1. Introduction
It is now common practice for an individual to share or backup documents using cloud storage services. Examples of services include Google Drive, Microsoft OneDrive, Apple iCloud, Dropbox and Amazon S3. This provides an individual with easy access to his/her data anywhere and anytime. In addition, more and more organizations from both the private and government sectors are moving their data and computations to the cloud. In the US, for instance, both Amazon and Microsoft provide specialized cloud services called AWS GovCloud and Azure Government to government agencies. These services are physically isolated from the regular cloud services offered by both providers and need to adhere to strict government security regulations. The existence of such services is probably attributable, in part, to the surge in usage of cloud-based services in the government sector.
According to a report by security audit firm Netwrix, the number of cloud adoptions in the surveyed organizations increased from 43% (2015) to 68% (2016) [
1]. The report also states that cloud security is a primary concern for 70% of organizations worldwide. In a report published in 2016, Cisco anticipates that by the year 2020, 59% of the world’s Internet users will use personal cloud storage, which is an increase from 47% in 2015 [
2]. These trends are not uncommon since a cloud storage service brings numerous benefits to the user. The service, however, is not without its downsides.
One common property inherited by all the current cloud services is that the user does not have total control of the privacy of the stored documents. This is inevitable since the provider is expected to have read access privileges in order to be able to search through documents related to the user’s query. A seemingly trivial solution would be for the user to encrypt all documents prior to storing them on the cloud. However, the user now loses the ability to search these documents. The workaround is either to download and decrypt all documents locally or give the encryption key to the cloud provider. The former approach is extremely inefficient while the latter raises privacy concerns.
In order to protect the privacy of documents while at the same time allowing a user to efficiently search them, we introduce a system based on our multi-server SSE scheme that we call the searchable data vault (SDV). The SDV enables a user to store encrypted documents in the cloud and to retrieve them in an efficient and privacy-preserving manner. Our main contributions are as follows:
SDV allows documents, or pieces of an encrypted document, called blocks, to be stored in different cloud storage services, in contrast to existing schemes and systems that focus on outsourcing to a single storage. It ensures with high probability that no single storage provider has a complete set of blocks, which it may use to learn additional information about the document. As far as we know, it is the first searchable encryption system that provides such a feature.
A core component of SDV is a controller that manages query indexes, document submission, and retrieval. The controller is designed in such a way that the underlying searchable symmetric encryption (SSE) scheme, utilized for efficient search, is “pluggable”. It means existing schemes that cater for single storage provider can be adapted for use with our system. The controller may be implemented and placed in a query gateway. This is the case for our deployment.
We further propose a multi-server SSE scheme, which is adapted from [
3], with an implementation for SDV.
The query index is designed to cater to a two-level dictionary structure, where the basic level is for a single-word query. An upper level can be included for future extension to more expressive queries (e.g., ranked, range, conjunctive).
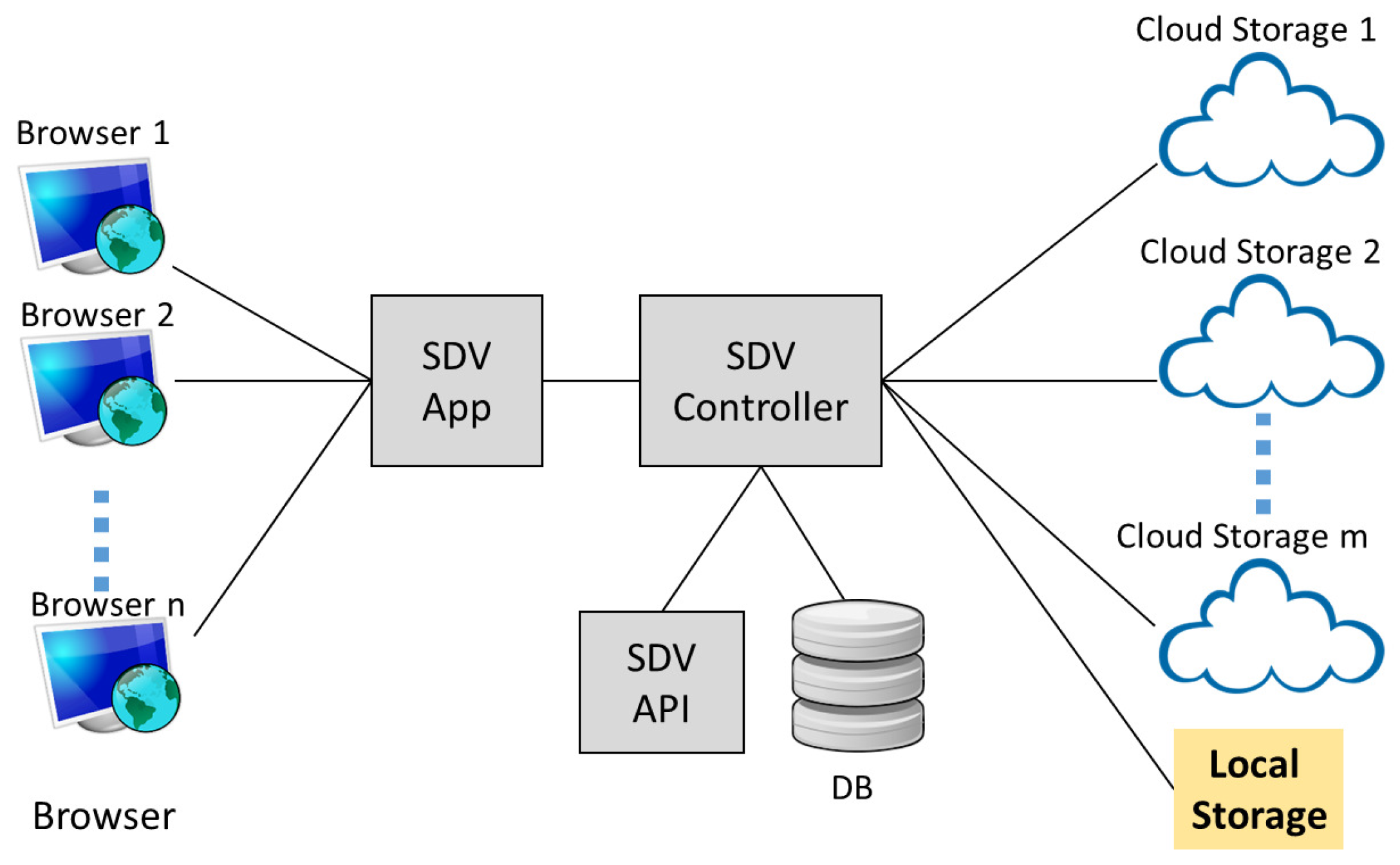
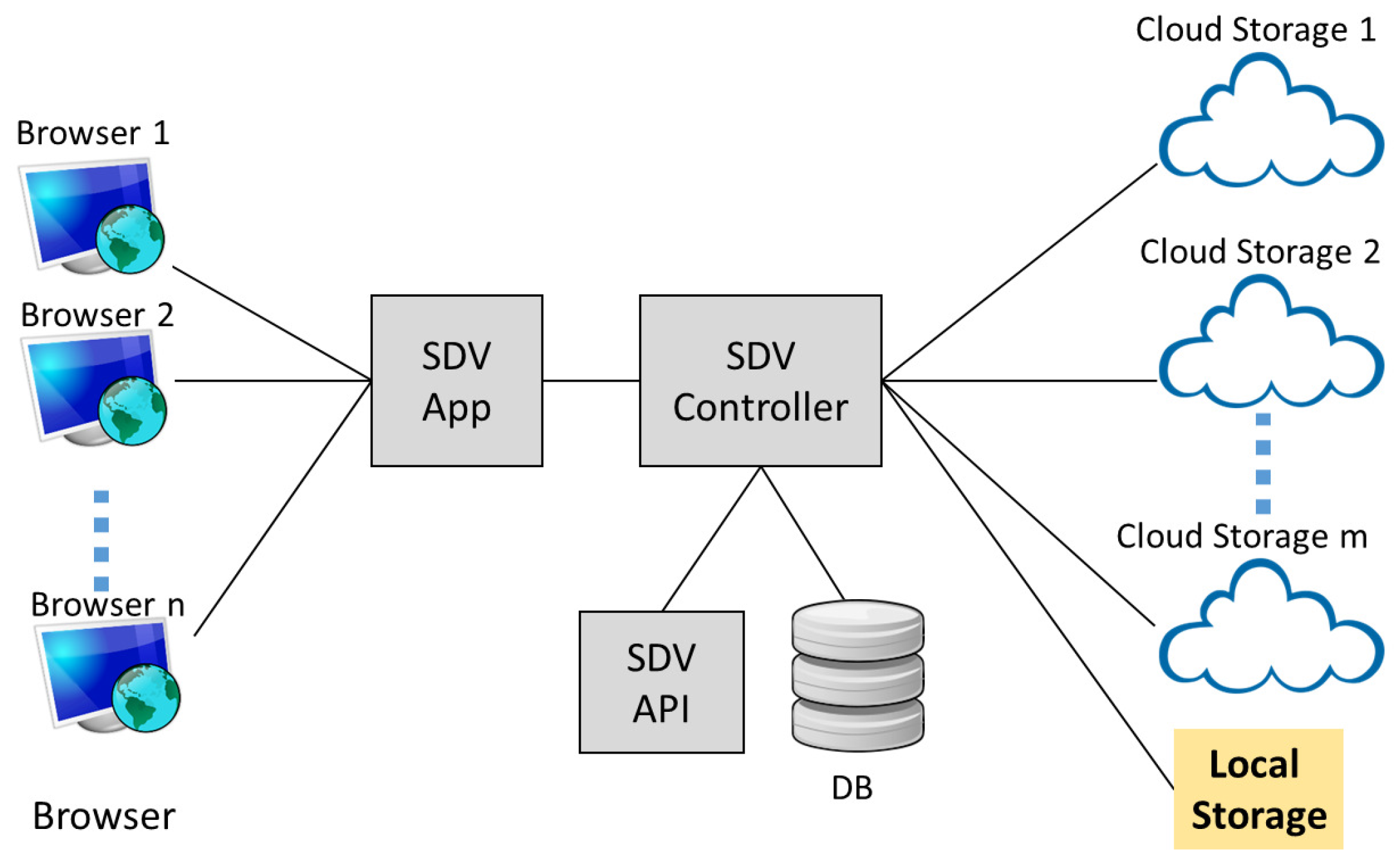
Figure 1 illustrates the architecture of SDV, which consists of three main modules that provide the mechanisms contributing to our main results:
SDV app: This module provides an interface for the SDV system to interact with the users for document upload and retrieval. In our deployment, it is also integrated with a unified authentication platform [
4] for the purpose of user registration and authentication.
SDV controller: This module maintains a database that contains credentials of users and cloud servers. It also creates a query index table, and manages the submission and retrieval of encrypted documents.
SDV API: This module contains an implementation of our multi-server SSE scheme. The scheme divides and encrypts blocks of documents, and generates index entries for query purposes.
