Multi-Source Deep Transfer Neural Network Algorithm

Abstract
1. Introduction
2. Related Works
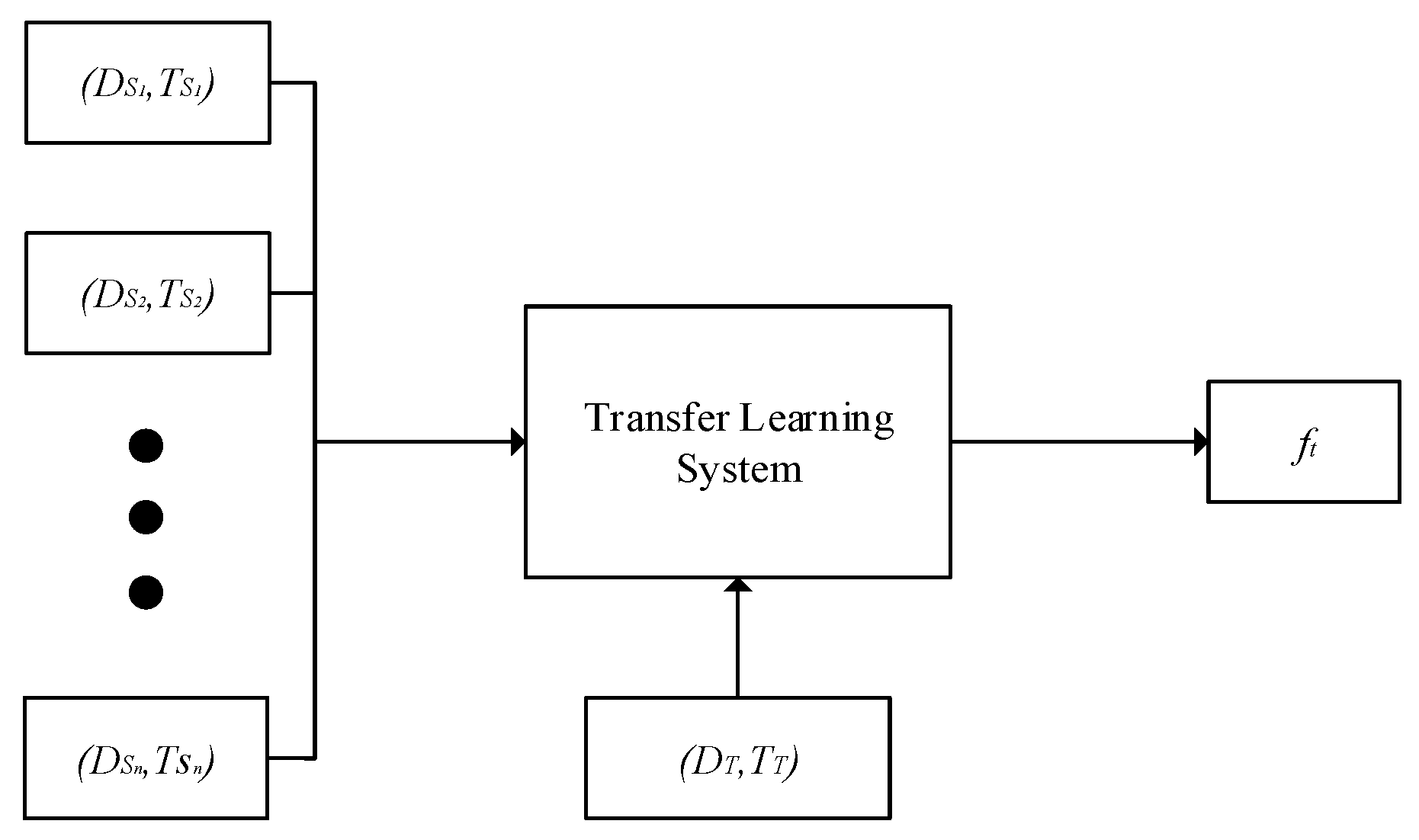
2.1. Multi-Source Transfer Learning
2.2. Convolutional Neural Network
2.3. Maximum Mean Discrepancy
3. Multi-Source Deep Transfer Neural Network
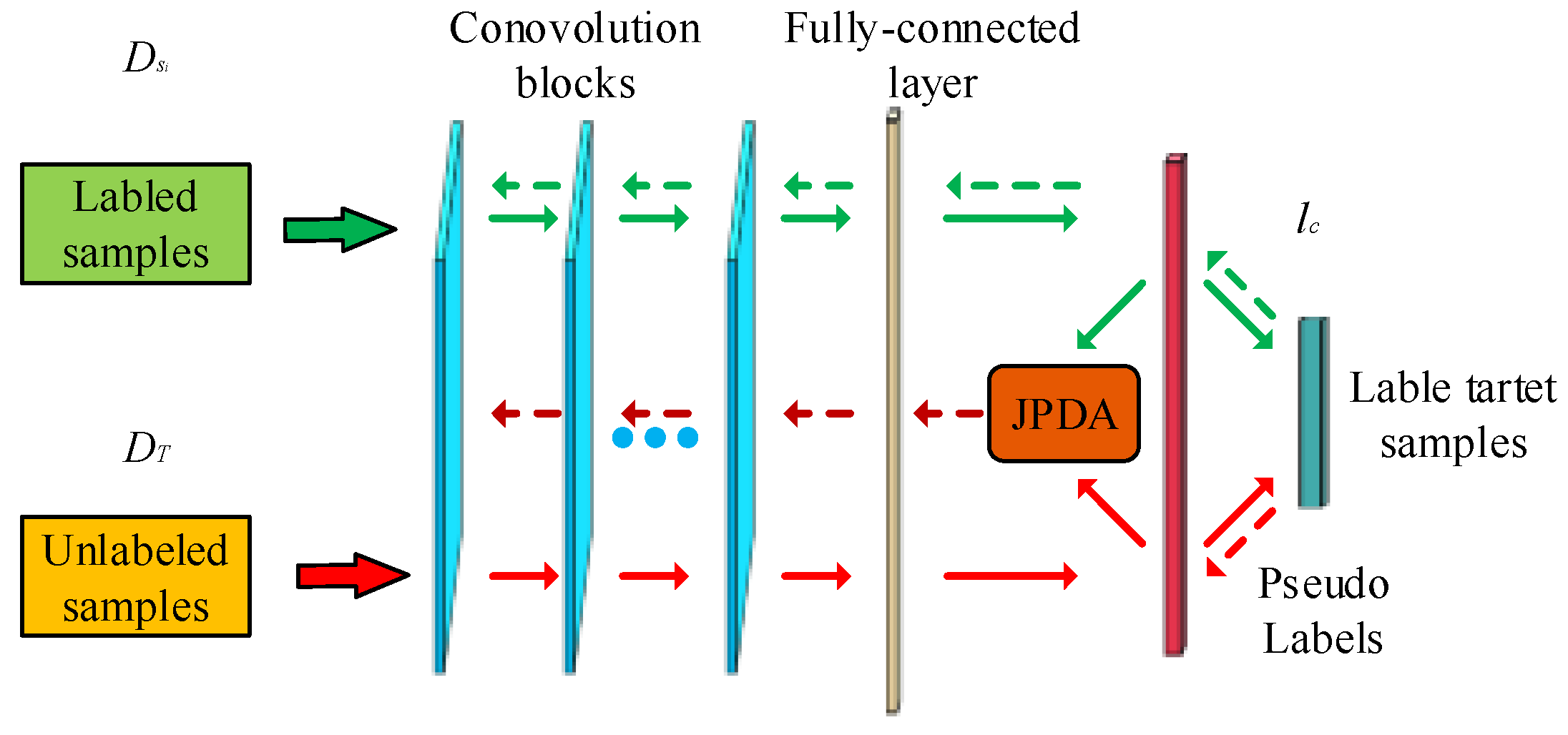
3.1. Joint Probability Distribution Adaptation
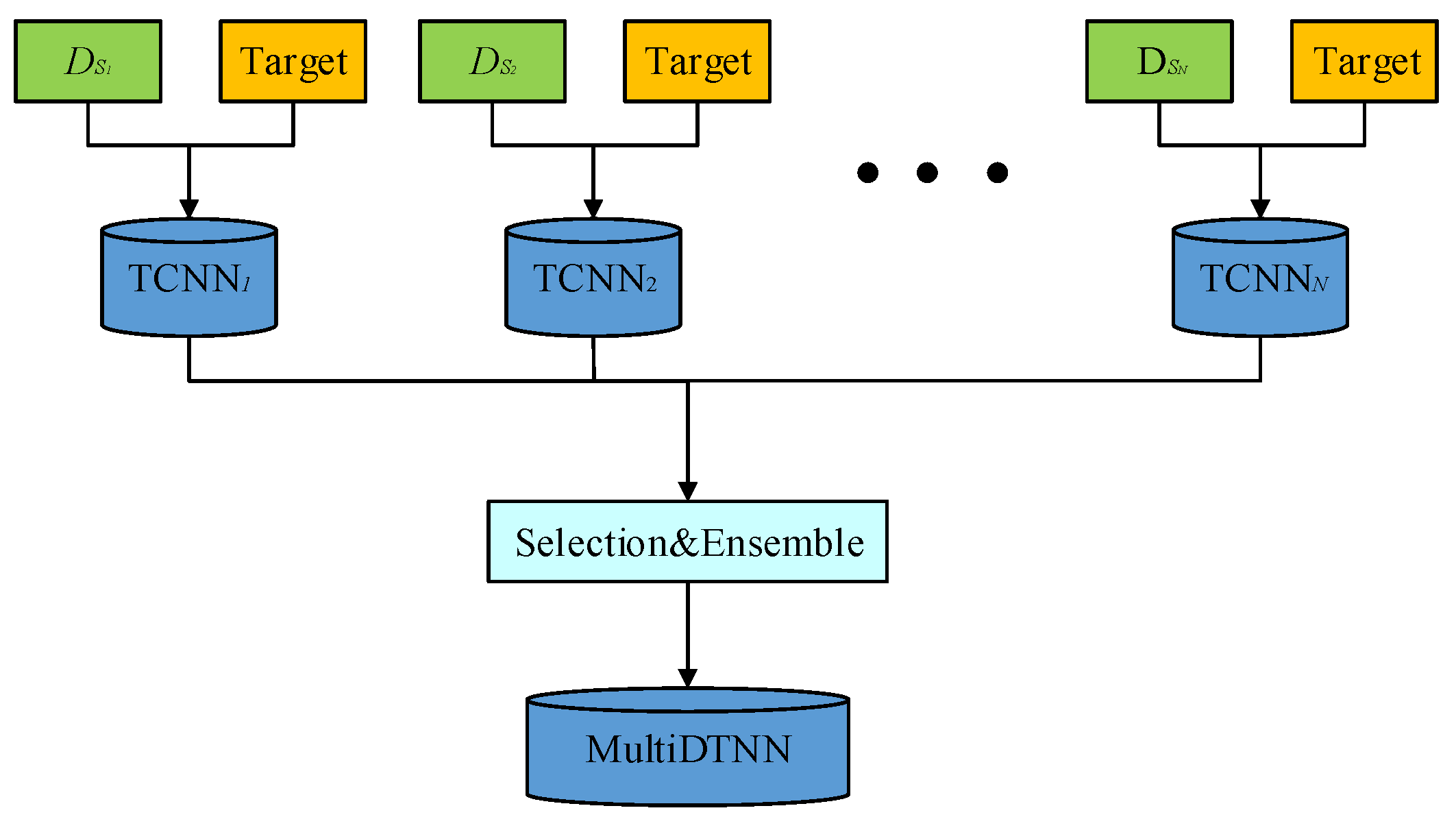
3.2. Construction of MultiDTNN
3.3. Training Strategy of MultiDTNN
4. Experimental Results
4.1. Experimental Setting
4.2. Datasets
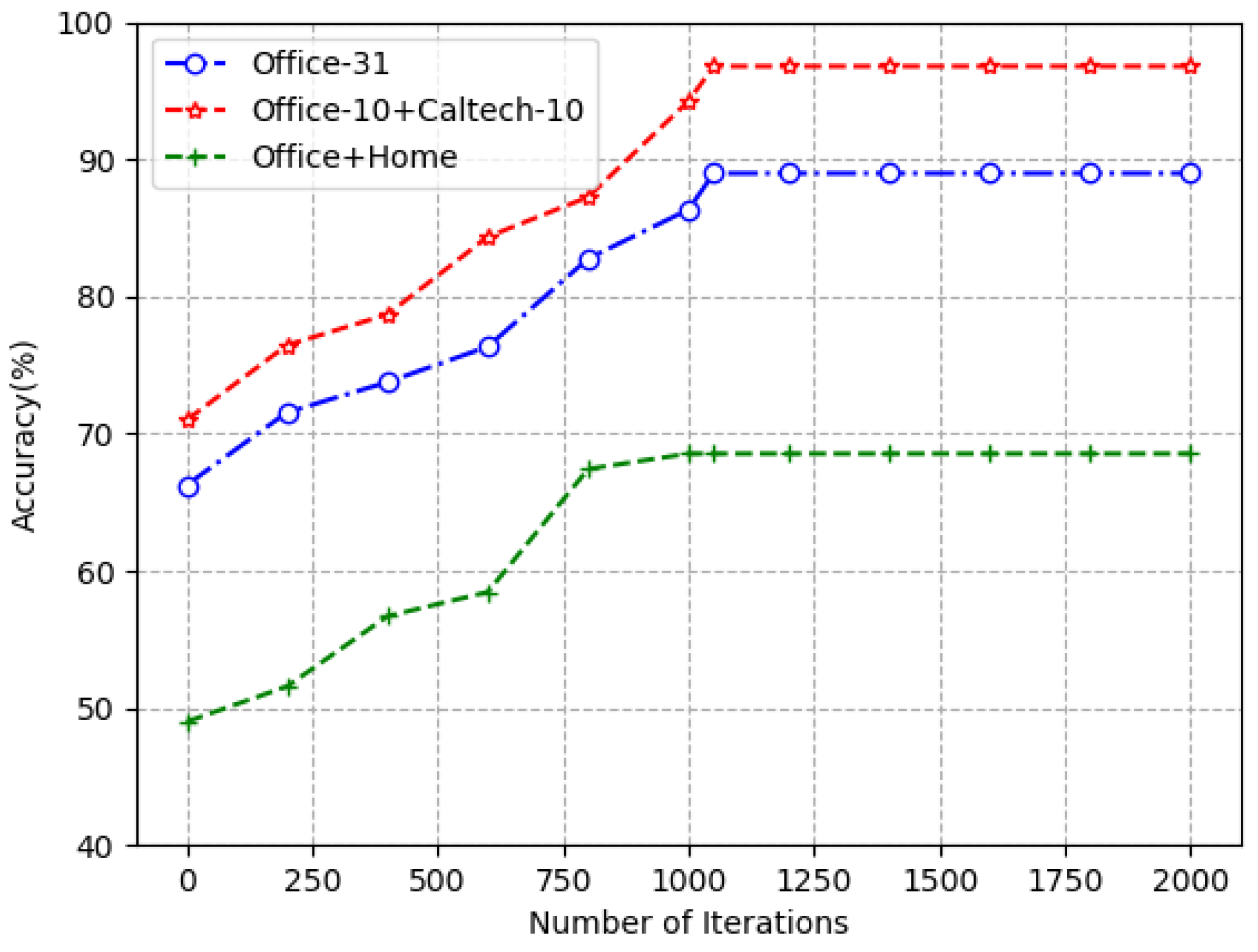
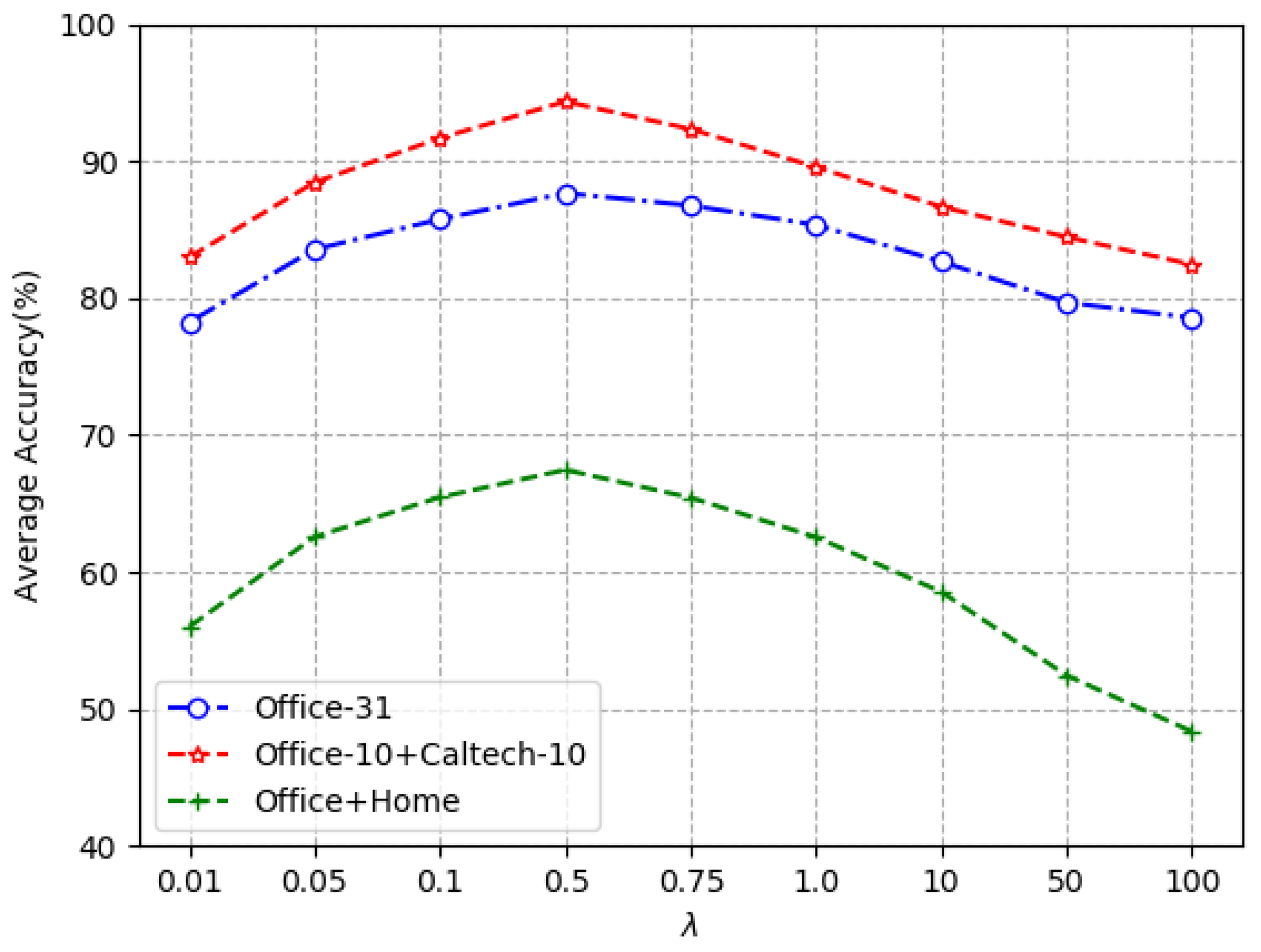
4.3. Analysis of Experimental Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Jordan, M.I.; Mitchell, T.M. Machine Learning: Trends, Perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef]
- Ashfaq, R.A.R.; Wang, X.Z.; Huang, J.Z.; Abbas, H.; He, Y.L. Fuzziness based semi-supervised learning approach for Intrusion Detection System. Inf. Sci. 2016, 378, 484–497. [Google Scholar] [CrossRef]
- Cavusoglu, U. A new hybrid approach for intrusion detection using machine learning methods. Appl. Intell. 2019, 49, 2735–2761. [Google Scholar] [CrossRef]
- Abdelhamid, O.; Mohamed, A.; Jiang, H.; Deng, L.; Penn, G.; Yu, D. Convolutional Neural Networks for Speech Recognition. IEEE Trans. Audio Speech Lang. Process. 2014, 22, 1533–1545. [Google Scholar] [CrossRef]
- Agarwalla, S.; Sarma, K.K. Machine learning based sample extraction for automatic speech recognition using dialectal Assamese speech. Neural Netw. 2016, 78, 97–111. [Google Scholar] [CrossRef] [PubMed]
- Athanasios, V.; Nikolaos, D.; Anastasios, D.; Protopapadakis, E. Deep Learning for Computer Vision: A Brief Review. Comput. Intell. Neurosci. 2018, 1–13. [Google Scholar] [CrossRef]
