
A New Approach of Modeling an Ultra-Super-Critical Power Plant for Performance Improvement

Abstract
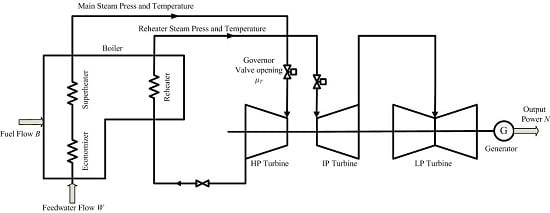
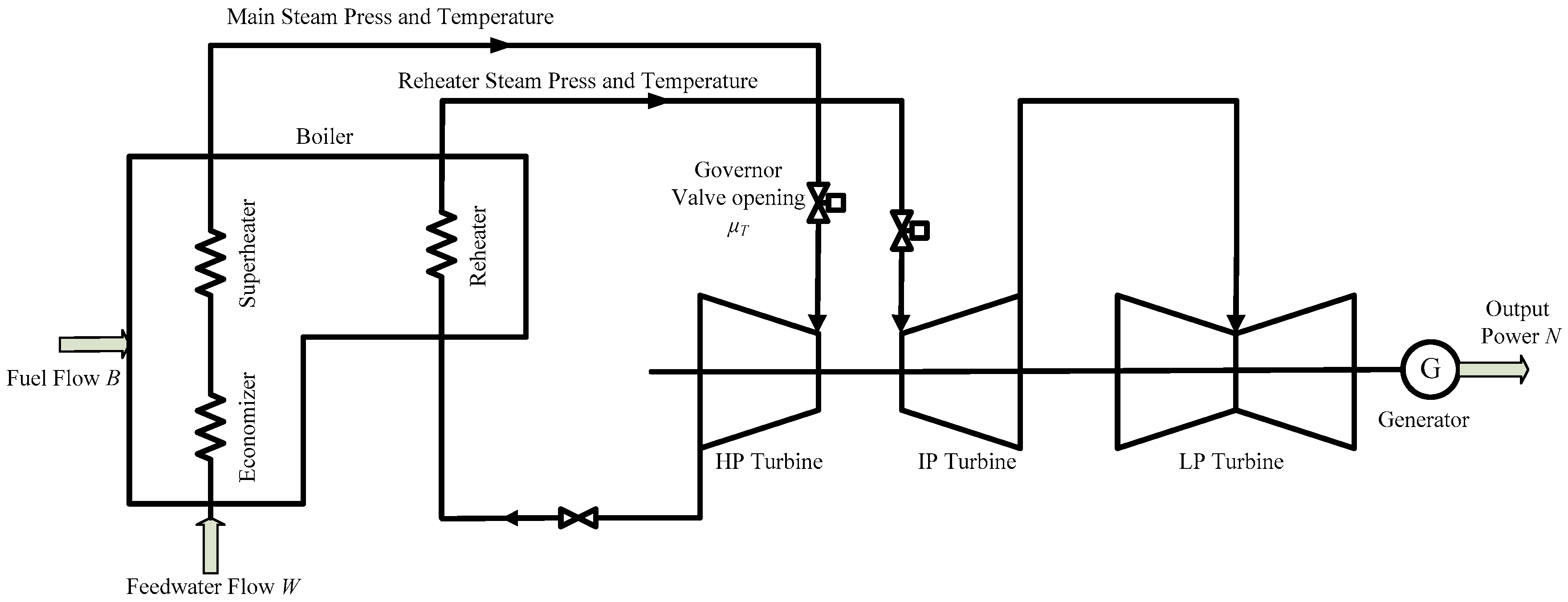
:
1. Introduction
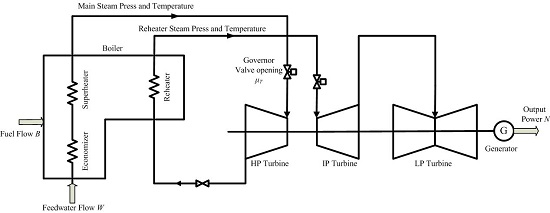
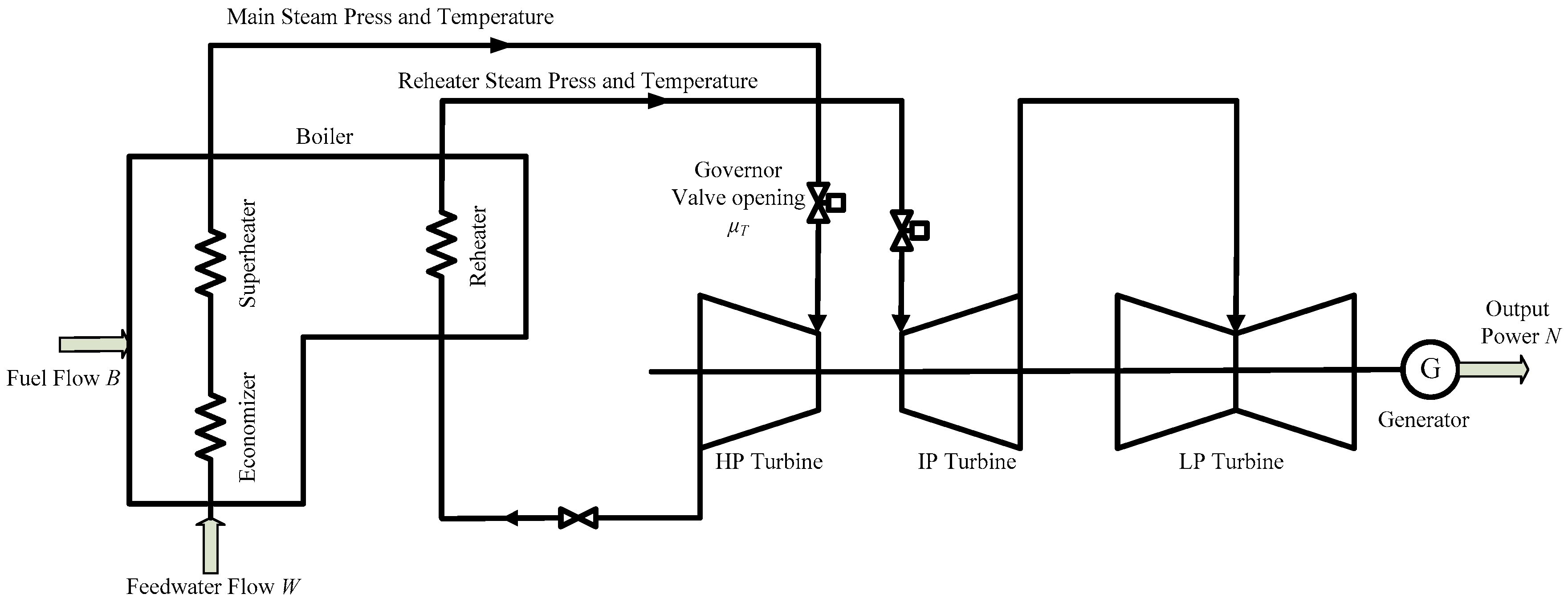
