1. Introduction
Agricultural applications, search/rescue missions, surveillance, supply and logistics are some of the operational fields of autonomous ground vehicles. These operations may necessitate for traversing some off-road or indoor terrains that can have an effect on the vehicle performance [
1]. In such operations, determining the environment of the vehicle improves its efficiency. Estimation of the current terrain type can be useful since the terrain conditions affect both planning and motion control stages [
2]. An automated terrain-dependent driving process can be obtained with terrain classification. In the literature, computer vision based algorithms are commonly used to classify the terrain which is being traversed [
3,
4]. However, these methods can be unreliable and their performance mostly depend on the lighting conditions. Vibrations of the ground vehicles obtained by inertial sensors can also be used to classify or characterize the terrain [
5].
A radial basis function (RBF) network is a special type of neural network that uses a radial basis function as its activation function [
6]. RBF networks are very popular for function approximation, curve fitting, time series prediction, control and
classification problems. The radial basis function network is different from other neural networks, possessing several distinctive features. Because of their universal approximation, more compact topology and faster learning speed, RBF networks have attracted considerable attention and they have been widely applied in many science and engineering fields [
7–
11].
In RBF networks, determination of the number of neurons in the hidden layer is very important because it affects the network complexity and the generalizing capability of the network. If the number of the neurons in the hidden layer is insufficient, the RBF network cannot learn the data adequately; on the other hand, if the neuron number is too high, poor generalization or an overlearning situation may occur [
12]. The position of the centers in the hidden layer also affects the network performance considerably [
13], so determination of the optimal locations of centers is an important task. In the hidden layer, each neuron has an activation function. The gaussian function, which has a spread parameter that controls the behavior of the function, is the most preferred activation function. The training procedure of RBF networks also includes the optimization of spread parameters of each neuron. Afterwards, the weights between the hidden layer and the output layer must be selected appropriately. Finally, the bias values which are added with each output are determined in the RBF network training procedure.
In the literature, various algorithms are proposed for training RBF networks, such as the gradient descent (GD) algorithm [
14] and Kalman filtering (KF) [
13]. These two algorithms are derivative based and have some weaknesses such as converging to a local minima and time-consuming process of finding the optimal gradient. Because of these limitations, several global optimization methods have been used for training RBF networks for different science and engineering problems such as genetic algorithms (GA) [
