Classification of Postprandial Glycemic Status with Application to Insulin Dosing in Type 1 Diabetes—An In Silico Proof-of-Concept

 ,
,  ,
,  ,
,
Abstract
:1. Introduction
2. Method to Classify Future Postprandial Glycemic Status
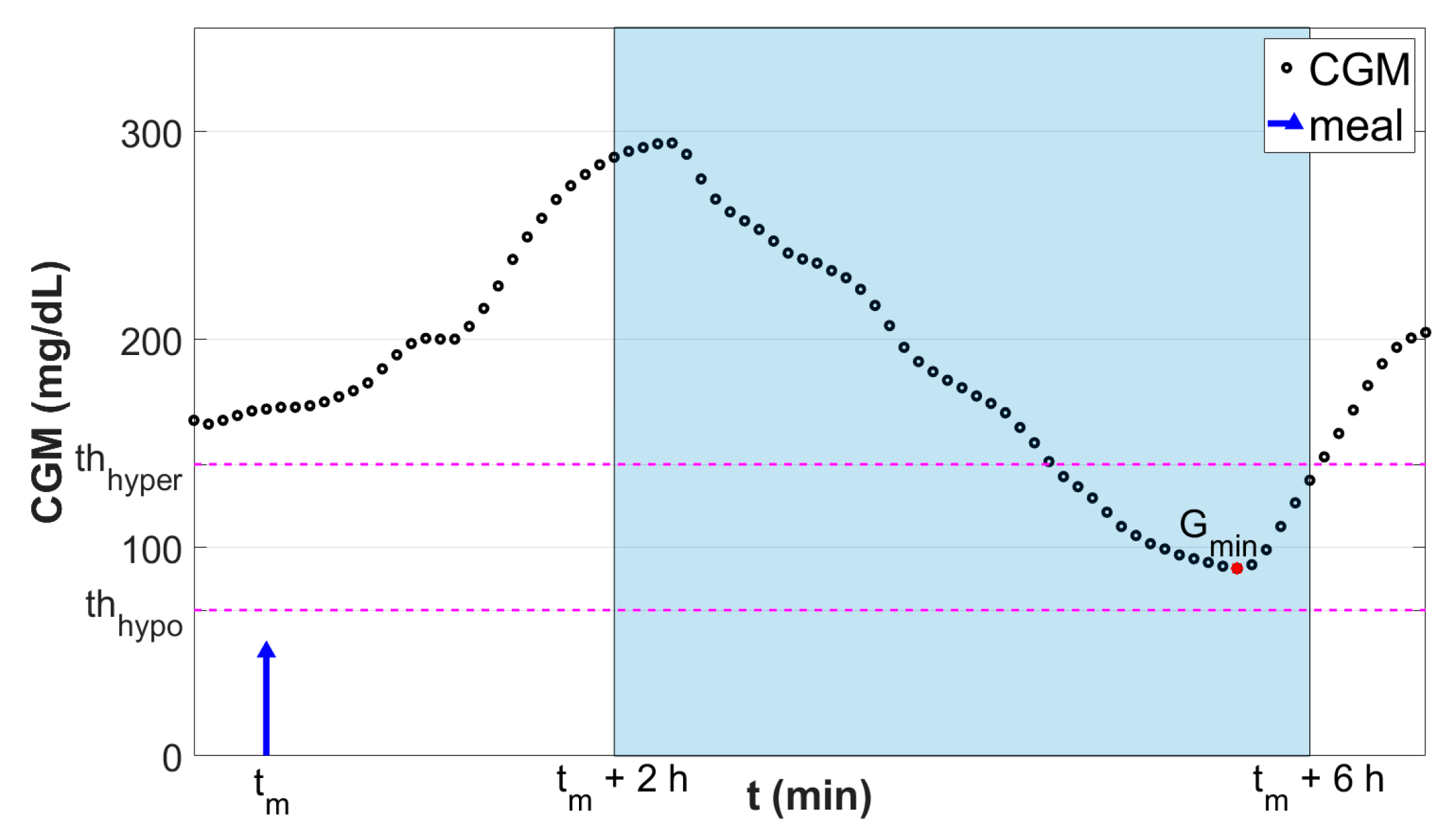
2.1. Classification Criterion
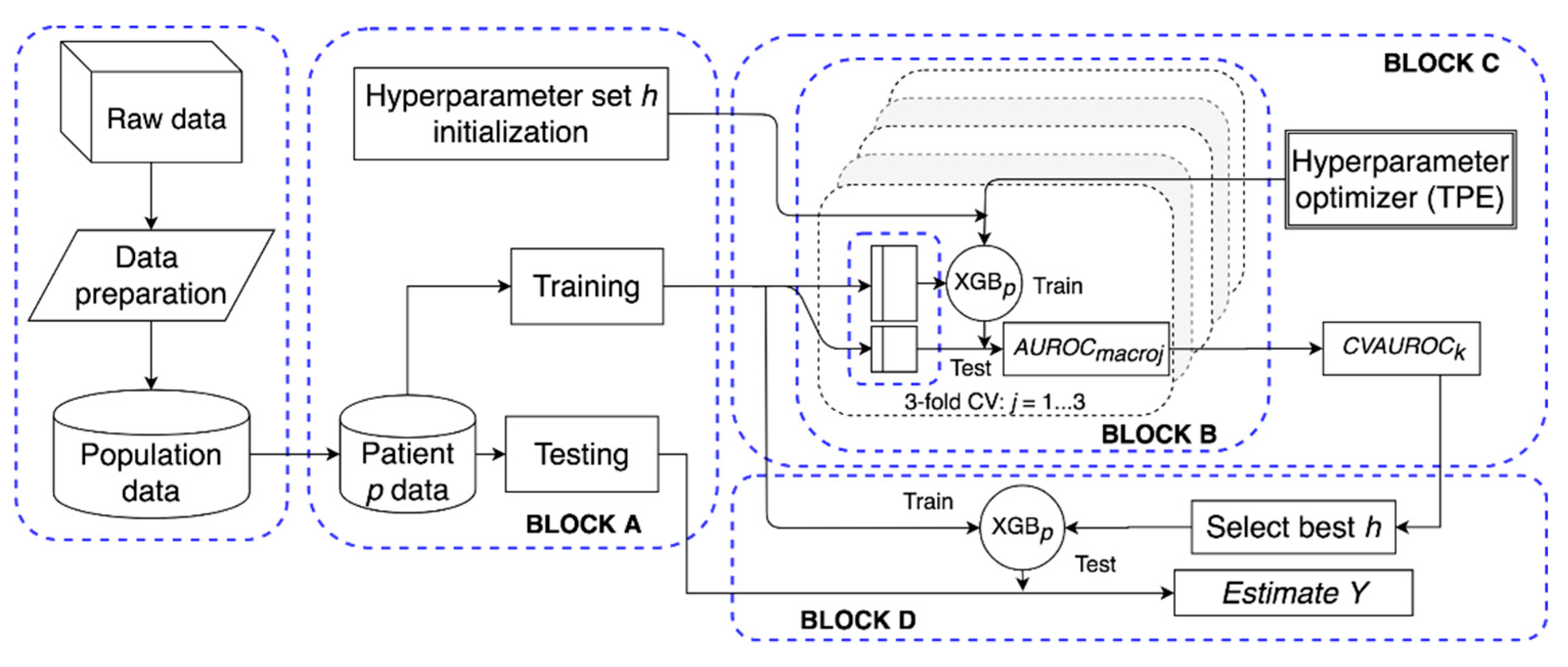
2.2. Extreme Gradient-Boosted Tree Model
2.2.1. Features Vector and Data Preparation
- Estimated amount of ingested carbohydrates (CHOi);
- Meal insulin bolus (IMBi);
- Two binary indicators denoting whether there was a hypo/hyperglycemic event in the last three hours. This feature allows us to capture the physiological response to hypoglycemia (e.g., secretion of glucagon) or the ingestion of rescue carbohydrates;