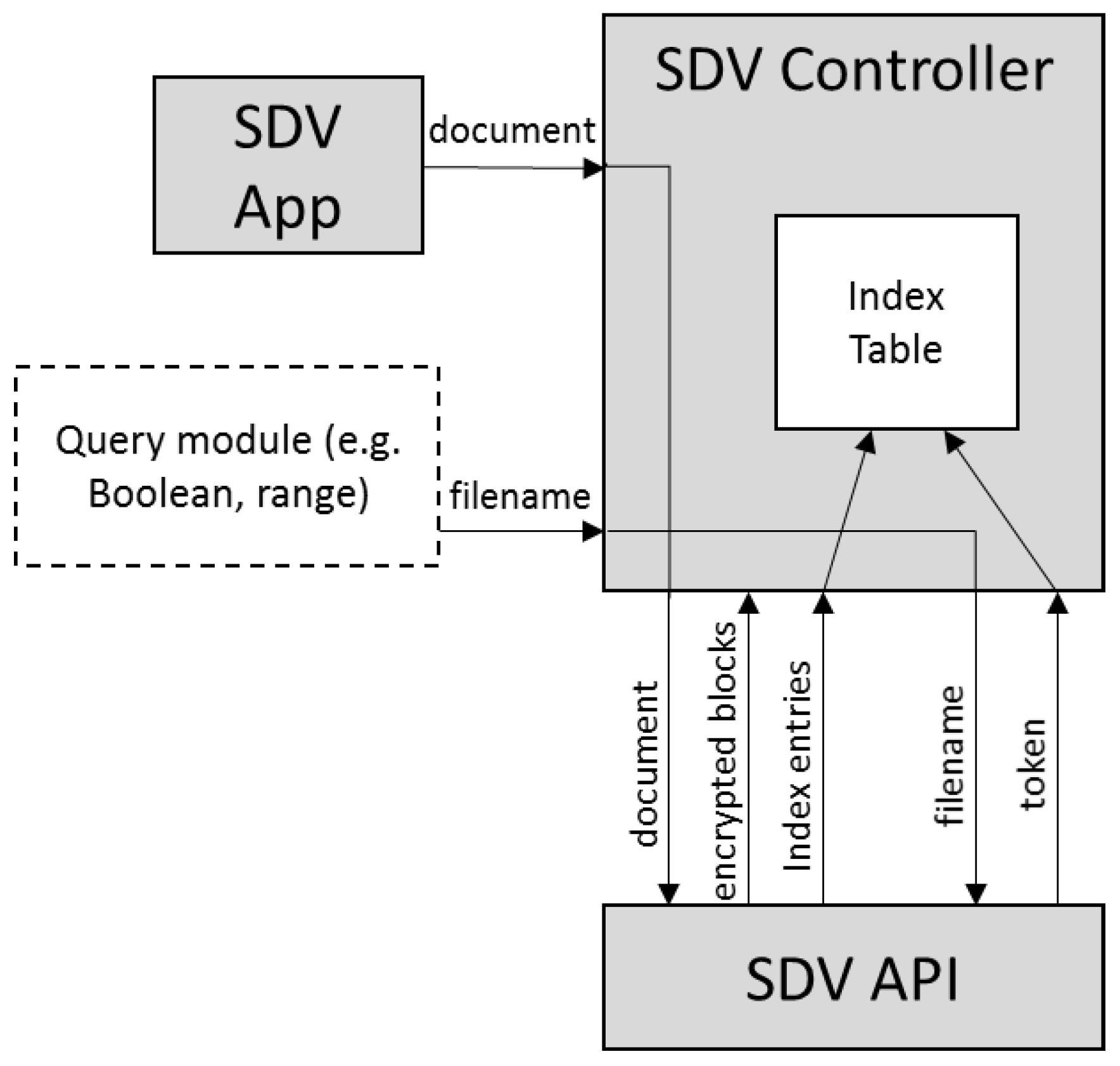
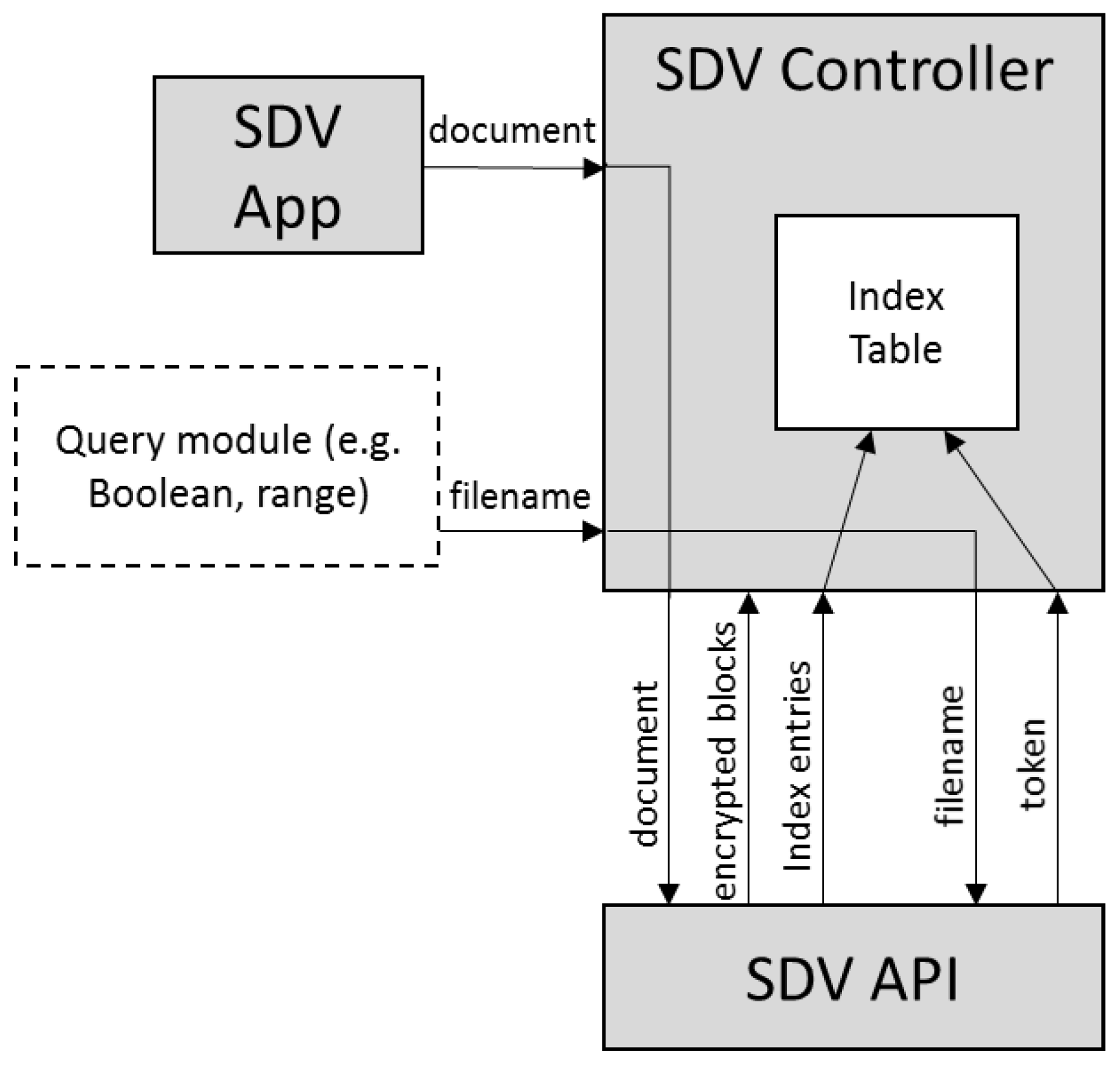
Figure 2 further illustrates our modular approach in designing the SDV controller, so that the underlying searchable encryption scheme can be replaced without too much modification in the system, as well as providing flexible extension to various search functionalities. The idea is to obtain only the index entries from the searchable encryption scheme. Creation of the query index table is done at the SDV controller, instead of the common approach of creating the index table by the SSE scheme. As for search functionalities, our intuition is to maintain a basic query index table with filename as the keyword token. This token links to the encrypted blocks and the servers that store these blocks. By doing so, query module based on information retrieval techniques, or expressive searchable encryption mechanisms, for example in [
5,
6] can be customized to return filenames matching the query keywords. These filenames can then be passed to the basic index table for document retrieval. We discuss our multi-server SSE scheme utilizing the filename as a keyword in
Section 4.
3. Definition
The main engine of SDV is a multi-server SSE scheme in the SDV API. In this section, we provide definition of such schemes as defined in [
3], and present our scheme in the subsequent section.
3.1. Notations
Table 1 provides notations used to describe the definition, and the proposed SSE scheme.
3.2. Multi-Server SSE Scheme
A multi-server SSE scheme consists of three algorithms, namely Setup, Search and Update.
We note that this is similar to a single server SSE scheme, for example, as proposed in [
19,
23,
26]. The only difference is the process of division/combination of documents and distribution over multiple storage servers within each algorithm.
Setup. The algorithm partitions a document into a list of blocks B and then encrypts and assigns an identifier and storage location to every block. Input to this algorithm is the set of documents D and a keyword index table which map each document to a list of keywords. Output of this algorithm is a set of cryptographic keys K to be stored securely by the user, index I and sets of encrypted blocks C.
Search. This is an interactive protocol initiated by the user which involves the storage servers. The user provides a keyword as input. The protocol takes the cryptographic keys K generated from Setup to produce a search token . The token is used to extract the list of blocks and their locations from the index I. Next, the listed blocks are retrieved from the respective storage servers and returned to the user. Finally, the user decrypts the encrypted blocks and reconstructs the documents.
Update. This is the algorithm for adding (Doc+) or removing (Doc-) documents in the storage servers. The input to the algorithm is an object (e.g., a document ), and the operation to be executed on the object. Output of this algorithm is an updated index, and a set of encrypted blocks (for document addition). It can also be extended for adding or removing storage servers from the system.
The scheme is correct if for any set of documents and a keyword index table, the set of index entries and encrypted documents (or blocks) resulting from Setup and Update would consequently allow Search to identify documents associated to the searched keyword exactly as listed in the initial keyword index table.
3.3. Security Model
An SSE scheme aims to protect confidentiality of documents being stored in the storage servers, including the keywords of the documents. Consequently, the entries of the index and search token must be protected so that no information about the stored documents is revealed. Nevertheless some information leak is inevitable for
Search to be efficient. This characteristic of the scheme is called the leakage profile as was first formalized in [
19]. The leakage profile normally consists of the following three functions.
is information the server obtained by looking at the encrypted objects and index, such as the block size.
is the information gathered by the server in observing messages in the Search protocol, such as the number of blocks associated to the input search token.
is the information disclosed to server by the changes to index and set of encrypted objects on the server, including number of keywords of each added or removed object.
Definition 1. A multi-server SSE scheme with leakage profile = (,,) is said to be -secure against non-adaptive attack by colluding servers, if for any adversary there exists a simulator such that:where the Real and Ideal games are defined as follows: Real The adversary chooses a set of documents D, a keyword index table, a set of servers S and a sequence of search and update queries, and submits them to the challenger. The challenger then runs Setup with the given input documents and keyword index table. Then the challenger runs Search on the sequence of search and update queries. All the responses are returned to . Finally, outputs a bit.
Ideal The adversary chooses a set of documents D, a keyword index table, a set of servers S and a sequence of search and update queries, and submits them to the challenger. The challenger gives the simulator the leakage ,, resulting from the given input. The result of the setup, search and update simulation is returned to . Finally, outputs a bit.
For Definition 1, colluding servers means that storage servers share their leakage profile and other information gathered from the execution of the system among themselves. We further remark that for our proposed scheme in the following section (a simplified version compared to the proposal in [
3]), the only keyword for each document is its filename and thus there is no keyword index table required, as in the above definition. This provides flexibility to include desired search functionalities (e.g., Boolean, conjunctive) on top of the filename search in our proposed scheme.
4. A Multi-Server SSE Scheme
Now, we describe our scheme implemented in the SDV API.
Figure 3 provides detailed steps of the scheme. The scheme consists of three functions. There is a
Setup algorithm, a
Search protocol and an
Update algorithm. In brief, a user submits a document and the
Setup algorithm processes it, resulting in encrypted blocks
, an index table
I, and secret keys
K that must be stored securely by the users. The index table
I stores the links between the filename, the blocks and the servers that store these blocks. In order to search for a document, a user submits a filename of a document
to the
Search protocol, which then generates a filename token
. The protocol checks the index table
I to find whether the
matches any of the entries. If yes, then the entry is retrieved. If not then it returns false. The entry contains the links from which servers all the encrypted blocks of the searched document can be retrieved. In our implementation, this entry is used by the SDV controller to retrieve the encrypted blocks, decrypt and combine them to form the document.