15], the particle swarm optimization (PSO) algorithm [
12], the artificial immune system (AIS) algorithm [
16] and the differential evolution (DE) algorithm [
17].
The ABC algorithm is a population based evolutional optimization algorithm that can be applied to various types of problems. The ABC algorithm is used for training feed forward multi-layer perceptron neural networks by using test problems such as XOR, 3-bit parity and 4-bit encoder/decoder problems [
18]. In this study, training the RBF network with ABC algorithm has been proposed and the training performance of the ABC algorithm has been compared with GD [
14], KF [
13] and GA on classification test problems and an inertial sensor based terrain classification problem.
The rest of the paper is organized as follows: Section 2 presents Radial Basis Function Networks and Section 3 gives brief descriptions of training algorithms of RBF networks. Section 4 illustrates the Artificial Bee Colony (ABC) Algorithm. Section 5 presents Training of RBF Neural Networks by Using ABC. In Section 6, the performance of training algorithms of RBF network that is applied to classification problems have been evaluated and experimental results have been given. Finally, in the last section, some concluding remarks are presented.
2. Radial Basis Function Networks
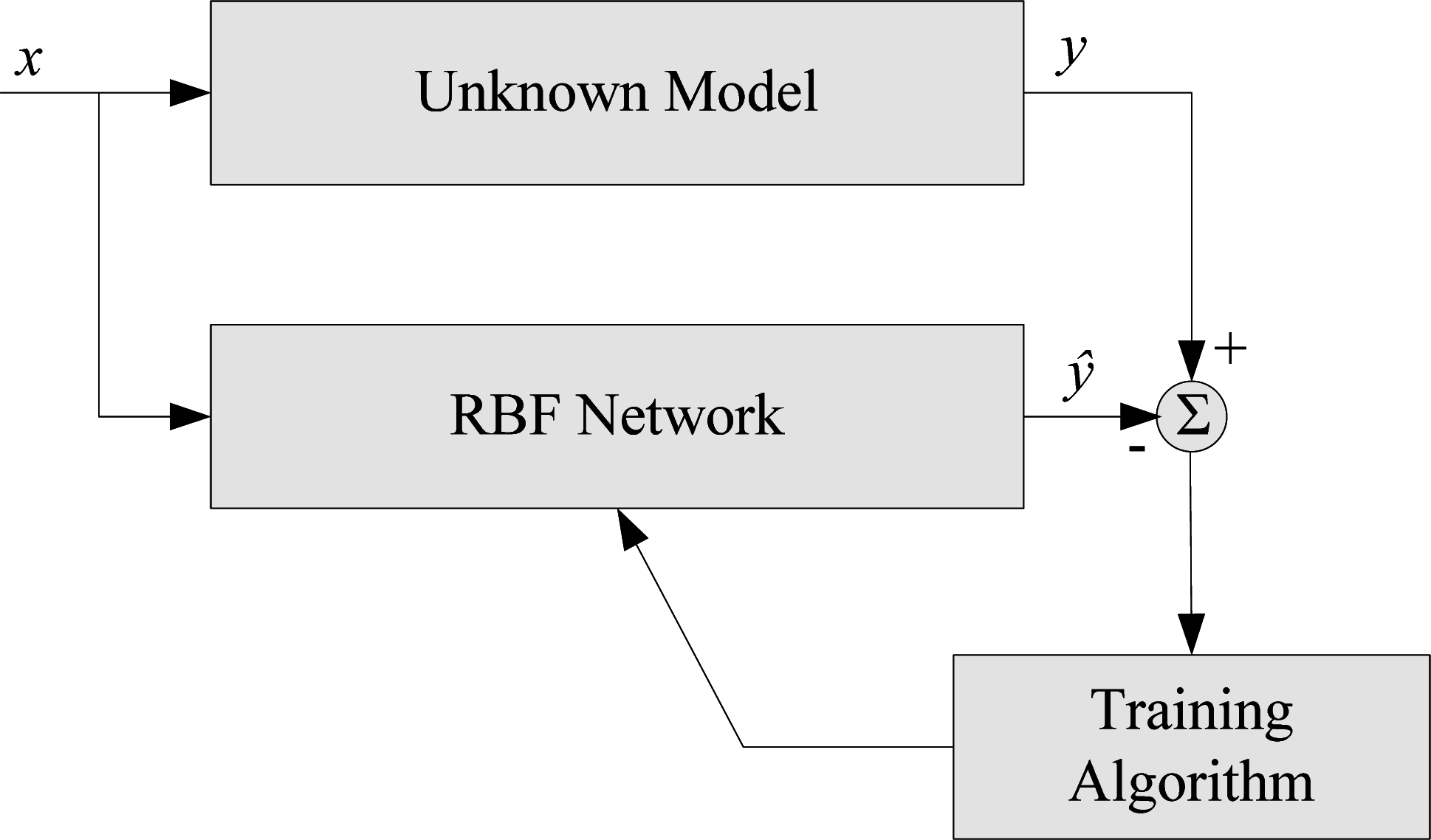
Neural networks are non-linear statistical data modeling tools and can be used to model complex relationships between inputs and outputs or to find patterns in a dataset. RBF network is a type of feed forward neural network composed of three layers, namely the input layer, the hidden layer and the output layer. Each of these layers has different tasks [
17]. A general block diagram of an RBF network is illustrated in
Figure 1.
In RBF networks, the outputs of the input layer are determined by calculating the distance between the network inputs and hidden layer centers. The second layer is the linear hidden layer and outputs of this layer are weighted forms of the input layer outputs. Each neuron of the hidden layer has a parameter vector called center. Therefore, a general expression of the network can be given as [
19]:
The norm is usually taken to be the Euclidean distance and the radial basis function is also taken to be Gaussian function and defined as follows:
where,
| I | Number of neurons in the hidden layer | i ∈ {1,2,…,I} |
| J | Number of neurons in the output layer | j ∈ {1,2,…,J} |
| wij | Weight of the ith neuron and jth output | |
| ϕ | Radial basis function | |
| αi | Spread parameter of the ith neuron | |
| x | Input data vector | |
| ci | Center vector of the ith neuron | |
| βj | Bias value of the output jth neuron | |
| ŷj | Network output of the jth neuron | |
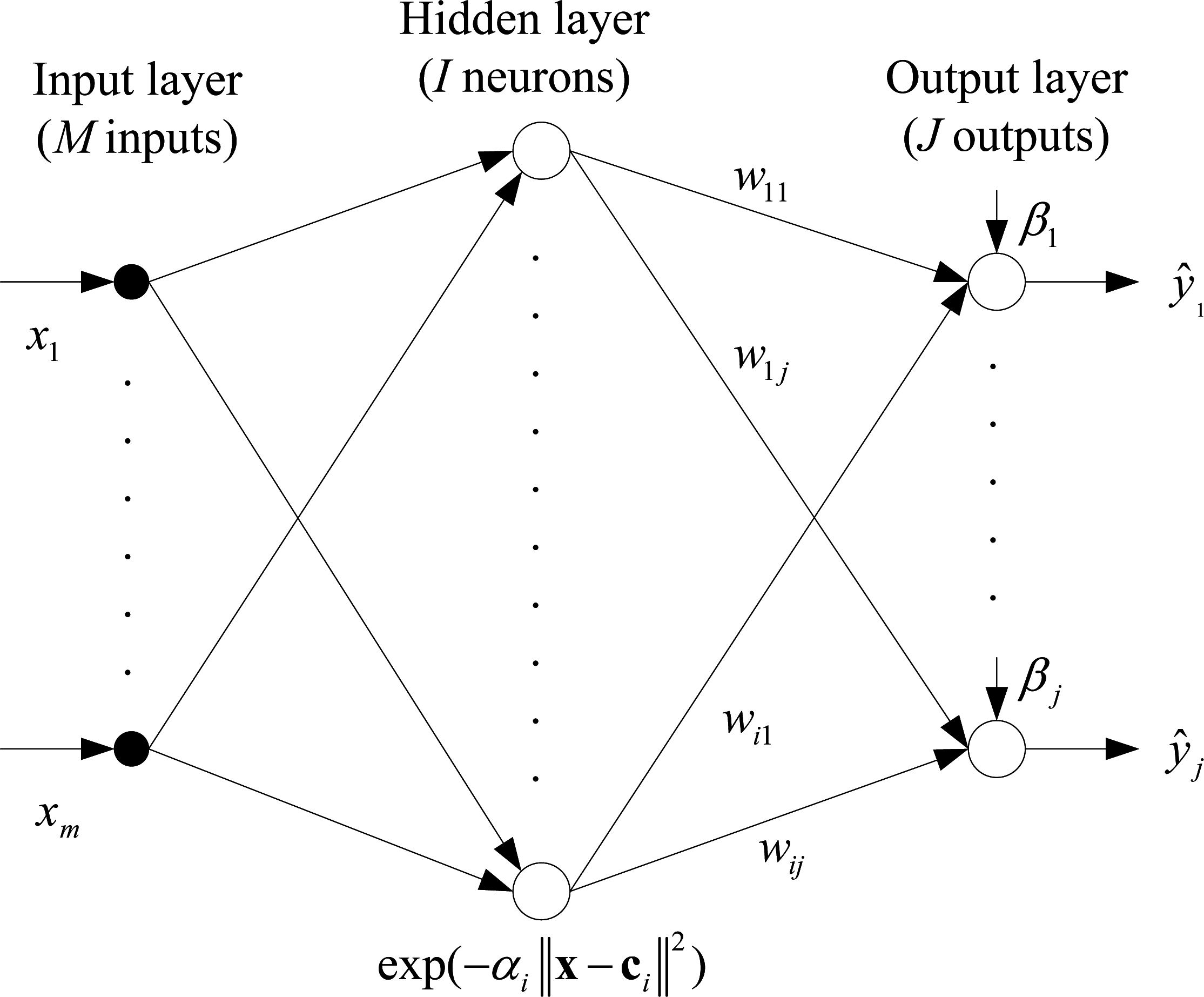
Figure 2 shows the detailed architecture of an RBF network.
