Feature Fusion of Deep Spatial Features and Handcrafted Spatiotemporal Features for Human Action Recognition


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- In this work, we propose a novel approach for human action recognition by fusing deep spatial feature and handcrafted spatiotemporal feature.
- We introduce a novel handcrafted feature descriptor, namely Weber’s law based Volume Local Gradient Ternary Pattern (WVLGTP), which brings out the spatiotemporal features. It also takes shape information into account by using gradient operation. Furthermore, Weber’s law based threshold value and the ternary pattern based on an adaptive local threshold is introduced to effectively handle the noisy center pixel value.
- Besides, a multi-resolution approach for WVLGTP based on an averaging scheme is also presented.
- Lastly, we present an extensive experimental analysis to prove the effectiveness of our approach over state-of-the-art.
2. Related Work
2.1. Hand-Crafted Descriptor
2.2. Deep Learning Based Descriptor
3. Proposed Method
3.1. Deep Spatial Feature Extraction Using Inception-Resnet-v2 Network
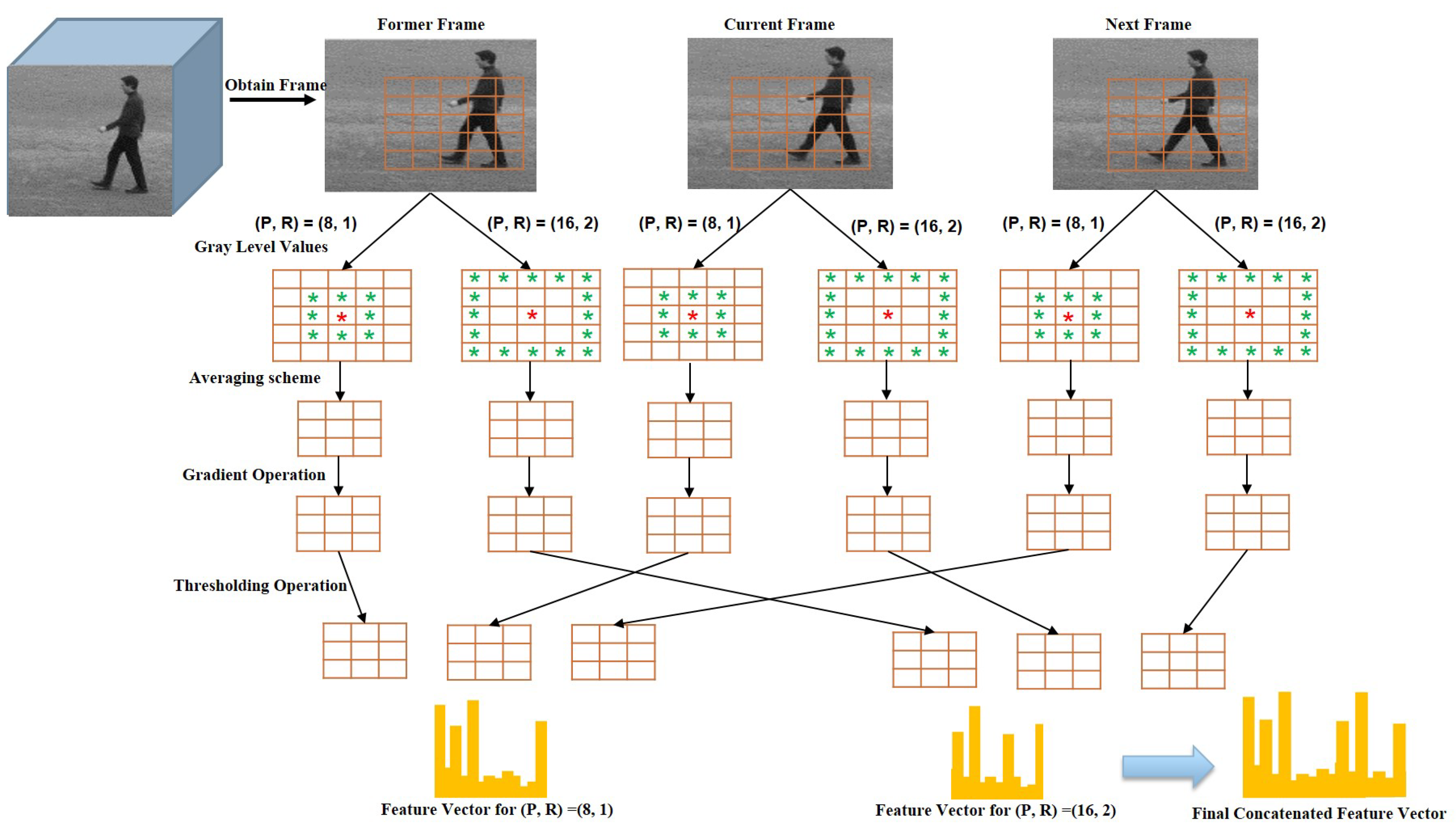
3.2. Spatiotemporal Feature Extraction Using WVLGTP
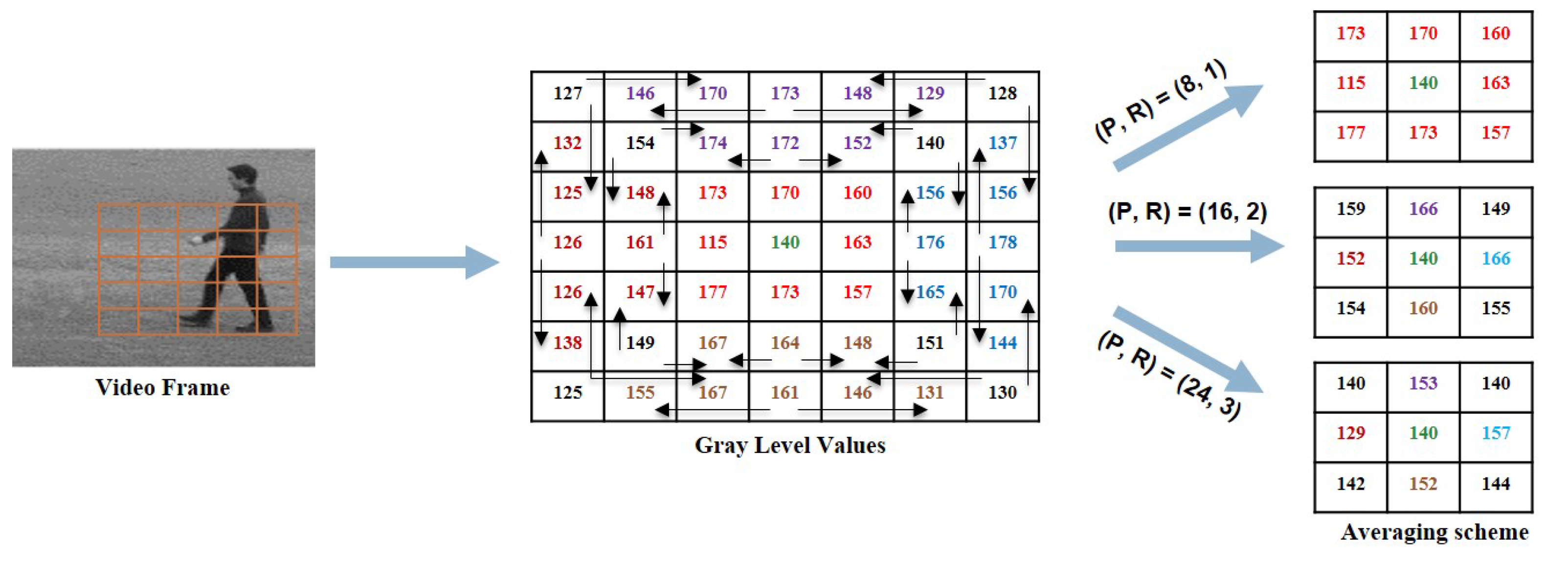
Multi-Resolution Approach for WVLGTP
3.3. Classification Using SVM
4. Experiments
4.1. KTH Dataset
4.2. UCF Sports Action Dataset