- Vodrahalli, K.; Bhowmik, A.K. 3D computer vision based on machine learning with deep neural networks: A review. J. Soc. Inf. Disp. 2017, 25, 676–694. [Google Scholar] [CrossRef]
- Kumari, K.R.V.; Kavitha, C.R. Spam Detection Using Machine Learning in R. In Proceedings of the International Conference on Computer Networks and Communication Technologies, Coimbatore, India, 26–27 April 2018. [Google Scholar]
- Olatunji, O.S. Improved email spam detection model based on support vector machines. Neural Comput. Appl. 2017, 31, 691–699. [Google Scholar] [CrossRef]
- Chen, C.L.P. Deep learning for pattern learning and recognition. In Proceedings of the 10th IEEE Jubilee International Symposium on Applied Computational Intelligence & Informatics, Timisora, Romania, 21–23 May 2015. [Google Scholar]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D.D. A survey of transfer learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef]
- Pan, S.J.; Qiang, Y. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Day, O.; Khoshgoftaar, T.M. A survey on heterogeneous transfer learning. J. Big Data 2017, 4, 29. [Google Scholar] [CrossRef]
- Gao, J.; Fan, W.; Jiang, J.; Han, J. Knowledge transfer via multiple model local structure mapping. In Proceedings of the 14th ACM SIGKDD international conference, Las Vegas, NV, USA, 21–23 August 2008. [Google Scholar]
- Quanz, B.; Huan, J. Large margin transductive transfer learning. In Proceedings of the 18th ACM Conference on Information and Knowledge Management, CIKM 2009, Hong Kong, China, 2–6 November 2009. [Google Scholar]
