
Emotion Recognition for Partial Faces Using a Feature Vector Technique


Abstract
:1. Introduction
2. Materials and Methods
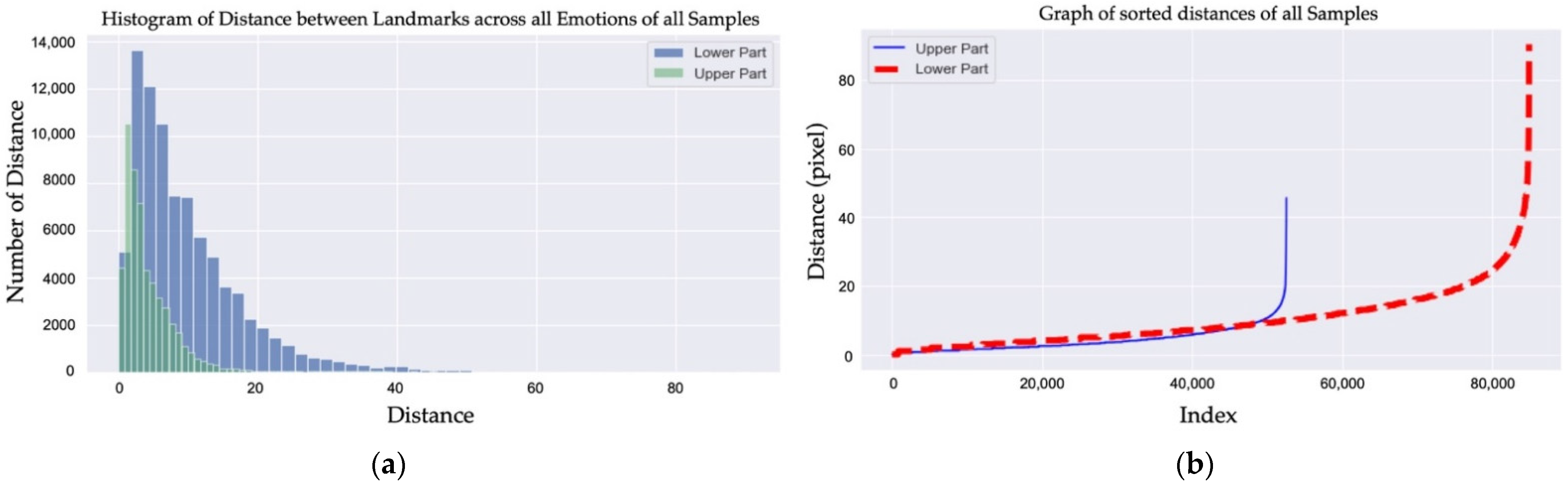
2.1. Analysis of Emotions in Facial Images
2.2. Proposed Method
| Algorithm 1: Landmark Detection and Feature Extraction |
| Input: Upper facial image Output: Landmark coordinate and HOG feature landmarks t x y points (x, y) for i=0 to (length of t) − 3 do startPoint points[i] midPoint points[i+1] endPoint points[i+2] connectedLineIntensity[i] connect(startPoint, midPoint, endPoint) end for height height of peak fwhm full width of half maximum for each lineIntensity in connectedLineIntensity do (indices, properties) findPeaks(lineIntensity) end for for i=0 to length of properties do if prominence of properties[i] >= height and width of properties[i]>=fwhm then property properties[i] landmarks[i] property[leftBase] end end for for i=0 to length of landmarks do landmarkHOG[i] histogramofOrientedGradient(landmarks[i]) features[i] (landmark[i], landmarkHOG[i]) end for |
2.2.1. Synthetic Masked Face and Upper Face Detection
2.2.2. Generated Points Creating Infinity Shape
2.2.3. Infinity Shape Normalization
2.2.4. Initial Seed Point of Upper Face
2.2.5. Landmark Detection (Eye and Eyebrow Boundary Detection)
2.2.6. Feature Extraction (Histograms of the Oriented Gradients)
| Algorithm 2: Histogram of Oriented Gradient (HOG) |
| Input: Upper face image, boundary coordinate, size of blob Output: HOG feature of each boundary coordinate image Upper face image x_landmark x coordinate of boundary y_landmark y coordinate of boundary distance size_of_blob/2 for i=0 to length of boundary coordinate do if x_landmark[i] > distance then x_start_blob x_landmark[i] − distance else x_start_blob 0 end if y_landmark[i] > distance then y_start_blob y_landmark[i] − distance else y_start_blob 0 end x_end_blob x_start_blob + size_of_blob y_end_blob y_start_blob + size_of_blob blob image[x_start_blob, x_end_blob][y_start, y_end_blob] hog_feature[i] HOG(blob) end for |
2.2.7. Classification
3. Results and Discussions
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Molnar-Szakacs, I.; Uddin, L.Q.; Heffernan, M.B. The face behind the mask: The future of interpersonal interaction. Neuron 2021, 109, 1918–1920. [Google Scholar] [CrossRef] [PubMed]
- Topic, A.; Russo, M.; Stella, M.; Saric, M. Emotion Recognition Using a Reduced Set of EEG Channels Based on Holographic Feature Maps. Sensors 2022, 22, 3248. [Google Scholar] [CrossRef] [PubMed]
- Devaram, R.R.; Beraldo, G.; De Benedictis, R.; Mongiovì, M.; Cesta, A. LEMON: A Lightweight Facial Emotion Recognition System for Assistive Robotics Based on Dilated Residual Convolutional Neural Networks. Sensors 2022, 22, 3366. [Google Scholar] [CrossRef] [PubMed]
- D’Onofrio, G.; Fiorini, L.; Sorrentino, A.; Russo, S.; Ciccone, F.; Giuliani, F.; Sancarlo, D.; Cavallo, F. Emotion Recognizing by a Robotic Solution Initiative (EMOTIVE Project). Sensors 2022, 22, 2861. [Google Scholar] [CrossRef]
- Wierciński, T.; Rock, M.; Zwierzycki, R.; Zawadzka, T.; Zawadzki, M. Emotion Recognition from Physiological Channels Using Graph Neural Network. Sensors 2022, 22, 2980. [Google Scholar] [CrossRef]