2. The Coordinated Control System of Ultra-Super-Critical Power Plant
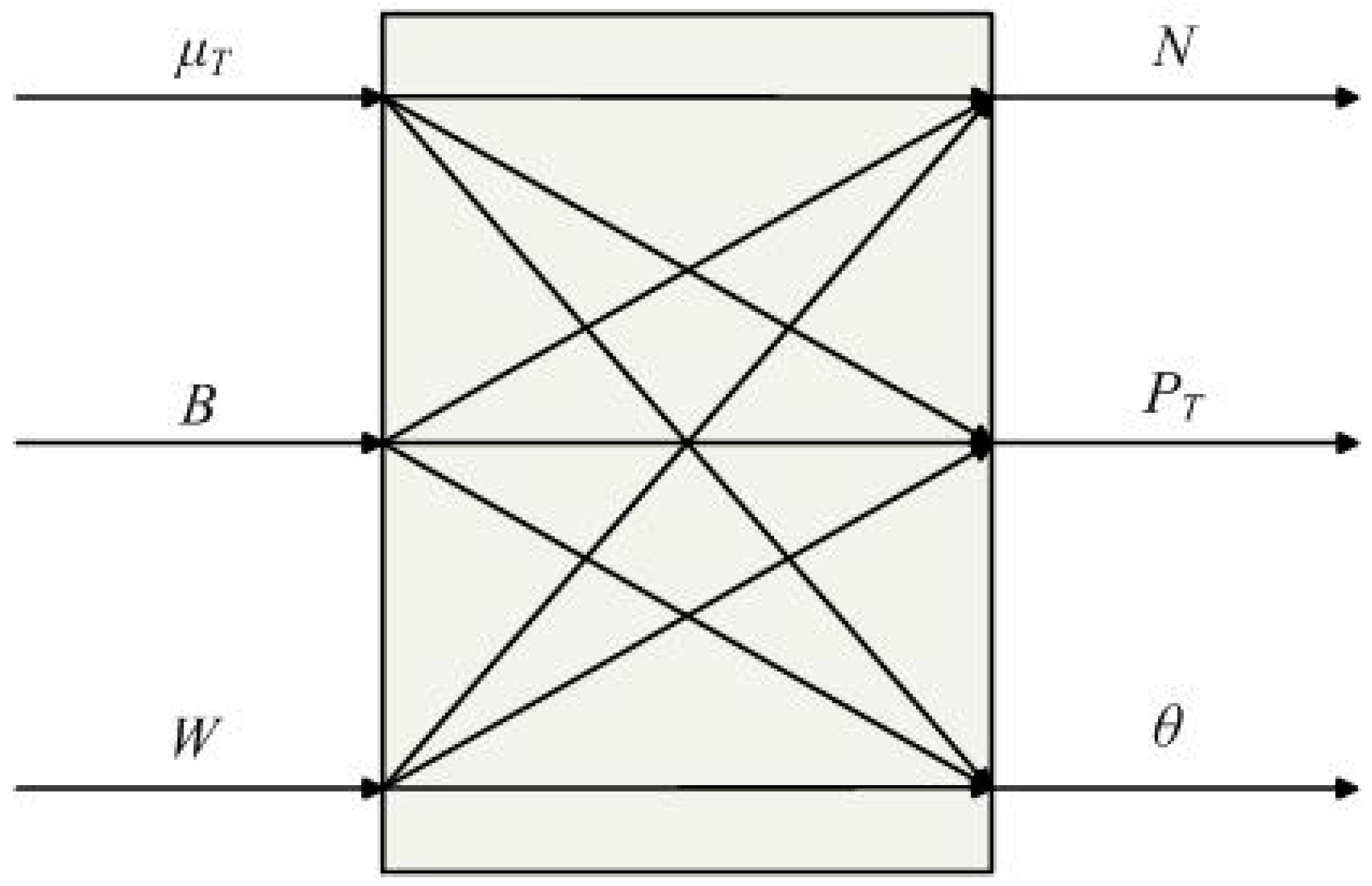
3. The New Structure of the T-S Fuzzy Model
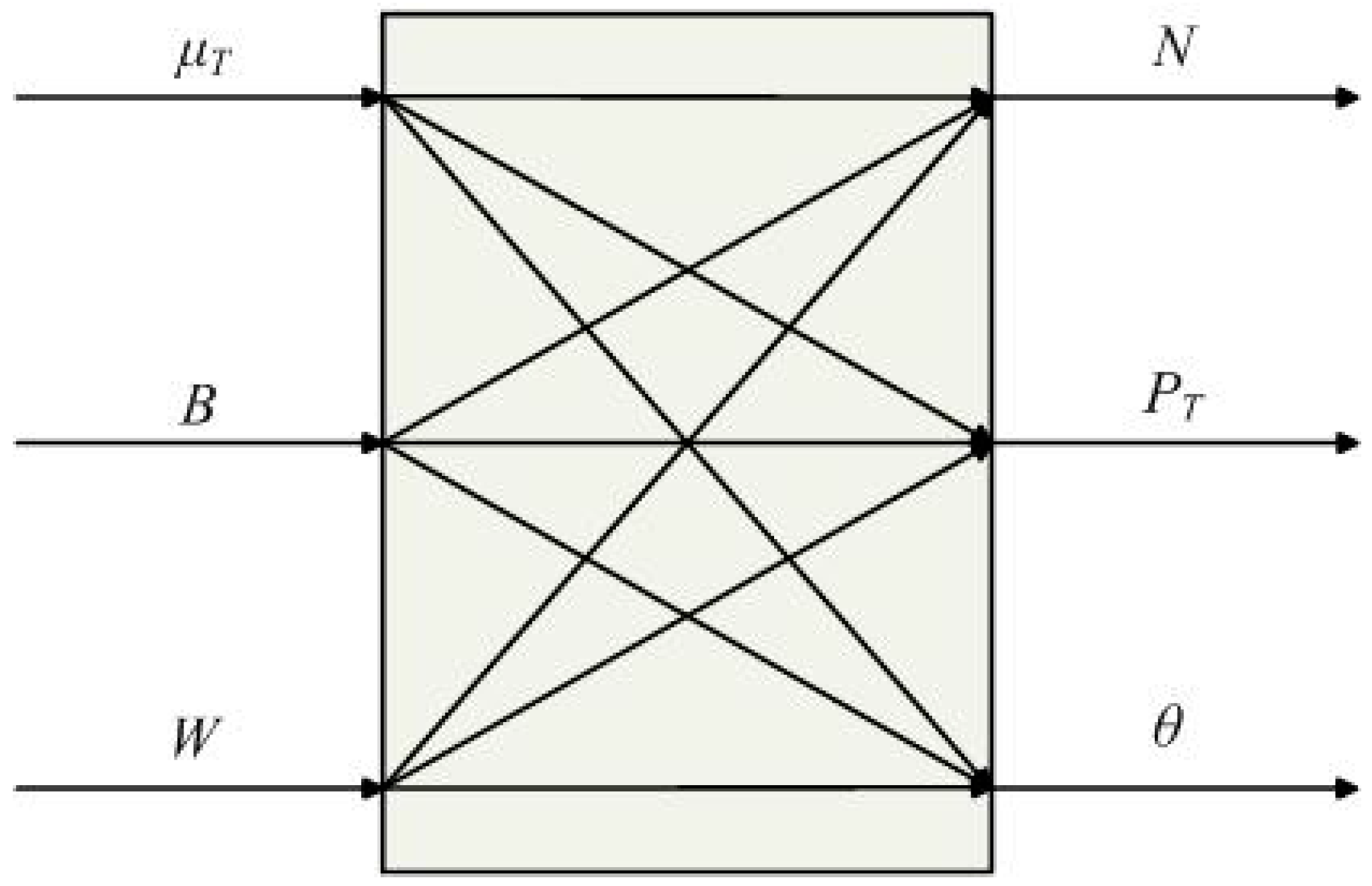
3.1. Definition of New Structure
- Seek the clustering center , which has the shortest distance between through Equation (8).