4.3. UT-Interaction Dataset
4.4. Hollywood2 Dataset
4.5. UCF-101 Dataset
4.6. Model Training and Testing
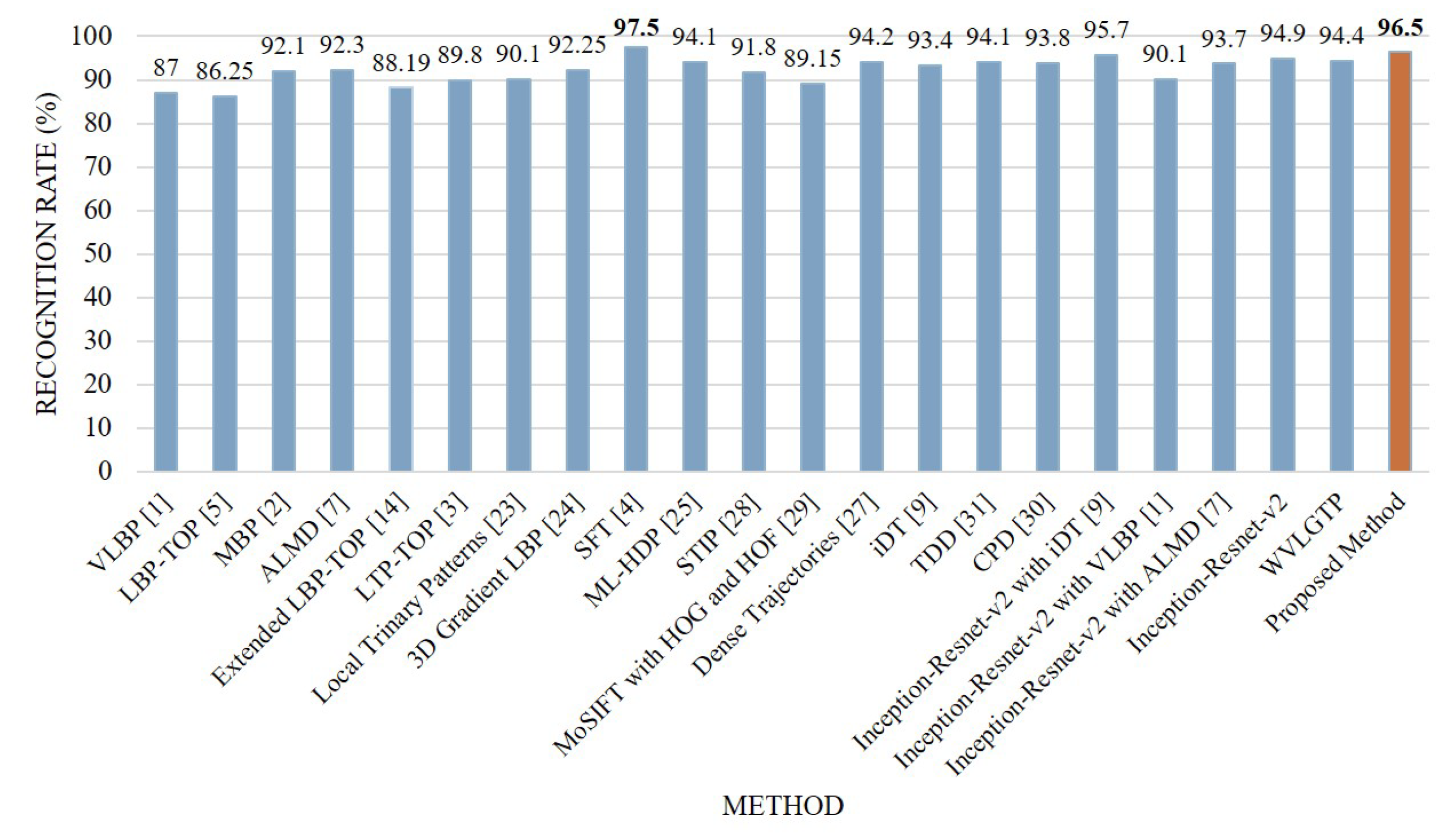
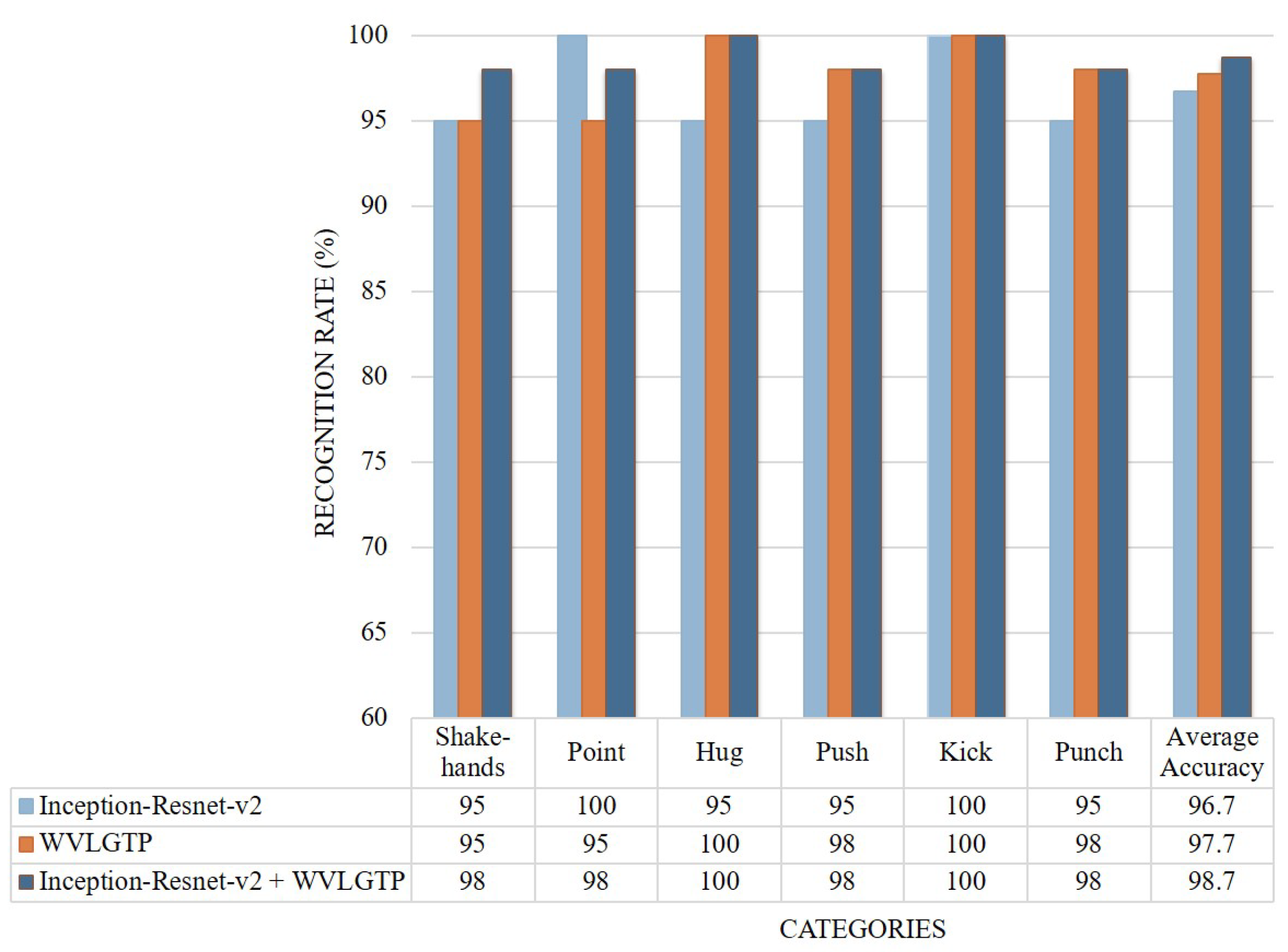
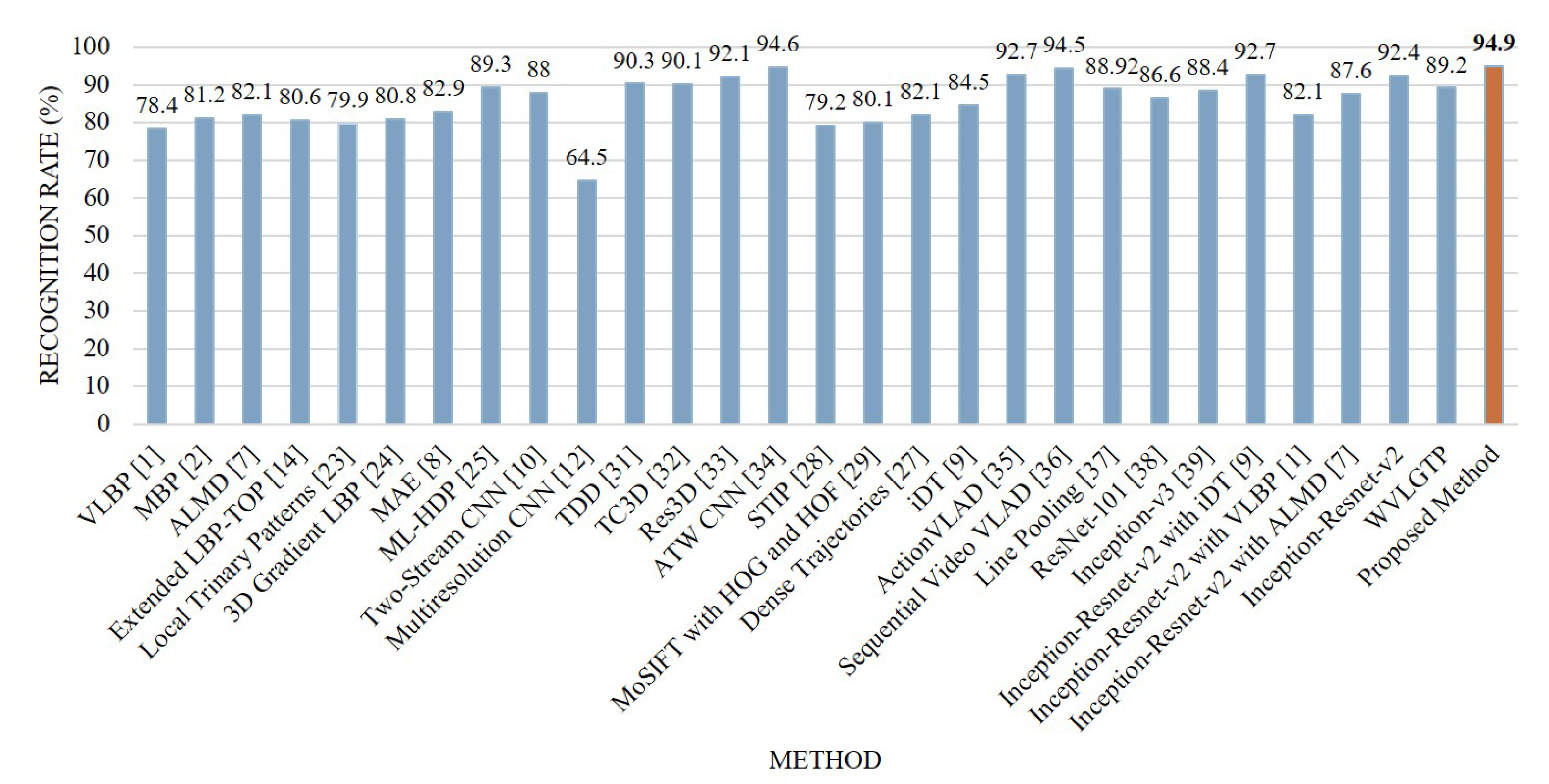
4.7. Experimental Analysis
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Baumann, F.; Liao, J.; Ehlers, A.; Rosenhahn, B. Computation strategies for volume local binary patterns applied to action recognition. In Proceedings of the 11th IEEE International Conference on Advanced Video and Signal-Based Surveillance (AVSS), Seoul, Korea, 26–29 August 2014. [Google Scholar]
- Baumann, F.; Ehlers, A.; Rosenhahn, B.; Liao, J. Recognizing human actions using novel space-time volume binary patterns. Neurocomputing 2016, 173, 54–63. [Google Scholar] [CrossRef]
- Laptev, I.; Marszalek, M.; Schmid, C.; Rozenfeld, B. Local Ternary Patterns from Three Orthogonal Planes for human action classification. Expert Syst. Appl. 2011, 38, 5125–5128. [Google Scholar] [Green Version]
- Yi, Y.; Zheng, Z.; Lin, M. Realistic action recognition with salient foreground trajectories. Expert Syst. Appl. 2017, 75, 44–55. [Google Scholar] [CrossRef]
- Zhao, G.; Pietikäinen, M. Dynamic Texture Recognition Using Local Binary Patterns with an Application to Facial Expressions. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 915–928. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ojala, T.; Pietikäinen, M.; Mäenpää, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 7, 971–987. [Google Scholar] [CrossRef]