- The hour-of-day of tmi and three binary indicators representing the meal type (i.e., breakfast, lunch, or dinner), which are used to capture the subject’s intra-day variability (e.g., circadian rhythms);
- Two features describing the time elapsed since the last insulin bolus and meal intake, respectively. This feature might help to capture specific patient behaviors, such as using multiple boluses to treat the same meal and/or snacking pattern;
- CGM data within the time window (tmi – 1 h, tmi); in addition, data were preprocessed in order to obtain additional features. In detail, for each ingested meal at time tmi, CGM data, the estimated amount of carbohydrates (CHO), and insulin data (INS), were considered within the time window (tmi – 1 h, tmi). Then, such data were processed as follows:
- CGM was used to obtain the corresponding glucose rate of change, static risk (SR), and dynamic risk (DR) [20] time series, which empower the model with additional features that capture the dynamics of the CGM signal (e.g., glycemic variability);
- CHO was used to calculate the rate of glucose appearance in the blood (Ra) within (tmi, tmi + 1 h) through the use of a gastrointestinal model [21] to describe carbohydrate digestion and glucose absorption;
- INS data were transformed into two continuous signals representing an estimate of plasma insulin concentration (IP) [22] and the insulin-on-board (IOB) [23] to account for insulin absorption and clearance. As