- Calculate the output of local linear model.
- The final output of the fuzzy model is:
3.2. Discussion of the New Structure
4. Parameters Estimation
4.1. Definition of Entropy
4.2. Improved Entropy Clustering Algorithm
- Calculate the entropy according to the input training data pairs and initialize the cluster number .
- The input vector xs which has the smallest entropy is selected as the cluster center cn. Then calculate similarity Sij between input data pairs xk (k = 1, 2, ..., N) and cn, the total number of data pairs which meet is NC. β is the decision-making constant; it decides whether the data pairs xk belong to the same class with the cluster center.
- Introduce the threshold va. If , accepting as the initial cluster center, go to step 4. If , refusing as the initial cluster center, then and are removed from and , respectively, and go step 2. This step can avoid selecting the isolated data pairs as cluster center.
- Remove the data pairs which meet from initial training data.
- The number of remaining data is . If , the cluster of data is finished and is taken as the initial cluster centers. If , , return to step 2.
4.3. Cluster Center Modification
- Through the above clustering, the initial cluster center can be achieved.
- Select any input data vector from training data pairs, and find out the nearest cluster center by Equation (16):
- Using to update the cluster center :where is the learning rate, and gradually decay to 0:
- Select another input vector from the training data and repeat steps 2 and 3, then the revised cluster centers can be obtained.
