1. Introduction
Programs in a real-time systems should be executed as fast as possible. However, the execution speed can severely affect the system’s energy consumption [
1,
2]. For a battery-powered real-time system, since the energy is limited, a tradeoff between energy consumption and execution time is necessary [
3]. But the precondition is that the execution time of all programs should meet the related deadline constraints. Otherwise it may lead to casualty, environmental damage, property loss and other disasters. In order to ensure safety, one primary task during designing such real-time systems is to accurately estimate the program’s worst-case execution time (WCET). WCET estimations are key parameters for the evaluation of software safety and the optimization of energy consumption.
A program’s WCET conventionally refers to the upper execution time bound
B on a processor X with normal voltage and frequency [
4]. Since WCET is influenced by many factors, such as inputs and control flow structure of the program, architecture and initial status of the processor, it is nearly impossible to obtain the actual value. Therefore, developers have to estimate WCET by measurement or analysis [
5]. Conventionally, WCET measurement is an unsafe approach [
6]. WCET analysis [
7] calculates WCET through analyzing the control flow of the program. Due to using abstract interpretation [
8] for modeling hardware (i.e., micro-architecture), calculated WCET is positively larger than the actual WCET. Therefore, WCET analysis is a safe approach.
For WCET analysis, overestimation is unavoidable and is even beneficial to ensure safety. However, from the perspective of software development, unreasonable WCET overestimation would seriously underestimate program performance, cause unnecessary optimization, raise development costs and even delay system delivery. From the perspective of task scheduling, it would waste a lot of system resources or energies, and even cause scheduling failure due to illusory resource scarcity.
In order to obtain a tighter WCET estimation, we propose a novel approach to reduce a kind of specific WCET overestimation. The overestimation occurs on the programs which contain non-orthogonal nested loops and their loop bounds cannot be expressed by integral constraints. So, the correction approach we proposed has three basic steps. The first step is to locate worst-case execution path (WCEP) in control flow graphs and then map it onto source code. The second step is to identify the non-orthogonal nested loops from the WCEP by means of an abstract syntax tree. The last step is to recursively calculate the WCET errors caused by the loose loop bound constraints, and then subtract the total errors from the overestimations. The novelty lies in the fact that the WCET correction is only conducted on the non-branching parts of the WCEP. The benefits are twofold: firstly, it saves overhead; code outside WCEP is excluded since it does not make contributions to WCET; secondly, it is safe because no WCEP switch was (or will be) triggered.
The remainder of this paper is organized as follows.
Section 2 gives a brief review of related work;
Section 3 analyzes the reasons for the WCET overestimations;
Section 4 demonstrates the specific situation which causes the WCET overestimations;
Section 5 proposes the approach to WCET correction and then proves the safety of its kernel algorithm;
Section 6 experimentally demonstrates the safety and effectiveness of the whole approach, and discusses the threats to the validity of the experimental results; the paper is concluded by
Section 7.
2. Related Work
Reducing WCET overestimation is essential to obtain a more precise WCET estimation. Many techniques, such as virtual inlining and virtual unrolling (VIVU) [
9,
10], multilayer persistence analysis [
11,
12], dead code elimination and infeasible path detection [
13,
14], can increase the accuracy of WCET analysis. Since our research is closely related to loop bounds, this section introduces related work mainly surrounding the computation of loop bounds.
Loop bound computation already has many research achievements. These approaches usually employ model checking [
15], pattern matching [
16], symbolic execution [
17,
18], abstract interpretation [
19], or other techniques to obtain precise loop bounds. For example, Maroneze [
20] and Blazy et al. [
21] proposed a novel approach which has three steps: loop extraction, program slicing and bound calculation. With the help of CompCert compiler, the approach can handle loop nesting and compute safe over-approximation bounds on the register transfer language (RTL) intermediate representation. Sewell et al. [
22] developed a translation–validation apparatus, based on which some source-level information missing in the binary can be used again. Thus, their approach can automatically determine high-assurance loop bounds. Pavel et al. [