per the Ra signal, IP and IOB were estimated within (tmi, tmi + 1 h) assuming no additional insulin infusion was in that period.
2.2.2. Model Tuning and Testing
2.3. Simulated Dataset
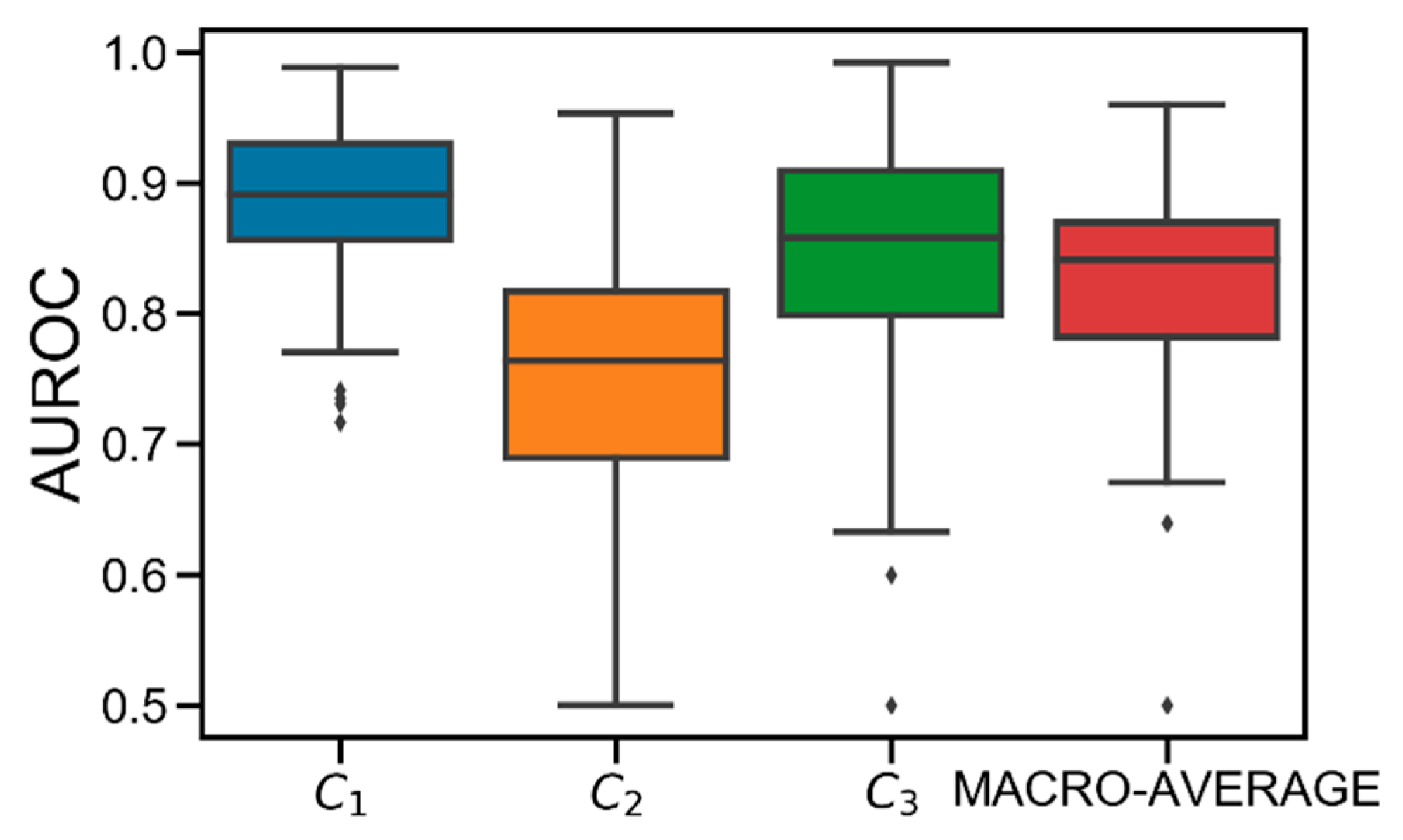
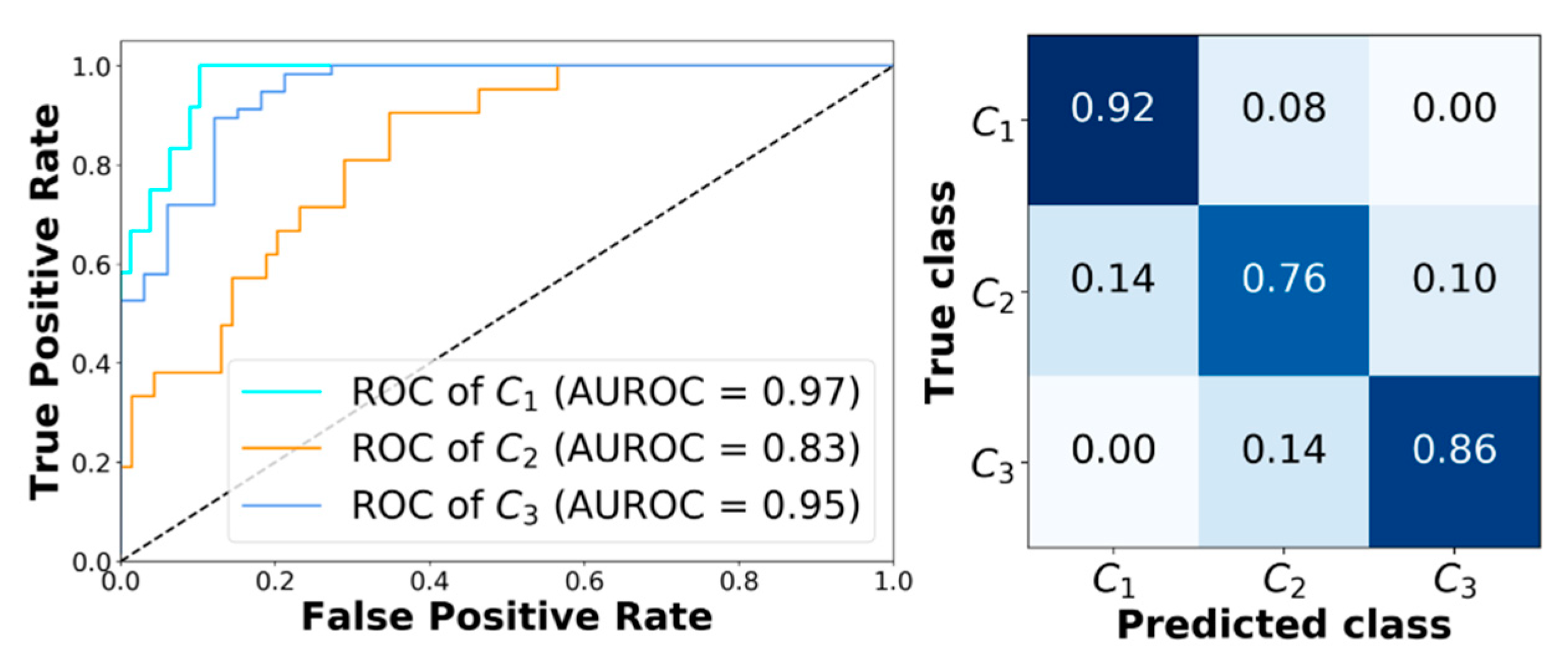
2.4. Classification Results
3. Application: Using the XGB Classifier to Adjust Meal Insulin Bolus
3.1. Meal Insulin Dose Adjustment Strategy
3.2. Simulated Scenario
3.3. Assessment of Glycemic Outcomes
4. Discussion and Conclusions
Author Contributions
Conflicts of Interest
References
- American Diabetes Association, Standards of medical care in diabetes, Diabetes Care 2017, 41, S1–S159. Available online: https://doi.org/10.2337/dc18-S002 (accessed on 6 June 2019).