4.4. Identification of Cluster Radius
- The initial value of radius is set to ri = 0 (i = 1, 2, …, n). Select an input vector and find the nearest cluster center :
- Update through the following equation:
- Repeating steps 1 and 2, the cluster radius can be obtained.
4.5. Identification of the Concluding Parameters
- Initialize matrix , is the identity matrix.
- Select the training data pairs , where is the input vector, is the output, and the dynamic parameters can be calculated through Equation (21).is the static value of output which can get from . can be calculated through , m is a positive integer, in this paper, and is set to 50.
- t = t + 1, and return to step 2; after all training data have been used, the dynamic parameters of the concluding part can be obtained.
5. Simulation
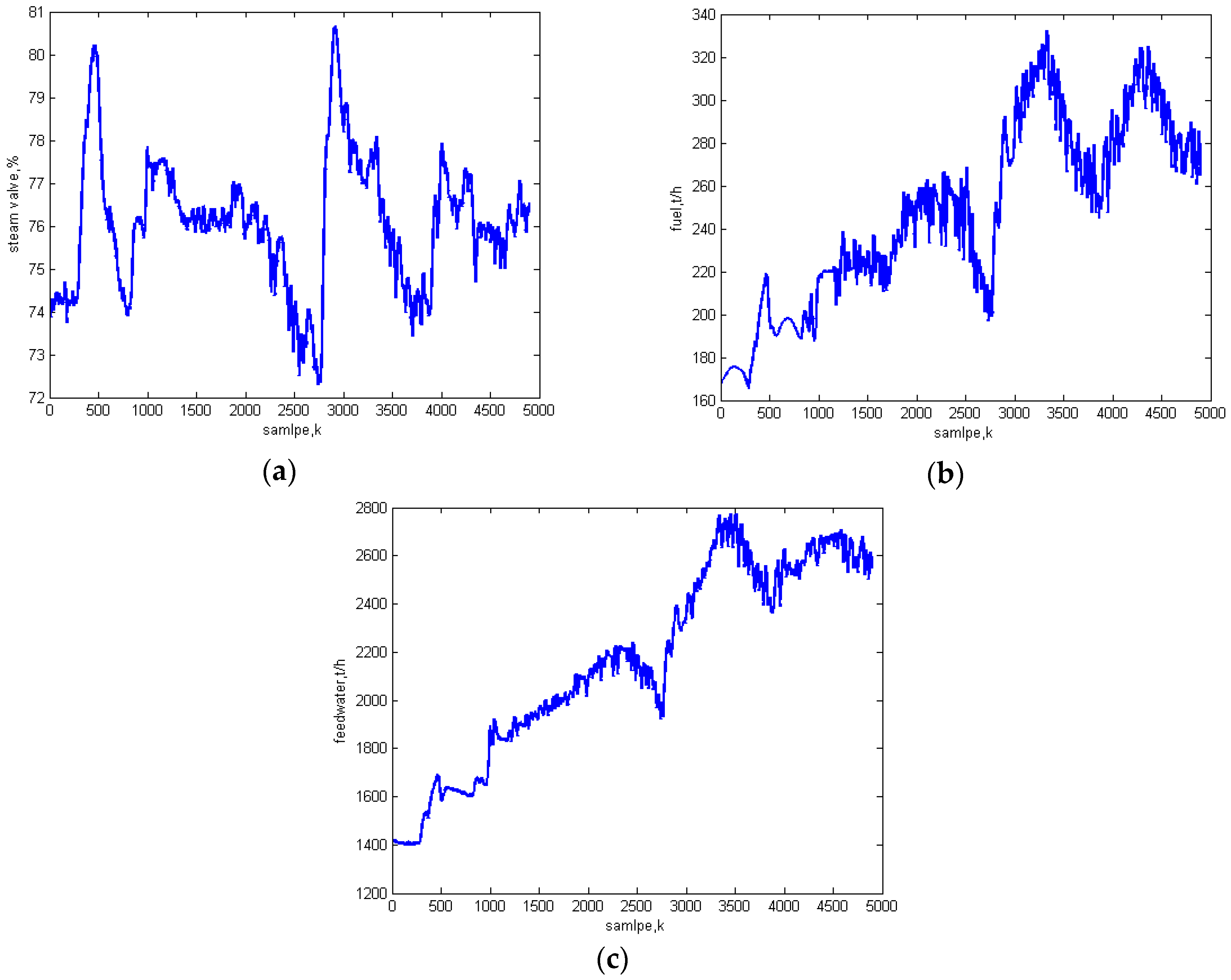
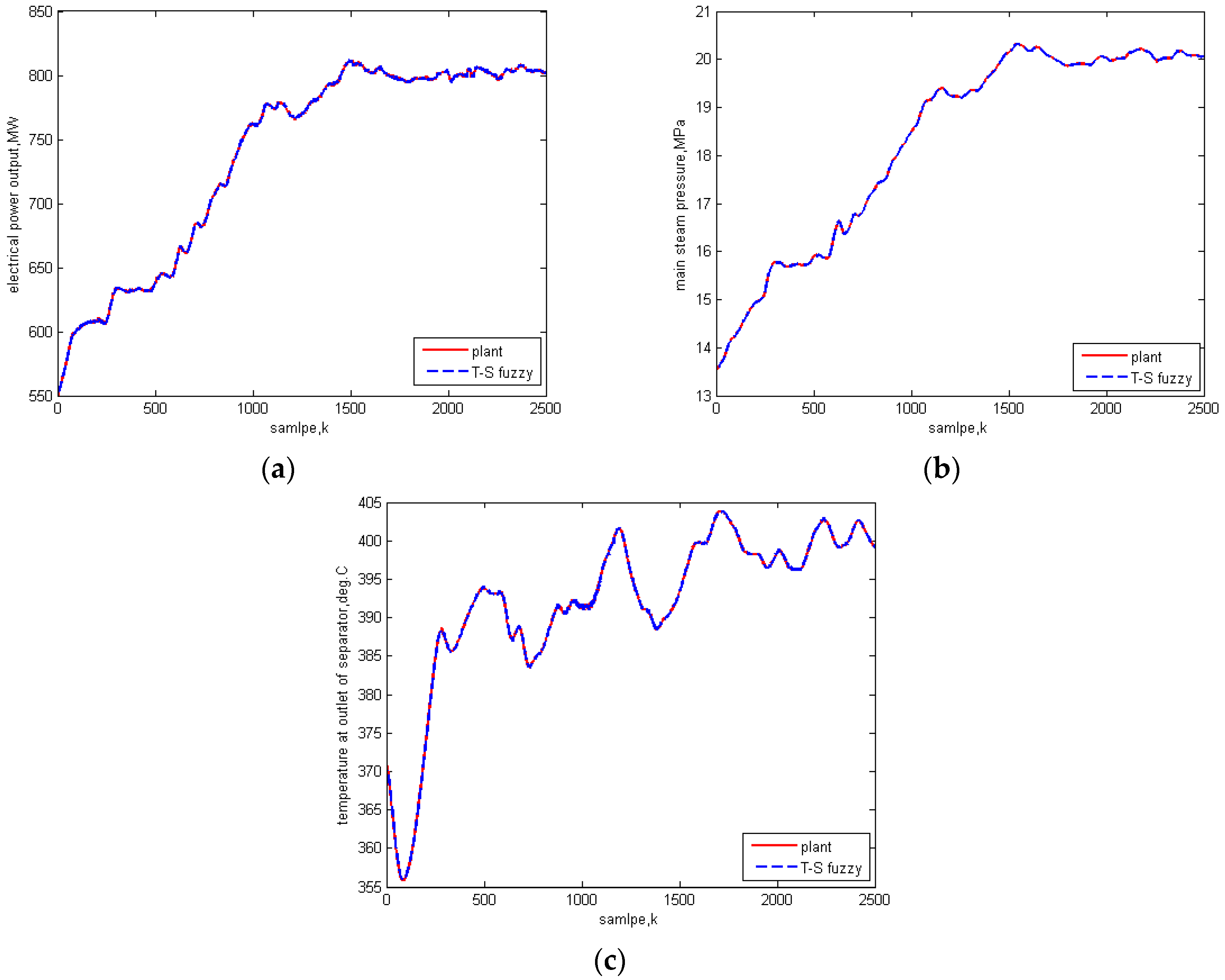
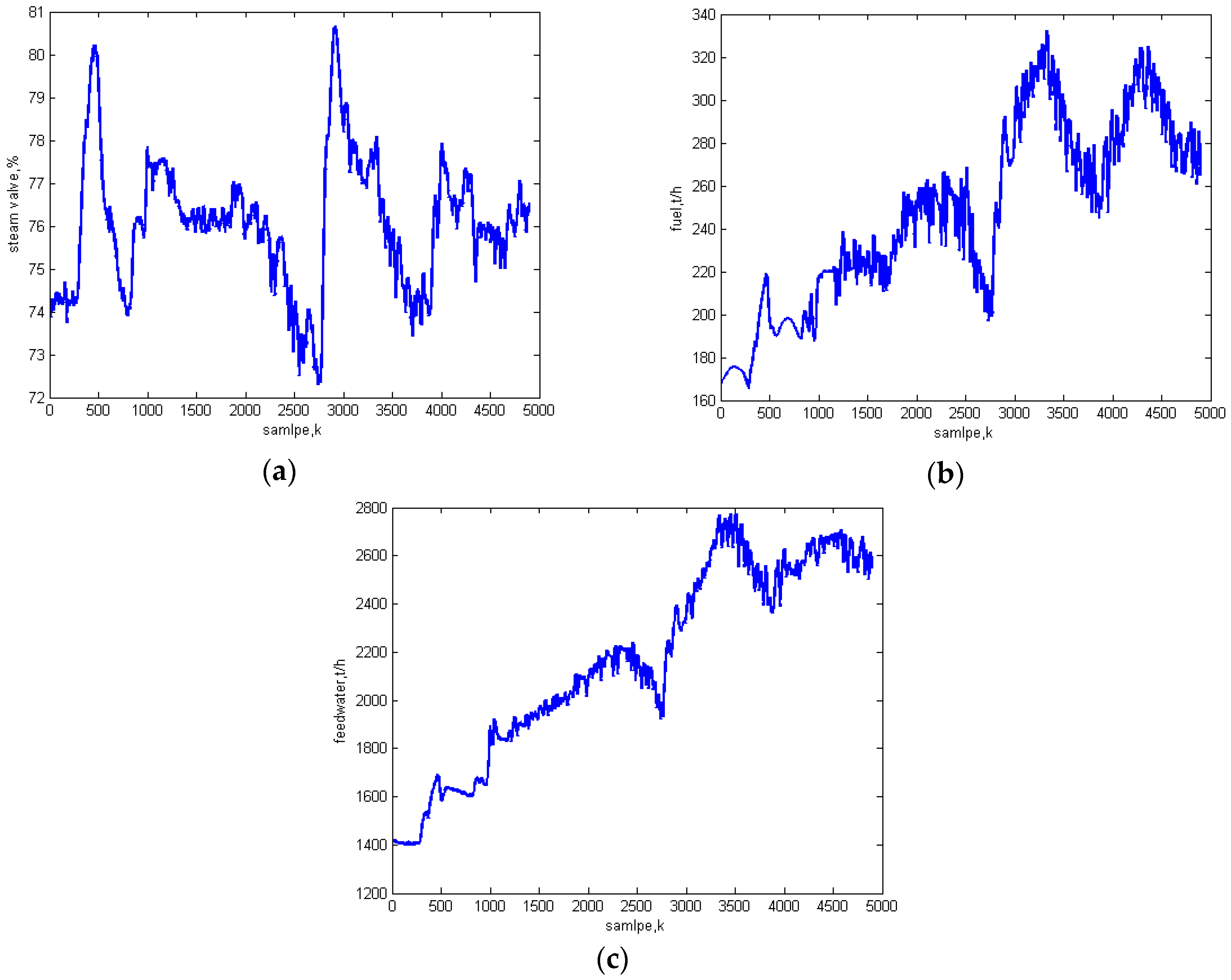
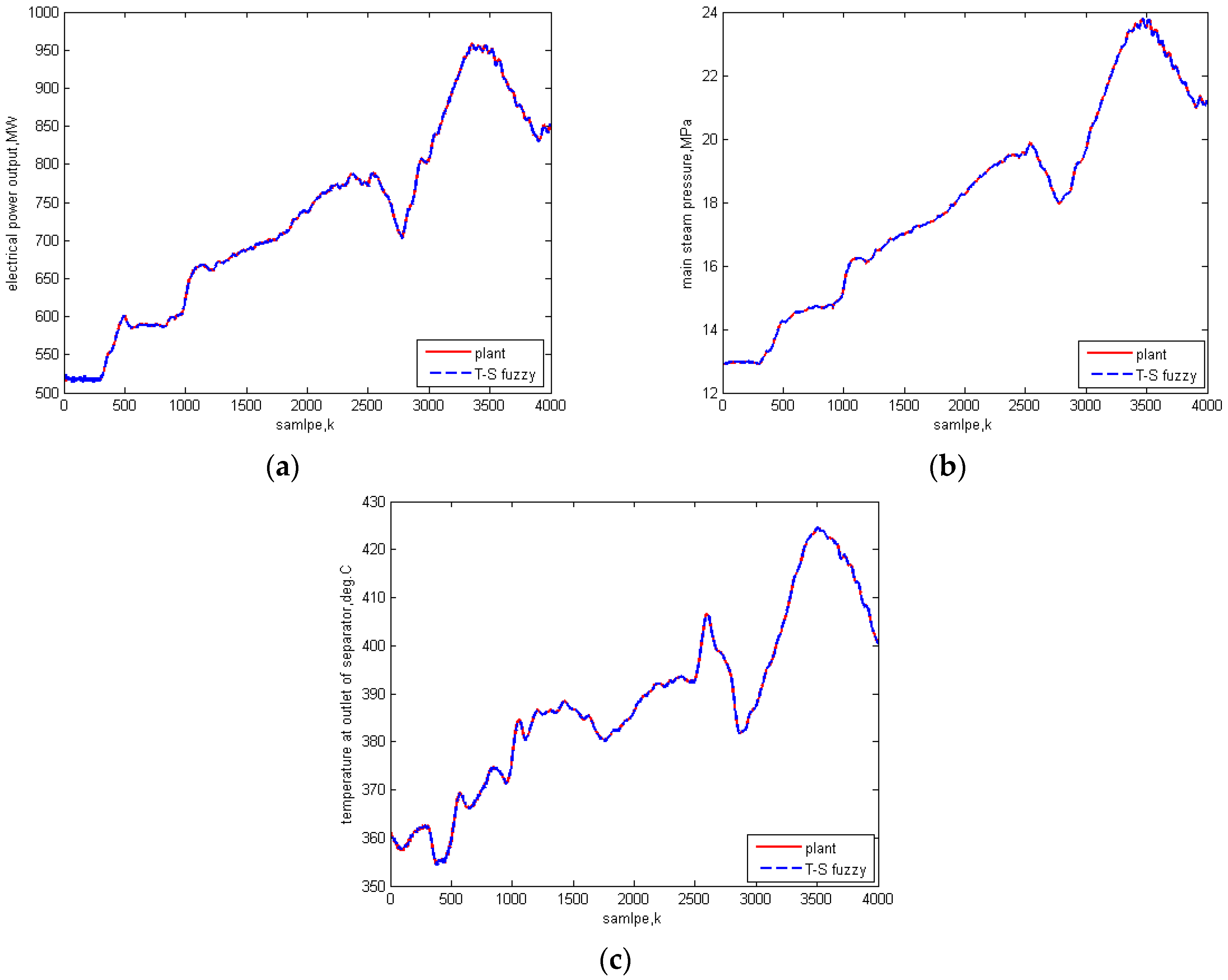
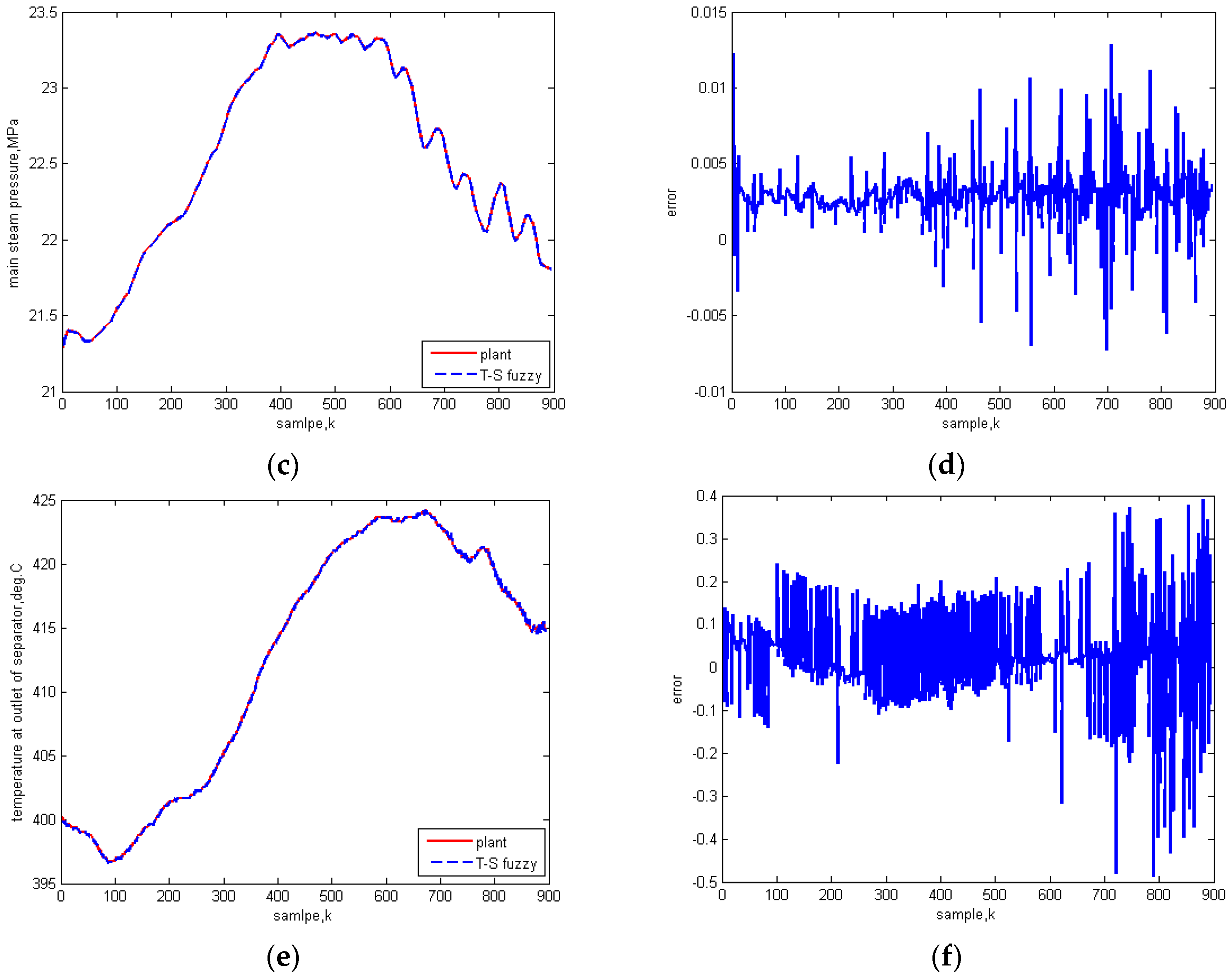
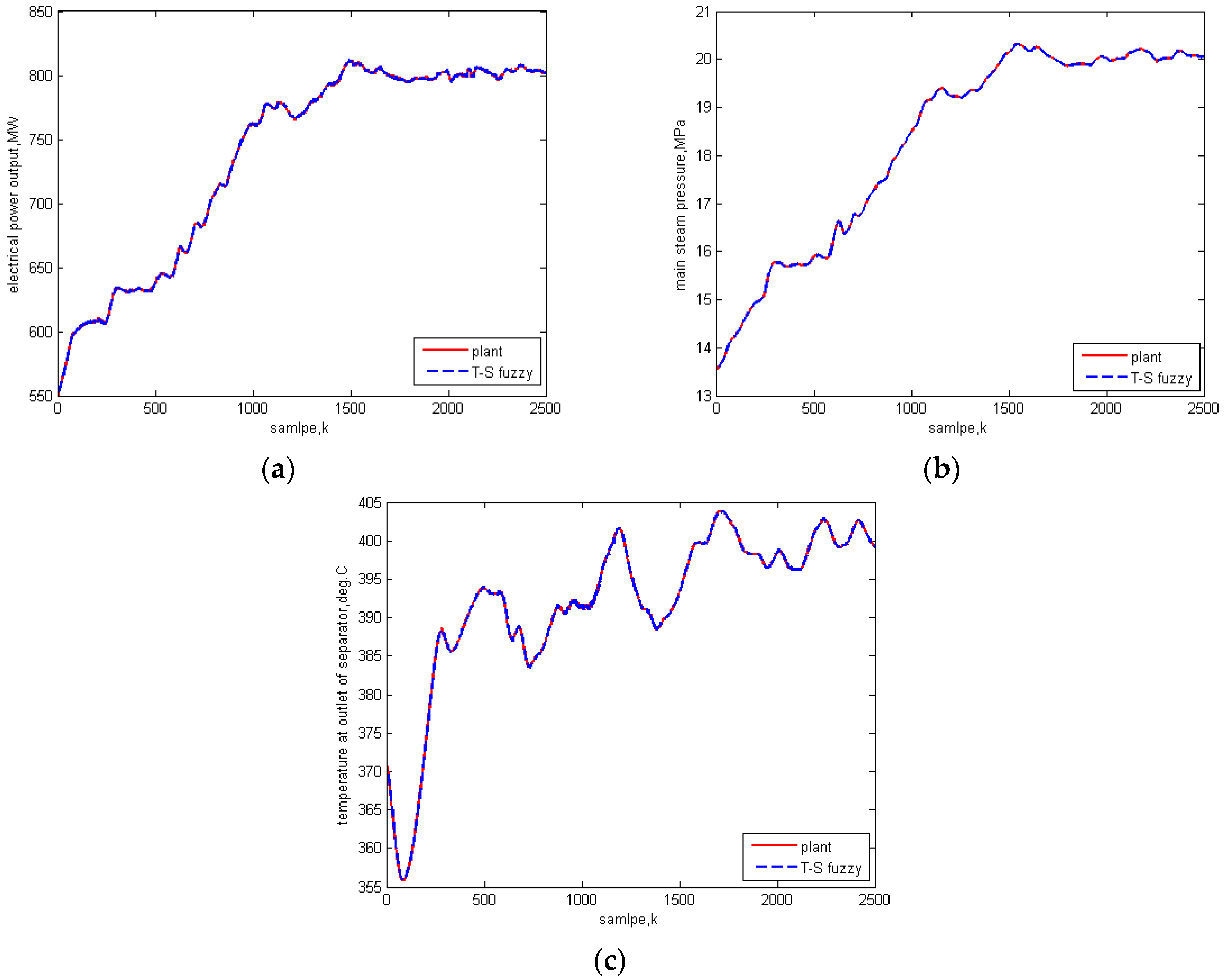
5.1. Identification Results
5.2. Comparison Test
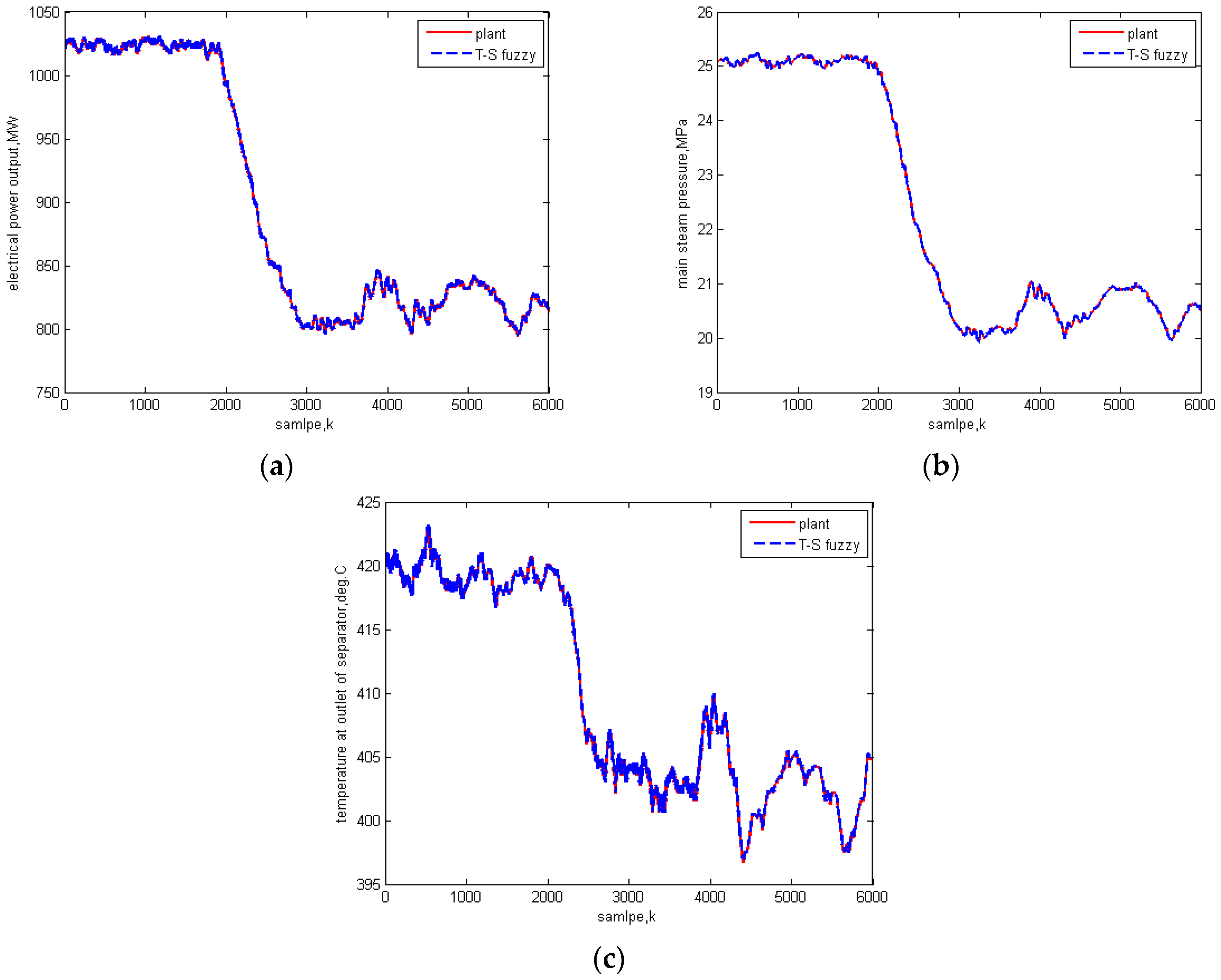
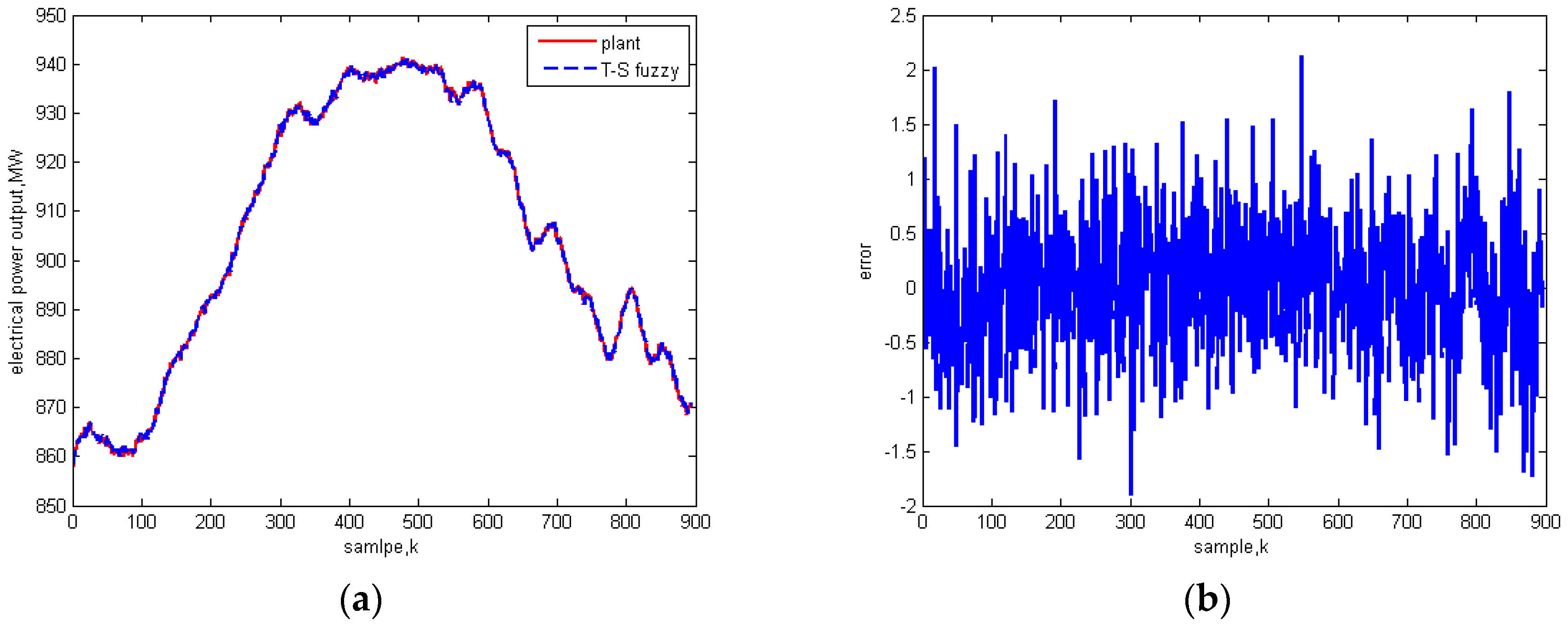
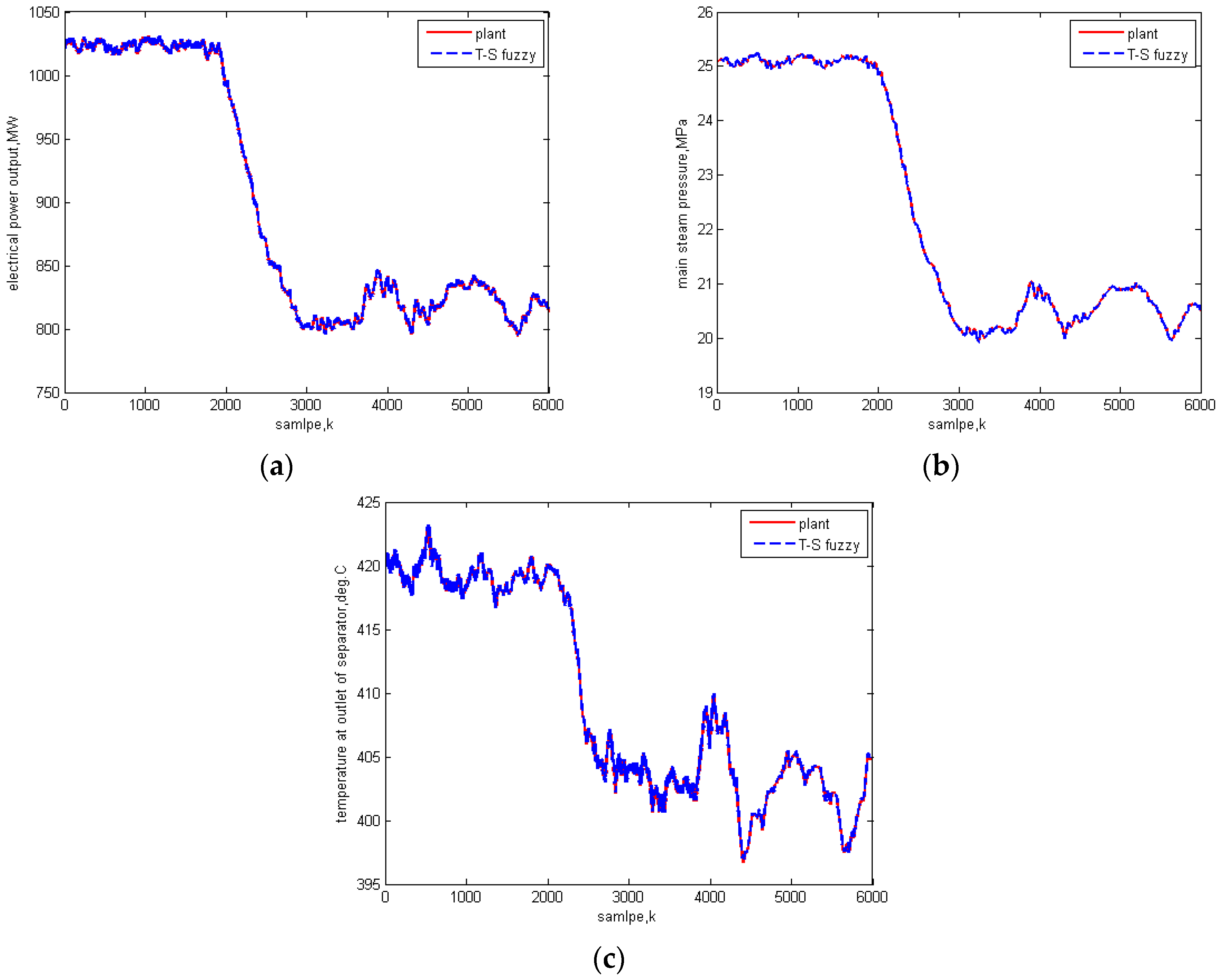
5.3. Universality Test
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A
References
- Wu, X.; Shen, J.; Li, Y.G.; Lee, K.Y. Data-driven modeling and predictive control for boiler-turbine unit using fuzzy clustering and subspace methods. ISA Trans. 2014, 53, 699–708. [Google Scholar] [CrossRef] [PubMed]