23] presented a new algorithm based on symbolic execution to compute more precise loop bounds for nested loops. The algorithm sums the bounds for the inner loop over all iterations of the outer, thus produced bounds are tighter than other approaches.
Tighter loop bounds undoubtedly make the WCET estimation more accurate. But to the best of our knowledge, any single approach cannot automatically handle all forms of loops. Therefore, the loop bound sometimes has to be provided by programmers. Aiming at this situation, our approach can generate references to max iteration counts for programmers by code instrumentation. However, improving loop bound computation cannot solve the specific WCET overestimation because the overestimation is caused by the inherent shortcoming of IPET-based WCET calculation rather than loop bound computation.
3. Reasons for WCET Overestimation
As a classical approach, IPET-based WCET analysis commonly has three basic steps [
24]: (1)
Micro-architecture modeling (or called low-level analysis), regarding pipeline, cache, branch predictor and cycle-accurate timing, etc.; (2)
Control-flow Analysis (or called high-level analysis), such as control-flow reconstruction [
25,
26], loop bound analysis [
27,
28], etc.; (3)
WCET Calculating, using integral linear programming (ILP) to compute a final result.
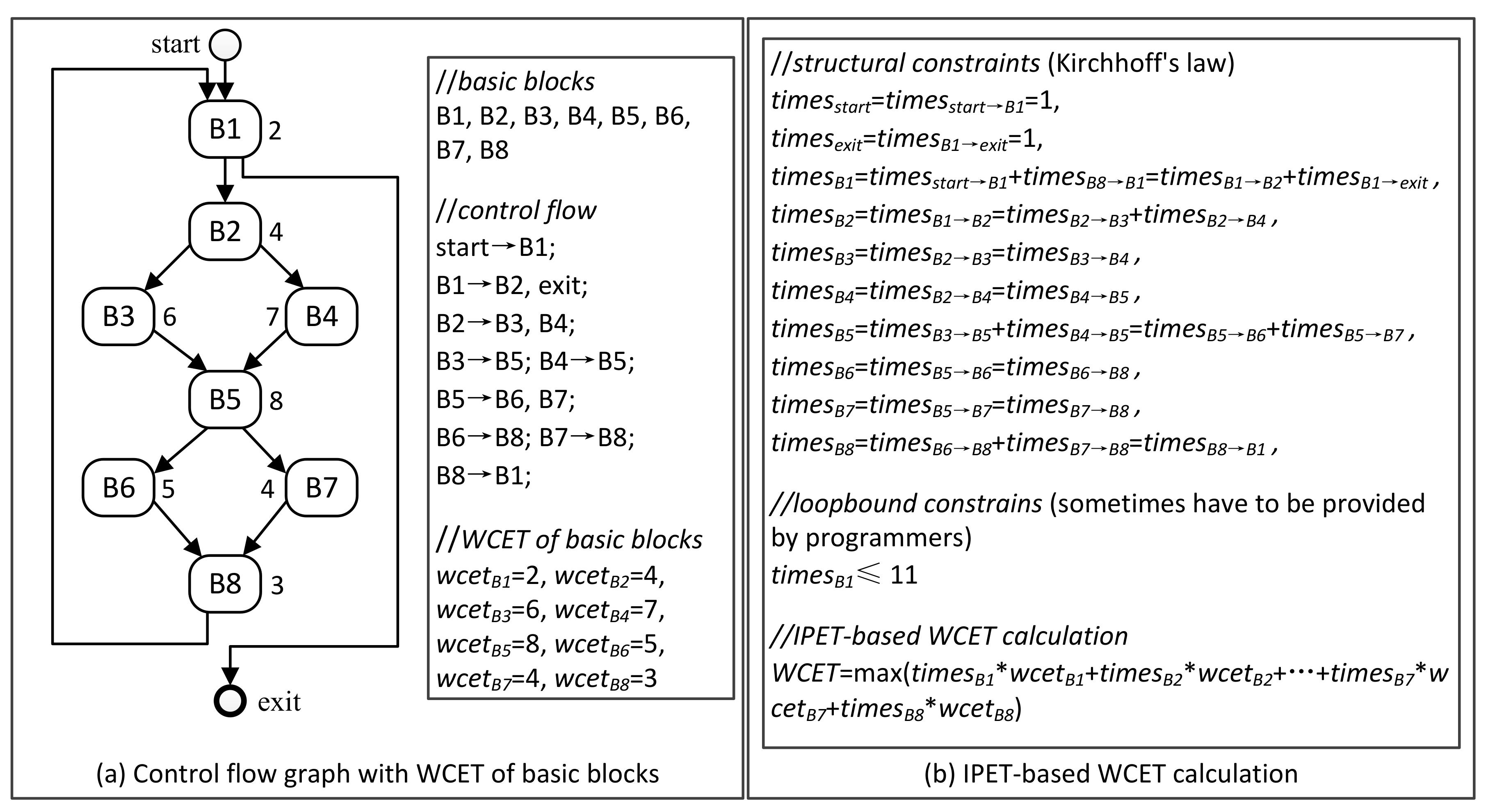
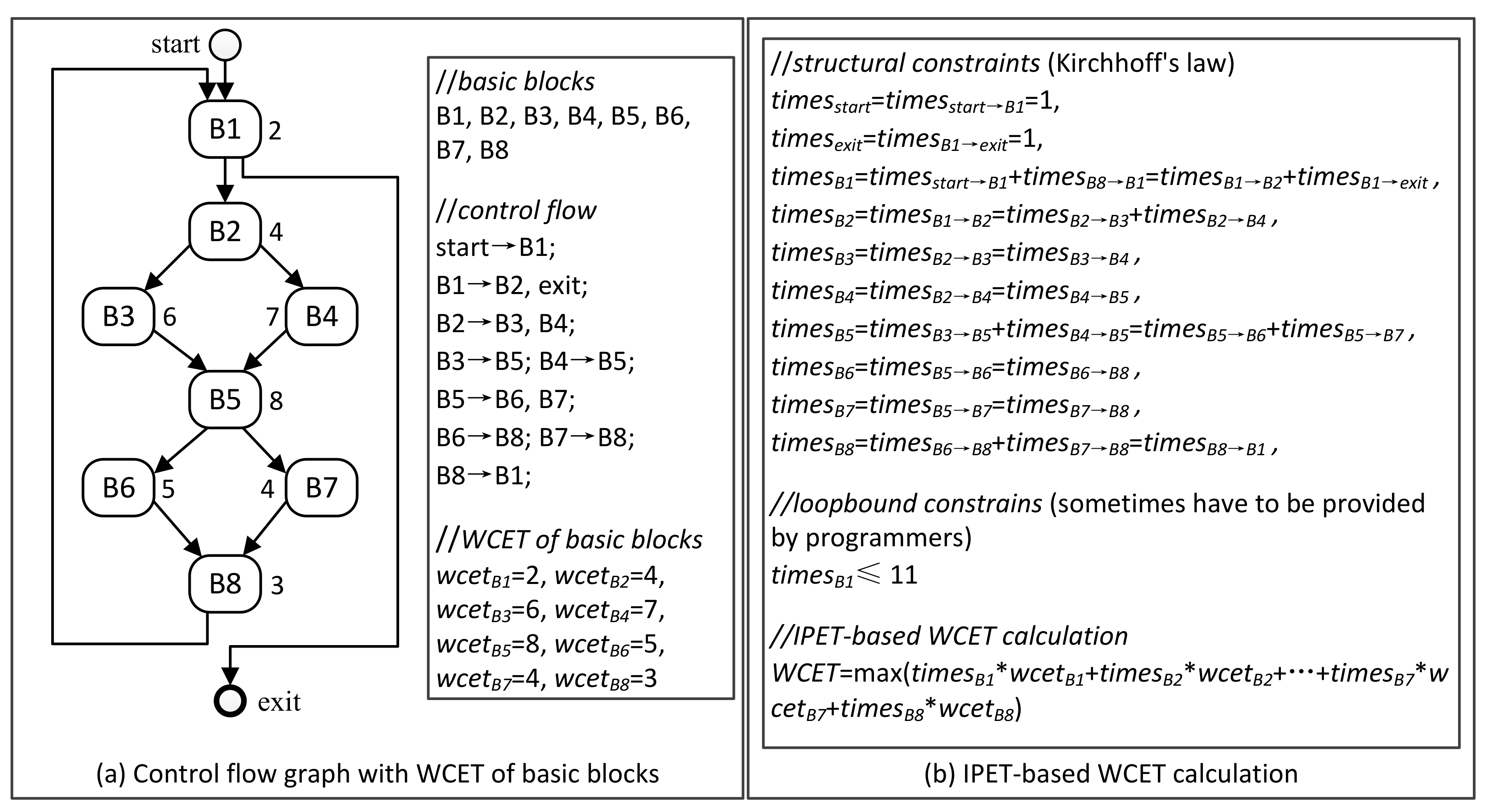
Figure 1 shows the principle of IPET-based WCET analysis, including a control-flow graph (CFG) generated by high-level analysis and IPET-based WCET calculation.
Definition 1. (Control Flow Graph [29]) a control flow graph G = (V, E) in which V is the set of all nodes and E is the set of all edges. Each node v ∈ V is a basic block, and each edge e ∈ E connects two nodes vi, vj ∈ V. 3.1. Overestimation in Micro-Architecture Modeling
IPET (implicit path enumeration technique) [
31,
32] is to establish a series of linear constraints for execution counts of each basic block according to the CFG, and then calculate the maximum execution time by ILP (see Equation (1)). Note that a basic block is a piece of sequential instructions. Only the last instruction can be a jump instruction and only the first instruction can be a jump target.
where,
B denotes a basic block in the CFG;
B denotes the set of all basic blocks;
is the execution counts of basic block
B;
is the WCET of basic block
B.
Usually, can be obtained from the low-level analysis, while needs to be calculated with some given flow constraints, and the goal is to maximize WCET. From the Equation (1), it is easy to see that WCET overestimation may come from both micro-architecture modeling and control-flow analysis.
For micro-architecture modeling abstract interpretation [
33,
34,
35] has a dominant position. It uses cache behavior classification (i.e.,
always hit,
always miss,
first miss,
not classified, etc.) to abstractly express the actual situation of instruction fetch [
36]. The advantage is that state-explosion problems can be solved. However, since all
non-classified cache behaviors are treated as
always miss, the fetching time of many instructions is magnified [
37]. Consequently,
is overestimated. It is the most common reason for WCET overestimation.
3.2. Overestimation in Control-Flow Analysis
Normally,
can be calculated by using ILP. The calculation needs some flow constraints which can be generated on the basis of Kirchhoff's law, see Equation (2). In addition, users may have to manually provide some linear constraints to express loop bounds and any infeasible path information.
where,
denotes the counts control flow goes through the CFG edge
;
denotes the counts control flow goes through the CFG edge
.
In this article, loop bound refers to the maximum iteration counts of a loop statement. For a loop nesting, denoted , the loop bound of an inner loop is usually expressed as a constraint relationship relative to its outer loop. Take the following code as an example (Example 1). Obviously, the loop bound of outer for loop (denoted ) is 5. The loop bound of inner for loop (denoted ) is 25, and it can be expressed as , since executes five times in every execution of . However, for non-orthogonal nested loop, the relationship of maximum iteration counts between inner loop and outer loop is unclear.
| Example 1. A loop nesting with an orthogonal nested loop |
| 1 for ( int i = 0; i < 5; i++) |
| 2 for ( int j = 0; j < 5; j++) |
| 3 { k++; } |
Definition 2. (Orthogonal Nested Loop) For a loop nesting , if always has the same execution counts during every execution of , then loop is called an orthogonal nested loop.
For an orthogonal nested loop, its loop control variable is context free. Note that the concept of non-orthogonal nested loop is opposite to orthogonal nested loop. In this paper, if the iteration counts of a nested loop (i.e., inner loop) are wholly or partly dependent on the variables modified by the outside loop, then the inner loop is called “non-orthogonal” nested loop.
