
Efficient Convolutional Neural Network-Based Keystroke Dynamics for Boosting User Authentication

 ,
,  , ,
, ,
Abstract
1. Introduction
- Uniqueness: According to [3], keystroke inputs can be accurately measured using software, which makes it extremely difficult to reproduce someone’s typing patterns at the same level of precision without a significant amount of effort.
- Low Cost: Unlike other biometric systems that rely on physical hardware, such as face or fingerprint recognition, keystroke dynamics can be implemented solely through software. This approach reduces installation costs and makes it suitable for remote authentication [4,5]. This has led many service providers to develop their own methods or utilize third-party solutions to validate their users’ credentials [6].
- Enhances Password Longevity and Robustness: Passwords remain the most widely used form of authentication, despite their vulnerability. Keystroke dynamics is being explored as a method to enhance the security of passwords and increase their durability [4].
- Ongoing Verification and Monitoring: Keystroke dynamics offer a way to continually authenticate a person’s legal identity as long as they continue to communicate with the system using input keyboards [7], as it is possible to continuously analyze and reassess keystroke typing behavior.
- Performance: We aim to enhance the recognition accuracy of keystroke dynamics, surpassing that of previous research.
- Robustness: The most crucial factor is to ensure that the suggested method can effectively handle issues such as overfitting, underfitting, noise, and outliers.
- Compared to other biometrics, keystroke dynamics offers certain benefits, but its main drawback is its lower accuracy. This research aims to address this limitation by investigating the performance and limitations of existing systems and proposing a model that can enhance the accuracy and performance of biometric systems.
- A novel data synthesization technique that effectively augments and increases the data using the standard deviation.
- Reduction of anomalies and extreme values in the data through the use of quantile transformation, which converts any distribution into a uniform distribution.
- An efficient, tailored convolutional neural network that is robust to overfitting and underfitting problems.
- Enhanced performance and robustness using a combination of data synthesization and quantile transformation techniques.
2. Related Works
2.1. Machine Learning Techniques
2.2. Deep Learning Techniques
3. Methodology
3.1. Preprocessing
- Data Synthesization (DS) is considered one of the most important phases in our approach. It generates new synthesized data-based statistical techniques. The standard deviation is utilized to generate new data by computing it for each column feature and then adding it to the old values of the column feature. For every user, there are 800 original rows (400 normal and 400 imposters). Data synthesization is used to generate 5 synthesized rows for each original row, resulting in 2000 normal rows and 2000 imposter rows, with a total of 4000 synthesized rows. Figure 2 illustrates the flow of data synthesization.
- Quantile Transformation (QT) is a creative approach that alters the features to achieve a normal distribution. Each feature is individually subjected to this transformation. The native features are converted into novel features that are uniformly distributed using the cumulative distribution function [28]:where a and b are two fixed values such that aThis method is very useful and successful at removing anomalies and extremes, which can have a significant impact on performance.
3.2. CNN Architecture
- Dropout Layer: This is a very important technique used to enhance deep learning layers and prevent overfitting problems. It works by shutting down or freezing some neurons according to the dropout rate while unfreezing other neurons. It sets 0 for certain neurons at a specific rate while other neurons are updated by multiplying their values by 1/(1-rate), which ensures that the total sum of all the inputs remains the same before applying dropout [29]. In our architecture, four dropout layers with a rate of 0.4 are used to mitigate the overfitting problem and enable the model to learn different features from a different perspective.
- Batch Normalization: Deep learning takes a long time in training due to the different distributions of the batches in each layer. Batch normalization normalizes all the batches of the different distributions into a standard distribution, with the mean set to 0 and the variance set to 1. Then, it scales the inputs and shifts them to another space [30]. The following equations show how batch normalization works.The mean and variance of the batch are computed, as shown in Equations (2) and (3). Every sample xi of the batch is normalized into a zero mean and unit variance. In Equation (5), the samples are scaled and shifted with learnable parameters and . In our architecture, we use two batch normalization layers, which enhances our approach and has a significant effect on preventing the overfitting problem.
