Time Series Data Fusion Based on Evidence Theory and OWA Operator


School of Computer and Information Science, Southwest University, Chongqing 400715, China
*
Author to whom correspondence should be addressed.
Sensors 2019, 19(5), 1171; https://doi.org/10.3390/s19051171
Submission received: 17 January 2019
/
Revised: 28 February 2019
/
Accepted: 4 March 2019
/
Published: 7 March 2019
(This article belongs to the Section Physical Sensors)
Abstract
:Time series data fusion is important in real applications such as target recognition based on sensors’ information. The existing credibility decay model (CDM) is not efficient in the situation when the time interval between data from sensors is too long. To address this issue, a new method based on the ordered weighted aggregation operator (OWA) is presented in this paper. With the improvement to use the Q function in the OWA, the effect of time interval on the final fusion result is decreased. The application in target recognition based on time series data fusion illustrates the efficiency of the new method. The proposed method has promising aspects in time series data fusion.
1. Introduction
Evidence theory, also called Dempster Shafer evidence theory [1,2], plays an important role in data fusion because of the efficiency to deal with uncertainty [3,4,5,6,7]. It is widely used in many applications, such as fault diagnoses [8,9,10,11], project assessment [12,13,14,15,16], risk management [17,18,19], target recognition [20,21,22,23,24,25], decision making [26,27,28,29] and so on [30,31,32,33,34].
Recently, besides uncertainty [35,36,37] and entropy [38,39,40,41,42] about evidence theory is well developed, how to take time series into consideration [43,44,45,46] and how to make a good data fusion [47,48,49] for different questions has received much attention. After many methods have been presented to deal with information statically, Smets [44] proposed a time decay model to combine information dynamically. Based on that model, Song et al. [43] reduced the effect of previous evidences through the discounting function in credibility decay model (CDM).
However, CDM has some shortcomings. For example, information collected from sensors may be unreasonably discounted in the CDM model when the time interval between two time nodes is relatively long. Simply dismissing the question may cause decisions to overly rely on the latest evidence without fully using existed collections of evidences and eventually lead to the wrong identification of the target. Additionally in CDM, there is also a lack of valid discussion on the relationship of time interval between old and new evidences and the credibility of old evidence.
To address this issue, a new method is proposed based on ordered weight aggregation (OWA) operator [50] to serve as a means redefining CDM. Past researches investigating OWA [51,52,53,54] showed the effectiveness of this operator in the information aggregation problem since OWA has the strength to easily adjust the degree of implicit “anding” and “oring” [50]. Based on time series, weights in OWA can be dynamically generated to effectively control the impact of old evidences on the final fusion result. The new decay model can identify the target using the information collected from sensors considering the role of old evidences in data fusion from the perspective of linguistic “anding” and “oring”, rather than time intervals, which is unreasonably used in original CDM.
The paper is arranged as follows. Section 2 introduces some preliminaries. Section 3 presents the new method to get discount for CDM based on OWA weights. Following that, two applications illustrate the performance of the proposed method in target recognition Section 4. Finally, a brief summary is given in Section 5.
2. Preliminaries
This section introduces some preliminary works including evidence theory, credibility decay model, and OWA.
2.1. Evidence Theory
It is inevitable to handle uncertainty in real applications [55,56,57], and transform complex situations into simple ones [58,59,60]. Evidence theory is effective in dealing with such a question [61,62,63,64,65] and other fields [66]. In the theory, a finite nonempty set with mutually exclusive and exhaustive attributes is called the frame of discernment, and denoted by . The power set of is , containing all subsets of .
Definition 1.
Let be a frame of discernment. Assume A . The basic probability distribution (BPA) of A or m(A) is a function defined as [1,2]:
and satisfies the following conditions:
If and , we know nothing about the frame of discernment.
One important advantage of evidence theory is that two BPAs can be combined together as follows.
Definition 2.
Data fusion happens in constant combinations [67,68,69]. Conflict management [70,71] is an important part during combination [72,73,74]. Evidences from different sources are not totally reliable, credibility measures the reliability of evidence, which are defined as follows:
Definition 3.
Let m be the BPA on the frame of discernment Ω with a credibility of α, then m could be discounted as [2]:
Although the unknownness of evidence increases by discounting the original BPA with credibility, the combination of evidence will be more effective due to the reduction of conflicts (Example 1).
Example 1.
Assume a sensor receives two evidence bodies , on the discernment frame , which are shown as follows:
The combination results without credibility are as follows:
Assume that the source of two evidence bodies and , the sensor , has only half the reliability, which means is not fully trusted. So the discounted BPAs with half credibility () and combination results are shown as follows:
For decision making in evidence theory, the final BPA after constant fusion can be transformed to a pignistic probability. Such a map from BPA to a kind of probability function is called the pignistic transformation, which is defined as follows [75].
