
Partial Transfer Ensemble Learning Framework: A Method for Intelligent Diagnosis of Rotating Machinery Based on an Incomplete Source Domain





Abstract
:1. Introduction
- (1)
- A partial transfer ensemble learning framework is designed to diagnose the fault with incomplete training datasets under various conditions;
- (2)
- To incorporate the classification ability of multiple classifiers into the PT-ELF model, a particular ensemble strategy is designed to combine a weak global classifier and two partial domain adaptation classifiers;
- (3)
- Two case studies using rotor bearing test bench data and motor bearing data are performed to validate and demonstrate the superiority of the proposed method.
2. Basic Theory
2.1. Convolutional Neural Network
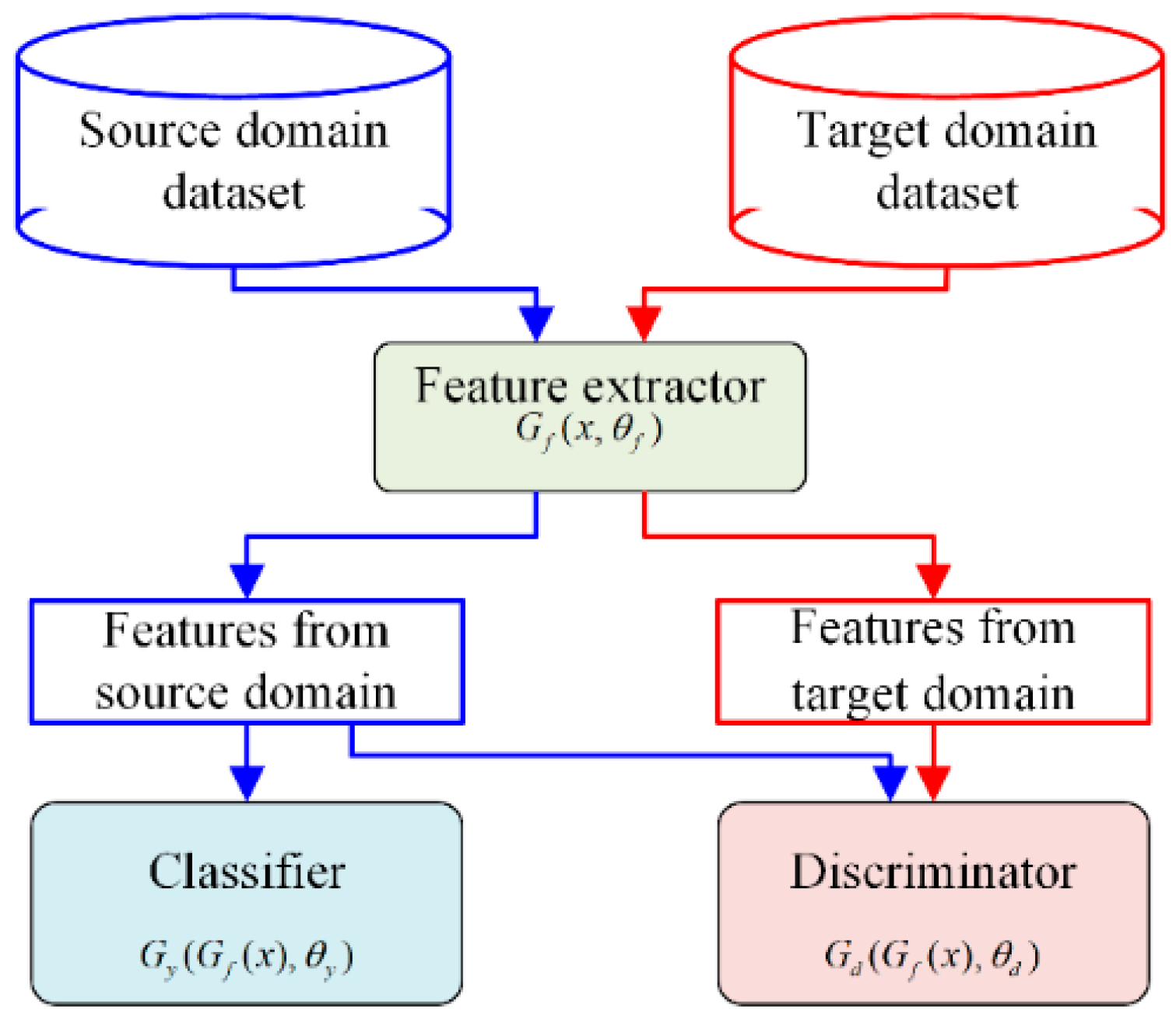
2.2. Deep Adversarial Convolutional Neural Network
3. The Proposed Method
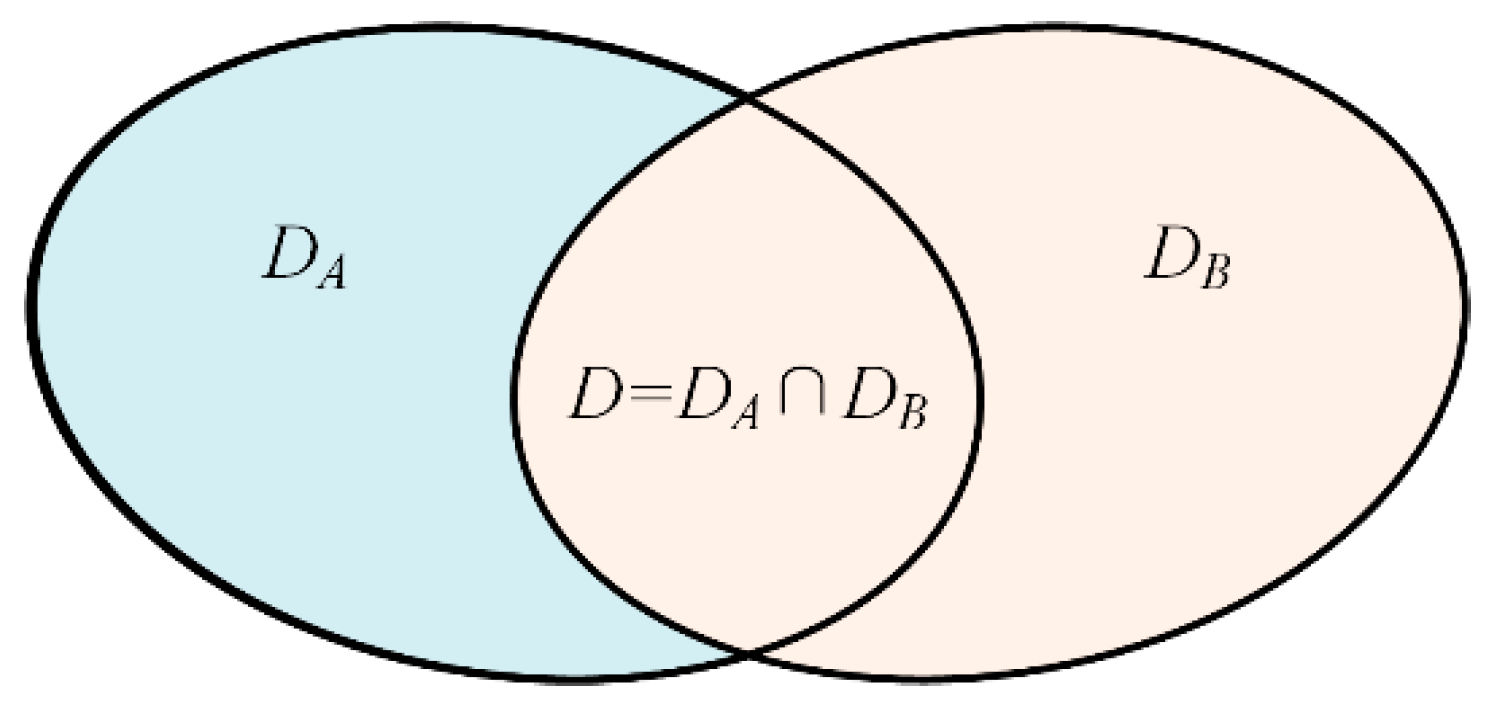
3.1. Problem Formulation
3.2. Classifier Training
3.3. Classifiers’ Ensemble
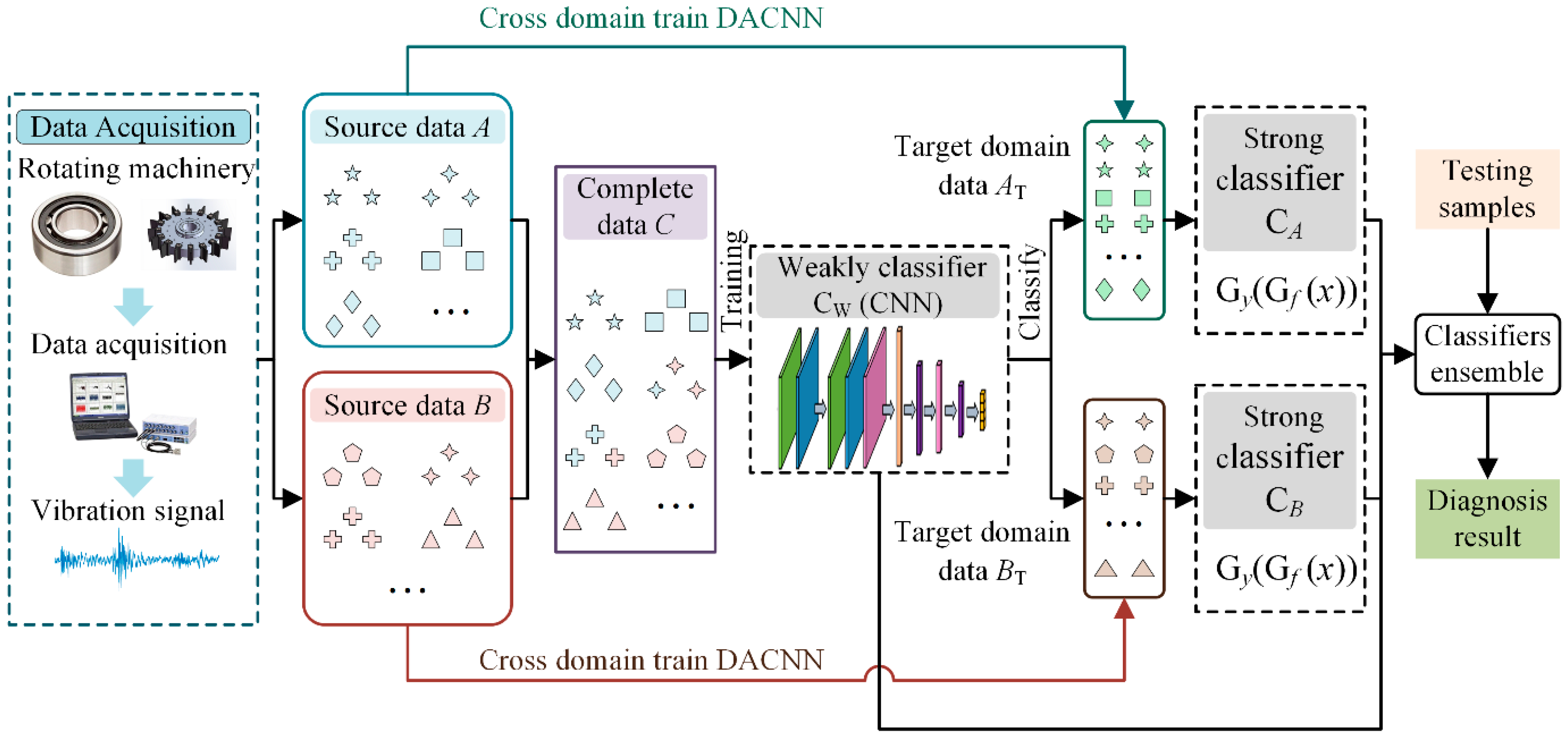
3.4. Architecture of the Proposed Method
- (1)
- Collect original vibration signals from different components or under different working conditions, and convert them into frequency domain signals for subsequent model training;
- (2)
- Construct a complete dataset by combing these incomplete datasets, and train a weak global classifier CNN;
- (3)
- Classify the target domain data using the weak classifier to obtain the two target domain training sets;
- (4)
- Train two DACNN models using two source datasets and target domain training sets to construct two strong partial classifiers;
- (5)
- Design a particular ensemble strategy to combine the three classifiers and obtain the final classification results.
4. Experimental Verification
4.1. Case 1
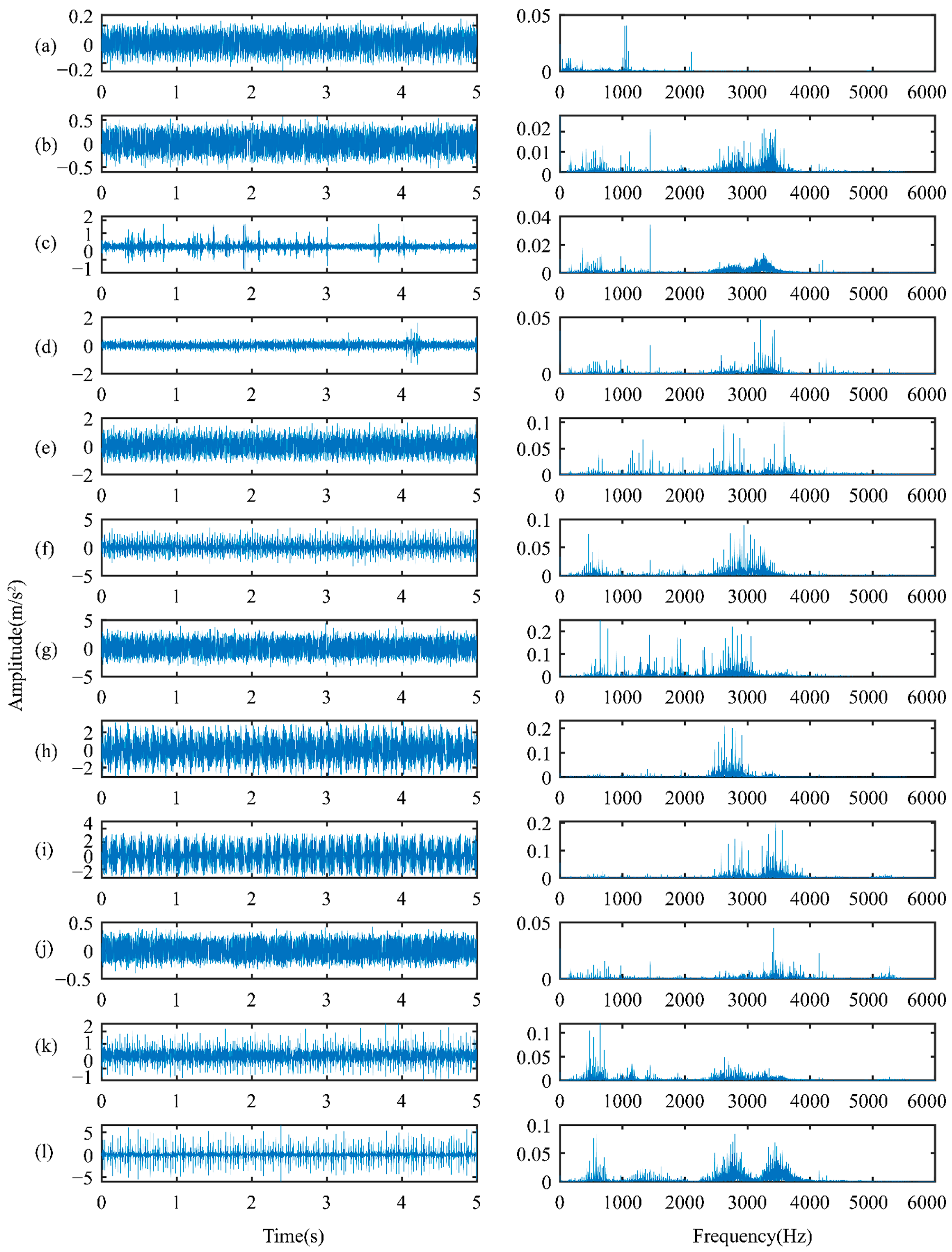
4.1.1. Rotor Experiment
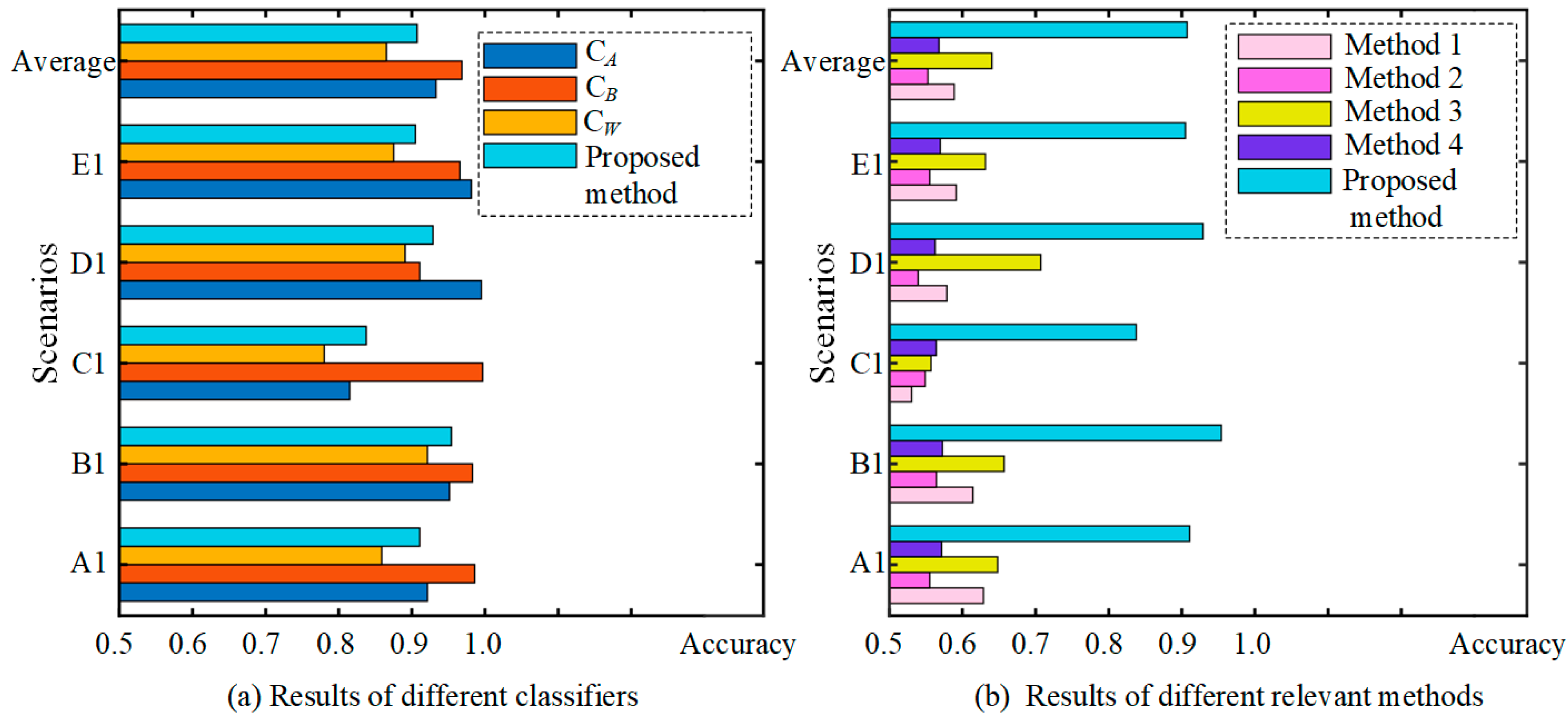
4.1.2. Results and Discussion
4.2. Case 2
