Bin-Picking for Planar Objects Based on a Deep Learning Network: A Case Study of USB Packs


Abstract
1. Introduction
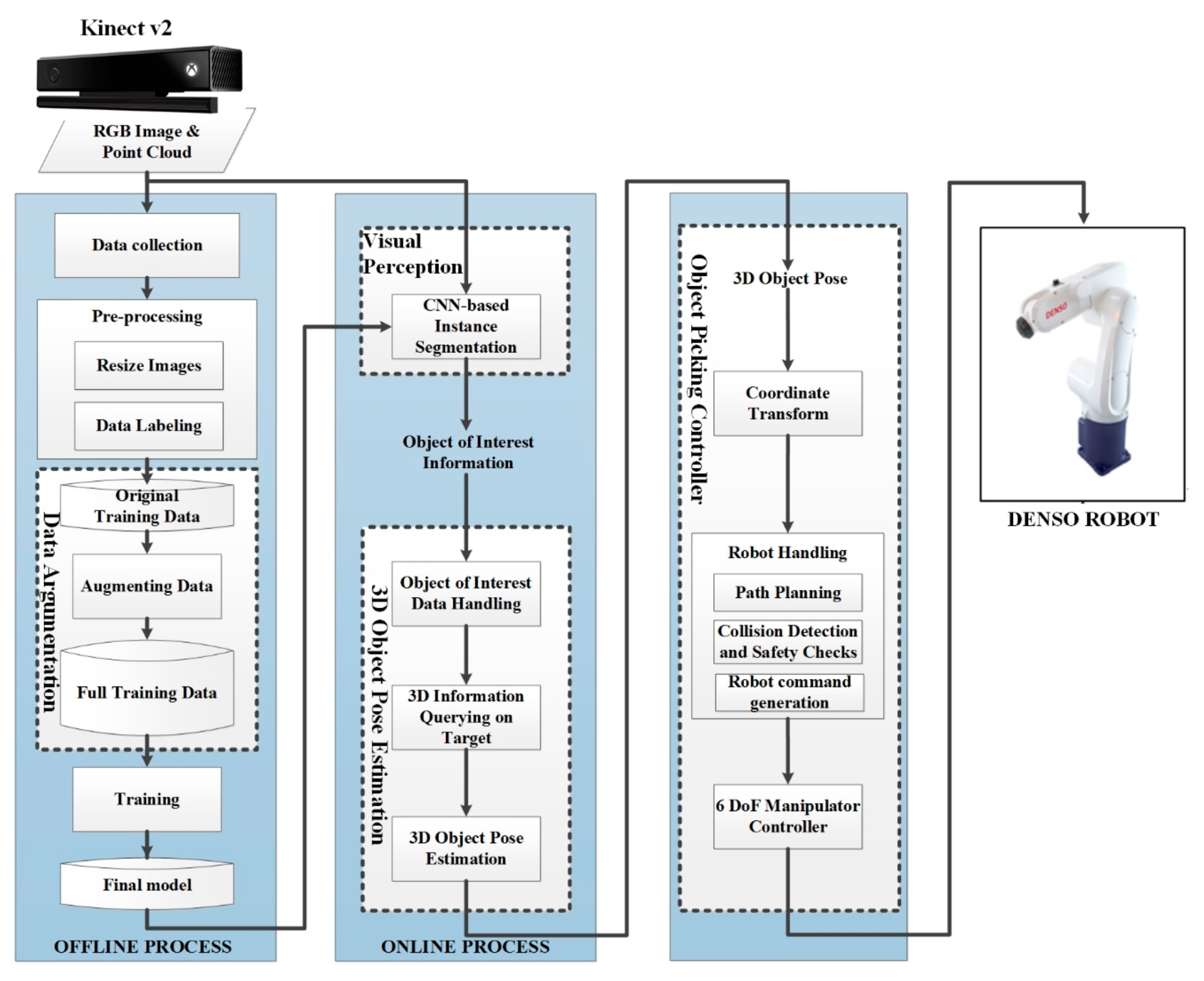
2. System Architecture
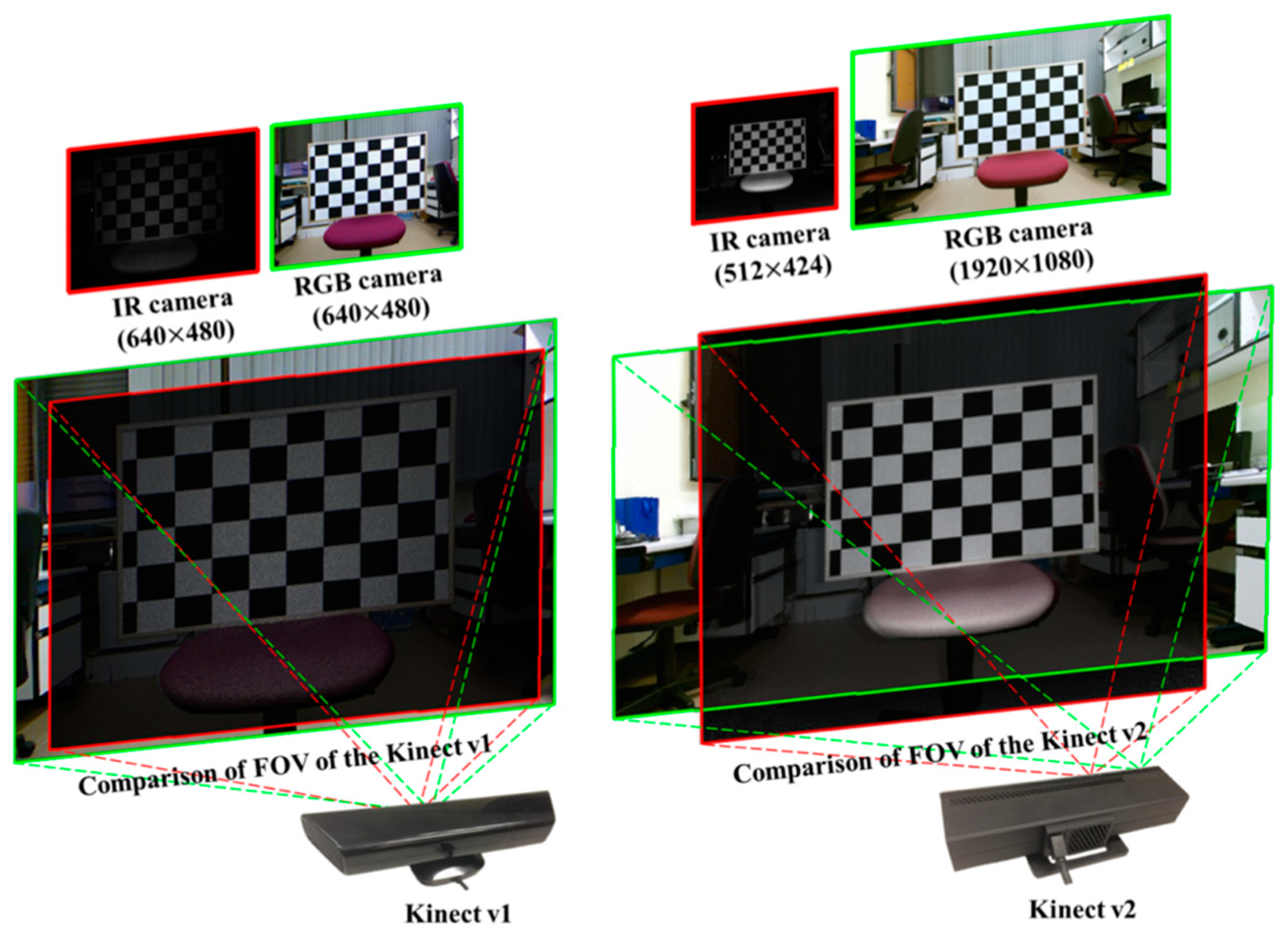
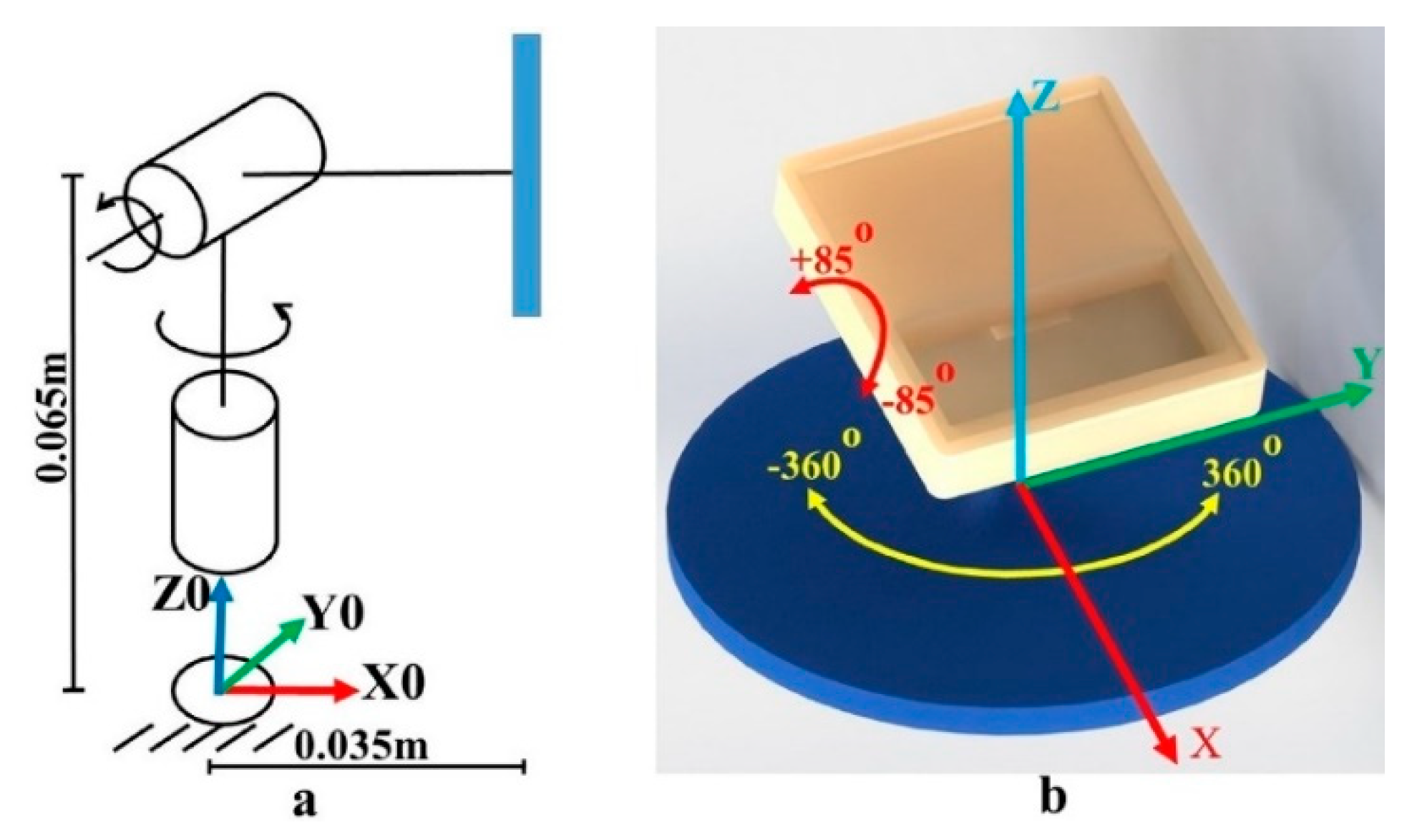
2.1. Kinect Sensor
2.2. Recognition and Appropriate Pose Estimation
2.3. Object Picking Controller
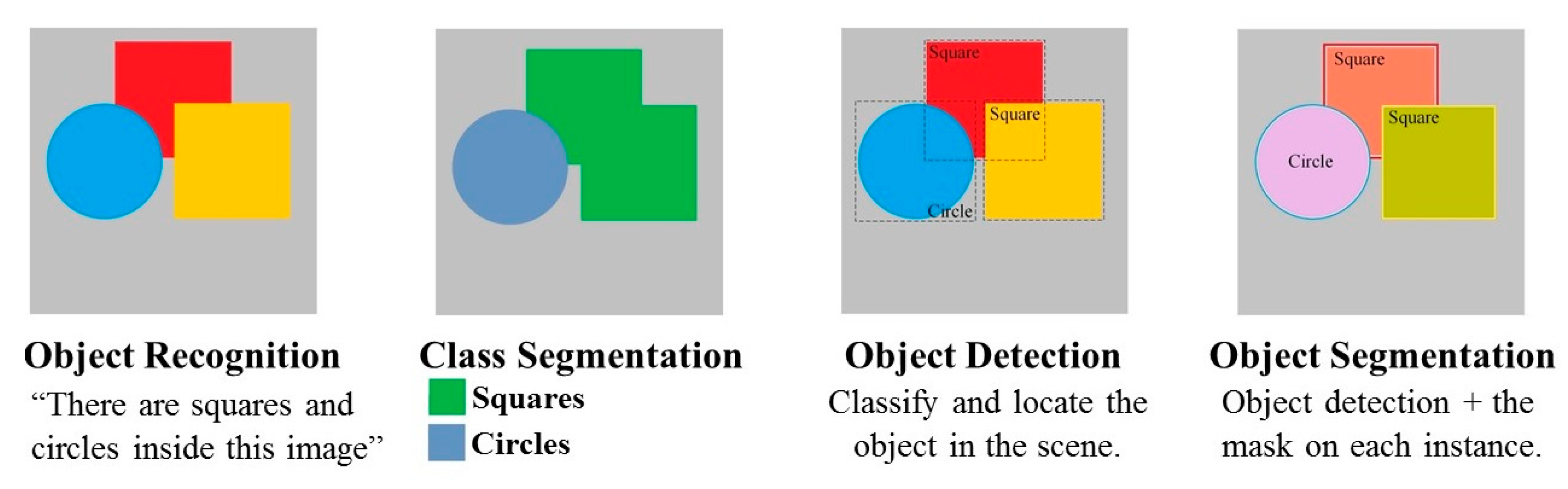
3. Proposed Deep Learning Algorithm
3.1. Surpervised Learning Approach
3.2. Materials and Methods
3.2.1. Dataset
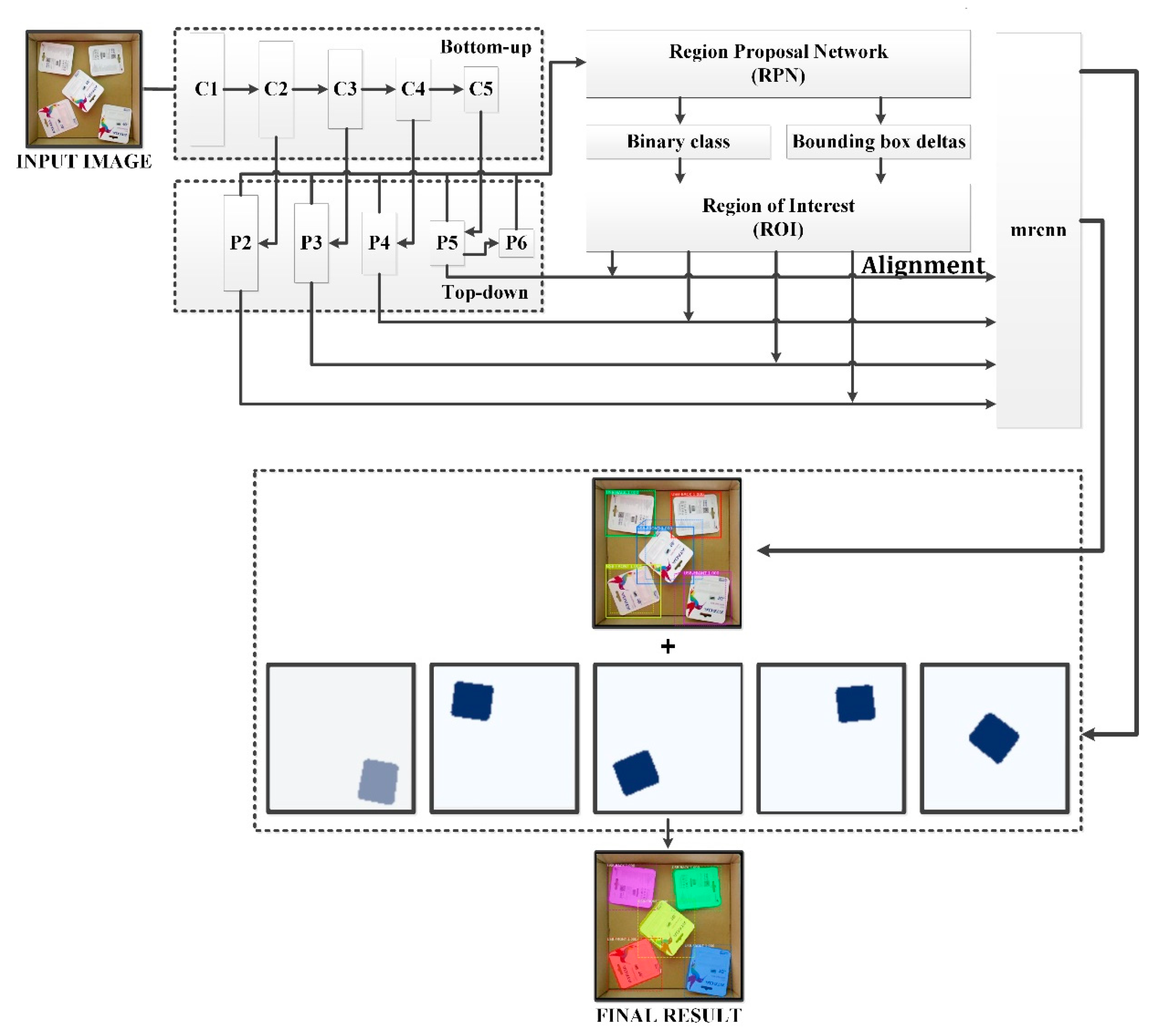
3.2.2. Deep Learning Networks
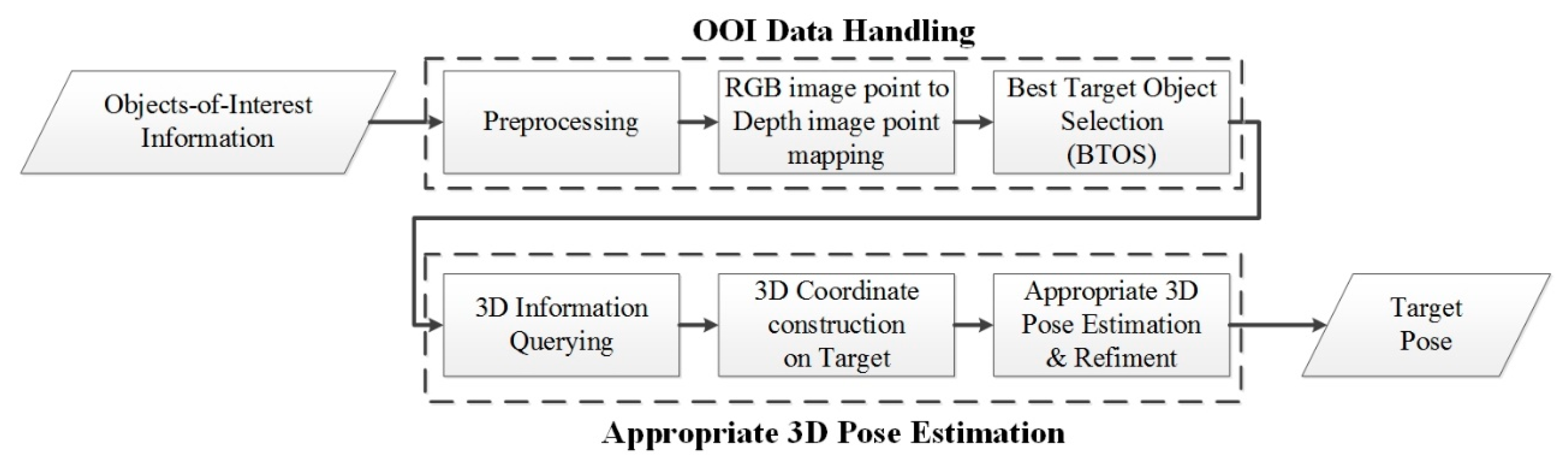
4. Appropriate 3D Pose Estimation
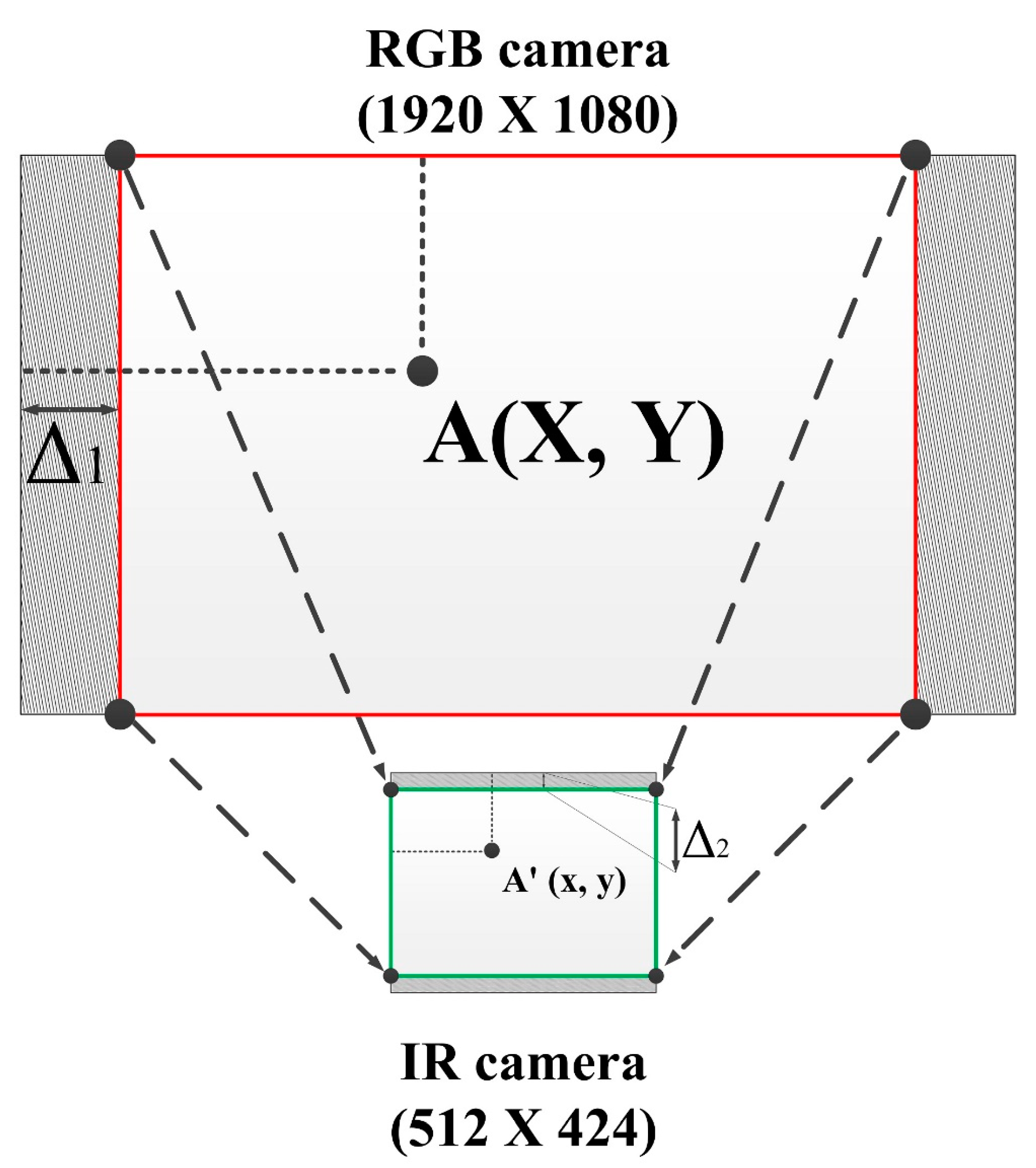
4.1. OOI Data Handling
4.2. The Appropriate 3D Pose Estimation
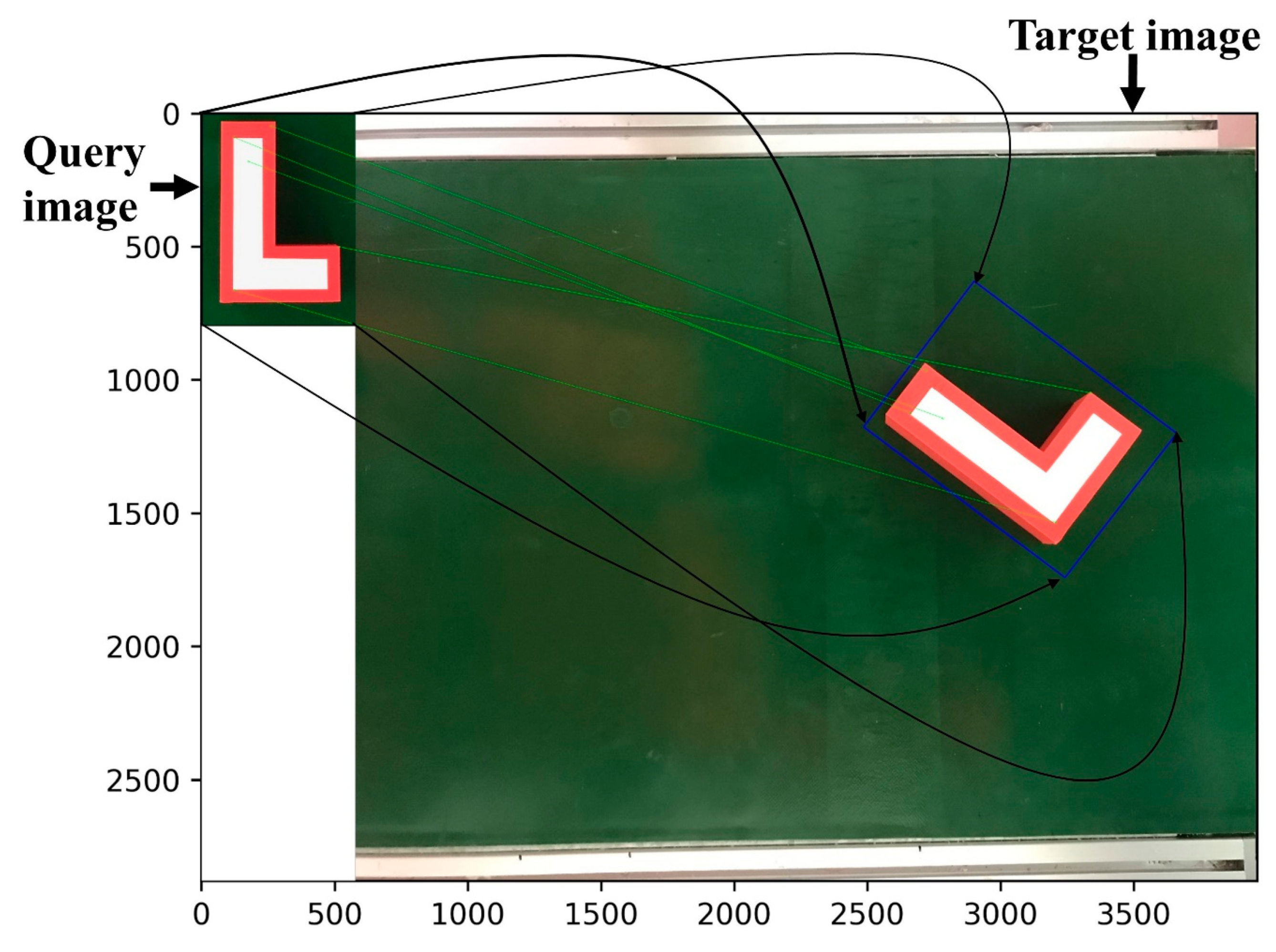
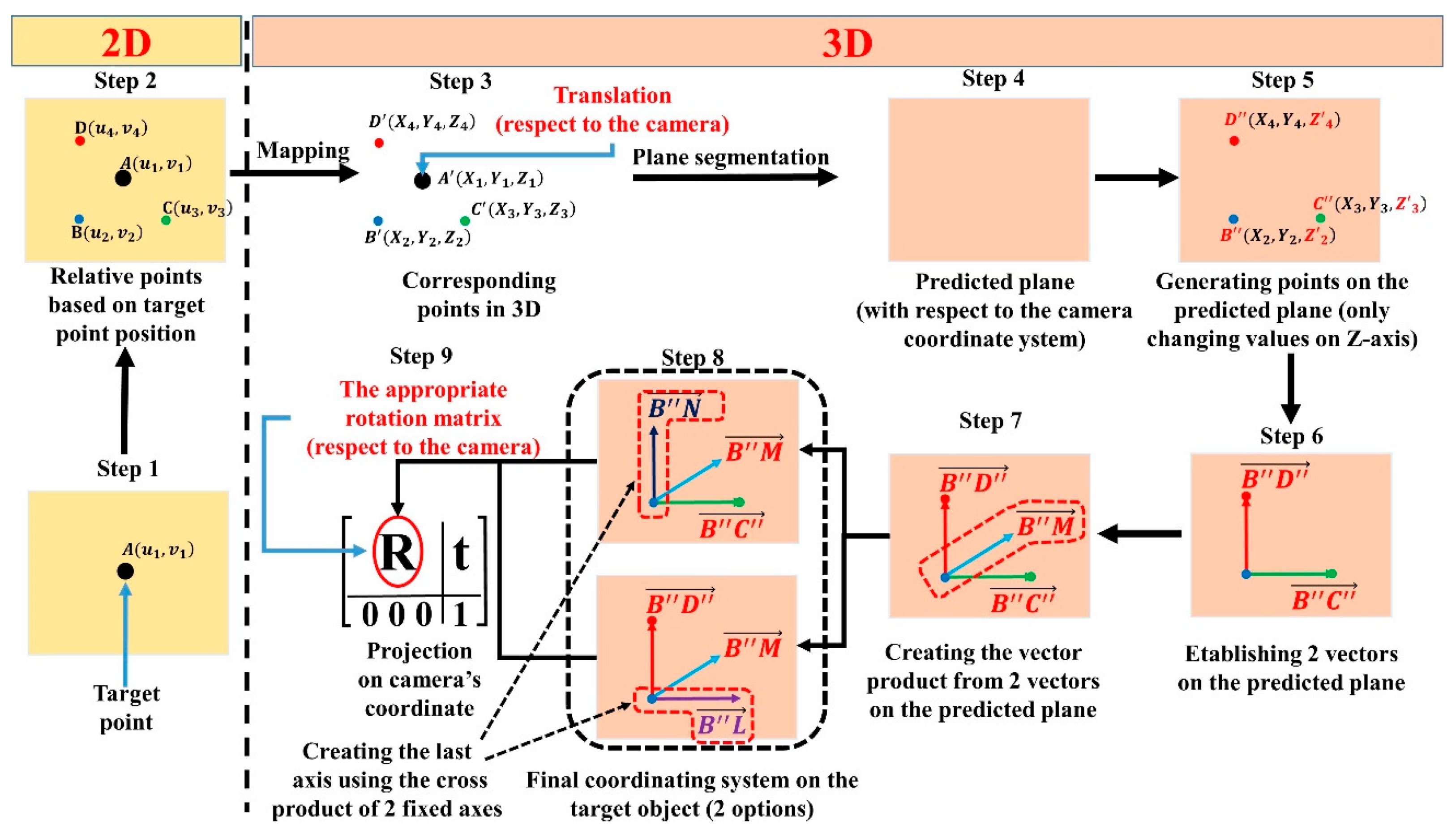
- Step 1. Determine the target point in the 2D RGB image. This step is done by OOI-DH module;
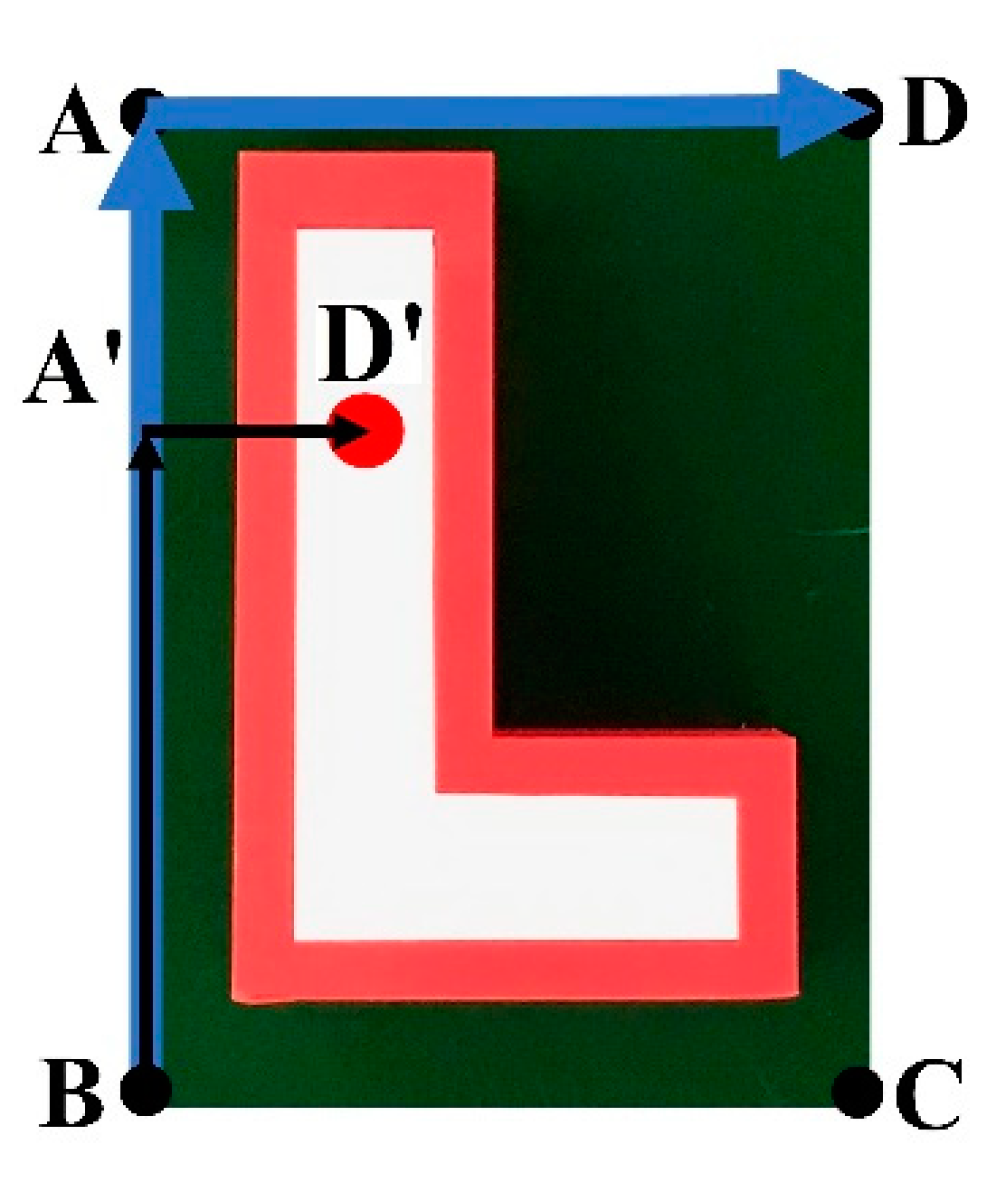
- Step 2. Collect sufficient relative points based on the target point in the 2D RGB image and choose the three key points, i.e., B, C, and D. B, C, and D are used to build the appropriate coordination system;
- Step 3. Map and acquire 3D information from the three sample points (B, C, and D) to create B’, C’, and D’, respectively;
- Step 4. Create the predicted plane in 3D based on B’, C’, and D’ using the plane segmentation method;
- Step 5. Use B’, C’, and D’ to create the three new respective points B’’, C’’, and D’’ on the predicted plane by finding new z values while keeping the x coordinate and y coordinate unchanged;
- Step 6. Create two vectors, and ;
- Step 7. Generate a vector product from and . The direction of the vector product must be considered for the robot motion to pick up objects;
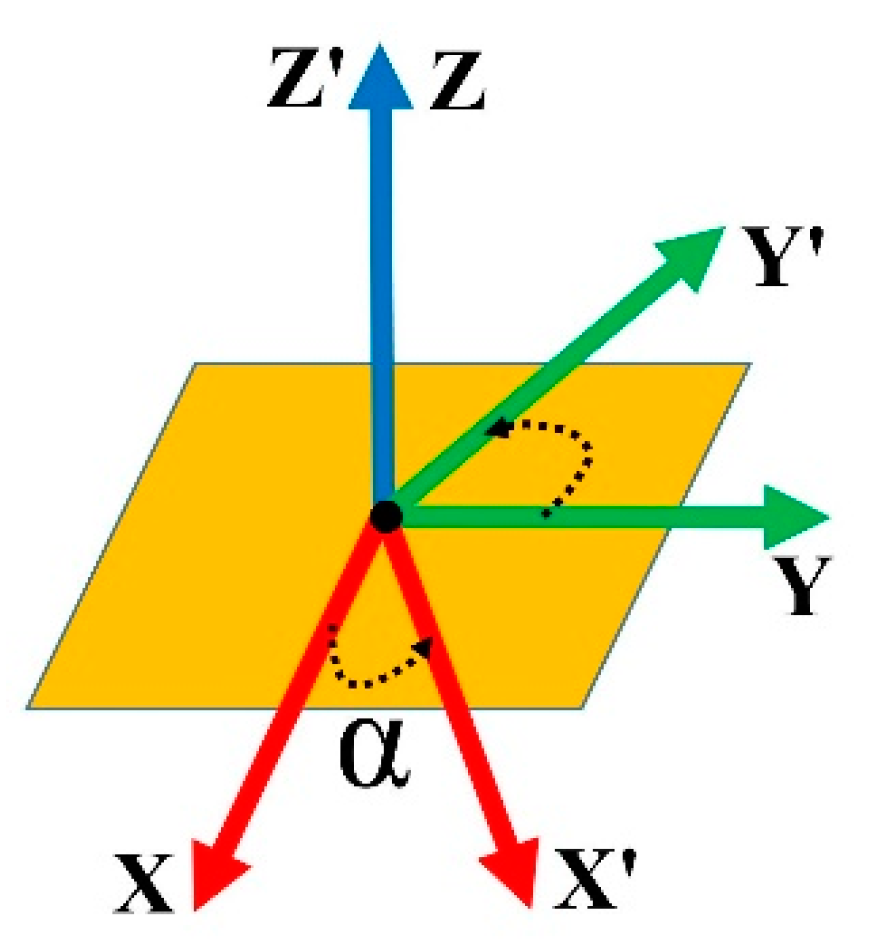