Set the following program as an example (Example 2). The maximum iteration counts of inner
while (Line 8) not only depend on control variable
i (Line 7, j = i), but also are relevant to the values of array
a. Thus, it is a typical non-orthogonal nested loop.
| Example 2. insertsort.c derived from WCET benchmarks (http://www.mrtc.mdh.se/projects/wcet/benchmarks.html) |
| 1 unsigned int a[11]; |
| 2 int main () |
| 3 { int i, j, temp; |
| 4 a[0] = 0; a[1] = 11; a[2] = 10; a[3] = 9; a[4] = 8; a[5] = 7; a[6] = 6; a[7] = 5; a[8] = 4; a[9] = 3; a[10] = 2; |
| 5 i = 2; |
| 6 while(i <= 10) |
| 7 { j = i; |
| 8 while (a[j] < a[j − 1]) //append condition “j <= 3” or “j <= 5” in Section 3 |
| 9 { temp = a[j]; a[j] = a[j − 1]; a[j − 1] = temp; j--; } |
| 10 i++; |
| 11 } |
| 12 return 1; |
| 13 } |
Considering the inner while loop runs at most nine times when the outer while loop runs once, to ensure safety, a pessimistic constraint can be used to express the loop bound of inner while loop. Since the iteration count of outer while loop is 9, the inequality makes the maximum iteration counts of inner while loop up to 81. However, the maximum iteration counts of inner while loop actually are 45, which is 1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 = 45. Therefore, a pessimistic constraint results in a WCET overestimation since of inner while loop is enlarged. To solve this overestimation problem, an absolute constraint can be appended according to the global maximum iteration counts of inner while. Then the WCET overestimation will be reduced.
Definition 3. (Pessimistic Constraint) pessimistic constraint refers to the loop bound of a nested loop statement expressed as the form , where and is the execution counts of the nested loop statement when its outer loop statement runs one time.
Definition 4. (Absolute Constraint) absolute constraint refers to the loop bound of a nested loop statement expressed as the form , where is the total execution counts of the nested loop statement when the whole program runs one time.
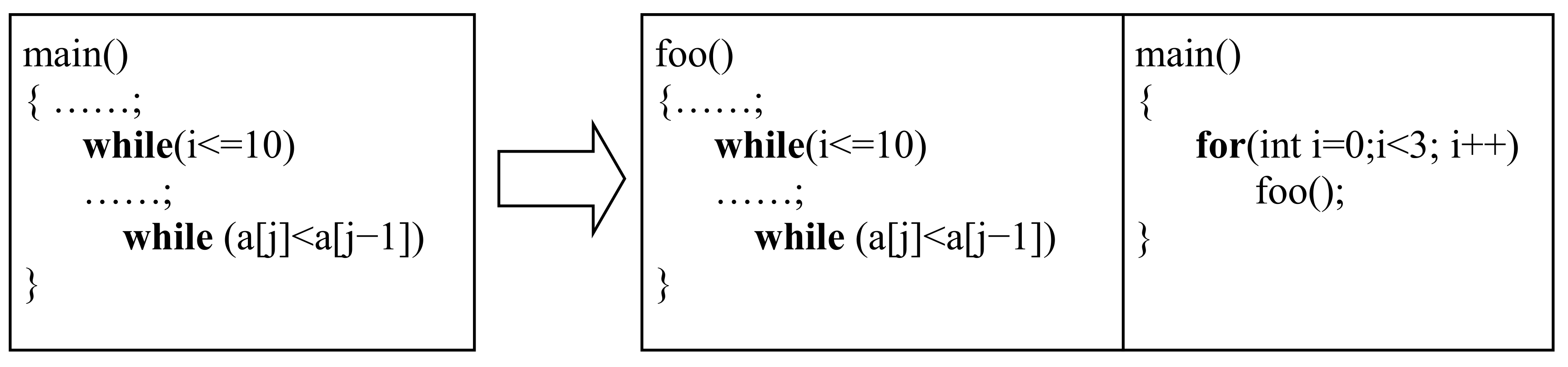
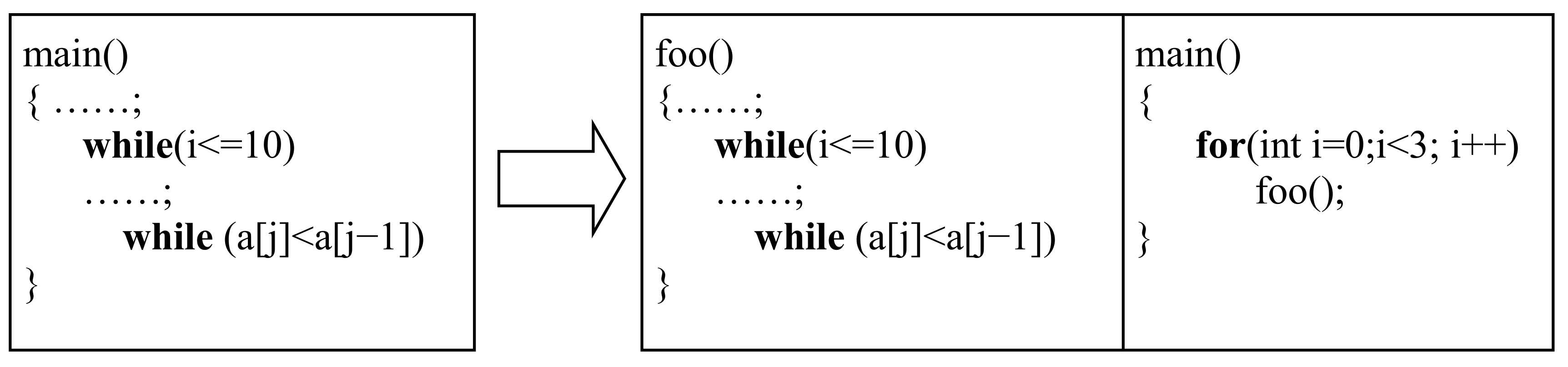
4. Specific WCET Overestimation
Supposing that the program in Example 2 was merely a part (or a function) of a long and complex program. For example, rename
main () to
foo (), and write a new
main () which invokes
foo () three times by a loop, see
Figure 2. As a result, 45 was no more the global maximum iteration counts of inner
while loop. So the constraint
was no more correct, and it should be
. To keep the useful knowledge of control flow, the local maximum iteration counts can be transformed into a new relative constraint
. It is because the local maximum iteration counts of outer
while loop are 9, and 45 ÷ 9 = 5. On the basis, since
, the actual global maximum iteration counts of inner
while loop will be
.
Definition 5. (Relative Constraint) relative constraint refers to the loop bound of a nested loop statement expressed as the form , where and , respectively is the execution counts of the nested loop statement and the outer loop statement when some function runs one time.
