1. Introduction
Localisation services–including indoor ones–are becoming more and more common. Because of the business application of indoor localisation systems, the issue of providing an accurate indoor position becomes critical and requires a specific level of accuracy from the localisation system. The most popular indoor localisation system type is based on a vector of received signal strength (RSS) calculated for access points (APs) from internal Wi-Fi infrastructure. The advantages of the system are low cost and accessibility, as the measurements can be performed on almost every mobile device with a Wi-Fi module.
Very often, such a system is trained using fingerprinting. In the localisation process, the current position can be determined by comparing the RSS vector to a created map of fingerprints. Different environments, test areas, and sensor technology have a significant impact on the Quality of Service (QoS)–measured by the localisation error–of the indoor localisation system [
1]. However, in the case of a localisation system based on fingerprinting there is one important additional factor: The QoS can drop if there are some changes in the characteristics of the RSS that were used to train the system.
There are various reasons for changes in system characteristics. One of them regards the model readings from a mobile AP during the creation of learning set. A mobile AP can change its position. As a result, the broadcast signal can be significantly different or even not observed. In performed experiments, Leca et al. [
2,
3] have estimated that approximately 3–4% of APs observed in an outdoor environment are mobile APs. Their existence in the learning data can increase the log-Gaussian Mean Error even by 37%, although the influence of mobile APs is not explicit for other error measures. Another reason for the changes is a modification of the Wi-Fi infrastructure. According to current needs, the network can be reconfigured to optimise the trade-off between the range and the latency [
4]. The last reason is the ageing of AP devices. Górak et al. [
5] have shown that the QoS of the localisation system based on unmodified Wi-Fi infrastructure deceases from 4 to 5 m over two years.
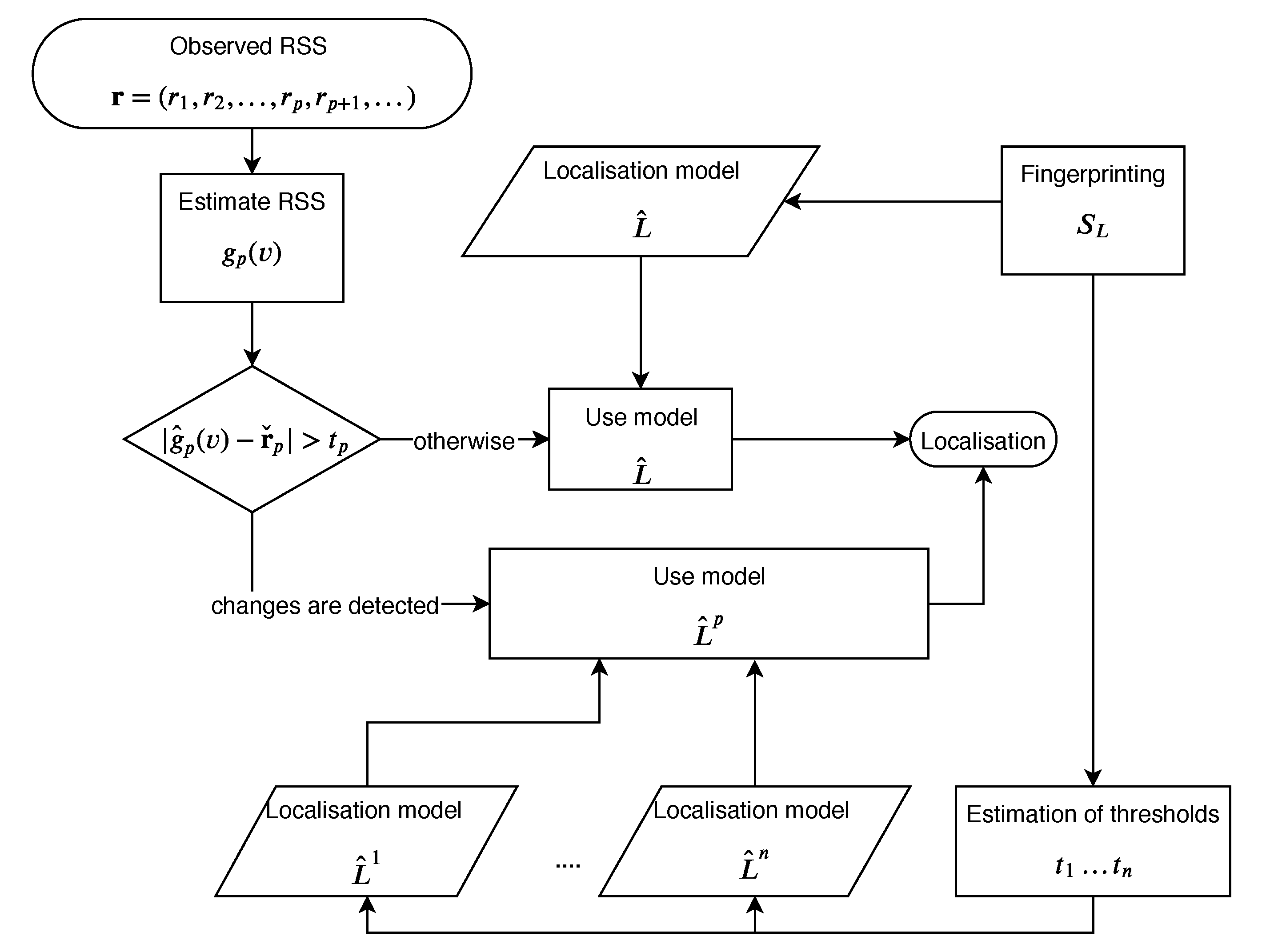
In this work, we propose a detection algorithm that can detect changes in AP signal characteristics. Using the Random Forest algorithm, we create an estimator that predicts the signal strength of the AP, based on the readings from all the remaining APs. Next, for every AP, we calculate an optimal threshold that will allow us to compare a predicted signal strength to the actual strength. If the difference between the prediction and the recorded signal strength is above the threshold, we predict that the AP has changed its characteristics for reasons other than typical environmental factors and this may substantially influence the accuracy of the localisation. If this is the case, we rebuild the localisation model, by excluding this AP from the learning data.