- Step 8. Generate an additional vector product either using and or and to create a coordination system. The output system of this step can be either the Cartesian coordinate system ( or (;
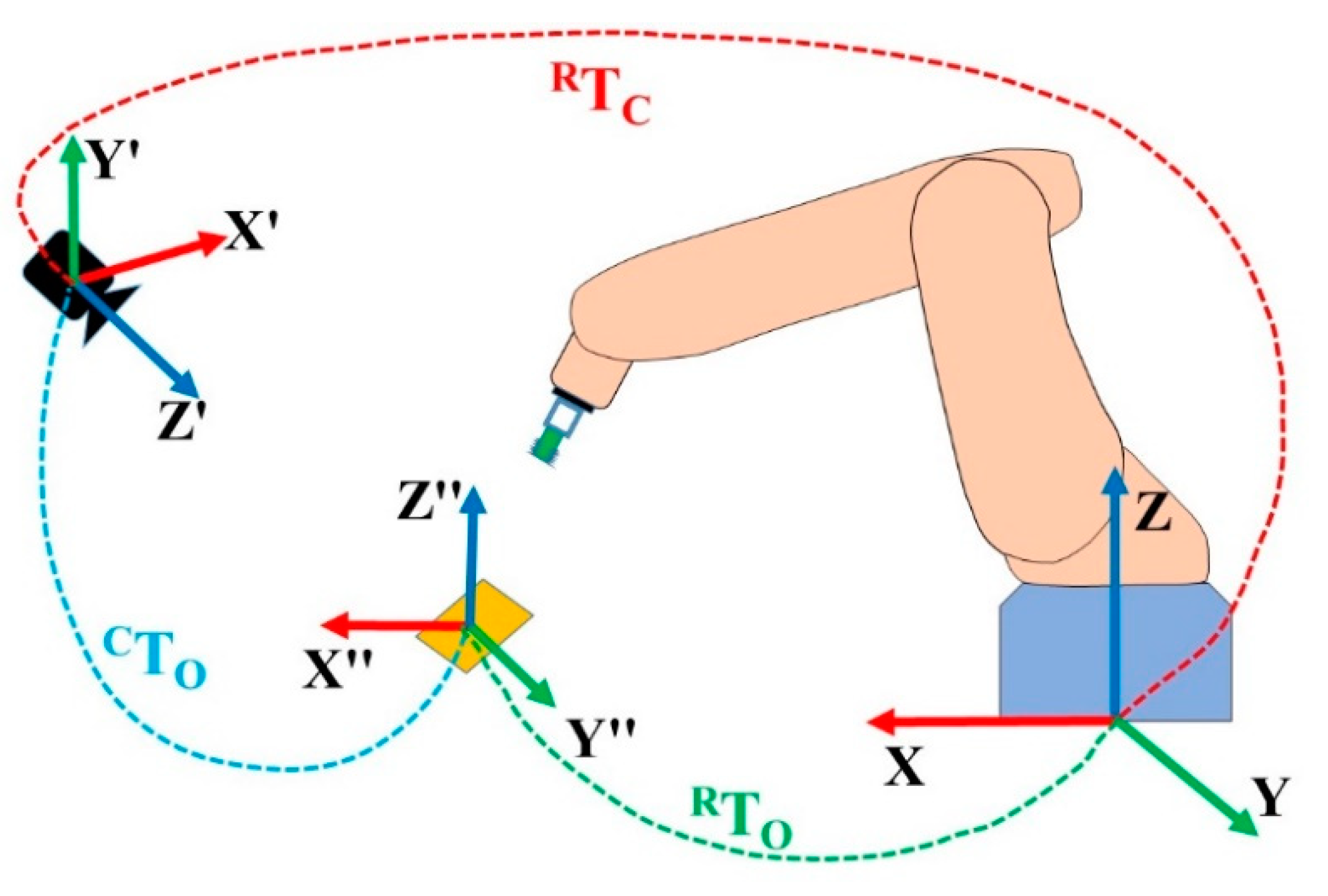
- Step 9. Project the built coordination system on the camera coordination system to define the rotation matrix.
4.3. Performance Evaluation of the Appropriate 3D Pose Estimation
5. Experimental Results and Discussion
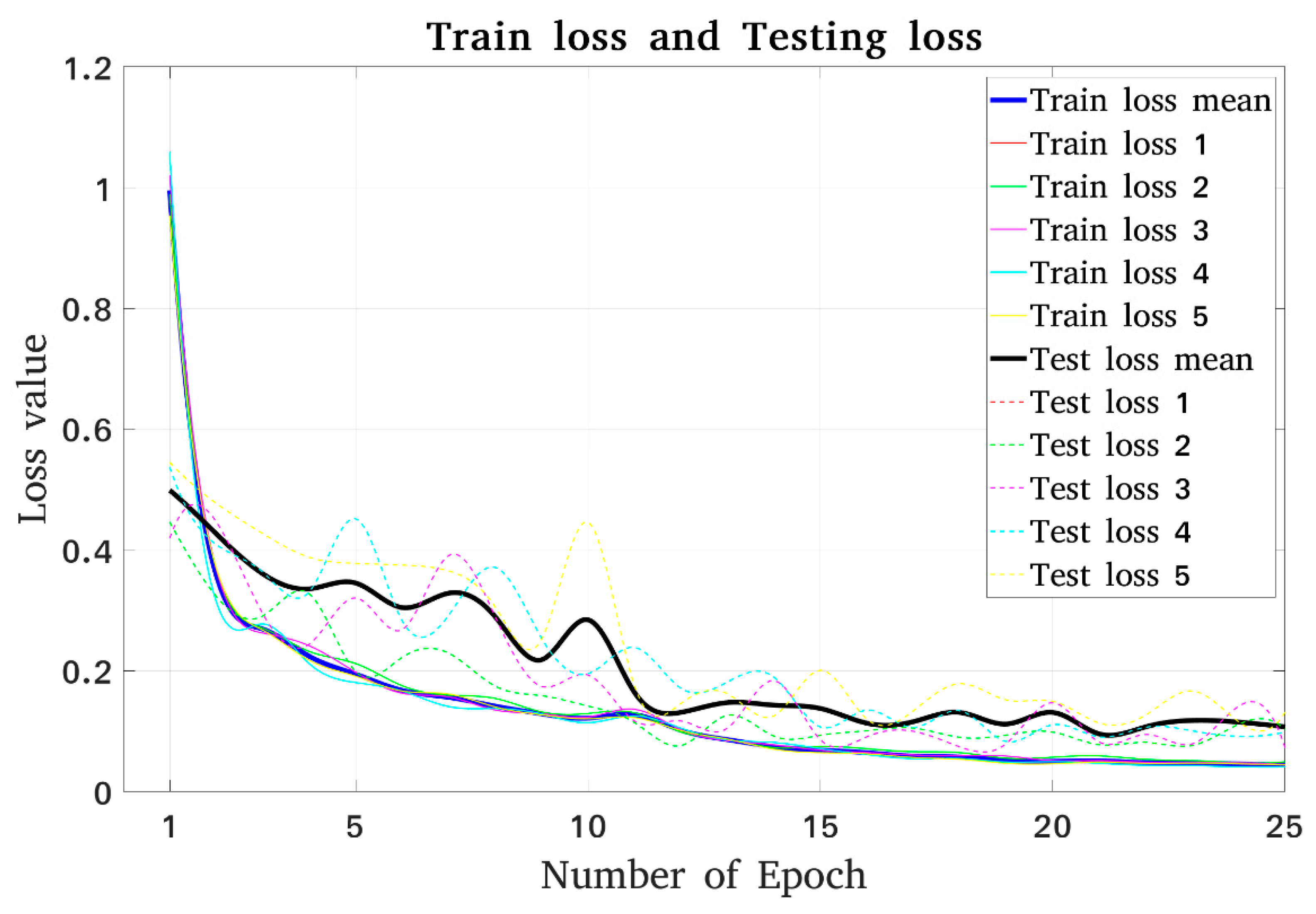
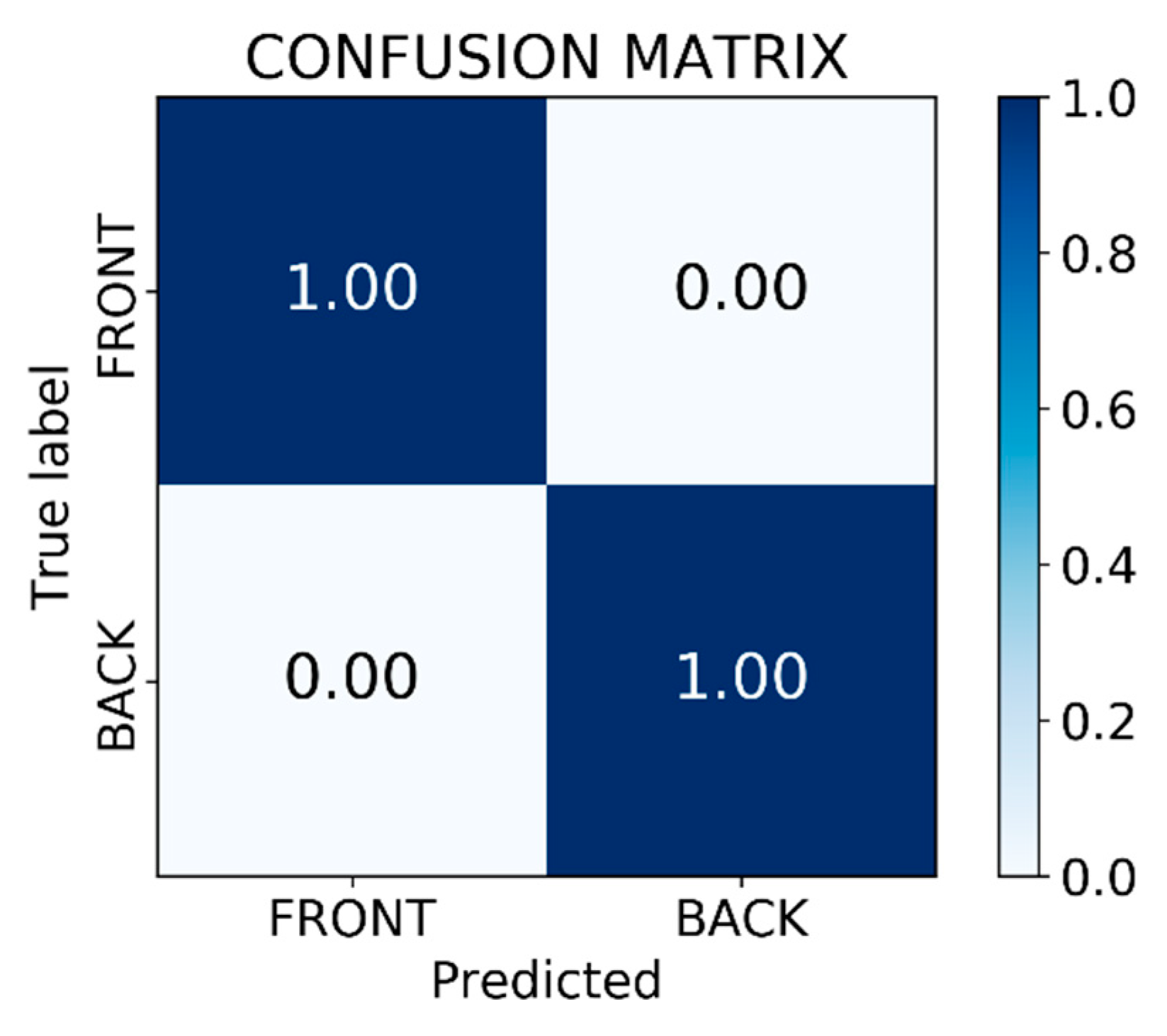
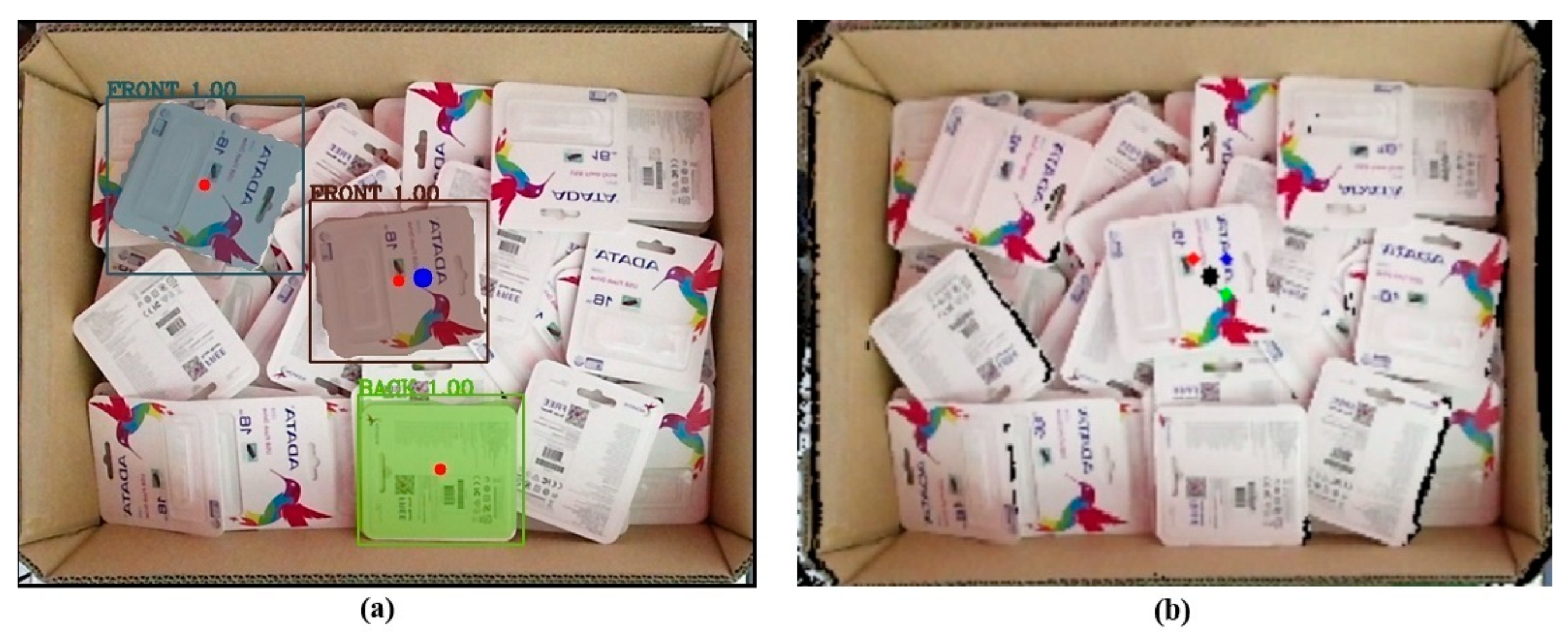
5.1. Image Processing Results
5.2. The Appropriate Pose Estimation Performance
5.3. Computational Efficiency and Picking Performance
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chang, W.C.; Wu, C.H. Eye-in-hand vision-based robotic bin-picking with active laser projection. Int. J. Adv. Manuf. Technol. 2016, 85, 2873–2885. [Google Scholar] [CrossRef]
- Liu, M.Y.; Tuzel, O.; Veeraraghavan, A.; Taguchi, Y.; Marks, T.K.; Chellappa, R. Fast object localization and pose estimation in heavy clutter for robotic bin picking. Int. J. Robot. Res. 2012, 31, 951–973. [Google Scholar] [CrossRef]
- Martinez, C.; Chen, H.; Boca, R. Automated 3D vision guided bin picking process for randomly located industrial parts. In Proceedings of the 2015 IEEE International Conference on Industrial Technology (ICIT), Seville, Spain, 17–19 March 2015; pp. 3172–3177. [Google Scholar]
- Lin, C.M.; Tsai, C.Y.; Lai, Y.C.; Li, S.A.; Wong, C.C. Visual object recognition and pose estimation based on a deep semantic segmentation network. IEEE Sens. J. 2018, 18, 9370–9381. [Google Scholar] [CrossRef]
- Vidal Verdaguer, J.; Lin, C.Y.; Lladó Bardera, X.; Martí Marly, R. A method for 6D pose estimation of free-form rigid objects using point pair features on range data. Sensors 2018, 18, 2678. [Google Scholar] [CrossRef] [PubMed]
