Multi-Step-Ahead Carbon Price Forecasting Based on Variational Mode Decomposition and Fast Multi-Output Relevance Vector Regression Optimized by the Multi-Objective Whale Optimization Algorithm

Abstract
1. Introduction
2. Materials and Methods
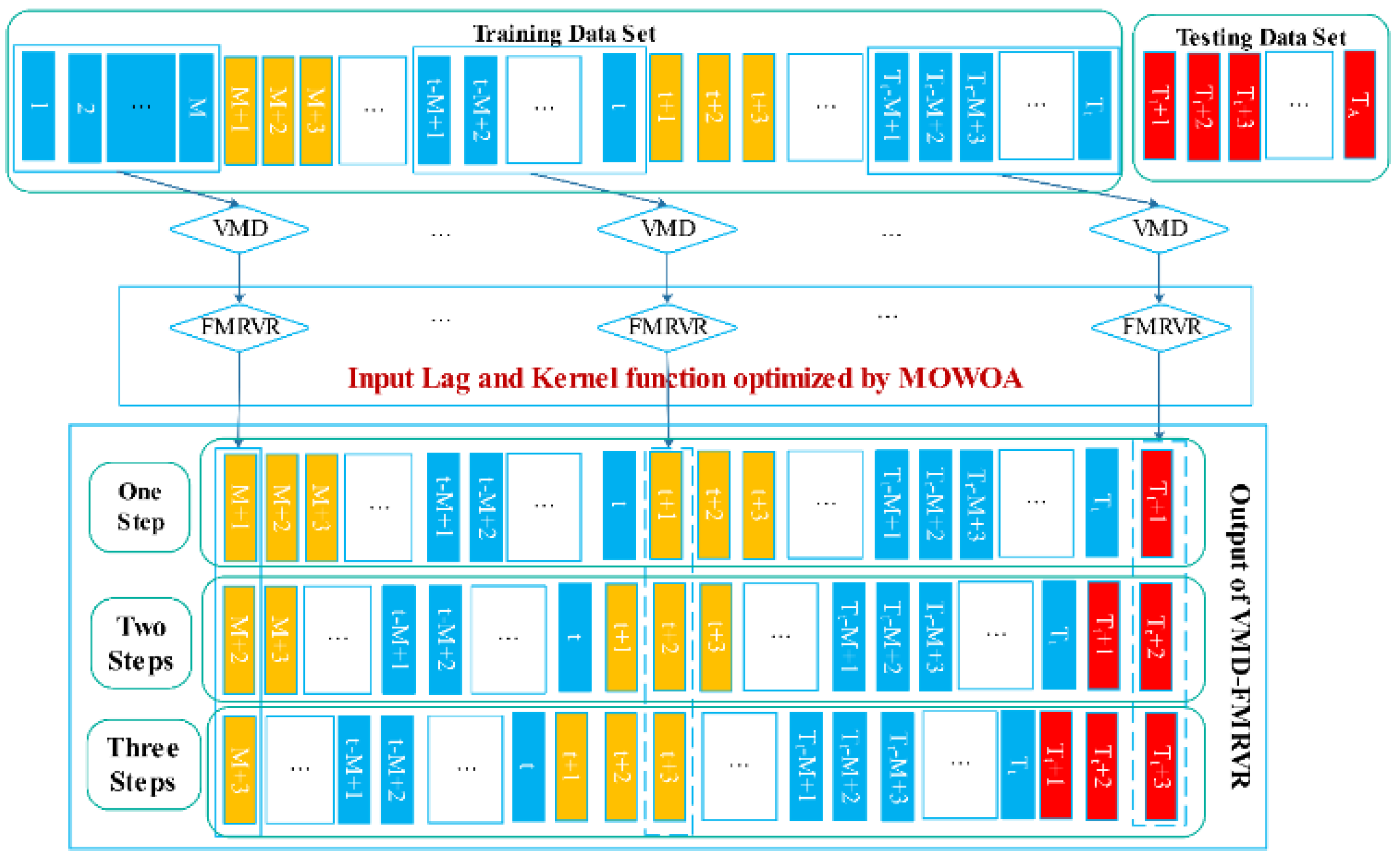
2.1. The Proposed Method
- Step 1:
- setting a moving window (window length equal to M) to select the input data for the VMD-FMRVR models.
- Step 2:
- denoising the data series in the fixed number window by VMD to obtain the denoised data series.
- Step 3:
- estimating the parameters in FMRVR based on the denoised data series in the given window and then forecasting to obtain the values of the three steps beyond the given window. The input lags and width of the kernel function in FMRVR module are randomly given.
- Step 4:
- repeating VMD-FMRVR modeling with the movement of the window.
- Step 5:
- finding the best input lags and width of the kernel function in the FMRVR by the MOWOA.
2.2. Modules in Proposed Model
2.2.1. Variational Mode Decomposition (VMD)
- (1)
- Obtaining the unilateral frequency spectrum of each mode by a Hilbert transformation.
- (2)
- Shifting the mode’s frequency spectrum to “baseband”
- (3)
- Estimating the bandwidth by the H1 Gaussian smoothness. The decomposition process is realized by solving the following optimization problem [22]:where are the modes, are the center frequencies of the modes. is the Dirac function, and is the convolution operation. is the original signal. The alternate direction method of multipliers (ADMM) is used to solve the above optimization problem. The complete algorithm of ADMM for obtaining the final parameters and modes in VMD is shown in Figure 2 (modified based on Dragomiretskiy’s pseudo-code [40]).