- ELU Activation Functions: The Exponential Linear Unit (ELU) is a modified and developed version of the RELU function that suffers from the dying problem. The RELU function works by passing the positive values while setting the negative values to zero. The network does not learn anything during the backpropagation due to the zero output for the negative values. This problem is called the dying problem. The ELU function solves this problem using the following equation [31]:
3.3. Learning Algorithms
- -
- LightGBM: Gradient Boosting Decision Tree (GBDT) is time-consuming and has low efficiency, especially in a large and high-dimensional dataset, as it scans all the features to calculate the information gain for each potential split. LightBoost is an extension and improvement of GBDT [32] that has proven to function effectively and extremely fast on big datasets and requires significantly less training time than the other algorithms.
- -
- XGBoost is exclusively designed and optimized for model effectiveness and computational speed. It makes full use of each byte of memory and hardware and offers the advantages of algorithm improvement, model tuning, and deployment in computing settings. XGBoost enhances performance by optimizing the objective function, as shown in the following equation [33]:The objective function consists of two terms (TL and R). TL refers to the training loss that computes the difference between the prediction and actual labels and R refers to the regularization that penalizes the training loss in order to solve the overfitting problem and makes the model generalize efficiently on the unseen data.
- -
- AdaBoost: The AdaBoost model of Freund and Schapire [34] was the first useful boosting model and is now one of the most popular and extensively studied models, with implementations in many different industries. The AdaBoost technique is built on the concept of merging numerous weak rules to obtain a high-accuracy prediction rule. The sign of a weighted aggregation of weak classifiers is computed by the final or combined classifier F [35].where the final classifier is computed as a weighted majority vote of the weak classifiers , where each classifier is given the weight .
- -
- CatBoost is an open source library that utilizes gradient boosting on decision trees. It is a machine learning algorithm that produces high-quality predictions by using categorical features to build an ensemble of decision trees. CatBoost uses a novel technique called “Ordered Boosting”, which helps to reduce overfitting and improve accuracy. The equation for CatBoost is as follows [36]:where is the weight of each tree in the ensemble, is the prediction of the ith tree, and x is the input vector.
4. Experiments and Results
4.1. Dataset
4.2. Evaluation
4.3. Data Exploration
4.4. Quantile Transformation Effect
