1. Introduction
Influenza diagnosis based solely on the presentation of symptoms is limited as these symptoms may be associated with many other diseases. Serologic and antigen tests require that a patient with influenza-like illness (ILI) be examined by a physician who can either conduct a rapid diagnostic test or take blood samples in a laboratory testing. This suggests that many cases of influenza remain undiagnosed. While the presence of influenza in an individual can be confirmed through specific diagnostic tests, the influenza prevalence in the population at any given time is unknown and can only be estimated. In the past, such estimates have relied solely on the extrapolation of diagnosed cases, making it difficult to identify the various phases of seasonal influenza or to identify a more serious manifestation of a flu epidemic.
Web and social media (WSM) provide a resource to detect increases in ILI. This paper evaluates blog posts, a type of WSM, that discuss influenza and the analyses show a significant correlation with patient reporting of ILI during the US 2008–2009 influenza season. Preliminary experimental results on data covering two months in 2008 have been published in conference proceedings [
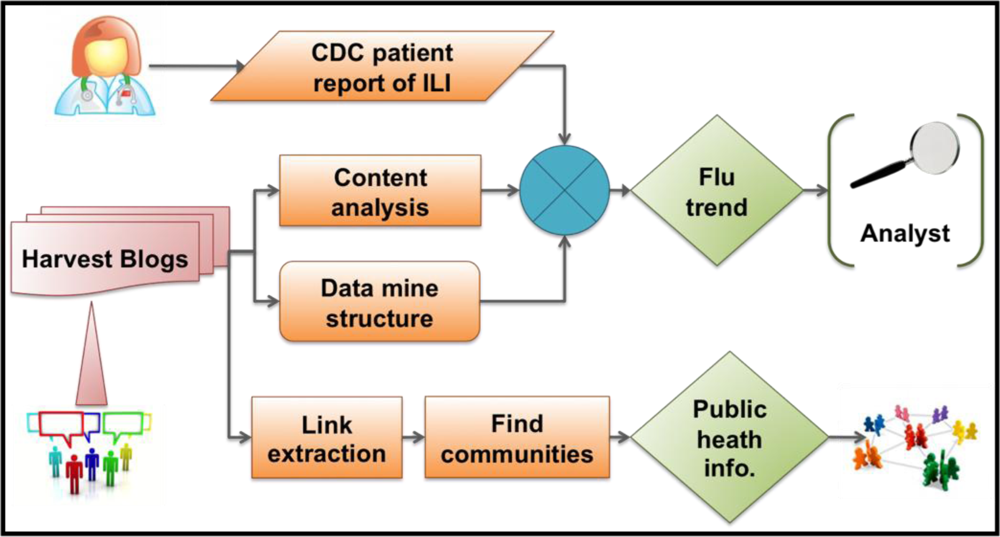
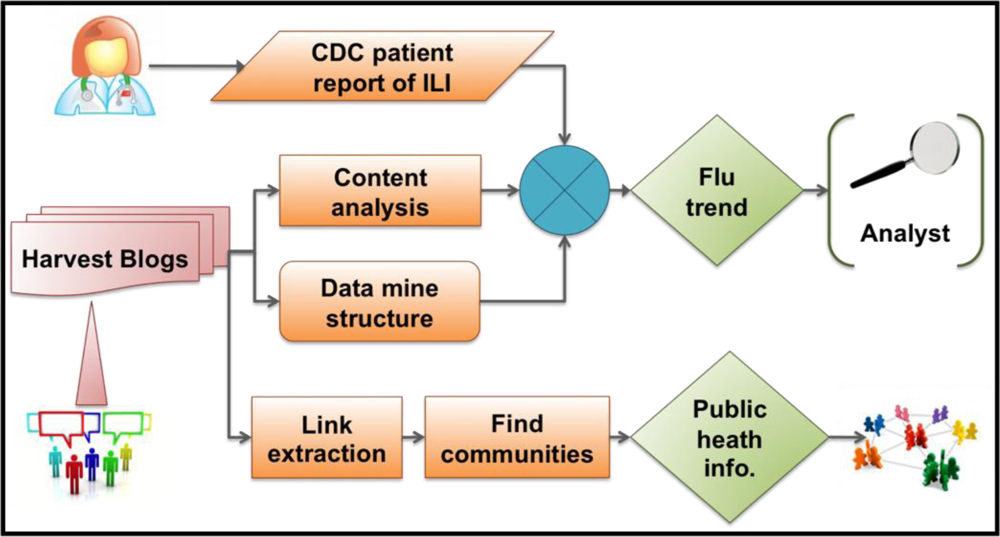
1]. In this article, we present comprehensive analysis, covering 24 months of data. A well-defined response strategy to an outbreak may make use of WSM to reduce population and human impact of the disease. We suggest a possible response that identifies WSM influenza-related communities that share flu-related postings. These community or crowd sources could broker and disseminate important intervention information in the case of an infectious disease outbreak. Our proposed framework, in
Figure 1, visually describes this approach to detecting and responding to influenza epidemics.