4.2.1. Rolling Bearing Experiment
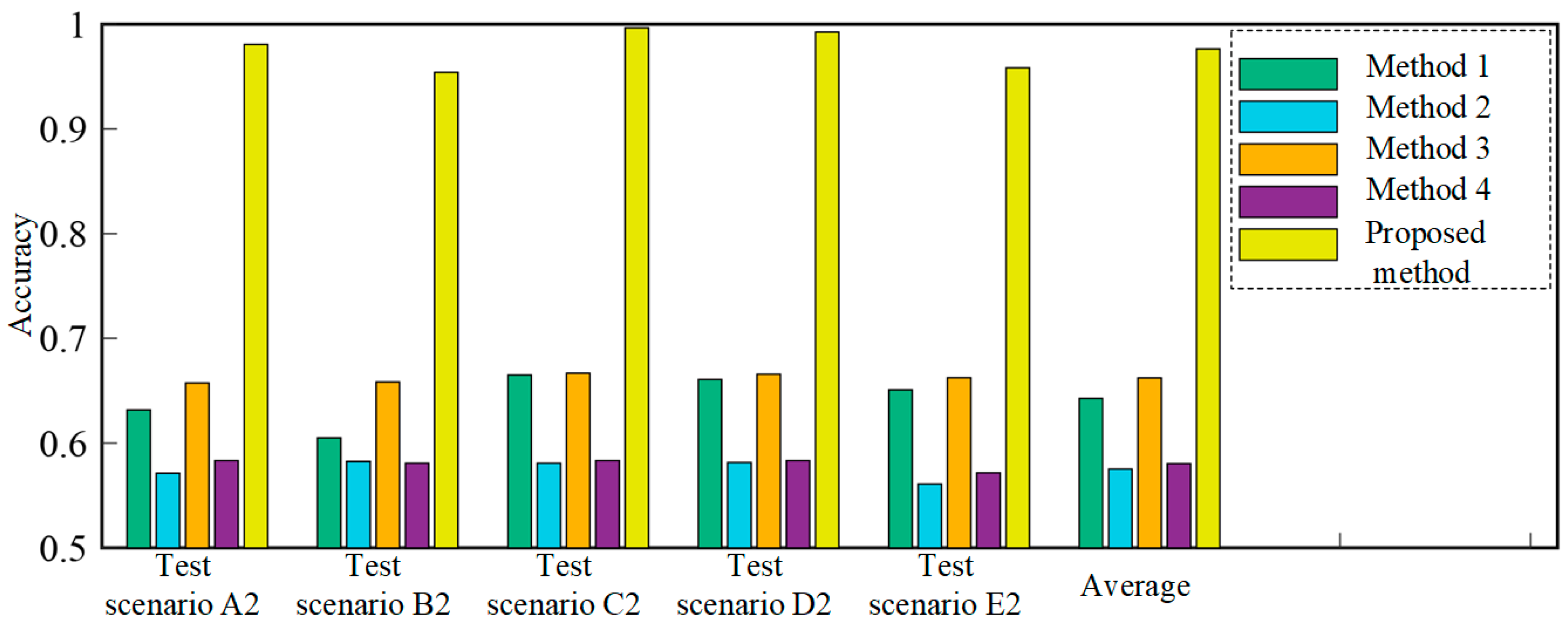
4.2.2. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN | convolutional neural network |
| DACNN | deep adversarial convolutional neural network |
| MMD | maximum mean discrepancy |
| PT-ELF | partial transfer ensemble learning framework |
| RF | random forest |
| RNN | recurrent neural network |
| SAE | stack autoencoder |
| SVM | support vector machine |
References
- Yongbo, L.; Xiaoqiang, D.; Fangyi, W.; Xianzhi, W.; Huangchao, Y.J. Rotating machinery fault diagnosis based on convolutional neural network and infrared thermal imaging. Chin. J. Aeronaut. 2020, 33, 427–438. [Google Scholar]
- Shao, H.; Jiang, H.; Zhang, X.; Niu, M. Rolling bearing fault diagnosis using an optimization deep belief network. Meas. Sci. Technol. 2015, 26, 115002. [Google Scholar] [CrossRef]
- Haidong, S.; Hongkai, J.; Xingqiu, L.; Shuaipeng, W. Intelligent fault diagnosis of rolling bearing using deep wavelet auto-encoder with extreme learning machine. Knowl.-Based Syst. 2018, 140, 1–14. [Google Scholar] [CrossRef]
- Yang, B.; Lei, Y.; Jia, F.; Xing, S. An intelligent fault diagnosis approach based on transfer learning from laboratory bearings to locomotive bearings. Mech. Syst. Signal Process. 2019, 122, 692–706. [Google Scholar] [CrossRef]
- Lei, Y.; Yang, B.; Jiang, X.; Jia, F.; Li, N.; Nandi, A.K. Applications of machine learning to machine fault diagnosis: A review and roadmap. Mech. Syst. Signal Process. 2020, 138, 106587. [Google Scholar] [CrossRef]
- Zhang, X.; Chen, W.; Wang, B.; Chen, X.J. Intelligent fault diagnosis of rotating machinery using support vector machine with ant colony algorithm for synchronous feature selection and parameter optimization. Neurocomputing 2015, 167, 260–279. [Google Scholar] [CrossRef]
- Ma, K.; Ben-Arie, J. Compound exemplar based object detection by incremental random forest. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 2407–2412. [Google Scholar]
