Hierarchical Transmuted Log-Logistic Model: A Subjective Bayesian Analysis
by
 ,
,
Carlos A. Dos Santos
1,*,† ,
,
Daniele C. T. Granzotto
1,†,
Vera L. D. Tomazella
2,† and
Francisco Louzada
3,† 1
Department of Statistics, State University of Maringá, 87020-900 Maringá-PR, Brazil
2
Department of Statistics, Federal University of São Carlos, 13565-905 São Carlos-SP, Brazil
3
Math Science Institute and Computing, University of São Paulo, 13560-970 São Carlos-SP, Brazil
*
Author to whom correspondence should be addressed.
†
These authors contributed equally to this work.
J. Risk Financial Manag. 2018, 11(1), 13; https://doi.org/10.3390/jrfm11010013
Submission received: 30 December 2017
/
Revised: 2 March 2018
/
Accepted: 5 March 2018
/
Published: 7 March 2018
(This article belongs to the Special Issue Extreme Values and Financial Risk)
Abstract
:In this study, we propose to apply the transmuted log-logistic (TLL) model which is a generalization of log-logistic model, in a Bayesian context. The log-logistic model has been used it is simple and has a unimodal hazard rate, important characteristic in survival analysis. Also, the TLL model was formulated by using the quadratic transmutation map, that is a simple way of derivating new distributions, and it adds a new parameter , which one introduces a skewness in the new distribution and preserves the moments of the baseline model. The Bayesian model was formulated by using the half-Cauchy prior which is an alternative prior to a inverse Gamma distribution. In order to fit the model, a real data set, which consist of the time up to first calving of polled Tabapua race, was used. Finally, after the model was fitted, an influential analysis was made and excluding only of observations (influential points), the reestimated model can fit the data better.

1. Introduction
The genetic prepotency of cows is an important issue since the development of livestock is directly related to the growth of the food production. Brazilians institutes are concerned with the development of a particular race, the Tabapua, which was the first humped cattle developed in the country. Due to the economic results of this particular race, this study is twofold: present the TLL model and fit the times up to the first calving of the cows pointing characteristics of this race.
Proposed by Granzotto and Louzada-Neto (2014), the TLL model presents important characteristics of a good model: it is flexible, tractable, interpretable and simple. Following the Shaw and Buckley (2007) idea, this new distribution incorporates a new third parameter that introduces skewness and preserve the moments of the baseline distribution. Several studies can be cited that proposed similar generalizations of survival models, see for example (Aryal and Tsokos 2009; Aryal and Tsokos 2011).
Due to good characteristics of the TTL model along with its simplicity (the main functions are analytically expressed) and the hazard properties (it has a larger range of choices for the shape of the hazard function most commonly observed in the survival analysis field), this paper present an application of the model in a Bayesian context.
In order to fit this new model, the subjective Bayesian analysis was used. For that, the half-Cauchy prior distribution, cited by several authors such as (Polson and Scott 2012; Gelman 2006), as an alternative prior to a inverse Gamma distribution, was used. Specially, Gelman (2006) made use of this particular prior for variance parameters in hierarchical models which is our case.
Furthermore, in order to provide an indication of bad model fitting or influential observations, an influential analysis was made, see for example (Ortega et al. 2003; Fachini et al. 2008).
The paper is organized as follows. The hierarchical log-logistic model built by using the half-Cauchy prior distribution is presented in Section 2. In Section 3 we presented an application by using a real data set on a polled Tabapua race time up to first calving data. An influence diagnostic was presented in Section 4 and the data set was re-analyzed refitting the model. Final remarks and conclusions are presented in Section 5.
2. Hierarchical TLL Model
Proposed by Granzotto and Louzada-Neto (2014), the TLL is a generalization of the log-logistic model containing the baseline model as a particular case (for log-logistic distribution see (Bennett 1983; Chen et al. 2001)). Tractable, Interpretable and flexible enough, the new construction can be used to analyze more complex dataset, introducing skew to a base distribution and preserving its moments. Let X be a nonnegative random variable denoting the lifetime of an individual in some population then, the probability density function (pdf) and the cumulative function of the TLL distribution are respectively given by
and
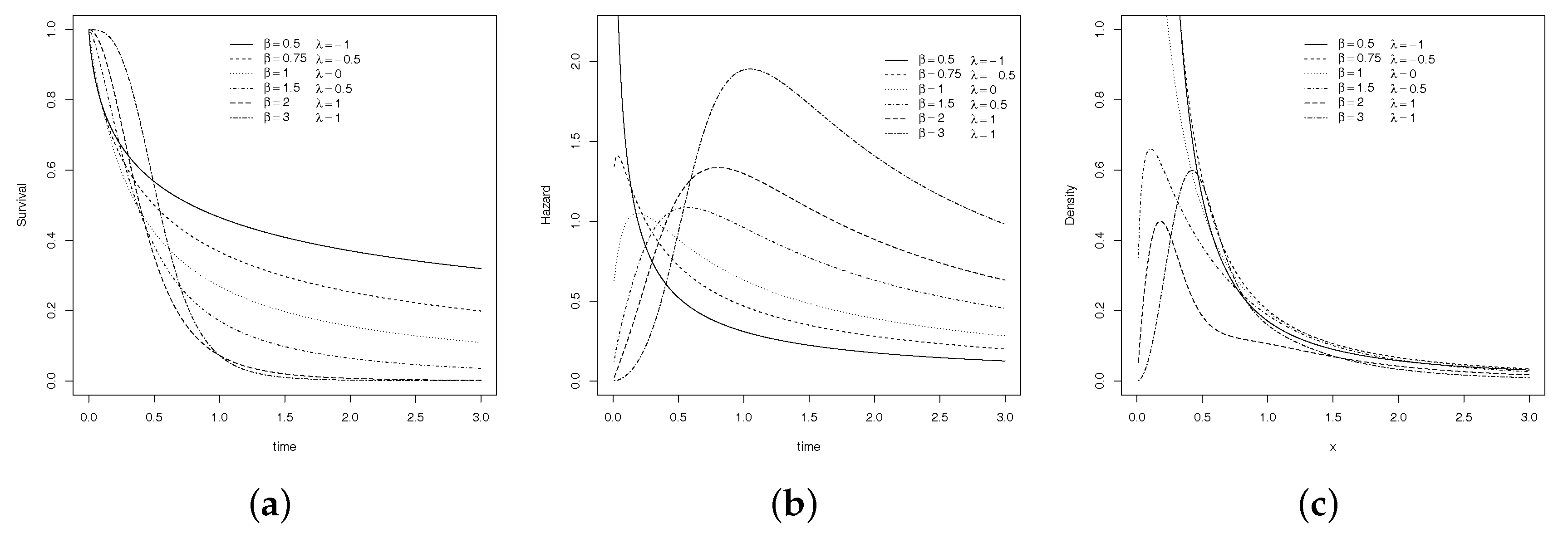
where , and . Since the distribution was proposed to model experiments in reliability analysis, Figure 1 presents several examples of survival, probability density and hazard rate functions for different values of the parameters.
