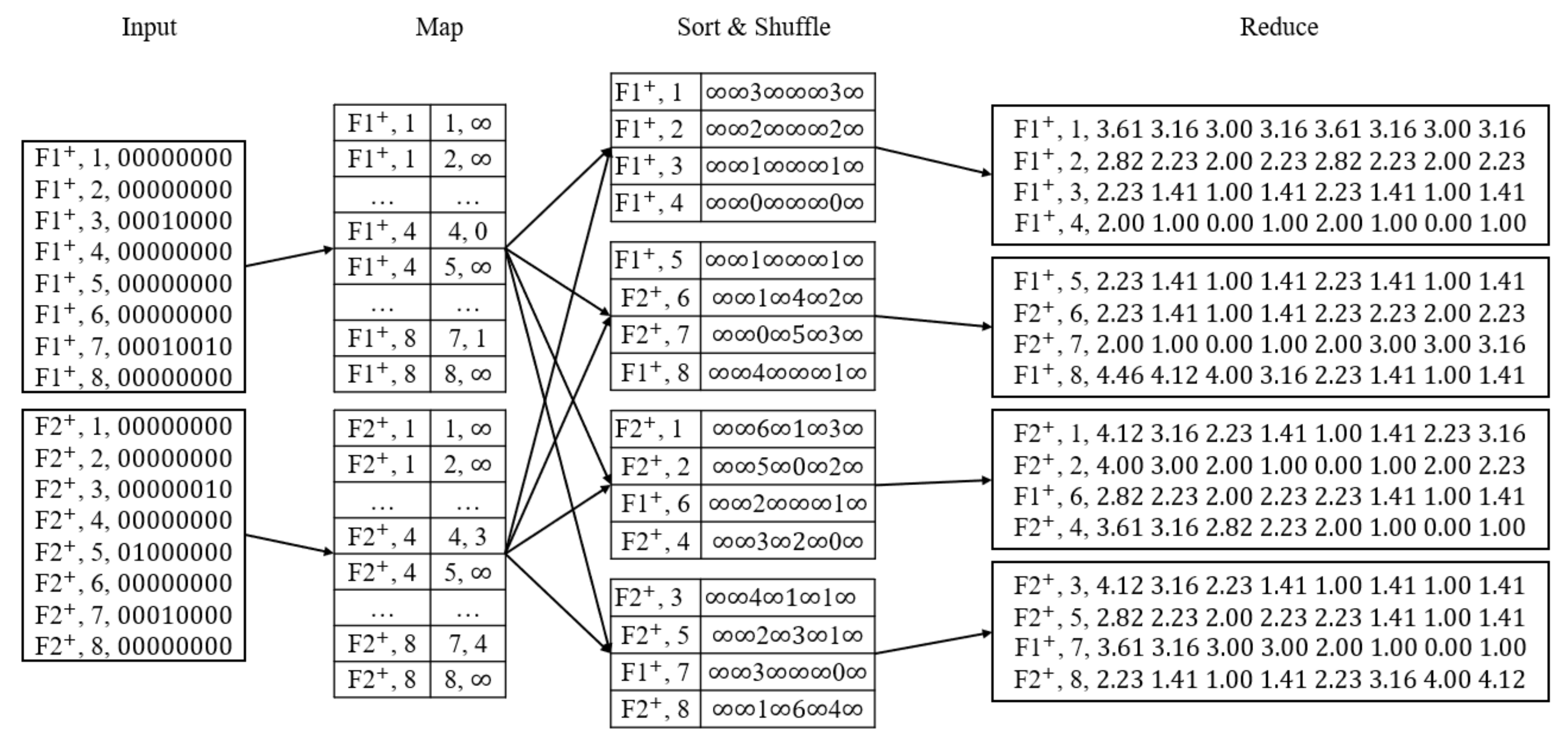
MRGASKY Algorithm
- Step 1
- Map function mainly calculates the distance to the closest facilities of each type in the same row.
- Step 1.1
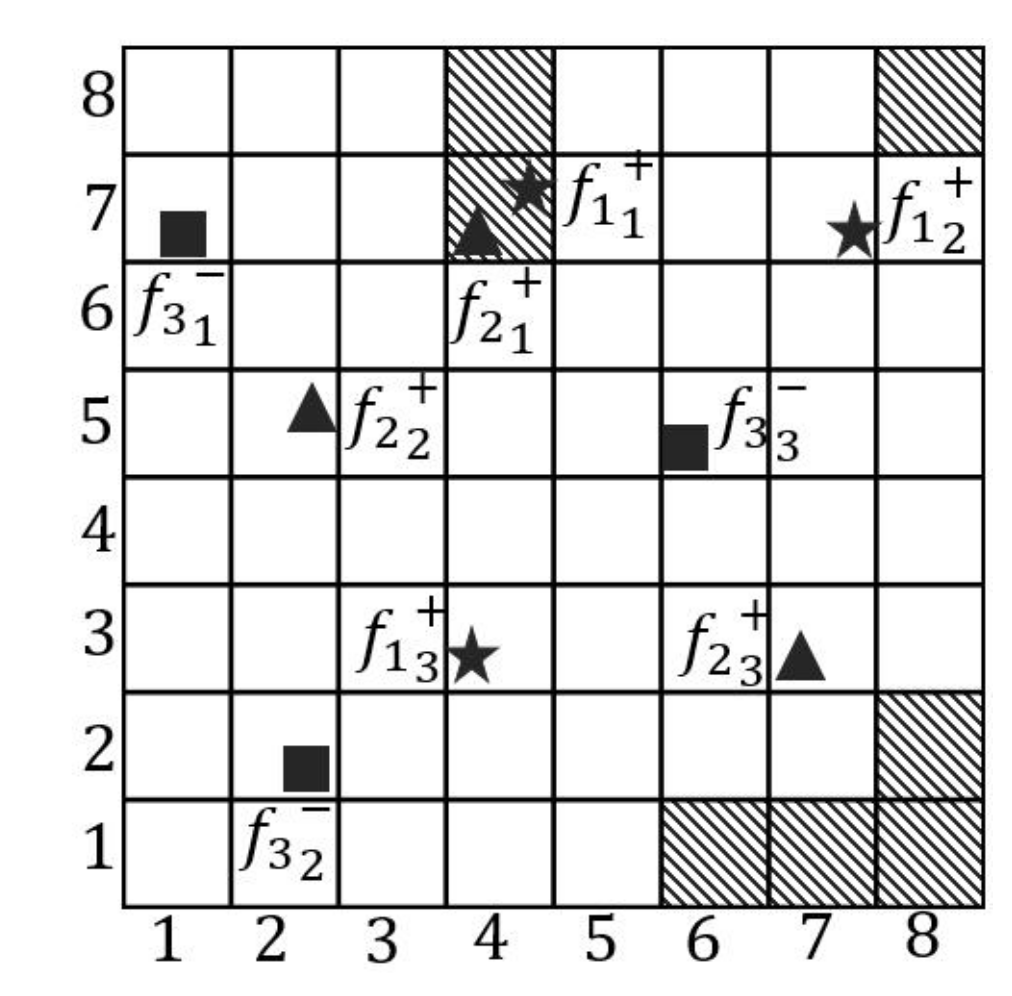
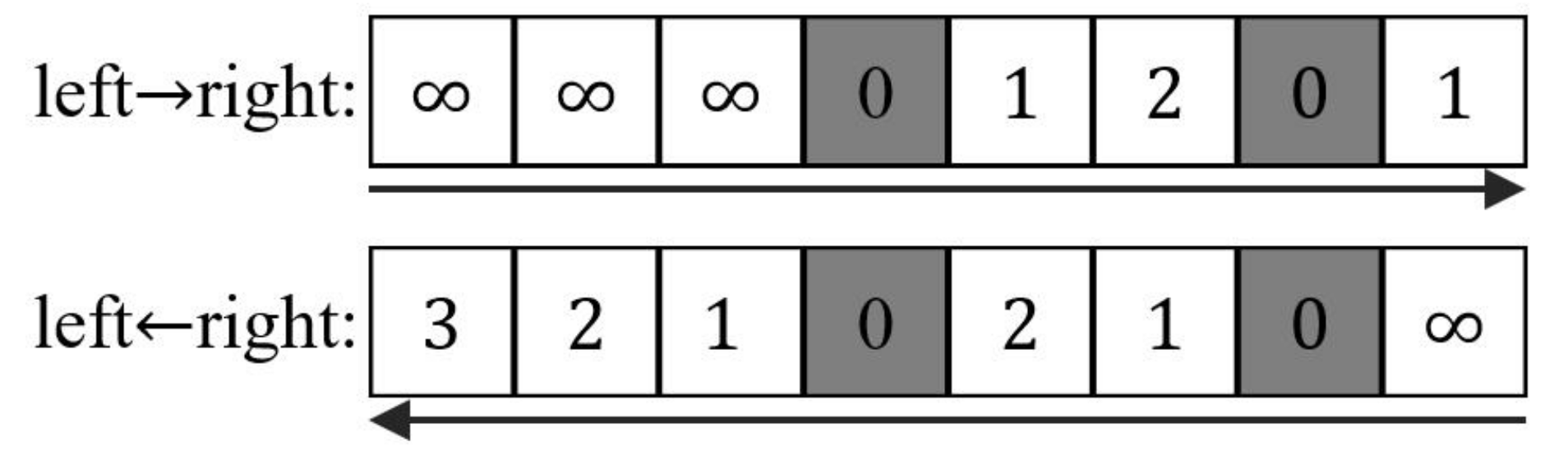
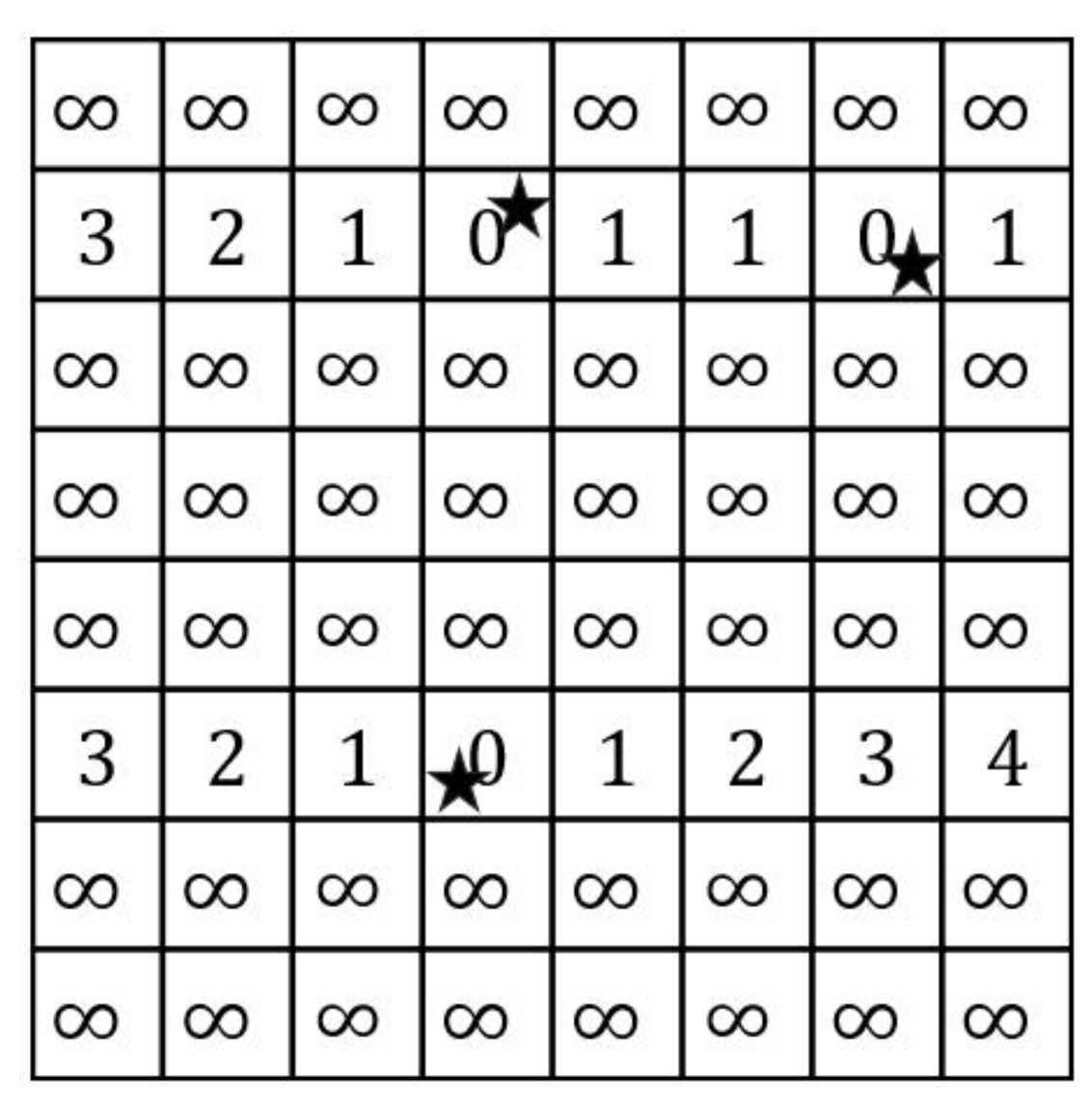
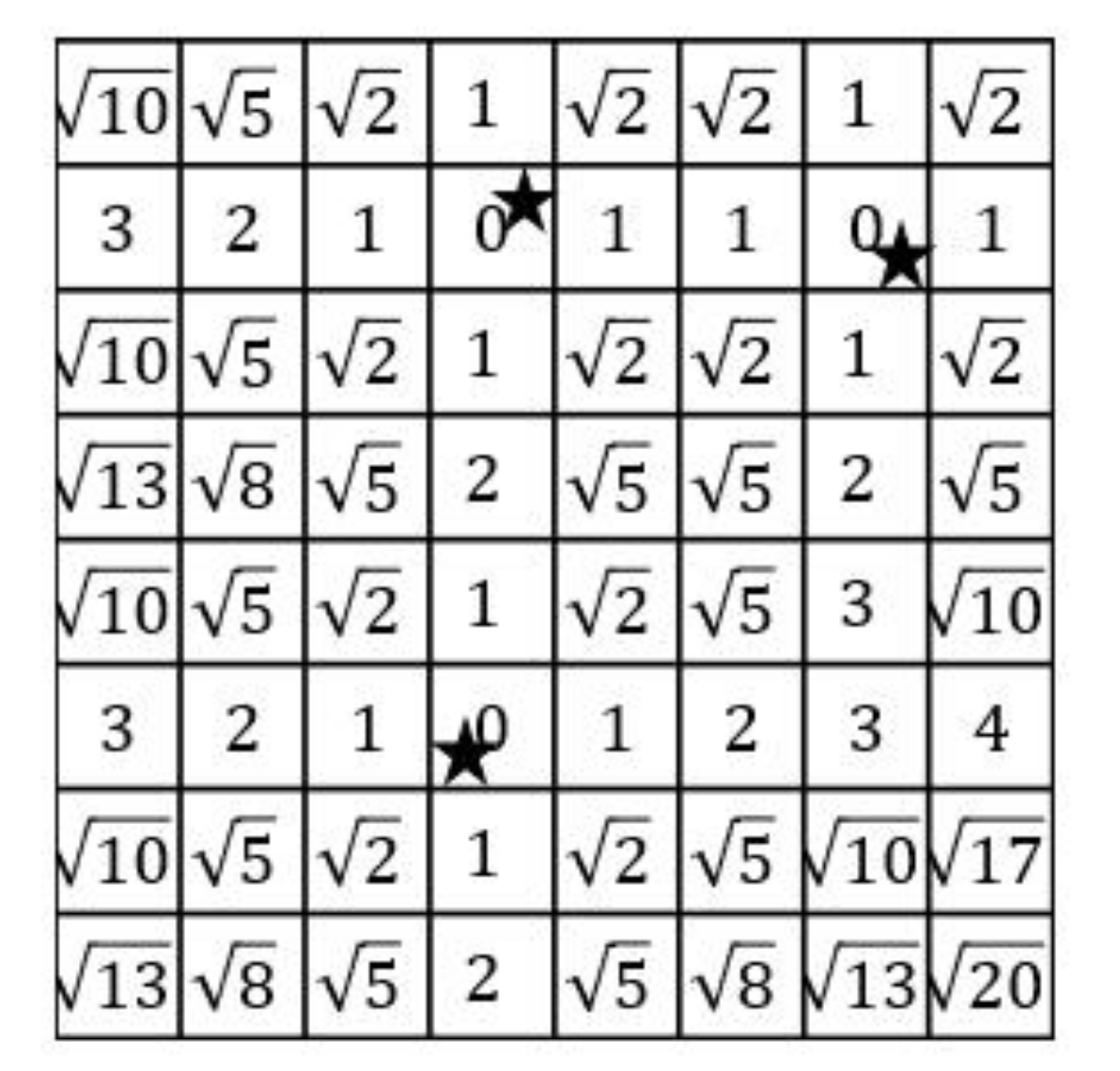
- A map is firstly separated to n rows. For each row, the Map function reads the grids from both sides to calculate the distance between grids and facilities. We assume that the initial values of all grids are infinite before facilities are encountered. When facilities are encountered, the values of the grids are considered as 0. Then, the value of the next grid is updated based on the former grid plus one until the next facility is encountered. An example of 7th row of Figure 3 demonstrates in Figure 4. The shaded grids are the facilities of . The values of these shaded grids are 0. From left to right side, the values of the 5th, 6th and 8th grids are updated to 1, 2 and 1. Similarly, we can also compute the values from right to left side.