- Andreopoulos, A.; Tsotsos, J.K. 50 years of object recognition: Directions forward. Comput. Vis. Image Underst. 2013, 117, 827–891. [Google Scholar] [CrossRef]
- Sansoni, G.; Trebeschi, M.; Docchio, F. State-of-the-art and applications of 3D imaging sensors in industry, cultural heritage, medicine, and criminal investigation. Sensors 2009, 9, 568–601. [Google Scholar] [CrossRef] [PubMed]
- Guo, Y.; Bennamoun, M.; Sohel, F.; Lu, M.; Wan, J. 3D object recognition in cluttered scenes with local surface features: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2270–2287. [Google Scholar]
- Horn, B.K.P. Extended gaussian images. Proc. IEEE 1984, 72, 1671–1686. [Google Scholar] [CrossRef]
- Rusu, R.B.; Bradski, G.; Thibaux, R.; Hsu, J. Fast 3d recognition and pose using the viewpoint feature histogram. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 2155–2162. [Google Scholar]
- Wohlkinger, W.; Vincze, M. Ensemble of shape functions for 3d object classification. In Proceedings of the 2011 IEEE International Conference on Robotics and Biomimetics, Phuket Island, Thailand, 7–11 December 2011; pp. 2987–2992. [Google Scholar]
- Aldoma, A.; Vincze, M.; Blodow, N.; Gossow, D.; Gedikli, S.; Rusu, R.B.; Bradski, G. CAD-model recognition and 6DOF pose estimation using 3D cues. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 585–592. [Google Scholar]
- Steger, C. Occlusion, clutter, and illumination invariant object recognition. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2002, 34, 345–350. [Google Scholar]
- Hinterstoisser, S.; Lepetit, V.; Ilic, S.; Fua, P.; Navab, N. Dominant orientation templates for real-time detection of texture-less objects. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2257–2264. [Google Scholar]