According to Chen and Ibrahim (2006), one of most common ways of combining several sources of information is though hierarchical modeling. Thus, the authors show us the relationship between the power prior and hierarchical models using as example the regression models.
Also, Gelman (2006) show us that several studies by using multilevel models are central to modern Bayesian statistics for both conceptual and practical reasons. The authors suggest to use the half-t family as a prior distribution for variance parameters such the half-Cauchy distribution, that is a special conditionally-conjugate folded-noncentral-t family case of prior distributions for parameters that represent the discrepancy. Even though several studies use the half-Cauchy prior for scale parameter (see for example Polson and Scott 2012), Gelman (2006) used this prior not for scale but for variance parameters and illustrated serious problems with the inverse-Gamma prior which is the most commonly used prior for variance component, see Daniels and Daniels (1998).
In this paper we proposed to use the hierarchical models in two levels, for that, suppose the hierarchical model given as , , , , and . The posterior distribution can be constructed as following.
Proposition 1.
Let us suppose that, in the first stage, we considered a class Γ of priors that led to following
Also, the second stage (sometimes called a hyperprior), would consist of putting a prior distribution on the hyperparameters and θ where
Thus, the hyerarchical log-logistic posterior distribution is written as
Proof.
The demonstration is direct.
Note that, the parameter is supposed to be a half-Cauchy distribution which probability density function given by