We briefly discuss a history of infectious disease outbreaks and recent approaches in online public health surveillance of influenza. We also discuss the value of social community with regard to outbreak responses. Next, the data set used in our analysis is presented and the methodology for information extraction and trend analysis is outlined. Through discovery and verification of trends in influenza-related blogs, we verify a correlation to Centers for Disease Control and Prevention (CDC) ILI patient reporting at sentinel healthcare providers. Additionally, categories, frequency, and influenza-post persistence qualitatively assist ILI trend identification in blogs. Strongly connected communities are evaluated and influential bloggers identified that should be part of a WSM outbreak response. Then we leverage graph-based data mining to further identify structural anomalies in the flu blogosphere that correspond to increases in ILI.
3. Results and Discussion
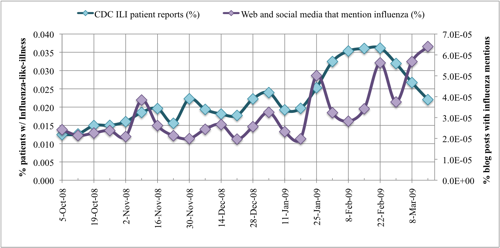
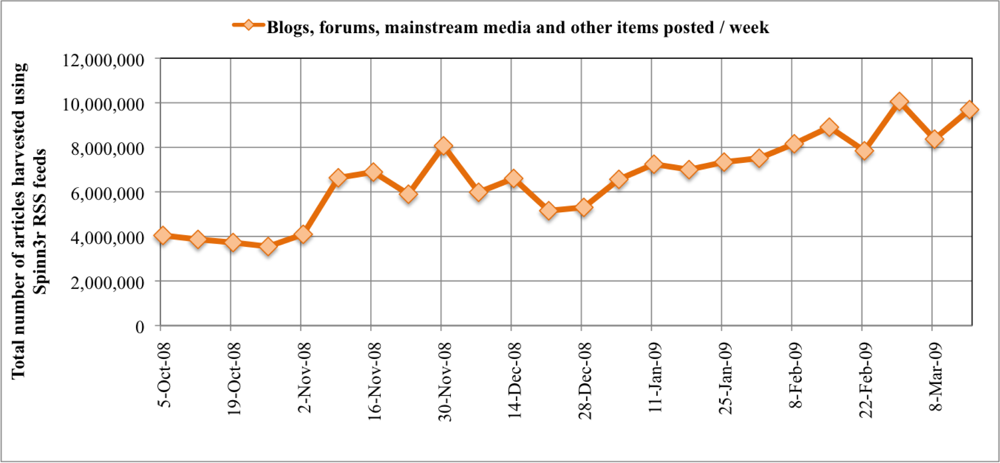
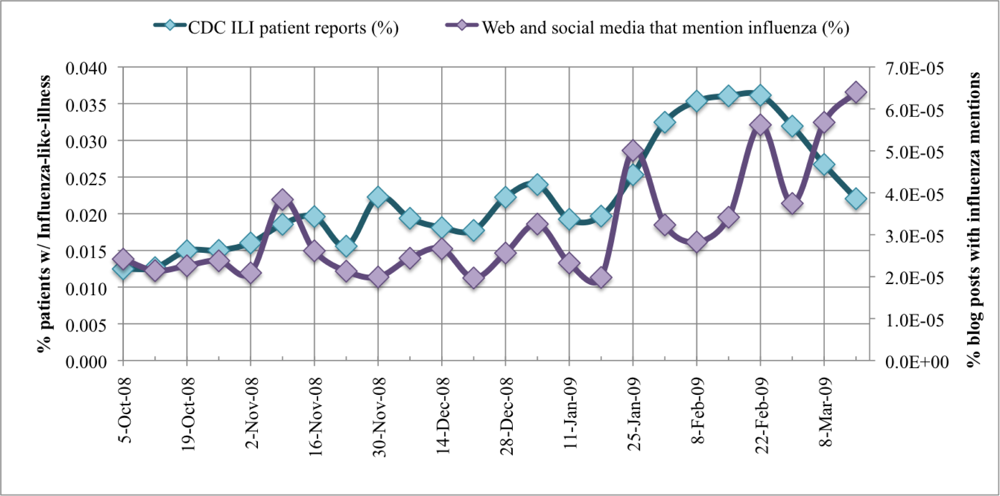
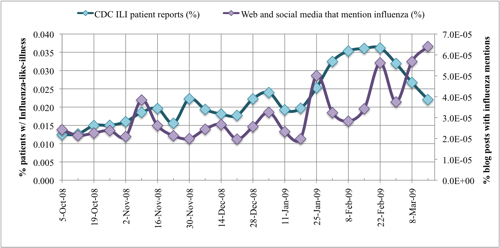
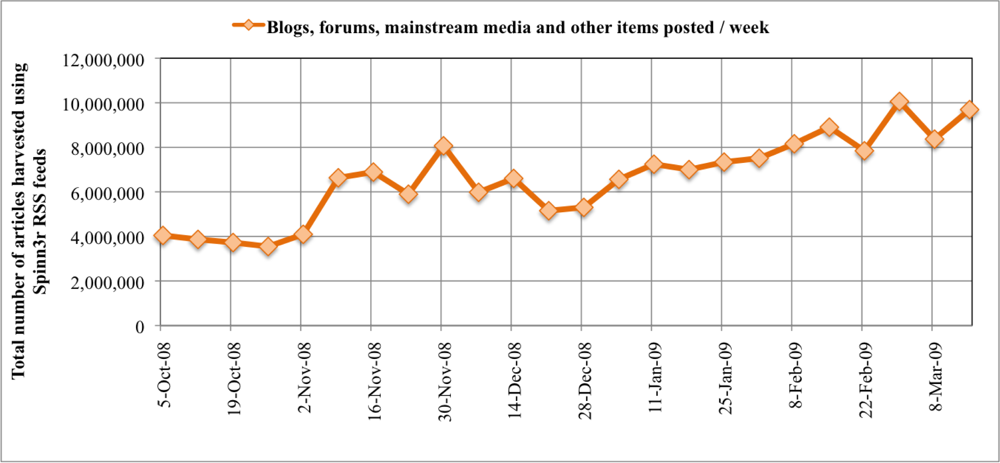
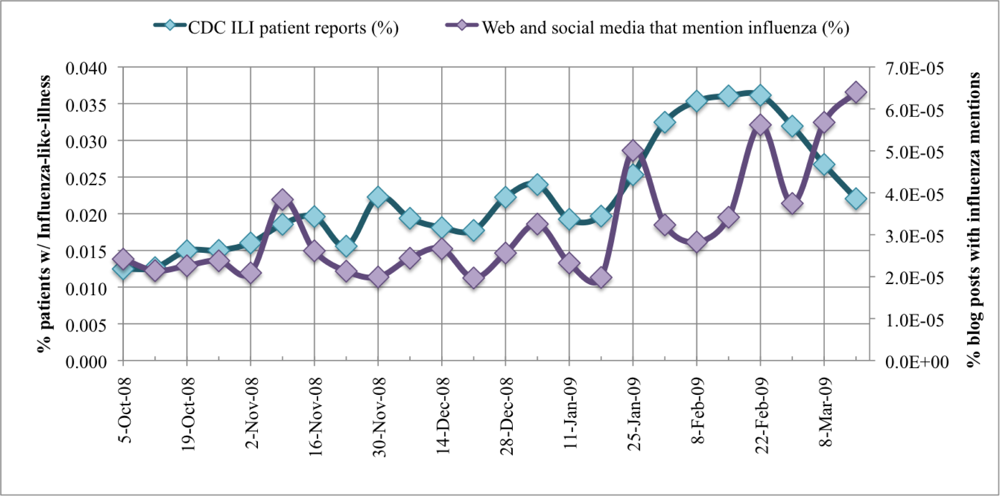
The CDC ILINet surveillance and FC-post per week data are plotted in. CDC ILI symptoms per visit at sentinel US healthcare providers label the primary Y-axis. The secondary Y-axis marks the FC-post per week frequency normalized by the total number of posts in the 24-week period. Correlation between the two data series is measured with a Pearson correlation coefficient, r. To prove our hypothesis that a correlation exists between CDC ILINet reports and mined WSM FC-post frequency, Pearson's correlation statistic is evaluated between the two data series. The Pearson statistic evaluates to unity if the two data series are exactly matching, r = 1. If no correlation exists between the data series, the Pearson statistic evaluates to zero, r = 0. In our analysis, the 24 ILI and FC-post data points correlate strongly with a high Pearson statistic, r = 0.545, and the correlation is significant with 95% confidence. Notice the deviation in the time series at 1 February to 21 March 2009. After close inspection of the data provided by Spinn3r, we identified a significant increase in blog coverage resulting from the success of their service and subsequent expansion of web crawlers, thereby biasing the influenza blog presence normalization. Moreover, graph-base data mining discovered substantial presence of MySpace blogs in the last three weeks of data. We manually inspected the blogs and discovered many of the MySpace blogs were discussing the health of American Idol contestants, several of whom were sick with the flu.