- Lu, Z.; Zhong, E.; Zhao, L.; Xiang, E.W.; Pan, W.; Yang, Q. Selective Transfer Learning for Cross Domain Recommendation. In Proceedings of the Proceedings of the 2013 SIAM International Conference on Data Mining, Austin, TX, USA, 2–4 May 2013. [Google Scholar]
- Long, M.; Wang, J.; Ding, G.; Pan, S.J.; Philip, S.Y. Adaptation Regularization: A General Framework for Transfer Learning. IEEE Trans. Knowl. Data Eng. 2014, 26, 1076–1089. [Google Scholar] [CrossRef]
- Xie, G.; Sun, Y.; Lin, M.; Tang, K. A Selective Transfer Learning Method for Concept Drift Adaptation. In Proceedings of the 14th International Symposium on Neural Networks (ISNN), Sapporo, Japan, 21–26 June 2017. [Google Scholar]
- Li, X.; Mao, W.; Jiang, W. Extreme learning machine based transfer learning for data classification. Neurocomputing 2016, 174, 203–210. [Google Scholar] [CrossRef]
- Li, M.; Dai, Q. A novel knowledge-leverage-based transfer learning algorithm. Appl. Intell. 2018, 48, 2355–2372. [Google Scholar] [CrossRef]
- Sun, S.; Shi, H.; Wu, Y. A survey of multi-source domain adaptation. Inf. Fusion 2015, 24, 84–92. [Google Scholar] [CrossRef]
- Yao, Y.; Doretto, G. Boosting for transfer learning with multiple sources. In Proceedings of the 23rd IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Sun, Q.; Chattopadhyay, R.; Panchanathan, S.; Ye, J. A Two-Stage Weighting Framework for Multi-Source Domain Adaptation. In Proceedings of the Advances in neural information processing system, Granada, Spain, 12–14 December 2011; pp. 505–513. [Google Scholar]
- Duan, L.; Xu, D.; Tsang, I.W. Domain Adaptation From Multiple Sources: A Domain-Dependent Regularization Approach. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 504–518. [Google Scholar] [CrossRef] [PubMed]