The Update algorithm provides for adding and removing of documents. Adding a document can be provided by using the processes in the Setup algorithm to encrypt the blocks and creating the index entry for the document. In a similar way, removing a document involves using the processes in the Search protocol to retrieve the index entry. However, instead of using the entry to retrieve the encrypted blocks, a delete command is issued to remove these blocks from the servers. We note that the mechanisms to submit and retrieve encrypted blocks are not discussed in the scheme. In our implementation we built a submit and a retrieve function in the SDV controller for this purpose.
Extension. The
Update algorithm may be extended to allow for adding or removing a storage server
. A basic approach for server addition is to add the server identifier
into the list of existing servers
S. The existing storage arrangements and index table
I will not be modified. The new server
is involved for storing encrypted blocks only when a new document is submitted. It is a bit more complicated for removing a server, since it involves all the encrypted blocks stored in the server. A simplest approach is to retrieve all blocks from the server, and runs
Setup to redistribute these blocks. Nevertheless, the index table
I must be updated by removing all the entries to the server beforehand. This was also discussed in [
3].
Expressive Search. The
Setup algorithm generates index entries that can be queried based on filename,
. These entries are passed to the SDV controller to create an index table
I, as was previously discussed in
Figure 1 and
Figure 2. While a query based only on filename seems to be a limitation, there are two main benefits in our consideration of using such an approach. Firstly, users normally send and view their documents to and from a cloud storage in a folder mode, by browsing through the documents. This fits well with the query by filename approach. Secondly, and more importantly, by using such an index entry setting, it is thus possible to create a two-level query index. The base level index provides query on filename that pulls the documents from the cloud storage as was presented in our scheme. An upper level index can then be created to allow for any type of expressive search (e.g., range, substring, Boolean, conjunctive) based on keywords that return filenames.
Security Analysis
By referring to Definition 1 and the description of the scheme in
Figure 3, we say that
SSE is
-secure against non-adaptive keyword attack by colluding servers, if the underlying pseudorandom function
F and the symmetric encryption scheme
is IND-CPA-secure. In the following, we define the leakage profiles
based on an adversary
who controls all storage servers. This means the adversary sees leakages from all storage servers involved in the system.
: For setup, the information leaked to the adversary is the number of blocks of a server and the block size of the encrypted blocks, where the block size is denoted as b. A fixed block size means the storage servers cannot even study the difference in size of the encrypted blocks to learn which document a block belongs to. However, in our current implementation, we use a range of different block sizes so that it is efficient in generating the index entries and submission of encrypted blocks of large documents. This means the storage servers learn different sizes of encrypted blocks.
: For search, the adversary learns the number of encrypted blocks associated to the input keyword token. This is because the SDV controller sends retrieval requests to the cloud storage servers to retrieve encrypted blocks of a document. Here, we denote the number of retrieved encrypted blocks as .
: Adding and removing a document includes submitting the encrypted blocks, or removing the encrypted blocks of a document from the cloud storage servers. Thus, the leakage is similar to , where the adversary learns the number of encrypted blocks associated to the document.
Given the above leakage, we now define the game and how to construct a simulator, . In a game for non-adaptive adversary, the adversary submits its sequence of queries to the challenger all at once. The sequence must begin with input for setup, and subsequent queries are search query, add document query or remove document query.
For any adversary , consider the simulator defined below. From = (, b), generates random binary strings with length b. These random strings becomes ’s set of unnamed blocks.
Then, by referring to search queries, is given = . checks whether the queried block identifiers exists in its set of labeled blocks. If the identifiers have not been used, chooses unnamed blocks and labels them with the block identifiers submitted by the SDV controller.
Similarly, refers to file removal queries and use = . If there is no encrypted block labeled with the list of block identifiers to be deleted from storage, chooses unnamed encrypted blocks and labels them accordingly.
For file addition queries with given = , generates binary strings of length b and labels them with the submitted block identifiers.
Finally, labels all other unnamed encrypted blocks with random binary string of length identical to the length of the block identifiers. Since the encryption scheme used in the SDV is IND-CPA, the random binary strings generated by are indistinguishable from the encrypted blocks generated by the SDV scheme. Thus, using the set of labeled blocks, the transcript for the query sequence produced by is indistinguishable from the transcript produced by the SDV scheme.
We note that the above security analysis is based on the assumption that the SDV controller resides on a trusted query gateway (proxy server). This means the index table I is stored at the gateway and thus leakage due to index is not factored in. In the case where the query gateway is assumed to be semi-honest (honest-but-curious), then the leakage profile of the index table must be considered. It means leakage of even before queries, compared to the above analysis where this leakage happens only after queries. We further remark that, if an additional query module with more expressive search is deployed, the leakage due to keywords, instead of just leakage due to filename, on the overall SDV system will be at least the leakage profile of the deployed query module.
5. Implementation
In this section, we describe in detail the implementation of the SDV prototype, as well as its performance evaluation. The SDV controller is implemented using Java Servlet on Apache Tomcat version 8. It is hosted in a virtual machine under MIMOS cloud platform. The virtual machine runs on Ubuntu 14.04 as the operating system, with 4GB memory. The SDV API with the implementation of the multi-server SSE scheme, SSE, is developed using Java and C++. The web interface for the SDV App, on the other hand, is based on JSP. MySQL is deployed as the underlying database. We incorporated a local storage server and Google drive as the cloud storage servers for our current deployment. We note that the number of servers is configurable.
5.1. Cryptograhic Building Blocks
We make use of the Advanced Encryption Standard in counter mode (AES-128-CTR) for encryption and decryption, a message authentication code based on SHA256 (HMAC-SHA256) for generating the keyword token, and hash function SHA256 for creating block identifiers.
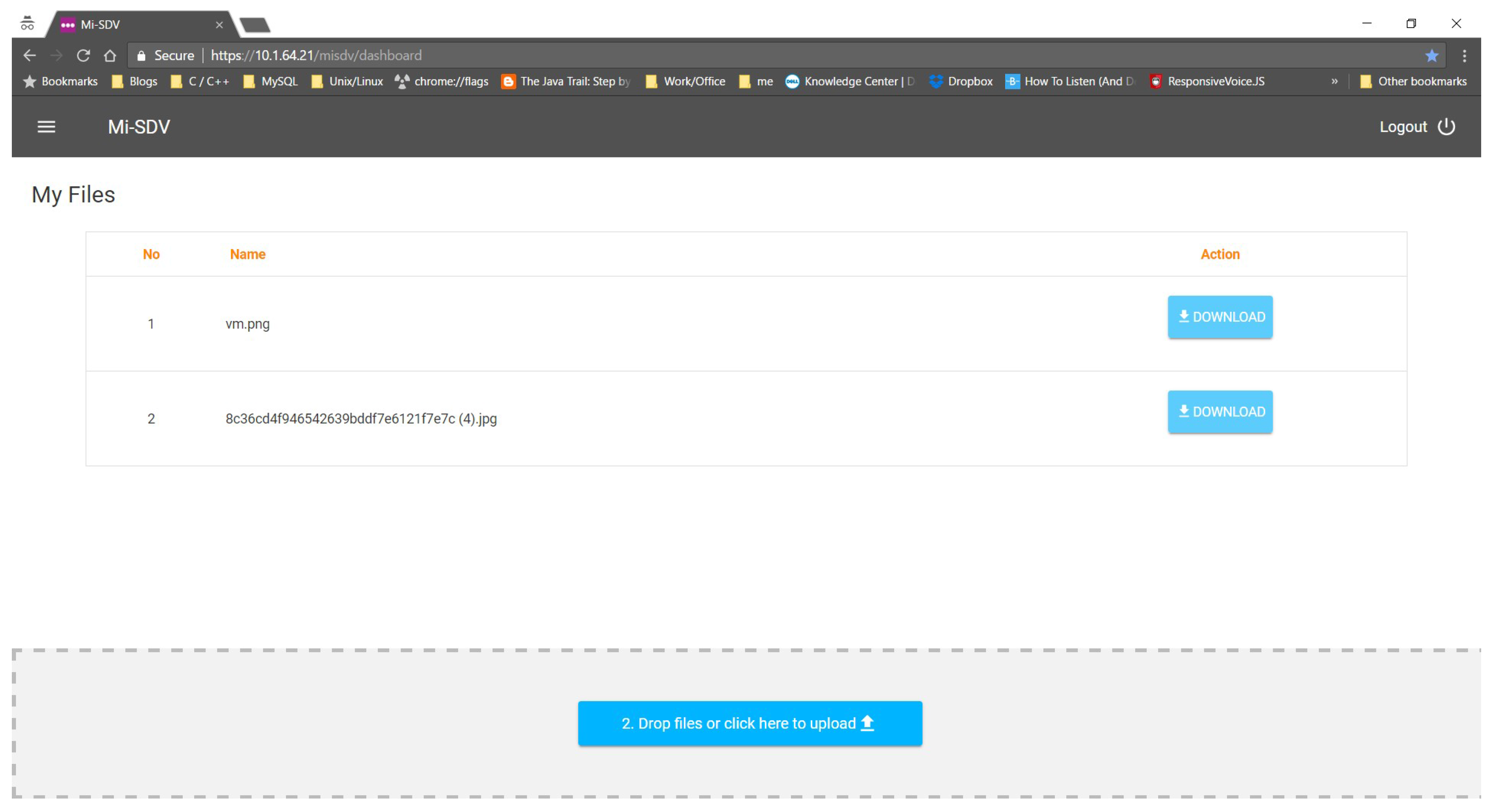
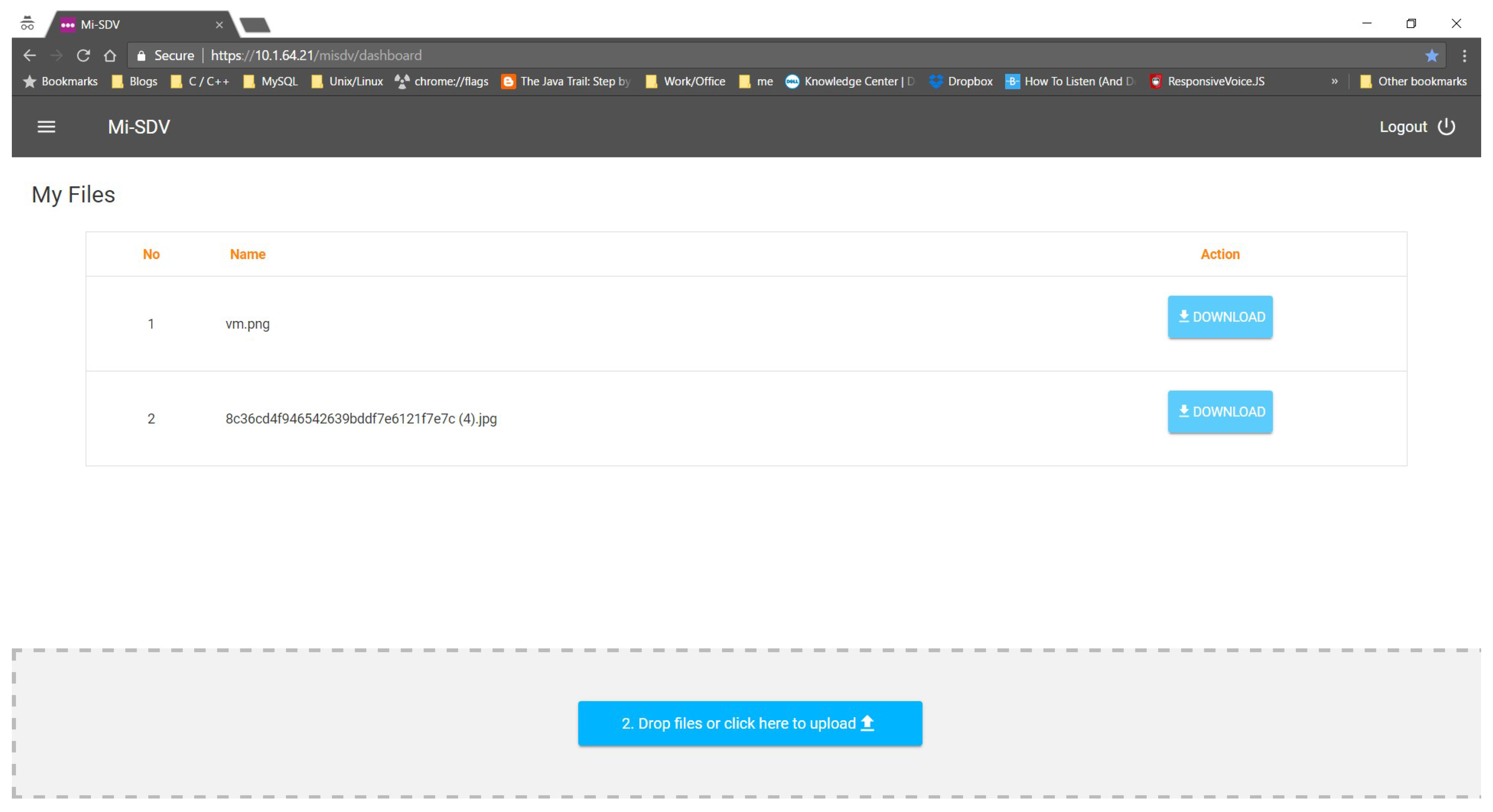
5.2. Main User Interface
Figure 4 shows the main interface for submitting and retrieving encrypted documents under the SDV system. A user uploads a document through drag-and-drop to the area at the bottom of the page, or click on the button, which pops up a document selection window. Uploaded (or submitted) documents are shown in a list, with a download button for each document being shown on the far right of the filename. Currently the SDV system prototype with this interface is integrated into the MIMOS internal workflow system as a test environment, in which the SDV dashboard is only accessible once the user is authenticated through a unified authentication platform [
4].