- Uddin, M.A.; Joolee, J.B.; Alam, A.; Lee, Y.K. Human Action Recognition Using Adaptive Local Motion Descriptor in Spark. IEEE Access 2017, 5, 21157–21167. [Google Scholar] [CrossRef]
- Lan, T.; Zhu, Y.; Zamir, A.R.; Savarese, S. Action recognition by hierarchical mid-level action elements. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2016; pp. 4552–4560. [Google Scholar]
- Wang, H.; Oneata, D.; Verbeek, J.; Schmid, C. Action recognition with improved trajectories. Int. J. Comput. Vis. 2016, 119, 219–238. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Two-Stream Convolutional Networks for Action Recognition in Videos. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 568–576. [Google Scholar]
- Wang, H.; Klaser, A.; Schmid, C.; Liu, C.-L. Action recognition by dense trajectories. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Li, F.-F. Large-scale Video Classification with Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Yue-Hei Ng, J.; Hausknecht, M.; Vijayanarasimhan, S.; Vinyals, O.; Monga, R.; Toderici, G. Beyond Short Snippets: Deep Networks for Video Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4694–4702. [Google Scholar]
- Mattivi, R.; Shao, L. Human Action Recognition Using LBP-TOP as Sparse Spatio-Temporal Feature Descriptor. In Proceedings of the 13th International Conference on Computer Analysis of Images and Patterns, Münster, Germany, 2–4 September 2009; pp. 740–747. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Burges, C.J. A tutorial on support vector machines for pattern recognition. Data Min. Knowl. Discov. 1998, 2, 121–167. [Google Scholar] [CrossRef]
- Schüldt, C.; Laptev, I.; Caputo, B. Recognizing Human Actions: A Local SVM Approach. In Proceedings of the 17th International Conference on Pattern Recognition, Cambridge, UK, 23–26 August 2004. [Google Scholar]
- Rodriguez, M.D.; Ahmed, J.; Shah, M. Action MACH: A Spatio-temporal Maximum Average Correlation Height Filter for Action Recognition. In Proceedings of the Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008. [Google Scholar]
- Soomro, K.; Zamir, A.R. Action Recognition in Realistic Sports Videos. In Computer Vision in Sports; Springer International Publishing: New York, NY, USA, 2014. [Google Scholar]
- Ryoo, M.S.; Aggarwal, J.K. Spatio-Temporal Relationship Match: Video Structure Comparison for Recognition of Complex Human Activities. In Proceedings of the 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 1593–1600. [Google Scholar]