- Wu, Q.; Zhou, X.; Yan, Y.; Wu, H.; Min, H. Online transfer learning by leveraging multiple source domains. Knowl. Inf. Syst. 2017, 52, 687–707. [Google Scholar] [CrossRef]
- Ding, Z.; Shao, M.; Fu, Y. Incomplete Multisource Transfer Learning. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 310–323. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Yan, R.; Hauptmann, A.G. Cross-domain video concept detection using adaptive SVMs. In Proceedings of the 15th International Conference on Multimedia, Augsburg, Germany, 24–29 September 2007. [Google Scholar]
- Huang, J.T.; Li, J.; Yu, D.; Deng, L.; Gong, Y. Cross-language knowledge transfer using multilingual deep neural network with shared hidden layers. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013. [Google Scholar]
- Ding, Z.; Fu, Y. Deep Transfer Low-Rank Coding for Cross-Domain Learning. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Han, T.; Liu, C.; Yang, W.; Jiang, D. Deep Transfer Network with Joint Distribution Adaptation: A New Intelligent Fault Diagnosis Framework for Industry Application. ISA Trans. 2019. [Google Scholar] [CrossRef]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M.I. Learning Transferable Features with Deep Adaptation Networks. arXiv 2015, arXiv:1502.02791. [Google Scholar]
- Tzeng, E.; Hoffman, J.; Darrell, T.; Saenko, K. Simultaneous Deep Transfer Across Domains and Tasks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 4068–4076. [Google Scholar]
- Zhang, W.; Peng, G.; Li, C.; Chen, Y.; Zhang, Z. A New Deep Learning Model for Fault Diagnosis with Good Anti-Noise and Domain Adaptation Ability on Raw Vibration Signals. Sensors 2017, 17, 425. [Google Scholar] [CrossRef] [PubMed]