5.3. Submitting a Document
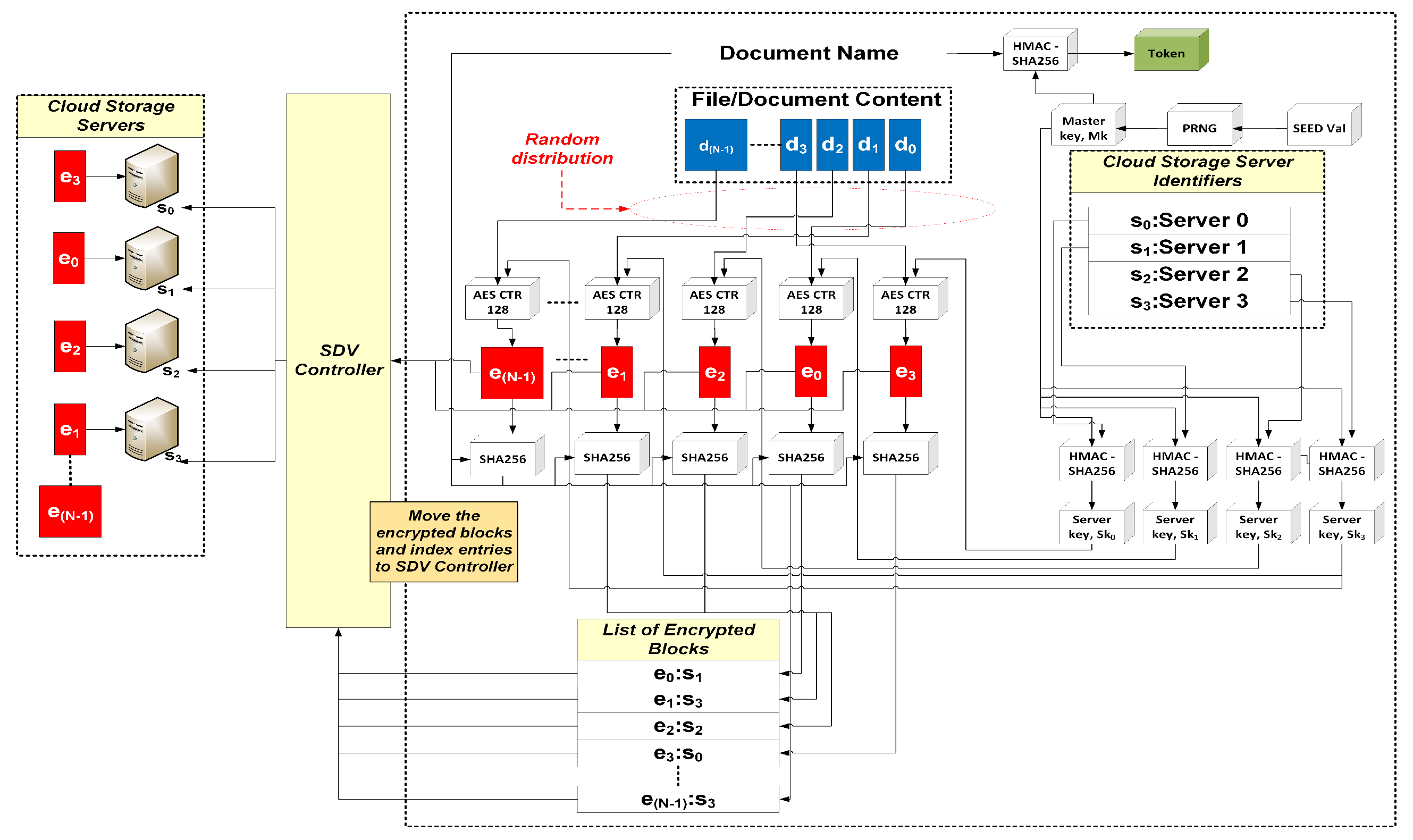
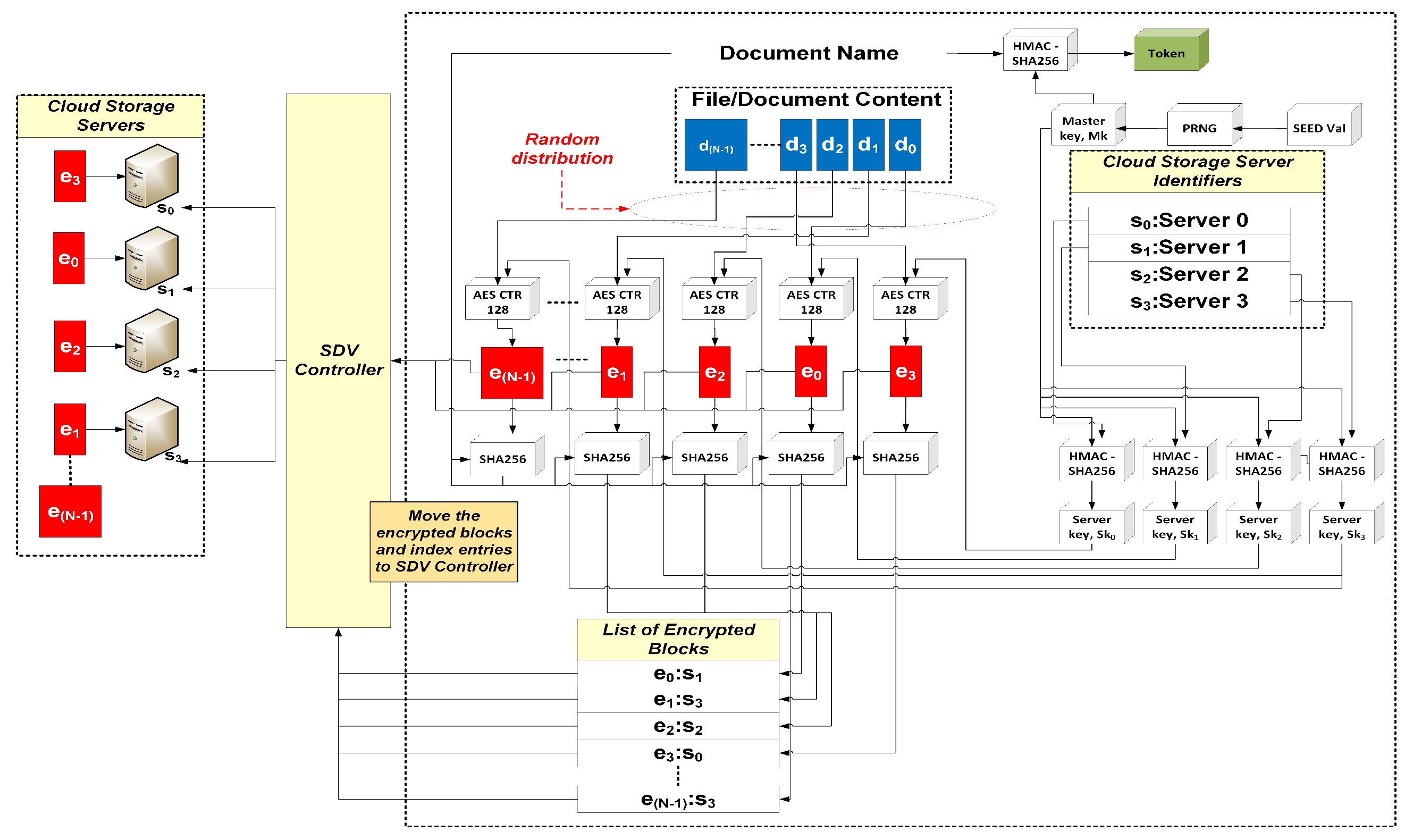
Figure 5 illustrates the details of the operations conducted by the SDV API for document submission. During
Setup, a master key is generated using a pseudorandom number generator (PRNG) and a random seed value. This master key is used to derive the server keys for the cloud storage servers. Server keys are derived using HMAC-SHA256 and the master key, with the server identifiers as inputs. When a document is sent in via the SDV App, the API divides them into blocks. The block size is a user configurable parameter, e.g., a 100 MB file is divided into 100 blocks if the block size configured is 1 MB per block.
