Advancing the Selection of Neurodevelopmental Measures in Epidemiological Studies of Environmental Chemical Exposure and Health Effects

Abstract
:1. Introduction
2. Experimental Section
3. Results and Discussion
3.1. Neurodevelopmental Measures and Domains
3.2. Broad versus Narrow Measures
3.3. Old versus New Versions of a Measure
3.4. Psychometrics: Conventional and Relevant Metrics
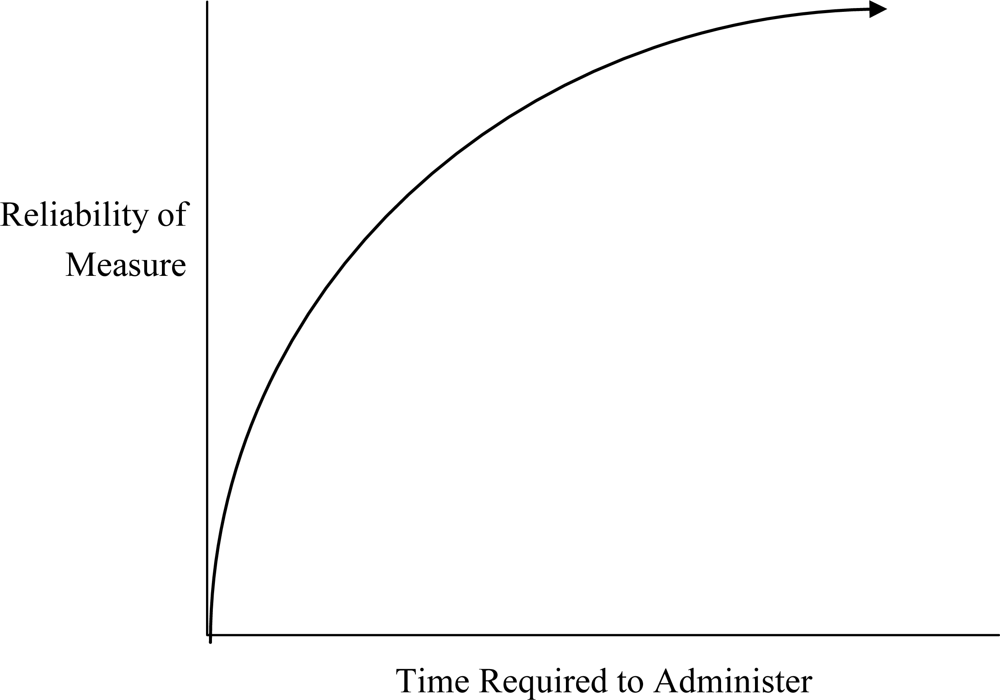
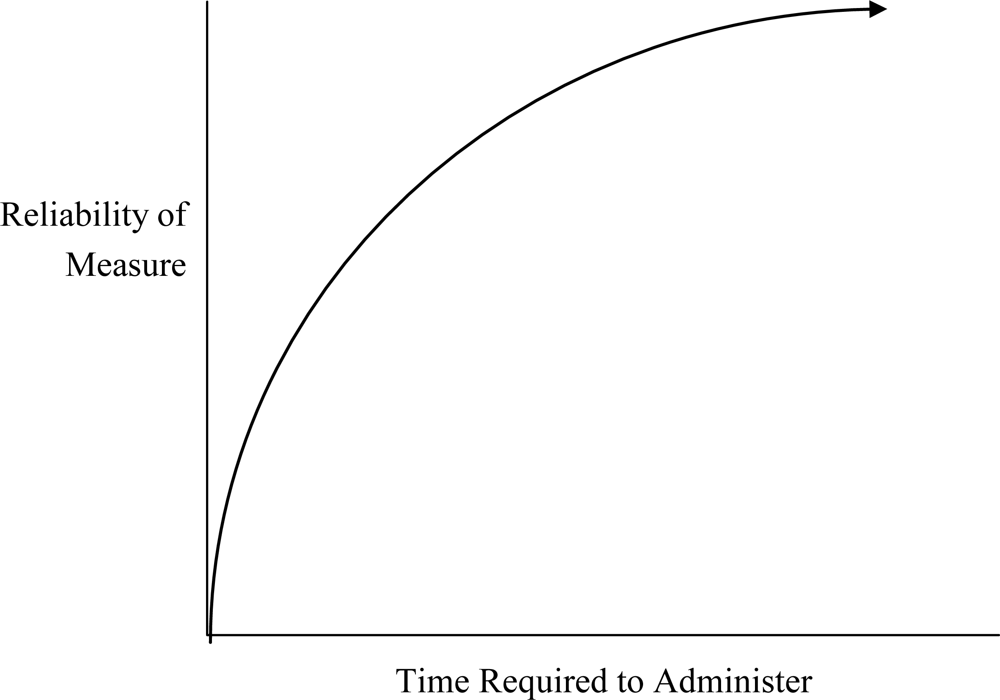
Reliability
Validity
3.5. Cultural Effects
3.6. Measuring Other Risk and Protective Factors
3.7. Statistical Significance versus Clinical Significance
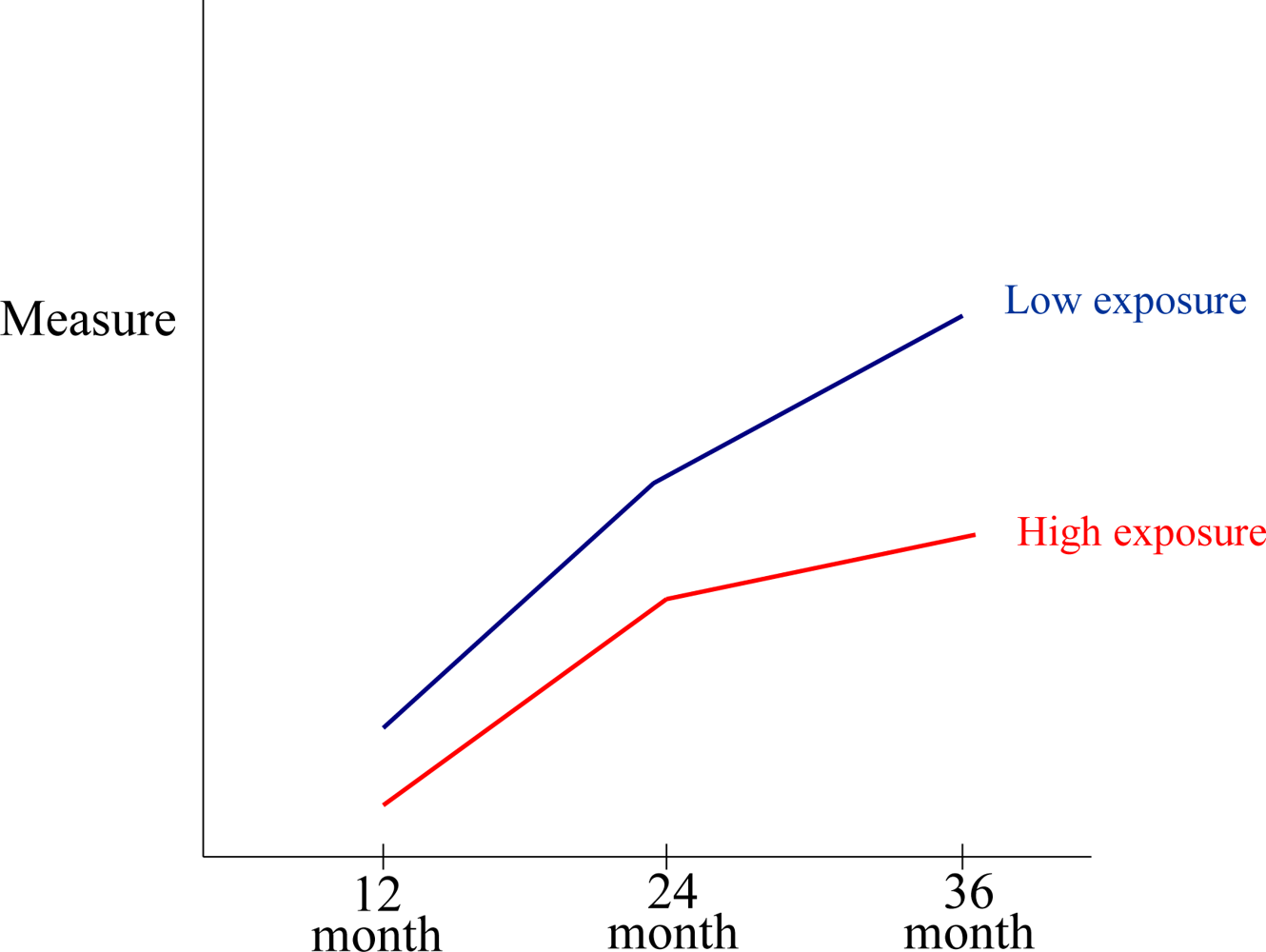
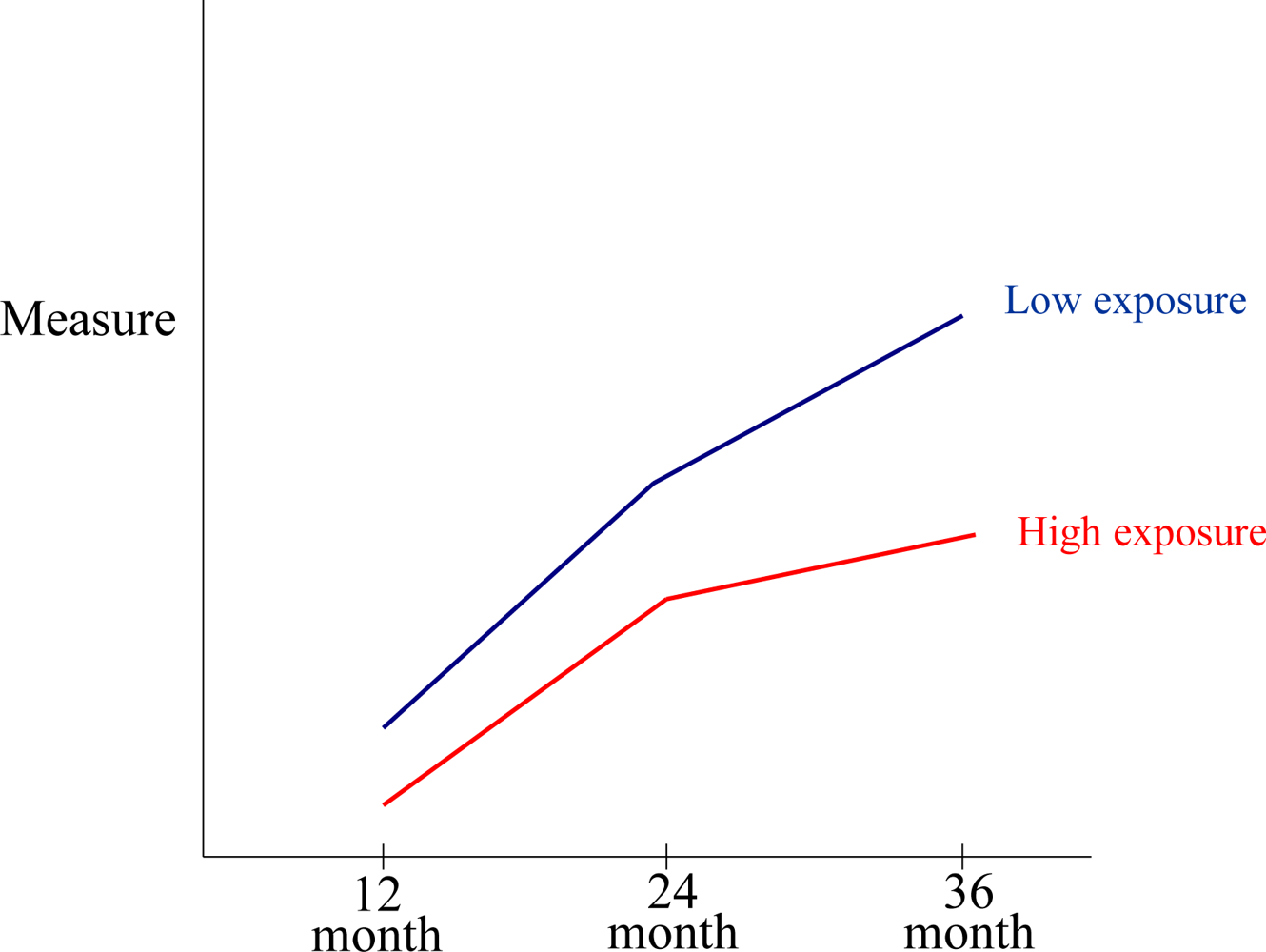
3.8. Developmental Effects on Neurocognitive Functioning and Consequent Changes in Assessment Stability and Validity
4. Conclusions
- there are a large number of measures that have been used, including both global and more narrowly-focused measures;
- there have been continued revisions and changes to many of the core measures, which necessitate changes in the selection of tests for new research protocols;
- entirely new measures are available that warrant consideration for inclusion in new studies of toxicants due to their superior psychometric properties;
- entirely new domains should be explored in new studies of toxicants due to their importance in real world functioning and/or the possibility that they would be sensitive to toxicants’ effects (e.g., adaptive functioning, executive functioning, articulation);
- the most commonly documented psychometric properties for measures (such as internal consistency reliability estimates or concurrent validity correlations) are only indirectly relevant to the main objectives of epidemiological studies of toxicants;
- the most relevant psychometric features for measures used in toxicant studies (such as retest stability or sensitivity to exposure effects) have been reported only rarely;
- the selection of covariates in environmental studies has been largely focused on demographics and confounders, whereas the inclusion of other covariates (e.g., IQ) that are highly correlated with the dependent variable (e.g., language) would further improve estimation of the effects of toxicants;