- Venkateswara, H.; Eusebio, J.; Chakraborty, S.; Panchanathan, S. Deep hashing network for unsupervised domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5018–5027. [Google Scholar]
- Tzeng, E.; Hoffman, J.; Zhang, N.; Saenko, K.; Darrell, T. Deep domain confusion: Maximizing for domain invariance. arxiv 2014, arXiv:1412.3474. [Google Scholar]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, L.; Wang, G.; et al. Recent Advances in Convolutional Neural Networks. Pattern Recognit. 2015, 77, 354–377. [Google Scholar] [CrossRef]
- Hinton, G.; Salakhutdinov, R.R. Reducing the dimensionality of data with neura1 networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Yuan, Q.; Zhang, Q.; Li, J.; Shen, H.; Zhang, L. Hyperspectral Image Denoising Employing a Spatial-Spectral Deep Residual Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2018, 57, 1205–1218. [Google Scholar] [CrossRef]
- Sun, B.; Saenko, K. Deep CORAL: Correlation alignment for deep domain adaptation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 443–450. [Google Scholar]
- Ding, C.; Tao, D. Trunk-Branch Ensemble Convolutional Neural Networks for Video-based Face Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1002–1014. [Google Scholar] [CrossRef] [PubMed]
- Wiatowski, T.; Bolcskei, H. A Mathematical Theory of Deep Convolutional Neural Networks for Feature Extraction. IEEE Trans. Inf. Theory 2017, 64, 1845–1866. [Google Scholar] [CrossRef]
- Gretton, A.; Borgwardt, K.; Rasch, M.J.; Schölkopf, B.; Smola, A.J. A Kernel Method for the Two-Sample Problem. In Advance in NIPS 19; MIP Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Li, J.; Wu, W.; Xue, D. Appl Intell (2019). Available online: https://doi.org/10.1007/s10489-019-01512-6 (accessed on 14 September 2019).