Definition 4.
Assume the frame of discernment is , the pignistic probability function is defined as:
where is the cardinality of set A.
2.2. The Credibility Decay Model
Song et al. [43] defined a model for dynamic information combination. Assume evidences are collected at n time nodes . is a group of BPAs of these evidences on the discernment frame.
Smets [44] gives the requirement of Markovian for data fusion on time series as follows.
Definition 5.
Markovian requirement improves the computational efficiency of BPAs’ combinations or data fusion for there is no need to store all past BPAs and compute repeatedly.
Evidences collected from sensors at different time nodes are not fully trusted in CDM. is the credibility used to discount the old evidences every time like Equation (4) shows. So the Equation (6) in CDM can be defined as follows.
Definition 6.
Let , for . Function g can combine two BPA being defined as [43]:
Further, the credibility in CDM is defined as follows.
Definition 7.
Let be a BPA on the frame of discernment collected at time , the dynamic credibility at time node is defined as [43]:
where .
2.3. The Ordered Weighted Aggregation Operator
OWA operator receives much attention and has been used in a wide range of applications [76,77] since it was first introduced. Furthermore, this aggregating way is defined as follows:
Definition 8.
Assume there are n criteria . A mapping (where ) is called an OWA operator when there is a weight vector satisfies [50]:
where is the largest element in the collections which meets . And the weight vector has the following properties:
- .
In [50], the way to generate OWA weight is defined as following:
3. A New CDM Based on OWA
In this section, a new dynamical generating OWA weights method is proposed to replace Equation (8) in original model. Then using Equations (10) and (11), proper OWA discount weight can be obtained in the new CDM when each new evidence comes. The whole process to generate dynamical discount weights is shown in Figure 1. More details are shown step by step as follows.
Since the OWA operator reorders different satisfaction degrees in descending order, the front weights always have comparatively large demands. Additionally, in time series, a newer time node has a bigger numerical value. So the vector component is always the weight for evidence collected at the latest time node n. This weight represents the current satisfactory degree to the fusion result got from time node . Similarly, at the earliest time node 1, before the first evidence comes, the system is totally unknown. So weight component always represents unknown.
The data fusion based on time series should take timeliness into consideration, which means the effect of old evidences (in fusion form) should gradually reduce. The proposed method evaluates such a degree as follows.
Definition 10.
Assume there are n time nodes . The measure to evaluate the effect degree of old evidences from time node m is as follows:
where is the credibility at time . Additionally, may represent the effect degree at current time from the old evidence collected time .
Normally let , which means is calculated from time node 2. As proposed, an additional threshold parameter k is used to control discount speed, which means k is a threshold and for the first time node satisfying , when new evidences come after , since the effect degree of old evidences has met our demand, reusing weights before is reasonable. Clearly, k with higher value causes higher credibility and lower discount speed to old evidence. When the data source is more reliable which may be judged by other information, the value of k can be more higher. Let set k equals to 0.01 in this paper.
Based on time series, the proposed method can dynamically generate a weight vector when new evidences comes as follows.
Definition 11.
Assume that we collect a series of evidences from n time nodes with . Let be the BPA of evidence collected at time , for with . Based on n time nodes, the weights can be obtained as follows:
t is the newest or latest time node. Particularly, is the weight of , and is the weight of .
In fact, based on time effectiveness and to get more sound fusion information by reducing the influence of interference data, is a prior focus.
Since the importance of evidence depends on the new and old level, by using fuzzy linguistic quantifier Q shown in Definition 9, the OWA operator in proposed method can assign satisfaction according to the new and old level of evidences collected from sensors on different time series.
Further more, some properties for the values of a and b in proposed method shown in Equation (11) are as follows:
- a must equal to 0, otherwise may equal to 0.
- When b closes to 0, more satisfaction is given to the newest fusion evidence.
- When b closes to 1, less satisfaction is given to the newest fusion evidence.
Lets and , Q function can be got as Figure 2 shows.
Example 2.
Assume evidences and are collected from sensors at five time nodes, s, s, s, s and s. According to Equations (11) and (10), the weights are as follows:
Clearly, weights have no relation to time interval.
Example 2 details the satisfaction level with old evidences at different time nodes. For example, the weight vector shows that at time node , the current old evidences (in fusion form) with satisfaction level need to be given credibility value and the past time nodes’ old evidences are given , , 0, 0 credibility value respectively. Since the Markovian requirement also need to be satisfied in proposed model like Equations (6) and (7) shows, from each weight vector should be given more attention.
Example 3.
Assume that there are 10 evidences collected at , . The effect degree of old evidences from time node 1 can be calculated as follows:
So we have:
More details and results are shown in Table 1.