where is a scale parameter which has a broad peak at zero and, in limit, this becomes a uniform prior density. However, large finite values for represent prior distributions which we call “weakly informative”. For example, Gelman (2006) show us that, for , the half-Cauchy is nearly flat although it is not completely. ☐
3. Application to Real Data
Founded in 70’s, the Brazilian Agricultural Research Corporation (Embrapa) is under the aegis of the Brazilian Ministry of Agriculture, Livestock, and Food Supply. Since the foundation, they have taken on the challenge to develop a genuinely Brazilian model of tropical livestock (and agriculture as well), to keep increasing the production of food. As a result of the intense research work, the beef and pork supply were quadrupled, helping the Brazilian food to one of the world’s largest food producers and exporters.
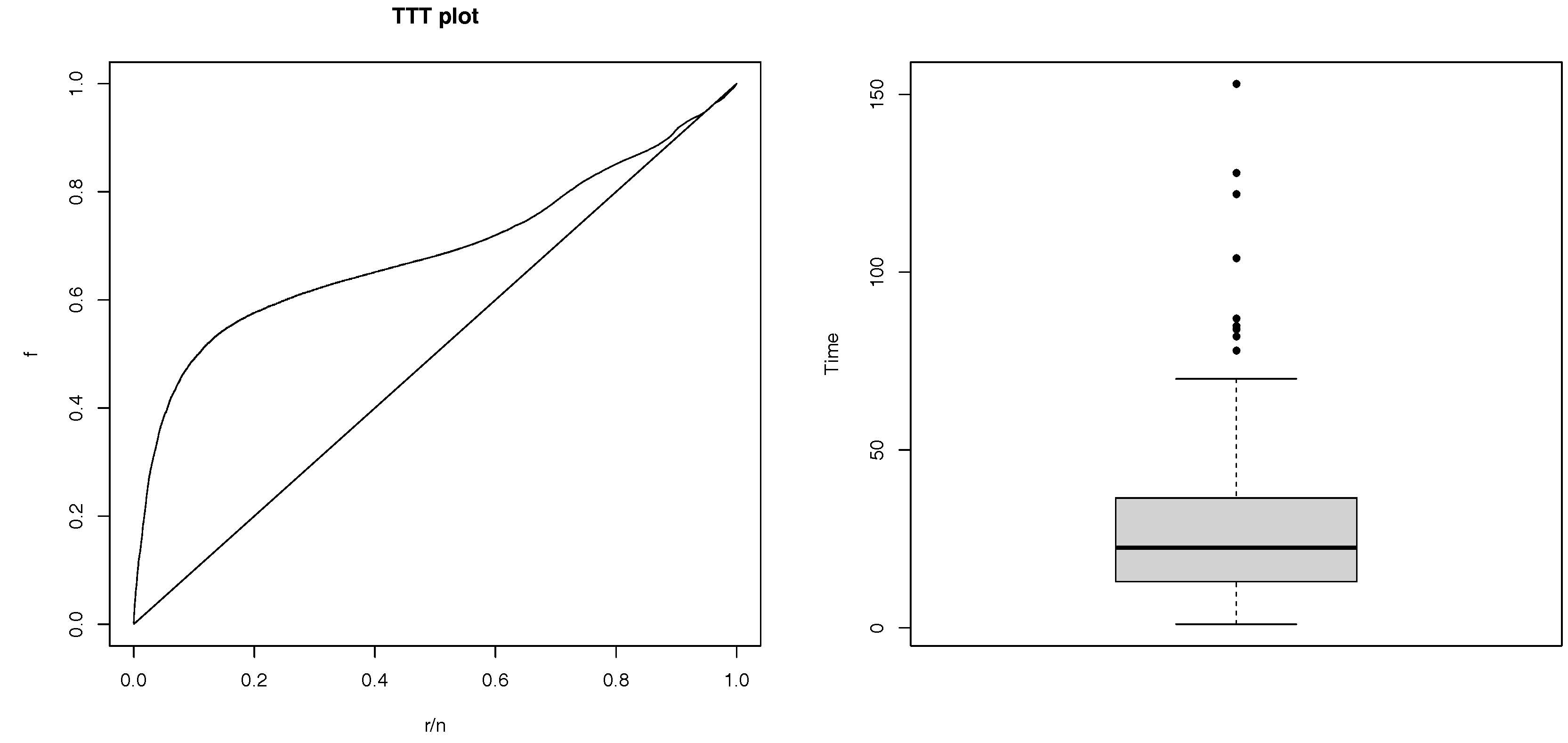
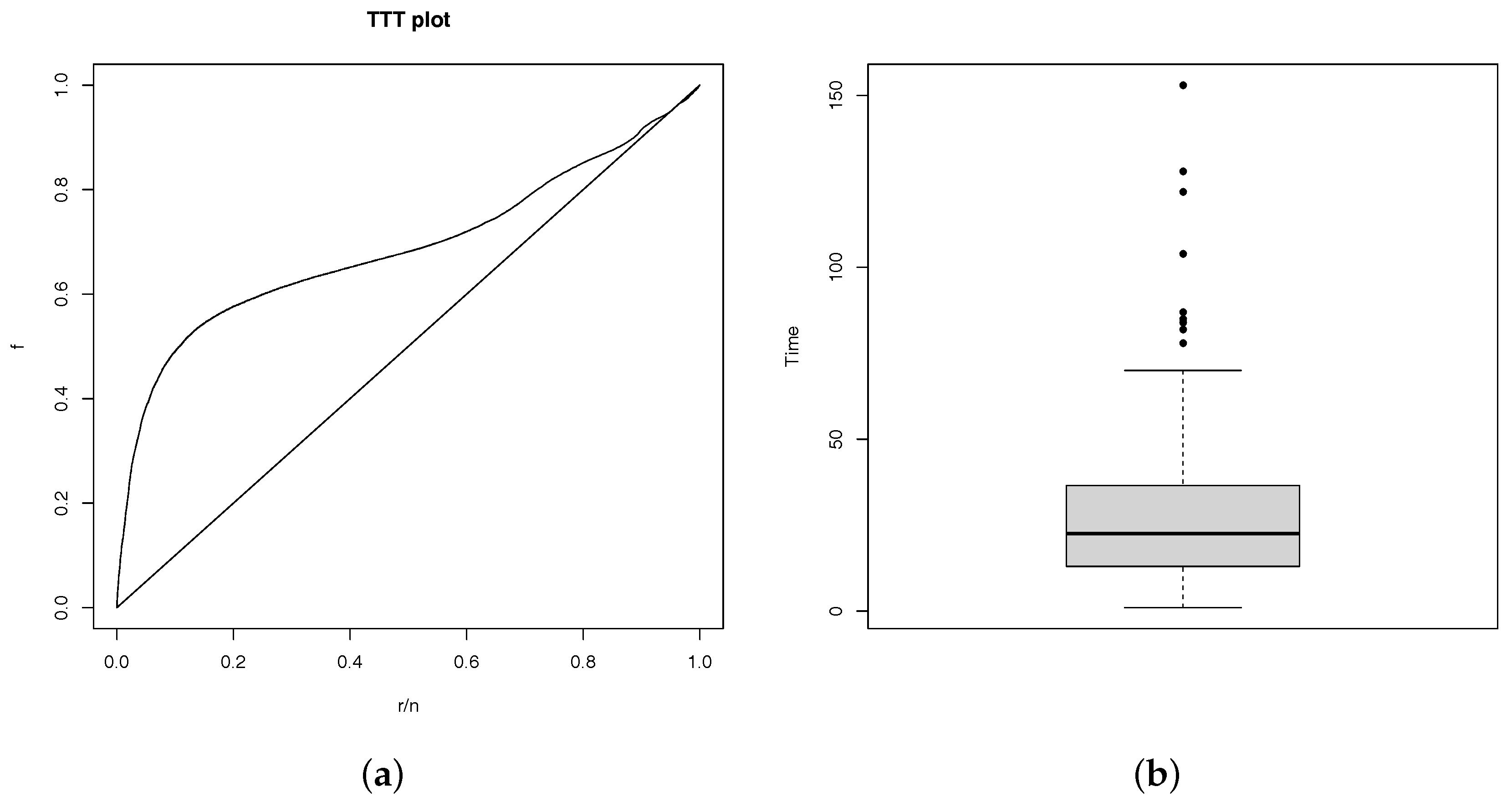
One of the special research is related to the genetic prepotency of cows whereas the economic results is directly related to beef cattle, see for example Pereira (2000). Granzotto and Louzada-Neto (2014) study the Tabapua race time up to first calving of animals observed from 1983 to 2007, held at Embrapa. Firstly, as the minimum observed calving was 721 days, we subtract this amount of the observed times and the distribution of the first calving times can be observed in the Figure 2b.
Also, the TTT plot, presented in Figure 2a shows the possible unimodal hazard rate as it is concave, convex and then concave again, see for example Barlow and Campo (1975).