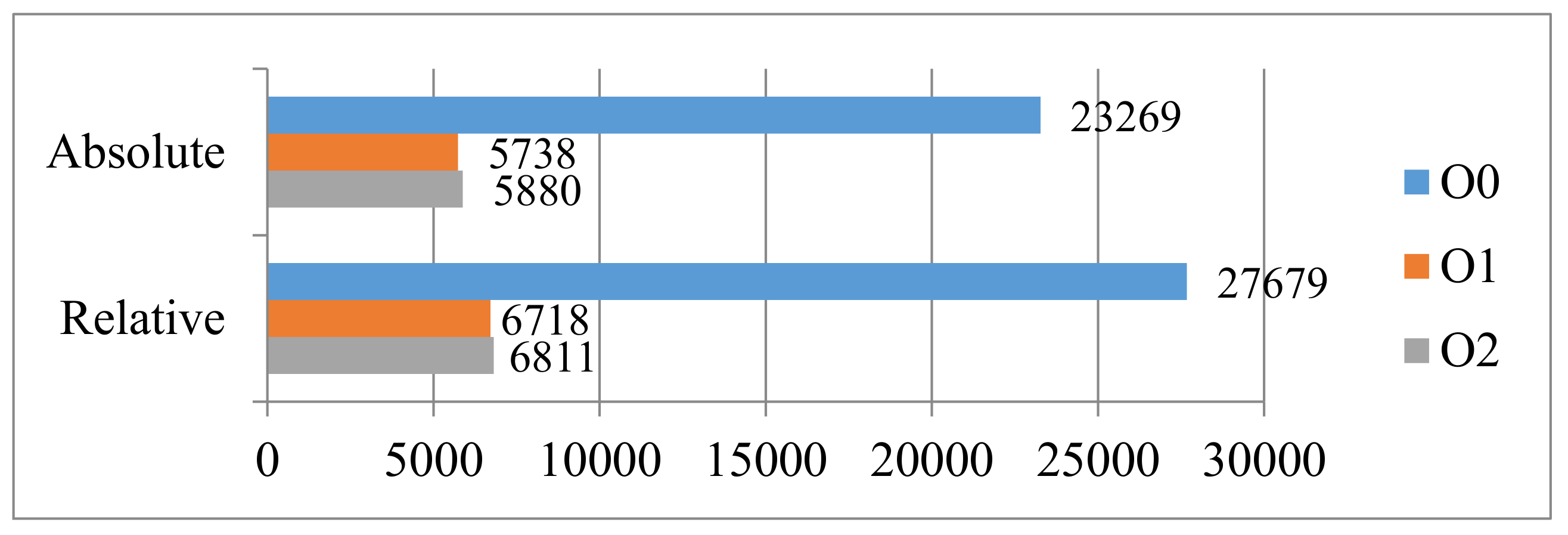
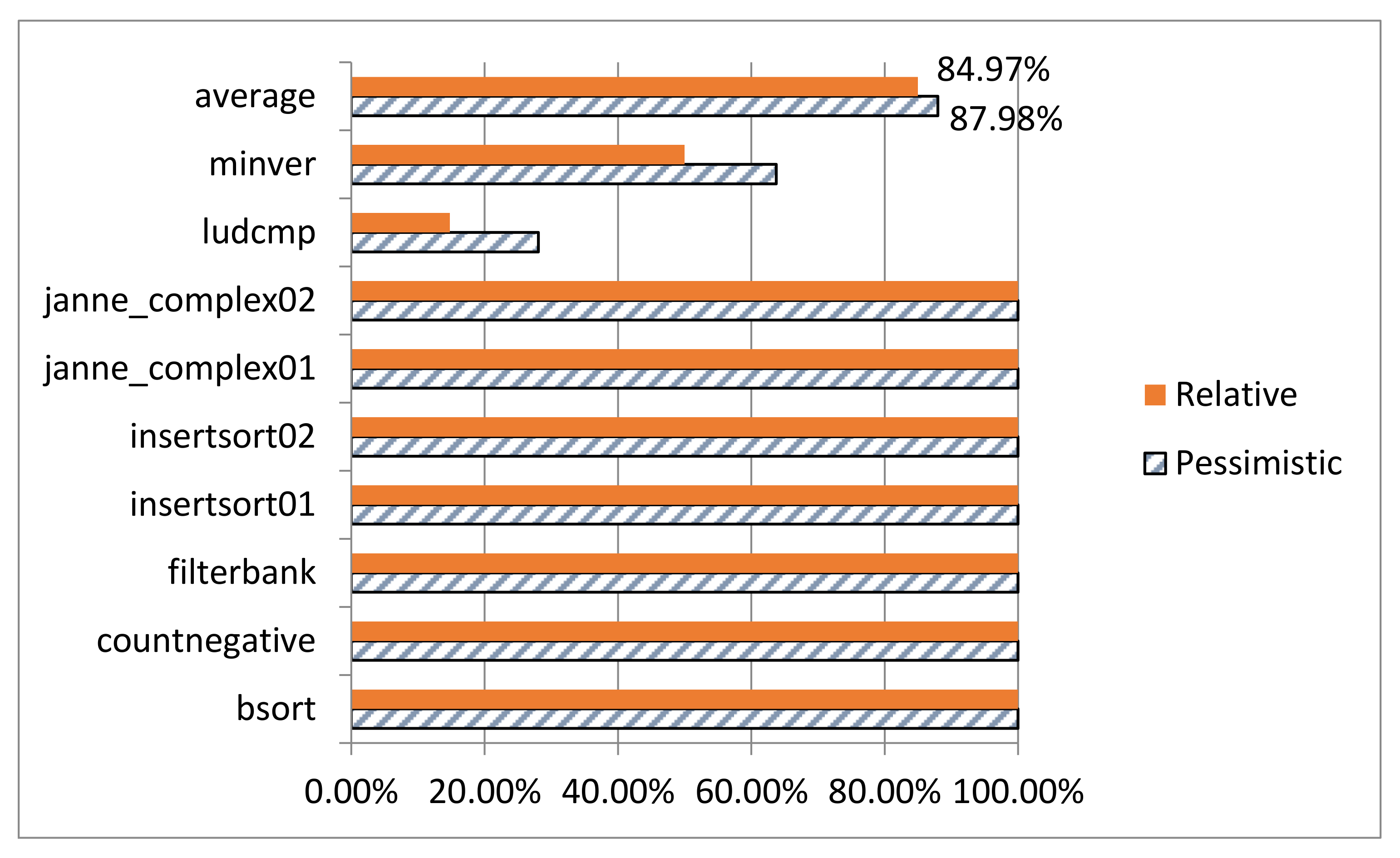
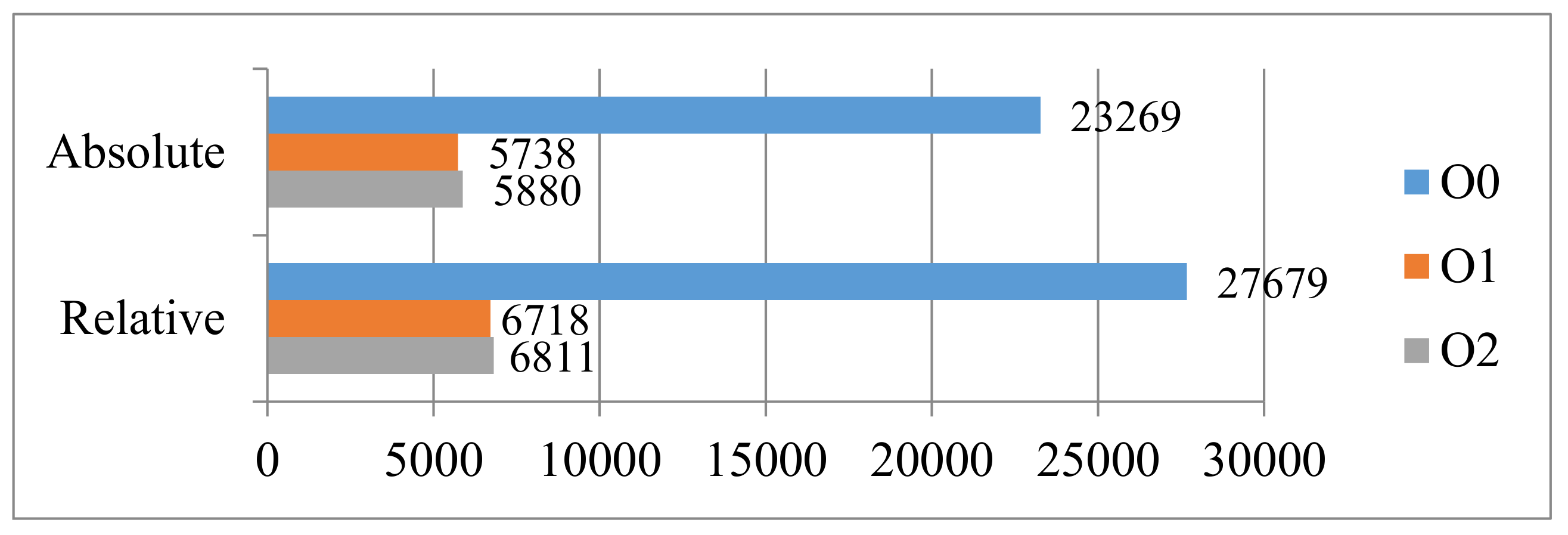
Table 1 shows the WCET estimations obtained by using different constraints. Note that the experimental tool is Chronos (
http://www.comp.nus.edu.sg/~rpembed/chronos/). Target processor is simple without cache and other complex architecture. The optimization level of compiler is
O1. The experimental results on “
insertsort” show that the relative constraint (Col. 3) has the same effect as the absolute constraint (Col. 4). They all reduce the overestimation caused by the pessimistic constraint (Col. 2).
However, not all non-orthogonal nested loops can transform their local maximum iteration counts into a relative integral constraint. For example, respectively replace the conditional expression “a[j] < a[j − 1]” of second while loop in Example 2 with “j <= 3 && a[j] < a[j − 1]” and “j <= 5 && a[j] < a[j − 1]” to generate two new programs, named insertsort01 and insertsort02. For insertsort01, the local maximum iteration counts of second loop are three. For insertsort02, the local maximum iteration counts of second loop are ten. Both of them are not an integral multiple of their outer loop. The first one is 3/9, and the second one is 10/9.