In Example 3, after time node 8, since the effect degree of old evidences is less than threshold. Fusion discount is reused from time node 9. The proposed method first ensures that the impact of old evidences falls as quickly as possible to a level less than expectation (0.01), and at this time, reusing as credibility to discount old evidences again is reasonable.
4. Application
In this section, two applications in target recognition are given with the comparison to original CDM to illustrate the new model.
In the next work, we call the new CDM as OWA model, and let the original model (OM) gets discount from Equation (8) with [43].
Example 4.
Assume there are three targets A, B, C constructing the discernment frame and the target A is the right one. The series of evidences to which support different targets collected from sensors are shown in Table 1. More details are shown in Table 2.
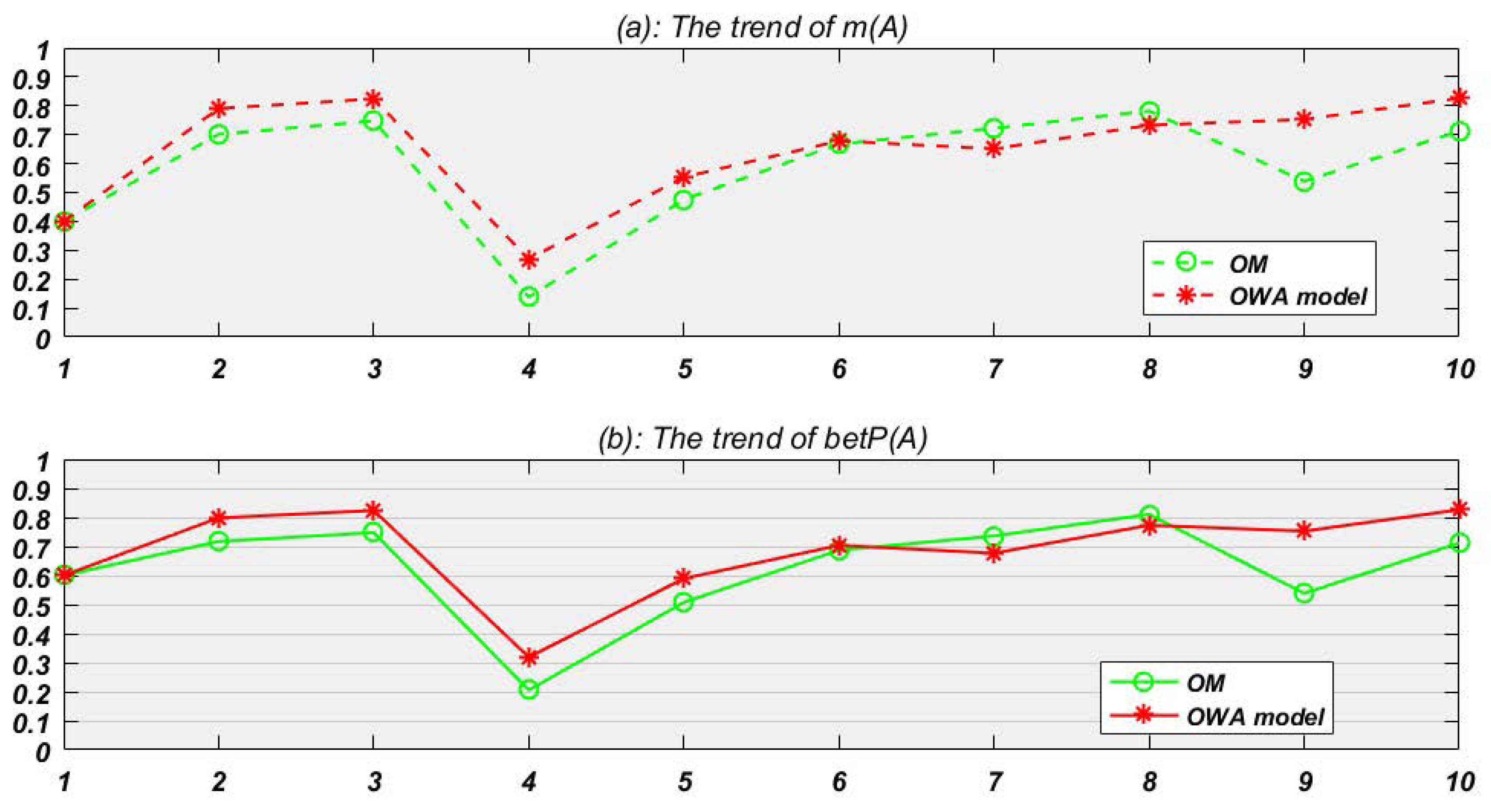
OM and OWA model are used for data fusion respectively for target identification. The fusion result of m(A) at each time node is shown in Figure 3a. And to identify the most possible target with known information, the pignistic probability trend of target A is obtained according to Equation (4) (Figure 3b).