- Ding, J.; Li, G.Y.; Wang, N. Research on simplified model for the control of 660 MW supercritical unit. Electr. Power Sci. Eng. 2011, 27, 29–34. [Google Scholar]
- Lee, K.Y.; Van Sickel, J.H.; Hoffman, J.A.; Jung, W.H.; Kim, S.H. Controller design for a large-scale ultrasupercritical once-through boiler power plant. IEEE Trans. Energy Convers. 2010, 25, 1063–1070. [Google Scholar] [CrossRef]
- Wei, J.L.; Wang, J.H.; Wu, Q.H. Development of a multi-segment coal mill model using an evolutionary computation technique. IEEE Trans. Energy Convers. 2007, 22, 718–727. [Google Scholar] [CrossRef]
- Yan, S.; Zeng, D.L.; Liu, J.Z.; Liang, Q.J. A simplified non-linear model of a once-through boiler-turbine unit and its application. Chin. Soc. Electr. Eng. 2012, 32, 126–134. [Google Scholar]
- Liu, X.J.; Kong, X.B.; Hou, G.L.; Wang, J.H. Modeling of a 1000 MW power plant ultra super-critical boiler system using fuzzy-neural network methods. Energy Convers. Manag. 2013, 65, 518–527. [Google Scholar] [CrossRef]
- Takigi, T.; Sugeno, M. Fuzzy identification of system and its application to modeling and control. IEEE Trans. Syst. Man Cybern. 1985, 15, 116–132. [Google Scholar] [CrossRef]
- Chakrborty, D.; Pal, N.R. Integrated feature analysis and fuzzy rule-based system identification in a neuro-fuzzy paradigm systems. IEEE Trans. Syst. Man Cybern. 2001, 31, 391–400. [Google Scholar] [CrossRef] [PubMed]