- the field of environmental epidemiology may be nearing a stage where a formal set of reporting guidelines could be developed to help the design of future studies, as has been done with clinical trials, studies of diagnostic assessment tools, and medical epidemiological studies;
- in terms of domains, it is clear that there have been changes over time and across studies in how assessment measures are categorized. A consistent rubric should be developed and adopted, even though it would necessarily be imperfect, provisional, and subject to periodic revision;
- predictive validity and exposure sensitivity are two highly relevant but rarely reported parameters. We recommend increased emphasis on reporting the relevant parameters, both in technical manuals and in research reports, to facilitate improving measure selection.
Acknowledgments
References
- Grandjean, P; Landrigan, PJ. Developmental neurotoxicity of industrial chemicals. Lancet 2006, 368, 2167–2178. [Google Scholar]
- Dietrich, KN; Eskenazi, B; Schantz, S; Yolton, K; Rauh, VA; Johnson, CB; Alkon, A; Canfield, RL; Pessah, IN; Berman, RF. Principles and practices of neurodevelopmental assessment in children: lessons learned from the Centers for Children's Environmental Health and Disease Prevention Research. Environ. Health Perspect 2005, 113, 1437–1446. [Google Scholar]
- Amler, RW; Barone, S, Jr; Belger, A; Berlin, CM, Jr; Cox, C; Frank, H; Goodman, M; Harry, J; Hooper, SR; Ladda, R; LaKind, JS; Lipkin, PH; Lipsitt, LP; Lorber, MN; Myers, G; Mason, AM; Needham, LL; Sonawane, B; Wachs, TD; Yager, JW. Hershey Medical Center Technical Workshop Report: optimizing the design and interpretation of epidemiologic studies for assessing neurodevelopmental effects from in utero chemical exposure. Neurotoxicology 2006, 27, 861–874. [Google Scholar]
- Davidson, PW; Weiss, B; Myers, GJ; Beck, C; Cory-Slechta, D; Orlando, M; Loiselle, D; Young, EC; Sloane-Reeves, J. Validation of Test Methods for Assessing Neurodevelopment in Children; Agency for Toxic Substances and Disease Registry: Atlanta, GA, USA, 2005.
- Roegge, CS; Schantz, SL. Motor function following developmental exposure to PCBS and/or MEHG. Neurotoxicol. Teratol 2006, 28, 260–277. [Google Scholar]
- DiPietro, J. Fetal Environment and neurodevelopmental outcomes: an overview, Presented at Maternal Influences on Fetal Neurodevelopment, JHUSOM, Fetal Physiology Foundation, Inc, Kennedy Krieger Institute, NICHD, Baltimore, Maryland, USA, 23 June 2008.
