
Spatiotemporal Interpolation Methods for the Application of Estimating Population Exposure to Fine Particulate Matter in the Contiguous U.S. and a Real-Time Web Application

Abstract
:
1. Introduction
2. Methods
2.1. Shape Function-Based Spatiotemporal Interpolation Using the Extension Approach
2.1.1. General Formula of the SF-Based 3D Spatial Interpolation Method
2.1.2. Extension Approach of the SF-Based Spatiotemporal Interpolation Method
2.2. IDW-Based Spatiotemporal Interpolation Using the Extension Approach
2.2.1. General Formula of the IDW-Based Spatial Interpolation Method
2.2.2. Extension Approach of the IDW-Based Spatiotemporal Interpolation Method
2.3. Cross Validation
2.3.1. K-Fold Cross Validation
- The points in one fold (test data) of the PM2.5 data set are interpolated using the remaining nine folds (training data). Therefore, each point in the test data will have both the original PM2.5 concentration measurement and an interpolated PM2.5 concentration value.
- Error statistics are calculated to compare the original and interpolated PM2.5 values in the test data.
2.3.2. Error Statistics
2.4. Linking PM2.5 to Census Population
3. Experimental Data
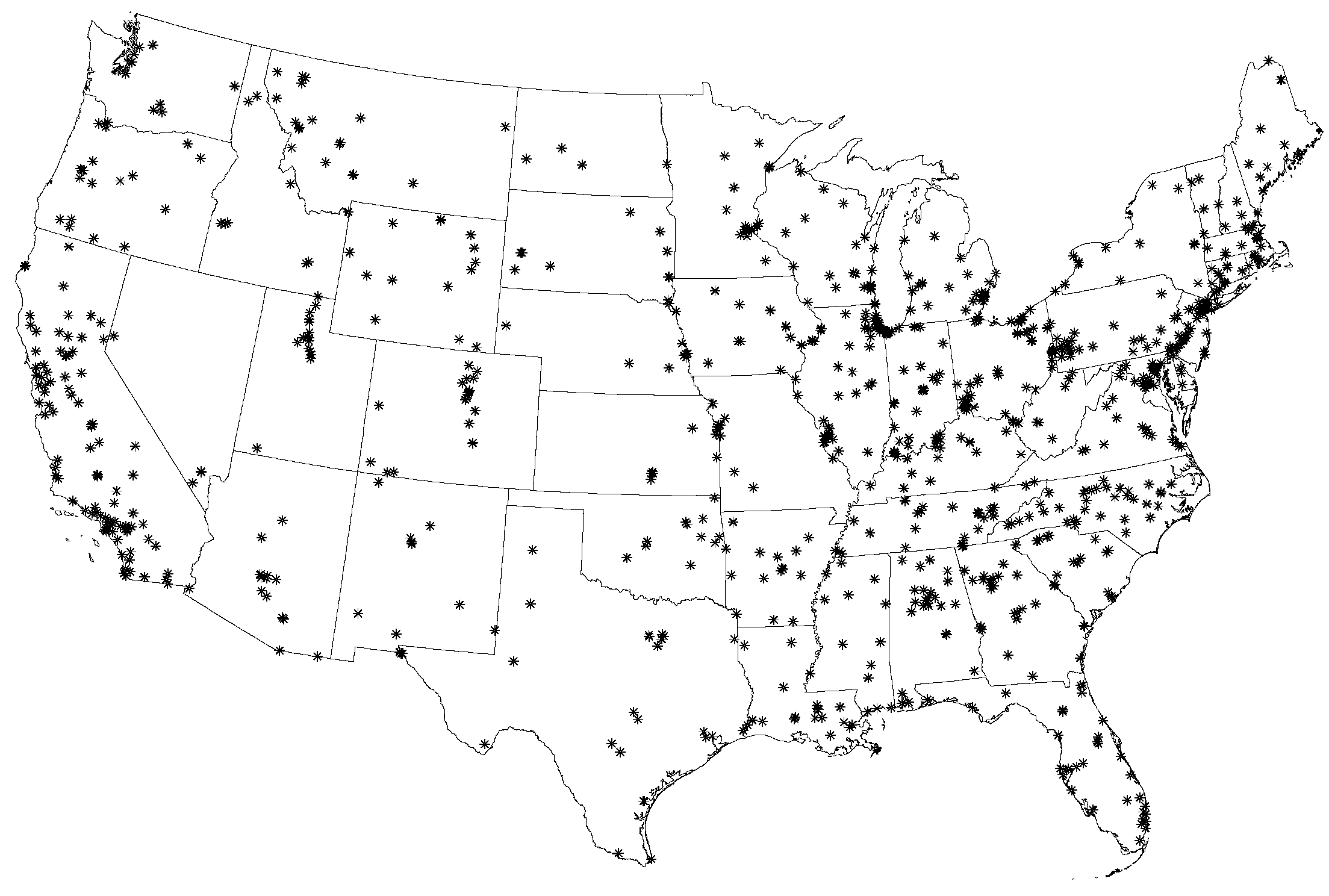
3.1. PM2.5 Data Set with Measurements