Each WSM item has rich metadata that can be leveraged for content analysis. A folksonomy is defined from WSM by associated author “tags” extracted from category metadata. Moreover, a folksonomy is a type of classification system for online content, created by an individual user who tags information with freely chosen keywords. The Porter stemming algorithm [
17] is used to find the morphological root from the author-tagged labels. Duplicate author-tagged labels are only counted once per blogger.
Table 1 lists the top 45 categories and how often they appear.
Figure 6 is a tag-cloud graphic, called a
Wordle (see
www.wordle.net), that visually depicts the frequency of categories in the data. The top categories (e.g., flu, health, bird, avian, influenza) are intuitive; however, one could monitor categories that imply self or close-proxy infection such as family, sick, symptom, home, school, and other representative terms.
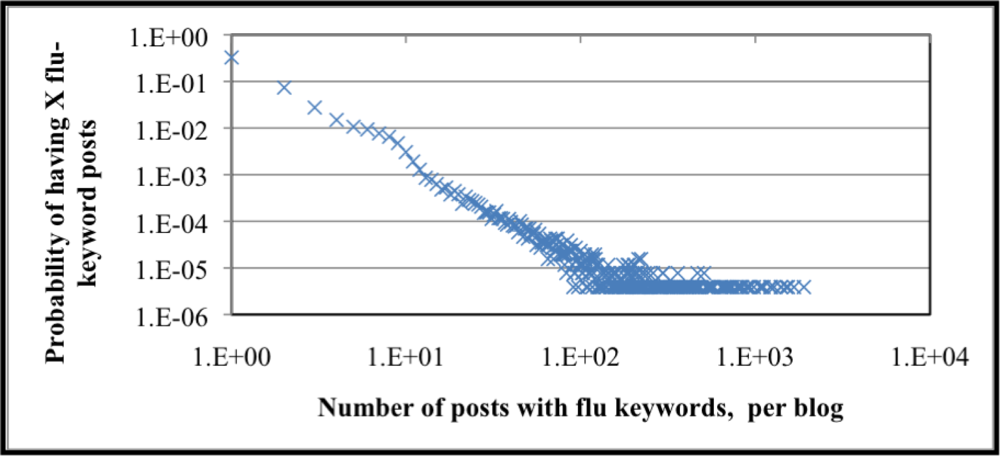
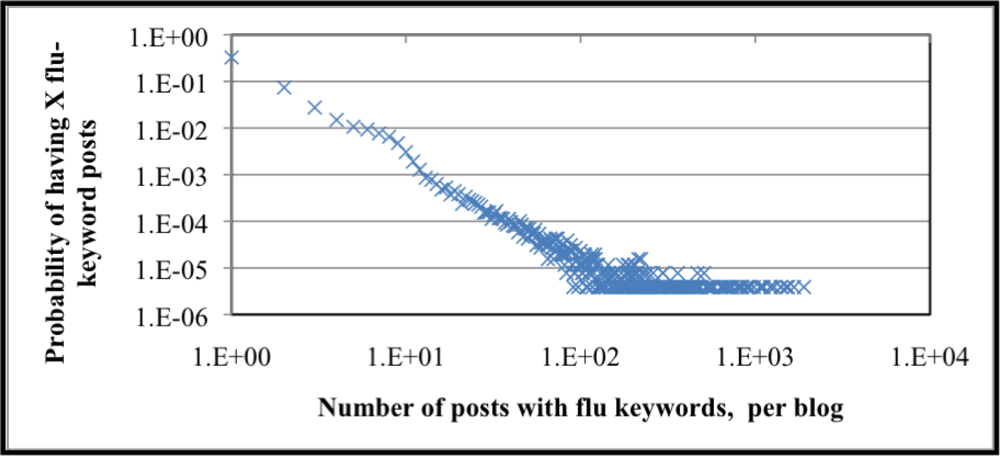
Monitoring self-identification and secondhand FC-post trends can mark increases in ILI. It can be said that bloggers that post often about influenza are more likely to a) be an authority on influenza (perhaps not an expert, however) where its readers find information on influenza or b) the blogger is frequently sick with influenza. How often or how persistently bloggers author FC-posts indicates trends as well; a blog-site that has FC-posts for a limited time is more likely to be a first- or secondhand identification of ILI. The cumulative probability distribution for how many posts a blogger writes about influenza is graphically summarized in
Figure 7. The number of posts with influenza keywords per blogger is plotted on the X-axis and the associated probability of a blogger posting X number of flu posts labels the Y-axis; the data is plotted on a log-log scale. We see from that over 95% of bloggers only post one “flu” post, whereas the most frequent flu post blogger authored 1,897 posts. The probability of a blogger posting 1,897 flu posts is approximately 0.0000388%. The heavy-tailed distribution is indicative of social processes (e.g., number of intimate partners [
18]) and is present in the distribution of flu posts per blogger. The cumulative probability distribution also supports the hypothesis that most bloggers do not frequently author influenza content. Content analysis supporting the claim that less frequent posters self-identify ILI is left for future work.