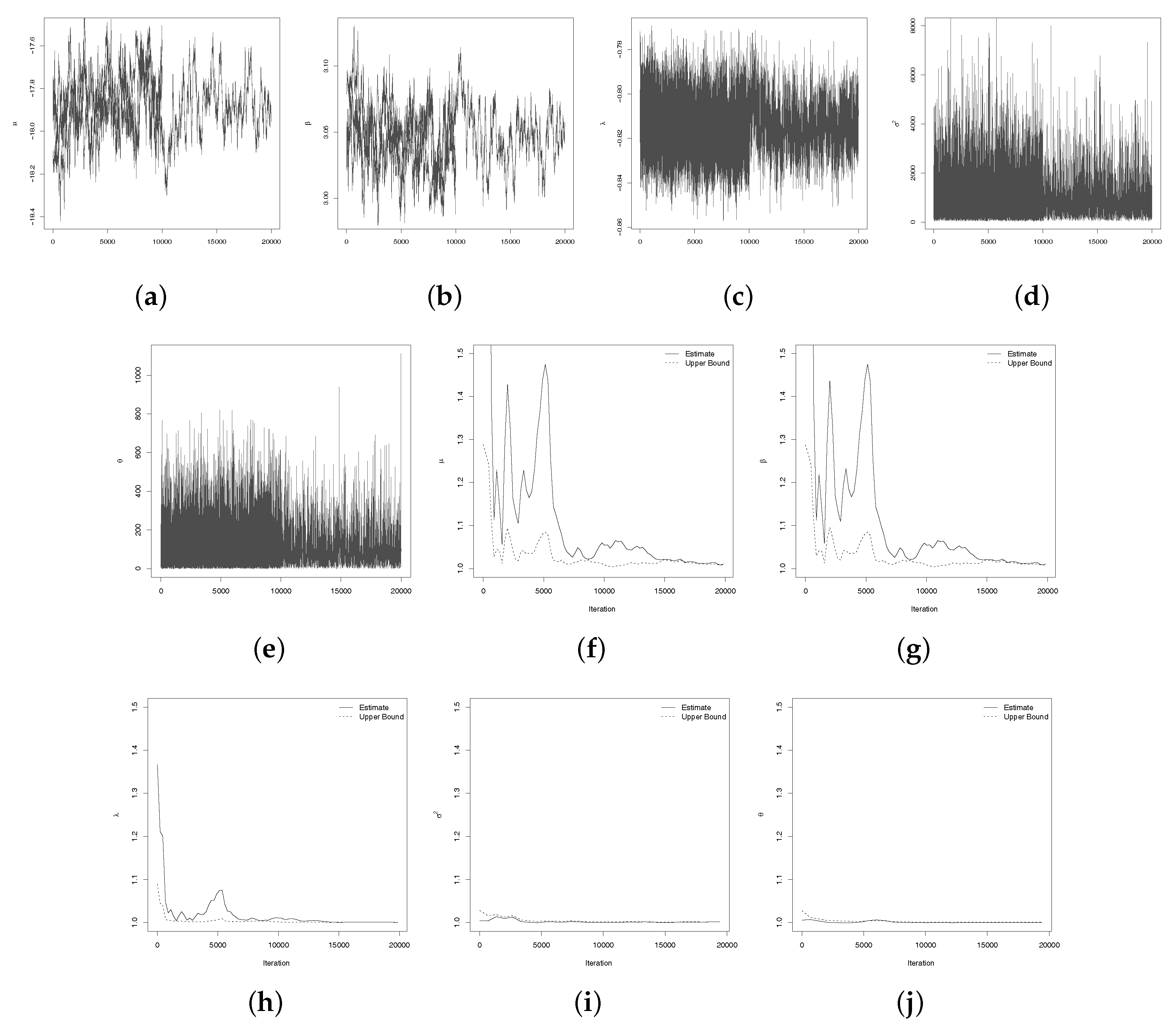
After initial analysis, we are considering the hierarchical TLL model, as we specify in Section 2, to fit the data. The posterior samples were generated by the Metropolis-Hastings technique. Three chains of the dimension was considered for each parameter, discarding the first 10,000 iterations (in order to eliminate the effect of the initial values), a lag size 10 was used to avoid the correlation problems, resulting in a final sample size 10,000. The posterior summaries for and are present in Table 1 and the credible intervals by considering the priors above-mentioned can be seem in Table 2.
The convergence of the chain was verified by Gelman and Rubin’s convergence diagnostic criterion, see for example (Gelman and Rubin 1992), which demonstrate that these criteria is satisfied (Table 3). Also, the convergence can be seem in Figure 3a–j.
Also, the marginal posterior densities for , and , respectively, can be analyzed by the Figure 4a–e.
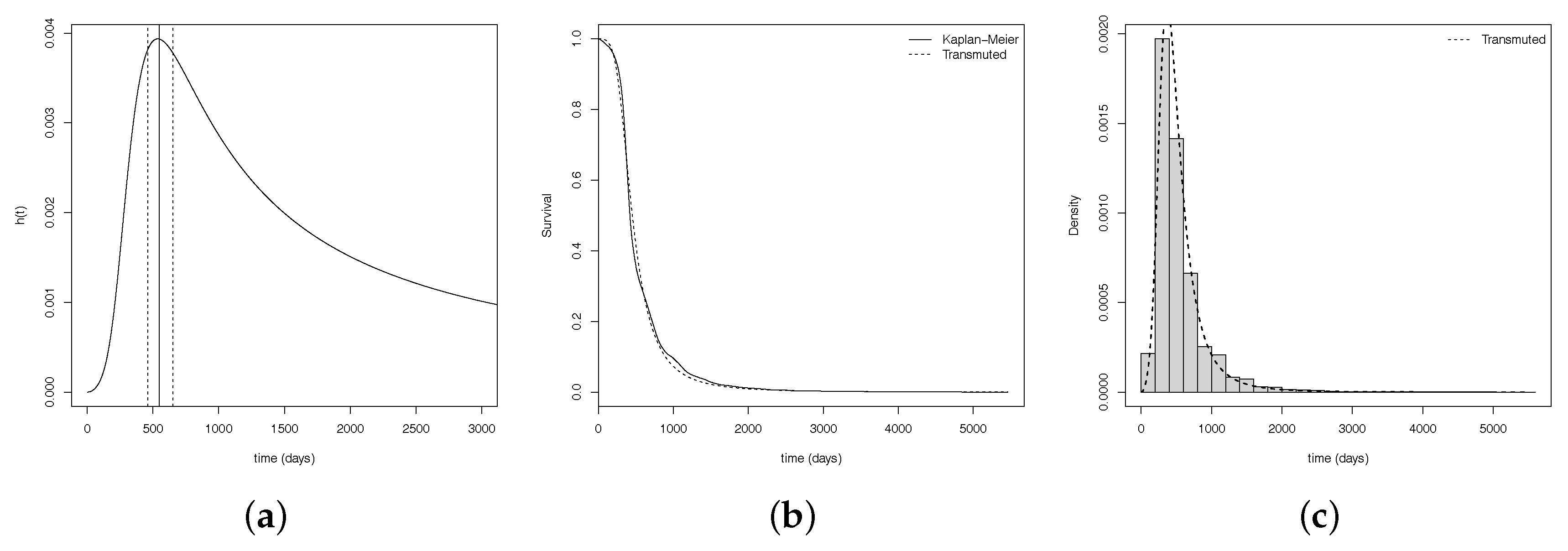
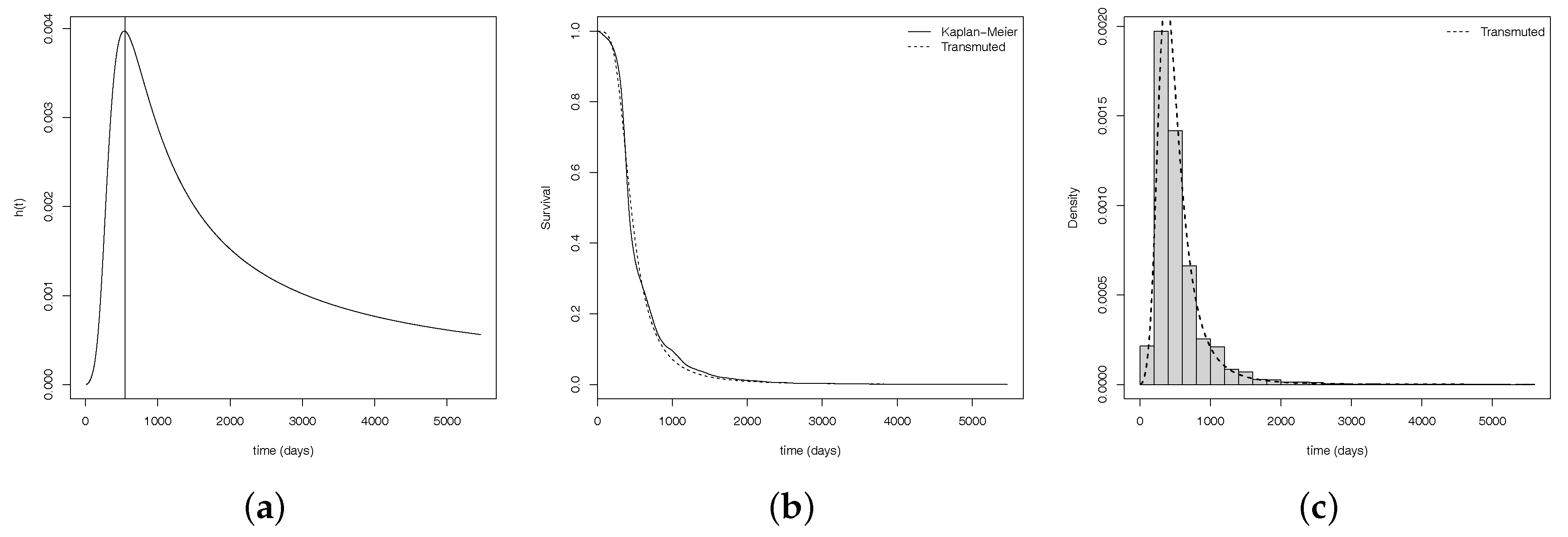
After estimate and analyze the convergence of the model, Figure 5a,b show us, respectively, the hazard estimate curve, with the and the confidence interval; the survival curves estimated vs empirical and the histograma which are possible to see how well it fits a set of observations.