M dimensional inputs (
x1,…,
xm) are located in the input layer, which broadcast the inputs to the hidden layer. The hidden layer includes
I neurons and each neuron in this layer calculates the Euclidean distance between the centers and the inputs. A neuron in the hidden layer has an activation function called the basis function. In the literature, the Gaussian function is frequently chosen as the radial basis function and it has a spread parameter to shape the curve (
α1,…,
αi). The weighted (
w11,…,
wij) outputs of the hidden layer are transmitted to the output layer. Here,
I (
i ∈ {1,2,…,
I}) denotes the number of neurons in the hidden layer and
J (
j ∈ {1,2,…,
J}) denotes the dimension of the output. The output layer calculates the linear combination of hidden layer outputs and bias parameters (
β1,…,
βj). Finally, the outputs of the RBF network are obtained (
ŷ1,…,
ŷj).
The design procedure of the RBF neural network includes determining the number of neurons in the hidden layer. Then, in order to obtain the desired output of the RBF neural network
w,
α, c and
β parameters might be adjusted properly. Reference based error metrics such as mean square error (MSE) or sum square error (SSE) can be used to evaluate the performance of the network. Error expression for the RBF network can be defined as follows:
Here yj indicates the desired output and ŷj indicates the RBF neural network output. The training procedure of the RBF neural network involves minimizing the error function.
3. Training Algorithms of RBF Networks
This section gives brief descriptions of training algorithms of RBF networks which were used in this paper for comparison purposes. The artificial bee colony (ABC) algorithm, which is newly applied to RBF training, is explained in detail in Section 4.
3.1. Gradient Descent (GD) Algorithm
GD is a first-order derivative based optimization algorithm used for finding a local minimum of a function. The algorithm takes steps proportional to the negative of the gradient of the function at the current point. In [
13], the output of a RBF network has been written as:
and
where the weight matrix is represented as
W and
φ matrix is represented as
H. GD algorithm can be implemented to minimize the error after defining the error function:
where
Y is the desired output. RBF can be optimized with adjusting the weights and center vectors by iteratively computing the partials and performing the following updates:
where
η is the step size [
13].
3.2. Kalman Filtering (KF) Algorithm
The state of a linear dynamic system can be efficiently estimated by Kalman filter from a series of noisy measurements. It is used in a wide range of engineering applications from INS/GPS integration [
20] to computer vision and many applications in control theory. A nonlinear finite dimensional discrete time system has been considered in [
13] as:
where the vector
θk is the state of the system at time
k,
ωk is the process noise,
yk the observation vector,
vk is the observation noise and
h is the nonlinear vector function of the state.