- Step 1.2
- After calculating the values from both sides, we select the minimum value of every grid as the output of the Map function, as illustrated in Figure 5.
| Algorithm 1 Map Function for Step 1 Process |
| Input: A binary image Output: (key, value)=(type x-coordinate of grids. y-coordinate of grids, distance)
|
- Step 2
- Again, we calculate the distance of every grid to the nearest facilities in the same column in Reduce function.
- Step 2.1
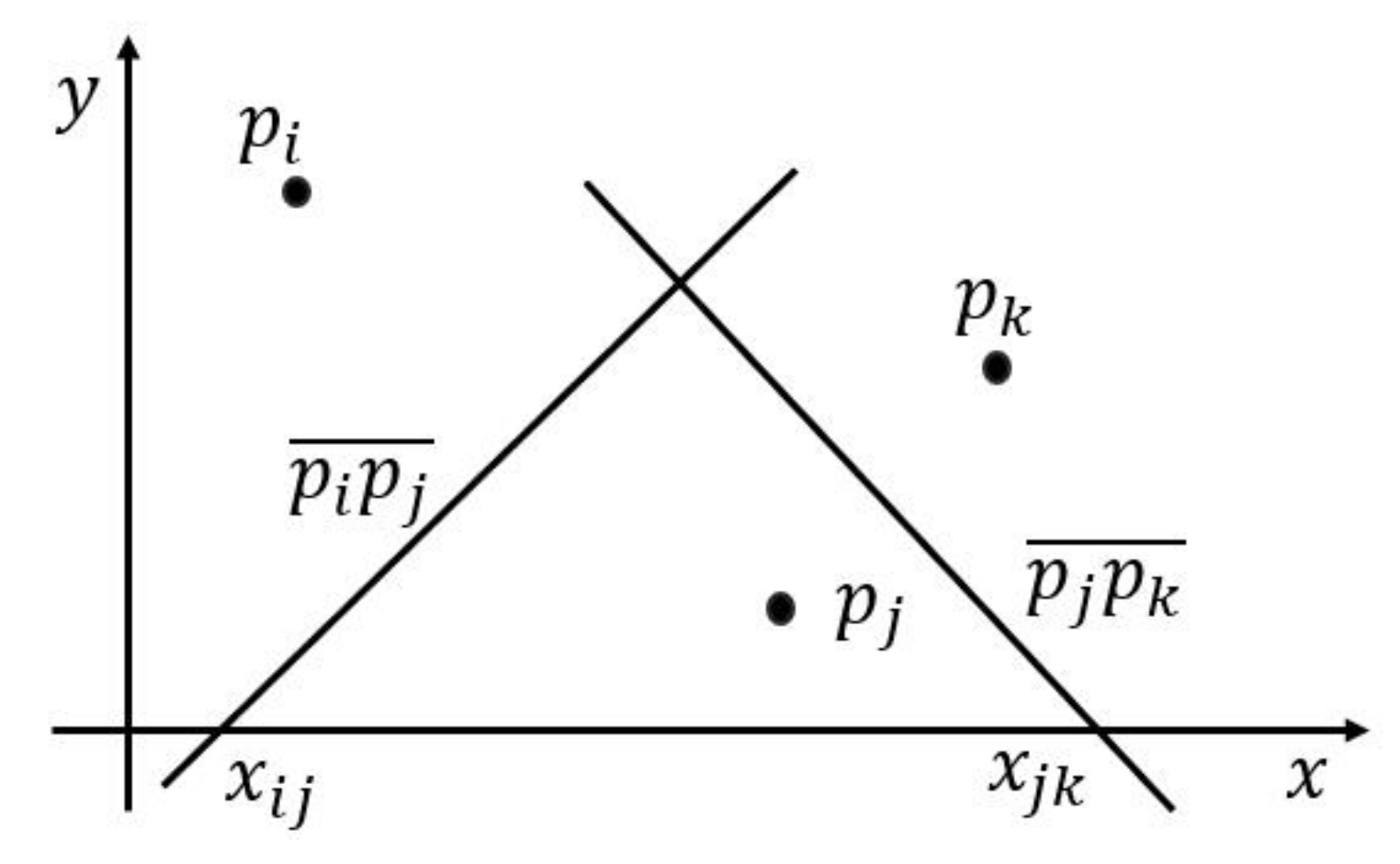
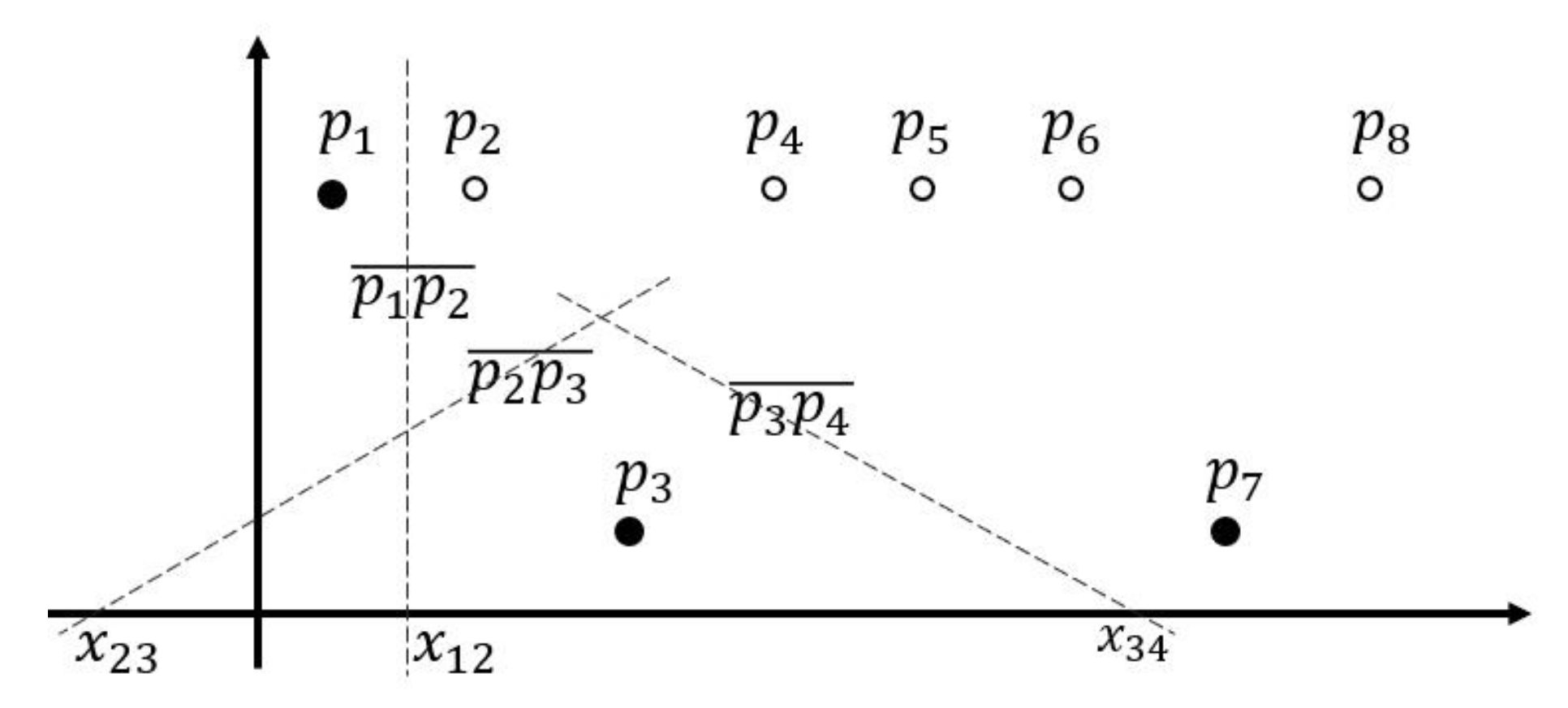
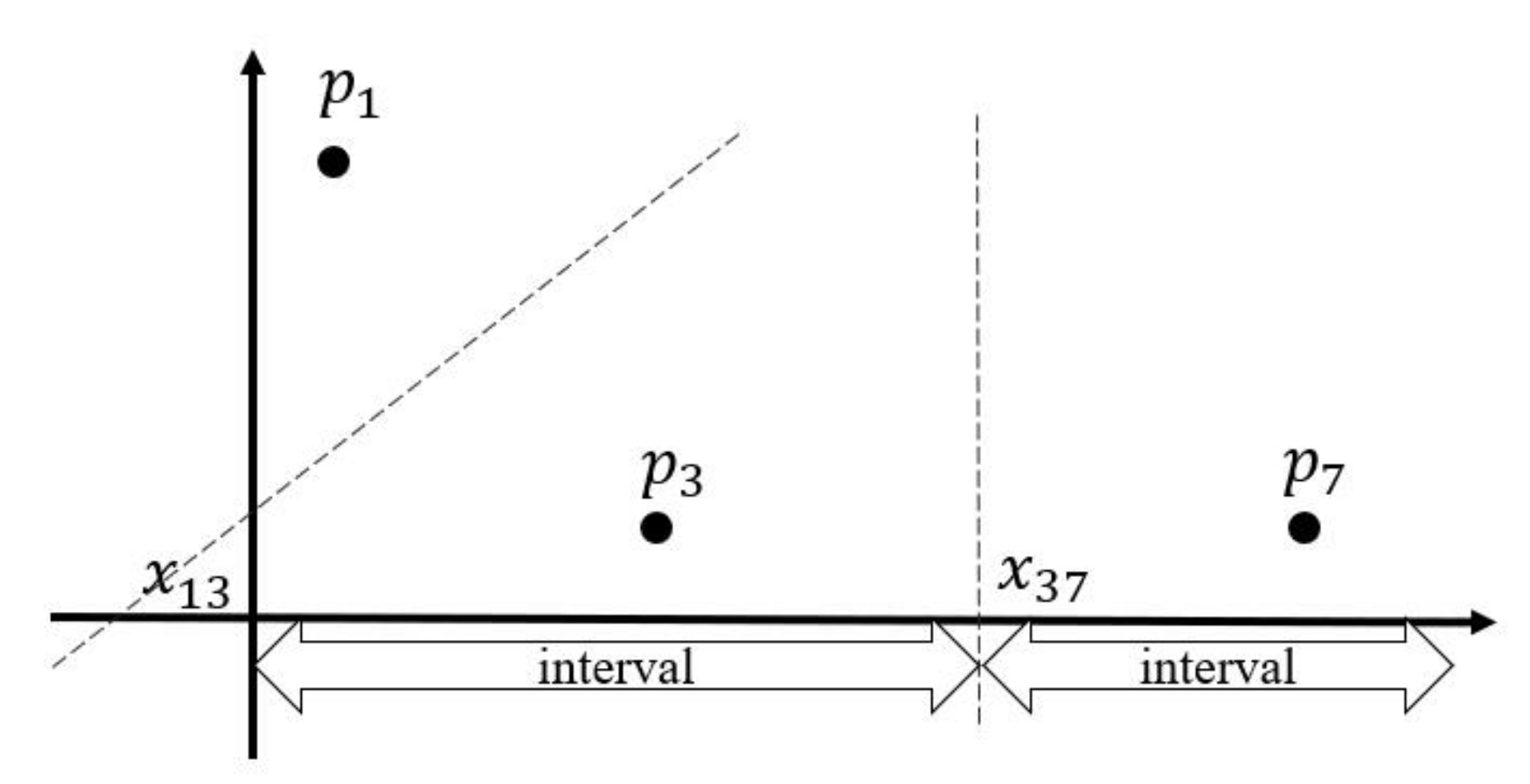