In this situation, since WCET calculation relies on ILP, and ILP only handles integral constraint, a potential WCET overestimation emerges. Take
insertsort01 as an example, one is the integer which is bigger than and the closest to the actual constraint value 3/9. Thus, the relative constraint for the second loop can be expressed as
. Consequently, estimating WCET with the constraint generates an overestimation, see second row in
Table 1 (324 > 228). Note that, for
insertsort01, pessimistic constraint is
since inner loop statement runs at most 2 times when outer loop statement runs once; absolute constraint is
since the global maximum iteration counts of inner loop are 3. For
insertsort02, pessimistic constraint is
, relative constraint is
, and absolute constraint is
.
This kind of overestimation is neither caused by imprecise micro-architecture analysis nor brought by unfaithful control-flow analysis. It is an inherent imperfection of IPET-based WCET calculation. To overcome the disadvantage, at least quickly find and partly correct the overestimation, the general existence conditions of the specific WCET overestimations are firstly proposed. Without loss of generality, the programs which have the specific WCET overestimations need to satisfy the following conditions:
Firstly, . Where denotes the set of all non-orthogonal nested loops in a program P, and denotes the set of all statements which lie in the WCEP of P. This condition means that there is at least one non-orthogonal nested loop in the WCEP.
Secondly, only relative constraint is available. Many reasons can result in this situation, such as, the program is long and complex, and/or the development is not yet completed. Thus, it is hard to analyze the global maximum iteration counts. However, if the outer loop is orthogonal, like “
for ( int 0; 5; i++)”, local maximum iteration counts of the inner non-orthogonal nested loop can be analyzed and obtained, for instance, by using program slicing [
21].
Thirdly, . Where and respectively denote the local loop bounds of the outer and inner loop statements. Note that is an unsigned modulo operator.
5. Reducing Unreasonable Overestimation