- Liu, H.; Zhou, J.; Zheng, Y.; Jiang, W.; Zhang, Y.J. Fault diagnosis of rolling bearings with recurrent neural network-based autoencoders. ISA Trans. 2018, 77, 167–178. [Google Scholar] [CrossRef]
- Zhang, W.; Li, C.; Peng, G.; Chen, Y.; Zhang, Z. A deep convolutional neural network with new training methods for bearing fault diagnosis under noisy environment and different working load. Mech. Syst. Signal Process. 2018, 100, 439–453. [Google Scholar] [CrossRef]
- Sun, W.; Shao, S.; Zhao, R.; Yan, R.; Zhang, X.; Chen, X.J. A sparse auto-encoder-based deep neural network approach for induction motor faults classification. Measurement 2016, 89, 171–178. [Google Scholar] [CrossRef]
- Khan, M.A.; Kim, Y.-H.; Choo, J. Intelligent fault detection via dilated convolutional neural networks. In Proceedings of the 2018 IEEE International Conference on Big Data and Smart Computing, Shanghai, China, 15–17 January 2018; pp. 729–731. [Google Scholar]
- Zhu, Z.; Peng, G.; Chen, Y.; Gao, H. A convolutional neural network based on a capsule network with strong generalization for bearing fault diagnosis. Neurocomputing 2019, 323, 62–75. [Google Scholar] [CrossRef]
- Zhu, J.; Chen, N.; Peng, W. Estimation of bearing remaining useful life based on multiscale convolutional neural network. IEEE Trans. Ind. Electron. 2019, 66, 3208–3216. [Google Scholar] [CrossRef]
- Guo, L.; Lei, Y.; Xing, S.; Yan, T.; Li, N. Deep Convolutional Transfer Learning Network: A New Method for Intelligent Fault Diagnosis of Machines With Unlabeled Data. IEEE Trans. Ind. Electron. 2019, 66, 7316–7325. [Google Scholar] [CrossRef]