2.2.2. Fast Multi-Output Relevance Vector Regression (FMRVR)
Model Specification of the FMRVR
Inference
Making Predictions
2.2.3. The Multi-Objective Whale Optimization Algorithm (MOWOA)
Multi-Objective Optimization Problems
WOA
3. Results and Analyses
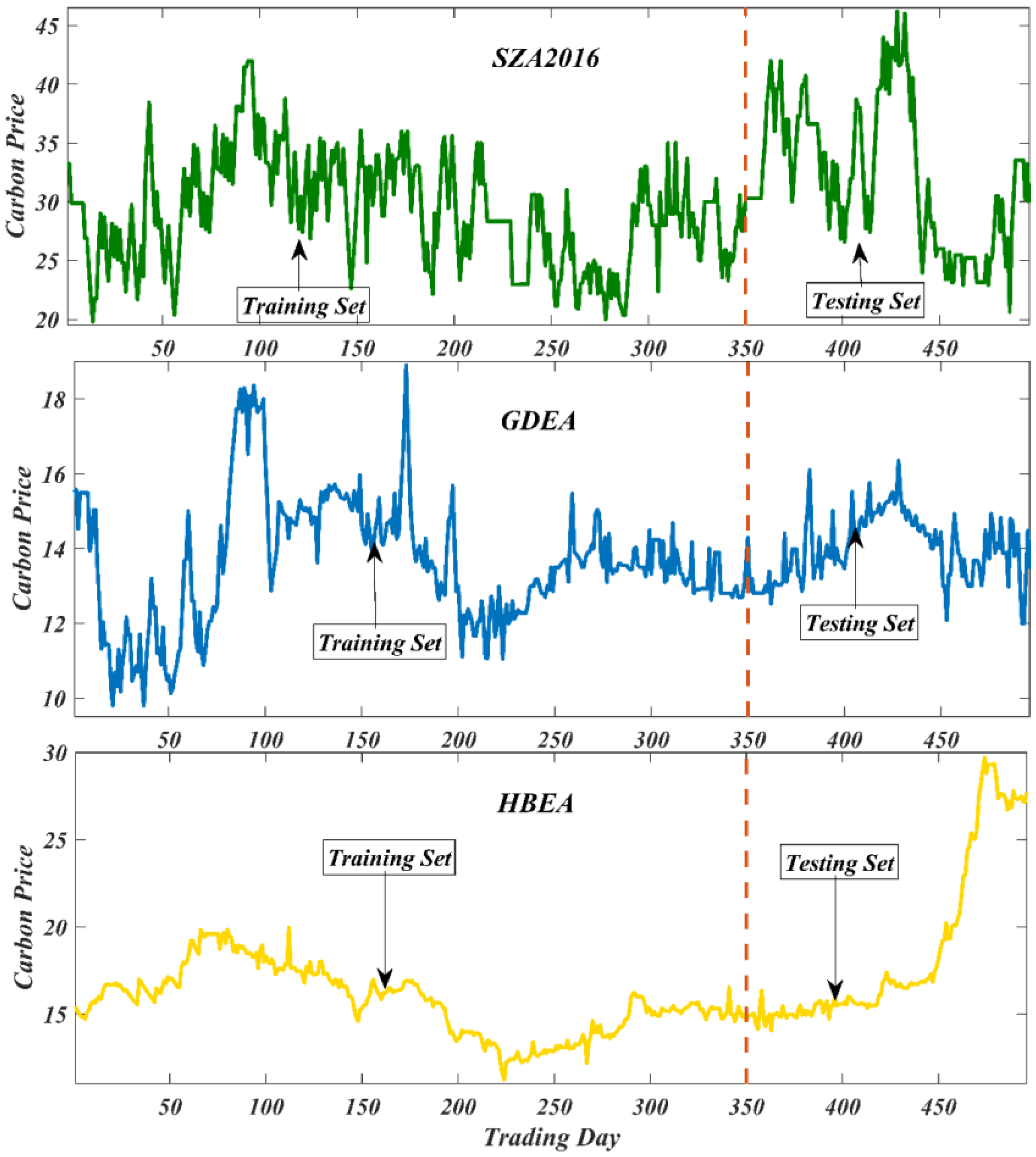
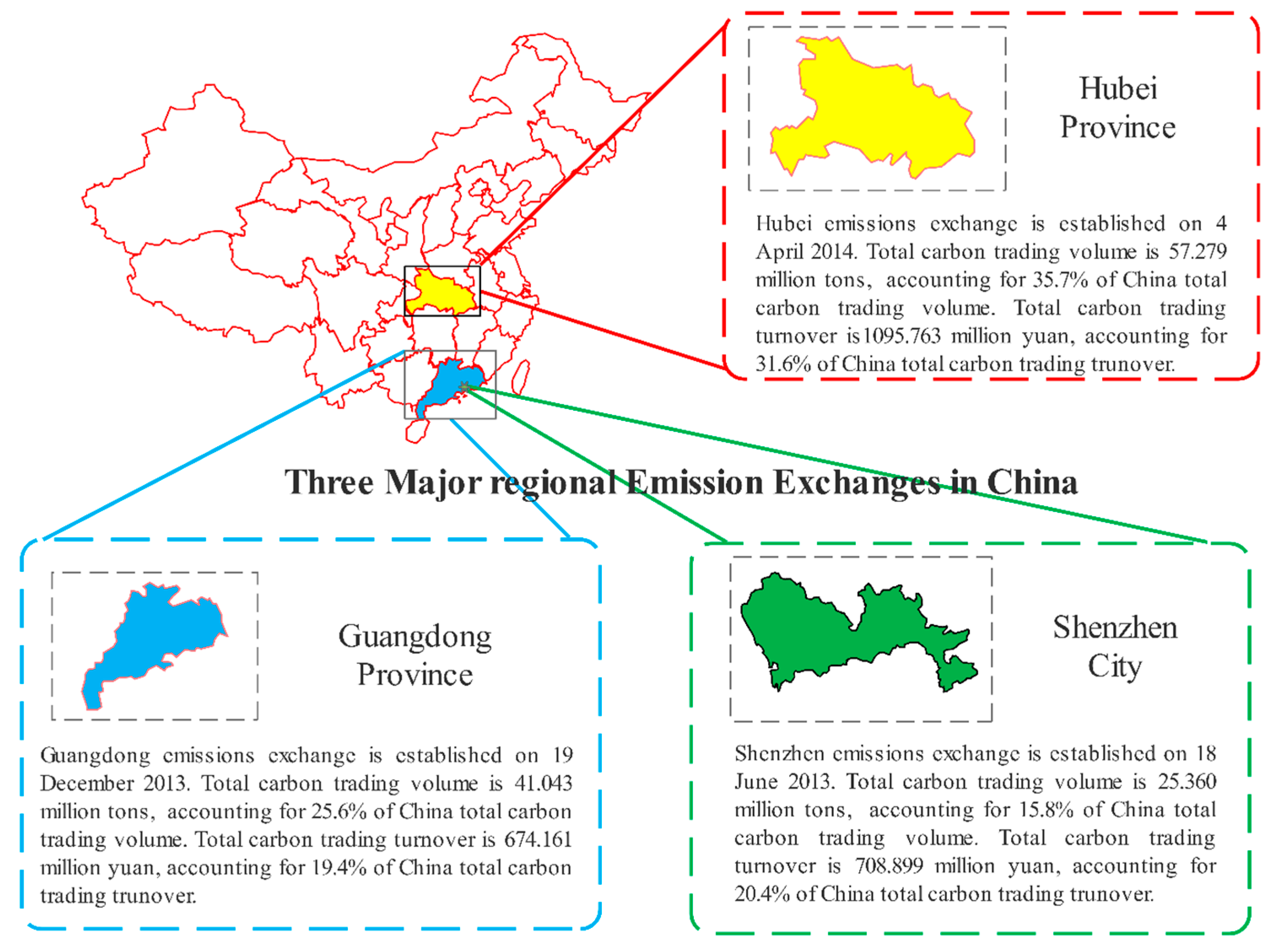
3.1. Data Descriptions
3.2. Evaluation Criteria
3.3. Data Preprocessing
3.4. Parameter Setting and Input Selection
3.5. Compared Models
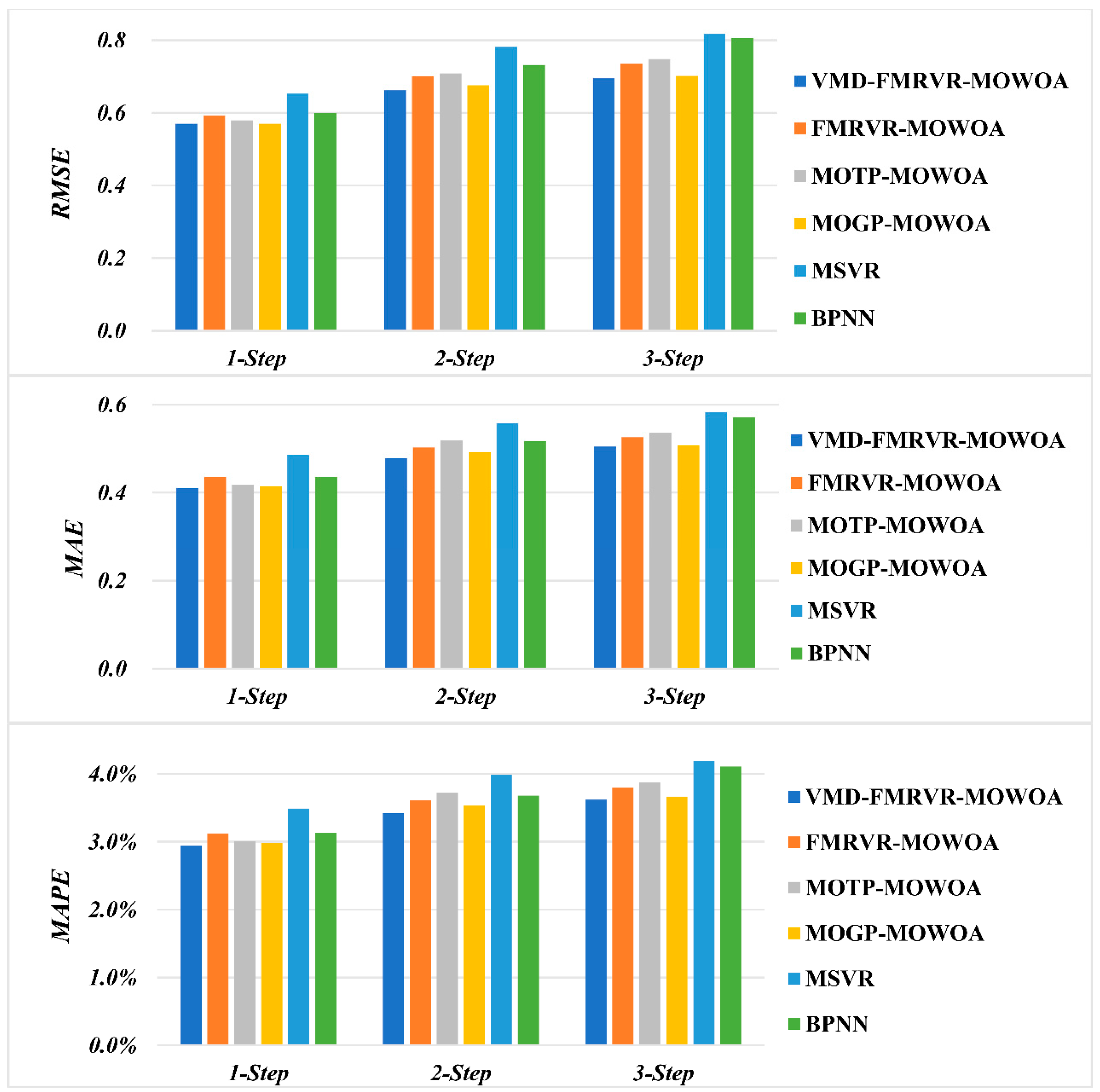
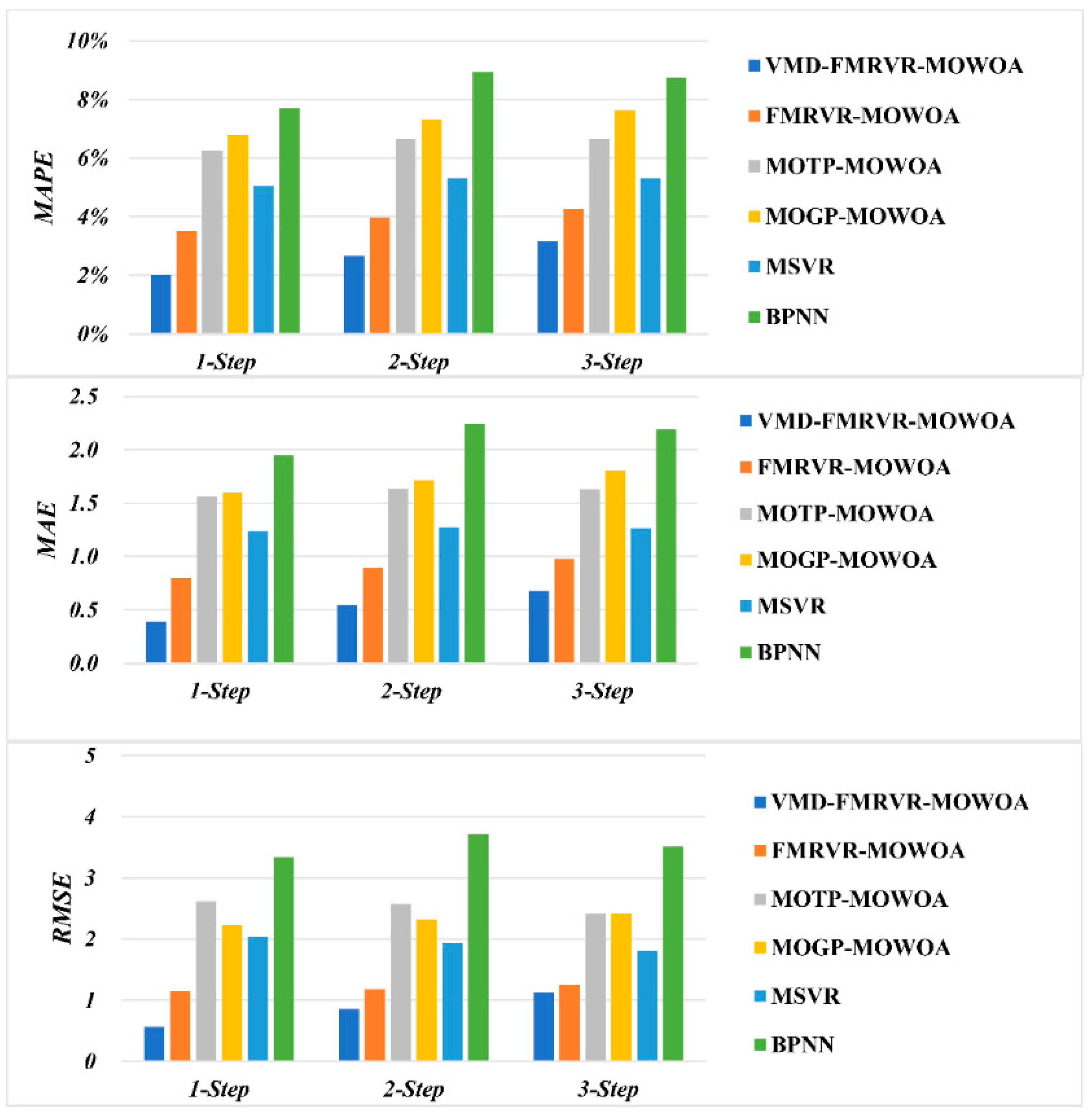
3.6. Results and Discussion
- (a)
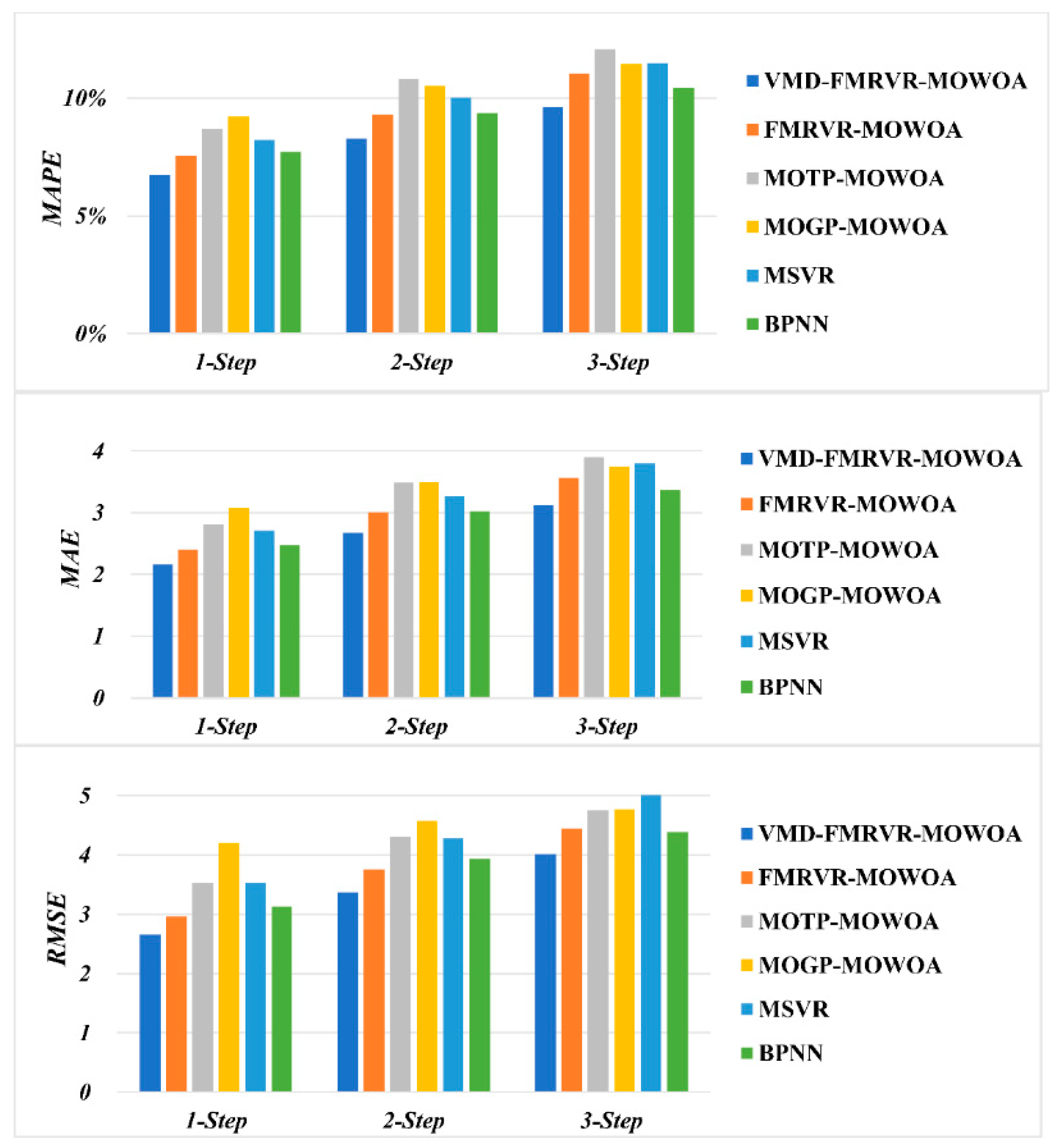
- The proposed model has the smallest MAPE, MAE, and RMSE in one-step, two-step, and three-step ahead forecasting performance. The MAPE values achieved by the proposed