KF can be used to optimize weight matrix and center vectors of RBF as a least squares minimization problem. In a RBF network,
y denotes the target output vector and
h(
θk) denotes actual output of the
kth iteration of the optimization algorithm.
The vector
θ thus consists of all RBF parameters:
For a detailed explanation of the use of GD and KF for RBF training see [
13].
3.3. Genetic Algorithms (GA)
GA is an optimization method used in many research areas to find exact or approximate solutions to optimization and search problems. Inheritance, mutation, selection and crossover are the main aspects of GA that inspired from evolutionary biology. The population refers to the candidate solutions. The evolution starts from a randomly generated population. For all generations, the fitness (typically a cost function) of every individual in the population is evaluated and the genetic operators are implemented to obtain a new population. In the next iteration the new population is then used. Frequently, GA terminates when either a maximum number of generations has been reached, or a predefined fitness value has been achieved. In RBF training, the individuals consist of the RBF parameters such as weights, spread parameters, center vectors and bias parameters. The fitness value of an individual can be evaluated using an error function such as MSE or SSE of the desired output and the actual output of the network.
4. The Artificial Bee Colony (ABC) Algorithm
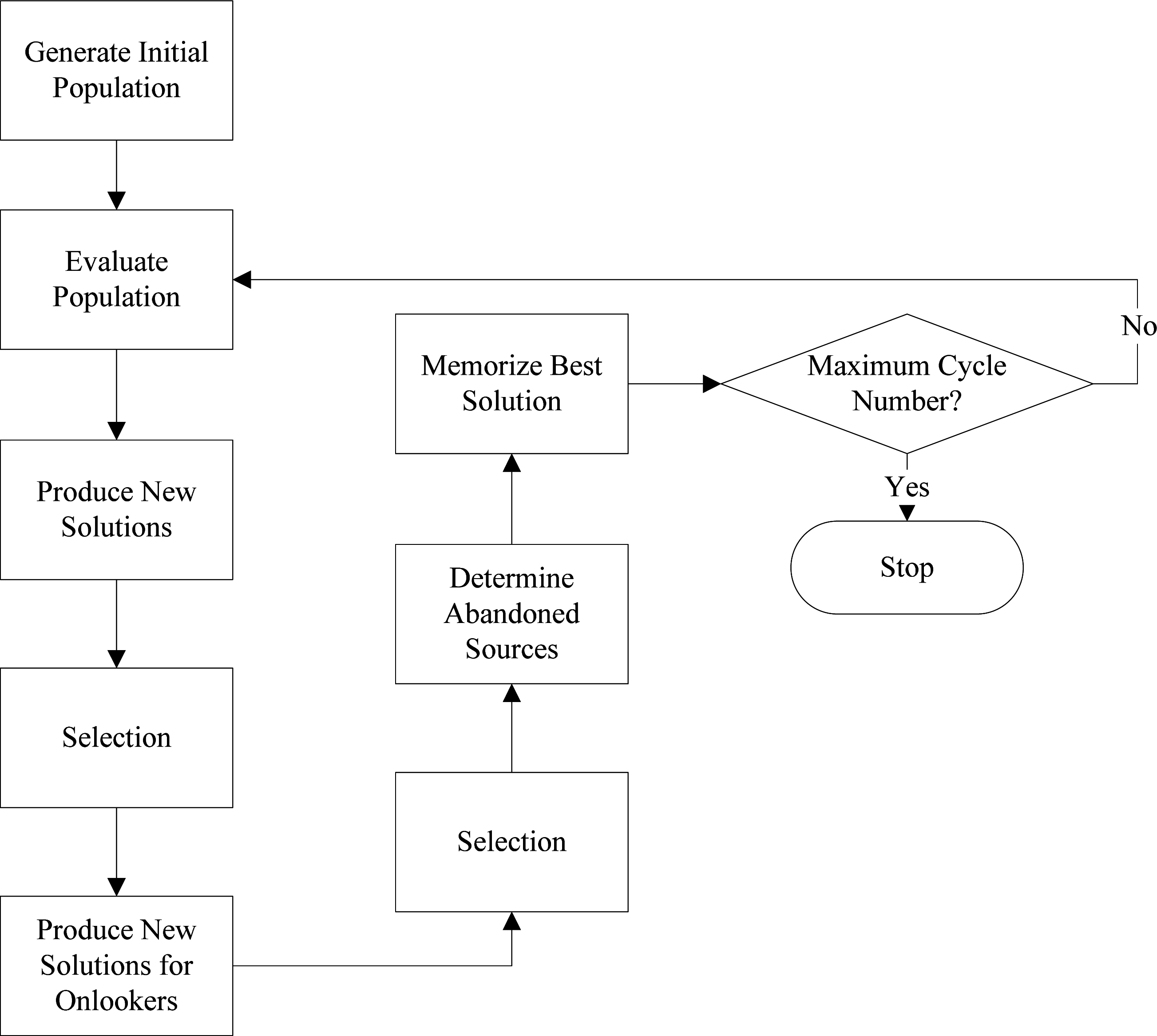
The Artificial Bee Colony algorithm is a heuristic optimization algorithm proposed by Karaboga in 2005 [
21]. The ABC algorithm has been inspired by honey bees’ intelligent foraging behavior. In the ABC model, the colony consists of three different bee groups, namely worker bees, onlooker bees and scout bees. For each food source there is only one associated employed bee. So, the number of the worker bees indicates the number of the food sources. Honey bees’ intelligent foraging behavior can be explained as follows: worker bees go to their food sources, after determining the nectar amount for that food source they explore new neighboring food sources. Then, they come back and dance around the hive. Onlooker bees which are watching the dance of the worker bees, choose a food source according to the worker bees’ dances. Probability of the food source that will be chosen is related with the quality of the food nectar and the left food amount. If a food source cannot be improved further through a predefined number of cycles, then the source is abandoned. Subsequently, randomly produced new sources are replaced with the abandoned ones by scouts. The best food source is determined and position of that food source is memorized. This cycle is repeated until requirements are met [
21–
23]. The basic flowchart of the ABC algorithm is illustrated in
Figure 3.