- Hinterstoisser, S.; Holzer, S.; Cagniart, C.; Ilic, S.; Konolige, K.; Navab, N.; Lepetit, V. Multimodal templates for real-time detection of texture-less objects in heavily cluttered scenes. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 858–865. [Google Scholar]
- Ulrich, M.; Wiedemann, C.; Steger, C. Combining scale-space and similarity-based aspect graphs for fast 3D object recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 1902–1914. [Google Scholar] [CrossRef]
- Ye, C.; Li, K.; Jia, L.; Zhuang, C.; Xiong, Z. Fast Hierarchical Template Matching Strategy for Real-Time Pose Estimation of Texture-Less Objects. In Proceedings of the International Conference on Intelligent Robotics and Applications, Hachioji, Japan, 22–24 August 2016; pp. 225–236. [Google Scholar]
- Su, J.; Liu, Z.; Yang, G. Pose estimation of occluded objects with an improved template matching method. In Proceedings of the First International Workshop on Pattern Recognition International Society for Optics and Photonics, Tokyo, Japan, 11–13 May 2016. [Google Scholar]
- Muñoz, E.; Konishi, Y.; Beltran, C.; Murino, V.; Del Bue, A. Fast 6D pose from a single RGB image using Cascaded Forests Templates. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 4062–4069. [Google Scholar]
- Kotsiantis, S.B.; Zaharakis, I.; Pintelas, P. Supervised machine learning: A review of classification techniques. Emerg. Artif. Intell. Appl. Comput. Eng. 2007, 160, 3–24. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 7, 68281–68289. [Google Scholar] [CrossRef] [PubMed]
- Blum, M.; Springenberg, J.T.; Wülfing, J.; Riedmiller, M. A learned feature descriptor for object recognition in rgb-d data. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, St. Paul, MN, USA, 14–18 May 2012; pp. 1298–1303. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the Thirty-first Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Brachmann, E.; Krull, A.; Michel, F.; Gumhold, S.; Shotton, J.; Rother, C. Learning 6d object pose estimation using 3d object coordinates. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 536–551. [Google Scholar]