In Table 2, BPA collected at represents that target A, B, C is given 0.4, 0.1, 0.1 belief respectively, and there is still 0.2 belief which cannot be divided to A or B and another 0.2 belief which also cannot be divided to A or C. Since is the first time node, so there is no credibility to old evidence and no fusion happens. Then at , just like the table shows, the credibility to old evidence (it is at this time) in proposed OWA model and OM is 1 and 0.638 respectively.
In most situations from Example 4, the new model presents better than the original one like Figure 3a red line shows, though at time node 7 and 8, OWA model seems do a bit worse. In fact, from Table 1 we can see that the threshold k controls the speed to discount old fusion evidences. Setting a comparative bigger numerical value for k can lower the decay speed and make discounts enter the next weight cycle quicker. Normally, the evidence source is more reasonable, the decay speed is slower.
To further study the identification rate of two methods in Example 4, the BPA is transformed to the pignistic probability to make decision. For example, the of A, B, C at is 0.6, 0.2, 0.2 according to Equation (5) as follows.
Then we can set the minimum requirement probability for sensors to make a decision which means when a target has met the probability, which can be thought correct. We can set the identification probability equal to 0.5 at first. The identification rate means that if , the sensors can conclude that the unknown target is A, which also means that at this time node the target is identified correctly. Note that at decision making happens at every time node. By gradually upgrading the minimum requirement for sensors’ judgment, we always find that the identification rate to the right target A (shown in Figure 4) of proposed OWA model is better than original model.
Example 4 dimly shows the shortcoming for OM. At time node 9, since the evidence comes only a bit slow, OM fails to converge to a sound decision. The next example further studies this kind of situation.
Example 5.
The identification rate of A in Example 5 is obtained and shown in Figure 6. Compared with performance of the OM in the figure, the proposed method clearly has a higher or identical identification rate to hit the right target A from to .
Example 5 also shows that OM is associated to time interval too much. Time node 3, 4 and 5 show the drawbacks in OM clearly. When bad information comes slowly, the original model recovers toughly. At this time, if reliable evidences come a little slowly as well, its recovery becomes much tougher except very high sound and correct evidences constantly happens. Another problem is that a short time interval may aggravate the effect of interference and slow down the converging speed like time node 3 and 4 show.
Clearly, new model with OWA weight as discount performs better in both situations, for it devotes attention to decay degree itself instead of time intervals. It can also resist interference and keep converging speed by reusing weights according to Equation (12).
5. Conclusions
How to combine time series data is still an open issue. To overcome the shortcomings of existing credibility decay model, a new method based on OWA operator is presented. OWA weights based on series of time nodes are used to substitute for discount function in original model. After the application in target recognition, it is explicit that new CDM can do better than the original one and adapt to various situations as well. One advantage of our proposed method is that the time interval is reasonably considered. The proposed method has the promising aspects in time series data fusion.
Author Contributions
F.X. and G.L. proposed the original idea and designed the research. L.G. wrote the manuscript.
Funding
This research was funded by the Chongqing Overseas Scholars Innovation Program (No. cx2018077).
Acknowledgments
The authors greatly appreciate the reviews’ suggestions and the editor’s encouragement.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Dempster, A.P. Upper and lower probabilities induced by a multivalued mapping. In Classic Works of the Dempster-Shafer Theory of Belief Functions; Springer: New York, NY, USA, 2008; pp. 57–72. [Google Scholar]
- Shafer, G. A Mathematical Theory of Evidence; Princeton University Press: Princeton, NJ, USA, 1976; Volume 42. [Google Scholar]