- Cooper, H. Literature searching strategies of integrative research reviewers. Amer. Psychol 1985, 40, 1267–1269. [Google Scholar]
- Cooper, HM. Integrating Research: A Guide for Literature Reviews, 2nd ed; Sage: Thousand Oaks, CA, USA, 1989. [Google Scholar]
- Boucher, O; Muckle, G; Bastien, CH. Prenatal exposure to polychlorinated biphenyls: a neuropsychologic analysis. Environ. Health Perspect 2009, 117, 7–16. [Google Scholar]
- Wilkinson, GS; Robertson, GJ. Wide Range Achievement Test 4 (WRAT4); PAR: Lutz, FL, USA, 2006. [Google Scholar]
- Woodcock, RW; McGrew, KS; Mather, N. Woodcock-Johnson Psychoeducational Battery—III NU Complete; Riverside Publishing Company: Rolling Meadows, IL, USA, 2005. [Google Scholar]
- Harrison, PL; Oakland, T. Adaptive Behavior Assessment System (ABAS), 2nd ed; The Psychological Corporation: San Antonio: TX, USA, 2003. [Google Scholar]
- Sparrow, S; Balla, DA; Cicchetti, D. Vineland Adaptive Behavior Scales, 2nd Edition: Survey Forms Manual; Pearson: San Antonio, TX, USA, 2005. [Google Scholar]
- Conners, CK. Conners, 3rd ed; Multi-Health Systems: North Tonawanda, NY, USA, 2008. [Google Scholar]
- Conners, CK; MHS Staff. Conners' Continuous Performance Test (CPT II); Multi-Health Systems: North Tonawanda, NY, USA, 2004. [Google Scholar]
- Gioia, GA; Isquith, PK; Guy, SC; Kenworthy, L. Behavior rating inventory of executive function. Child Neuropsychol 2000, 6, 235–238. [Google Scholar]
- Heaton, RK; Chelune, GJ; Talley, JL; Kay, JH; Curtiss, G. Wisconsin Card Sorting Test Manual; Psychological Assessment Resources: Odessa, FL, USA, 1993. [Google Scholar]
- Bayley, N. Bayley Scales of Infant and Toddler Development: Technical Manual; Harcourt Brace and Company: San Antonio, TX, USA, 2006. [Google Scholar]
- Mullen, EM. Mullen Scales of Early Learning; American Guidance Service: Circle Pines, MN, USA, 1995. [Google Scholar]
- Wechsler, D. Wechsler Intelligence Scale for Children—Fourth Edition: Technical and Interpretive Manual; The Psychological Corporation: San Antonio, TX, USA, 2003. [Google Scholar]
- Wechsler, D. Wechsler Adult Intelligence Scale–Third Edition, Wechsler Memory Scale-Third Edition Technical Manual; The Psychological Corporation: San Antonio, TX, USA, 1997. [Google Scholar]
- The Psychological Corporation. Wechsler Abbreviated Scale of Intelligence Manual; Harcourt Brace and Company: San Antonio, TX, USA, 1999. [Google Scholar]
- Hammill, DD; Pearson, NA; Wiederholt, JL. Comprehensive Test of Nonverbal Intelligence; PRO-ED, Inc: Austin, TX, USA, 1996. [Google Scholar]
- Roid, GH; Miller, LJ. Leiter International Performance Scale-Revised; Stoelting Co.: Wood Dale, IL, USA, 1998. [Google Scholar]
- Elliott, CD. Differential Ability Scales-Second Edition, Administration & Scoring Manual; The Psychological Corporation: San Antonio, TX, USA, 2007. [Google Scholar]
- McCarthy, DA. Manual for the McCarthy Scale of Children's Abilities; The Psychological Corporation: New York, NY, USA, 1972. [Google Scholar]
- Folio, MR; Fewell, RR. Peabody Developmental Motor Scales-Second Edition; PRO-ED Inc: Austin, TX, USA, 2000. [Google Scholar]
- Brandon, AD; Bennett, TL. Digital Finger Tapping Test; Western Psychological Services: Los Angeles, CA, USA, 1989. [Google Scholar]
- Reitan, RM. Halstead-Reitan Neuropsychological Test Battery; Reitan Neuropsychology Laboratory/Press: Tucson, AZ, USA, 1979. [Google Scholar]
- Baron, IS. Neuropsychological Evaluation of the Child; Oxford University Press: New York, NY, USA, 2004. [Google Scholar]
- Goldman, R; Fristoe, M. Goldman Fristoe Test of Articulation, 2nd ed; American Guidance Service: Circle Pines, MN, USA, 2000. [Google Scholar]
- Zimmerman, IL; Steiner, VG; Pond, RE. Preschool Language Scale, Fourth Edition; Harcourt Brace Jovanovich: San Antonio, TX, USA, 2002. [Google Scholar]
- Semel, E; Wiig, E; Secord, WA. Clinical Evaluation of Language Fundamentals, 4th ed; The Psychological Corporation: San Antonio, TX, USA, 2003. [Google Scholar]
- Wechsler, D. Manual for the Wechsler Intelligence Scale for Children–Revised Edition; The Psychological Corporation: New York, NY, USA, 1974. [Google Scholar]
- Delis, DC; Kramer, JH; Kaplan, E; Ober, BA. California Verbal Learning Test—Children's Version; Harcourt Brace and Company: San Antonio, TX, USA, 1994. [Google Scholar]
- Sheslow, D; Adams, W. Wide Range Assessment of Memory and Learning, 2nd ed; PAR: Lutz, FL, USA, 2003. [Google Scholar]
- Achenbach, TM; Rescorla, LA. Manual for the ASEBA School—Age Forms & Profiles; University of Vermont: Burlington: VT, USA, 2001. [Google Scholar]
- Aman, MG; Singh, NN. Aberrant Behavior Checklist; Slosson Educational Publications, Inc.: East Aurora, NY, USA, 1986. [Google Scholar]
- Briggs Gowan, MJ; Carter, AS. ITSEA/BITSEA: Infant-Toddler and Brief Infant-Toddler Social and Emotional Assessment; The Psychological Corporation: San Antonio: TX, USA, 2006. [Google Scholar]
- Meyers, JE; Meyers, KR. Rey Complex Figure Test and Recognition Trial; Psychological Assessment Resources: Odessa, FL, USA, 1996. [Google Scholar]
- Bowers, L; Huisingh, R; LoGiudice, C. Test of Problem Solving 3: Elementary; LinguiSystems: East Moline, IL, USA, 2005. [Google Scholar]
- Constantino, JN; Gruber, CP. Social Responsiveness Scale (SRS); Western Psychological Services: Los Angeles, CA, USA, 2005. [Google Scholar]
- Beery, KE; Beery, NA. The Beery-Buktenica Developmental Test of Visual-Motor Integration, 5th ed; NCS Pearson: Minneapolis, MN, USA, 2004. [Google Scholar]
- Anastasi, A; Urbina, S. Psychological Testing, 7th ed; Macmillan Publishers: New York, NY, USA, 1997. [Google Scholar]
- Neisser, U; Boodoo, G; Bouchard, TJ, Jr; Boykin, AW; Brody, N; Ceci, SJ; Halpern, DF; Loehlin, JC; Perloff, R; Sternberg, RJ; Urbina, S. Intelligence: Knowns and unknowns. Am. Psychol 1996, 51, 77–101. [Google Scholar]
- Schmidt, FL; Hunter, JE. The validity and utility of selection methods in personnel psychology: Practical and theoretical implications of 85 years of research findings. Psychol. Bull 1998, 124, 262–274. [Google Scholar]
- Gottfredson, LS. Why g matters: The complexity of everyday life. Intelligence 1997, 24, 79–132. [Google Scholar]
- Glutting, JJ; Adams, W; Sheslow, D. Wide Range Intelligence Test Manual; Wide Range: Wilmington, DE, USA, 2000. [Google Scholar]
- The New Rules of Measurement: What Every Psychologist and Educator Should Know; Embretson, SE; Hershberger, SL (Eds.) Lawrence Erlbaum Associates, Inc., Publishers: Mahwah, NJ, USA, 1999.