- World Health Organization (WHO), Definition, diagnosis and classification of diabetes mellitus and its complications: Report of a WHO consultation. Part 1, diagnosis and classification of diabetes mellitus, Geneva, 1999. Available online: http://www.who.int/iris/handle/10665/66040 (accessed on 6 June 2019).
- Cappon, G.; Marturano, F.; Vettoretti, M.; Facchinetti, A.; Sparacino, G. In silico assessment of literature insulin bolus calculation methods accounting for glucose rate of change. J. Diabetes Sci. Technol. 2018, 13, 103–110. [Google Scholar] [CrossRef] [PubMed]
- Lane, J.E.; Shivers, J.P.; Zisser, H. Continuous glucose monitors: Current status and future developments. Curr. Opin. Endocrinol. Diabetes Obes. 2013, 20, 106–111. [Google Scholar] [CrossRef]
- Lodwig, V.; Kulzer, B.; Schnell, O.; Heinemann, L. Current trends in continuous glucose monitoring. J. Diabetes Sci. Technol. 2014, 8, 390–396. [Google Scholar] [CrossRef] [PubMed]
- Cappon, G.; Acciaroli, G.; Vettoretti, M.; Facchinetti, A.; Sparacino, G. Wearable continuous glucose monitoring sensors: A revolution in diabetes treatment. Electronics 2017, 6, 65. [Google Scholar] [CrossRef]
- Oviedo, S.; Vehi, J.; Calm, R.; Armengol, J. A review of personalized blood glucose prediction strategies for T1DM patients. Int. J. Number Method Biomed. Eng. 2017, 33, e2833. [Google Scholar] [CrossRef] [PubMed]
- Cappon, G.; Vettoretti, M.; Facchinetti, A.; Sparacino, A. A neural-network-based approach to personalize insulin bolus calculation using continuous glucose monitoring. J. Diabetes Sci. Technol. 2018, 12, 265–272. [Google Scholar] [CrossRef]
- Herrero, P.; Pesl, P.; Reddy, M.; Oliver, N.; Georgiou, P.; Toumazou, C. Advanced insulin bolus advisor based on run-to-run control and case-based reasoning. IEEE J. Biomed. Health Inform. 2015, 19, 1087–1096. [Google Scholar]
- Gadeleta, M.; Facchinetti, A.; Grisan, E.; Rossi, M. Prediction of adverse events from continuous glucose monitoring signal. IEEE J. Biomed. Health Inform. 2018, 23, 650–659. [Google Scholar] [CrossRef]
- Aiello, E.M.; Toffanin, C.; Messori, M.; Cobelli, C. Postprandial glucose regulation via KNN meal classification in type 1 diabetes. IEEE Control Sys. Letters 2019, 3, 230–235. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGDD Int Conf on Knowledge Discovery, San Francisco, CA, USA, August 2016; pp. 13–17. [Google Scholar]
- Schiavon, M.; Dalla Man, C.; Cobelli, C. Insulin sensitivity index based optimization of insulin to carbohydrate ratio: In silico study shows efficacious protection against hypoglycemic events caused by suboptimal therapy. Diabetes Technol. Ther. 2018, 20, 98–105. [Google Scholar] [CrossRef]
- Contreras, I.; Oviedo, S.; Vettoretti, M.; Visentin, R.; Vehí, J. Personalized blood glucose prediction: A hybrid approach using grammatical evolution and physiological models. PLoS ONE 2017, 12, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Toffanin, C.; Visentin, R.; Messori, M.; Di Palma, F.; Magni, L.; Cobelli, C. Towards a run-to-run adaptive artificial pancreas: In silico results. IEEE Trans. Biomed. Eng. 2017, 65, 479–488. [Google Scholar] [CrossRef] [PubMed]