To evaluate our algorithm, we created a unique testbed. The change is simulated by replacing AP signals by signals of an AP from a different location. Both APs are the same model (Cisco AIR-LAP1142N-E-K9). Therefore, it is practically the same as physically moving one AP to a different location. Moreover, our approach allows us to avoid modelling of the propagation of signal strength in the dynamic environment of a public building, which is a very difficult task. Instead, we gather a huge amount of fingerprinting data (millions of records), each record containing many features (RSS readings from many APs). Next, we use machine learning methods to detect APs with substantially changed characteristics. After the detection of changes, the algorithm starts the recalculation of the localisation model.
Our algorithm was tested inside the big modern multi-floor building of the Faculty of Mathematics and Information Science (MIS) of the Warsaw University of Technology. The algorithm automatically detected simulated changes in the Wi-Fi infrastructure and triggered the recalculation of the localisation model. As a result, our solution reduces localisation errors created by changes.
The remaining part of the paper is organised as follows. In
Section 2, the related work is discussed.
Section 3 presents the proposed localisation model and describes how the system detects the changes. The created simulations and data sets of fingerprints collected in the MIS building are described and discussed in
Section 4. The results obtained for three scenarios are described in
Section 5.
Section 6 presents our conclusions.
2. State-of-the-Art
Tuta et al. [
6] stressed the issue of developing an indoor positioning system with the main aim of making it useful for real-world deployments, including the creation of self-calibrating and self-adaptive systems. Several such localisation systems were proposed.
Cai et al. [
7] proposed an adaptive indoor localisation system—an integration of received signal strength indication (RSSI)-based and inertial navigation system (INS)-based approaches—called coupled RSSI and INS localisation (CRIL). The system used the results from RSS and INS and updated the channel model in the RSSI in real-time. However, the adaptation is based on infrastructure of anchors of known location. Tuta et al. [
6] merged a free-space path loss model and a propagation model to create a self-calibrating and self-adaptive model. This procedure infers parametres of the space and simulates the propagation of the signal. The historical points are used for localisation improvement.