- Sattler, J. Assessment of Children: Cognitive Applications, 4th ed; Jerome M. Sattler, Publisher: San Diego, CA, USA, 2001. [Google Scholar]
- Glutting, JJ; Watkins, M; Youngstrom, EA. Multifactored and cross-battery assessments: are they worth the effort? In Handbook of Psychological and Educational Assessment of Children, 2nd ed; Reynolds, CR, Kamphaus, R, Eds.; Guilford Press: New York, NY, USA, 2003; pp. 343–374. [Google Scholar]
- American Psychological Assn. Ethics C. Ethical principles of psychologists and code of conduct. Am. Psychol 1992, 47, 1597–1611. [Google Scholar]
- Chen, C; Burton, M; Greenberger, E; Dmitrieva, J. Population migration and the variation of dopamine D4 receptor (DRD4) allele frequencies around the globe. Evol. Hum. Behav 1999, 20, 309–324. [Google Scholar]
- Flynn, JR. Searching for justice: The discovery of IQ gains over time. Am. Psychol 1999, 54, 5–20. [Google Scholar]
- Rodgers, JL. A critique of the Flynn Effect: Massive IQ gains, methodological artifacts, or both? Intelligence 1998, 26, 337–356. [Google Scholar]
- Pedhazur, EJ; Schmelkin, LP. Measurement, Design, and Analysis: An Integrated Approach; Erlbaum: Hillsdale, NJ, USA, 1991. [Google Scholar]
- Streiner, DL; Norman, GR. Health Measurement Scales: A Practical Guide to Their Development and Use, 2nd ed; Oxford University Press: New York, NY, USA, 1995. [Google Scholar]
- Zhou, X-H; Obuchowski, NA; McClish, DK. Statistical Methods in Diagnostic Medicine; Wiley: New York, NY, USA, 2002. [Google Scholar]
- Cicchetti, D; Bronen, R; Spencer, S; Haut, S; Berg, A; Oliver, P; Tyrer, P. Rating scales, scales of measurement, issues of reliability: resolving some critical issues for clinicians and researchers. J. Nerv. Ment. Dis 2006, 194, 557–564. [Google Scholar]
- Campbell, DT; Kenny, DA. A Primer on Regression Artifacts; The Guilford Press: New York, NY, USA, 1999. [Google Scholar]
- Analysis of longitudinal data, 2nd ed; Diggle, P; Heagarty, P; Liang, K-Y; Zeger, S (Eds.) Oxford University Press: New York, NY, USA, 2002.
- Duncan, TE; Duncan, SC; Stoolmiller, M. Modeling developmental processes using latent growth structural equation methodology. Appl. Psychol. Meas 1994, 18, 343–354. [Google Scholar]
- Messick, S. Validity of psychological assessment: Validation of inferences from persons' responses and performances as scientific inquiry into score meaning. Am. Psychol 1995, 50, 741–749. [Google Scholar]
- Kraemer, HC. Evaluating Medical Tests: Objective and Quantitative Guidelines; Sage Publications: Newbury Park, CA, USA, 1992. [Google Scholar]
- Cohen, J. The cost of dichotomization. Appl. Psychol. Meas 1983, 7, 249–253. [Google Scholar]
- Kraemer, HC; Lowe, KK; Kupfer, DJ. To Your Health: How to Understand What Research Tells Us about Risk; Oxford University Press: New York, NY, USA, 2005. [Google Scholar]
- Straus, SE; Richardson, WS; Glasziou, P; Haynes, RB. Evidence-based Medicine: How to Practice and Teach EBM, 3rd ed; Churchill Livingstone: New York, NY, USA, 2005. [Google Scholar]
- Swets, JA; Dawes, RM; Monahan, J. Psychological science can improve diagnostic decisions. Psychol. Sci. Public Int 2000, 1, 1–26. [Google Scholar]
- Meyer-Baron, M; Blaszkewicz, M; Henke, H; Knapp, G; Muttray, A; Schaper, M; van Thriel, C. The impact of solvent mixtures on neurobehavioral performance: conclusions from epidemiological data. Neurotoxicology 2008, 29, 349–360. [Google Scholar]
- Kazdin, AE. The meanings and measurement of clinical significance. J. Consult. Clin. Psychol 1999, 67, 332–339. [Google Scholar]
- Anthony, B; Anthony, LG; Morrel, T; Acosta, M. Evidence for social and behavior problems in low-income, urban preschoolers: Effects of site, classroom and teacher. J. Youth Adolesc 2005, 34, 31–39. [Google Scholar]
- Budtz-Jorgensen, E; Grandjean, P; Weihe, P. Separation of risks and benefits of seafood intake. Environ. Health Perspect 2007, 115, 323–327. [Google Scholar]
- Caldwell, BM; Bradley, RH. Home Observation for Measurement of the Environment, revised ed; University of Arkansas: Little Rock, AR, USA, 1984. [Google Scholar]
- Dunn, LM; Dunn, LM. Examiner's Manual for the Peabody Picture Vocabulary Test, 3rd ed; American Guidance Service: Circle Pines, MN, USA, 1997. [Google Scholar]
- Hollingshead, A. Four Factor Index of Social Status; Yale University: New Haven, CT, USA, 1975. [Google Scholar]
- Schafer, JL; Kang, J. Average causal effects from nonrandomized studies: a practical guide and simulated example. Psychol. Methods 2008, 13, 279–313. [Google Scholar]
- Brown, L; Sherbenou, R; Johnson, S. Test of Nonverbal Intelligence, 3rd ed Examiner's Manual; Pro-Ed: Austin, TX, USA, 1997. [Google Scholar]
- Raven, J. Standard Progressive Matrices; HK Lewis: Cambridge, England, 1958. [Google Scholar]
- LaKind, JS; Berlin, CM, Jr; Mattison, DR. The heart of the matter on breast milk and environmental chemicals: Essential points for health care providers and new parents. Breastfeed. Med 2008, 4, 251–259. [Google Scholar]
- The National Children’s Study.