- The pairs of step 1 process are sorted and shuffled by column. The Reduce function reads the pairs in the ith column from bottom to up and saves the values into a stack. Notice that every column is saved in its corresponding stack. We project the grids in the same column into a two-dimensional coordinate where x-axis represents the column IDs of grids, which we count them from bottom to up, and the values of y-axis are the results in step 1.2. We name all n points as . Then, we bisect the adjacent two points , and where (). is the intersection of the vertical bisector and x-axis. We compute by formula (1):
| Algorithm 2 Reduce Function for Step 2 Process |
| Input: The results of the sorted and shuffle phase Output: Area skyline objects
|
4. Experimental Evaluation
- Synthetic datasets:
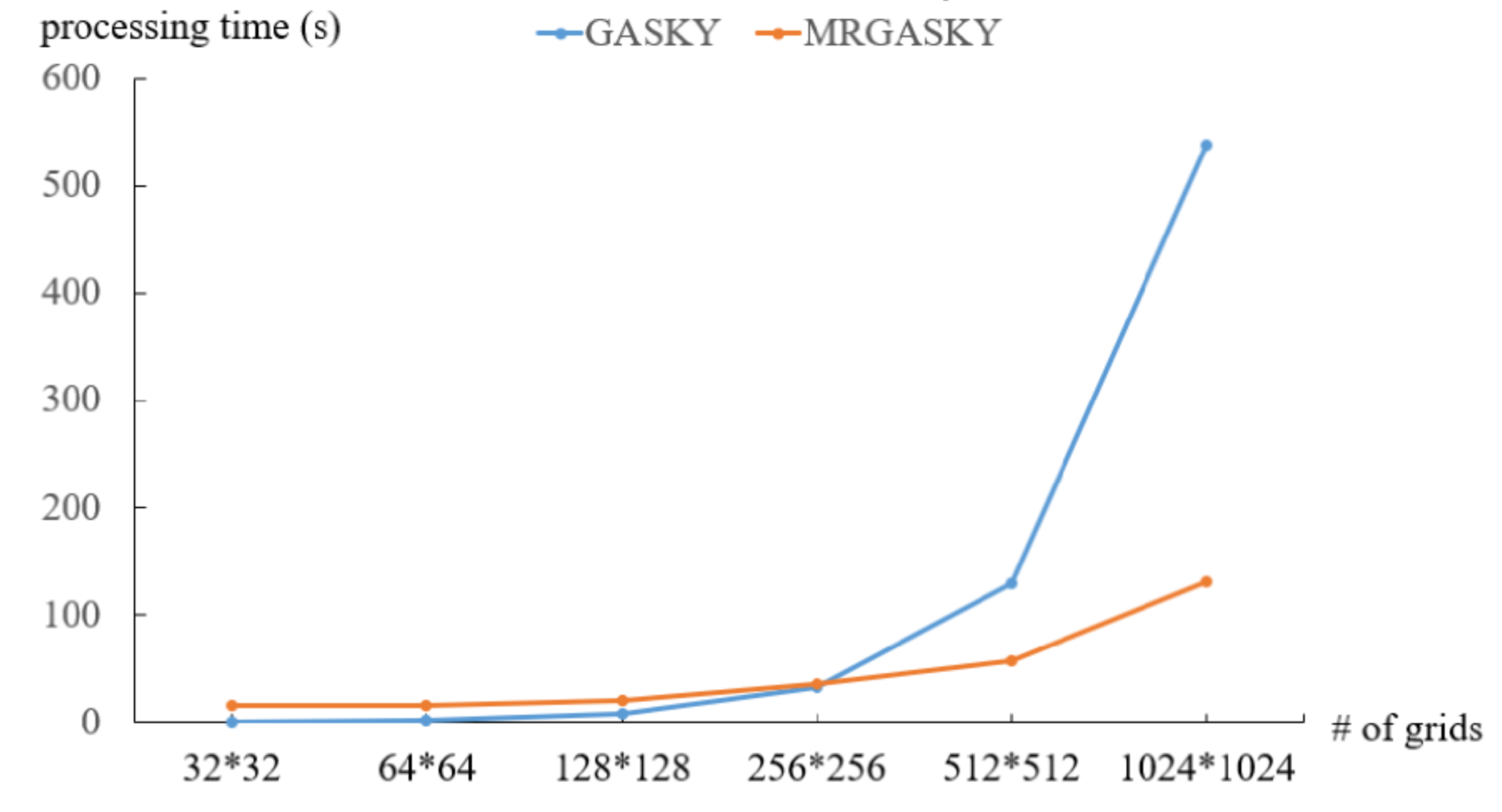
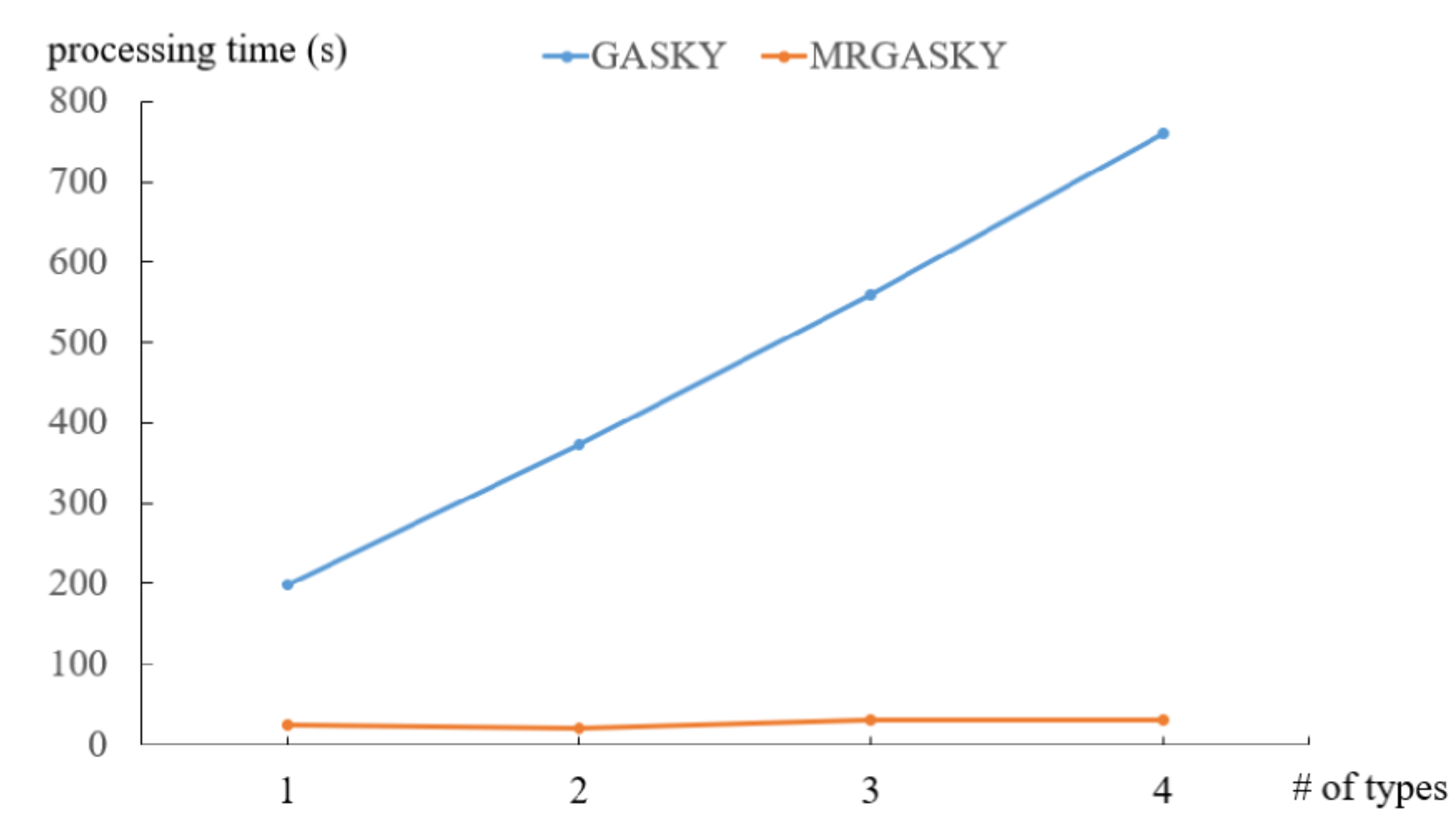
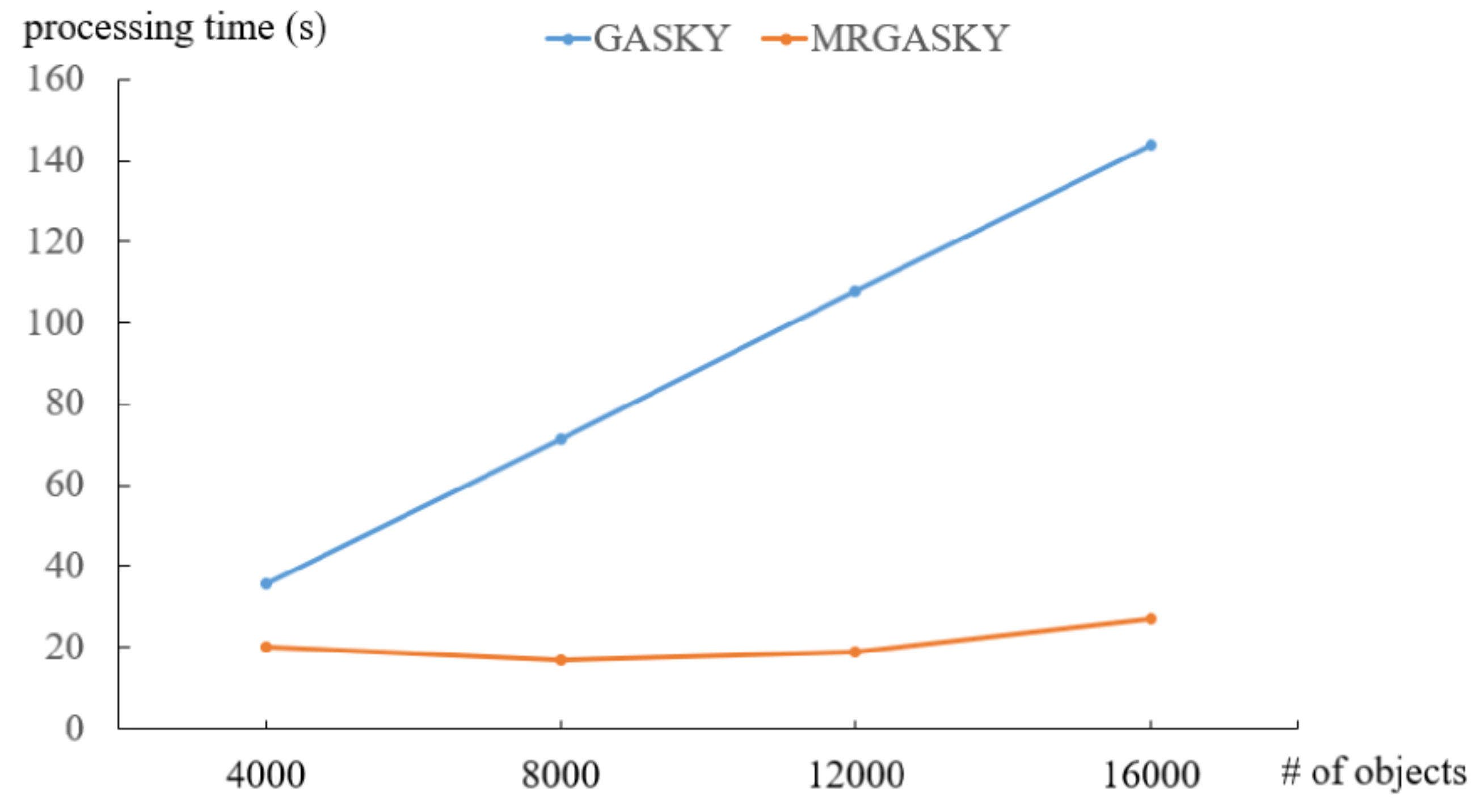
- We create a synthetic dataset to study the scalability of the algorithms, denoted by SYN, in the experiments. The objects and facilities are randomly generated in two-dimensional space. Specifically, there are four synthetic datasets, SYN_A1, SYN_A2, SYN_B and SYN_C with different number of grids, number of facility types and number of objects respectively.