Considering the hyerarchical TLL fitting, the is equals to days ( months) and its confidence interval is given by IC days (see Figure 5a). Furthermore, the median time up to first calving is equals to days (or approximately months), and the mean of time is days (or approximately 18 months), with standard deviation equals to months.
4. Influence Analysis
In this section we present an analysis of global influence for the data set given, using the TLL model in a bayesian context.
In few words, the influence analysis is a case-deletion, that we study the effect of withdraw of the ith element sampled. Several measures of global influence analysis are presented in the literature. In this study we are considering two: the generalized Cook’s distance (CD) and the likelihood difference (LD). The first one, CD, defined as the standard norm of and , and the LD are given, respectively, by
and
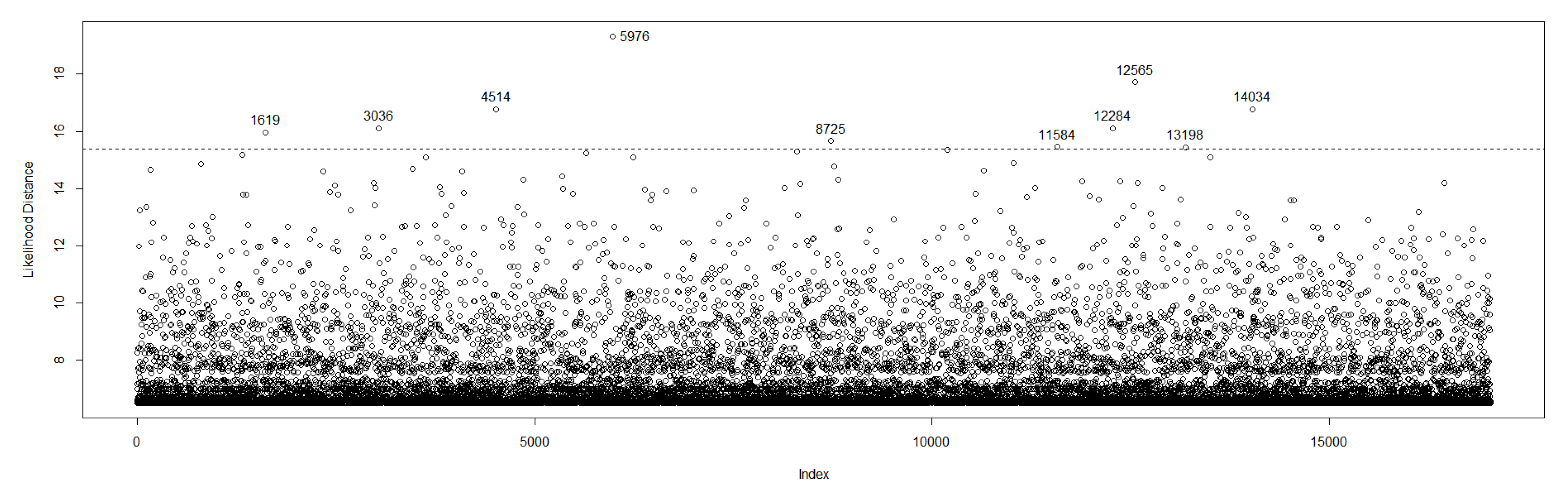
According to Lee et al. (2006), can be approximated by the estimated covariance and variance matrix. Some possible influence points are identified in the LD plot, Figure 6.