model are 6.738%, 8.278%, and 9.646% in one-step, two-step, and three-step ahead forecasting, respectively. The smallest MAPE values from the remaining five models are 7.538%, 9.310%, and 10.457% in the one-step, two-step, and three-step ahead forecasts achieved by FMRVR-MOWOA, FMRVR-MOWOA, and BPNN, respectively. The MAE values achieved using the proposed model are 2.164, 2.677, and 3.122 in one-step, two-step, and three-step ahead forecasting, respectively. The smallest MAE values from the remaining five models are 2.405, 3.001, and 3.367 in one-step, two-step, and three-step ahead forecasting achieved by the FMRVR-MOWOA, FMRVR-MOWOA, and BPNN, respectively. The RMSE values achieved by the proposed model are 2.655, 3.373, and 4.009 in one-step, two-step, and three-step ahead forecasting, respectively. The smallest RMSE values from the remaining five models are 2.960, 3.757, and 4.390 in one-step, two-step, and three-step ahead forecasting achieved by FMRVR-MOWOA, FMRVR-MOWOA, and BPNN, respectively. The MAPE, MAE, and RMSE obtained by the proposed model are smaller than the smallest MAPE, MAE, and RMSE values achieved by the other five models, respectively. These results show that the proposed method has a high accuracy in forecasting SZA2016 price series.
- (b)
- The proposed model outperforms the FMRVR-MOWOA in all of the one-step, two-step, and three-step ahead forecasting, which can be mainly attributed to the fact that VMD denoises the carbon price series. This shows that the VMD algorithm helps to improve the forecasting performance in carbon price series.