- Han, T.; Liu, C.; Yang, W.; Jiang, D. A novel adversarial learning framework in deep convolutional neural network for intelligent diagnosis of mechanical faults. Knowl.-Based Syst. 2019, 165, 474–487. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q.J. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Qian, W.; Li, S.; Wang, J.; Xin, Y.; Ma, H. A New Deep Transfer Learning Network for Fault Diagnosis of Rotating Machine Under Variable Working Conditions. In Proceedings of the 2018 Prognostics and System Health Management Conference (PHM-Chongqing), Chongqing, China, 26–28 October 2018; pp. 1010–1016. [Google Scholar]
- Chen, Z.; Gryllias, K.; Li, W. Intelligent Fault Diagnosis for Rotary Machinery Using Transferable Convolutional Neural Network. IEEE Trans. Ind. Inform. 2019, 16, 339–349. [Google Scholar] [CrossRef]
- Wen, L.; Gao, L.; Li, X. A new deep transfer learning based on sparse auto-encoder for fault diagnosis. IEEE Trans. Syst. Man Cybern. -Syst. 2017, 49, 136–144. [Google Scholar] [CrossRef]
- Xu, K.; Li, S.; Wang, J.; An, Z.; Qian, W.; Ma, H.J. A novel convolutional transfer feature discrimination network for imbalanced fault diagnosis under variable rotational speed. Meas. Sci. Technol. 2019, 30, 105107. [Google Scholar] [CrossRef]
- Zhang, M.; Wang, D.; Lu, W.; Yang, J.; Li, Z.; Liang, B. A Deep Transfer Model With Wasserstein Distance Guided Multi-Adversarial Networks for Bearing Fault Diagnosis Under Different Working Conditions. IEEE Access 2019, 7, 65303–65318. [Google Scholar] [CrossRef]
- Zhang, Z.; Li, X.; Wen, L.; Gao, L.; Gao, Y. Fault Diagnosis Using Unsupervised Transfer Learning Based on Adversarial Network. In Proceedings of the 2019 IEEE 15th International Conference on Automation Science and Engineering (CASE), Vancouver, BC, Canada, 22–26 August 2019; pp. 305–310. [Google Scholar]
- Zhang, B.; Li, W.; Hao, J.; Li, X.-L.; Zhang, M.J. Adversarial adaptive 1-D convolutional neural networks for bearing fault diagnosis under varying working condition. arXiv 2018, arXiv:1805.00778. [Google Scholar]