Several solutions use a specialised chipset. Nevat et al. [
8] proposed two-way time-of-arrival ranging devices to perform localisation. The approach was based on nonlinear regression analysis, where the missing observations were treated as Missing Not at Random. A similar idea was proposed by Batstone et al. [
9,
10]. However, such solutions are hard for broad implementation on commonly used mobile phones [
11].
Several works aim to eliminate the missing signals. Lin et al. [
12] recovered a fingerprinting map created during the fingerprinting process in place of the missing signals. Chang et al. [
13] proposed a similar solution. Saleem et al. [
14] discussed—on a laboratory testbed—how to recover missing APs’ RSS if the radio map covers all measurement points for all APs. Górak et al. [
15] detected the missing signals and eliminated their sources from the localisation model.
Designing our solution, we assumed that the system should work on commonly used devices. Therefore, the solution cannot be based on a specialised chipset as in [
8,
9,
10]. Our solution can work using standard Wi-Fi APs and mobile devices. Also, the designed system should work with unreliable infrastructure. Therefore, the concept of Wi-Fi anchors used in [
7] cannot be applied. The anchors can be a major source of system weakness in the case of changes in their RSS characteristics. The central concept of our solution lies in the detection of such changes. The main works that analyse the localisation QoS are focused on managing lack of data [
12,
13,
14,
15]. Although the detection of missing signals is critical for QoS, we extend this idea to detect all significant changes in the observed signals. Finally, to design a universal solution, we avoid signal propagation modelling [
6] and the necessity of a knowledge of the Wi-Fi infrastructure scheme [
7] using by fingerprinting and machine learning techniques.
The method proposed in this work could be extended using crowdsourcing [
16], as we did previously to detect a disabled AP [
15]. The previously introduced methods allow the system to limit rebuilding frequency by waiting for a significant number of raised alarms to recreate the localisation model. Moreover, the proposed methods can extend a set of observed APs. However, the current work introduces the new concept of RSS characteristics changes detection and we intentionally limited additional factors during the experiments. This aspect could be an area of future work.
The tests in our work were performed on data collected in the multi-floor MIS building. Other analyses for the building—multi-floor localisation and feature selection—can be found in [
15,
17,
18,
19,
20]. Mostly, we cannot compare our results directly with the mentioned works. However, we performed a comparison of the proposed system with the approaches presented in [
14,
15].
3. Methodology
3.1. Localisation Model
Following the work in [
15], let us formally define the localisation problem which we deal with in the following part of this work.
By and we denote the learning and testing data sets, respectively. They consist of vectors (fingerprints) , where is the RSS reading from the pth AP, from a given set of APs , at the time t, in the location where are the horizontal coordinates, and z is the vertical one.
For a subset
, we consider new data sets
,
that are modified data sets
,
, respectively:
In other words, we take in , only RSS readings from APs from .
Problem 1. Construct a localisation model based on a measurement series (learning series). The localisation model is a function (2D case, z is constant) or (3D case), depending on the localisation area. For a given RSS vector , estimates the location where the measurement v was taken.
The localisation issue formulated as Problem 1 is not a tracking problem and the historical RSS readings are not taken into account. The localisation is based on a single RSS reading from multiple APs.
To evaluate the model, we introduce the following standard measures of QoS.
Definition 1. Let (testing series) be a measurement series and a localisation model. For an element , we introduce the the following natural error measurement,where . In other words, although is the true position of fingerprint s, is its predicted position based on RSS vector . Definition 2. For a testing series and the localisation model , let us define the following QoS measures, The goal of localisation is minimising these measures.
We construct the localisation model
using the Random Forest algorithm as presented in [
21]. This will be one of the main parts of the localisation solution. The main advantages of the algorithm are speed and high quality. Alternatively, the AdaBoost algorithm can be used [
22].
First, we create estimators
,
and
by applying the Random Forest algorithm where the training set is
, which predicts separately coordinates of
x,
y and
z, respectively. For creating the estimators, regression trees are grown. The selected number of grown trees is 100 as the analysis based on
(see, e.g., in [
15]) suggests that growing more trees does not improve QoS.