- Real datasets:
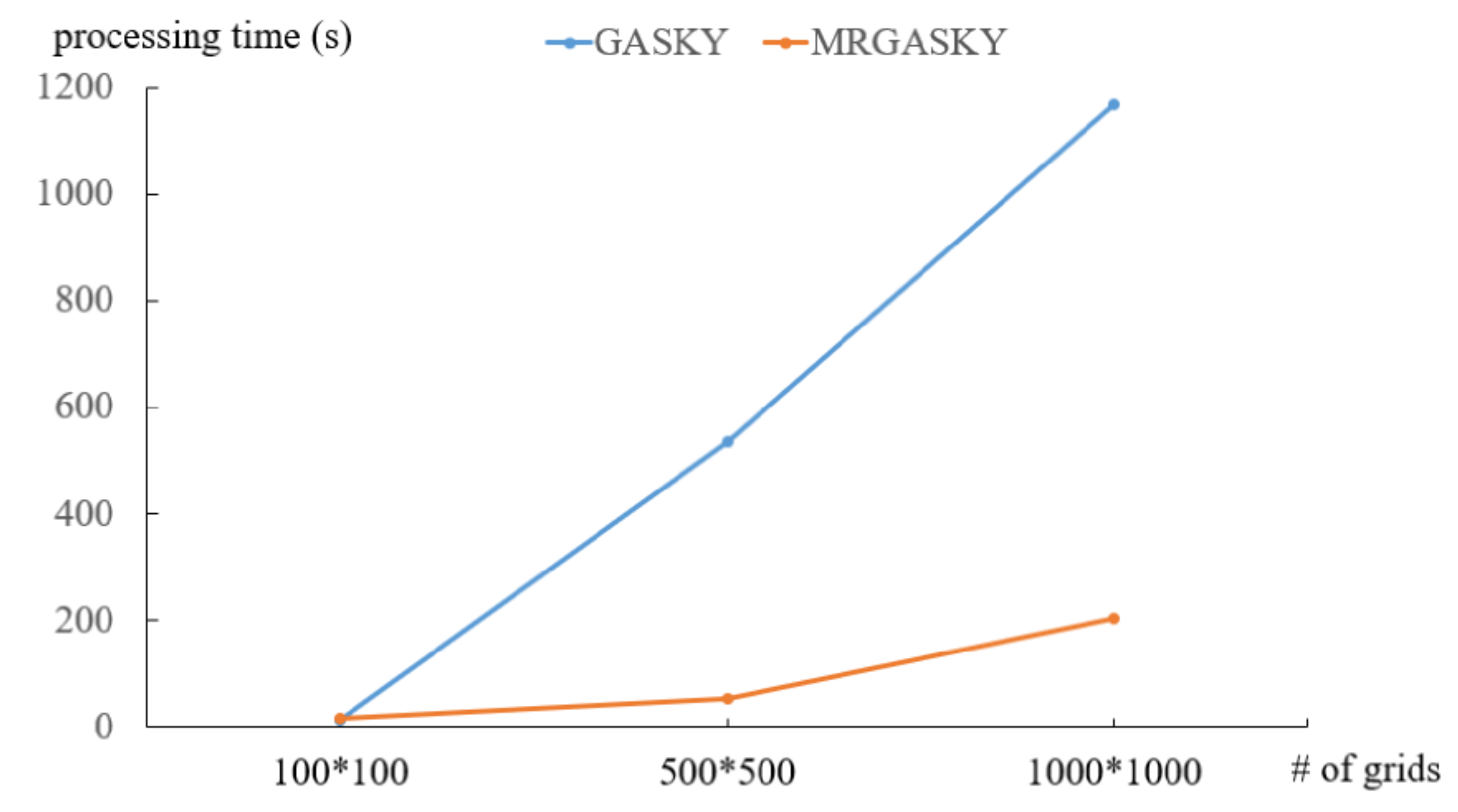
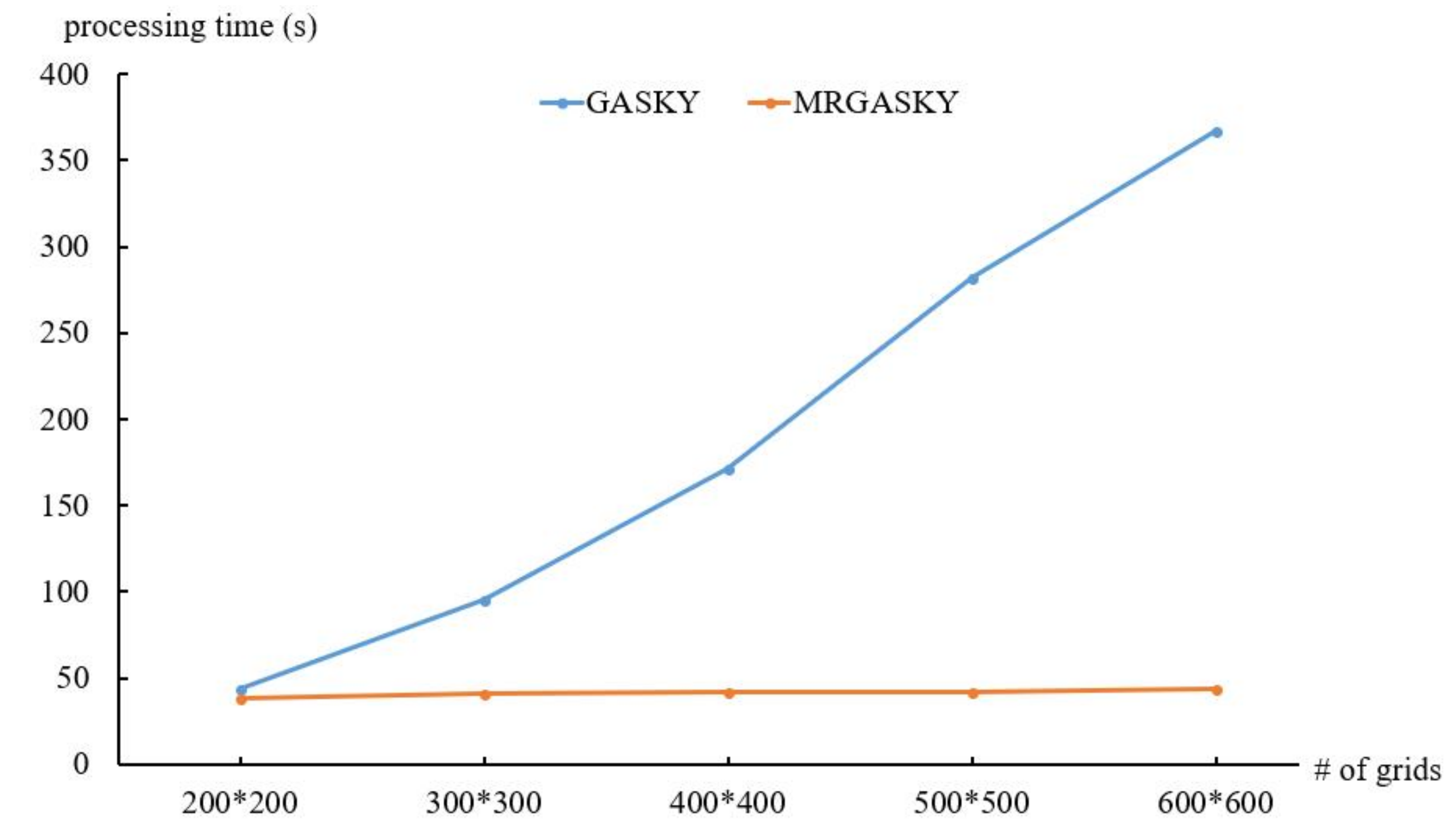
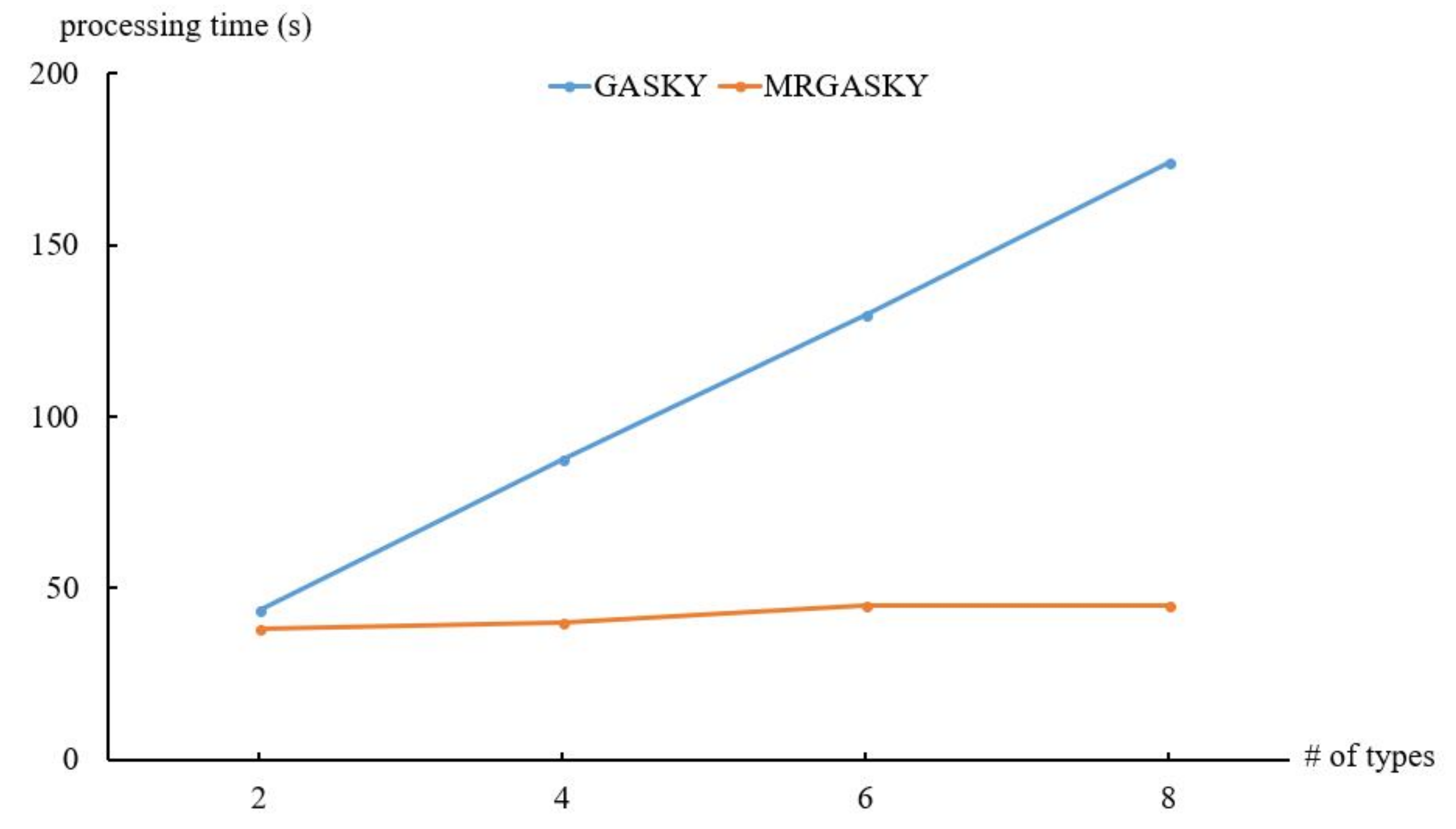
- The real dataset, called US, is employed in the experiment. US dataset comes from the U.S. Geological Survey (USGS). It consists of 406,709 locations with 40 types. The number of objects in the US dataset is 2,033,545. We create three datasets by using these real data, denoted US_A, US_B, and US_C, with the different number of grids, facility types and objects respectively.
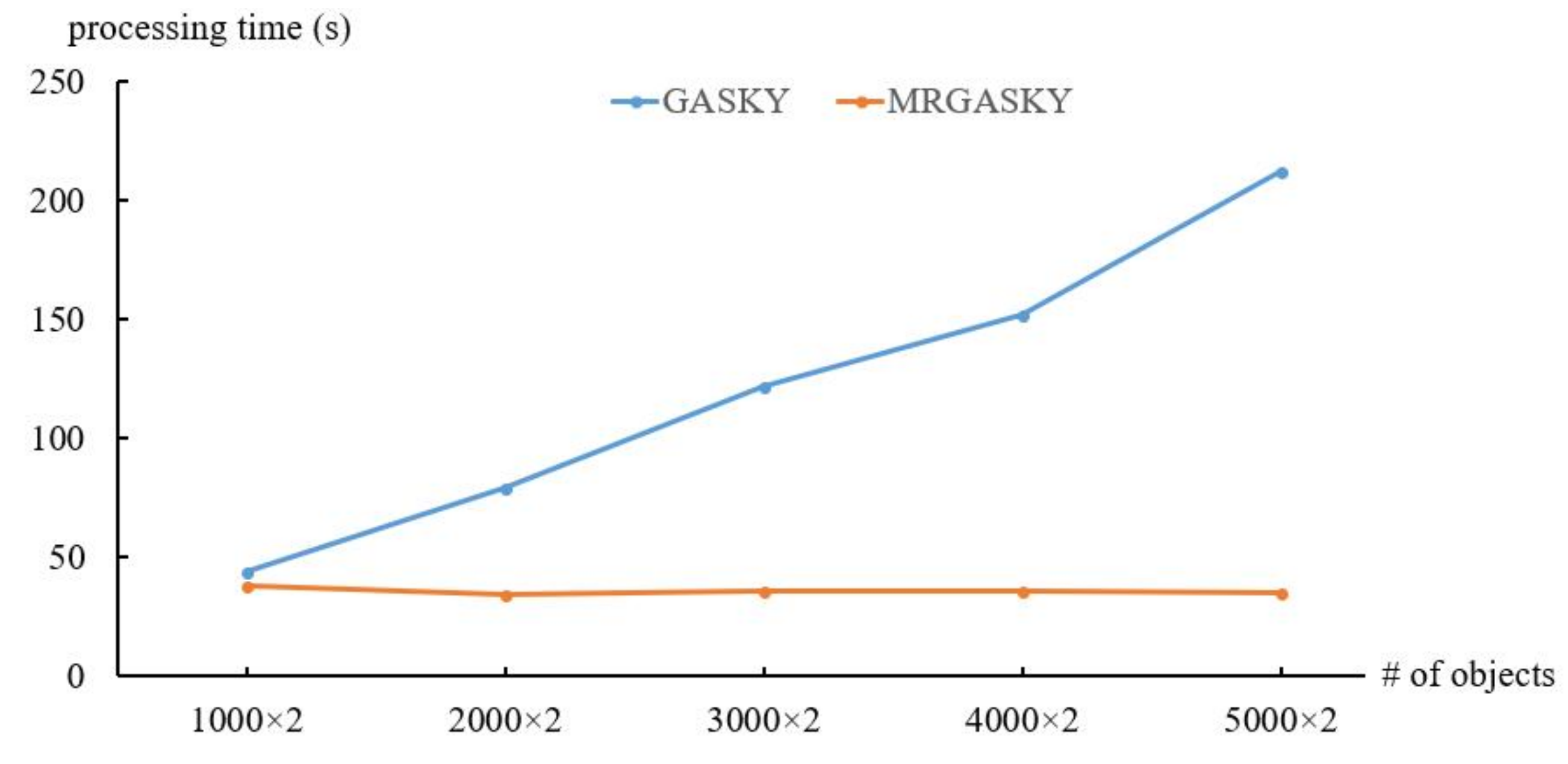
4.1. Efficiency of Synthetic Dataset
4.2. Efficiency of Real Dataset
5. Conclusions
- In the business field: Suppose a real estate developer would like to find a region to build a community. In general, a good region of the community should be close to some highly popular places such as bus/train stations, malls, and schools. Besides, it should be far from some unpopular places such as noisy factories and open landfills. Our proposed algorithm can help the real estate developer find some potential areas on a map, which could reduce the survey cost the whole regions.