- (c)
- The proposed model outperforms the MOTP-MOWOA and MOGP-MOWOA in one-step, two-step, and three-step ahead forecasting. These results show that the VMD-FMRVR has a stronger performance in SZA2016 price forecasting than the MOTP and MOGP.
- (d)
- Forecasting accuracy decreases as the forecasting step size increases. All MAPE, MAE, and RMSE values increase by the increase in one-step, two-step, and three-step ahead forecasting for all six models. These results indicate that the difficulty in forecasting increases with the forecasting step.
3.7. Improvement of the Proposed Hybrid Model
- (a)
- For the improvement ratio in the MAPE shown in Table 8, the largest improvement ratios for one-step, two-step, and three-step ahead forecasting of SZA2016 are 26.886%, 23.566%, and 20.153%, and the smallest improvement ratios are 10.614%, 11.082%, and 7.755%, respectively. These results show that the proposed model outperforms the other five models and shows a steady performance in forecasting of SZA2016. Similar results are also shown in the MAPE improvement ratio for GDEA and HBEA.
- (b)
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
List of Abbreviations
| VMD | variational mode decomposition |
| RVR | relevance vector regression |
| RVM | relevance vector machine |
| MRVR | multi-output relevance vector regression |
| FMRVR | fast multi-output relevance vector regression |
| WOA | whale optimization algorithm |
| MOWOA | multi-objective whale optimization algorithm |
| VMD-FMRVR | module based on fast multi-output relevance vector regression |
| FMRVR-MOWOA | hybrid forecasting model based on fast multi-output relevance vector regression optimized by multi-objective whale optimization algorithm |
| VMD-FMRVR-MOWOA | hybrid forecasting model based on variational mode decomposition, fast multi-output relevance vector regression and multi-objective whale optimization algorithm |
| MOGP-MOWOA | multi-output gaussian process regression optimized by multi-objective whale optimization algorithm |
| MOTP-MOWOA | multi-output student-t process regression optimized by multi-objective whale optimization algorithm |
| GARCH | generalized autoregressive conditional heteroscedastic model |
| HAR-RV | heterogeneous autoregressive model for realized volatility |
| SVM | support vector machine |
| LSSVM | least square support vector machine |
| SVR | support vector regression |
| MSVR | multi-output support vector regression |
| ANN | artificial intelligence models |
| MLP-ANN | multi layered perceptron |
| BPNN | back propagation neural network |
| SNN | spiking neural networks |
| ICE | InterContinental Exchange |
| EMD | empirical mode decomposition |
| EEMD | ensemble empirical mode decomposition |
| ELM | extreme learning machine |
| ECE | European Climate Exchange |
| ARIMA | autoregressive integrated moving average model |
| ANFIS | adaptive neuro-fuzzy inference system |
| IMF | Intrinsic Mode Functions |
| ADMM | alternate direction method of multipliers |
| EM | expectation-maximization algorithm |
| MAPE | mean absolute percentage error |
| MAE | mean absolute error |
| RMSE | root mean square error |
References
- Zhu, B.; Ye, S.; Wang, P.; He, K.; Zhang, T.; Wei, Y.-M. A novel multiscale nonlinear ensemble leaning paradigm for carbon price forecasting. Energy Econo. 2018, 70, 143–157. [Google Scholar] [CrossRef]
- Ju, Y.; Fujikawa, K. Modeling the cost transmission mechanism of the emission trading scheme in China. Appl. Energy 2019, 236, 172–182. [Google Scholar] [CrossRef]
- Zhu, B.; Han, D.; Wang, P.; Wu, Z.; Zhang, T.; Wei, Y.-M. Forecasting carbon price using empirical mode decomposition and evolutionary least squares support vector regression. Appl. Energy 2017, 191, 521–530. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, S. The impacts of GDP, trade structure, exchange rate and FDI inflows on China’s carbon emissions. Energy Policy 2018, 120, 347–353. [Google Scholar] [CrossRef]
- International Energy Agency. CO2 Emissions from Fuel Combustion Highlights; International Energy Agency: Paris, France, 2017; Available online: http://t.cn/REVfVt7 (accessed on 20 December 2018).
- Janssens-Maenhout, G.; Crippa, M.; Guizzardi, D.; Muntean, M.; Schaaf, E.; Olivier, J.G.J.; Peters, J.A.H.W.; Schure, K.M. Fossil CO2 and GHG emissions of all world countries. Publ. Off. Eur. Union 2017. [Google Scholar] [CrossRef]
- Zhou, K.; Li, Y. An Empirical Analysis of Carbon Emission Price in China. Energy Procedia 2018, 152, 823–828. [Google Scholar] [CrossRef]
- Zhu, B.; Shi, X.; Chevallier, J.; Wang, P.; Wei, Y.-M. An Adaptive Multiscale Ensemble Learning Paradigm for Nonstationary and Nonlinear Energy Price Time Series Forecasting. J. Forecast. 2016, 35, 633–651. [Google Scholar] [CrossRef]
- Zhang, Y.-J.; Wei, Y.-M. An overview of current research on EU ETS: Evidence from its operating mechanism and economic effect. Appl. Energy 2010, 87, 1804–1814. [Google Scholar] [CrossRef]
- Guðbrandsdóttir, H.N.; Haraldsson, H.Ó. Predicting the Price of EU ETS Carbon Credits. Syst. Eng. Procedia 2011, 1, 481–489. [Google Scholar] [CrossRef]
- Paolella, M.S.; Taschini, L. An econometric analysis of emission allowance prices. J. Bank. Financ. 2008, 32, 2022–2032. [Google Scholar] [CrossRef]
- Chevallier, J.; Sévi, B. On the realized volatility of the ECX CO2 emissions 2008 futures contract: Distribution, dynamics and forecasting. Ann. Financ. 2011, 7, 1–29. [Google Scholar] [CrossRef]
- Zhu, Z.B.; Ming, W.Y. Carbon price prediction based on integration of GMDH, particle swarm optimization and least squares support vector machines. Syst. Eng.-Theory Pract. 2011, 31, 2264–2271. [Google Scholar]
- Fan, X.; Li, S.; Tian, L. Chaotic characteristic identification for carbon price and an multi-layer perceptron network prediction model. Expert Syst. Appl. 2015, 42, 3945–3952. [Google Scholar] [CrossRef]
- Wang, J.; Wang, Y.; Li, Y. A Novel Hybrid Strategy Using Three-Phase Feature Extraction and a Weighted Regularized Extreme Learning Machine for Multi-Step Ahead Wind Speed Prediction. Energies 2018, 11, 321. [Google Scholar] [CrossRef]