3.2. Census Block Group Data Set to Interpolate
4. Results
4.1. Cross Validation Results of the SF-Based Method
4.1.1. Choice of Time Scale
4.1.2. Cross Validation and Error Statistics
4.2. Cross Validation Results of the IDW-Based Method
4.2.1. Choice of Time Scale, Number of Neighbors, and Exponents
4.2.2. Cross Validation and Error Statistics
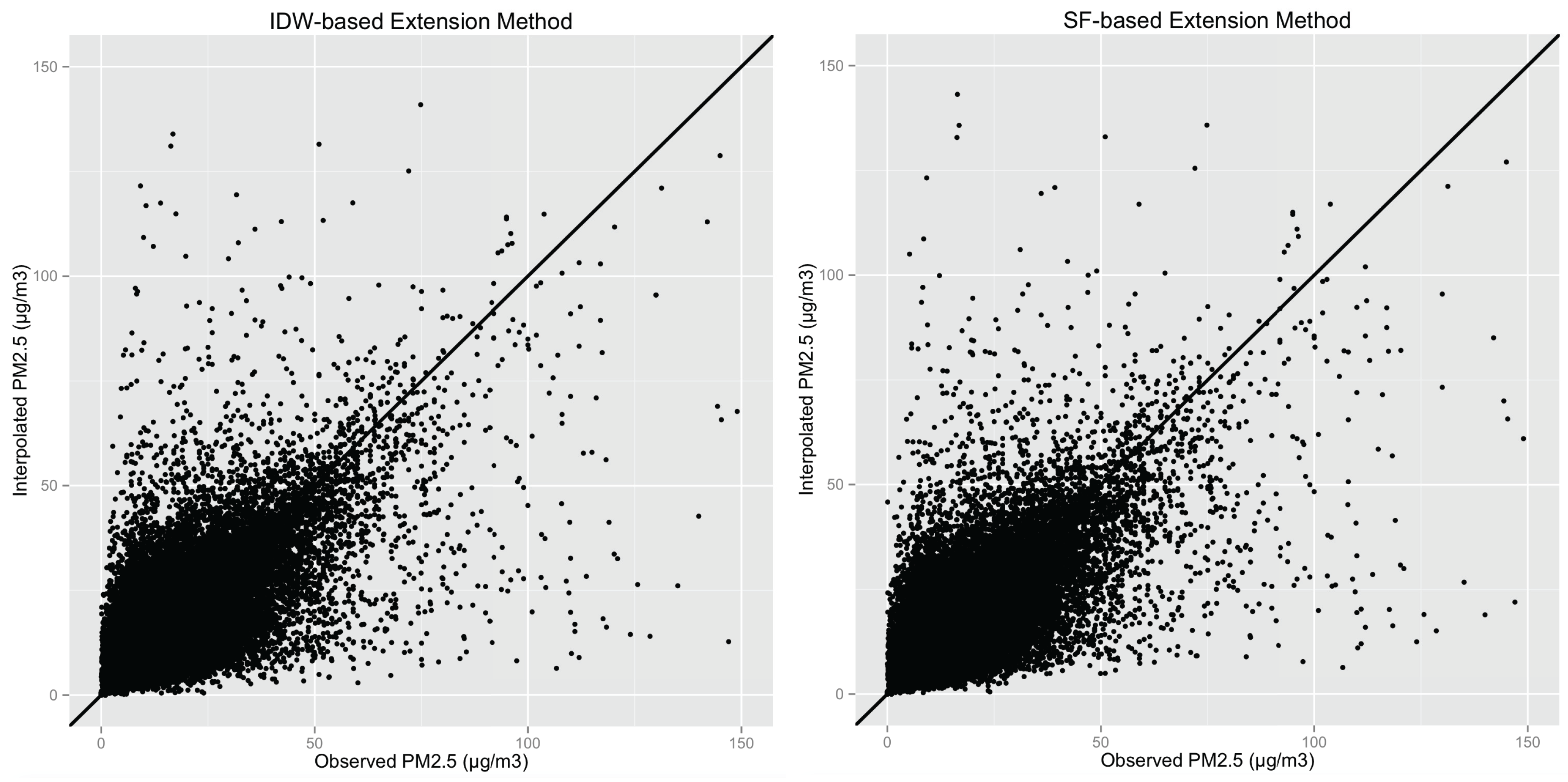
4.3. Comparison of SF-Based and IDW-Based Extension Methods
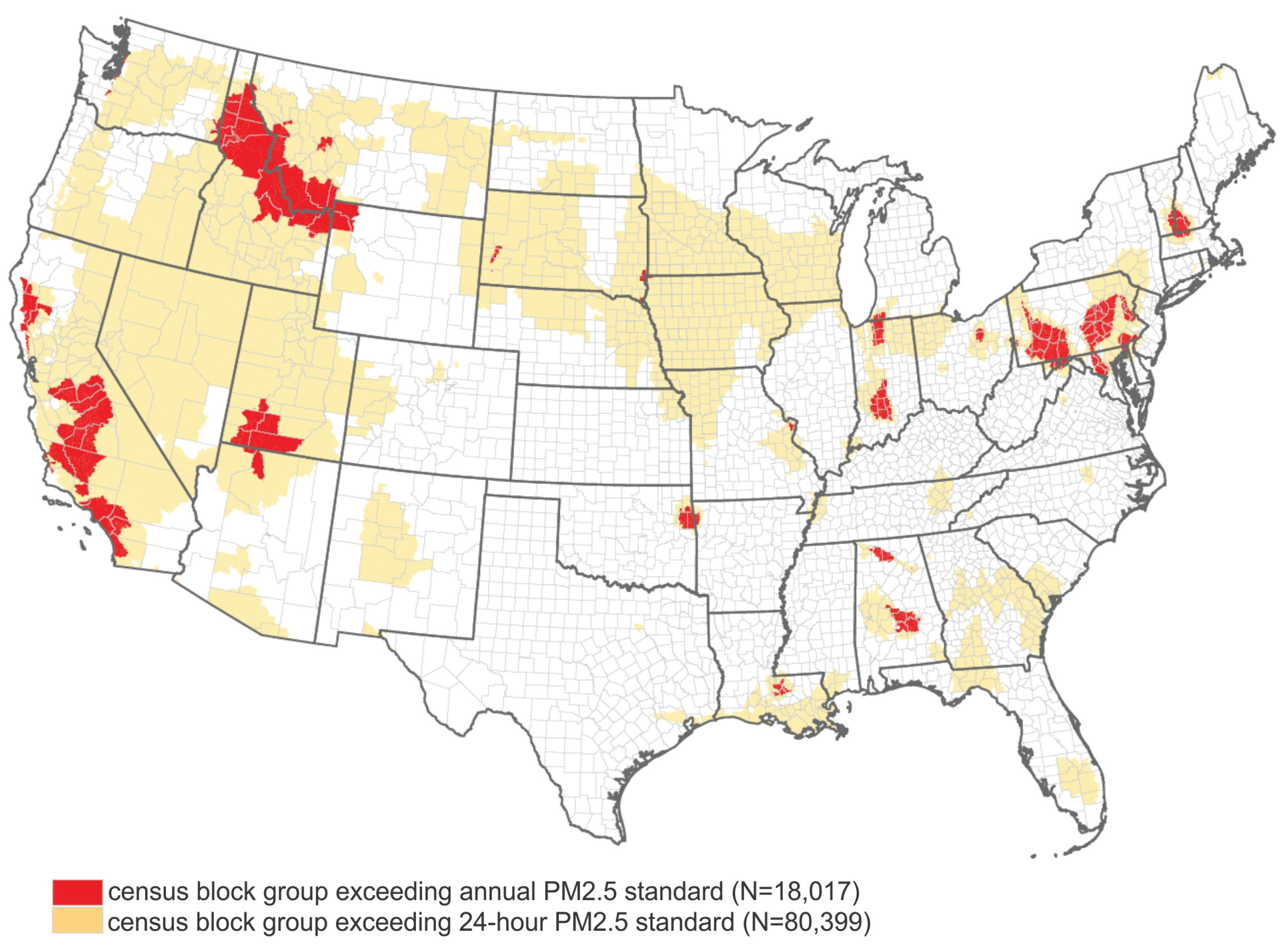
4.4. Population Exposure Analysis
- 35 micrograms per cubic meter () for 24 h:We identify block groups that have PM2.5 values greater than for at least one day.