- Algarni, M.; Saeed, F.; Al-Hadhrami, T.; Ghabban, F.; Al-Sarem, M. Deep Learning-Based Approach for Emotion Recognition Using Electroencephalography (EEG) Signals Using Bi-Directional Long Short-Term Memory (Bi-LSTM). Sensors 2022, 22, 2976. [Google Scholar] [CrossRef]
- Penčić, M.; Čavić, M.; Oros, D.; Vrgović, P.; Babković, K.; Orošnjak, M.; Čavić, D. Anthropomorphic Robotic Eyes: Structural Design and Non-Verbal Communication Effectiveness. Sensors 2022, 22, 3060. [Google Scholar] [CrossRef]
- Cornejo, J.Y.R.; Pedrini, H. Emotion recognition from occluded facial expressions using weber local descriptor. In Proceedings of the 2018 25th International Conference on Systems, Signals and Image Processing (IWSSIP), Maribor, Slovenia, 20–22 June 2018; pp. 1–5. [Google Scholar]
- Yang, J.; Qian, T.; Zhang, F.; Khan, S.U. Real-Time Facial Expression Recognition Based on Edge Computing. IEEE Access 2021, 9, 76178–76190. [Google Scholar] [CrossRef]
- Maghari, A.Y.A. Recognition of partially occluded faces using regularized ICA. Inverse Probl. Sci. Eng. 2021, 29, 1158–1177. [Google Scholar] [CrossRef]
- Gan, Y.; Chen, J.; Yang, Z.; Xu, L. Multiple Attention Network for Facial Expression Recognition. IEEE Access 2020, 8, 7383–7393. [Google Scholar] [CrossRef]
- Li, S.; Deng, W. Reliable crowdsourcing and deep locality-preserving learning for unconstrained facial expression recognition. IEEE Trans. Image Process. 2018, 28, 356–370. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Zeng, J.; Shan, S.; Chen, X. Occlusion Aware Facial Expression Recognition Using CNN With Attention Mechanism. IEEE Trans. Image Process. 2018, 28, 2439–2450. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Zeng, J.; Shan, S.; Chen, X. Patch-gated CNN for occlusion-aware facial expression recognition. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2209–2214. [Google Scholar]
- Riaz, M.N.; Shen, Y.; Sohail, M.; Guo, M. EXnet: An Efficient Approach for Emotion Recognition in the Wild. Sensors 2020, 20, 1087. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, H.; Ciftci, U.; Yin, L. Facial expression recognition by de-expression residue learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2019; pp. 2168–2177. [Google Scholar]
- Krishnaveni, K.; Priyadharsini, G.R. Facial Expression Recognition using Low Level Histogram Features. In Proceedings of the 2020 Fourth International Conference on Inventive Systems and Control (ICISC), Coimbatore, India, 8–10 January 2020; pp. 1–7. [Google Scholar]
- Allaert, B.; Ward, I.R.; Bilasco, I.M.; Djeraba, C.; Bennamoun, M. Optical Flow Techniques for Facial Expression Analysis: Performance Evaluation and Improvements. arXiv 2019, arXiv:1904.11592. [Google Scholar]
- Shao, J.; Qian, Y. Three convolutional neural network models for facial expression recognition in the wild. Neurocomputing 2019, 355, 82–92. [Google Scholar] [CrossRef]
- Jyoti, S.; Sharma, G.; Dhall, A. Expression empowered ResiDen network for facial action unit detection. In Proceedings of the 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), Lille, France, 14–19 May 2019; pp. 1–8. [Google Scholar]
- Miao, S.; Xu, H.; Han, Z.; Zhu, Y. Recognizing Facial Expressions Using a Shallow Convolutional Neural Network. IEEE Access 2019, 7, 78000–78011. [Google Scholar] [CrossRef]