3.2. Detection of Changes of AP Location
Let us describe the method of detecting that the RSS characteristics of AP
p have changed. The method presented in
Figure 1 starts denoting for vector
a vector
, which is vector
with the
pth coordinate removed. For a learning data set
we define a set of such vectors
. Therefore, we have a function (possibly a multifunction)
that for a given vector
returns a missing coordinate
of RSS from the removed AP. Now, based on
and using the Random Forrest algorithm once again, we create an estimator,
, that predicts the RSS of the removed AP
p, based on the readings from all the remaining APs.
We define the estimation error of the RSS prediction as , where and is the pth coordinate of . Next, we calculate the threshold t that separates errors obtained for valid characteristics from the rest. Regarding typical noises that can occur in a real environment, the estimation errors for valid characteristics will be higher than zero. However, we assume that errors introduced by a change (such as a change of AP location) will be significantly higher than typical errors. If not, we can assume that the influence of the change on QoS will not be substantial.
The threshold belongs to a set of unique error values calculated on the learning data set . For computational reasons, the size of the set can be reduced, decreasing the precision of its elements.
The optimal threshold is calculated using the formula
We classify an AP
p as one that has changed its characteristics (possibly due to a change of its location) if for an RSS vector
,
. In such a case, a new localisation model
is created, as described in
Section 3.1. However, this time the learning data set is
In other words, we remove readings from AP
p from the readings of the learning series
. Therefore, we can define the modified localisation model
by
To estimate the quality of the model
, it is compared with the system that ideally detects if AP
p changed its characteristics. Therefore, we introduce
, such that
The proposed method is universal and works for various localisation models . However, as mentioned before, we will work with , i.e., the model that was created using a Random Forest.
5. Results
This section aims to show the benefits we obtain by using the detection method described in
Section 3.2. Therefore, we compare three different systems with an AP
p being put aside for testing purposes. That is, for a given AP
p, localisation model
we denote by
a new model that was created using the same method but using only
as a learning data set. Thus, we consider three possible modifications. The first, which was already defined,
, later
and
. For a given localisation model
and two given APs
and
, let us introduce the following QoS measure
that measures, on set
, how replacing readings from AP
with readings from AP
increases the mean error.
Based on the above, we can see the relation between
and the distance
, by looking at the parametres that describe loss QoS caused by the movement of AP by distance
d
where
d is an integer.
The results of the proposed system detecting changes as presented in Formula (
9)—labelled as
Proposed model—are described by the function
. In the tests, we compare it with two reference models. The first reference localisation model—labelled as
Not modified model—is not modified despite the change. The results are described by
. The second reference localisation model—labelled as
Ideally modified model—is modified assuming a perfect detection of the change, as presented in Formula (
10). The results are described by
.