- Brachmann, E.; Michel, F.; Krull, A.; Ying Yang, M.; Gumhold, S. Uncertainty-driven 6d pose estimation of objects and scenes from a single rgb image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3364–3372. [Google Scholar]
- Do, T.T.; Cai, M.; Pham, T.; Reid, I. Deep-6d pose: Recovering 6D object pose from a single RGB image. arXiv 2018, arXiv:1802.10367. [Google Scholar]
- Wu, C.H.; Jiang, S.Y.; Song, K.T. CAD-based pose estimation for random bin-picking of multiple objects using a RGB-D camera. In Proceedings of the 2015 15th International Conference on Control, Automation and Systems (ICCAS), Busan, Korea, 13–16 October 2015; pp. 1645–1649. [Google Scholar]
- Chen, Y.K.; Sun, G.J.; Lin, H.Y.; Chen, S.L. Random Bin Picking with Multi-view Image Acquisition and CAD-Based Pose Estimation. In Proceedings of the 2018 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Miyazaki, Japan, 7–10 October 2018; pp. 2218–2223. [Google Scholar]
- Drost, B.; Ulrich, M.; Navab, N.; Ilic, S. Model globally, match locally: Efficient and robust 3D object recognition. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 998–1005. [Google Scholar]
- Vidal, J.; Lin, C.Y.; Martí, R. 6D pose estimation using an improved method based on point pair features. In Proceedings of the 2018 4th International Conference on Control, Automation and Robotics (ICCAR), Auckland, New Zealand, 20–23 April 2018; pp. 405–409. [Google Scholar]
- Choi, C.; Taguchi, Y.; Tuzel, O.; Liu, M.Y.; Ramalingam, S. Voting-based pose estimation for robotic assembly using a 3D sensor. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 1724–1731. [Google Scholar]