Furthermore, the impact of the identified influential points should be measured. For that, we consider the relative changes that can be measured as , where denotes the MLE of after the set I of observations has been removed.
Three measures of influential observations are considered: TRC is the total relative changes, MRC the maximum relative changes and LD the likelihood displacement, see for example (Lee et al. 2006; Granzotto and Louzada-Neto 2014). Table 4 presents the values when we withdrew from 0.01 to 5% of the outstand identified points in Figure 6.
By considering the RC’s, 10 most influential points were withdrew and the model was re-fitted. Again, by using the Metropolis-Hastings technique we generated a chain of observations, burn in of and lag 10, resulting in a final sample size . Table 5 and Table 6 shows the posterior summaries and the credible intervals.
Clearly, the most affected estimate parameter was if we compare to the parameters estimated by using the original dataset. Further, withdrawing of sample, i.e., just 17 observations, we do not lose much information and also improve the fitted model, see Figure 7a–c, that show us the fitted model.
5. Concluding Remarks
In this paper study the model propose by Granzotto and Louzada-Neto (2014), the TLL distribution, in a Bayesian context. The two levels hierarchical TLL model was formulated by using the half-Cauchy as a prior to the parameter of discrepancy.
Techniques of influential analysis were used to identify and measure the influence of the outstanding observed points. It is important to observe that the re-fitted model presents a reduction in the estimated likelihood value plus a reduction in the estimated standard deviation, which shortens the range of the confidence interval obtained for the most probable time up to first calving.
Finally, considering the final fitted model, the changes to against days ( months) and its confidence interval is given by IC months. The median time up to first calving is equals to days (or approximately months), and the mean of time is days (or approximately months), with standard deviation equals to months.
Author Contributions
All authors contributed equally to this manuscript insomuch that Francisco Louzada and Vera L. D. Tomazella worked in the theoretical part and Carlos A. dos Santos and Daniele C. T. Granzotto provided the simulation and application.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Aryal, Gokarna R., and Chris P. Tsokos. 2009. On the transmuted extreme value distribution with applications. Nonlinear Analysis 71: 1401–7. [Google Scholar] [CrossRef]
- Aryal, Gokarna R., and Chris P. Tsokos. 2011. Transmuted Weibull distribution: A generalization of the Weibull probability distribution. European Journal of Pure and Applied Mathematics 4: 89–102. [Google Scholar]
- Barlow, Richard E., and Rafael A. Campo. 1975. Total Time on Test Processes and Applications to Failure Data Analysis. Berkeley: California University Berkeley Operations Research Center. [Google Scholar]
- Bennett, Steve. 1983. Log-logistic regression models for survival data. Journal of the Royal Statistical Society Series C: Applied Statistics 32: 165–71. [Google Scholar] [CrossRef]
- Chen, Ming-Hui, Joseph G. Ibrahim, and Debajyoti Sinha. 2001. Bayesian Survival Analysis. Springer Series in Statistics; New York: Springer. [Google Scholar]
- Chen, Ming-Hui, and Joseph G. Ibrahim. 2006. The relationship between the power prior and hierarchical models. Bayesian Analysis 1: 551–74. [Google Scholar] [CrossRef]
- Daniels, Michael J. 1998. A prior for the variance in hierarchical models. The Canadian Journal of Statistics/La Revue Canadienne de Statistique 27: 567–78. [Google Scholar] [CrossRef]
- Fachini, B. Juliana, Edwin M. M. Ortega, and Francisco Louzada. 2008. Influence diagnostics for polyhazard models in the presence of covariates. Statistical Methods and Applications 17: 413–33. [Google Scholar] [CrossRef]
- Gelman, Andrew. 2006. Prior distributions for variance parameters in hierarchical models. Communications in Statistics. Theory and Methods 1: 515–33. [Google Scholar]
- Gelman, Andrew, and Donald B. Rubin. 1992. Inference from iterative simulation using multiple sequences. Statistical Science 7: 457–511. [Google Scholar] [CrossRef]
- Granzotto, Daniele Cristina Tita, and Louzada-Neto Francisco. 2014. The Transmuted Log-Logistic distribution: modeling, inference and an application to a polled tabapua race time up to first calving data. Communications in Statistics—Theory and Methods 44: 3387–402. [Google Scholar] [CrossRef]
- Lee, Sik-Yum, Bin Lu, and Xin-Yuan Song. 2006. Assessing local influence for nonlinear structural equation models with ignorable missing data. Computational Statistics & Data Analysis 50: 1356–77. [Google Scholar]
- Ortega, Edwin M. M., Heleno Bolfarine, and Gilberto A. Paula. 2003. Influence diagnostics in generalized log-gamma regression models. Computational Statistics and Data Analysis 42: 165–86. [Google Scholar] [CrossRef]
- Pereira, Jonas C. C. 2000. Contribuição genética do Zebu na pecuária bovina do Brasil. Informe Agropecuário 21: 30–38. [Google Scholar]
- Polson, Nicholas G., and James G. Scott. 2012. On the half-Cauchy prior for a global scale parameter. Bayesian Analysis 7: 887–902. [Google Scholar] [CrossRef]
- Shaw, William T., and Ian R. C. Buckley. 2007. The alchemy of probability distributions: Beyond Gram-Charlier expansions, and a skew-kurtotic-normal distribution from a rank transmutation map. arXiv, arXiv:0901.0434. [Google Scholar]
Figure 1.
Transmuted model curves: (a) Survival, (b) hazard and (c) probability density function.

Figure 2.
(a) TTT Plot and (b) boxplot of times.