{kind=link}
{kind=link}
| Measure | Exists in PCBs literature [E]/Recommended alternative for future studies [R] | Scale Name | Rationale for recommended alternative measure (see above) |
|---|---|---|---|
| Academic Achievement | |||
| Wide Range Achievement Test | E (WRAT 3rd Edition)/R (WRAT 4th Edition) | Word Reading Sentence Comprehension Reading Composite Spelling Math Computation | 3 |
| Woodcock-Johnson-III | R | Academic Fluency Subtests | 1 |
| Adaptive Behavior | |||
| Adaptive Behavior Assessment System-II | R | Parent Form Global Assessment of Competence | 2 |
| Vineland Adaptive Behavior Scale-II | R | Parent Interview Edition | 2 |
| Attention | |||
| Conners’ Continuous Performance Test (CPT II) | E | Sustained attention Omissions d Prime Commissions Variability Standard Error | NA |
| Conners Rating Scales, Third Edition | R | Conners III Total Score | 1 |
| ADHD Rating Scale | R | Inattention Hyperactivity/Impulsivity | 1 |
| Executive Function—Omnibus | |||
| Wisconsin Card Sorting Test (WCST) | E | Multiple scores | NA |
| Behavior Rating Inventory of Executive Functioning (BRIEF) | R | Global Executive Composite | 1 |
| Executive Function—Flexibility | |||
| Wisconsin Card Sorting Test (WCST) | E | Perseverative Errors | NA |
| BRIEF | R | Flexibility Index | 1 |
| Executive Function—Organization/Planning | |||
| Rey Complex Figure Test | E | Copy Strategy | NA |
| Tower of London-DX | R | Total Move Score | 1 |
| Executive Function—Response Inhibition | |||
| CPT II | E | Commissions | NA |
| BRIEF | R | Inhibit Scale | 1 |
| Executive Functioning—Working Memory | |||
| Wechsler Intelligence Scale for Children-Revised (WISC-R) | E | Arithmetic | NA |
| Wechsler Intelligence Scale for Children, 4th Edition (WISC-IV) | R | Working Memory Index | 3 |
| General Cognitive Measures:Infants and Toddlers | |||
| Mullen Scales of Early Learning | E | Early Learning Composite | NA |
| Bayley Scales of Infant Development | E/R (3rdEdition) | Adaptive behavior Cognitive Language Composite Motor Composite | 3 |
| General Cognitive Measures: Preschool and Older | |||
| McCarthy Scales of Children’s Ability (MSCA) | E | General Cognitive Index (GCI) Verbal Perceptual-Performance Memory | NA |
| Differential Abilities Scale-II (DAS-II) | R | General Cognitive Ability Verbal Ability Nonverbal Ability Spatial Ability | 1 |
| General Cognitive Measures: Childhood and Older | |||
| Wechsler Intelligence Scales for Children—Fourth Edition (WISC-IV) | E (WISC-R)/R (WISC-IV) | Full Scale Verbal Comprehension Perceptual Reasoning Working Memory Processing Speed | 3 |
| Wechsler Adult Intelligence Scales (WAIS-III) | E (WAIS-R)-R (WAIS-III) | Full Scale Verbal Performance Verbal Comprehension Perceptual Organization Working Memory Processing Speed | 3 |
| Wechsler Abbreviated Scale of Intelligence (WASI) | R | Full Scale Verbal Performance | 1 |
| General Cognitive Measures: Non-verbal | |||
| Comprehensive Test of Nonverbal Intelligence (CTONI) | R | Nonverbal Intelligence Composite Pictorial Nonverbal Intelligence Composite Geometric Nonverbal Intelligence Composite | 2 |
| Leiter | R | Visualization & Reasoning Attention & Memory | 2 |
| Gross, Fine Motor Function | |||
| McCarthy Scales of Children’s Ability | E | Motor | NA |
| Peabody Developmental Motor Scales | R | Fine Motor Quotient Gross Motor Quotient | 1 |
| Finger tapping | R | Finger tapping raw scores | 1 |
| Language—Expressive Language | |||
| Verbal subtests from IQ measures (e.g., WISC, MSCA) | E | Vocabulary, Information, Similarities, Comprehension | NA |
| Clinical Evaluation of Language Fundamentals (4th Ed.) (CELF) | R | Expressive Language | 1 |
| Pre-School Language Scale (PLS 4) | R | Auditory Comprehension Expressive Communication | 1 |
| Language—Receptive Language | |||
| CELF | R | Receptive Language | 2 |
| PLS 4 | R | Auditory Comprehension Expressive Communication | 2 |
| Language—Articulation | |||
| Goldman-Fristoe Test of Articulation | R | Sounds in Words Sounds in Sentences Stimulability | 2 |
| Language—Pragmatic Language | |||
| Test of Problem Solving—Child and Adolescent (TOPS) | R | Pragmatic Language | 2 |
| Learning/Memory-Verbal | |||
| California Verbal Learning Test-II (CVLT-II) | E (CLVT-II)/R (CLVT-II, 2nd Edition) | Total Correct | 3 |
| Learning/Memory-Visual | |||
| Wide Range Assessment of Memory and Learning, 2nd Edition (WRAML-II) | R | Visual Memory Index | 2 |
| Maladaptive Behavior | |||
| Achenbach Child Behavior Checklist (CBCL) | R | Total Problems Externalizing Internalizing Attention Problems | 2 |
| Aberrant Behavior Checklist (ABC) | R | Irritability; Lethargy; Stereotypy; Hyperactivity; Inappropriate Speech | 2 |
| Infant-Toddler Social and Emotional Assessment (ITSEA) | R | Problem Total; Competence Total; also Externalizing, Internalizing, Dysregulation, Competence, and Maladaptive | 1 |
| Processing Speed | |||
| CPT II | E | Reaction time (Conner's) | NA |
| WISC-IV | R | Symbol Search subtest | 1 |
| Social Cognition | |||
| Social Responsiveness Scale (SRS) | R | SRS Total Total - Parents (Female) Total - Parents (Male) Total - Teachers (Male) Total - Teachers (Female) Clinical Ratings (Both) | 2 |
| Visual Motor | |||
| Beery Test of Visual Motor Integration, 5th Ed. (VMI) | E | Visual Motor Total Score | NA |
| Visual Spatial | |||
| WASI | R | Performance IQ | 2 |
| Measure | Scale Name | Age Range (yrs unless otherwise indicated) | Admin. Time | Norm (N)/Norm Quality | Reliability (Type) | Standard Error of Measurement | Stability (r) | Construct Validity | Predictive Validity | Advantages | Disadvantages | References |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Standard Score M (SD) | ||||||||||||
| Academic Achievement | ||||||||||||
| Wide Range Achievement Test 4 | Word Reading Sentence Comprehension Reading Composite Spelling Math Computation | 5– 94 yr 11 mo | 15–25 minutes for ages 5 to 7 for whole test; 30–45 minutes for over age 7 for whole test | 3021/**** _______ 100 (15) | 0.96 (median alpha); 0.90 immediate retest alt. form 0.96 (median alpha); 0.86 immediate retest alt. form 0.98 (median alpha) 0.95 (median alpha); 0.89 immediate retest alt. form 0.94 (median alpha); 0.88 immediate retest alt. form | 3.0 3.0 2.3 3.4 3.7 | 0.85 r for alternate form delayed test retest (Mean=1 month; range 8 to 86 days) 0.74 r for alternate form delayed test retest (M=1 month; range 8 to 86 days) 0.88 r for alternate form delayed test retest (M=1 month; range 8 to 86 days) 0.83 r for alternate form delayed test retest (M=1 month; range 8 to 86 days) 0.83 r for alternate form delayed test retest (M=1 month; range 8 to 86 days) | Good: Moderate to high correlations with other achievement measures | Some evidence of predictive validity in terms of educational classification | Short, alternative forms allows re-testing, part can be administered in group format | Captures basic learning difficulties with reading decoding, and math computation, but is not sensitive to learning disabilities associated with executive function, processing speed, motor output, reading comprehension, or written expression. | [10] |
| Woodcock-Johnson-III | Academic Fluency Subtests | 2 to 90+ | Variable, ~5 min. per test | 8818/**** 100 (15) | Relatively easy to administer; sensitive to the effects of processing speed and motor output deficits on academics. | Moderately old norms | [11] | |||||
| Adaptive Behavior | ||||||||||||
| Adaptive Behavior Assessment System-II | Parent Form Global Assessment of Competence | Birth to adult | 15–20 min | 1350/**** 100 (15) | 0.97 (alpha) | 2.12 | 0.88 (2 days to 5 weeks, M=12 days) | Extensive | Used in identification of mental retardation | Multiple versions for different ages and parents and day care providers; extensive construct validity | Like any parent checklist, ABAS is susceptible to misinterpretation and bias. | [12] |
| Vineland Adaptive Behavior Scale-II (a brief research edition is also available) | Parent Interview Edition Parent Form Global Assessment of Competence (GAC) | 0–18 5–21 | 20–60 minutes and 15–30 minutes to score 15–20 min | 1670/**** 1670/**** 100(15) | 0.98 (alpha) | 1.57 | 0.93 (5 days to 6 weeks; avg of 11 days) | Extensive | Used in identification of mental retardation | Well validated in multiple clinical groups Self-report version; multiple versions for different ages and parents and day care providers; extensive construct validity | Time and expertise intensive measure for the interview version; can take more than 1 hour to complete. Administration of interview version requires expertise gained through graduate level training programs in psychology or social work. | [13] |