- Vettoretti, M.; Facchinetti, A.; Sparacino, G.; Cobelli, C. Type-1 diabetes patient decision simulator for in silico testing safety and effectiveness of insulin treatments“. IEEE Trans. Biomed. Eng. 2018, 65, 1281–1290. [Google Scholar] [CrossRef] [PubMed]
- Dalla Man, C.; Micheletto, F.; Lv, D.; Breton, M.D.; Kovatchev, B.; Cobelli, C. The UVa/Padova type 1 diabetes simulator: New features. J. Diabetes Sci. Technol. 2017, 8, 26–34. [Google Scholar]
- Herrero, P.; Pesl, P.; Bondia, J.; Reddy, M.; Oliver, N.; Georgiou, P.; Toumazou, C. Method for automatic adjustment of an insulin bolus calculator: In silico robustness evaluation under intra-day variability. Comput. Methods Programs Biomed. 2015, 119, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Walsh, J.; Roberts, R.; Heinemann, L. Confusion regarding duraztion if insulin action: A potential source for major insulin dose errors by bolus calculators. J. Diabetes Sci. Technol. 2014, 8, 170–178. [Google Scholar] [CrossRef] [PubMed]
- Guerra, S.; Sparacino, G.; Facchinetti, A.; Schiavon, M.; Dalla Man, C.; Cobelli, C. A dynamic risk measure from continuous glucose monitoring data. Diabetes Technol. Ther. 2011, 13, 843–852. [Google Scholar] [CrossRef]
- Hovorka, R.; Canonico, V.; Chassin, L.J.; Haueter, U.; Massi-Benedetti, M.; Orsini Federici, M.; Pieber, T.R.; Schaller, H.C.; Schaupp, L.; Vering, T.; et al. Nonlinear model predictive control of glucose concentration in subjects with type 1 diabetes. Physiol. Meas. 2004, 25, 905–920. [Google Scholar] [CrossRef] [Green Version]
- Willinska, M.E.; Chassin, L.J.; Schaller, H.C.; Schaupp, L.; Pieber, T.R.; Hovorka, R. Insulin kinetics in type 1 diabetes: Continuous and bolus delivery of rapid acting insulin. IEEE Trans. Biomed. Eng. 2005, 52, 3–12. [Google Scholar] [CrossRef]
- Howsmon, D.P.; Cameron, F.; Baysal, N.; Ly, T.T.; Forlenza, G.P.; Maahs, D.M.; Buckingham, B.A.; Hahn, J.; Bequette, B.W. Continuous glucose monitoring enables the detection of losses in infusion set actuation (LISAs). Sensors 2017, 17, 161. [Google Scholar] [CrossRef]
- Trevor, J.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer: New York, NY, USA, 2009; ISBN 978-0-387-84857-0. [Google Scholar]
- Florkowski, C.M. Sensitivity, specificity, receiver-operating characteristic (ROC) curves and likelihood ratios: Communicating the performance of diagnostic tests. Clin. Biochem. Rev. 2008, 29, S83–S87. [Google Scholar]
- Bergstra, J.; Bardenet, R.; Bengio, Y.; Kegl, B. Algorithms for hyper-parameter optimization. In Proceedings of the 24th Int Conf in Advances in Neural Information Processing Systems, Granada, Spain, December 2015; pp. 12–15. [Google Scholar]
- Vettoretti, M.; Facchinetti, A.; Sparacino, G.; Cobelli, C. A model of self-monitoring blood glucose measurement error. J. Diabetes Sci. Technol. 2017, 11, 724–735. [Google Scholar] [CrossRef] [PubMed]