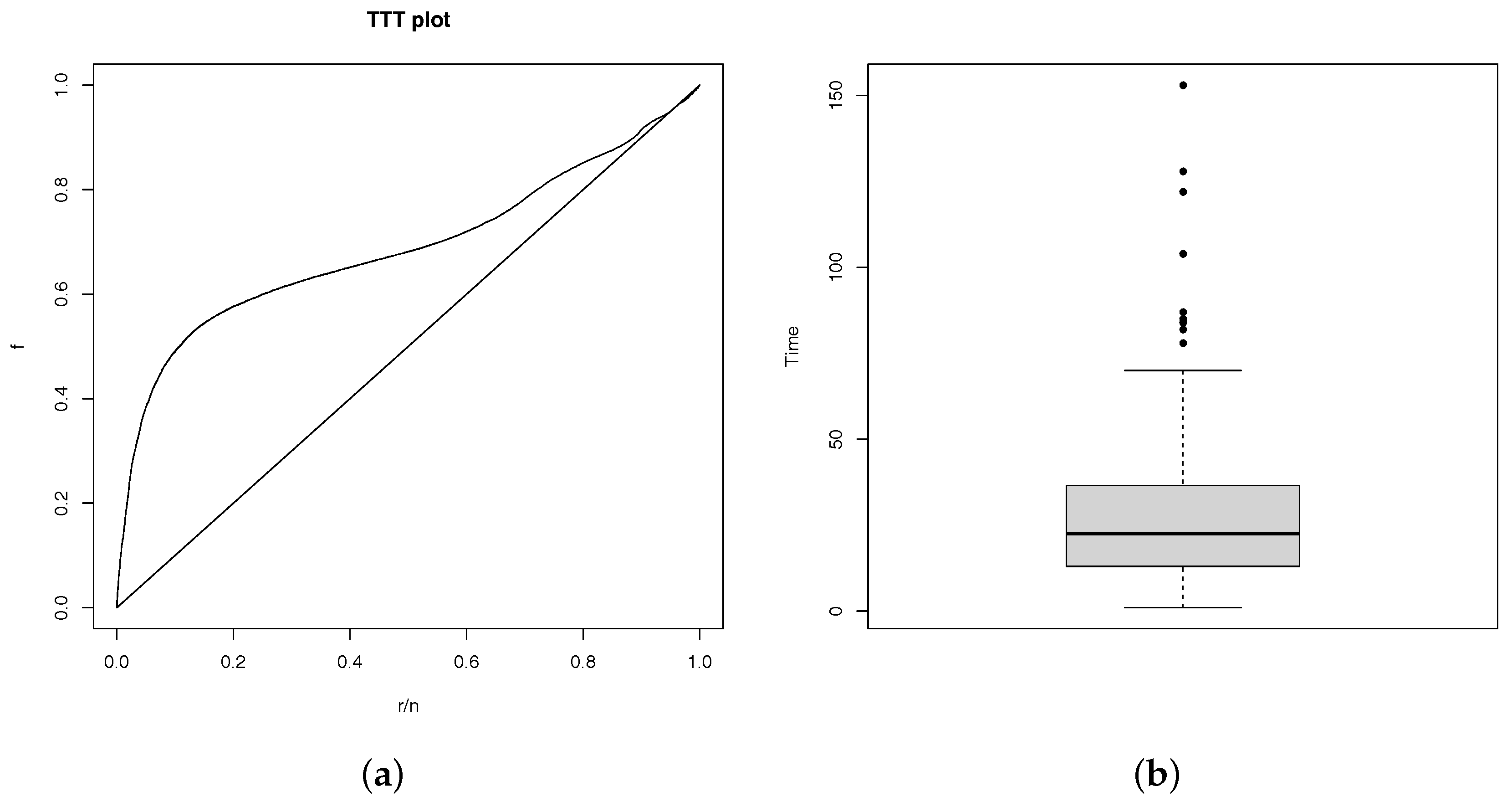
Figure 3.
Traceplots and convergence plots, respectively, for: (a,f): ; (b,g): ; (c,h): ; (d,i): and; (e,j): .
Figure 3.
Traceplots and convergence plots, respectively, for: (a,f): ; (b,g): ; (c,h): ; (d,i): and; (e,j): .

Figure 4.
Marginal posteriors densities for: (a) , (b) , (c) , (d) and (e) .

Figure 5.
(a) hazard estimate curve, with the and the confidence interval, (b) survival curves and (c) histogram.
Figure 5.
(a) hazard estimate curve, with the and the confidence interval, (b) survival curves and (c) histogram.
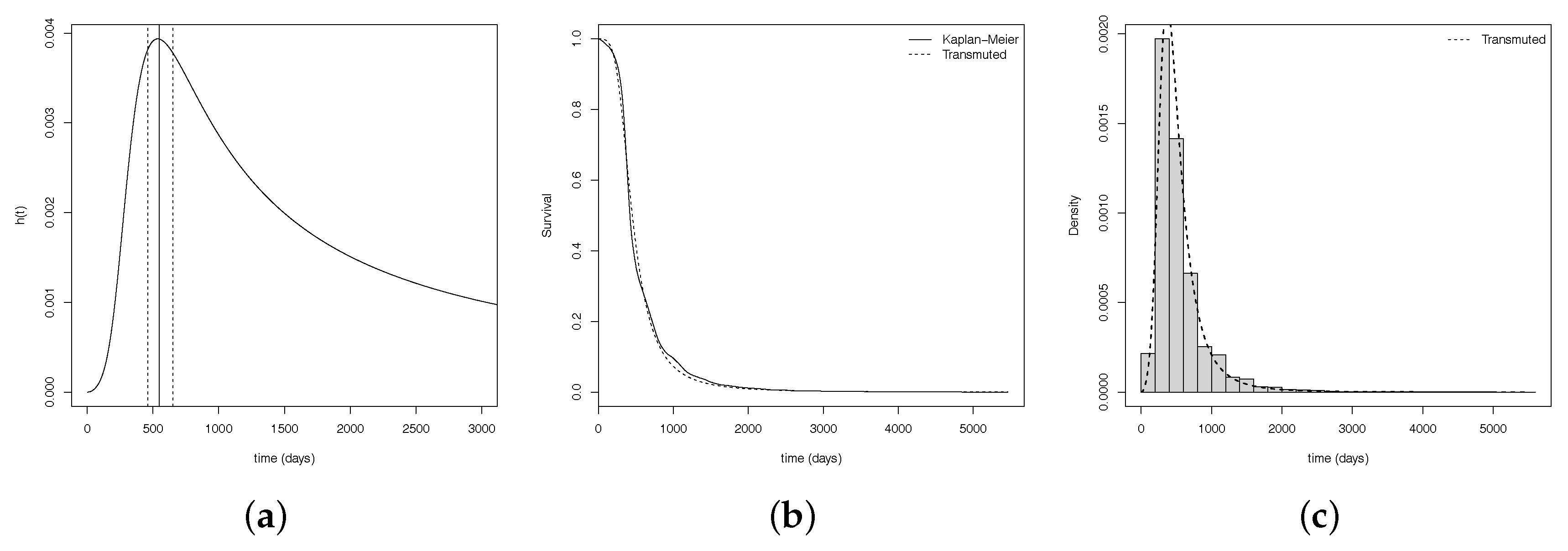
Figure 6.