- Ding, Z.; Shao, M.; Fu, Y. Deep Low-Rank Coding for Transfer Learning. In Proceedings of the 1st International Workshop on Social Influence Analysis/24th International Joint Conference on Artificial Intelligence (IJCAI), Buenos Aires, Argentin, 25–31 July 2015. [Google Scholar]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain Adaptation via Transfer Component Analysis. IEEE Trans. Inf. Theory 2011, 22, 199–210. [Google Scholar] [CrossRef] [PubMed]
- Christodoulidis, S.; Anthimopous, M.; Ebner, L.; Christe, A.; Mouqiakakou, S. Multi-source Transfer Learning with Convolutional Neural Networks for Lung Pattern Analysis. IEEE J. Biomed. Health Inform. 2016, 21, 76–84. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Procedure of MultiDTNN |
| Input: labeled source domains , the number of sample in is . An unlabeled training dataset in target domain, the architecture of deep neural network, the trade-off parameter , the maximum number of iterations . Output: Training: Step 1. Pre-train a set of classifier on ; for to do Train base deep network on Predict the pseudo labels on by using Repeat Compute the regularization term JPDA according to Equation (9) Obtain by optimizing with Equation (10) Update the pseudo labels with optimized network Until convergence or , Step 2. Initialize the weight vector for to do Step 3. The weight vector are normalized to 1 Step 4. Empty the current weak classifier set for to do Step 5. Compute the error of on if then Step 6. Step 7. Update by compute Step 8. Step 9. Find the weak classifier Step 10. Step 11. Set Step 12. Update the weight Step 13. Return |
| Algorithms | A->W | D->W | A->D | W->D | D->A | W->A |
|---|---|---|---|---|---|---|
| CNN [38] | 60.15 (0.45) | 94.33 (0.35) | 63.16 (0.46) | 98.23 (0.19) | 50.98 (0.58) | 50.01 (0.38) |
| DTLC [29] | 70.78 (0.31) | 97.11 (0.56) | 68.67 (0.52) | 99.23 (0.36) | 55.56 (0.32) | 54.11 (0.56) |
| STLCF [16] | 58.11 (0.39) | 92.26 (0.41) | 60.87 (0.36) | 96.14 (0.26) | 48.98 (0.45) | 48.87 (0.43) |
| DAN [31] | 69.52 (0.43) | 95.96 (0.34) | 67.14 (0.42) | 99.01 (0.21) | 54.23 (0.37) | 53.23 (0.34) |
| SDT [32] | 67.78 (0.32) | 96.12 (0.43) | 66.57 (0.52) | 98.86 (0.38) | 54.45 (0.23) | 54.12 (0.37) |
| DHN [34] | 68.27 (0.43) | 96.15 (0.23) | 66.55 (0.28) | 98.56 (0.33) | 55.97 (0.27) | 52.65 (0.23) |
| ARTL [12] | 57.27 (0.51) | 93.57 (0.37) | 59.31 (0.45) | 95.45 (0.22) | 49.14 (0.43) | 47.36 (0.33) |
| D-CORAL [40] | 67.24 (0.37) | 95.68 (0.35) | 66.87 (0.58) | 99.23 (0.26) | 52.35 (0.34) | 51.26 (0.32) |
| DDC [35] | 62.02 (0.46) | 95.02 (0.53) | 65.23 (0.39) | 98.43 (0.41) | 52.13 (0.67) | 51.98 (0.46) |
| {A,W,D}->W | {A,W,D}->D | {A,W,D}->A | ||||
| TaskTrBoost [22] | 66.67 (0.42) | 94.67 (0.48) | 64.76 (0.35) | 95.67 (0.43) | 51.34 (0.38) | 50.24 (0.34) |
| FastDAM [24] | 68.34 (0.37) | 95.86 (0.46) | 65.32 (0.38) | 98.43 (0.35) | 52.72 (0.42) | 52.36 (0.32) |
| IMTL [26] | 70.45 (0.35) | 96.98 (0.51) | 66.15 (0.43) | 99.11 (0.36) | 53.98 (0.53) | 53.65 (0.41) |
| MultiDTNN | 73.65 (0.29) | 98.13 (0.52) | 70.01 (0.43) | 99.56 (0.38) | 57.11 (0.54) | 56.98 (0.35) |