- Wang, R.; Li, J.; Wang, J.; Gao, C. Research and Application of a Hybrid Wind Energy Forecasting System Based on Data Processing and an Optimized Extreme Learning Machine. Energies 2018, 11, 1712. [Google Scholar] [CrossRef]
- Dong, Y.; Wang, J.; Wang, C.; Guo, Z. Research and Application of Hybrid Forecasting Model Based on an Optimal Feature Selection System—A Case Study on Electrical Load Forecasting. Energies 2017, 10, 490. [Google Scholar] [CrossRef]
- Dong, Y.; Ma, X.; Ma, C.; Wang, J. Research and Application of a Hybrid Forecasting Model Based on Data Decomposition for Electrical Load Forecasting. Energies 2016, 9, 1050. [Google Scholar] [CrossRef]
- Sun, G.; Chen, T.; Wei, Z.; Sun, Y.; Zang, H.; Chen, S. A Carbon Price Forecasting Model Based on Variational Mode Decomposition and Spiking Neural Networks. Energies 2016, 9, 54. [Google Scholar] [CrossRef]
- Zhou, J.; Yu, X.; Yuan, X. Predicting the Carbon Price Sequence in the Shenzhen Emissions Exchange Using a Multiscale Ensemble Forecasting Model Based on Ensemble Empirical Mode Decomposition. Energies 2018, 11, 1907. [Google Scholar] [CrossRef]
- Zhu, B.; Wei, Y. Carbon price forecasting with a novel hybrid ARIMA and least squares support vector machines methodology. Omega 2013, 41, 517–524. [Google Scholar] [CrossRef]
- Atsalakis, G.S. Using computational intelligence to forecast carbon prices. Appl. Soft Comput. 2016, 43, 107–116. [Google Scholar] [CrossRef]
- Guo, Z.; Zhao, W.; Lu, H.; Wang, J. Multi-step forecasting for wind speed using a modified EMD-based artificial neural network model. Renew. Energy 2012, 37, 241–249. [Google Scholar] [CrossRef]
- Wang, J.; Yang, W.; Du, P.; Li, Y. Research and application of a hybrid forecasting framework based on multi-objective optimization for electrical power system. Energy 2018, 148, 59–78. [Google Scholar] [CrossRef]
- Wang, J.; Li, Y. Multi-step ahead wind speed prediction based on optimal feature extraction, long short term memory neural network and error correction strategy. Appl. Energy 2018, 230, 429–443. [Google Scholar] [CrossRef]
- Upadhyay, A.; Pachori, R.B. Instantaneous voiced/non-voiced detection in speech signals based on variational mode decomposition. J. Frank. Inst. 2015, 352, 2679–2707. [Google Scholar] [CrossRef]
- Huang, S.-C.; Wu, T.-K. Combining wavelet-based feature extractions with relevance vector machines for stock index forecasting. Expert Syst. 2008, 25, 133–149. [Google Scholar] [CrossRef]
- Fei, S.-W.; He, Y. Wind speed prediction using the hybrid model of wavelet decomposition and artificial bee colony algorithm-based relevance vector machine. Int. J. Electr. Power Energy Syst. 2015, 73, 625–631. [Google Scholar] [CrossRef]
- Alamaniotis, M.; Bargiotas, D.; Bourbakis, N.G.; Tsoukalas, L.H. Genetic Optimal Regression of Relevance Vector Machines for Electricity Pricing Signal Forecasting in Smart Grids. IEEE Trans. Smart Grid 2015, 6, 2997–3005. [Google Scholar] [CrossRef]
- Li, T.; Zhou, M.; Guo, C.; Luo, M.; Wu, J.; Pan, F.; Tao, Q.; He, T. Forecasting Crude Oil Price Using EEMD and RVM with Adaptive PSO-Based Kernels. Energies 2016, 9, 1014. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, H.; Srinivasan, D.; Hu, Q. Robust functional regression for wind speed forecasting based on Sparse Bayesian learning. Renew. Energy 2019, 132, 43–60. [Google Scholar] [CrossRef]
- Wang, Y.; Xie, Z.; Hu, Q.; Xiong, S. Correlation aware multi-step ahead wind speed forecasting with heteroscedastic multi-kernel learning. Energy Convers. Manag. 2018, 163, 384–406. [Google Scholar] [CrossRef]
- Thayananthan, A.; Navaratnam, R.; Stenger, B.; Torr, P.H.S.; Cipolla, R. Pose estimation and tracking using multivariate regression. Pattern Recognit. Lett. 2008, 29, 1302–1310. [Google Scholar] [CrossRef]
- Ha, Y. Fast multi-output relevance vector regression. arXiv, 2017; arXiv:1704.05041. [Google Scholar]
- Du, P.; Wang, J.; Yang, W.; Niu, T. Multi-step ahead forecasting in electrical power system using a hybrid forecasting system. Renew. Energy 2018, 122, 533–550. [Google Scholar] [CrossRef]
- Heng, J.; Wang, J.; Xiao, L.; Lu, H. Research and application of a combined model based on frequent pattern growth algorithm and multi-objective optimization for solar radiation forecasting. Appl. Energy 2017, 208, 845–866. [Google Scholar] [CrossRef]
- Wang, J.; Heng, J.; Xiao, L.; Wang, C. Research and application of a combined model based on multi-objective optimization for multi-step ahead wind speed forecasting. Energy 2017, 125, 591–613. [Google Scholar] [CrossRef]
- Niu, T.; Wang, J.; Zhang, K.; Du, P. Multi-step-ahead wind speed forecasting based on optimal feature selection and a modified bat algorithm with the cognition strategy. Renew. Energy 2018, 118, 213–229. [Google Scholar] [CrossRef]
- Wang, J.; Du, P.; Niu, T.; Yang, W. A novel hybrid system based on a new proposed algorithm—Multi-Objective Whale Optimization Algorithm for wind speed forecasting. Appl. Energy 2017, 208, 344–360. [Google Scholar] [CrossRef]
- Dragomiretskiy, K.; Zosso, D. Variational Mode Decomposition. IEEE Trans. Signal Process. 2014, 62, 531–544. [Google Scholar] [CrossRef]
- Tipping, M.E. Sparse bayesian learning and the relevance vector machine. J. Mach. Learn. Res. 2001, 1, 211–244. [Google Scholar] [CrossRef]
- Thayananthan, A. Template-based Pose Estimation and Tracking of 3D Hand Motion. Ph.D. Thesis, University of Cambridge, Cambridge, UK, 2005. [Google Scholar]
- Mirjalili, S.; Lewis, A. The Whale Optimization Algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Edgeworth, F.Y. Mathematical Physics; P. Keagan: London, UK, 1881. [Google Scholar]
- Pareto, V. Cours D’économie Politique; Librairie Droz: Genève, Suisse, 1964; Volume 1. [Google Scholar]
- Niu, T.; Wang, J.; Lu, H.; Du, P. Uncertainty modeling for chaotic time series based on optimal multi-input multi-output architecture: Application to offshore wind speed. Energy Convers. Manag. 2018, 156, 597–617. [Google Scholar] [CrossRef]
- Carbon Market Data. Available online: http://k.tanjiaoyi.com/ (accessed on 19 September 2018).