- Wang, B.; Shen, C.; Yu, C.; Yang, Y. Data Fused Motor Fault Identification Based on Adversarial Auto-Encoder. In Proceedings of the 2019 IEEE 10th International Symposium on Power Electronics for Distributed Generation Systems (PEDG), Xi’an, China, 3–6 June 2019; pp. 299–305. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015. [Google Scholar]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.J. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef] [Green Version]
- Shao, S.; McAleer, S.; Yan, R.; Baldi, P.J. Highly accurate machine fault diagnosis using deep transfer learning. IEEE Trans. Ind. Inform. 2018, 15, 2446–2455. [Google Scholar] [CrossRef]
- Jiao, J.; Zhao, M.; Lin, J.; Zhao, J.J. A multivariate encoder information based convolutional neural network for intelligent fault diagnosis of planetary gearboxes. Knowl. Based Syst. 2018, 160, 237–250. [Google Scholar] [CrossRef]
- Wang, J.; Li, S.; Han, B.; An, Z.; Bao, H.; Ji, S. Generalization of Deep Neural Networks for Imbalanced Fault Classification of Machinery Using Generative Adversarial Networks. IEEE Access 2019, 7, 111168–111180. [Google Scholar] [CrossRef]
- Jia, F.; Lei, Y.; Lu, N.; Xing, S.J. Deep normalized convolutional neural network for imbalanced fault classification of machinery and its understanding via visualization. Mech. Syst. Signal Process. 2018, 110, 349–367. [Google Scholar] [CrossRef]
- Arjovsky, M.; Bottou, L.J. Towards principled methods for training generative adversarial networks. arXiv 2017, arXiv:1701.04862. [Google Scholar]
- Available online: https://csegroups.case.edu/bearingdatacenter/home (accessed on 7 March 2022).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifiers | Range of Classification | Ability of Classification |
|---|---|---|
| CA | DA | Strong |
| CB | DB | Strong |
| CW | DA ∪ DB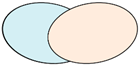 | Weak |
| No | Component |
|---|---|
| 1 | Support bearing pedestal |
| 2 | Displacement sensor bracket |
| 3 | Friction assembly and bracket |
| 4 | Shaft |