Likelihood distance.
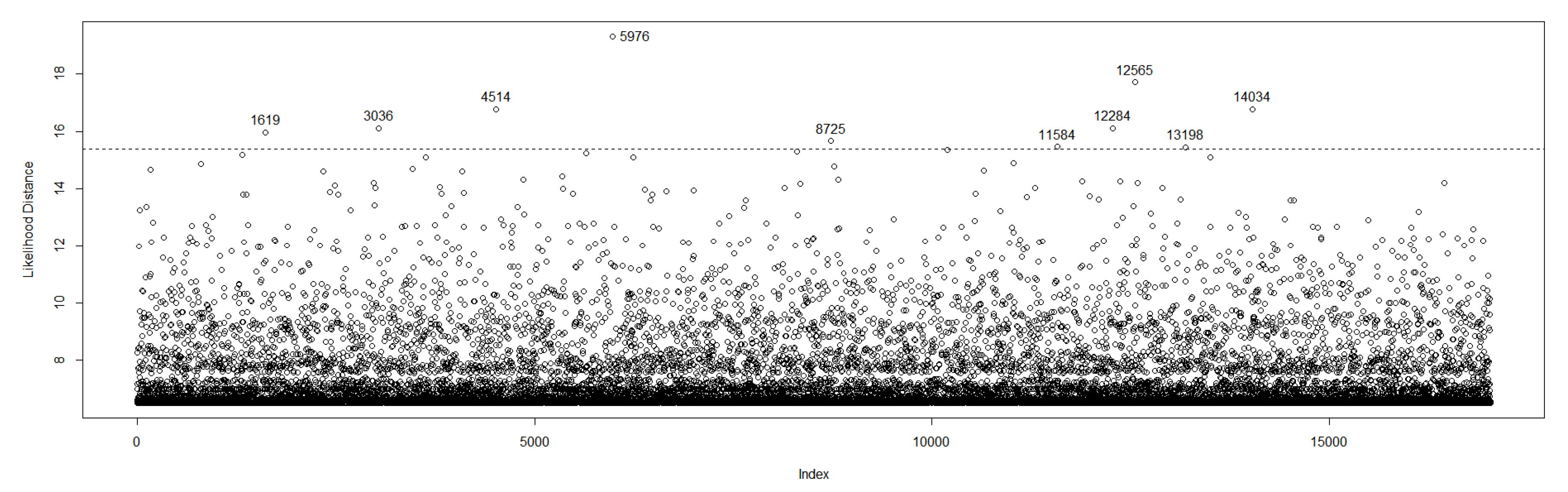
Figure 7.
(a) Hazard estimate curve, with the , (b) survival curves and (c) histogram.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Posterior model summary of the hierarchical TLL model parameters.
| Parameter | Mean | Standard Deviation | Percentiles | ||
|---|---|---|---|---|---|
| 25% | 50% | 75% | |||
Table 2.
95% Credible Interval of parameters estimated.
| Parameter | Equal-Tail Interval | HPD Interval | ||
|---|---|---|---|---|
Table 3.
Gelman and Rubin’s criterion to verify the parameters convergence of the hierarchical TLL distribution.
Table 3.
Gelman and Rubin’s criterion to verify the parameters convergence of the hierarchical TLL distribution.
| Parameter | Estimate | Upper Bound |
|---|---|---|
Table 4.
RC (in %) and the corresponding TRC, MRC and LD.
| Removed Case | Parameter | RC | TRC | MRC | LD |
|---|---|---|---|---|---|
| Identify Points | |||||
| 0.1% | |||||
| 0.5% | |||||
| 1% | |||||
| 2% | |||||
| 3% | |||||
| 4% | |||||
| 5% | |||||
Table 5.
Posterior model summary of the hierarchical TLL model parameters.
| Removed Case | Parameter | Mean | Standard Deviation | Percentiles | ||
|---|---|---|---|---|---|---|
| 25% | 50% | 75% | ||||
| Identify Points | ||||||
| 0.1% | ||||||
| 0.5% | ||||||
| 1% | ||||||
| 2% | ||||||
| 3% | ||||||
| 4% | ||||||
| 5% | ||||||
Table 6.
95% Credible Interval of parameters estimated.
| Removed Case | Parameter | Equal-Tail Interval | HPD Interval | ||
|---|---|---|---|---|---|
| Identify Points | |||||
| 0.1% | |||||
| 0.5% | |||||
| 1% | |||||
| 2% | |||||
| 3% | |||||
| 4% | |||||
| 111 | |||||
| 5% | |||||
| 119 | |||||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Dos Santos, C.A.; Granzotto, D.C.T.; Tomazella, V.L.D.; Louzada, F. Hierarchical Transmuted Log-Logistic Model: A Subjective Bayesian Analysis. J. Risk Financial Manag. 2018, 11, 13. https://doi.org/10.3390/jrfm11010013
AMA Style
Dos Santos CA, Granzotto DCT, Tomazella VLD, Louzada F. Hierarchical Transmuted Log-Logistic Model: A Subjective Bayesian Analysis. Journal of Risk and Financial Management. 2018; 11(1):13. https://doi.org/10.3390/jrfm11010013
Chicago/Turabian StyleDos Santos, Carlos A., Daniele C. T. Granzotto, Vera L. D. Tomazella, and Francisco Louzada. 2018. "Hierarchical Transmuted Log-Logistic Model: A Subjective Bayesian Analysis" Journal of Risk and Financial Management 11, no. 1: 13. https://doi.org/10.3390/jrfm11010013