- Marszalek, M.; Laptev, I.; Schmid, C. Actions in context. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A Dataset of 101 Human Action Classes From Videos in The Wild. arXiv, 2012; arXiv:1212.0402. [Google Scholar]
- Yeffet, L.; Wolf, L. Local Trinary Patterns for human action recognition. In Proceedings of the 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009. [Google Scholar]
- Guo, Z.; Wang, B.; Xie, Z. A Novel 3D Gradient LBP Descriptor for Action Recognition. IEICE Trans. Inf. Syst. 2017, 100, 1388–1392. [Google Scholar] [CrossRef]
- Tu, N.A.; Huynh-The, T.; Khan, K.U.; Lee, Y.K. ML-HDP: A Hierarchical Bayesian Nonparametric Model for Recognizing Human Actions in Video. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 800–814. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B.; Schmid, C. Human detection using oriented histograms of flow and appearance. In Proceedings of the 9th European conference on Computer Vision (ECCV), Graz, Austria, 7–13 May 2006. [Google Scholar]
- Wang, H.; Kläser, A.; Schmid, C.; Liu, C.L. Dense trajectories and motion boundary descriptors for action recognition. Int. J. Comput. Vis. 2013, 103, 60–79. [Google Scholar] [CrossRef]
- Chakraborty, B.; Holte, M.B.; Moeslun, T.B.; Gonzàlez, J.; Xavier Roca, F. A selective spatio-temporal interest point detector for human action recognition in complex scenes. In Proceedings of the International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Chen, M.; Hauptmann, A. MoSIFT: Recognizing Human actions in Surveillance Videos. Ph.D. Dissertation, Carnegie Mellon Universtiy, Pittsburgh, PA, USA, 2009. [Google Scholar]