To study the link-based structure of bloggers authoring influenza-related content, we extract the URLs linked in each blog post. These URLs and blog permalinks (829,662 URLs) are truncated to the network location and path resulting in 694,388 unique URLs. A link graph is then constructed from the blogger source URL and out-links from the influenza posts, removing self-references and parallel out-links and the largest weak component producing an aggregate graph of 694,388 nodes (bloggers) and 3,529,362 directed edges (unique blogger to blogger links).
Table 2 lists the seven most prolific flu bloggers and their degree (In, Out, and Total). The relatively low In degree supports the claim that frequent posters are news- and opinion-oriented and not always the most influential in online communities. Centrality metrics are evaluated on the same most frequent bloggers. The results are listed in
Table 3. Three of the top posters have no in-links, implying they are spam blogs and have no influence in the “flu” blogosphere. We verify this statement with a quick hand-check of the URL. The RSS feed BirdFluMonitor has the highest out closeness centrality, but no In degree, implying they are adept at publishing links to popular blogs but are not influential themselves. Three blogs (h5n1, a flu diary, fluwikie2) are interesting hubs of the flu blogosphere. The blog “A Flu Diary” has the largest betweenness centrality (interpersonal influence) with high In and Out degree and demonstrates the capability to broker influential information in the target blogosphere. The blog h5n1 has the greatest PageRank and in-closeness centrality; moreover, it has the most published items of the most frequent bloggers and is influential in disseminating h5n1 information.
Using the most frequent flu bloggers is a naïve approach to finding target WSM communities to be leveraged for public health response. To advance our approach, we target strongly connected components within our flu link graph community identification (Flake, Lawrence, and Gilles definition of community [
19,
20]). The link graph’s largest strongly connected component is over 17,000 unique URLs. However, its nodes are spam bloggers; specifically, they were all LiveJournal blogs, and each post had exactly eight out-links The uniformity and a manual inspection of these as spam blogs show they were written for the purpose of search engine optimization. Therefore, we cluster the second largest strongly connect component, which consists of 2,306 blogs, 26,768 edges, and an average degree of 23. The Girvan-Newman community finding algorithm (recursively removes the node with the highest betweenness centrality) identifies 11 communities.
Table 4 reports centralities and size for the six largest communities. An interesting finding is that these communities are clustered not only by publisher types but also by parent company. Not surprisingly, the largest community comprises personal blogs and general reporting newspapers; the remaining consist of mainstream and local news outlets, international audience media, LiveJournal, and entertainment industry (e.g., Viacom, Reed), large news conglomerates (e.g., News Corp, Disney), and commentary, opinion and editorial content. A successful WSM public health campaign should have a presence and influence in each of the reported blog communities to ensure wide coverage and dissemination of pertinent information.
Detecting anomalies in various data sets is an important endeavor. We define an anomaly as a surprising or unusual occurrence. Using statistical approaches has led to various successes such as detecting computer and network intrusions. Recent research in graph-based anomaly detection has paved the way for new approaches that not only complement the non-graph-methods but also provide mechanisms for handling data that cannot be easily analyzed with traditional statistical approaches [
21]. Again, Subdue can be used to address this challenge. Subdue examines an entire graph and reports unusual substructures, or substructures that occur infrequently, within it [
14]. Subdue also takes into account the regularity of the data to determine how likely it is for a substructure to occur given the predictability of the structural data surrounding the substructure. These ideas have been tested in applications including intrusion detection and terrorist activity analysis.