- Frank, K.; Rudoif, K.; Roland, W. Fuzzy clustering: More than just fuzzification. Fuzzy Sets Syst. 2015, 281, 272–279. [Google Scholar]
- Wang, N.; Yang, Y.P. A fuzzy modeling method via Enhanced Objective Cluster Analysis for designing TSK model. Expert Syst. Appl. 2009, 36, 12375–12382. [Google Scholar] [CrossRef]
- Zhang, B.J.; Qin, S.; Wang, W.; Wang, D.; Xue, L. Data stream clustering based on fuzzy c-mean algorithm and entropy theory. Signal Process. 2015, 1–6. [Google Scholar] [CrossRef]
- Zhang, J.A.; Jia, M.P. Segmentation algorithm for small targets based on improved data field and fuzzy c-means clustering. Optik 2015, 126, 4330–4336. [Google Scholar]
- Kannan, S.R.; Ramathilagam, S.; Chung, P.C. Effective fuzzy c-means clustering algorithms for data clustering problems. Expert Syst. Appl. 2012, 39, 6292–6300. [Google Scholar] [CrossRef]
- Li, C.S.; Zhou, J.Z.; Li, Q.Q. A new T-S fuzzy-modeling approach to identify a boiler-turbine system. Expert Syst. Appl. 2010, 37, 2214–2221. [Google Scholar] [CrossRef]
- Shimoji, S.; Lee, S. Data clustering with entropic scheduling. In Proceeding of the IEEE Conference on Fuzzy Systems, Orlando, FL, USA, 26–29 June 1994; pp. 2423–2428.
- Hou, G.L.; Hou, Q.; Zhang, J.H. T-S Fuzzy modeling based on compatible relation and its application in power plant. In Proceeding of the IEEE Conference on Industrial Electronics and Applications, Beijing, China, 21–23 June 2011; pp. 1308–1313.
- Yao, J.; Dash, M.; Tan, S.T.; Liu, H. Entropy-based fuzzy clustering and fuzzy modeling. Fuzzy Sets Syst. 2000, 113, 381–388. [Google Scholar] [CrossRef]