In the ABC algorithm, a food source indicates a possible solution of the optimization problem and the nectar amount of the food source indicates the fitness value of that food source. The number of worker bees corresponds to the possible solutions. First, an initial randomly distributed population is generated. After initialization, a search cycle of the worker, onlooker and scout bees in the population is repeated, respectively. A worker bee changes the food source and discovers a new food source. If the nectar amount of the new source is more than the old one, the worker bee learns the new position instead of the old one. Otherwise it keeps the old position. After all the worker bees complete the search process; they share the position information with the onlooker bees. Onlooker bees evaluate the nectar amounts and choose a food source. The probability value of a food source is calculated by using:
where
pi is the probability value of the source
i,
fi is the fitness value of the solution
i that is proportional with the nectar amount and
SN is the number of the food sources or worker bees.
ABC algorithm uses
equation 12 to obtain a new food position from the old position in the memory:
where
j ∈ {1,2,…,
SN} and
i ∈ {1,2,…,
D} are the randomly selected indices and
j must be different from
i. D indicates the number of the parameters to be optimized. Θ
ij is a random number between [−1, 1] and this number controls the production of the food sources around x
ij As can be seen from
equation 12, if the difference between x
ij and x
kj decreases, the step size get a decrease, accordingly. Therefore, the step size is adaptively modified while the algorithm reaches the optimal solution in the search area. The food source which does not progress for a certain number of cycles is abandoned. This cycle number is very important for ABC algorithm and is called “limit”. Control parameters of the ABC algorithm are number of the source (
SN), limit parameter and number of the maximum cycle [
24,
25].
5. Training of RBF Neural Networks by Using ABC
As mentioned before, training of an RBF neural network can be obtained with the selection of the optimal values for the following parameters:
weights between the hidden layer and the output layer (w)
spread parameters of the hidden layer base function (α)
center vectors of the hidden layer (c)
bias parameters of the neurons of the output layer (β)
The number of neurons in the hidden layer is very important in neural networks. Using more neurons than that is needed causes an overlearned network and moreover, increases the complexity. Therefore, it has to be investigated how the numbers of neurons affect the network’s performance.
The individuals of the population of ABC include the parameters of the weight (
w⃗), spread (
α⃗), center (
c⃗) and bias (
β⃗) vectors. An individual of the population of ABC algorithm can be expressed as:
The quality of the individuals (possible solutions) can be calculated using an appropriate cost function. In the implementation, SSE between the actual output of the RBF network and the desired output is adopted as the fitness function:
6. Experiments
The experiments conducted in this study are divided into two sub-sections. First, comparisons on well-known classification problems obtained from UCI repository are given. The second part of this section deals with terrain classification problem using inertial sensors in which the data was obtained experimentally.
6.1. Comparison of Algorithms on Test Problems
In the experiments of test problems, the performance of RBF network trained by using ABC is compared with GA, KF and GD algorithms. The well-known classification problems—Iris, Wine and Glass—which were obtained from UCI repository [
26] are used.
For all datasets, experiments are repeated 30 times. For each run, datasets are randomly divided into train and test subsets. 60% of the data set is randomly selected as the training data and remained data set is selected as the testing data. Afterwards, average and standard deviation of the 30 independent runs are calculated. General characteristics of the test and train dataset are illustrated in
Table 1.
One of the most important design issue of an RBF network is the number of the neurons in the hidden layer. Therefore, the experiments are conducted on different RBF networks which has 1 neuron to 8 neurons located in the hidden layer.
In the experiments, learning parameter of GD is selected as
η = 0.01 [
13]. For the KF algorithm
P0 = 40
I,
Q = 40
I, and
R = 40
I are chosen [
13]. Here,
I denotes the appropriate sized identity matrix. The control parameters of GA and ABC used in the experiments are given at
Tables 2 and
3, respectively.
In the experiments percent of correctly classified samples (PCCS) metric is used as the performance measure:
The statistical results of 30 replicates are given at
Tables 4—6 for Iris, Wine and Glass datasets, respectively. In the tables, the average PCCS values and the standard deviations (given in the parenthesis) are illustrated.