| 5 | Casing friction support and blade disc |
| 6 | Test bearing pedestal |
| 7 | Worm gear and worm |
| Label | Health States | The Number of Training/Testing Samples |
|---|---|---|
| 0 | Health | 220/80 |
| 1 | Full annular rub | 220/80 |
| 2 | Blade crack and bearing fault | 220/80 |
| 3 | Blade crack | 220/80 |
| 4 | Blisk crack | 220/80 |
| 5 | Shaft coupling fault | 220/80 |
| 6 | Shaft crack | 220/80 |
| States | Source Domain Dataset A | Source Domain Dataset B | Target Domain Data | |||
|---|---|---|---|---|---|---|
| Data | Labels | Data | Labels | Data | Labels | |
| 1 | √ | √ | √ | |||
| 2 | √ | √ | √ | |||
| 3 | √ | √ | √ | |||
| 4 | √ | √ | √ | √ | √ | |
| 5 | √ | √ | √ | √ | √ | |
| 6 | √ | √ | √ | |||
| 7 | √ | √ | √ | |||
| Test Scenarios | Source Dataset A | Source Dataset B | Target Data |
|---|---|---|---|
| A1 | Load 0% (states 1–5) | Load 20% (states 4–7) | Load 40% (states 1–7) |
| B1 | Load 0% (states 1–5) | Load 40% (states 4–7) | Load 20% (states 1–7) |
| C1 | Load 40% (states 1–5) | Load 20% (states 4–7) | Load 0% (states 1–7) |
| D1 | Load 20% (states 1–5) | Load 0% (states 4–7) | Load 40% (states 1–7) |
| E1 | Load 40% (states 1–5) | Load 0% (states 4–7) | Load 20% (states 1–7) |
| Test Scenarios | Strong Classifier CA | Strong Classifier CB | Weak Classifier CW | Proposed Method |
|---|---|---|---|---|
| A1 | 92.14% | 98.58% | 85.89% | 91.08% |
| B1 | 95.15% | 98.28% | 92.14% | 95.41% |
| C1 | 81.50% | 99.68% | 78.03% | 83.75% |
| D1 | 99.50% | 91.07% | 89.07% | 92.89% |
| E1 | 98.14% | 96.56% | 87.50% | 90.48% |
| Average | 93.29% | 96.83% | 86.52% | 90.73% |
| Test Scenarios | Method 1 (CNN Trained by Source A) | Method 2 (CNN Trained by Source B) | Method 3 (DACNN Trained by Source A) | Method 4 (DACNN Trained by Source B) | The Proposed Method |
|---|---|---|---|---|---|
| A1 | 62.86% | 55.54% | 64.82% | 57.14% | 91.08% |
| B1 | 61.43% | 56.43% | 65.71% | 57.28% | 95.41% |