As mentioned previously, for our prototype only the filename acts as the keyword token. This token is generated through HMAC-SHA256 using the master key and the filename as input. Once the document is divided, every block is randomly assigned to one of the available storage servers. The assignment information is recorded as part of the index entry. The assigned block is then encrypted with the corresponding server key. Finally, the encrypted blocks and the index entry are sent to the SDV controller, which then proceed to process and upload the encrypted blocks to the designated cloud storage servers. All encrypted blocks will then be hashed with SHA256 to produce the block identifier, which will be used in the index to locate the block during retrieval. As an example,
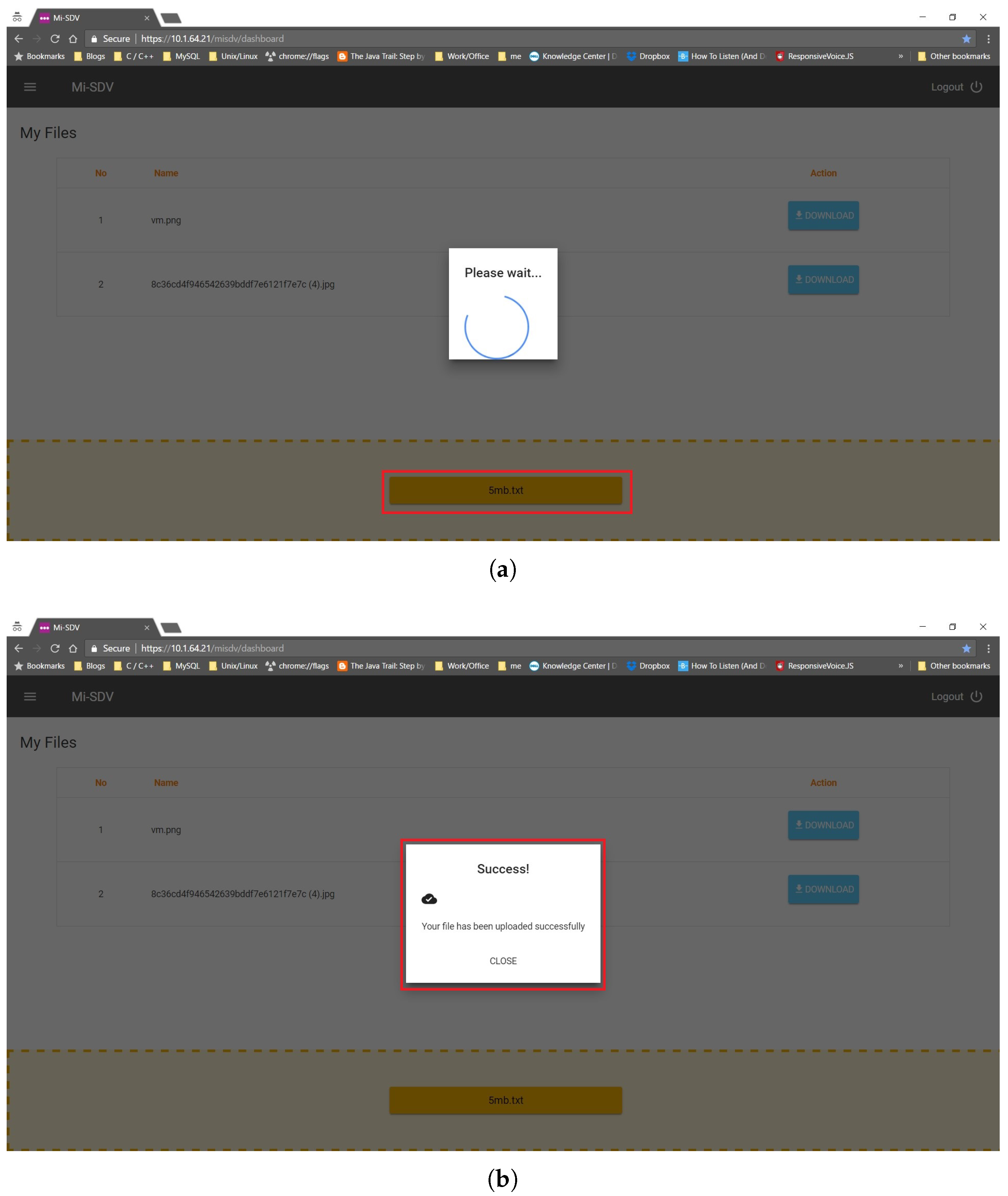
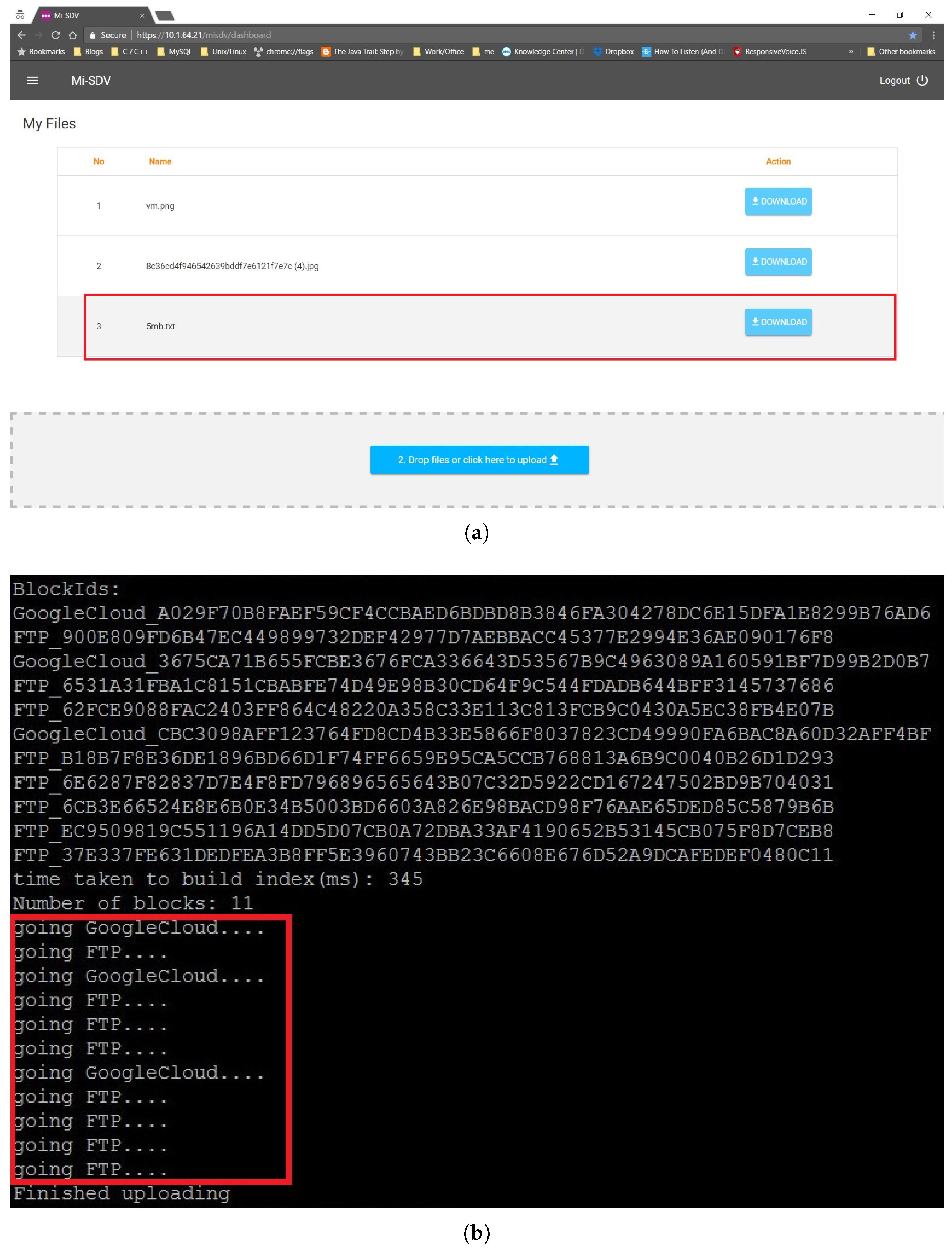
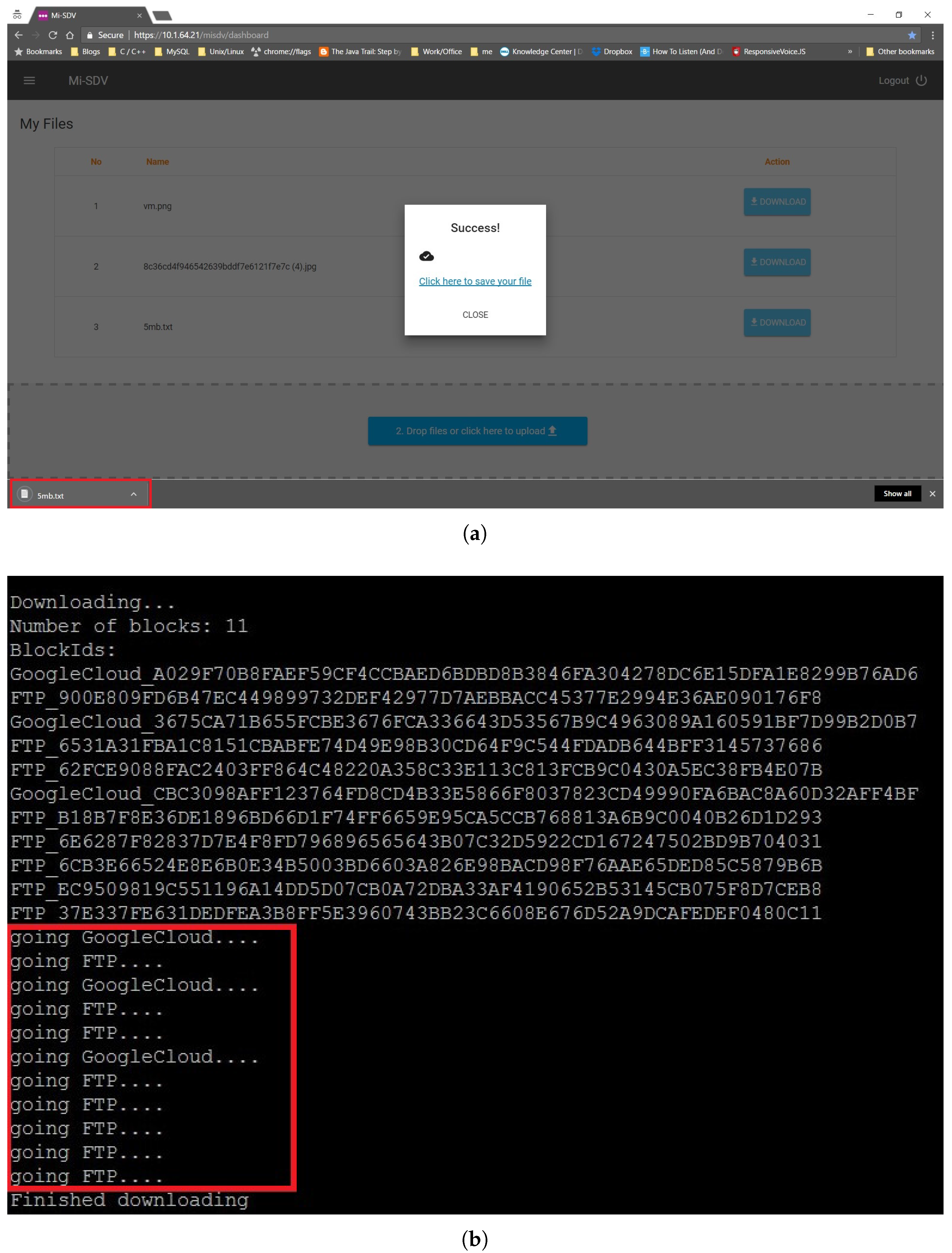
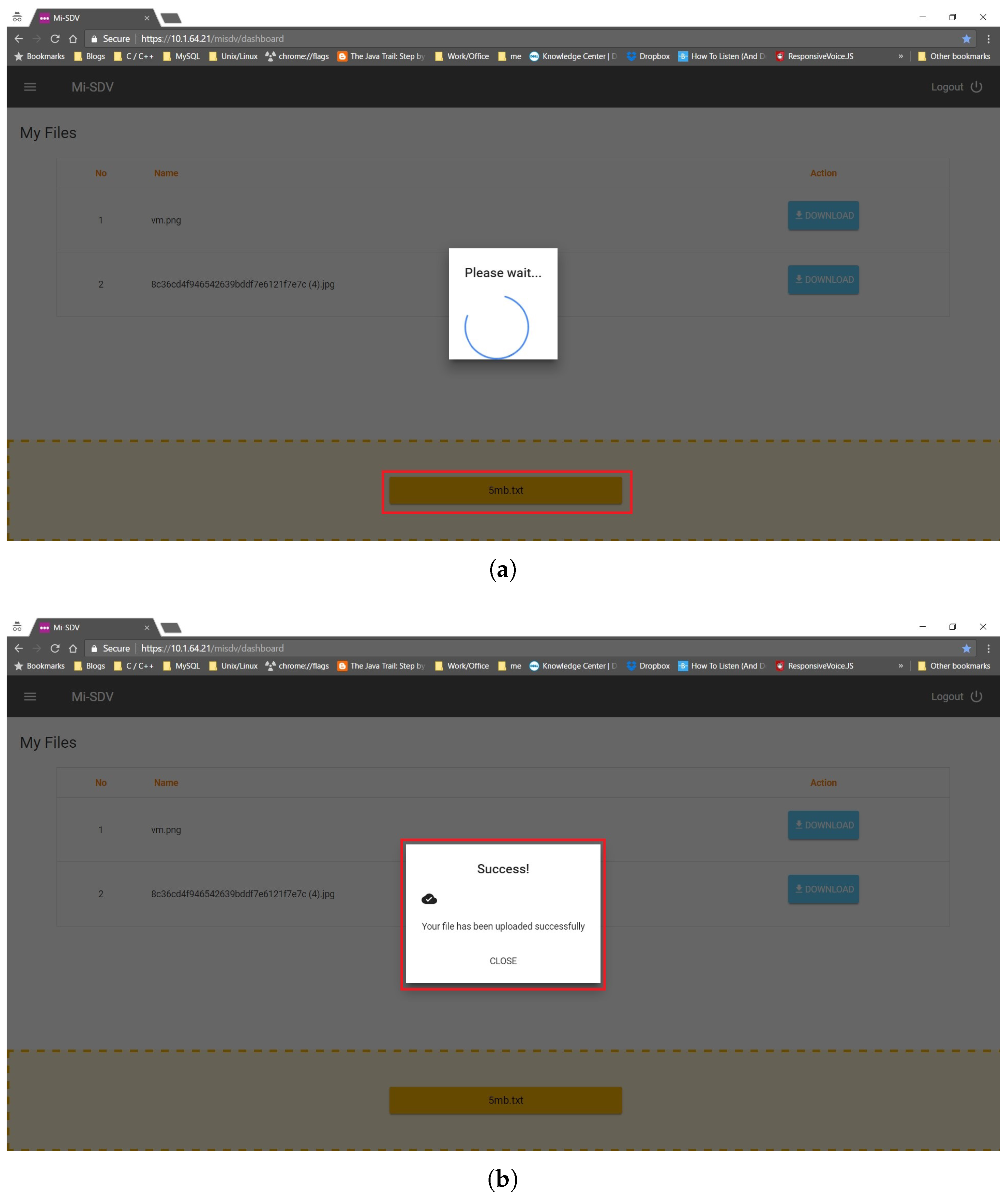
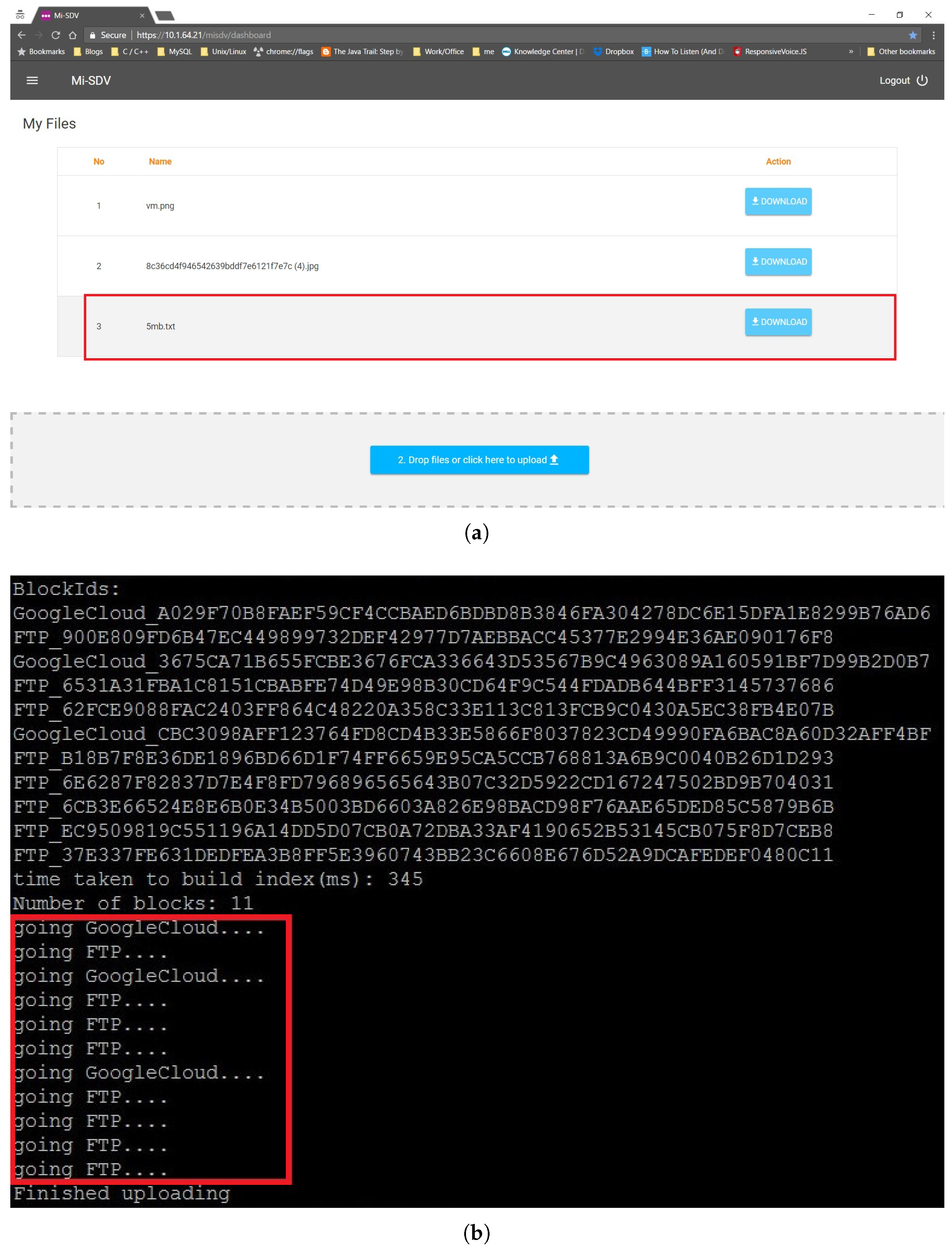
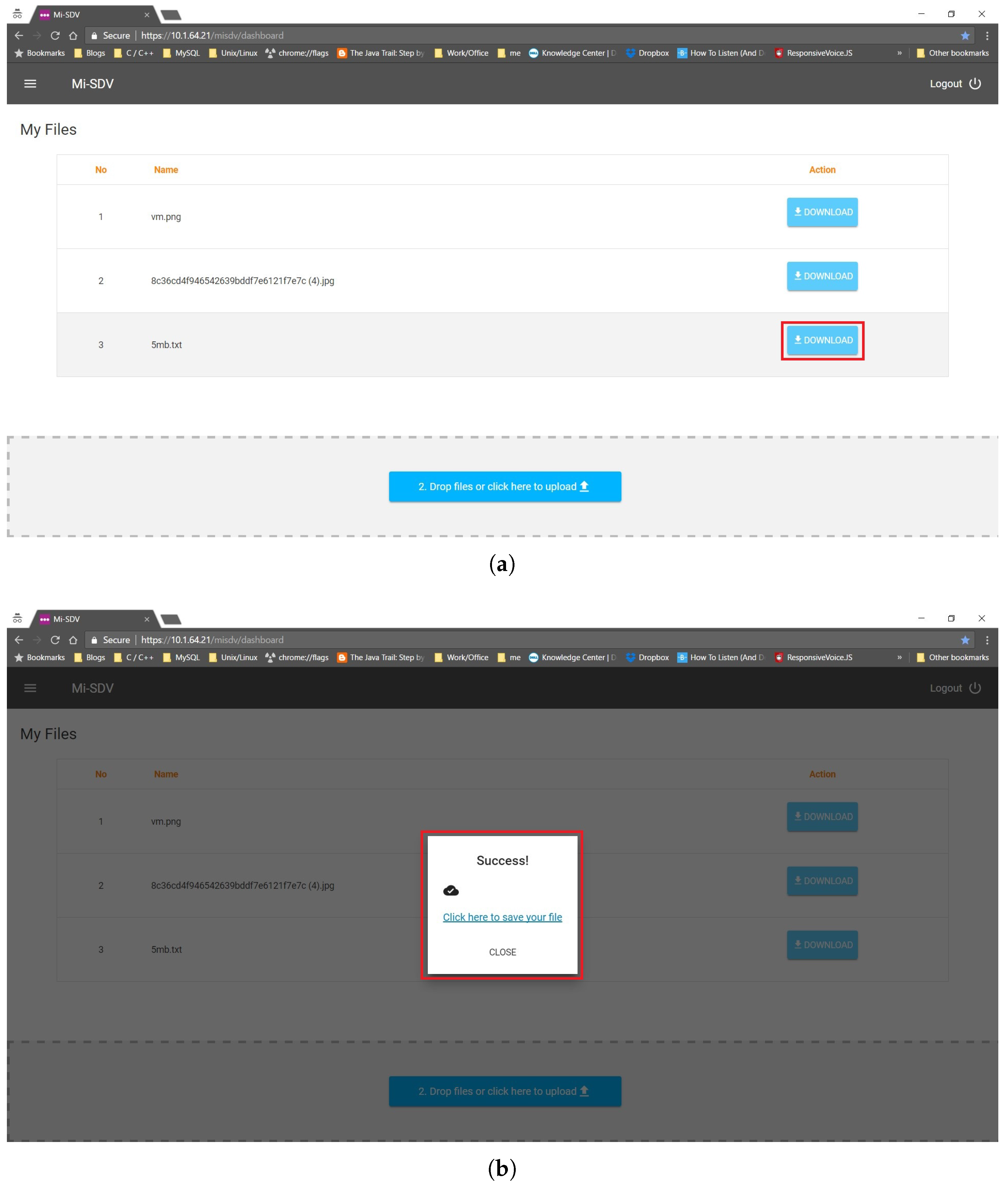
Figure 6 and
Figure 7 present the execution steps of submitting a 5 MB file to Google Drive and a local storage server. The file is listed (
Figure 7a) once it is successfully uploaded (
Figure 6b). The submissions to Google drive and a local server through the SDV controller are shown in
Figure 7b.