To fundamentally eliminate the specific unreasonable WCET overestimation, the program must not have at least one of the above three conditions. However, it is unrealistic because the structure and the features of a program are mainly determined by the realistic demands. The code should directly reflect the program’s function. Intentionally changing the code’s structure to destroy the conditions will reduce the readability, or even bring bugs into the code. Therefore, in this article we do not research how to fundamentally eliminate the overestimation, but try our best to safely and effectively reduce the overestimation by improving the WCET calculation.
5.1. The Correction Example
In order to more clearly introduce the algorithm, firstly, the issue is simplified as: the program
P only has one loop nesting whose depth is 2, and the non-orthogonal nested loop is not contained by any branch statement. Example 3 can reduce the WCET overestimation of
P.
| Example 3. Reducing WCET overestimation for one non-orthogonal nested loop |
| Input: Program P with an non-orthogonal loop nesting {} |
| Output: Corrected WCET |
| 1:
|
| 2: Set Constraint For Inner Loop () |
| 3: WCET1 ← WCET Analyse (P) |
| 4: |
| 5: Set Constraint For Inner Loop () |
| 6: WCET2 ← WCET Analyse (P) |
| 7: |
| 8: |
| 9:
|
| 10: Return WCET |
Make
insertsort01 mentioned in
Section 4 as an example to explain the algorithm.
= 9 and
= 3, thus
= 1 and
= 2. Since the constraints
and
are the same as the constraints used in
Section 4, we can see from
Table 1 that
WCET1 is 324 (Relative) and
WCET2 is 468 (Pessimistic). Then
error will be 16 and the corrected WCET will be 228. Note that the result is the same as the result obtained by using the absolute constraint
. Using the algorithm, the WCET overestimation in
insertsort02 can also be reduced.
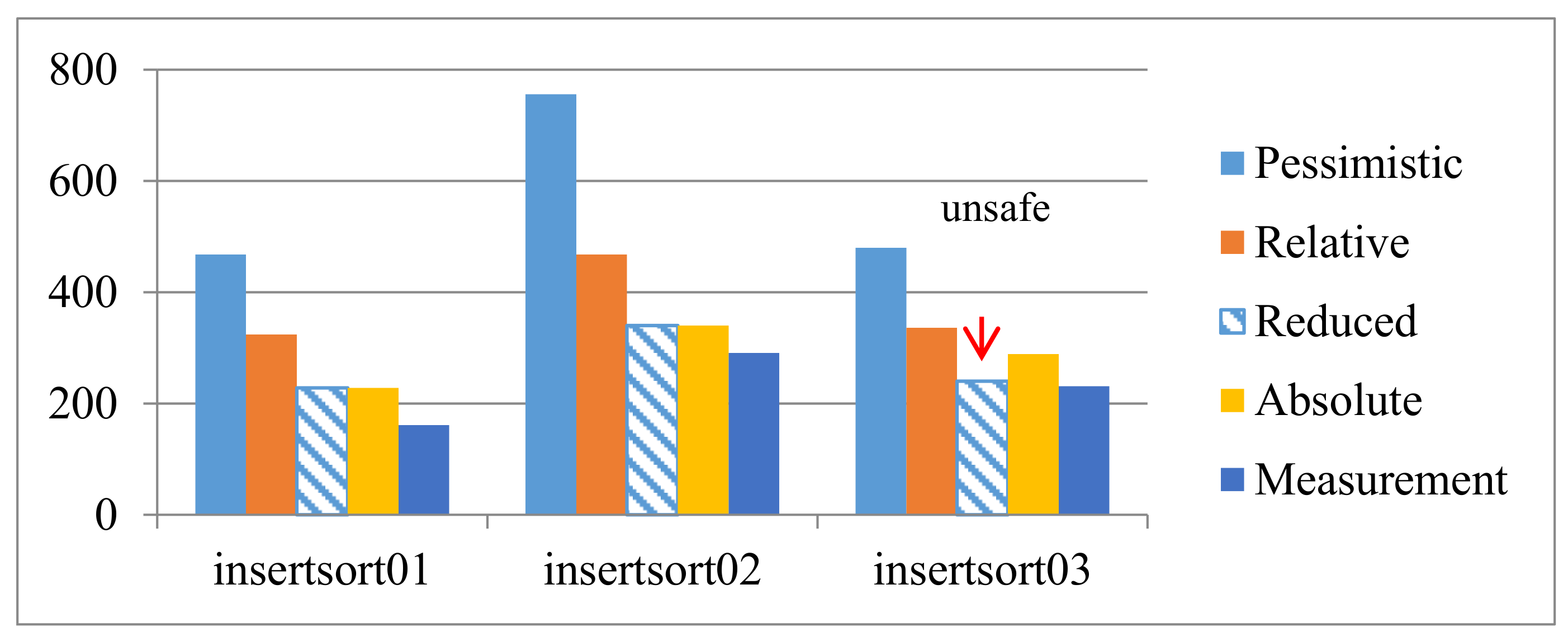
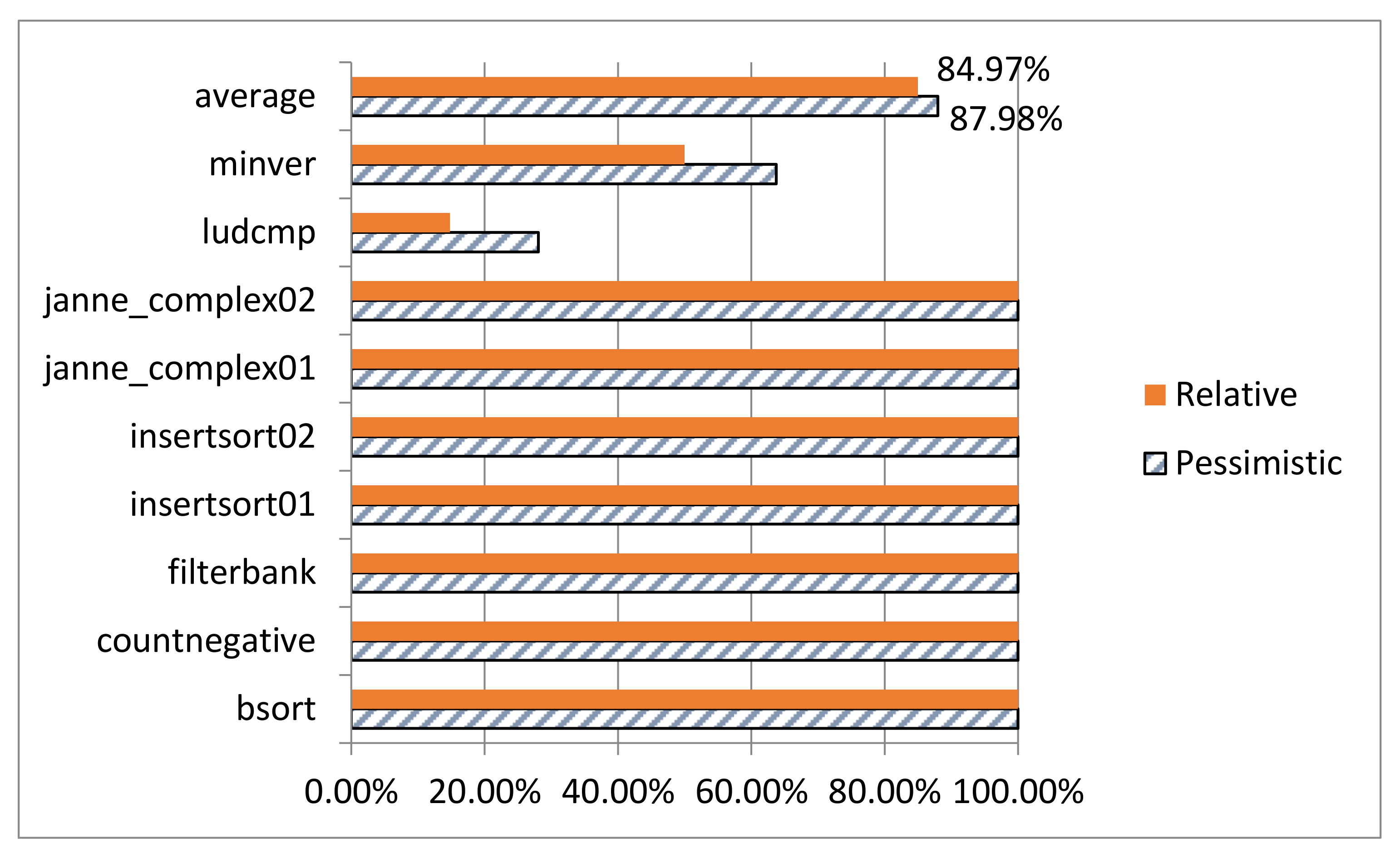
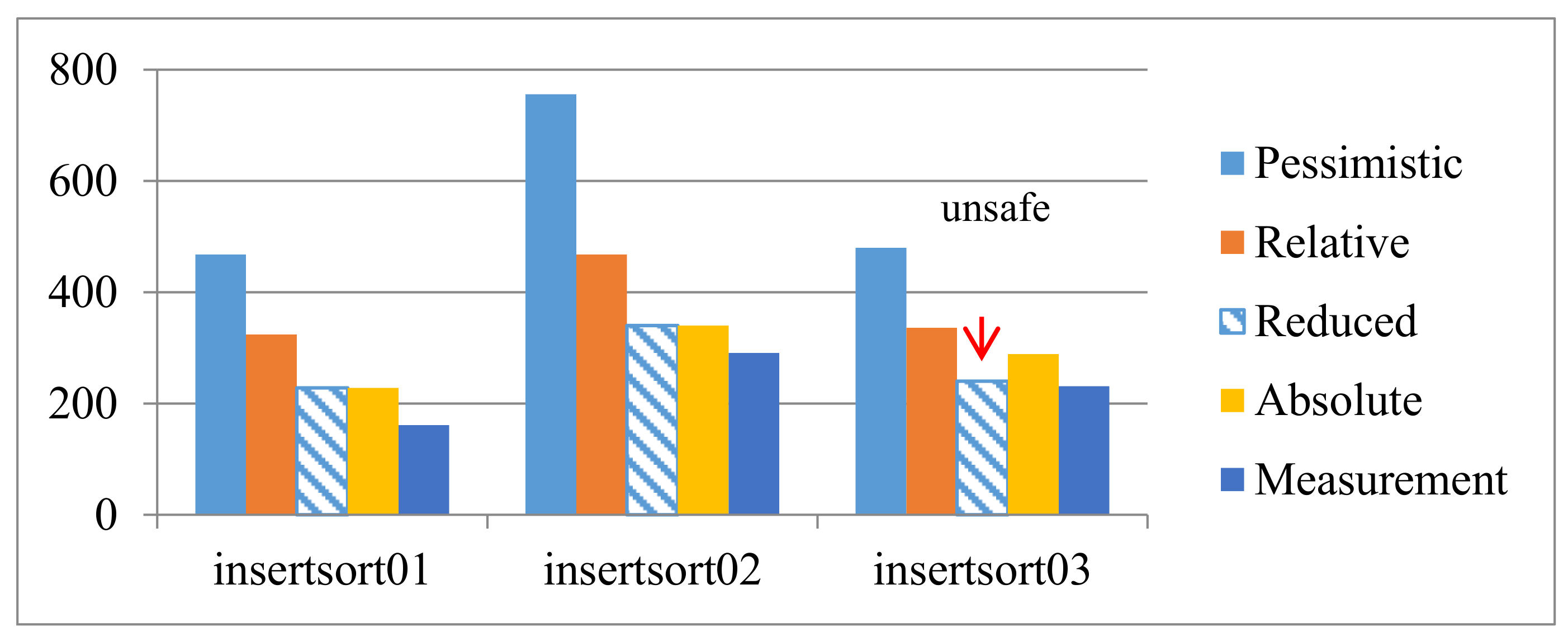
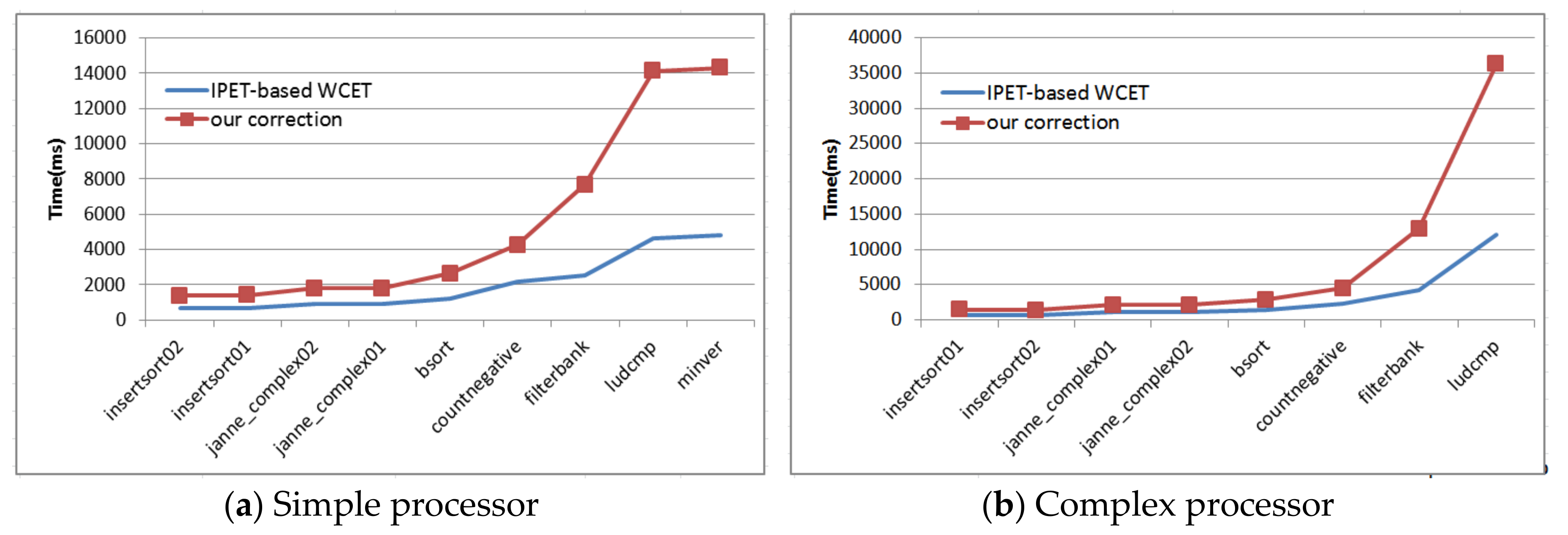
The reducing effects on
insertsort01 and
insertsort02 are shown in
Figure 3. The two reduced WCET values are safe because both of them are no less than the WCET calculated from the absolute constraints. However, the result may be unsafe when the restrictions presupposed at the beginning of this section are removed, see
insertsort03 in
Figure 3.