- Yager, R.R. On the Dempster-Shafer framework and new combination rules. Inf. Sci. 1987, 41, 93–137. [Google Scholar]
- Smets, P. The combination of evidence in the transferable belief model. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 447–458. [Google Scholar] [Green Version]
- Murphy, C.K. Combining belief functions when evidence conflicts. Decis. Support Syst. 2000, 29, 1–9. [Google Scholar]
- Lefevre, E.; Colot, O.; Vannoorenberghe, P. Belief function combination and conflict management. Inf. Fusion 2002, 3, 149–162. [Google Scholar]
- Haenni, R. Are alternatives to Dempster’s rule of combination real alternatives? Comments on about the belief function combination and the conflict management problem?—Lefevre et al. Inf. Fusion 2002, 3, 237–239. [Google Scholar]
- Zhang, H.; Deng, Y. Engine fault diagnosis based on sensor data fusion considering information quality and evidence theory. Adva. Mech. Eng. 2018, 10. [Google Scholar] [CrossRef]
- Chen, L.; Deng, Y. A new failure mode and effects analysis model using Dempster-Shafer evidence theory and grey relational projection method. Eng. Appl. Artif. Intell. 2018, 76, 13–20. [Google Scholar]
- Janghorbani, A.; Moradi, M.H. Fuzzy evidential network and its application as medical prognosis and diagnosis models. J. Biomed. Inform. 2017, 72, 96–107. [Google Scholar]
- Chen, L.; Diao, L.; Sang, J. Weighted Evidence Combination Rule Based on Evidence Distance and Uncertainty Measure: An Application in Fault Diagnosis. Math. Probl. Eng. 2018, 2018, 5858272. [Google Scholar]
- Han, Y.; Deng, Y. A hybrid intelligent model for Assessment of critical success factors in high risk emergency system. J. Ambient Intell. Hum. Comput. 2018, 9, 1933–1953. [Google Scholar] [CrossRef]
- Chen, L.; Deng, X. A Modified Method for Evaluating Sustainable Transport Solutions Based on AHP and Dempster-Shafer Evidence Theory. Appl. Sci. 2018, 8, 563. [Google Scholar] [CrossRef]
- Deng, X.; Jiang, W. Dependence assessment in human reliability analysis using an evidential network approach extended by belief rules and uncertainty measures. Annal. Nuclear Energy 2018, 117, 183–193. [Google Scholar]
- Dahooie, J.H.; Zavadskas, E.K.; Abolhasani, M.; Vanaki, A.; Turskis, Z. A Novel Approach for Evaluation of Projects Using an Interval–Valued Fuzzy Additive Ratio Assessment ARAS Method: A Case Study of Oil and Gas Well Drilling Projects. Symmetry 2018, 10, 45. [Google Scholar] [CrossRef]
- Chatterjee, K.; Pamucar, D.; Zavadskas, E.K. Evaluating the performance of suppliers based on using the R’AMATEL-MAIRCA method for green supply chain implementation in electronics industry. J. Clean. Prod. 2018, 184, 101–129. [Google Scholar]
- Seiti, H.; Hafezalkotob, A.; Najafi, S.; Khalaj, M. A risk-based fuzzy evidential framework for FMEA analysis under uncertainty: An interval-valued DS approach. J. Intell. Fuzzy Syst. 2018, 35, 1–12. [Google Scholar]
- Behrouz, M.; Alimohammadi, S. Uncertainty Analysis of Flood Control Measures Including Epistemic and Aleatory Uncertainties: Probability Theory and Evidence Theory. J. Hydrol. Eng. 2018, 23, 04018033. [Google Scholar]
- Wu, B.; Yan, X.; Wang, Y.; Soares, C.G. An Evidential Reasoning-Based CREAM to Human Reliability Analysis in Maritime Accident Process. Risk Anal. 2017, 37, 1936–1957. [Google Scholar]
- Li, M.; Zhang, Q.; Deng, Y. Evidential identification of influential nodes in network of networks. Chaos Solitons Fractals 2018, 117, 283–296. [Google Scholar]
- Han, Y.; Deng, Y. An enhanced fuzzy evidential DEMATEL method with its application to identify critical success factors. Soft Comput. 2018, 22, 5073–5090. [Google Scholar]
- Lachaize, M.; Le Hégarat-Mascle, S.; Aldea, E.; Maitrot, A.; Reynaud, R. Evidential framework for Error Correcting Output Code classification. Eng. Appl. Artif. Intell. 2018, 73, 10–21. [Google Scholar]
- Su, Z.g.; Denoeux, T.; Hao, Y.s.; Zhao, M. Evidential K-NN classification with enhanced performance via optimizing a class of parametric conjunctive t-rules. Knowl-Based Syst. 2018, 142, 7–16. [Google Scholar]
- Xu, X.; Zheng, J.; Yang, J.B.; Xu, D.L.; Chen, Y.W. Data classification using evidence reasoning rule. Knowl-Based Syst. 2017, 116, 144–151. [Google Scholar] [Green Version]
- Han, Y.; Deng, Y. An Evidential Fractal AHP target recognition method. Def. Sci. J. 2018, 68, 367–373. [Google Scholar]
- He, Z.; Jiang, W. An evidential dynamical model to predict the interference effect of categorization on decision making. Knowl-Based Syst. 2018, 150, 139–149. [Google Scholar]