- Spenrath, F.; Pott, A. Using Neural Networks for Heuristic Grasp Planning in Random Bin Picking. In Proceedings of the 2018 IEEE 14th International Conference on Automation Science and Engineering (CASE), Munich, Germany, 20–24 August 2018; pp. 258–263. [Google Scholar]
- Bedaka, A.K.; Vidal, J.; Lin, C.Y. Automatic robot path integration using three-dimensional vision andoffline programming. Int. J. Adv. Manuf. Technol. 2019, 102, 1935–1950. [Google Scholar] [CrossRef]
- Samir, M.; Golkar, E.; Rahni, A.A.A. Comparison between the KinectTM V1 and KinectTM V2 for respiratory motion tracking. In Proceedings of the 2015 IEEE International Conference on Signal and Image Processing Applications (ICSIPA), Kuala Lumpur, Malaysia, 19–21 October 2015; pp. 150–155. [Google Scholar]
- Sarbolandi, H.; Lefloch, D.; Kolb, A. Kinect range sensing: Structured-light versus time-of flight kinect. Comput. Vis. Image Underst. 2015, 139, 1–20. [Google Scholar] [CrossRef]
- Khan, M.; Jan, B.; Farman, H. Deep Learning: Convergence to Big Data Analytics; Springer: Singapore, 2019. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 770–778. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Le, T.T.; Lin, C.Y. Deep learning for noninvasive classification of clustered horticultural crops–A case for banana fruit tiers. Postharvest Biol. Technol. 2019, 156, 110922. [Google Scholar] [CrossRef]
- Everingham, M.; Eslami, S.A.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Pagliari, D.; Pinto, L. Calibration of kinect for xbox one and comparison between the two generations of microsoft sensors. Sensors 2015, 15, 27569–27589. [Google Scholar] [CrossRef]
- Lachat, E.; Macher, H.; Mittet, M.; Landes, T.; Grussenmeyer, P. First experiences with Kinect v2 sensor for close range 3D modelling. In Proceedings of the 6th International Workshop 3D-ARCH, Avila, Spain, 25–27 February 2015. [Google Scholar]