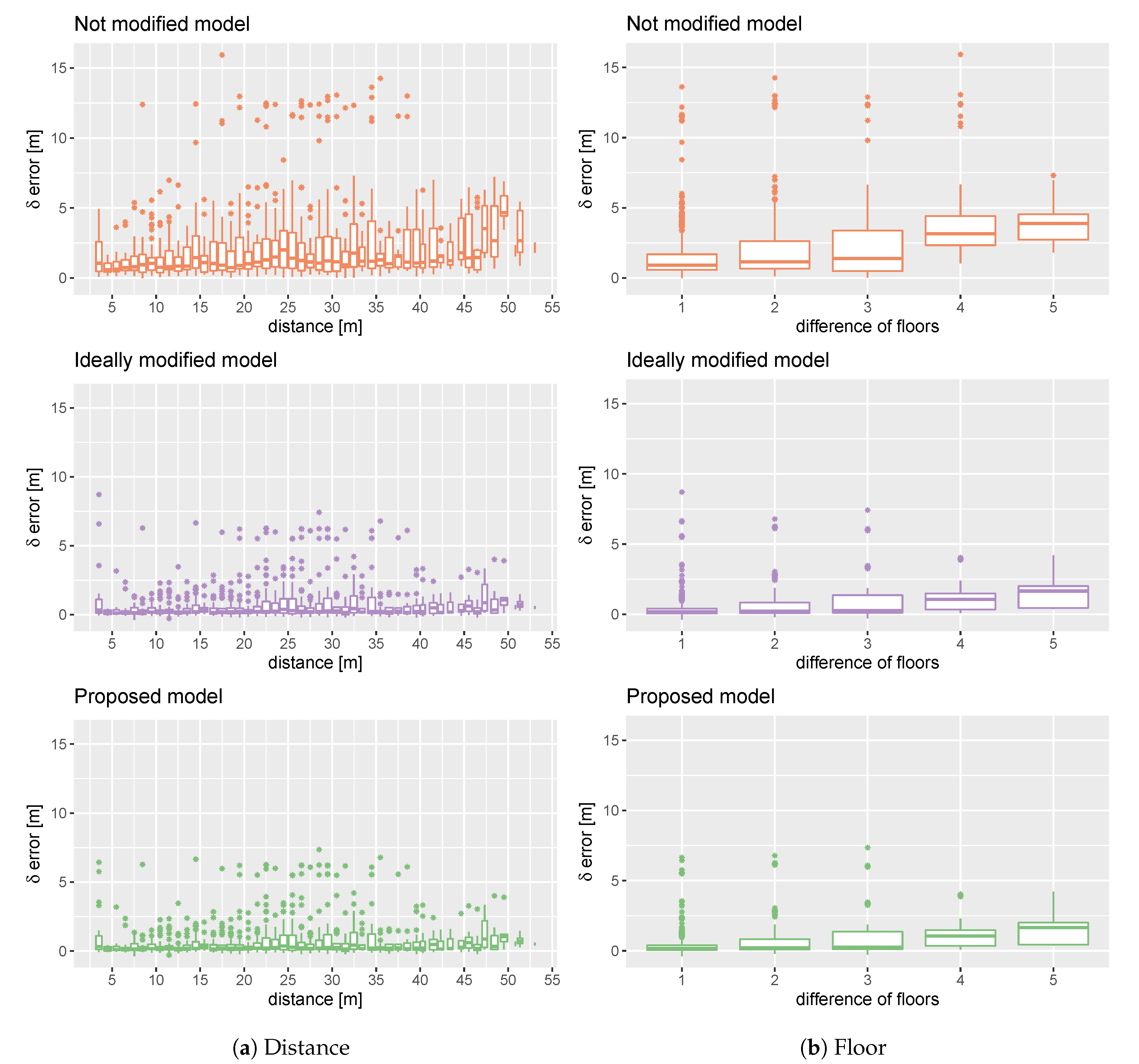
5.1. 2D Scenarios
Figure 3 shows the results for a two-dimensional localisation problem. The results were presented as box plots calculated for sets
, where
and
. This allows the reader to compare the error distribution for the proposed and reference models calculated for shifts with one-metre resolution.
Figure 3a shows the correlation between an AP shift and the localisation error change that occurs in Scenario 1.
Figure 3b shows the same for Scenario 2. We observe that changes performed in a localisation model based on a small number of APs (Scenario 1) result in higher errors than for a model with a larger number of APs (Scenario 2). The maximum error is 15 and 10 m, respectively.
Comparing the results obtained by the proposed system and the ideally modified model—that detects all the changes—we find them very similar. The main difference is the higher standard deviation of errors obtained for very big AP displacements (about 50 m) by the proposed model in Scenario 1. This effect does not occur in Scenario 2.
One can observe that the ideal model and proposed model obtain negative values for shifts less than one metre. This is because the figures show the difference between the localisation error obtained after and before the change. In this case, the elimination of some APs increases the QoS of the localisation system by reducing the localisation error.
Observing the results for the not modified model, we see that the localisation error arises according to the distance. Our system eliminates this tendency and the errors—especially in Scenario 2—are on a similar level for all distances. Moreover, the results obtained by our system are visibly better than for the localisation model without an update. In Scenario 1, the maximum error of the proposed system does not exceed 10 m. The maximum error for the model without the update exceeds 15 m. For Scenario 2, the maximum error is less than 6 m and over 10 m, respectively.