- 15 micrograms per cubic meter () for the annual mean:We identify block groups that have annual PM2.5 values greater than .
- there is a population of (27.8 million) residing in census block groups in the contiguous United States with an annual PM2.5 exceeding the national standard of ;
- more than one-third of the U.S. population () residing in census block groups where PM2.5 exceeded for at least one day in 2009.
4.5. Web Application
5. Discussion
- This study is limited to investigating only four choices for time scales, five choices for the number of nearest neighbors, and nine choices for the exponents. In future work, we plan to apply machine learning methods to efficiently learn the best possible configurations in the model, using a lightning-fast cluster computing framework Apache Spark [61].
- The SF-based and IDW-based methods are deterministic methods. In this paper, we did not compare our methods with geostatistical interpolation methods such as Kriging, neural networks, and land use regression. In future work, we plan to develop multidimensional and stochastic spatiotemporal interpolation methods suitable for ambient air pollution data (NO2, O3, PM2.5, and PM10) by incorporating factors associated with the environmental exposure of interest, and then make comparisons with other commonly-applied geostatistical interpolation methods.
- Finally, there is a limitation in the currently implemented SF-based algorithm with respect to missing data close to some boundaries of the contiguous United States. For example, along the west coast in Oregon and Washington, there are monitoring stations relatively far away from the coastal border. Because of missing data, an unrealistic stripe next to the coast is visible in our map presentations of the interpolated results. In order to avoid this type of problem, we will need additional measurements along the coast, or use meshless interpolation methods such as IDW with a limited number of neighboring measurements in future work.
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- EPA. Particulate Matter (PM). Available online: https://www.epa.gov/pm-pollution (accessed on 26 March 2016).
- Seinfeld, J.H.; Pandis, S.N. Atmospheric Chemistry and Physics: From Air Pollution to Climate Change, 3rd ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2016. [Google Scholar]
- Sloane, C.S.; Watson, J.; Chow, J.; Pritchett, L.; Willard Richards, L. Size-segregated fine particle measurements by chemical species and their impact on visibility impairment in Denver. Atmos. Environ. 1991, 25, 1013–1024. [Google Scholar] [CrossRef]
- Ghim, Y.S.; Moon, K.C.; Lee, S.; Kim, Y.P. Visibility Trends in Korea during the Past Two Decades. J. Air Waste Manag. Assoc. 2005, 55, 73–82. [Google Scholar] [CrossRef] [PubMed]
- Hong, Y.C.; Lee, J.T.; Kim, H.; Ha, E.H.; Schwartz, J.; Christiani, D.C. Effects of air pollutants on acute stroke mortality. Environ. Health Perspect. 2002, 110, 187–191. [Google Scholar] [CrossRef] [PubMed]
- Laden, F.; Neas, L.M.; Dockery, D.W.; Schwartz, J. Association of fine particulate matter from different sources with daily mortality in six U.S. cities. Environ. Health Perspect. 2000, 108, 941–947. [Google Scholar] [CrossRef] [PubMed]
- Robichaud, A.; Ménard, R. Multi-year objective analyses of warm season ground-level ozone and PM2.5 over North America using real-time observations and Canadian operational air quality models. Atmos. Chem. Phys. 2014, 14, 1769–1800. [Google Scholar] [CrossRef]
- Shepard, D. A two-dimensional interpolation function for irregularly spaced data. In Proceedings of the 23nd National Conference ACM, New York, NY, USA, 1968; pp. 517–524.