| Algorithms | A->C | D->C | W->C | A->W | C->W | D->W | A->D | C->D | W->D | C->A | D->A | W->A |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CNN [38] | 83.76 (0.33) | 81.23 (0.43) | 75.89 (0.55) | 83.24 (0.29) | 82.87 (0.35) | 97.53 (0.24) | 88.65 (0.36) | 89.34 (0.31) | 98.14 (0.27) | 91.01 (0.23) | 89.23 (0.28) | 83.25 (0.32) |
| DTLC [29] | 88.76 (0.65) | 83.23 (0.34) | 82.45 (0.41) | 93.56 (0.48) | 93.01 (0.58) | 99.54 (0.31) | 93.77 (0.43) | 91.39 (0.36) | 99.47 (0.13) | 93.46 (0.62) | 93.18 (0.52) | 94.12 (0.59) |
| STLCF [16] | 82.25 (0.43) | 80.56 (0.56) | 74.32 (0.58) | 82.11 (0.53) | 81.22 (0.51) | 96.34 (0.52) | 87.34 (0.42) | 88.34 (0.48) | 97.21 (0.24) | 89.53 (0.43) | 88.43 (0.51) | 82.13 (0.47) |
| DAN [31] | 86.01 (0.28) | 82.56 (0.38) | 81.62 (0.36) | 93.88 (0.43) | 92.12 (0.37) | 99.11 (0.22) | 92.16 (0.29) | 90.83 (0.27) | 99.12 (0.11) | 91.87 (0.31) | 92.11 (0.48) | 92.46 (0.35) |
| SDT [32] | 85.24 (0.32) | 81.98 (0.45) | 80.87 (0.36) | 93.67 (0.34) | 92.11 (0.54) | 99.26 (0.41) | 91.58 (0.46) | 90.45 (0.37) | 99.32 (0.18) | 91.12 (0.31) | 91.34 (0.43) | 91.42 (0.48) |
| DHN [34] | 86.35 (0.26) | 82.12 (0.42) | 81.23 (0.32) | 93.32 (0.25) | 92.45 (0.21) | 99.15 (0.37) | 89.57 (0.31) | 90.11 (0.35) | 99.26 (0.19) | 92.11 (0.28) | 91.68 (0.36) | 91.63 (0.34) |
| ARTL [12] | 81.46 (0.43) | 79.26 (0.43) | 73.87 (0.49) | 81.87 (0.55) | 80.87 (0.52) | 95.23 (0.56) | 86.32 (0.48) | 87.96 (0.47) | 98.43 (0.28) | 88.41 (0.38) | 88.01 (0.44) | 81.97 (0.54) |
| D-CORAL [40] | 85.87 (0.37) | 82.45 (0.28) | 81.34 (0.22) | 92.59 (0.32) | 91.37 (0.38) | 99.34 (0.31) | 89.26 (0.35) | 89.98 (0.42) | 99.56 (0.15) | 92.43 (0.33) | 91.76 (0.37) | 91.64 (0.24) |
| DDC [35] | 84.23 (0.52) | 81.26 (0.37) | 78.13 (0.53) | 86.54 (0.41) | 82.15 (0.43) | 98.26 (0.38) | 89.11 (0.38) | 89.74 (0.45) | 99.67 (0.21) | 92.21 (0.35) | 90.12 (0.42) | 85.15 (0.47) |
| {A,D,W,C}->C | {A,D,W,C}->W | {A,D,W,C}->D | {A,D,W,C}->A | |||||||||
| TaskTrBoost [22] | 83.56 (0.41) | 81.64 (0.34) | 80.26 (0.53) | 88.34 (0.52) | 87.45 (0.47) | 97.33 (0.46) | 88.35 (0.51) | 89.56 (0.43) | 97.78 (0.24) | 91.25 (0.33) | 89.23 (0.38) | 88.67 (0.36) |
| FastDAM [24] | 84.32 (0.35) | 82.11 (0.45) | 81.23 (0.47) | 90.32 (0.48) | 89.21 (0.43) | 98.32 (0.49) | 89.35 (0.46) | 90.65 (0.39) | 98.34 (0.29) | 92.56 (0.29) | 92.27 (0.42) | 92.35 (0.48) |
| IMTL [26] | 85.77 (0.43) | 83.43 (0.36) | 82.15 (0.52) | 92.61 (0.46) | 91.23 (0.53) | 99.65 (0.44) | 92.36 (0.51) | 91.01 (0.36) | 99.45 (0.27) | 93.79 (2.31) | 93.44 (0.45) | 94.86 (0.52) |
| MultiDTNN | 89.34 (0.53) | 85.64 (0.31) | 84.58 (0.43) | 94.78 (0.42) | 94.55 (0.44) | 99.96 (0.37) | 94.38 (0.46) | 92.24 (0.32) | 99.98 (0.14) | 94.15 (0.27) | 95.01 (0.48) | 95.28 (0.53) |
| Algorithms | Ar->Cl | Pr->Cl | Rw->Cl | Ar->Pr | Rw->Pr | Cl->Pr | Ar->Rw | Cl->R | Pr->Rw | Cl->Ar | Pr->Ar | Rw->Ar |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CNN [38] | 30.11 (0.56) | 34.56 (0.37) | 38.72 (0.38) | 39.23 (0.54) | 60.32 (0.33) | 46.76 (0.46) | 50.23 (0.45) | 49.54 (0.39) | 54.32 (0.46) | 32.25 (0.53) | 28.45 (0.41) | 42.54 (0.65) |