| C1 | 53.04% | 54.89% | 55.71% | 56.42% | 83.75% |
| D1 | 57.86% | 53.93% | 70.71% | 56.25% | 92.89% |
| E1 | 59.14% | 55.54% | 63.14% | 56.96% | 90.48% |
| Average | 58.87% | 55.27% | 64.02% | 56.79% | 90.73% |
| Loads | Values |
|---|---|
| Load 1 | 1797 rpm, 0 hp |
| Load 2 | 1772 rpm, 1 hp |
| Load 3 | 1750 rpm, 2 hp |
| Load 4 | 1750 rpm, 3 hp |
| Parameters | Values |
|---|---|
| Type | 6205-2RS JEM SKF |
| The number of balls | 9 |
| Pitch diameter | 1.537 inches |
| Ball diameter | 0.3126 inches |
| Sampling frequency | 12 (kHz) |
| Motor speed | 1797/1772/1750/1730 rpm |
| Labels | Failure Location | Failure Orientation | Failure Severities (Inches) | The Number of Testing/Training Samples |
|---|---|---|---|---|
| 0 | Health | - | 0 | 100/200 |
| 1 | Rolling element | - | 0.007 | 100/200 |
| 2 | Rolling element | - | 0.014 | 100/200 |
| 3 | Rolling element | - | 0.021 | 100/200 |
| 4 | Inner race | - | 0.007 | 100/200 |
| 5 | Inner race | - | 0.021 | 100/200 |
| 6 | Inner race | - | 0.028 | 100/200 |
| 7 | Outer race | Center | 0.007 | 100/200 |
| 8 | Outer race | Vertical | 0.007 | 100/200 |
| 9 | Outer race | Center | 0.014 | 100/200 |
| 10 | Outer race | Center | 0.021 | 100/200 |
| 11 | Outer race | Vertical | 0.021 | 100/200 |
| States | Source Domain Dataset A | Source Domain Dataset B | Target Domain Data | |||
|---|---|---|---|---|---|---|
| Data | Labels | Data | Labels | Data | Labels | |
| 1 | √ | √ | √ | |||
| 2 | √ | √ | √ | |||
| 3 | √ | √ | √ | |||
| 4 | √ | √ | √ | |||
| 5 | √ | √ | √ | |||
| 6 | √ | √ | √ | √ | √ | |
| 7 | √ | √ | √ | √ | √ | |
| 8 | √ | √ | √ | √ | √ | |
| 9 | √ | √ | √ | |||
| 10 | √ | √ | √ | |||
| 11 | √ | √ | √ | |||
| 12 | √ | √ | √ | |||
| Test Scenarios | Source Dataset A | Source Dataset B | Target Data |
|---|---|---|---|
| A2 | Load 1 (states 1–8) | Load 2 (states 6–12) | Load 3 (states 1–12) |
| B2 | Load 3 (states 1–8) | Load 4 (states 6–12) | Load 1 (states 1–12) |