5.4. Searching and Retrieving a Document
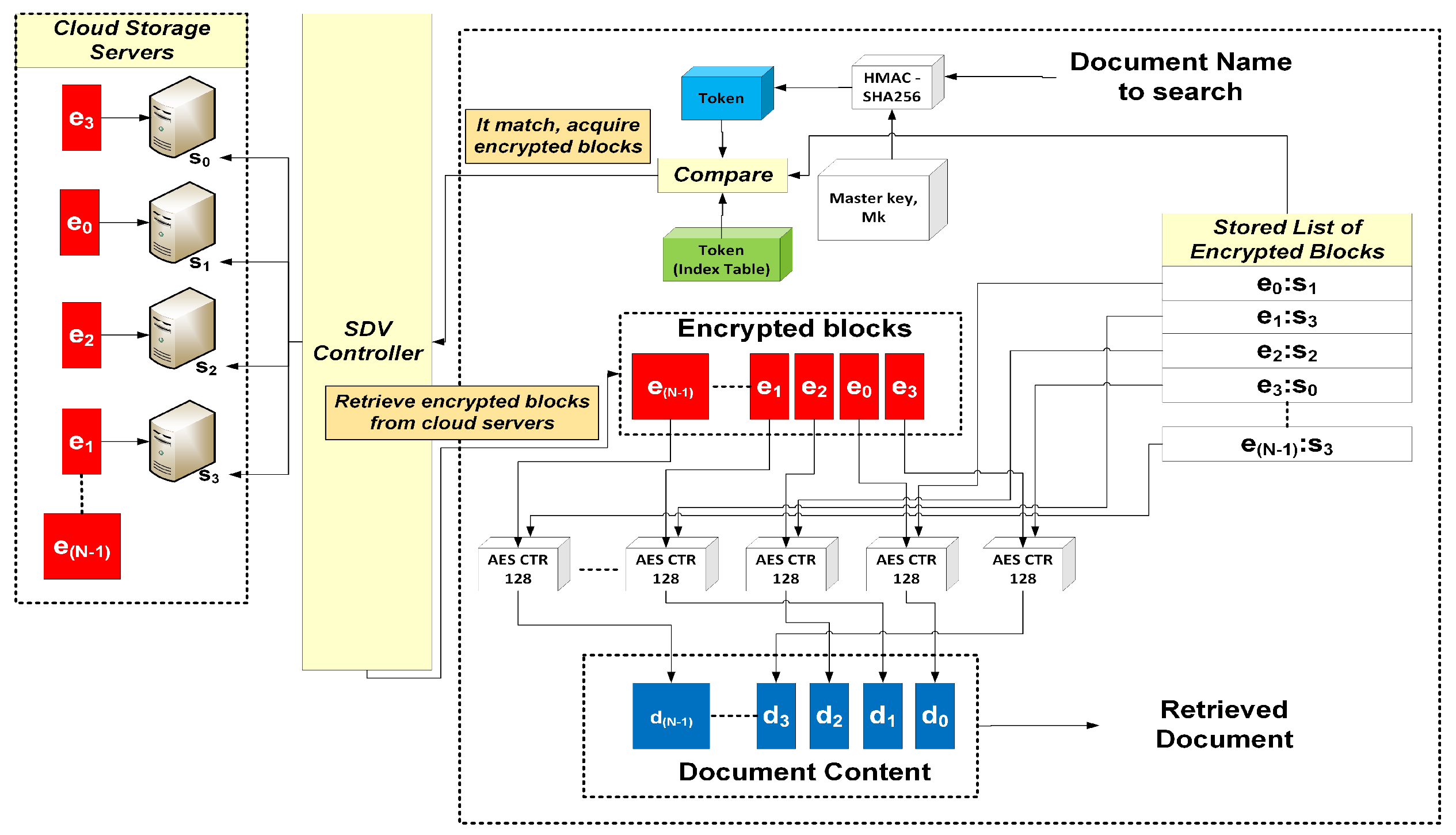
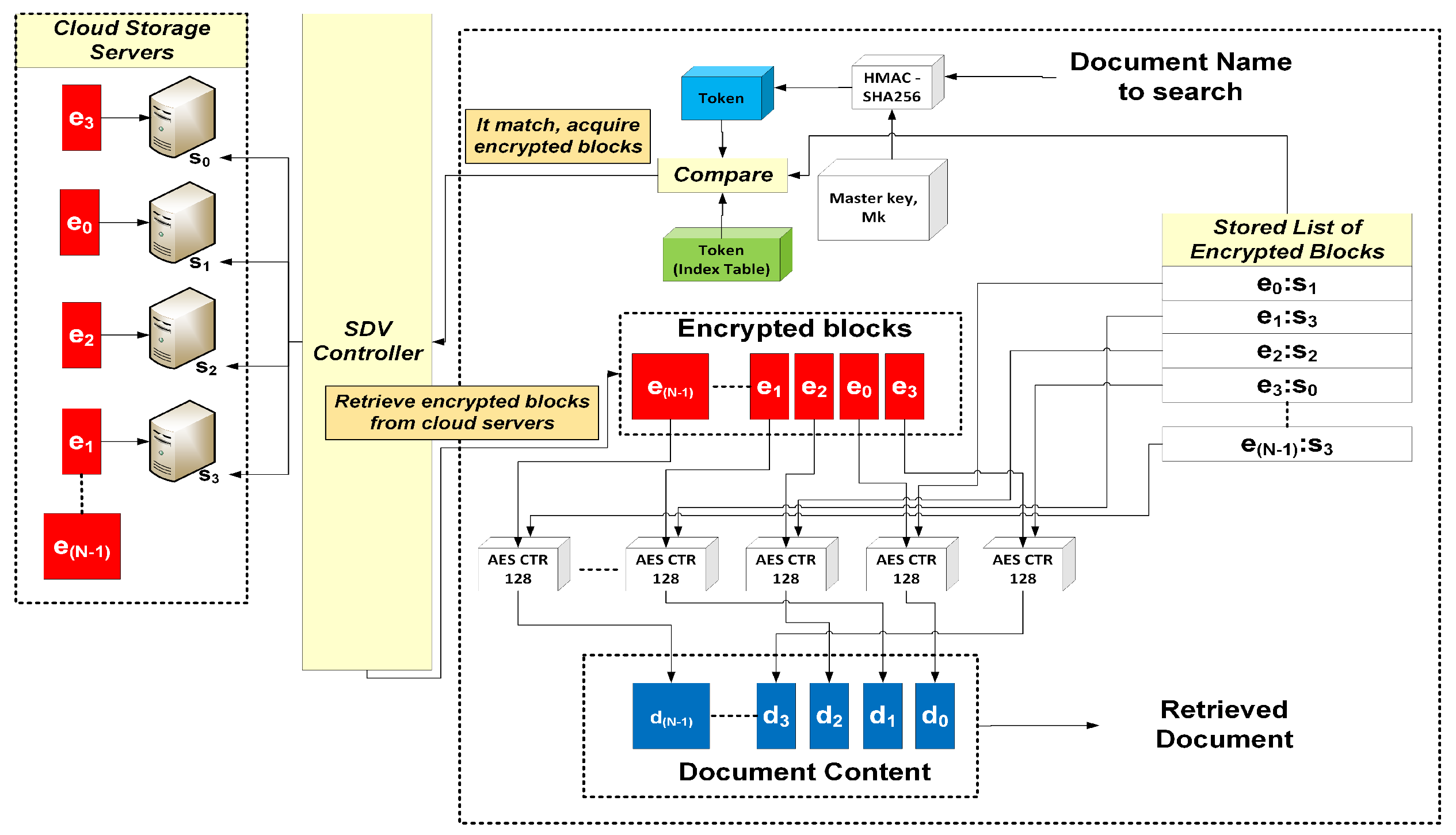
The user chooses the document to be retrieved through the SDV App. The filename is forwarded to the API via the SDV controller, where a keyword token is then generated and compared through the index table to check if the uploaded file exists. If a match is found, the block identifiers and corresponding servers where they are located are retrieved. The SDV controller retrieves the encrypted blocks from their servers and instructs the SDV API to decrypt these blocks with the corresponding server keys. The decrypted blocks are reassembled into the document with the filename chosen by the user. Details of file retrieval are likewise illustrated in
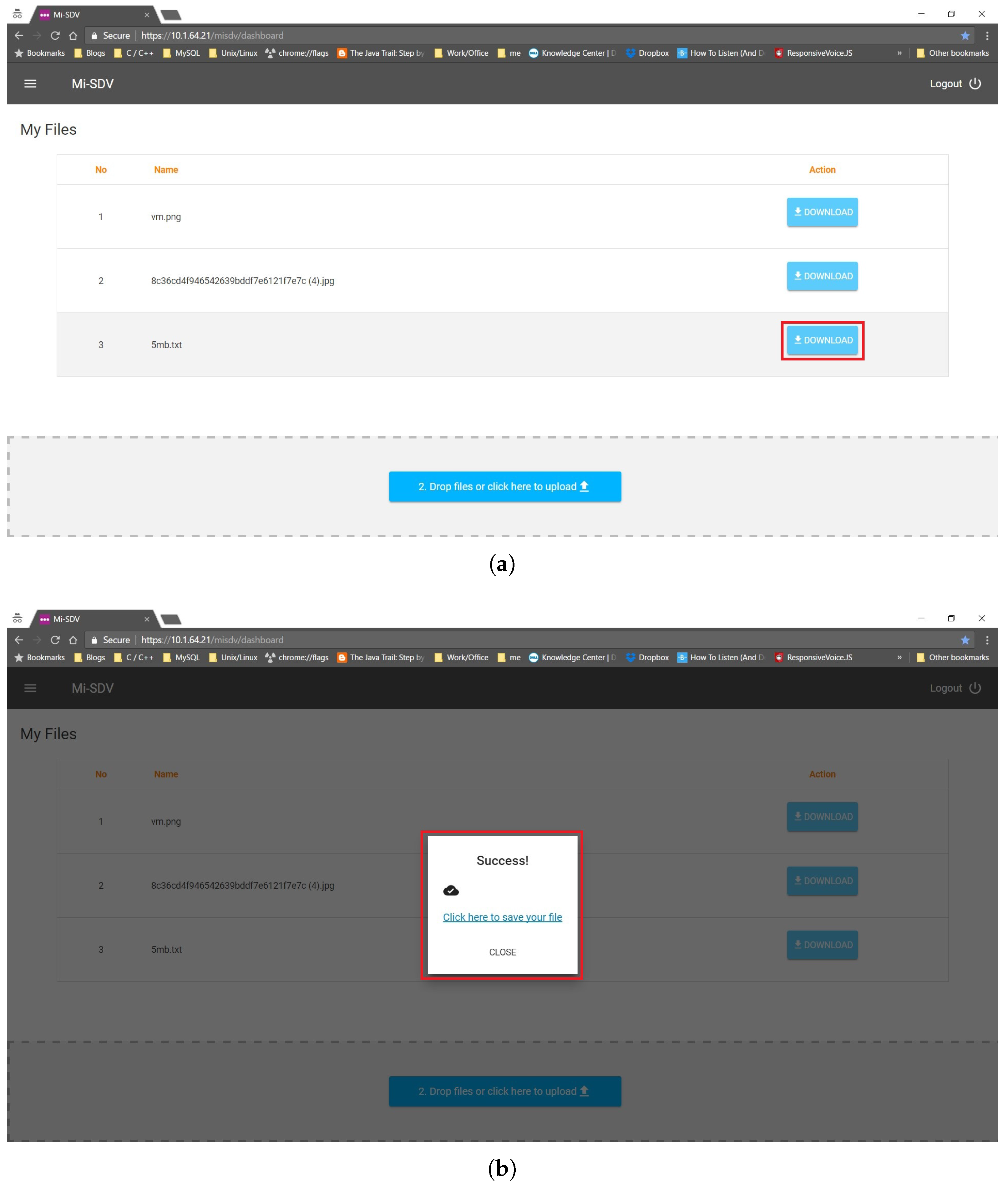
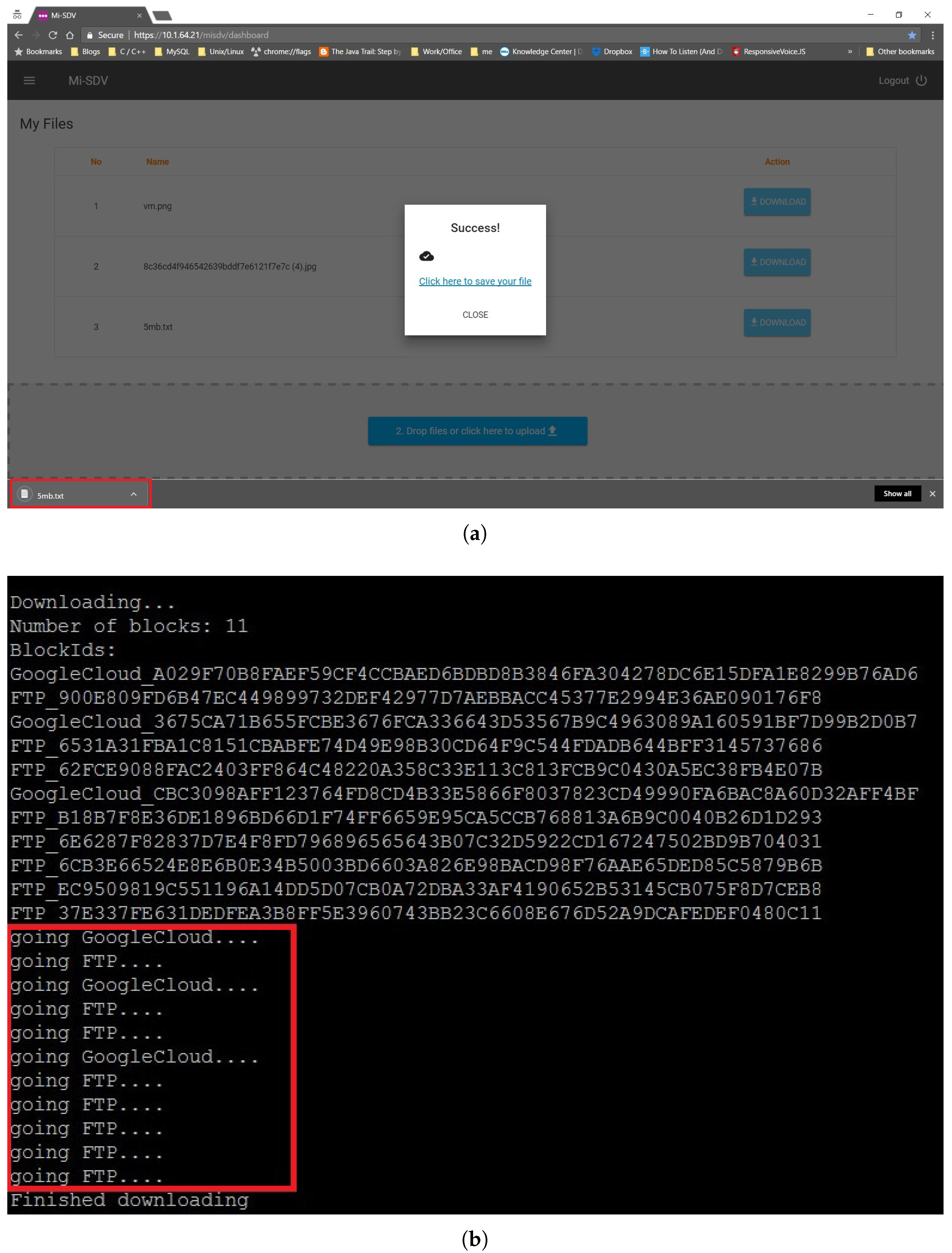
Figure 8, while the steps for downloading a file are presented in
Figure 9 and
Figure 10.