- Ohnishi, K.; Hidaka, M.; Harada, T. Improved Dense Trajectory with Cross Streams. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016. [Google Scholar]
- Wang, L.; Qiao, Y.; Tang, X. Action Recognition with Trajectory-Pooled Deep-Convolutional Descriptors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Lu, X.; Yao, H.; Zhao, S.; Sun, X.; Zhang, S. Action recognition with multi-scale trajectory-pooled 3D convolutional descriptors. Multimed. Tools Appl. 2017, 78, 507–523. [Google Scholar] [CrossRef]
- Yao, G.; Lei, T.; Zhong, J.; Jiang, P. Learning multi-temporal-scale deep information for action recognition. Appl. Intell. 2018, 1–13. [Google Scholar] [CrossRef]
- Wang, L.; Zang, J.; Zhang, Q.; Niu, Z.; Hua, G.; Zheng, N. Action Recognition by an Attention-Aware Temporal Weighted Convolutional Neural Network. Sensors 2018, 18, 1979. [Google Scholar] [CrossRef] [PubMed]
- Girdhar, R.; Ramanan, D.; Gupta, A.; Sivic, J.; Russell, B. ActionVLAD: Learning spatio-temporal aggregation for action classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 971–980. [Google Scholar]
- Xu, Y.; Han, Y.; Hong, R.; Tian, Q. Sequential Video VLAD: Training the Aggregation Locally and Temporally. IEEE Trans. Image Process. 2018, 27, 4933–4944. [Google Scholar] [CrossRef] [PubMed]