| Teacher Form GAC Teacher Form GAC | 2 to 5 5 to 21 | 15–20 min 15–20 min | 750/**** 100 (15) 1690/**** 100 (15) | 0.98 (alpha) 0.99 (alpha) | 2.94 1.97 | 0.91 (2 days to 6 weeks, avg of 13 days) 0.96 (3 days to 3 weeks; avg of 11 days) | Extensive Extensive | |||||
| Attention | ||||||||||||
| Conners, 3rd Edition | Conners III Total (also a short form, a DSM form, and a global form) | 6 to 18 | 5–20 min | 1200 parents, 1200 teachers, 1000 youths/*** 50 (10) | 0.91 parent, 0.94 teacher, 0.88 youth (alpha) | 1.7 to 4.8, depending on scale | 0.85 parent, 0.85 teacher, 0.79 youth (2–4 week interval) | Extensive | Discriminates ADHD from normal or clinical comparisons; sensitive to treatment effects in multiple trials | Parent, teacher, and youth forms (no Global Index on youth version); includes DSM-IV content; extensive research base; includes validity scales | Cumbersome to score without computer software; short forms validated in embedded version (not separate administration) | [14] |
| CPT II | Sustained attention Omissions d Prime Commissions Variability Standard Error | 6+ (A pre-school version is also available) | 15–20 min | 1920C/*** 50 (10) | 0.87 (split half) | Range of SEM is: 2.6 to 4.6 | 0.65 (Average retest interval of 3 months, N only 23) | Moderate | Less predictive than behavior scales | Standardized task that measures multiple performance facets of attention | Relatively small number of minorities included in the norm sample; overall mild correlations between CPT and ADHD rating scales | [15] |
| Executive Function—Omnibus | ||||||||||||
| Behavior Rating Inventory of Executive Functioning (BRIEF) | Global Executive Composite | 2 to adult | 10–15 min | 1419/** 50 (10) | 0.98 (alpha, parent and teacher) | 1.41 | 0.81 parent 3 week; 0.91 teacher 3.5 week | Good | Some evidence of predictive validity for diagnoses | Parent and teacher forms; inexpensive; collateral source of information about executive functioning. Comprehensive coverage of subdomains of executive functioning; ecologically valid measure; used extensively in research with good sensitivity; easy to administer and complete. | Parent rating are susceptible to bias; report of everyday executive function does not necessarily accurately parse subdomains of executive function. Normative sample not nationally representative; variable correlations between scores and underlying processes | [16] |
| Flexibility | ||||||||||||
| Wisconsin Card Sorting Test (WCST) | Perseverative Errors | 6.5 to 89 yr 11 mo | 20–30 min | 5 samplesA/*** 100 (15) | 0.92–0.97 for perseverative errors (inter-scorer, ICC) | 10.39 for perseverative errors in child/adolescent; 11.91 for % perseverative errors in child/adolescent | 0.52 for 1 mo test-retest perseverative errors; 0.37 for 1 mo test-retest (n=46) for percent perseverative errors | Moderate -- group differences | None | Relevant construct for neurotoxicity | Difficult to reliably score if not using computer administration; not representative norms; complex relationship between scales and executive function | [17] |
| General Cognitive Measures: Infants and Toddlers | ||||||||||||
| Bayley Scales of Infant Development | Adaptive behavior Cognitive Language Composite Motor Composite | 1 to 42 months | 50–90 minutes | 1700/**** 100 (15) | 0.99 (split half) 0.91 (split half) 0.93 (split half) 0.92 (split half) | 3.11 0.95 4.47 4.42 | 0.92 0.81 0.87 0.83 | Moderate to good (0.6 for similar scales) | One of the only instruments available in the age range, recently re-standardized, extended floors and ceilings, improved evidence of reliability and validity | Difficult to administer; and confounded by significant language demands. | [18] | |
| Mullen Scales of Early Learning (AGS Edition) | Early Learning Composite (Also five subscores: Gross Motor; Visual Reception; Fine Motor; Receptive Language; Expressive Language) | Birth to 68 months | ~15 min (for 1 year olds) to 60 min (for 5 year olds) | 1849/*** 100 (15) [50 (10) for the five subscores] | 0.91 (split half) | 4.5 | 0.71 to 0.96 (median = 0.84) (1 to 2 week interval) | Factor validity; good convergent validity with Bayley | Discriminates low birth weight from normal; predicts school readiness on Metropolitan test longitudinally (two years later) | Limited language demands | Old normative data | [19] |
| General Cognitive Measures: Childhood and Older | ||||||||||||
| Wechsler Intelligence Scales for Children – Fourth Edition (WISC-IV) | Full Scale Verbal Comprehension Perceptual Reasoning Working Memory Processing Speed | 6 to 16 | 60–90 min | 2200/**** 100 (15) | 0.97 (split half) 0.94 (split half) 0.92 (split half) 0.92 (split half) 0.88 (split half) | 2.68 3.78 4.15 4.27 5.21 | 0.89 (~1 month) 0.89 (~1 month) 0.85 (~1 month) 0.85 (~1 month) 0.79 (~1 month) | Excellent Excellent Good Good Good | FSIQ - Excellent prediction of achievement criteria; well established use in classification; much less known about factor indices (newer) | Most widely used test of cognitive ability in children and adolescents; excellent norms; familiar; stronger measurement of working memory than previous | Not tied to strong theory of intelligence; relatively weak assessment of processing speed | [20] |
| Wechsler Adult Intelligence Scales (WAIS-III) | Full Scale Verbal Performance Verbal Comprehension | 16 to 89 years | 60–90 min | 2450/**** 100 (15) | 0.98 (split half) 0.97 (split half) 0.94 (split half) 0.96 (split half) | 2.12 2.60 3.67 3.00 | 0.96 (1 month retest) 0.96 (1 month retest) 0.91 (1 month retest) 0.95 (1 month retest) | Exceptional construct validity for broadest scores; stronger construct validity for working memory than in previous versions of WAIS | Extensive | Reliable, norms, more commonly administered and owned (familiar to psychologists) | Not tied to strong theory of intelligence; relatively weak assessment of processing speed and working memory | [21] |
| Perceptual Organization Working Memory Processing Speed | 0.93 (split half) 0.94 (split half) 0.88 (split half) | 3.97 3.67 5.20 | 0.88 (1 month retest) 0.89 (1 month retest) 0.89 (1 month retest) | |||||||||
| Wechsler Abbreviated Scale of Intelligence (WASI) | Full Scale Verbal Performance | 6 to 89 | 30 min | 2245/**** 100 (15) | 0.96 (split half) 0.93 (split half) 0.94 (split half) | 3.08 3.99 3.75 | 0.93 ~1 month 0.92 ~1 month 0.88 ~1 month | Exceptional construct validity | Good, based on convergence with WISC and WAIS | Validated as a brief measure of verbal, nonverbal, and general cognitive ability; very precise scores; Matrix Reasoning can be administered nonverbally | No coverage of processing speed, working memory, or other aspects of cognitive ability | [22] |
| General Cognitive Measures: Non-verbal | ||||||||||||
| Comprehensive Test of Nonverbal Intelligence (CTONI) | Nonverbal Intelligence Composite Pictorial Nonverbal Intelligence Composite Geometric Nonverbal Intelligence Composite | 6 to 18 yr 11 mo | 40–60 min | 2901/**** 1 00 (15 for composites); 10 (3) for subtest | 0.97 (alpha) 0.93 (alpha) 0.95 (alpha) | 2.6 4.0 3.4 | 0.92 for Nonverbal IQ for 1 month retest; inter-scorer for the subtests (not composites) range from 0.95 to 0.99 (rating same protocols) 0.87 for test-retest 1 mo 0.91 for test-retest 1 mo | Good criterion validity (0.64 to 0.81 correlation w/FSIQ on WISC-III | Minimizes cultural bias | Less predictive of some aspects of functioning than verbally loaded scales; weaker norms at youngest ages | [23] | |
| Leiter, Revised Edition | Visualization & Reasoning (VR); Attention & Memory (AM) | 2 to 21 | 40 to 90 min | 1719 (VR) 763 (AM)/*** 100 (15) | 0.75 to 0.90 (median 0.82) (split half) | -- | 0.83 to 0.92 (but time interval not reported in manual) | Content validity based on examiner ratings of item content; convergent with other IQ tests | Some discriminative validity for cognitive delay, to a lesser degree for ADHD | Covers wide age range; minimal bias across cultures; strong theoretical model guiding revision | Special training may be needed for good standardization; AM subtests not very stable over time | [24] |
| General Cognitive Measures: Preschool and Older | ||||||||||||