- Xiao, F. A Hybrid Fuzzy Soft Sets Decision Making Method in Medical Diagnosis. IEEE Access 2018, 6, 25300–25312. [Google Scholar]
- Xiao, F. A novel multi-criteria decision making method for assessing health-care waste treatment technologies based on D numbers. Eng. Appl. Artif. Intell. 2018, 71, 216–225. [Google Scholar]
- Zhu, W.; Ku, Q.; Wu, Y.; Zhang, H.; Sun, Y.; Zhang, C. A research into the evidence reasoning theory of two-dimensional framework and its application. Kybernetes 2018, 47, 873–887. [Google Scholar]
- Han, Y.; Deng, Y. A novel matrix game with payoffs of Maxitive Belief Structure. Int. J. Intell. Syst. 2019, 34, 690–706. [Google Scholar]
- Fei, L.; Deng, Y. A new divergence measure for basic probability assignment and its applications in extremely uncertain environments. Int. J. Intell. Syst. 2019, 34, 584–600. [Google Scholar] [CrossRef]
- Xu, X.; Li, S.; Song, X.; Wen, C.; Xu, D. The optimal design of industrial alarm systems based on evidence theory. Control Eng. Pract. 2016, 46, 142–156. [Google Scholar]
- Zhou, Y.; Tao, X.; Luan, L.; Wang, Z. Safety justification of train movement dynamic processes using evidence theory and reference models. Knowl-Based Syst. 2018, 139, 78–88. [Google Scholar]
- Du, Y.W.; Shan, Y.K.; Li, C.X.; Wang, R. Mass Collaboration-Driven Method for Recommending Product Ideas Based on Dempster-Shafer Theory of Evidence. Math. Probl. Eng. 2018, 2018, 1980152. [Google Scholar]
- Yin, L.; Deng, X.; Deng, Y. The negation of a basic probability assignment. IEEE Trans. Fuzzy Syst. 2019, 27, 135–143. [Google Scholar]
- Yager, R.R.; Alajlan, N. Maxitive Belief Structures and Imprecise Possibility Distributions. IEEE Trans. Fuzzy Syst. 2017, 25, 768–774. [Google Scholar]
- Zhou, X.; Hu, Y.; Deng, Y.; Chan, F.T.S.; Ishizaka, A. A DEMATEL-Based Completion Method for Incomplete Pairwise Comparison Matrix in AHP. Annal. Oper. Res. 2018, 271, 1045–1066. [Google Scholar]
- Li, Y.; Deng, Y. Generalized Ordered Propositions Fusion Based on Belief Entropy. Int. J. Comput. Commun. Control 2018, 13, 792–807. [Google Scholar]
- Pan, L.; Deng, Y. A New Belief Entropy to Measure Uncertainty of Basic Probability Assignments Based on Belief Function and Plausibility Function. Entropy 2018, 20, 842. [Google Scholar] [CrossRef]
- Deng, X.; Jiang, W.; Wang, Z. Zero-sum polymatrix games with link uncertainty: A Dempster-Shafer theory solution. Appl. Math. Comput. 2019, 340, 101–112. [Google Scholar]
- Xiao, F. An Improved Method for Combining Conflicting Evidences Based on the Similarity Measure and Belief Function Entropy. Int. J. Fuzzy Syst. 2018, 20, 1256–1266. [Google Scholar]
- Cao, Z.; Lin, C.T. Inherent Fuzzy Entropy for the Improvement of EEG Complexity Evaluation. IEEE Trans. Fuzzy Syst. 2018, 26, 1032–1035. [Google Scholar] [CrossRef] [Green Version]
- Song, Y.; Wang, X.; Lei, L.; Xing, Y. Credibility decay model in temporal evidence combination. Inf. Process. Lett. 2015, 115, 248–252. [Google Scholar]
- Smets, P. Analyzing the combination of conflicting belief functions. Inf. Fusion 2007, 8, 387–412. [Google Scholar]
- Wang, J.; Liu, F. Temporal evidence combination method for multi-sensor target recognition based on DS theory and IFS. J. Syst. Eng. Electron. 2017, 28, 1114–1125. [Google Scholar]
- Xu, P.; Zhang, R.; Deng, Y. A Novel Visibility Graph Transformation of Time Series into Weighted Networks. Chaos Solitons Fractals 2018, 117, 201–208. [Google Scholar]
- Xiao, F. Multi-sensor data fusion based on the belief divergence measure of evidences and the belief entropy. Inf. Fusion 2019, 46, 23–32. [Google Scholar]
- Lu, F.; Jiang, C.; Huang, J.; Wang, Y.; You, C. A novel data hierarchical fusion method for gas turbine engine performance fault diagnosis. Energies 2016, 9, 828. [Google Scholar]
- Axenie, C.; Richter, C.; Conradt, J. A Self-Synthesis Approach to Perceptual Learning for Multisensory Fusion in Robotics. Sensors 2016, 16, 1751. [Google Scholar] [Green Version]
- Yager, R.R. On ordered weighted averaging aggregation operators in multicriteria decisionmaking. IEEE Trans. Syst. Man Cybern. 1988, 18, 183–190. [Google Scholar]
- Yager, R.R. Applications and extensions of OWA aggregations. Int. J. Man-Mach. Stud. 1992, 37, 103–122. [Google Scholar]
- Kang, B.; Deng, Y.; Hewage, K.; Sadiq, R. Generating Z- number based on OWA weights using maximum entropy. Int. J. Intell. Syst. 2018, 33, 1745–1755. [Google Scholar]