| DTLC [29] | 35.53 (0.65) | 41.57 (0.36) | 44.62 (0.43) | 43.76 (0.45) | 66.11 (0.32) | 52.89 (0.69) | 56.32 (0.54) | 53.54 (0.35) | 61.56 (0.51) | 36.79 (0.53) | 32.35 (0.48) | 45.75 (0.33) |
| STLCF [16] | 29.43 (0.47) | 33.67 (0.43) | 37.65 (0.34) | 38.55 (0.51) | 59.87 (0.43) | 45.78 (0.55) | 49.45 (0.53) | 48.43 (0.47) | 53.76 (0.48) | 31.34 (0.42) | 27.54 (0.54) | 41.65 (0.53) |
| DAN [31] | 30.32 (0.54) | 34.16 (0.32) | 38.45 (0.42) | 42.56 (0.51) | 62.76 (0.28) | 47.65 (0.55) | 54.27 (0.58) | 50.12 (0.33) | 56.82 (0.45) | 32.67 (0.49) | 30.11 (0.45) | 43.67 (0.31) |
| SDT [32] | 32.65 (0.42) | 35.87 (0.54) | 42.55 (0.34) | 41.32 (0.48) | 64.45 (0.33) | 49.56 (0.46) | 52.77 (0.53) | 50.56 (0.35) | 54.82 (0.48) | 33.67 (0.34) | 30.67 (0.43) | 43.45 (0.29) |
| DHN [34] | 31.75 (0.44) | 40.13 (0.37) | 45.23 (0.41) | 40.85 (0.56) | 62.89 (0.36) | 52.01 (0.58) | 51.75 (0.55) | 52.82 (0.46) | 61.23 (0.53) | 34.78 (0.35) | 31.24 (0.43) | 45.23 (0.38) |
| ARTL [12] | 28.23 (0.57) | 32.74 (0.53) | 36.66 (0.38) | 37.12 (0.41) | 58.58 (0.47) | 44.27 (0.42) | 48.87 (0.54) | 47.84 (0.56) | 52.57 (0.44) | 30.13 (0.52) | 26.62 (0.51) | 40.54 (0.43) |
| D-CORAL [40] | 30.85 (0.43) | 34.28 (0.38) | 40.35 (0.39) | 42.34 (0.53) | 62.56 (0.45) | 47.26 (0.61) | 54.56 (0.52) | 48.87 (0.41) | 55.67 (0.48) | 32.67 (0.46) | 28.75 (0.44) | 43.81 (0.42) |
| DDC [35] | 31.25 (0.56) | 36.52 (0.31) | 39.65 (0.37) | 41.87 (0.43) | 63.65 (0.53) | 48.54 (0.55) | 53.56 (0.48) | 51.67 (0.32) | 57.31 (0.44) | 31.82 (0.36) | 29.67 (0.46) | 44.78 (0.38) |
| {Ar,Pr,Rw,Cl}->Cl | {Ar,Pr,Rw,Cl}->Pr | {Ar,Pr,Rw,Cl}->Rw | {Ar,Pr,Rw,Cl}->Ar | |||||||||
| TaskTrBoost [22] | 30.32 (0.46) | 34.26 (0.34) | 38.46 (0.43) | 39.35 (0.46) | 61.88 (0.37) | 49.87 (0.51) | 51.86 (0.55) | 49.56 (0.39) | 56.43 (0.51) | 32.65 (0.31) | 29.54 (0.53) | 42.34 (0.32) |
| FastDAM [24] | 31.54 (0.43) | 35.65 (0.37) | 41.87 (0.39) | 41.23 (0.42) | 62.44 (0.41) | 50.54 (0.48) | 53.25 (0.57) | 51.28 (0.36) | 59.53 (0.53) | 34.43 (0.44) | 30.23 (0.58) | 43.11 (0.36) |
| IMTL [26] | 32.24 (0.47) | 36.54 (0.33) | 43.32 (0.48) | 43.45 (0.38) | 64.56 (0.45) | 52.37 (0.52) | 55.11 (0.49) | 52.21 (0.34) | 61.88 (0.55) | 35.98 (0.46) | 32.11 (0.51) | 45.21 (0.43) |
| MultiDTNN | 36.88 (0.44) | 41.34 (0.28) | 46.21 (0.45) | 45.45 (0.42) | 68.65 (0.43) | 53.56 (0.54) | 57.63 (0.51) | 55.32 (0.37) | 63.27 (0.57) | 38.23 (0.34) | 34.24 (0.56) | 46.34 (0.44) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Wu, W.; Xue, D.; Gao, P. Multi-Source Deep Transfer Neural Network Algorithm. Sensors 2019, 19, 3992. https://doi.org/10.3390/s19183992
Li J, Wu W, Xue D, Gao P. Multi-Source Deep Transfer Neural Network Algorithm. Sensors. 2019; 19(18):3992. https://doi.org/10.3390/s19183992
Chicago/Turabian StyleLi, Jingmei, Weifei Wu, Di Xue, and Peng Gao. 2019. "Multi-Source Deep Transfer Neural Network Algorithm" Sensors 19, no. 18: 3992. https://doi.org/10.3390/s19183992
APA StyleLi, J., Wu, W., Xue, D., & Gao, P. (2019). Multi-Source Deep Transfer Neural Network Algorithm. Sensors, 19(18), 3992. https://doi.org/10.3390/s19183992