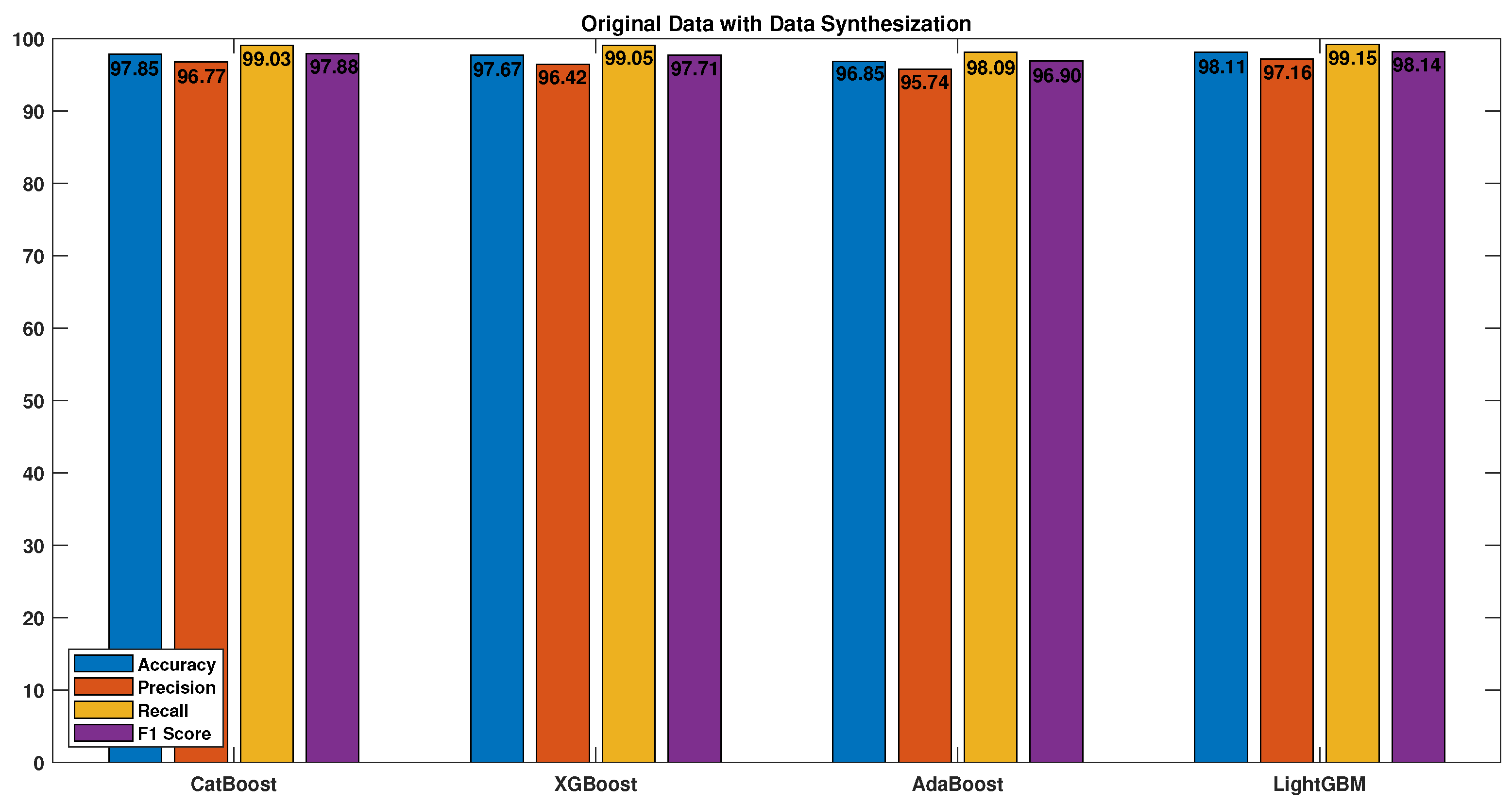
4.5. Results
- Performance:
- Robustness:
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Preventing Crime and Protecting Police. Available online: https://www.interpol.int/en/News-and-Events/News/2020/Preventing-crime-and-protecting-police-INTERPOL-s-COVID-19-global-threat-assessment (accessed on 10 January 2023).
- O’Gorman, L. Comparing passwords, tokens, and biometrics for user authentication. Proc. IEEE 2003, 91, 2021–2040. [Google Scholar] [CrossRef]
- Senk, C.; Dotzler, F. Biometric authentication as a service for enterprise identity management deployment: A data protection perspective. In Proceedings of the Sixth International Conference on Availability, Reliability and Security, Vienna, Austria, 22–26 August 2011; pp. 43–50. [Google Scholar]
- Teh, P.S.; Teoh, A.B.J.; Yue, S. A survey of keystroke dynamics biometrics. Sci. World J. 2013, 2013, 408280. [Google Scholar] [CrossRef] [PubMed]
- Solami, E.A.; Boyd, C.; Clark, A.; Islam, A.K. Continuous biometric authentication: Can it be more practical? In Proceedings of the 12th International Conference on High Performance Computing and Communications (HPCC), Melbourne, VIC, Australia, 1–3 September 2010; pp. 647–652. [Google Scholar]
- Moskovitch, R.; Feher, C.; Messerman, A.; Kirschnick, N.; Mustafic, T.; Camtepe, A.; Lohlein, B.; Heister, U.; Moller, S.; Rokach, L.; et al. Identity theft, computers and behavioral biometrics. In Proceedings of the 2009 IEEE International Conference on Intelligence and Security Informatics, Richardson, TX, USA, 8–11 June 2009; pp. 155–160. [Google Scholar]
- Ru, W.G.D.; Eloff, J.H.P. Enhanced password authentication through fuzzy logic. IEEE Expert 1997, 12, 38–45. [Google Scholar]
- Shafiq, A.; Ayub, M.F.; Mahmood, K.; Sadiq, M.; Kumari, S.; Chen, C. An identity-based anonymous three-party authenticated protocol for iot infrastructure. J. Sens. 2020, 2020, 8829319. [Google Scholar] [CrossRef]
- Ahmed, S.; Kumari, S.; Saleem, M.A.; Agarwal, K.; Mahmood, K.; Yang, M.-H. Anonymous key-agreement protocol for V2G environment within social Internet of Vehicles. IEEE Access 2020, 8, 119829–119839. [Google Scholar] [CrossRef]
- Garg, S.; Kaur, K.; Kaddoum, G.; Choo, K.K. Toward secure and provable au- thentication for Internet of Things: Realizing industry 4.0. IEEE Internet Things J. 2019, 7, 4598–4606. [Google Scholar] [CrossRef]
- Ibrahim, M.; Abdelraouf, H.; Amin, K.M.; El-Moez Semary, N.A. Keystroke dynamics based user authentication using Histogram Gradient Boosting. IJCI Int. J. Comput. Inf. 2023, 10, 36–53. [Google Scholar] [CrossRef]
- Chang, H.; Li, J.; Wu, C.; Stamp, M. Machine Learning and Deep Learning for Fixed-Text Keystroke Dynamics. In Cybersecurity for Artificial Intelligence; Springer: Cham, Switzerland, 2022; pp. 309–329. [Google Scholar]