- Fei, L.; Wang, H.; Chen, L.; Deng, Y. A new vector valued similarity measure for intuitionistic fuzzy sets based on OWA operators. Iran. J. Fuzzy Syst. 2018. [Google Scholar] [CrossRef]
- Mardani, A.; Nilashi, M.; Zavadskas, E.K.; Awang, S.R.; Zare, H.; Jamal, N.M. Decision making methods based on fuzzy aggregation operators: Three decades review from 1986 to 2017. Int. J. Inf. Technol. Decis. Making 2018, 17, 391–466. [Google Scholar]
- Seiti, H.; Hafezalkotob, A. Developing the R-TOPSIS methodology for risk-based preventive maintenance planning: A case study in rolling mill company. Comput. Ind. Eng. 2019, 128, 622–636. [Google Scholar]
- Dutta, P.; Hazarika, G. Construction of families of probability boxes and corresponding membership functions at different fractiles. Expert Syst. 2017, 34, e12202. [Google Scholar]
- Keshavarz Ghorabaee, M.; Amiri, M.; Zavadskas, E.K.; Antucheviciene, J. Supplier evaluation and selection in fuzzy environments: a review of MADM approaches. Econ. Res-Ekonomska Istraživanja 2017, 30, 1073–1118. [Google Scholar] [Green Version]
- Yin, L.; Deng, Y. Toward uncertainty of weighted networks: An entropy-based model. Phys. A Stat. Mech. Appl. 2018, 508, 176–186. [Google Scholar] [CrossRef]
- Fei, L.; Zhang, Q.; Deng, Y. Identifying influential nodes in complex networks based on the inverse-square law. Phys. A Stat. Mech. Appl. 2018, 512, 1044–1059. [Google Scholar] [CrossRef]
- Yang, H.; Deng, Y.; Jones, J. Network Division Method Based on Cellular Growth and Physarum-inspired Network Adaptation. Int. J. Unconv. Comput. 2018, 13, 477–491. [Google Scholar]
- Song, Y.; Wang, X.; Lei, L.; Yue, S. Uncertainty measure for interval-valued belief structures. Measurement 2016, 80, 241–250. [Google Scholar]
- Wang, X.; Song, Y. Uncertainty measure in evidence theory with its applications. Appl. Intell. 2017. [Google Scholar] [CrossRef]
- Deng, X. Analyzing the monotonicity of belief interval based uncertainty measures in belief function theory. Int. J. Intell. Syst. 2018, 33, 1869–1879. [Google Scholar]
- Sun, R.; Deng, Y. A new method to identify incomplete frame of discernment in evidence theory. IEEE Access 2019, 7, 15547–15555. [Google Scholar]
- Xiao, F. A multiple criteria decision-making method based on D numbers and belief entropy. Int. J. Fuzzy Syst. 2019. [Google Scholar] [CrossRef]
- Yager, R.R. Fuzzy rule bases with generalized belief structure inputs. Eng. Appl. Artif. Intell. 2018, 72, 93–98. [Google Scholar]
- Seiti, H.; Hafezalkotob, A. Developing pessimistic-optimistic risk-based methods for multi-sensor fusion: An interval-valued evidence theory approach. Appl. Soft Comput. 2018. [Google Scholar] [CrossRef]
- Shi, F.; Su, X.; Qian, H.; Yang, N.; Han, W. Research on the Fusion of Dependent Evidence Based on Rank Correlation Coefficient. Sensors 2017, 17, 2362. [Google Scholar] [Green Version]
- Mönks, U.; Dörksen, H.; Lohweg, V.; Hübner, M. Information fusion of conflicting input data. Sensors 2016, 16, 1798. [Google Scholar]
- Sun, G.; Guan, X.; Yi, X.; Zhao, J. Conflict Evidence Measurement Based on the Weighted Separate Union Kernel Correlation Coefficient. IEEE Access 2018, 6, 30458–30472. [Google Scholar]
- Wang, Y.; Deng, Y. Base belief function: an efficient method of conflict management. J. Ambient Intell. Hum. Comput. 2018. [Google Scholar] [CrossRef]
- Zhang, W.; Deng, Y. Combining conflicting evidence using the DEMATEL method. Soft Comput. 2018. [Google Scholar] [CrossRef]
- Yang, J.B.; Xu, D.L. Evidential reasoning rule for evidence combination. Artif. Intell. 2013. [Google Scholar] [CrossRef]
- Dutta, P. An uncertainty measure and fusion rule for conflict evidences of big data via Dempster–Shafer theory. Int. J. Image Data Fusion 2018, 9, 152–169. [Google Scholar] [CrossRef]
- Smets, P.; Kennes, R. The transferable belief model. Artif. Intell. 1994, 66, 191–234. [Google Scholar]
- Xu, Z. Uncertain linguistic aggregation operators based approach to multiple attribute group decision making under uncertain linguistic environment. Inf. Sci. 2004, 168, 171–184. [Google Scholar]
- Calvo, T.; Mayor, G.; Mesiar, R. Aggregation Operators: New Trends and Applications; Physica: Ringwood, Australia, 2012; Volume 97. [Google Scholar]
- Zadeh, L.A. A computational approach to fuzzy quantifiers in natural languages. Comput. Math. Appl. 1983, 9, 149–184. [Google Scholar] [Green Version]
Figure 1.