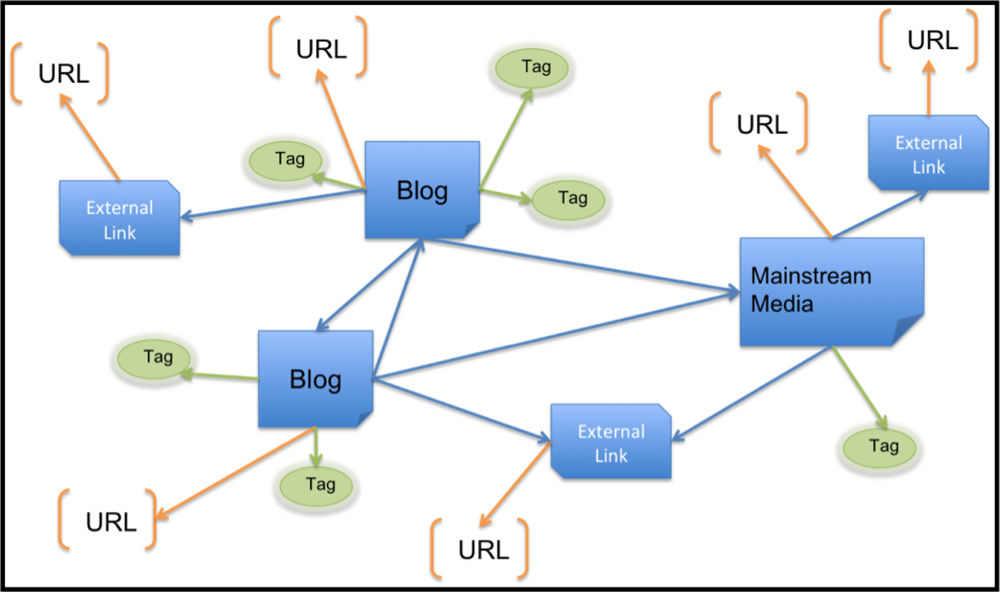
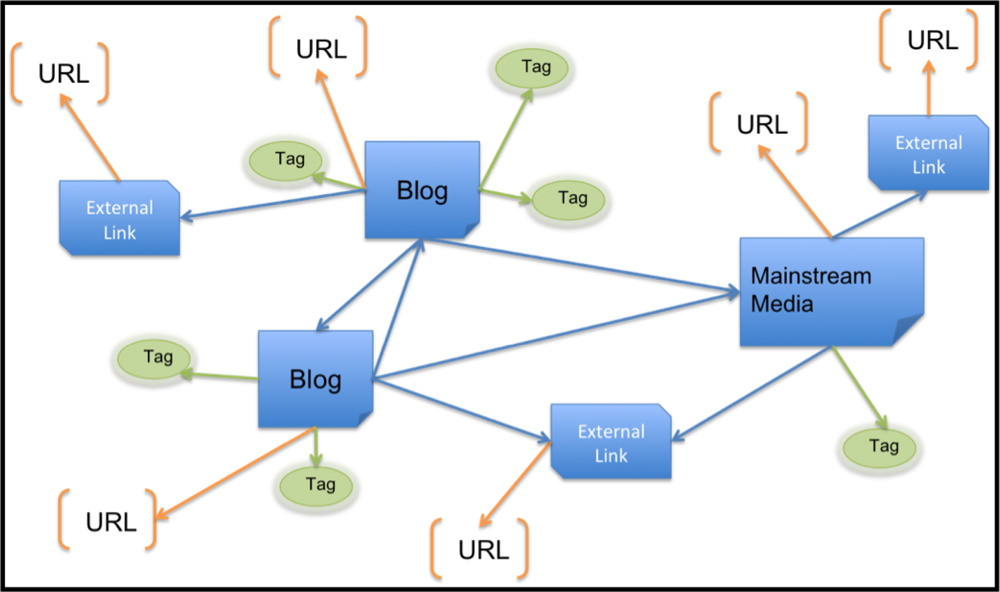
To facilitate identification of ILI through graph-based data mining of influenza blogs, we base the representation on the link graph. Multiple posts by the same author are aggregated, representing a unique blogger; similarly, multiple tags and out and in links are only counted once per blogger. To structurally enrich the link graph, we connect the blogger URL and tags to a node labeled by the publisher type (e.g., blog, forum, mainstream media, external link) as depicted in
Figure 8 Graph structures are created from weekly influenza blog posts to facilitate anomaly detection and correlation to CDC ILI patient reports.
Figure 8 demonstrates how URLs are disaggregated from their WSM article, thereby creating a relationship between two entities (the WSM article and the URL). This allows Subdue to find informative subgraphs of blogs with differing content (news, personal blogs) in addition to traditional URL structures. The structurally enriched data and temporal format facilitate anomaly detection by Subdue (this is in contrast to the 24-week aggregate link graph used for community identification).
Table 5 lists the substructure features discovered by Subdue and identifies if they correspond to an anomaly for the purpose of outbreak detection. An analyst can then review the reported substructures for outbreak information. The first discovery of interest is during the week beginning 7 December 2008 identifying the UK Yahoo Answers site. During the same time frame, the United Kingdom was in the middle of its worst flu season in eight years. While correlating influenza post frequency to CDC ILINet data was unsuccessful in February and March 2009, Subdue is able to identify novel substructures in personal blogs that mention influenza. The third anomaly discovered by Subdue shows a high number of substructures occurrences, composed of MySpace blog posts discussing several American Idol contestants that contracted influenza and were unable to perform at their best during the weekly performance competition.