- Pan, B.; Wang, S.; Xia, B. Occluded facial expression recognition enhanced through privileged information. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 566–573. [Google Scholar]
- Wang, K.; Peng, X.; Yang, J.; Meng, D.; Qiao, Y. Region attention networks for pose and occlusion robust facial expression recognition. IEEE Trans. Image Process. 2020, 29, 4057–4069. [Google Scholar] [CrossRef] [Green Version]
- Wang, K.; Peng, X.; Yang, J.; Lu, S.; Qiao, Y. Suppressing uncertainties for large-scale facial expression recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6897–6906. [Google Scholar]
- Farzaneh, A.H.; Qi, X. Facial expression recognition in the wild via deep attentive center loss. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 2402–2411. [Google Scholar]
- Shi, J.; Zhu, S.; Liang, Z. Learning to amend facial expression representation via de-albino and affinity. arXiv 2021, arXiv:2103.10189. [Google Scholar]
- Zhao, G.; Yang, H.; Yu, M. Expression recognition method based on a lightweight convolutional neural network. IEEE Access. 2020, 8, 38528–38537. [Google Scholar] [CrossRef]
- Ding, H.; Zhou, P.; Chellappa, R. Occlusion-adaptive deep network for robust facial expression recognition. In Proceedings of the 2020 IEEE International Joint Conference on Biometrics (IJCB), Houston, TX, USA, 28 September–1 October 2020; pp. 1–9. [Google Scholar]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The extended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 94–101. [Google Scholar]
- Li, S.; Deng, W.; Du, J. Reliable crowdsourcing and deep locality-preserving learning for expression recognition in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2852–2861. [Google Scholar]
- King, D.E. Dlib-ml: A machine learning toolkit. J. Mach. Learn. Res. 2009, 10, 1755–1758. [Google Scholar]
- Savitzky, A.; Golay, M.J.E. Smoothing and Differentiation of Data by Simplified Least Squares Procedures. Anal. Chem. 1964, 36, 1627–1639. [Google Scholar] [CrossRef]
- Zhong, Y.; Sun, L.; Ge, C.; Fan, H. HOG-ESRs Face Emotion Recognition Algorithm Based on HOG Feature and ESRs Method. Symmetry 2021, 13, 228. [Google Scholar] [CrossRef]
- Kim, J.-C.; Kim, M.-H.; Suh, H.-E.; Naseem, M.T.; Lee, C.-S. Hybrid Approach for Facial Expression Recognition Using Convolutional Neural Networks and SVM. Appl. Sci. 2022, 12, 5493. [Google Scholar] [CrossRef]
- Lakshmi, D.; Ponnusamy, R. Facial emotion recognition using modified HOG and LBP features with deep stacked autoencoders. Microprocess. Microsyst. 2021, 82, 103834. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Input Features | Type | Limitation |
|---|---|---|---|
| Light-CNN [19] | Lower + Upper | Face-based | Mainly rely on Lower |
| eXnet [15] | Lower + Upper | Face-based | Mainly rely on Lower |
| Pre-trained CNN [19] | Lower + Upper | Face-based | Mainly rely on Lower |
| PG-CNN [14] | Lower + Upper | Face-based | Mainly rely on Lower |
| DLP-CNN [12] | Lower + Upper | Face-based | Mainly rely on Lower |
| gACNN [13] | Lower + Upper | Face-based | Mainly rely on Lower |
| RASnet [11] | Lower + Upper | Face-based | Mainly rely on Lower |
| DeRL [16] | Lower + Upper | Face-based | Mainly rely on Lower |