Process to generate OWA discounts.

Figure 2.
Function Q.

Figure 3.
Results of Example 4.

Figure 4.
Identification effect in Example 4.

Figure 5.
Results of Example 5.

Figure 6.
Results of Example 5.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Weights and σ.
| Time Node | (Credibility ) | (Effect Degree) |
|---|---|---|
| = 1 s | - | - |
| = 4 s | 1.000 | 1.000 |
| = 7 s | 0.800 | 0.800 |
| = 17 s | 0.600 | 0.480 |
| = 20 s | 0.480 | 0.230 |
| = 23 s | 0.400 | 0.092 |
| = 25 s | 0.343 | 0.032 |
| = 29 s | 0.300 | 0.009 |
| = 39 s | 1.000 | 0.009 |
| = 42 s | 0.800 | 0.002 |
Table 2.
10 evidences with BPAs and their discounts.
| m(A) | m(B) | m(C) | m(AB) | m(AC) | m(BC) | m() | in OWA Model | in OM | |
|---|---|---|---|---|---|---|---|---|---|
| = 1 s | 0.4 | 0.1 | 0.1 | 0.2 | 0.2 | 0 | 0 | - | - |
| = 4 s | 0.6 | 0.2 | 0.1 | 0 | 0.05 | 0.05 | 0 | 1 | 0.638 |
| = 7 s | 0.65 | 0.15 | 0 | 0 | 0 | 0.2 | 0 | 0.8 | 0.638 |
| = 17 s | 0.1 | 0.75 | 0 | 0.15 | 0 | 0 | 0 | 0.6 | 0.223 |
| = 20 s | 0.6 | 0.3 | 0 | 0.1 | 0 | 0 | 0 | 0.48 | 0.638 |
| = 23 s | 0.65 | 0.25 | 0 | 0 | 0 | 0 | 0.1 | 0.4 | 0.638 |
| = 25 s | 0.6 | 0.3 | 0 | 0 | 0 | 0 | 0.1 | 0.343 | 0.741 |
| = 29 s | 0.7 | 0.2 | 0 | 0.1 | 0 | 0 | 0 | 0.3 | 0.549 |
| = 39 s | 0.5 | 0.5 | 0 | 0 | 0 | 0 | 0 | 1 | 0.223 |
| = 42 s | 0.65 | 0.1 | 0.15 | 0 | 0 | 0.1 | 0 | 0.8 | 0.638 |
Table 3.
BPAs from sensors in Example 5.
| Time Node | BPA | in OWA Model | in OM |
|---|---|---|---|
| = 1 s | m(A) = 0.5, m(B) = 0.1 | ||
| m(C) = 0.1, m(AB) = 0.2 | - | - | |
| m(AC) = 0.1 | |||
| = 10 s | m(A) = 0.7, m(B) = 0.1 | ||
| m(C) = 0.1, m(AC) = 0.05 | 1.00 | 0.259 | |
| m(BC) = 0.05 | |||
| = 20 s | m(A) = 0.1, m(B) = 0.7 | 0.80 | 0.223 |
| m(AB) = 0.2 | |||
| = 22 s | m(A) = 0.5, m(B) = 0.2 | 0.60 | 0.741 |
| m(ABC) = 0.3 | |||
| = 30 s | m(A) = 0.7, m(B) = 0.1 | 0.48 | 0.638 |
| m(AB) = 0.2 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Liu, G.; Xiao, F. Time Series Data Fusion Based on Evidence Theory and OWA Operator. Sensors 2019, 19, 1171. https://doi.org/10.3390/s19051171
AMA Style
Liu G, Xiao F. Time Series Data Fusion Based on Evidence Theory and OWA Operator. Sensors. 2019; 19(5):1171. https://doi.org/10.3390/s19051171
Chicago/Turabian StyleLiu, Gang, and Fuyuan Xiao. 2019. "Time Series Data Fusion Based on Evidence Theory and OWA Operator" Sensors 19, no. 5: 1171. https://doi.org/10.3390/s19051171
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.