Gradient descent algorithm is a traditional derivative based method that is used for training RBF networks [
14]. However, it has some drawbacks such as trapping at local minima and computational complexity in consequence of slow convergence rate.
Kalman filtering is another derivative based method and several studies are performed for training RBF network with Kalman filtering [
13]. It converges in a few iterations so it reduces the computational complexity. Therefore, Kalman filtering is preferable over GD because of this feature.
GA is population based evolutional optimization algorithm and it has been used for training RBF network in several studies [
27]. Because of non-derivative based characteristic, it is distinguished from previous two algorithms and it is more robust for finding the global minimum. However, population based methods have a disadvantage such as slow converging rate. In this study, MATLAB Genetic Algorithms Toolbox
® is used to perform the experiments with GA. Population size and generation/cycle count are the same with ABC settings for comparing the training performances.
ABC is an evolutional optimization algorithm that is inspired by the foraging behavior of honey bees. It is a very simple and robust optimization technique. The results show that the ABC algorithm is more robust than GA because of the changes in standard deviations. Average results of the training results show that the ABC algorithm is better than the other methods.
As can be seen from
Tables 4—6, the performance of the ABC algorithm is better than the performances of the GD and KF methods. The performance of the ABC algorithm is nearly same with GA. However, standard deviations of the algorithms have pointed that ABC is more robust and stable than other methods. For the Iris, Wine and Glass datasets, standard deviations of the four algorithms can be seen in the tables. These results show that randomly selected data do not affect the performance of the ABC algorithm.
In addition, the number of neurons affects the network performance. As can be seen from the figures, as the number of neurons increases, the performance of the network does not increase accordingly. However, in the experiments it is realized that using three neurons gives acceptable results for the ABC algorithm. Other algorithms can reach the same performance by using more than three neurons. Since the number of neurons directly influences the time complexity of the algorithm, the required minimum number of neurons has to be used in the applications. In this context, the ABC algorithm is better than the others.
6.2. Comparison of Algorithms on Inertial Sensor based Terrain Classification
In this section, a terrain classification experiment is presented. The goal of this experiment is to identify the type of the terrain being traversed, from among a list of candidate terrains. Our proposed terrain classification system uses typically available an inertial measurement unit (IMU): XSens MTi-9 [
28,
29]. The Xsens MTi-9 sensor is a miniaturized, MEMS gyro-based Attitude and Heading Reference System whose internal signal processor provides drift-error free 3D acceleration, 3D orientation, and 3D earth-magnetic field data. The drift-error growing nature of inertial systems limits the accuracy of inertial measurement devices. Inertial sensors can supply reliable measurements only for small time intervals. The inertial sensors have been used in some recent research for stabilization and control of digital cameras, calibration patterns and other equipment [
30].
The experimental platform is shown in
Figure 4. The Xsens IMU is attached to the body of the mobile vehicle and connected to the notebook PC with USB cable.
In this study, we try to identify which one of the four different candidate terrains the vehicle travelled on: pavement, asphalt, grass and tile. Our hypothesis is that the vibrations of different terrains influence the output of the IMU sensor. The data sampled at 100 Hz for 80 seconds duration for each terrain type. Afterwards, the data is preprocessed before classification using proposed RBF scheme. Outdoor terrain types analyzed in this study are pavement, asphalt and grass. For indoor applications tile floor is used. The terrain types are shown in
Figure 5.
Previous experiments have shown that RBF networks are efficient classifiers. In this experiment the proposed RBF scheme is also used for terrain classification. RBF network structure for this problem has four outputs that help to identify the terrain type. Each output can vary from zero to one, in proportion to the likelihood that a given signal presented in the input of the RBF network belongs to one of the four subject terrains: pavement, asphalt, grass or tile. The RBF has n inputs corresponds to sensor data.
The
ith sample of Xsens IMU can be given as:
where
acc is 3D acceleration (m/s
2),
gry is 3D rate of turn (deg/s) and
mag is 3D earth magnetic field (mGauss).