- Hong, S.; Saavedra, G.; Martinez-Corral, M. Full parallax three-dimensional display from Kinect v1 and v2. Opt. Eng. 2016, 56, 041305. [Google Scholar] [CrossRef]
- Kim, C.; Yun, S.; Jung, S.W.; Won, C.S. Color and depth image correspondence for Kinect v2. In Advanced Multimedia and Ubiquitous Engineering; Springer: Berlin/Heidelberg, Germany, 2015; pp. 111–116. [Google Scholar]
- Xiang, L.; Echtler, F.; Kerl, C.; Wiedemeyer, T.; Lars, H.; Gordon, R.; Facioni, F.; Wareham, R.; Goldhoorn, M.; Fuchs, S.; et al. Libfreenect2: Release 0.2. Available online: https://zenodo.org/record/50641#.W5o99FIXccU (accessed on 17 August 2019).
- Holz, D.; Holzer, S.; Rusu, R.B.; Behnke, S. Real-time plane segmentation using RGB-D cameras. In Proceedings of the Robot Soccer World Cup, Istanbul, Turkey, 5–11 July 2011; pp. 306–317. [Google Scholar]
- Kurban, R.; Skuka, F.; Bozpolat, H. Plane segmentation of kinect point clouds using RANSAC. In Proceedings of the 7th international conference on information technology, Amman, Jordan, 12–15 May 2015; pp. 545–551. [Google Scholar]
- Tsai, R.Y.; Lenz, R.K. A new technique for fully autonomous and efficient 3D robotics hand/eye calibration. IEEE Trans. Robot. Autom. 1989, 5, 345–358. [Google Scholar] [CrossRef]
- Shiu, Y.C.; Ahmad, S. Calibration of wrist-mounted robotic sensors by solving homogeneous transform equations of the form AX = XB. IEEE Trans. Robot. Autom. 1989, 5, 16–29. [Google Scholar] [CrossRef]
- Horaud, R.; Dornaika, F. Hand-eye calibration. Int. J. Robot. Res. 1995, 14, 195–210. [Google Scholar] [CrossRef]
- Daniilidis, K. Hand-eye calibration using dual quaternions. Int. J. Robot. Res. 1999, 18, 286–298. [Google Scholar] [CrossRef]
- Slabaugh, G.G. Computing Euler Angles from a Rotation Matrix. Available online: http://www.close-range.com/docs/Computing_Euler_angles_from_a_rotation_matrix.pdf (accessed on 17 August 2019).






