| ResiDen [20] | Lower + Upper | Face-based | Mainly rely on Lower |
| SHCNN [21] | Lower + Upper | Face-based | Mainly rely on Lower |
| ResNet-PL [22] | Lower + Upper | Face-based | Mainly rely on Lower |
| RAN [23] | Lower + Upper | Face-based | Mainly rely on Lower |
| SCN [24] | Lower + Upper | Face-based | Mainly rely on Lower |
| DACL [25] | Lower + Upper | Face-based | Mainly rely on Lower |
| ARM [26] | Lower + Upper | Face-based | Mainly rely on Lower |
| RTFER [11] | Lower + Upper | Constituent-based | Mainly rely on Lower |
| DenseNet [27] | Lower + Upper | Constituent-based | Mainly rely on Lower |
| OADN [28] | Lower + Upper | Constituent-based | Mainly rely on Lower |
| Proposed Method | Upper | Constituent-based | Rely only on Upper |
| CK+ | RAF-DB | ||||
|---|---|---|---|---|---|
| Methods | Accuracy (%) | Parameters (M) | Methods | Accuracy (%) | Parameters (M) |
| Light-CNN [19] | 92.86 | 1.1 | ResiDen [20] | 76.54 | 12.1 |
| eXnet [15] | 95.81 | 4.6 | Light-CNN [19] | 77.23 | 1.1 |
| Pre-trained CNN [19] | 95.29 | 7.1 | SHCNN [21] | 81.17 | 8.7 |
| PG-CNN [14] | 97.03 | 20.5 | DenseNet [27] | 81.93 | 7 |
| DLP-CNN [12] | 95.73 | 17.5 | gACNN [13] | 85.07 | 21.4 |
| gACNN [13] | 96.40 | 21.4 | eXnet [15] | 85.59 | 4.6 |
| RASnet [11] | 96.28 | 10.4 | ResNet-PL [22] | 86.97 | 13.2 |
| DeRL [16] | 97.30 | 21.1 | RAN [23] | 86.99 | 15.6 |
| RTFER [11] | 93.85 | 0.5 | SCN [24] | 87.03 | 16.7 |
| Proposed Method | 99.30 | 1.3 | OADN [28] | 87.16 | 17.8 |
| DACL [25] | 87.78 | 16.6 | |||
| ARM [26] | 88.23 | 16.3 | |||
| Proposed Method | 95.58 | 1.3 | |||
| CK+ | RAF-DB | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Emotions | Precision | Recall | F1-Score | Accuracy | Emotions | Precision | Recall | F1-Score | Accuracy |
| Neutral | 0.996 | 0.997 | 0.997 | 0.997 | Neutral | 0.968 | 0.967 | 0.968 | 0.967 |
| Anger | 1.00 | 0.996 | 0.998 | 0.996 | Anger | 0.932 | 0.941 | 0.937 | 0.941 |
| Contempt | 0.958 | 0.958 | 0.958 | 0.958 | Disgust | 0.890 | 0.952 | 0.920 | 0.952 |
| Disgust | 0.969 | 0.998 | 0.983 | 0.998 | Fear | 0.972 | 0.911 | 0.941 | 0.911 |
| Fear | 0.955 | 0.984 | 0.969 | 0.984 | Happiness | 0.968 | 0.967 | 0.968 | 0.967 |
| Happiness | 0.993 | 0.976 | 0.984 | 0.976 | Sadness | 0.955 | 0.951 | 0.953 | 0.951 |
| Sadness | 0.972 | 0.994 | 0.983 | 0.994 | Surprise | 0.947 | 0.933 | 0.940 | 0.933 |
| Surprise | 0.997 | 0.981 | 0.989 | 0.981 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khoeun, R.; Chophuk, P.; Chinnasarn, K. Emotion Recognition for Partial Faces Using a Feature Vector Technique. Sensors 2022, 22, 4633. https://doi.org/10.3390/s22124633
Khoeun R, Chophuk P, Chinnasarn K. Emotion Recognition for Partial Faces Using a Feature Vector Technique. Sensors. 2022; 22(12):4633. https://doi.org/10.3390/s22124633
Chicago/Turabian StyleKhoeun, Ratanak, Ponlawat Chophuk, and Krisana Chinnasarn. 2022. "Emotion Recognition for Partial Faces Using a Feature Vector Technique" Sensors 22, no. 12: 4633. https://doi.org/10.3390/s22124633
APA StyleKhoeun, R., Chophuk, P., & Chinnasarn, K. (2022). Emotion Recognition for Partial Faces Using a Feature Vector Technique. Sensors, 22(12), 4633. https://doi.org/10.3390/s22124633