Note that,
insertsort03 is derived from program “
insertsort”. Its structure is simply shown as Example 4. The loop nesting is moved into
then part of a branch. The same or indifferent parts are omitted. Program
insertsort03 has two mutually exclusive paths:
path1 = <1,2,3,6> and
path2 = <1,4,5,6>. In fact, the correct WCEP is
path2. However, since a relative constraint
has to be used for the loop at line 3, the WCEP switches to
path1 from
path2. Then the WCET correction is conducted on
path1, and finally the reduced WCET becomes less than the correct WCET which belongs to
path2. That is the reason why the above method may be unsafe when the non-orthogonal nested loop lies in a branch statement. To handle the more common cases,
Section 5.2 introduces the whole process of the WCET corrections.
| Example 4. insertsort03.c derived from insertsort |
| 1 if ( … ) |
| 2 while ( i <= 10){ j = i; |
| 3 while ( j <= 3 && a[j] < a[j − 1]) {…}…} |
| 4 else //the correct WCEP |
| 5 {…} |
| 6 … |
5.2. The Whole Process
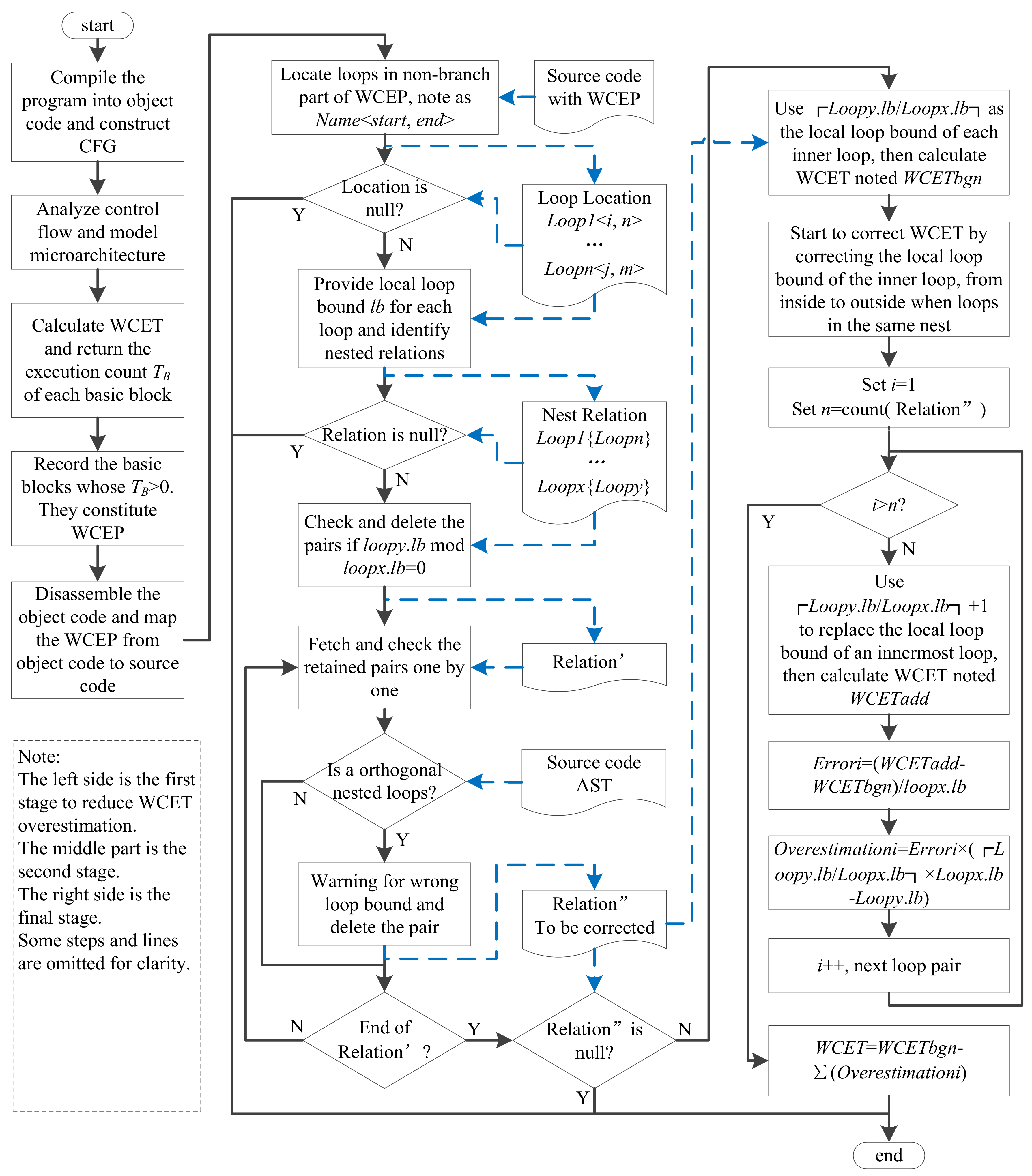
To avoid a wrong correction caused by WCEP switch during reducing WCET overestimation, the correction is limited to the non-branching part of WCEP. Note that the non-branching part refers to the code (i.e., the non-orthogonal nested loop) which does not belong to any branch statement. It means that the non-branching part of WCEP is a public sub-path that all execution traces must pass. So, no path switches can happen during reducing WCET overestimation.
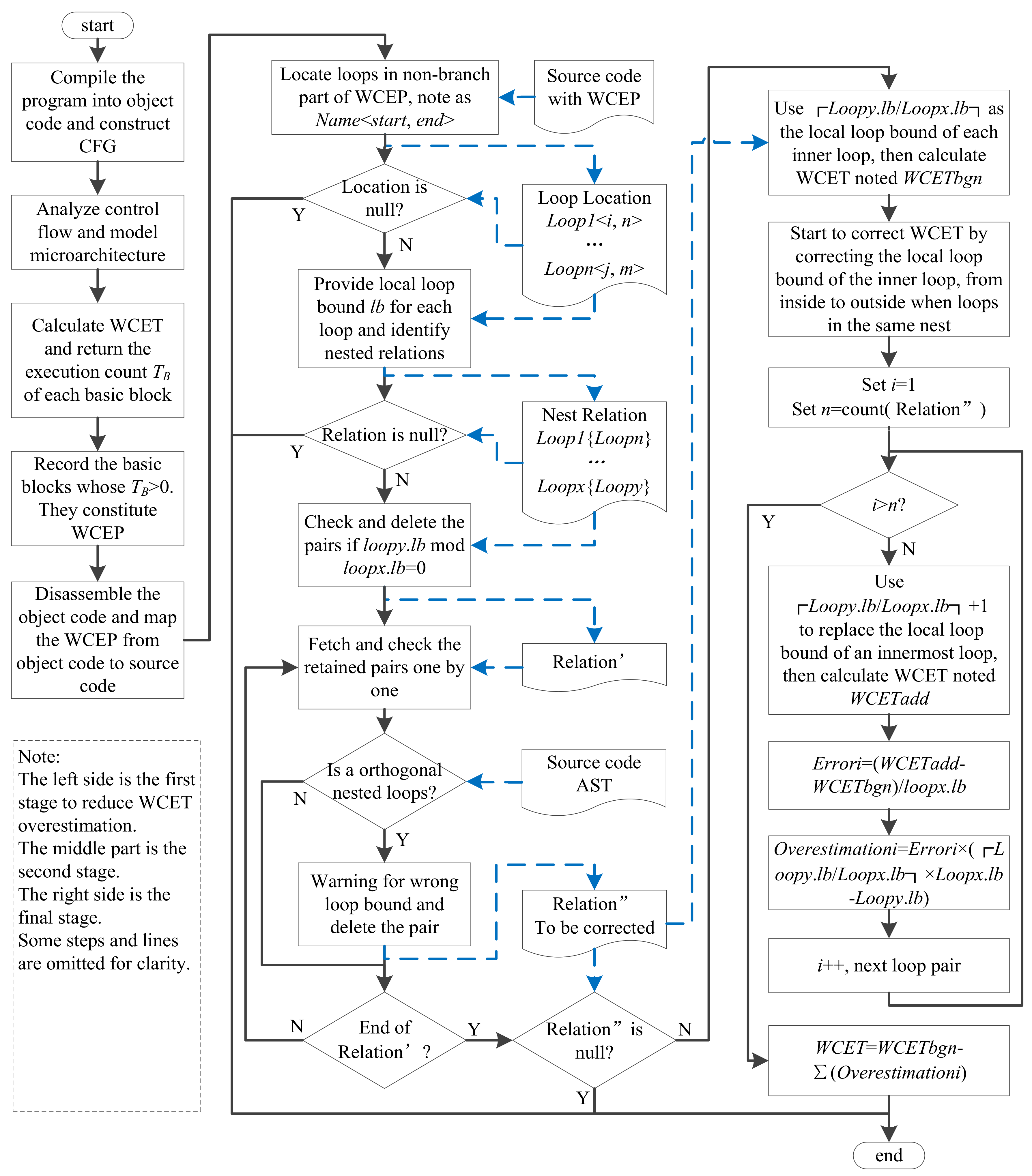
The WCET overestimation correction has three stages The first stage is to locate WCEP in CFG and then map it onto source code. The second stage is to identify the non-orthogonal nested loops in WCEP by means of abstract syntax tree (AST). The last stage is to recursively calculate the WCET errors caused by the loose constraint relationships of loop bounds, and reduce the WCET overestimation via subtracting the total errors.