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Kinect v1 | Kinect v2 | |||
|---|---|---|---|---|
| Resolution Pixel × Pixel | Frame Rate (Hz) | Resolution Pixel × Pixel | Frame Rate (Hz) | |
| Color | 640 × 480 | 30 | 1920 × 1080 | 30 |
| Depth | 320 × 240 | 30 | 512 × 424 | 30 |
| Infrared | 320 × 240 | 30 | 512 × 424 | 30 |
| Front | Back | Total | |
|---|---|---|---|
| No. of Instances | 458 | 387 | 845 |
| Threshold Intersection over Union (IoU) | Average Precision (%) | |||||
|---|---|---|---|---|---|---|
| Run | Run | Run | Run | Run | Average | |
| AP@0.5 | 100 | 100 | 100 | 100 | 100 | 100 |
| AP@0.75 | 100 | 100 | 100 | 100 | 100 | 100 |
| AP@0.5:0.95 | 91.94 | 90.28 | 91.21 | 90.37 | 92.13 | 91.18 |
| Pose | Mean Error | |||||
|---|---|---|---|---|---|---|
| 1 | 1.208 | 1.971 | 2.893 | 2.277 | 3.119 | 1.621 |
| 2 | 0.724 | 2.319 | 2.206 | 2.416 | 2.870 | 1.658 |
| 3 | 2.308 | 2.238 | 2.094 | 2.579 | 2.445 | 1.114 |
| 4 | 2.852 | 2.118 | 2.812 | 3.164 | 2.536 | 1.020 |
| 5 | 0.480 | 3.506 | 0.834 | 2.203 | 3.744 | 1.003 |
| 6 | 1.116 | 4.025 | 1.431 | 2.252 | 2.831 | 0.689 |
| 7 | 2.583 | 3.102 | 4.634 | 2.187 | 3.292 | 0.818 |
| 8 | 0.743 | 0.813 | 0.879 | 1.569 | 3.548 | 1.000 |
| 9 | 0.476 | 1.208 | 1.490 | 1.429 | 4.043 | 0.744 |
| 10 | 0.791 | 3.284 | 2.779 | 1.557 | 4.269 | 0.885 |
| 11 | 3.193 | 1.106 | 4.359 | 1.724 | 1.178 | 0.337 |
| 12 | 2.185 | 2.850 | 0.888 | 1.621 | 1.841 | 0.759 |
| 13 | 0.734 | 1.335 | 1.228 | 1.641 | 2.497 | 1.178 |
| 14 | 2.709 | 1.025 | 3.538 | 1.253 | 1.437 | 0.765 |
| 15 | 1.067 | 0.824 | 3.534 | 3.374 | 1.148 | 0.707 |
| 16 | 1.981 | 0.863 | 3.759 | 1.276 | 1.218 | 0.725 |
| 17 | 0.614 | 2.337 | 3.576 | 1.645 | 1.571 | 2.494 |
| 18 | 2.344 | 1.499 | 4.968 | 1.497 | 0.915 | 3.522 |
| 19 | 1.318 | 2.057 | 2.273 | 2.219 | 1.176 | 4.529 |
| 20 | 1.583 | 0.701 | 0.684 | 2.389 | 1.221 | 3.088 |
| 21 | 2.264 | 1.696 | 0.615 | 1.484 | 1.537 | 3.904 |
| 22 | 0.909 | 4.171 | 0.969 | 2.551 | 1.946 | 4.427 |
| 23 | 3.160 | 4.061 | 0.999 | 2.848 | 2.023 | 0.502 |
| 24 | 3.698 | 3.511 | 0.881 | 2.314 | 2.433 | 2.101 |
| 25 | 3.941 | 1.465 | 1.437 | 1.733 | 2.100 | 2.851 |
| Average | 1.799 | 2.164 | 2.230 | 2.048 | 2.278 | 1.698 |
| Pose | Mean Error | |||||
|---|---|---|---|---|---|---|
| 1 | 0.164 | 2.150 | 3.294 | 2.065 | 1.223 | 1.312 |
| 2 | 0.719 | 1.093 | 1.451 | 2.403 | 1.781 | 1.059 |
| 3 | 1.878 | 1.207 | 1.738 | 2.335 | 1.674 | 1.121 |
| 4 | 1.145 | 0.405 | 1.869 | 3.792 | 1.314 | 1.127 |
| 5 | 2.496 | 1.085 | 1.140 | 4.638 | 2.372 | 0.691 |
| 6 | 1.050 | 0.792 | 1.092 | 2.000 | 2.098 | 0.738 |
| 7 | 0.872 | 0.126 | 1.713 | 3.018 | 2.883 | 1.334 |
| 8 | 2.287 | 1.263 | 1.211 | 2.827 | 2.731 | 0.878 |
| 9 | 1.101 | 0.208 | 1.362 | 3.006 | 2.480 | 0.564 |
| 10 | 0.422 | 0.829 | 2.494 | 2.707 | 2.992 | 0.812 |
| 11 | 1.417 | 0.092 | 1.873 | 2.515 | 3.098 | 0.387 |
| 12 | 0.465 | 0.923 | 2.026 | 2.095 | 2.712 | 1.225 |
| 13 | 0.961 | 0.346 | 1.239 | 2.279 | 2.866 | 1.342 |
| 14 | 0.899 | 0.431 | 2.266 | 1.891 | 1.879 | 1.867 |
| 15 | 0.224 | 0.619 | 1.635 | 0.703 | 0.858 | 0.695 |
| 16 | 0.521 | 1.185 | 3.899 | 1.730 | 1.342 | 1.613 |
| 17 | 1.517 | 0.948 | 3.520 | 2.738 | 1.839 | 2.549 |
| 18 | 0.430 | 1.297 | 3.118 | 2.602 | 1.348 | 3.363 |
| 19 | 1.100 | 1.257 | 3.185 | 2.788 | 1.660 | 4.581 |
| 20 | 1.333 | 0.704 | 3.707 | 2.055 | 1.523 | 2.772 |
| 21 | 0.972 | 0.640 | 2.879 | 2.150 | 1.793 | 3.337 |
| 22 | 1.110 | 1.654 | 1.641 | 2.906 | 1.457 | 4.432 |
| 23 | 0.593 | 0.760 | 0.900 | 1.763 | 1.719 | 0.527 |
| 24 | 1.509 | 1.224 | 1.904 | 1.869 | 1.616 | 2.692 |
| 25 | 2.129 | 1.158 | 0.755 | 2.743 | 1.650 | 2.622 |
| Average | 1.093 | 0.896 | 2.076 | 2.465 | 1.956 | 1.746 |
| MAE Value | Translation Error (mm) | Rotation Error (degrees) | Total Test Number | ||||
|---|---|---|---|---|---|---|---|
| N | |||||||
| Back | 1.799 | 2.164 | 2.230 | 2.048 | 2.278 | 1.698 | 25 |
| Front | 1.093 | 0.896 | 2.076 | 2.465 | 1.956 | 1.746 | 25 |
| Average | 1.446 | 1.530 | 2.153 | 2.256 | 2.117 | 1.722 | 50 |
| Object | Length | Width | Depth |
|---|---|---|---|
| USB Flash Drive Pack | 101 mm | 115 mm | 2 mm |
| Subfunction | Front | Back | Average | |
|---|---|---|---|---|
| Visual Perception | Preprocessing | 0.074 | 0.074 | 0.074 |
| Instance Segmentation | 0.532 | 0.532 | 0.532 | |
| Object Pose Estimation | Feature Matching | 0.270 | 0 | 0.135 |
| Pose Estimation | 0.121 | 0.121 | 0.121 | |
| Total Processing Time | 0.997 | 0.727 | 0.862 | |
| (In Seconds) | ||||
| Total Trials | Success | Failed | Success Rate |
|---|---|---|---|
| 843 | 840 | 3 | 99.64% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Le, T.-T.; Lin, C.-Y. Bin-Picking for Planar Objects Based on a Deep Learning Network: A Case Study of USB Packs. Sensors 2019, 19, 3602. https://doi.org/10.3390/s19163602
Le T-T, Lin C-Y. Bin-Picking for Planar Objects Based on a Deep Learning Network: A Case Study of USB Packs. Sensors. 2019; 19(16):3602. https://doi.org/10.3390/s19163602
Chicago/Turabian StyleLe, Tuan-Tang, and Chyi-Yeu Lin. 2019. "Bin-Picking for Planar Objects Based on a Deep Learning Network: A Case Study of USB Packs" Sensors 19, no. 16: 3602. https://doi.org/10.3390/s19163602
APA StyleLe, T.-T., & Lin, C.-Y. (2019). Bin-Picking for Planar Objects Based on a Deep Learning Network: A Case Study of USB Packs. Sensors, 19(16), 3602. https://doi.org/10.3390/s19163602