- Chen, Z.; Wang, B.; Gorban, A.N. Multivariate Gaussian and Student$-t$ Process Regression for Multi-output Prediction. arXiv, 2017; arXiv:1703.04455. [Google Scholar]
- Hu, J.; Wang, J.; Xiao, L. A hybrid approach based on the Gaussian process with t-observation model for short-term wind speed forecasts. Renew. Energy 2017, 114, 670–685. [Google Scholar] [CrossRef]
- Hu, J.; Wang, J. Short-term wind speed prediction using empirical wavelet transform and Gaussian process regression. Energy 2015, 93, 1456–1466. [Google Scholar] [CrossRef]
- Tuia, D.; Verrelst, J.; Alonso, L.; Perez-Cruz, F.; Camps-Valls, G. Multioutput Support Vector Regression for Remote Sensing Biophysical Parameter Estimation. IEEE Geosci. Remote Sens. Lett. 2011, 8, 804–808. [Google Scholar] [CrossRef]
- Werbos, P. Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Sciences. Ph.D. Dissertation, Harvard University, Cambridge, MA, USA, 1974. [Google Scholar]
- Rumelhart, D.E.; Mcclelland, J.L. Parallel Distributed Processing: Explorations in the Microstructure of Cognition. Volume 1. Foundations; MIT Press: Cambridge, MA, USA, 1986; p. 564. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Asset | Data | Count | Mean | Std | Min | 25% | 50% | 75% | Max | Skew | Kurt |
|---|---|---|---|---|---|---|---|---|---|---|---|
| All samples | 496 | 29.99 | 5.23 | 19.80 | 25.91 | 29.81 | 33.23 | 46.20 | 0.47 | −0.14 | |
| SZA2016 | Training | 350 | 29.09 | 4.53 | 19.80 | 25.60 | 28.99 | 32.39 | 42.00 | 0.22 | −0.31 |
| Testing | 146 | 32.13 | 6.12 | 20.64 | 26.87 | 30.63 | 36.83 | 46.20 | 0.28 | −0.92 | |
| All samples | 496 | 13.74 | 1.52 | 9.80 | 12.87 | 13.70 | 14.69 | 18.90 | 0.27 | 0.86 | |
| GDEA | Training | 350 | 13.62 | 1.71 | 9.80 | 12.59 | 13.50 | 14.70 | 18.90 | 0.42 | 0.43 |
| Testing | 146 | 14.01 | 0.86 | 12.00 | 13.29 | 13.99 | 14.63 | 16.35 | 0.09 | −0.51 | |
| All samples | 496 | 16.62 | 3.39 | 11.26 | 14.93 | 15.85 | 17.29 | 29.70 | 2.05 | 4.64 | |
| HBEA | Training | 350 | 15.73 | 1.91 | 11.26 | 14.31 | 15.70 | 16.91 | 19.97 | 0.09 | −0.57 |
| Testing | 146 | 18.76 | 4.90 | 14.07 | 15.46 | 16.54 | 20.40 | 29.70 | 1.14 | −0.34 |
| Metric | Definition | Equation |
|---|---|---|
| MAPE | the mean absolute percentage error | (1) |
| MAE | the mean absolute error | (2) |
| RMSE | the root mean of square error | (3) |
| Modules | Parameter | Value |
|---|---|---|
| VMD | Number of IMFs (Intrinsic Mode Functions ) | 6 |
| Omegas initialization | Uniformly distributed | |
| Tolerance of convergence criterion | 10−7 | |
| FMRVR | Width of kernel function | Select within [0.1,5] |
| Input lags | Select within [1,20] | |
| Kernel type | Gaussian kernel | |
| Maximum iteration number of EM (expectation-maximization) algorithm | 1000 | |
| Tolerance value to check convergence of EM algorithm | 0.1 | |
| MOWOA | Number of search agents | 10 |
| Maximum number of iterations | 20 | |
| Maximum number of archives | 10 | |
| The dimension of the problem | 3 |
| Models | 1-Step | 2-Step | 3-Step | ||||||
|---|---|---|---|---|---|---|---|---|---|
| MAPE | MAE | RMSE | MAPE | MAE | RMSE | MAPE | MAE | RMSE | |
| VMD-FMRVR-MOWOA | 6.738% | 2.164 | 2.655 | 8.278% | 2.677 | 3.373 | 9.646% | 3.122 | 4.009 |
| FMRVR-MOWOA | 7.538% | 2.405 | 2.960 | 9.310% | 3.001 | 3.757 | 11.057% | 3.565 | 4.449 |
| MOTP-MOWOA | 8.715% | 2.812 | 3.522 | 10.830% | 3.484 | 4.309 | 12.081% | 3.896 | 4.749 |
| MOGP-MOWOA | 9.215% | 3.076 | 4.198 | 10.526% | 3.495 | 4.574 | 11.448% | 3.752 | 4.772 |
| MSVR | 8.237% | 2.708 | 3.525 | 10.015% | 3.269 | 4.283 | 11.484% | 3.798 | 5.012 |
| BPNN | 7.724% | 2.477 | 3.135 | 9.361% | 3.018 | 3.932 | 10.457% | 3.367 | 4.390 |
| MODELS | 1-Step | 2-Step | 3-Step | ||||||
|---|---|---|---|---|---|---|---|---|---|
| MAPE | MAE | RMSE | MAPE | MAE | RMSE | MAPE | MAE | RMSE | |
| VMD-FMRVR-MOWOA | 2.944% | 0.411 | 0.570 | 3.422% | 0.478 | 0.662 | 3.620% | 0.504 | 0.694 |
| FMRVR-MOWOA | 3.117% | 0.435 | 0.593 | 3.607% | 0.502 | 0.700 | 3.796% | 0.526 | 0.735 |
| MOTP-MOWOA | 3.005% | 0.419 | 0.579 | 3.717% | 0.518 | 0.709 | 3.873% | 0.536 | 0.748 |
| MOGP-MOWOA | 2.981% | 0.414 | 0.570 | 3.537% | 0.492 | 0.676 | 3.666% | 0.508 | 0.701 |
| MSVR | 3.489% | 0.486 | 0.654 | 3.994% | 0.558 | 0.782 | 4.183% | 0.583 | 0.819 |
| BPNN | 3.128% | 0.436 | 0.599 | 3.679% | 0.518 | 0.731 | 4.107% | 0.571 | 0.805 |
| MODELS | 1-Step | 2-Step | 3-Step | ||||||
|---|---|---|---|---|---|---|---|---|---|
| MAPE | MAE | RMSE | MAPE | MAE | RMSE | MAPE | MAE | RMSE | |
| VMD-FMRVR-MOWOA | 2.018% | 0.390 | 0.565 | 2.668% | 0.549 | 0.856 | 3.149% | 0.677 | 1.125 |