- Ma, L.Y.; Kwang, Y.L.; Wang, Z.Y. Intelligent coordinated controller design for a 600 MW supercritical boiler unit based on expanded-structure neural network inverse models. Control Eng. Pract. 2015, 9, 1–8. [Google Scholar] [CrossRef]
- Han, Z.X.; Zhang, Z.; Qi, X.H. Analysis of linear increment mathematic model for multivariate boiler-turbine coordinated control object. Chin. Soc. Elec. Eng. 2005, 25, 24–29. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (a) Comparison of different β for electrical power output while va = 0.004N | β | Cluster Number | MSE |
| 0.5 | 20 | 0.0087 | |
| 0.6 | 12 | 0.0097 | |
| 0.65 | 4 | 0.0123 | |
| 0.7 | 2 | 0.0260 | |
| (b) Comparison of different β for the main steam pressure while va = 0.004N | β | Cluster Number | MSE |
| 0.6 | 13 | 4.2561 × 10−5 | |
| 0.65 | 7 | 1.1322 × 10−4 | |
| 0.7 | 5 | 7.3223 × 10−5 | |
| 0.75 | 3 | 2.8506 × 10−4 | |
| (c) Comparison of different β for the separator outlet steam temperature while va = 0.004N | β | Cluster Number | MSE |
| 0.5 | 28 | 0.0016 | |
| 0.6 | 11 | 0.0017 | |
| 0.65 | 5 | 0.0018 | |
| 0.7 | 3 | 0.0024 |
| (a) Comparison of different va for electrical power output while β = 0.65 | va | Cluster Number | MSE |
| 0.002N | 25 | 0.0084 | |
| 0.003N | 9 | 0.0098 | |
| 0.004N | 4 | 0.0123 | |
| 0.005N | 2 | 0.0248 | |
| (b) Comparison of different va for the main steam pressure while β = 0.7 | va | Cluster Number | MSE |
| 0.002N | 23 | 4.1539 × 10−5 | |
| 0.003N | 8 | 4.8359 × 10−5 | |
| 0.004N | 5 | 7.3223 × 10−5 | |