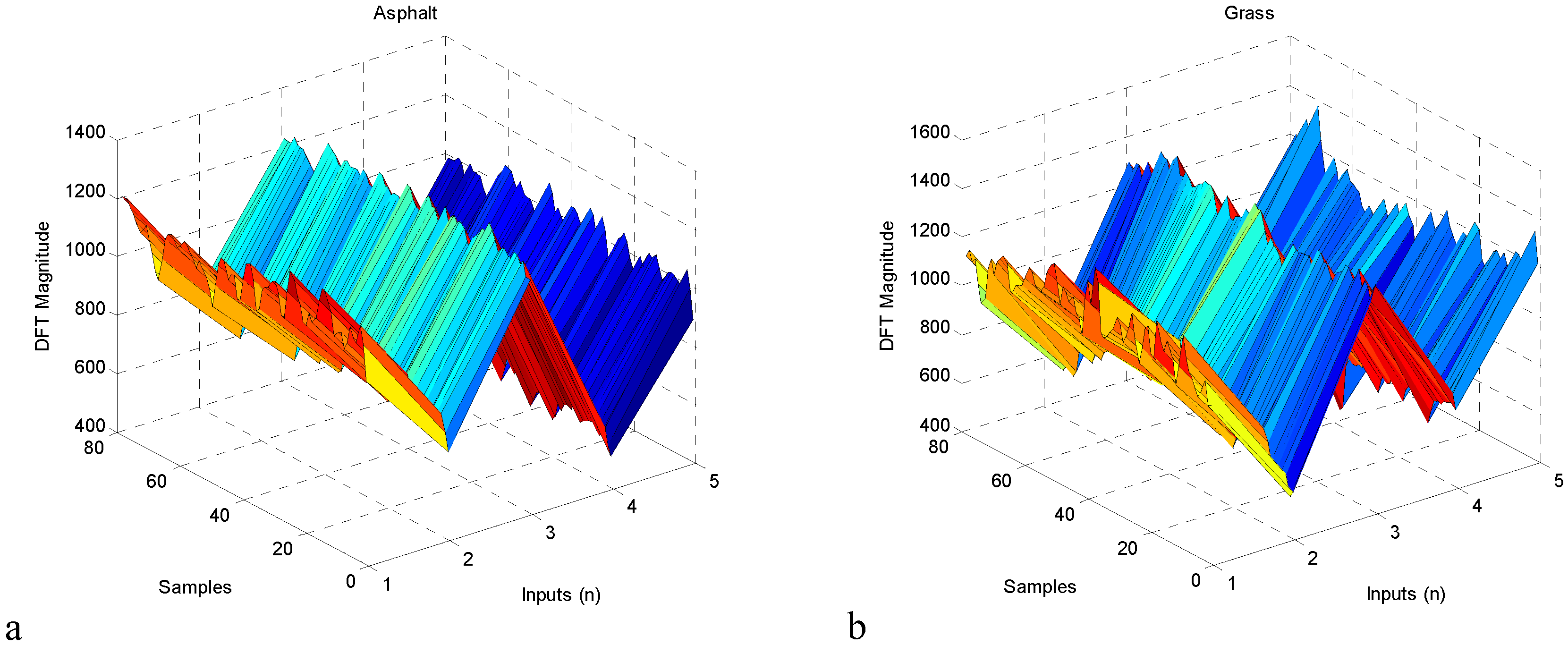
Discrete Fourier transform (DFT) is performed on the inertial data obtained from Xsens IMU. The sensor acquires data at 100 Hz. Therefore, the input signal at fixed intervals of 100 samples (1 second duration) is obtained and then DFT of the signal is computed. In the experiments, we use the first
n=5 values of the processed data. Several unreported experiments show that bigger
n values do not affect the results significantly. Preprocessed input data for the proposed classifier system is shown in
Figure 6.
Terrain classification dataset contains five inputs and four outputs. The dataset has 320 total samples. As in the previous experiment, this experiment is also repeated 30 times. For each run, 60% of the dataset is randomly divided into train and the rest is selected as test subsets. Average and standard deviation PCCS results of the 30 independent runs are given in
Table 7.
As can be seen from
Table 7, from best to worst, the algorithms can be ordered as ABC, GA, GD and KF, respectively. GA and ABC has smaller standard deviations then GD and KF which shows the robustness of population based intelligent optimization algorithms then traditional training algorithms. As a result, it can be said that ABC is better than the others from the point of view of higher average PCCS results and lower standard deviations.
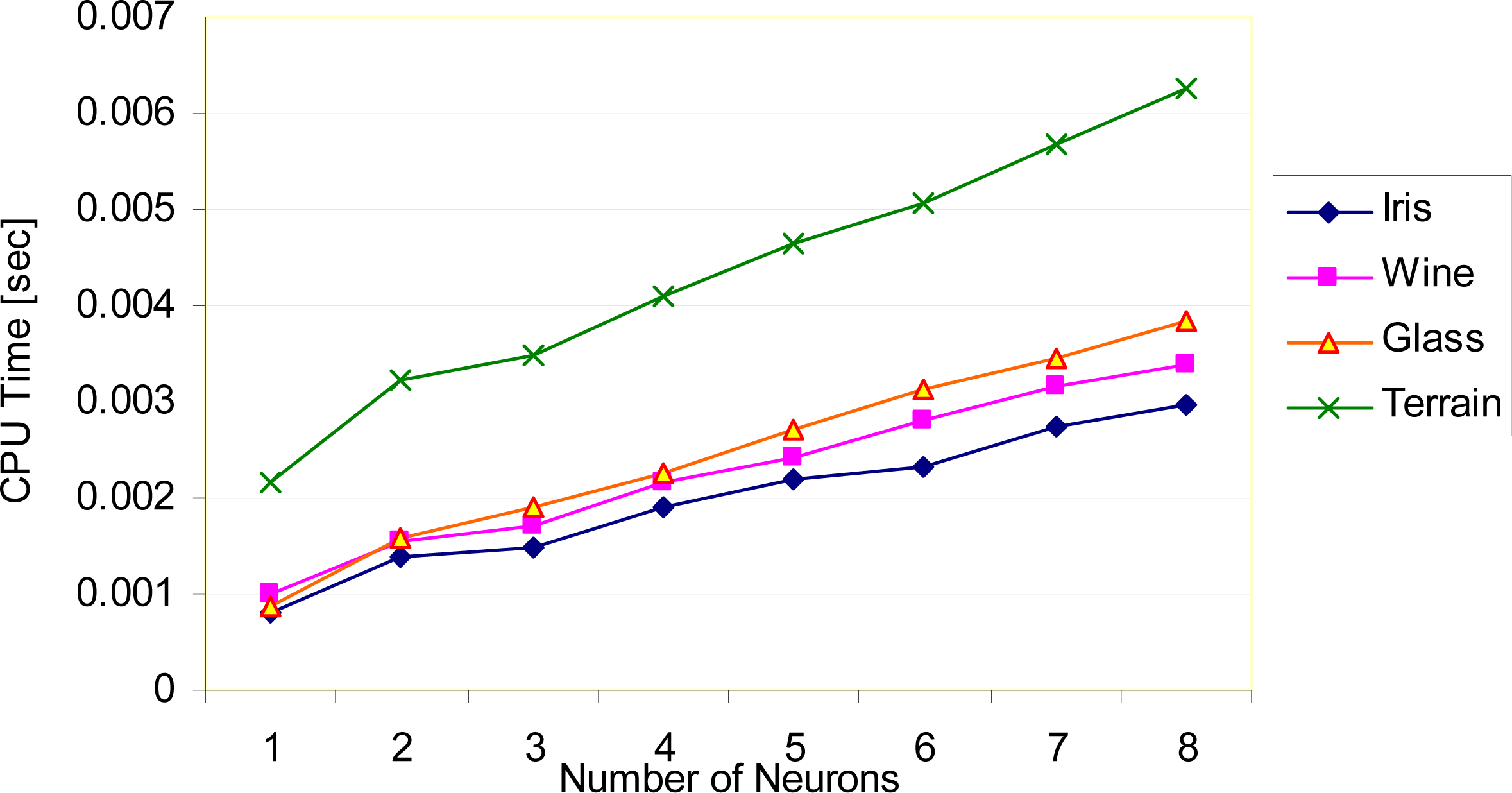
Figure 7 shows the evaluation CPU time of the RBF network after training stage. As can be seen from the figure, number of neurons located in the hidden layer of the RBF network affects the CPU time of the RBF network in real-time applications. While the number of neurons increase, CPU time increase proportionally. In the experiments, an Intel Q6600 2.4 GHz personal computer and MATLAB software are used.
7. Conclusions
In this study, the Artificial Bee Colony (ABC) Algorithm, which is a new, simple and robust optimization algorithm, has been used to train radial basis function (RBF) neural networks for classification purposes. First, well-known classification problems obtained from UCI repository have been used for comparison. Then, an experimental setup has been designed for an inertial sensor based terrain classification. Training procedures involves selecting the optimal values of the parameters such as weights between the hidden layer and the output layer, spread parameters of the hidden layer base function, center vectors of the hidden layer and bias parameters of the