Figure 4 shows the whole process of our WCET correction.
In the first stage, the variable values of ILP (i.e., in Equation (1)) are used to locate WCEP. For a basic block , if its execution counts in the final result, then belongs to WCEP. So, it is easy to locate all basic blocks which constitute WCEP. Note that using different constraints (i.e., pessimistic, relative or absolute) to express the maximum iteration counts of nested loops may result in different WCEP. However, it is unconsidered since our approach only deals with a non-branching part, and the part is always the same even in different WCEP.
In the second stage, two ways can achieve identifying nested relations. The first way (showing in
Figure 2) is using the start and end line information. Generally, for two loops (denoted
loopx and
loopy respectively), if
loopx.
start_
line <
loopy.
start_
line and
loopx.
end_
line >
loopy.
end_
line, then
loopy is nested by
loopx. The second way identifies nested relations with the help of AST. When the nodes of
loopy are children of the node of
loopx, then
loopx nests
loopy.
To identify the non-orthogonal nested loops, and help programmers analyze loop bounds, we have developed a lightweight syntax analysis tool for C language (supporting C99 standard), called CParser [
38]. Through three basic steps, i.e., lexical analysis, preprocessing and syntax analysis, CParser not only creates AST, but also identifies non-orthogonal nested loops. Meanwhile, by means of source code instrumentation, CParser provides referential loop bounds for programmers. Moreover, CParser has also been used in error locating of C programs [
39]. Usually manual analysis is inevitable to obtain loop bounds since other methods, such as symbolic execution, have many limitations in availability. Therefore, the referential loop bounds are beneficial for making sure that the loop bounds provided by programmers are not smaller than the actual values.
It should be noted that, a non-orthogonal nested loop may not necessarily be the object of the correction unless its local maximum iteration counts are not integral multiples relative to its outer loop. Meanwhile, orthogonal nested loop must meet the integral multiple relations. So, if the provided local loop bound for orthogonal nested loops does not meet the integral multiple relations, the annotations for local maximum iteration counts must be wrong.
In the final stage, if the depth of a loop nesting is more than two, the correction will start from the innermost loop. For example, for two loop nests Loopx {Loopy} and Loopy {Loopz}, obviously Loopz is the innermost loop, so our approach corrects Loopy {Loopz} first. Otherwise, it will result in new errors during Loopx {Loopy} correction.
5.3. The Safety Analysis
If the reduced WCET (denoted
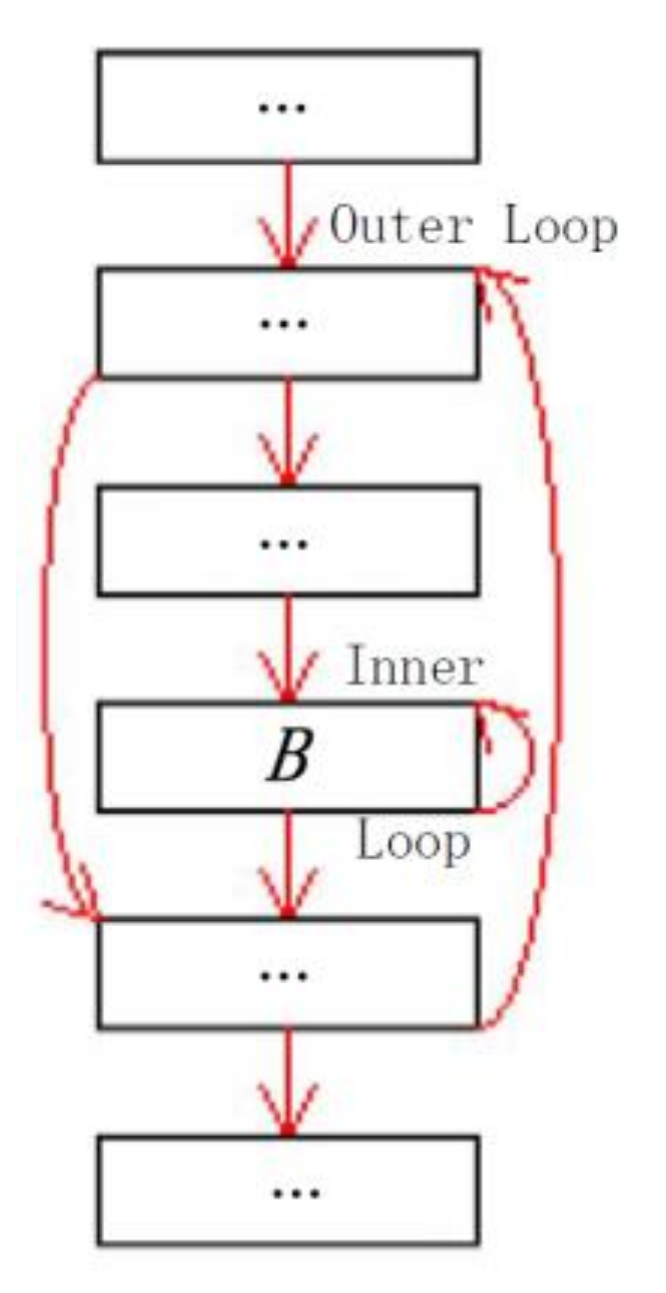
RWCET) is no less than the WCET which is calculated by using absolute constraints (denoted WCET), then the correction algorithm must be safe. For making the safety analysis easy to be understood, we suppose that the program has a CFG which is simply shown in
Figure 5. It should be pointed out that the correction only affects the total execution time of the basic block
(denoted
). Therefore, the question is simplified as: if
then the correction algorithm is safe. Where
is the total WCET of the basic block
B after correction. According to Equation (1),
. Therefore, if
then the algorithm is safe.
For a loop nesting , supposing their max execution counts respectively are and . We firstly prove the safety of the algorithm without considering Cache.
Proof. According to the Example 1, obviously , and , so we have , and .
Obviously, .
Since , now we have , which completes the proof. ☐
When considering cache, the basic block B has two kinds of execution time: for Cache hit and for cache miss. So . According to the classification of cache behaviors, the safety is analyzed from three aspects. Firstly, if B is always hit, then . Thus . The proof under this case is the same with the previous one, so we don’t repeat it. Secondly, if B is always miss, then . Therefore . The proof under this case is also the same with the previous one. Thirdly, if B is first miss, then it has two cases. If , then and , so ; if , then and , so . Following is the proof in the third case.
Proof. According to the Example 1, obviously , and .
So we have , and .
Obviously, .
If , then ;
If , then
Since and , we have ☐
Summing up the above, is always true. Therefore, the WCET correction algorithm is safe. Note that the inner loop may have many basic blocks and the processor may have other configurations, such as data cache and pipeline, but the theory is similar. Thus, the safety, when considering more details, can also be proved using the same method. However, the algorithm is only the kernel of the whole correction process. Even if it is safe, it does not mean that the whole process must be safe since the whole process involves identifying correctable non-orthogonal nested loops and other details. For example, if a programmer provides wrong loop bounds, any safe approach including our correction cannot guarantee safety.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}