- Li, L.; Revesz, P. Interpolation methods for spatio-temporal geographic data. J. Comput. Environ. Urban Syst. 2004, 28, 201–227. [Google Scholar] [CrossRef]
- Zienkiewics, O.C.; Taylor, R.L. Finite Element Method; Butterworth Heinemann: London, UK, 2000; Volume 1. [Google Scholar]
- Franke, C.; Schaback, R. Solving Partial Differential Equations by Collocation using Radial Basis Functions. Appl. Math. Comput. 1998, 93, 73–82. [Google Scholar] [CrossRef]
- De Boor, C. A Practical Guide to Splines; Springer: New York, NY, USA, 2001; Volume 27. [Google Scholar]
- Sibson, R. A brief description of natural neighbor interpolation. In Interpreting Multivariate Data; Barnett, V., Ed.; John Wiley & Sons, Inc.: New York, NY, USA, 1981; Chapter 2; pp. 21–36. [Google Scholar]
- Zurflueh, E.G. Applications of Two-dimensional Linear Wavelength Filtering. Geophysics 1967, 32, 1015–1035. [Google Scholar] [CrossRef]
- Krige, D. Two dimensional weighted moving average trend surfaces for ore evaluation. J. Soc. Afr. Inst. Min. Metall. 1966, 66, 13–38. [Google Scholar]
- Blond, N.; Vautard, R. Three-dimensional ozone analyses and their use for short-term ozone forecasts. J. Geophys. Res. Atmos. 2004. [Google Scholar] [CrossRef]
- Pagowski, M.; Grell, G.A.; McKeen, S.A.; Peckham, S.E.; Devenyi, D. Three-dimensional variational data assimilation of ozone and fine particulate matter observations: some results using the Weather Research and Forecasting—Chemistry model and Grid-point Statistical Interpolation. Q. J. R. Meteorol. Soc. 2010, 136, 2013–2024. [Google Scholar] [CrossRef]
- Robichaud, A.; Ménard, R.; Zaïtseva, Y.; Anselmo, D. Multi-pollutant surface objective analyses and mapping of air quality health index over North America. Air Qual. Atmos. Health 2016. [Google Scholar] [CrossRef]
- Liao, D.; Peuquet, D.J.; Duan, Y.; Whitsel, E.A.; Dou, J.; Smith, R.L.; Lin, H.M.; Chen, J.C.; Heiss, G. GIS Approaches for the Estimation of Residential-Level Ambient PM Concentrations. Environ. Health Perspect. 2006, 114, 1374–1380. [Google Scholar] [CrossRef] [PubMed]
- Zou, B.; Wilson, J.G.; Zhan, F.B.; Zeng, Y. Air pollution exposure assessment methods utilized in epidemiological studies. J. Environ. Monit. 2011, 11, 475–490. [Google Scholar] [CrossRef] [PubMed]
- Cressie, N.; Wikle, C.K. Statistics for Spatio-temporal Data; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2011. [Google Scholar]
- Pebesma, E. Spacetime: Spatio-temporal data in R. J. Stat. Softw. 2012, 51, 1–30. [Google Scholar] [CrossRef]
- Li, L.; Losser, T.; Yorke, C.; Piltner, R. Fast Inverse Distance Weighting-based Spatiotemporal Interpolation: A Web-based Application of Interpolating Daily Fine Particulate Matter PM2.5 in the Contiguous U.S. using Parallel Programming and k-d Tree. Int. J. Environ. Res. Public Health 2014, 11, 9101–9141. [Google Scholar] [CrossRef] [PubMed]
- Losser, T.; Li, L.; Piltner, R. A Spatiotemporal Interpolation Method Using Radial Basis Functions for Geospatiotemporal Big Data. In Proceedings of the 5th International Conference on Computing for Geospatial Research and Application, Washington, DC, USA, 4–6 Auguat 2014; IEEE: Washington, DC, USA; pp. 17–24.