| FMRVR-MOWOA | 3.506% | 0.799 | 1.143 | 3.969% | 0.899 | 1.186 | 4.267% | 0.975 | 1.250 |
| MOTP-MOWOA | 6.271% | 1.561 | 2.615 | 6.666% | 1.632 | 2.577 | 6.665% | 1.630 | 2.420 |
| MOGP-MOWOA | 6.792% | 1.596 | 2.228 | 7.302% | 1.711 | 2.322 | 7.645% | 1.804 | 2.419 |
| MSVR | 5.046% | 1.236 | 2.038 | 5.303% | 1.273 | 1.934 | 5.299% | 1.268 | 1.807 |
| BPNN | 7.701% | 1.948 | 3.343 | 8.928% | 2.248 | 3.719 | 8.747% | 2.194 | 3.515 |
| Metric | Definition | Equation |
|---|---|---|
| improvement ratio of MAPE | (4) | |
| improvement ratio of MAE | (5) | |
| improvement ratio of RMSE | (6) |
| MODELS | SZA2016 | GDEA | HBEA | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 1-Step | 2-Step | 3-Step | 1-Step | 2-Step | 3-Step | 1-Step | 2-Step | 3-Step | |
| FMRVR-MOWOA | 10.614% | 11.082% | 12.763% | 5.551% | 5.146% | 4.643% | 42.440% | 32.777% | 26.191% |
| MOTP-MOWOA | 22.689% | 23.566% | 20.153% | 2.030% | 7.950% | 6.533% | 67.824% | 59.977% | 52.748% |
| MOGP-MOWOA | 26.886% | 21.359% | 15.744% | 1.221% | 3.244% | 1.252% | 70.292% | 63.464% | 58.804% |
| MSVR | 18.201% | 17.340% | 16.007% | 15.608% | 14.321% | 13.457% | 60.010% | 49.690% | 40.573% |
| BPNN | 12.765% | 11.571% | 7.755% | 5.875% | 6.991% | 11.854% | 73.797% | 70.117% | 63.997% |
| MODELS | SZA2016 | GDEA | HBEA | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 1-Step | 2-Step | 3-Step | 1-Step | 2-Step | 3-Step | 1-Step | 2-Step | 3-Step | |
| FMRVR-MOWOA | 10.035% | 10.821% | 12.415% | 5.545% | 4.811% | 4.111% | 51.278% | 38.932% | 30.576% |
| MOTP-MOWOA | 23.049% | 23.172% | 19.869% | 1.917% | 7.665% | 5.957% | 75.050% | 66.372% | 58.452% |
| MOGP-MOWOA | 29.656% | 23.421% | 16.795% | 0.840% | 2.790% | 0.648% | 75.602% | 67.926% | 62.478% |
| MSVR | 20.103% | 18.127% | 17.798% | 15.478% | 14.359% | 13.419% | 68.478% | 56.888% | 46.598% |
| BPNN | 12.629% | 11.312% | 7.277% | 5.795% | 7.598% | 11.597% | 80.006% | 75.583% | 69.135% |
| MODELS | SZA2016 | GDEA | HBEA | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 1-Step | 2-Step | 3-Step | 1-Step | 2-Step | 3-Step | 1-Step | 2-Step | 3-Step | |
| FMRVR-MOWOA | 10.301% | 10.230% | 9.874% | 3.984% | 5.417% | 5.559% | 50.561% | 27.837% | 9.989% |
| MOTP-MOWOA | 24.634% | 21.730% | 15.574% | 1.670% | 6.596% | 7.167% | 78.384% | 66.798% | 53.507% |
| MOGP-MOWOA | 36.767% | 26.261% | 15.973% | 0.052% | 2.041% | 0.972% | 74.634% | 63.151% | 53.480% |
| MSVR | 24.696% | 21.241% | 20.007% | 12.838% | 15.338% | 15.198% | 72.270% | 55.757% | 37.723% |
| BPNN | 15.328% | 14.215% | 8.662% | 4.870% | 9.491% | 13.768% | 83.095% | 76.993% | 67.986% |
| MAPE | MAE | RMSE | |||||||
|---|---|---|---|---|---|---|---|---|---|
| MODELS | 1-Step | 2-Step | 3-Step | 1-Step | 2-Step | 3-Step | 1-Step | 2-Step | 3-Step |
| FMRVR-MOWOA | 19.535% | 16.335% | 14.532% | 22.286% | 18.188% | 15.701% | 21.615% | 14.495% | 8.474% |
| MOTP-MOWOA | 30.848% | 30.498% | 26.478% | 33.339% | 32.403% | 28.093% | 34.896% | 31.708% | 25.416% |
| MOGP-MOWOA | 32.799% | 29.356% | 25.267% | 35.366% | 31.379% | 26.640% | 37.151% | 30.484% | 23.475% |
| MSVR | 31.273% | 27.117% | 23.346% | 34.686% | 29.791% | 25.938% | 36.601% | 30.779% | 24.309% |
| BPNN | 30.813% | 29.559% | 27.869% | 32.810% | 31.498% | 29.336% | 34.431% | 33.566% | 30.139% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiong, S.; Wang, C.; Fang, Z.; Ma, D. Multi-Step-Ahead Carbon Price Forecasting Based on Variational Mode Decomposition and Fast Multi-Output Relevance Vector Regression Optimized by the Multi-Objective Whale Optimization Algorithm. Energies 2019, 12, 147. https://doi.org/10.3390/en12010147
Xiong S, Wang C, Fang Z, Ma D. Multi-Step-Ahead Carbon Price Forecasting Based on Variational Mode Decomposition and Fast Multi-Output Relevance Vector Regression Optimized by the Multi-Objective Whale Optimization Algorithm. Energies. 2019; 12(1):147. https://doi.org/10.3390/en12010147
Chicago/Turabian StyleXiong, Shenghua, Chunfeng Wang, Zhenming Fang, and Dan Ma. 2019. "Multi-Step-Ahead Carbon Price Forecasting Based on Variational Mode Decomposition and Fast Multi-Output Relevance Vector Regression Optimized by the Multi-Objective Whale Optimization Algorithm" Energies 12, no. 1: 147. https://doi.org/10.3390/en12010147
APA StyleXiong, S., Wang, C., Fang, Z., & Ma, D. (2019). Multi-Step-Ahead Carbon Price Forecasting Based on Variational Mode Decomposition and Fast Multi-Output Relevance Vector Regression Optimized by the Multi-Objective Whale Optimization Algorithm. Energies, 12(1), 147. https://doi.org/10.3390/en12010147