For all compared approaches, the obtained errors are smaller in Scenario 2. This is natural because the number of APs used for localisation on each floor grows six times on average (see
Table 1). Therefore, the changes in RSS from a single AP are much less important.
5.2. 3D Scenario
Figure 4 shows the results for the three-dimensional localisation case described in Scenario 3.
Figure 4a presents the results identically as for the two-dimensional localisation cases, showing the error distribution for the proposed and reference models calculated for shifts with a one-metre resolution. However, because of the discrete vertical shift that could be present in this scenario, we introduced an additional presentation of the error distribution according to the change in the number of floors (
Figure 4b).
Analysing the errors according to the distance (
Figure 4a) we obtain similar conclusions as for the two-dimensional scenarios. The results obtained by the proposed method are very similar to the ideal model. However, the improvement of QoS observed in the two-dimensional scenarios for a shift smaller than one metre is absent in Scenario 3. The proposed solution improves the results obtained by the not modified model. The maximum error is less than 8 m and over 15 m respectively.
Figure 4b shows that the localisation error grows according to the number of floors between the swapped APs. Once again, the proposed system gives results that are closer to the ideal model than to the model without the update.
For a more formal comparison of the results, statistics for the scenarios were calculated.
Table 2 presents statistics calculated for all scenarios. For comparison, the errors obtained in the three-dimensional case are calculated only horizontally.
The reference localisation errors, presented as (B), vary from 3.6 to 4.3 m for the mean. After the change (A), the mean error rises by 1.2 to 2 m. However, the application of our system (S) reduces this growth and the localisation error increases by 0.2 to 0.6 metres only. After the change, the median error grows by 1–1.6 m. Using our system, the QoS drops only by 0.1 to 0.3 m. The main change is visible for gross errors (the 80th percentile). The QoS after the change plunged by 1.7 to 3.2 m. By using our system, the decrease can be reduced to 0.2 to 1 m.
5.3. Comparison with other Solutions
We have shown in the previous tests the correlation between error and distance between a previous and future location of an AP. The location change causes a change in RSS. Analysing the collected data, we can say that the RRS change varies between −1 and −73 [dBm]. However, the change can mute the signal entirely and then it is noticed as a missing signal [dBm]. In such a case, the difference varies between −13 and −86 [dBm].
Therefore, an approach that focuses on missing RSS values to improve localisation results is legitimate. There are two approaches to the missing RSS values: The missing values can be eliminated at the beginning when the radio map is created [
12,
13,
14] or detected dynamically [
15].
To compare the two approaches, we created a testbed based on Scenario 1. Because of the limitations of the compared methods, we eliminated from the tests all RSS vectors without ∅ values and consisting of ∅ values only. It was necessary because the method proposed in [
15] detects if a terminal should receive a signal from the AP using information from the other APs. For this, the learning set must contain cases describing RSSs from the other APs when the observer AP is turned on as well as when it is turned off. The second method [
14] replaces ∅ values with the mean of RSS values from a given AP over the whole learning set. Therefore, vectors consisting of ∅ values only are not allowed.