- Revesz, P.; Wu, S. Spatiotemporal reasoning about epidemiological data. Artif. Intell. Med. 2006, 38, 157–170. [Google Scholar] [CrossRef] [PubMed]
- Anderson, S.; Revesz, P.Z. Efficient MaxCount and threshold operators of moving objects. Geoinformatica 2009, 13, 355–396. [Google Scholar] [CrossRef]
- Hussain, I.; Spöck, G.; Pilz, J.; Yu, H.L. Spatio-temporal interpolation of precipitation during monsoon periods in Pakistan. Adv. Water Resour. 2010, 33, 880–886. [Google Scholar] [CrossRef]
- Yu, H.L.; Wang, C.H. Quantile-Based Bayesian Maximum Entropy Approach for Spatiotemporal Modeling of Ambient Air Quality Levels. Environ. Sci. Technol. 2013, 47, 1416–1424. [Google Scholar] [CrossRef] [PubMed]
- Lu, G.Y.; Wong, D.W. An adaptive inverse-distance weighting spatial interpolation technique. Comput. Geosci. 2008, 34, 1044–1055. [Google Scholar] [CrossRef]
- Li, J.; Heap, A.D. A review of comparative studies of spatial interpolation methods in environmental sciences: Performance and impact factors. Ecol. Inform. 2011, 6, 228–241. [Google Scholar] [CrossRef]
- De Mesnard, L. Pollution Models and Inverse Distance Weighting: Some Critical Remarks. Comput. Geosci. 2013, 52, 459–469. [Google Scholar] [CrossRef]
- Li, L.; Zhang, X.; Piltner, R. An Application of the Shape Function Based Spatiotemporal Interpolation Method on Ozone and Population Exposure in the Contiguous U.S. J. Environ. Inform. 2008, 12, 120–128. [Google Scholar] [CrossRef]
- Buchanan, G.R. Finite Element Analysis; McGraw-Hill: New York, NY, USA, 1995. [Google Scholar]
- Revesz, P.; Li, L. Representation and Querying of Interpolation Data in Constraint Databases. In Proceedings of the Third National Conference on Digital Government Research, 19–22 May 2002; pp. 225–228.
- Li, J.; Narayanan, R. A shape-based approach to change detection of lakes using time series remote sensing images. IEEE Trans. Geosci. Remot. Sen. 2003, 41, 2466–2477. [Google Scholar]
- Gao, J.; Revesz, P. Voting prediction using new spatiotemporal interpolation methods. In Proceedings of the Seventh Annual International Conference on Digital Government Research, San Diego, CA, USA, 21–24 May 2006; pp. 293–300.
- Li, L. Spatiotemporal Interpolation Methods in GIS - Exploring Data for Decision Making; VDM Verlag: Saarbrücken, Germany, 2009. [Google Scholar]
- Revesz, P. Introduction to Databases: From Biological to Spatio-Temporal; Springer: New York, NY, USA, 2010. [Google Scholar]
- Murphy, R.; Curriero, F.; Ball, W. Comparison of Spatial Interpolation Methods for Water Quality Evaluation in the Chesapeake Bay. J. Environ. Eng. 2010, 136, 160–171. [Google Scholar] [CrossRef]
- Rahman, H.; Alireza, K.; Reza, G. Application of Artificial Neural Network, Kriging, and Inverse Distance Weighting Models for Estimation of Scour Depth around Bridge Pier with Bed Sill. J. Softw. Eng. Appl. 2010, 3, 944–964. [Google Scholar] [CrossRef]
- Eldrandaly, K.A.; Abu-Zaid, M.S. Comparison of Six GIS-Based Spatial Interpolation Methods for Estimating Air Temperature in Western Saudi Arabia. J. Environ. Inform. 2011, 18, 38–45. [Google Scholar] [CrossRef]
- Xie, Y.; Chen, T.; Lei, M.; Yang, J.; Guo, Q.; Song, B.; Zhou, X. Spatial distribution of soil heavy metal pollution estimated by different interpolation methods: Accuracy and uncertainty analysis. Chemosphere 2011, 82, 468–476. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Zhang, X.; Holt, J.B.; Tian, J.; Piltner, R. Estimating Population Exposure to Fine Particulate Matter in the Conterminous U.S. using Shape Function-based Spatiotemporal Interpolation Method: A County Level Analysis. GSTF Int. J. Comput. 2012, 1, 24–30. [Google Scholar] [PubMed]
- Li, L.; Zhang, X.; Piltner, R. A Spatiotemporal Database for Ozone in the Conterminous U.S. In Proceedings of the Thirteenth International Symposium on Temporal Representation and Reasoning, Budapest, Hungary, 15–17 June 2006; pp. 168–176.