- Facchinetti, A.; Del Favero, S.; Sparacino, G.; Cobelli, C. Model of glucose sensor error components: Identification and assessment for new Dexcom G4 generation devices. Med. Biol. Eng. Comput. 2015, 53, 1259–1269. [Google Scholar] [CrossRef]
- Visentin, R.; Dalla Man, C.; Kudva, Y.C.; Basu, A.; Cobelli, C. Circadian variability of insulin sensitivity: Physiological input for in silico artificial pancreas. Diabetes Technol. Ther. 2015, 17, 1–7. [Google Scholar] [CrossRef]
- Fabris, C.; Patek, S.D.; Breton, M.D. Are risk indices derived from CGM interchangeable with SMBG-based indices? J. Diabetes Sci. Technol. 2015, 10, 50–59. [Google Scholar] [CrossRef] [PubMed]
- Schmidt, S. Bolus calculators. J. Diabetes Sci. Technol. 2014, 8, 1035–1041. [Google Scholar] [CrossRef]
- Maahs, D.M.; Buckingham, B.A.; Castle, J.R.; Cinar, A.; Damiano, E.R.; Dassau, E.; DeVries, J.H.; Doyle, F.J., III; Griffen, S.C.; Haidar, A.; et al. Outcome measures for artificial pancreas clinical trials: A consensus report. Diabetes Care 2016, 39, 1175–1179. [Google Scholar] [CrossRef]
- Vettoretti, M.; Cappon, G.; Acciaroli, G.; Facchinetti, A.; Sparacino, G. Continuous glucose monitoring: Current use in diabetes management and possible future applications. J. Diabetes Sci. Technol. 2018, 12, 1064–1071. [Google Scholar] [CrossRef]
- Facchinetti, A. Continuous glucose monitoring sensors: Past, present and future algorithmic challenges. Sensors 2016, 16, 2093. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SF-IMB | XGB-IMB | P-VALUE | |
|---|---|---|---|
| MEANBG | 167.12 [155.28, 181.16] | 161.05 [151.74, 169.33] | <0.01 * |
| SDBG | 54.97 [48.03, 63.95] | 51.02 [44.92, 59.97] | <0.01 * |
| BGRI | 9.36 [7.06, 11.43] | 8.00 [6.60, 9.83] | <0.01 * |
| %THYPO | 1.93 [0.07, 3.81] | 1.82 [0.09, 3.81] | 0.34 |
| %THYPER | 35.18 (±14.06) | 29.84 (±11.50) | <0.01 ** |
| %TTARGET | 61.98 (±13.89) | 67.00 (±11.54) | <0.01 ** |
| %TTTARGET | 28.22 [18.54, 40.56] | 31.17 [24.49, 42.60] | <0.01 * |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cappon, G.; Facchinetti, A.; Sparacino, G.; Georgiou, P.; Herrero, P. Classification of Postprandial Glycemic Status with Application to Insulin Dosing in Type 1 Diabetes—An In Silico Proof-of-Concept. Sensors 2019, 19, 3168. https://doi.org/10.3390/s19143168
Cappon G, Facchinetti A, Sparacino G, Georgiou P, Herrero P. Classification of Postprandial Glycemic Status with Application to Insulin Dosing in Type 1 Diabetes—An In Silico Proof-of-Concept. Sensors. 2019; 19(14):3168. https://doi.org/10.3390/s19143168
Chicago/Turabian StyleCappon, Giacomo, Andrea Facchinetti, Giovanni Sparacino, Pantelis Georgiou, and Pau Herrero. 2019. "Classification of Postprandial Glycemic Status with Application to Insulin Dosing in Type 1 Diabetes—An In Silico Proof-of-Concept" Sensors 19, no. 14: 3168. https://doi.org/10.3390/s19143168