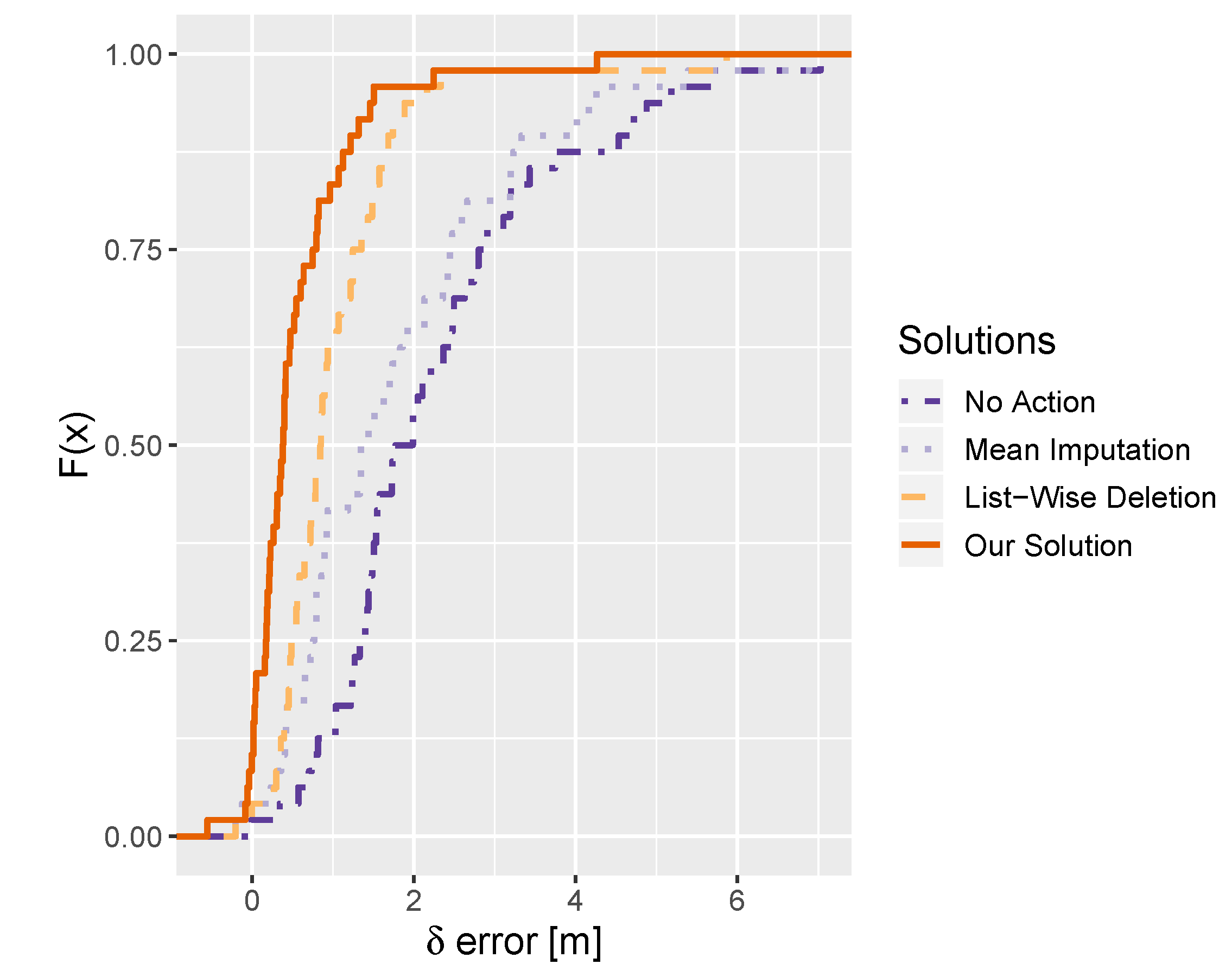
Using the created testbed, we performed 386 tests.
Figure 5 compares the results obtained by the discussed methods using the empirical distribution function. For all methods,
error was compared. The comparison includes a situation without any preventing methods (No Action), recovering the missing values with the mean (Mean Imputation), detection of missing signals to eliminate their source from the model (List-Wise Deletion) and our changes detection system (Our Solution).
All methods are successful and obtain a better result than ignoring the changes. However, the mean imputation of the missing AP signals has a much higher gross error that the other methods working with the updated model. Among them, the best results are obtained by the system proposed in this work. For our solution and the list-wise deletion model, we observe some negative values. This means, that the updated system gives better results than the system before the change in some cases and the error is negative.
Our method obtained a mean error smaller by 1 and 0.5 m in comparison to [
14] and [
15], respectively. Similarly, the median error is less by 1 and 0.4 m. The difference is the highest for the gross error, where the results obtained by our method are better by 1.8 and 0.8 m. The detailed statistics for all models are given in
Table 3.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}