- Li, L. Constraint Databases and Data Interpolation. In Encyclopedia of Geographic Information System; Shekhar, S., Xiong, H., Eds.; Springer: New York, NY, USA, 2008; pp. 144–153. [Google Scholar]
- Tobler, W.R. A computer movie simulating urban growth in the Detroit region. Econ. Geogr. 1970, 46, 234–240. [Google Scholar] [CrossRef]
- Johnston, K.; Hoef, J.M.V.; Krivoruchko, K.; Lucas, N. Using ArcGIS Geostatistical Analyst; ESRI Press: Redlands, CA, USA, 2001. [Google Scholar]
- Refaeilzadeh, P.; Tang, L.; Liu, H. Cross Validation. In Encyclopedia of Database Systems; Özsu, M.T., Liu, L., Eds.; Springer: New York, NY, USA, 2009; pp. 532–538. [Google Scholar]
- Keller, J.P.; Olives, C.; Kim, S.Y.; Sheppard, L.; Sampson, P.D.; Szpiro, A.A.; Oron, A.P.; Lindström, J.; Vedal, S.; Kaufman, J.D. A Unified Spatiotemporal Modeling Approach for Predicting Concentrations of Multiple Air Pollutants in the Multi-Ethnic Study of Atherosclerosis and Air Pollution. Environ. Health Perspect. 2015, 123, 301–309. [Google Scholar] [CrossRef] [PubMed]
- EPA. Air Quality System (AQS). Available online: http://www3.epa.gov/pm (accessed on 26 March 2016).
- EPA. Particulate Matter (PM) Standards – Table of Historical PM NAAQS. Available online: http://www3.epa.gov/ttn/naaqs/standards/pm/s_pm_history.html (accessed on 26 March 2016).
- MEAN.IO. MEAN. Available online: http://mean.io (accessed on 26 March 2016).
- MongoDB. Available online: https://www.mongodb.org (accessed on 26 March 2016).
- Express. Available online: http://expressjs.com (accessed on 26 March 2016).
- AngularJS. Available online: https://angularjs.org (accessed on 26 March 2016).
- NodeJS. Available online: https://nodejs.org (accessed on 26 March 2016).
- Zur Muehlen, M.; Nickerson, J.V.; Swenson, K.D. Developing web services choreography standards–the case of REST vs. SOAP. Decis. Support Syst. 2005, 40, 9–29. [Google Scholar] [CrossRef]
- EPA. AirNow. Available online: http://www.airnow.gov (accessed on 26 March 2016).
- AirNow Web Services Documentation. Available online: http://airnowapi.org/webservices (accessed on 26 March 2016).
- A Real-Time Web Application to Interpolate and Visualize Spatiotemporal Variation of Ambient Air Pollution Across the Contiguous U.S. Available online: http://52.86.86.190:3000 (accessed on 26 March 2016).