4. Methods and Materials
Wasserman and Faust state closeness can be productive in communicating information to other actors. It is defined in
Equation 1 as the average shortest paths or geodesics distance from actor
v and all reachable actors (
t in
V\
v) in [
22]:
Betweenness centrality (
Eqn. 2) measures interpersonal influence. Specifically, a blog is central if it lies between other blogs on their geodesics—the blog is “between” many others, where
gjk is the number of geodesics linking blog
j and blog
k [
22] :
Page Rank is an example of eigenvector centrality and measures the importance of a
node by assuming links from more central nodes contribute more to its ranking than less central nodes [
23]. Let
d be a damping factor (usually 0.85),
n be the index to the node of interest,
pn be the node, M(
pi) be the set of nodes linking to
pn and L(
pj) be the out-link counts on page
pj:
We take an intuitive and simple definition of WSM community and identify possible first responder bloggers by link analysis. Blog ranking enhances the idea that these communities can disseminate information as part of a broader public health response triggered by anomalies in ILINet and WSM surveillance. Community herein is defined similar to Flake, Lawrence, and Giles where there are more edges between member nodes than edges to external nodes. Formally, a community is a vertex subset
C in V, such that for all vertices
v ∈
C,
v has at least as many edges connecting to vertices in
C as it does to vertices in (V-C) [
19,
20]. Links from a non FC-post to an FC-post and vice versa are not defined in this community definition. The Girvan-Newman algorithm is used to identify communities in our data. The general form of this community structure finding algorithm is enumerated below, components remaining in the graph at the end of each iteration are the communities [
24]:
Calculate betweenness scores for all edges in the network.
Find the edge with the highest score and remove it from the network. If two or more edges tie for highest score, choose one of them at random and remove that edge.
Recalculate betweenness for all remaining edges.
Repeat from step 2 until the desired number (if known a priori) of communities is reached, otherwise repeat from step 2 until no edges remain.
Subdue accepts as input directed or undirected graphs with labeled vertices (nodes) and edges (links), and outputs graphs representing the discovered pattern or learned concept. Formally, Subdue uses a labeled graph G = (V,E,L) as both input and output, where V = {v1, v2, …, vn} is a set of vertices, E = {(vi, vj) | vi, vj ∈ V} is a set of edges, and L is a set of labels that can appear on vertices and edges. The graph G can contain directed edges, undirected edges, self-edges, and multi-edges. As an unsupervised algorithm, Subdue searches for a substructure, or subgraph of the input graph, that best compresses the input graph. Subdue uses a variant of beam search for its main search algorithm. A substructure in Subdue consists of a subgraph definition and all its occurrences throughout the graph.
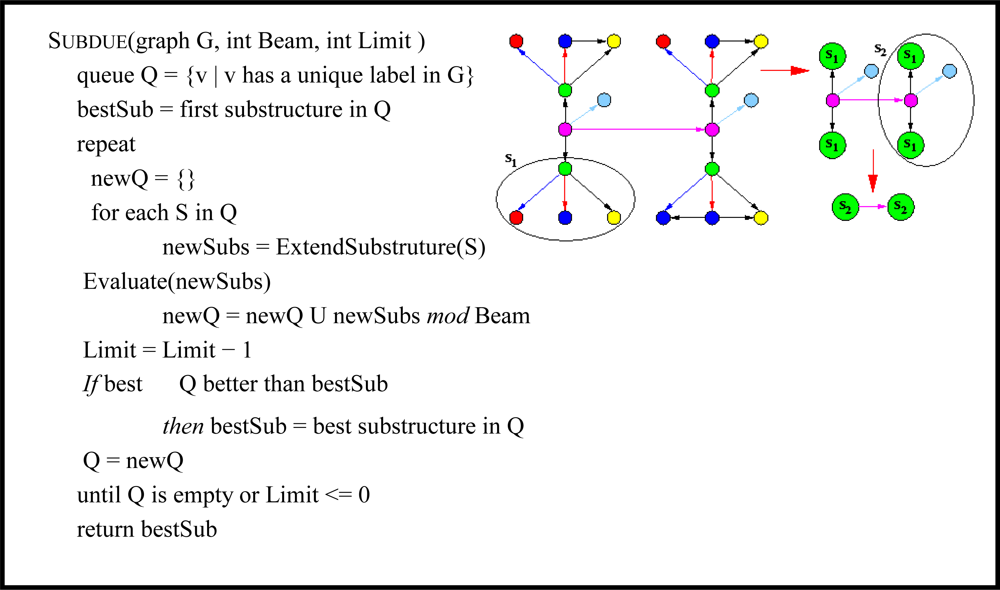
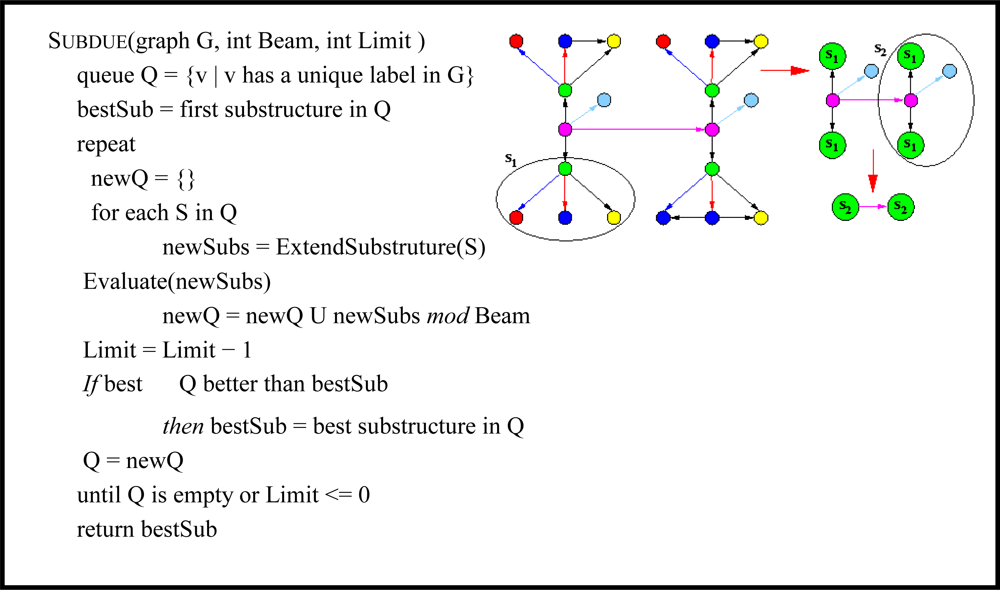
Subdue uses a polynomial-time beam search for its discovery algorithm, as summarized in
Figure 9. The initial state of the search is the set of substructures consisting of all uniquely labeled vertices. Search progresses by applying the ExtendSubstructure operator to each substructure in the current state. As its name suggests, it extends a substructure in all possible ways by a single edge and a vertex or by only a single edge if both vertices are already in the subgraph. The resulting new substructures are ordered based on their compression (sometimes referred to as