| Differential Abilities Scale-II | General Cognitive Ability Verbal Ability Nonverbal Ability Spatial Ability | 2.5–17 yr 11 mo | 60 min | 3480/**** 100 (15) | .96 (split half) .90 (split half) .89 (split half) .95 (split half) | 2.91 4.77 5.15 3.4 | .92 (used overall standardization sample) .90 .73 .89 | Excellent (0.87 w/WPSSI-III) | Good norms, conceptual model, strong psychometrics | No working memory or processing speed | [25] | |
| McCarthy | General Cognitive Index (GCI) Verbal Perceptual-Performance Memory | 2 yr 4 mo to 8 yr 7 mo | 60–90 min | 1032/*** (well-matched to 1970 Census; excluded exceptional children) 100 (15) | 0.93 (split half) | 3.97 | 0.90 for 1 month | Excellent correlations with IQ measures, but can have substantial differences in average scores | Good predictive validity of later school functioning (r ~0.5); no diagnostic efficiency reported | Exemplary technical manual; engaging, game-like, non-threatening format; may engage shy and minority children more than other tests | Complex administration and scoring (requiring practice), especially for gross motor Norms are more than 20 years old | [26] |
| Gross, Fine Motor Function | ||||||||||||
| MSCA | Motor | 2 yr 4 mo to 8 yr 7 mo | 15 min | 1032/*** (well-matched to 1970 Census; excluded exceptional children) | 0.69 (split half) | 8.35 | 0.33 for “longer term” | Content valid, but not stable | Low to moderate | Engaging | Can be difficult to administer and score (more so than other MCSA subtests) | [26] |
| Peabody Developmental Motor Scales | Fine Motor Quotient; Gross Motor Quotient; plus 9 subtest scores | Birth to 72 months | 2–3 hours (20–30 min per subtest) | 2003/*** 100 (15) | 0.96 (split half) | 3.0 | .93 Fine Motor 0.89 Gross Motor (one week retest) | Good evidence of factor and convergent validity | Unknown; goal of test is to measure treatment effects; but relevant data not included in technical manual | Minimal training needed because of clear instructions and objective scoring; easy to administer | Limited data on children with special needs; kit does not include all materials needed for administration; small objects are a choke hazard and need cleaning if mouthed | [27] |
| Digital Finger-tapping | Digital Finger Tapping | Various norms; college student for digital version | 10 minutes with scoring | 80/* Raw score (number of taps) | Not reported | Not reported | Not reported | Fair correlation with other fine motor tasks | Unknown | Easy to administer; electronic counter enhances accuracy | Poor norms; limited psychometric data; primarily suited to research use with comparison groups | [28] |
| Finger Tapping (Halstead-Reitan) | Finger Tapping | 15 to 64 | 10 minutes with scoring | 190/* | Not reported | Not reported | Not reported | Fair correlation with other fine motor tasks | Unknown | Easy to administer; widely recognized test | Small and dated norms | [29] |
| Finger Tapping (Findeis & Weight Meta-Norms) | Finger Tapping | 5 to 14 | 10 minutes with scoring | 1591 dominant; 1558 non-dominant hand/* | Not reported | Not reported | Not reported | Fair correlation with other fine motor tasks | Unknown | Easy to administer | Pools data from 20 different studies to create “norms” | [30] |
| Language – Articulation | ||||||||||||
| Goldman-Fristoe Test of Articulation, 2nd Edition | Sounds in Words; Sounds in Sentences; Stimulability | 2 to 21 | 15–30 min | 2350/**** 100 (15) | 0.90 to 0.93 (median inter-rater) | 4.0 to 4.7 | 0.98 (within session) | Moderate: Exper review, but limited construct validation data published | Unknown | Strong standardization sample; good norm-referenced scores | Technical information based on administrations by speech pathologists; unclear how results would vary with less trained raters; use with caution with speakers of non-standard English | [31] |
| Language--Expressive Language | ||||||||||||
| Pre-School Language Scale, 4th Edition | Auditory Comprehension; Expressive Communication | Birth to 6 yr 11 mo | 20–45 min | 2400/*** | 0.81 to 0.97 (split half) | 2.6 to 9.2 | 0.82 to 0.95 (1 week) | Good – Expert review of content; convergent with PLS3 and Denver II, evidence of response process validity | Some discriminative validity for language disorders and autism | New norms; Spanish version available (though less technical data available) | Standardized only in English; no information about how bilingual status influences performance (though ~7% of sample was bilingual); potential for marked variability in administration and scoring means that a high degree of training is needed for consistency | [32] |
| Clinical Evaluation of Language Fundamentals (4th Ed.) (CELF) | Expressive Language | 5–21 (A pre-school version is also available) | 30–45 min | 2,650/**** | 0.89 to 0.95 (alpha); 0.88 to 0.99 inter-scorer | -- | 0.90+ (~16 days) | Good – content, response-process, and factor validity | Good for language disability | Easy to learn; computer-assisted scoring; focuses on specific skills and areas of functioning (versus achievement) | 18 subtests if do full battery; low reliability for a few subtests | [33] |
| WISC-R, MSCA | Vocabulary | Various | Variable | Variable/*** 10 (3) | Generally good | Moderate | Good | Good | Good for achievement criteria | Brief; well-normed; clear scoring | Subtest scores reflect multiple component skills and factors | [26,34] |
| Language--Receptive Language | ||||||||||||
| Clinical Evaluation of Language Fundamentals (4th Ed.) (CELF) | Receptive Language | 5–8, 9–12, 13–21 | 30–45 min | 2,650/**** | 0.89 to 0.95 (alpha); 0.88 to 0.99 inter-scorer | .90+ (~16 days) | Good – content, response-process, and factor validity | Good for language disability | Easy to learn; computer-assisted scoring; focuses on specific skills and areas of functioning (versus achievement) | 18 subtests if do full battery; low reliability for a few subtests | [33] | |
| Verbal subtests from IQ measures (e.g., WISC, MSCA) | Vocabulary, Information, Similarities, Comprehension, etc. | Various | Various | Various/*** 10 (3) | Good | Good | Good | Good for crystallized ability | Good for achievement criteria | Well-normed; clear scoring; readily available | Not validated as stand-alone tests; scores on single scale driven by multiple factors (not just receptive language) | [20] |
| Learning/Memory-Verbal | ||||||||||||
| California Verbal Learning Test (CVLT) | 5 to adult | 30–50 minutes | 920/*** 50 (10); some are 0 (1) | 0.85 (split half) | 3.83 | 0.61–0.73 for List A (ages 8, 12 & 16 tables for 28 day median test-retest); 0.37–0.78 for Discriminability (ages 8, 12, & 16 tables for 28 day median test-retest) | Some evidence of factor validity and correlations w/other measures of ability | Widely used test of verbal learning and memory, short, measures recognition and recall | [35] | |||
| Learning/Memory-Visual | ||||||||||||
| WRAML-II | Visual Memory Index Verbal Memory Index Attention/Concentration | 5 – 84 yr 11 mo | 60 minutes for all core subtests | 1200/**** 100 (15) | 0.89 (median alpha) 0.92 (median alpha) 0.86 (median alpha) | 5.0 median 4.2 median 5.6 median | 0.67 test-retest 0.85 test-retest 0.68 test-retest | Moderately high convergent validity; good discriminant validity | Wide age range; new norms; stronger factor structure than earlier version | Lengthy administration time; often only specific subtests are used. | [36] | |
| General Memory Index Screening Memory Index | 20 min | 0.93 (median alpha) 0.93 (median alpha) | 4.0 median 4.0 median | 0.81 test-retest 0.78 test-retest (Mean time b/w all tests = 49 days, range 14 to 401 days. | ||||||||
| Maladaptive Behavior | ||||||||||||
| Achenbach Child Behavior Checklist | Total Problems Externalizing Internalizing Attention Problems | 1.5 to young adult | 10–15 min | 1753/**** 50 (10) | 0.97 (alpha) 0.94 (alpha) 0.90 (alpha) 0.86 (alpha) | 1.73 2.45 3.16 3.74 | 0.94 ~8 days; 0.81 ~12 mos 0.92 ~8 days; 0.82 ~12 mos 0.91 ~8 days; 0.80 ~12 mos 0.92 ~8 days; 0.70 ~12 mos | Good to excellent | Excellent predictive validity of diagnoses and long term longitudinal outcomes | Multiple versions, multiple informants, forms and norms for multiple age ranges, large research and clinical literature with wide variety of medical conditions | Omits some content likely to be relevant, including theory of mind, mania scale; scales do not map directly onto psychiatric diagnoses. | [37] |