| 0.005N | 3 | 7.1348 × 10−5 | |
| (c) Comparison of different va for separator outlet steam temperature while β = 0.65 | va | Cluster Number | MSE |
| 0.002N | 34 | 0.0037 | |
| 0.003N | 15 | 0.0017 | |
| 0.004N | 5 | 0.0018 | |
| 0.005N | 4 | 0.0019 |
| Methods | Power Model | Pressure Model | Temperature Model |
|---|---|---|---|
| ARX model [2] | 0.1058 | 0.0026 | 0.0964 |
| Original T-S [16] | 0.0705 | 0.0012 | 0.0233 |
| Proposed method | 0.0123 | 7.3223 × 10−5 | 0.0018 |
| Methods | Power Model | Pressure Model | Temperature Model |
|---|---|---|---|
| Original T-S | 6 | 4 | 4 |
| Proposed method | 4 | 5 | 5 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, G.; Yang, Y.; Jiang, Z.; Li, Q.; Zhang, J. A New Approach of Modeling an Ultra-Super-Critical Power Plant for Performance Improvement. Energies 2016, 9, 310. https://doi.org/10.3390/en9050310
Hou G, Yang Y, Jiang Z, Li Q, Zhang J. A New Approach of Modeling an Ultra-Super-Critical Power Plant for Performance Improvement. Energies. 2016; 9(5):310. https://doi.org/10.3390/en9050310
Chicago/Turabian StyleHou, Guolian, Yu Yang, Zhuo Jiang, Quan Li, and Jianhua Zhang. 2016. "A New Approach of Modeling an Ultra-Super-Critical Power Plant for Performance Improvement" Energies 9, no. 5: 310. https://doi.org/10.3390/en9050310
APA StyleHou, G., Yang, Y., Jiang, Z., Li, Q., & Zhang, J. (2016). A New Approach of Modeling an Ultra-Super-Critical Power Plant for Performance Improvement. Energies, 9(5), 310. https://doi.org/10.3390/en9050310