- Zhao, S.; Liu, Y.; Han, Y.; Hong, R.; Hu, Q.; Tian, Q. Pooling the Convolutional Layers in Deep ConvNets for Video Action Recognition. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 1839–1849. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Jain, A.K. Fundamentals of Digital Signal Processing; Prentice-Hall: Englewood Cliffs, NJ, USA, 1989. [Google Scholar]
- Chen, J.; Shan, S.; He, C.; Zhao, G.; Pietikainen, M.; Chen, X.; Gao, W. WLD: A Robust Local Image Descriptor. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1705–1720. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]


















© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Uddin, M.A.; Lee, Y.-K. Feature Fusion of Deep Spatial Features and Handcrafted Spatiotemporal Features for Human Action Recognition. Sensors 2019, 19, 1599. https://doi.org/10.3390/s19071599
Uddin MA, Lee Y-K. Feature Fusion of Deep Spatial Features and Handcrafted Spatiotemporal Features for Human Action Recognition. Sensors. 2019; 19(7):1599. https://doi.org/10.3390/s19071599
Chicago/Turabian StyleUddin, Md Azher, and Young-Koo Lee. 2019. "Feature Fusion of Deep Spatial Features and Handcrafted Spatiotemporal Features for Human Action Recognition" Sensors 19, no. 7: 1599. https://doi.org/10.3390/s19071599