- Apache Spark. Available online: https://databricks.com/spark (accessed on 26 March 2016).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time | Scale A | Scale B | Scale C | Scale D |
|---|---|---|---|---|
| (c = 1) | (c = 1/10) | (c = 1/5) | (c = 1/15) | |
| 01/01/2009 | 1 | 0.1 | 0.2 | 0.067 |
| 01/02/2009 | 2 | 0.2 | 0.4 | 0.133 |
| 01/03/2009 | 3 | 0.3 | 0.6 | 0.2 |
| 01/04/2009 | 4 | 0.4 | 0.8 | 0.267 |
| … | … | … | … | … |
| 12/31/2009 | 365 | 36.5 | 73 | 24.333 |
| Error | Scale A | Scale B | Scale C | Scale D |
|---|---|---|---|---|
| Statistics | () | () | () | () |
| 3.1512 | 3.5576 | 3.2463 | 3.7307 | |
| 85.8621 | 78.5322 | 78.4890 | 77.1072 | |
| 8.8832 | 8.6045 | 8.6067 | 8.5023 | |
| 3.2162 | 0.4158 | 0.3745 | 0.4365 | |
| 0.3079 | 0.3226 | 0.3138 | 0.3382 |
| Error | Scale A | Scale B | Scale C | Scale D |
|---|---|---|---|---|
| Statistics | () | () | () | () |
| 3.0941 | 3.4976 | 3.1812 | 3.6751 | |
| 42.2910 | 37.7745 | 35.6601 | 39.2077 | |
| 6.5032 | 6.1461 | 5.9716 | 6.2616 | |
| 3.2135 | 0.4128 | 0.3708 | 0.4349 | |
| 0.4817 | 0.5371 | 0.5630 | 0.5195 |
| Error | Scale A | Scale B | Scale C | Scale D |
|---|---|---|---|---|
| Statistics | () | () | () | () |
| 3.1586 | 3.2856 | 3.1070 | 3.4207 | |
| (N = 4, p = 1.0) | (N = 3, p = 2.0) | (N = 3, p = 2.0) | (N = 5, p = 2.5) | |
| 75.3792 | 67.8379 | 68.0293 | 68.2309 | |
| (N = 7, p = 1) | (N = 7, p = 1.5) | (N = 6, p = 1.0) | (N = 7, p = 1.5) | |
| 8.3258 | 7.8888 | 7.8967 | 7.9143 | |
| (N = 7, p = 1.0) | (N = 7, p = 1.5) | (N = 7, p = 1.0) | (N = 7, p = 1.5) | |
| 2.7005 | 0.3803 | 0.9717 | 0.3963 | |
| (N = 7, p = 1.0) | (N = 3, p = 5.0) | (N = 3, p = 5.0) | (N = 3, p = 2.5) | |
| 0.3789 | 0.4413 | 0.4416 | 0.4374 | |
| (N = 7, p = 1.0) | (N = 4, p = 1.0) | (N = 7, p = 1.0) | (N = 7, p = 1.0) |
| Error Statistics | |||
|---|---|---|---|
| Scale B () | Scale B () | Scale B () | |
| before Removing Outliers | before Removing Outliers | after Removing Outliers | |
| 3.4519 | 3.3378 | 3.2765 | |
| 68.0348 | 79.5497 | 37.5608 | |
| 7.8909 | 8.6320 | 6.1287 | |
| 1.2594 | 0.3803 | 0.3773 | |
| 0.4413 | 0.3359 | 0.5399 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, L.; Zhou, X.; Kalo, M.; Piltner, R. Spatiotemporal Interpolation Methods for the Application of Estimating Population Exposure to Fine Particulate Matter in the Contiguous U.S. and a Real-Time Web Application. Int. J. Environ. Res. Public Health 2016, 13, 749. https://doi.org/10.3390/ijerph13080749
Li L, Zhou X, Kalo M, Piltner R. Spatiotemporal Interpolation Methods for the Application of Estimating Population Exposure to Fine Particulate Matter in the Contiguous U.S. and a Real-Time Web Application. International Journal of Environmental Research and Public Health. 2016; 13(8):749. https://doi.org/10.3390/ijerph13080749
Chicago/Turabian StyleLi, Lixin, Xiaolu Zhou, Marc Kalo, and Reinhard Piltner. 2016. "Spatiotemporal Interpolation Methods for the Application of Estimating Population Exposure to Fine Particulate Matter in the Contiguous U.S. and a Real-Time Web Application" International Journal of Environmental Research and Public Health 13, no. 8: 749. https://doi.org/10.3390/ijerph13080749