| C2 | Load 2 (states 1–8) | Load 3 (states 6–12) | Load 4 (states 1–12) |
| D2 | Load 1 (states 1–8) | Load 2 (states 6–12) | Load 4 (states 1–12) |
| E2 | Load 2 (states 1–8) | Load 3 (states 6–12) | Load 1 (states 1–12) |
| Test Scenarios | Method 1 (CNN Trained Using Source Dataset A) | Method 2 (CNN Trained Using Source Dataset B) | Method 3 (DACNN Trained Using Source Dataset A) | Method 4 (DACNN Trained Using Source Dataset B) | The Proposed Method |
|---|---|---|---|---|---|
| A2 | 63.17% | 57.13% | 65.75% | 58.33% | 98.08% |
| B2 | 60.50% | 58.25% | 65.83% | 58.08% | 95.41% |
| C2 | 66.50% | 58.08% | 66.67% | 58.33% | 99.66% |
| D2 | 66.08% | 58.14% | 66.58% | 58.33% | 99.25% |
| E2 | 65.08% | 56.08% | 66.25% | 57.17% | 95.83% |
| Average | 64.27% | 57.53% | 66.22% | 58.05% | 97.65% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mao, G.; Zhang, Z.; Jia, S.; Noman, K.; Li, Y. Partial Transfer Ensemble Learning Framework: A Method for Intelligent Diagnosis of Rotating Machinery Based on an Incomplete Source Domain. Sensors 2022, 22, 2579. https://doi.org/10.3390/s22072579
Mao G, Zhang Z, Jia S, Noman K, Li Y. Partial Transfer Ensemble Learning Framework: A Method for Intelligent Diagnosis of Rotating Machinery Based on an Incomplete Source Domain. Sensors. 2022; 22(7):2579. https://doi.org/10.3390/s22072579
Chicago/Turabian StyleMao, Gang, Zhongzheng Zhang, Sixiang Jia, Khandaker Noman, and Yongbo Li. 2022. "Partial Transfer Ensemble Learning Framework: A Method for Intelligent Diagnosis of Rotating Machinery Based on an Incomplete Source Domain" Sensors 22, no. 7: 2579. https://doi.org/10.3390/s22072579
APA StyleMao, G., Zhang, Z., Jia, S., Noman, K., & Li, Y. (2022). Partial Transfer Ensemble Learning Framework: A Method for Intelligent Diagnosis of Rotating Machinery Based on an Incomplete Source Domain. Sensors, 22(7), 2579. https://doi.org/10.3390/s22072579