- In the travel field: It is very common for tourists to utilize map applications on mobile devices during a trip. In most instances, tourists would like to find some sightseeing spots where should be surrounded by preferable facilities and away from unpreferable facilities. Our algorithm can recommend such locations to the users of mobile devices in a short time.
Author Contributions
Funding
Conflicts of Interest
References
- Borzsonyi, S.; Kossmann, D.; Stocker, K. The skyline operator. In Proceedings of the 17th International Conference on Data Engineering (ICDE), Heidelberg, Germany, 2–6 April 2001; pp. 421–430. [Google Scholar]
- Chomicki, J.; Godfrey, P.; Gryz, J.; Liang, D. Skyline with presorting. In Proceedings of the 19th International Conference on Data Engineering (ICDE), Bangalore, India, 5–8 March 2003; pp. 717–719. [Google Scholar]
- Tan, K.L.; Eng, P.K.; Ooi, B.C. Efficient progressive skyline computation. In Proceedings of the 27th International Conference on Very Large Data Bases (VLDB), Rome, Italy, 11–14 September 2001; pp. 301–310. [Google Scholar]
- Xia, T.; Zhang, D.; Tao, Y. On skylining with flexible dominance relation. In Proceedings of the 24th International Conference on Data Engineering (ICDE), Cancun, Mexico, 7–12 April 2008; pp. 1397–1399. [Google Scholar]
- Zaman, A.; Morimoto, Y. Area skyline query for selecting good locations in a map. J. Inf. Process 2016, 24, 946–955. [Google Scholar]
- Chan, C.Y.; Jagadish, H.; Tan, K.L.; Tung, A.K.; Zhang, Z. On high dimensional skylines. In Proceedings of the 10 International Conference on Extending Database Technology, Munich, Germany, 26–31 March 2006; pp. 478–495. [Google Scholar]
- Chan, C.Y.; Jagadish, H.; Tan, K.L.; Tung, A.K.; Zhang, Z. Finding k-dominant skylines in high dimensional space. In Proceedings of the International Conference on Management of Data and Symposium on Principles Database and Systems, Chicago, IL, USA, 27–29 June 2006; pp. 444–457. [Google Scholar]
- Lin, X.; Yuan, Y.; Zhang, Q.; Zhang, Y. Selecting stars: The k most representative skyline operator. In Proceedings of the 23rd International Conference on Data Engineering, Istanbul, Turkey, 11–15 April 2007; pp. 86–95. [Google Scholar]
- Sharifzadeh, M.; Shahabi, C. The Spatial Skyline Queries. In Proceedings of the 32nd International Conference on Very Large Data Bases (VLDB), Seoul, Korea, 12–15 September 2006; pp. 751–762. [Google Scholar]
- Kodama, K.; Iijima, Y.; Guo, X.; Ishikawa, Y. Skyline queries based on user locations and perferences for making location-based recommendations. In Proceedings of the 19th International Workshop on Location Based Social Networks (LBSN), Washington, DC, USA, 3 November 2009; pp. 9–16. [Google Scholar]
- Arefin, M.; Xu, J.; Chen, Z.; Morimoto, Y. Skyline query for selecting spatial objects by utilizing surrounding objects. J. Softw. 2013, 8, 1742–1749. [Google Scholar] [CrossRef]
- You, G.W.; Lee, M.W.; Im, H.; Hwang, S.W. The farthest spatial skyline queries. Inf. Syst. 2013, 38, 286–301. [Google Scholar] [CrossRef]
- Lin, Y.W.; Wang, E.T.; Chiang, C.F.; Chen, A.L.P. Finding targets with the nearst favor neighbor and farthest disfavor neighbor by a skyline query. In Proceedings of the 29th Annual ACM Symposium on Applied Computing (SAC), Gyeongju, Korea, 24–28 March 2014; pp. 821–826. [Google Scholar]
- Siddique, M.A.; Zaman, A.; Morimoto, Y. A Method for selecting desirable unfixed shape areas from integrated geographic information system. In Proceedings of the 4th International Congress on Advanced Applied Informatics, Okayama, Japan, 12–16 July 2015; pp. 195–200. [Google Scholar]
- Hose, K.; Vlachou, A. A survey of skyline processing in highly distributed environments. Int. J. Very Large Data Bases 2012, 21, 359–354. [Google Scholar] [CrossRef]
- Zhang, B.; Zhou, S.; Guan, J. Adapting skyline computation to the mapreduce framework: Algorithms and experiments. In Proceedings of the 16th International Conference on Database Systems for Advanced Applications, Hong Kong, China, 22–25 April 2011; pp. 403–414. [Google Scholar]
- Chen, L.; Hwang, K.; Wu, J. MapReduce skyline query processing with new angular partitioning approach. In Proceedings of the 2012 IEEE 26th International Parallel and Distributed Processing Symposium Workshops and PhD Forum, Shanghai, China, 21–25 May 2012; pp. 2262–2270. [Google Scholar]
- Papadias, D.; Tao, Y.; Fu, G.; Seeger, B. Progressive skyline computation in database systems. ACM Trans. Database Syst. 2005, 30, 41–82. [Google Scholar] [CrossRef]
- Wu, P.; Zhang, C.; Feng, Y.; Zhao, B.; Agrawal, D.; Abbadi, A. Parallelizing skyline queries for scalable distribution. In Proceedings of the 10 International Conference on Extending Database Technology, Munich, Germany, 26–31 March 2006. [Google Scholar]
- Wang, W.; Zhang, J.; Sun, M.T.; Ku, W.S. Efficient parallel spatial skyline evaluation using MapReduce. In Proceedings of the 20th International Conference on Extending Database Technology, Venice, Italy, 21–24 March 2017. [Google Scholar]
- Man, D.; Uda, K.; Ito, Y.; Nakano, K. Accelerating computation of Euclidean distance map using the GPU with efficient memory access. Int. J. Parallel Emergent Distrib. Syst. 2012, 25, 383–406. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Price | Distance |
|---|---|---|
| 3 | 8 | |
| 5 | 4 | |
| 4 | 3 | |
| 9 | 2 | |
| 7 | 3 |
| Point | |||
|---|---|---|---|
| 3 | 5 | −10 | |
| 4 | 9 | −7 | |
| 8 | 1 | −8 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Annisa, A.; Zaman, A.; Qaosar, M.; Ahmed, S.; Morimoto, Y. MapReduce Algorithm for Location Recommendation by Using Area Skyline Query. Algorithms 2018, 11, 191. https://doi.org/10.3390/a11120191
Li C, Annisa A, Zaman A, Qaosar M, Ahmed S, Morimoto Y. MapReduce Algorithm for Location Recommendation by Using Area Skyline Query. Algorithms. 2018; 11(12):191. https://doi.org/10.3390/a11120191
Chicago/Turabian StyleLi, Chen, Annisa Annisa, Asif Zaman, Mahboob Qaosar, Saleh Ahmed, and Yasuhiko Morimoto. 2018. "MapReduce Algorithm for Location Recommendation by Using Area Skyline Query" Algorithms 11, no. 12: 191. https://doi.org/10.3390/a11120191
APA StyleLi, C., Annisa, A., Zaman, A., Qaosar, M., Ahmed, S., & Morimoto, Y. (2018). MapReduce Algorithm for Location Recommendation by Using Area Skyline Query. Algorithms, 11(12), 191. https://doi.org/10.3390/a11120191