neurons of the output layer. Additionally, number of neurons in the hidden layer is very important for complexity of the network structure. The performance of the proposed algorithm is compared with the traditional GD, and novel KF and GA methods. GD and KF methods are derivative based algorithms. Trapping a local minimum is a disadvantage for these algorithms. The GA and ABC algorithms are population based evolutional heuristic optimization algorithms. These algorithms show better performance than derivative based methods for well known classification problems such as Iris, Glass, and Wine and also for experimental inertial sensor based terrain classification. However, these algorithms have the disadvantage of a slow convergence rate. If the classification performances are compared, experimental results show that the performance of the ABC algorithm is better than those of the others. The success of the classification results of test problems are superior and also correlates with the results of many papers in the literature. In real-time applications, number of neurons may affect the time complexity of the system. For terrain classification problem, it is proved that inertial measurement units can be used to identify the terrain type of a mobile vehicle. The results of terrain classification problem are reasonable and may help to the planning algorithms of autonomous ground vehicles.
The main contributions of this study can be summarized as:
Training algorithms of RBF networks significantly affect the performance of the classifier.
Complexity of the RBF network is increased with the number of neurons in the hidden layer.
GD and KF offer faster training but tolerable classification performance. GA and ABC show better performance than others.
ABC is the applied for the first time to RBF training for classification problems in this study.
ABC is more robust and requires less control parameters than other training algorithms.
ABC reaches the best score of GD and KF using only two neurons, while GD and KF use eight neurons. Therefore, the complexity of the RBF-ABC scheme is much less than those of others in the real-time usage after training.
Proposed RBF structure includes the training of spread parameters for each hidden neuron and bias parameters for the output layer which is also newly applied for RBF training.
Terrain classification by using an inertial sensor and RBF network is achieved with 80% success rate.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}