value) as calculated using the Minimum Description Length (MDL) [
21] principle described below, and the top substructures (as determined by the beam) remain on the queue for further expansion.
Search terminates upon reaching a limit on the number of substructures extended or upon exhaustion of the search space. Once the search terminates and Subdue returns the list of best substructures, the graph can be compressed using the best substructure. The compression procedure replaces all instances of the substructure in the input graph by single vertices, which represent the substructure definition. Incoming and outgoing edges to and from the replaced instances will point to or originate from the new vertex that represents the instance. The Subdue algorithm can be invoked again on this compressed graph. As an example
Figure 9 shows patterns that Subdue discovers in an example input graph and a compressed version of the graph.
6. Conclusions
Text and structural data mining of WSM provides a novel disease surveillance resource and technique to identify online “flu” topic health information communities. Our proposed framework of complementary data-mining methods supports our hypothesis. We comprehensively evaluate blog posts containing influenza topic keywords through text, link, and structural data mining. Results from analysis show strong co-occurrence of flu blog posts during the US 2008–2009 flu season. That is, from 5 October 2008 to 21 March 2009, a high correlation exists between the frequency of posts, containing influenza keywords, per week and CDC ILI surveillance data. Frequency of flu posts per blogger follows a heavy-tailed distribution, and we show through graph metrics that the most prolific bloggers are not the most influential. Pertinent health information should have a presence in all identified WSM communities. The Girvan-Newman algorithm is leveraged to identify clusters of similar sites as potential target communities for online health information campaigns. The results show distinct WSM communities clustered by publisher and content type, such as News Corp & Disney properties, international audiences, or personal blogs.
Harvesting WSM is a continuing challenge with the explosive growth of internet usage. To complement the text mining approach to ILI monitoring, we apply a graph-based data mining technique, Subdue, to detect anomalies and informative substructures among flu blogs connected by publisher type, links, and user-tags. This technique flags anomalies not discovered with content analysis that correspond to the United Kingdom’s worst influenza season in eight years and the emergence of strong personal blog communications during the U.S. seasonal influenza peak incidence.
Link analysis reveals communities, clustered by content and in many cases corporate ownership, which should be targeted in a successful public health communications campaign to assure wide dissemination of pertinent information. Text mining of influenza mentions in WSM is shown to identify trends in flu posts that correlate to real-world ILI patient reporting data. Moreover, graph-based data mining is able to identify significant anomalies in flu blogs that were not identified through text analysis and can be flagged for further investigation by an analyst.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}