- Alpar, O. Biometric keystroke barcoding: A next-gen authentication framework. Expert Syst. Appl. 2021, 177, 114980. [Google Scholar] [CrossRef]
- Krishna, G.J.; Ravi, V. Keystroke based user authentication using modified differential evolution. In Proceedings of the TENCON Region 10 Conference (TENCON), Kochi, India, 17–20 October 2019; pp. 739–744. [Google Scholar]
- Hazan, I.; Margalit, O.; Rokach, L. Supporting unknown number of users in keystroke dynamics models. Knowl.-Based Syst. 2021, 221, 106982. [Google Scholar] [CrossRef]
- Ivannikova, E.; David, G.; Hamalainen, T. Anomaly detection approach to keystroke dynamics based user authentication. In Proceedings of the 2017 IEEE Symposium on Computers and Communications (ISCC), Heraklion, Greece, 3–6 July 2017; pp. 885–889. [Google Scholar]
- Sahu, C.; Banavar, M.; Schuckers, S. A novel distance-based algorithm for multiuser classification in keystroke dynamics. In Proceedings of the 2020 54th Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 1–5 November 2020; pp. 63–67. [Google Scholar]
- Bhatia, A.; Hanm, L.M.; Vasikarla, S.; Panigrahi, B.K. Keystroke dynamics based authentication using gfm. In Proceedings of the International Symposium on Technologies for Homeland Security (HST), Woburn, MA, USA, 23–24 October 2018; pp. 1–5. [Google Scholar]
- Ali, M.L.; Thakur, K.; Obaidat, M.A. A Hybrid Method for Keystroke Biometric User Identification. Electronics 2022, 11, 2782. [Google Scholar] [CrossRef]
- Nkenlifack, M.; Azanguezet Quimatio, B.M.; Njike, O.F.Y. User Authenti- cation through Keystroke dynamics based on ensemble learning approach. In Proceedings of the CARI 2022—Colloque Africain sur la Recherche en Informatique et en Mathémathiques Appliquées, Tunis, Tunisia, 7 October 2022. [Google Scholar]
- Thakare, A.; Gondane, S.; Prasad, N.; Chigale, S. A Machine Learning-Based Ap- proach to Password Authentication Using Keystroke Biometrics. In Machine Learning, Deep Learning and Computational Intelligence for Wireless Communication; Springer: Singapore, 2021; pp. 395–406. [Google Scholar]
- Gedikli, A.M.; Efe, M.O.N. A simple authentication method with multilayer feedforward neural network using keystroke dynamics. In Mediterranean Conference on Pattern Recognition and Artificial Intelligence; Springer: Cham, Switzerland, 2019; pp. 9–23. [Google Scholar]
- Tewari, A.; Verma, P. An improved user identification based on keystroke-dynamics and transfer learning. WEB 2022, 19, 5369–5387. [Google Scholar] [CrossRef]
- Patel, Y.; Ouazzane, K.; Vassilev, V.T.; Faruqi, I.; Walker, G.L. Keystroke dynamics using auto encoders. In Proceedings of the International Conference on Cyber Security and Protection of Digital Services (Cyber Security), Oxford, UK, 3–4 June 2019; pp. 1–8. [Google Scholar]