5.5. Performance
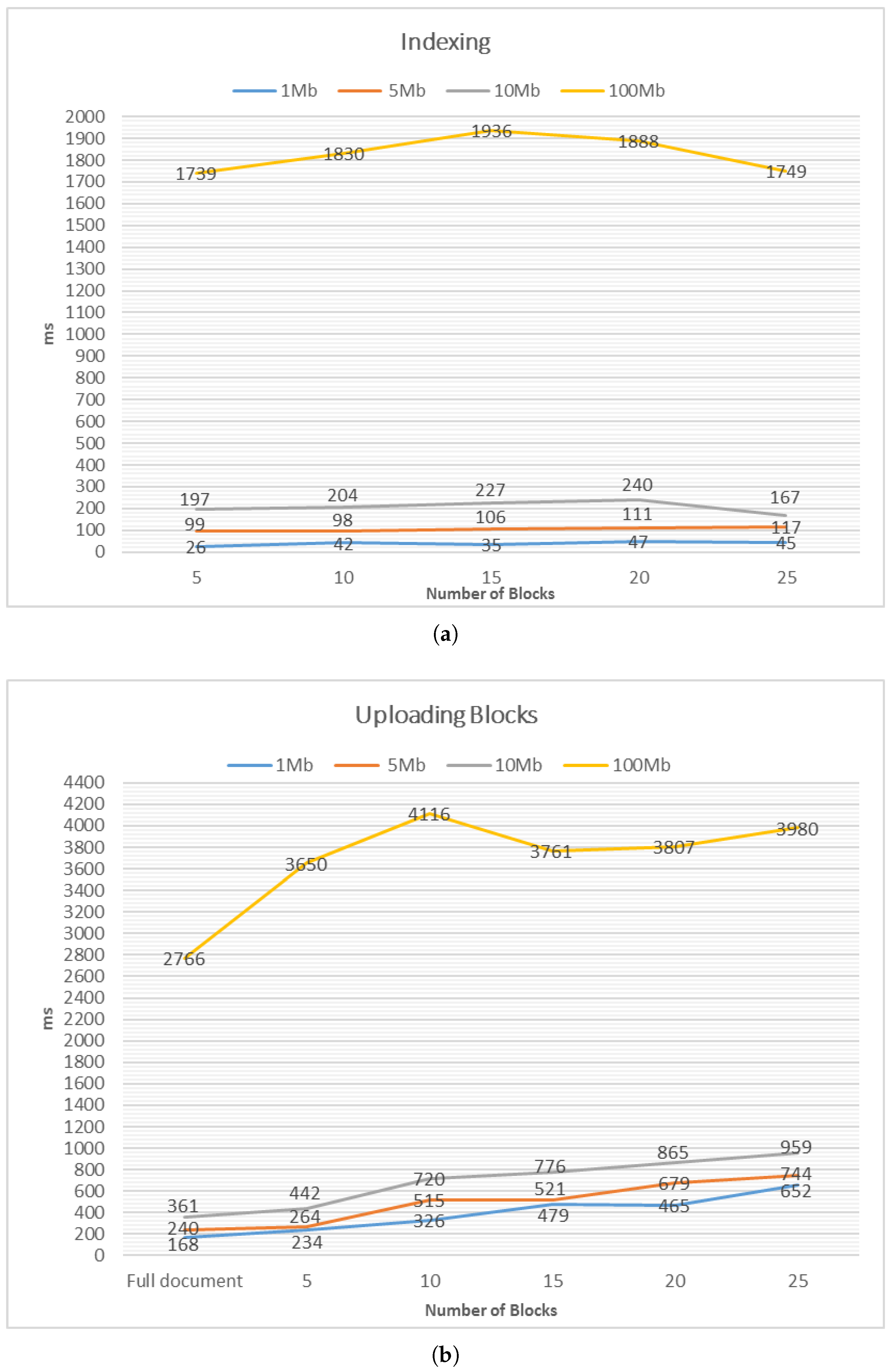
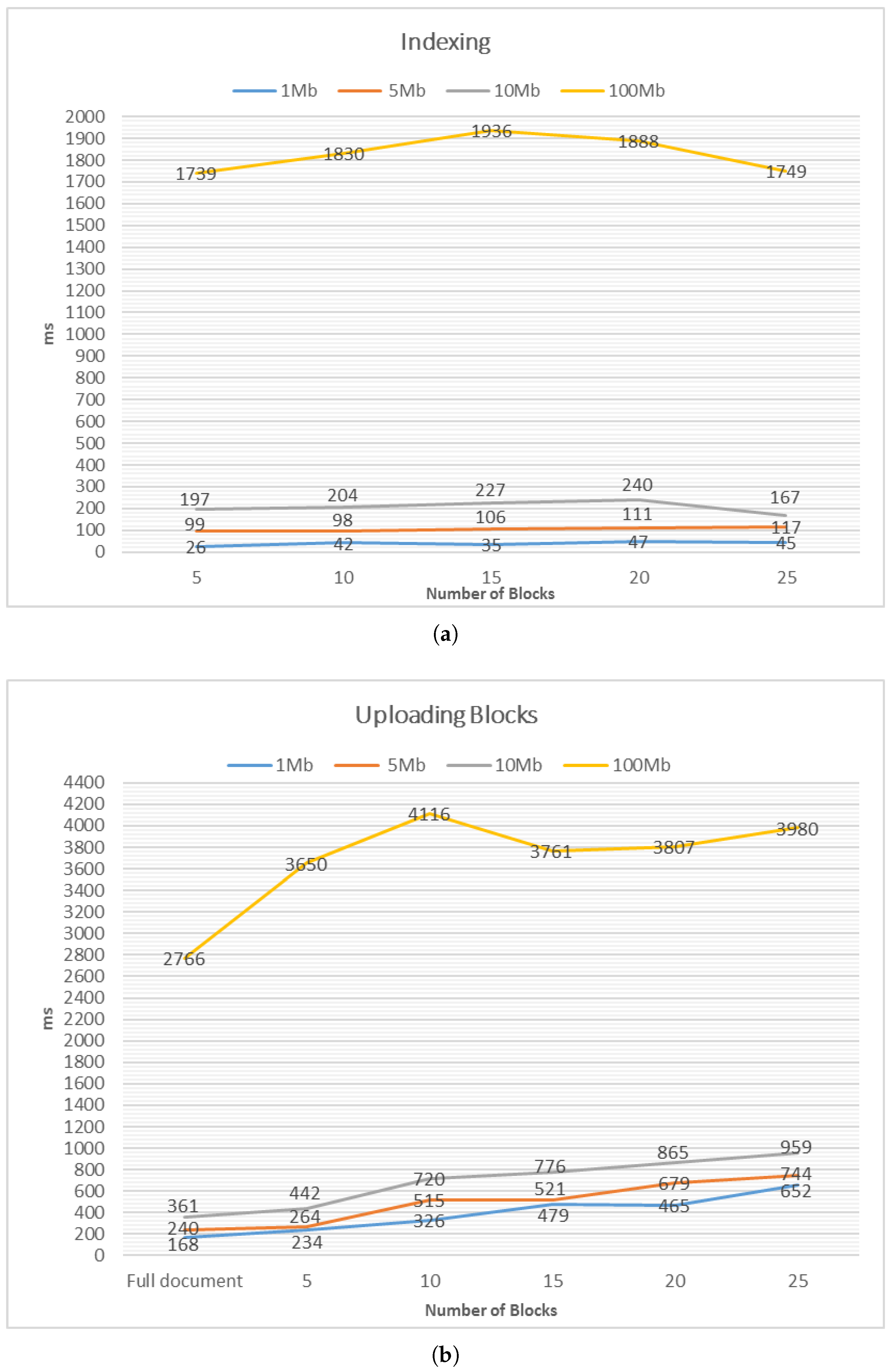
For performance, we measure the computation time for building the index table (
Figure 11a) and for uploading the encrypted blocks (
Figure 11b), as compared to directly uploading the original document unencrypted. This gives us the computation overhead due to the SDV system, and how practical it is. The uploading process is simulated by submitting blocks and documents through a FTP server, so that we do not have to take into account Internet connection delays. However, we note that the current deployed prototype does distribute encrypted blocks to both local storage and third-party cloud servers (i.e., Google Drive) and can be configured to add more servers. We divided a document into 5, 10, 15, 20, or 25 blocks, and applied them to four different text documents with increasing file sizes: 1 MB, 5 MB, 10 MB and 100 MB.
Table 2 shows the test data for 5 blocks and 25 blocks, while the detailed results are displayed in the graphs in
Figure 11. The time measured is in milliseconds (ms).
From
Figure 11a, we may summarize that computation time of index generation grows linearly with the size of the document, which is an expected behavior. However, the number of blocks seems to have a marginal effect on computation to generating indexes, at least in the range of 5–25 blocks. In contrast, the number of blocks affects the efficiency of uploading a document to the storage server, as can be observed in
Figure 11b, where “Full document” denotes an original unencrypted document. Given the time required grows linearly with the number of blocks when uploading these blocks, a smaller number of blocks per document is desirable. However, there is a question as to whether such a configuration leaks more information as compared to having a large number of blocks.
On the other hand, if we fix the block size, then the number of blocks grows linearly with the size of the document. Uploading blocks of a large document will thus incur larger overhead. For instance, we set the block size to 500 KB in our experiment. This means for a 100 MB document, 200 blocks were generated and it takes 2 s to build the index and 7.2 s to upload the document.
7. Conclusions
In this work, we have developed and implemented the SDV system prototype that runs on a multi-server SSE scheme, and showed that encrypting documents into blocks and uploading to several cloud storage providers entails acceptable cost overhead compared to uploading original files unencrypted. Our system is easy to use and robust, with an intuitive web interface that is compatible with any browser. It solves the problem of privacy and searchability of encrypted documents with minimal leakage as no single cloud service provider will have the complete document block set.
For future work, we plan to improve the robustness and scalability of the system by allowing users to remove cloud service providers easily. In addition, we will continue to study the issue of block size and its implications for information leakage. Also, the current system setup is more suitable for use in an organization environment, where an organization maintains a gateway containing the SDV controller. In view of this, we want to examine a client-side implementation that potentially stores the keys and index table on the client side, therefore providing another approach that is user-centric. This means that submitting and retrieving documents is performed through direct interaction between the user devices and the cloud storage servers without any intermediary.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}