| Aberrant Behavior Checklist (ABC) | Irritability; Lethargy; Stereotypy; Hyperactivity; Inappropriate Speech | 5 to 51+ | ~5 min for a rater familiar with subject’s behavior | 754 New Zealanders; 508 USA (both residential with mental retardation)/** | 0.86 to 0.95 (alpha) | Varies across scales and ages | 0.96 to 0.99 (4 week retest) | Good factor validity; good convergent validity with other rating scales | Moderate discriminative validity; good treatment sensitivity | Good content coverage; sensitive to treatment effects | Manual provides incomplete psychometric information; much technical data in outside sources; although often used as parent or teacher rating, less validation of these formats | [38] |
| Infant-Toddler Social and Emotional Assessment (ITSEA) | Problem Total; Competence Total; also Externalizing, Internalizing, Dysregulation, Competence, and Maladaptive Item Clusters | 12 to 35 months | 20–30 min | 600/*** 50 (10) | >0.80 for all scales (>0.90 for Externalizing, Dysregulation) (alpha) | Varies across scales | 0.76 to 0.91 (~6 day retest) | Good factor validity; content analysis; convergent and discriminant validity | Discriminative validity for autism versus unaffected (Sensitivity = 100%; Specificity = 89%) | Parent form, parent interview form, and childcare provider form; Spanish translation available; brief screening version (BITSEA) | Little technical information about childcare provider or Spanish forms | [39] |
| Organization/Planning | ||||||||||||
| Rey Complex Figure Test | Copy Strategy | 6 to 89 | 45 min, including 30 min delayed interval | 505 age 6–17; 601 age 18–89/*** R aw & age-corrected | 0.94 (inter-rater ICC) | 0.92, but retest is problematic concept because of learning | Good evidence of validity for memory | Moderate evidence of discriminant validity | New manual (1996) improves scoring criteria & guidelines, as well as norms. Developmental scoring norms capture problem solving strategy (as opposed to outcome score) which is a key correlate of executive functions that is often not addressed. | Wide developmental variation and limited normative sample compromise sensitivity. Scoring system is complex and prone to error; requires specific training for adequate accuracy. | [40] | |
| Pragmatic Language | ||||||||||||
| Test of Problem Solving -Child and Adolescent (TOPS 3 Elementary) | Pragmatic Language | 6 to 12 yr 11 mo | 35 minutes | 1406/**** 100 (15) | 0.56 to 0.69 internal consistency (0.65= average internal consistency across domains); 0.89 inter-rater | 0.84 | Concurrent and criterion and some discriminative | Assesses language based critical thinking skills | Lengthy to administer. | [41] | ||
| Processing Speed | ||||||||||||
| CPT II | Reaction time (Conner's) Omissions d Prime Commissions Variability Standard error | 6+ | 15–20 min | 1920C/*** 50 (10) | 0.95 (split half) 0.94 (split half) 0.83 (split half) 0.83 (split half) 0.66 (split half) 0.87 (split half) | 35.02–55.70B 1.16 to 2.66 0.06 to 0.10 10.03– 12.79 0.42 to 0.53 2.60 – 4.59 | 0.55 0.84 0.76 0.65 0.60 0.65 (Average retest interval of 3 months, N only 23) | Correlations w/CPT and ADHD rating scales range from 0.33 to 0.44 in some studies; CPT overall index and teacher rating correlations were nonsignificant; modest Correlations w/CPT omission errors and teacher ratings; overall mild correlations b/w CPT and rating scales | Standardized task that measures multiple performance facets of attention | Relatively small number of minorities included in the norm sample; overall mild correlations between CPT and ADHD rating scales | [15] | |
| WISC-IV | Processing Speed Index | 6 to 16 | 1–15 min | 2200/**** 100 (15) | 0.88 (split half) | 5.21 | .79 (~1 month) | Good | Some evidence of discriminating ADHD from other youths | Strong norms, good reliability | Not validated as stand-alone administration | [20] |
| Response Inhibition | ||||||||||||
| Behavior Rating Inventory of Executive Functioning (BRIEF) | Inhibit scale | 2 to 18 years | 10–15 min | 1419/** | Parent and teacher forms; inexpensive; collateral source of information about executive functioning. Comprehensive coverage of subdomains of executive functioning; ecologically valid measure; used extensively in research with good sensitivity; easy to administer and complete. | Parent rating are susceptible to bias; report of everyday executive function does not necessarily accurately parse subdomains of executive function. Normative sample not nationally representative; variable correlations between scores and underlying processes | [16] | |||||
| CPT II | Errors of Commission | 6+ years | 15–20 min | 1920C *** | Standardized task that measures multiple performance facets of attention | Relatively small number of minorities included in the norm sample; overall mild correlations between CPT and ADHD rating scales | [15] | |||||
| Social Cognition | ||||||||||||
| Social Responsiveness Scale (SRS) | SRS Total Total - Parents (Female) Total - Parents (Male) Total - Teachers (Male) Total - Teachers (Female) Clinical Ratings (Both) | 15 min | 1636/*** 50 (10) | 0.94 (alpha) 0.93 (alpha) 0.97 (alpha) 0.96 (alpha) 0.97 (alpha) | 2.4 2.6 1.7 2.0 2.1 | 0.85 (~17 month) 0.77 (~17 month) | Good -- Discriminative validity (AUC = 0.85 PDD+Autistic vs. psychiatric control and normal) | Diagnostic and longitudinal | Exceptional evidence of construct validity; inexpensive to administer | Norms not fully nationally representative | [42] | |
| Visual Motor | ||||||||||||
| Beery VMI (5th Ed.) | 2 to 18 years for full form; 2 to 7 years for short form | 10–15 minutes | 2512/**** (11,000 over 5 standardization; 2512 in the 2003 norm sample) 100 (15) | 0.82 (alpha) and 0.88 (odd-even); 0.92 for inter-scorer ratings of 100 | Listed by age ranging from 4 to 6 (5.25 but this is not weighted for number in each group, and the numbers in table were already rounded). | 0.89 for 10 day test-retest on 115 kids | Correlates 0.62 w WISC-R, 0.63 w/Comp Test of Basic Skills, 0.89 w/age, 0.52 w/Wide Range Assessment of Visual Motor Abilities, and 0.75 with Developmental Test of Visual Perception-2 | Good | Culture free, easy to administer, used in many countries | Scoring somewhat difficult | [43] | |
| Visual Spatial | ||||||||||||
| WASI | Performance IQ | 6 to 89 | 15 min for 2 scales | 2245/**** 100 (15) | 0.94 (split half) | 3.75 | 0.88 ~1 month | Good | Good, based on WAIS | Brief, excellent precision; validated as brief instrument | No additional constructs covered | [22] |
| Working Memory | ||||||||||||
| WISC R | Arithmetic | 6 to 16 | 5–7 min | 2200/**** 10 (3) | Moderate | Moderate | Moderate | Poor – task combines multiple functions in addition to working memory | Poor | At time, most widely used test | Arithmetic blends multiple neurocognitive functions into single test; WISC-R now outdated | [34] |
| WISC-IV | Working Memory Index | 6 to 16 | 15–20 min | 2200/**** 100 (15) | 0.92 (split half) | 4.27 | 0.85 (~1 month) | Good | Good | Measured as factor; strong norms; widely used test | Working Memory tasks not designed to be administered as stand-alone | [20] |
© 2010 by the authors; licensee Molecular Diversity Preservation International, Basel, Switzerland. This article is an open-access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Youngstrom, E.; S. LaKind, J.; Kenworthy, L.; Lipkin, P.H.; Goodman, M.; Squibb, K.; R. Mattison, D.; J. Anthony, B.; Gutermuth Anthony, L. Advancing the Selection of Neurodevelopmental Measures in Epidemiological Studies of Environmental Chemical Exposure and Health Effects. Int. J. Environ. Res. Public Health 2010, 7, 229-268. https://doi.org/10.3390/ijerph7010229
Youngstrom E, S. LaKind J, Kenworthy L, Lipkin PH, Goodman M, Squibb K, R. Mattison D, J. Anthony B, Gutermuth Anthony L. Advancing the Selection of Neurodevelopmental Measures in Epidemiological Studies of Environmental Chemical Exposure and Health Effects. International Journal of Environmental Research and Public Health. 2010; 7(1):229-268. https://doi.org/10.3390/ijerph7010229
Chicago/Turabian StyleYoungstrom, Eric, Judy S. LaKind, Lauren Kenworthy, Paul H. Lipkin, Michael Goodman, Katherine Squibb, Donald R. Mattison, Bruno J. Anthony, and Laura Gutermuth Anthony. 2010. "Advancing the Selection of Neurodevelopmental Measures in Epidemiological Studies of Environmental Chemical Exposure and Health Effects" International Journal of Environmental Research and Public Health 7, no. 1: 229-268. https://doi.org/10.3390/ijerph7010229