- Muliono, Y.; Ham, H.; Darmawan, D. Keystroke dynamic classification using machine learning for password authorization. Procedia Comput. Sci. 2018, 135, 564–569. [Google Scholar] [CrossRef]
- Maheshwary, S.; Ganguly, S.; Pudi, V. Deep secure: A fast and simple neural network based approach for user authentication and identification via keystroke dynamics. In Proceedings of the IWAISe: First International Workshop on Artificial Intelligence in Security, Melbourne, Australia, 19–25 August 2017; Volume 59. [Google Scholar]
- Andrean, A.; Jayabalan, M.; Thiruchelvam, V. Keystroke dynamics based user authentication using deep multilayer perceptron. Int. J. Mach. Learn. Comput. 2020, 10, 134–139. [Google Scholar] [CrossRef]
- How to Use Quantile Transforms for Machine Learning. 2022. Available online: https://machinelearningmastery.com/quantile-transforms-for-machine-learning/ (accessed on 25 January 2023).
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to pre- vent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normaliza- tion: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; PMLR: London, UK, 2015; pp. 448–456. [Google Scholar]
- Clevert, D.J.; Unterthiner, T.; Hochreiter, S. Fast and accurate deep network learning by exponential linear units (elus). arXiv 2015, arXiv:1511.07289. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural-Infor-Mation Process. Syst. 2017, 30, 3149–3157. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Freund, Y.; Schapire, R.E. A decision- theoretic generalization of on-line learning and an appli- cation to boosting. J. Comput. Syst. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Schapire, R.E. Explaining adaboost. In Empirical Inference: Festschrift in Honor of Vladimir N. Vapnik; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013; pp. 37–52. [Google Scholar]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. Adv. Neural Inf. Process. Syst. 2018, 31, 6639–6649. [Google Scholar]
- Killourhy, K.S.; Maxion, R.A. Comparing anomaly-detection algorithms for keystroke dynamics. In Proceedings of the International Conference on Dependable Systems & Networks, Lisbon, Portugal, 29 June–2 July 2009; pp. 125–134. [Google Scholar]
- Swets, J. Evaluation of Diagnostic Systems; Elsevier: Amsterdam, The Netherlands, 2012. [Google Scholar]
- der Maaten, L.V.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Classifier | Date | Accuracy (%) | EER (%) |
|---|---|---|---|---|
| [11] | Histogram Gradient Boosting | 2023 | 97.96 | 1.4 |
| [12] | XGBoost-augment | 2022 | 96.39 | - |
| [13] | One-class SVM | 2021 | - | 1.83 |
| [14] | MDE | 2019 | - | 3.48 |
| [15] | X-means with QT | 2021 | AUC is 0.942 | 11.2 |
| [16] | Dependence Clustering + KNN | 2017 | - | 7.7 |
| [17] | Kernel PCA with KNN | 2020 | 87.5 | - |
| [18] | GFM | 2018 | - | 7.86 |
| [19] | POHMM/SVM | 2022 | 91.3 | - |
| [20] | Ensemble (KNN, SVM, DT) | 2022 | 95.65 | - |
| [21] | ANN | 2021 | 91.8 | - |
| [22] | FFMNN | 2020 | 94.7 | - |
| [23] | Transfer Learning | 2022 | 98.57 | - |
| [24] | Autoencoder | 2019 | - | 6.51 |
| [25] | Nadam optimizer | 2018 | 92.60 | - |
| [26] | Deep Secure | 2017 | 93.59 | 3 |
| [27] | MLP | 2020 | - | 4.45 |
| Layer Type | Kernel Size | Padding | Activation Function | # of Kernels | Output Shape | Learned Parameters |
|---|---|---|---|---|---|---|
| Conv 1D | 7 × 1 | Same | Elu | 128 | 31 × 128 | 1024 |
| Conv 1D | 7 × 1 | Same | Elu | 128 | 31 × 128 | 114,816 |
| Dropout | - | Rate = 0.4 | - | - | 31 × 128 | 0 |
| BatchNormalization | - | - | - | - | 31 × 128 | 512 |
| Conv 1D | 5 × 1 | Same | Elu | 64 | 31 × 64 | 41,024 |
| Conv 1D | 5 × 1 | Same | Elu | 64 | 31 × 64 | 20,544 |
| Dropout | - | Rate = 0.4 | - | - | 31 × 64 | 0 |
| BatchNormalization | - | - | - | - | 31 × 64 | 256 |
| Flatten | - | - | - | - | 1984 | 0 |
| Dense (120) | - | - | Elu | - | 120 | 238,200 |
| Dropout | - | Rate = 0.4 | - | - | 120 | 0 |
| Dense (60) | - | - | Elu | - | 60 | 7260 |
| Dropout | - | Rate = 0.4 | - | - | 60 | 0 |
| Dense (30) | - | - | Elu | - | 30 | 1830 |
| Method/Metric | Accuracy (%) | Precision (%) | Recall (%) | F1 Score (%) | ERR (%) | |
|---|---|---|---|---|---|---|
| DS + QT (Off) | LightGBM | 90.58 | 91.68 | 89.49 | 90.50 | 8.2 |
| XGBoost | 90.47 | 91.83 | 89.01 | 90.34 | 8.5 | |
| AdaBoost | 88.68 | 89.28 | 88.10 | 88.64 | 11.2 | |
| CatBoost | 90.89 | 92.34 | 89.34 | 90.77 | 7.6 | |
| DS + QT (On) | LightGBM | 99.84 | 99.85 | 99.83 | 99.84 | 0.15 |
| XGBoost | 99.76 | 99.75 | 99.77 | 99.76 | 0.24 | |
| AdaBoost | 99.51 | 99.45 | 99.57 | 99.51 | 0.53 | |
| CatBoost | 99.95 | 99.98 | 99.91 | 99.95 | 0.65 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
AbdelRaouf, H.; Chelloug, S.A.; Muthanna, A.; Semary, N.; Amin, K.; Ibrahim, M. Efficient Convolutional Neural Network-Based Keystroke Dynamics for Boosting User Authentication. Sensors 2023, 23, 4898. https://doi.org/10.3390/s23104898
AbdelRaouf H, Chelloug SA, Muthanna A, Semary N, Amin K, Ibrahim M. Efficient Convolutional Neural Network-Based Keystroke Dynamics for Boosting User Authentication. Sensors. 2023; 23(10):4898. https://doi.org/10.3390/s23104898
Chicago/Turabian StyleAbdelRaouf, Hussien, Samia Allaoua Chelloug, Ammar Muthanna, Noura Semary, Khalid Amin, and Mina Ibrahim. 2023. "Efficient Convolutional Neural Network-Based Keystroke Dynamics for Boosting User Authentication" Sensors 23, no. 10: 4898. https://doi.org/10.3390/s23104898
APA StyleAbdelRaouf, H., Chelloug, S. A., Muthanna, A., Semary, N., Amin, K., & Ibrahim, M. (2023). Efficient Convolutional Neural Network-Based Keystroke Dynamics for Boosting User Authentication. Sensors, 23(10), 4898. https://doi.org/10.3390/s23104898